分治
The Divide-and-Conquer Approach
The Divide-and-Conquer Approach(分治策略)
- Divide the given problem into a number of subproblems that are smaller instances of the same problem.
- Conquer the subproblems by solving them recursively.
- Or, use brute-force if a subproblem is small enough.
- Combine the solutions for the subproblems to obtain the solution for the original problem.
Correctness
Use (strong) mathematical induction, proceeding by induction on the "size" of the inputs.
- Induction basis: prove the algorithm can correctly solve small problem instances.
- Induction hypothesis: the algorithm can correctly solve any problem instance of size at most, says .
- Inductive step: assuming induction hypothesis, prove the algorithm can correctly solve problem instance of size .
Partial or Total Correctness? Termination and partial correctness can be encapsulated!
本课程基本不考虑终止性。
Merge Sort

Time complexity
For subroutine Merge, the three while processes involves scanning all the elements in and .
- The
ifprocesses has fewer comparisons thanwhileprocesses. - Therefore, the time complexity of subroutine
Mergeis , where is the sum of elements of and .
For the main procedure MergeSort:
- Let be the runtime of
MergeSOrtof instance of size . - Clearly, for some constant .
- For larger , .
A recurrence equation:
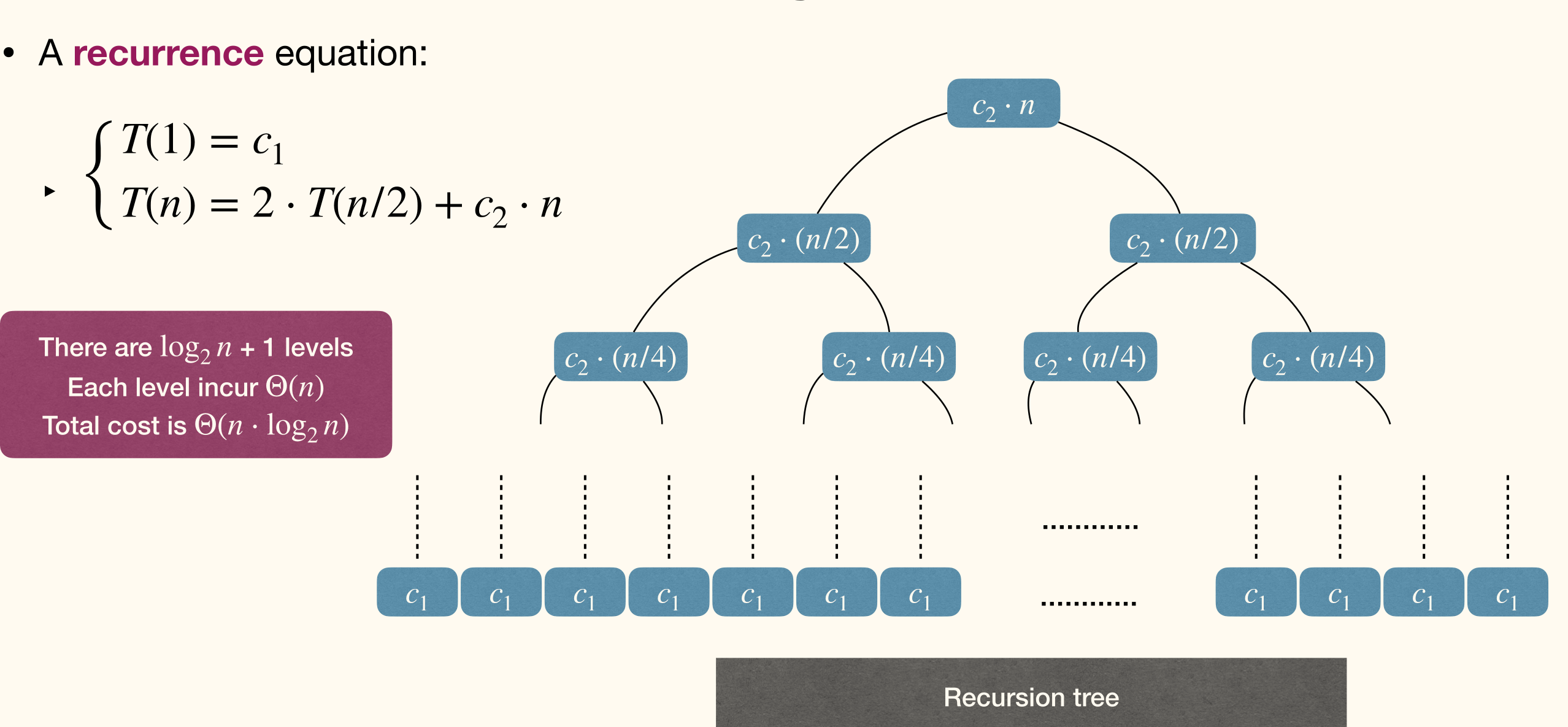
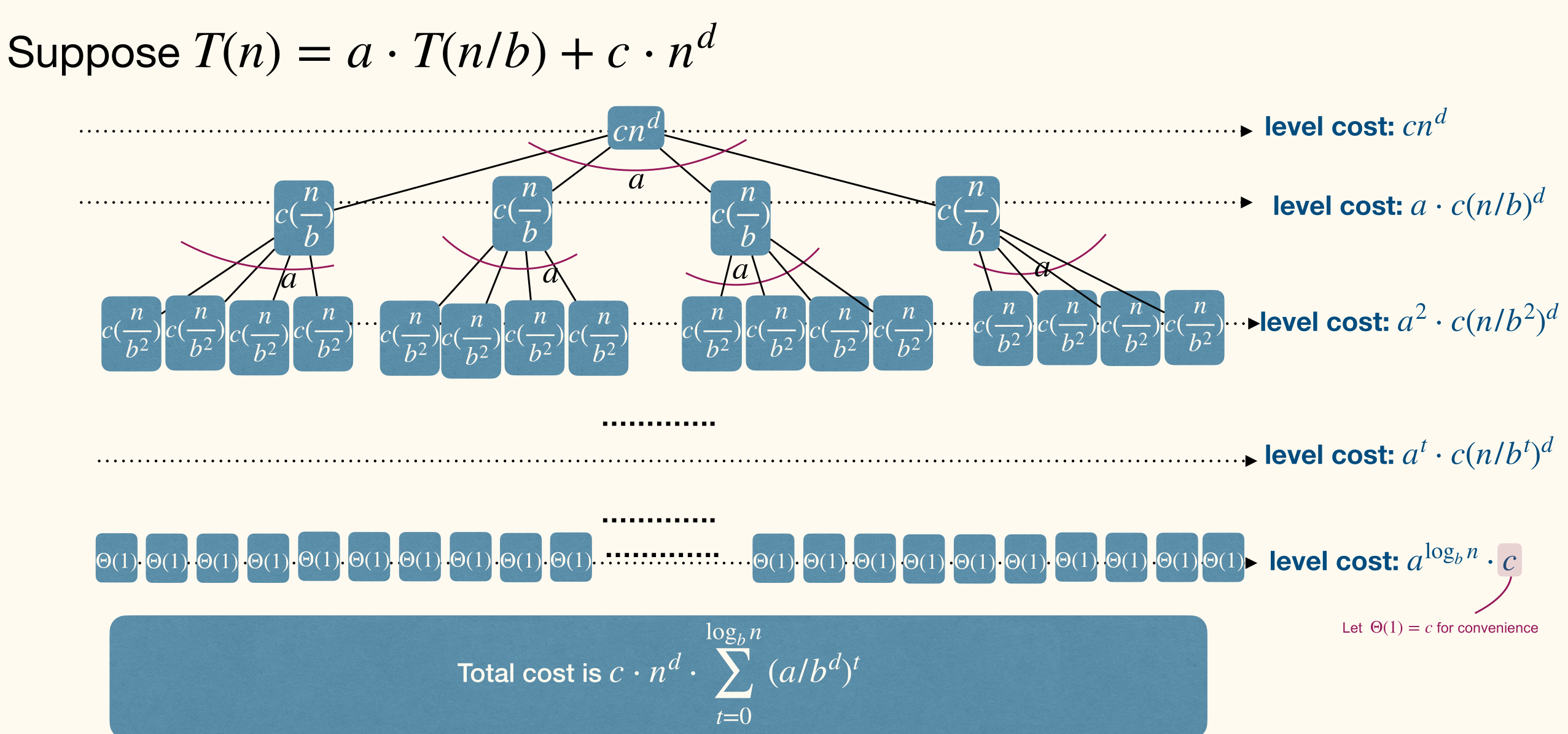
There are levels, each level incur . Total cost is .
