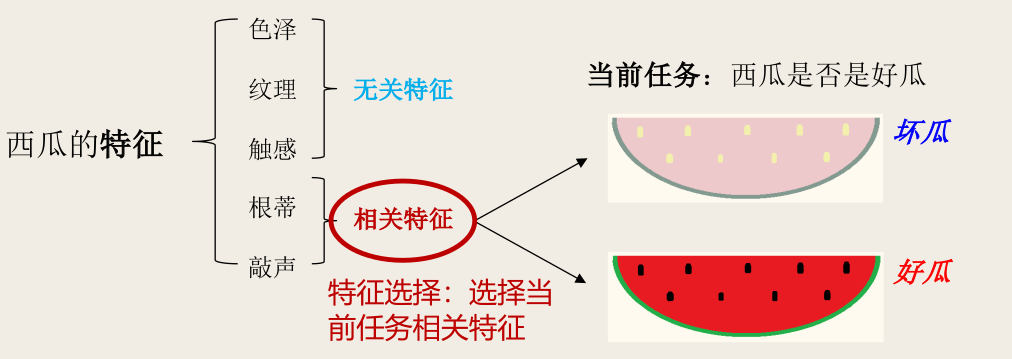
特征(feature)是描述物体的属性。可分类为:
- 相关特征(relevant feature):对当前的学习任务有用的属性;
- 无关特征(irrelevant feature):与当前的学习任务无关的属性;
- 冗余特征(redundant feature):其所包含信息能由其他特征推演出来。
从给定的特征集合中选择出相关特征子集的过程,必须确保不丢失重要特征,称为「特征选择」(feature selection)。
原因:
- 减轻维度灾难:在少量属性上构建模型
- 降低学习难度:留下关键信息
原始的方法有遍历所有可能的子集,但计算上遭遇组合爆炸,实际上不可行。
可行方法:
- 产生初始候选子集;
- 评价候选子集的好坏;
- 基于评价结果产生下一个候选子集;
- 重复步骤 2 和 3,直到满足停止条件。
因此有两个关键环节:子集搜索和子集评价。
子集搜索与评价
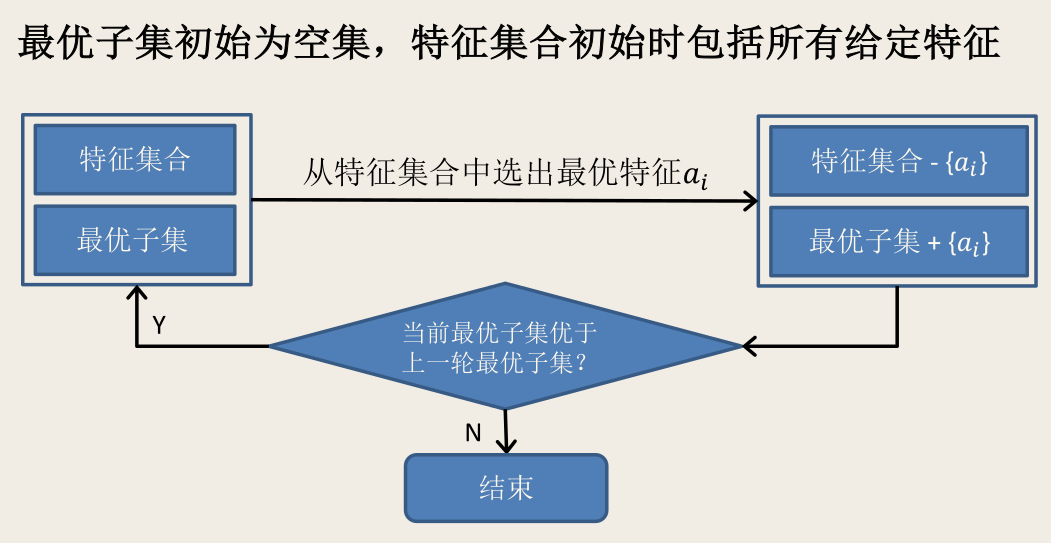
子集搜索(subset search)
给定特征集合 {a1,…,ad},可将每个特征看作一个候选子集。
用贪心策略选择包含重要信息的特征子集:
- 前向搜索(forward search):从空集开始,逐渐增加相关特征;
- 后向搜索(backward search):从全集开始,逐渐减少无关特征。
- 双向搜索(bidirectional search):结合前向和后向搜索,每一轮逐渐增加相关特征,同时逐渐减少无关特征。
前向搜索的流程:
子集评价(subset evaluation)
特征子集确定了对数据集的一个划分,每个划分区域对应着特征子集上的某种取值。如下图所示:
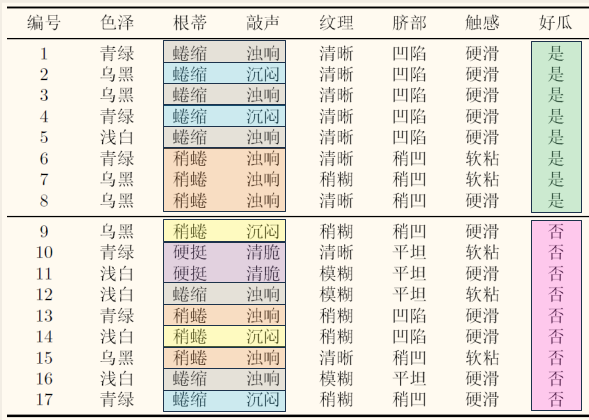
样本标记则对应着对数据集的真实划分。因此通过估算这两个划分的差异,就能对特征子集进行评价,与样本标记对应的划分差异越小,说明当前特征子集越好。
给定数据集 D,假定 D 中第 i 类样本所占的比例为 pi,类别数目有 ∣Y∣。
假定样本属性均为离散型,对于属性子集 A,假定根据其取值将 D 分成了 V 个子集 {D1,…,DV},每个子集中的样本在 A 上取值相同。
于是可计算属性子集 A 的信息增益
