排序
The Sorting Problem
The original idea is sorting numbers into ascending order.
We can actually sort a collection of any type of data, as long as a total order(全序) is defined for that type of data.
That is, for any distinct data items a and b, we compare them, i.e., we can determine: or , otherwise where "" is a binary relation.
We can also sort partially ordered items.
Characteristics
- In-place(原地): a sorting algorithm is in-place if extra space is needed beyond input.
- Stability(稳定): a sorting algorithm is stable if numbers with the same value appear in the output array in the same order as they do in the input array.
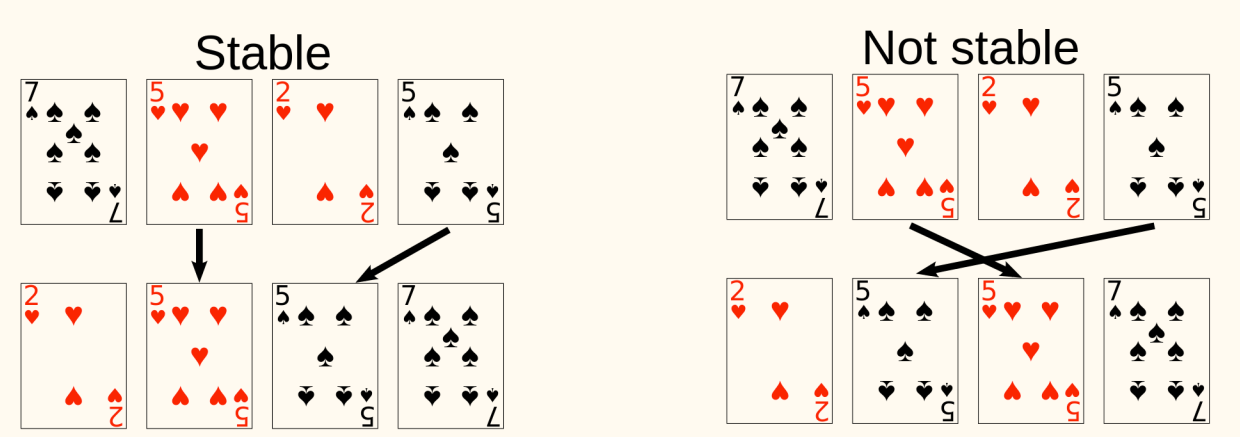
We have learned several sorting algorithms:
- Insertion Sort: gradually increase size of sorted part.
- time
- space
- In-place
- Stable
- Merge Sort: example of divide-and-conquer
- time
- space
- Not in-place
- Stable
- Heap Sort: Leverage the heap data structure
- time
- space
- In-place
- Not stable[1]
Elementary Sorting
Selection Sort
Basic idea
Pick out minimum element from input, then recursively sort remaining elements, and finally concatenate the minimum element with sorted remaining elements.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | SelectionSortRec(A): if |A| == 1 return A else min := Min(A) A' := A - {min} return Concatenate(min, SelectionSortRec(A')) SelectionSort(A): for i := 1 to A.length min_idx := i for j := i + 1 to A.length if A[j] < A[min_idx] min_idx := j Swap(A[i], A[min_idx]) |
Time complexity: .
Space complexity: extra space, thus in-space.
It is not stable. Swap operation can mess up relative order.
Consider a counterexample for stability [2a, 2b, 1]. It's sorted after the first swap, becoming [1, 2b, 2a].
It's similar to HeapSort. Let A get organized as a heap, then it leads to the faster algorithm. Therefore, the choice of data structure affects the performance of algorithms.
Bubble Sort
Basic idea
Repeatedly step through the array, compare adjacent pairs and swaps them if they are in the wrong order. Thus, larger elements "bubble" to the "top".
1 2 3 4 5 | BubbleSort(A): for i := A.length down to 2 for j := 1 to i - 1 if A[j] > A[j + 1] Swap(A[j], A[j + 1]) |
Time complexity: .
Space complexity: extra space, thus in-space.
It is stable. Adjacent elements are swapped only if they are in the wrong order.
When we never swap data items in one iteration, then we are done, the array is sorted.
1 2 3 4 5 6 7 8 9 10 | BubbleSortImproved(A): n := A.length repeat swapped := false for i := 1 to n - 1 if A[i] > A[i + 1] Swap(A[i], A[i + 1]) swapped := true n := n - 1 until swapped == false |
When the input is mostly sorted, this variant performs much better. Particularly, when the input is sorted, this variant has runtime.
Nonetheless, the worst case performance is still , e.g., when input is reversely sorted.
We can be more aggressive when reducing after each iteration: in A[1...n], items after the last swap are all in correct sorted position.
1 2 3 4 5 6 7 8 9 10 | BubbleSortImprovedFurther(A): n := A.length repeat lastSwapIdx := -1 for i := 1 to n - 1 if A[i] > A[i + 1] Swap(A[i], A[i + 1]) lastSwapIdx := i + 1 n := lastSwapIdx - 1 until n <= 1 |
Comparison of simple sorting algorithms
- Insertion
- swaps and comparisons in worst case.
- swaps and comparisons in average case.
- Selection
- swaps and comparisons in worst case.
- Bubble
- swaps and comparisons in worst case.
