EL 项目作品「春紛 Bloomink」记录
2024 年 6 月 2 日:现在还没什么时间补充与批注,只是将开发记录搬运过来。文档地址,目前第四篇记录还未并入 main 分支,然后应该还会有第五篇记录,讲一下答辩的准备和过程。
记录的图片直接引用 GitHub 了,反正本来也就是复制粘贴,而且图片好多好大。
中期文档和最后答辩的材料放在 GitHub 上,这里最多引用一下。(答辩材料还没上传)
这些开发记录基本不会作改动了(还是改了点),额外补充与感想会用下面的 adm 标识:
补充就像这样。
四月五月均没有新博文产出,很大程度上是因为这个 EL 项目。当然我也不是空闲时间全用来做 EL 了,还是摆了不少的,只不过确实还是占用了不少时间。三月没有那就纯纯是懒到极致了。
简介
暂略。先只写个仓库地址和功能不完整的线上版。
记录
记录前期是把记录当成相当于是小组的「开发日志」这样的,因此自称会用诸如「组长本人」之类比较滑稽的名称。后面就渐渐放飞自我,当成个人的杂记了,因此也就回归「我」等了。
4 月 13 日组会
- 记录人:@PilgrimLyieu
- 记录时间:2024 年 4 月 14 日
会前
第一周任务
- 确定选题与大致思路,头脑风暴一下,每个人都提出一点自己的想法、见解(最重要的一点!不用太过详细,细节、分工等工作在下周进行)
- 注册 GitHub 账户并告诉我,我拉每个人 Collaborator,所有代码任务包括项目文档均使用 GitHub 进行管理。(有困难可以搜索或者发群里,总之得尽快解决)(同时到时候每个人创建一个分支,在自己的分支进行工作,并在完成阶段性目标时提 Pull Request 并入主分支。这点不急,等项目细节敲定后才会正式开始。只不过 GitHub 账户与 Collaborator 这周一定得弄完)
- 使用 VSCode(虽然说强制这个似乎不太好,但是据我观察似乎也没有比 VSCode 更合适的了)作为代码开发工具,因为有很多有用的插件比如 Copilot 以及代码格式化等,有利于规范代码开发(也是跟上面一样,还没写代码所以只是准备工作)
- 这点不强制,但是如果希望能有 A 助力代码开发的话,例如说编程出现问题进行咨询、提供编程建议、优化代码等,可以考虑弄个 GitHubStudentPack, 里面就包括了 Copilot.(也是一样。有困难就查+问)
- 这点也不强制,那就是 Al 工具,会用 ChatGPT, NewBing 等自然最好,只是再推荐一个 https://arena.lmsys.org, 有概率能刷出 GPT-4 等强力 BOSS
- 这点只是置顶问一下,有人会 LaTeX 或 Typst 等排版工具吗,没有的话那就我来排版文档之类的东西了(其实也不一定要用前面几个,markdown 也行,到时候我看看排版需求用不用的上 LaTeX)
这部分是下发在 QQ 公告的。
组名确定
因都给不出建议,使用随机生成器进行生成:

由此确定了初版组名 Loco Leopards。
后面因为 Leopards 有实意,改成第二版组名 Loco。
接着组员指出 Loco 与一韩国男星同名:
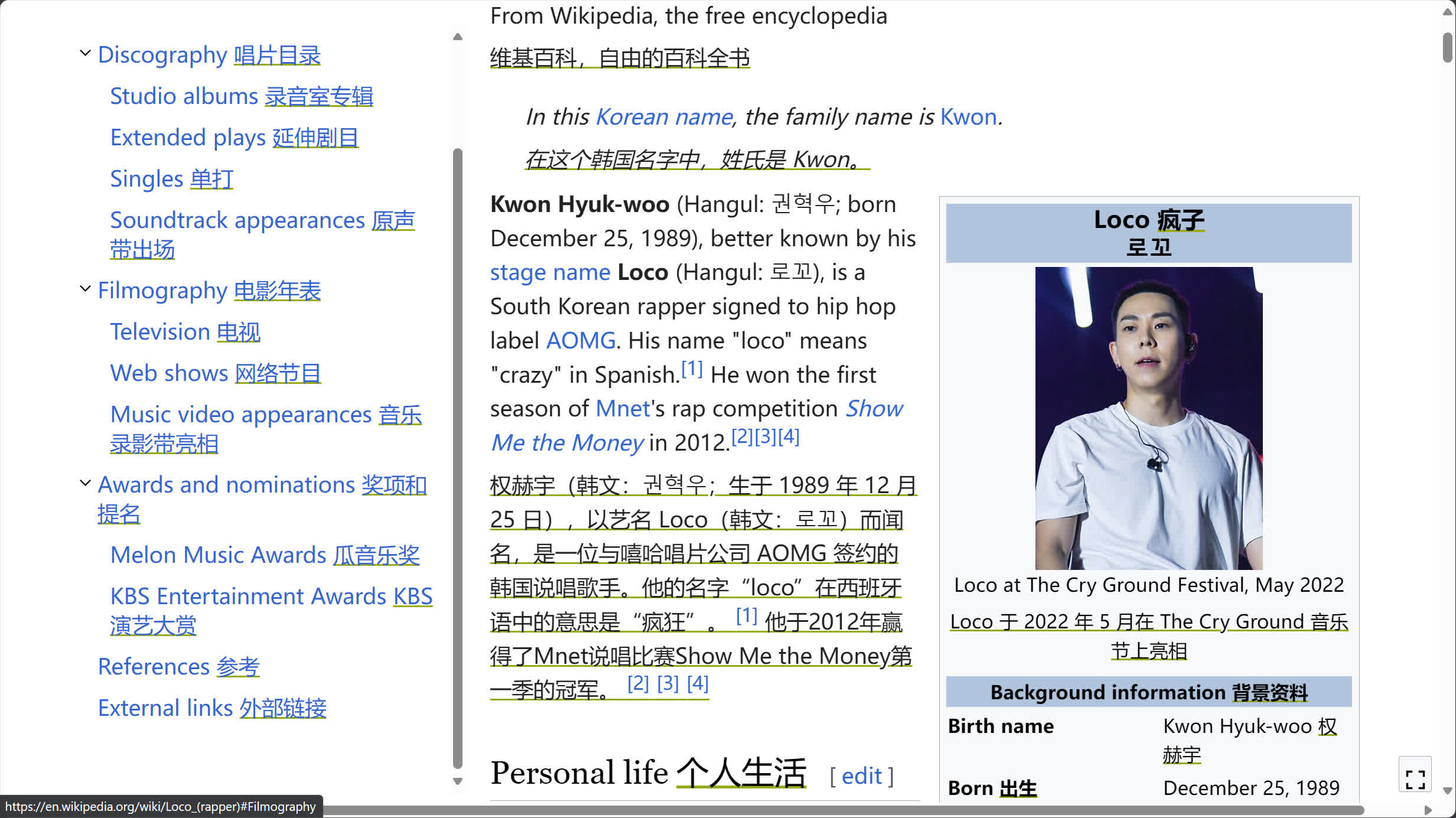
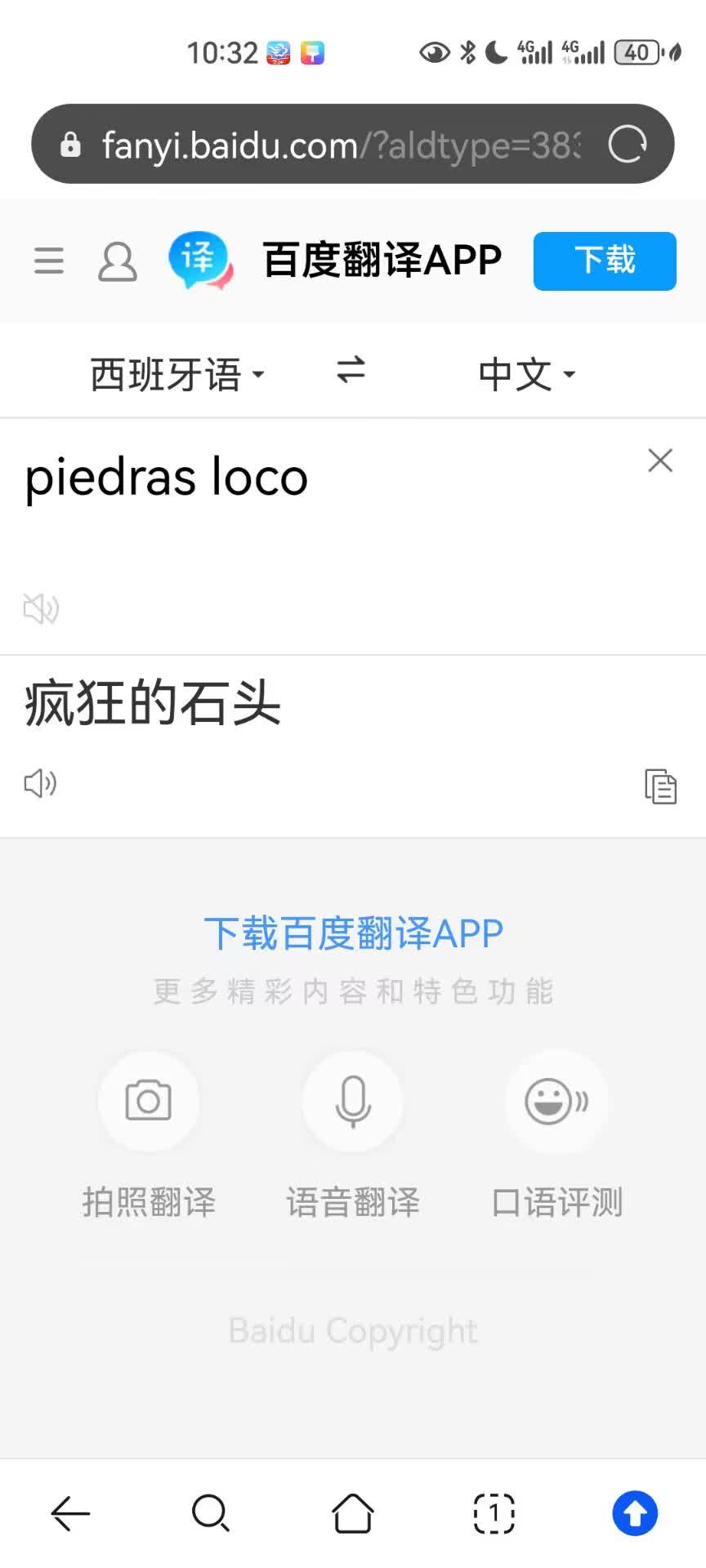
虽然都不认识这是谁,但为了避嫌,最终采用组员给出的第三版也是最终版组名 Piedras Loco。
会议内容
- 组长协助组员完成 GitHub Student Pack 的申请
- 讨论并确定项目选题、方向分工等
- 组长简单介绍开发流程,使用 Git 进行版本控制
- 进行简单的分工确定
GitHub Student Pack
组长本人在去年八月份拿到录取通知书后就迅速申请并通过了,在指导组员进行申请时,也发现了 GitHub 政策的变动:例如由于 GitHub 安全政策的收紧,现在学生包认证需要先完成 2FA,而当时则是不必要的[1];再比如学信网资料认证时,部分组员需要完善 GitHub 个人信息等。

选题方向
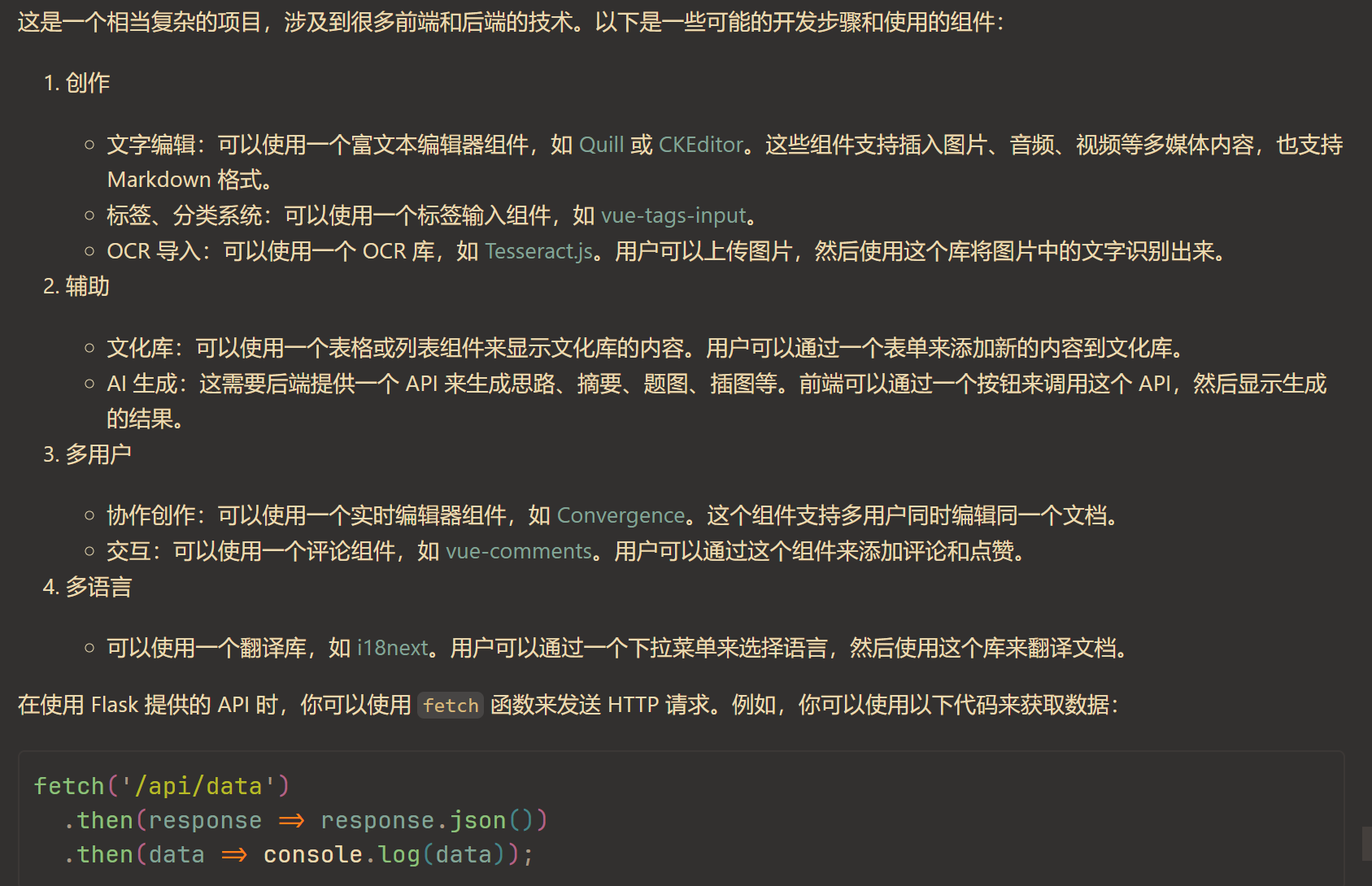
在 AI 的帮助下,确定了基本框架是制作一个用户创作平台,并包含以下特性(在开发过程中可能进行舍弃):