Gain(A)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
其中信息熵定义为
Ent(D)=−i=1∑∣Y∣pilog2pi
信息增益 Gain(A) 越大,意味着特征子集 A 包含的有助于分类的信息越多。
因此对于每个候选特征子集,可基于训练数据集 D 来计算其信息增益,以此作为评价标准。
将特征子集搜索机制与子集评价机制相结合,即可得到特征选择方法。例如将「前向搜索」与「信息熵」相结合,这显然与「决策树」算法非常相似。事实上,决策树可用于特征选择,树结点的划分属性所组成的集合就是选择出的特征子集。
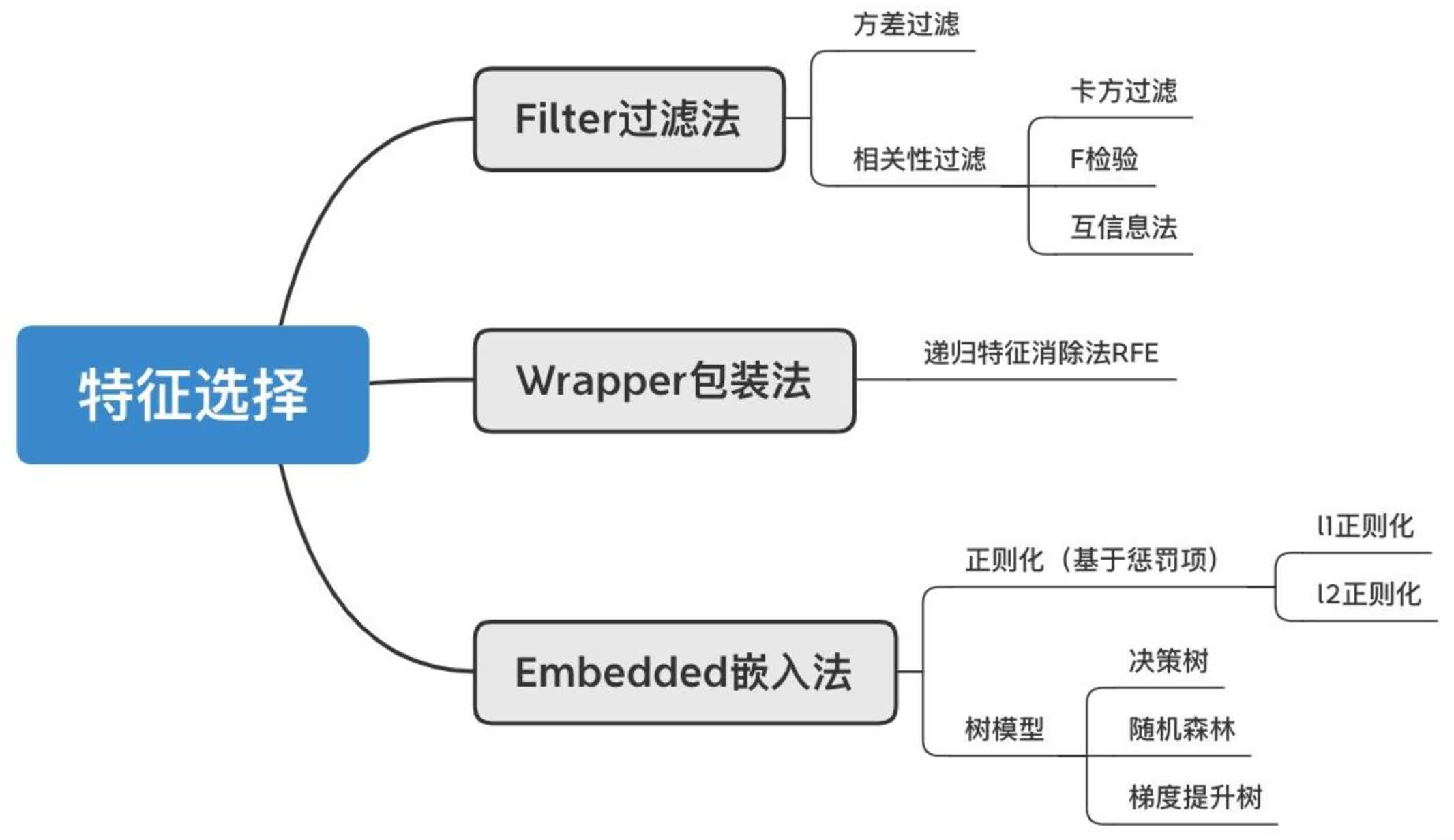
常见的特征选择方法大致可分为三类:
- 过滤式(filter)
- 包裹式(wrapper)
- 嵌入式(embedded)
过滤式选择
「过滤式方法」先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。这相当于先用特征选择过程对初始特征进行「过滤」,再用过滤后的特征来训练模型。
Relief (Relevant Features) 是一种著名的过滤式特征选择方法:
- 为每个初始特征赋予一个「相关统计量」,度量特征的重要性
- 特征子集的重要性由子集中每个特征所对应的相关统计量之和决定
- 设计一个阈值 τ,然后选择比阈值 τ 大的相关统计量分量所对应的特征
- 或者指定欲选取的特征个数 k,然后选择相关统计量分量最大的 k 个特征
因此 Relief 关键是如何确定相关统计量。
给定训练集 {(xi,yi)}i=1m,对每个示例 xi,Relief 定义:
- 猜中近邻(near-hit):xi 的同类样本中的最近邻 xi,nh;
- 猜错近邻(near-miss):xi 的异类样本中的最近邻 xi,nm。
Relief 的相关统计量对应于属性 j 的分量为
δj=i∑−diff(xij,xi,nhj)2+diff(xij,xi,nmj)2
其中 xaj 表示样本 xa 在属性 j 上的取值,diff(xaj,xbj) 取决于属性 j 的类型:
- 若 j 为离散型,则 diff(xaj,xbj)=1 当 xaj=xbj,否则为 0;
- 若 j 为连续型,则 diff(xaj,xbj)=∣xaj−xbj∣,其中 xaj,xbj 已规范化到 [0,1] 区间。
