2024 年 11 月记事板
4 日
不是一个寻常来写的日子,不过等周末的话,这个月就建得有点晚了。还有半个多钟,稍微写点吧。
NeoNotes
思考了一秒,最终还是决定先将这个讲了,虽然说可能根本讲不完,其他想讲的也讲不了了。而且现在是边跟阿温聊天边写,更无法专注了,将就随便写写吧。
本来想说周末,不过看了一下居然不是,是周五一个晚上弄的。周五晚上差不多八点半左右开始弄,弄了近两个小时,帮了青子小姐的一个忙,这也给了我个思维的火花。
简而言之,就是我有了一个 NeoNotes[1] 计划:将笔记部分从 Hexo 博客中剥离出来,与之独立,并使用 mdBook 呈现。
mdBook 我其实也见得不少了,Rust 官方书籍、Anki 文档等等,但其实从来都没想过用 mdBook 做笔记。这一次灵光乍现,也确实挺突然、挺意外的,但思来想去又觉得挺合理。
但我在这写并不是说我要开展这个「宏伟」的新项目,并投入很多时间精力了。相反,恰恰是我是要「搁置」或「废弃」这个生命不足三天的项目。至于是「搁置」还是「废弃」,取决于我能否给出一个合理的,能够说服我的理由了。
这里应该来个攻守双方的观点与辩论,但只有二十分钟了,可能得明天补充一下。
算了,十五分钟也不想写啥了,今天下午学累了(真的在学,没有在摆),放松个十五分钟不过分吧。所以说今天就留个云里雾里的内容吧。
5 日
不得不说宿舍真的是摆烂的天堂,本来想借上午没课的契机,用上周因调课而翘掉的概率论的录屏补一下笔记的,结果又墨迹了,快十一点了才刚背完 Anki。这也就一个小时左右了,补笔记我寻思着时间也不太够了,那还是来写这个吧。不过今早不补,那我在外面也没啥机会补了,毕竟看录屏还是副屏比较方便。
另外 NeoNotes 因为上面几乎啥也没讲,不打算补在上面了,而是在下面另起一个。
Anki

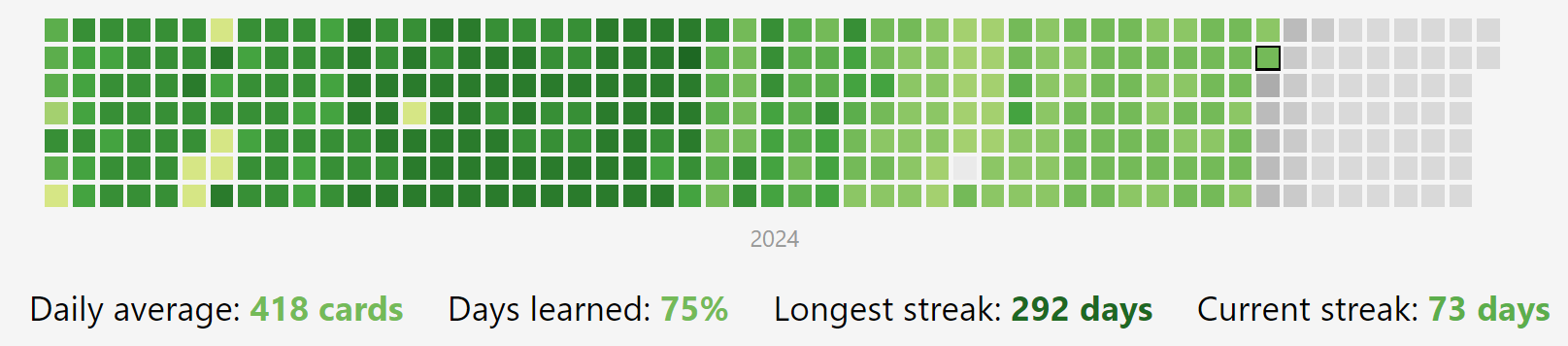
今天是 2024 年 11 月 5 日,而 2023 年 11 月 6 日那天,开始了正式的大学的 Anki 旅程。要是算上 8 月 24 日忘记了的那天,正好 365 天,一年。
6 日:数错了,不算上已经有 365 天了,算上就有 366 天了,因为 2024 是闰年。
当然,这里面是有很多注水的,不过呢勉勉强强还是算的。
这一年我也没啥想说的了,其实也没啥必要说。倒是前面我挺想看看的,给出几个时间节点吧。
2023 年 11 月 6 日前还有一个非常浅的格点,那是 10 月 4 日刷了 17 张卡,没刷完就跑了,所以不是正式的起点。
左边那一块比较杂乱的还是高三那会,最后一个格点是 6 月 9 日的 302 次 reviews。那天似乎是高考最后一天吧,应该是在刷生物卡,只是我已经将所有高中的卡片导出来备份了,倒没法知道细节。


往回看就能知道大学这一年多以来,虽然比较注水,但还是算一片连贯的绿瓷砖有多难得了。
第一天是 2021 年的 5 月 5 日,72 次 reviews,不知道这三年多以前的卡片,是否还保留着呢?若是还在备份里的话,那确实就是元老功勋了。
有点感慨,又不知道说点什么。
NeoNotes
为何要使用 mdBook,取代 Hexo 重新呈现我的笔记呢?我这里尽力给出几点理由吧。
首先是这样能够将笔记与博客分离。这里的分离并不是说完全拆解开来,博客依然可以导航到笔记中。而是说可以跟博客的管理分开,毕竟平时博客中的 Git 提交基本都是笔记的提交,分开这两块关联不大的部分,可以有助于针对性的管理。
这样可以提出第一个反对意见。那就是既然如此,其实用 Git Submodules 就可以了,为何要多此一举呢?
博客与笔记分离,也是我最近才有的想法,一开始确实是没有这个念头。回忆我的笔记记录,一开始还是以博文的形式呈现的呢,然后导致非常杂乱无章,而且跟正常博文混杂在一起,很不好。接着就是现在的模式了,我开了一块新的板块,专心将笔记更在那里,第一次实现了博文与笔记的分离。然而这时候我仍然是认为笔记是博客的一个子版块,而非一个单独的项目的,因此也就没有进一步的考虑了。
也就是说,与其说是将笔记再提升一个档次与博客并列的念头促使我想要开展 NeoNotes 计划,不如说是给这个计划找补,寻找它的优势时,顿时发现了这一点,同时也转变了观念。
也正如上面的反驳所说,要做到这一点,其实使用 Git Submodules 就行了。当然这个方案还是稍微差过一点,毕竟明面上仍旧是子版块。
不过呢,不管 NeoNotes 计划是否未来会推进下去,将笔记分离出来也是近期我一定会做的一件事情。
在开始 NeoNotes 计划后,我就建了个专门的文件夹。但同时我又突然意识到了一件事情。
很早以前我也计划了一件事情,虽然不如这个有更深的规划,但也算是一个计划了。那就是将整个博客迁移到 WSL 上。这主要是考虑到了 WSL 上可能比较合适,就像是 编译的速度在 WSL 上更快一样。还有很重要的一点就是,现在写笔记都是在 WSL 上,但是笔记文件却是在 Windows 上,跨系统的 I/O 性能问题,在之前没怎么在意,但后面我认为是我不得不纳入考虑的一点了。
但这个 NeoNotes 计划让我熄灭了这个从未开始过的念头,我认识到我其实可以不将整个博客都迁移到 WSL 上的。虽然说我笔记都是在 WSL 上写,但普通的博文、记事基本还是在 Windows 的 gvim 下完成的。迁移到 WSL 上首当其冲就是隐私问题了,毕竟 Windows 下 Markdown 我是不开 Copilot 的,但 WSL 下记笔记不开 Copilot,那是非常难受的。
所以说若是将笔记单独抽离出来,放在 WSL 上,那简直就是完美无缺。因此我将整个笔记文件夹复制到了 WSL 上一份,并尝试在 WSL 上进行笔记的记录。也许是因为文件还比较小的缘故,也也许是因为心理作用,似乎是好了不少。同时内存什么的的占用,也小了不少。
当然迁移过来还有个问题,就是 fileformats,很多笔记都是 DOS 格式的,即 CRLF 的换行,但是 WSL 上还是 Unix,即 LF 比较合适。不过这点使用 for f in *.md; do vim "$f" -c "set ff=unix" -c ":wq"; done 解决了。
当然还有很多的问题,比如说 WSL 上的文件有时候会出现一个奇怪的 Zone.Identifier 文件,可能是将 Windows 上的文件复制到 WSL 上会出现了,没能找到稳定复现问题的步骤,解决方法也没有详细去找。我现在也还没有清理。当然,这个应该是启动 NeoNotes 计划后才应当考虑的事情。
十一点五十了,才写了一点,后面的后面再写吧。
美国大选
晚上跑完步,看了会视频再来写。还是半个多小时,所以说 NeoNotes 还是先不写了,不过因为已经写了一点了,后面就不另外开了。
终于是把脑子跑坏了,今天跑完后脑子冰冰的,有点疼。然后呢走到宿舍楼下、按了电梯按钮才突然发现书包还在南雍一楼柜台那里没拿。之前最迟钝的时候也是在走过了学校正门那里反应过来回去拿,这次是直接回到了宿舍楼下才反应过来。估计下次再来说,就是回到宿舍才发现没拿书包了。
今天就是美国大选投票日了啊。这四年感觉又很长,经历了很多事情,感觉又很短,转眼一瞬间就过去了。
四年前关注美国大选的时候还是高一入学没多久时,在宿舍看的新闻。而现在已经是一个大二的大学生了,虽然还只是一个十几岁的小孩。
比较有意思的是,我对于特朗普这个中美贸易战的始作俑者的印象,居然大致是从上次美国大选时他要竞选连任时才开始有的。
尽管当时也听说过中美贸易战的事情,不过当时我终究是不太关注时事热点,反倒是下一个总统任期才对上一个期间发生的事情了解得更多。
我的记性很差,小时候很多事情都不记得了,但有一个我印象比较深。不知道是什么时候,我对「国家」的概念就是一个一个的星球,中国是一个,美国是一个等等。现在想来,真是又荒诞但又充满童趣与想象力啊。
还有一个,小学时看《阿衰》漫画(应该是这个吧),提美国有提到过什么「美丽坚强」的,至于「合众国」部分我忘记了。
还有一个也有点印象,阿衰将「尼加拉瓜大瀑布」写成了「你家那块大破布」,问题是最大的瀑布还是怎的?不过我查了一下可能是记错了,有个瀑布叫「尼亚加拉瀑布」,是北美最大的瀑布。然后中美洲有个国家叫「尼加拉瓜」就是了。
小时候可能也有想过,为什么美国、英国这些是一个单字加一个国,但别的国家例如日本,却不是「日国」之类的。很像是小孩子会问的问题呢。
也确实会想过,「美」「英」「法」「德」这些字都是有着很好的含义的,因此确实是会有一种懵懂的憧憬与向往。当然,小孩子都是这样的,这点向往其实甚至比不过一根糖果。
说到糖果,又想到小时候吃零食其实相当节制,我基本上是没有机会自己买零食的,都是蹭同学分享的各种小零食。小时候吃得非常欢,感觉特别香,虽然吃的现在看来都是些啥垃圾食品(只不过我现在食堂吃的也差不多就是了),但就是很开心。结果上学期我买了挺多小时候很馋的卫龙辣条,吃了没几个就感觉吃不动了,剩下的全退回去了(当然,只要了一半退款)。可能也有点怀念以前简单的快乐?
说回这美国大选,假如给我一票,我会投给谁呢?
考虑这个问题自然要从「我」是谁出发,在这里「我」并不是一个普通的美国公民,实际上我也无法真正代入进去,所以自然是从一个中国公民的角度出发。
只不过我想了一下,选不出来。毕竟我投的这票应当是代表我支持谁的,实际上我谁也不支持,为何一定是要在两个讨厌的家伙中挑选出一个相对没那么讨厌的家伙呢?
那换个问题,我希望大选的结果如何呢?
这个问题比较好回答,我也已经准备好了答案。那就是哈里斯 270 对特朗普 268 票,同时摇摆州票差极小,并爆出大量选举舞弊事件,随即共和党方面宣布选举结果无效,不承认民主党胜选,来个 2020 国会山 Pro Plus Ultra。
当然这个想法比较阴暗就是了,所以说我只是宏观上这么讲,具体到个人层面,我也希望普通美国民众不会受到波及就是了。只是怎么可能如此两全其美呢?
当然前一个也许容易发生,但后一个可能就不太简单了,毕竟已经有了前车之鉴了,再来一次,嗯,也不是不行?
剩下十多分钟,也许写点青子小姐还够,但饶了我吧,青子小姐后面再谈。
6 日
美国大选
这么快就尘埃落定了,特朗普大胜哈里斯,真是没意思啊。
今天,不管是怎样的地方都在聊美国大选,世界热点话题属于是了:我几个不相干的群在关注,甚至有一个在实时直播并创造出一些屌图;游泳课时旁边同学在聊当前局势;朋友圈中留美的同学在发见解等等。
确实是出乎了意料。选前看媒体的宣传,感觉选情会是比较焦灼的。结果怎么说呢,七个摇摆州全部飘红。截至现在(快十一点),还有五个州还没宣布结果,其中只有一个缅因州浅蓝,其余全部浅红,还包括了三个「关键竞选」的摇摆州。而这四个浅红州虽然还没开完票,但也基本大局已定,要被共和党笑纳了。缅因州四张选举人票,无济于事。
当然即便直接把这五州划给民主党,依旧是改变不了败局,因为美联社快七点时才终于更新了结果(其他各种预测更早就已经出了,胜局其实在此之前早早已定),也是目前的结果,特朗普 277 对哈里斯 224,已经拿到了 270 张选举人票,锁定胜局了。
最终结果应该就是特朗普 312 对哈里斯 228 了。
实际结果是 312:226,不知为何上面我还算得清总票数,这里就错了。但也挺奇怪的,我不是总票数相减的,而是分别统计的。哈里斯 224 的时候还有缅因州的 4 张,特朗普我也有数剩下的票,为何 224 + 4 = 226 呢?