Iterative
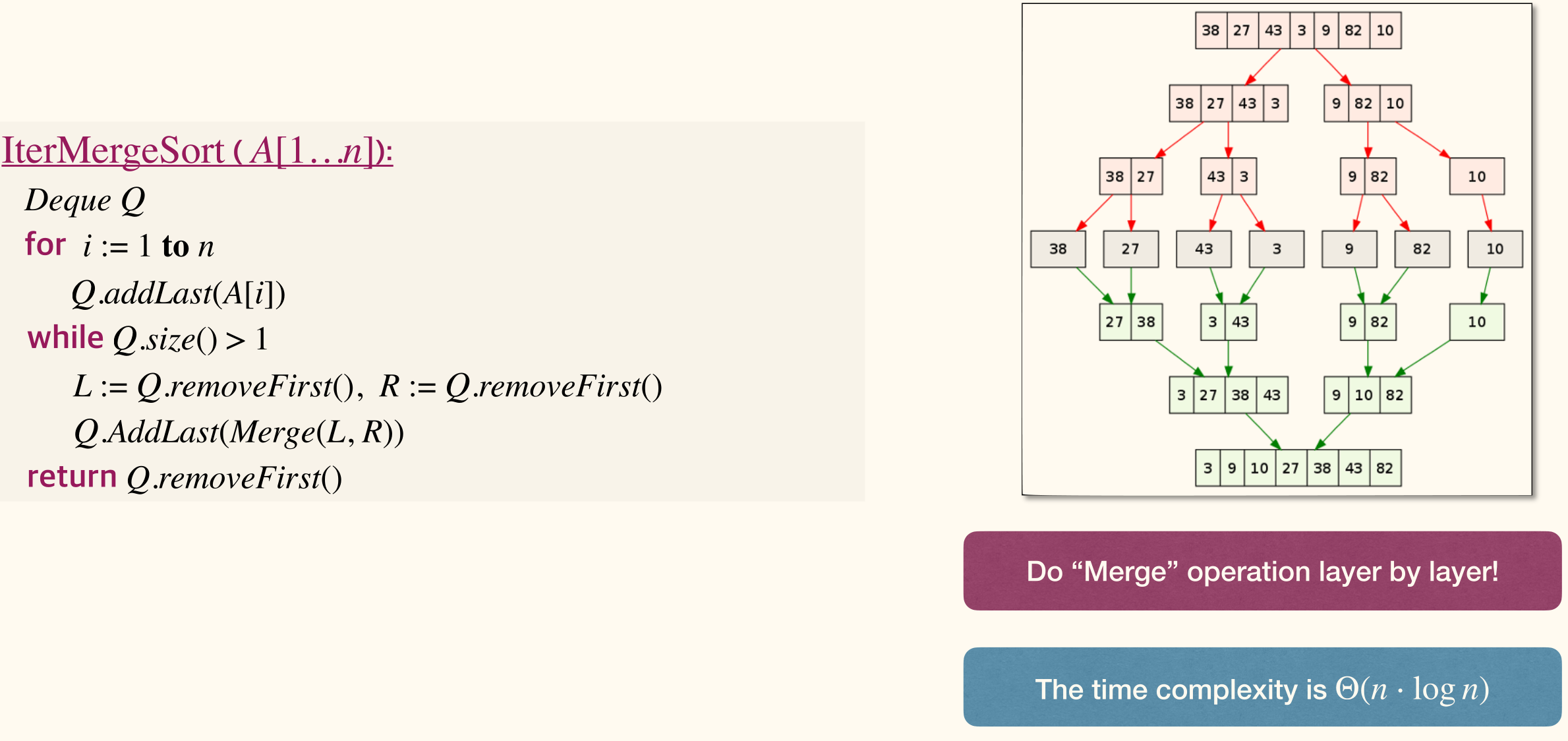
The time complexity is .