相关统计量越大,属性 j 上,猜中近邻比猜错近邻越近,即属性 j 对区分对错越有用。
由此可见,Relief 方法是为二分类问题设计的。其扩展变体 Relief-F 能处理多分类问题。
数据集中的样本来自 ∣Y∣ 各类别,其中 xi 属于第 k 类,定义:
- 猜中近邻:第 k 类中 xi 的最近邻 xi,nh;
- 猜错近邻:第 k 类之外的每个类中找到一个 xi 的最近邻作为猜错近邻,记为 xi,l,nm。
相关统计量对应于属性的份量为
δj=i∑−diff(xij,xi,nhj)2+l=k∑(pl×diff(xij,xi,l,nmj)2)
其中 pl 表示第 l 类样本在数据集 D 中的比例。
包裹式选择
过滤式特征选择不考虑后续学习器,而「包裹式选择」直接把最终将要使用的学习器的性能作为特征子集的评价准则。
包裹式特征选择的目的就是为给定学习器选择最有利于其性能、「量身定做」的特征子集。
包裹式选择方法直接针对给定学习器进行优化,因此从最终学习器性能来看,包裹式特征选择比过滤式特征选择更好。
但另一方面,包裹式特征选择过程中需多次训练学习器,计算开销通常比过滤式特征选择大得多。
LVW (Las Vegas Wrapper) 是一个典型的包裹式特征选择方法。它在「拉斯维加斯方法」(Las Vegas method)框架下使用随机策略来进行子集搜索,并以最终分类器的误差作为特征子集评价准则。
算法描述如下:

基本步骤:
- 在循环的每一轮随机产生一个特征子集
- 在随机产生的特征子集上通过交叉验证推断当前特征子集的误差
- 进行多次循环,在多个随机产生的特征子集中选择误差最小的特征子集作为最终解
若有运行时间限制,则该算法可能给不出解。
嵌入式选择
「嵌入式特征选择」是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,在学习器训练过程中自动地进行特征选择。
考虑线性回归模型,以平方误差为损失函数,引入 L2 范数正则化防止过拟合,有
wmini=1∑m(yi−w⊺xi)2+λ∥w∥22
其中正则化参数 λ>0。该式称为「岭回归」(ridge regression)。
可以将正则化项中的 L2 范数替换为 L1 范数,有
wmini=1∑m(yi−w⊺xi)2+λ∥w∥1
