基本形式
给定由 d 个属性描述的示例 x=(x1;x2;⋯;xd),其中 xi 是 x 的第 i 个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即
f(x)=w1x1+w2x2+⋯+wdxd+b
一般用向量形式写成
f(x)=wTx+b
其中 w=(w1;w2;⋯;wd)。w,b 学得后,模型就得以确定。
线性模型形式简单、易于建模,有很好的可解释性(comprehensibility),蕴含着机器学习中一些重要的基本思想,许多功能更强大的非线性模型(nonlinear model)可在线性模型的基础上通过引入层级结构或高维映射而得。
线性回归
给定数据集 D={(x1,y1),(x2,y2),⋯,(xm,ym)},其中 xi=(xi1;xi2;⋯;xid),yi∈R。线性回归(linear regression)试图学得一个线性模型以尽可能准确地预测实值输出标记。
先考虑一种简单的情形(单一属性线性回归):输入的属性数目只有一个。为了便于讨论,此时忽略关于属性的下标。
线性回归试图学得
f(xi)=wxi+b
使得
f(xi)≃yi
确定 w,b 的方法有很多,最常见的是最小二乘法(least squares method),即使得均方误差最小化:
(w∗,b∗)=(w,b)argmini=1∑m(f(xi)−yi)2
求解 w,b 使得 E(w,b) 最小化的过程,称为线性回归模型的最小二乘「参数估计」(parameter estimation)。
过程
求偏导有
⎩⎨⎧∂w∂E(w,b)∂b∂E(w,b)=2(wi=1∑mxi2−i=1∑m(yi−b)xi)=2(mb−i=1∑m(yi−wxi))
令两式为零可得 w,b 最优解的闭式(closed-form)解
⎩⎨⎧wb=i=1∑mxi2−m1(i=1∑mxi)2i=1∑myi(xi−xˉ)=m1i=1∑m(yi−wxi)
其中 xˉ=m1i=1∑mxi 为 x 的均值。
更一般的情形就是多元线性回归(multivariate linear regression),即输入的属性数目大于一个。此时,线性回归试图学得
f(xi)=wTxi+b
使得
f(xi)≃yi
过程
为了便于讨论,将 w,b 吸收入向量形式 w^=(w;b)。相应的,把数据集 D 表示为一个 x×(d+1) 大小的矩阵 X,其中每一行对应于一个示例,该行前 d 个元素对应于示例的 d 个属性值,最后一个元素恒置为 1,即
X=x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1dx2d⋮xmd11⋮1=x1Tx2T⋮xmT11⋮1
标记也写成向量形式 y=(y1;y2;⋯;ym)。类似地有
w^∗=w^argmin(y−Xw^)T(y−Xw^)
令 Ew^=(y−Xw^)T(y−Xw^),求导有
∂w^∂Ew^=2XT(Xw^−y)
令上式为零可得 w^ 最优解的闭式解。但涉及矩阵逆的计算,比单变量复杂一点。下面进行一个简单的讨论。
当 XTX 为满秩矩阵(full-rank matrix)或正定矩阵(positive definite matrix)时,XTX 可逆,此时有
w^∗=(XTX)−1XTy
令 x^i=(xi,1),则最终学得的多元线性回归模型为
f(xi)=x^iT(XTX)−1XTy
现实中 XTX 往往不是满秩矩阵。例如在很多任务中会遇到大量的变量,甚至超出样例数,导致 X 列数多于行数,此时 XTX 显然不满秩。此时可解出多个 w^,它们都能使均方误差最小化,选择哪一个解作为输出,由学习算法的归纳偏好决定。常见的做法是引入正则化(regularization)项。
对数线性回归(log-linear regression)类似,即
lny=wTx+b
这里就不再多谈。
更一般地,考虑单调可微函数 g,令
y=g−1(wTx+b)
这样得到的模型称为广义线性模型(generalized linear model)。其中函数 g 称为联系函数(link function)。
对数几率回归
上一节讨论的是如何使用线性模型进行回归学习。对于分类任务,可以利用上面的广义线性模型,找到一个单调可微函数将分类任务的真实标记 y 与线性回归模型的预测值联系起来。
考虑二分类问题,输出标记 y∈{0,1}。对于线性回归模型,产生的预测值 z=wTx+b 为实数,需要将其转换为 0/1 值。
一种方法是使用单位阶跃函数(unit-step function):
y=⎩⎨⎧0,0.5,1,z<0;z=0;z>0.