怎么说呢,其实感觉这算是最不好的结局之一了。赢得酣畅淋漓,民主党也很难发难吧;此外参议院共和党也过半,夺得了多数党地位;众议院选举倒尚未结束,但此时共和党也 198 对民主党 180 领先,同时众议院本来就是共和党 220 对民主党 213 多数,因此共和党可能还可以在众议院获得多数党地位;再加上最高法院保守派大法官 6 位对自由派大法官 3 位,也是占据优势。这样一来,他的执政地位可能比较稳固,推行施政方针可能也比较顺畅。这其实是我不太希望看到的,我更希望看到的是一位跛脚总统,而非现在三权归一人(党)所有。
此外,特朗普在四年后卷土重来并重新赢得大选,听起来有点像是爽文剧本。他的政治头脑可能会变得更清醒、成熟,四年前众叛亲离而现在王者归来,也许他也能因此涅槃重生。这在将来可能会是一个非常可怕且棘手的敌人,未来四年估计不好过了。
同时七月那会未遂的刺杀,甚至可能给他披上了「神性」的羽纱,在宗教上可能也能给予他加持。共和党估计也要成为 MAGA 党了。干脆也别叫啥总统了,叫「元首」得了。
结果已经注定了,哈里斯目前还没承认败选。不过民主党那边会不会像四年前那样发难呢?我个人是感觉不会的,首先是这次也输得太难看了点,七大摇摆州一个蓝的都没有,只能说民主党执政这四年确实是不得人心。这四年里还能沉浸在媒体织成的茧中自欺欺人,大选倒是将真相赤裸裸地呈现在了民众面前,也许其实也能说明美国民众对于媒体的不信任感?或者说进一步加剧这种不信任感?然后呢我觉得那帮老爷面子功夫还是要做做的,明面上不太像是会撕破脸皮的样子,但暗地里使绊子我觉得倒是会的。
总的来说就是目前结果不太好。但其实还是有一个机会扭转局面,直接将这个烂局一转为好局,那就是特朗普遇刺身亡。这样一来那就确实是大好的局面了。不过要是发生了这样的局面,美国也还是别当这个世界警察,丢了这个霸权地位吧,几个月前刚发生过这样的事情,还能重蹈覆辙,而且这次身份还都不一样了,上次还只是总统候选人,现在真的就是未就任总统了。
臭豆浆
周一上午上课时,上了一阵子,突然感觉有一股恶臭,像是呕吐物那种臭味。一开始我还没整明白是啥原因,后面看到前排有人讨论,才发现是我正好前面的座位的抽屉,有一个放了挺长时间的豆浆漏了出来,不知道发酵了多久,奇臭无比。等到下课后我才大体从议论中得知,大概是一开始豆浆不在我前面那个座位,而是在其左边,然后有人坐到了那个座位,发现了里面有那个豆浆,就放到了我正前方那个座位的抽屉里,然后这一通操作导致豆浆漏出来了,因此一开始没有异味,而后面才有恶臭。
中途下课那个座位左边的人将其清理掉了,漏出来一点,滴到了座位和地上,估计抽屉里也有不少。即使是纸巾擦过,覆盖在上面,恶臭依然丝毫没有减弱。我剩下的课都是用嘴巴呼吸的,那座位左边的人则是戴上了口罩。
课程后面我都感觉我有点晕乎乎了,好在现在已经没啥感觉了。
这是同学在书院群发的消息。
其实那个座位我可能还坐过,只不过以后是不敢坐了。
下面简单介绍一下我的选座位策略,就可以发现那个座位为何我可能多次光临过(当然,豆浆肯定不会是我的,我豆浆都是在食堂喝的。想了想我从没把早餐带到教室过)。
先规定一下方向,取正常上课时,面向讲台的视角。
我一般是从右边的门进,然后图来去的方便,会挑中间靠右边走廊的座位坐。教室的座位分左、中、右三大块,为了比较好的视野,我一般都是选中间的,很少选两侧。
然后呢倒不是完全靠右,而是空一个座位靠右。因为我现在基本是左手使用鼠标,而从右数第一、二个座位之间有插座,要是我选第一个,那笔记本充电线就和手臂重合了。而选第二个,就可以从笔记本后绕过去,手臂活动不会受限。
讲完了列的选择,然后就是具体的选座位算法了,也就是挑出哪一行。一般是从第二排开始扫描,非思修课一般是从第三排开始扫描(不一定,主要是非早九的课一般就是从第二排,因为此时人也不少了),总之就是尽量避免坐太靠前。然后往后依次扫描,选取第一个满足两侧都没有人的座位作为最终选择,因为我不喜欢主动坐别人旁边。从前往后扫描也是因为虽然我不喜欢坐太靠前,但太靠后也不好,除了思修很多课我还是要听课看 PPT 和黑板的。
所以也就能知道为啥那个座位我可能多次光临过了:因为当天扫描过程中,那一排靠右第一个座位已经有了一个女生了,故被我排除了,坐在了后面一排。
周一下课后我一出门第一件事就是翻课表,我西 426 这个教室绝对不要再坐右侧了,宁可来去时多走一段路程。然后就是今早的《机器学习》课了。
早上从右侧门进,一进去就是一股臭味,看来还没完全消散干净,学长学姐们估计也大都不知道这个情况。我果断选择了走远一点到中间左侧第一个(也是符合上面的标准哦),同时选择了第二排(不敢坐后面了,怕气味往后飘,这是正坐在后面的阴影)。
写得稍微有点久了,今早的笔记还没补完呢,就先这样吧。
9 日
梦
写一写今早做的梦。本来应该上午写的,但我的拖延有目共睹,快三点了再来写,希望没忘太多。当然,梦大部分其实都只是碎片,下面很多叙述可能其实在潜意识被我后面人为加工过了,并不能反映真实的梦境,但是我觉得记录下来还是挺有意思的。
记忆不知道是从哪里开始的,一开始大概是我与一群同学(在梦中的设定是比较熟悉的,有男有女。可能是以理想中的高中同学为模板打造的,但这并不重要)一起玩游戏,不是电子类的,可能是牌类的?
然后玩完了,大致是要选择下一个玩的游戏。好像有四摞牌堆,我捧在手上。然后我可能想玩第一摞的游戏,一直盯着最上面那张牌,画像忘了是啥,技能好像是「生命 +2」之类的,感觉很鸡肋,但就是一直盯着。
然后其他同学各自去抽牌,我就一直捧着,但没抽。然后中间不知道发生了什么,毕竟是梦,醒来后记忆肯定不是完整的,有部分残缺。反正我就是把第三摞一部分牌抽了出来,可能是放别其他同学抽牌吧。反正姿势就很诡异,既捧着这几摞牌,又有一只手拿着第三摞的几张牌,不停地晃动着。
然后终于下定了决心,在大部分同学都抽完后,我物归原处,然后在第一摞牌中间抽了一张。
上面一直在讲这个牌、游戏什么的,其实跟下面关联一点都没有。
然后大致是活动的组织者,下面称为 D,原型似乎是我的一个高中同学,虽然我不知道为啥会是他,招呼着大家,似乎是去他的宿舍玩,于是大家就出发了。
D 好像说了个二楼的一个房号,具体是啥我记不清了。然后这个宿舍布局也很怪,来到了二楼后,有两个方向能走:其中一个就是正常的走廊;另一个就是一间宿舍的门,但是经过这间宿舍后可以到另一个宿舍,也就是说这是一串宿舍串联起来的。
然后我前面似乎有几个女生,她们走了第二条路,也就是穿越多个宿舍,然后我可能犹豫了一下,跟随大流跟她们一起走了。
走了一会后似乎碰到了 D,他说改地点了,改到了 101。于是我就往回走,走到楼梯处,像是双层巴士的楼梯,抑或是旋转楼梯什么的,反正很狭窄,然后我往下走。
然后来到了像是飞机的地方,当然因为这是在梦境中,只能说这个地方是以现实中的飞机作为模板搭建的,实际上非常不合常理。例如说,我所处的位置大致是飞机的「下方」,像是在一个平台处,然后记得有几个座位,但人挺少的,没啥印象。但是呢我所处的位置又似乎离驾驶员挺近的。这个飞机可能没有客机那么大,也许以客机为飞行的模板,但小型的私人飞机为我周围的环境大小模板。
反正我坐下后,没过多久飞机就起飞了。这个飞机似乎动力不是很足,首先就有一堵墙横在前面,然后感觉飞机爬升得很慢,最终果然是「擦」过去了。这个「擦」的意思就是撞到了,但是呢力大势沉,直接撞过去了,没啥影响。后面好像又依次突破了几个类似的障碍?我印象没多少了。
后面又出现了电线,远看没发现,到了近处才发现像是密密麻麻的电线织成的网。然后驾驶员好像骂了一句,然后飞机冲了过去。
飞机撞到线网,并继续前进了一点点,使得线网不再是平面的一刹那,闹钟响了,我醒了。
总的来说就是天马行空,但又前言不搭后语,挺有意思的梦境,毕竟醒来后还能记得这么多挺难得的。
说了点睡中的梦,不如再讲点睡前的想。
睡前一样是会想点东西,想的其实大体上跟上个学期想的差不多,只是人物不同罢了。但是可能因为习惯了,偶尔还是会出现人物已经设定好了,结果一开口吐出了上学期的人物的名字。
我这笨蛋脑袋瓜子也想不出啥创意,上学期的剧情也迟迟没能推进,至于目前想的,也是没啥进展。
不过这挺好,说明没想多久我就睡着了,反而要是想很久失眠了,我也不会继续想下去了。
惯性
之前说写多了私博不想写公博了,现在又倒反天罡,写多了公博不想写私博了。十月就写了三次,十一月也就草草开了个板、放了张图,没写啥内容。因此前面的理论就是有一点问题的,需要进行更新。
现在我想,可能是一种惯性,在一个地方写久了,下次来写时就会维持这种惯性。
与此同时还可以根据实际情况批驳一下之前纸上的想法。虽然说私博能谈的多,但其实我很懒啊,写了公博就不想写私博了,而其实公博还是能写不少的,像是十月就创今年纪录了。同时,在公博也能隐晦地提点私博的话题,这个刺激度是私博做不到的。在公博遮遮掩掩地聊了部分私博的话题后,相当于已经讲了部分信息了,剩下的信息我又懒得在私博写了(当然其他压根没提的信息我也没写就是了,只不过我觉得还是可能有这个原因,所以才加上去)。
归根结底其实还是懒吧。
脚本
NeoNotes 搁浅(不仅是项目搁浅,还有在博客的说明也搁浅了,上面没啥动力去补充了),因此还是正常地需要将 WSL 上的笔记同步到 Windows 的博客文件夹上。暂时还没把笔记单独抽出来的想法,因为这样需要笔记那边提交一下,博客那边拉一下子模块,多了一步,何况现在并不是跟 NeoNotes 并行,而是只有博客这一块,因此更新还是要及时点。
因此我一开始写了一个 updateBlog.py 脚本,大致内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 | import os import shutil import hashlib import json # Root directory of the project os.chdir((os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) RECURSION_DEPTH = 2 MD5_CACHE_FILE = "cache/updateBlog_md5.json" VERBOSE = True def load_md5_cache(): """ Load the MD5 cache from a file if it exists. This function checks if the MD5 cache file exists. If it does, it reads the file and loads the JSON content into a dictionary. If the file does not exist, it returns an empty dictionary. Returns: dict: A dictionary containing the MD5 cache data if the file exists, otherwise an empty dictionary. """ if os.path.exists(MD5_CACHE_FILE): with open(MD5_CACHE_FILE, "r", encoding="utf8") as f: return json.load(f) return {} def save_md5_cache(cache): """ Save the given MD5 cache to a file. Args: cache (dict): A dictionary containing the MD5 cache to be saved. Raises: IOError: If there is an issue writing to the file. """ with open(MD5_CACHE_FILE, "w", encoding="utf8") as f: json.dump(cache, f) if VERBOSE: print("MD5 缓存保存成功") md5_cache = load_md5_cache() def calculate_md5(file_path): """ Calculate the MD5 hash of a file. Args: file_path (str): The path to the file for which the MD5 hash is to be calculated. Returns: str: The MD5 hash of the file as a hexadecimal string. """ hash_md5 = hashlib.md5() with open(file_path, "rb") as f: for chunk in iter(lambda: f.read(4096), b""): hash_md5.update(chunk) return hash_md5.hexdigest() def is_different(src, dst): """ Determines if the source file or directory is different from the destination file. Args: src (str): The path to the source file or directory. dst (str): The path to the destination file. Returns: bool: True if the source is a directory, the destination does not exist, or the MD5 checksums of the source and destination files are different. False otherwise. """ if os.path.isdir(src): return True else: if not os.path.exists(dst): return True src_md5 = calculate_md5(src) dst_md5 = md5_cache.get(dst, None) if dst_md5 is None: dst_md5 = calculate_md5(dst) md5_cache[dst] = dst_md5 if src_md5 != dst_md5: md5_cache[dst] = src_md5 return True return False def copy_directory(src, dst, excl=None, depth=0): """ Recursively copies a directory from the source to the destination, with options to exclude certain items and limit recursion depth. Args: src (str): The source directory path. dst (str): The destination directory path. excl (list, optional): A list of directory or file names to exclude from copying. Defaults to None. depth (int, optional): The current depth of recursion. Defaults to 0. Raises: OSError: If an OS error occurs during copying. shutil.Error: If a shutil error occurs during copying. Notes: - If the destination directory