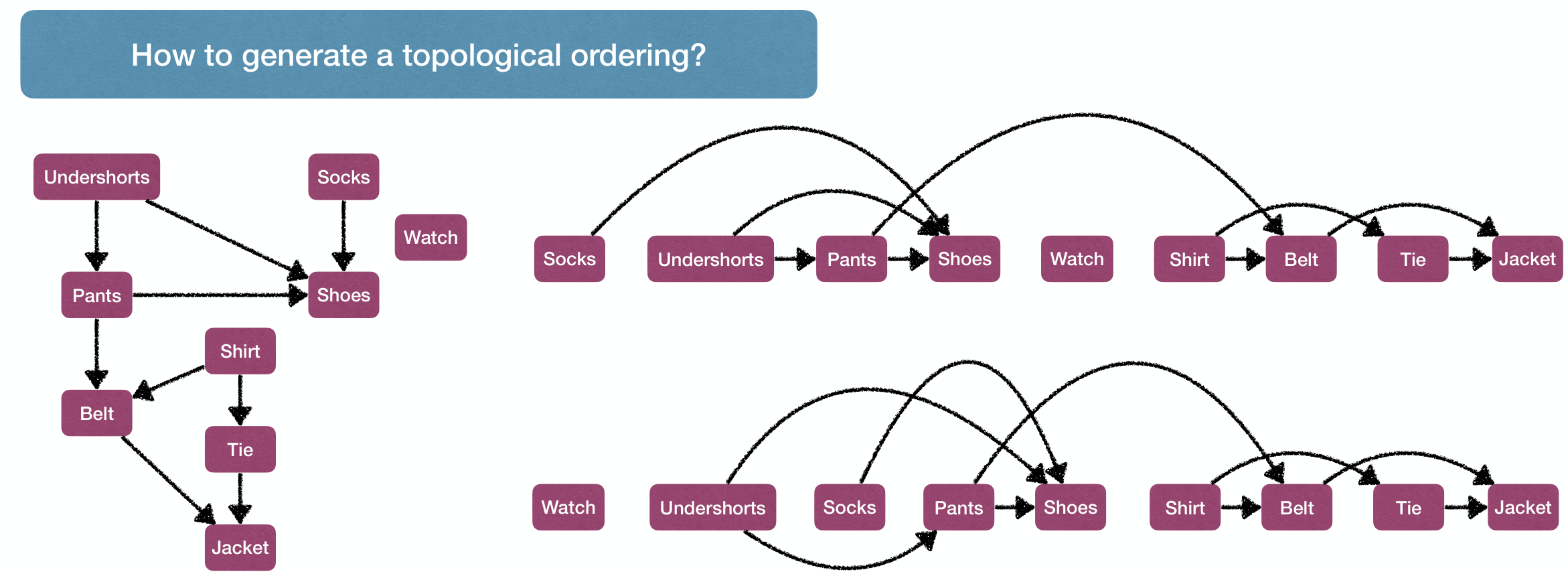
图及其遍历
本节可以参考《离散数学》笔记「图论初步」。
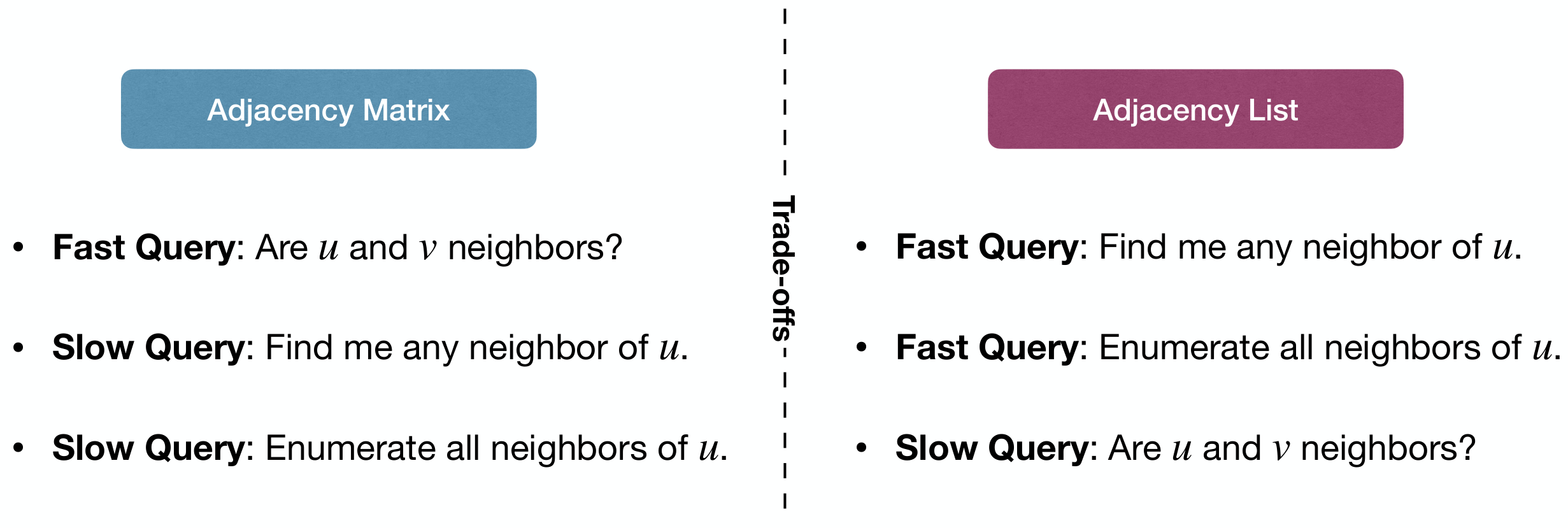
Representations
一些定义直接复制《离散数学》笔记了。
and .
邻接矩阵(Adjacency Matrix)
简单有向图 ,不妨设 。
则 称为 的邻接矩阵( 阶矩阵),其中
相邻即存在 使得 。
Space cost memory regardless of .
邻接表(Adjacency List)
邻接表:对于每个顶点 ,记录与之相邻的顶点。(有向图无向图均可用)

邻接矩阵中元素为 ,称为布尔矩阵。若表示包含多重边的图,则不是布尔矩阵。
Space cost .
Comparison:
Graph Traversal (Searching in a Graph)
Use adjacency list below.
Goal:
- Start at source node and find some node .
- Or visit all nodes reachable from .
Strategies:
- Breadth-first search (BFS, 广度优先搜索)
- Depth-first search (DFS, 深度优先搜索)
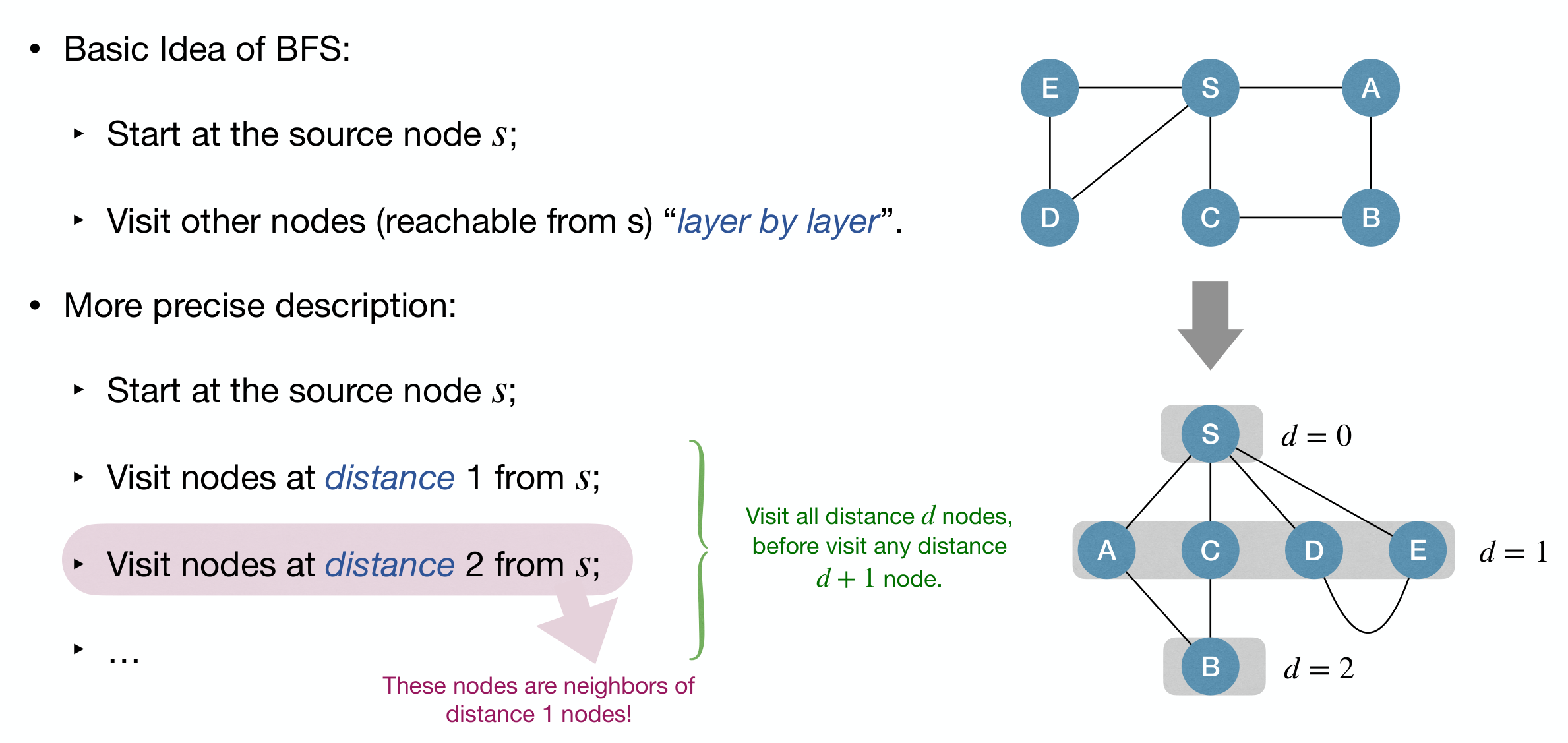
Breadth-First Search (BFS)
Basic idea:
- Start at the source node ;
- Visit other nodes layer by layer.