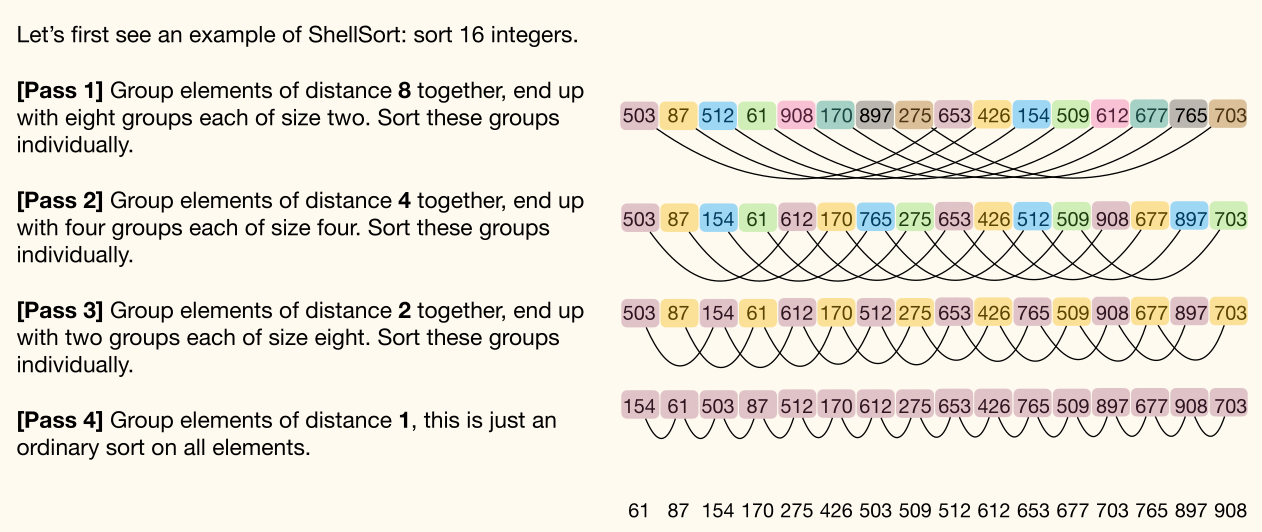
Shell Sort
- Insertion sorting is effective when:
- Input size is small
- The input array is nearly sorted (resulting in few comparisons and swaps)
- Insertion sorting is ineffective when:
- Elements must move far in array
So we will
- Allow elements to move large steps
- Bring elements close to final location
- Make array almost sorted
Idea
for some decreasing step size h, e.g. (), the sequence must end with (to ensure the correctness of sorting)
- For each step, sort the array so elements separated by exactly elements apart are in order


Quick Sort
Here's a unified view of many sorting algorithms: Divide problem into subproblems. Conquer subproblems recursively. Combine solutions of subproblems.
- Divide the input into size and size .
InsertionSort: easy to divide, combine needs efforts.MergeSort: divide needs efforts, easy to combine.
- Divide the input into two parts each of same size.
MergeSort: easy to divide, combine needs efforts.
- Divide the input into two parts of approximately same size.
QuickSort: divide needs efforts, easy to combine.
Basic idea
Given an array of items
- Choose one item in as the pivot.
- Use the pivot to partition the input into and , so that items in are and items in are .
- Recursively sort and .
