树
Tree
本节也许可以参考《离散数学》——树。
Recursive definition
A tree(树) is either empty, or has a root(根) that connects to the roots of zero or more non-empty (sub)trees.
- Root of each subtree is called a child(子) of the root of the tree. And is the parent(父) of each subtree's root.
- Nodes with no children are called leaves(叶子).
- Nodes with same parent are siblings(兄弟).
- If a node is on the path from to , then is an ancestor(祖先) of , and is a descendant(后代) of .
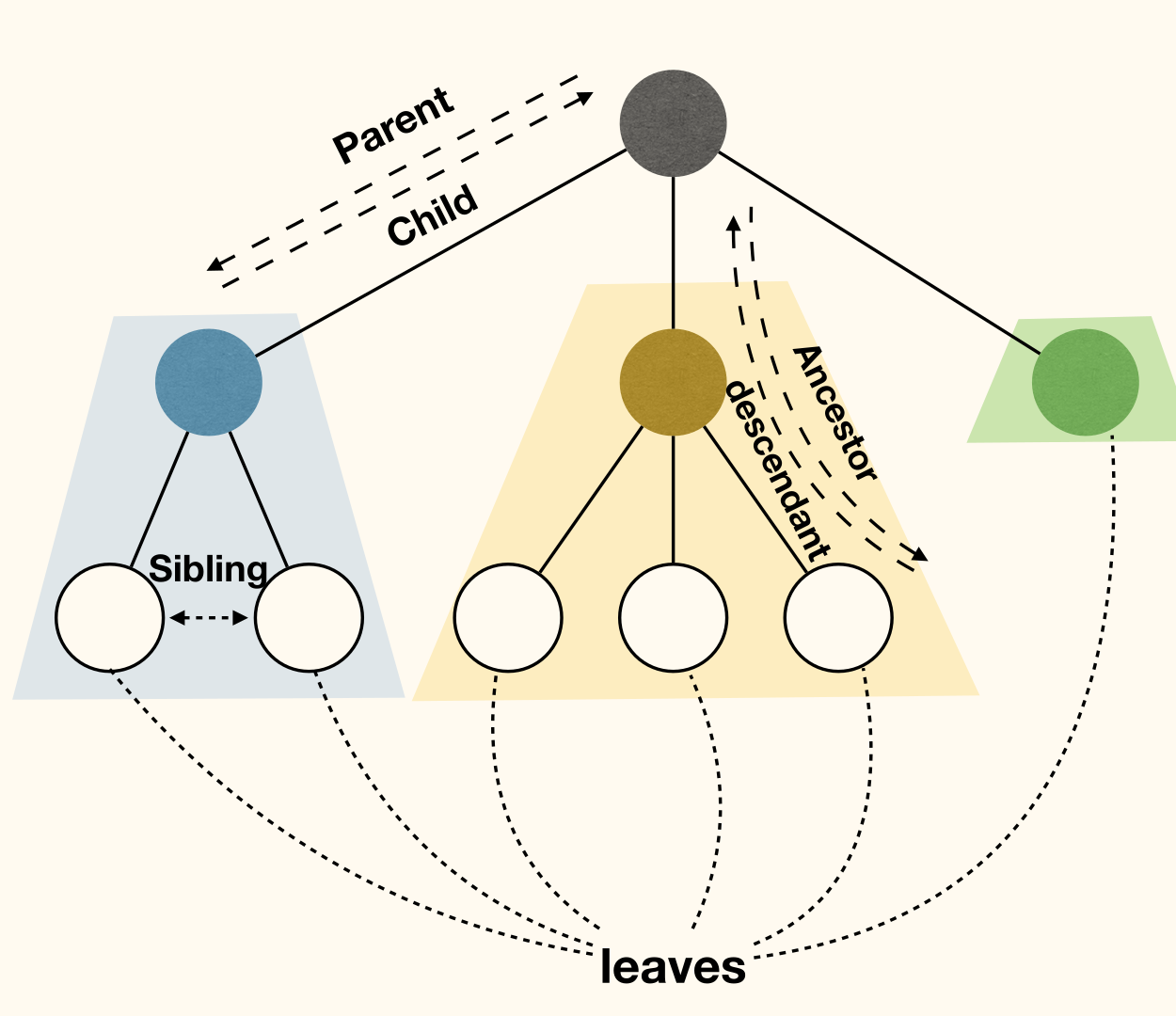
More terminology
- The depth(深度) of a node is the length of the path from to the root .
- The height(高度) of a node is the length of the longest path from to one of its descendants.
- Height of a leaf node is zero.
- Height of a non-leaf node is the maximum height of its children plus one.
Binary Trees
A binary tree(二叉树) is a tree where each node has at most two children. Often call these children as left child and right child.
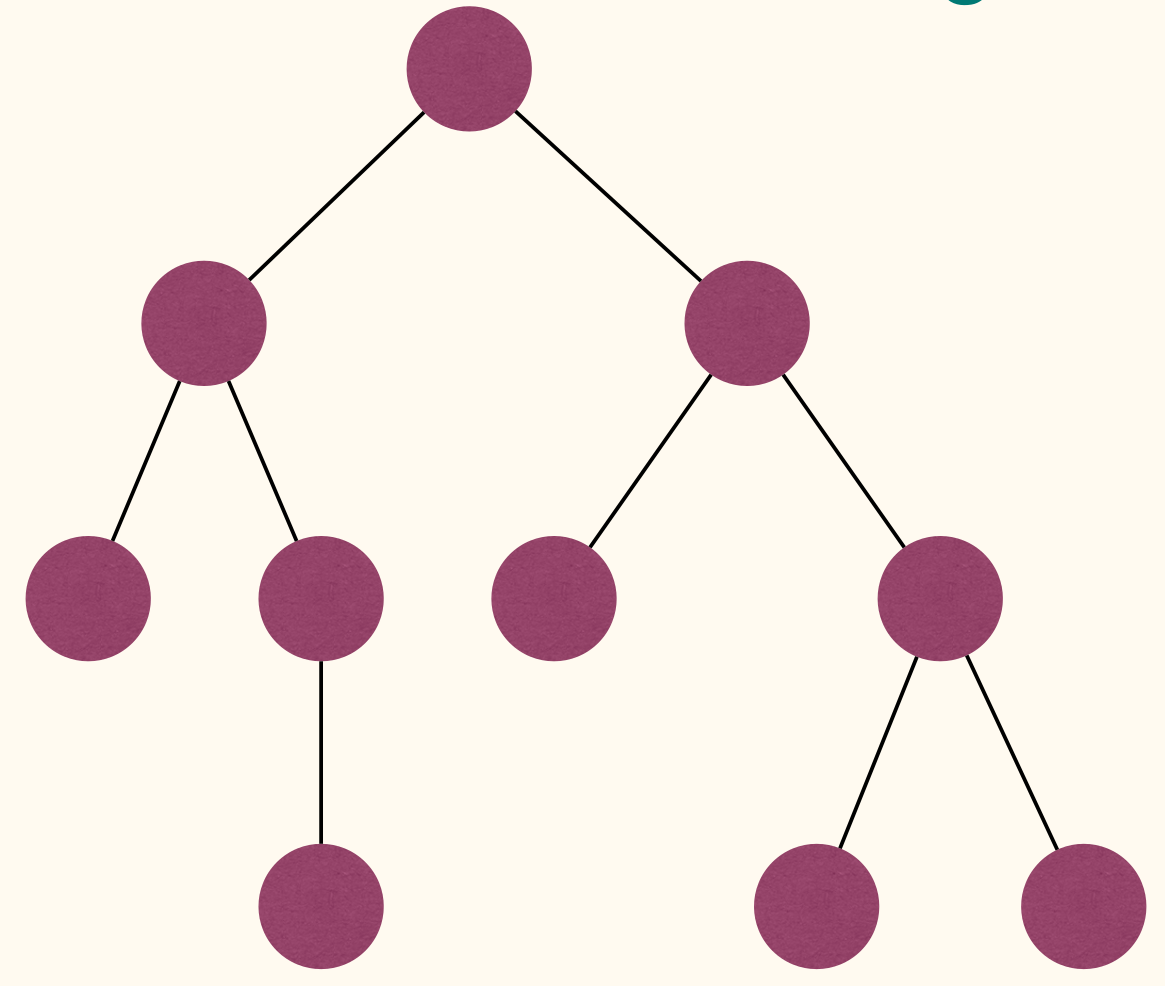
Full Binary Trees
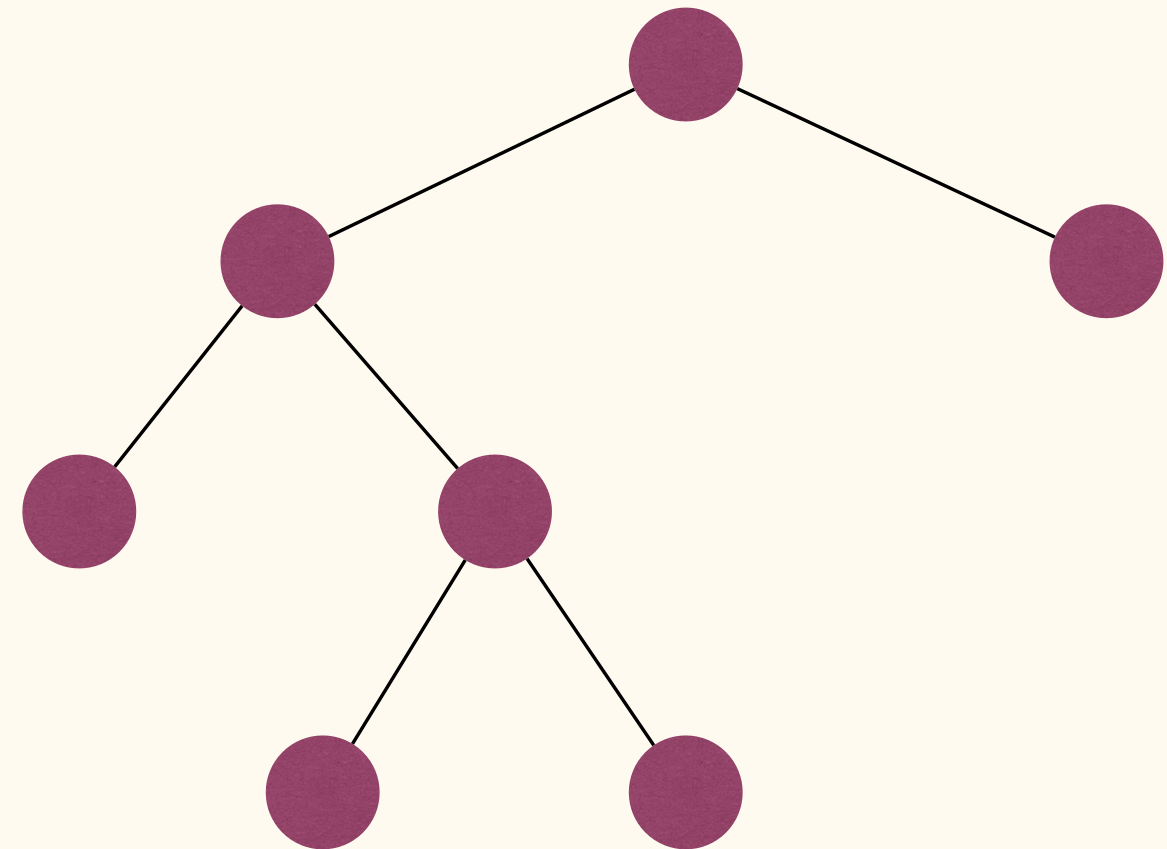
A full binary tree(满二叉树) is a binary tree where each node has either zero or two children.
A full binary tree is either a single node, or a tree where the two subtrees of the root are full binary trees.
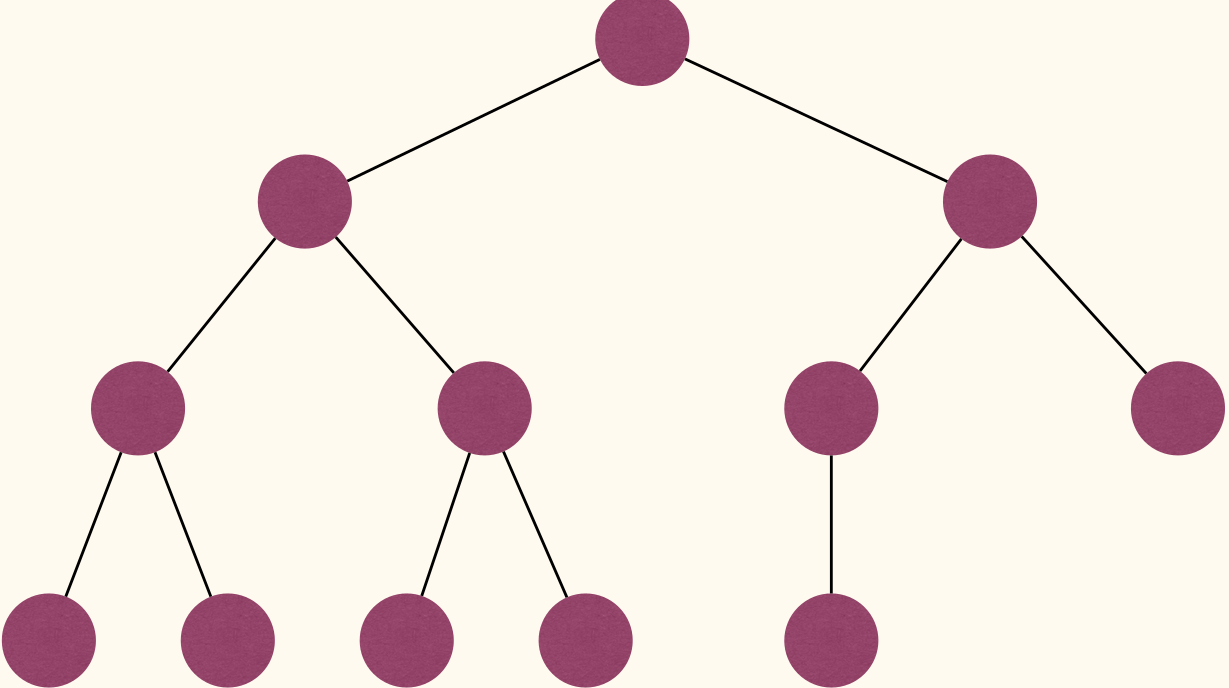
Complete Binary Trees
A complete binary tree(完全二叉树) is a binary tree where every level, except possibly the last, is completely filled, and all nodes are as far left as possible.
A complete binary tree can be efficiently represented using an array.
Perfect Binary Trees
A perfect binary tree(完美二叉树) is a binary tree where all non-leaf nodes have two children and all leaves are at the same level (have same depth).
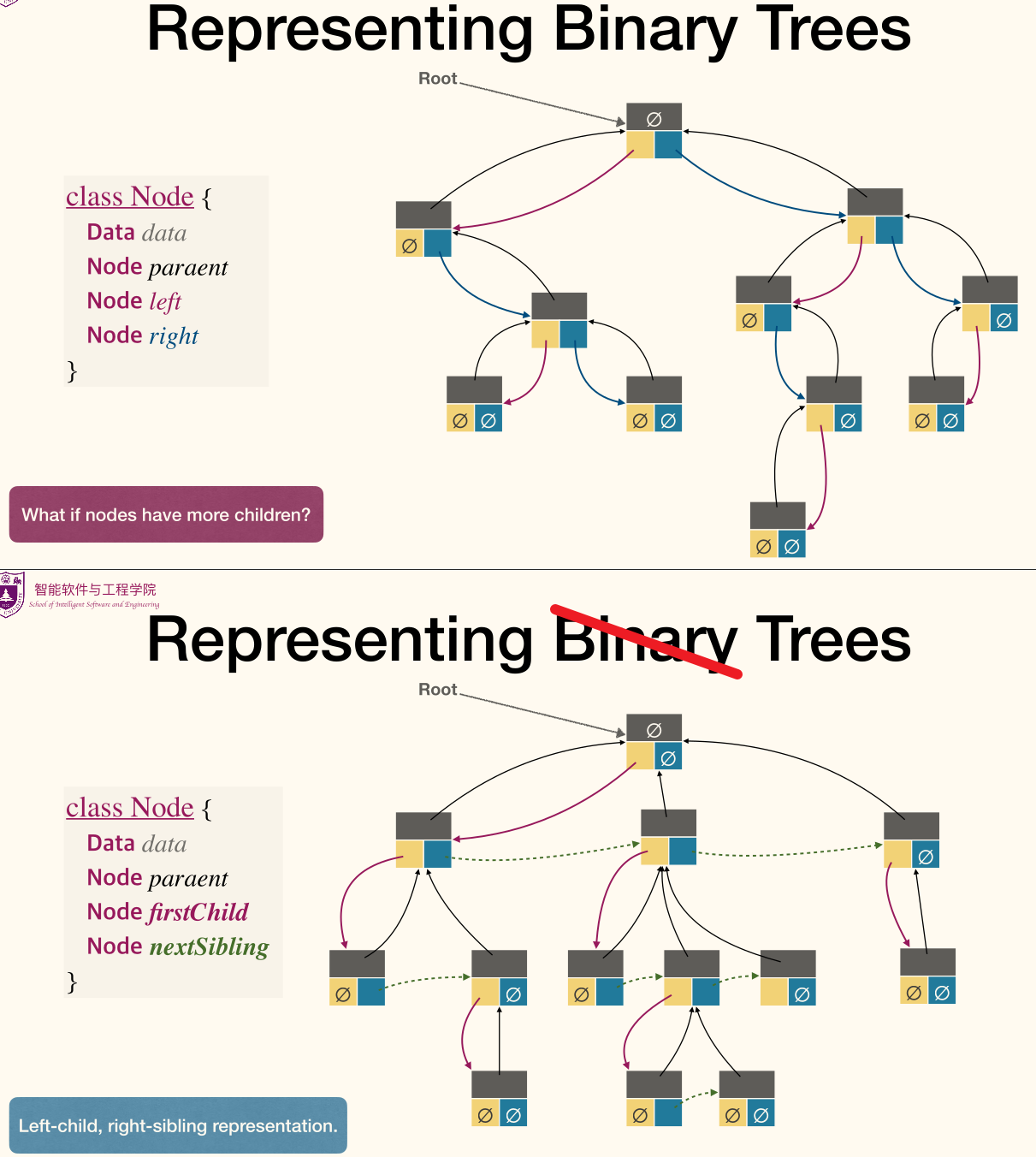
Representation
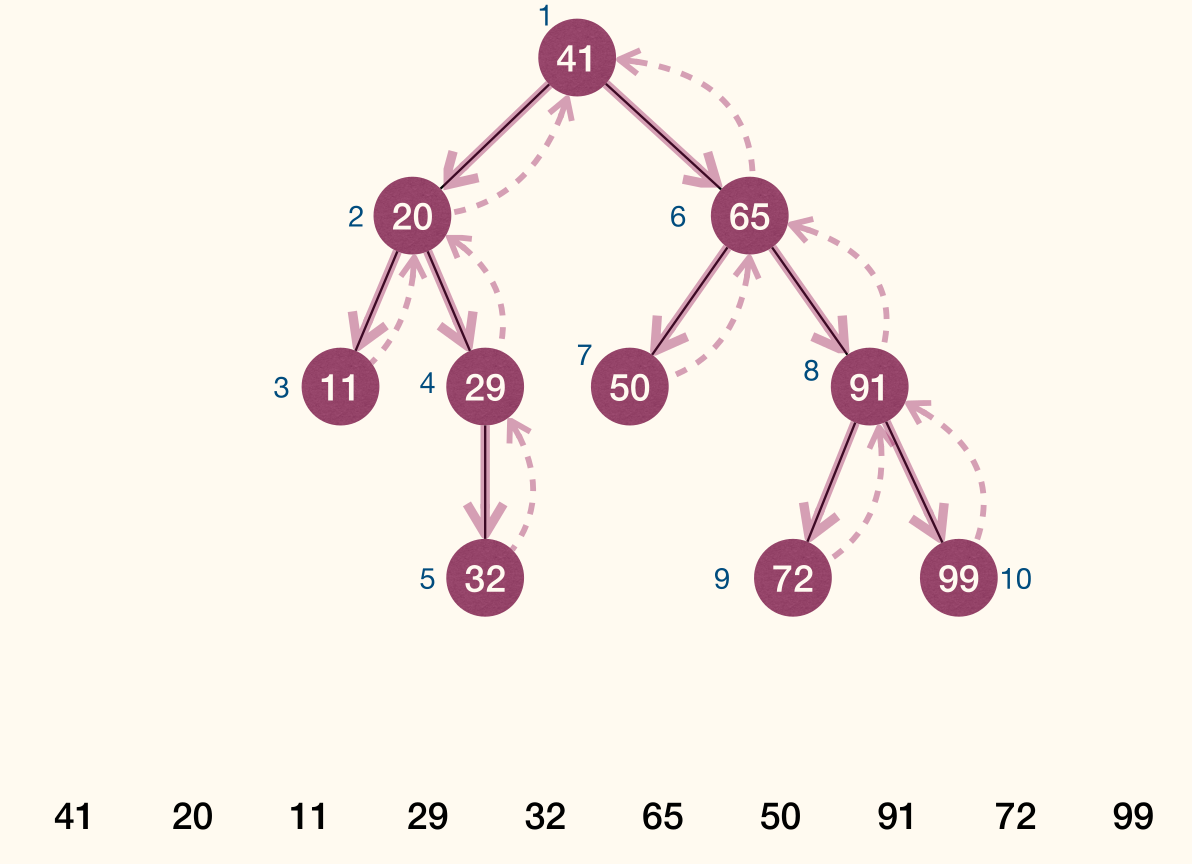
Traversal
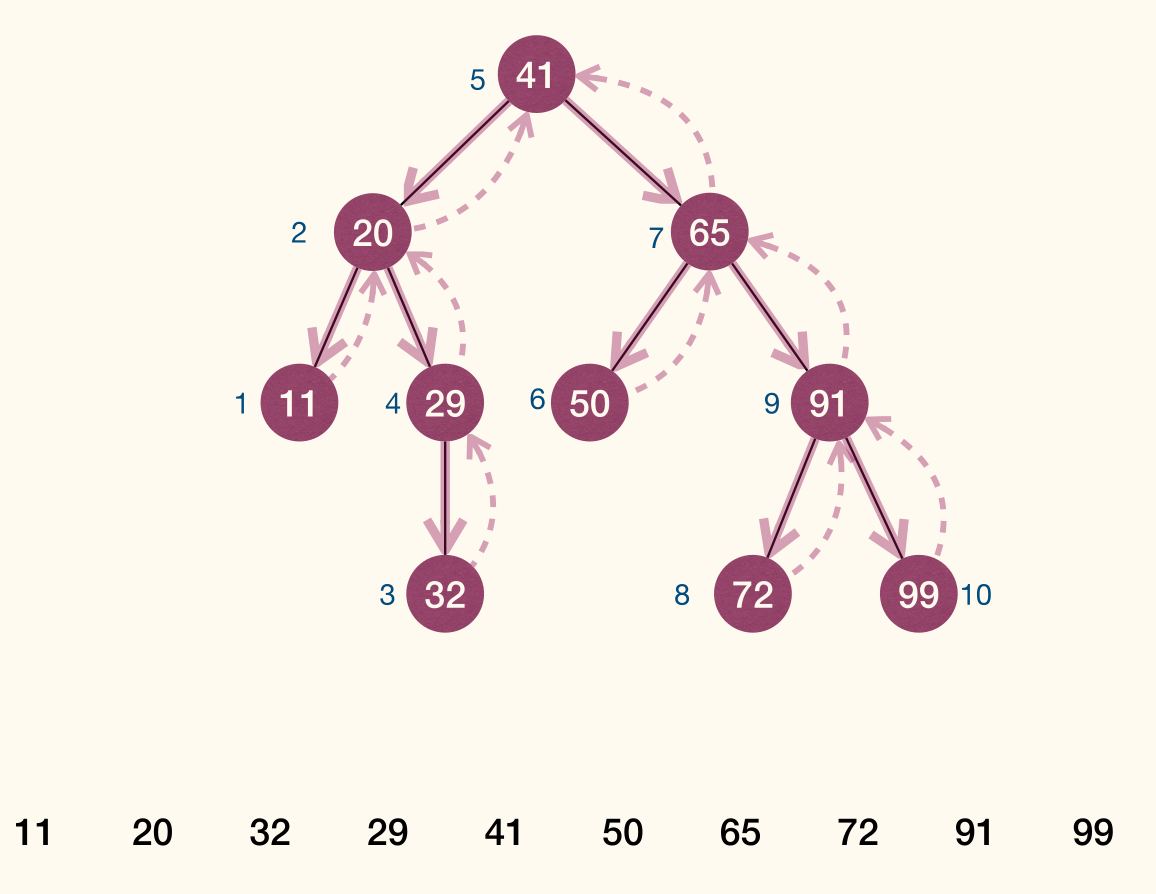
- Preorder traversal(先序遍历): given a tree with root , first visit , then visit subtrees rooted at 's children, using preorder traversal.