does not exist, it will be created. - If an item in the source directory is in the exclusion list, it will be skipped. - If the item is a directory and the recursion depth is less than the maximum allowed depth, the function will call itself recursively. - If the item is a directory and the recursion depth is equal to or greater than the maximum allowed depth, the destination directory will be removed and the source directory will be copied in its entirety. - If the item is a file, it will be copied directly. - If VERBOSE is set to True, the function will print messages indicating the success of each copy operation. """ if excl is None: excl = [] if not os.path.exists(dst): os.makedirs(dst) for item in os.listdir(src): s = os.path.join(src, item) d = os.path.join(dst, item) if item in excl: continue try: if is_different(s, d): if os.path.isdir(s): if depth < RECURSION_DEPTH: copy_directory(s, d, None, depth+1) else: shutil.rmtree(d) shutil.copytree(s, d) if VERBOSE: print(f"目录 {s} 复制到 {d} 成功") else: shutil.copy(s, d) if VERBOSE: print(f"文件 {s} 复制到 {d} 成功") except (OSError, shutil.Error) as e: print(f"复制 {s} 到 {d} 失败: {e}") if __name__ == "__main__": sourceDir = "src" targetDir = "/mnt/d/Blog/source/notes/" exclude = [ "SUMMARY.md", "updateSummary.py", ] update_index_script = "tools/autoIndex.py" if os.path.exists(update_index_script): os.system(f'python {update_index_script}') if VERBOSE: print("索引更新完成") copy_directory(sourceDir, targetDir, exclude) save_md5_cache(md5_cache) |
简单来说就是弄了一个博客那边笔记文件的 md5 缓存,可以通过比较文件 md5 具体判断哪些文件经过了修改,从而可以更「高效」地实现更新。具体我是没比较过全部移除然后复制,与这种比较再针对复制,哪种更高效。
里面还有限制递归深度为两层,超过了就直接覆盖替换了。然而其实没必要,我的文件结构,两层就到了最深处了,因此在后面的更新中也移除了这个限制。
然而还是太慢了。测试了一下,从零开始,没有缓存的情况下大概需要 10s,而有了缓存,没有更新的情况下差不多要 3s。另外这个是比较早期的脚本了,我从 GitHub 上抄下来的,后面还添加了比较 MD5 缓存是否更新的,只不过没提交。因此这个是只会显示保存成功的,不会说更新没更新的。
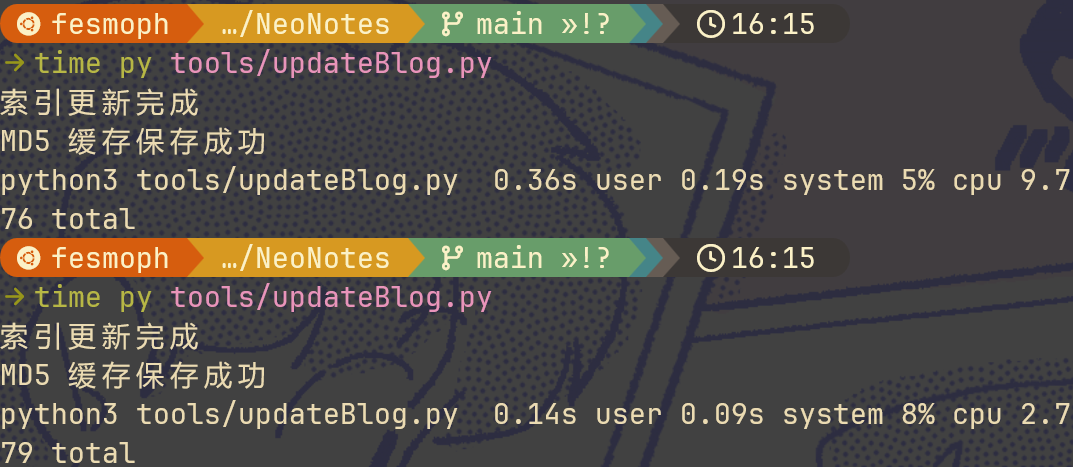
于是我就寻求用 Rust 重写一个。当然我是没这个本事的,直接丢给 Copilot 让它改,然后遇到问题就不停地提问调教,最终可以成功运行了。
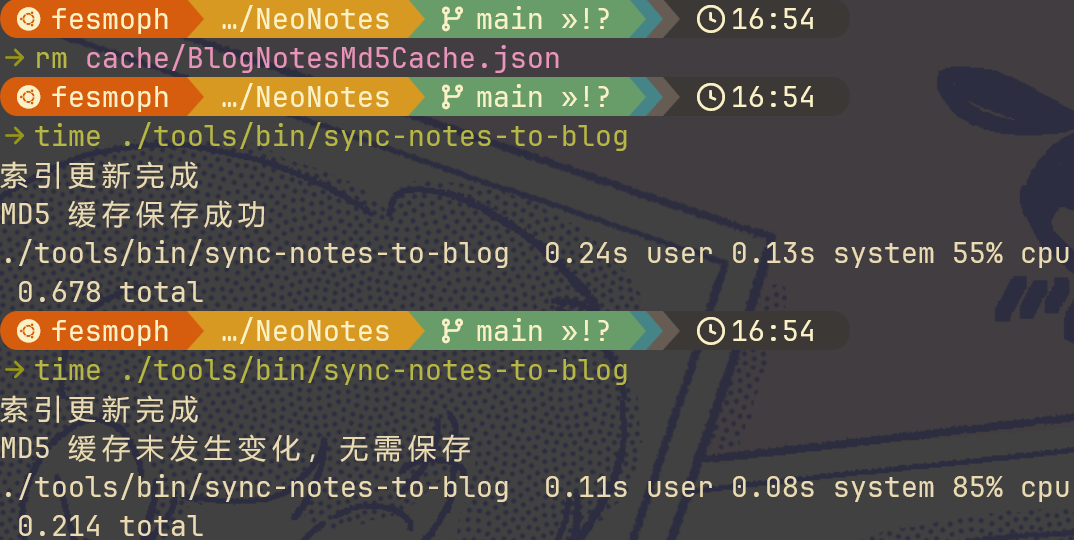
结果还是很慢,时间上几乎差不多,有差别完全也是在误差范围允许以内。一点都没提升,相当于我是白写了。
不过紧接着问 Copilot 还能怎么改,它就告诉我可以用并行。于是我哼哧哼哧继续提问、改代码,终于成功了,果然快多了,有缓存的时候几乎是秒出(0.2s 左右),只是缓存建立依旧需要近 8s。
然后我又想到,并行估计 Python 也能快不少,要是也一样快到一定程度,那其实也没啥换语言的必要。所以我就让 Copilot 继续改它的 Python 脚本了。当然因为我中途没提交的缘故,对比前一个其实不止加了个并行。Python 并行倒是比 Rust 写得简单不少:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 | import os import shutil import hashlib import json from concurrent.futures import ThreadPoolExecutor # Root directory of the project os.chdir((os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) MD5_CACHE_FILE = "cache/BlogNotesMd5Cache.json" VERBOSE = True CACHE_CHANGED = False def load_md5_cache(): """ Load the MD5 cache from a file if it exists. This function checks if the MD5 cache file exists. If it does, it reads the file and loads the JSON content into a dictionary. If the file does not exist, it returns an empty dictionary. Returns: dict: A dictionary containing the MD5 cache data if the file exists, otherwise an empty dictionary. """ if os.path.exists(MD5_CACHE_FILE): with open(MD5_CACHE_FILE, "r", encoding="utf8") as f: return json.load(f) return {} def save_md5_cache(cache): """ Save the MD5 cache to a file if it has changed. Args: cache (dict): The MD5 cache to be saved. Returns: None """ if not CACHE_CHANGED: if VERBOSE: print("MD5 缓存未发生变化,无需保存") return with open(MD5_CACHE_FILE, "w", encoding="utf8") as f: json.dump(cache, f, separators=(",", ":")) if VERBOSE: print("MD5 缓存保存成功") md5_cache = load_md5_cache() def calculate_md5(file_path): """ Calculate the MD5 hash of a file. Args: file_path (str): The path to the file for which the MD5 hash is to be calculated. Returns: str: The MD5 hash of the file as a hexadecimal string. """ hash_md5 = hashlib.md5() with open(file_path, "rb") as f: for chunk in iter(lambda: f.read(4096), b""): hash_md5.update(chunk) return hash_md5.hexdigest() def is_different(src, dst): """ Determines if the source file or directory is different from the destination file. Args: src (str): The path to the source file or directory. dst (str): The path to the destination file. Returns: bool: True if the source is a directory, the destination does not exist, or the MD5 checksums of the source and destination files are different. False otherwise. """ global CACHE_CHANGED if os.path.isdir(src): return True else: if not os.path.exists(dst): return True src_md5 = calculate_md5(src) dst_md5 = md5_cache.get(dst, None) if dst_md5 is None: dst_md5 = calculate_md5(dst) md5_cache[dst] = dst_md5 CACHE_CHANGED = True if src_md5 != dst_md5: md5_cache[dst] = src_md5 CACHE_CHANGED = True return True return False def copy_directory(src, dst, excl=None): """ Recursively copies a directory from the source path to the destination path, excluding specified items. Args: src (str): The source directory path. dst (str): The destination directory path. excl (list, optional): A list of directory or file names to exclude from copying. Defaults to None. Raises: OSError: If an OS error occurs during the copying process. shutil.Error: If a shutil error occurs during the copying process. Notes: - If the destination directory does not exist, it will be created. - The function uses a thread pool to copy items concurrently. - The `is_different` function is assumed to be defined elsewhere, and it determines if the source and destination items are different. - The `VERBOSE` variable is assumed to be defined elsewhere, and it controls whether to print success messages. """ if excl is None: excl = [] if not os.path.exists(dst): os.makedirs(dst) def copy_item(item): s = os.path.join(src, item) d = os.path.join(dst, item) if item in excl: return try: if is_different(s, d): if os.path.isdir(s): copy_directory(s, d, excl) else: shutil.copy(s, d) if VERBOSE: print(f"文件 {s} 复制到 {d} 成功") except (OSError, shutil.Error) as e: print(f"复制 {s} 到 {d} 失败: {e}") with ThreadPoolExecutor() as executor: executor.map(copy_item, os.listdir(src)) if __name__ == "__main__": sourceDir = "src" targetDir = "/mnt/d/Blog/source/notes/" exclude = [ "SUMMARY.md", "updateSummary.py", ] update_index_script = "tools/autoIndex.py" if os.path.exists(update_index_script): os.system(f'python {update_index_script}') if VERBOSE: print("索引更新完成") copy_directory(sourceDir, targetDir, exclude) save_md5_cache(md5_cache) |
对照了一下,除了加了并行外,首先是更名了,因为原名不太合适,然后更改了缓存名称,还加了个是否更新的检查,更改了 JSON 分隔符(以压缩空格的体积),移除了递归深度的限制,最后就是 Copilot 重写文档注释,因此看起来改动比较大。
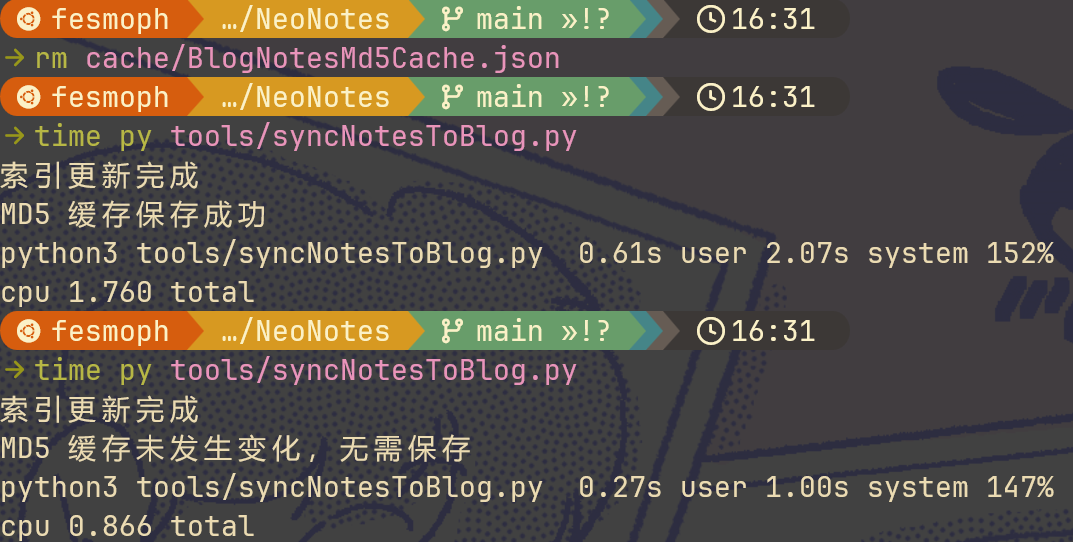
果然也是快了许多,在有缓存的情况下大约是 0.8s 的样子,比 Rust 慢不少,但也在能接受范围内。但是没缓存的情况下却是吊打 Rust,只要不到 2s。
虽然说缓存建立只要一次,后面有缓存更快才是王道,但我还是想弄明白这到底是为什么。
于是我就继续去请教拷打 Copilot 这是怎么一回事。他重复车轱辘话好多遍,但一行代码也没改(反而删光了文档注释)。不过后面重复问,给了一点回答。
一开始转的 Rust 代码是将缓存作为函数的参数进行传递,但是在引入并行的过程中报错了,大致是这样的:cannot borrow *md5_cache as mutable, as it is a captured variable in a Fn closure cannot borrow as mutable.