- Output is concatenation of sorted , , and sorted .
1 2 3 4 | QuickSortAbs(A): x := GetPivot(A) B, C := Partition(A, x) return Concatenate(QuickSortAbs(B), x, QuickSortAbs(C)) |
Choosing the pivot
Ideally the pivot should partition the input into two parts of roughly the same size.
Median-of-three technique
Choose median of first, middle, and last element as pivot.
For every simple deterministic method of choosing pivot, we can construct corresponding "bad input".
For now just use the last item as the pivot.
The Partition Procedure
- Allocate array of size
- Sequentially go through
A[1...(n-1)], put small items at the left side of , and large items at the right side of . - Finally put the pivot in the (only) remaining position
The time complexity is and space complexity is . And it's unstable.
1 2 3 4 5 6 7 8 9 10 11 12 13 | Partition(A): x := A[n] l := 1 r := n for i := 1 to n - 1 if A[i] <= x B[l] := A[i] l := l + 1 else B[r] := A[i] r := r - 1 B[l] := x return <B, l> |
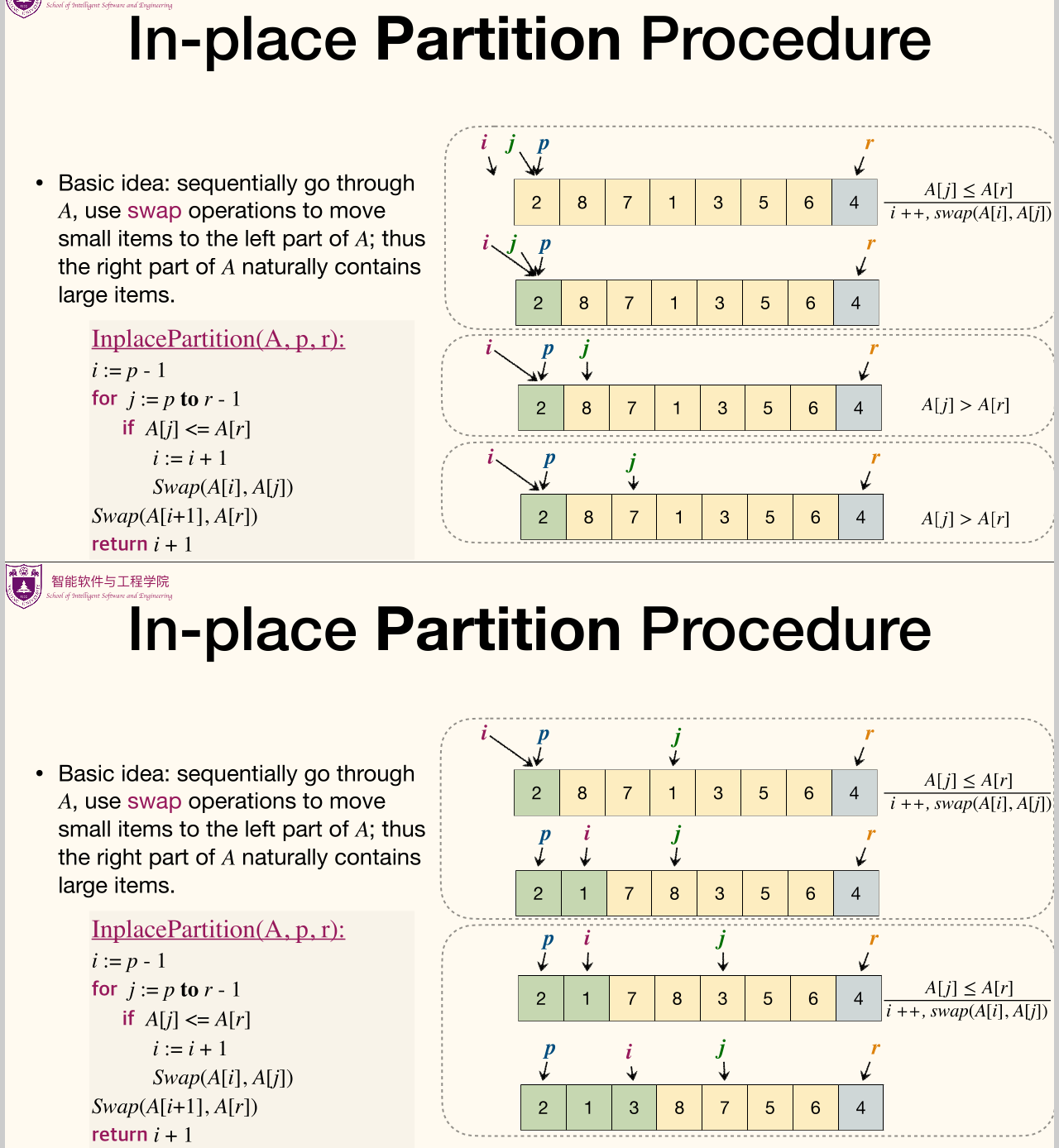
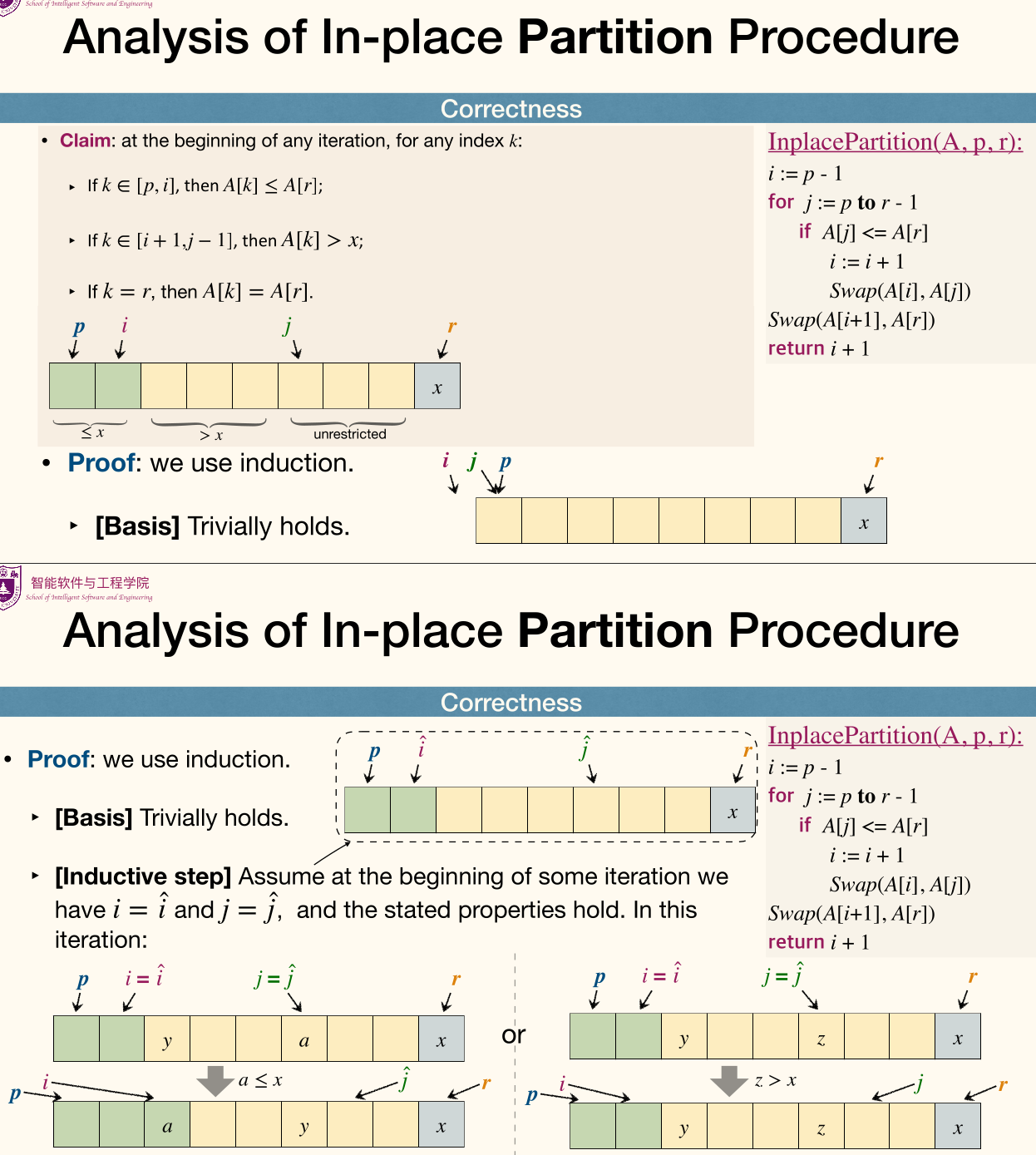
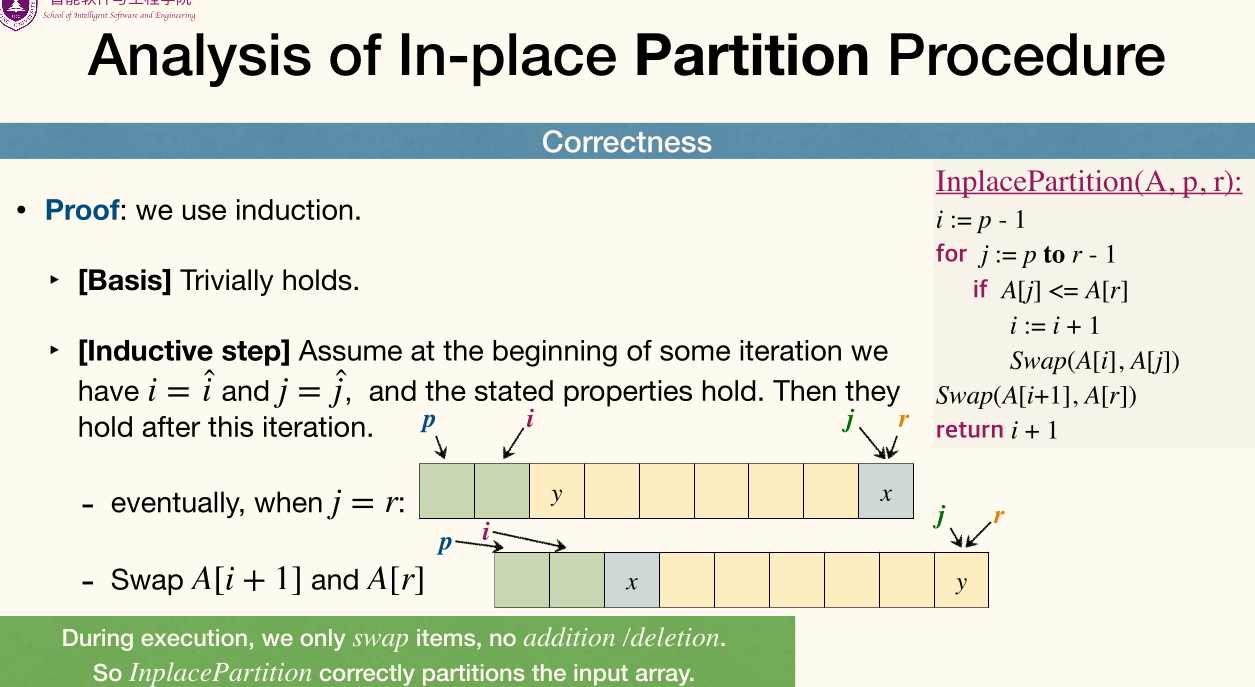
In-place Partition Procedure
Basic idea
Sequentially go through , use swap operations to move small items to the left part of ; thus the right part of naturally contains large items.