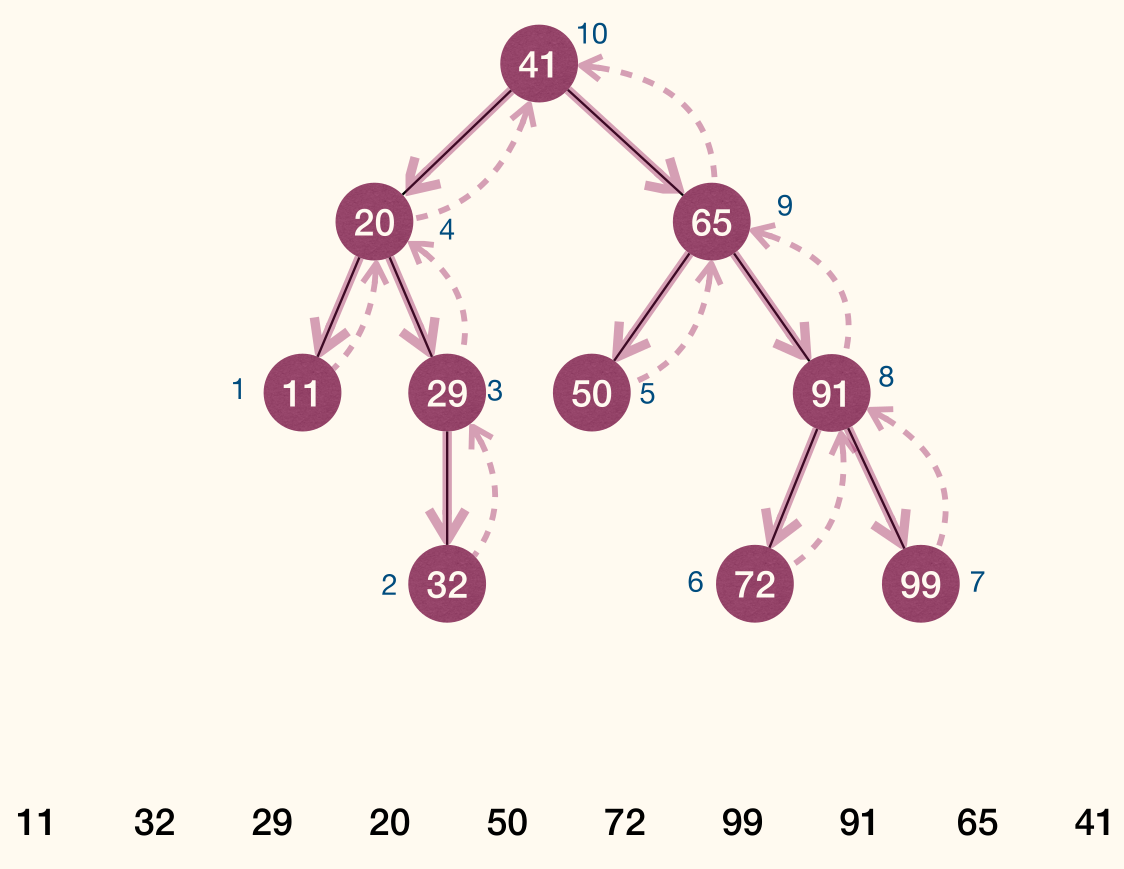
- Postorder traversal(后序遍历): given a tree with root , first visit subtrees rooted at 's children using postorder traversal, then visit .
- Inorder traversal(中序遍历): given a binary tree with root , first visit subtree rooted at
r.left, then visit , finally visit subtree rooted atr.right.
Preorder traversal
1 2 3 4 5 | PreorderTrav(r): if r != NULL Visit(r) for each child u of r PreorderTrav(u) |
Postorder traversal
1 2 3 4 5 | PostorderTrav(r): if r != NULL for each child u of r PostorderTrav(u) Visit(r) |
Inorder traversal
1 2 3 4 5 | InorderTrav(r): if r != NULL InorderTrav(r.left) Visit(r) InorderTrav(r.right) |
Complexity
Complexity
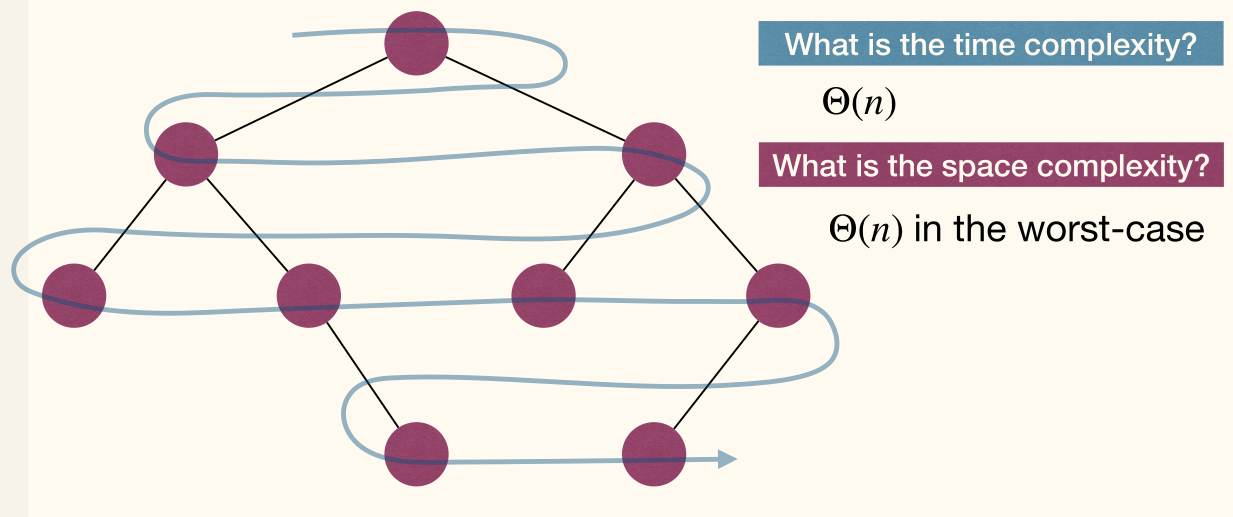
- Time Complexity: as processing each node takes .
- Space complexity: as worst-case call stack depth is .
Iterative
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | class Frame { Node node bool visited Frame(Node n, bool v) { node := n visited := v } } PreorderTravIter(r): Stack s s.push(Frame(r, false)) while !s.empty() f := s.pop() if f.node != NULL if f.visited Visit(f.node) else // Exchange this two lines to get postorder traversal for each child u of f.node s.push(Frame(u, false)) s.push(Frame(f.node, true)) InorderTravIter(r): Stack s s.push(Frame(r, false)) while !s.empty() f := s.pop() if f.node != NULL if f.visited Visit(f.node) else s.push(Frame(f.node.right, false)) // Cos Stack is LIFO s.push(Frame(f.node, true)) s.push(Frame(f.node.left, false)) |
Complexity
- Time Complexity: .
- Space Complexity: in worst-case.
Morris Inorder Traversal is a tree traversal algorithm aiming to achieve a space complexity of without recursion or an external data structure.
Level-order traversal
Previous methods are all depth-first(深度优先) traversal. And another special kind of traversal is breadth-first(广度优先) traversal, which is also called level-order traversal.
In a breadth-first traversal, the nodes are visited level-by-level starting at the root and moving down, visiting the nodes at each level from left to right.
1 2 3 4 5 6 7 8 9 10 | LevelorderTrav(r): if r!= NULL Queue q q.add(r) while !q.empty() node := q.remove() if node != NULL Visit(node) for each child u of node q.add(u) |
Search Trees
The Dictionary ADT
Dictionary
A Dictionary(字典, also called symbol-table, relation or map) ADT is used to represent a set of elements with (usually distinct) key values.
Each element has a key field and a data field.
Operations:
Search(S, k): Find an element inSwith key valuek.Insert(S, x): AddxtoS.- Convention of existence of same key: the new value replaces the old one.
Remove(S, x): Remove elementxfromS, assumingxis inS.Remove(S, k): Remove element with key valuekfromS.
In typical applications, keys are from an ordered universe (Ordered Dictionary):
Min(S)andMax(S): Find the element inSwith minimum/maximum key.Successor(S, x)orSuccessor(S, k): Find smallest element inSthat is larger thanx.keyor keyk.Predecessor(S, x)orPredecessor(S, k): Find largest element inSthat is smaller thanx.keyor keyk.
Efficient implementation of ORDERED DICTIONARY:
| Operations | Search(S, k) |
Insert(S, x) |
Remove(S, x) |
|---|---|---|---|
| SimpleArray | |||
| SimpleLinkedList | |||
| SortedArray | |||
| SortedLinkedList | |||
| BinaryHeap |
A data structure implementing all these operations is called efficient, if all these operations cost time.
Binary Search Tree (BST)
Binary Search Tree (BST)
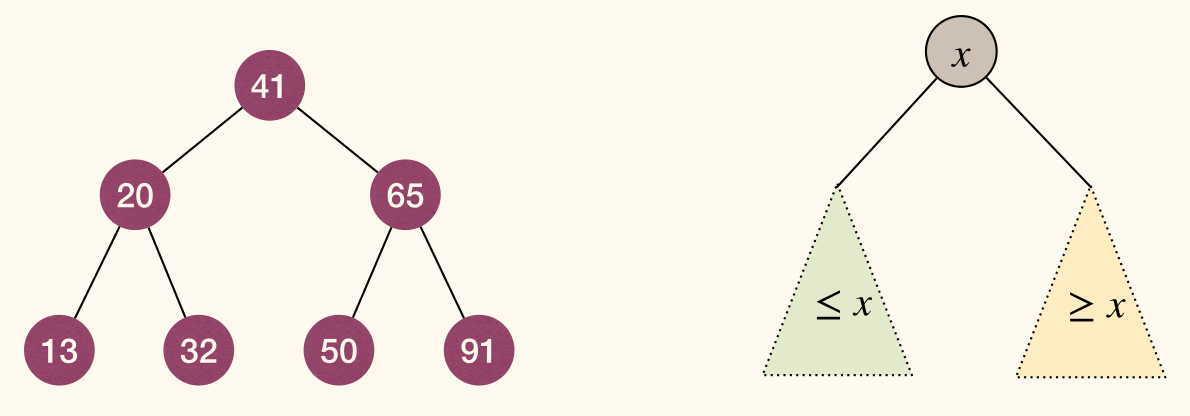
A binary search tree (BST) is a binary tree in which each node stores an element, and satisfies the binary-search-tree property (BST property):
- For every node
xin the tree, ifyis in the left subtree ofx, theny.key <= x.key; ifyis in the right subtree ofx, theny.key >= x.key. - Given a BST
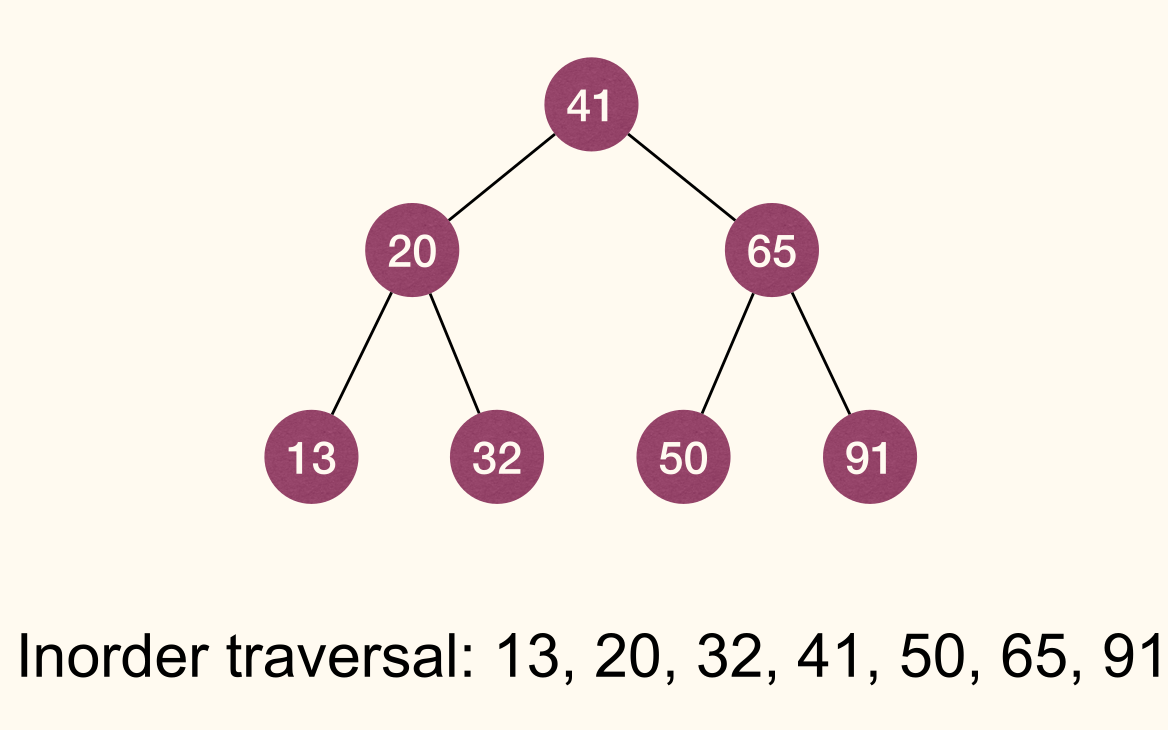
T, letSbe the set of elements stored inT, then the sequence of inorder traversal ofTis elements ofSin ascending order.
Operations
Searching
Given a BST root x and key k, find an element with key k:
- If
x.key == k, then returnxand we are done. - If
x.key > k, then recurse into the BST rooted atx.left. - If
x.key < k, then recurse into the BST rooted atx.right.
1 2 3 4 5 6 7 | BSTSearch(x, k): if x == NULL or x.key == k return x else if x.key > k return BSTSearch(x.left, k) else return BSTSearch(x.right, k) |
We can transform tail recursion into iterative version:
1 2 3 4 5 6 7 | BSTSearchIter(x, k): while x != NULL and x.key != k if x.key > k x = x.left else x = x.right return x |
Complexity
- Worst-case time complexity
- where is the height of the BST.
- How large can be in an -node BST?
- where the BST is like a path (image below).
- How small can be in an -node BST?
- where the BST is well balanced (image below).
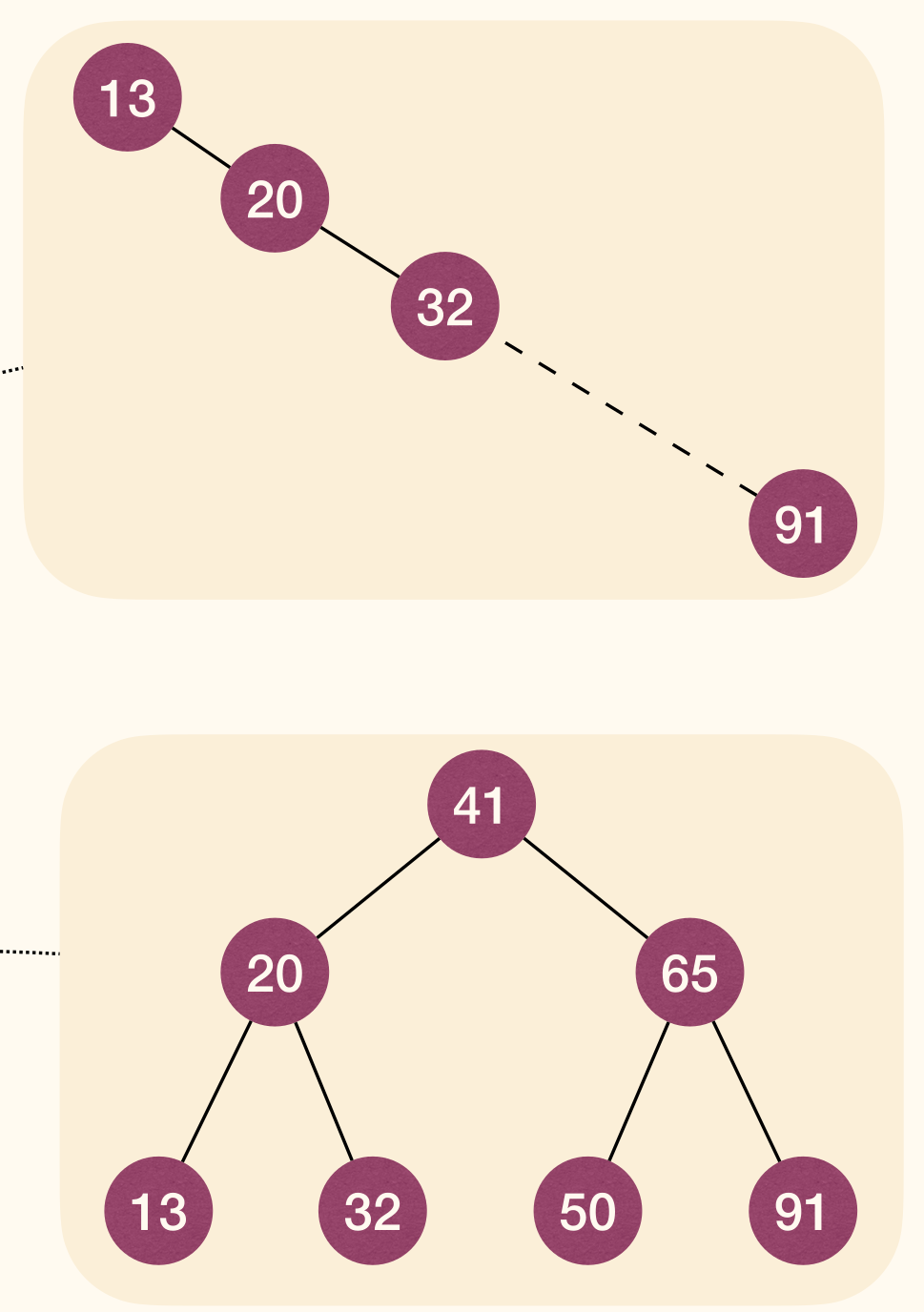
As a result, the height of the BST affects the efficiency of Searching operation.