我让 Copilot 解释,大致就是这样:「这个错误是由于在并行迭代器中使用了可变借用的 md5_cache 引起的。并行迭代器会尝试在多个线程中同时执行闭包,而可变借用在这种情况下是不安全的。」
它给了我两个建议,一个是使用互斥锁 Mutex,另一个是不要并行。我果断选了前者。
但印象中似乎问题并没有因此而解决,我后面还使用了 lazy_static 将其转化为了全局静态变量。
在问 Copilot 后,它给了我一点建议:
Rust 版本在计算 MD5 时使用了一个全局的缓存(
MD5_CACHE),并且在每次计算时都需要锁定缓存,这可能会导致性能瓶颈。
……
减少锁的开销:
- 在 MD5 缓存的实现中,尽量减少锁的使用,可以考虑使用无锁数据结构或减少锁的粒度。
- 可以使用
RwLock代替Mutex,在读取缓存时使用读锁,只有在写入缓存时才使用写锁。
然后我让它使用读写锁 RwLock 进行替换。除此以外后面还做了很多修改,比较明显的有函数重命名等,具体也记不清了。
最终版本代码如下(文档注释不像 Python 一样可以方便地让 Copilot 生成,因此很多其实还没更新):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 | use lazy_static::lazy_static; use md5::{Digest, Md5}; use rayon::iter::{IntoParallelRefIterator, ParallelIterator}; use serde::{Deserialize, Serialize}; use std::collections::HashMap; use std::env; use std::fs::{self, read, File}; use std::io; use std::path::Path; use std::process::Command; use std::sync::RwLock; const MD5_CACHE_FILE: &str = "cache/BlogNotesMd5Cache.json"; const VERBOSE_MODE: bool = true; /// 如果启用了详细模式,则打印消息。 /// /// # 参数 /// /// * `msg` - 要打印的消息。 fn print(msg: &str) { if VERBOSE_MODE { println!("{}", msg); } } lazy_static! { static ref SOURCE_DIR: &'static Path = Path::new("src/"); static ref TARGET_DIR: &'static Path = Path::new("/mnt/d/Blog/source/notes/"); static ref MD5_CACHE: RwLock<Md5Cache> = RwLock::new(Md5Cache::load()); } /// MD5 缓存结构体,用于存储文件路径及其对应的 MD5 值 #[derive(Serialize, Deserialize)] struct Md5Cache { cache: HashMap<String, String>, changed: bool, } enum Diff { Dir, SameFile, DiffFile, } impl Md5Cache { /// 从文件加载 MD5 缓存,如果文件不存在则创建一个新的缓存 /// /// # 返回值 /// /// 返回一个 `Md5Cache` 实例 fn load() -> Self { if Path::new(MD5_CACHE_FILE).exists() { let file = File::open(MD5_CACHE_FILE).expect("Unable to open MD5 cache file"); Md5Cache { cache: serde_json::from_reader(file).expect("Unable to read MD5 cache file"), changed: false, } } else { Md5Cache { cache: HashMap::new(), changed: false, } } } /// 将 MD5 缓存保存到文件 fn save(&self) { if !self.changed { print("MD5 缓存未发生变化,无需保存"); return; } let file = File::create(MD5_CACHE_FILE).expect("Unable to create MD5 cache file"); serde_json::to_writer(file, &self.cache).expect("Unable to write MD5 cache file"); print("MD5 缓存保存成功"); } } /// 计算文件的 MD5 值 /// /// # 参数 /// /// * `file_path` - 文件路径 /// /// # 返回值 /// /// 返回文件的 MD5 值字符串 fn calculate_md5(file_path: &Path) -> String { let data = read(file_path).expect("Unable to read file"); let mut hasher = Md5::new(); hasher.update(&data); format!("{:x}", hasher.finalize()) } /// 判断源文件和目标文件是否不同 /// /// # 参数 /// /// * `src` - 源文件路径 /// * `dst` - 目标文件路径 /// /// # 返回值 /// /// 返回一个 `Diff` 枚举,表示源文件和目标文件的差异类型: /// - `Diff::Dir` 表示源路径是一个目录。 /// - `Diff::SameFile` 表示源文件和目标文件相同。 /// - `Diff::DiffFile` 表示源文件和目标文件不同。 fn diff_with_short_dst(src: &Path, dst: &Path) -> Diff { if src.is_dir() { return Diff::Dir; } let src_md5 = calculate_md5(src); if !dst.exists() { let mut md5_cache = MD5_CACHE.write().unwrap(); md5_cache .cache .insert(dst.to_str().unwrap().to_string(), src_md5); md5_cache.changed = true; return Diff::DiffFile; } let dst_md5 = { let md5_cache = MD5_CACHE.read().unwrap(); md5_cache.cache.get(dst.to_str().unwrap()).cloned() }; let dst_md5 = match dst_md5 { Some(md5) => md5, None => { let new_dst_md5 = calculate_md5(dst); let mut md5_cache = MD5_CACHE.write().unwrap(); md5_cache .cache .insert(dst.to_str().unwrap().to_string(), new_dst_md5.clone()); md5_cache.changed = true; new_dst_md5 } }; if src_md5 != dst_md5 { let mut md5_cache = MD5_CACHE.write().unwrap(); md5_cache .cache .insert(dst.to_str().unwrap().to_string(), src_md5); md5_cache.changed = true; return Diff::DiffFile; } Diff::SameFile } /// 复制源目录到目标目录,排除指定的文件列表 /// /// # 参数 /// /// * `src` - 源目录路径 /// * `dst` - 目标目录路径 /// * `excl` - 排除的文件列表 /// /// # 返回值 /// /// 返回 `io::Result<()>` fn copy_with_exclusion(src: &Path, dst: &Path, excl: &[&str]) -> io::Result<()> { if !dst.exists() { fs::create_dir_all(dst)?; } let entries: Vec<_> = fs::read_dir(src)?.collect(); entries.par_iter().try_for_each(|entry| { let entry = entry.as_ref().unwrap(); let s = entry.path(); let d = dst.join(entry.file_name()); if excl.contains(&entry.file_name().to_str().unwrap()) { return Ok(()); } match diff_with_short_dst(&s, &d) { Diff::Dir => { copy_with_exclusion(&s, &d, &[])?; } Diff::DiffFile => { fs::copy(&s, &d)?; print(&format!("文件 {} 复制到 {} 成功", s.display(), d.display())); } _ => {} }; Ok(()) }) } /// 主函数,设置当前目录并执行文件复制和索引更新 fn main() { let home_dir = env::var("HOME").expect("Failed to get home directory"); let project_root = Path::new(&home_dir).join("Space/Study/NeoNotes"); env::set_current_dir(&project_root).expect("Failed to set current directory"); let exclude = ["SUMMARY.md", "updateSummary.py"]; let update_index_script = Path::new("tools/autoIndex.py"); if update_index_script.exists() { Command::new("python") .arg(update_index_script) .status() .expect("Failed to run update index script"); print("索引更新完成"); } copy_with_exclusion(&SOURCE_DIR, &TARGET_DIR, &exclude).expect("Failed to copy directory"); MD5_CACHE.read().unwrap().save(); } |
Cargo.toml 如下。Copilot 给的依赖版本都挺低的(甚至一开始还有问题,例如 md5 的名称问题等),我上 crate.io 用了最新的也没问题,所以就这样了:
1 2 3 4 5 6 7 8 9 10 11 | [package] name = "sync-notes-to-blog" version = "0.1.0" edition = "2021" [dependencies] serde = { version = "1.0.132", features = ["derive"] } serde_json = "1.0.132" md-5 = "0.10.6" rayon = "1.10.0" lazy_static = "1.5.0" |
要我看我大致是能看明白的,不过要我写难度就比较大了。
最终时间测试结果如下:
最终编译产物 760k,感觉相较而言好像有点大?不过这点倒是小意思啦。
另外,直接删除目标地址,以及删除缓存,所需时间大概一秒多,因为同时会输出复制的文件(开了 VERBOSE),就不截图了,还是相当快的。
缓存现在则有 59k,不过因为键是完整路径,一开始还有优化的念头。但后面试了一下发现按目前的代码逻辑,要是要改的话可能得大动干戈一番,就懒得弄了。
我也没写测试什么的,感觉也不太好写。加上实际测试使用,根据 Git 的跟踪,没出现啥问题,也就作罢了。
要说优化空间,那应该还是有不少的。但就目前这个效率,说实在的我也没动力去优化了,已经够用了。
此乃谎言,我其实还试过另一项优化。上面 Copilot 提到的读写锁只是一个优化方案,还有一个是异步 IO。弄完上面的读写锁后,我又去尝试了一下异步 IO,试验下来发现,无论是 Rust 还是 Python,异步 IO 处理都大大降低了速度,因此就回滚了。
不管怎样,这算是「我」的第一个 Rust「项目」吧。但还没有传 GitHub 的念头,毕竟只是个脚本,等我有时间看看能不能建个管理多个 Rust 脚本的仓库再说吧。
讲个题外话,就当作今天的收尾。就是算上私博,总字数已经破 70w 了,具体来说,现在是 710k。可喜可贺、普天同庆,联合国知道了。
晚上又写了个脚本,检查博客内文章(包括普通博文、笔记、记事等)图片是否有效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 | import os import re from pathlib import Path from difflib import get_close_matches os.chdir(Path(__file__).resolve().parent.parent) POST = "_posts" PAGES = [ "daily", "notes", ] IMG_REGEX = re.compile(r"!\[.*\]\((?P<path>.+)\)") IMG_NOTE = re.compile(r' "[^"]+"$') IMG_SUFFIX = re.compile(r"#\w+$") def is_url(path: str): return path.startswith('http') def find_ambiguity(start: Path, image_path: str): image_dir = (start / image_path).parent image_name = (start / image_path).name if not image_dir.exists(): parent_dir = image_dir.parent if not parent_dir.exists(): return "" candidates = [f.name for f in parent_dir.iterdir() if f.is_dir()] matches = get_close_matches(image_dir.name, candidates, n=1, cutoff=0.6) if matches: corrected_dir = parent_dir / matches[0] corrected_image_path = corrected_dir / image_name if corrected_image_path.exists(): return corrected_image_path.relative_to(start).as_posix() return "" candidates = [f.name for f in image_dir.iterdir() if f.is_file()] matches = get_close_matches(image_name, candidates, n=1, cutoff=0.6) return ((image_dir / matches[0]).relative_to(start)).as_posix() if matches else "" def has_image(start: Path, image_path: str, post: str =""): if is_url(image_path): return True image_path = IMG_SUFFIX.sub("", IMG_NOTE.sub("", image_path)) image = Path(image_path) if post: if image_path.startswith("/"): return Path(image_path[1:]).exists() return (start / post / image).exists() else: return (start / image).exists() def check_images(file: Path, is_post: bool =False): start = Path(file).parent missing = [] with open(file, encoding="utf-8") as f: for i, line in enumerate(f, 1): for match in IMG_REGEX.finditer(line): image_path = match.group("path").strip() post_name = file.stem if is_post else "" image_found = has_image(start, image_path, post_name) if not image_found: ambiguity = find_ambiguity(start, image_path) missing.append((i, image_path, ambiguity)) if missing: print(f"\033[91m{file.as_posix()}\033[0m:") for i, image_path, ambiguity in missing: if ambiguity: print(f" \033[93m{i}\033[0m:\t\033[94m{image_path}\033[0m\n ->\t\033[96m{ambiguity}\033[0m?") else: print(f" \033[93m{i}\033[0m:\t\033[94m{image_path}\033[0m") def main(): for page in PAGES: for file in Path(page).rglob("*.md"): check_images(file) for file in Path(POST).rglob("*.md"): check_images(file, is_post=True) if __name__ == "__main__": main() |
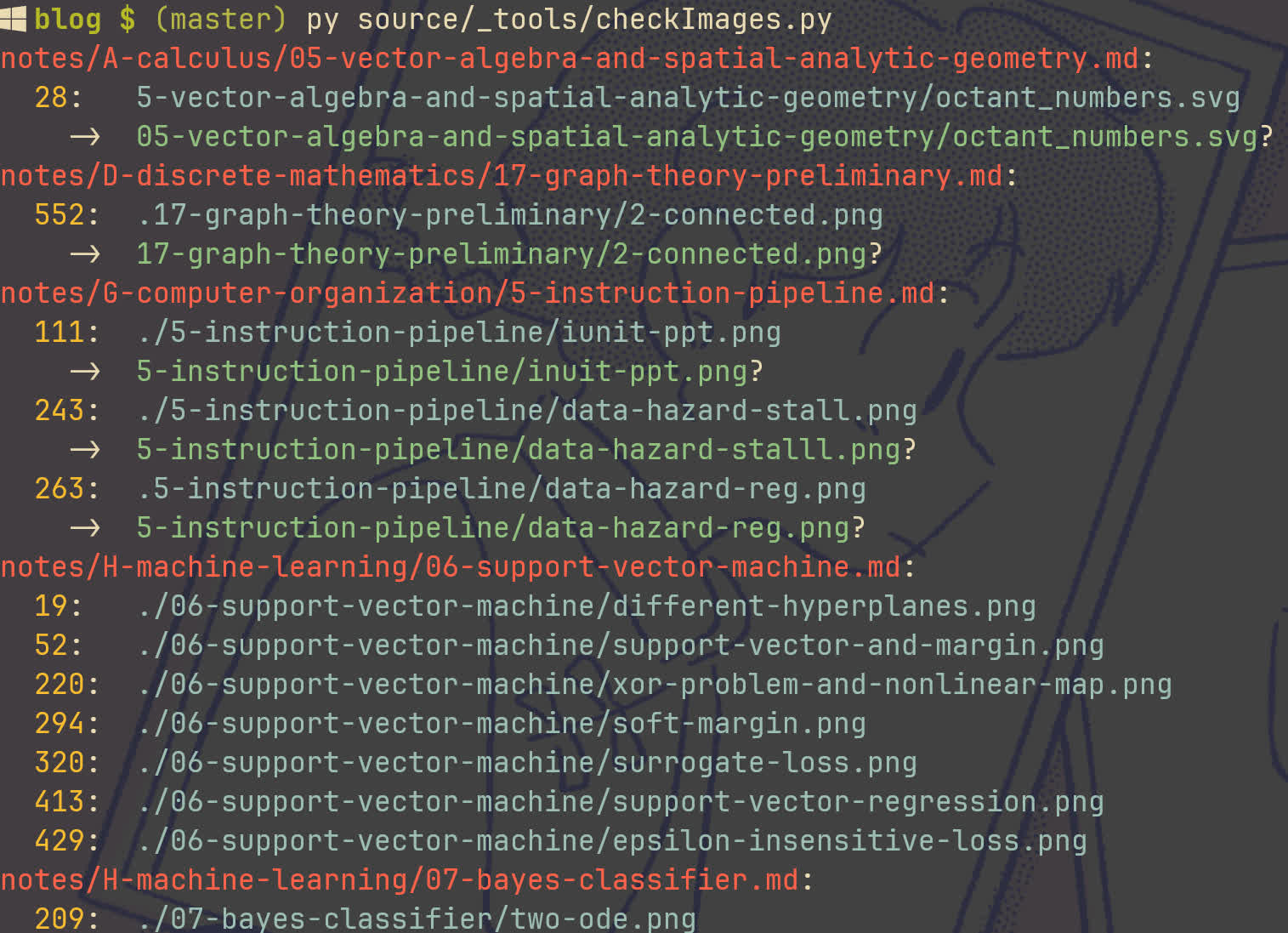
还有帮忙检查可能相似、误键的名称等。上面《机器学习》「支持向量机」的笔记没有相似的,这确实,因为那里的图片我只写了个名,还没补充呢(都蛮久以前的任务了)。
看上去已经不错了,其实还有可以改进的地方。例如可以加入交互,将可能的命名错误进行修改等。不过今天有点晚了就算了。
此外改一下就可以检查引用博客内部的链接了,同样的,也是今天有点晚了就算了。
17 日
惯性不仅仅是写博位置的惯性,还有写博频率的惯性。在频繁更新时,即使没多少东西也会常常来看看;而不常更新时,堆积了很多东西也迟迟未下笔。
24H2
之前说过那个更新迟迟未能成功,后面消失了,但是我看更新历史还是没有它的身影。然后又有一个更新失败,错误码好像还是一样的,不过更新编号不同。
我不耐烦了,加上听说 24H2 有一些性能上的提升,于是周五晚我自己去更新了 24H2。
更新后说实话没啥实感,不过简单搜索了一下 PCManager 又回来了,只是开始菜单没有,我也懒得管了,后面有闲情雅致再来杀。
然后更新还是有点问题,24H2 也有个累积更新失败。然后还有个 Intel 的更新,点重试后秒失败。于是我禁用了一周的更新。
家教
昨天早上去吃早餐[2],走的时候一个女士拦住了我,问我有没有时间,好像要给她儿子请家教还是什么的。
我立刻回绝了,说我没有时间。然后回想起高考假那会应该有些同学是去做家教了(还有卖笔记赚第一桶金什么的),以及来南大后经常也能看到各种家教的信息。
不过边想边迈向门口时我才猛地意识到最离谱的事情,那就是她儿子才二年级啊。这也太哈人了吧,二年级就请家教?真的假的?现在鸡娃到这种地步了吗?说真的二年级有啥家教的必要吗?
