贪心策略
The Greedy Strategy
For many games, you should think ahead, a strategy which focuses on immediate advantage could easily lead to defeat. Such as playing chess.
最近好像是国际象棋世界冠军赛。高三那会丁立人夺冠,还上 chess.com 玩了点,两个 AI(chess.com 的与云库查询)对对碰,后者比较厉害。
12.13:我嘞个开了光的嘴,随便提了嘴红眼 GOAT,红眼寄,提了嘴丁立人,丁立人寄。
But for many other games, you can do quite well by simply making whichever move seems best at the moment, without worrying too much about future consequences.
The Greedy Algorithmic Strategy(贪心策略): given a problem, build up a solution piece by piece, always choosing the next piece that offers the most obvious and immediate benefit.
An Activity-Selection Problem
Assume we have one hall and activities :
- Each activity has a start time and a finish time .
- Two activities cannot happen simultaneously in the hall.
So what's the maximum number of activities can we schedule?
Divide and Conquer:
- Define to be the set of activities start after finishes;
- Define to be the set of activities finish before starts.
- .
In any solution, some activity is the first to finish, . This cause subproblems, which is not efficient.
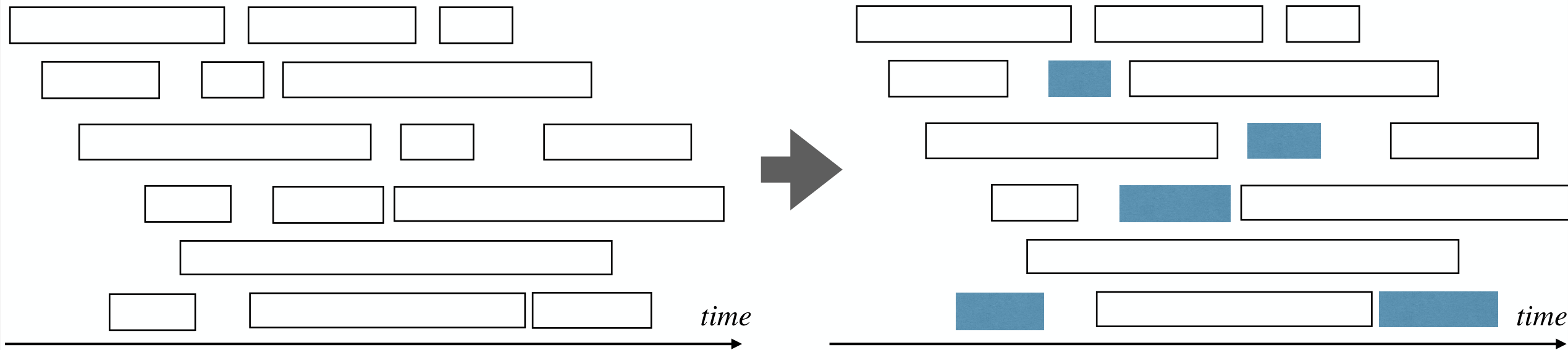
Observation: To make as large as possible, the activity that finishes first should finish as early as possible.
1 2 3 4 5 6 7 8 9 | ActivitySeletion(S): Sort S into increasing order of finish time SOL := {a1} a' := a1 for i := 2 to n: if ai.start > a'.finish: SOL := SOL + {ai} a' := ai return SOL |
How to formally prove the correctness of this algorithm?
- The firstly selected activity is in some optimal solution.
- The following selection is correct to this optimal solution.