Matrix Multiplication
Suppose we want to multiply two matrices . The most straightforward method needs time.
The recurrence equation is . The time complexity is still (There're layers and each layer has subproblems).
Strassen's algorithm
where
Recurrence: .
Time complexity of Strassen's algorithm
We use the guess and verify method.
- Guess the form of the solution;
- Use induction to find proper constants and prove the solution works
.
Let .
- Induction basis
- as long as .
- Inductive step
- .
- However there is a problem, .
As a result, we should subtract some lower order term from our guess! Cos Subtraction gives us stronger induction hypothesis to work with.
Guess .
- Induction basis
- as long as .
- Inductive step
- as long as .
The recursion-tree method
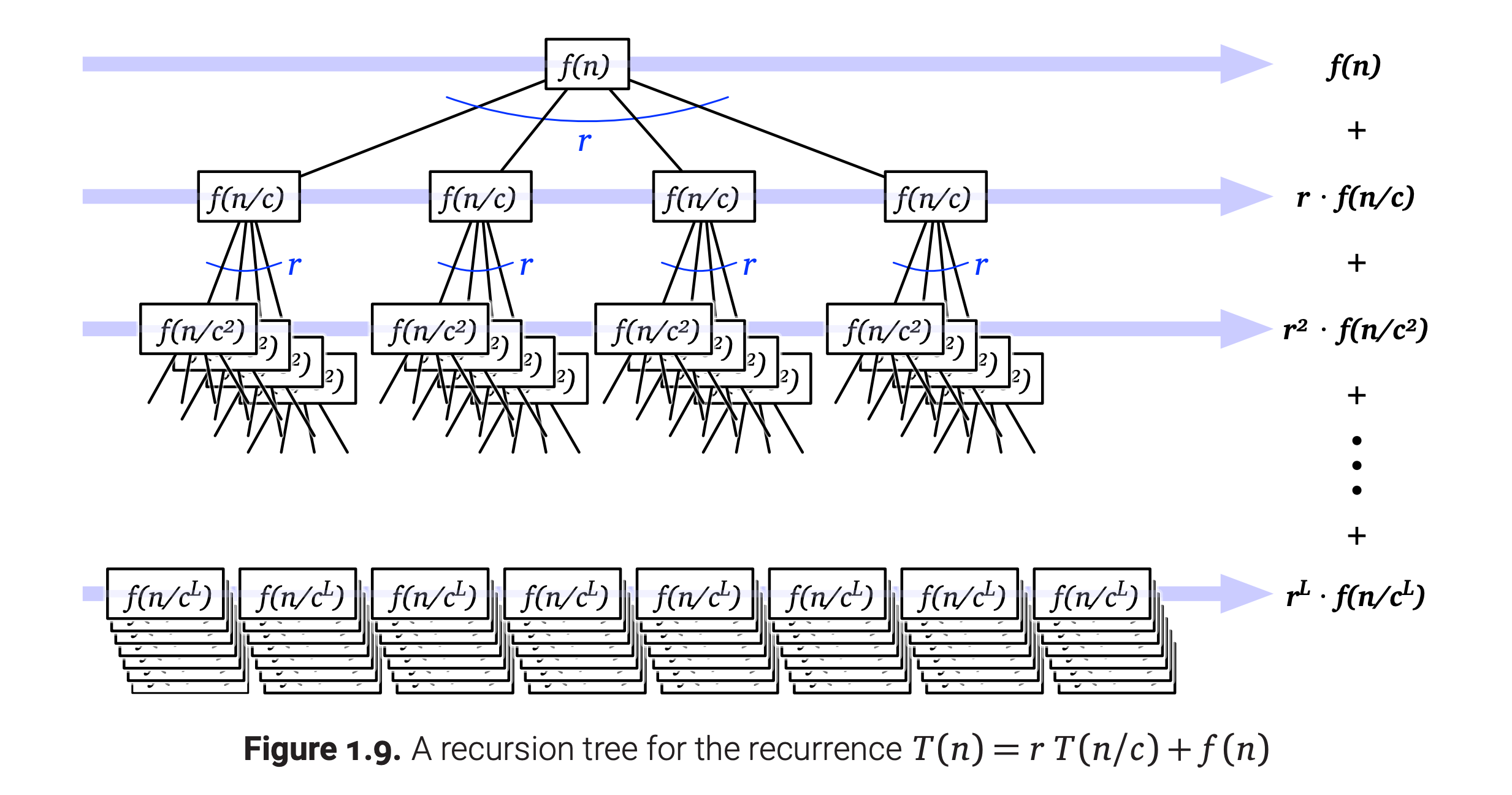
A recursion tree is a rooted tree with one node for each recursive subproblem.