1 2 3 4 5 6 7 8 | InplacePartition(A, p, r): i := p - 1 for j := p to r - 1 if A[j] <= A[r] i := i + 1 Swap(A[i], A[j]) Swap(A[i + 1], A[r]) return i + 1 |
Here's part of in-place partition procedure:
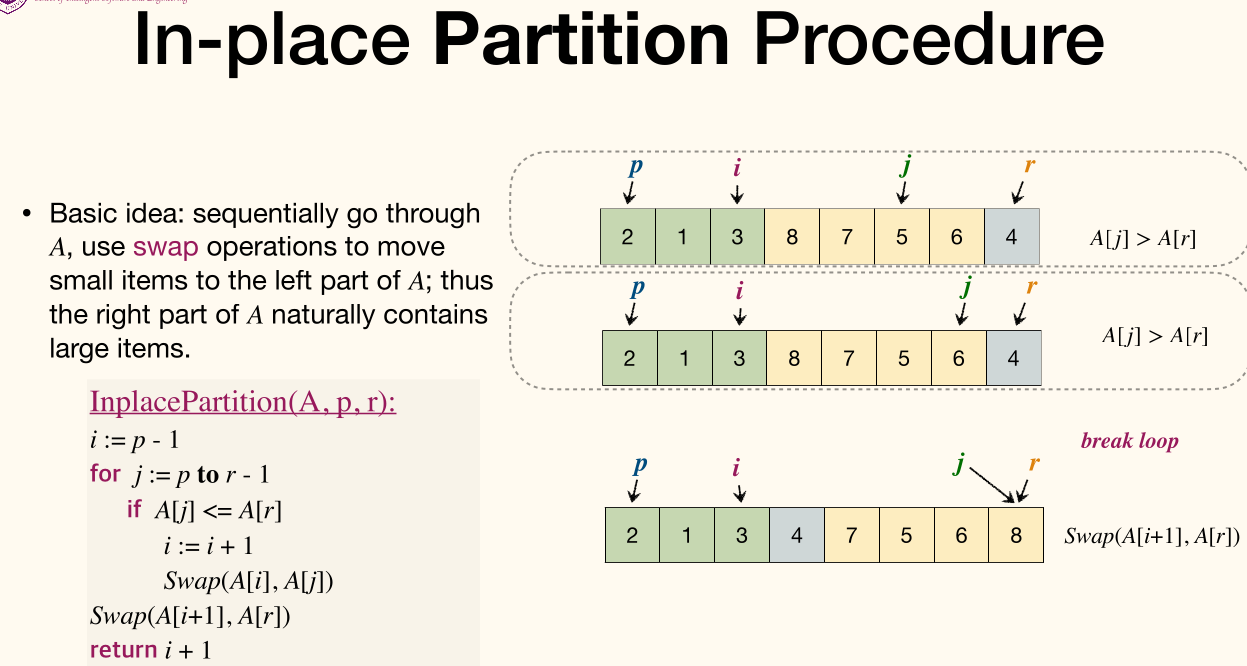
Analysis of In-place Partition Procedure:
Performance of InplacePartition:
- time (i.e. linear time)
- space
- unstable
Performance
Worst-case
Cost at each level is , where is number of pivots removed in lower level Partition.
If the partition is balanced, then there will be few levels, and will increase rapidly.
Recurrence for the worst-case runtime of QuickSort:
Guess and we now verify:
Thus .
Best-case
Balanced partition gives best case performance. implies .
Partition does not need to be perfectly balanced, we only need each split to be constant proportionality. where . It's still .
Average-case
Average-case analysis: the expected time of algorithm over all inputs of size : .
For QuickSort, particular values in the array are not important, instead, the relative ordering of the values is what matters (since QuickSort is comparison-based).
Therefore, it is important to focus on the permutation of input numbers. A readable assumption is that all permutations of the input numbers are equally likely.
To make the analysis simple, we also assume that the elements are distinct (duplicate values will be discussed later).
Randomized QuickSort
1 2 3 4 5 6 7 | RandQuickSort(A, p, r): if p < r i := Random(p, r) Swap(A[r], A[i]) q := InplacePartition(A, p, r) RandQuickSort(A, p, q - 1) RandQuickSort(A, q + 1, r) |
Cost of a call to RandQuickSort:
- Choose a pivot in time;
- Run
InplacePartition, whose cost is ; - Need to call
RandQuickSorttwice, the calling process (not the subroutines themselves) needs time.
Total cost of RandQuickSort:
- Time for choosing pivots is , since each node can be pivot at most once.
- All calls to
InplacePartitioncost . - Total time for calling
RandQuickSortis , since each time a pivot is chosen, two recursive calls are made.
Cost of RandQuickSort is where is a random variable denoting the number of comparisons happened in InplacePartition throughout entire execution.
Each of pair of items is compared at most once. Cos items only compare with pivots and each items can be the pivot at most once.
For ease of analysis, we let index the elements of the array A by their position in the sorted output, rather than their position in the input. For all elements, we refer them to be .
Let be the indicator random variable that is if and are compared in InplacePartition, and otherwise. Then we have
Let where , and be the first item in that is chosen as a pivot.
Then and are compared if and only if or . Cos items from stay in the same split until the pivot is chosen from .