- 创作
- 以文字为基础,并提供图片、音频、视频等多媒体支持
- 支持标签、分类系统
- 支持富文本、markdown 等格式
- 支持 OCR 导入旧文档
- 辅助
- 支持文化库,根据类型提供合适的诗词、典故、成语等
- 允许用户自定义文化库
- 允许用户分享文化库
- 允许用户从文化库中诗词等了解更多信息
- 支持 AI 生成思路、摘要、题图、插图等
- 支持文化库,根据类型提供合适的诗词、典故、成语等
- 多用户
- 支持多用户协作共同创作
- 支持多用户交互如评论、点赞等
- 多语言
- 支持多语言创作(可以自行创作双语版本,或使用机器翻译)
解决的痛点、需求:
- 用户对日常生活中有丰富的灵感,同时有旺盛的创作欲望,但创作时间、文化水平不足
- 一些追求高质量的创作者提高自己作品中文化水平的追求
- 通过构建文化创作社区,鼓励用户分享、讨论和合作文化创作,提高文化创作的参与度和创新性
现有写作平台的不足:
- 缺乏文化支持,用户创作时无法方便地获取文化信息
- 缺乏 AI 辅助,用户创作时无法方便地获取创作灵感
- 缺乏多用户支持,用户创作时无法方便地与他人合作
- 缺乏多语言支持,用户创作时无法方便地创作多语言作品
还缺乏具体的对比
流程控制
使用 Git 进行版本控制。
- 每个人创建一个分支,在自己的分支进行工作
- 原子化提交,提交信息要有意义,提交内容要有意义
- 在完成阶段性目标时提 Pull Request 并入主分支
- 组长进行代码审查,通过后合并到主分支
- 合并后每个人拉取主分支,更新自己的分支
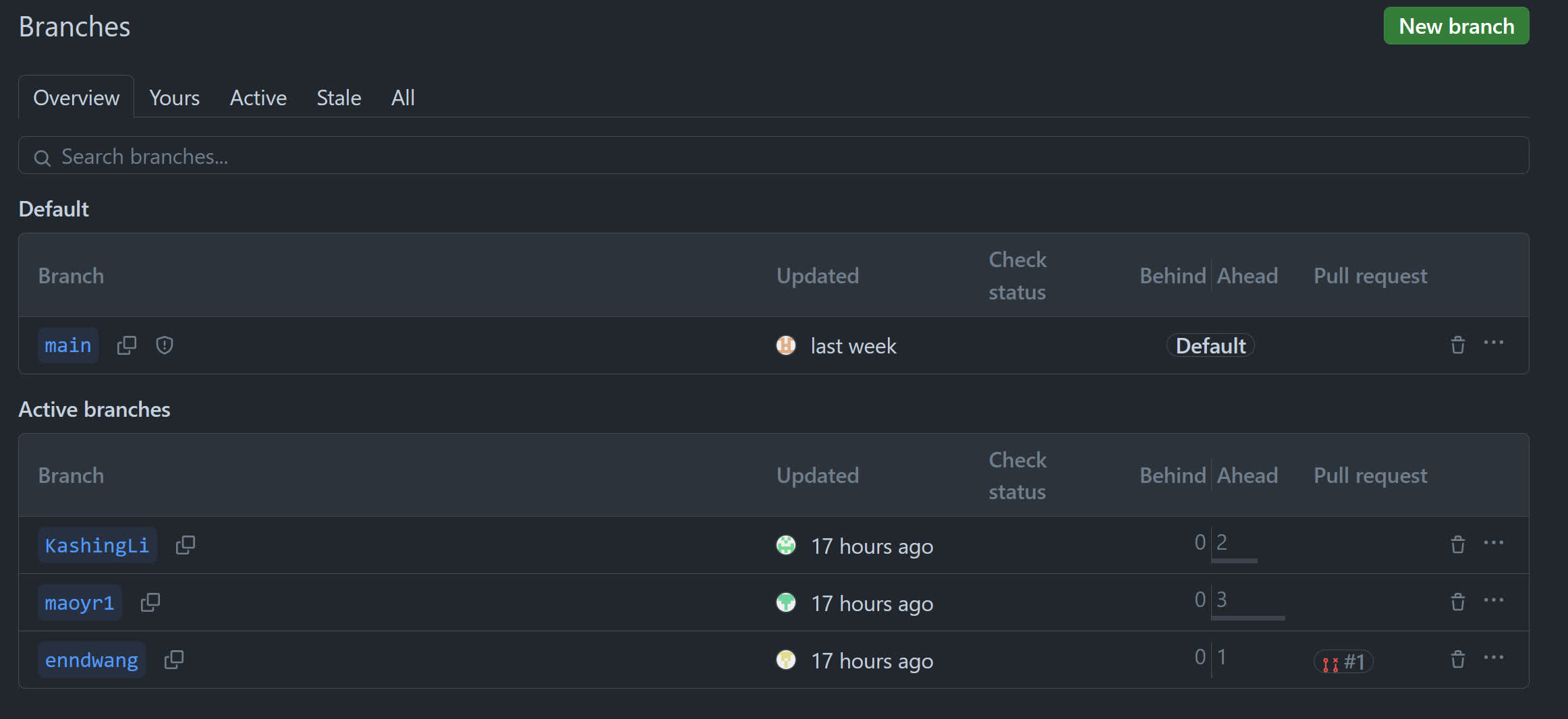
在组长的协助下每个人创建了自己的分支:
并尝试了 Pull Request 与组长代码审查:
项目分工
初步分工如下:
- 前端使用 Vue.js
- 后端使用 Flask
- 组长 @PilgrimLyieu
- 项目统筹规划
- 撰写项目报告与各种文档
- 搜寻有关资料
- 同时参与前后端开发
- 项目流程控制
- 项目代码审查
- 组员 @EnndWang
- 前后端知识学习
- 前端开发
- 组员 @KashingLiking
- 前后端知识学习
- 后端开发
- 组员 @t0mo0n
- 前后端知识学习
- 后端开发
- 答辩 PPT 制作
4 月 20 日组会
- 记录人:@PilgrimLyieu
- 记录时间:2024 年 4 月 20 日
会前
Copilot
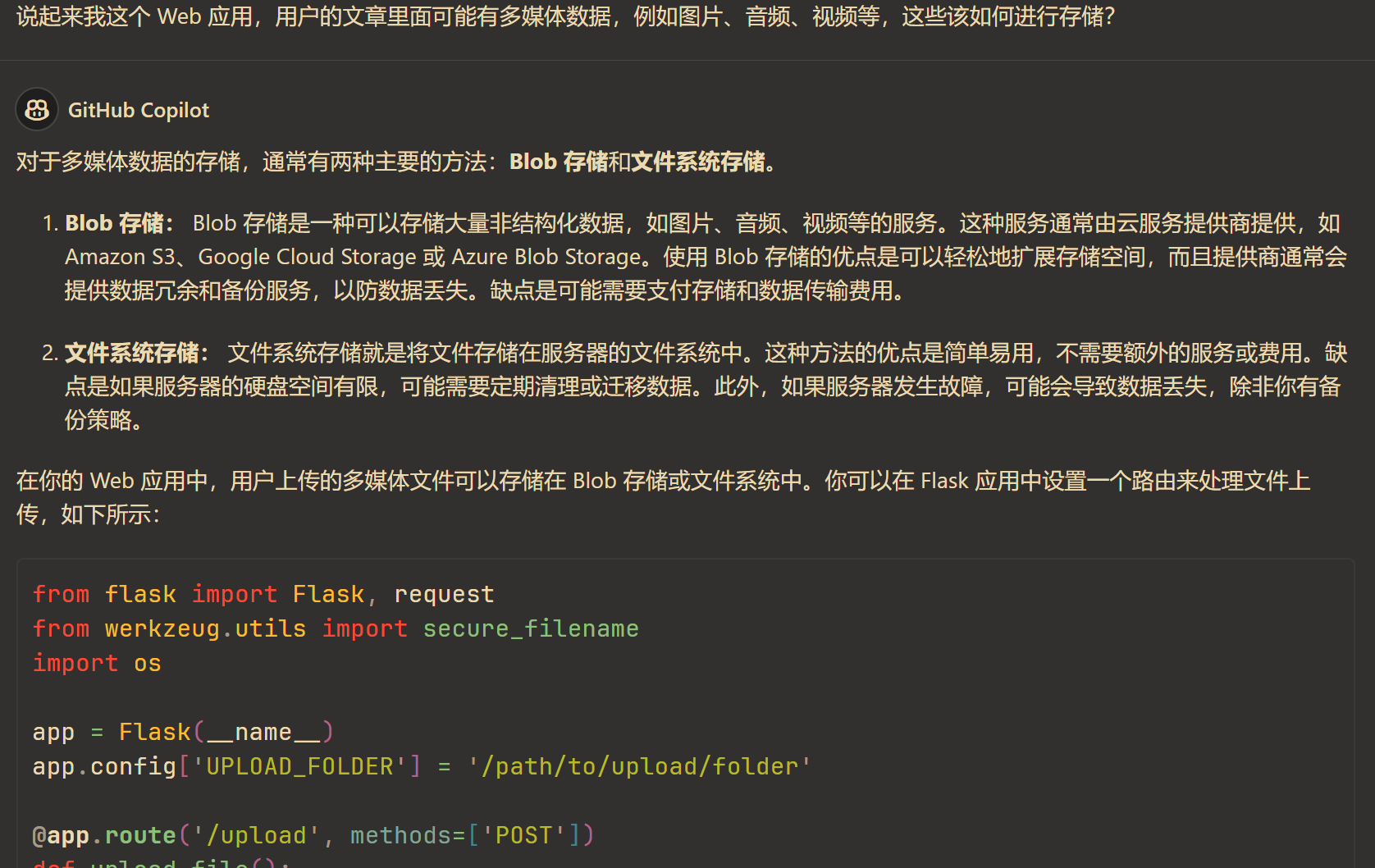
鉴于组长与组员均没有 Web 开发的经验,向 Copilot 进行咨询就成为了必不可少的一步。如下图是向 Copilot 了解 API Reference 的构成,与 API 的编写等。

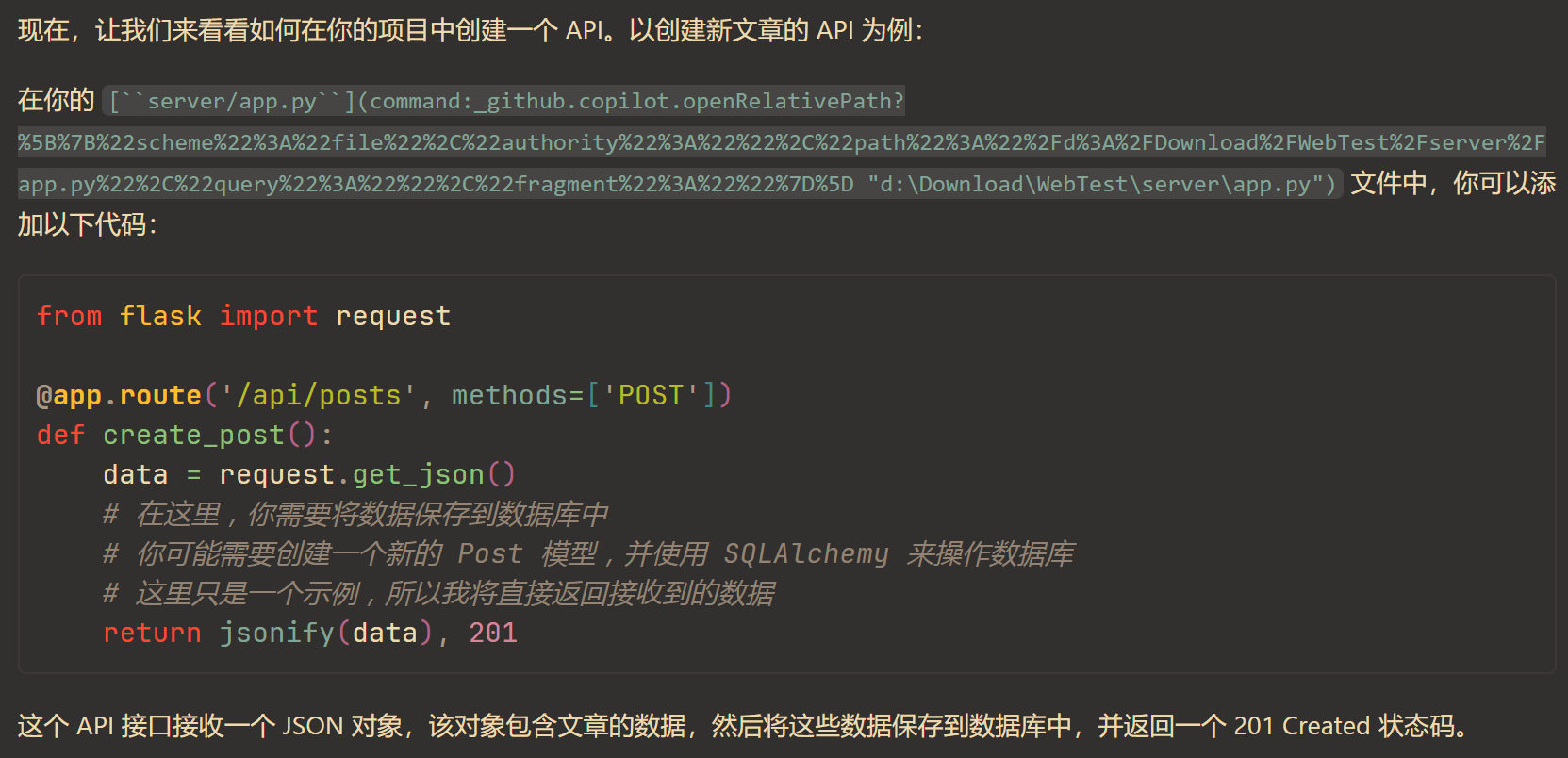
以及后端编写拆分为多个模块的思路,也由 Copilot 提供帮助。
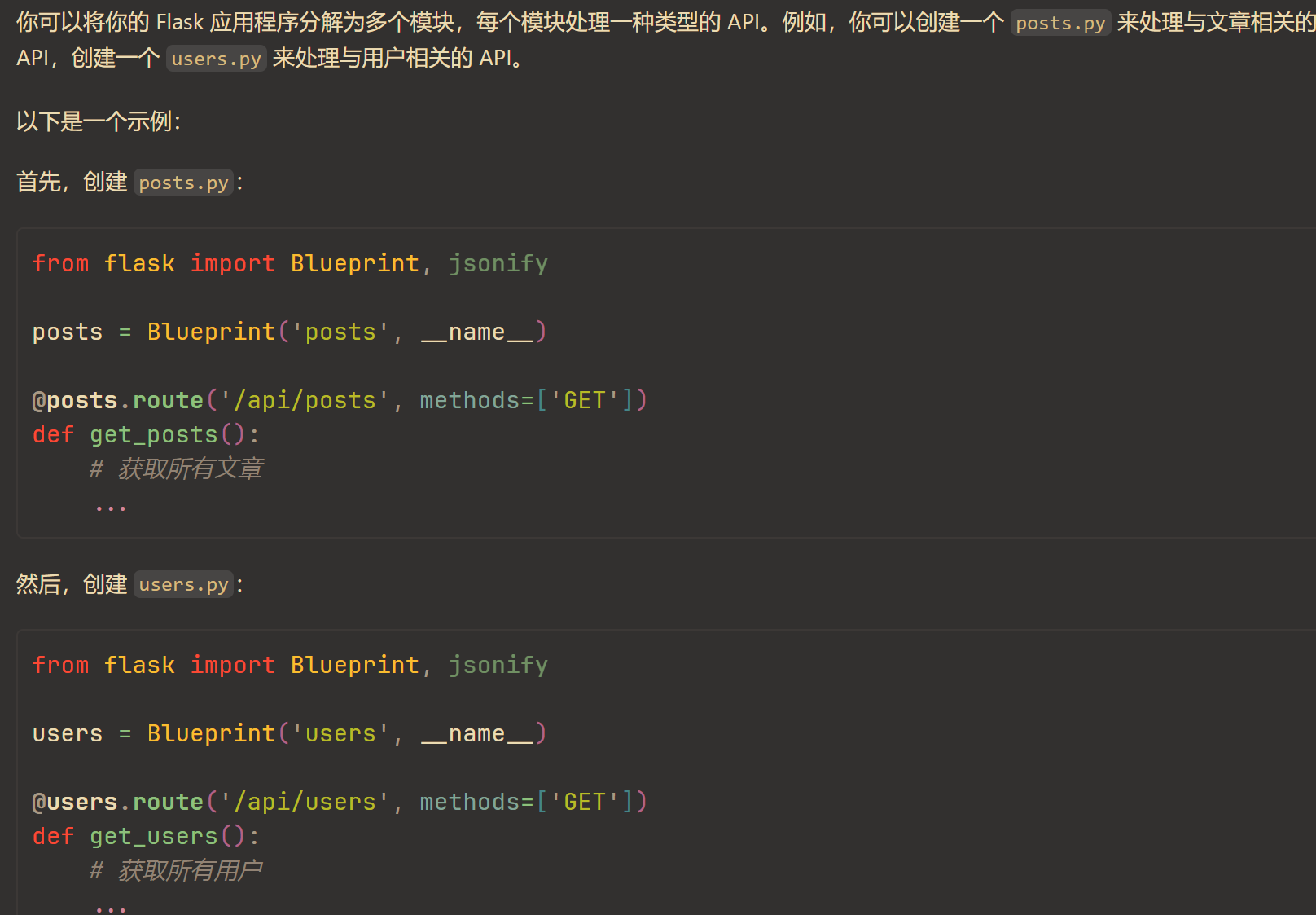
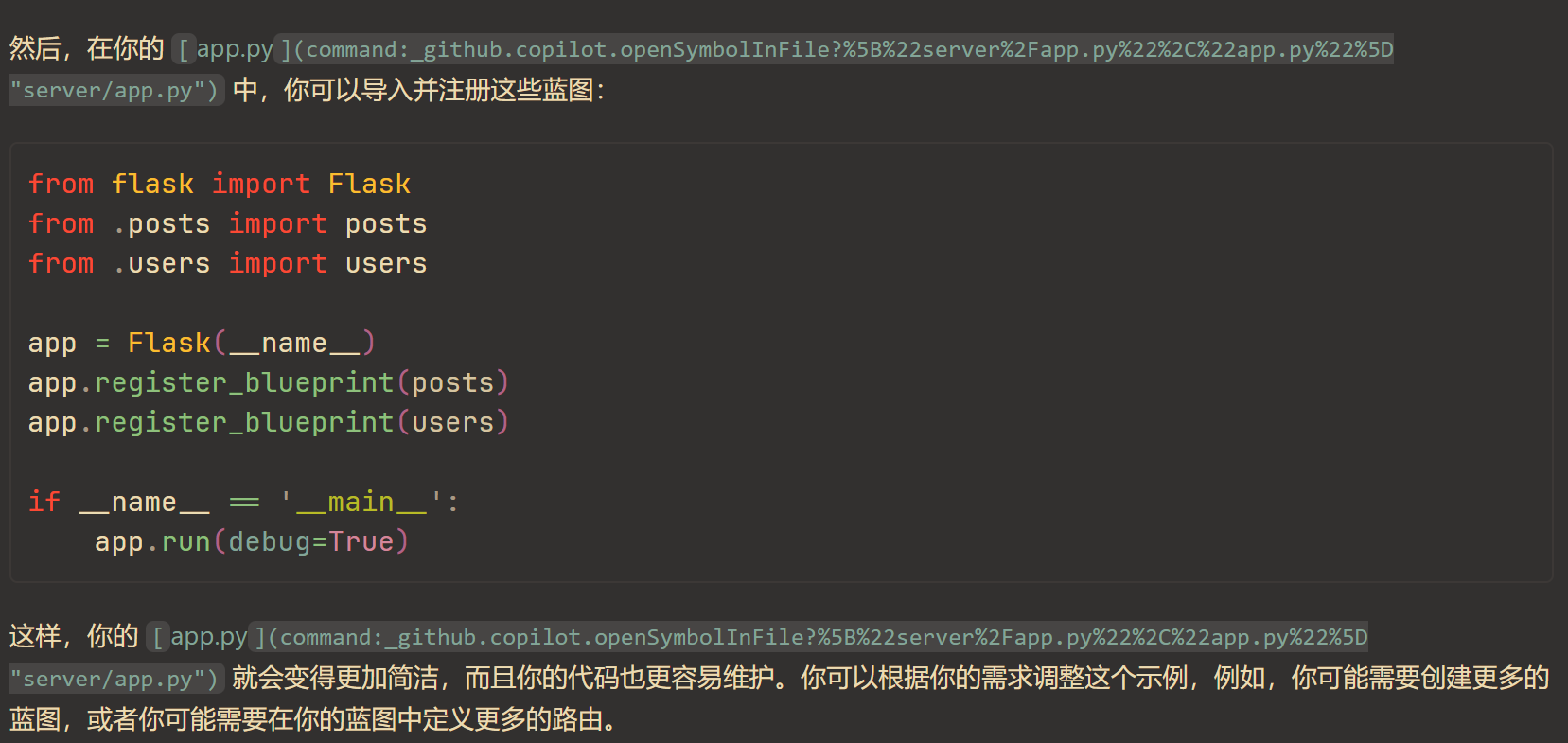
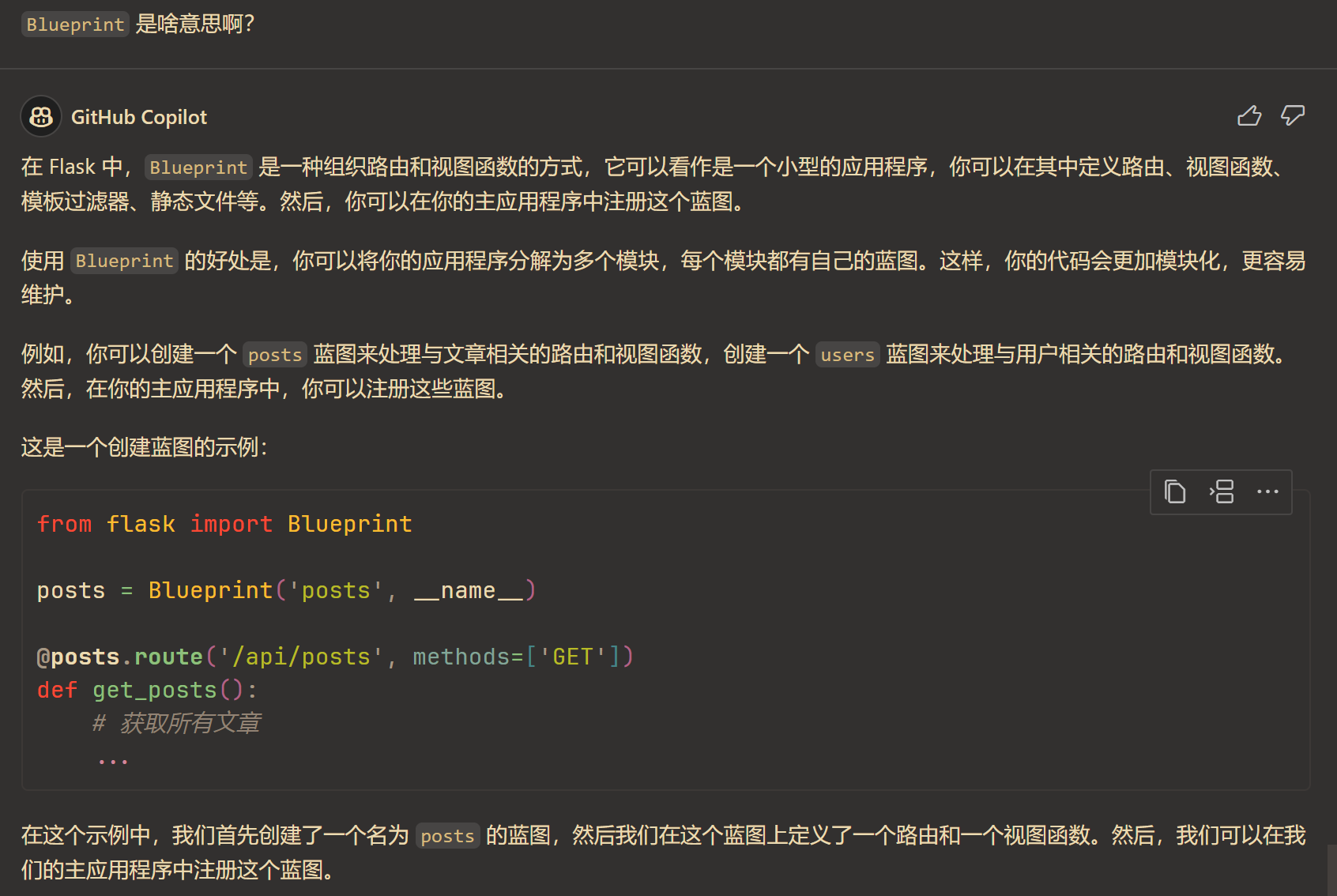
后端外,还有就是组长本人觉得格外棘手的前端了。