Implementation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | BFSSkeleton(G, s): for each u in V u.dist := INF u.discovered := False s.dist := 0 s.discovered := True Q.enqueue(s) while !Q.isEmpty() u := Q.dequeue() for each edge(u, v) in E if !v.discovered v.dist := u.dist + 1 v.discovered := True Q.enqueue(v) |
Nodes have 3 status:
- Undiscovered: Not in queue yes;
- Discovered but not visited: In queue but not processed;
- Visited: Ejected from queue and processed.
Use Color instead, WHITE, GRAY, BLACK.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | BFD(G, s): for each u in V u.c := WHITE u.d := INF u.p := NIL s.c = GRAY s.d = 0 s.p = NIL Q.enqueue(s) while !Q.isEmpty() u := Q.dequeue() u.c = BLACK for each edge(u, v) in E if v.c = WHITE v.c = GRAY v.d = u.d + 1 v.p = u Q.enqueue(v) |
The improved version also records the shortest path, instead of just the distance.
Process:
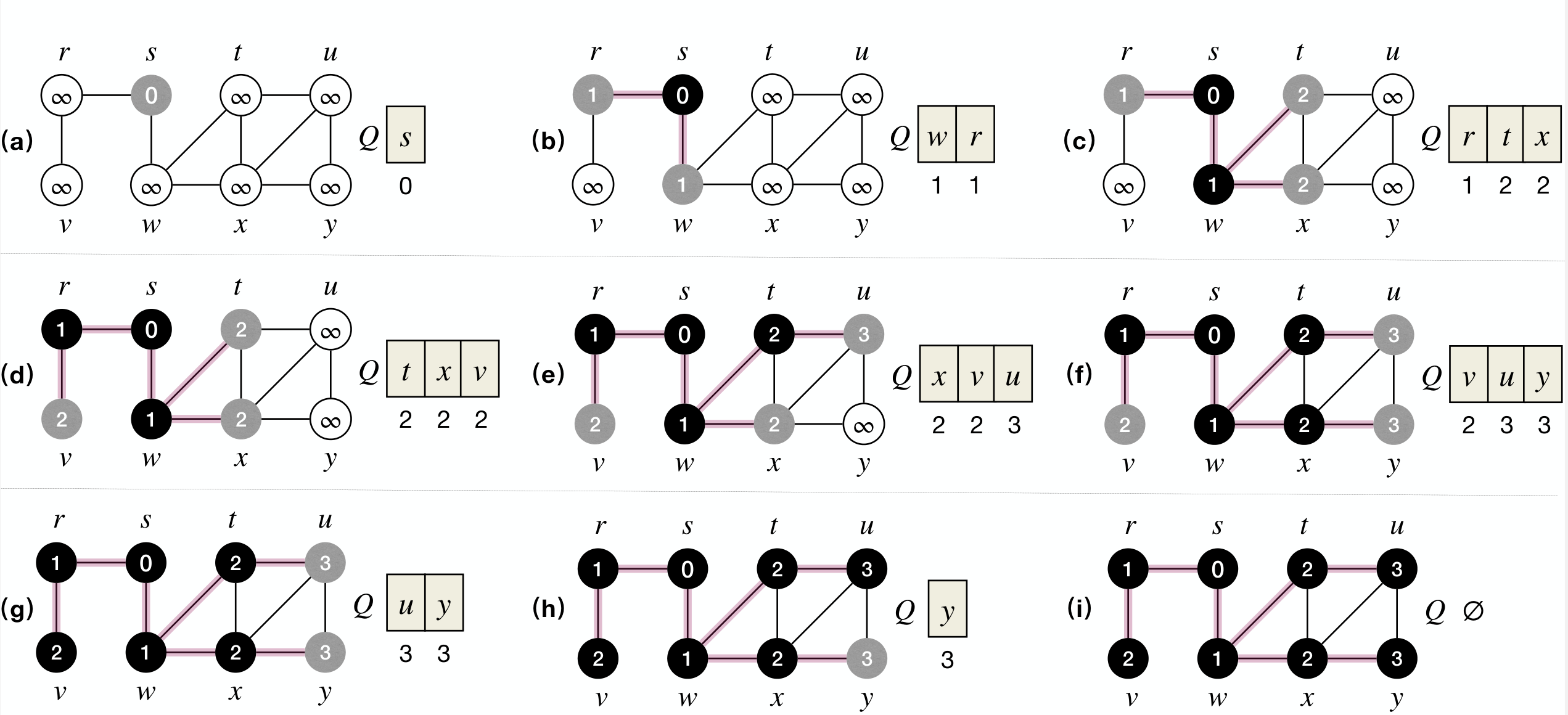
Performance:
whileloop costs times since each node in at most once.forloop costs times since each edge visited at most once or twice.- Total cost: .
Some theorems without proof (cos I'm lazy):
BFS visits a node iff it is reachable from the source node.
BFS correctly computes u.dist for every node reachable from the source node.
Corollay: For any that is reachable from , one of the shortest path from to is a shortest path from to 's parent followed by the edge between 's parent and .
is a breadth-first tree, which can print on a shortest path from any node to the source node .
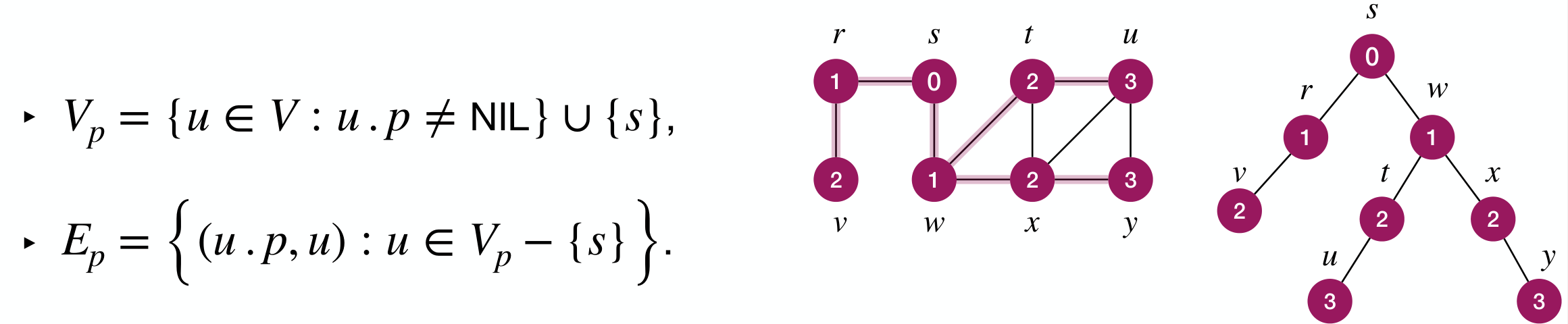
What if graph is not connected? Do a BFS for each connected component.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | BFD(G, s): for each u in V u.c := WHITE u.d := INF u.p := NIL for each u in V if u.c = WHITE u.c = GRAY u.d = 0 u.p = NIL Q.enqueue(u) while !Q.isEmpty() v := Q.dequeue() v.c = BLACK for each edge(v, w) in E if w.c = WHITE w.c = GRAY w.d = v.d + 1 w.p = v Q.enqueue(w) |
Depth-First Search (DFS)
Like exploring a maze:
- Use a ball of string and a piece of chalk.
- Chalk: Boolean variables.
- String: A stack.
- Follow path (unwind string and mark at intersections), until stuck (reach dead-end or already-visited place).
- Backtrack (rewind string), until find unexplored neighbor (intersection with unexplored direction).
- Repeat above two steps.
1 2 3 4 5 | DFSSkeleton(G, s): s.visited := True for each edge(s, v) in E if !v.visited DFSSkeleton(G, v) |
1 2 3 4 5 6 7 8 9 10 11 12 | DFSIterSkeleton(G, s): Stack Q Q.push(s) while !Q.isEmpty() u := Q.pop() u.visited := True for each edge(u, v) in E if !v.visited Q.push(v) // This code is a little different from PPT. // `Q` here only contains node unvisited while // `Q` in PPT contains all sub nodes. |
Process:
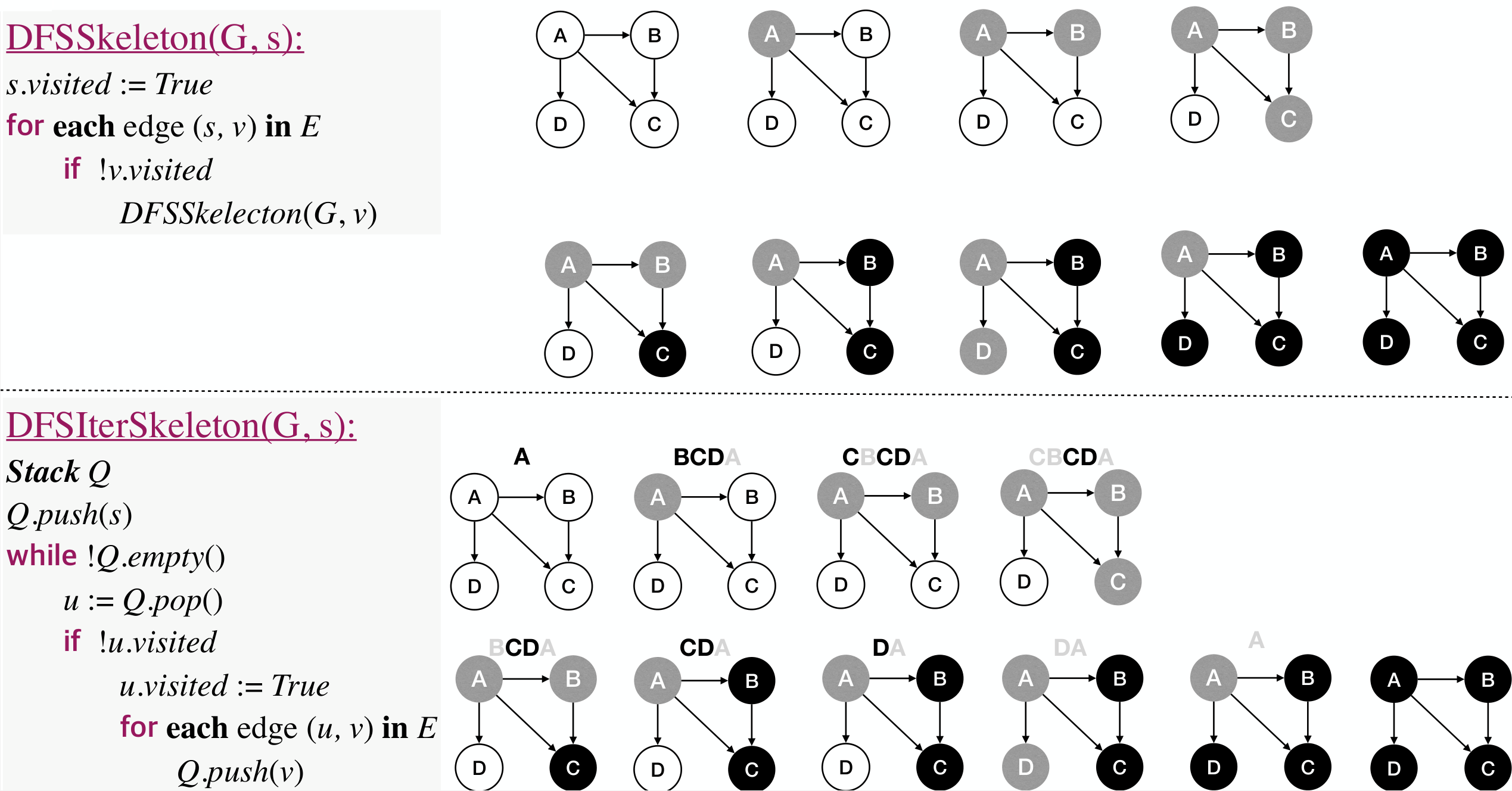
Do DFS from multiple sources if the graph is not (strongly) connected.