Therefore
Substitute this back to the expectation formula, we get
Combined the fact that in the best case, randomized quick sort is , the expected running time is .
In fact, runtime of RandQuickSort is with high probability.
Stop recursion once the array is too small.
- Recursion has overhead,
QuickSortis slow on small arrays. - Usually using
InsertionSortfor small arrays, resulting in fewer swaps, comparisons or other operations on such small arrays.
Comparison
-
HeapSortis non-recursive, minimal auxiliary storage requirement (good for embedded system), but with poor locality of reference, the access of elements is not linear, resulting many caches being missed! It is the slowest among three algorithms. -
In most (not all) tests,
QuickSortturns out to be faster thanMergeSort. This is because althoughQuickSortperforms 39% more comparisons thanMergeSort,
but much less movement (copies) of array elements. -
MergeSortis a stable sorting, and can take advantage of partially pre-sorted input. Further,MergeSortis more efficient at handling slow-to-access sequential media.
External Sorting*
External sorting is required when the data being sorted do not fit into the main memory of a computing device and instead they must reside in the slower external memory, usually a disk drive.
Since I/O is rather expensive, the overall execution cost may be far dominated by the I/O, the target of algorithm design is to reduce I/Os.
External merge sort
External merge problem
- Input: 2 sorted lists with and pages
- Output: 1 merged sorted list with pages
We can efficiently (in terms of I/O) merge two lists using a memory buffer of size at least 3 by using only I/Os.
To find an element that is no larger than all elements in two lists, one only needs to compare minimum elements from each list Each time put the current minimum elements back to disk.
Deal with unsorted large files:
- Split into chunks small enough to sort in memory.
- each sorted sub-file is called a "run".
- Merge pairs (or groups) of runs using the external merge algorithm.
- Keep merging the resulting runs (each time = a "pass") until left with one sorted file.
The 2-way merge algorithm only uses 3 buffer pages
- What if we have more available memory?
- Use as much of the available memory as possible in every pass
- Reducing the number of passes reduces I/O
Suppose we have buffer pages available, we can increase length of initial runs.
IO cost becomes (starting with runs of length ) from (starting with runs of length ).
Then, we can perform a -way merge.
On each pass, we can merge groups of runs at a time, instead of merging pairs of runs.
IO cost becomes smaller, (performing -way merge).
Complexity of a problem
Upper bound and Lower bound
Consider a problem .
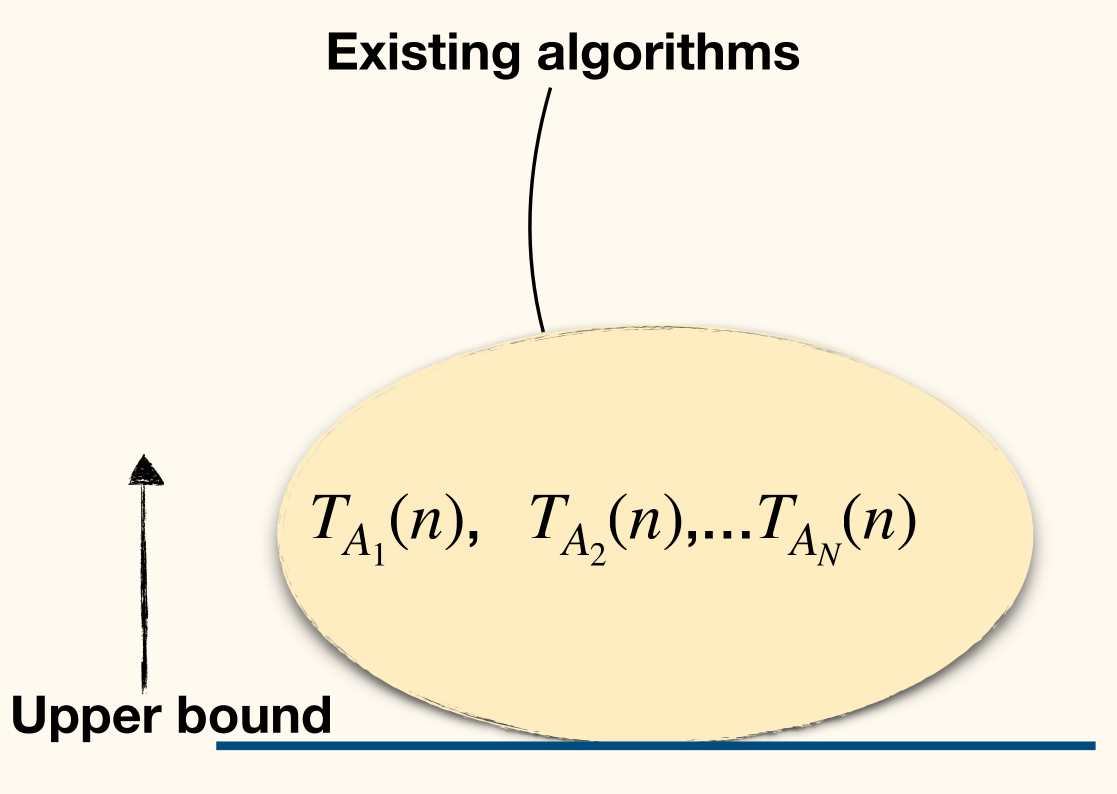
- Upper bound: how fast can we solve the problem?
- 需要多少代价就能解决这个问题?
- The (worst-case) runtime of an algorithm on input size is
- upper bounds the complexity of solving problem .
- Every valid algorithm gives an upper bound on the complexity of .
