网络层:数据平面
网络层功能概述
网络层(Network Layer)位于 TCP/IP 协议栈的第三层,介于运输层(Transport Layer)和数据链路层(Data Link Layer)之间。其核心任务是实现数据包在网络中的传输。
主要功能
- 发送端:将运输层产生的报文段(Segment)封装成数据报(Datagram)。
- 接收端:将数据报解封装,提取报文段并交付给运输层。
- 路由(Routing):确定数据包从源主机到目标主机的路径。
- 涉及多个路由器(Router)。
- 使用路由算法(Routing Algorithm)计算最佳路径。
- 转发(Forwarding):在路由器内部,将数据包从输入端口转移到合适的输出端口。
- 仅涉及单个路由器。
- 依据转发表(Forwarding Table)进行决策。
类比:旅行规划
- 路由:规划从南京到上海的行程路线(例如:南京 -> 无锡 -> 苏州 -> 上海)。
- 转发:在苏州站内,根据指示牌从进站口走到正确的出站口。
graph LR
subgraph 发送端
A[运输层] --> B(报文段)
B --> C[网络层]
C --> D(数据报)
D --> E[数据链路层]
end
subgraph 接收端
F[数据链路层] --> G(数据报)
G --> H[网络层]
H --> I(报文段)
I --> J[运输层]
end
subgraph 路由器
K[输入端口] --> L(转发表)
L --> M[输出端口]
end
E --> K
M --> F
style C fill:#ccf,stroke:#888,stroke-width:2px
style H fill:#ccf,stroke:#888,stroke-width:2px
style L fill:#fcc,stroke:#888,stroke-width:2px协议位置
网络层协议存在于每个主机和路由器中。路由器会检查所有经过的 IP 数据报的头部字段。
数据平面与控制平面
网络层的功能可以划分为两个相互作用的平面:
- 数据平面(Data Plane):负责数据包的实际转发。
- 局部的,每个路由器独立运作。
- 根据数据报头部字段和转发表,决定如何将数据包从输入端口转发到输出端口。
- 高速处理,通常用硬件实现。
- 控制平面(Control Plane):负责生成和维护转发表。
- 网络范围的,涉及多个路由器协同工作。
- 决定数据包在网络中的路由路径。
- 两种实现方式:
- 传统路由算法:在路由器中实现。
- 软件定义网络(Software-Defined Networking, SDN):在远程服务器中实现。
graph
direction LR
subgraph SDN
direction TB
E[远程服务器] --> F(控制器)
F --> G(转发表)
G --> H[路由器]
H --> I[数据平面]
end
subgraph 传统路由算法
direction TB
A[路由器] --> B(路由算法)
B --> C(转发表)
C --> D[数据平面]
end
style B fill:#ccf,stroke:#888,stroke-width:2px
style C fill:#fcc,stroke:#888,stroke-width:2px
style D fill:#ccf,stroke:#888,stroke-width:2px
style F fill:#ccf,stroke:#888,stroke-width:2px
style G fill:#fcc,stroke:#888,stroke-width:2px
style I fill:#ccf,stroke:#888,stroke-width:2px在传统路由算法中,每个路由器都包含一个独立的路由算法组件,这些组件在控制平面中相互交互,共同构建和维护转发表。
在 SDN 架构中,远程控制器负责计算和分发转发表,路由器仅负责执行转发操作。
网络服务模型
网络服务模型(Network Service Model)定义了网络层提供的「服务质量」(Quality of Service, QoS)。
服务类型
- 单个数据包:
- 可靠交付:确保数据包成功送达。
- 延迟保证:确保数据包在指定时间内送达。
- 数据包流:
- 有序交付:确保数据包按发送顺序到达。
- 带宽保证:确保数据流获得最低带宽。
- 间隔限制:限制数据包之间的间隔变化。
IP 协议的服务模型
