并查集
DisjointSet ADT
DisjointSet
A DisjointSet(并查集) ADT (also known as Union-Find ADT) maintains a collections
of sets that are disjoint and dynamic.
Each set is represented by a representative element (i.e., a leader)
The ADT supports the following operations:
MakeSet(x): Create a set containing onlyx, add the set toS.Union(x, y): Find the sets containingxandy, say and , remove and fromS, and add toS.Find(x): Return a pointer to the leader of the set containingx.
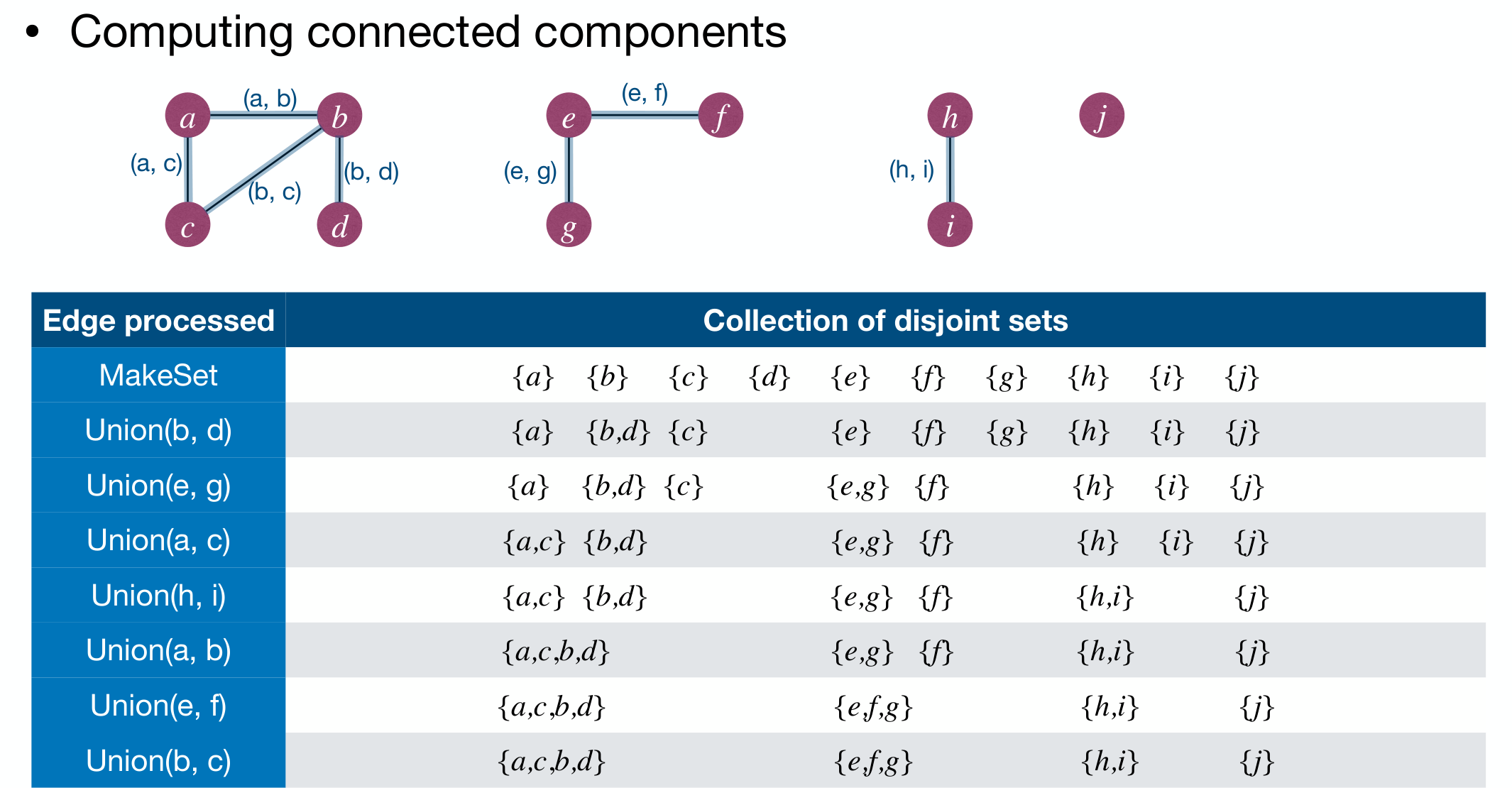
Sample application of DisjointSet ADT: Computing connected components.