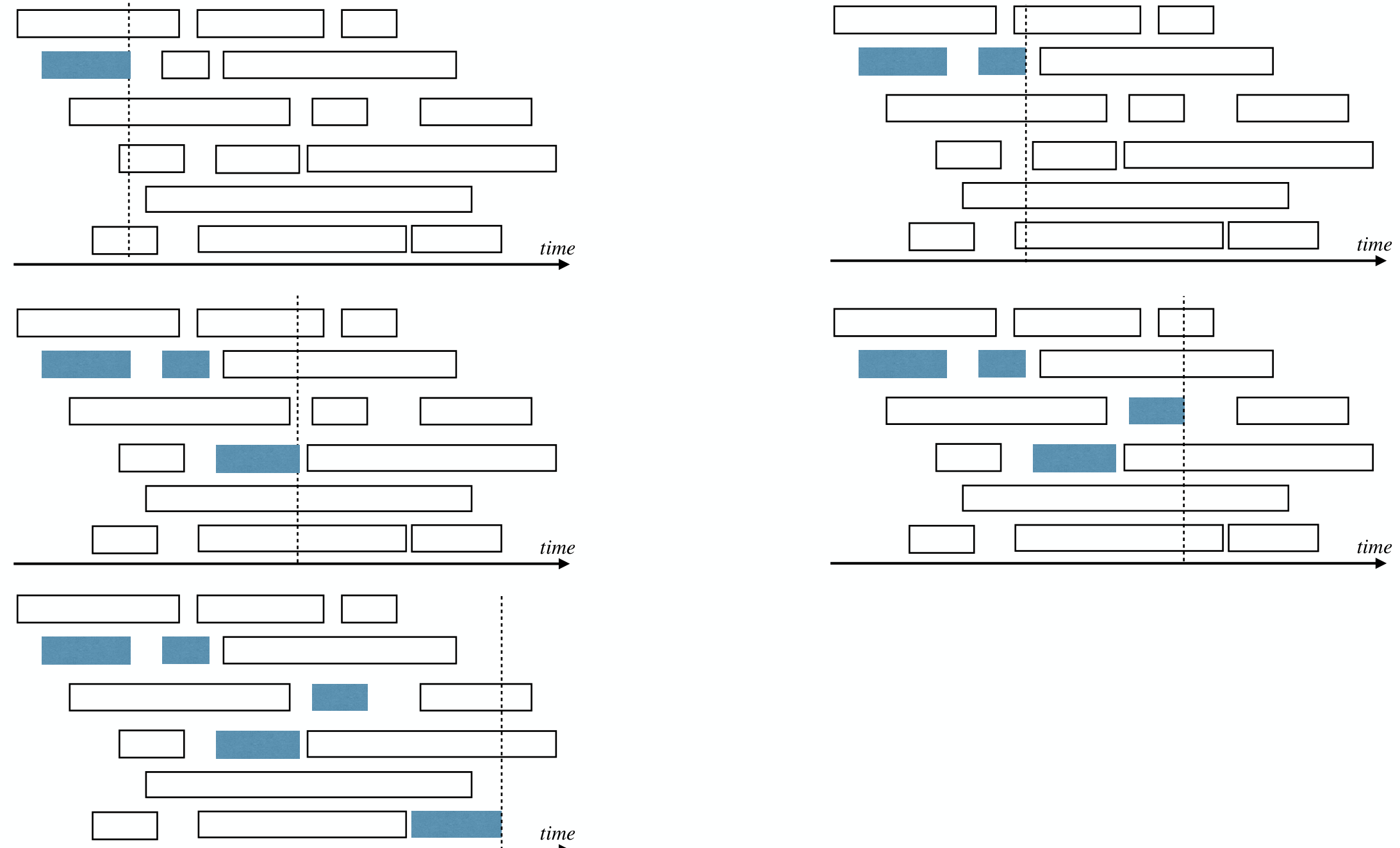
Lemma 1
Let a' be the earliest finishing activity in S, then a' is in some optimal solution of the problem.
Proof.
Let be an optimal solution solution to the problem, let be the earliest finishing activity in .
Assume , otherwise we are done.
Then is also a feasible solution, and it has same size as .
So is also an optimal solution.
Lemma 2
Let a' be the earliest finishing activity in S, S' be the activities starting after a' finishes. Then is an optimal solution of the problem.
Proof.
Let be an optimal solution to the original problem, and by Lemma 1.
Thus .
If is not an optimal solution to the original problem, then it must be the case that .
But this contradicts that is an optimal solution for problem .
Then proof by induction.
Elements of the Greedy Strategy
If an (optimization) problem has following two properties, then the greedy strategy usually works for it:
- Optimal substructure
- Greedy property
Optimal Substructure
A problem exhibits optimal substructure if an optimal solution to the problem contains within it optimal solution(s) to subproblem(s):
- Size problem and optimal solution of is .
- Solving needs to solve size subproblem .
- Optimal solution of is .
- contains a solution of : .
- Optimal Substructure Property: .
即,问题的最优解包含了子问题的最优解。
Counterexample: Longest path problem.

Greedy-Choice Property
At each step when building a solution, make the choice that looks best for the current problem, without considering results from subproblems. That is, make local greedy choice at each step.
If the problem only admits optimal structure:
- Find that maximize utility .
- We have to compute for all first.
With greedy choice, we have a way to pick correct without knowing any .
Examples
Fractional Knapsack Problem
A thief robbing a warehouse finds items .
Item is worth dollars and weighs pounds.
The thief can carry at most pounds in his knapsack.
The thief can carry fraction of items.
What should the thief take to maximize his profit?
A greedy strategy: Keep taking the most cost efficient item (i.e. ) until the knapsack is full.
The greedy solution is optimal.