MIN/MAX in BST
Time complexity: in the worst-case where is height.
Successor in BST
BSTSuccessor(x) finds the smallest element in the BST with key value larger than x.key.
Inorder traversal of BST lists elements in sorted order.
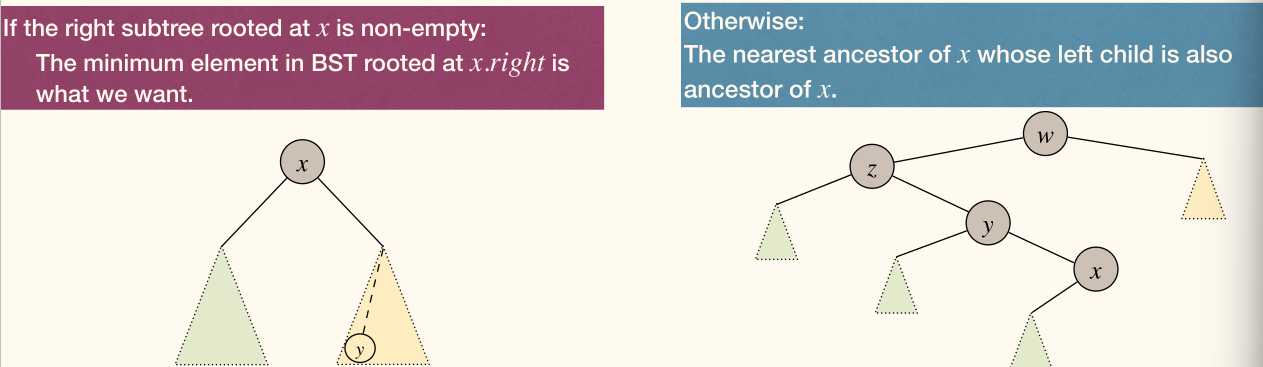
1 2 3 4 5 6 7 8 | BSTSuccessor(x): if x.right != NULL return BSTMin(x.right) y := x.parent while y != NULL and y.right == x x := y y := y.parent return y |
Time complexity of BSTSuccessor is in the worst-case where is height.
BSTPredecessor can be designed and analyzed similarly.
Insert in BST
BSTInsert(T, z) adds z to BST T. Insertion should not break the BST property.
Like doing a search in T with key z.key. This search will fail and end at leaf y. Insert z as left or right child of y.
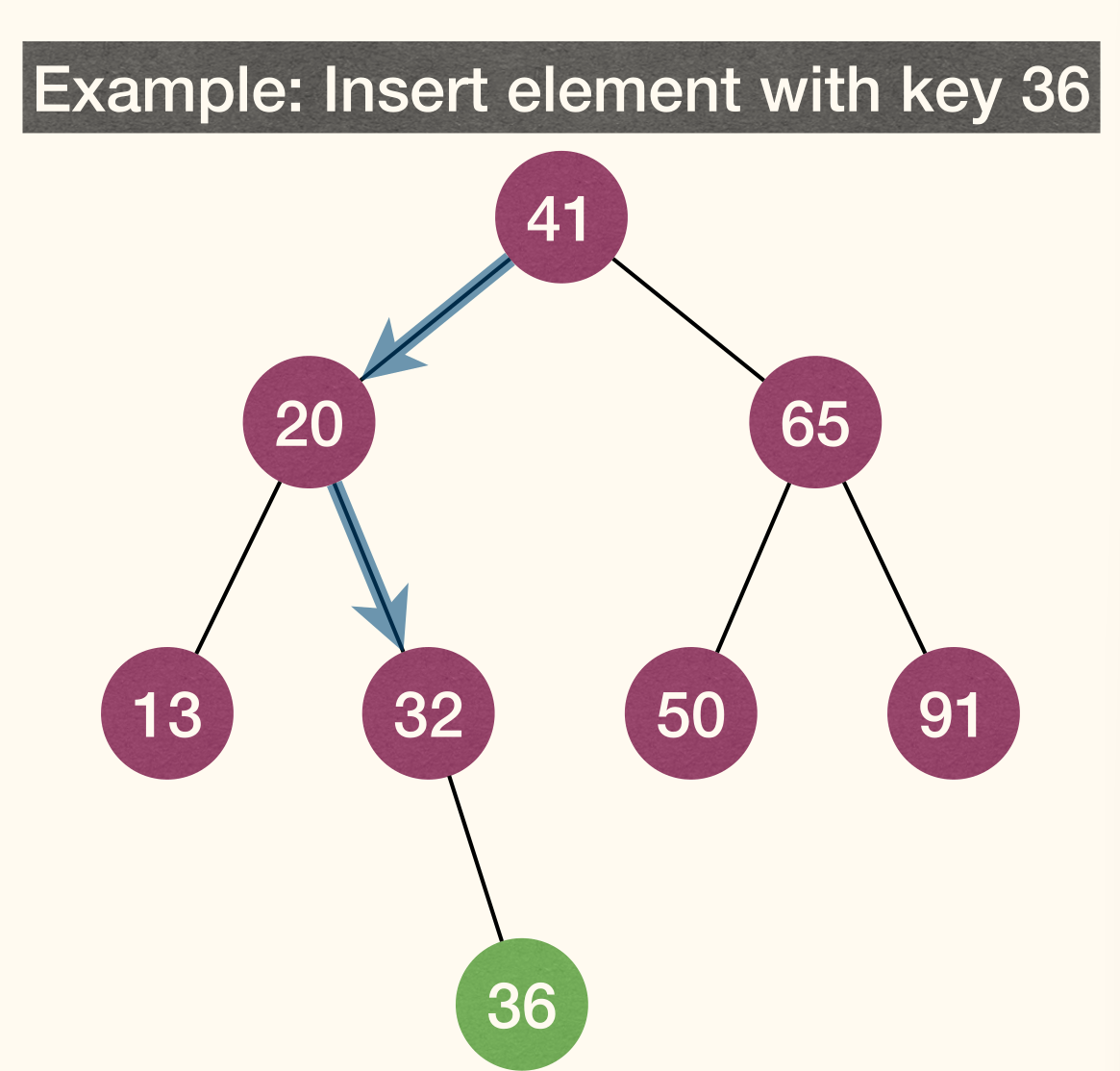
Time complexity: in the worst-case where is height.
Remove in BST
BSTRemove(T, z) removes z from BST T. There are three cases:
zhas no children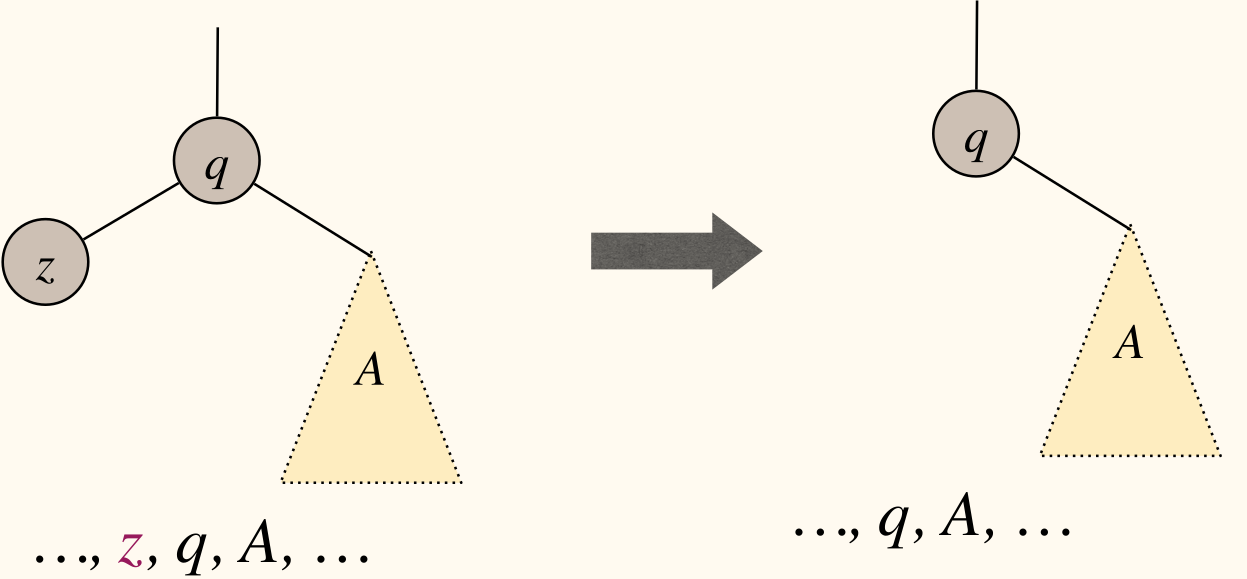
- We can simply remove
zfrom the BST tree
zhas one child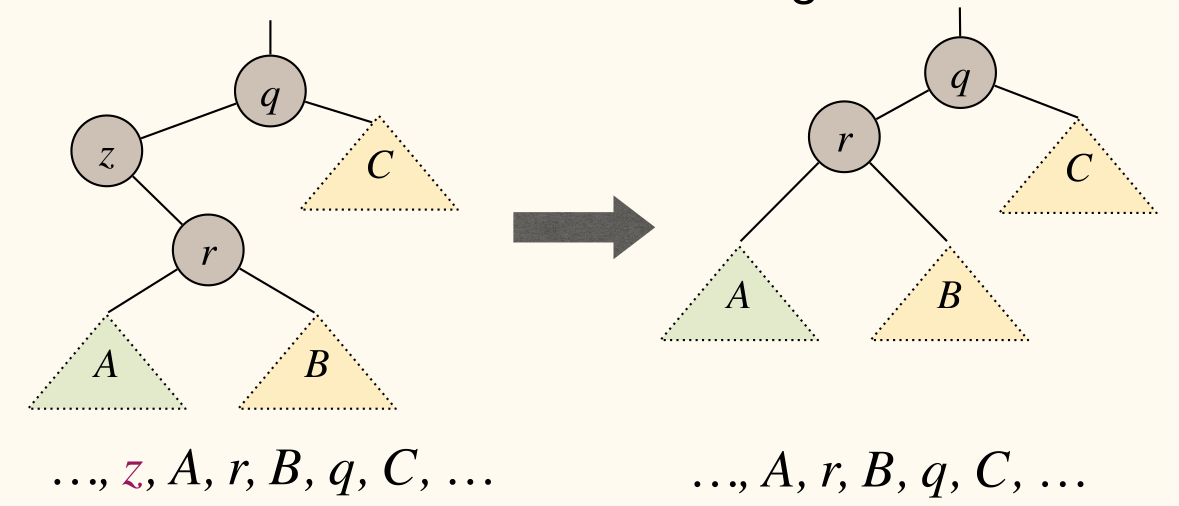
- We can elevate subtree rooted at
z's single child to takez's position.
zhas two children
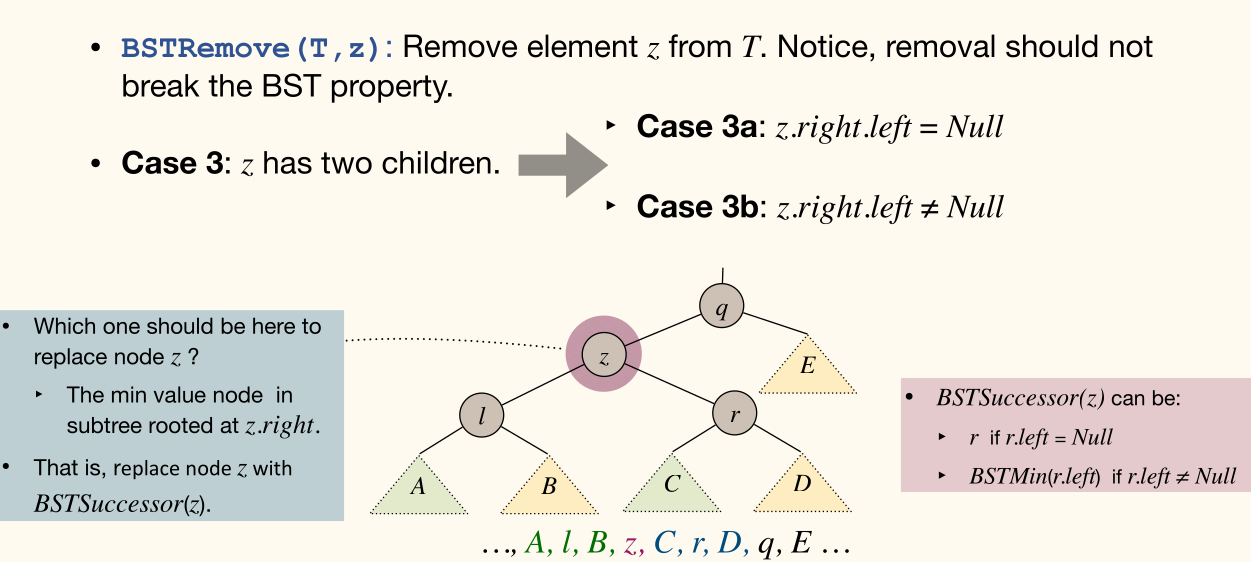
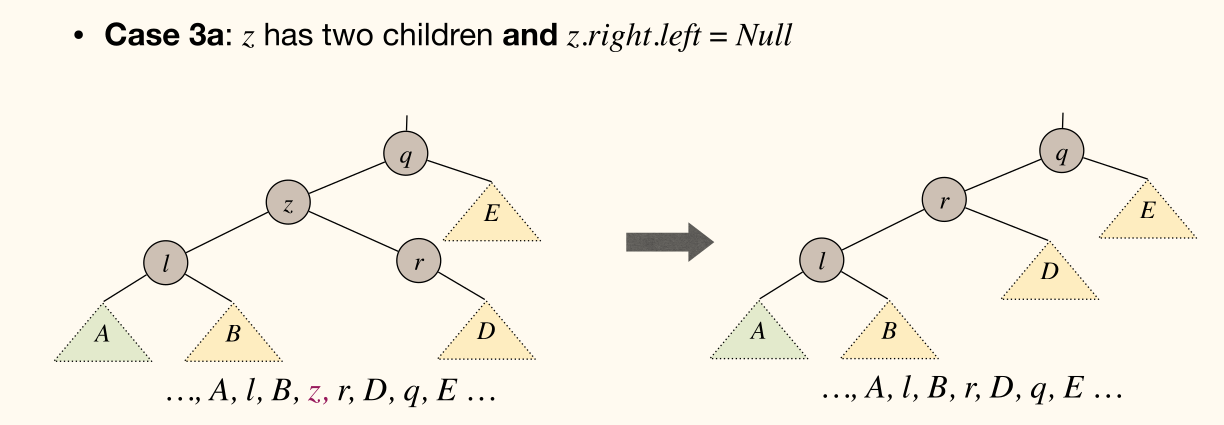
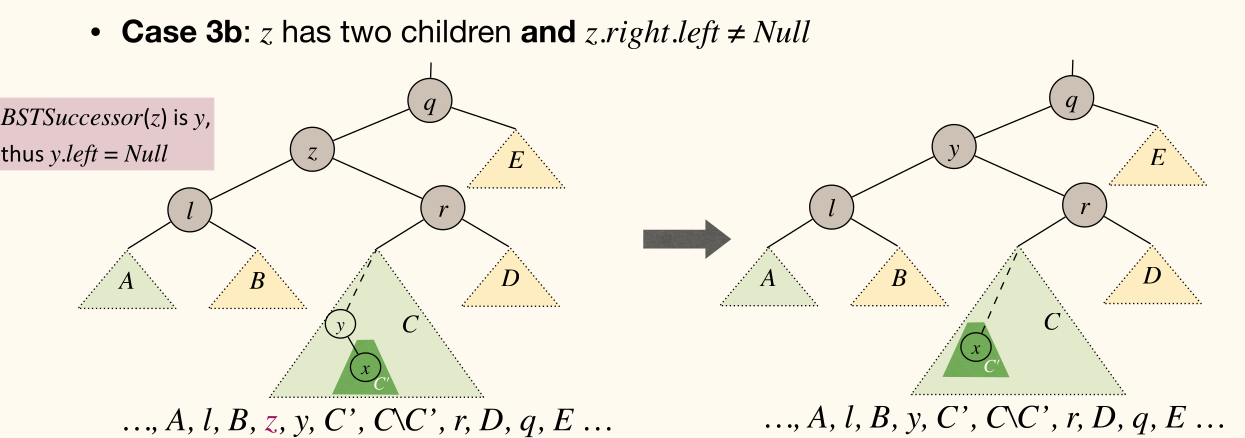
Complexity: in the worst-case where is height.
We can update the table:
| Operations | Search(S, k) |
Insert(S, x) |
Remove(S, x) |
|---|---|---|---|
| SimpleArray | |||
| SimpleLinkedList | |||
| SortedArray | |||
| SortedLinkedList | |||
| BinaryHeap | |||
| BinarySearchTree |
BST also supports other operations of ORDERED DICTIONARY in time. But the height of a -node BST varies between and .
Height of BST
Consider a sequence of insert operations given by an adversary, the resulting BST can have height . E.g., insert elements in increasing order.
Build the BST from an empty BST with insert operations. Each of the insertion orders is equally likely to happen.
The expected height of a randomly built BST is .
Treaps
A Treap(Binary-Search-Tree + Heap, 树堆) is a binary tree where each node has a key value, and a priority value (usually randomly assigned).
The key values must satisfy the BST-property:
- For each node
yin the left subtree ofx:y.key <= x.key. - For each node
yin the right subtree ofx:y.key >= x.key.
The priority values must satisfy the MinHeap-property:
- For each descendant
yofx:y.priority >= x.priority.
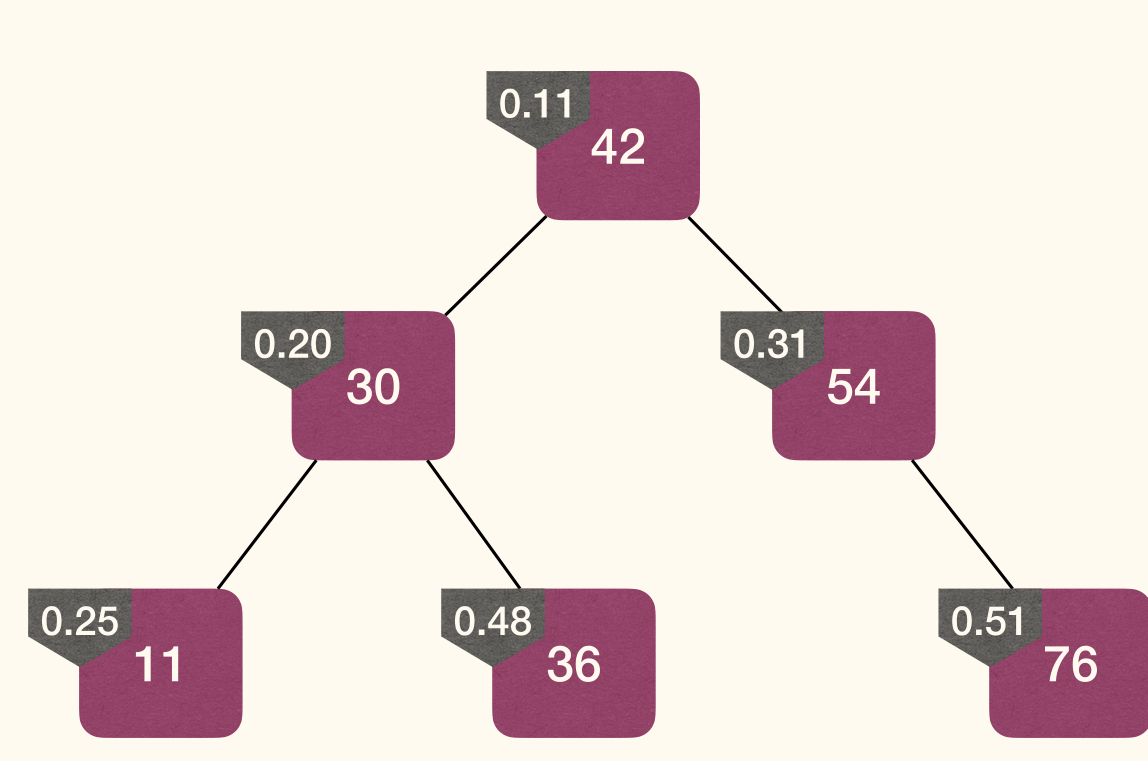
A TREAP is not necessarily a complete binary tree, thus it is not a BinaryHeap.