不过这个惊奇归惊奇,还是属于从自己的视角看他人的想法。于是我震惊一会儿后就继续去思考这件事了。
要说我完全没有家教的念头,那是不可能的。不过在一年多前我就已经否定了这种可能,最为核心的自然就是懒了。但是所有事情都用懒来概括,不能说有问题,但是这也掩盖了其他可能的存在,而这些可能往往更加复杂、多样,也许更接近问题的本质,更值得我去深入地思考。
有一点原因那就是无能。这个无能由两部分,第一部分就是字面意思的「无能为力」。毕竟已经毕业了,荒废了,想要重捡起来必然是需要一点时间与精力的,何况也未必捡得起来。
不过二年级,说实话我秒拒后就隐隐有点「后悔」了,这种后悔不是说再给我一次机会我就会多点时间斟酌了,而是说有点被吸引了。因为这个年纪也很难学啥奥数啥的吧,那凭我的知识水平大抵还是能应付的[3]。
因此就引申出第二点,就是「教育能力」,我是不认为我有啥教学能力的,实际上教多了挺不耐烦的。
但说实话我一度认为我是有点这个能力的,因为高中的时候跟同学讨论问题,以及教别人的时候还是很有成就感的。
我自己想了一个原因,那就是「知识共鸣」。在高中的时候,讨论问题是很让人兴奋的,即使教别人并没有让自己有所收获,仍然是很有成就感的一件事情。我把这个称为「知识共鸣」。
但是在现在却没有这种感受,感受到的更多的可能还是负担吧,感觉就是在做无意义的事情。
前者也许是因为知识水平差距不大,基本是平等的交流,而后者的知识跨度比较大。同时,前者讨论的内容很难在公共网络资源中找到答案,而后者往往会心里吐槽,这不是一搜就有吗。
只是,我也并非一直处于这样的「上位」,更多的时候,在网上学习的过程中还是发现处于「下位」的,是处于「不知道从哪里找答案」的境地。
还有家教的目的无非是为了钱,但仔细想想,我觉得对我来说是得不偿失的。虽然说不敢讲能把所有的时间都投入到学习新知识当中,但是只要有一部分,我觉得都还是胜过我去做家教。
不在意这样的收入,也是因为我姑且还算是比较「省吃俭用」的,倒是没啥需要花很多钱的地方。
之前还有想过要不要大学了换一部新手机,毕竟这部至少跟到现在跟了我四年了吧。但真正当有了奖学金时,反而里面一分钱都不想动了。
感觉手机虽然屏幕已经有了岁月的侵蚀,右下角甚至比较难点了,但好像真的没啥换的必要。经常看人说啥现在 256G 都不够用了,我不否认,只是我 128G 还用得好好的,共计不到 90G。
诚然确实到现在已经是「不够好用」了,但也仅仅如此,而非「不能正常使用」。我手机使用频率、使用强度,完全支撑不起我换一部好一点的手机的需求。因此我感觉这部手机起码还能继续作战,一直战到我真正收获人生中自己亲手赚到的第一笔钱时。
真要说的话,其实还是比较后悔当时买电脑时为了省点钱而选的 16G 内存吧。其他方面我都没啥后悔的,很多给大学生的推荐都是推荐游戏本、32G,我这两点都没有遵从。
前者判断是非常精准的,大学到现在确实没玩过游戏(严格来说当然不是,例如前面讲过 Minecraft 稍微看了眼,但这肯定不算啊)。而后者确实是有点偏差了,我仔细研究了下需求,认为我没啥大的应用,用不到很多的内存。实际看来这个判断是失误了的。
当然,当时选 16G 还有一点原因是打算后面有需要再拓展。这就暴露出另一个知识的匮乏了,我确实是调研不足,了解不多,因此我是买了后才知道内存是焊在里面的,没法拓展。
不过说了这么多,其实还是「能用」,所以还是没有更新换代的打算。
晨跑
昨天早上去吃早餐,是因为早上去跑步了。
在此之前先简单提一下。因为下周六要考 1000m 的体测,所以这几天我的 2400m 就换成 1000m 了。当然也有点偷懒的私心在。
算上今天已经四次了(才四次啊)。实际感受就是跑 1000m 比 2400m 累多了,第一次跑甚至没跑完,跑到 800m 就崩溃了。
还是我看轻了 1000m,自以为跑多了几次 2400m,突破一下上次体测的记录那还不是手到擒来、易如反掌?结果第一次一开始就冲过头了,后面崩了。
然后再更是震惊,初中同学马拉松的配速比我 1000m 的配速还快上不少。要是换成那些顶尖的世界级运动员我还没啥感受,但就是曾在我身边朝夕相处的同学,那种不真实感就油然而生了。
朋友圈里昔日的同学们都在大放异彩,又有点让我自惭形秽了。
不过好在今晚还是稍微破了上次体测的成绩(二、三次甚至没摸到门槛),这周再练练吧。
然后跑 1000m 还不够乐跑,剩下的 1400m 就靠我走路了。然后呢即使走到宿舍楼底也一般就 1800m 左右,这时候就往往绕到快递站那边,走个来回。当然其实可以在操场走个两圈再回来,我后面也是这样打算的,从明天开始实施。
有天晚上往远处走了走,另一侧是工地,走一段路后我居然发现有条小路,只不过当时已经 2100m 多了,可以返程了,于是就打算后面来看看。
然后周五因为悦读老师时间的安排问题,开始时间延后了,于是当天计划的跑步就只能延后了。当然,按照我的定义这是不属于「不可抗力」的,即我要补一整天。所以我就打算周六早上走一遭。
这是最后跑的路径:
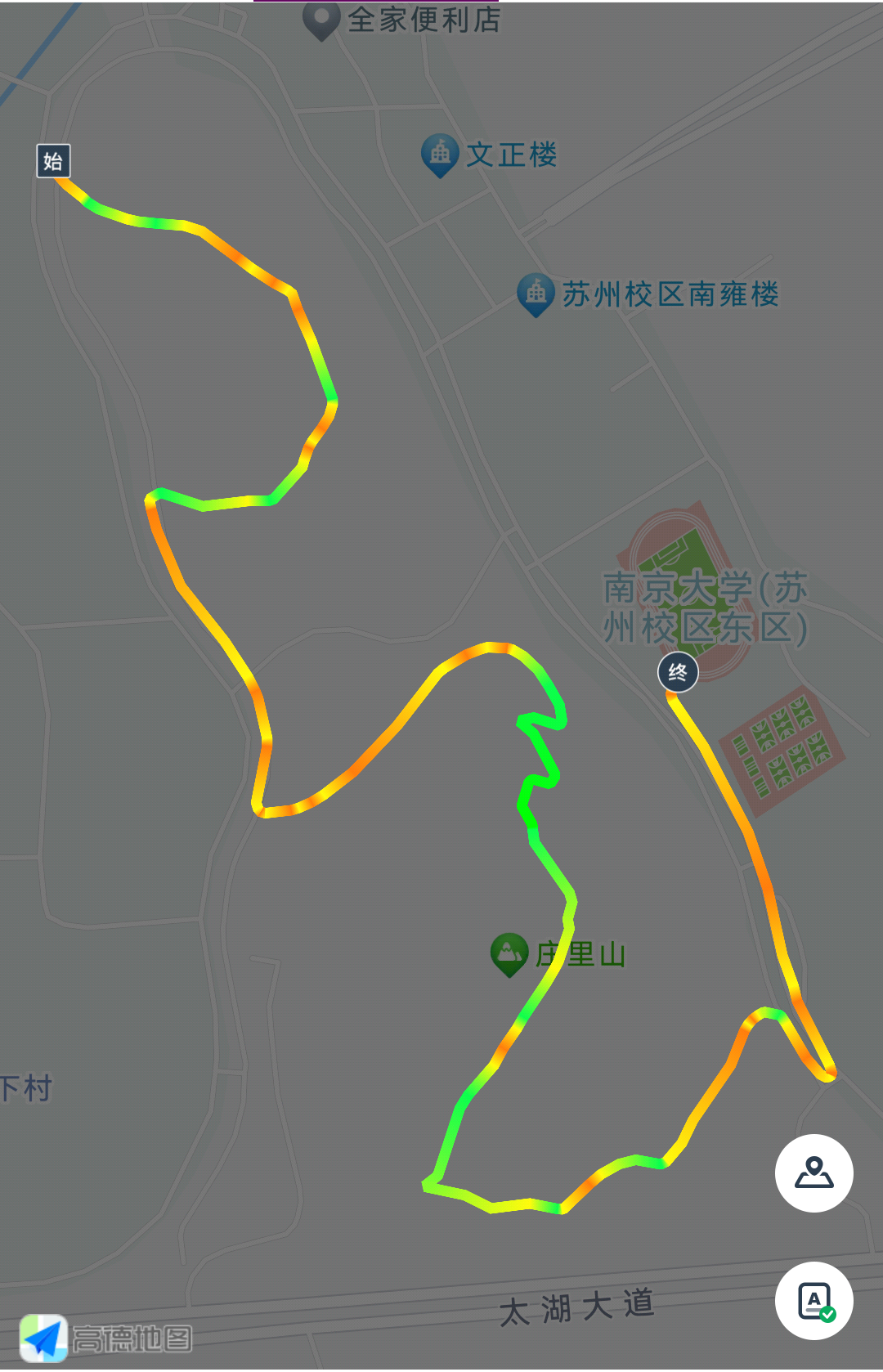
其实说是跑,中途起起落落很多,中间走的比重也许更大。
从地图上看,大致是进出了两次。第一次进那个石阶道,然后往上走,再往下走,走出来了。紧接着有条可以行车的道路,沿着走又有一个能进去的石阶道,再上去,这会比较长,上面还能见到亭子,再走一阵子就出来了,出口有个湖。
放几张第二次进山时拍的照片吧,前面大部分都是在高处,不过不是最高处,最高处似乎没看到比较近的、明显的道路?