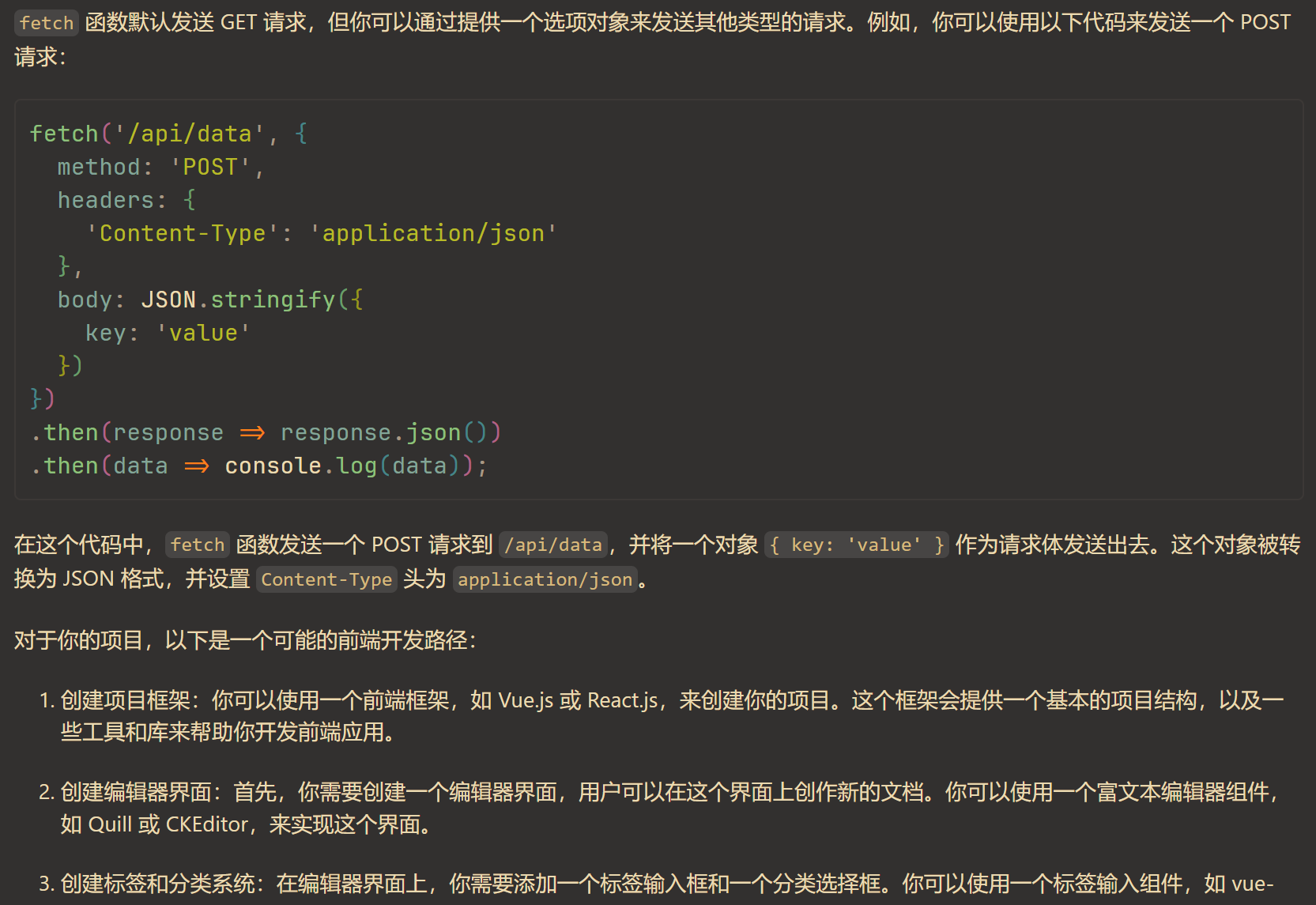

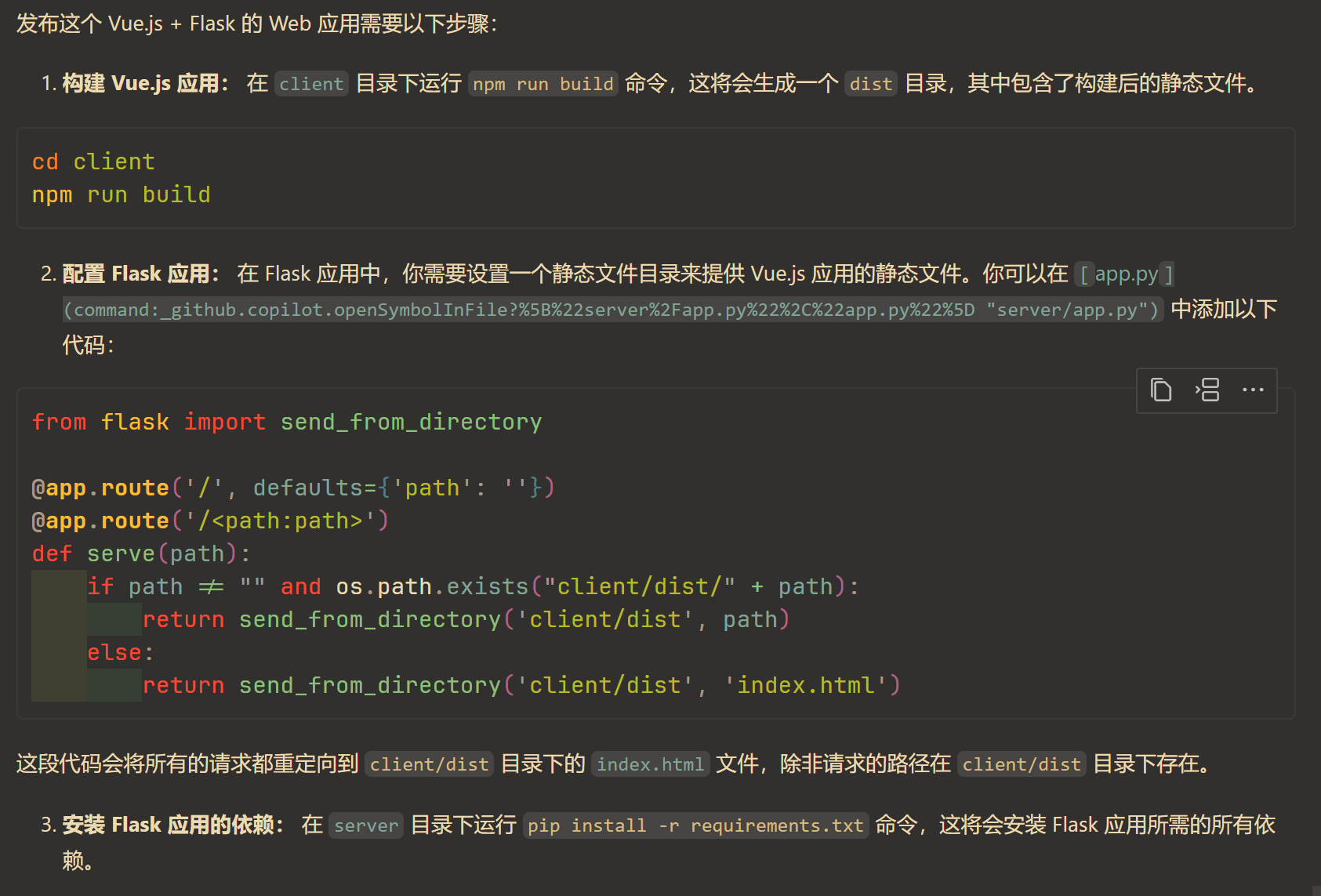
虽然一行代码都还没开始写,但是还是提前了解了一下发布的流程。
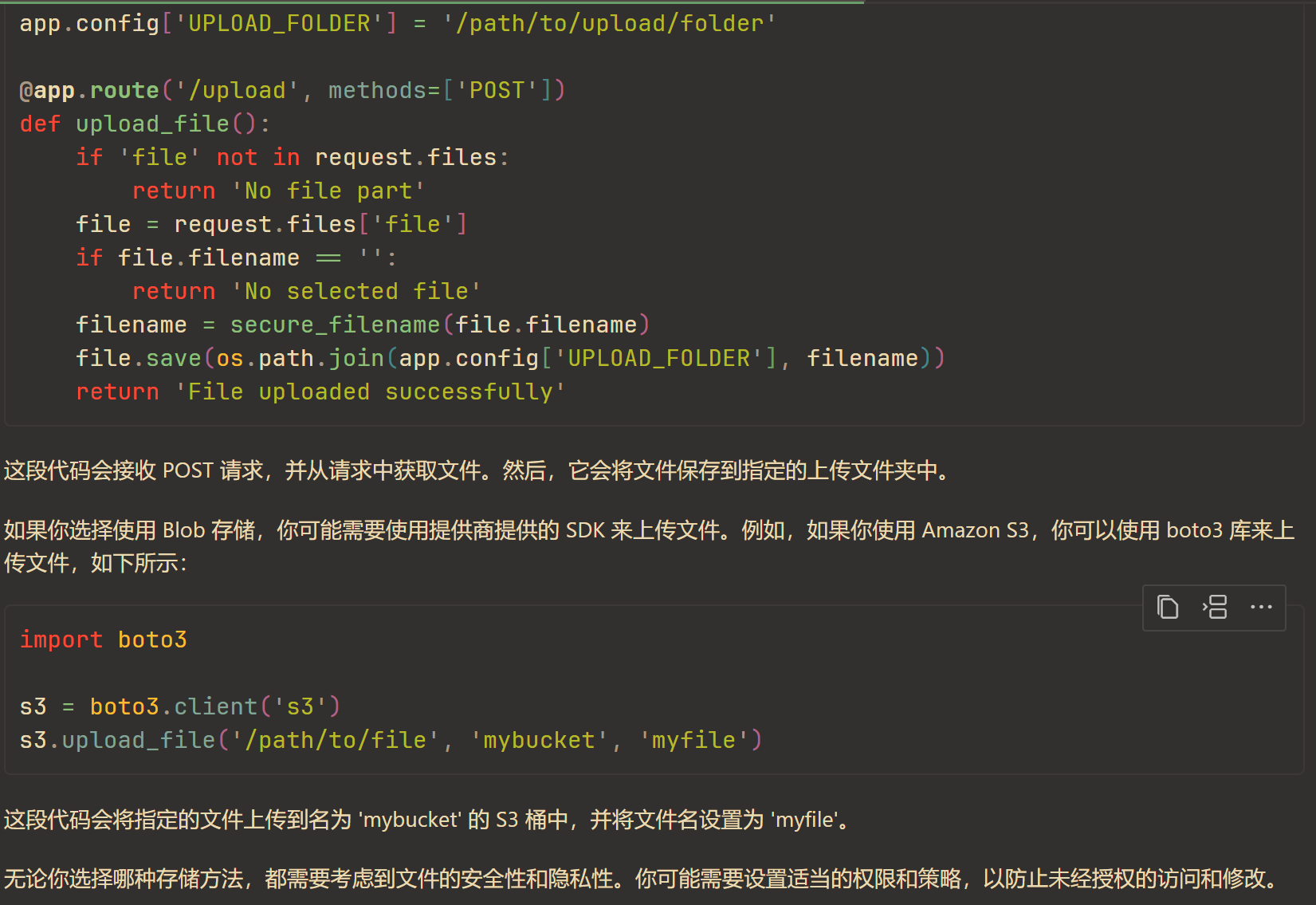
以及一些数据存储的信息。
代码规范
为了统一代码格式,全组在组长的要求下安装了 Black Formatter 等插件,并开启了保存自动格式化的功能。
除此以外,约定后端 Python 代码采用 Snake 命名法(get_data_reference),而前端 Vue.js 代码采用 Camel 命名法(getDataReference)。
代码框架
搭建
毫无 Web 开发经验的组长,在网上翻阅了很多资料,堪堪摸索出一条搭建项目框架的路线。
为了与组员保持一致,组长也最终放弃了在 WSL 进行开发的决定。
安装 Node.js, Python 等基本内容不再赘述。
首先是安装 Vue.js 命令行,这样就能直接使用 vue 命令。使用下面的命令进行安装(可能需要配置 NPM 镜像):
npm install -g @vue/cli |
随后创建前端项目
vue create client |
然后创建 Python 虚拟环境
python -m venv .venv |
启动虚拟环境
source .venv/Scripts/activate |
然后安装 Flask
pip3 install flask |
紧接着创建后端文件夹 server
mkdir server |
在其中创建一个 app.py 作为应用的入口文件,并根据 Copilot 的指导,输入以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 | from flask import Flask, jsonify app = Flask(__name__) @app.route("/api/data", methods=["GET"]) def get_data(): data = {"message": "Hello, Vue.js!"} return jsonify(data) if __name__ == "__main__": app.run(debug=True) |
同时修改 client/src/components/HelloWorld.vue 组件中 script 标签为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | export default { name: 'HelloWorld', data() { return { message: 'Loading...' }; }, async mounted() { const response = await fetch('/api/data'); const data = await response.json(); this.message = data.message; } } |
并修改 client/vue.config.js 为
1 2 3 4 5 6 7 8 9 10 11 12 | const { defineConfig } = require('@vue/cli-service') module.exports = defineConfig({ transpileDependencies: true, devServer: { proxy: { '/api': { target: 'http://localhost:5000', changeOrigin: true, } } } }) |
以将 Vue.js 的 API 请求转发到 5000 端口,供后端进行处理。
最后使用两个 Bash 终端分别在后端 server 和前端 flask 执行 flask run(或 flask run --reload)和 vue serve 启动前后端进行检查。
成功启动后,按指示打开 https://localhost:8080,并使用 F12 打开开发者工具,在网络选项卡使用 Ctrl + R 刷新后,成功发现 data 名称的 GET 请求,同时状态码返回 200,并能看到预期的 JSON 数据,验证成功。
复刻
下一个难题便是如何让组员本地获得与组长相同的环境。经过摸索,组长也发现了下面的路径。
首先组长导出需要安装的 Python 依赖
pip3 freeze > server/requirements.txt |
随后组员按下面的步骤进行重复操作,即可复刻组长的本地环境。
- Git
- 同步 main 分支(先切换到 main 再切回来)
- 合并 main 分支更改(分支 > 合并 > main)
- Python 虚拟环境
python -m venv .venvsource .venv/Scripts/activatepip3 install -r server/requirements.txt
- Node.js 包
npm install -g @vue/clicd clientnpm install
- 运行并测试
flask runvue serve
至此便完成了框架的搭建。
组长也将 VSCode 设置一并传入库中,免去了组员的设置之苦(当然格式化工具还是手动帮助组员完成了设置)
1 2 3 4 | { "editor.formatOnSave": true, "editor.formatOnPaste": true } |
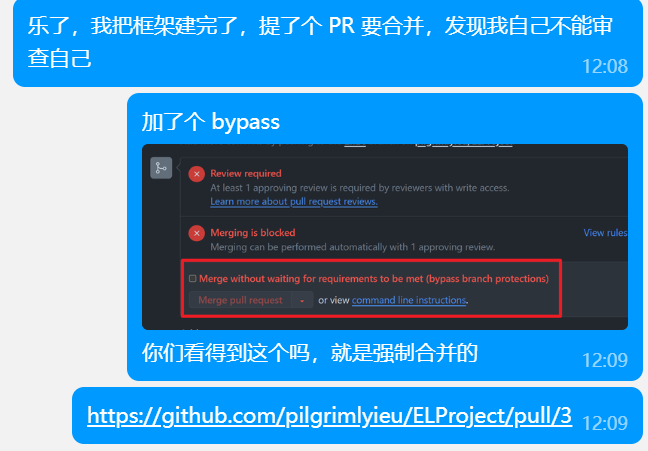
完成上面的工作后发布了 Pull Request #3 初始化项目框架。
然而因为组长设置了 main branch 保护机制,必须要一个 Review Approve 才能合并到主分支,而组长不能审阅自己的代码,组员也并不了解其中的机制,无奈之下组长给 Repo Admin 开了 bypass,并强行合并了 PR。
资料
组长也搜罗了很多资料供组员进行参考。
- 3W(HTML, JavaScript, CSS)
- 前端
- 后端
目前组长本人看完了 3W 的概述,快速翻阅了 JavaScript 的基本语法、面向对象语法、回调与模块等,以及 Vue.js 和 Flask 的快速上手部分。
并为了节约时间,向组员提出了一些阅读建议:
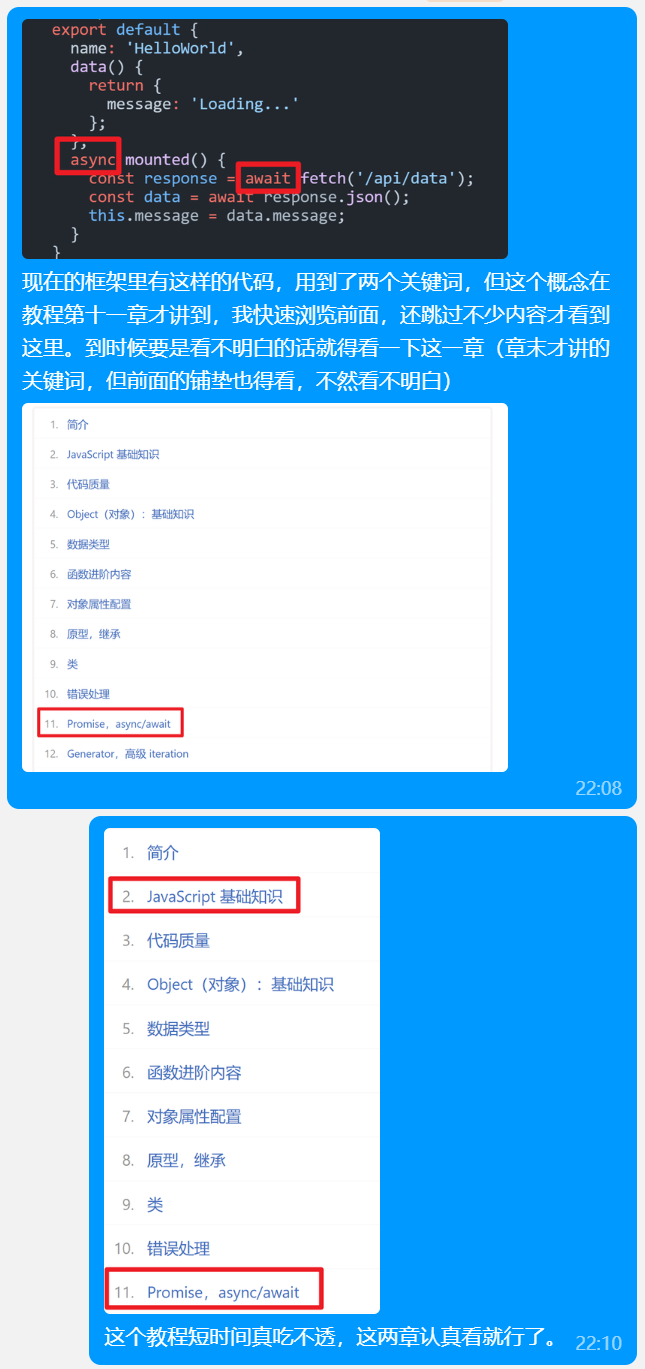
未来也许会对这些资料继续进行补充。
会议内容
- 组长协助组员完成合并主分支操作,及环境复刻等
- 前后端分别讨论并制定开发路线图,进一步确定部分细节、分工与 DDL 等内容,
组长划水 - 组长进一步介绍 Pull Request 发布流程,并正式开始开发
开发线路图
前端