但单位阶跃函数不连续,不可微。于是希望找到能在一定程度上近似单位阶跃函数的替代函数(surrogate function),并希望它单调可谓。
对数几率函数(logistic function,对率函数)是一个常用的替代函数:
y=1+e−z1
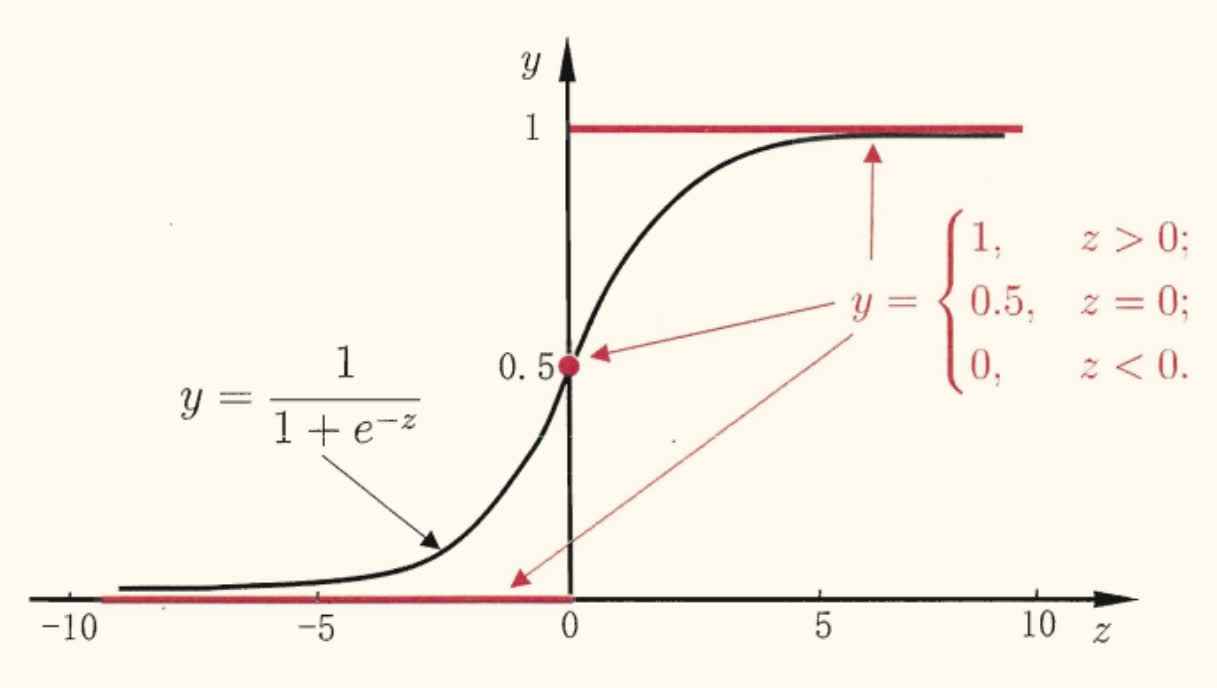
如图所示,对率函数是一种 Sigmoid 函数,即形似 S 的函数。它将 z 值转化为一个接近 0/1 的 y 值,并在 z=0 附近变化陡峭。
对于单调可谓函数 g,广义线性模型有
y=g−1(wTx+b)
将对率函数作为其中的 g−1,有
y=1+e−(wTx+b)1
从而得到
ln1−yy=wTx+b
若将 y 视为样本 x 作为正例的可能性,则 1−y 为其反例可能性,两者的比值 1−yy 称为几率(odds),这反映了 x 作为正例的相对可能性。同理有对数几率(log odds, a.k.a. logit)ln1−yy。
即式 (2) 实际上是在用线性回归模型的预测结果去逼近真实标记的对数几率,因此这个对应的模型才被称为对数几率回归(logistic regression, a.k.a. logit regression)。
虽然被称为是「回归」,但这实际上是一种学习方法。这种方法有很多优点,例如它是直接对分类可能性进行建模,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题;它不是仅预测出「类别」,而是可得到近似概率预测,这对许多需利用概率辅助决策的任务很有用;此外,对率函数是任意阶可导的凸函数,有很好的数学性质,现有的许多数值优化算法都可直接用于求取最优解。
接下来是确定式 (2) 中的 w,b。若将其中的 y 视为类后验概率估计 p(y=1∣x),则有
lnp(y=0∣x)p(y=1∣x)=wTx+b
从而有
⎩⎨⎧p(y=1∣x)p(y=0∣x)=1+ewTx+bewTx+b=1+ewTx+b1
可以通过极大似然法(maximum likelihood method,最大似然估计)来估计 w,b。给定数据集 {(xi,yi)}i=1m,对率回归模型最大化对数似然(log-likelihood)
ℓ(w,b)=i=1∑mlnp(yi∣xi;w,b)
即令每个样本属于其真实标记的概率越大越好。
为便于讨论,令 β=(w;b),x^=(x;1),则 wTx+b 可记为 βTx^。
再令 p1(x^;β)=p(y=1∣x^;β),p0(x^;β)=p(y=0∣x^;β)=1−p1(x^;β),则对数似然项可重写为
p(yi∣xi;w,b)=yip1(x^i;β)+(1−yi)p0(x^i;β)
将上式代入对率回归模型对数似然有
ℓ(β)=i=1∑mln(yip1(x^i;β)+(1−yi)p0(x^i;β))=i=1∑mln(yi1+eβTx^ieβTx^i+(1−yi)1+eβTx^i1)