1 2 3 4 5 6 | DFSAll(G): for each u in V u.visited := False for each u in V if !u.visited DFSSkeleton(G, u) |
Each node have 3 status during DFS:
- Undiscovered WHITE: before calling
DFSSkeleton(G, u); - Discovered GRAY: during execution of
DFSSkeleton(G, u); - Finished BLACK:
DFSSkeleton(G, u)returned.
DFS(G, u) builds a tree among nodes reachable from :
- Root of this tree is ;
- For each non-root, its parent is the node that makes it turns GRAY.
DFS on entire graph builds a forest.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | DFSAll(G): for each node u in V u.c := WHITE u.p := NIL for each node u in V if u.c = WHITE DFS(G, u) DFS(G, s): s.c := GRAY for each edge(s, v) in E if v.c = WHITE v.p := s DFS(G, v) s.c := BLACK |
Process:
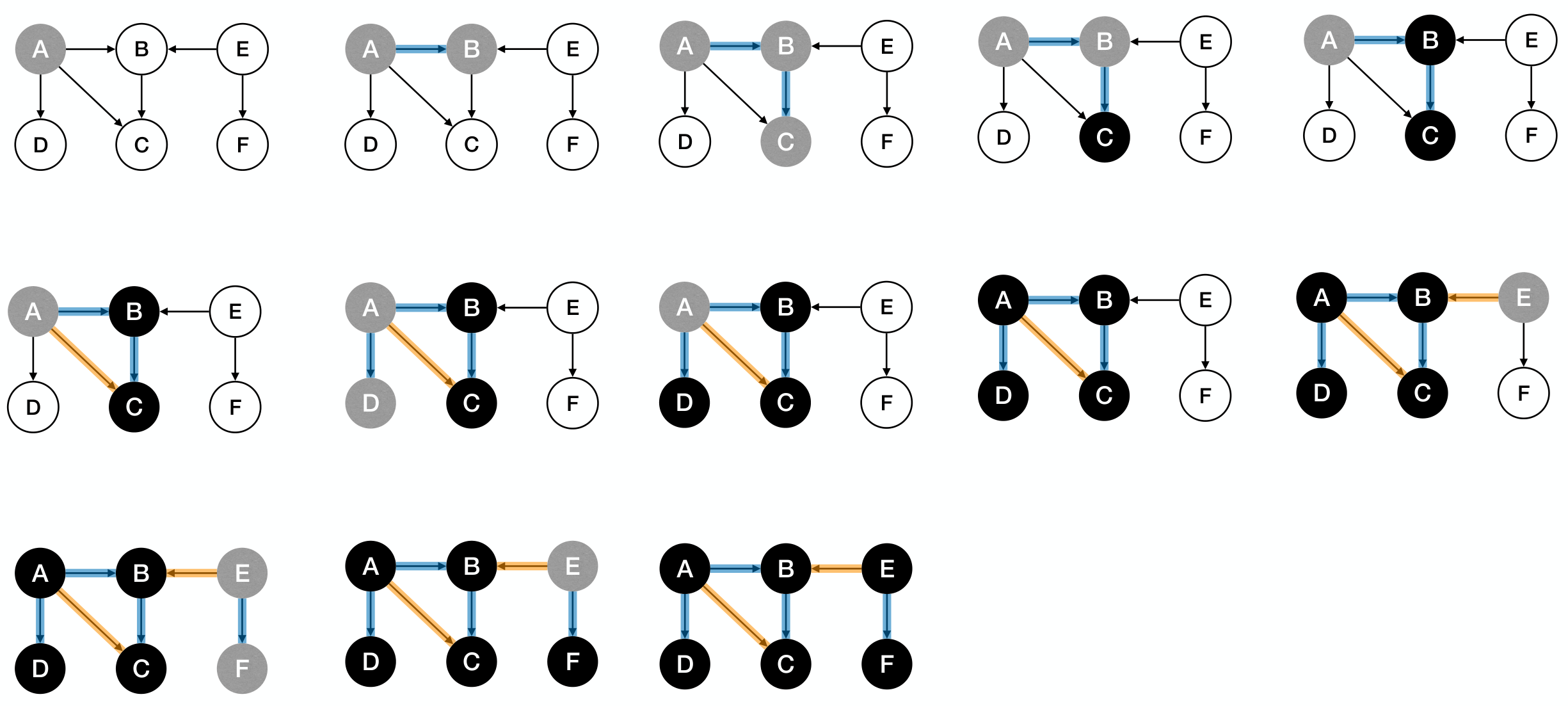
DFS provides (at least) two chances to process each node:
- Pre-visit: WHITE to GRAY
- Post-visit: GRAY to BLACK
1 2 3 4 5 6 7 8 | DFSAll(G): PreProcess(G) ... DFS(G, s): PreVisit(s) ... PostVisit(s) |
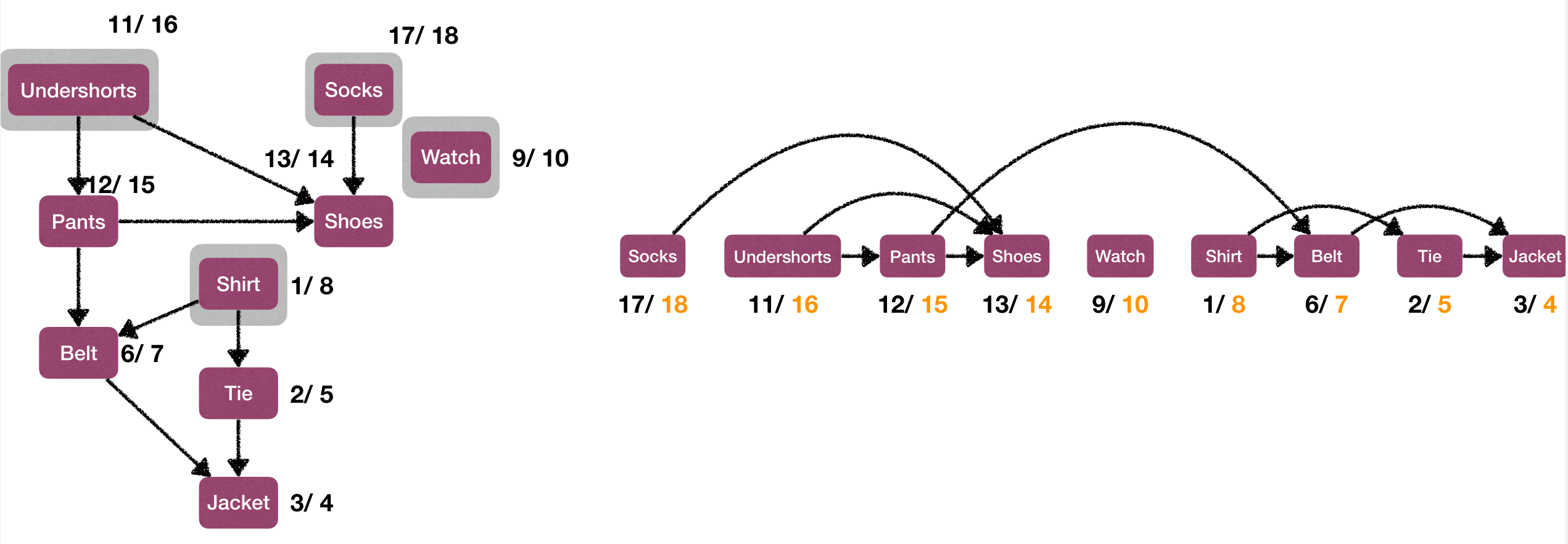
Some application: Track active intervals of nodes
- Clock ticks whenever some nodes's color changes.
- Discovery time: when the node turns to GRAY.
- Finish time: when the node turns to BLACK.