前端开发路线图初稿
原稿
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | #### step_one **1**.**主页面**,包含搜索界面(中部偏上),用户登录,注册,头像按钮(右上角),主体功能(右上角),AI助手(按钮),创作空间(按钮),(个性化)推荐总览(主体),文化库(按钮) #### step_two **2**.**用户界面**(主页),显示头像(左上),用户名(头像右),模块:我的创作,草稿,浏览历史,我的点赞,我的收藏,我的黑名单,我的关注,我的粉丝,我的转发 (1)“**我的草稿**“:搜索页面,新建草稿,已创作草稿(草稿模块),回收站, - 【1】新建草稿页面,标签分类:小说,散文,诗歌...,输入投稿人姓名,投稿人想对读者说的话,新建(按钮) - 【2】已创作草稿页面(草稿编辑页面),字数(左下角),投稿(右上角按钮)(确认or取消),标题名称编辑,目录名称编辑, - 【3】回收站,草稿已有的标签,删除(永久),恢复, (2)“**我的创作**“:搜索页面,创作的过往文章,有获赞数,收藏数,转发数(文章模块) - 【1】文章模块浏览页面(预览):标题,文章,投稿人,发布时间,点赞数,文章所含标签 - 【2】点进某一个模块之后:文章浏览页面:投稿人想对读者说的话,标题,目录,文章,投稿人,(右上,以头像形式显示,点击可进入该作者主页),发布时间,读者点评,文章所含标签 (3)”**浏览历史**“:(左边竖线)浏览时间,(右侧)文章模块 - 【1】文章模块浏览页面(预览):标题,文章,投稿人,发布时间,点赞数,文章所含标签 - 【2】点进某一个模块之后:文章浏览页面:投稿人想对读者说的话,标题,目录,文章,投稿人,(右上,以头像形式显示,点击可进入该作者主页),发布时间,读者点评,文章所含标签 (4)”**我的点赞**“:(左边竖线)浏览时间,(右侧)文章模块 - 【1】文章模块浏览页面(预览):标题,文章,投稿人,发布时间,点赞数,文章所含标签 - 【2】点进某一个模块之后:文章浏览页面:投稿人想对读者说的话,标题,目录,文章,投稿人,(右上,以头像形式显示,点击可进入该作者主页),发布时间,读者点评,文章所含标签 - (5)”**我的收藏**“:(左边竖线)浏览时间,(右侧)文章模块 - 【1】文章模块浏览页面(预览):标题,文章,投稿人,发布时间,点赞数,文章所含标签 - 【2】点进某一个模块之后:文章浏览页面:投稿人想对读者说的话,标题,目录,文章,投稿人,(右上,以头像形式显示,点击可进入该作者主页),发布时间,读者点评,文章所含标签 (6)”**我的关注**“:用户列表 (7)”**我的粉丝**“:用户列表 (8)”**我的转发**“:文章模块 (9)”**我的黑名单**“:文章模块 #### step_three **3**.**分类页面**,搜索,分类。(个性化)推荐, #### step_three **3**.**创作空间**:搜索,文章分类,排行榜,(个性化)推荐总览, (1)**(个性化)推荐总览**:文章模块预览 (2)**文章分类**:小说,散文,诗歌...,点进某一个分类后: - 【1】文章模块预览 - 【2】点进某一个模块之后:文章浏览页面:投稿人想对读者说的话,标题,目录,文章,投稿人,(右上,以头像形式显示,点击可进入该作者主页),发布时间,读者点评,文章所含标签 (3)**排行榜**:文章模块预览 - 【1】点进某一个模块之后:文章浏览页面:投稿人想对读者说的话,标题,目录,文章,投稿人,(右上,以头像形式显示,点击可进入该作者主页),发布时间,读者点评,文章所含标签 #### step_four **4**.**AI助手**,参考chatgpt页面 |
后端
后端开发路线图初稿
原稿
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 | ### Steps #### 1.Users DDL-4.30 **Li** 1. 创建用户 - API: `POST /api/users/register` - req: name, password. - res: 2. 注销用户 - API: `DELETE /api/users/delete/{id}` - req: ; - res: ; 3. 用户登录 - API: `POST /api/users/login` - req: name, password. - res: 4. 用户登出 - API: `DELETE /api/users/logout/{id}` - req: ; - res:; 5. 用户信息界面 - API: `GET /api/users/info/{id}` - req: ; - res: 性别,生日,... 6. 更新用户信息 - API: `PUT /api/users/info/{id}` - req: 性别,生日,... - res: ; **Mao** 7. 显示收藏列表 - API: `GET /api/users/{id}/collect` - req: (进入收藏文章,我的想法是使用查看文章功能) - res: 8. 显示作品列表 - API: `GET /api/users/{id}/works` - req:; - res:; 9. 显示关注列表 - API: `GET /api/users/{id}/following` - req:; - res:; #### 2.Article DDL-5.12 **Li** 1. 新建文章 - API: `POST /api/article/new` - req: (content),作者info,header... - res: ; 2. 更新文章 - API: `PUT /api/article/update/{id}` - req: content - res: ; 3. 查看文章 - API: `GET /api/article/get/{id}` - req: ; - res: 内容,作者info, 4. 下载文章 - API: `GET /api/article/get/download/{id}` - req: ; - res: 内容 5. 删除文章 - API: `DELETE /api/article/delete/{id}` - req: ; - res: ; 6. 为文章添加分类 - API: `PUT /api/article/{id}/categories` - req: 类型(网页给定) - res: ; 7. 从指定文章删除分类 - API: `DELETE /api/article/{id}/categories/{categoryld}` - req: ; - res:; 8. OCR导入旧文档 - API: `POST /api/ocr` - ...? #### 2.Assistant DDL-5.12 **Mao** 1. 获取文化库到本地 - API: `GET /api/library/` - req: 文化库id - res: ; 2. 新增文化库中内容 - API: `POST /api/library` 3. 更新个人文化库中的内容 - API: `PUT /api/library/{id}` - req: 内容; - res: ; 4. 删除文化库中内容 - API: `DELETE /api/library/{id}` - req: ; - res: ; 5. 分享文化库到公用 - API: `POST /api/library/share` - req: ; - res: ; 6. 将文化库设置为本地独有 - API: `DELETE /api/library/share/{id}` - req: ; - res: ; 7. AI生成文字 - API: `GET /api/ai/words` - req: 需求; - res: ; 8. AI生成图片 - API: `GET /api/ai/images` - req: ; - res: ; 9. AI引用文化库 - API: `GET /api/ai/refer` - req: 要求; - res: ; 10. 翻译功能 - API: `GET /api/translate` - req: 内容; - res: ; #### 3.Interaction DDL-5.23 1. 为指定文章点赞 - API: `POST /api/article/{id}/likes` - req: ;(谁给你赞不重要) - res: ; 2. 取消点赞 - API: `DELETE /api/article/{id}/likes` - req: ; - res: ; 3. 为指定文章添加评论 - API: `POST /api/article/{id}/comments` - req: 评论用户info,评论内容 - res: ; 4. 更新指定评论 - API: `PUT /api/article/{id}/comments/{comid}` - req: 内容 - res: ; 5. 删除评论 - API: `DELETE /api/article/{id}/comments/{comid}` - req: ; - res: ; 6. 回复评论 - API: `POST /api/article/{id}/comments/{comid}/reply` - req: 评论用户info,评论内容 - res: ; 7. 更新回复 - API: `PUT /api/article/{id}/comments/{comid}/reply/{replyid}` - req: 内容; - res: ; 8. 删除回复 - API: `DELETE /api/article/{id}/comments/{comid}/reply/{replyid}` - req: ; - res: ; 9. 收藏文章 - API: `POST /api/article/{id}/users/{id}/collect` - req: ; - res: ; 10. 进入某一类 - API: `GET /api/categories` - req: 类名; - res: ; 11. 关注 - API: `POST /api/users/{id}/follow` - req: ; - res: ; 12. 搜索header中的关键词 - API: `POST /api/search` - req: 关键词 - res: 返回搜索结果界面 |
- 后端组成员
- 撰写人:@t0mo0n
前端开发流程
主页面
内容:
- 用户信息
- 创作空间
- 分类
- 收藏
- 搜索框
- 文化库
- 个性化推荐
用户信息界面
- 未登录
- 注册
- 登录
- 登录后
- 用户信息:头像、昵称、性别、生日、简介等
- 信息编辑
- 作品列表
- 草稿列表
- 关注列表
- 粉丝列表
- 收藏列表
- 关注列表
- 草稿
- 新建草稿:标题、内容、标签
- 编辑草稿:字数统计、保存、发布
- 删除草稿:回收站、彻底删除
- 作品
- 新建作品:标题、内容、标签
- 作品信息:作者、字数、点赞量、评论量
- 编辑作品:字数统计、保存、发布
- 删除作品:回收站、彻底删除
- 历史记录
- 浏览记录
- 搜索记录
- 点赞记录
- 评论记录
分类
- 分类列表
创作空间
- 编辑器
- 文化库
- AI 助手
API Reference
二版 API Reference,随后可能在实际开发中进一步确定参数、返回值等细节,以及调整现有 API 或增加新的 API。
- Users
users.py
| HTML 方法 | URL | 参数 | 返回值 | 说明 |
|---|---|---|---|---|
POST |
/api/users/register |
name, password |
- | 创建用户 |
DELETE |
/api/users/delete/{uid} |
- | - | 注销用户 |
POST |
/api/users/login |
name, password |
- | 用户登录 |
DELETE |
/api/users/logout/{uid} |
- | - | 用户登出 |
GET |
/api/users/info/{uid} |
- | gender, birthday, … |
用户信息 |
PUT |
/api/users/info/{uid} |
gender, birthday, … |
- | 更新用户信息 |
GET |
/api/users/{uid}/collect |
- | - | 收藏列表 |
GET |
/api/users/{uid}/works |
- | - | 作品列表 |
GET |
/api/users/{uid}/following |
- | - | 关注列表 |
- Article
article.py
| HTML 方法 | URL | 参数 | 返回值 | 说明 |
|---|---|---|---|---|
POST |
/api/article/new |
content, author_info, header, … |
- | 新建文章 |
PUT |
/api/article/update/{aid} |
content |
- | 更新文章 |
GET |
/api/article/get/{aid} |
- | content, author_info, … |
查看文章 |
GET |
/api/article/download/{aid} |
- | content |
下载文章 |
DELETE |
/api/article/delete/{aid} |
- | - | 删除文章 |
PUT |
/api/article/{aid}/categories |
type |
- | 添加分类 |
DELETE |
/api/article/{aid}/categories/{category} |
- | - | 删除分类 |
POST |
/api/ocr |
… | … | OCR 导入旧文档 |
- Assistant
assistant.py
| HTML 方法 | URL | 参数 | 返回值 | 说明 |
|---|---|---|---|---|
GET |
/api/library |
lid |
- | 获取文化库到本地 |
POST |
/api/library |
- | - | 新增文化库中内容 |
PUT |
/api/library/{lid} |
content |
- | 更新文化库中内容 |
DELETE |
/api/library/{lid} |
- | - | 删除文化库中内容 |
POST |
/api/library/share |
- | - | 分享文化库到公用 |
DELETE |
/api/library/share/{lid} |
- | - | 将文化库设置为本地独有 |
GET |
/api/ai/words |
demand |
- | AI 生成文字 |
GET |
/api/ai/images |
- | - | AI 生成图片 |
GET |
/api/ai/library |
requirement |
- | AI 引用文化库 |
GET |
/api/translate |
content |
- | 翻译功能 |
- Interaction
interaction.py
| HTML 方法 | URL | 参数 | 返回值 | 说明 |
|---|---|---|---|---|
POST |
/api/article/{aid}/likes |
- | - | 为指定文章点赞 |
DELETE |
/api/article/{aid}/likes |
- | - | 取消点赞 |
POST |
/api/article/{aid}/comments |
comment_user_info, content |
- | 为指定文章添加评论 |
PUT |
/api/article/{aid}/comments/{cid} |
content |
- | 更新指定评论 |
DELETE |
/api/article/{aid}/comments/{cid} |
- | - | 删除评论 |
POST |
/api/article/{aid}/comments/{cid}/reply |
reply_user_info, content |
- | 回复评论 |
PUT |
/api/article/{aid}/comments/{cid}/reply/{rid} |
content |
- | 更新回复 |
DELETE |
/api/article/{aid}/comments/{cid}/reply/{rid} |
- | - | 删除回复 |
POST |
/api/article/{aid}/users/{uid}/favorite |
- | - | 收藏文章 |
GET |
/api/categories |
category |
- | 进入某一类 |
POST |
/api/users/{uid}/follow |
- | - | 关注 |
POST |
/api/search |
keyword |
- | 搜索 header 中的关键词 |
流程
写代码与合并更改流程:
- 写代码前,切换到 main 分支,同步 GitHub 的更改,再切回来
- 如果 main 上有更新,将 main 上的更新合并到自己的分支上
- 写代码……
- 每完成一个部分(一个部分的界定可以有自己的理解),提交一个 Pull Request,写好标题,同时内容详细说明这个 Pull Request 实现了什么,我会尽快审查合并或提出建议
- 或者完成了一天的代码工作,今天不会更新了,即使一个函数或某个部分还没写完,也先用注释标记未完成部分,提交一个 Pull Request,跟上面一样,而且需要另外说明未完成的部分
- 打开后端:先启动 Python 虚拟环境,再在 server 文件夹打开 Bash,运行
flask run(或flask run --reload) - 打开前端:在 client 文件夹打开 Bash,运行
vue serve - 关闭前/后端:Ctrl + C
5 月 10 日记录
- 记录人:@PilgrimLyieu
- 记录时间:2024 年 5 月 10 日
距离上次记录已经过去快三周了,随后因为期中考试中断了一次组会,在五一我也忙着开发,也没来得及对当前进度进行记录。恰逢今日是中期报告 DDL,于是借此机会总结一下近段时间的工作进度,同时为中期报告提供素材。
Bash
由于前后端调试的命令过于冗长,如后端需要先启动虚拟环境再启动 Flask 服务,因此我写了两个 Bash 脚本 elc.sh(EL Client)与 els.sh(EL Server),放在了项目 asset 文件夹,内容分别如下:
1 2 3 | pushd "$elproject_path/client" > /dev/null vue serve popd > /dev/null |
1 2 3 4 5 | pushd "$elproject_path/server" > /dev/null source ../.venv/Scripts/activate flask run --reload deactivate popd > /dev/null |
随后在 ~/.bash_profile 加入如下别名,并将对应 elproject_path 赋值为自己的 EL 项目路径:
1 2 3 | elproject_path='/d/project/school/elproject' alias elc="elproject_path='$elproject_path' '$elproject_path/asset/elc.sh'" alias els="elproject_path='$elproject_path' '$elproject_path/asset/els.sh'" |
这是最终改进版本,一开始用的是在 .bash_profile 定义两个函数,但是考虑到如果用 Ctrl + C 中止 Vue 或 Flask 服务时,会直接终止函数,也即不会回到执行命令时的地方,后端也不会退出 Python 虚拟环境,因此在查阅相关资料后改为了使用外部脚本。
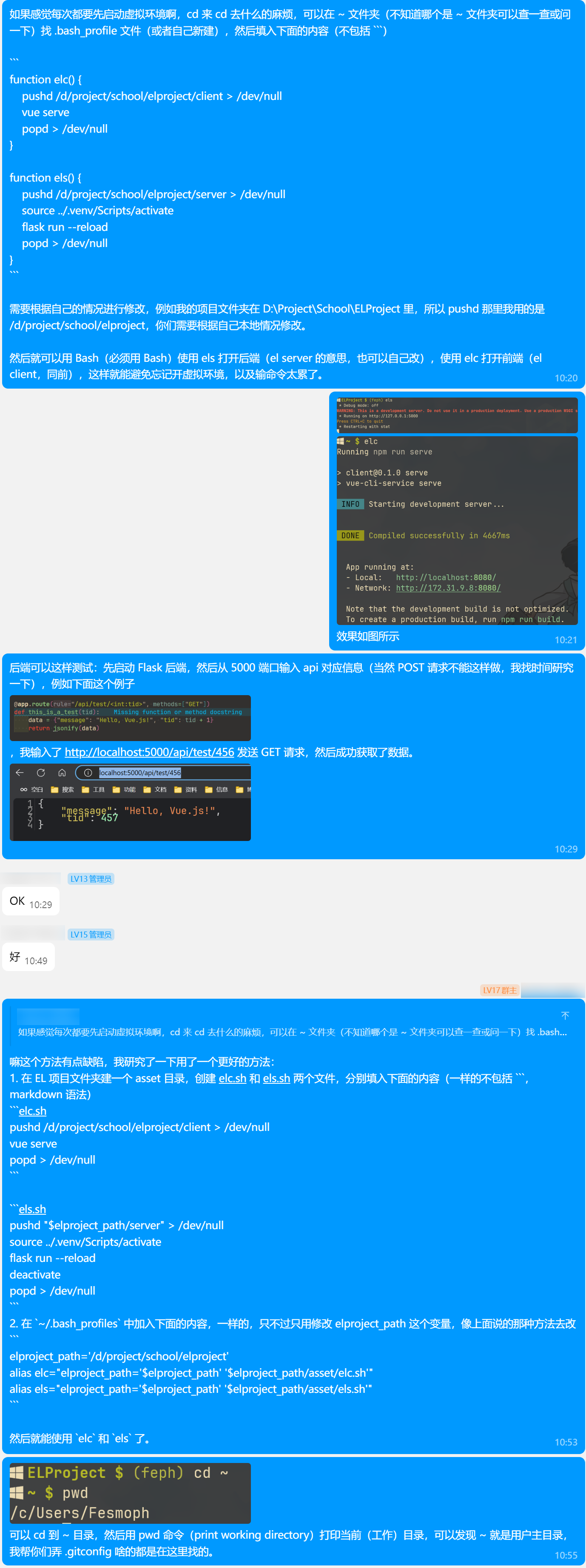
图中是 QQ 群聊天记录中的初版,也有一些错误,后面修正了。
资料
四月底通宵时发现了一个仓库:javayhu/poetry,里面存储了古诗文网的数据,包括诗词、作者甚至还有标签等信息,出乎我的意料。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | { "about": "创作背景\n\n 唐玄宗天宝初年,李白xxx", "content": "君不见,黄河之水天上来,奔流到海不复回。xxx", "dynasty": "唐代", "fanyi": "译文\n你难道看不见那黄河之水从天上奔腾而来,波涛翻滚直奔东海,从不再往回流。xxx", "id": 7722, "name": "将进酒", "poet": { "desc": "李白(701年-762年),字太白,号青莲居士,唐朝浪漫主义诗人,被后人誉为“诗仙”。xxx", "id": 247, "image": "https://raw.githubusercontent.com/hujiaweibujidao/poetry/master/image/image_247.jpg", "name": "李白", "star": 0 }, "shangxi": "鉴赏\n\n 将进酒,唐代以前乐府歌曲的一个题目,内容大多咏唱饮酒放歌之事。xxx", "star": 32615, "tags": [ "乐府", "唐诗三百首", "咏物", "抒情", "哲理", "宴饮" ] } |
1 2 3 4 5 6 7 8 9 | { "content": "轶事典故\n\n姓名由来\nxxx", "desc": "李白(701年-762年),字太白,号青莲居士,唐朝浪漫主义诗人,被后人誉为“诗仙”。xxx", "dynasty": "唐代", "id": 247, "image": "https://raw.githubusercontent.com/hujiaweibujidao/poetry/master/image/image_247.jpg", "name": "李白", "star": 4895 } |
这让我比较头疼的数据方面得到了解决。
同时在五一期间,让 Copilot 写了两个 Python 脚本 cutData.py 与 extractTags.py 对这些数据作进一步的处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import os import json import heapq def keep_top_star_files(directory, count): # 创建一个列表来存储 (star, filename) 对 star_files = [] # 遍历目录中的所有文件 for filename in os.listdir(directory): with open(os.path.join(directory, filename), "r") as f: data = json.load(f) star = data.get("star", 0) star_files.append((star, filename)) # 只保留 star 数量排名前 count 的文件 top_star_files = set(file for star, file in heapq.nlargest(count, star_files)) # 删除 star 数量不在前 count 的文件 for filename in os.listdir(directory): if filename.endswith(".json") and filename not in top_star_files: os.remove(os.path.join(directory, filename)) ### 使用函数 count = 1000 source = "./poetry" keep_top_star_files(source, count) |
原数据足有 72000+ 的诗词,出于性能方面以及只是一个玩具的考量,仅保留了 star 排名前 1000 的诗词。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | import os import json ### 创建一个空字典来存储标签和对应的诗词信息 tags_dict = {} source_folder = "./poetry" target_folder = "./tag" star_count = 10 ### 遍历文件夹中的每个 JSON 文件 for filename in os.listdir(source_folder): with open(os.path.join(source_folder, filename), "r", encoding="utf-8") as f: data = json.load(f) tags = data["tags"] for tag in tags: if tag not in tags_dict: tags_dict[tag] = [] tags_dict[tag].append({"id": data["id"], "star": data["star"]}) ### 对字典中的每个标签,将其诗词列表按照 star 数递减的顺序排序 for tag, poems in tags_dict.items(): tags_dict[tag] = sorted(poems, key=lambda x: x["star"], reverse=True) for pid, poem in enumerate(tags_dict[tag], start=1): poem["pid"] = pid ### 计算每个标签的前几首诗词的 star 总和 tag_star_sum = { tag: sum(poem["star"] for poem in poems[:star_count]) for tag, poems in tags_dict.items() } ### 根据 star 总和排序标签 sorted_tags = sorted(tag_star_sum.items(), key=lambda x: x[1], reverse=True) ### 将排序后的数据写入新的 JSON 文件 for tid, (tag, _) in enumerate(sorted_tags, start=1): poems = tags_dict[tag] with open( os.path.join(target_folder, f"{tid:03d}-{tag}.json"), "w", encoding="utf-8" ) as f: json.dump( {"tid": tid, "tag": tag, "sum": len(poems), "poems": tags_dict[tag]}, f, ensure_ascii=False, indent=4, ) |
单独抽离出了标签信息,以及每个标签下的诗词信息,这样就可以方便按标签列举诗词了。
变化
四月底时,焦虑于进度缓慢,无从下手,深感无力。之前宏伟的构想,现在看来也只是空中楼阁,不切实际。于是我个人做出了决定,只关注最初构想中与主题最为相关的核心功能,也即编辑器附上文化库,便是我们最大的特色。
因此我也私自做了决定,重新进行了构想。画出了下面的框架图,决定以这为目标进行开发。
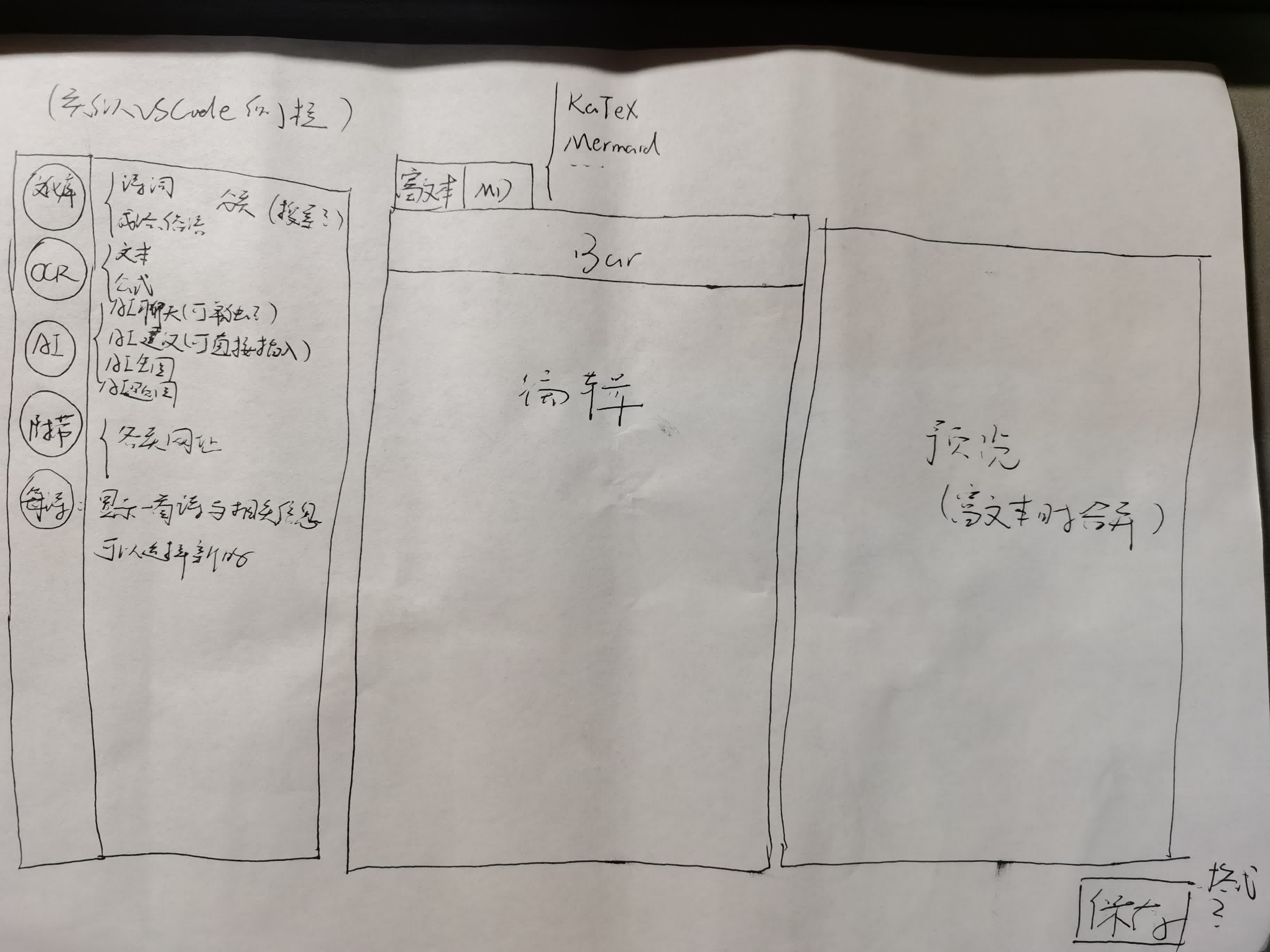
也不知是应该值得庆幸还是,组员们五一期间并没有作出什么实质性的 commit,因此我做了这样大方向的调整也没有太大的心理负担。
因此也顺带关闭了 #4 ~ #11 这 8 个跟踪项目开发进度的 issue。手动关闭一个后感觉挺慢挺累的,于是决定使用 gh 命令行进行关闭:
for i in {4..11}; do gh issue close --reason "not planned" $i; done |
于是我五一开始朝着这个方向,全身心投入开发前端,目前进度如下:
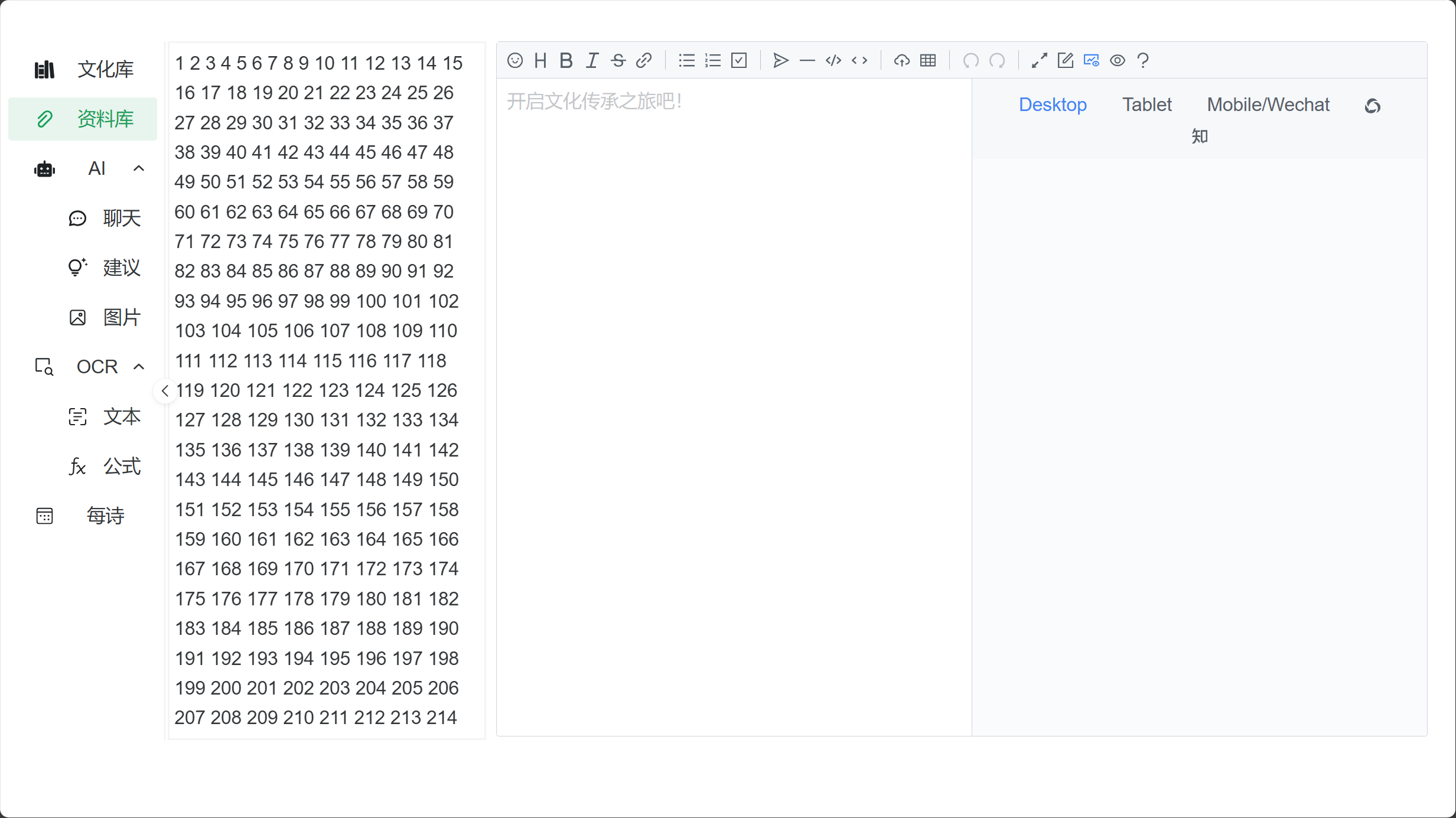
这个项目中我感受最深的便是无力,由于毫无 Web 应用开发经验,甚至是怎么问、怎么查这样最基础的问题也都是束手无策,只能自己不断和 Copilot, Google, StackOverflow 斗智斗勇,摸着石头过河。
五一期间大体就完成了框架,并在实践过程中决定放弃了富文本编辑器,因为引入的 markdown 编辑器足够好了,同时也有 WYSIWYG(What You See Is What You Get, 所见即所得) 的特性,也足以承载其承担富文本编辑器的功能。
即使是最简单的一个点击左侧 Menu 切换类 VSCode 侧边栏内容组件的功能,我也是费了九牛二虎之力才弄出来了,确实是心力憔悴。
现在的任务便是将左侧的几个组件进行实现。
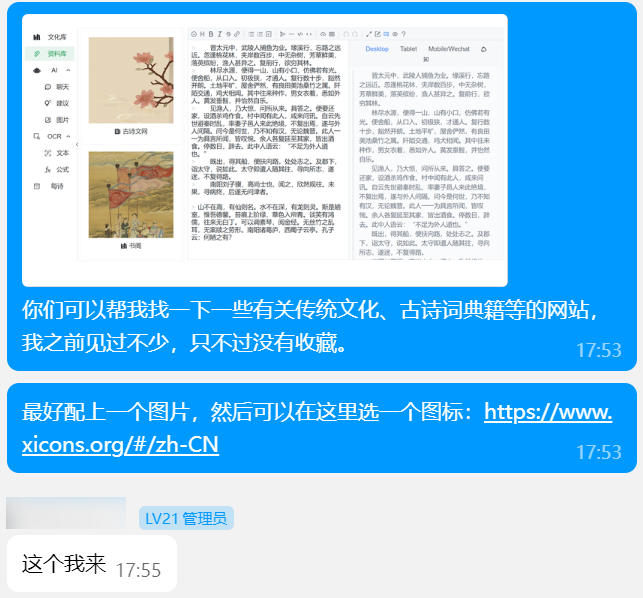
- 文化库:有很多按标签分类的诗词,可以通过点击了解详细信息,并且可以插入到编辑器中。也是项目的特色功能。
- 资料库:提供一些文化相关的网站进行参考,如古诗文网与一些古籍网站等。可能是这几个组件中实现起来最为容易的一个了,只需要贴上图片和名称,再附上链接即可。
- AI:本计划提供聊天、建议和图片三种功能,但是可能能力与时间不足以支撑完成这个功能,因此优先级最低。
- OCR:算是我自己的小私货,优先级次之。
- 每诗:名字起得不太好,暂时没想到更好的。简而言之就是随机显示文化库中一首诗词与相关信息,对用户进行诗意的熏陶。
大概优先级是「文化库」>「每诗」>「资料库」>「OCR」>「AI」。难度我估计是「AI」>「文化库」>「OCR」>「每诗」>「资料库」。
由于我目前全部投入到前端的工作中,也不知道后端方面该如何开展工作,甚至不知道还有没有必要后端,似乎可以全由前端方面来完成。
再加上项目方向的大变动,初版的 API Reference 已经跟当前的方向相差甚远了,因此我也弃用了 API Reference。
变故
6 号的时候负责前端的组员私聊告诉我,因为个人原因以及对项目无从下手,决定退出了项目。私聊内容出于隐私原因不便在此给出。
我同意了请求,并接过了前端开发的任务,目前项目的前端开发全部由我来负责。