Implementation
LinkedList
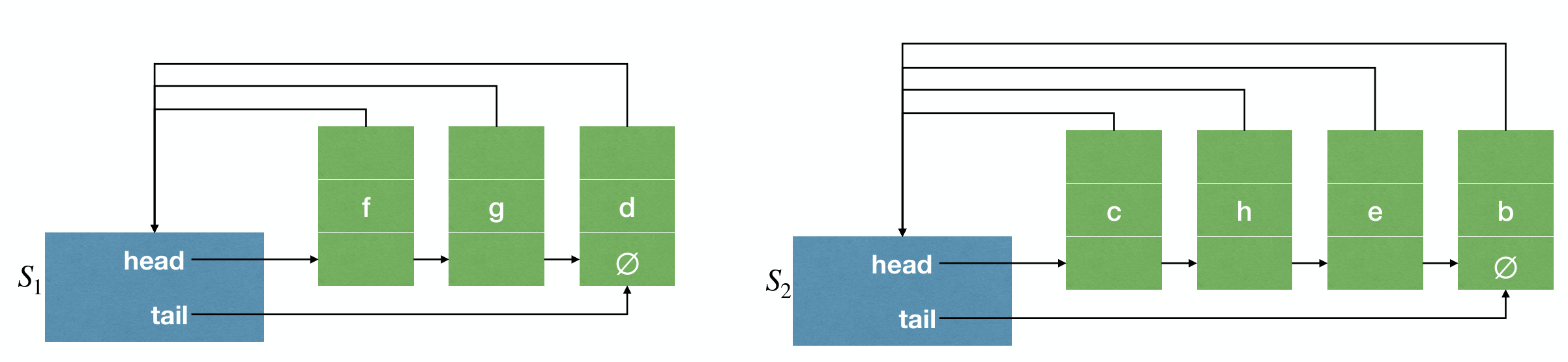
Basic Idea: Use a LinkedList to store and represent a set.
Details:
- A set object has pointers pointing to head and tail of the LinkedList.
- The LinkedList contains the elements in the set.
- Each element has a pointer pointing back to the set object.
- The leader of a set is the first element in the LinkedList.
Operations:
MakeSet(x): Create a new set containing onlyx.Find(x): Follow pointer from x back to the set object, then return pointer to the first element in the LinkedList.Union(x, y):- Append list in to list in , Destroy set object
- Update set object pointers for elements originally in
- Time depends on size of
- Append list in to list in , Destroy set object
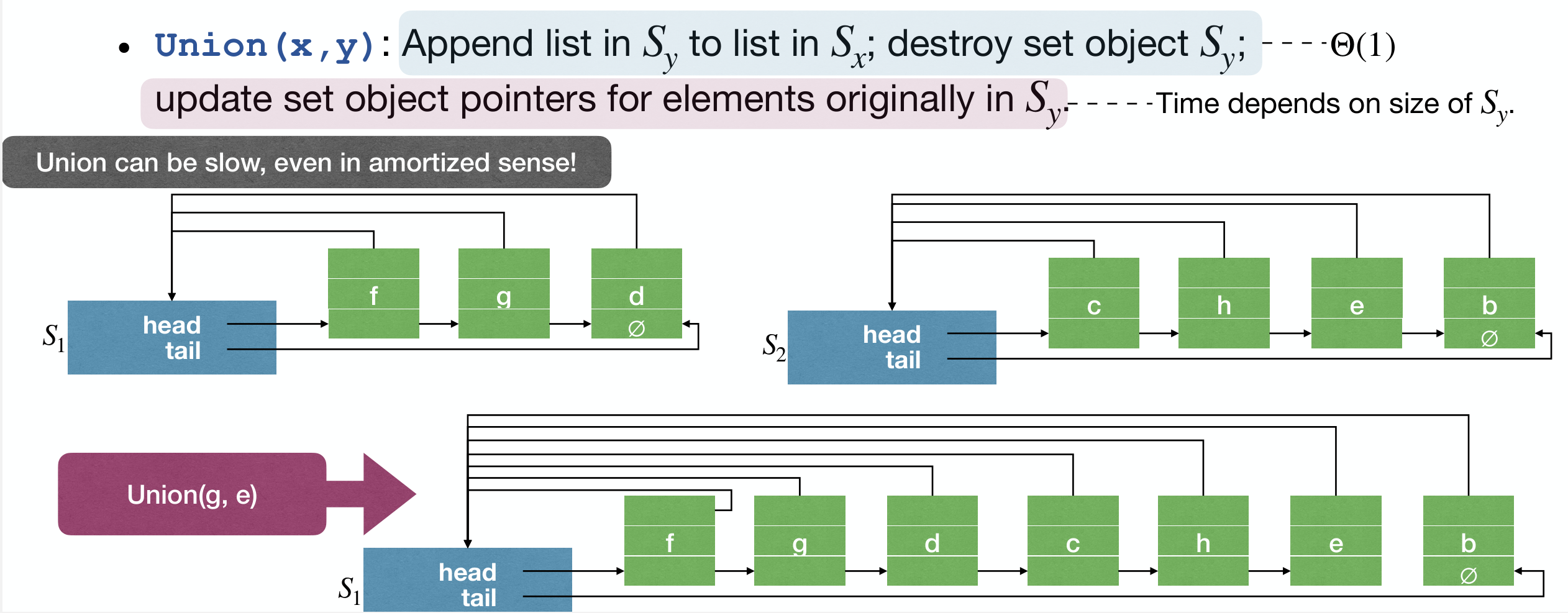
The worst case of Union(x, y):
次
Union操作的最差序列,这里计算的是 amortized cost。
1 2 3 4 | MakeSet(x0) for i := 1 to n MakeSet(xi) Union(xi, x0) |
causing time in total.
