《软件工程与计算Ⅱ》总复习
第一、二章:软件工程基础
- 名词解释:软件工程
- 简答:从 1950s~2000s 之间的特点
软件工程(Software Engineering)是:
- 将系统的、规范的、可量化的方法应用于软件的开发、运行和维护的过程,即工程化应用于软件。
- 对 1. 中所述方法的研究。
演进:
- 1950s:软件工程 ≈ 硬件工程
- 1960s:软件 ≠ 硬件
- 1970s ~ 1980s:程序 = 算法 + 数据结构
- 1990s ~ 2000s:软件开发 >> 编程
第四章:项目启动
- 如何管理团队?
- 在实验中采取了哪些办法?有哪些经验?
- 团队结构有哪几种?
- 质量保障有哪些措施?
- 结合实验进行说明
- 配置管理有哪些活动?
- 实验中是如何进行配置管理的?
常见的软件开发团队结构有:
- 主程序员团队(Chief Programmer Team):
- 结构:类似外科手术团队,由一位能力极强的主程序员负责核心设计和编码,辅以备份程序员、管理员、文档员、测试员等支持角色。
- 特点:等级化,沟通路径清晰,效率高,但对主程序员依赖性强,不利于成员成长。
graph TD CP(主程序员) --> P1(程序员1) CP --> P2(程序员2) CP --> P3(...) style CP fill:#f9f,stroke:#333,stroke-width:2px - 民主团队(Democratic Team/Egoless Team):
- 结构:扁平化,成员地位平等,决策通过协商或投票产生。
- 特点:沟通充分,成员积极性高,有利于解决复杂问题,但决策效率可能较低,责任分散。
graph TD P1 --- P2 P1 --- P3 P1 --- P4 P2 --- P3 P2 --- P4 P3 --- P4 style P1 fill:#ccf,stroke:#333,stroke-width:1px style P2 fill:#ccf,stroke:#333,stroke-width:1px style P3 fill:#ccf,stroke:#333,stroke-width:1px style P4 fill:#ccf,stroke:#333,stroke-width:1px - 开放团队(Open Team/Adaptive Team):
- 结构:介于前两者之间,通常有一个技术负责人或协调者,但鼓励成员主动承担责任和贡献想法。类似于开源社区的组织模式。
- 特点:灵活性高,能适应变化,鼓励创新,但需要较强的自管理能力和良好的沟通机制。
graph TD direction LR Leader(协调者/负责人) -.-> Member1 Leader -.-> Member2 Leader -.-> Member3 Member1 <--> Member2 Member1 <--> Member3 Member2 <--> Member3 style Leader fill:#9cf,stroke:#333,stroke-width:2px
质量保障主要活动:
- 评审(Review):对软件开发过程中的制品(如需求文档、设计文档、代码、测试计划等)进行检查,以发现和移除缺陷。
- 质量度量(Quality Measurement):对软件产品或过程的特定属性进行量化测量,以评估质量状态。
- 测试(Testing):(虽然测试本身是发现缺陷的活动,但 QA 会关注测试过程的有效性)
- 过程改进:基于度量和反馈,改进开发过程以提升质量。
配置管理主要包括以下活动:
- 标识配置项:确定哪些制品需要纳入 SCM 管理,并为每个配置项分配唯一的标识符。
- 版本管理(Version Control):管理配置项随时间发生的变更,记录不同版本,允许多人协同工作。
- 问题:并发修改可能导致覆盖丢失(Lost Update)。
- 解决方案:
- 锁定-修改-解锁(Lock-Modify-Unlock):用户修改前锁定文件,阻止他人修改,完成后解锁。简单但可能降低并发性,易发生死锁或长时间等待。
- 拷贝-修改-合并(Copy-Modify-Merge):用户拷贝文件到本地修改,完成后尝试合并回仓库。如果仓库版本已被他人修改,需要解决冲突。这是 Git, SVN 等现代版本控制系统的常用模式。
- 变更控制(Change Control):对基线化配置项的修改请求进行管理、评估、批准或拒绝的正式流程。
- 通常涉及变更请求表单(Change Request Form) 和变更控制委员会(Change Control Board, CCB)。
- 配置审计(Configuration Auditing):验证配置项是否完整、准确,是否符合基线要求,以及变更控制流程是否被遵守。
- 状态报告(Status Reporting/Accounting):记录和报告配置项的状态、变更历史和审计结果,提供项目可见性。
- 软件发布管理(Release Management):管理软件产品的构建、打包和交付过程。
第五章:软件需求基础
- 名词解释:需求
- 区分需求的三个层次
- 给出一个实例,给出其三个层次的例子
- 对给定的需求示例,判定其层次
- 例如课程实验/ATM/图书管理。
- 掌握需求的类型
- 对给定的实例,给出其不同类型的需求例子
- 对给定的需求示例,判定其类型
- 例如课程实验/ATM/图书管理。
需求是:
- 用户为了解决问题或达到某个目标所需要的条件或能力。
- 系统或系统部件为了满足合同、标准、规范或其他正式文档所规定的要求而需要具备的条件或能力。
- 对 1. 或 2. 中的一个条件或一种能力的文档化表述。
需求的三个层次:
| 层次 | 核心问题 | 描述视角 | 特点 |
|---|---|---|---|
| 业务需求 | Why? | 组织/战略 | 系统建立的战略出发点,描述高层次的目标和商业价值。 |
| 用户需求 | What? | 用户/任务 | 用户为完成具体任务期望系统提供的功能。通常较模糊,关注「帮我做什么」。 |
| 系统需求 | How? | 开发/系统 | 开发人员需要实现的具体系统行为或交互细节。精确、无歧义,是规格说明的主体。 |
- 业务需求(Business Requirement):
- 最高层次,系统建立的战略出发点。
- 描述组织「为什么」要开发系统,要达到的高层目标(Objective)。
- 通常也包含系统应具备的高层特性(Feature)、共同愿景(Vision) 和系统范围(Scope)。
- 例子:
- R2: 在系统使用 3 个月后,销售额度应该提高 20%。(目标)
- SF1: 管理 VIP 顾客信息。(特性)
- SF3: 使用多样化的特价方案,吸引顾客购买,增加销售额。(特性)
- 用户需求(User Requirement):
- 中间层次,描述执行实际工作的用户对系统完成具体任务的期望。
- 说明系统能「帮助用户做什么」。
- 通常从用户视角描述,可能带有一定的模糊性,允许多特性、多逻辑混杂。
- 需要充分的问题域知识作为背景支持。
- 例子:
- R3: 系统要帮助收银员完成销售处理。(任务)
- UR1.1: 系统应该允许客户经理添加、修改或者删除会员个人信息。(具体功能期望)
- UR1.3: 系统应该允许客户经理查看会员的个人信息和购买信息。
- 系统需求(System Requirement):
- 最低层次,最具体,描述开发人员需要实现的系统行为和属性。
- 反映了外界与系统的一次交互行为或系统的某个实现细节。
- 是用户需求经过分析、细化和转化为系统视角的结果,构成了需求规格说明的主体。
- 应尽可能精确、无歧义。
- 例子:
- R4: 收银员输入购买的商品时,系统要显示该商品的描述、单价、数量和总价。(交互细节)
- SR1.3.1: 在接到客户经理的请求后,系统应该为客户经理提供所有会员的个人信息。(系统行为)
- SR1.3.3: 在客户经理选定一个会员并申请查看购买信息时,系统要提供该会员的历史购买记录。(系统行为)
- SR1.3.4: 经理可以通过键盘输入客户编号,也可以通过读卡器输入客户编号。(实现细节)
需求的分类:
- 功能需求(Functional Requirement)
- 定义:描述系统应该做什么,即系统需要提供的服务、执行的任务、与环境的行为交互。它们是系统核心价值的基础。
- 特点:
- 最常见、最主要、最重要的需求。
- 通常需要按照业务、用户、系统三个抽象层次进行展开。
- 直接关系到用户能否使用系统完成工作。
- 例:前面提到的 R1, R3, R4, UR1.1, UR1.3, SR1.3.1, SR1.3.3 等都是功能需求。
- 非功能需求(Non-functional Requirement)
- 定义:描述系统运作时的质量、特性或限制,而不是具体的功能。它们说明了系统应该「如何」工作,或者在什么条件下工作。
- 类型:
- 性能需求(Performance Requirement):系统执行功能的效率和能力。
- 速度(Speed):响应时间、处理时间。
- PR1: 所有用户查询必须在 10 秒内完成。
- PR6: 98% 的查询不能超过 10 秒。
- 容量(Capacity):能存储的数据量。
- PR2: 系统应能存储至少 100 万个销售信息。
- 吞吐量(Throughput):单位时间内处理事务的数量。
- PR3: 解释器每分钟应至少解析 5000 条无错误语句。
- 负载(Load):能同时处理的并发用户数或工作量。
- PR4: 系统应允许 50 个营业服务器同时上传下载数据。
- 实时性(Time-Critical):严格的时间限制。
- PR5: 监测到病人异常后,监控器必须在 0.5 秒内发出警报。
- 灵活性:性能需求可以设置不同标准(最低、一般、理想)。
- 速度(Speed):响应时间、处理时间。
- 质量属性(Quality Attribute):系统在特定方面的「好坏」程度,通常是隐式的,但对设计影响巨大。
- 可靠性(Reliability):在规定条件下无故障运行的能力。
- QA1: 数据传输中网络故障,系统不能崩溃。
- 可用性(Availability):系统可操作和可访问的程度(通常用百分比表示)。
- QA2: 系统可用性达到 98%。
- 安全性(Security):阻止未授权访问程序和数据的能力。
- QA3: VIP 顾客只能查看自己的信息;收银员只能查看,不能修改删除 VIP 信息。
- 可维护性(Maintainability):修改(修复故障、改进性能、适应环境)的容易程度,包括可修改性(Modifiability) 和可扩展性(Extensibility)。
- QA4: 增加新特价类型需在 2 人月内完成。
- 可移植性(Portability):从一个软硬件环境迁移到另一个环境的能力。
- QA5: 集中服务器能在 1 人月内从 Windows 7 迁移到 Solaris 10。
- 易用性(Usability):用户学习、操作、理解和评价系统的容易程度。
- QA6: 收银员 1 个月销售处理效率达到 10 件商品/分钟。
- 开发关注点:用户通常不明确提质量要求,需求工程师需结合功能需求判断可能存在的质量属性(如形容词副词暗示),并在特定场景下识别全局质量属性。
- 可靠性(Reliability):在规定条件下无故障运行的能力。
- 对外接口(External Interface):系统与外部世界交互的连接点。
- 用户界面(UI):人机交互方式。
- 硬件接口:与物理设备的连接。
- 软件接口:与其他软件系统(如操作系统、数据库、API)的交互。
- 通信接口:网络通信协议。
- 需要定义接口用途、输入输出、数据格式、命令格式、异常处理等。
- 约束(Constraint):对开发过程或最终产品施加的限制,限制了设计和实现的选择范围。
- 开发/运行环境:目标机器、操作系统、网络、编程语言、数据库等。
- C1: 系统要使用 Java 语言开发。
- 问题域标准:法律法规、行业协定、企业规章。
- 商业规则:用户任务执行中的潜在规则。
- 例子:Google Maps API 使用约束:24 小时内来自同一 IP 的地址解析请求超过 15,000 次或速率过快,将收到 620 错误,持续过多可能被永久阻止。
- 开发/运行环境:目标机器、操作系统、网络、编程语言、数据库等。
- 性能需求(Performance Requirement):系统执行功能的效率和能力。
第六章:需求分析方法
为给定的描述:
- 建立用例图
- 建立分析类图(概念类图)(只有属性,没有方法)
- 建立系统顺序图
- 建立状态图
用例图以图形化的方式展示系统功能、参与者以及它们之间的关系。
- 参与者(Actor)
- 表示与系统交互的角色,可以是人、外部系统或设备。
- 注意:参与者代表的是角色,而非特定的个体。一个用户可能扮演多个角色,一个角色也可能对应多个用户。
- 参与者总是位于系统边界之外。
- 图标:小人形状。
- 用例(Use Case)
- 表示系统提供的一个完整且有意义的功能单元,通常能为参与者带来价值。
- 用例总是位于系统边界之内。
- 图标:椭圆形。
- 关系(Relationship)
- 关联(Association):连接参与者和用例,表示参与者参与执行该用例。用直线表示。
- 包含(Include):表示一个用例(基础用例)的行为包含了另一个用例(被包含用例)的行为。被包含用例是基础用例执行的必要部分。用带箭头的虚线表示,指向被包含用例,并标有
<<include>>。 - 扩展(Extend):表示一个用例(扩展用例)在特定条件下可以扩展另一个用例(基础用例)的行为。扩展用例是可选的,基础用例无需知道扩展用例的存在。用带箭头的虚线表示,指向基础用例,并标有
<<extend>>。 - 泛化(Generalization):表示参与者或用例之间的一般与特殊关系(类似继承)。用带空心三角箭头的实线表示,指向更一般的元素。
- 系统边界(System Boundary)
- 通常用一个矩形框表示,框内是用例,框外是参与者。
- 明确定义了正在建模的系统范围,区分系统内部功能和外部交互。
概念类图基本元素:
- 类(Class):对具有相同属性、行为和关系的一组对象的抽象。表示问题域中的一个重要概念。
- 属性(Attribute):描述类的特征或状态的数据项。在概念类图中,通常只列出重要的、领域相关的属性。
- 关联(Association):表示类之间存在的某种结构化或业务联系。
- 角色(Role):关联端点可以有名称,说明该类在关联中扮演的角色。
- 多重性(Multiplicity):表示一个类的实例可以与另一个类的多少个实例相关联(如 1, 0…1, *, 1…*, 0…*)。
- 依赖(Dependency):表示一个类(客户端)的改变可能会影响到另一个类(供应端),但这种关系通常比较弱,不是结构化的关联。对象间的临时协作(链接 link)是依赖在实例层面的体现。
- 聚合(Aggregation):一种特殊的关联,表示整体与部分的关系(has-a),部分可以独立于整体存在。用带空心菱形的线表示,菱形指向整体。
- 组合(Composition):一种更强的聚合,表示整体与部分的关系,部分不能脱离整体存在(生命周期绑定)。用带实心菱形的线表示,菱形指向整体。
- 继承/泛化(Inheritance/Generalization):表示一般与特殊的关系(is-a),子类继承父类的属性和行为,并可以有自己的特性。用带空心三角箭头的线表示,箭头指向父类。
系统顺序图基本元素:
- 参与者(Actor):发起交互或接收系统响应的外部角色。
- 系统(System):通常用一个带有
:System标签的对象框表示,代表整个被测系统。 - 生命线(Lifeline):从参与者或系统框向下延伸的垂直虚线,表示对象存在的时间。
- 激活/执行规格(Activation/Execution Specification):生命线上的矩形条,表示对象正在执行操作或处理消息的时间段。
- 消息(Message):表示对象间的通信。用带箭头的线表示。
- 同步消息(Synchronous Message):发送者发送消息后必须等待接收者返回结果。用实心箭头表示。
- 异步消息(Asynchronous Message):发送者发送消息后无需等待,可继续执行。用开放箭头表示。
- 返回消息(Return Message):表示操作执行完毕后返回结果或控制权。用虚线箭头表示(有时可省略)。
- 组合片段(Combined Fragment):用带标签的框包围部分交互,表示特殊的控制逻辑。常用类型:
opt(Optional):片段中的交互是可选的。alt(Alternative):表示多个互斥的交互选择(类似 if-else)。loop(Loop):表示片段中的交互会重复执行。
系统顺序图示例(销售处理 - 简化):
sequenceDiagram
actor 收银员
participant 系统 as 系统
收银员 ->> 系统: 开始新销售
activate 系统
系统 -->> 收银员: (系统准备就绪)
opt 会员
收银员 ->> 系统: 输入会员号(id)
系统 -->> 收银员: 显示会员信息
end
loop 还有下一项商品
收银员 -) 系统: 输入商品标识(code)
系统 -) 收银员: 显示商品信息(price, desc)
end
收银员 ->> 系统: 结束输入
系统 -->> 收银员: 显示总价(total)
收银员 ->> 系统: 输入收款金额(amount)
系统 -->> 收银员: 计算找零(change)
收银员 ->> 系统: 确认完成
系统 -->> 收银员: 打印收据
deactivate 系统状态图基本概念:
- 状态(State):对象或系统在其生命周期中的一种可观察到的、稳定的状况或条件。通常用圆角矩形表示。
- 初始状态(Initial State):状态机开始时的状态。用实心圆表示。
- 最终状态(Final State):状态机结束时的状态。用带圆圈的实心圆表示。
- 转换(Transition):从一个状态到另一个状态的迁移。由特定事件触发。用带箭头的线表示。
- 事件(Event):导致状态发生转换的外部或内部发生的事情(如用户输入、时间到达、条件满足)。通常标记在转换线上。
- 动作(Action):在转换过程中或进入/退出某个状态时执行的原子性操作(如调用方法、发送信号)。通常标记在转换线上,跟在事件后面,用
/分隔。 - 监护条件(Guard Condition):一个布尔表达式,只有当其值为真时,相应的转换才能发生。用方括号
[]括起来,标记在转换线上。
销售处理用例状态图示例:
---
title: 销售状态图
---
stateDiagram-v2
[*] --> 空闲 : 登录/授权
state 空闲
state 销售开始
state VIP 顾客信息显示
state 商品信息显示
state 列表显示
state 错误提示
state 账单处理
state 销售结束
空闲 --> 销售开始 : 开始新销售
销售开始 --> VIP 顾客信息显示 : 输入 VIP 顾客号 [合法]/显示信息
销售开始 --> 商品信息显示 : 输入商品标识 [合法]/显示信息
VIP顾客信息显示 --> 商品信息显示 : 输入商品标识 [合法]/显示信息
商品信息显示 --> 列表显示 : 输入下一商品标识 [合法]/更新列表
商品信息显示 --> 错误提示 : 输入商品标识 [非法]/提示错误
列表显示 --> 列表显示 : 输入下一商品标识 [合法]/更新列表
列表显示 --> 错误提示 : 输入商品标识 [非法]/提示错误
列表显示 --> 账单处理 : 结束输入/计算总价并显示
错误提示 --> 商品信息显示 : 重新输入 [商品标识合法]/显示信息
错误提示 --> 列表显示 : 重新输入 [商品标识合法]/更新列表
账单处理 --> 销售结束 : 支付完成/更新库存, 打印收据
销售结束 --> 空闲 : 完成
销售开始 --> 空闲 : 取消销售
VIP顾客信息显示 --> 空闲 : 取消销售
商品信息显示 --> 空闲 : 取消销售
列表显示 --> 空闲 : 取消销售
账单处理 --> 空闲 : 取消销售
销售结束 --> [*] : 退出/完成例题一
为下列描述建立用例模型(6 分),要求明确给出建模过程(4 分)。
- 现在需要开发一个简化了的大学图书馆系统,它有几种类型的借书人,包括教职工借书人、研究生借书人和本科生借书人等。借书人的基本信息包括姓名、地址和电话号码等。对于教职工借书人,还要包括诸如办公室地址和电话等信息。对于研究生借书人,还要包括研究项目和导师信息等。对于本科生借书人,还要包括项目和所有学分信息等。
- 图书馆系统要跟踪借出书本信息。当一个借书人捧着一堆书去借书台办理借书手续时,借出这个事件就发生了。随着时间的过去,一个借书人可以多次从图书馆中借书。一次可以借出多本图书。
- 如果借书人想要的书已被借出,他可以预约。每个预约只针对一个借书人和一个标题。预约日期、优先权和完成日期等信息需要维护。当借书完成,系统会将这本书与借出联系起来。
- 借书人根据图书馆的信息来检索书名,同时检索这本书是否可以被借出。如果一本书的所有副本都被借出了,那么借书人可以根据书名预订这本书。当借书人把书拿到借书台的时候,管理员可以为这些书办理归还手续。管理员要跟踪新书到达的情况。
- 图书馆的管理者有属于自己的活动。他们要分类打出关于书的标题的表格,还要在线检查所有过期未还的书,也标出来。而且,图书馆系统还可以从另外一个大学的数据库中访问和下载借书人的信息。
例题二
下面是一段需求描述,请依据其建立 ATM 机系统的领域类图(即分析类图)。
- A 银行计划在 B 大学开设银行分部,计划使用 ATM 机提供全部服务。ATM 系统将通过显示屏幕、输入键盘(有数字键和特殊符号键)、银行卡读卡器、存款插槽、收据打印机等设备与客户交互。客户可以使用 ATM 机进行存款、取款、余额查询等操作,它们对帐户的更新将交由账户系统的一个接口来处理。安全系统将为每个客户分配一个 PIN 码和安全级别。每次事务执行之前都需要验证该 PIN 码。在将来,银行还计划使用 ATM 机支持一些常规的操作,例如地址和电话号码修改。
第七章:需求文档化与验证
- 为什么需要需求规格说明?结合实验进行说明
- 对给定的需求示例,判定并修正其错误
- 对给定的需求规格说明片段,找出并修正其错误
- 对给定的需求示例,设计功能测试用例
- 结合测试方法
为什么需要文档化需求?
- 团队协作与沟通:为项目经理、架构师、设计师、程序员、测试人员、维护人员等不同角色提供统一的理解基础。
- 知识传递与持久化:将需求固化下来,避免信息丢失或失真。
- 契约与基线:作为用户与开发团队之间确认需求的依据,以及后续设计、开发、测试和变更控制的基线。
- 项目管理:为项目估算、进度安排、人员分工提供基础。
第八章:软件设计基础
- 名词解释:软件设计
- 软件设计的核心思想是什么?
- 软件工程设计有哪三个层次?各层的主要思想是什么?
软件设计(Software Design)可以被视为一个规划过程,为构建软件系统奠定基础。它是一个将用户需求和项目约束(问题空间)转化为具体软件解决方案(解空间)的创造性活动。
- 名词:指软件系统的规格说明,描述其结构、组件、接口和行为。
- 动词:指创建这个规格说明的过程。
软件设计的核心思想是:
- 分解(Decomposition):将复杂系统拆分成更小、更易于管理的部分(子系统、模块、类)。
- 抽象(Abstraction):隐藏实现的细节,关注于组件的接口和行为。用户只需了解「做什么」(What),无需关心「怎么做」(How)。
软件工程设计的三个层次:
- 低层设计(代码设计/Software Construction)
- 关注点:单个函数或方法内部的逻辑实现。
- 核心:使用基本的编程语言构造(类型、语句、控制结构)来实现特定的数据结构和算法。
- 目标:编写简洁、清晰、正确、高效的代码。屏蔽数据结构和算法的实现细节,提供明确的语义和性能。
- 本质:将算法思想和数据组织方式转化为具体的代码指令。
- 中层设计(模块化设计/OO 设计)
- 关注点:如何将系统划分为独立的、可协作的单元(如模块、类、包)。
- 核心:应用模块化、信息隐藏、封装、抽象数据类型、面向对象原则(如 SOLID)等。
- 目标:实现高内聚、低耦合,使得模块易于理解、开发、测试、修改和复用。
- 本质:隐藏单个模块(或类)的内部实现细节,通过定义清晰的接口暴露其功能。
- 高层设计(软件体系结构设计)
- 关注点:系统的整体组织结构,包括主要的部件、部件之间的连接件以及它们的配置。
- 核心:定义系统的宏观结构,满足关键的功能性需求、质量属性和项目约束。
- 目标:为系统建立一个稳定、健壮的骨架,指导后续的详细设计和实现。
- 本质:进行更高层次的抽象,将系统视为可交互部件的集合,关注系统级行为和特性。
第九、十章:软件体系结构
- 体系结构的概念
- 体系结构的风格的优缺点
- 体系结构设计的过程?