出来后还看到了「黑天鹅」:

Python
这周写 Python 的时候,写变量,然后输入 .,有些变量不显示方法,让人很是苦恼啊。只有在这种时候,才会稍微怀念一下其他「强类型」的语言。
不过我也是知道 Python 是有类型标注的,因此就试着给没有自动推断出类型的地方写了一下,写了类型后确实舒服多了,感觉有点爽。
这里就要再推荐一篇文章了:Python Type Hints 简明教程(基于 Python 3.13)。
是熟悉的作者呢,因为这个作者的文章写得好,所以我把他的文章,感兴趣的大致都翻阅了一下。
但其实这篇简明教程我好像没看完,只看了一部分,因为内容还是非常广阔的,暂时还没有了解的必要,看了也很快就忘了。
目前 3.12 在我写的类型中就基本够用了,也就一个「前向引用」得等 3.14 支持,现在暂时用 " 包裹来作为 workaround。
Python 真的是越学越感觉好啊。之前挺多感觉一直是在原地踏步,这段时间才又了解了一点知识,更觉得 Python 很不错了。
Python 差不多是我的编程入门语言吧,即便如此我仍旧还有很多知识盲区,是从未接触、了解过的。前路漫漫呐。
跑步前还看了看 FastAPI 的文档,感觉与 Flask 形成了鲜明的对比。
虽然 Bloomink 没后端,但我一开始计划的时候用的是 Flask。原因无他,网上搜了一下,于是就随便选了这个。
个人感觉,相较而言,FastAPI 学得更舒服一点,尤其是近期我正好开始写类型标注,那自然是非常契合。
这也算是给了我一个提醒吧,在一个事情有多种选项时,不要急于立刻从中选择一个作为最终选项,应该是对每一个选项都进行了解、评估,而且不要只是看别人是怎么说的,而是要亲眼看看每种选项对应的实例,自己做出一个判断。这样做的时间,也许可以比随便选择一个选项,后续付出的时间代价更少。
说到 Python 还有个事。这周的时候把神经网络的代码重新看了下,同时更新了一下笔记,这才算是消化了一点知识吧。只是其实有点迟了,神经网络已经是第五章的事情了,而已经到第九章了好像,而且作业感觉也是一个月前的了,才终于抽出一段时间来看。
然后周六拿神经网络玩了一下,用来做一个二分类任务。因为当时正好在做另一件事,可以收集到一部分话语,而这周又正好重新理解神经网络,因此就打算拿来练练手。当然其实意义不大,因为神经网络代码没啥要动的,所以纯粹只是玩玩。
这个二分类任务数据集是话语,属于两个人,比例接近 53:47,所以一开始的任务就是把输入的字符串转化为数值向量。
这个有两个方案,一个是我一开始想的,每个字符对应一个数值,然后填充 0 到最长的那个字符长度。当然很烂,只不过我也纯粹只是玩一下。还有一个就是 AI 给出的。
神经网络也有两个方案,一个就是我自建的神经网络,还有一个是用 PyTorch 弄的。
前者的数值向量维度近 300 维,后者 2000+ 维。
前者效果相当差,训练集精度都很难上 7/80%,后者倒挺不错的,很快就能上 90%,逼近 100%。不过后者训练时间也要长不少。
但即便如此,测试精度都非常差劲,前者一般在 55% ~ 60%,后者试了一次差不多 63%,是相当差劲的成绩了,毕竟无脑猜其中一个都有 53% 的准确度。
不过一开始的目的本来也就是玩玩而已,确实没指望它精度能有多高。
笔记
谈及到笔记,不管怎么说,下周我就要开始做 Anki 卡片了,这是军令状。
今天随手点开了考试安排,才发现 1 月初要考试了。虽然说还有不到两个月,虽然说比去年晚了几天,但我还是有了点紧迫感,因为我笔记卡片那是一个都没有做啊。
先是废掉微积分、线代、离散等课程的卡片。没错,我其实还有背专业课程的卡片,只是一样,已经荒废好久了。「废掉」指的就是重置进度,因为已经完全乱掉了。另外,这应该起码是第二次「废」了。
本来开学初想着,废卡后继续背那几个数学的卡片,不过现在看来是不太现实了,还是先把现在的专业课放前面吧。
笔记的复习就能与制卡合并,制卡本身就是复习的过程。
只是,除去复习旧知识,我其实还积累了很多事务。例如计组已经落下进度太多了,作业也还没开始写等等。只是这不能成为阻碍我这周开始制卡的理由。
今天先这样,不到一分钟了。
20 日
今天忙了一天了,晚上就不干正事了,来写点东西吧[4]。
笔记与制卡
今天确实挺忙的:早上《机器学习》记了一节课笔记;下午第一节游泳课,生病了就懒得游了,到一楼大堂玩了一会手机后补了点笔记;通识课制了一节课的卡;晚上听讲座制卡 + 笔记修正;讲座后刷了会手机笔记本,然后又做了点,九点半以后才回宿舍。
制卡进度也挺可观了:我觉得有必要制卡的大概包括计组、机器学习、概率论、数据结构与算法这四门,机器学习和概率论进度也非常喜人了。C++ 有的我感觉需要记笔记(目前没记),但不太适合制卡。
大致来说就是,机器学习现在上到了第十章(按我的编号记),制了七章卡,差不多也正好是我整体重温过笔记、理解了个大概的部分,剩下的可以晚点再弄了;概率论是九章,制了六章卡,后面是因为有很多需要修正,就先完成了修正,制卡就停止了。
机器学习因为大部分是抄书,不会动太多内容。而概率论不完全是照抄 PPT,毕竟 PPT 是英文的,我要转述再加工,因此重看概率论笔记时发现了大片错误,下面是两个比较长的例子(当然第一个「修正」不只是修正笔记):


说是「修正」,其实也有一点补充内容——我觉得这里可以加上什么什么,或者没看明白的地方,不想打断检查进程,因此标记一下,回头再看看等。
第二张图这个「笔记补充」,也就是今晚点了完成的,虽然还有两个没搞定,但还是点了完成。因为这个清单已经很长了,老是没清理,堆到最后才去弄导致的。所以就把这两个移到新开的地方了。
大部分都是概率论也是因为游泳课通勤车上来回就能看不少了,大部分 Todo 也是此时加的,又迟迟没有清理,所以堆得比较多。
这两个科目也应该是最容易制卡的了,其他两个都还比较棘手。
计组我觉得制卡之前,我还是得先理解内容再说吧,我感觉不用感觉,就是,我的知识水平已经远远落后于进度了,甚至有一节已经懒得抄 PPT 了。
而数据结构与算法是英文的,嗯,相较上一个还是轻松一点,毕竟我大体还是能看懂我记的内容的。
冷笑话与创新
生病头晕脑胀有点难受,这也是上面不想重看笔记完成其中一个 Todo 的原因之一。
生病脑袋都迟缓了不少,虽然本来也没多灵光。因为我还想了下这是不是我大二第一次生病啊,然后才迟钝地想起,大二刚开始那会一直在病,特别难受,才几个月咋就忘了呢。
不过说实话,确实,两个月以前的事情跟现在比较起来,感觉真的挺久远了。也许这就是怅然若失的感觉,因为一个阶段结束了,感觉心里空落落的,虽说只有两个月,但却是两个阶段,因此感到特别久远。
也有可能是因为这学期忙碌了不少。虽然这学期课程比上学期少,甚至开学很长一阵子以来我都相当摆烂,但不得不说似乎是充实了点,虽然我也不知道充实了点啥,金玉其外,败絮其中。
近期,摆烂还是不少,但就是似乎更能投入到正事了。这挺好,我感觉这也是压力带来的点动力吧。
然后是这一节的正题。今晚回宿舍路上,冷啊冷,当然其实也没有很冷,比起最冷的时候。我就在想,似乎现在的天气要么很热要么很冷,几乎没有全天阳光明媚、天气宜人的舒适,换言之,「秋」。因此我就想到了个冷笑话:
为什么现在只有「夏」和「冬」了呢?
因为《春秋》是古代的。
挺有意思的。
我感觉我非常缺乏点子,也就是创新的能力。给我一个选题,我很难去发挥想象力凭空创造出一个意识产物。
原因可能有几个,我随便讲讲吧。
一个就是见得太少了,阅历不够。这个确实,下面还会有一个提到这一点的,不过今天未必能讲到。人难以想象出自己没见过的东西。
一个就是我比较安于现状,缺乏改变的动力,因此比较少主动出击打破现状。这个要扯可以扯很多很远了,比如说因为我到现在的人生基本都是风平浪静的,没啥大起大落;比如说倾向于借助其他工具解决问题,而非自己亲自尝试等等。
还有可能就是动脑比较少。但这就比较抽象了,该咋动脑培养创造力呢?
洗澡时想了个点子也不知能否坚持下去,就每天记录一个创新的小想法,例如上面的冷笑话。只要是创新的就好了,而且一定要小、短。当然我觉得对我来说难度可能太高了,所以还可以是另一个,也是我最初的想法,那就是记一个能给予我正向情绪波动的小点,也是要小、短。
当然,尽力而为,办不到也没办法,有时候有灵感一下子能记好几个,有时候连续几天憋不出一个。这类最好做个特殊的标记,因为我也不是每天来这里更新,就一批一批搬过来吧。
上面那个冷笑话自然是这两种都符合的,不过第二个还能给一个例子:
在 Typst 群里看到了个「知识点」,上划线可以用 dash 函数,效果非常好:如下图所示
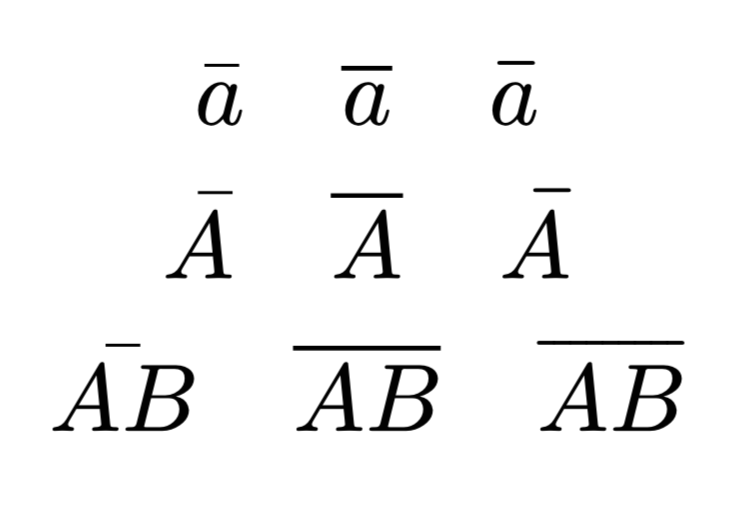
代码是
1 2 3 4 5 6 7 8 | $ #let test(a) = { math.macron(a); math.quad; math.overline(a); math.quad; math.dash(a) } test(a) \ test(A) \ test(A B) $ |
也就是第一列是 macron,也正是我当初看文档找到的 中的 \bar,第二列是 overline,也对应 中的 \overline,第三列就是 dash,在 中应该是没有对应的。
从这个效果上就可以知道多好了。
再来个 的例子,这里就不用官网的截图了,直接渲染:
因为 \bar 不适用于 AB 这种例子,因此这种例子我一般就得用 \overline。而 \overline 对一些单字符而言又特别丑陋,用 a 其实不太显著,A 比较明显,因此单字符我又一般用 \bar。
这样其实挺不便的,因此我用了 snippets:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | global !p special_bar_hat_vec = ['i', 'j'] special_hbar = ['\\bar{h}', '\\hbar'] map_bar_hat_vec = {'bar': '\\overline', 'hat': '\\widehat', 'vec': '\\overrightarrow'} bars = ['\\bar', '\\overline'] hats = ['\\hat', '\\widehat'] vecs = ['\\vec', '\\overrightarrow'] def bar_hat_vec(target, word, subscript = ''): return '\\' + target + '{' + ('\\' + word + 'math' if word in special_bar_hat_vec else word) + '}' + (subscript or '') def long_bar_hat_vec(target, word, subscript = ''): return map_bar_hat_vec[target] + '{' + word + '}' + (subscript or '') endglobal context "math()" snippet "\\?(vec|bar|hat)" "拔/帽/向量 Bar/Hat/Vector" wr \\`!p snip.rv = match.group(1) + "{"`${1:${VISUAL}}}$0 endsnippet context "math()" snippet "(\\bar{h}|\\hbar)\\" "hbar" ir `!p snip.rv = choose_next(match.group(1), special_hbar, 2)` endsnippet context "math()" snippet "(\b[a-zA-Z0]|\\[a-zA-Z]+)([_^](?:\{\S+\s?\}|[\da-zA-Z]))?(bar|hat|vec)" "拔/帽/向量 Bar/Hat/Vector" Ar `!p snip.rv = bar_hat_vec(match.group(3), match.group(1), match.group(2))` endsnippet context "math()" snippet "((\\(bar|overline|hat|widehat|vec|overrightarrow))\{(.*)\})" "拔/帽/向量 Bar/Hat/Vector" r `!p snip.rv = command_swap(match.group(1), *(bars if match.group(2) in bars else hats if match.group(2) in hats else vecs))` endsnippet priority -1 context "math()" snippet "(?<!\\)\b(\w{2,}?)([_^](?:\{\S+\s?\}|[\da-zA-Z]))?(bar|hat|vec)" "长拔/帽/向量 Long Bar/Hat/Vector" Ar `!p snip.rv = long_bar_hat_vec(match.group(3), match.group(1), match.group(2))` endsnippet priority 1 # 为避免冲突,仅支持包含简单下标的变形 # Only support simple subscript to avoid comflict # √: \bar{a}_a --> \overline{a}_a # √: \bar{a}_{\alpha} --> \overline{a}_{\alpha} # ×: \bar{a}_{\dfrac{1}{2}} --> \overline{a}_{\dfrac{1}{2}} context "math()" snippet "(\\bar|\\overline)(\{[\\a-zA-Z]+\s?\})((?:[_^](?:[\da-zA-Z]|\{[\\\w\d\s]+\}))?)" "拔 Bar" r `!p snip.rv = choose_next(match.group(1), bars, 2) + match.group(2) + match.group(3)` endsnippet context "math()" snippet "(\\hat|\\widehat)(\{[\\a-zA-Z]+\s?\})((?:[_^](?:[\da-zA-Z]|\{[\\\w\d\s]+\}))?)" "帽 Hat" r `!p snip.rv = choose_next(match.group(1), hats, 2) + match.group(2) + match.group(3)` endsnippet context "math()" snippet "(\\vec|\\overrightarrow)(\{[\\0a-zA-Z]+\s?\})((?:[_^](?:[\da-zA-Z]|\{[\\\w\d\s]+\}))?)" "向量 Vector" r `!p snip.rv = choose_next(match.group(1), vecs, 2) + match.group(2) + match.group(3)` endsnippet |
这个代码很久以前写的了,比较丑陋,不过现在也懒得改了。
大致就是实现了对单个字符(包括 a A 甚至是 \alpha)使用 \bar,对多字符 AB 使用 \overline。
上面的代码倒不止这么点,例如还有 与 的转换(刚刚实测已经失效了,不过本来也没用过,懒得修了,虽然好像加个 priority 就行了);对 ivec 等使用特殊的,即不使用 ,而是使用 (这个实测还正常);\bar \overline 等长短对互转;包含简单下标的互转等。
毫无疑问这些是 out of scope 的,但不得不说的是,这些确实很有「创意」,因此我当时写这些的时候很开心。而且这些用的其实不能算少吧(不过大部分其实都是 ibar 或 \alphavec 这样,互转及其他的特性确实用得少,几乎没用过),倒是挺不错的。
好像扯得有点远了,反正我的意思就是看到 Typst 有这个 dash 我挺惊喜的,很开心。就是这样,给予我了一个正向的情绪波动。
跑步
昨晚生病还要跑步,真的难受啊,跑完喉咙如刀割。
一生病不知为何就特别缺水,明明喝的量都比平时多不知多少,但就是口干舌燥、喉咙痛痒。
不过这倒不是重点。之前说过了在操场走两圈再回宿舍,我昨天就这样干了,走了两圈差不多 1.5km,虽然说还有 900m,但感觉也差不多,多个 100m 不碍事,就也回宿舍了。
离宿舍还有不到 50m 时,感觉可能不太行,于是绕着一个圈走了三四圈吧,走到了 2.2km 再回宿舍。此时配速已经 7min50s+ 了,之前差不多是 7min30s+ 或者 7min40s+。不过我觉得问题不大,走电梯上去距离会瞬移的,即使后面超了一点,我爆发跑一点就完事了。
然后 2.3km 到电梯下,已经差不多是 8min 了,这时我已经有点紧张了,电梯内不动,配速时间渐渐上升,感觉可能待会得爆发跑一下了,何况距离还有差不多 100m。
然后电梯到了后,果然瞬移了,不过好像不到 50m,挺少的。但是配速时间猛增,直接到 8min10s+ 了,我直接惊呆了。
于是放书包在宿舍门口,在走廊来回冲刺,结果配速时间不降反增。而且距离还不到。
这可把我急死了,这难道是要我前功尽弃?