5 月 30 日记录
- 记录人:@PilgrimLyieu
- 记录时间:2024 年 5 月 30 日
距离上次记录又过去了近三周。上次记录是在中期文档 DDL 时记录的,而今天则是在最终项目 DDL 来写下从中期文档以来项目的进程。
昨天,也就是 29 号晚,已经把最终项目成品发邮件提交了,最重要的代码部分也就此告一段落了。也算是长舒一口气了。
还是感慨万分,我和组员们是完全没有前端开发经验的,从几次开会才确定具体方向,但一直没有开始真正写代码,到后面推倒重来,重新开辟一条新的路径,才让项目焕发了新的生机。
即便如此,在中期文档时我也是内心含着忧虑,心中其实已经将 AI 组件放弃了,想着要是能完成其它组件,就已经基本算「大功告成」了,而 AI 部分,就可以写在所谓的「未来展望」当中了。
然后即使开始写代码,毕竟是懵懂无知的新手,在开发第一个组件,也就是 CultureLibrary 组件时也曾对着 VSCode 一个下午毫无进展,内心濒临崩溃,一度关掉全部窗口,打算就此放弃了。
好在,还是最终坚持下来了,组件的进度突飞猛进,还有组员的学习进度也超出了我的预期,帮助我完成了部分 AI 组件的代码。可以说是超预期实现了我起初的构想。
垃圾邮件
已经发了中期文档,但是却位列尚未提交的名单,原来是中期文档邮件被当成垃圾邮件了。
历程
下面截取一些 QQ 群里的开发历程,基本是我本人完成一部分工作后比较兴奋的写照。
CultureLibrary 组件
11 日终于基本实现了文化库组件,可见相较于现在,最初的版本还是比较简陋的(虽然现在其实也不怎么样)。
随后经过差不多三个小时,也终于完成了预想中点击出现详细信息的效果。
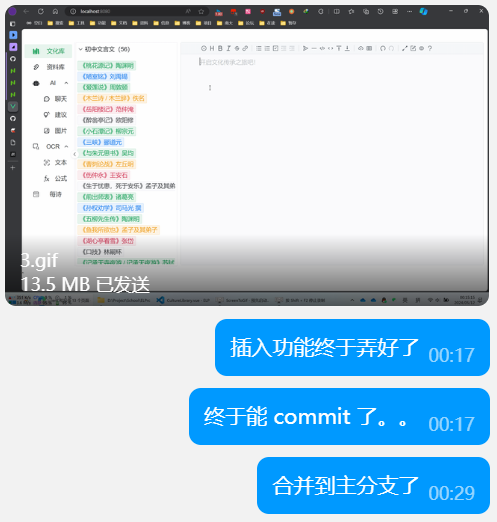
零点后也在写,总算是基本完成了构想中的全部功能。并提交了我的第一个代码 PR:完成 CultureLibrary 组件。
Copilot 的经验之谈
在完成 CultureLibrary 组件后,我也算是有点「开窍」了。在与 Copilot 的拉扯、相爱相杀中,我也逐渐掌握了一点技巧。
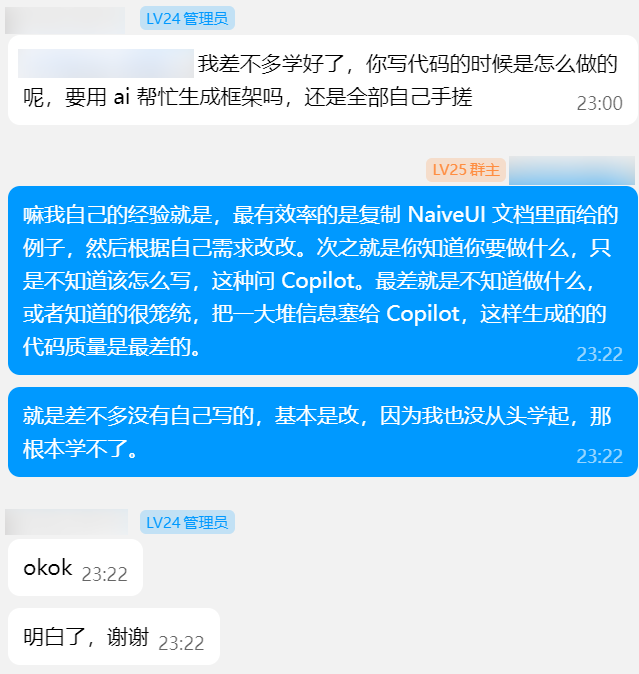
其实说「差不多没有自己写的」也不甚准确,至少后面不太准确了。后面熟悉一点写法后,自己写的比例就大大提高了,只有一些可能只出现一次两次的用法还是会去请教 Copilot。
而这时候实际上已经到 16 号了。
Attachment 组件
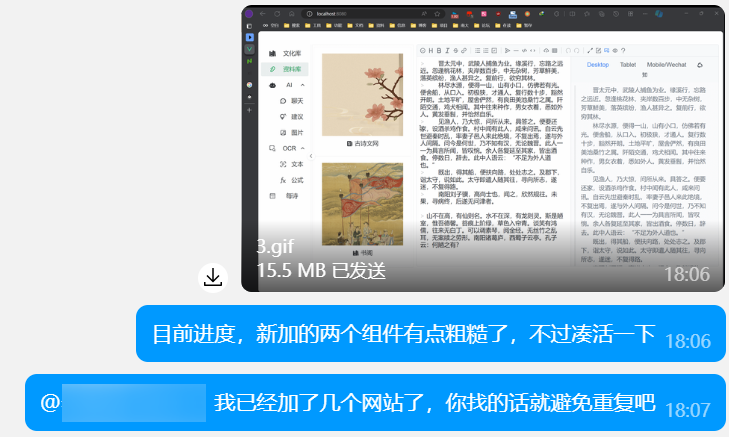
然后到了 18 号,完成了最简单的组件「资料库」,即便如此调图片也耗费了蛮多精力,最后也是随便糊弄一下了。
在逐渐适应了,有点「如鱼得水」后,我也给组员委派了比较简单的工作,只是简单的重复工作,完全不需要有相应的代码基础。
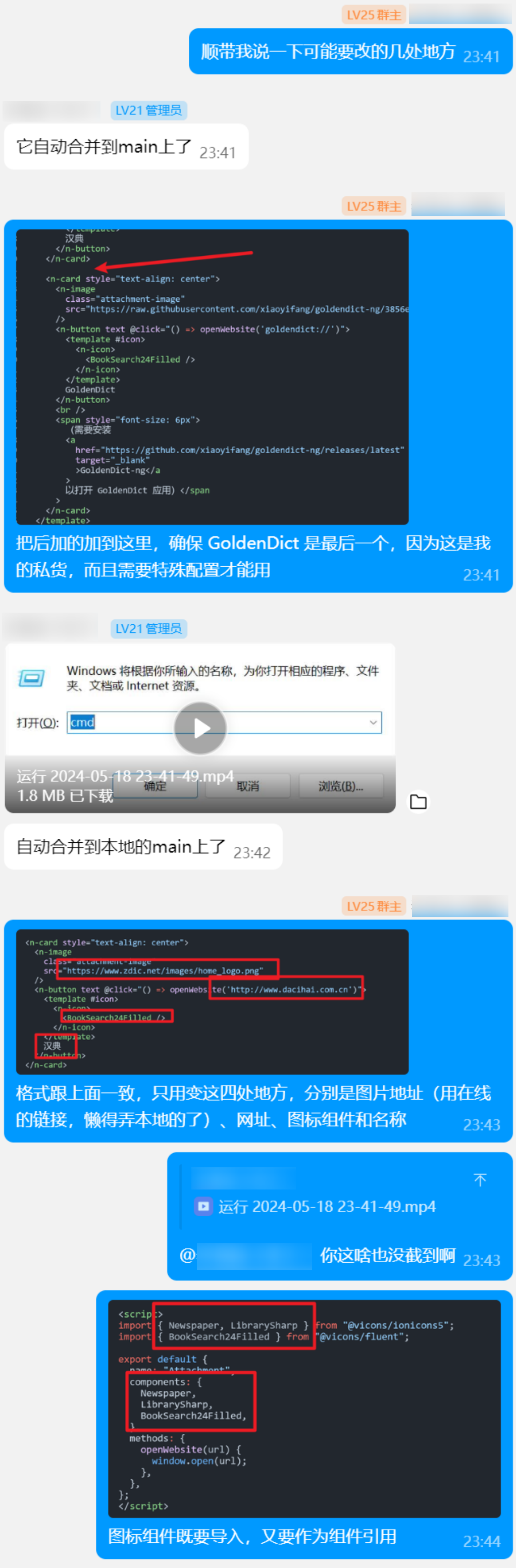