- 包的原则
- 体系结构构件之间接口的定义
- 体系结构开发集成测试用例
- Stub 和 Driver
体系结构的概念:
- 定义:软件体系结构是系统的一个或多个结构,它包括软件部件、这些部件的外部可见属性以及它们之间的关系。
- 核心三要素(Shaw's Model):
- 部件(Component):承担计算和数据存储的单元。
- 连接件(Connector):定义和协调部件间交互的机制,是与部件同等重要的一等公民。
- 配置(Configuration):描述部件和连接件如何组合成系统拓扑。
- 重要性:
- 沟通媒介:为所有利益相关者提供统一认知。
- 早期决策:决定了系统的质量属性、成本和演化能力。
- 可传递的抽象:便于知识和设计的复用。
| 风格 | 部件 | 连接件 | 优点 | 缺点 |
|---|---|---|---|---|
| 主程序-子程序 | 主程序、子程序 | 函数/过程调用 | 流程清晰,易于理解、强控制性 | 强耦合,依赖接口,难修改/复用、易产生不必要的公共数据耦合 |
| 面向对象 | 对象(数据 + 方法) | 方法调用 | 内部实现可修改性好、易开发、理解、复用 | 接口耦合、副作用和重入问题使正确性验证困难 |
| 分层 | 层 | 层间受限调用 | 关注点分离,设计清晰、支持并行开发、可复用性与内部可修改性好 | 性能损失(层级调用开销)、交互协议难以修改、层次数量和粒度难确定 |
| MVC | 模型、视图、控制器 | 方法调用、事件通知 | 关注点分离(逻辑/展示/控制)、模型独立,视图/控制可修改性好、支持多视图、并行开发 | 增加了系统复杂性、模型修改困难 (视图和控制都依赖它) |
- 主程序-子程序风格(Main Program and Subroutine)
- 部件:主程序、子程序(函数、过程、模块)。
- 连接件:过程/函数调用。
- 拓扑:层次化结构,通常是单向调用(上层调用下层)。
- 约束:通常单线程执行,控制权按调用层级转移和返回。
- 优点:流程清晰,易于理解,强控制性。
- 缺点:强耦合(依赖接口规格),难以修改和复用,可能存在全局数据耦合问题。
- 应用:简单系统,功能可按层次分解的顺序执行任务。
- 面向对象风格(Object-Oriented)
- 部件:对象(封装了数据和方法)。
- 连接件:方法调用(消息传递)。
- 拓扑:对象网络,对象间通常是平级关系。
- 约束:对象负责维护自身数据一致性(信息隐藏),通过接口交互。
- 优点:内部实现可修改性好,易开发、理解、复用。
- 缺点:接口耦合,标识耦合,副作用和重入问题可能使正确性验证更难。
- 应用:基于数据信息分解和组织的系统,如图形用户界面、模拟系统。
- 分层风格(Layered)
- 部件:层,每层是一组相关功能的集合(过程或对象)。
- 连接件:层间调用(通常是下层提供的服务接口),可见性受限。
- 拓扑:线性或环状层次结构。
- 约束:
- 上层只能调用其直接下层提供的服务。
- 禁止跨层调用(如第 I 层不能直接调用 I+2 层)。
- 禁止逆向调用(如第 I 层不能调用 I-1 层)。
- 层间交互需遵守稳定、标准化的协议。
- 优点:关注点分离(每层处理不同抽象级别),支持并行开发,可复用性好,内部可修改性强。
- 缺点:交互协议难以修改,可能引入性能损失(层级调用开销),层数和粒度难以确定。
- 应用:网络协议栈(OSI, TCP/IP),操作系统,复杂业务系统。
- 模型-视图-控制器风格(Model-View-Controller, MVC)
- 部件:
- 模型(Model):封装核心数据和业务逻辑。独立于 UI。
- 视图(View):负责数据的展示,向用户呈现界面。可以有多个视图对应一个模型。
- 控制器(Controller):接收用户输入,解释用户操作,调用模型进行处理,并选择合适的视图进行更新。
- 连接件:方法调用、事件通知(如观察者模式)。
- 拓扑:三角关系。
- Controller Model (调用业务逻辑)
- Controller View (选择视图)
- View Controller (传递用户输入)
- Model View (状态变更通知,通常通过观察者模式)
- View Model (查询状态)
- 约束:
- Model 独立于 View 和 Controller。
- View 查询 Model 状态,但不修改。
- Controller 处理用户输入,修改 Model。
- 优点:
- 分离关注点:业务逻辑、数据展示、用户交互分离。
- 易修改性:修改视图或控制器不影响模型。
- 多视图支持:同一模型可对应多个视图。
- 并行开发。
- 缺点:
- 复杂性增加:引入了更多组件和交互。
- 模型修改困难:视图和控制器都依赖模型。
- 应用:Web 应用框架(如 Spring MVC, Ruby on Rails),GUI 应用。
- 部件:
包内聚原则
- CCP(共同闭包原则): 一起修改的类,应该放在同一个包里。目的是将变更的影响限制在最小数量的包内,有利于维护者。
- CRP(共同重用原则): 要被一起重用的类,应该放在同一个包里。目的是避免用户依赖他们不需要的东西,有利于重用者。
- REP(重用发布等价原则): 重用的单元就是发布的单元。一个包应作为整体被重用和发布。
包耦合原则
- ADP(无环依赖原则): 包之间的依赖关系图中不允许出现环。
- 解决方法:依赖倒置(引入抽象接口);提取新包。
- SDP(稳定依赖原则): 依赖关系应该指向更稳定的方向。
- 不稳定性(I):
I = Ce/(Ca + Ce)(传出依赖/(传入依赖 + 传出依赖)) I=0:最稳定;I=1:最不稳定。
- 不稳定性(I):
- SAP(稳定抽象原则): 包的抽象程度应与其稳定性成正比。
- 抽象度(A):
A = Na/Nc(抽象类与接口数/总类数) - 目标:稳定的包应该是抽象的(
I接近 0,A接近 1),不稳定的包应该是具体的(I接近 1,A接近 0)。
- 抽象度(A):
接口是构件之间的契约,其定义至关重要。
- 定义来源:
- 看需求:逻辑层接口满足表示层的需求;数据层接口满足逻辑层的需求。
- 看交互:接口的参数是调用方传入的数据,返回值是响应方返回的结果。
- 数据对象(VO & PO):
- PO(Persistent Object):持久化对象,用于逻辑层与数据层之间的数据传递,通常与数据库表结构一一对应。
- VO(Value Object):值对象,用于表示层与逻辑层之间的数据传递,其结构由表示层(视图)的需求决定,可能聚合多个 PO 的数据。
- 接口规约:一个完整的接口定义应包含语法(方法签名)、前置条件、后置条件等。
在增量集成和测试中,需要模拟缺失的部分:
- 桩:模拟被调用模块。当测试模块 A,而 A 需要调用模块 B,但 B 尚未完成时,用 Stub B 代替。Stub B 接收调用,可能返回预设的简单数据或执行简单逻辑。
- 驱动:模拟调用模块。当测试模块 B,而 B 需要被模块 A 调用,但 A 尚未完成时,用 Driver A 代替。Driver A 设置测试环境,调用 B,并可能验证 B 的返回结果。
graph TD
D(驱动 Driver) -- 调用 --> T(被测模块);
T -- 调用 --> S(桩 Stub);
S -- 返回模拟结果 --> T;
T -- 返回结果 --> D;
style T fill:#lightgreen,stroke:#333,stroke-width:2px
style D fill:#lightblue,stroke:#333,stroke-width:1px
style S fill:#lightyellow,stroke:#333,stroke-width:1px例题
- 如果这个薪酬管理系统是 Web 框架实现的,按照分层体系结构风格设计,画出能体现系统体系结构的具体的物理包图(包括所用分层,注意要体现系统所有功能模块,体现实现跨网络,浏览器(包含前端 HTML, CSS, JS)位于客户端,逻辑层和数据层(后端)位于服务器端,网络通信采用 HTTP,基于 REST 风格 API 的接口)。(4 分)
- 请设计「社会保险录入」这个页面对应的展示层和逻辑层交互的接口,以及其涉及的逻辑层与数据层交互的接口(写出接口声明的代码,不用实现)。每个接口都要写出其所属的包名。请考虑接口在包中的分布。(6 分)
第十一章:人机交互设计
- 名词解释:可用性
- 能够列出至少 5 个界面设计的注意事项,并加以解释
- 例子 xx 违反了哪些条界面设计原则
- 精神模型、差异性
- 导航、反馈、协作式设计
可用性是衡量人机交互设计好坏的关键多维度属性,它并非单一指标。可用性有五要素:
- 易学性:用户能多快地学会使用系统完成基本任务?