该式称为 LASSO (Least Absolute Shrinkage and Selection Operator, 最小绝对收缩选择算子)。
L1 范数和 L2 范数正则化都有助于降低过拟合风险,但前者还会带来一个额外的好处:L1 更容易获得「稀疏」(sparse)解,即求得的 w 会有更少的非零分量。
直观理解
假设 x 仅有两个属性,则 w 有两个分量 w1,w2。
目标优化的解要在平方误差项与正则化项之间折中,即出现在图中平方误差项等值线与正则化等值线相交处:
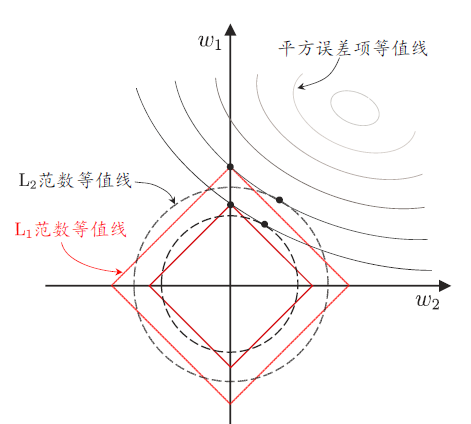
如图所示,采用 L1 范数时交点常出现在坐标轴上,即产生 w1 或 w2 为零的稀疏解。
好像有点理解了,L1 范数是「平」的,而 L2 范数「凸」了出来,相较而言更容易在凸出处与平方误差等值线相交,而非在坐标轴上的四个「端点」。
事实上,对 w 施加「稀疏约束」,即希望 w 的非零分量尽可能少,最自然的是使用 L0 范数(非零元素个数),但 L0 范数不连续,难以优化求解,因此常使用 L1 范数近似。
L1 正则化问题的求解可使用「近端梯度下降」(Proximal Gradient Descent, PGD)求解。
f(x) 二阶泰勒展式为
f(x)≃f(xk)+⟨∇f(xk),x−xk⟩+21(x−xk)⊺δxk2δ2f(xk)(x−xk)
对优化目标
xminf(x)+λ∥x∥1
若 f(x) 可导,且 ∇f 满足 L-利普希茨(Lipschitz)条件,即存在常数 L>0 使得
∥∇f(x′)−∇f(x)∥2⩽L∥x′−x∥2
对于任意 x,x′ 成立,
将 L-利普希茨条件代入泰勒展式,有
f^(x)≃f(xk)+⟨∇f(xk),x−xk⟩+2L∥x−xk∥22=f(xk)+∇f(xk)⊺(x−xk)+2L(x−xk)⊺(x−xk)=2L(∥x−xk∥22+2L1∇f(xk)⊺(x−xk)+L21∥∇f(xk)∥22)+f(xk)−2L21∥∇f(xk)∥22=2Lx−(xk−L1∇f(xk))22+const
其中 const 是与 x 无关的常数。因此上式的最小值在
xk+1=xk−L1∇f(xk)
时取得。
于是通过梯度下降法对 f(x) 进行最小化,每一步梯度下降迭代实际上等价于最小化二次函数 f^(x)。
于是可得