1 2 3 4 5 6 7 8 9 10 | PreProcess(G): time := 0 PreVisit(s): time := time + 1 s.d := time // indicates the discovery time PostVisit(s): time := time + 1 s.f := time // indicates the finish time |
Example:
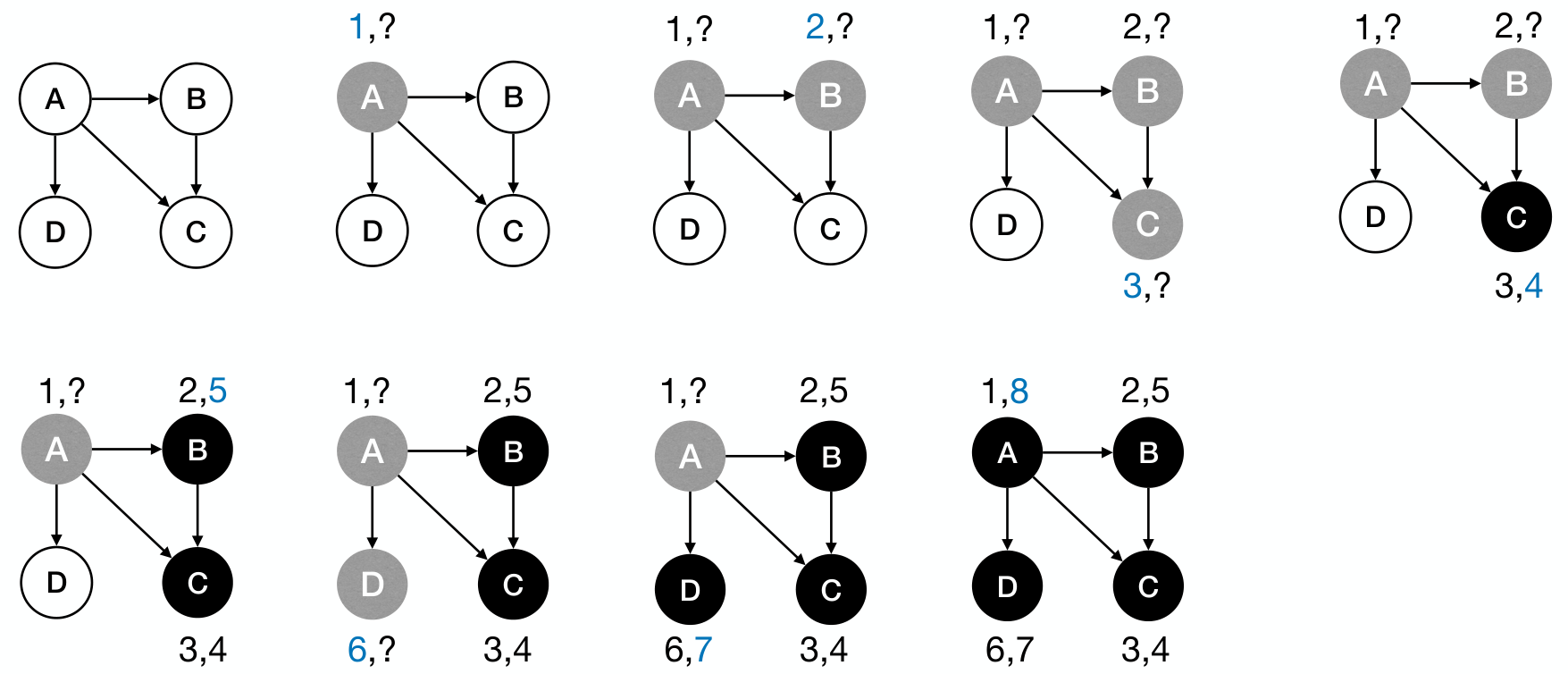
Performance:
- Time spent on each node is and
DFS(G, u)is called once for each node . - Time spent on each edge is and each edge is examined time.
- Total cost: .
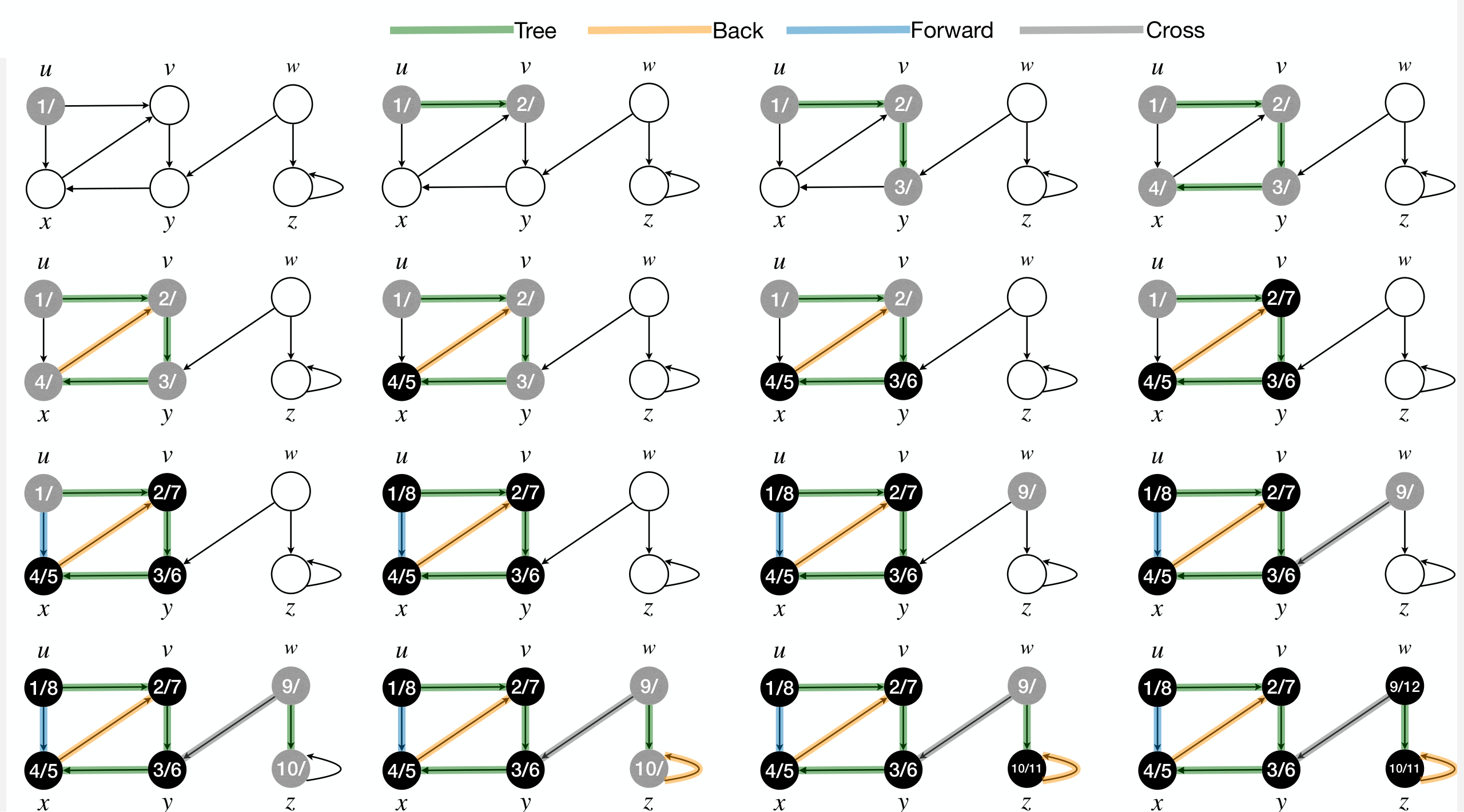
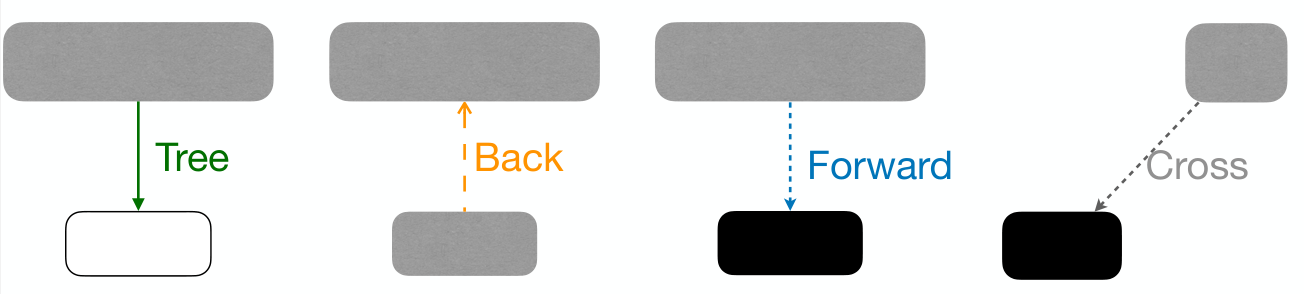
DFS process classify edges of input graph into 4 types:
- Tree Edges: Edges in DFS forest.
- Back Edges: Edges connecting to an ancestor in a DFS tree.
- Forward Edges: Non-tree edges connecting to a descendant in a DFS tree.
- Cross Edges: Other edges.
- Connecting nodes in same DFS tree with no ancestor-descendant relation, or connecting nodes in different DFS trees.