- 效率性:熟练用户能多快地通过界面完成任务?
- 易记性:用户在一段时间未使用后,重新使用时是否容易记起如何操作?是否需要从头学起?
- 出错率:用户在使用过程中出错的频率和严重程度如何?能否轻松地从错误中恢复?
- 主观满意度:用户在使用系统时是否感到愉悦和满意?
源于「黄金原则」和「协作式设计」思想:
- 保持界面一致性(Be Consistent)
这是最重要的原则。一致性意味着在整个应用程序中,相似的元素和操作应具有一致的外观和行为。例如,术语、图标、颜色、布局、操作方式(如确定按钮总在右侧)都应保持统一。- 目的:降低用户的学习成本,形成使用习惯,使用户能够根据以往经验预测系统行为,从而提高效率和满意度。
- 减轻用户的记忆负担(Reduce the User's Memory Load)
人类的短期记忆有限(7±2 定律)。设计应避免让用户记忆过多的信息。核心是识别优于回忆。- 实践:
- 使用菜单、图标、选择列表等可见选项,而不是让用户凭空输入命令。
- 提供有意义的默认值,减少用户输入负担。
- 在界面上直观地展示完成任务所需的信息和上下文。
- 实践:
- 提供明确、及时的反馈(Provide Feedback)
对于用户的每一个重要操作,系统都应给出清晰、及时的响应,告知用户「发生了什么」。- 实践:
- 点击按钮后,按钮应有状态变化(如下陷、变色)。
- 耗时操作应显示进度条或加载动画。
- 操作成功或失败都应有明确的提示信息。
- 实践:
- 让用户掌控全局(Place the User in Control)
用户应感觉自己是交互的主导者,而不是被动地被系统驱使。- 实践:
- 允许用户随时中断或取消操作。
- 提供易于使用的撤销(Undo) 和重做(Redo) 功能。
- 允许用户根据自己的偏好定制界面或交互流程。
- 交互流程应基于用户的任务模型,而不是暴露底层的技术实现。
- 实践:
- 低出错率设计与错误处理(Error Prevention and Handling)
好的设计应该首先帮助用户预防错误。如果错误不可避免,则应提供简单、友好的恢复机制。- 实践:
- 预防:禁用无效选项、提供输入格式提示、在执行破坏性操作(如删除)前进行确认。
- 处理:错误信息应使用清晰、友好的自然语言(而非错误代码),准确指出问题所在,并提供有建设性的解决方案。
- 实践:
精神模型是用户对于一个系统(或任务)如何工作的内部认知和理解。用户基于这个模型来预测系统的行为并决定如何操作。
- 设计目标:HCI 设计应努力理解并匹配用户的精神模型。当系统行为符合用户的精神模型时,用户会觉得系统直观易用。
- 隐喻:精神模型常常包含隐喻,即用户将熟悉的现实世界概念(如桌面、文件夹、购物车)映射到软件界面上,以帮助理解和操作。设计时应谨慎选择和使用一致的隐喻。
- 例子:炉灶旋钮的布局应直观地对应加热单元的位置,否则用户需要额外记忆,容易出错。
- 发现模型:通过用户研究(访谈、观察)了解用户的目标、任务流程和现有习惯,从而推断其精神模型。避免仅因技术上容易实现而添加不符合用户任务模型的功能。
好的导航如同服务周到的推销员或清晰的餐厅菜单,能主动、简明地引导用户找到所需功能或信息的入口,使其符合用户的精神模型。
- 全局结构导航:组织软件整体功能,区分重要性与主题。常用控件包括窗口、菜单、列表、快捷方式、热键等。设计依据是功能分层和任务交互过程。
- 局部结构导航:通过界面布局细节(控件组合、按钮样式、文本颜色/大小等)制造视觉线索,引导用户在当前界面内操作。设计依据是用户关注的任务细节。
反馈是告知用户其操作结果或系统当前状态的关键机制。用户需要知道他们的操作是否被接收、是否成功、系统是否在处理等。
- 即时性:反馈应及时。
- 明确性:反馈应清晰告知用户发生了什么。
协作式设计核心思想是调整计算机因素以更好地适应和帮助用户(因为人的因素相对固定)。这体现了以用户为中心的设计理念。关键原则包括:
- 简洁性:避免不必要的复杂性,界面元素应清晰、直接。
- 一致性:在整个系统中,相似的操作和元素应具有一致的外观和行为,减少用户的学习负担和困惑。
- 低出错率设计:
- 预防:通过设计手段避免用户犯错(如禁用无效选项、输入格式限制)。
- 纠正:出错时提供清晰、有建设性、友好的错误信息(不用代码,语言精练,提供帮助),并引导用户修正。
- 恢复:提供撤销等错误恢复机制。
- 易记性设计(减轻记忆负担):
- 减少短期记忆负担:界面直接展示所需信息,而不是让用户回忆。
- 逐层递进展示信息:对于复杂信息,分层展示,逐步深入。
- 使用直观快捷方式:如图标、工具栏按钮,利用识别而非回忆。
- 设置有意义的缺省值:减少用户输入,符合常见场景。
例题
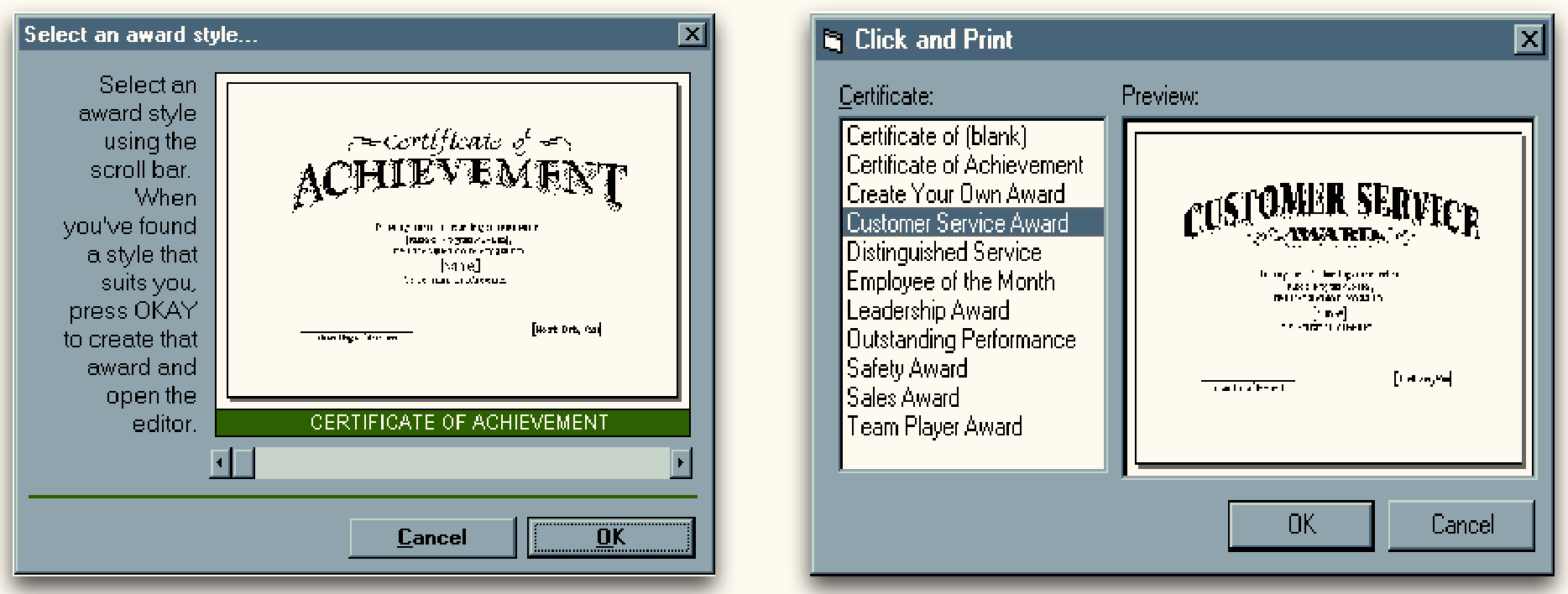
分析下图:它们分别体现(或违反)了哪些人机交互设计原则?请详细解释这些原则(10 分)。
第十二章:详细设计基础
- 详细设计的出发点
- 职责分配
- 协作
- 控制风格
- 给定分析类图、系统顺序图和设计因素描述
- 建立设计类图
- 或者详细顺序图
- 协作的测试
- MockObject
详细设计的直接出发点:
- 软件体系结构设计:定义了系统的宏观结构、模块划分、模块规格以及模块间的接口。
职责是一个类或对象所承担的义务,它可以是执行某项任务(行为职责)或维护某些数据(数据职责)。
- 行为职责:通常由类的方法来实现。例如,「计算订单总价」是一个行为职责。
- 数据职责:通常由类的属性来实现。例如,「维护订单包含的商品列表」是一个数据职责。
职责驱动分解:面向对象设计常常以职责为驱动力来进行系统分解。
- 职责可以在不同的抽象层次上描述,并且可以被分解。
- 高层职责分配给高层组件(模块),然后进一步分解并将子职责分配给内部的类或对象。
- 这种分解方式与纯粹的功能分解不同,因为它同时考虑了数据和行为的归属。
职责分配启发式规则:良好的职责分配有助于实现高内聚和低耦合。
- 确保模块/类的职责不重叠。
- 一个模块/类中的操作和数据应该仅仅是为了帮助其履行自身职责。
- 委托:当一个模块(委托者, Delegator)自身无法完成某个职责时,可以将该职责委托给另一个模块(被委托者, Delegate)来完成。这是一种常见的协作机制。