Each MakeSet takes time, but the average cost of Union reaches .
- Improvement: Weighted-union heuristic (union-by-size)
- Basic Idea: In
Unionoperation, always append the smaller list to the larger list. - Complication: Need to maintain the size of each set.
However, in this case, the sequence above is no longer the worst case now.
Worst complexity of any sequence of MakeSet and then Union is .
Proof Steps:
- The
MakeSetoperation take time in total. - For
Unionoperation, cost dominated by set object pointer changes. - For each element, whenever its set object pointer changes, its set size at least doubles. (Improvement Definition)
- Each element's set object pointer changes at most times.
- Therefore the total cost of
Unionoperations is . ( elements)
Average cost of Union operation is .
Rooted-tree
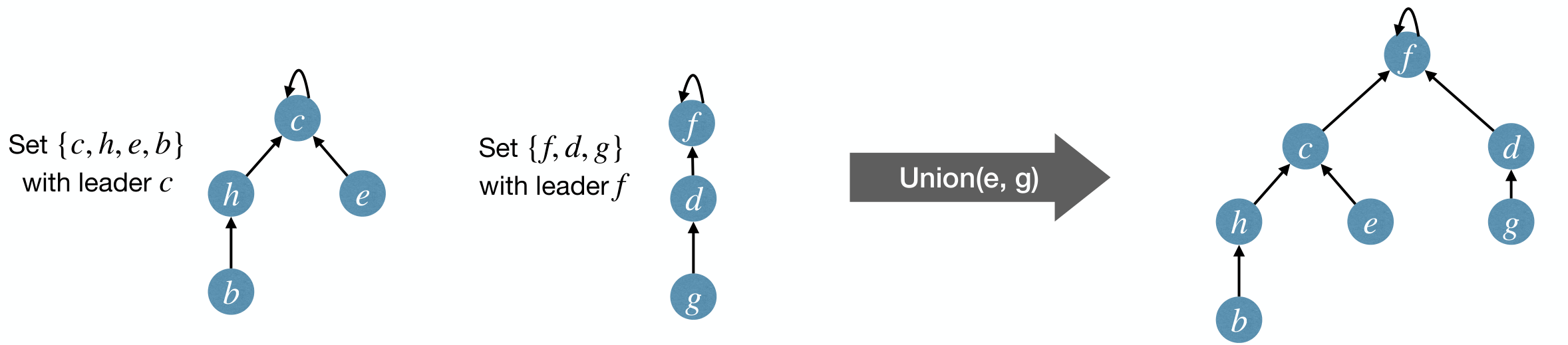
Basic Idea: Use a rooted tree to store and represent a set. The root of a tree is the leader of the set.