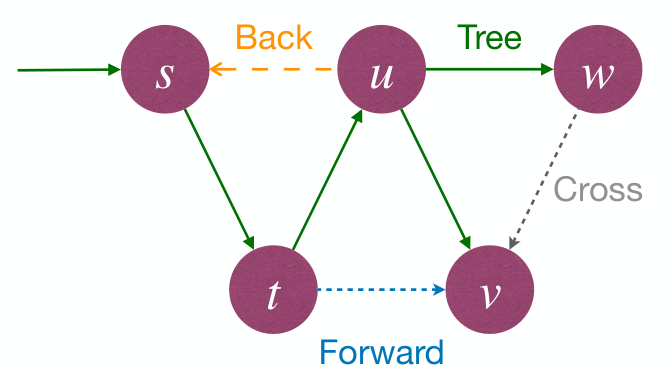
Properties
Parenthesis Theorem
Active intervals of two nodes are either:
- entirely disjoint
- one is entirely contained within another
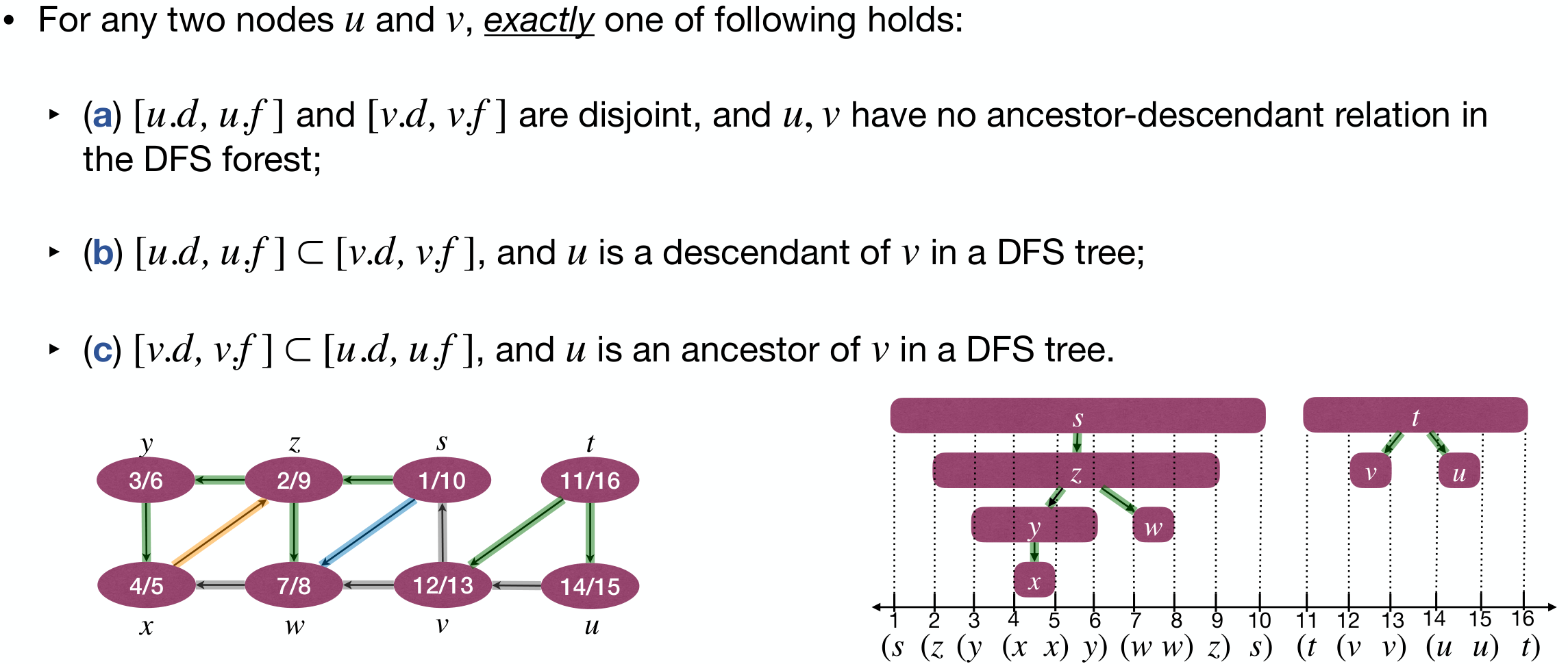
Proof.
W.l.o.g., assume .
- If : then is discovered (WHITE to GRAY) while is being processed (GRAY); and DFS will finish first before returning to .
- In this case, and is an ancestor of .
- If : then obviously ; and DFS has finished exploring (BLACK), before is discovered (WHITE to GRAY).
- In this case, and are disjoint, and have no ancestor-descendant relation.
White-path Theorem
In the DFS forest, is a descendant of iff when is discovered, and there is a path in the graph from to containing only WHITE nodes.
Proof.
:
Claim: If is a proper descendant of , then is WHITE when is discovered. Since if is a proper descendant of , then .
For any node along the path from to in the DFS forest, above claim holds.
Therefore direction of the theorem holds.
:
W.l.o.g., assume is the first node along the path that does not become a descendant of . So we get .
But is discovered after is discovered and must before is finished. So we have .
Then it must be , implying is a descendant of .

Classification of edges
Determine edge type by color of during DFS execution:
- Tree Edges: Node is WHITE.
- Back Edges: Node is GRAY.
- Forward Edges: Node is BLACK
- Cross Edges: Node is BLACK
Types of edges in undirected graphs
In DFS of an undirected graph , every edge of is either a Tree Edge or a Back Edge.
Proof
Consider an arbitrary edge . W.l.o.g., assume .
Edge must be explored while is GRAY.
Consider the first time the edge is explored:
- If the direction is : Then must be WHITE by then, for otherwise the edge would have been explored from direction earlier.
- If the direction is : Then the edge is GRAY to GRAY, which is a Back Edge.
Other queuing disciplines lead to other search.
Applications of DFS
Directed Acyclic Graphs (DAGs)
A graph without cycles is called acyclic(无环).
A directed graph without cycles is a directed acyclic graph (DAG, 有向无环图).
DAGs are good for modeling relations such as: causalities, hierarchies, and temporal dependencies.
Topological Sort
A topological sort(拓扑序) of a DAG is a linear ordering of its vertices such that if contain an edge , then appears before in the ordering.
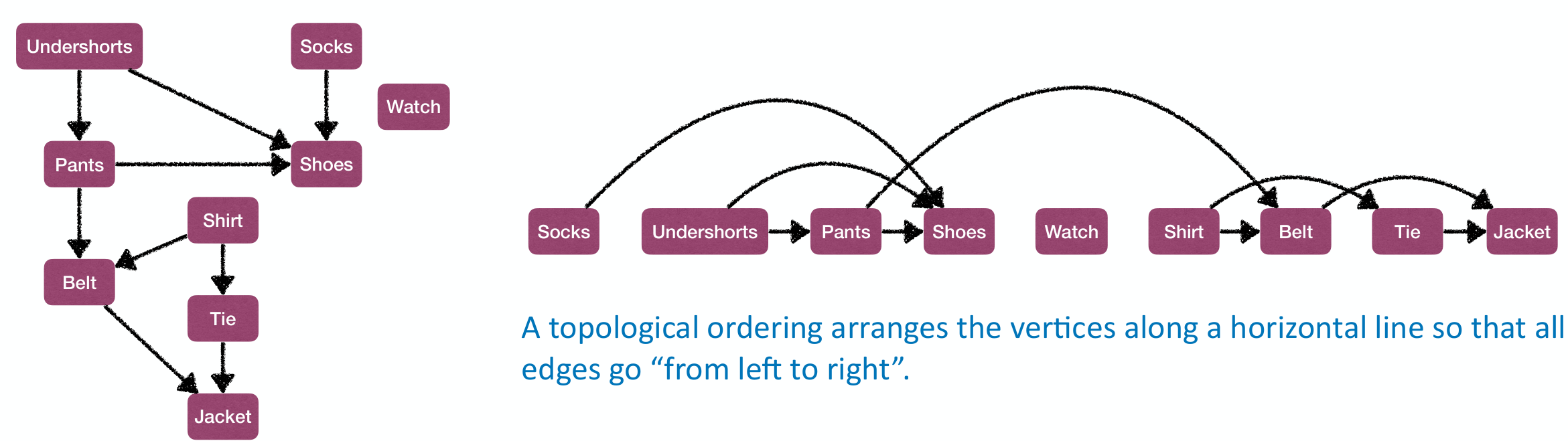
defines a partial order over , a topological sort gives a total order over satisfying .
Topological sort is impossible if the graph contains a cycle.
A given graph may have multiple different valid topological ordering.
Questions:
- Does every DAG has a topological ordering?
- If true, How to tell if a directed graph is acyclic?
- If true, how to do a topological sort on a DAG?
Lemma 1
Directed graph is acyclic iff a DFS of yields no back edges.
Proof.
:
For the sake of contradiction, assume DFS yields back edge .
So is ancestor of in DFS forest, meaning there's a path from to in .
But together with edge this creates a cycle. Contradiction!
:
For the sake of contradiction, assume contains a cycle .
Let be the first node to be discovered in C.
By the White-path theorem, is a descendant of in DFS forest.
But then when processing , becomes a back edge!
Lemma 2
If we do a DFS in DAG , then for every edge in .
Proof.
When exploring , cannot be GRAY, otherwise we have a back edge.
If is WHITE, then becomes a descendant of and .
If is BLACK, then .
As a result, decreasing order of finish times of DFS on DAG gives a topological ordering. Therefore, every DAG has a topological ordering.
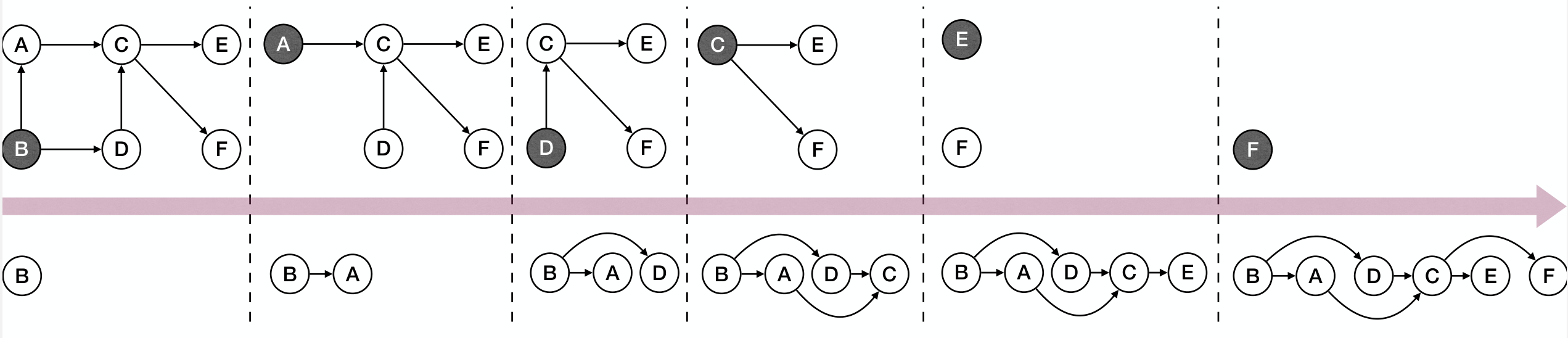
Topological Sort of :
- Do DFS on and compute finish times for each node along the way;
- When a node finishes, insert it to the head of a list;
- If no back edge is found, then the list eventually gives a Topological Ordering.