协作是指对象之间为了完成某个特定行为(通常是实现一个用例或一个较大的职责)而进行的交互与合作。
- 必要性:如果对象间不协作,整个系统要么无法工作,要么就会退化成一个包揽一切的巨大对象,失去面向对象设计的优势。
- 本质:协作体现为对象网络中消息传递的模式。一个特定的系统行为通常由一组对象通过明确的协作模式来实现。
- 分布式:协作逻辑通常分布在参与协作的多个对象中,而不是集中在单一位置。
- 重要性:协作设计直接关系到系统行为的正确性和健壮性。如果协作设计不当,应用程序可能会不准确或变得脆弱。
设计类图和详细顺序图看原笔记。
第十三章:详细设计中的模块化与信息隐藏
- 名词解释:解释耦合与内聚
- 耦合与内聚
- 对例子 xx,说明它们之间的耦合程度与内聚,给出理由
- 信息隐藏
- 基本思想
- 两种常见的信息隐藏决策
- 对例子 xx,说明其信息隐藏程度好坏
- 耦合衡量的是模块之间相互依赖或关联的强度。
- 内聚衡量的是一个模块内部各个元素(代码、数据)之间关联的紧密程度,即模块执行单一、明确定义任务的程度。
耦合和内聚详细见原笔记。
信息隐藏是一种设计原则,主张每个模块都应该向其他模块隐藏其内部的设计决策(称为「秘密」),只通过明确定义的接口暴露必要的信息。
常见决策:
- 硬件依赖
- 外部系统接口
- 输入输出格式
- 数据库模式、UI 实现细节
- 非标准的语言特性或库
- 平台细节(操作系统、中间件、框架)
- 困难的设计和实现区域(可能需要重构)
- 复杂的算法、调度逻辑、性能关键代码
- 复杂的数据结构
- 全局变量(应尽量避免,若必须使用则通过访问例程隐藏)
- 数据大小约束(如数组大小、循环限制)
- 业务规则
第十四章:详细设计中面向对象方法下的模块化
- Principles from Modularization
- Global Variables Consider Harmful
- To be Explicit
- Do not Repeat
- Programming to Interface (Design by Contract)
- The Law of Demeter
- Interface Segregation Principle(ISP)
- Liskov Substitution Principle (LSP)
- Favor Composition Over Inheritance
- Single Responsibility Principle
- 对给定的示例,发现其所违反的原则,并进行修正
源于模块化的基本原则:
- 全局变量是有害的
- 显式化
- 不要重复(DRY)
- 面向接口编程(Programming to Interface)/契约式设计(Design by Contract)
面向对象特有的重要原则(部分 SOLID):
- 迪米特法则(LoD):减少不必要的了解。
- 接口分离原则(ISP):客户端不应依赖于它不需要的接口。
- 里氏替换原则(LSP):子类必须能够替换父类。
- 组合优于继承(Favor Composition Over Inheritance):优先使用组合/委托实现代码复用。
- 单一职责原则(SRP):一个类只有一个变化的原因。
- 权限最小化原则(Minimize Accessibility):尽可能限制类和成员的可见性。
- 开放/封闭原则(OCP):对扩展开放,对修改关闭。
- 依赖倒置原则(DIP):依赖于抽象,而非具体实现。
第十五章:详细设计中面向对象方法下的信息隐藏
- 信息隐藏的含义
- 封装
- OCP
- DIP
信息隐藏是模块化设计的核心原则之一,旨在隐藏模块内部的设计决策(称为「秘密」),使得模块的修改不影响其他部分。
封装是实现信息隐藏的机制。它将数据(属性)和操作这些数据的行为(方法)捆绑在一起,并对外隐藏内部实现细节,只暴露必要的接口。
- 接口:对象对外的可见部分,描述了对象的基本特征和可进行的操作。包括方法名、参数、返回类型、不变量、异常等。
- 实现:对象内部的细节,如数据结构、具体算法、对其他对象的引用、类型信息等。这些都应该被隐藏。
开放/封闭原则(Open/Closed Principle, OCP)指出:软件实体(类、模块、函数等)应该对于扩展是开放的,但对于修改是关闭的。
- 对扩展开放:模块的行为可以被扩展,以满足新的需求。
- 对修改关闭:一旦模块完成并通过测试,其源代码不应被修改。
依赖倒置原则(Dependency Inversion Principle, DIP)包含两条:
- 高层模块不应该依赖于低层模块。两者都应该依赖于抽象。
- 抽象不应该依赖于细节。细节应该依赖于抽象。
传统的结构化设计中,高层模块调用低层模块,形成自顶向下的依赖关系。DIP 将这种依赖关系「倒置」了过来。
- 高层模块:包含业务策略和主要流程的模块。
- 低层模块:提供具体实现和工具功能的模块。
- 抽象:通常指接口或抽象类。
DIP 的核心思想:通过引入抽象层,解除高层模块与低层模块之间的直接依赖。高层模块定义其需要的接口(抽象),低层模块实现这些接口。
里氏替换原则例题
数据结构栈有四个功能:压栈、弹栈、得到栈的大小、得到栈是否为空。Akagi 同学使用继承如下设计了栈。
1 2 3 4 5 6 7 8 9 10 | public class MyStack extends Vector { public void push(Object element) { insertElementAt(element, 0); } public Object pop() { Object result = firstElement(); removeElementAt(0); return result; } } |
Kogure 同学在设计雇员类的时候,如下设计:
1 2 3 4 5 6 7 | public Person { private string name; public string getName() { return name; } public class Employee extends Person {} |
- 指出两个关于继承的设计是否合理?是否违反设计原则?