Uniqueness
Given a set of nodes with distinct key values and distinct priority values, a unique TREAP is determined.
Proof
Proof by induction on :
- Basic: The claim clearly holds when
- Hypothesis: The claim holds when
Inductive Step:
-
- Given a set of nodes, let
rbe the node with minimum priority. By MinHeap-property,rhas to be the root of the final TREAP.
- Given a set of nodes, let
- Let
Lbe set of nodes with key values less thanr.key, andRbe set of nodes with key values larger thanr.key. - By BST-property, in the final TREAP, nodes in
Lmust in left sub-tree ofr, and nodes inRmust in right sub-tree ofr. - By induction hypothesis, nodes in
Llead to a unique TREAP, and nodes inRlead to a unique TREAP.
Build
Starting from an empty TREAP, whenever we are given a node x that needs to be added, we assign a random priority for node x, and insert the node into the TREAP.
Here's an alternative view of an -node TREAP: A TREAP is a BST built with insertions in the order of increasing priorities.
Then, a TREAP is like a randomly built BST, regardless of the order of the insert operations, since we use random priorities.
A TREAP has height in expectation. Therefore, all ordered dictionary operations are efficient in expectation.
Insert


Rotation changes level of x and y, but preserves BST property:
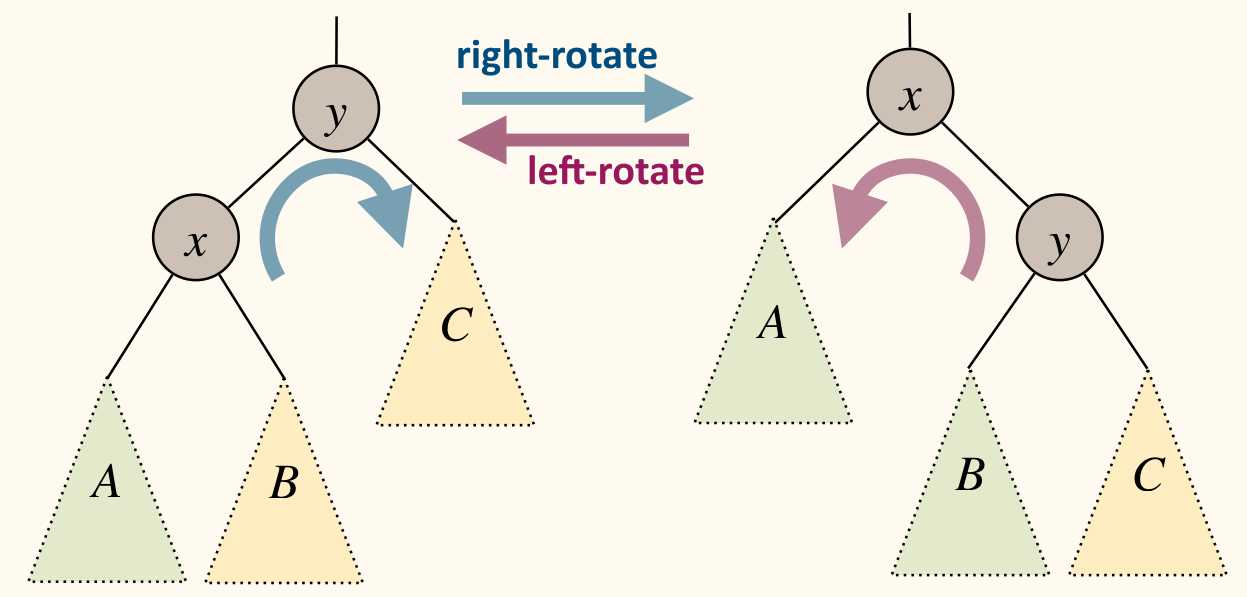
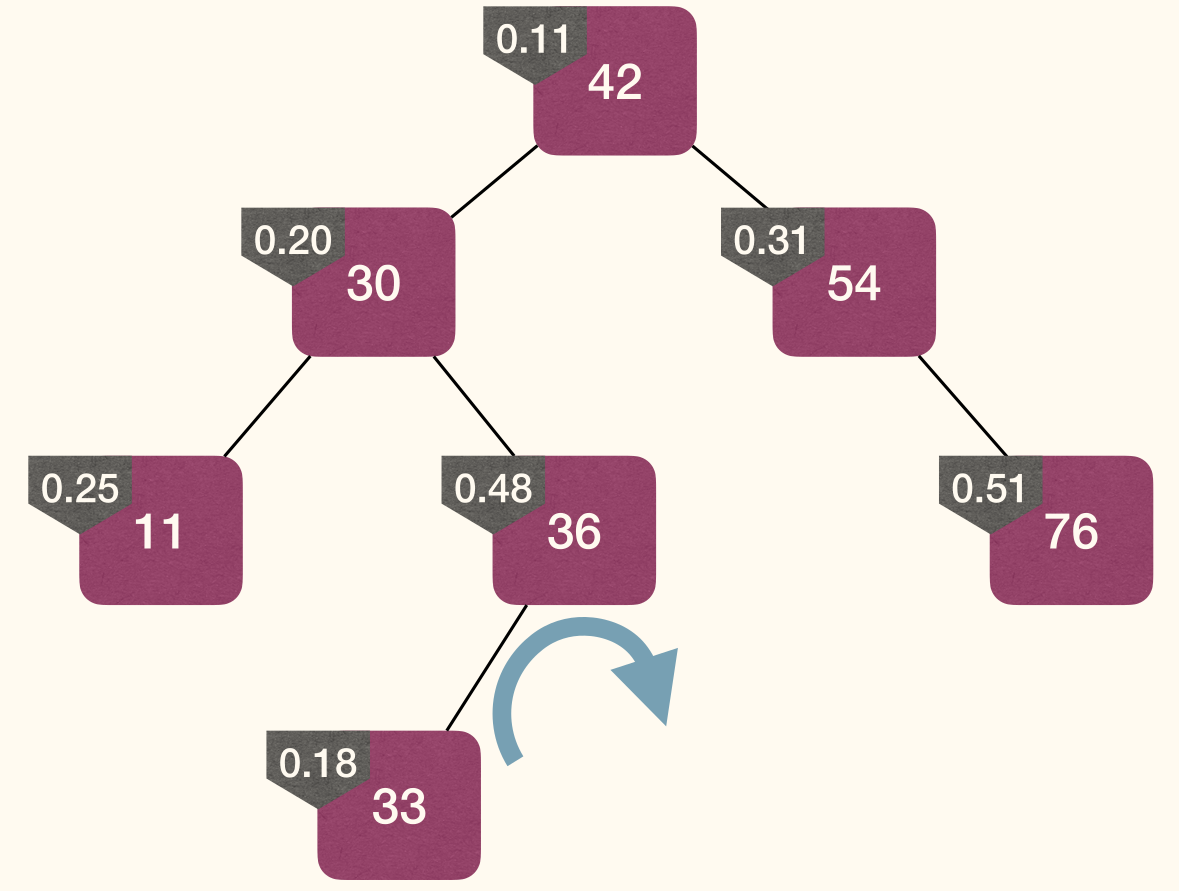
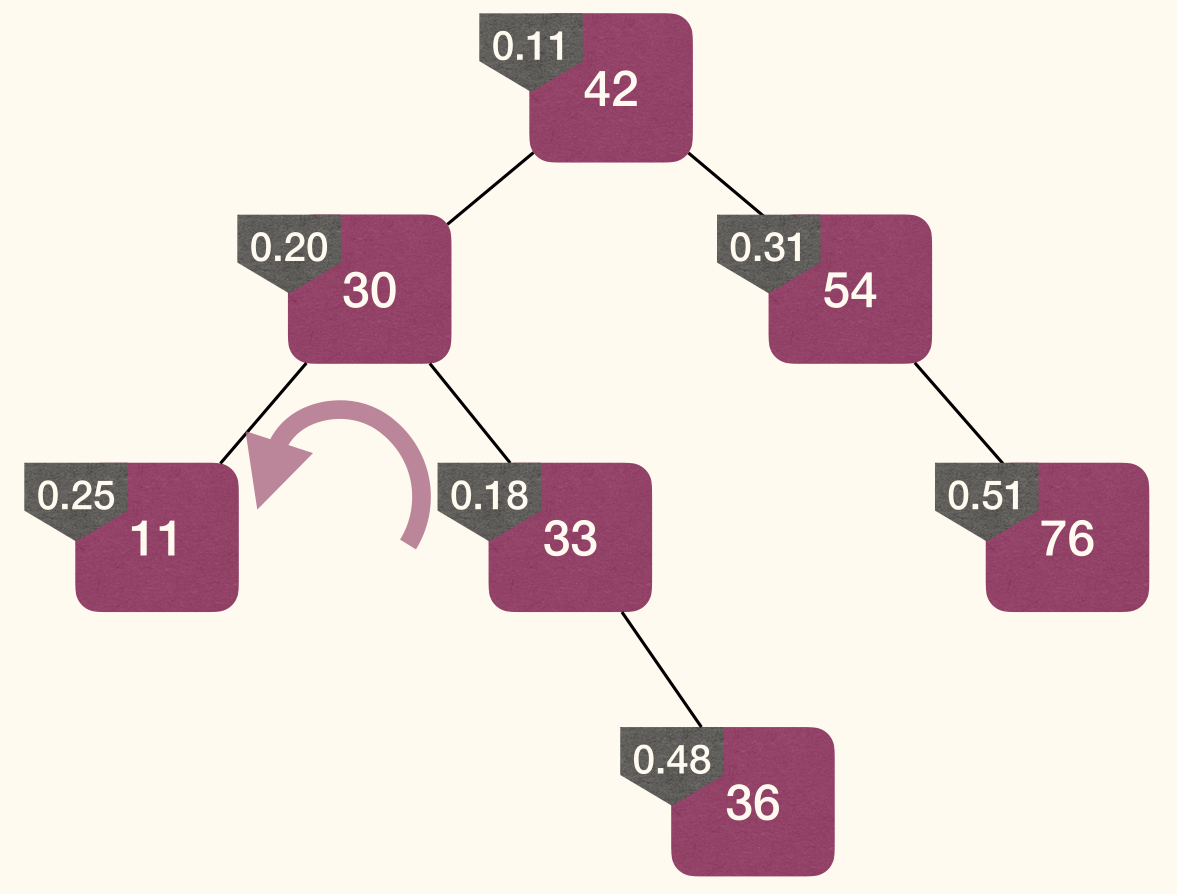
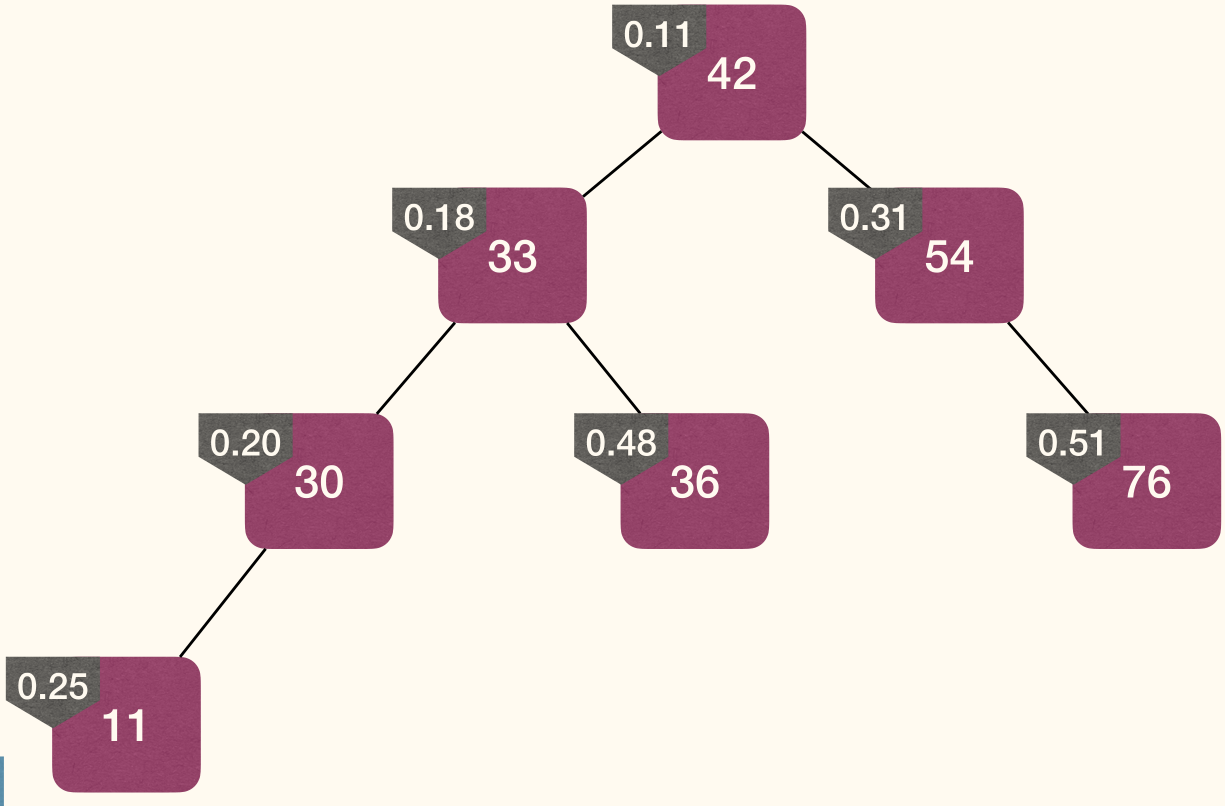
Steps:
- Assign a random priority to the node to be added.
- Insert the node following BST-property.
- Fix MinHeap-property (without violating BST-property).
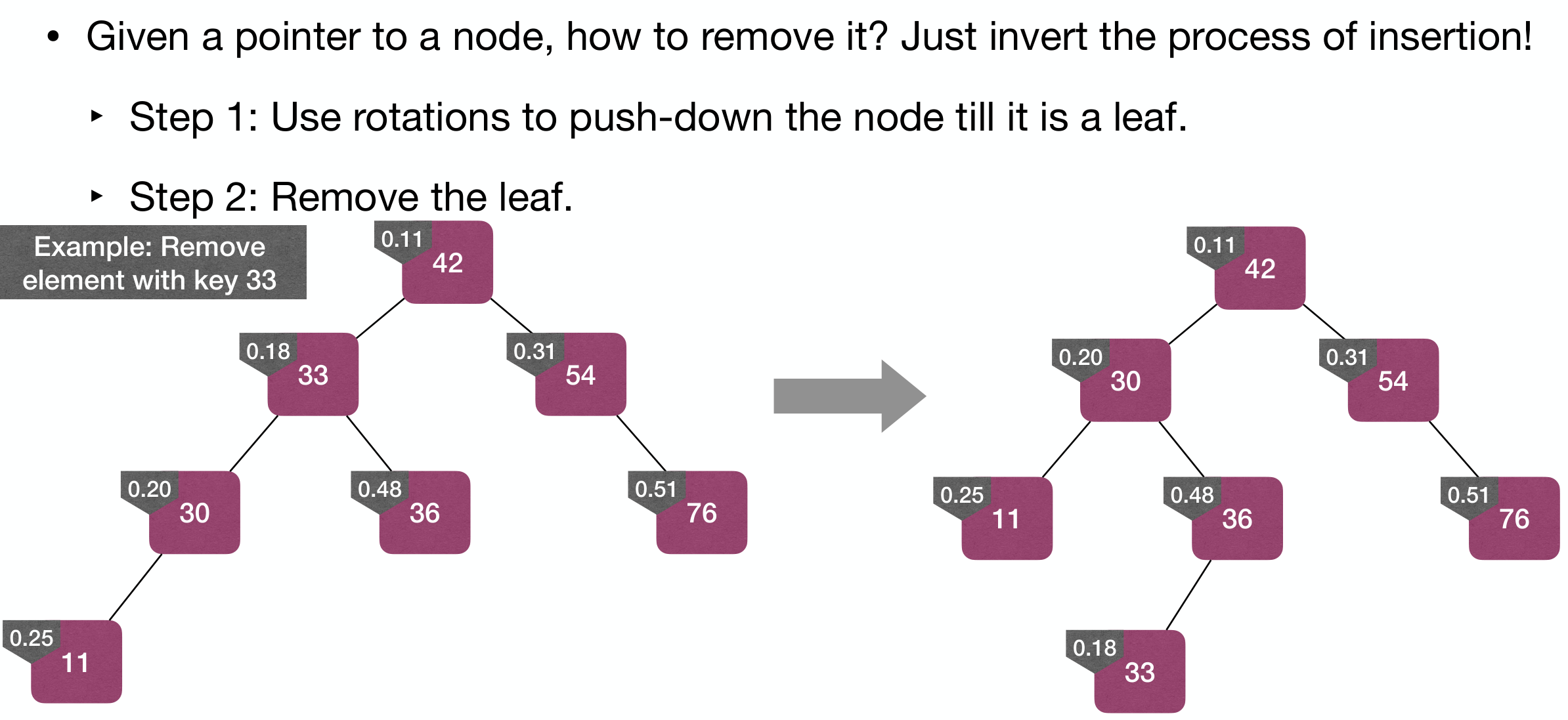
Remove
Steps:
- Use rotations to push-down the node till it is a leaf.
- Remove the leaf.
Red-Black Tree
TREAP is nice, but can we have a DST supporting ordered dictionary operations in time, even in worst-case?
An -node BST is balanced if it has height .
Red-Black Tree (RB-Tree)
A Red-Black Tree (红黑树, RB-Tree) is a BST in which each node has a color, and satisfies es the following properties:
- Every node is either or .
- The root is .
- Every leaf (NIL) is .
- No red edge: If a node is , then both its children are .
- Black height: For every node, all paths from the node to its descendant leaves contain same number of nodes.
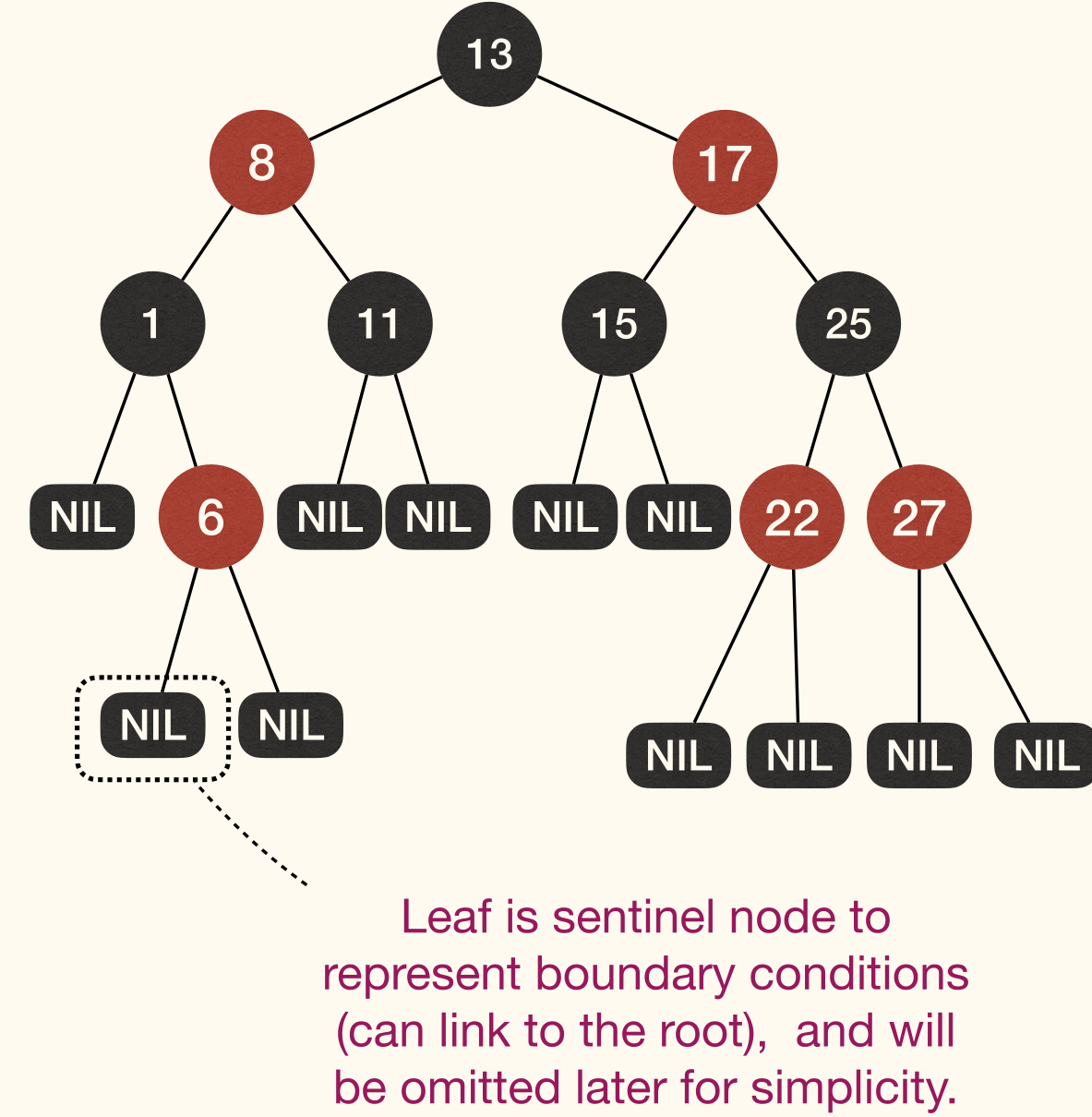
Black Height
Call the number of nodes on any simple path from, but not including, a node x down to a leaf the black-height of the node, denoted by bh(x).