Time complexity is .
Alternative Algorithm for Topological Sort
A source node(源头点) is a node with no incoming edges.
A sink node(汇点) is a node without outgoing edges.
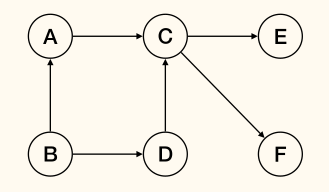
is source and are sink.
Obviously, each DAG has at least one source and one link.
Here are two observations:
- In DFS of a DAG, node with max finish time must be a source.
- Node with max finish time appears first in topological sort, it cannot have incoming edges.
- In DFS of a DAG, node with min finish time must be a sink.
- Node with min finish time appears last in topological sort, it cannot have outgoing edges.
Alternative Algorithm for Topological Sort:
- Find a source node in the (remaining) graph and output it;
- Delete and all its outgoing edges from the graph;
- Repeat until the graph is empty.
(Strongly) Connected Components
可部分参考《离散数学》笔记关于「连通分支」的内容。
Connected Components
For an undirected graph , a connected component (CC, 连通分量) is a maximal set , such that for any pair of nodes in , there is a path from to .
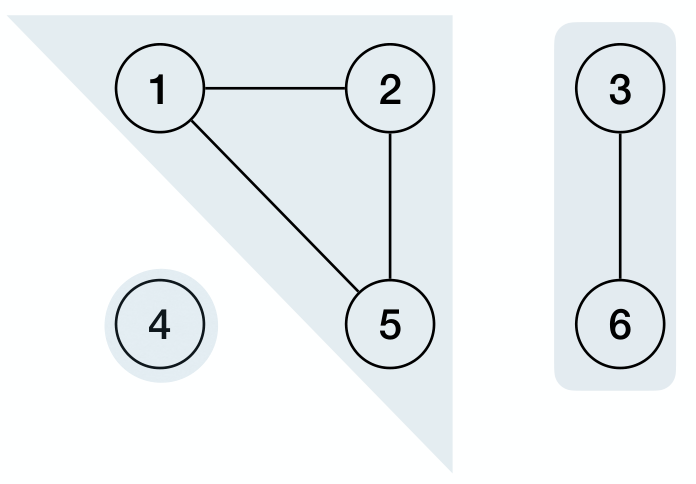
For a directed graph , a strongly connected component (SCC, 强连通分量) is a maximal set , such that for any pair of nodes in , there is a directed path from to and a path from to , and vice versa.
Given an undirected graph, just do DFS or BFS on the entire graph can compute its CC.
However for a directed graph, it's not that easy.
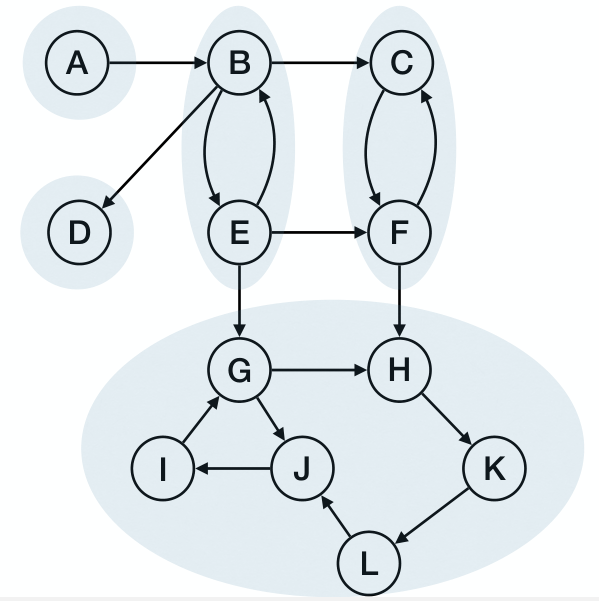
Component Graph & Computing SCC
Given a directed graph , assume it has SSC . Then the component graph is .
- The vertex set , each representing one SCC.
- There is an edge if there exists where .
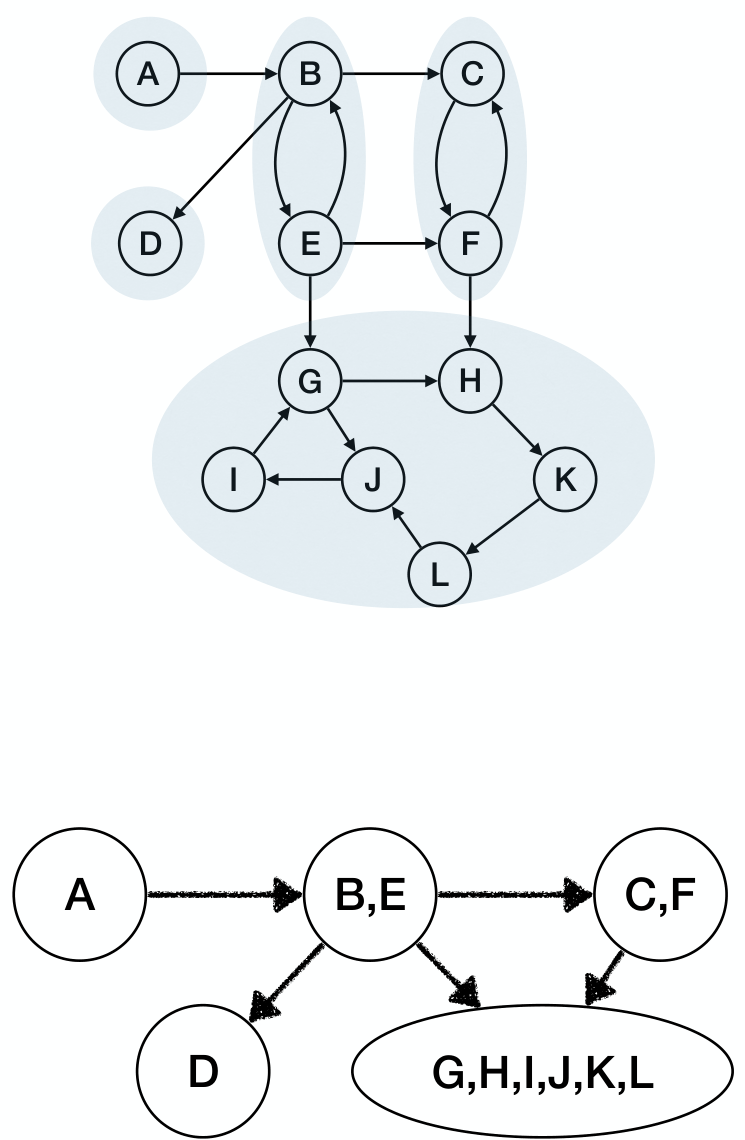
Claim: A component graph is a DAG. Otherwise the components in the circle becomes a bigger SCC, contradicting the maximality of SCC.
Since each DAG has at least one source and one sink, we can do one DFS starting from a node in a sink SCC, and explore exactly nodes in that SCC and stop.
However:
- How to identify a node that is in a sink SCC?
- We don't know the structure of component graph.
- The node with earliest finished time is not always in a sink SCC.
- What to do when the first SCC is done?
Though the node with earliest finished time is not always in a sink SCC, the node with latest finished time is always in a source SCC.
Therefore, we can reverse the direction of each edge in getting , then the sink SCC in is the source SCC in .
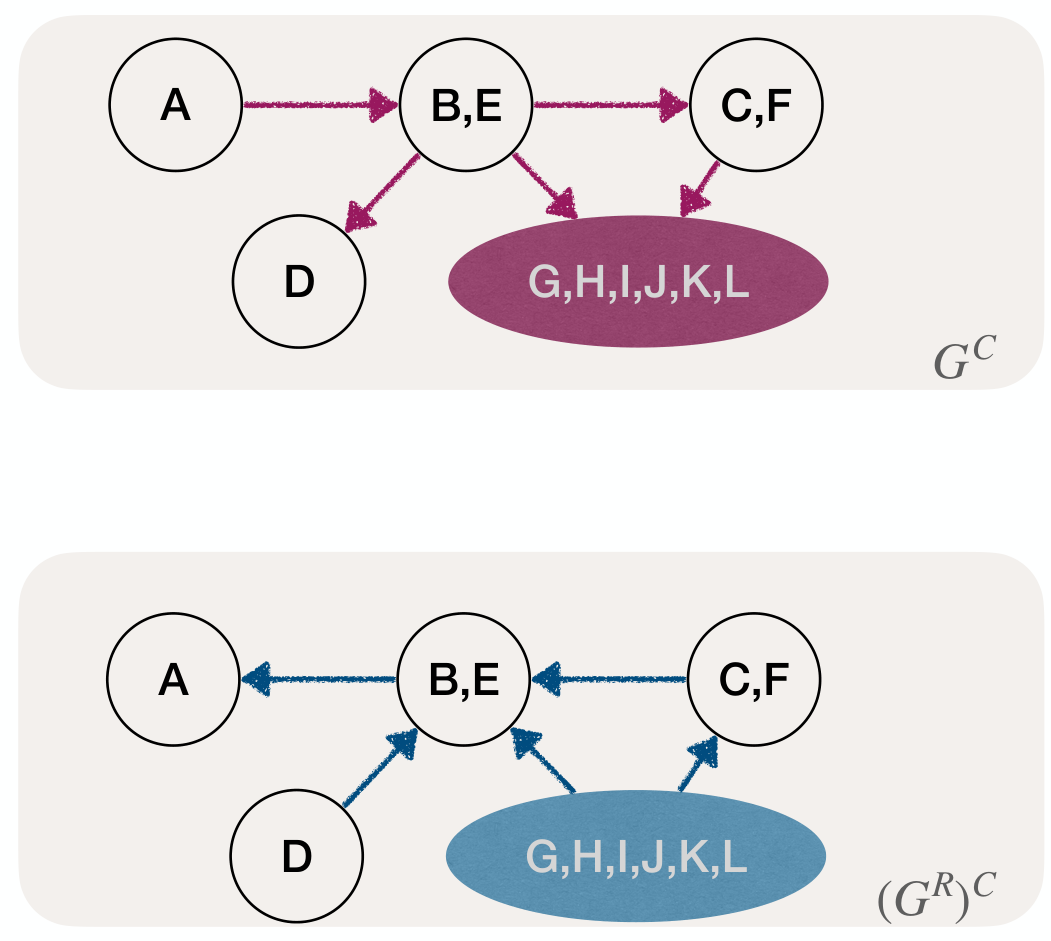
Compute in time, then find a node is a source SCC in . Do DFS in , the nod ewith maximum finish time is guaranteed to be in source SCC.