- 对两段代码,如果合理,请解释其合理性。如果违反,请解释该原则,并修改
-
MyStack extends Vector的设计不合理,它严重违反了里氏替换原则(LSP)。-
原则解释:里氏替换原则(LSP) 要求「所有派生类都必须可以替代它们的基类」。这意味着在程序中任何使用基类引用的地方,换成其派生类的对象后,程序的行为和正确性不应受到影响。子类只能增强父类的功能,不能削弱或改变其原有行为。
-
违反原因:
Vector类提供了许多公有方法,如elementAt(int index),insertElementAt(Object, int),removeElement(Object)等。这些方法允许在任意位置插入、删除或访问元素。- 而
Stack(栈)的契约是严格的后进先出(LIFO)。 - 当
MyStack继承Vector后,客户端代码可以得到一个MyStack的引用,并将其作为Vector使用,然后调用vector.insertElementAt(someObject, 5)这样的方法,这会破坏栈的 LIFO 特性。 - 因此,
MyStack对象不能安全地替换Vector对象而不改变程序的预期行为,这违背了 LSP。这种设计是典型的为了代码复用而滥用继承。
-
修改方案:应使用组合优于继承的原则。让
MyStack类包含(has-a) 一个Vector或List对象来存储数据,而不是是(is-a) 一个Vector。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
// 使用组合进行修正 public class MyStack { // 使用组合,将 Vector 作为内部实现细节封装起来 private Vector<Object> elements = new Vector<>(); public void push(Object element) { // 委托给内部的 Vector 对象 elements.insertElementAt(element, 0); } public Object pop() { if (isEmpty()) { throw new EmptyStackException(); } Object result = elements.firstElement(); elements.removeElementAt(0); return result; } public boolean isEmpty() { return elements.isEmpty(); } public int size() { return elements.size(); } // MyStack 不再暴露 Vector 的其他方法,保证了其 LIFO 特性 }
-
-
Employee extends Person的设计是合理的。- 合理性解释:
- 从概念上讲,一个「雇员(Employee)」是一种「人(Person)」。这种关系是自然的 "is-a" 关系。
Employee类继承了Person的属性(如name)和行为(如getName()),并可以在此基础上进行扩展(例如,添加employeeId,salary等)。- 只要
Employee子类没有覆盖Person的方法并引入与基类不兼容的行为,它就符合里氏替换原则(LSP)。在任何需要Person对象的地方,传入一个Employee对象都是安全和符合逻辑的。 - 这是一种恰当的、用于实现类型特化和多态的继承。
- 合理性解释:
第十六章:详细设计的设计模式
如何实现可修改性、可扩展性、灵活性
策略模式
抽象工厂模式
单件模式
迭代器模式
给定场景,应用设计模式并写出代码
给出代码,要求用设计模式改写
如何实现可修改性:接口与实现的分离
- 策略模式定义了一系列算法,并将每一个算法封装起来,使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户。
- 抽象工厂模式提供一个接口,用于创建一系列相关或相互依赖的对象,而无需指定它们具体的类。它使得一个「家族」的对象的创建与使用分离。
- 单件模式,也称单例模式,确保一个类只有一个实例,并提供一个全局访问点来获取这个唯一实例。
- 迭代器模式提供一种方法来顺序访问一个聚合对象(例如列表、集合)中的各个元素,而又不暴露该对象的内部表示。
第十七、十八章:软件构造与代码设计
- 构造所包含的内容
- 名词解释:重构
- 名词解释:测试驱动开发
- 名词解释:结对编程
- 给定代码段示例,对其进行改进或发现其中的问题
- 简洁性/可维护性
- 使用数据结构消减复杂判定
- 控制结构
- 变量使用
- 语句处理
- How to write unmaintainable code
- 防御与错误处理
- 单元测试用例的设计
- 契约式设计
- 防御式编程
- 表驱动
软件构造是以编程为核心的活动,但其内涵远不止于编写代码本身。它是一个旨在生产出可工作的、有意义的软件的详细创建过程。
根据 SWEBOK (Software Engineering Body of Knowledge),软件构造是通过编码、验证、单元测试、集成测试和调试等工作的结合,生产可工作的、有意义的软件的详细创建过程。
McConnell 在其著作中也强调,软件构造除了核心的编程任务外,还系统地整合了其他关键活动,包括:
- 详细设计(例如,数据结构与算法设计)
- 单元测试
- 集成与集成测试
- 调试
- 代码评审
名词解释:
- 重构(Refactoring)是一种对软件系统进行修改的严谨、有纪律的方法,其核心在于在不改变代码外部行为(即软件功能)的前提下,系统地改进其内部结构。重构的主要目的是提升软件的详细设计质量,使其更易于理解、维护和扩展,从而能够更好地持续演化。
- 测试驱动开发(Test-Driven Development, TDD),有时也被称为测试优先的开发方法,是一种软件开发实践,它要求程序员在编写一小段具体的功能代码之前,首先为其编写自动化测试代码。
- 结对编程是一种敏捷软件开发实践,其中两位程序员共同协作,在同一台计算机上一起完成设计、编码、测试等软件构造活动。
契约式设计(Design by Contract, DbC)核心思想:软件模块(如类、方法)之间的交互建立在明确的「契约」之上。契约规定了调用方和被调用方的责任和权利。
防御式编程:方法在与外部环境(其他方法、操作系统、用户输入等)交互时,不能完全信任外部的正确性。要在发生错误时保护方法内部不受损害。
表驱动编程:对于多重条件判断(尤其是 if-else if-else 或 switch 结构),可以使用表(如数组、Map)来存储条件和对应的动作/结果,通过查表代替复杂的逻辑判断。这使得逻辑更清晰,且易于修改和扩展。
第十九章:软件测试
- 掌握白盒测试和黑盒测试的常见方法,并进行能够优缺点比较
- 能解释并区别白盒测试三种不同的方法:语句覆盖、分支覆盖和路径覆盖
- 给出一个场景,判断应该使用哪种测试方法,如何去写
- 对给定的场景和要求的测试方法,设计测试用例
- 给出功能需求,则要求写功能测试用例
- 给出设计图,则要求写集成测试用例,Stub and Driver
- 给出方法的描述,则要求写单元测试用例,Mock Object
- JUnit 基本使用方法
常用的白盒测试覆盖标准:
- 语句覆盖
- 目标是确保被测试对象的每一行可执行程序代码都至少执行一次。
- 是最弱的覆盖标准。
- 条件覆盖(或分支覆盖的变种)
- 目标是确保程序中每个判断(如
if,while中的条件表达式)的每个可能结果(真和假)都至少出现一次。 - 比语句覆盖强,因为它能发现因条件判断错误而导致分支未执行的问题。
- 目标是确保程序中每个判断(如
- 路径覆盖
- 目标是确保程序中每条独立的执行路径都至少执行一次。
- 是最强的覆盖标准之一,但对于包含循环或大量分支的复杂程序,路径数量可能非常庞大,难以完全覆盖。
第二十、二十一章:软件交付、维护与演化
- 如何理解软件维护的重要性?