- Due to black-height property, from the black-height perspective, RB-Trees are "perfectly balanced".
- Due to no-red-edge property, actual height of a RB-Tree does not deviate a lot from its black-height.
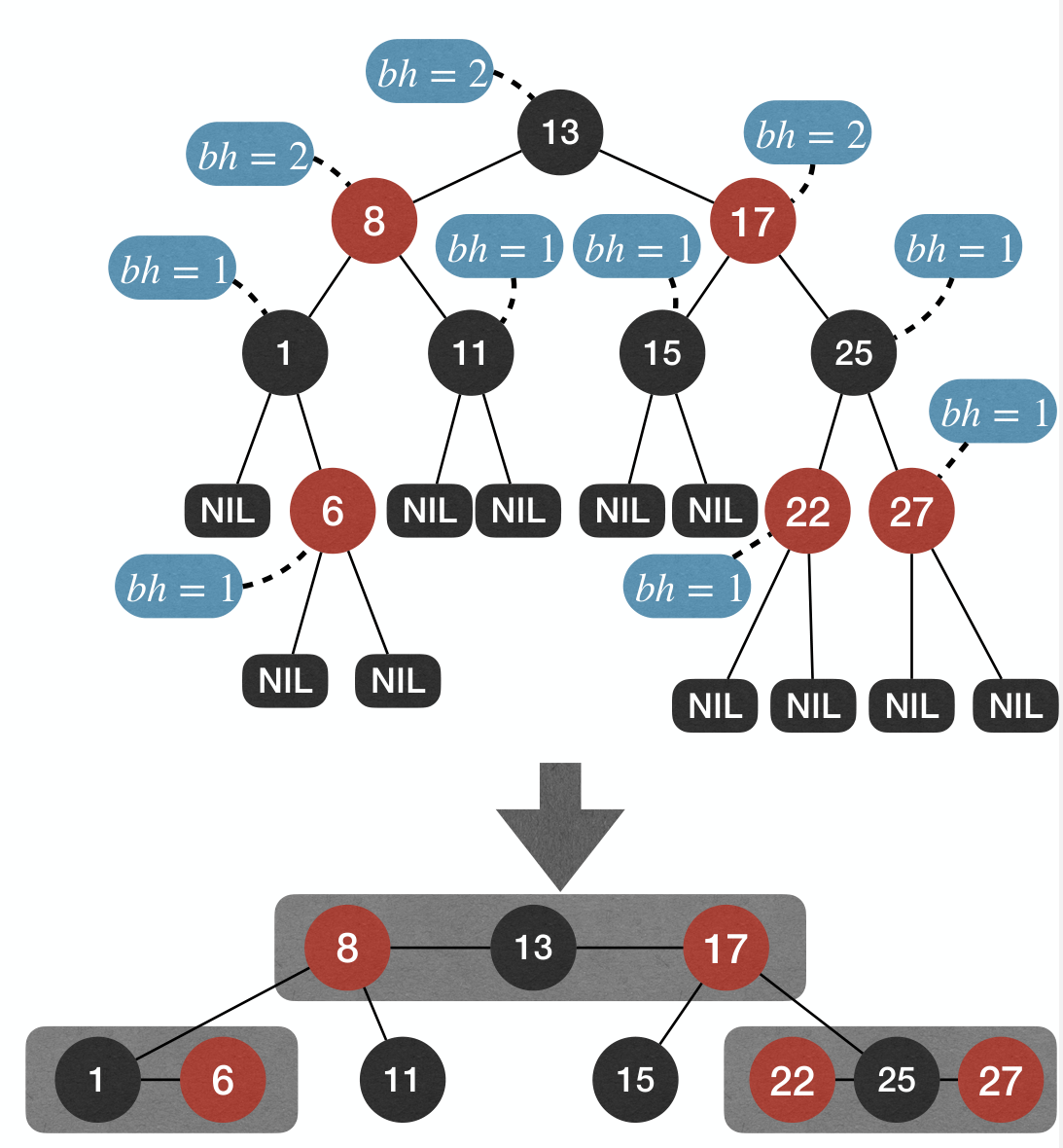
Height of RB-Tree
In a RB-Tree, the subtree rooted at x contains at least internal nodes.
Proof
Proof by induction on black-height of x:
- Basic: If
xis a leaf, and the claim holds. - Hypothesis: The claim holds for all nodes with height at most .
Inductive Step: Consider a node x with height . It must have two children. So the number of internal nodes rooted at x is:
Due to no-red-edge, .
Therefore, implying that .
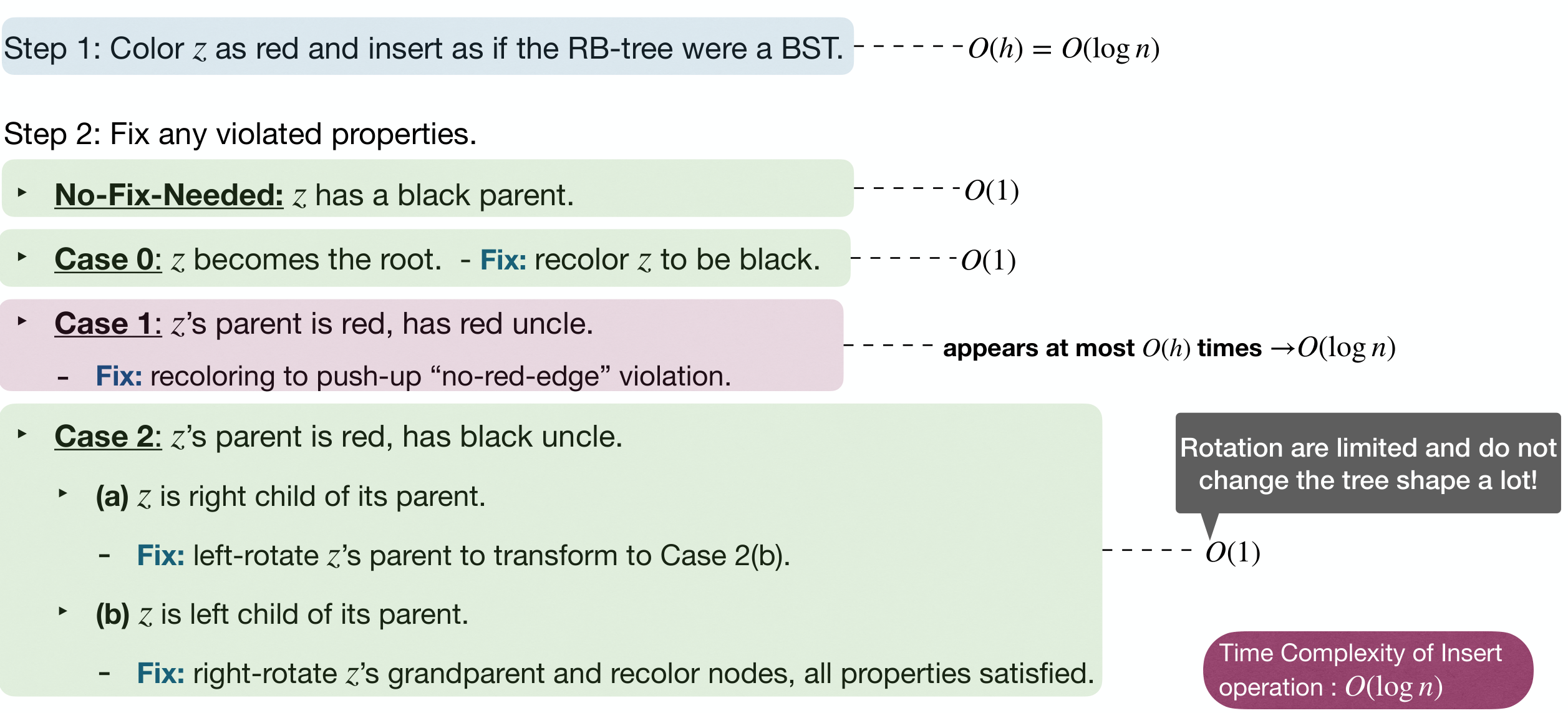
Then, the height of an -node RB-Tree is . Search, Min, Max, Predecessor, Successor operations in worst-case is time.
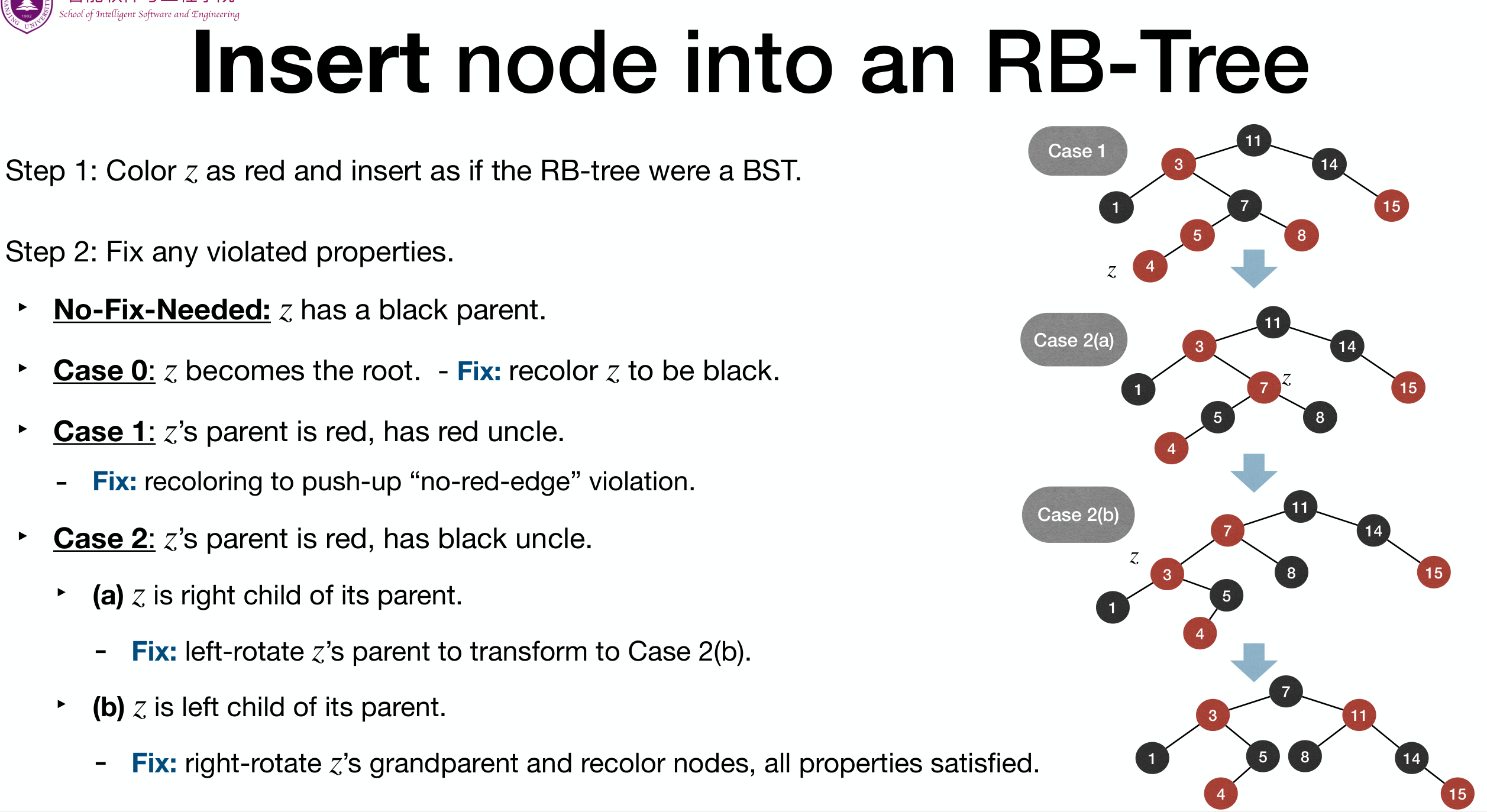
Insert
Steps:
- Colorize
zas and insert as if the RB-Tree was a BST.- The colorization should maintain b-h and fix n-r-e if necessary.
- Fix any violated properties.
- No fix is needed if
zhas a parent. In this case, nodes are few.
- No fix is needed if
Step two haves some cases.
Note: with the execution of algorithm, we change our focus of the node: At the beginning, it is the node to be inserted. Later, it is the node that needs to be changed to fix some property ! We refer to the currently focused node as
z.
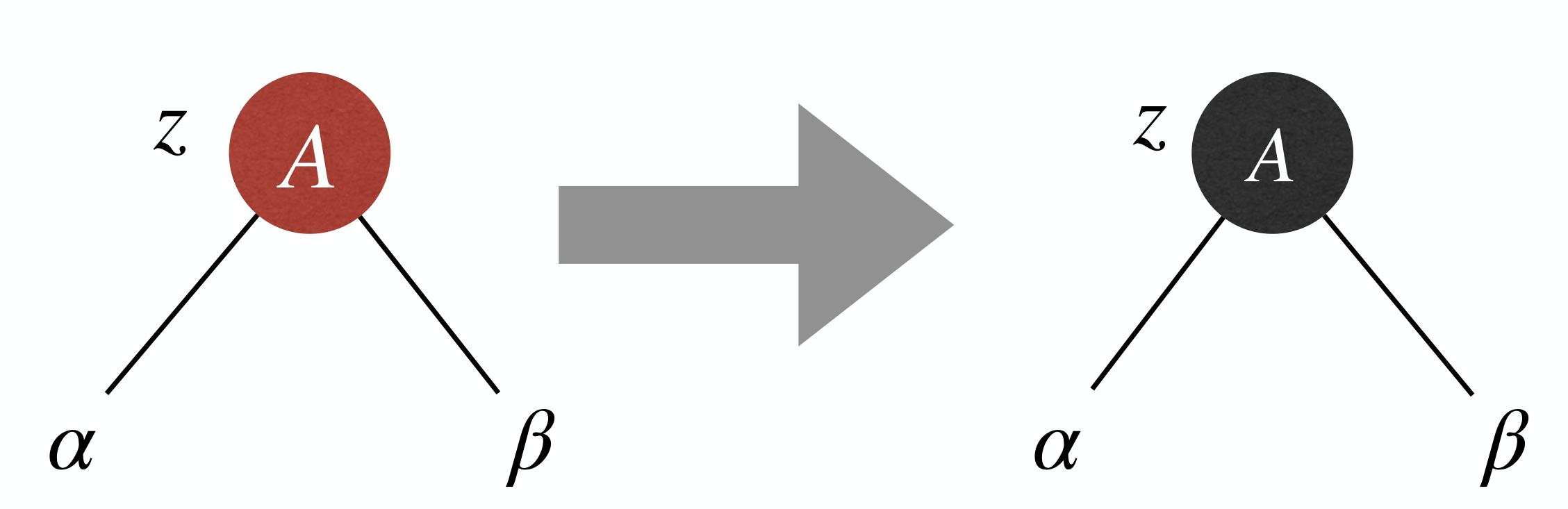
Case 0: z becomes the root of the RB-Tree.
- Fix: Simply recolor
zas .
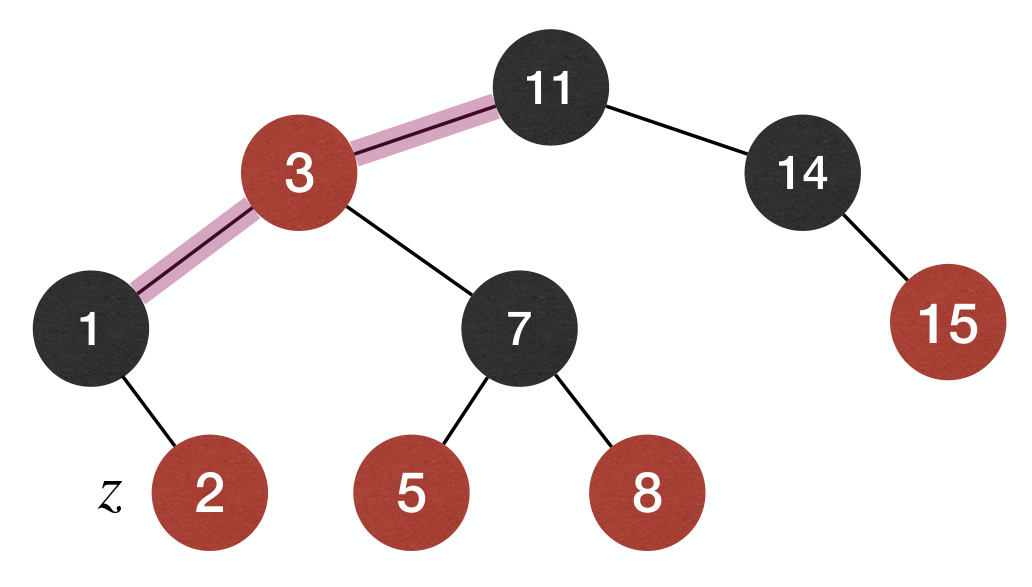
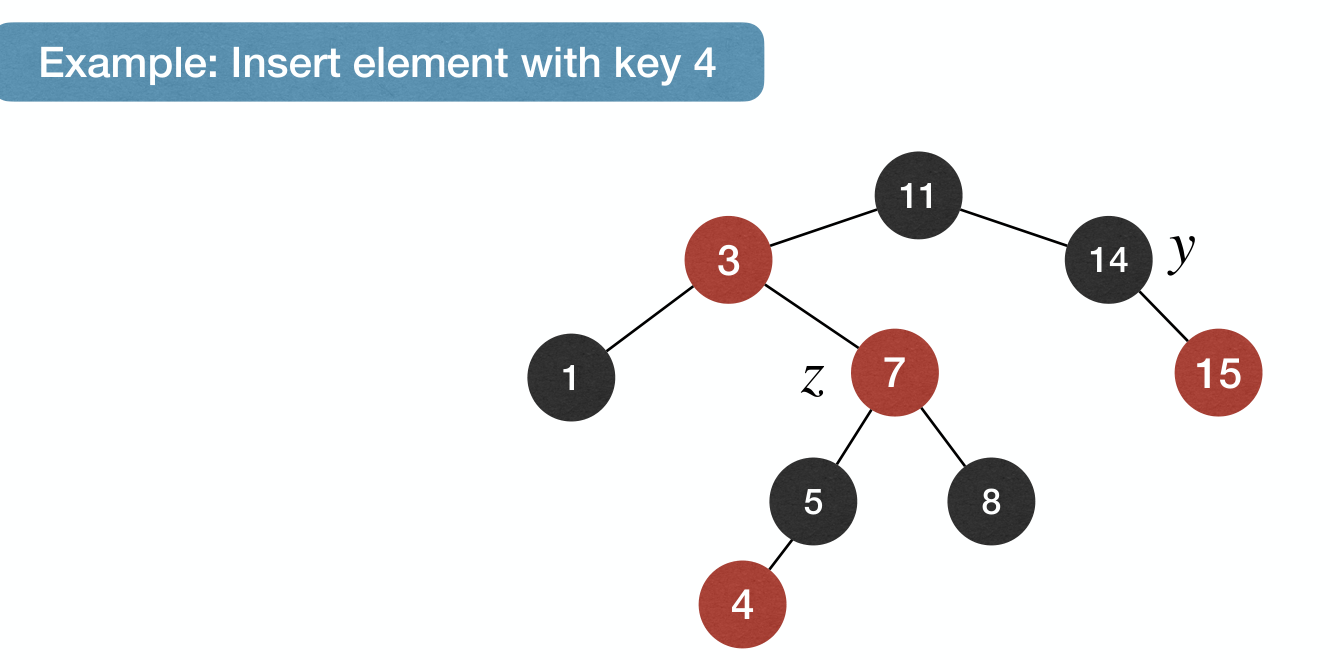
Case 1: z's parent is , so z has grandparent and uncle y.