然后呢,ln 移到 p0/1(x^i;β) 上(可能我没搞懂其中的原理),就有
ℓ(β)=i=1∑m(yiβTx^i−ln(1+eβTx^i))
最大似然估计即要使上式最大化。按书上的说法,将其取负(相同的记号,不停变式子内容…)
ℓ(β)=i=1∑m(−yiβTx^i+ln(1+eβTx^i))
这个是关于 β 的高阶可导连续凸函数,根据凸优化理论,可以使用经典的数值优化算法(如梯度下降法、牛顿法等)求得其最优解,得到
β∗=βargminℓ(β)
牛顿法
以牛顿法为例,其 t+1 轮迭代解的更新公式为
βt+1=βt−(∂β∂βT∂2ℓ(β))−1∂β∂ℓ(β)
其中关于 β 的一二阶导数分别为
⎩⎨⎧∂β∂ℓ(β)∂β∂βT∂2ℓ(β)=−i=1∑mx^i(yi−p1(x^i;β))=i=1∑mx^ix^iTp1(x^i;β)(1−p1(x^i;β))
线性判别分析
线性判别分析(linear discriminant analysis, LDA)是一种经典的线性学习方法。
LDA 的思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
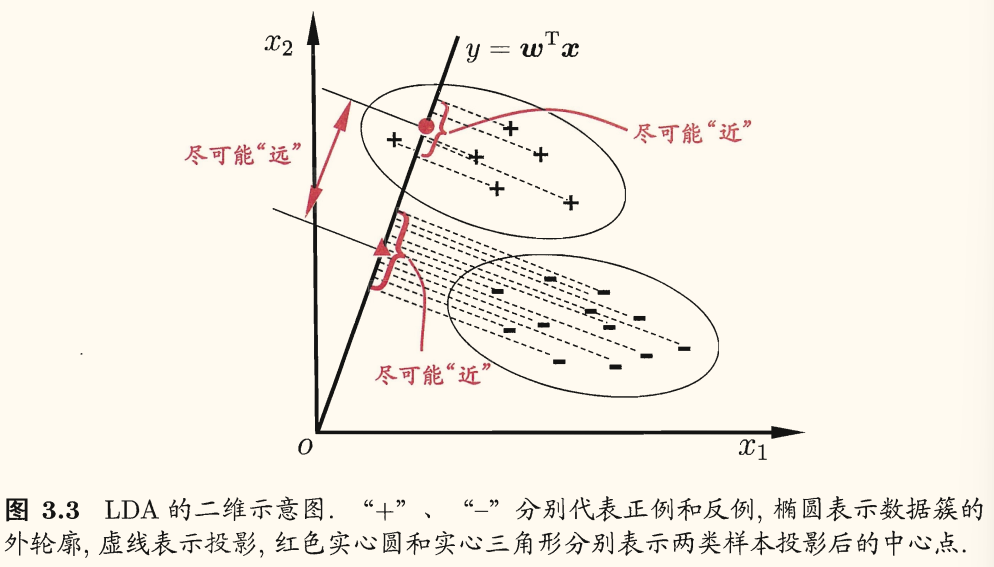
由于将样例投影到一条直线(低维空间),因此这也被视为一种「监督降维」技术(第 10 章)。
给定数据集 {(xi,yi)}i=1m,yi∈{0,1},其中第 i∈{0,1} 类示例有
- 集合 Xi
- 均值向量 μi
- 协方差矩阵 Σi
若将数据投影到直线 w 上,则
- 两类样本的中心在直线上的投影分别为 wTμ0 和 wTμ1
- 两类样本的协方差在直线上的投影分别为 wTΣ0w 和 wTΣ1w。
若使同类样例投影点尽可能接近,可以让同类样例协方差尽可能小,即 wTΣ0w+wTΣ1w 尽可能小;若使异类样例投影点尽可能远离,可以让异类样例中心点尽可能远离,即 wTμ0−wTμ122(不知道下标的 2 何解)尽可能大。
同时考虑二者,可得欲最大化的目标函数为
J=wTΣ0w+wTΣ1wwTμ0−wTμ122=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw
定义类内散度矩阵(within-class scatter matrix)
Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T
与类间散度矩阵(between-class scatter matrix)
Sb=(μ0−μ1)(μ0−μ1)T
(3) 可重写为
J=wTSwwwTSbw
即 LDA 欲最大化的目标就是,Sb 与 Sw 的广义瑞利商(generalized Rayleigh quotient)。
过程