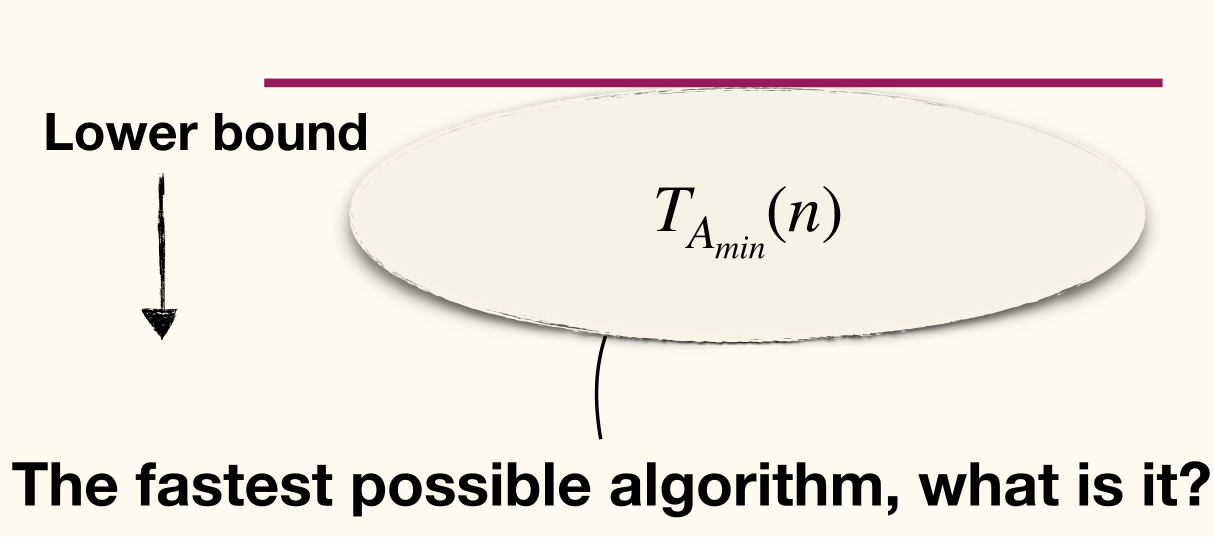
- Lower bound: how slow solving the problem has to be?
- 少于多少代价就一定解决不了这个问题?
- The worst-case complexity of is the worst-case runtime of the fastest algorithm that solves .
- , usually in the form of , lower bounds the complexity of solving problem .
- means any algorithm has to spend time to solve problem .
Larger lower bound is a stronger lower bound. (On the other hand, smaller upper bound is better.)
How to prove a lower bound?
- It is usually unpractical to examine all possible algorithms
- Instead, rely on structures/properties of the problem itself
Trivial Lower Bounds
Lower Bound based on output size
- Any algorithm that for inputs of size has a worst-case output size of needs to have a runtime of .
However, Lower Bound may not based on input size.
Consider output the first element of a -length array, the lower bound is while its input size is .
The problem with trivial techniques is that it often suggests a lower bound that it is too low.
Adversary Argument
The lower bound is .
The key is to design the worst input for an algorithm, and this algorithm must solve it.
We first have to specify precisely what kinds of algorithms we will consider by using key operations. And then devise an adversary strategy to construct a worst case input.
Key operation
A key operation is a step that is representative of the computation overall.
Properties:
- Can be constant-time operations
- Represent or dominate other operations
- Number of key operations should give a function of the input size
A model of computation might be designed around key operations (other computation are omitted)
Examples:
- Access one data item (e.g. query the -th value in an array)
- Compare two categorical items (outcome or )
- Compare two ordinal items (outcome or )
- Determine if two vertices in a graph are adjacent
Adversary Strategy
Consider a game similar to -card Monte:
- Suppose we have an array of bits and we want to determine if any of them is a .
Can we do better, without looking at every bit?
Basic idea:
- An all-powerful malicious adversary pretends to choose an input for the algorithm.
- When the algorithm wants checks a bit, the adversary sets that bit to whatever value will make the algorithm do the most work.
- If the algorithm does not check enough bits before terminating, then there will be several different inputs, each consistent with the bits already checked, and should result in different outputs.
- Whatever the algorithm outputs, the adversary can "reveal" an input that is has all the examined bits but contradicts the algorithm's output, and then claim that that was the input that he was using all along.
- One absolutely crucial feature of this argument is that the adversary makes absolutely no assumptions about the algorithm.
- The adversary strategy can’t depend on some predetermined order of examining bits, and it doesn't care about anything the algorithm might or might not do when it's not looking at bits.
- However, as long as there are at least two possible answers to the problem that are consistent with all answers given by the adversary, the algorithm cannot be done.
Comparison-based sorting
Setup for comparison sorting
- The input to the problem is elements in some initial order.
- The algorithm knows nothing about the elements.
- The algorithm may compare two elements at a cost of . Particularly, the algorithm can not inspect the values of input items.
- Moving/copying/swapping items is free.
- Assume that the input contains no duplicates.
There are different permutations that sorting algorithm must decide between.
The adversary maintains a list of all of the permutations that are consistent with the comparisons that the algorithm has made so far.
Initially contains all permutations.
The adversary's strategy for responding to the comparison is as follows:
- The adversary answers in such a way to keep as large as possible. That is, the worst input construction.
有个问题,这像是贪心的,此刻的最大一定能导向未来的最大吗?不过不影响后面的推导。
At least half of the permutations in remain, and the algorithm can not be done until , the number of comparisons required is at least .
Therefore, the lower bound of comparison-based sorting is .
Information-Theoretic Argument
The amount of the information
Consider the minimum number of distinct outputs that a sorting algorithm must be able to produce to be able to sort any possible input of length . Then must be at least .
In other words, the algorithm must be capable of outputting at least different permutations, or there would exist some input that it was not capable of sorting.
The algorithm is deterministic and its behavior is determined entirely by the results of the comparisons.
If a deterministic algorithm makes comparisons, at most different possible outputs can be produced. This is because one comparison can only has two different outcomes.
Therefore, , and is at least .
An alternative view: Decision Trees
Decision Tree(决策树) can be used to describe algorithms:
- A decision tree is a tree.
- Each internal node denotes a query the algorithm makes on input.
- Outgoing edges denote the possible answers to the query.
- Each leaf denotes an output.
One execution of the algorithm is a path from root to a leaf.
The worst-case time complexity is at least the length of the longest path from root to some leaf, i.e., the height of the tree.

The comparison-based sorting algorithm can be described by a binary comparison tree:
- Each internal node has two outgoing edges
- Each internal node denotes a query of the form
The tree must have leaves. The height of the tree must be , which is .
Information
Information content, or self-information or Shannon information of an event :
or equivalently .
It measures the informational value of an event depending on its surprising.
If a highly likely event occurs, it carries very little information. On the other hand, if a highly unlikely event occurs, it is much more informative.
Information entropy
Given a discrete random variable , which takes values in the alphabet and is distributed according to , the entropy(熵) of a random variable is the avenge level of information, surprise or uncertainty inherent to the variable's possible outcomes.
Information-theoretic lower bound
Sorting an array of size, the entropy of such a random permutation is bits.