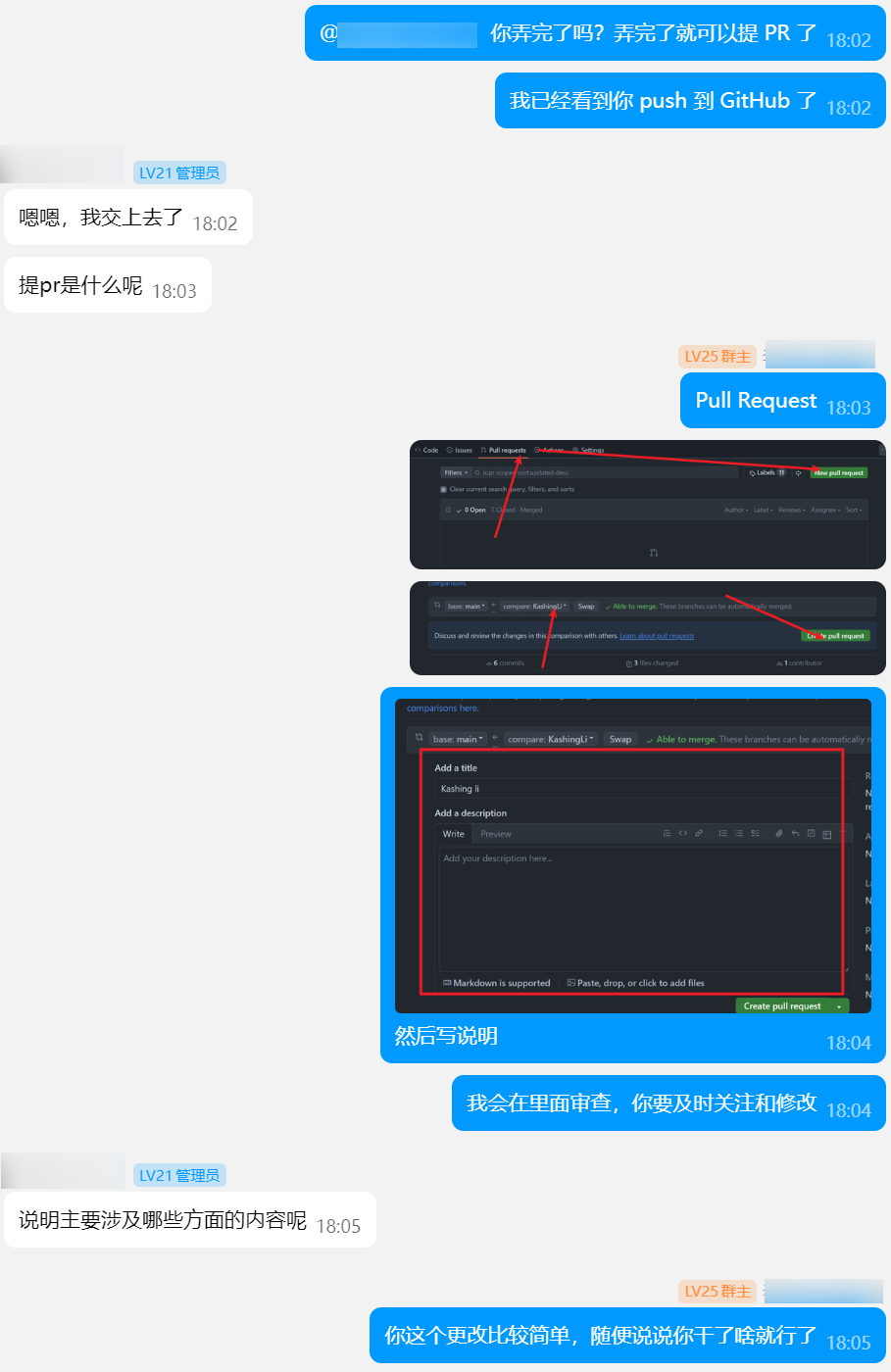
即便如此我也详细地说明了要改什么、怎么改。除此之外还有 VSCode 的 Git、GitHub Pull Request 等等的指导。
也让每个组员都能够体验一下合并一个 PR:为 Attachment 组件添加俩个文化库(经典国学网和中国国学网),并修复一处网址错误
与此同时,另一个组员也揽了 AI 组件的任务。
TextOCR 组件
OCR 组件基本是很早就定下来了,毕竟是我个人的私货,以及 OCRC 至少目前在我这里还是有很重的地位的。最终在 18 日完成。
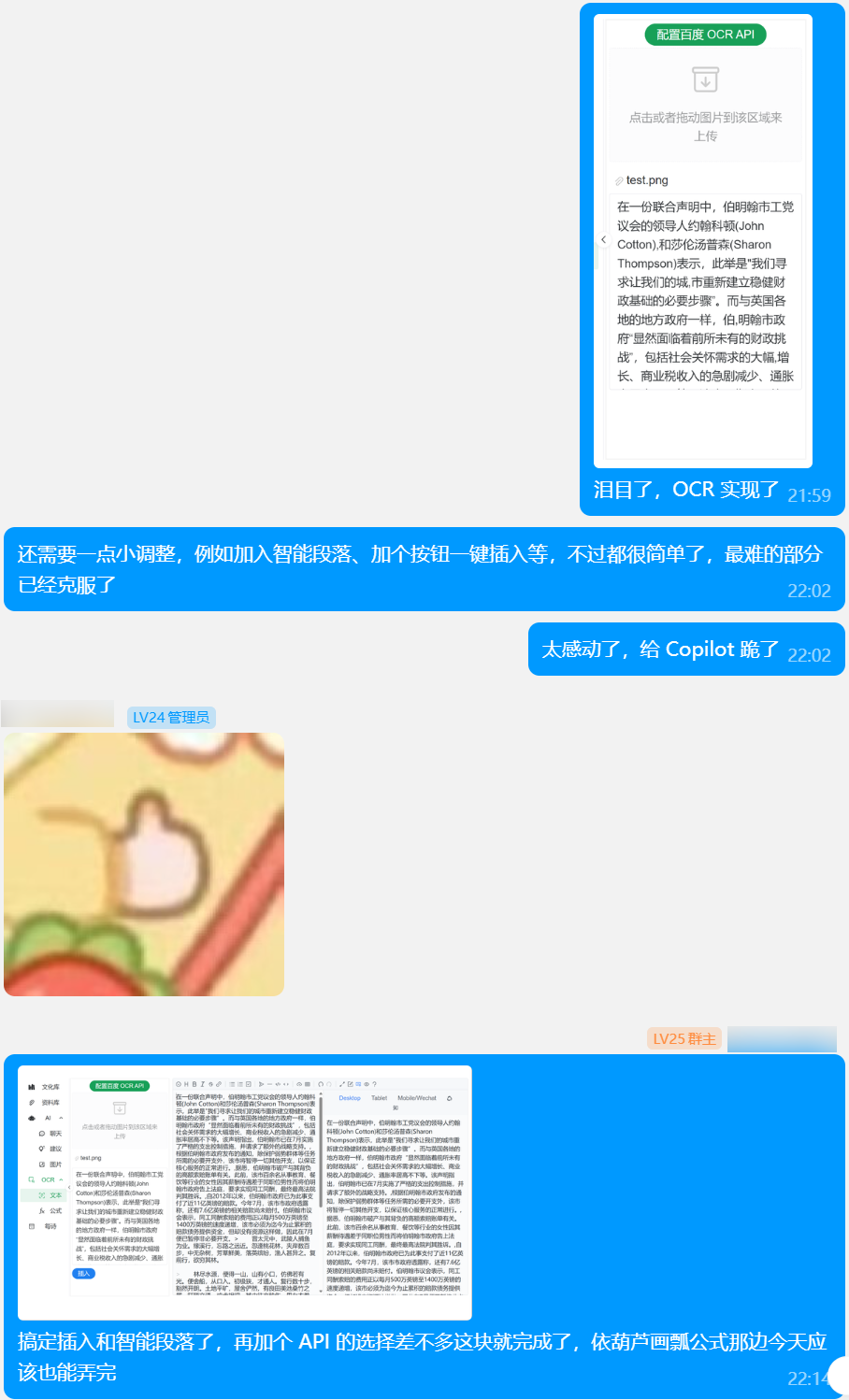
可以发现用来测试的图片,与 OCRC 的介绍文档一模一样。
隐私意外
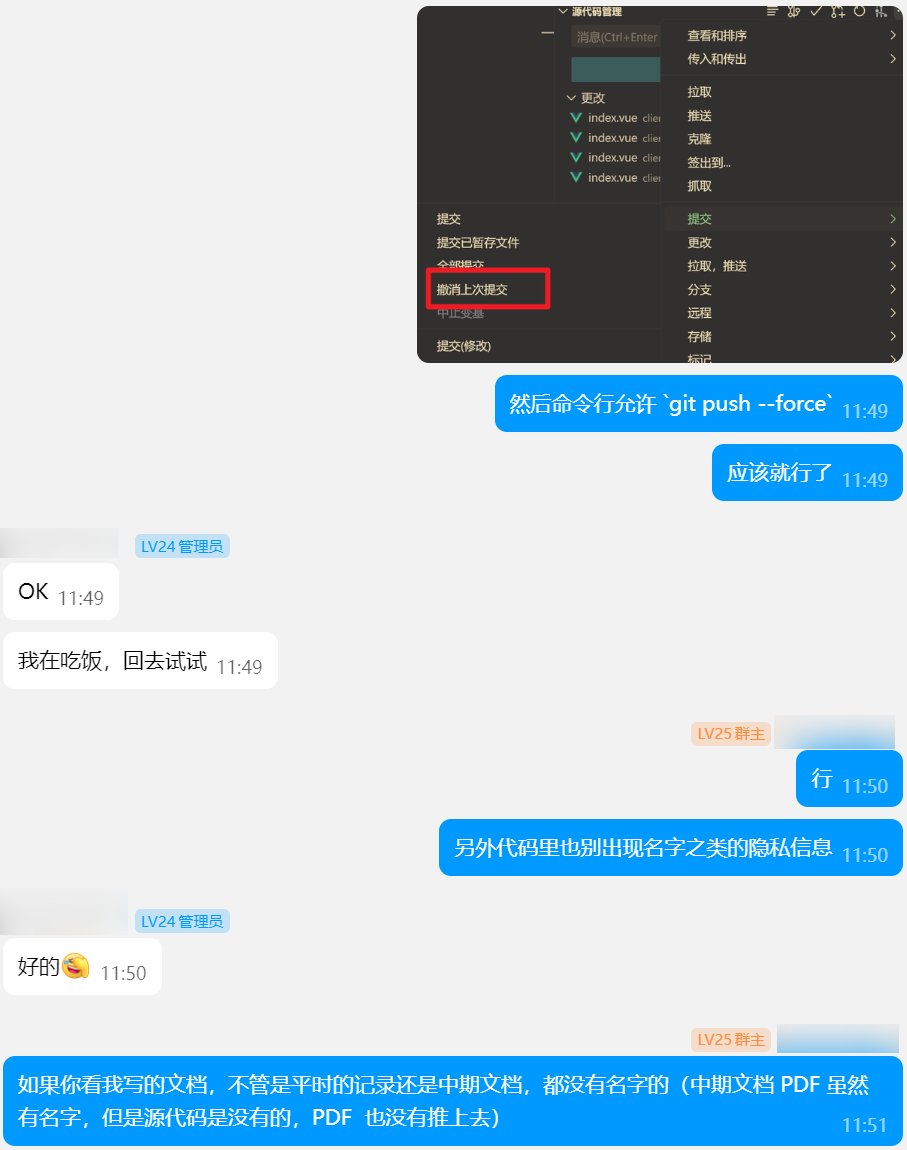
21 日时一位组员意外将隐私信息提交到了 GitHub 上,被我发现了。
其实远没有这么简单就能解决,GitHub 记录了每个 commit,即使 force push 了 commit 还是在的,只不过是 dangling 的。
然后 23 年 GitHub 增加了个 activity page,那就更致命了,还能直接定位 force push,直接找到隐私信息。
好在这种局面我也不是没遇见过,解决方法就是找 GitHub Support,去清理仓库 cahce。不过上次开 ticket 也为时已久了,刚去弄时还忘了咋搞,以为可以了实际上还没创建 ticket。
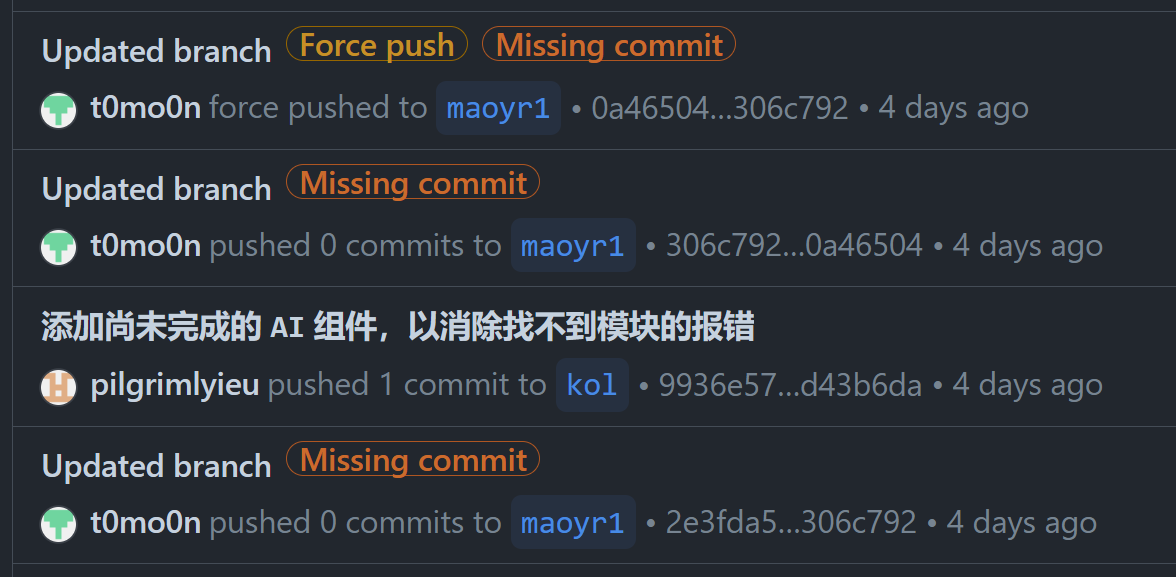
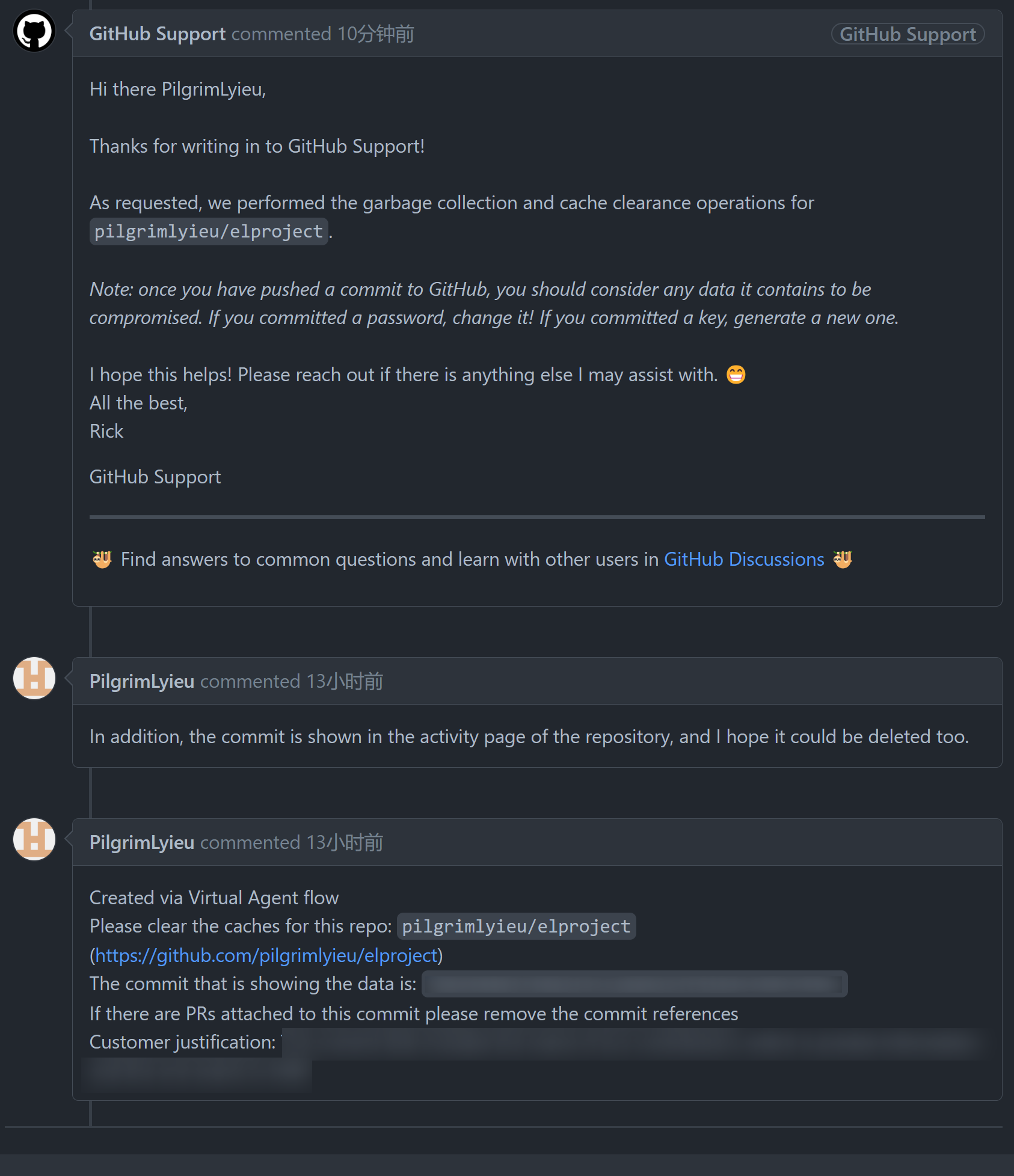
这样才算是清理掉了隐私信息。
另外今天(5 月 30 日)还更新了中期文档,增加了用以区分公开和私密版本中期文档的代码,同时提交了下公开版本的中期文档。
1 2 3 4 5 6 7 | \def\PUBLICVERSION{} \ifdefined\PUBLICVERSION \input{public.tex} \else \input{private.tex} \fi |
FormulaOCR 组件
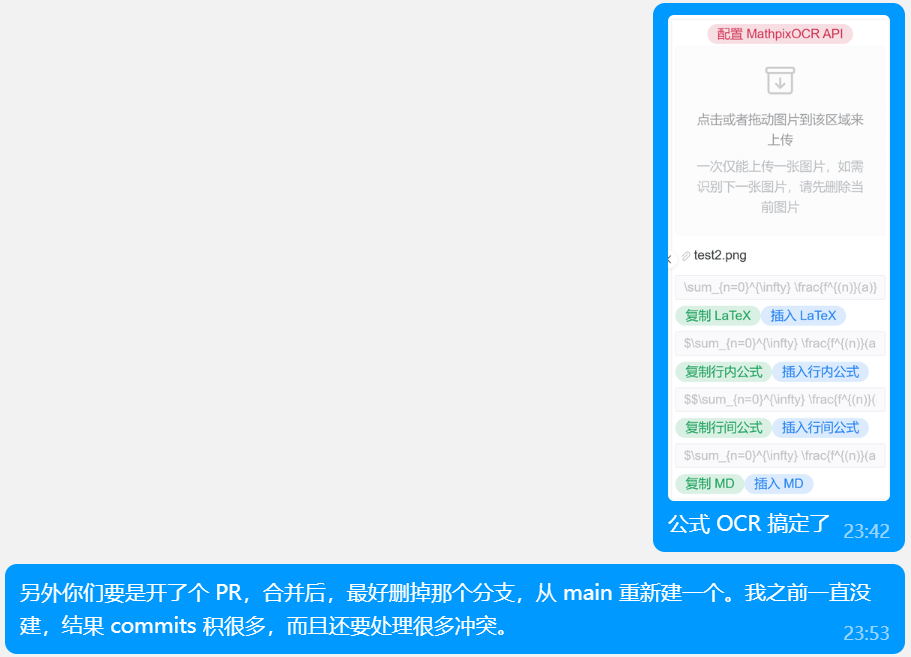
21 日晚,公式 OCR 组件也顺利完工了。当然没有像 18 日晚说的那样,当天「依葫芦画瓢」就能搞定。
AI 指导
22 日,完成挺多组件后,我没有立刻投入到新组件的开发,而是决定优化一下现有的组件。与此同时,也给开发 AI 组件的组员提供了一些指导。
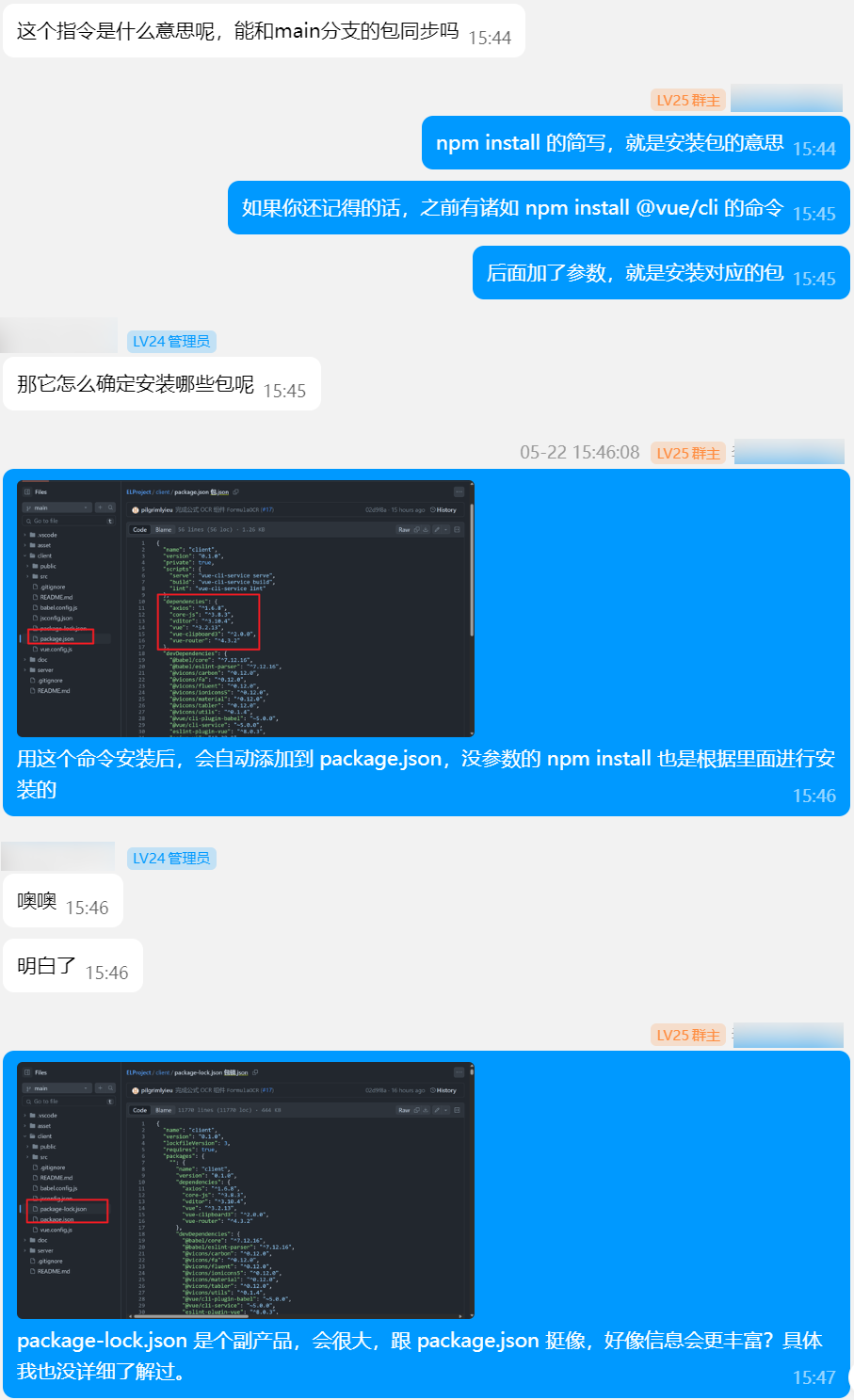
上面的内容是我乱讲的,纯粹是我个人的感觉,只不过也懒得去查证真实的答案。