xk+1=xargmin2Lx−(xk−L1∇f(xk))22+λ∥x∥1
即在每一步对 f(x) 进行梯度下降迭代的同时,考虑 L1 范数最小化。
对于该式,可先计算 z=xk−L1∇f(xk),然后求解
xk+1=xargmin2L∥x−z∥22+λ∥x∥1
令 xi 表示 x 的第 i 个分量,将上式按分量展开可看出,其中不存在 xixj 这样的项,即 x 的各分量互不影响。
因此上式有闭式解
xk+1i=⎩⎨⎧zi−Lλ,0,zi+Lλ,Lλ<zi∣zi∣⩽Lλzi<−Lλ
其中 xk+1i 与 zi 分别是 xk+1 与 z 的第 i 个分量。
闭式解
按分量展开有
2L(xi−zi)2+λ∣xi∣=2Lxi2−Lxizi+2Lzi2+λ∣xi∣=⎩⎨⎧2Lxi2−(Lzi−λ)xi+2Lzi2,2Lxi2−(Lzi+λ)xi+2Lzi2,xi⩾0xi<0
是两个二次函数的杂交物,xi>0 与 xi<0 时对称轴分别为 zi−Lλ 与 zi+Lλ。
当 zi>Lλ 时,xi<0 时函数恒单调递减,同时在 xi>0 时先单调递减,再单调递增,因此最小值在正半边二次函数的对称轴 zi−Lλ 处取得,这是第一种情况。
同理,当 zi<−Lλ 时,xi>0 时函数恒单调递增,同时在 xi<0 时先单调递减,再单调递增,因此最小值在负半边二次函数的对称轴 zi+Lλ 处取得,这是第三种情况。
而 ∣zi∣⩽Lλ 时,这时候二者的对称轴都在另一侧,因此负半边始终单调递减,正半边始终单调递增,因此最小值在 xi=0 处取得,这是第二种情况。
因此通过 PGD 能使 LASSO 和其他基于 L1 范数最小化的方法得以快速求解。
稀疏表示与字典学习
将数据集看成一个矩阵,每行对应一个样本,每列对应一个特征。
特征选择所考虑的问题是特征具有稀疏性,即矩阵中的许多列与当前学习任务无关,可通过特征选择去除这些列,则学习器训练过程仅需在较小的矩阵上进行,学习任务的难度可能有所降低,涉及的计算和存储开销会减小,学得模型的可解释性也会提高。
另一种稀疏性:矩阵中有很多零元素,且非整行整列出现的。
例如文档分类任务中,每个文档看作一个样本,每个字作为一个特征,出现频率或次数作为特征的取值。
稀疏表示的优势:
因此若给定数据集是稠密的,即普通非稀疏数据,能否将其转化为「稀疏表示」(sparse representation)形式呢?