Since a comparison can give only two results, the maximum amount of information it provides is bit.
Therefore, after comparisons, the remaining entropy of the permutation given the results of those comparisons, is at least bits on average.
To perform the sort, complete information is needed, which means the remaining entropy must be . It follows must be at least on average.
Non-comparison-based sorting
Bucket Sort (桶排序)
Bucket Sort
- Create empty lists, each list is a bucket.
- Scan through input. For each item, append it to the end of the corresponding list.
- Concatenate all lists.
This algorithm takes time.
It's not a comparison based algorithm. No comparison between items are made.
1 2 3 4 5 | BucketSort(A, d): <L1, L2, ..., Ld> := CreateBuckets(d) for i := 1 to A.length AssignToBucket(A[i]) CombinBuckets(L1, L2, ..., Ld) |
Total time complexity is :
- time to create buckets.
- time to assign items to buckets.
- time to combine buckets.
If the range of items' values is too large, allow each bucket to hold multiple values.
Allocate bucket each responsible for an interval of size .
Now we need to sort each bucket before coming them.

1 2 3 4 5 6 7 | BucketSort(A, k): <L1, L2, ..., Lk> := CreateBuckets(k) for i := 1 to A.length AssignToBucket(A[i]) for j := 1 to k SortWithinBucket(Lj) CombinBuckets(L1, L2, ..., Lk) |
Runtime is , plus cost for sorting within buckets.
If items are uniformly distributed and we use insertion sort, expected cost for sorting is .
Expected total runtime is , which is when we have buckets.
BucketSort can be stable.
Radix Sort (基数排序)
Assuming we want to sort decimal integers each of -digits.
Recursive bucket sort:
- Based on most significant bit, assign items to 10 buckets
- Sort recursively in each bucket
RadixSort is iterative, starting from least significant bit.
1 2 3 | RadixSort(A, d): for i := 1 to d use-a-STABLE-SORT-to-sort-A-on-digit-i |
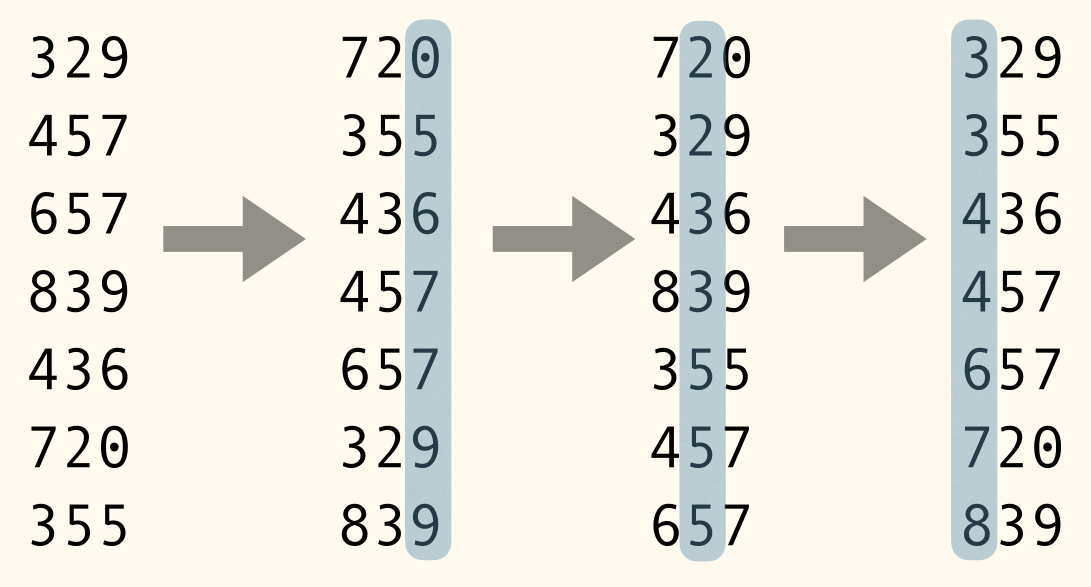
If we use BucketSort as the stable sorting method, since we only consider decimal numbers, we need buckets.
RadixSort can sort decimal -digits numbers in time.
Lower bound for sorting by querying value
Solving the "Sort integers" problem by querying values of input has a time complexity of .
Selection
Given a set of items, the -th order statistic (顺序统计量) of it is the -th smallest element of it.
The Selection Problem: given a set of distinct numbers and an integer , find the -th order statistic of .
Find MIN/MAX
Strategy
- Group items into pairs.
- The first item becomes a pair if is odd.
- For each pairs, find local MIN and MAX.
- Costing comparisons.
- Among local MIN, find global MIN. Similarly find global MAX.
- Costing at most comparisons.
Total number of comparisons is at most .
It's the best way we can do.
- An item has mark if it can be MAX, and has mark if it can be MIN.
- Initially each item has both and .
- An adversary answer queries like "compare with "
- The adversary can find input such that: at most comparisons each remove two marks
- If in pair , , then removes mark and removes mark. It removes two marks in total.
- Each other comparison removes at most one mark.
- However if in pair having , which means removes mark and removes mark. Then we compare with and get , we can only remove 's mark. It removes one mark at most.
- In total need to remove marks.
So at least comparisons needed, which can be .