比如讲了一下如何看调用结果,以及端口转发的事情。讲述了我踩的一些坑以及解决方案。当然也都是个人经验,实际上可能有很多问题。
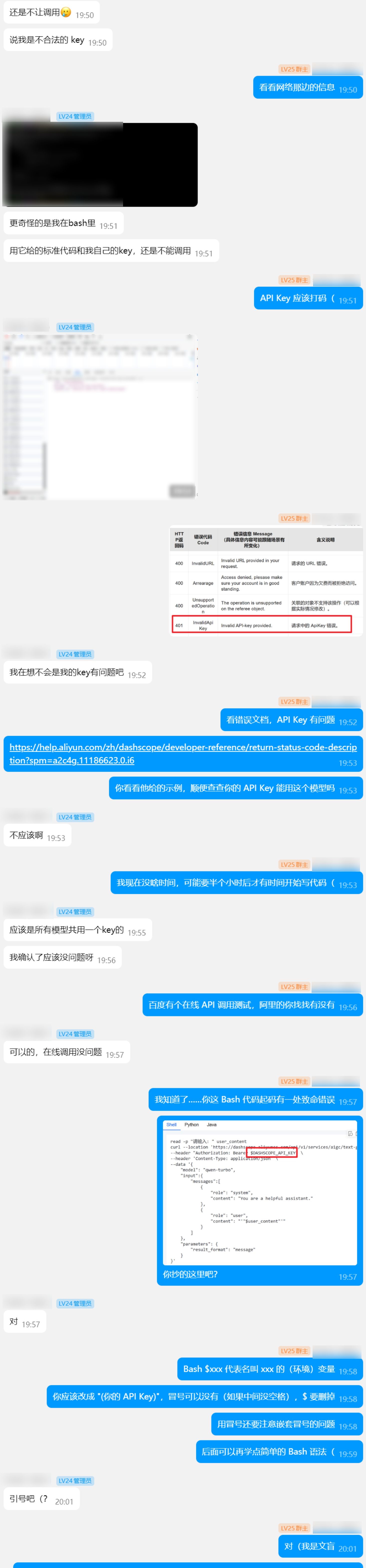
比如 Bash 的语法问题。

还有代码问题……(太多了我就只截取开头的部分了,后面还有关于 message 等等方面的问题)