感觉走廊里不太方便,我还在楼梯里从三楼冲到一楼,再从一楼冲回三楼,但都收效甚微。
冲完楼梯后又只能冲走廊了,来回冲,我都要绝望,放弃希望了,然后后面好像又瞬移了一下?反正就似乎突变了,时间也跌回 8min 内,到了 7min56s 左右,我赶紧结束掉了,最终近 2.6km。
下次不敢这样玩了,一定在操场弄到 1.8km 再回宿舍。在宿舍外面来回冲、来回上下楼梯,跟个傻子似的。不对,可以说「就是」。
还有件事,体测完要不要恢复 2.4km 呢?感觉 1km 挺差劲的啊,要不剩下的全练 1km 了?
今天就写到这里吧,没写几点。
29 日
来了!
今天于情,嗯,没有于理,纯粹是于情都应该来写。不过这是一开始时的想法,后面想到了,于理就是也是月底了,该写点了。因此确确实实就是于情于理都该再来写点了。
病
上周三的时候已经降温了,那会有点生病,因此就没下水了。咦我忘了我讲过没了,好像有提过一点?后面就是在下面玩了会手机开始补笔记。
然后这周下水了,果然天气冷的时候,水温体感反而更暖和。
然后呢,就是今天的课了。座位旁边有人生病的时候,坐久了头就晕乎乎了。这个感觉跟臭豆浆那会差不多。才刚好没多久我不会又要病了吧。
体测
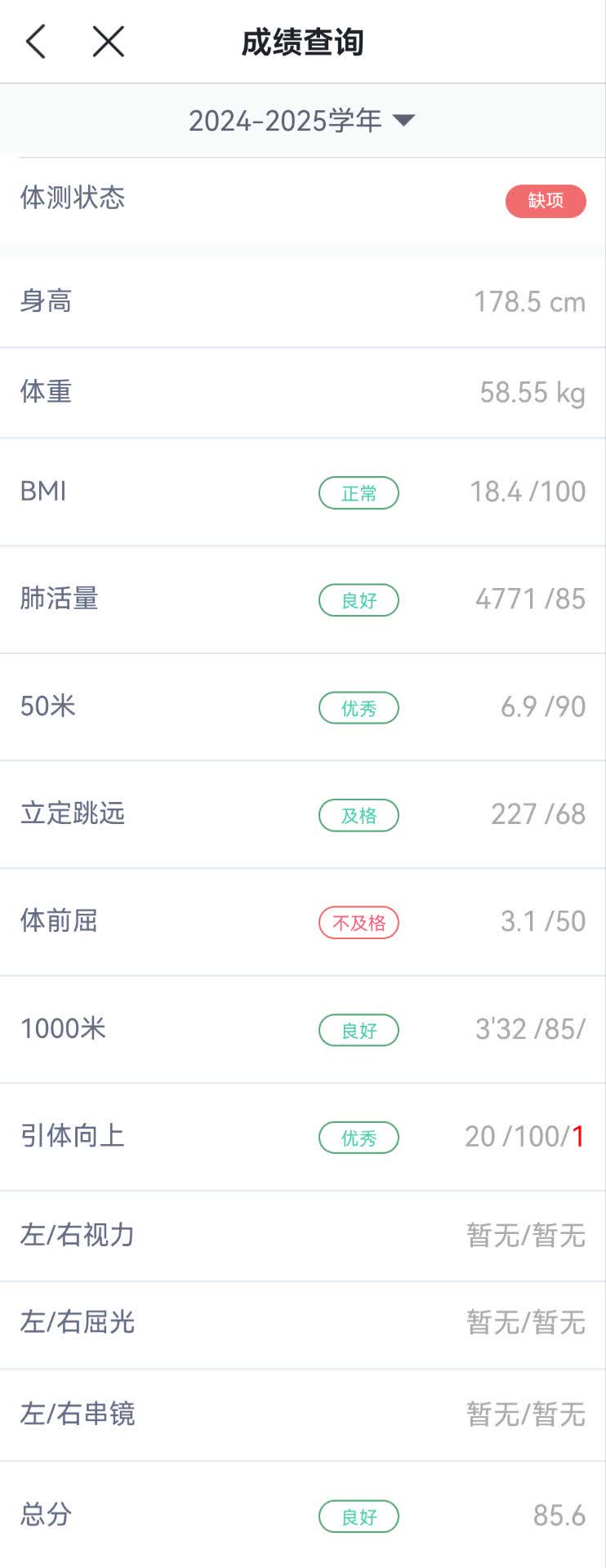
这是一个靠跑步拉回来的励志故事。
在其他全面崩盘的情况下,居然是跑步力挽狂澜,让体测总分反而还涨了 3.6 分。
50m 这个 6.93s 没啥好讲的,手记,看看就得了。不过有一点比鼓楼好的,那就是不是四个人一组测了,而是两个人,两个人那先后顺序还是好分的,实力差距不大时你四个人怎么分得清。
1000m 这个倒值得说道说道。我觉得是有点问题的,因为当时我也同步启动了乐跑。嗯,没同步,早启动了大概几秒,然后跑完后也没立刻看。不过两者加起来最多也就十秒左右吧。但我记得当时看好像是 3min50s 还是 4min 啥的,记得配速跟时间是不一致的。
不过也不管这么多了,要真有这成绩就好了。更感觉到初中同学的恐怖,用这个配速跑完了马拉松,然后 1km 速率跟我 50m 差不多。
30 日:夸张了,后面查了下世界纪录发现不对,于是重新去检查了一下,只记得个 2min,实际上差不多是 2min50s。但马拉松这个应该是没啥问题的。
还有这个引体,这个加分细则也不知道是什么。之前看到了说加分,但也没太关注。后面似乎听说超过了越多越好?那早知道那会再做几个了。
跑完 1km 后确实体会到了十足的痛苦。离开操场后,直接坐在了路边歇了好一会才起来继续走。然后在天枢楼底绕了好几圈(凑距离)才回宿舍。中途那种想吐,又吐不出来的感受真的折磨。好像那天中午也没吃饭?忘了有没有喝燕麦了,清库存真难受。
再说到这呕吐,我也忘记了我上次呕吐是什么时候了。而且说来也神奇,高中以前我的标签始终是有个「体弱多病」的,我也坦然接受面对了这个标签,同时也无意去改变事实。不过现在看来,我也许确实是多病,但绝对算不上体弱了。
这个印象的惯性也贯穿了我高中三年,以及大学第一年,直到现在我才真真正正稍微有了点实感——我体质没那么差。
这个感觉为什么能持续这么久呢?我当时记下来时给出的理由是「旧竹竿带来的惯性错觉」。「竹竿」评价我倒还是挺贴切的,不过现在稍微有点不符合了,毕竟我已经朝 60kg 进发了。剩下的不多谈了。
再说到这跑步,乐跑差不多也要完成了。到今天已经 22 次了,还差 2 次。今天本来也是计划要跑的,不过要是跑了估计就没时间写了,就推了。
不过这个推,倒不是一般的推。这个推指的是今天没必要跑,只是要补之前没跑的,然后推到后面去补。原因是「入冬」了,挺冷了,一周三次就差不多了。因此还是周二、周四要跑,剩下一次在周六、周日选一次(周六现在一般是算给周五)。也就是说现在周五可以不跑了。
还有 1km 是真的难跑。2.4km 按印象,好像一次也没跑崩。结果 1km 没几次,感觉跑崩的比例有 50%(具体没数)。一般是跑到 800m 没劲了,昨天更是笑掉大牙了,400m 就肚子有点疼停下来了,不过后面补了个 800m,勉强过关吧。
跑 1km 心路大概是这样的:前 150m,还算轻松。200m,怎么这么久才半圈啊。300m,怎么还有 100m 才一圈啊。400m,怎么才跑了一圈啊,怎么还有 100m 才一半啊。500m,怎么才一半啊。600m,怎么还有一圈啊,我要死了。700m,怎么还有 100m 就回到原点、还差半圈了啊,我坚持不住了。800m,两圈了,回到原地了,撑不住了。
一般来说 800m 是个重要分界线,能突破基本就能跑完了。主要是 800m 正好回到原点是个很强的诱惑。剩下 200m 基本上就是一边计算距离,一遍重复想我要死了。
食
食堂一直在几个餐位吃也有点好处,那就是食堂阿姨可能都能认识你了。
有一天早餐,食堂阿姨多给了我一个还是半个鸡蛋饼。不过这个不一定是因为认识我了,十六食堂早餐餐位也就那两个。
然后又一天吃辛拉面,食堂叔叔还给我加了个关东煮。
好像还有遇到过其他福利,可能我记不清了,大致一手之数不到差不多吧。
当然也不一定都是「好处」吧。前几个月经常去汉堡那里吃,然后一天记得汉堡餐位那个阿姨就讲我是经常到访她那里的顾客,让我羞得恨不得钻到地底里。
因为按我的认知是不太应该多吃的。于是后面就立了个规矩一周最多一次,后面偶尔还是有打破。不过一段时间熟悉后大概还挺长一段时间没吃,直到最近才又吃了点。
说实话这汉堡其实也没多好吃,甚至可以说没啥好吃的,每次吃了这汉堡后都相当难受。而且尤其不能去跑步,吃了汉堡后去跑步那是真的要吐了。一段时间没怎么吃了也是因为跑步不能吃。
不过就是那种油炸食品的香味,深深吸引了我,这也许就是生物的本能,刻在了 DNA 中。
借此机会聊点吃的内容吧。
早餐基本现在就是标准三件套了:鸡蛋饼(1.5 元)、麻球(2 元,鼓楼还是深中那边好像叫麻圆)、豆浆(2 元)。麻球偶尔会换成油条,或者是有时候奢侈点的蛋挞。
午餐若是有课,一般就是在二楼吃面,因为没啥人排队。常吃的就两个,炸酱面(13 元好像)和番茄鸡蛋汤面(9 元,以前是 8 元好像)。炸酱面据餐位的员工讲好像是最火的?不过炸酱面吃完后味道能残留很久,后面喝水还能感觉到。但吃得爽倒也是。番茄鸡蛋汤面就是为了有点水喝,番茄鸡蛋纯属是加点颜色用的,不然纯素面也差不多。
剩下时间的午餐晚餐都差不多,一般是在三楼。汉堡已经提过了,不过最常光顾的应该是韩餐那边。
说是韩餐,其实我没感觉有啥「韩」的特征,也许是菜单上有「泡菜」?