General Selection Problem
Find -th smallest element
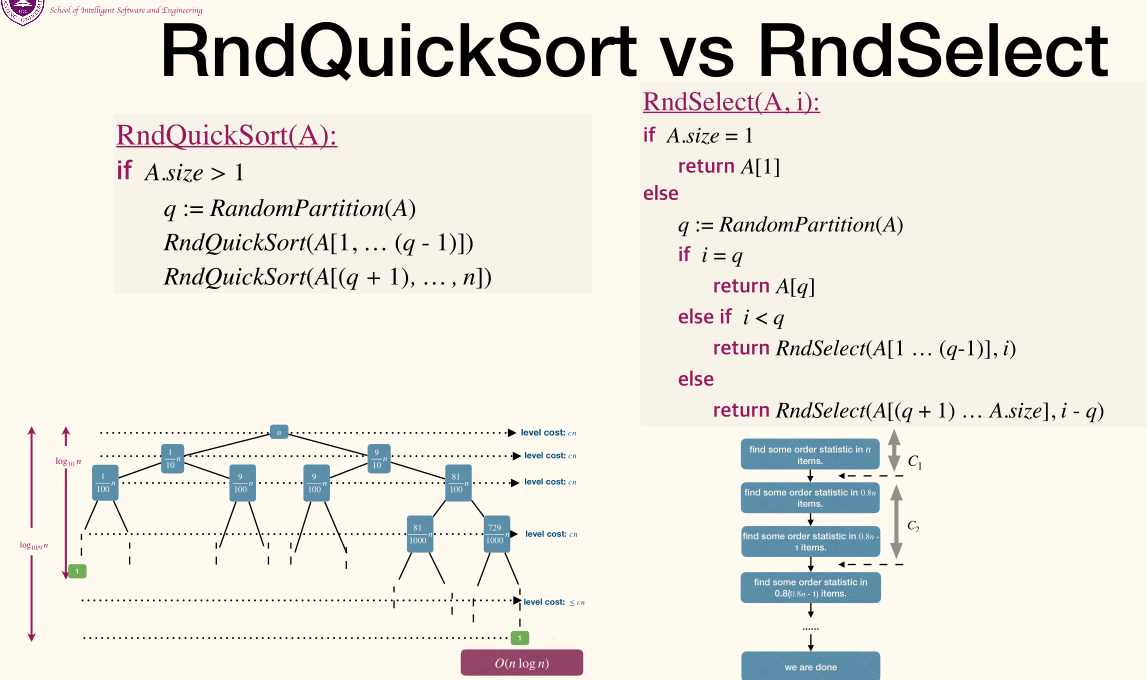
1 2 3 4 5 | RndQuickSort(A): if A.size > 1 q := RandomPartition(A) RndQuickSort(A[1...q-1]) RndQuickSort(A[q+1...n]) |
Cases:
- What if ?
A[q]is what we need.
- What if ?
- Find -th order statistic in
A[1...q-1]
- Find -th order statistic in
- What if ?
- Find -th order statistic in
A[q+1...n]
- Find -th order statistic in
Then we get Reduce-and-Conquer.
1 2 3 4 5 6 7 8 9 10 11 | RndSelect(A, i): if A.size == 1 return A[1] else q := RandomPartition(A) if i == q return A[q] else if i < q return RndSelect(A[1...q-1], i) else return RndSelect(A[q+1...n], i-q) |
Complexity
- Best case
- Choosing the answer as the pivot in the first call.
- Worst case
- Partition reduces array size by one each time.
- Average case
- Analysis will be delivered later.
Average performance of Randomized Selection
What's unlikely to happen is either get the exactly right pivot or reduces the size just by one.
Instead, what's likely to happen is: partition process reduces problem size by a constant factor.
Call a partition good if it reduces problem size to at most for some constant , says .
Let the random variable be the cost since the last good partition to the -th good partition.
Then we have and get at most good partitions can occur.
The times that we get the first good partition, as a random variable, follows Geometric Distribution.
As we all knows, its expectation has nothing to do but with its probability ().
As a result, The cost of not good partition can be seen as constant, above.
Then the total time cost
Median of medians
Can we guarantee worst-case runtime of ?
The reason that RndSelect could be slow is that RandomPartition might return an unbalanced partition.
We needs a partition procedure that guarantees to be balanced without using to much time ( time to be specific).
Procedure:
- Divide elements into groups, each containing elements, call these groups .
- time
- Find the medians of these groups, let be this set of medians.
- time
- Find the median of , call it .
- Use
QuickSelectrecursively
- Use
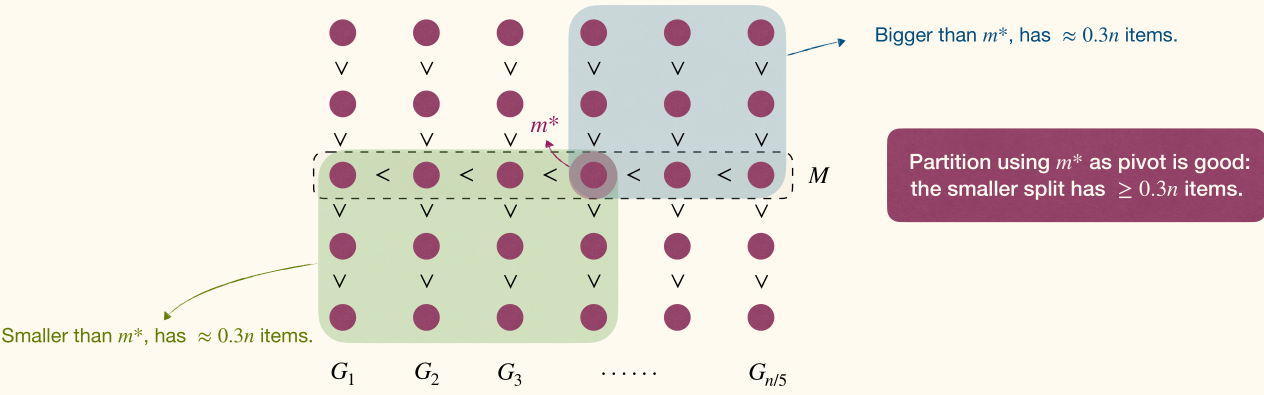
Obviously, is not the median of the original array, but it is guaranteed to be between the -th and -th percentile(百分位数) of the original array.
Then we can use as the pivot to partition the array.
1 2 3 4 5 6 7 8 | MedianOfMedian(A): if A.size == 1 return A[1] <G1, ..., Gn/5> := GreateGroups(A) for i := 1 to n/5 Sort(Gi) M := GetMediansFromSortedGroups(G1, ..., Gn/5) return QuickSelect(M, (n/5)/2) |
1 2 3 4 5 6 7 8 9 10 11 | QuickSelect(A, i): if A.size == 1 return A[1] m := MedianOfMedian(A) q := PartitionWithPivot(A, m) if i == q return A[q] else if i < q return QuickSelect(A[1...q-1], i) else return QuickSelect(A[q+1...n], i-q) |

QuickSelectuses O(n) time/comparisons.- Solving general selection needs at least comparisons.
- Since finding MIN/MAX needs at least comparisons.
- So the lower and upper bounds match asymptotically.
- But if we care about constants, needs (much) more efforts, which is not the topic of this course.
Consider
[2a, 2b, 1], it's already a max-heap. At first2ais extracted and placed in the end. Then2bis extracted and placed in the end but one index. At last we get[1, 2b, 2a]. ↩︎