Details:
- Each node has a pointer pointing to its parent. Parent of a leader is itself.
Operations:
MakeSet(x): Create a new tree containing onlyx.Find(x): Follow parent pointer from back to the root, and return root.Union(x, y): Change the parent pointer of the root of to the root of .
Time complexity of Find(x) and Union(x, y) depends on depth of and .
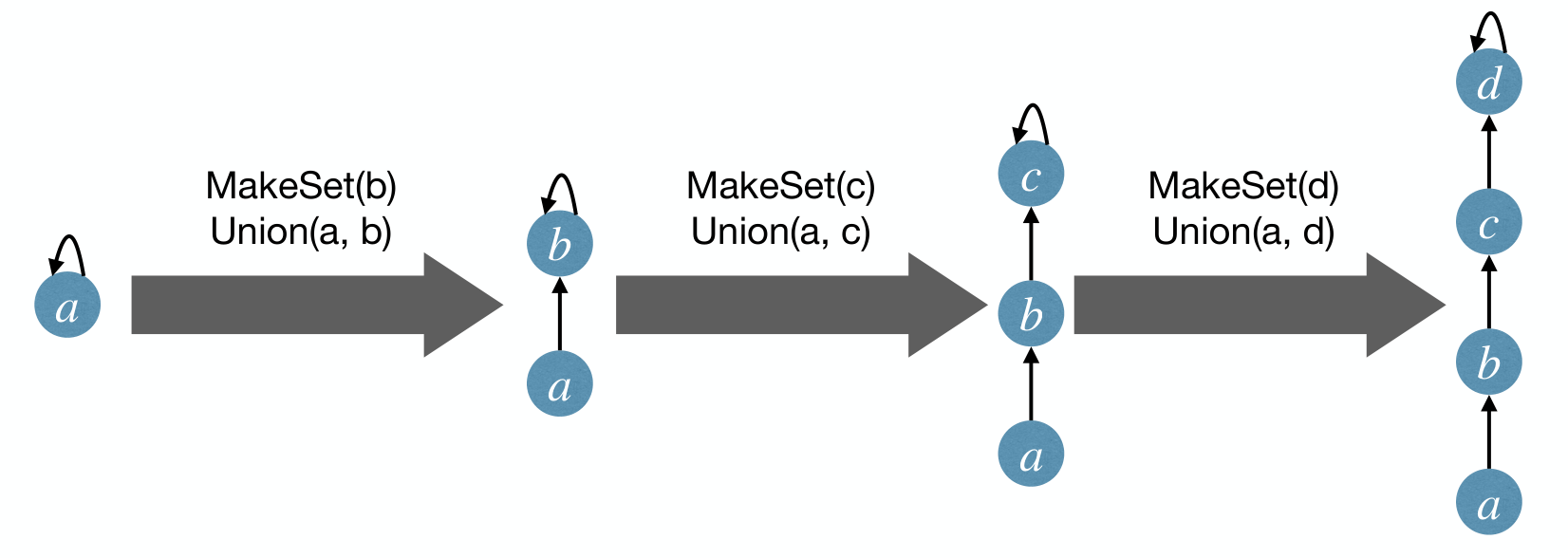
The worst case of Union(x, y): A sequence of Union can cost on average. And many following Find will also cost .
- Improvement
- Use union-by-size heuristic. Reduce worst-case cost of
UnionandFindto . - Use union-by-height heuristic. In
Union, let tree of smaller height be subtree of larger height.