- Fix: Recolor
z's parent and uncle to andz's grandparent to .
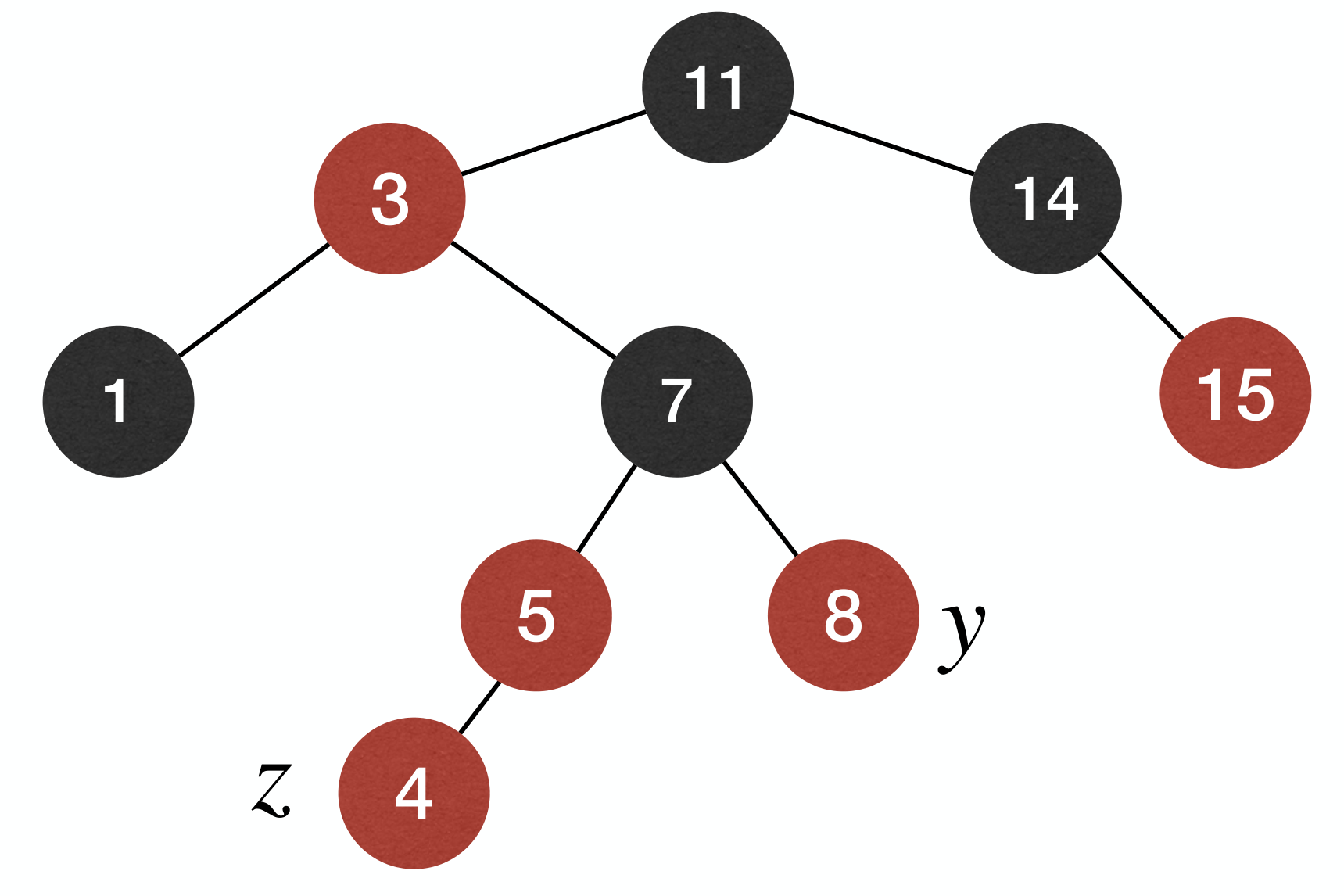
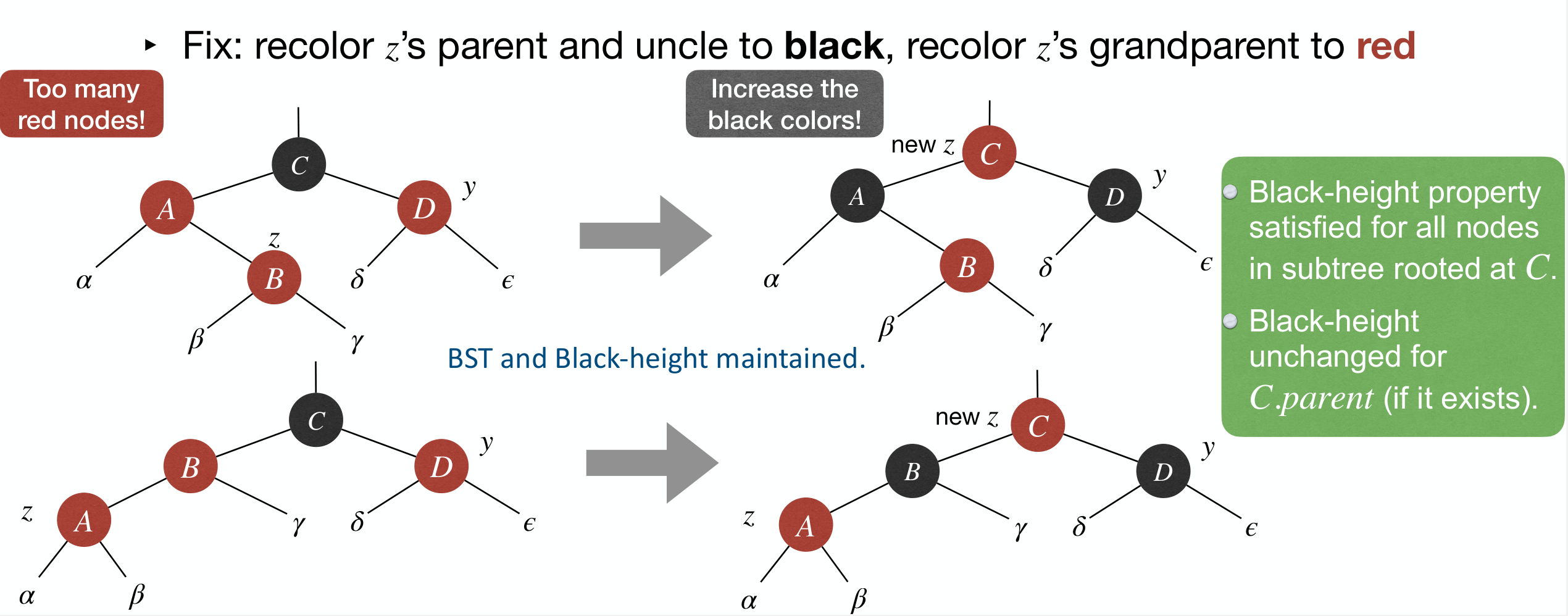
The effect of the fix: b-h property is maintained, and we push-up violation of n-r-e property to z's grandparent.
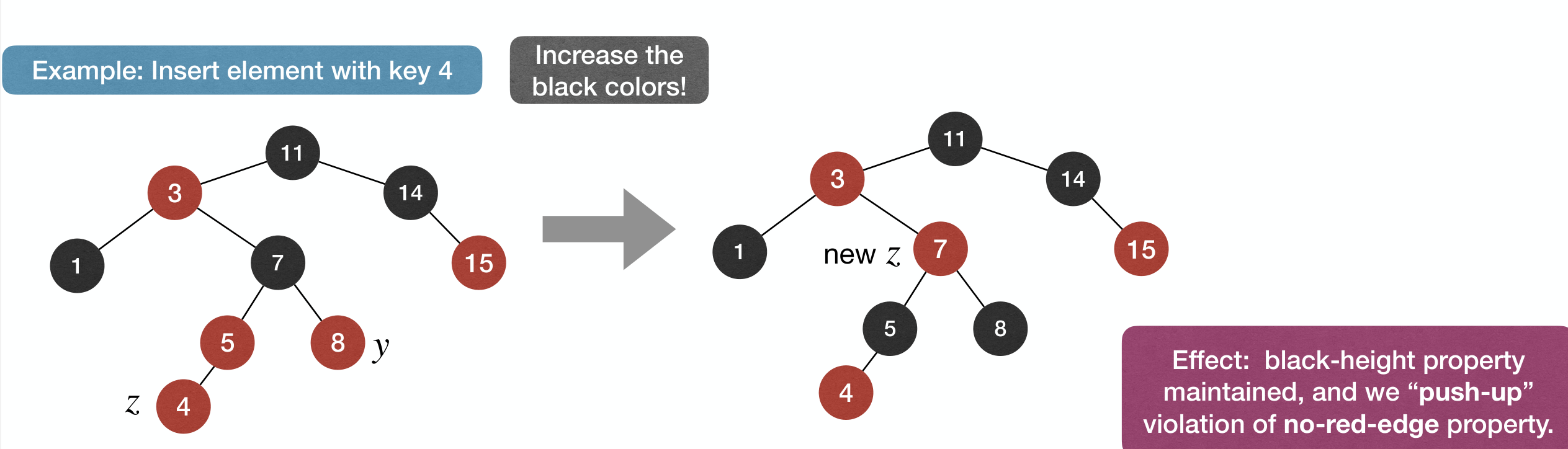
Case 2: z's parent is , and has uncle y.
zis right child of its parent.zis left child of its parent.
Case 2(a): z's parent is , has uncle y, and z is right child of its parent.
- Fix: Left rotate at
z's parent, and then turn to Case 2(b).
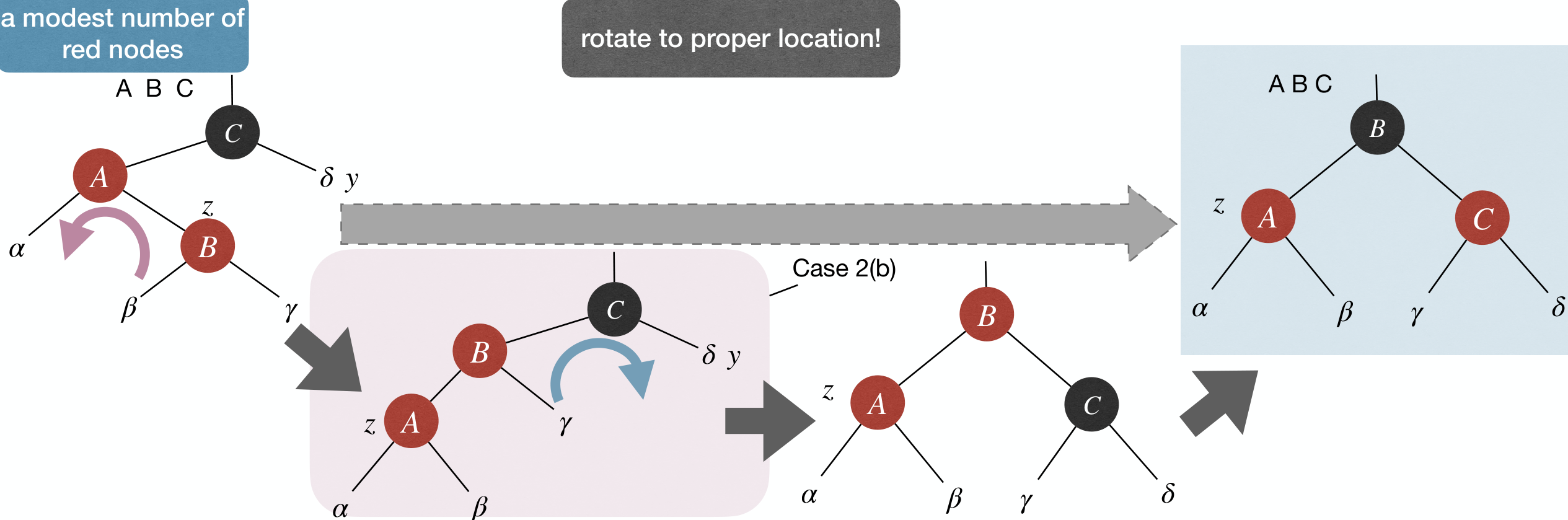
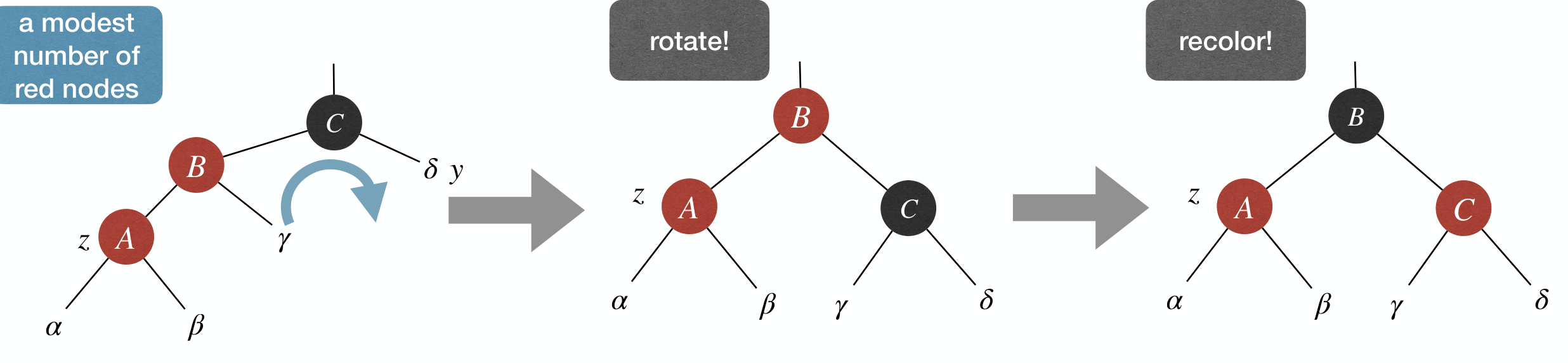
Case 2(b): z's parent is , has uncle y, and z is left child of its parent.
- Fix: Right rotate at
z's grandparent, recolorz's parent and grandparent.
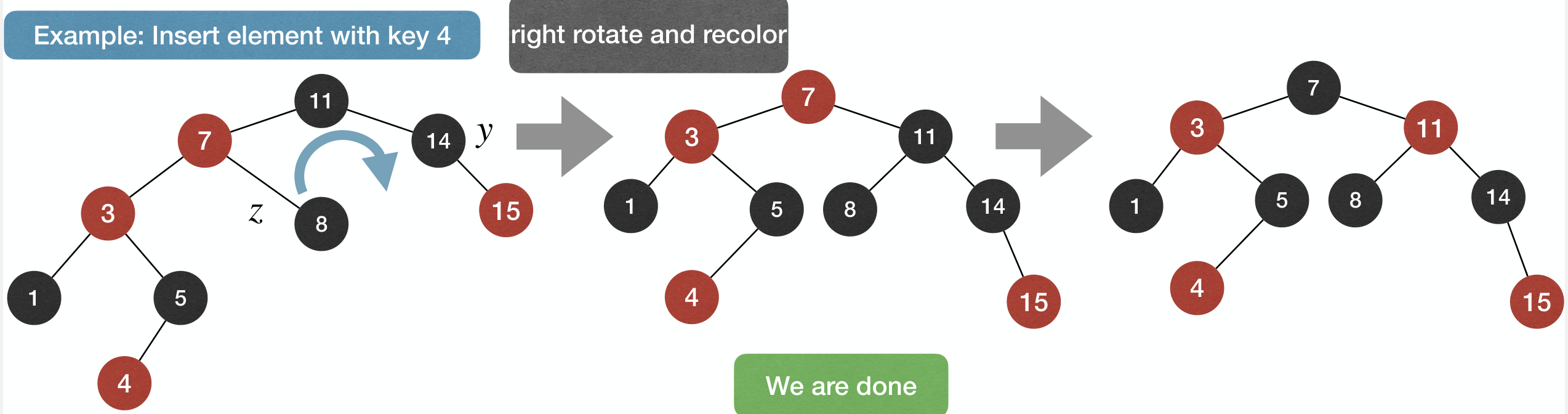
Summary:
Time Complexity:
Remove
First execute the normal remove operation for BST:
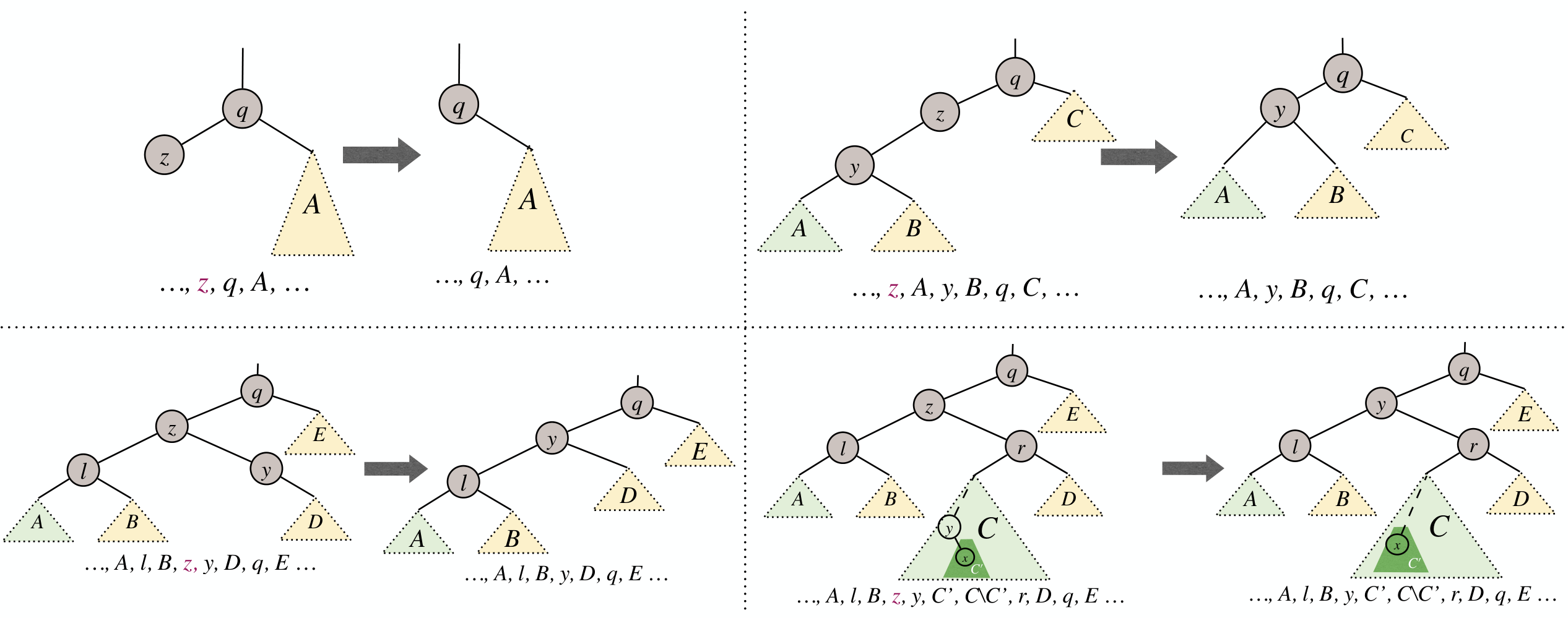
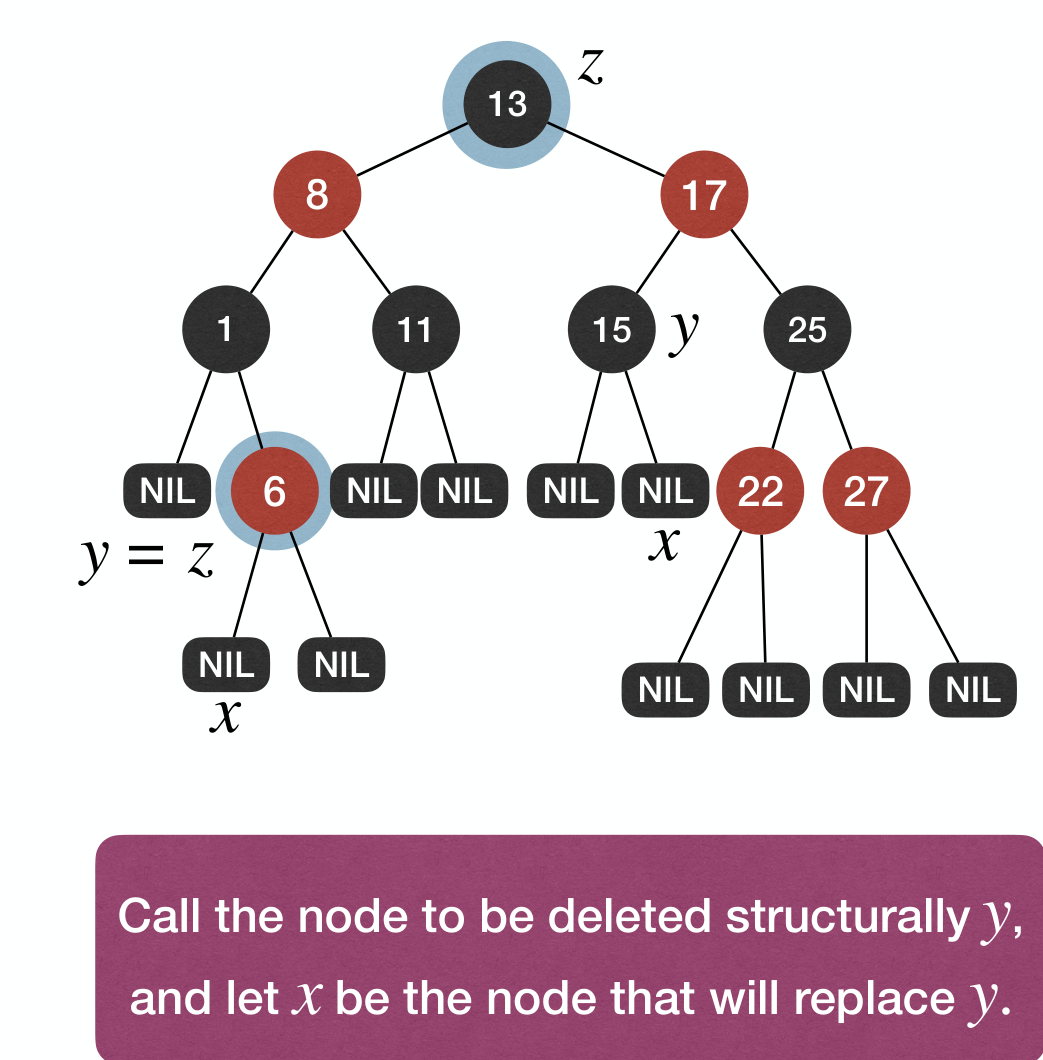
We can reduce this 4 cases to 2 cases. Structurally deleted node:
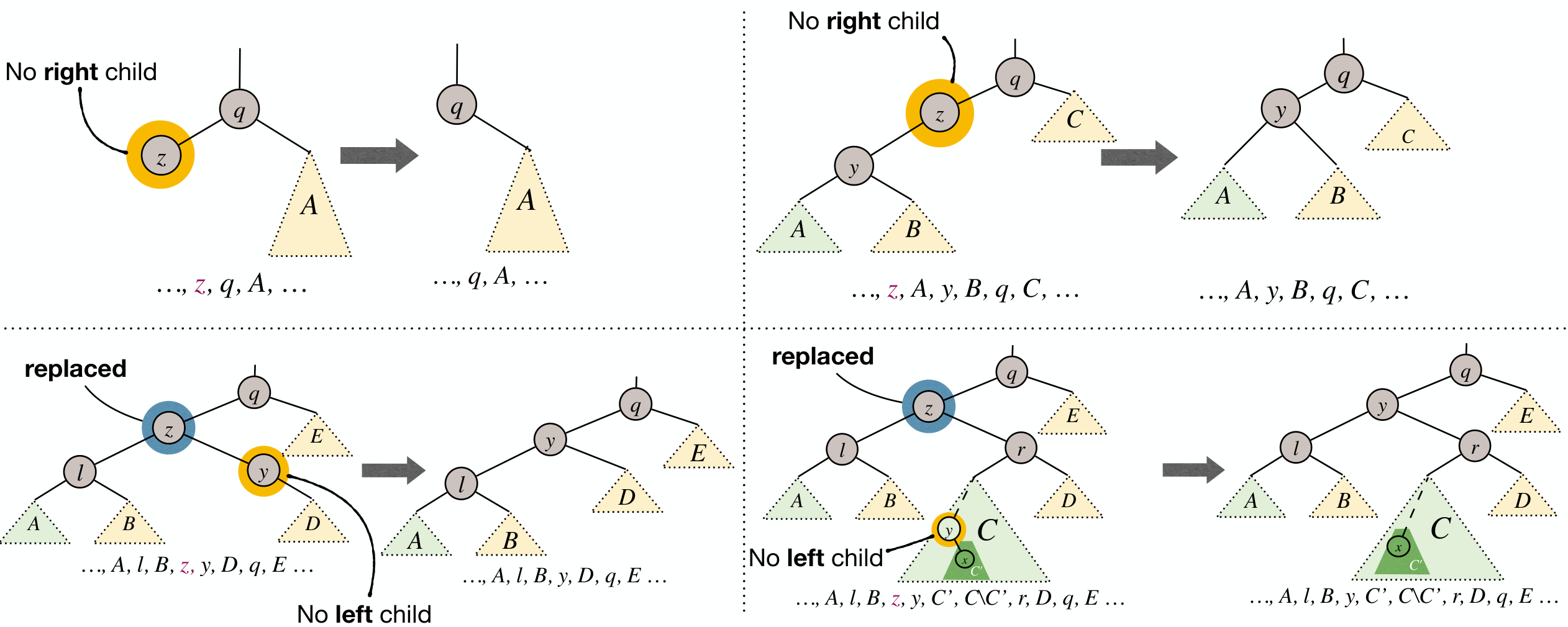
Cases:
- If
z's right child is an external node (leaf) , then z is the node to be deleted structurally: subtree rooted atz.leftwill replacez. - If
z's right child is an internal node, then letybe the min node in subtree rooted atz.right. Overwritez's info withy's info, andyis the node to be deleted structurally: subtree rooted aty.rightwill replacey.