The value of each node is the time spent on that subproblem excluding recursive calls.
The sum of all values is the runtime of the algorithm.
Combine recursion tree and substitution
Unbalanced, different root-to-leaf having different lengths.
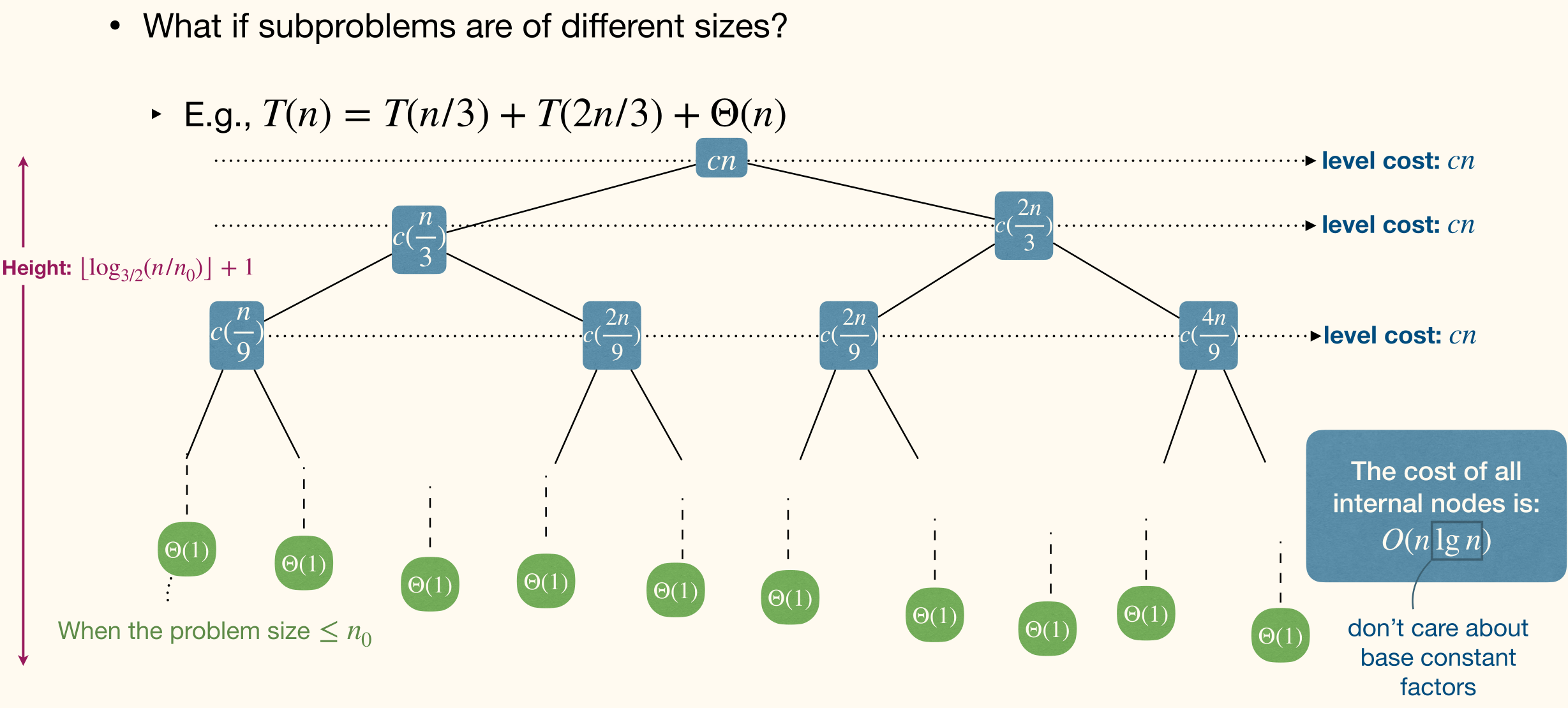
Since the height (max lengths from root to leaf) , then the size of leaves will be smaller than .