Path-compression in Find
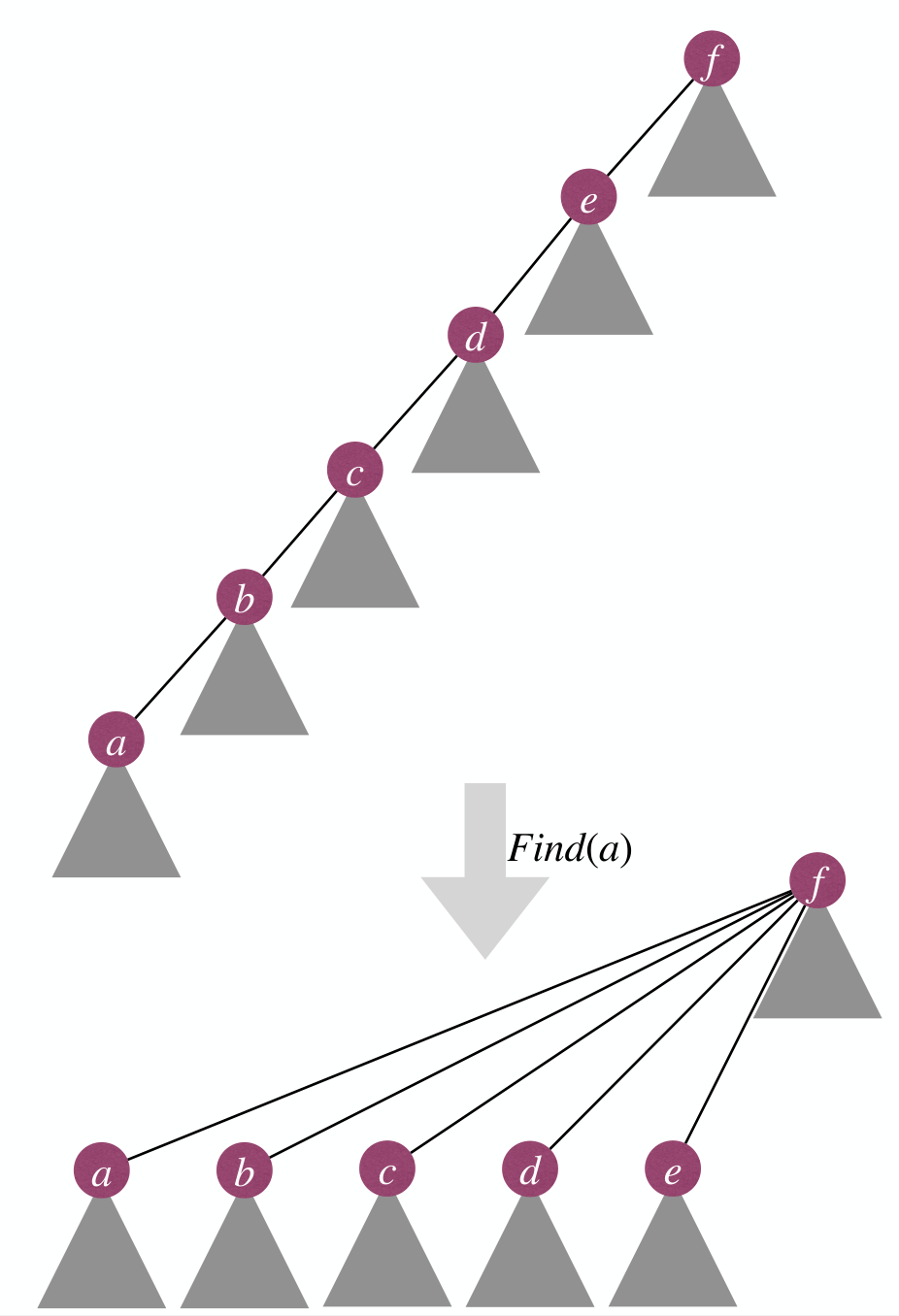
Do some work in Find to speed up future Find without increasing asymptotic cost of Find.
Path-Compression: In Find(x), when traveling from to root , make all nodes on this path directly point to root .
Path-compression will not increase cost of Find asymptotically.
Find can now change heights. Then maintaining heights becomes expensive.
- Solution: Ignore the impact on height when doing path compression. In such case, the height is referred to rank. The rank is always an upper bound of height.
The Find and Union operation of this implementation is almost .
Performance analysis for rooted-tree implementation with union-by-rank and path-compression*
Slowly Growing Functions
Consider the recurrence
In this equation, represents the number of times, starting at that we must iteratively apply until we reach or less.
We assume that is a nicely defined function that reduces . Call the solution to the equation .
- When , .
- When , .
- When , , which grows extremely slow.
Performance Analysis*
懒得记了,看 PPT 得了。