The proof is obvious: if the greedy solution is not optimal, then we can replace the last item with a fraction of it to get a better solution.
0-1 Knapsack Problem
…
The thief can only take an item or not.
…
The greedy solution is NOT optimal.
A simple counterexample:
- Two items
- Item One has value and weighs pound.
- Item Two has value and weighs pounds.
If we use greedy strategy, we will only take Item One, value .
The greedy solution can be arbitrarily bad.
The proof above doesn't work cos we can't do the replace operation in this case.
A data compression problem
这个应该与《离散数学》中「前缀码」有关,可以参考(给的链接是其下面的「生成树」的链接,因为里面子标题不够,需要往上翻)。
Assume we have a data file containing 100k characters. Further assume the file only uses 6 characters. How to store this file to save space?
The simplest way is to use 3 bits to encode for each char.
Instead of using fixed-length codeword for each char, we should let frequent chars use shorter codewords. That is, use a variable-length code.

Use a binary tree to visualize a prefix-free code.
- Each leaf denotes a char.
- Each internal node: left branch is 0, right branch is 1.
- Path from root to leaf is the codeword of that char.
Optimal code must be represented by a full binary tree: a tree each node having zero or two children. Since if a node has only one child, we can merge it with its child.
Consider a file using a size alphabet . For each char, let be the frequency of char .
Let be a full binary tree representing a prefix-free code. For each char , let be the depth of in .
So the length of encoded message is .
Alternatively, recursively(bottom-up) define each internal node's frequency to be sum of its two children.
So the length of encoded message is .
Huffman codes: Merge two least frequent chars and recurse.
1 2 3 4 5 6 7 8 9 | Huffman(C): Build a priority queue Q based on frequency for i := 1 to n-1 Allocate new node z x := z.left := Q.ExtractMin() y := z.right := Q.ExtractMin() z.freq := x.freq + y.freq Q.Insert(z) return Q.ExtractMin() |
Process:
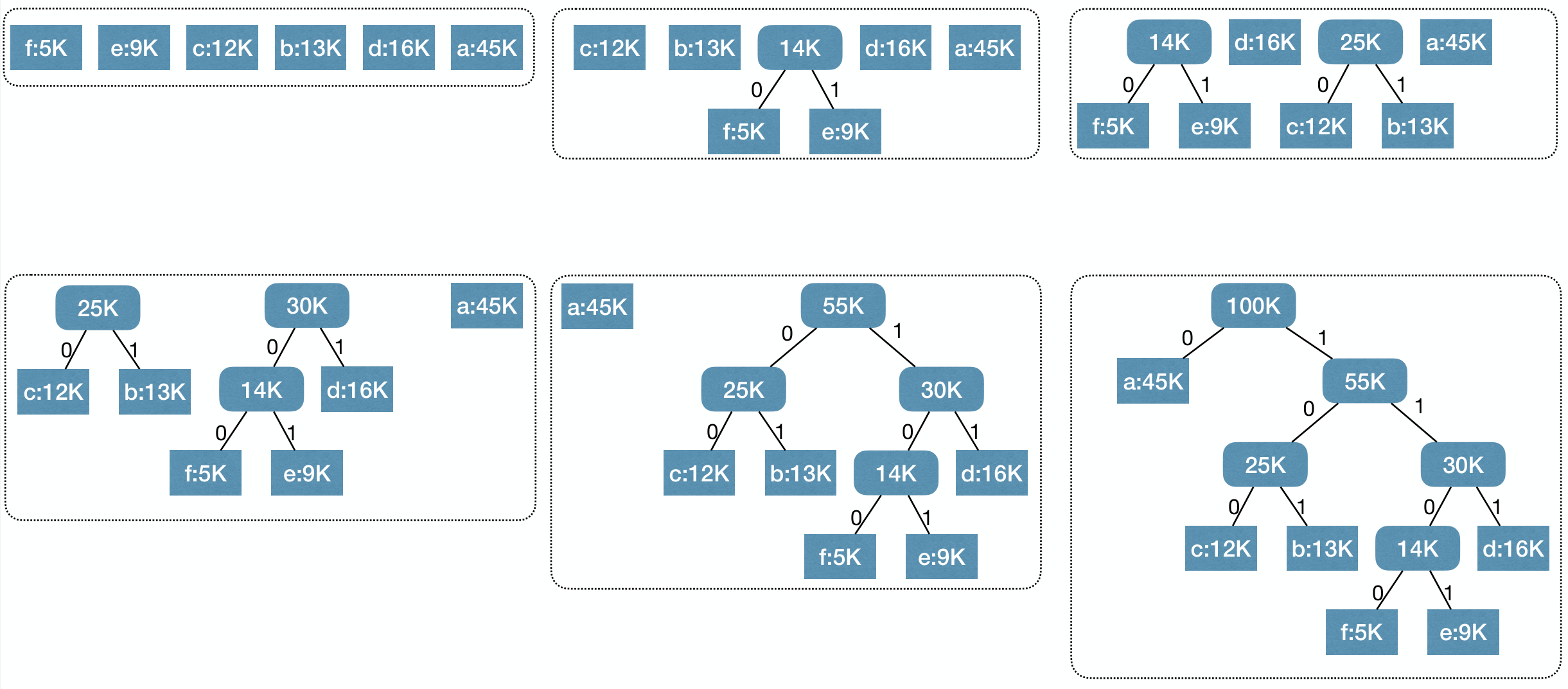
Proof. Correctness of Huffman Codes
- Lemma 1 [greedy choice]: Let be two least frequent chars, then in some optimal code tree, then are siblings and have largest depth.