此外我们所希望的稀疏是「恰当稀疏」而非「过度稀疏」。以汉语文档为例,基于《现代汉语常用字表》得到的可能是恰当稀疏,但基于《康熙字典》可能是过度稀疏。
为普通稠密表达的样本找到合适的字典,将样本转化为稀疏表示,这一过程称为「字典学习」(dictionary learning)或「码书学习」(codebook learning)或「稀疏编码」(sparse coding)。
给定数据集 {xi}i=1m,学习目标是字典矩阵 B∈Rd×k,以及样本 xi∈Rd 的稀疏表示 αi∈Rk,其中 d 是样本维度,k 称为字典的词汇量(通常由用户指定)。
最简单的字典学习的优化形式为
B,αimini=1∑m∥xi−Bαi∥22+λ∥αi∥1
第一项希望由 αi 能很好地重构 xi,第二项希望 αi 尽量稀疏。
与 LASSO (1) 相比,除了类似 w 的 αi 外,还需学习字典矩阵 B。
可采用「变量交替优化」的策略求解 (2)。
- 固定字典 B,按分量展开 (2),其中不含 αiuαiv 的交叉项,可参照 LASSO 解法求解下式,从而为每个样本 xi 找到相应的 αi
αimin∥xi−Bαi∥22+λ∥αi∥1
- 固定 αi 更新字典 B,可改写 (2) 为
Bmin∥X−BA∥F2
其中 X=(x1,…,xm)∈Rd×m,A=(α1,…,αm)∈Rk×m,∥⋅∥F 是矩阵的 Frobenius 范数,即矩阵元素平方和的平方根。
常用基于「逐列更新策略」的 KSVD。
令 bi 表示字典矩阵 B 的第 i 列,αi 表示稀疏矩阵 A 的第 i 行,可重写优化目标为
Bmin∥X−BA∥F2=biminX−j=1∑kbjαjF2=biminX−j=i∑bjαj−biαiF2=biminEi−biαiF2
更新字典第 i 列时,其他各列都是固定的,即 Ei=X−∑j=ibjαj 是固定的。
于是最小化 Ei−biαi 原则上只需对 Ei 进行奇异值分解,取最大奇异值对应的正交向量。但直接对 Ei 进行奇异值分解会同时修改 bi 与 αi,从而可能破坏 A 的稀疏性。
因此 KSVD 对 Ei 与 αi 进行专门处理:
- αi 仅保留非零元素;
- Ei 仅保留 bi 与 αi 的非零元素的乘积项。
然后再进行奇异值分解,就保持了第一步所得到的稀疏性。
初始化字典矩阵后反复迭代上面两步,最终可求得字典 B 和样本 xi 的稀疏表示 αi。上述字典学习过程中,用户通过设置词汇量 k 来控制字典的规模,从而影响稀疏程度。
压缩感知
在现实任务中,我们常希望根据部分信息来恢复全部信息。
例如为了便于传输、存储,实践中人们通常对采样的数字信号进行压缩,可能损失一些信息。同时信号传输过程中,由于信道出现丢包等问题,又可能损失部分信息。
「压缩感知」(compressed sensing)为解决此类问题提供了新的思路。
长度为 m 的离散信号 x,用远小于奈奎斯特采样定理要求的采样率采样得到的长度为 n 的采样后信号 y,其中 n≪m,即
y=Φx
其中 Φ∈Rn×m 是对信号 x 的测量矩阵,它确定了以什么频率进行采样,以及如何将采样样本组成采样后的信号。
一般情况下 n≪m,不能利用 y 还原 x。因此 y,x,Φ 组成的上面的方程是一个「欠定方程」(underdetermined system),有无穷多解,无法轻易求出数值解。