Either way, only 1 structural deletion is needed.
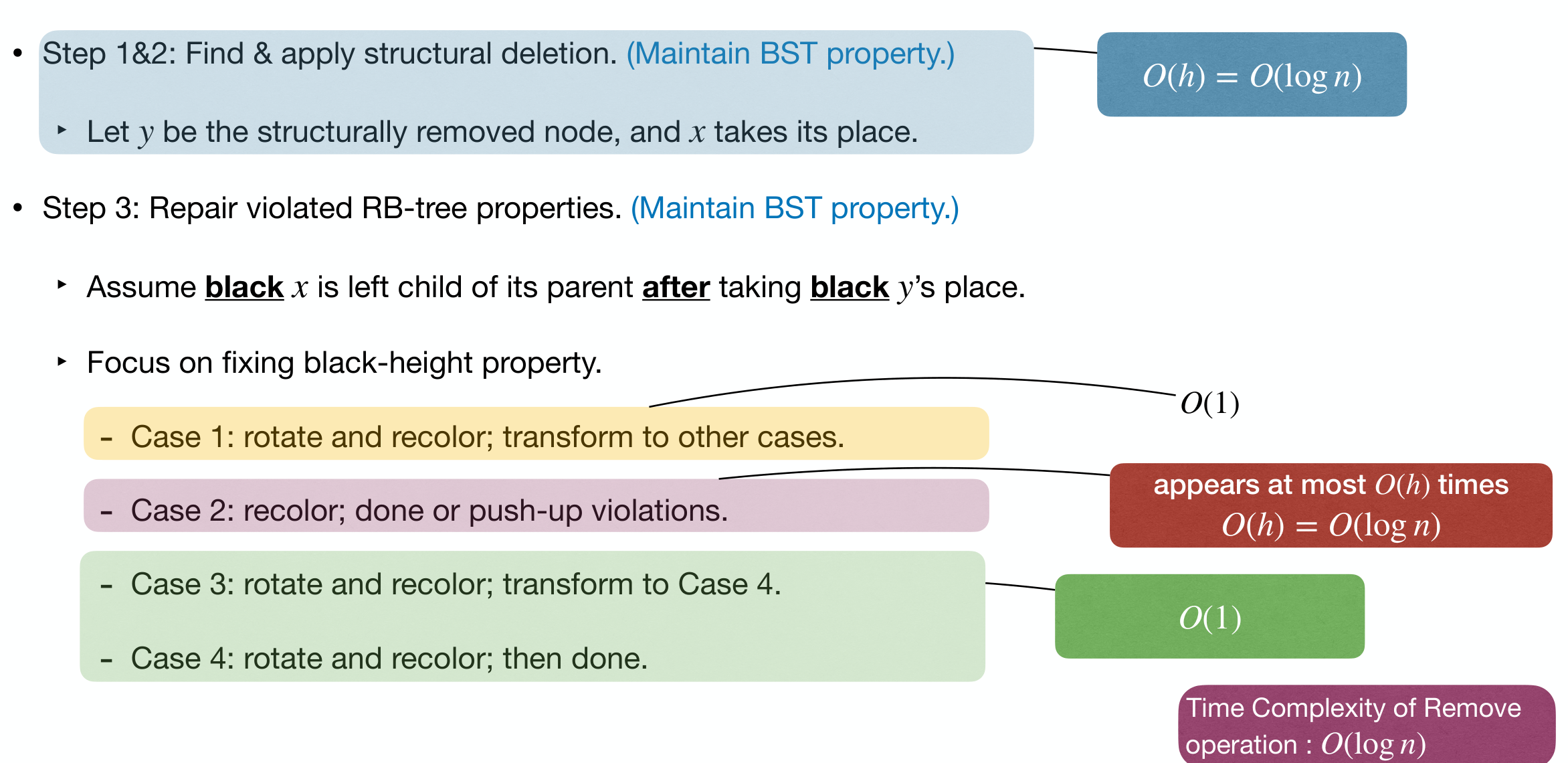
Apply the structural deletion, and repair violated properties.
Steps:
- Identify the node to be deleted structurally.
- Apply the structural deletion
- Maintain BST property.
- Repair violated RB-Tree properties
- If
yis a node:- Fix: No violations.
- If
yis a node andxis a node:- Fix: Recolor
xto and done.
- Fix: Recolor
- If
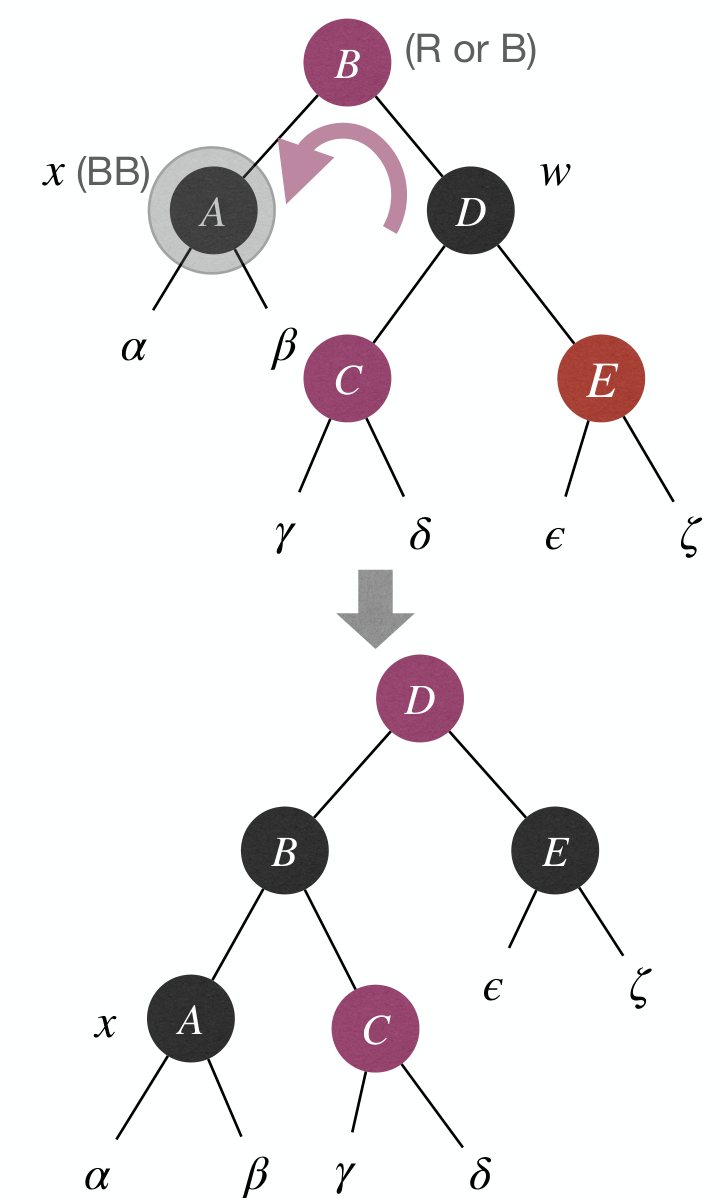
yis a node andxis a node:- Fix: Fix double- violation. To be introduced later.
- If
Assume x is left child of its parent after taking y's place. And we focus on fixing b-h property.
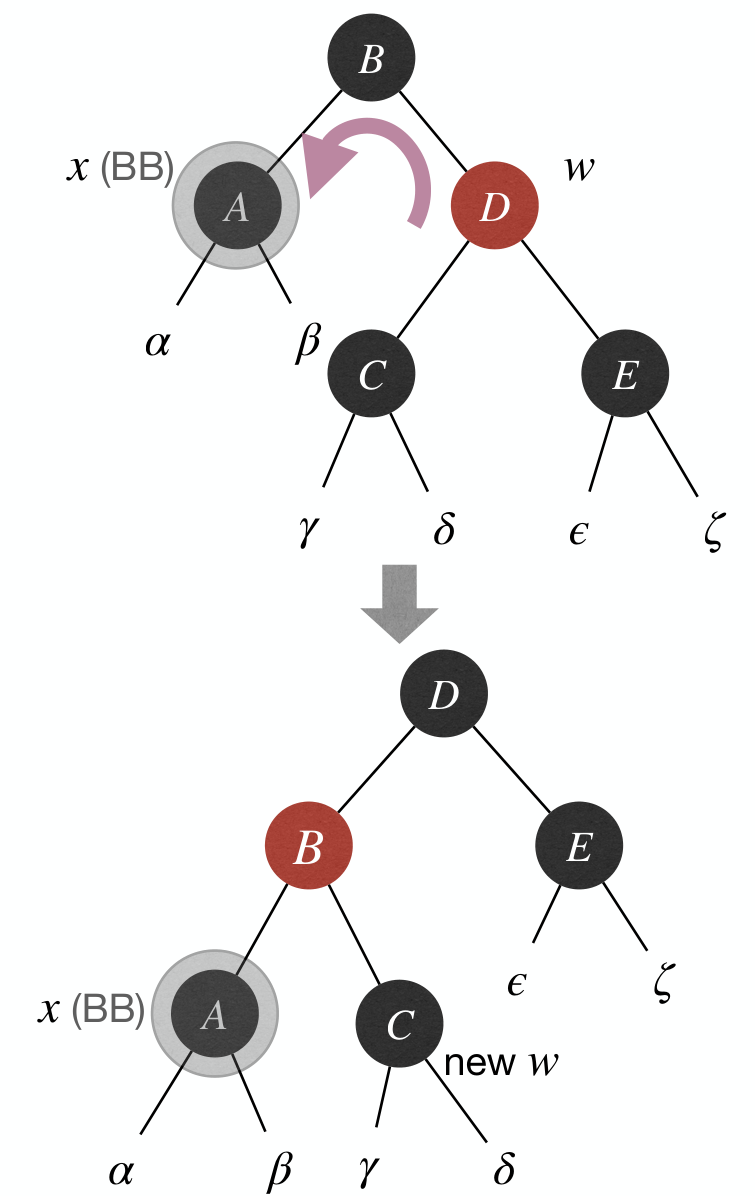
Case 1: x's sibling w is .
- Fix: Rotate and recolor.
- Effect: Change
x's sibling's color to black, and transform to other cases.
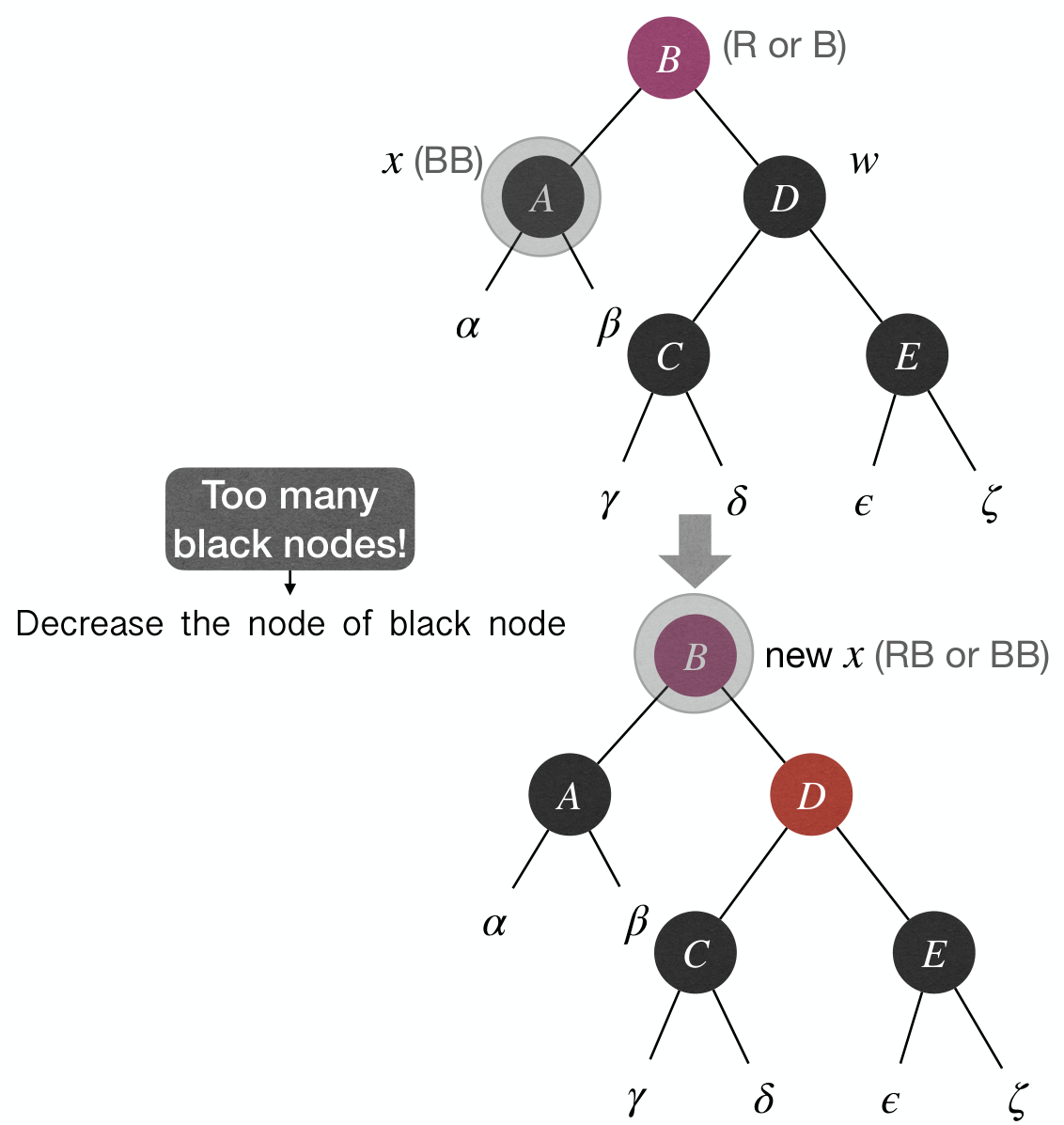
Case 2: x's sibling w is , and both w's children are .
- Fix: Recolor and push-up extra blackness in
x. - Effect: Either we are done (RB), or we have push-up
x(RR).
Case 3: x's sibling w is , and w's left child is and right child is .
- Fix: Rotate and recolor.
- Effect:
w.rightbecomes and transform to Case 4.