- Lemma 2 [optimal substructure]: Let and be two least frequent chars in . Let with . Let be an optimal code tree for . Let be a code tree obtained from by replacing leaf node with an internal node having and as children. Then, is an optimal code tree for .
Lemma 1 Proof sketch:
- Let be an optimal code tree with depth .
- Let and be siblings with depth . (Recall is a full binary tree.)
- Assume and are not and . (Otherwise we are done.)
- Let be the code tree obtained by swapping and .
- Swapping and , obtaining , further reduces the total cost.
- So must also be an optimal code tree.
Lemma 2 Proof sketch:
- Let be an optimal code tree for with being sibling leaves.
- So must be an optimal code tree for .
Set Cover
Suppose we need to build schools for towns. Each school must be in a town, no child should travel more than 30km to reach a school. So what's the minimum number of schools we need to build?
The Set Cover Problem:
- Input: A universe of elements and where each .
- Output: such that .
- That is, a subset of that covers .
- Goal: Minimize .
Simple greedy strategy:
- Keep picking the town that covers most remaining uncovered towns, until we are done.
- Pick the set that covers most uncovered elements, until all elements are covered.
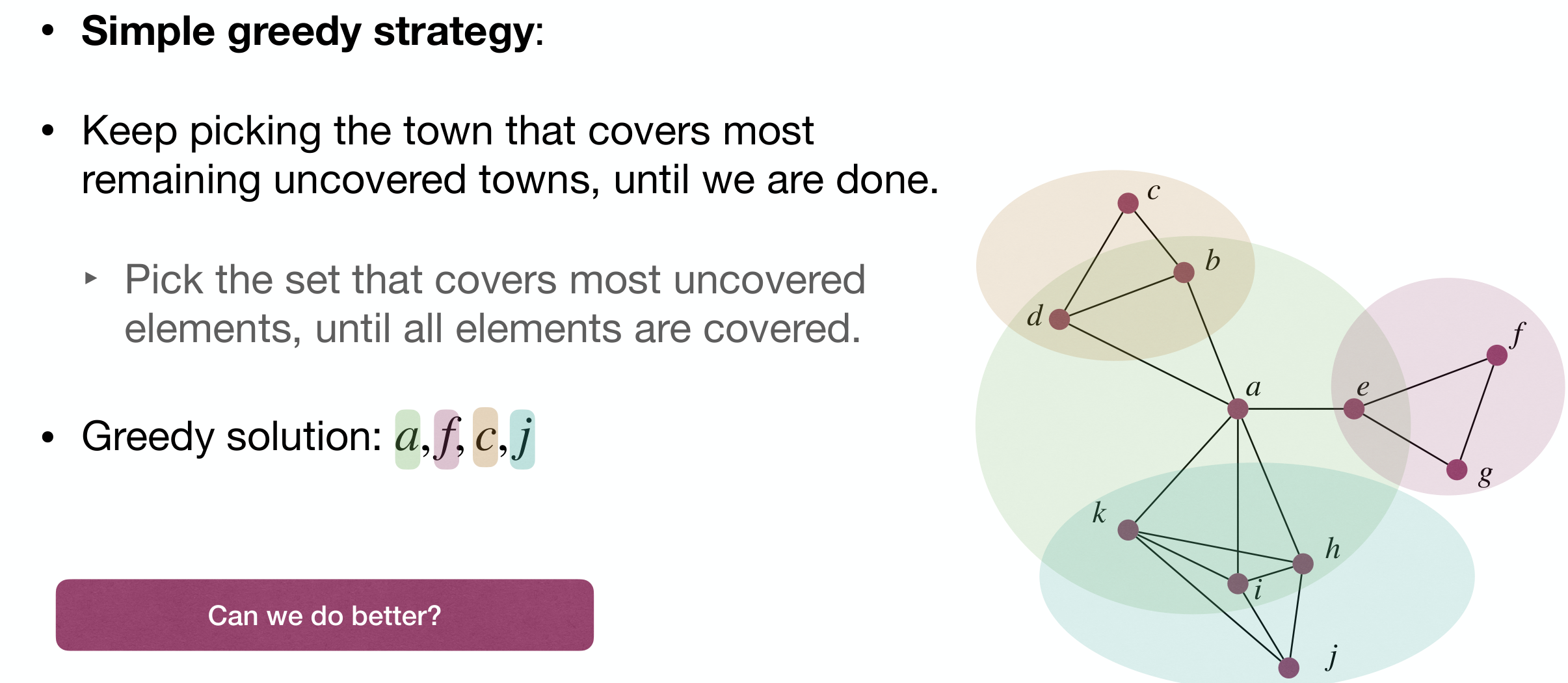
However this is not optimal:
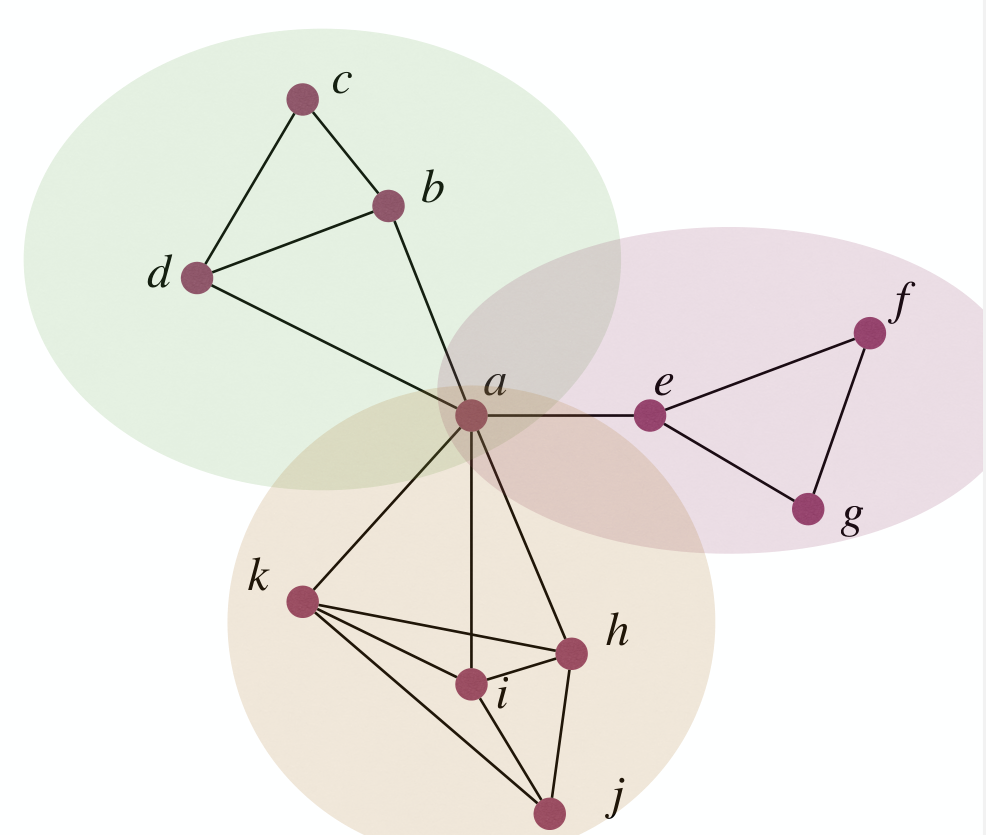
Though, greedy solution of Set Cover is close to optimal.
Throrem
Suppose the optimal solution uses sets, then the greedy solution will use at most sets.
Proof.
Let be number of uncovered elements after iterations. .
These elements can be covered by some sets.
So one of the remaining sets will cover at least of these uncovered elements. Since we pick the set that covers most uncovered elements, we will cover at least elements in the next iteration.
Thus .
So
With , we have . By then we must have done.
So the greedy strategy gives a approximation algorithm, and it has efficient implementation(Polynomial runtime).
We most likely can not do better if we only care about efficient algorithms.
[Dinur & Steuer STOC14]: There is no polynimial-runtime approximation algorithm unless P=NP.
So Greed can gives optimal (MST, Huffman codes), arbitrarily (0-1 knapsack) bad or near-optimal (Set cover) solutions.