但若存在某个线性变换 Ψ∈Rm×m 使得 x=Ψs,其中 s 是稀疏向量,即
y=Φx=ΦΨs=As
其中 A=ΦΨ∈Rn×m,于是若能根据 y 恢复出 s,则可通过 x=Ψs 恢复出信号 x。
若 s 具有稀疏性,这个问题可以很好地得到解决。这是因为稀疏性使得未知因素的影响大为减少。此时 Ψ 称为「稀疏基」(sparse basis),s 称为「稀疏表示」(sparse representation)。
事实上,在很多应用中均可获得具有稀疏性的 s,例如图像或声音的数字信号通常在时域上不具有稀疏性,但经过傅里叶变换、余弦变换、小波变换等处理后却会转化为频域上的稀疏信号。
限定等距性(Restricted Isometry Property, RIP)
对 A∈Rn×m,其中 n≪m,若存在常数 δk∈(0,1) 是的对于任意向量 s 和 A 的所有子矩阵 Ak∈Rn×k 有
(1−δk)∥s∥22⩽∥Aks∥22⩽(1+δk)∥s∥22
则称 A 满足 k 限定等距性(k-RIP)。
此时可通过下面的优化问题近乎完美地从 y 中恢复出稀疏信号 s:
smin∥s∥0s.t.y=As
这涉及 L0 范数的最小化,是个 NP 难问题。不过 L1 范数最小化一定条件下与 L0 范数最小化问题共解,于是只需关注
smin∥s∥1s.t.y=As
这样压缩感知问题就通过 L1 范数最小化问题求解。例如上式可转化为 LASSO 的等价形式,再通过近端梯度下降法求解,即使用「基寻踪去噪」(Basis Pursuit De-Nosising)。
基于部分信息来恢复全部信息的技术在许多现实任务中有重要应用。例如下表,给出了部分客户对书籍的喜好程度评分:
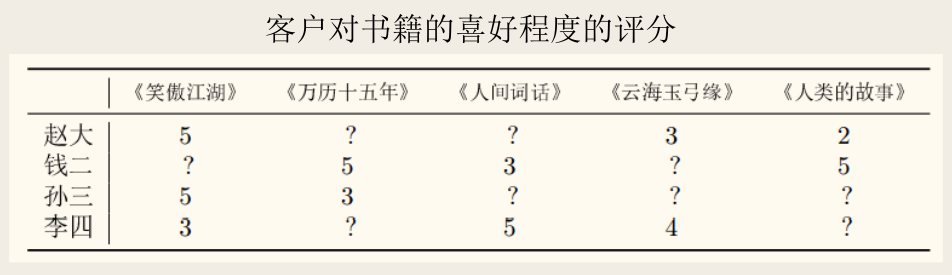
能否将表中已经通过读者评价得到的数据当作「部分信号」,基于压缩感知的思想「恢复」出「完整信号」从而进行书籍推荐呢?从题材、作者、装帧等角度看(相似题材的书籍有相似的读者),表中反映的信号是「稀疏」的,能通过类似压缩感知的思想加以处理。
可以通过「矩阵补全」(matrix completion)技术来处理这类问题。其形式为
Xminr(X)s.t.(X)ij=(A)ij,(i,j)∈Ω
其中 X 表示需恢复的稀疏信号,A 表示已观测信号,Ω 表示 A 中已观测到的元素的下标集合。
约束表明,恢复出的矩阵 Xij 应与已观测的对应元素相同。
这是一个 NP 难问题。注意到 r(X) 在集合 {X∈Rm×n:∥X∥F2} 上的凸包是 X 的「核范数」(nuclear norm)
∥X∥∗=j=1∑min{m,n}σj(X)
其中 σj(X) 表示 X 的奇异值,即矩阵的核范数为矩阵的奇异值之和。
于是可通过最小化矩阵核范数来近似求解矩阵补全问题:
Xmin∥X∥∗s.t.(X)ij=(A)ij,(i,j)∈Ω
这是一个凸优化问题,可通过「半正定规划」(Semi-Definite Programming, SDP)求解。
理论研究表明,在满足一定条件时,若 A 秩为 r,n≪m,则只需观察到 O(mrlog2m) 个元素就能完美恢复出 A。