我的重构优化进行中……以及产品名称「春纷」此刻已经诞生了。
重构优化
18 日的时候就已经计划进行代码优化了。

22、23 两天,我重构了部分现有的组件,修改了数据结构,以实现优化:优化现有组件,以提高代码可读性、可拓展性等及 Web 应用性能。
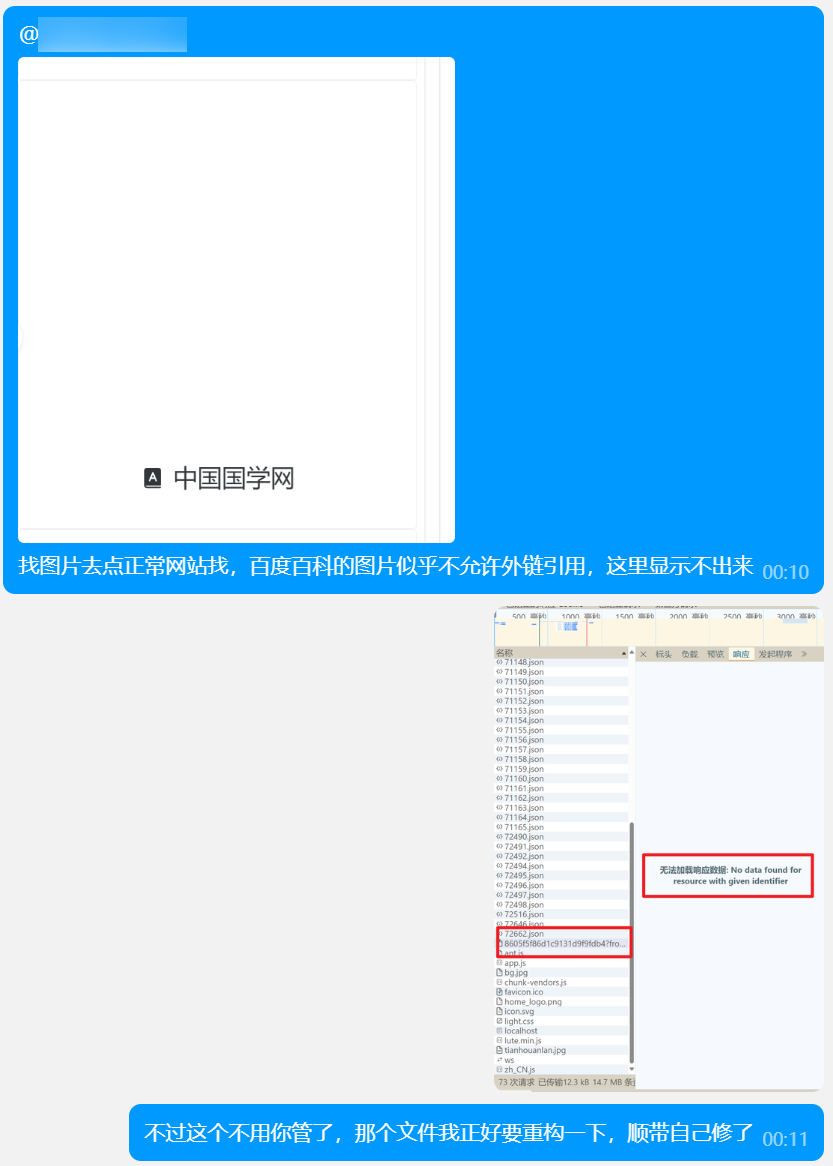
例如将 Attachment 组件的网站弄到一个数组里,再使用 v-for,这样就可以很方便地添加新的网站了。
然后还修复了其它组件的各种问题,同时为 OCR 等组件添加了切换组件时能够缓存信息的功能。
然后原本的诗词数据是离散的,而且序号也不连续(因为我筛选了数据),于是我也重新分配的序号,并且整合到了单个文件,免去了多次请求以及需要在代码对数据进行重新、多次整理的烦扰。而且通过将这些数据保存在 indexDB 中,只需要在开始时请求一次,之后就可以直接从 indexDB 中获取数据,大大优化了性能。
AI 组件开发
手机 QQ 可以快速地截取聊天记录,同时隐去头像、名称(但马赛克程度对头像来说不够,因此我还是手动裁掉了,对后面大部分对话没有影响,但某些三个人均参与的对话,可能会造成理解上的障碍)。
同时,@ 人也没有打码,这也是需要我手动进行的,不过比起之前每块都要我手动打码,还是方便多了。

24 日我也投入到了 AIImage 组件的开发,与组员 AIChat 和 AITips 的开发并行。

也是一样,只截取了开头的部分,后面还有很多聊天记录。
24 晚,也包括 25 号凌晨,组员完成了开发,进行了 commit,然后我也进行了代码审核:完成 AIChat 和 AITips 组件。并与 25 号下午合并到了主分支(不过解决冲突时引入了新错误)。
AI 组件优化
虽然组员完成了 AIChat 和 AITips 两个组件的开发,但其实还有许多问题亟待解决,例如缓存内容、聊天框样式等等,而这些也就由我承包了。

与此同时,在我进行 AI 组件的优化时,也让组员去准备答辩的材料、素材、PPT 等工作了。

各种各样的问题:如跨域图片保存、AI 上下文等等等等……

跟上面一样。

还谈了点 Markdown, 的事情。

还有因为对流式理解错误而浪费了一点时间。
图标
虽然名字已经决定了,但是图标也是一大难点,我起初也没啥头绪,打算随便应付一下。
![]()
随便夹带了点私货。
![]()
只可惜效果不好。
![]()
甲方的要求——有「春天气息」的图标。
![]()
最后还是在图标库选择了最终的图标。
![]()
然后就是标题、图标以及简介的制作。
![]()
![]()
还得是 ChatGPT 4o,说到我心坎了。
打包
弄图标过程中还穿插尝试了下打包发布。
使用的是 Vue CLI。
然后发现 Vue CLI 已经过时了,于是在周一(27 日)中午迁移到了 Vite。
游戏
然后我又想到了高中时火过的 Wordle,以及高二、高三时玩过类似的,成语形式的,想着看能不能弄进去。

一开始去 clone 了汉兜的源码,研究了一阵子如何嵌入项目,最终失败了。最后采用了 iframe 的方式。

同时还进行了一些优化,例如把 xicons 的图标保存为本地 SVG,这样就可以移除掉很大的依赖了。
打包完后才发现端口转发对打包产物不生效,这代表就无法进行 API 请求。短时间内也没时间去探索解决方案了,因此就决定不进行打包了。
结语
代码部分的记录基本到此便结束了,至于答辩部分的记录,就得等我有时间再继续写了(大概七月前会写吧)。
6 月 9 日记录
- 记录人:@PilgrimLyieu
- 记录时间:2024 年 6 月 9 日
首先恭喜一下我们组作品最终获得三等奖!
项目结构
eza 真好用,本来还打算去装个 tree,然后发现 eza 自己就有树状功能,还可以显示图标。差不多就是下面的命令,然后手动修正了一点。
eza --tree --level=2 --group-directories-first --icons . |
有时间时要总结一些现代化的内置工具替代品。
答辩材料
由于手机 QQ 清理了下聊天记录,因此又要用电脑截了。
准备答辩材料的素材。
答辩时间一砍再砍,最后只剩下五分钟,因此只能迅速略过去,完全无法细讲。
还研究了一下,将项目部署到了我的 GitHub Pages 上面。由于没有后端,跨域访问的问题导致 OCR 与 AI 的功能是无法使用的。
同时因为我们项目的结构(建项目时还不太了解,而且最初计划有后端)还额外建了两个分支,一个用来对 GitHub Pages 专门修改了部分(如资源链接,以及跨域问题的说明等),另一个gh-pages 分支用 git subtree 的命令推送过去,用来部署。
因为对 main 分支的保护,所以也不能用 GitHub Actions 自动部署。
使用 ScreenToGif 录制演示动图。本来想使用更现代化的 APNG 与 WebP 格式,结果 PPT 都不支持,只好回归 GIF。
然后意外地发现 ScreenToGif 还能录制 MKV,本来打算用 OBS 的,ScreenToGif 录 MKV 还挺方便的。然后 PPT 预览 MPV 效果还不错,而且后面基本上都要比较长的演示(虽然实际上也不超过十秒),所以就一张 GIF,剩下都是 MKV。
弄 ScreenToGif 时还意外修复了一个之前遇到过挺多次的问题,不过这就是题外话了,我大概后面会在博客的记事板上记录。

我拿到 PPT 初稿后,修改了里面的文字、格式等,同时补充了各种图片,录制了全部的演示视频,用以演示的那个「荆轲刺秦」文字稿也是我找的,还蛮契合的。
答辩讲稿好像没上传到 GitHub 上,就在下面贴吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | 1:这是我们的作品——「春纷」,各位有条件的也可以访问红字链接一起体验,不过因为特殊原因,一些功能无法使用。以及我们全组都没有相关开发经验,因此对于作品中一些问题也请理解海涵。 3~7:背景与设计理念因时间不足,而且中期文档有所阐述,不再赘述。 8:(PPT) 9:熟悉 Markdown 语法的小伙伴们肯定不陌生,我也不在此赘述。但我们这个编辑器的优越之处就在于,可以像富文本编辑器那样去使用它,这里的视频简单呈现了一下一些用法。 10:编辑器还有很多用法:比如可以全屏专心创作;还有可能有人像我一样更喜欢分屏预览,而非那样所见即所得的模式;还可以专心欣赏自己的作品。 11:与此同时,预览界面上面有几个按钮,可以提供不同平台的呈现效果。还可以一键复制到微信公众号和知乎,实现分享传播的目的。 12:我们的文化库搜集了千首诗词名篇,按标签进行分类,同时每首诗词都提供了详实的翻译、赏析等相关信息,能让用户沐浴在诗词的海洋当中。 13:同时也有插入功能,便利了用户。 14:接下来是我们的资料库。考虑到用户可能有搜索中文信息的需求,但苦于没有渠道获取信息,所以我们提供了资料库供用户使用,同时也弥补我们网站内资料相对有限的局限性。 15:当然,还可以调用本地词典。 16:然后便是我们的重磅功能,也就是 AI 功能。 17. 当然模型和用户名都是可配置的。而且聊天记录被缓存。 18. 也可以让 AI 总结用户的作品,抑或是提供一些建议。 19:AI 还可以生成相关的图片。这几个是占位图。如果选择「重新生成题图」,那么会先生成一个 prompt,紧接着再生成图片,由于这个时间比较漫长,用户在此期间也可以自由地做自己想做的事情。如果对这批图片不满意,则可以使用旧 prompt 再进行一次生成,这样也可以节约时间。 20:用户可以放大查看图片细节,并将其插入到作品当中,真正融入作品。 21:也有很多用户有将纸质作品电子化等将图片转文字的需求,我们的 OCR 功能满足了这个需求。底下也有置信度条,可以看出来准确率还是相当高的。 22:我们也提供了 LaTeX 的公式识别。也可以自行设定数学公式分隔符。 23:还有随机诗词,给你不一样的惊喜。 24:还有放松的游戏。高中时流行了一个叫 Wordle 的游戏,而这些游戏可以算是中文版的 Wordle,这里演示一个比较简单的。 26:我们小组学习了现代开源项目的工作流程,使用 Git 进行版本管理,并将项目托管在 GitHub 上,组员在各自分支上工作,随后通过 Pull Request 的方式进行贡献,经代码审核后再合并进入主分支。 27:同时我们也通过文字的形式将开发的过程记录下来。 29:(简单念几句内涵)我们在中期文档中也已经写明了,因为时间不足的原因,我们原本预想的一个多用户的创作平台也并未能实现。除此以外,还有将传统文化传播至海外的多语言构想以及一些更细节的功能,也没能实现。 |
当然实际上基本没有按上面讲,漏讲了挺多,以及后面还有计划要讲的可能也匆忙间忘记了,也有点随机应变。
除了非常长的部分是照着稿子念的外,其它基本就是粗略带过了。
答辩
共 32 组,我们组是第 26 组。我大概在 17 组左右时去听了。
实际进程比计划的慢上一组。我到时大概三点半以后。
看了几组感觉都非常厉害,我不仅惊叹于他们的创意,还震撼于他们的技术。尤其是看到了 VR 那组,我看完就感觉他们组能拿一等奖,果不其然。
本来让组员我讲漏的补充,不过我也讲得飞快,话筒声音也很大,完全没有插话的机会。
讲完后,评委没有提问……于是我感觉就要寄了,本来就创新不足,再没提问,似乎就是不感兴趣、不看好。然后再对比其他组的优秀作品,愈发觉得得奖希望渺茫。
因此最后能得奖时还是很意外惊喜的,也算是为这两个月的努力画上了一个圆满的句号。
我讲完后又看了几组,不过没看完就去吃饭了。吃完饭再赶回来颁奖典礼。

当时的记录(后面的因为超长度了没截上,也懒得再截了)。
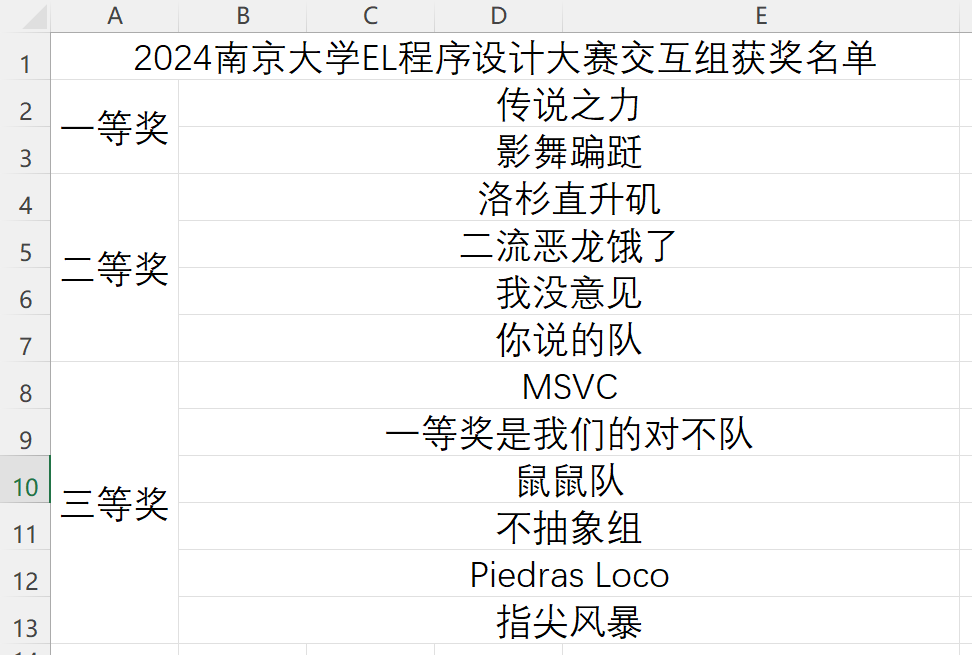
获奖名单
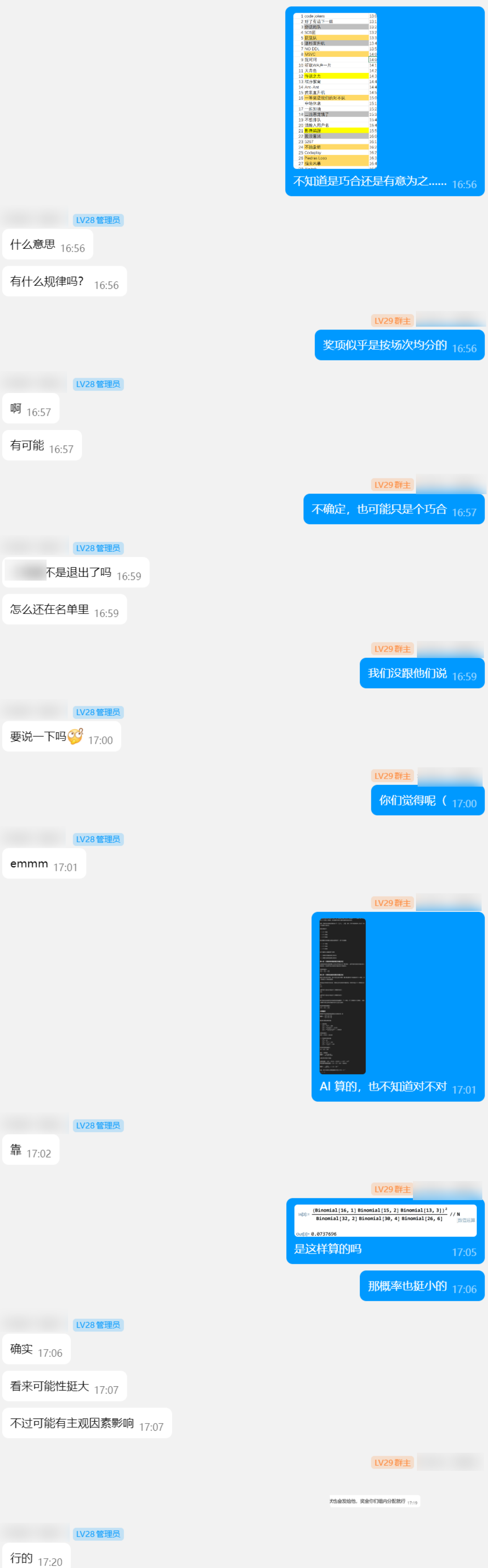
然后我去划定了一下获奖队伍的答辩顺序,想凭借印象回忆一下其它获奖的作品,意外发现了一个「巧合」——获奖按上下两个场次均分。
然后算了下概率,概率还挺小的(不过还不算小概率事件)。
其它
然后是其他的记录。在开发过程中用 Microsoft Todo 记录了点「灵感」,打算后面在文档弄的。
这个是 5 月 3 日建立的,只有三个,而且第三个也已经讲过了。
这么说来的话,可能还想再开个新记录,根据代码来讲讲。不过这个应该越早越好,后面就忘记了。
按需引入
这好像也没啥好说的,根据 Naive UI 的文档完成了,还挺方便的。
Naive UI 问题
居然剩下两个稍微能讲的都与 Naive UI 有关。
我在用 Naive UI 的 Modal 组件时,发现把预设 preset 设置为 card,内容 content 无法显示,折腾了很久,也查了很多内容,但都没能找到类似的问题。
一般遇到诡异的问题肯定是先找找自己的原因嘛,但是真的太奇怪了,撞得头破血流都没找到问题所在。
后面也不知道是在 GitHub 仓库搜索,还是从 Google 搜到的,居然是 Naive UI 自己的问题……
这个问题在 2.38.2 修复,但是当时还没发布,我当时用的版本是 2.38.1。
找到这个问题时,Todo 上面写的「麻」很好地概括了我当时的内心状况。
后面更新到了 2.38.2(在 PR:完成 CultureLibrary 组件中),问题解决。
也未必如此,在此之前本人就已使用 GitHub Mobile,也可以完成 2FA。 ↩︎