Leads to the cost of leaves to be .
, it's not tight!
To get a more accurate number of leaves. Guess the leaves are also .
Let be the number of leaves in recursion tree for .
- Inductive hypothesis
- for all values less than .
- Base case
- which is very easy to be satisfied by choosing proper .
- Inductive step
- .
So the cost of all leaves is . Time complexity is .
Master Method
Simple version of Master Theorem:
Master theorem (主定理)
Let , be constants (independent of ), and be defined on the non-negative integers by the recurrence[1]
Then has the following asymptotic bounds:
The meanings of :
- : number of subproblems
- : factor by which input size shrinks
- : need to do work to create all the subproblems and combine their solutions
Application
- Karatsuba integer multiplication
- leading to
- MergeSort
- leading to
- Extra example
- leading to
Proof
第二层开始的蓝色圆角矩形中的 漏写了上标 ,即应当是 。
Total cost is .
-
-
-
-
Branching causes the number of problems to explode.
- The most work is at the bottom of the tree.
-
The problems lower in the tree are smaller.
- The most work is at the top of the tree.
General Master Theorem
General Master Theorem
Let be constants, be a function, and be defined on the non-negative integers by the recurrence
Then has the following asymptotic bounds:
- If for some constant , then .
- If , then .
- If for some constant , and if for some constant and all sufficiently large , then .
The Master Theorem does not cover all cases!
Here's something to be noticed, that's the meaning of . is not mentioned in case 1, cos for all , is always .
Ignoring Floors and Ceilings
The actual recurrence of MergeSort is .
How to get the real time complexity of this recurrence?
We can transform the recurrence into a more familiar form, by defining a new function in terms of the one we want to solve. This method is called Domain transformation.
First, let's overestimate the time bound, we have the following relation to eliminate the ceiling:
Define a new function , choosing the constant so that satisfies the simpler recurrence .
We just need to make and get to simplifies the recurrence.
. Then we have .
Similarly, we get the matching lower bound . Therefore, .
- Similar domain transformations can be used to remove floors, ceilings, and even lower order terms from any divide and conquer recurrence
- But now that we realize this, we don't need to bother grinding through the details ever again
Reduce and Conquer
- We might not need to consider all subproblems.
- In fact, sometimes only need to consider one subproblem.
- The "combine" step will also be easier, or simply trivial…
- It is also called decrease and conquer
The Search Problem
Worst-case runtime is .
Binary Search for a sorted array.
1 2 3 4 5 6 7 8 9 | left := 1, right := n while true middle := (left + right) / 2 if A[middle] = x return middle else if A[middle] < x left := middle + 1 else right := middle - 1 |
This is not completely true, cos it may not terminate. It doesn't take the case when is not in the array into consideration.
1 2 3 4 5 6 7 8 9 10 11 | BinarySearch(A, x): left := 1, right := n while left <= right middle := (left + right) / 2 if A[middle] = x return middle else if A[middle] < x left := middle + 1 else right := middle - 1 |
Peak finding
Global max takes more time: Sequential scan needs time and it's inevitable. Finding a peak costs much less time.