首先确定 w。注意到 (4) 分子分母都是关于 w 的二次项,因此解与 w 长度无关,仅与其方向有关。不失一般性,令 wTSww=1,即 (4) 等价于
wmin−wTSbws.t.wTSww=1
拉格朗日乘子法有拉格朗日函数(λ 是拉格朗日乘子)
L(w,λ)=−wTSbw+λ(wTSww−1)
偏导有
⎩⎨⎧∂w∂L∂λ∂L=2(λSww−Sbw)=wTSww−1
即
Sbw=λSww
注意到 Sbw 方向恒为 μ0−μ1,不妨设
Sbw=λ(μ0−μ1)
代入 (5) 有
w=Sw−1(μ0−μ1)
实践中通常是对 Sw 进行奇异值分解,即 Sw=UΣVT,其中 Σ 是一个实对角矩阵,对角线上的元素是 Sw 的奇异值,再由 Sw−1=VΣ−1UT 得到 Sw−1。
LDA 的贝叶斯决策理论解释:两类数据同先验、满足高斯分布且协方差相等时,LDA 达到最优分类。
推广到多分类任务
假定存在 N 个类,第 i 类示例数为 mi,先定义全局散度矩阵
St=Sb+Sw=i=1∑m(xi−μ)(xi−μ)T
其中 μ 是所有示例的均值向量。
将类内散度矩阵 Sw 重定义为每个类别的散度矩阵之和,即
Sw=i=1∑NSwi
其中
Swi=x∈Xi∑(x−μi)(x−μi)T
从而有
Sb=St−Sw=i=1∑Nmi(μi−μ)(μi−μ)T
从而多分类 LDA 有多种实现方法:使用 Sb,Sw,St 三者中的任何两个即可。
常见的一种实现是采用优化目标
\max_{\mathbf{W}} \dfrac{\trace(\mathbf{W}^{\mathrm{T}} \mathbf{S}_b \mathbf{W})}{\trace(\mathbf{W}^{\mathrm{T}} \mathbf{S}_w \mathbf{W})
其中 W∈Rd×(N−1),tr 是矩阵的迹(trace)。上式可通过广义特征值问题求解:
SbW=λSwW
W 的闭式解是 Sw−1Sb 的 N−1 个最大广义特征值所对应的特征向量组成的矩阵。
多分类学习
现实中常遇到多分类学习任务。有些二分类学习方法可直接推广到多分类,但在更多情形下,我们是基于一些基本策略,利用二分类学习器来解决多分类问题。
不失一般性,考虑 N 个类别 C1,C2,⋯,CN,多分类学习的基本思路是「拆解法」,即将多分类任务拆为若干个二分类任务求解。
上面的方法具体而言是:先对问题进行拆分,为拆出的每个二分类任务训练一个分类学习器,即分类器(classifier)。在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果。
因此关键在于「如何对多分类任务进行拆分」以及「如何对多个分类器进行集成」。本节主要介绍拆分策略。
最经典的拆分策略有一对一(One vs. One, OvO)、一对其余(One vs. Rest, OvR)和多对多(Many vs. Many, MvM)。