- 开发可维护软件的方法
- 演化式生命周期模型
- 用户文档、系统文档
- 逆向工程、再工程
软件维护是软件交付之后为修正缺陷、提高性能、适应变化环境而进行的修改活动。其重要性主要体现在其高昂的成本和对软件价值的决定性作用。
软件维护四种类型:
- 修正性维护(Corrective): 修复在运行中发现的缺陷。
- 适应性维护(Adaptive): 修改软件以适应外部环境(如操作系统、硬件)的变化。
- 完善性维护(Perfective): 增加新功能或改进现有功能,以满足用户的新需求。
- 预防性维护(Preventive): 为提升软件未来的可维护性而进行修改,如代码重构、优化结构等。这是为了应对 Lehman 定律中提到的「软件复杂度会持续增加」的问题。
软件的生命周期可以划分为以下五个连续的阶段,每个阶段有不同的目标和团队角色。
- 初始开发(Initial Development)
- 目标: 完成软件的第一个可用版本。核心任务是建立一个良好的、可扩展的软件体系结构,为后续演化奠定基础。
- 团队: 完整的开发团队,包括架构师、需求工程师、设计师等,需建立对产品的整体理解。
- 演化(Evolution)
- 目标: 持续增加软件价值。通过处理变更请求和开发预定的需求增量,不断满足用户的新需求。
- 特征: 此时软件需同时具备良好的可演化性和业务价值。若业务价值不足,项目会提前终止;若可演化性丧失,则会进入服务阶段。
- 团队: 规模可能缩小,但核心成员(如架构师、需求工程师)仍需保留,以指导演化方向。
- 服务(Servicing)
- 目标: 维持软件的基本可用性。不再增加新功能,仅进行周期性的缺陷修复(主要是修正性维护)。
- 原因: 通常因为软件结构已变得僵化,难以修改,或者出于市场考虑,团队将重心转移到新产品上。
- 团队: 不再需要架构师等角色,维护人员只需了解局部细节即可。
- 逐步淘汰(Phase-out)
- 目标: 准备替换系统。开发者不再提供任何服务和维护,但用户可能因迁移成本等原因继续使用。
- 活动: 开发者考虑将此系统作为遗留资源用于新系统开发;用户则需规划数据迁移和系统更换。
- 停止(Stop)
- 目标: 软件正式退役,开发者和用户均停止使用和维护。
- 用户文档:为终端用户编写,旨在帮助他们理解和有效使用软件。
- 系统管理员文档:为系统维护人员编写,更注重系统维护而非使用细节。
「逆向工程」和「再工程」是处理遗留软件的两种关键技术,旨在理解和改进那些难以维护但仍有价值的旧系统。
逆向工程:它是一个分析过程,旨在从现有系统(尤其是只有二进制代码或缺少文档的系统)中,提取出更高层次的抽象,如设计模型和需求规格。
- 目标:理解软件,而非修改软件。
- 过程: 从源代码或可执行文件出发,推导出系统的体系结构、组件交互关系和设计模式。
- 作用: 为后续的维护或再工程活动建立清晰的系统理解。
再工程:它是在逆向工程理解系统的基础上,对系统进行检查和改造,以新的模式或技术重新实现,从而提升其可维护性、可复用性或性能。
- 目标:改造软件,以获得新生。
第二十二、二十三章:软件开发过程模型
- 软件生命周期模型
- Build-and-fix model
- Waterfall model
- Iterative Models
- Incremental model
- Incremental Delivery
- Evolutionary
- Evolutionary development
- Prototyping
- Spiral Model
- 解释与比较不同过程模型(要求、特征描述、优点、缺点)
- 对给定的场景,判定适用的开发过程模型
- 软件工程知识体系的知识域
- 软件生命周期(Software Lifecycle):指软件从产生到报废的整个过程,通常划分为不同阶段。
- 软件生命周期模型(Software Lifecycle Model):对软件生命周期中各阶段的划分和组织方式,定义了各阶段的典型输入/输出、主要活动和执行者,形成一个明确、连续的顺次过程。
- 软件过程模型(Software Process Model):在生命周期模型的基础上,进一步详细说明各阶段的任务、活动、对象、组织和控制过程。可以看作是网络化的活动组织,比生命周期模型更具体、更灵活。
- 构建-修复模型(Build-and-Fix Model)
- 核心特征:
- 最原始的开发方式,缺少规划和组织。
- 流程:构建第一个版本 -> 不断修复直到满意 -> 维护。
- 完全依赖开发人员个人能力。
- 优点:
- 无管理开销,简单直接。
- 缺点:
- 无文档,维护极其困难。
- 无需求分析,风险极高。
- 无质量保证,代码质量随修改次数增加而急剧下降。
- 随系统复杂度提升,很快会失效。
- 适用场景:
- 规模极小(如几百行代码的程序)。
- 对质量和后期维护要求不高的「一次性」软件。
- 核心特征:
- 瀑布模型(Waterfall Model)
- 核心特征:
- 线性顺序:将开发分为固定的、顺序的阶段(需求->设计->实现->测试->维护)。
- 阶段性审查:每个阶段结束后必须进行验证,通过后才能进入下一阶段。
- 文档驱动:每个阶段都产出完整的文档,作为下一阶段的输入。
- 优点:
- 阶段划分清晰,便于管理和分工。
- 强调早期分析与设计,为复杂项目提供了关注点分离的手段。
- 缺点:
- 缺乏灵活性:线性顺序不切实际,难以应对需求变更。
- 文档依赖过重:编写和维护文档成本高,且难以保证与需求完全一致。
- 用户参与度低:用户仅在项目初期参与,后期问题发现晚,修复成本高。
- 里程碑粒度粗:「早发现缺陷早修复」的思想基本丧失。
- 适用场景:
- 需求非常成熟、稳定,在开发过程中不会发生变化。
- 所需技术成熟可靠,无技术难点。
- 项目复杂度适中。
- 核心特征:
- 增量迭代模型(Incremental Model)
- 核心特征:
- 迭代开发:将系统功能分块,每次迭代开发一小部分功能(一个增量)。
- 渐进交付(Incremental Delivery):每个增量都是一个可交付、可工作的部分软件。
- 并行开发:不同增量可并行开发。
- 需求驱动:先完成核心功能,再逐步扩展。
- 优点:
- 缩短开发周期:并行开发提高效率,用户能更早看到部分产品。
- 降低风险:渐进交付能及早获得用户反馈。
- 比瀑布模型更灵活,符合软件开发实践。
- 缺点:
- 需要开放式架构:体系结构必须易于扩展,否则集成新构件会破坏原有系统。
- 前期规划要求高:项目初期需对整体目标和范围有清晰的认识,否则难以规划增量。
- 适用场景:
- 适用于大规模软件系统开发。
- 项目需求比较成熟和稳定的领域。
- 核心特征:
- 演化模型(Evolutionary Model)
- 核心特征:
- 与增量模型类似,也是迭代、并行、渐进交付。
- 核心区别:更擅长应对需求变更,适用于需求频繁变化或不确定性高的领域。
- 模糊了「新开发」与「维护」的界限,每次迭代都是在前一版本基础上的演化。
- 优点:
- 灵活性强:能有效适应需求变更。
- 与增量模型一样,能缩短周期、降低风险。
- 缺点:
- 难以规划:项目早期无法建立准确的整体计划和范围。
- 易退化:若后续迭代忽略分析设计,容易退化为「构建-修复」模式。
- 适用场景:
- 需求不稳定、不确定性高的大规模软件系统开发。
- 核心特征:
- 原型模型(Prototyping Model)
- 核心特征:
- 解决不确定性:主要目标是解决(尤其是需求的)不确定性。
- 抛弃式原型(Throwaway Prototyping):快速构建一个简易原型来澄清需求,需求明确后抛弃原型,再用传统模型(如瀑布)开发。
- 优点:
- 加强与用户的交流,提高最终产品满意度。
- 有效解决新颖领域中的需求不确定性问题。
- 缺点:
- 成本风险:原型开发本身需要成本,可能耗尽项目时间和费用。
- 管理风险:管理者或客户可能不舍得「抛弃」原型,导致质量差的代码进入最终产品。
- 适用场景:
- 需求不确定性大的新颖领域。
- 核心特征:
- 螺旋模型(Spiral Model)
- 核心特征:
- 风险驱动:将风险管理和原型方法结合,完全按照风险解决的方式组织开发。
- 迭代与瀑布结合:开发阶段是瀑布式的,但整体过程是迭代的。
- 四个象限:每个螺旋周期包含四个活动:
- 制定计划:确定目标、方案、约束。
- 风险分析:评估方案,识别并解决风险(常通过原型)。
- 实施工程:开发和验证当前阶段的产品。
- 客户评估:评审结果,计划下一轮。
- 优点:
- 强大的风险控制能力,能显著降低项目风险。
- 缺点:
- 模型复杂,对管理者的风险管理能力要求高。
- 继承了原型方法的风险(成本、不舍得抛弃等)。
- 适用场景:
- 高风险、大规模、复杂的软件系统开发。
- 核心特征:
| 如果项目特征是… | 优先考虑的模型 | 关键词 |
|---|---|---|
| 需求非常稳定、清晰,技术成熟 | 瀑布模型 | 稳定、不变、清晰 |
| 需求不确定、模糊,需要探索和澄清 | 原型模型 | 不确定、新颖、探索 |
| 风险高,大型复杂系统,需要严格管理 | 螺旋模型 | 风险、复杂、大型 |
| 需求相对稳定,但系统规模大,希望尽早交付核心功能 | 增量迭代模型 | 大规模、渐进交付 |
| 需求频繁变更,系统规模大 | 演化模型 | 需求变更、演化 |
| 练手的小程序,或一次性使用的工具 | 构建-修复模型 | 临时、个人、无维护 |