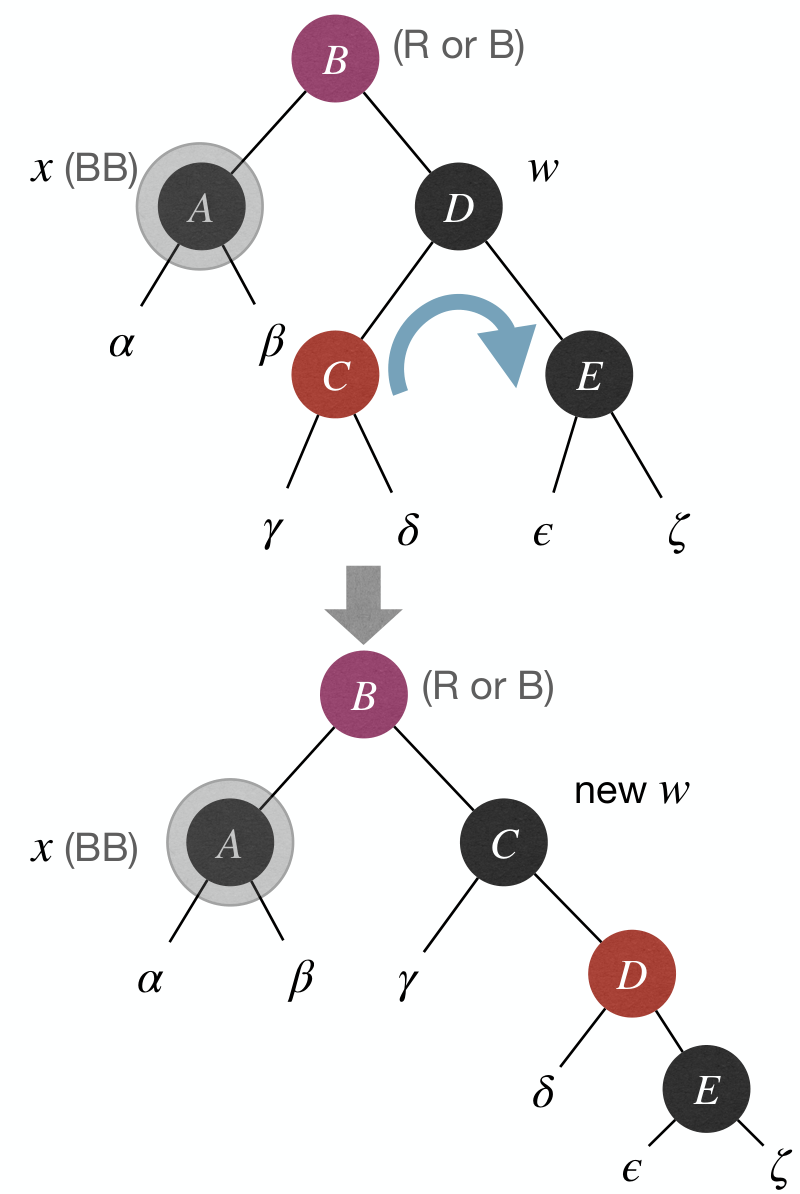
Case 4: x's sibling w is , and w's right child is .
- Fix: Rotate and recolor.
- Effect: Done.
Summary & Time Complexity:
Skip List (跳表)
Why sorted LinkedList is slow? Because to reach an element, you have to move from current position to the destination one at a time.
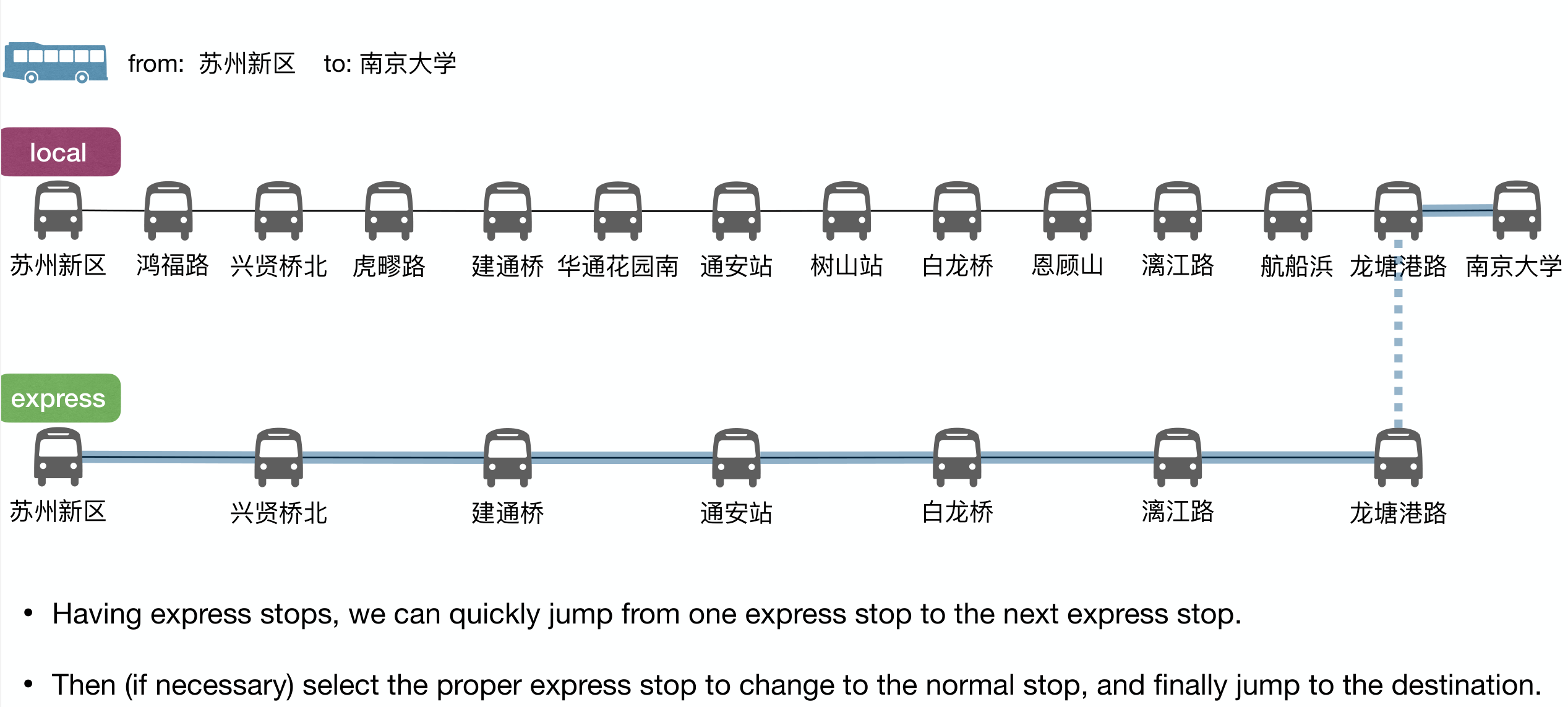
We can represent the ordered LinkedList as two LinkedLists, one for express stops and one for all stops.
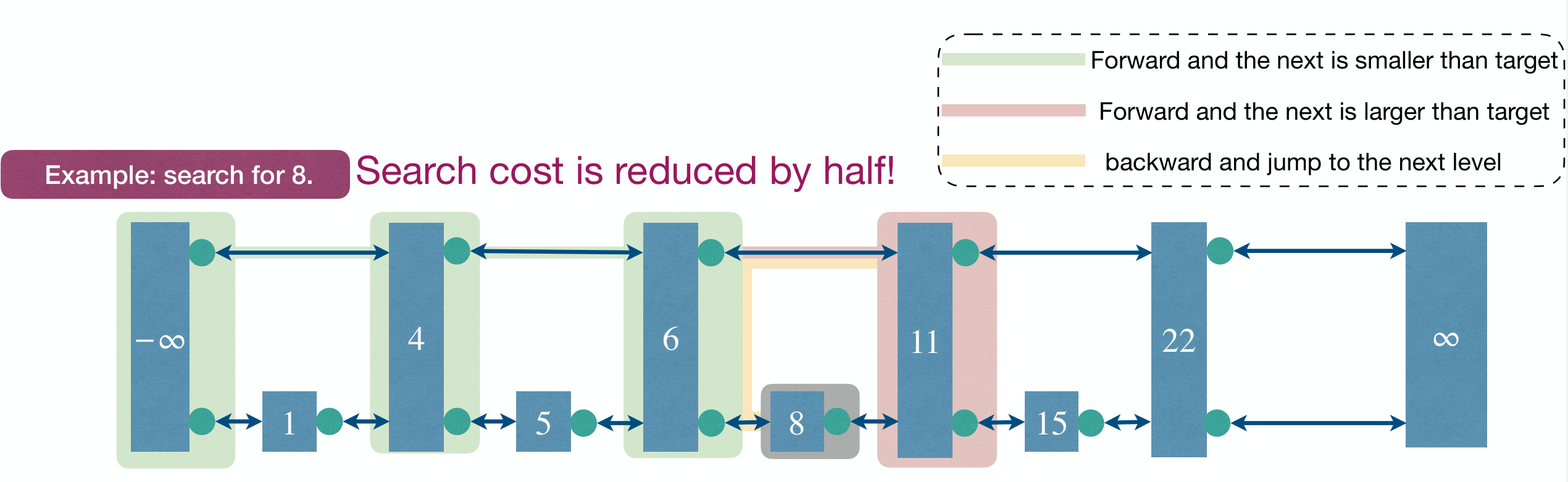
We can build multiple express ways to reduce number of elements by half at each level. This is just binary search, reducing search range by half at each level.
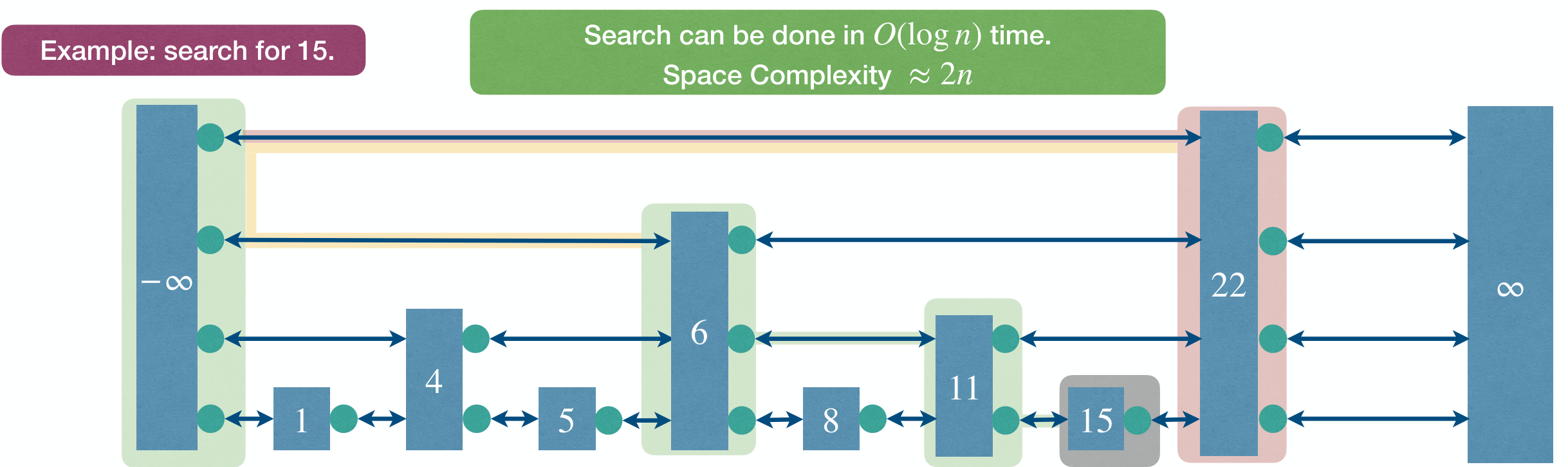
This is efficient, time at each level and levels in total.

Insert
1 2 3 4 5 6 7 8 | Insert(L, x): level := 1 done := False while !done Insert x into level k List Flip a fair coin: With probability 1/2: done := True With probability 1/2: level := level + 1 |
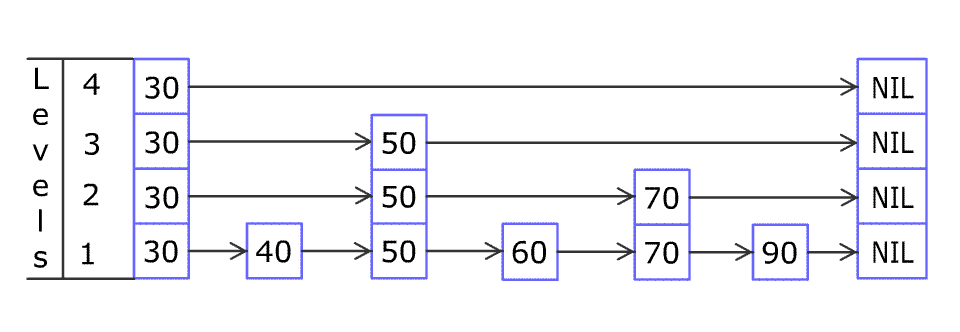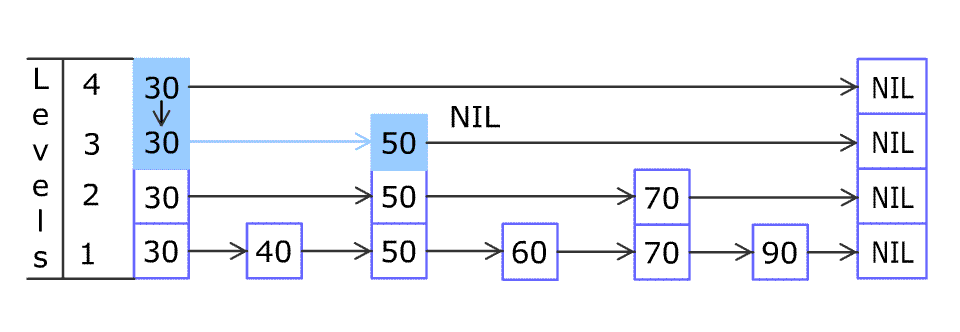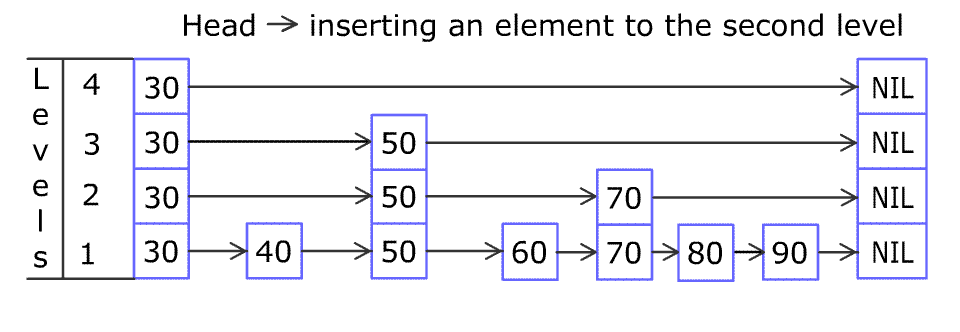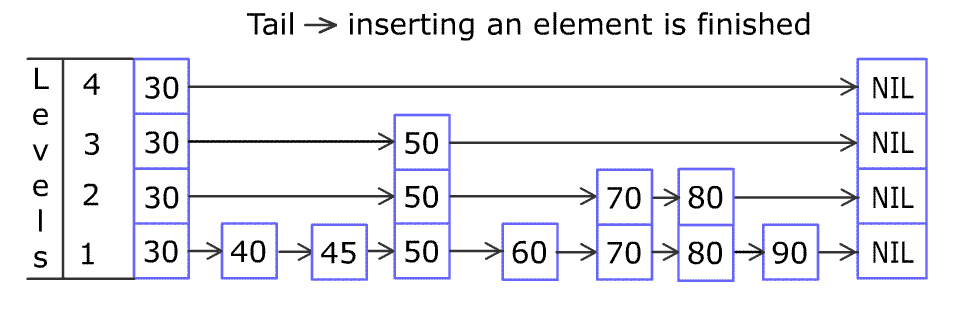
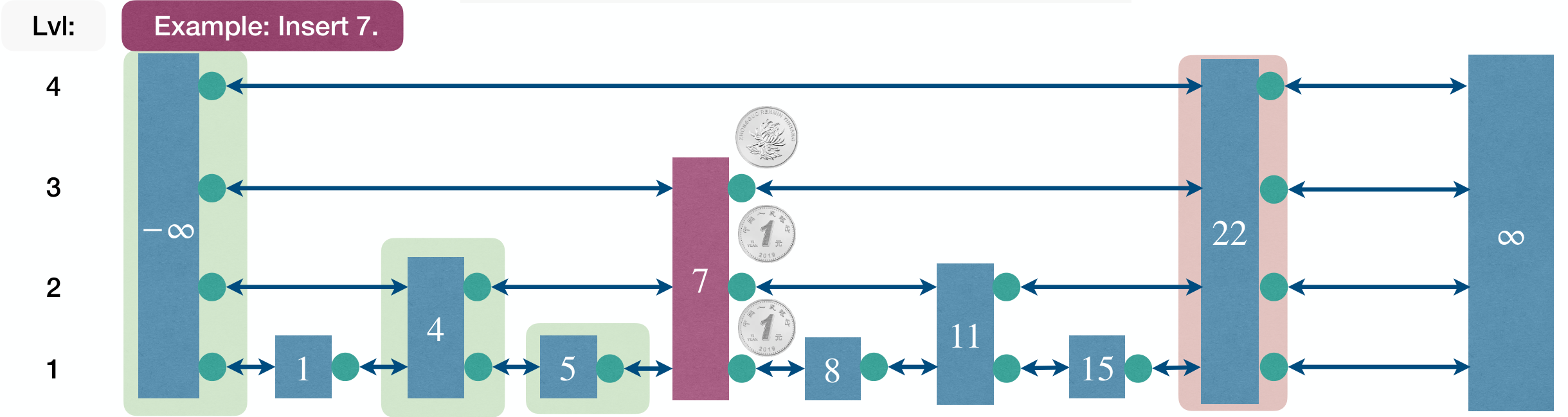
Complexity
Time complexity
- in expectation
- with high probability, i.e., with .
The maximum level of -element SkipList is with high probability.
Consider the reverse of the path taken to find . We always move up as we can, because we always enter a node from its topmost level when doing a find.
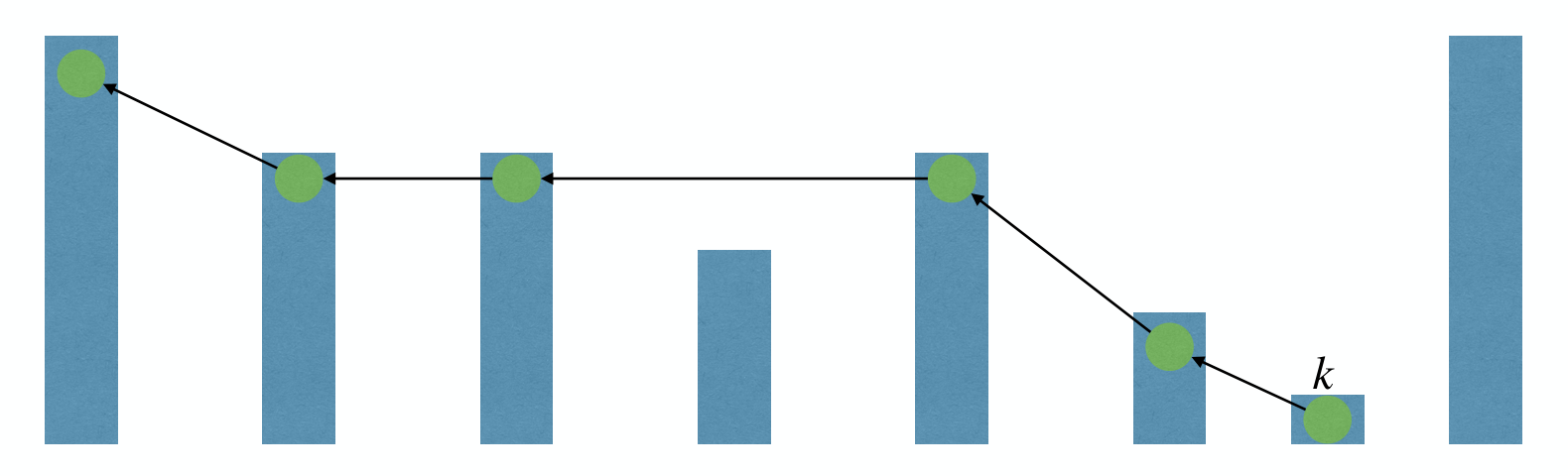
The probability that we can move up at a given step of the reverse walk is , since the probability of the existence of the next level is (we flip a fair coin to determine whether to insert at a higher level).
Steps to go up levels
- Make one step, then make either
- steps if this step went up
- steps if this step went left
Expected number of steps to walk up levels is:
Then we get
and
Since there are levels expected, we have steps expected.
Height expectation
For each level , define the IRV
The height of the SkipList is then given by .
Note that is never more than length of (number of elements), hence where is the number of elements in the SkipList.
Then we have
Summary
Efficient implementation of ORDERED DICTIONARY:
Search(S, k) |
Insert(S, x) |
Remove(S, x) |
|
|---|---|---|---|
| BinarySearchTree | in worst case | in worst case | in worst case |
| Treap | in expectation | in expectation | in expectation |
| RB-Tree | in worst case | in worst case | in worst case |
| SkipList | in expectation | in expectation | in expectation |