给定数据集 {(x1,y1),(x2,y2),⋯,(xm,ym)},yi∈{C1,C2,⋯,CN}。
OvO 将这 N 个类别两两配对,从而产生 2N(N−1) 个二分类任务。测试阶段,新样本将同时提交给所有分类器,于是将得到 2N(N−1) 个分类结果,最终结果由投票决定:即把被预测得最多的类别作为最终的分类结果。
OvR 则是每次将一个类的样例作为正例、所有其他类的样例作为反例训练 N 个分类器。测试时若仅有一个分类器预测为正例,则对应的类别标记作为最终分类结果。若有多个分类器预测为正例,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
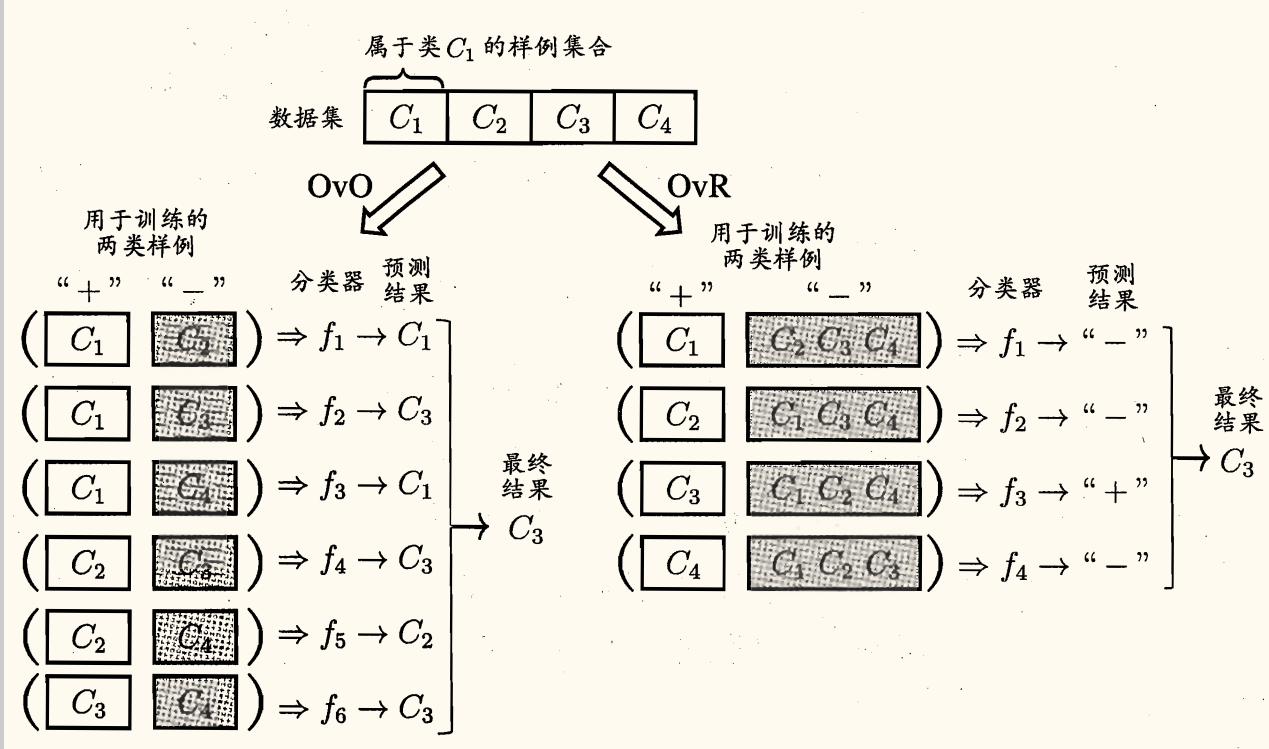
OvR 只需训练 N 个分类器,而 OvO 需训练 2N(N−1) 个分类器,因此 OvO 的存储开销和测试时间开销通常比 OvR 更大。但在训练时, OvR 的每个分类器均使用全部训练样例,OvO 的每个分类器仅用到两个类的样例,因此类别很多时 OvO 的训练时间开销同时比 OvR 更小。
预测性能取决于具体的数据分布,多数情形下两者差不多。
MvM 是一种折中的策略。它每次将若干个类作为正类,若干个其他类作为反类。正、反类的构造必须有特殊的设计,下面是一种最常用的 MvM 技术——纠错输出码(Error Correcting Output Codes, ECOC)。
ECOC 是将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性。工作过程主要分为两步:
- 编码:对 N 个类别做 M 次划分,每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集。一共产生 M 个训练集,可训练 M 个分类器。
- 解码:M 个分类器分别对测试样本进行预测,这些预测标记组成一个编码。将这个编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。

对同等长度的编码,理论上来说,任意两个类别之间的编码距离越远,则纠错能力越强。因此,在码长较小时可根据这个原则计算出理论最优编码。然而,码长稍大一些就难以有效地确定最优编码,事实上这是 NP 难问题。不过,通常我们并不需获得理论最优编码,因为非最优编码在实践中往往已能产生足够好的分类器。
另一方面,并不是编码的理论性质越好,分类性能就越好,因为机器学习问题涉及很多因素,例如将多个类拆解为两个「类别子集」,不同拆解方式所形成的两个类别子集的区分难度往往不同,即其导致的二分类问题的难度不同;于是,一个理论纠错性质很好、但导致的二分类问题较难的编码,与另一个理论纠错性质差一些、但导致的二分类问题较简单的编码,最终产生的模型性能孰强孰弱很难说。
类别不平衡问题
前面介绍的分类学习方法基于一个共同的基本假设,即「不同类别的训练样例数目相当」。