An element A[i] is a peak (local maximum) if it is no smaller than its adjacent elements.
Every non-empty (limited) array A has at least one peak.
- Find middle element.
- Compare middle element to its adjacent elements.
- Reduce the array to one of the two splits.
- There must exist a peak in the part containing the large neighbor.
- Recurse.
1 2 3 4 5 6 7 8 9 10 11 | PeakFinding(A): left := 1, right := n while left <= right # Current array is not empty. middle := (left + right) / 2 # Get the middle element. if middle > left and A[middle - 1] > A[middle] # If middle < left neighbor (if there is such neighbor), recurse into left part. right := middle - 1 else if middle < right and A[middle + 1] > A[middle] # Same as above. left := middle + 1 else # If middle is a peak, return it. return middle |
Time complexity is .
Peak finding in 2D
Every non-empty 2D array has at least one peak. Start from a node, follow an increasing path and eventually must reach a peak.
Algorithm 1
Compress each column into one element, resulting an 1D array.
- Use maximum of each column to represent that column.
- Run previous algorithm on the 1D array and return a peak.
Time complexity is .
Algorithm 2
- Scan the middle column and find the max element .
- If is a peak, then return it and we are done.
- Otherwise, left of right neighbor of is bigger than .
- Recurse into that part.

Correctness
- Max of middle column is a peak; or a peak exists in the part containing the large neighbor, and that peak is the max of its column.
- A peak (found by the algorithm) in the part containing the large neighbor is also a peak in the original matrix.
- The algorithm eventually returns a peak of some (sub)matrix.
The mistake occurs in . We still need to do a search to find the maximum value in the current column. Cos this is a 2D problem, requiring two variable to describe.
where is column number and is row number.
However, we use one variable in Matrix Multiplication problem because the matrix is reduced in proportion.
Algorithm 3
- Scan the cross and find max element .
- If is a peak, then return it and we are done.
- Otherwise, some neighbor of is bigger than .
- Recurse into that quadrant.

However this is wrong. False Claim: A peak (found by the algorithm) in the quadrant containing the large neighbor is also a peak in the original matrix.
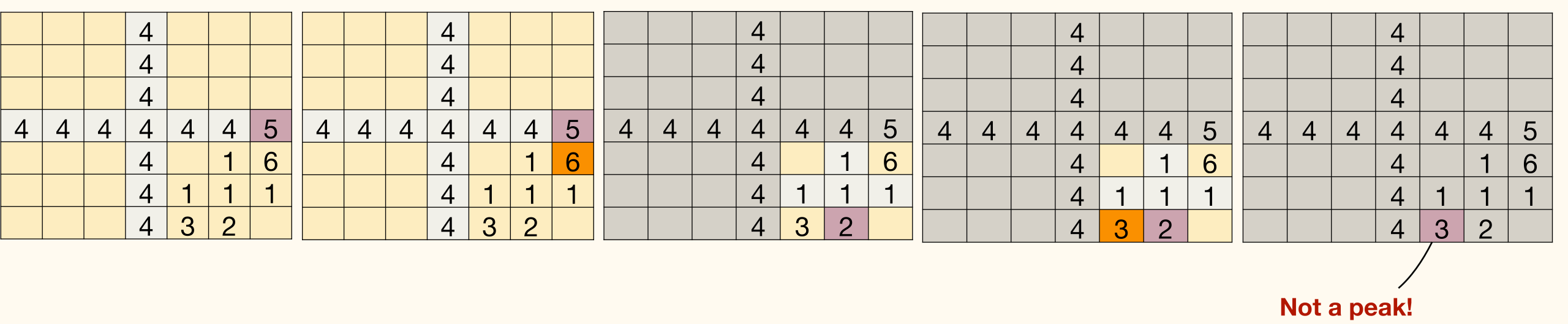
To fix it, scan the cross and boundary (window frame) instead of just scanning the cross.

is either or and the theorem is still true. ↩︎