Lemma
For any edge , if , then .
Proof.
Consider nodes in and , let be the first node visited by DFS.
If , then all nodes in will be visited before any nodes in is visited. In this case, the lemma is true.
If , at the time that DFS visits , for any node in , there is a white-path from to that node. In this case, due to the white-path theorem, the lemma again holds.
The second question. For remaining nodes in , the node with max finish time (in DFS of ) is again in a sink SCC for whatever remains of .
Tarjan's Algorithm*
这个部分纯听了,不记了。
Minimum Spanning Trees
最小生成树部分一样可以参考《离散数学》笔记关于「生成树」的内容。
Consider a connected, undirected, weighted graph . That is, we have a graph together with a weight function that assigns a real weight to each edge .
A spanning tree(生成树) of is a tree containing all nodes in and a subset of all the edges .
A minimum spanning tree(最小生成树, MST) is a spanning tree whose total weight is minimized.
Kruskal's Algorithm
Kruskal 算法:从空集开始,每次加入权重最小的安全边,直到生成树。
Identifying Safe Edges
A cut(割) of is a partition of into two parts.
An edge crosses the cut if one of its endpoint is in and the other endpoint is in .
A cut respects an edge set if no edge in crosses the cut.
An edge is a light edge crossing a cut if the edge has minimum weight among all edges crossing the cut.
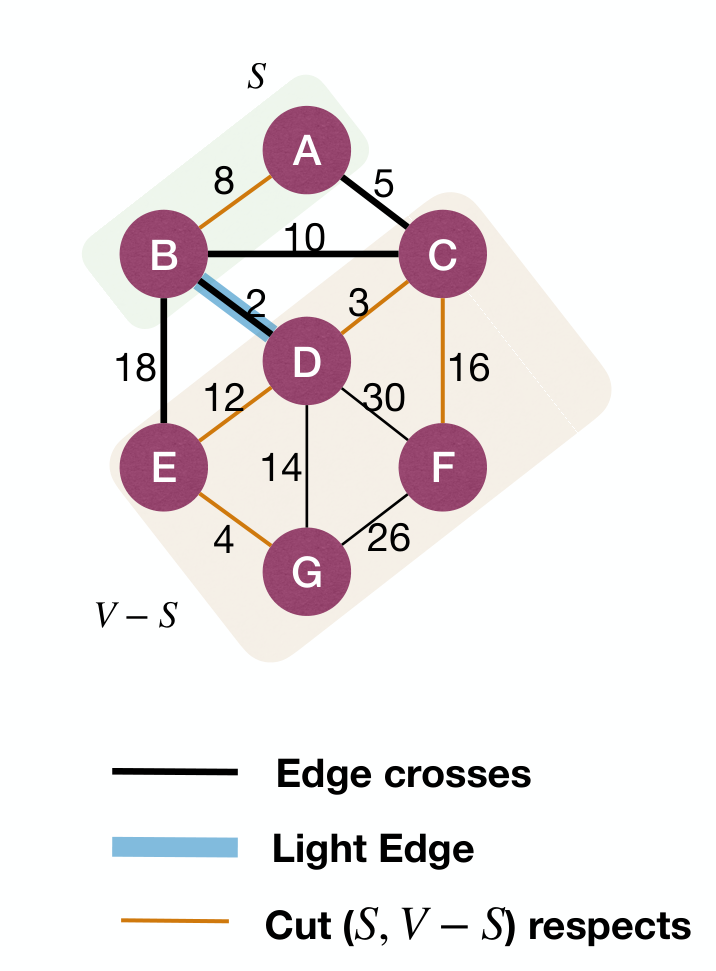
Cut Property
Assume is included in the edge set of some MST, let be any cut respecting . If is a light edge crossing the cut, then is safe for .
Proof.
Proof PPT:

Corollary: Assume is included in some MST, let . Then for any connected component in , its minimum-weight-outgoing-edge^outgoing in is safe for .
Strategy for finding safe edge in Kruskal's algorithm: Find minimum weight edge connecting two CC in .
1 2 3 4 5 6 7 | KruskalMST(G): A := {} Sort edges into weight increasing order for each edge (u, v) taken in weight increasing order if adding edge (u, v) does not form cycle in A A := A + {(u, v)} return A |
Put another way:
- Start with CC, each node itself is a CC. And .
- Find minimum weight edge connecting two CC. Then the number of CC is reduced by 1.
- Repeat until one CC remain.
Kruskal's Algorithm process:
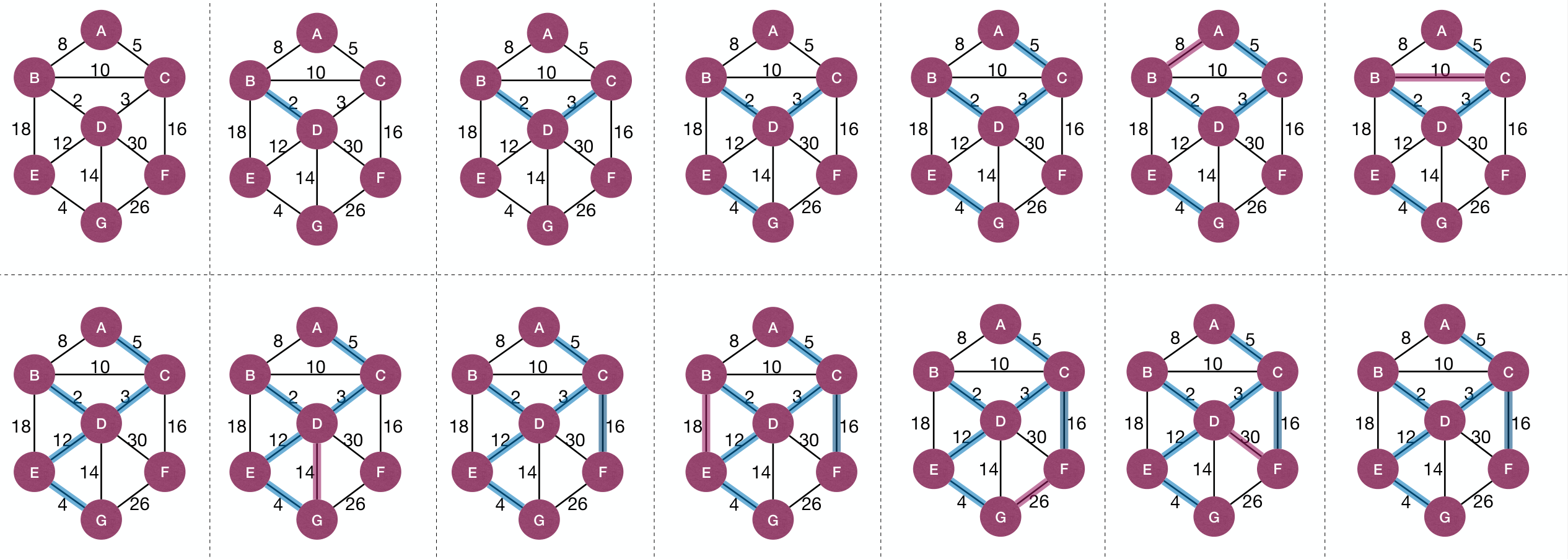
How to determine an edge forms a cycle? Put another way, how to determine if the edge is connecting two CC?
The answer is using disjoint-set data structure. Each set is a CC, and in same CC if Find(u) = Find(v).
1 2 3 4 5 6 7 8 9 10 | KruskalMST(G, w): A := {} Sort edges into weight increasing order for each node u in V MakeSet(u) for each edge (u, v) taken in weight increasing order if Find(u) != Find(v) A := A + {(u, v)} Union(u, v) return A |
Runtime of Kruskal's Algorithm: when using disjoint-set data structure.
一开始想过,为何不可以维护一个集合,包含当前解答中含有的顶点,若新的边包含两个顶点都在这个集合中,说明会形成环,不加入解答。这样就不需要并查集了。
实际上这是不正确的,关键在于「两个顶点都在集合中,会形成环」这是不正确的。有可能这两个顶点分别在两个连通分支上,这时候就需要加入这条边。
参考了 Could Kruskal’s algorithm be implemented in this way instead of using a disjoint-set forest? 中的解答。
Prim's Algorithm
Prim Algorithm: Keep find MWOE in one fixed CC in .
1 2 3 4 5 6 7 8 | PrimMST(G, w): A := {} Cx := {x} while Cx is not a spanning tree Find MWOE (u, v) of Cx A := A + {(u, v)} C := C + {v} return A |
Put another way:
- Start with CC, each node itself is a CC. And .
- Pick a node .
- Find MWOE of the component containing . The number of CC is reduced by 1.
- Repeat until one CC remain.