若不同类别的训练样例数差别很大,会对学习过程造成困扰。例如有 998 个正例,2 个反例,一个分类器只需将所有样例都预测为正例,就能达到 99.8% 的准确率。但这样的分类器显然是无用的。
类别不平衡(class-imbalance)就是指分类任务中不同类别的训练样例数目差别很大的情况。不失一般性,本节假定正类样例较少,反类样例较多。
从线性分类器的角度进行讨论。
在用 y=wTx+b 对新样本 x 进行分类时,事实上是在用预测出的 y 值与一个阈值进行比较,例如通常在 y>0.5 时判别为正例,否则为反例。
y 实际上表达了正例的可能性,几率 1−yy 则反映了正例可能性与反例可能性之比值,阈值设置为 0.5 恰表明分类器认为真实正、反例可能性相同,即分类器决策规则为
若 1−yy>1,则预测为正例。
然而,当训练集中正、反例数目不同时,令 m+,m− 分别表示正、反例数目,则观测几率是 m−m+。由于我们通常假设训练集是真实样本总体的无偏采样,因此观测几率就代表了真实几率。于是只要分类器的预测几率高于观测几率就应判定为正例,即
若 1−yy>m−m+,则预测为正例。
但是分类器基于第一个决策规则进行决策。因此需要对其观测值进行调整,使其基于第一个决策规则,但实际上是在执行第二个决策规则。只需令
1−y′y′=1−yy⋅m+m−
这就是类别不平衡学习的一个基本策略——再缩放(rescaling, 亦称再平衡 rebalance)。
然而,「训练集是真实样本总体的无偏采样」这个假设往往并不成立,即未必能有效地基于训练集观测几率来推断真实几率。
现有技术大体上有三类做法:
- 欠采样(undersampling):去除一些反例使得正、反例数目接近。
- 过采样(oversampling):增加一些正例使得正、反例数目接近。
- 阈值移动(threshold-moving):直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将式 (5) 嵌入到其决策过程中。
欠采样法的时间开销通常远小于过采样法,因为前者丢弃了很多反例,使得分类器训练集远小于初始训练集,而过采样法增加了很多正例,其训练集大于初始训练集。
过采样法不能简单地对初始正例样本进行重复采样,否则会招致严重的过拟合;一方面,欠采样法若随机丢弃反例,可能丢失一些重要信息。
过采样法的代表性算法 SMOTE 是通过对训练集里的正例进行插值来产生额外的正例;欠采样法的代表性算法 EasyEnsemble 则是利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息。
「再缩放」也是代价敏感学习(cost-sensitive learning)的基础。在代价敏感学习中将式 (5) 中的 m+m− 用 cost−cost+ 代替即可,其中 cost+,cost− 分别表示将正、反例错分的代价。