印象中菜单上有几类,一种是石锅拌饭,吃过几次。很烫,那个酱挺香的,但是剩下的都很差,前几次吃体验都非常差,终于在最后一次不信邪后,决定绝不再碰石锅拌饭了。
还有一种是炒面和炒饭,一般我都是选肉丝的,其他试过都一般。另外我也知道了,那不叫「火腿」,那叫「培根」,鼓楼那会好吃的里面有的是「火腿」,难吃的那个是「培根」。不过大部分都是选炒面,很久没吃炒饭了。似乎是因为那阵子炒饭吃不完,炒面能吃完的缘故。不过近期我炒面也吃不完了。胃口是真的差。
然后是米线和粉丝。之前还有尝过粉丝,不过多试几次后,我就决定了要是没米线就换一个了,不要粉丝作为替代。这个没啥好说的,只是最近也有决定,那就是跑步前也别吃米线了,也挺难受的。
最后是辛拉面,这应该是我所有菜品中最新探索的(说是最新,起码也是个把月以前的事了),现在基本上可以算是餐食的大头了。一般会加个荷包蛋(2 元),也许是因为可以跟基础 8 元凑个 10 元,方便计价?经常吃倒也不是有多好吃,冬天还是喜欢吃点热腾腾还有汤的东西的。不过这个辛拉面跟鼓楼那边差异相当大,这里的面太少了,不过质感感觉比鼓楼的好?
就没了。我就没尝过了。其他餐位都没咋试过。因为我一个「社恐」,虽然说改口称「社懒」了,但其实还是比较恐惧陌生人的线下社交。感觉在一个餐位那边徘徊,不知道咋点餐的感受太尴尬了,再加上我已经有了可以接受的选择,何必要付出额外的成本去学习新的餐品呢?于是就这样吧。能有几个选择已经是我的重大突破了。
说到吃,能吃确实是福,但我自己绝不是这样的。晚上看到了点丰富的大餐图片,看到非常诱人的烤肉时,我的意识告诉我这是个美味的食物,但是生理感觉是犯恶心。
我能从「吃」上感受到快乐吗?不能说没有,但只能说很少,甚至可以说少过带给我的痛苦吧。所以说要是可以让我不吃不喝(也就是我不用浪费时间去觅食,这下连仅存的出门机会也没了),但也体会不到各种佳肴的味道,我也许会毫不犹豫地愿意这样做吧。
当然朋友圈的分享,确实是让我垂涎,怎么都这么会选食物啊。大一那会还点过几次外卖,别人吃的和自己点的完全就是两个境界。所以我在苏州也懒得点了,不过这也与交通有点关系吧,而且也与需要跟商家、骑手进行沟通有点联系。
所以说,能吃的可爱的家伙,就请以后都要一直高高兴兴地、幸福地吃下去啊。虽然吃不能给我带来快乐,但吃带给你的快乐,也能让我快乐。
冬眠
冬天确实是一个容易犯困的季节。最近屡屡有点困了。
不过呢「冷」有助于睡眠。大一那会基本上是硬抗,缩在被窝里很快就能入睡了。现在宿舍开着空调,挺暖和的,甚至不用盖大被子,反而睡得比前阵子差挺多的,要挺久才能入睡。
还有就是教室里真的热啊,在外面冷,到里面又热得要死,一定要把外套脱下来。
本性
之前说过教室里学习的效率问题。现在看来还是本性难移,周三在一个教室最后一排,直接开摆。虽然稍微还是干了点事情,还是比在宿舍好上那么一点,不过也就那么一点了。
WSLg 左右键
这个不太确定,有待后面观察。今天上课遇到个事情,就是我 Win + F3 切换鼠标左右键,并没有反映到 WSLg 上。我现在一般是左手持鼠标,即右侧单击,左侧功能。也就是说,我用上面的快捷键切换回大多数人使用的模式后,变成左键点击 WT,是单击,但点击 Zathura,却是功能的状况。这样体验特别割裂,于是我后面又换回去了。
切换的缘故是座位比较少,只能挑了个偏僻点的,插座在左侧,充电线和鼠标重叠,因此打算恢复用右手。只不过最后还得是使用左手(当然其实用触控板最多)。
洗完个澡回来,泡个热牛奶。说起来这热牛奶,昨天特地没泡,就是留最后一只今天喝。
差不多十一点了,今天写的比较晚,尽管没跑步。加上等会还要私博写点,因此日常的假大空牢骚,有机会的话就留到明天吧,今天剩下的讲点实的。
项目
C++ 项目要做个游戏。唉,我不喜欢做游戏的。去年 C 期末作业就是为了逃避做游戏,才选了 RAMFShell,现在看来还是逃不掉。
而且这样一来我其实还有个劣势,那就是其他同学做 C 时已经做过了 GUI,对此有一定了解,而我当时不选择游戏除了不喜欢外,还有就是对 GUI,或者说 C 的 GUI 开发没有兴趣了解。C++ 也是同理的,上完课我就不写了,再学个 GUI 的的确确是不感兴趣。
不过事情总是要往好的方面看一下的嘛。不做游戏一开始的想法也是感觉不会有啥正反馈,因为那些游戏看起来就没啥好玩的。但这个想法其实稍稍有点改变了,大一下学期的时候感觉或许并不是这样的。
当然,其他方面还是一样的提不起劲。但总得去做,于是周一周二选定了 Qt,配了下环境与项目,可折磨死我了。
选 Qt 一是因为大名鼎鼎,可以参考的资料文档也会比较多,虽然说我实际看下来体验不算太好。二是因为 GoldenDict 用的 Qt,留下了个印象:因为在看到反馈 bug 的时候,常常看到说是 Qt 的问题,差印象也算是印象吧。
其实简单的配置并不复杂,把它那个下载器弄下来,加个镜像,选一下就差不多了。但是啊但是,我是简简单单的配置就能束缚得了的吗?我想在 VS Code 里写。
Qt 可以在它的那个编辑器里写,我一下子就否掉了。在它的编辑器里确实可能最方便,配置最少,需要操心的没那么多,但同样的,我自己量身定做的一些东西,也就无法生效了。
还可以在 VS 里写,结果我刚装完,一打开,就泄气了,不想用它写了,转头就卸了。也是因为我对 C/C++ 兴致不高,属于是学完即走的,没有深入了解的打算。
于是只能是 VS Code 了,配置了周二一天,终于弄完了。Qt 安装了 10G 以上(有 5G 以上是为了提供调试信息的支持)。然后实现了 .ui 文件使用 Qt 的 Designer 打开、断点调试(非常简单的程序,所以说后面项目大了会不会有问题也一概不知)等比较基础的功能。
想到了,周一周二并不都是在搞 Qt,甚至周二很大一部分似乎还是在弄另一个。
在搜索资料的过程中,其实我还发现了别的选择,那就是使用现成的游戏框架。这个我找到了 cocos2d-x。
然后配置了一会,但是也不甚满意。首先它要 Python2,虽然说已经是六七年前就停止支持的老东西了,但行吧,我还是给你整上,脚本也稍微改动一下匹配上;然后文档中英文也有点差异,观感也不是太好。最后一锤定音的是看到有人说用游戏框架就失去了这个项目的意义,毕竟不是真正去开发一个游戏,只是一个很简单初步的体验,因此我最终放弃了使用游戏框架的想法,还是回到了图形化库的原点。
当然,周二辛辛苦苦弄好的配置,周四又推翻了,我又不打算用 Qt 了。这里的细节就不多说了,等到时候有时间,我像 RAMFShell 一样写篇博文讲讲吧。
反正呢昨天 VS Code 键盘 39766,鼠标 10158,合计 49924(比较关键的键盘与合计数据都差一点破新万,这何尝不是一种「败」呢?[5]),大致能看出昨天稍稍有点上头了,即使是在宿舍也没咋摆了,很投入地去写。
所以说我一旦有了专注的事情,就会相当投入了,关键就在于大部分时刻我是相当迷茫无措的,拔剑四顾心茫然。
这两天其实还是在配置过程(重配置,跟 Qt 相关的基本删掉了只不过环境还留着,以备不时之需,指等项目完工就卸掉),不过今天大致是完成了基础的配置了。
在此过程中还是了解到、学到、并用到了一些东西。
例如说之前 C/C++ 代码懒得去弄格式化的事情,因为现成的规则基本上跟我的喜好都不太一致,具体去调又比较麻烦,所以就不了了之了。然后呢这次弄了个 .clang-format,然后基于 LLVM 格式调了一下,调到了目前看来还算是可以的样子。用的是 clang-format configurator v2。
网上还搜到有另一个,但是提供的示例代码比较短,而且没标注,我看不出效果,同时选项全显示「默认」,默认哪个我也不知道。
但即使是这个我用的也不太行,首先一样是示例代码不够,我看不出效果。只有一部分是有注释标注对应选项的,其他的看不出效果,我也没去看文档,毕竟选项太多了。简单配了点,还有一点就是,昨天我点右上角的「Config」,以为能给我配置,结果没反应,最后是我开了个新的 LLVM 默认选项,对照着自己加了。不过刚刚试了一下可以显示了,但选项是全的,我实际上只想要我修改过的部分。
所以说其实我是没找到一个令我满意的 clang-format 选项配置器的。我记得 CLion 里面有一个,似乎效果很不错,每个选项都有效果显示来着?
有了 .clang-format,自然就能开启保存自动格式化了。
然后还学了点,头文件之间发生了循环引用,该如何解决。这期间还有比较奇葩的事情,让我误会了 clang-tidy,这个一样等到时候去写。最后是把循环引用改成了线性,提前声明,虽然要多写几个 #include 了,但是引用层次更清晰明了了。
还学到了模板不能定义在 .cpp 文件中,必须在 .h 头文件中实现。顺带了解了一下其背后的原理机制。
另外昨天还尝试弄了一下 XMake[6] 构建工具,并今天大致完成了配置。已经可以构建与调试了。
还好我没因为一直没用就卸掉,今天看正好落后一个中版本,升级了一下。用 XMake 也是因为不想写 Makefile 抑或是用 CMake。写起来确实顺眼多了。
总而言之,还是有很多东西在前面等着我去学习的。
远观才害怕,只有靠近了才能放下心中的恐惧与胆怯,实现进步。上周五与周三等时间,看了看另一个东西的代码,实际上并没有那么吓人。虽然说依旧是我没学习过的,属于是未知领域,但在 Copilot 等的辅助下,还是一样能大致搞明白一部分的。
博文
说到这博文,我忏悔。上次还是六月初的 EL,本以为那会闲置个把月已经很懒惰了,结果现在已经过去要半年了,依旧是没有半点动静。要不是还在板子和笔记那里勤更,真就容易给以为博主死了。
不过这也说明另一件事情,若是我在非考试周的在校学习日时,长久没有更新笔记,同时长时间没有更新板子闲聊唠嗑,那大抵确实是出事了。
不过今年底还是能预定一篇年终总结的,那会都期末复习停课了,一定是能抽出时间写的……吧?
一月份要是项目顺利的话,也许也会写篇博文记录一下历程。
然后寒假期间如果没这次暑假那么摆的话,应该会写点的。毕竟我真的是有灵感了(虽然只有一点点,不足以支撑起全文,但跟板子一样,本身就是各种灵感的堆砌,想到哪写哪,才最终变得像个庞然大物),只差写出来了。
另外明年年底还能预定两篇,除了年终总结外,大概会多个步入二十岁的一点想法吧。会在生日的时候写,但因为我不太想暴露自己的生日,所以会放在 12 月 31 日,也就是未来时间发布,因此只有等明年底才会正式发布。
十岁时还是懵懂无知的,不会有这样那样的想法。但是到了二十岁时,我就已经基本能决定自己的人生了,因此还是有必要记录一下自己不再能被称为是一个十几岁的孩子时,会有怎么样的感受。
没想到写了五十分钟差不多,就到这里吧,也是时候去私博稍微写一点了。只不过也写不了太多,只能表明我的一个态度,我没有忘记,我很重视[7]。
有几种表示「新」的词缀,例如这个 neo-,代表有 Neovim 等。抑或是 -ng,意思是 next generation,代表有 GoldenDict-ng 等。还有别的一时半会想不起来了。因此 NeoNotes 的意思就是「新笔记」。 ↩︎
挺稀罕的,因为我周末早上现在常常因为懒,以及为了消耗好多燕麦库存,而在宿舍吃。 ↩︎
说实话,如果是四年级以上我就不敢这样肯定了。现在的小孩(我也还是小孩呢)学的东西比较离谱,感觉我还没出浪头地时就已经给拍死在沙滩上了。 ↩︎
这怎么能不算正事呢?! ↩︎
昨天没破 99w,今天差一点 100w,又何尝不是一种「败」呢? ↩︎
这个我一直不知道是 XMake 还是 Xmake,官网似乎两个用法都有,让我挺折磨的呀…… ↩︎
重视到只留十多分钟,同时这十多分钟大概仅仅不到五分钟留来写是吧。 ↩︎