Prim's Algorithm process:
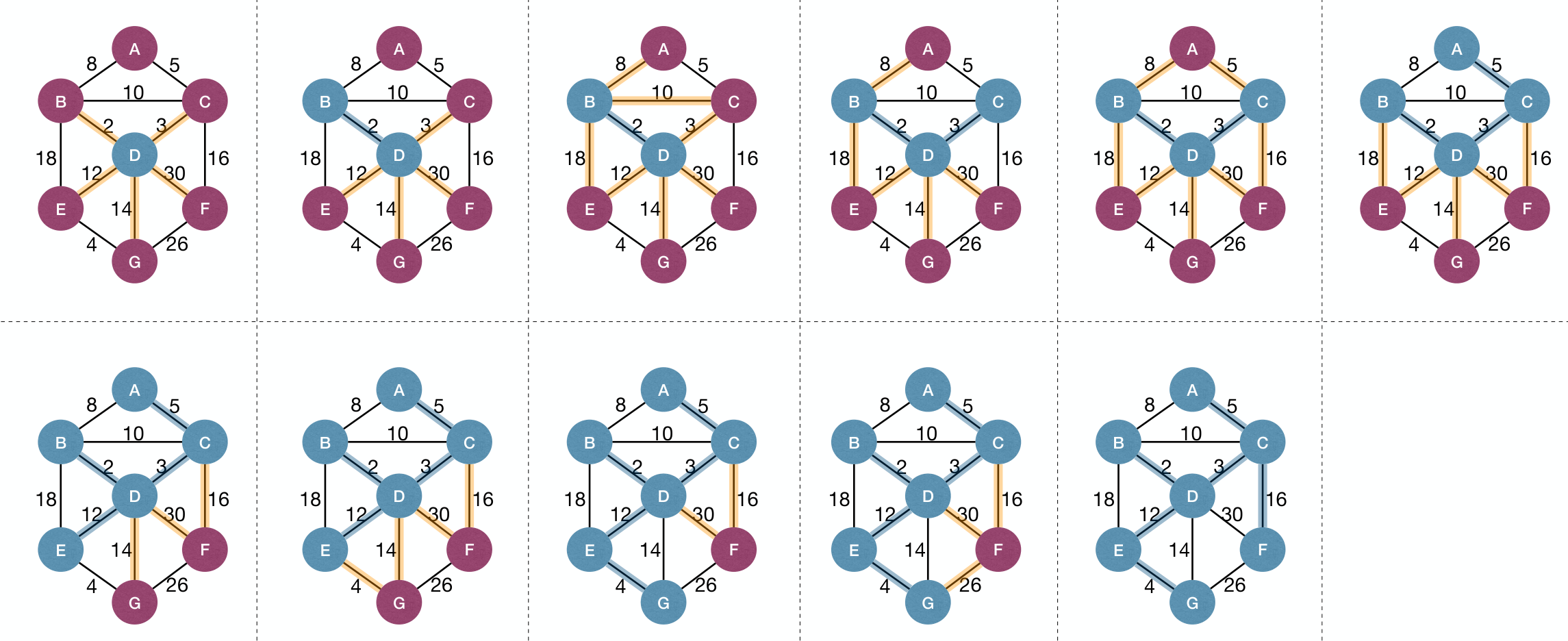
How to find MWOE efficiently? Put another way, how to find the next node that is closest to ?
The answer is using a priority queue to maintain each remaining node's distance to .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | PrimeMST(G, w): x := Pick an arbitrary node in G for each node u in V u.dist := INF u.parent := NIL u.in := False x.dist := 0 PriorityQueue Q := Build a priority queue based on 'dist' values. while Q is not empty u := Q.ExtractMin() u.in := True for each edge (u, v) in E if v.in = False and w(u, v) < v.dist v.parent := u v.dist := w(u, v) Q.Update(v, w(u, v)) |
using binary heap to implement priority queue.
Borůvka's Algorithm
The earliest MST algorithm.
- Starting with all nodes and an empty set of edges .
- Find MWOE for every remaining CC in , add all of them to .
- Repeat above step until we have a spanning tree.
Borůvka's Algorithm process:
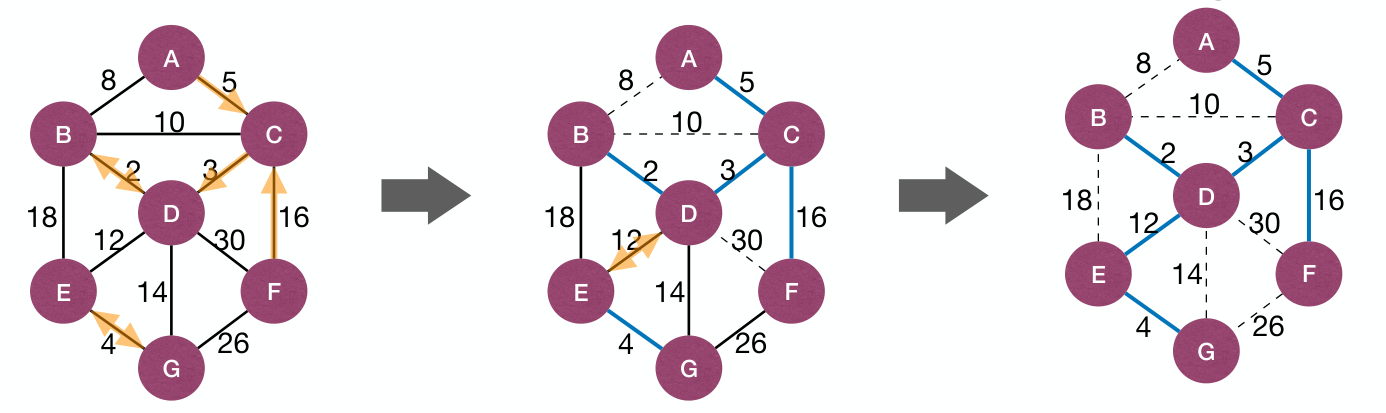
It's okay to add multiple edges simultaneously. Pick each CC at one time and it's safe:
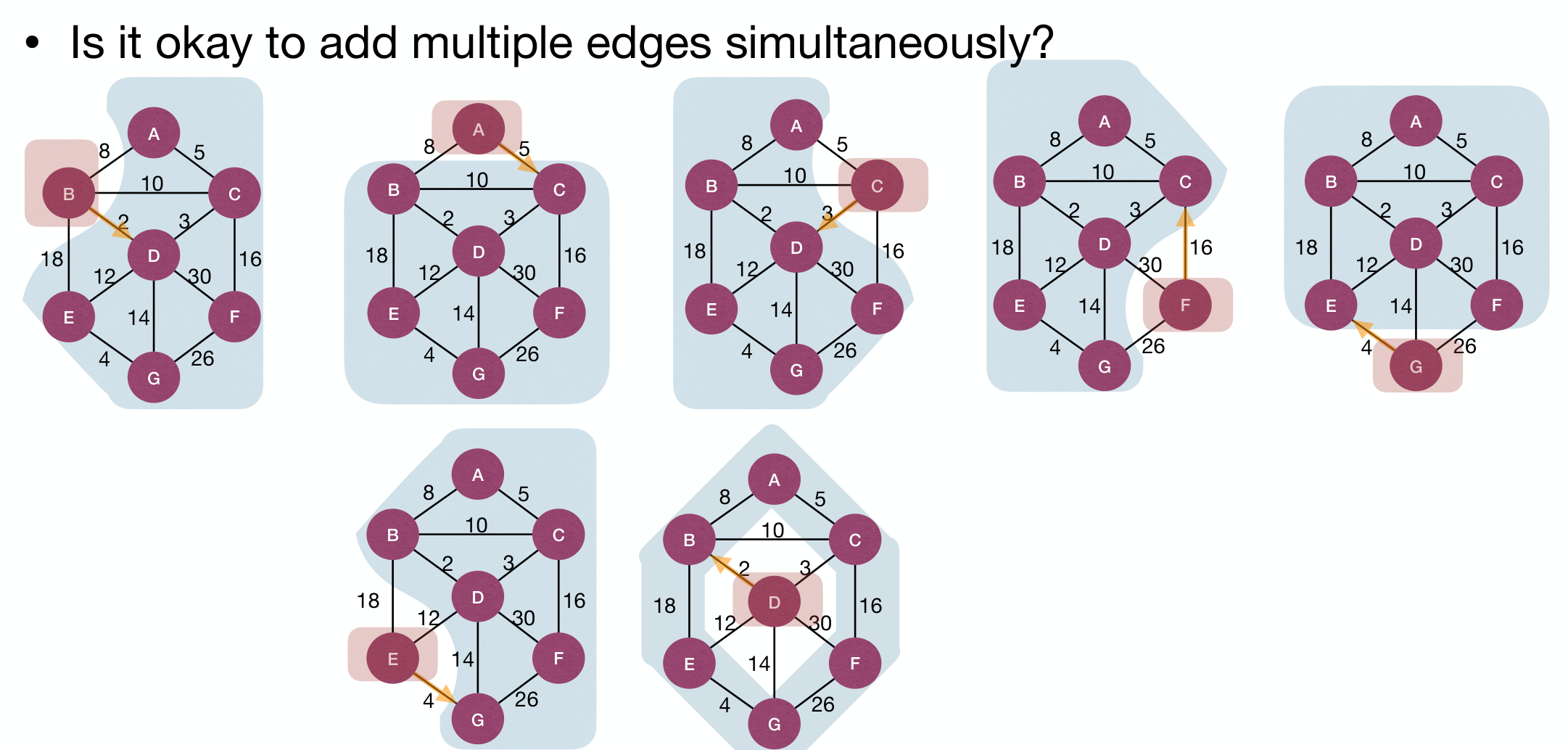
But may it result in circles?
Assume all weights of edges are distinctly, if CC propose MWOE to connect , and proposes MWOE to connect , then .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | BoruvkaMST(G, w): G' := (V, {}) do // Do DFS/BFS, count numbers of CC, give ccNum-th to nodes ccCount := CountCCAndLabel(G') // O(n) for i := 1 to ccCount // O(n) safeEdge[i] := NIL for each edge (u, v) in E(G) // O(m + n) = O(m) if u.ccNum != v.ccNum if safeEdge[u.ccNum] = NIL or w(u, v) < w(safeEdge[u.ccNum]) safeEdge[u.ccNum] := (u, v) if safeEdge[v.ccNum] = NIL or w(u, v) < w(safeEdge[v.ccNum]) safeEdge[v.ccNum] := (u, v) for i := 1 to ccCount // O(n) Add safeEdge[i] to E(G') while ccCount > 1 // O(log n) interactions return E(G') |
because we at least combine two CC into one CC for each CC in one iteration.
Borůvka’s algorithm allows for parallelism naturally; while the other two are intrinsically sequential.
Randomized algorithm with expected runtime exists.