互联网的网络层协议(即 IP 协议)提供尽力而为服务。
- 不保证可靠交付。
- 不保证延迟。
- 不保证有序交付。
- 不保证带宽。
- 不提供拥塞指示。
尽管 IP 协议本身提供的是尽力而为服务,但其上层的 TCP 协议通过流量控制、拥塞控制等机制,实现了可靠的、面向连接的数据传输。
尽力而为服务的优势:
- 简单性:机制简单使得互联网能够广泛部署和应用。
- 带宽充足:通过提供足够的带宽,可以满足大多数实时应用(如语音、视频)的需求。
- 分布式服务:通过复制和分布式应用层服务(如数据中心、内容分发网络),可以将服务部署在离用户更近的位置,提高服务质量。
- 弹性服务:拥塞控制机制有助于弹性服务适应网络状况。
路由器工作原理
路由器(Router)是网络层的核心设备,负责连接不同的网络,并在网络间转发数据包。
路由器容量
路由器容量 =
- :外部路由器端口数量
- :端口速率
路由器类型
| 类型 | 端口速率(R) | 总容量(NR) |
|---|---|---|
| 核心路由器 | 10/40/100/200/400 Gbps | O(100) Tbps(聚合) |
| 边缘路由器 | 1/10/40/100 Gbps | O(100) Gbps |
| 小型企业路由器 | 1 Gbps | < 10 Gbps |
路由器架构
graph LR
subgraph 路由器
A[输入端口] --> B{交换结构}
B --> C[输出端口]
D[路由处理器] --> B
style A fill:#ccf,stroke:#888,stroke-width:2px
style B fill:#fcc,stroke:#888,stroke-width:2px
style C fill:#ccf,stroke:#888,stroke-width:2px
style D fill:#ccf,stroke:#888,stroke-width:2px
end- 输入端口(Input Port):
- 物理层:接收比特级信号。
- 数据链路层:处理数据链路层协议,进行解封装。
- 查找:根据数据包的目的 IP 地址,在转发表中查找对应的输出端口。
- 排队:如果数据包到达速率超过交换结构的转发速率,则进行排队。
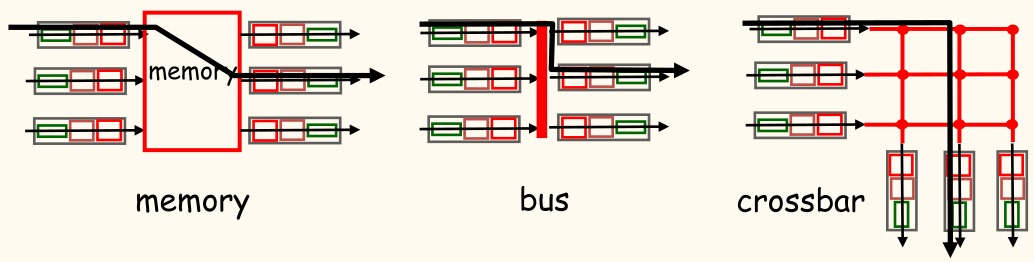
- 交换结构(Switching Fabric):
- 将数据包从输入端口转发到输出端口。
- 交换速率:数据包从输入端口到输出端口的传输速率。
- 三种类型:
- 基于内存的交换(Switching via Memory):
- 早期路由器采用。
- 在 CPU 的直接控制下进行交换。
- 数据包复制到系统内存。
- 受限于内存带宽。
- 基于总线的交换(Switching via a Bus):
- 数据报通过共享总线从输入端口内存传输到输出端口内存。
- 受限于总线带宽。
- 基于互连网络的交换(Switching via a Mesh):
- 克服总线带宽限制。
- 采用 Banyan 网络、纵横式交换(crossbar)等互连网络。
- 将数据报分割成固定长度的信元(cell),通过交换结构进行交换。
- 基于内存的交换(Switching via Memory):
- 输出端口(Output Port):
- 缓冲管理:决定何时丢弃数据包。
- 调度:决定何时发送哪个数据包。
- 数据链路层:处理数据链路层协议,进行封装。
- 物理层:发送比特级信号。
- 路由处理器(Routing Processor):
- 执行路由协议。
- 计算和更新转发表。
- 在传统路由器中,路由处理器参与控制平面。
- 在 SDN 架构中,路由处理器与远程控制器通信。
输入端口
输入端口的主要挑战是处理速度。
- 40Gbps 速率下,100B 数据包每 20 纳秒就会到达一个。
- 因此通常使用专用集成电路(ASIC,网络处理器)实现。
查找输出端口:
- 若每个地址对应一个条目,则会有 40 亿条目,这是不可行的。
- 为了可扩展性,地址是聚合的。
假设一个路由器有 4 个端口,目标地址范围映射如下:
- 11 00 00 00 到 11 00 00 11:端口 1
- 11 00 01 00 到 11 00 01 11:端口 2
- 11 00 10 00 到 11 00 11 11:端口 3
- 11 01 00 00 到 11 01 11 11:端口 4
最长前缀匹配规则:在转发表中查找给定目标地址的条目时,使用与目标地址匹配的最长地址前缀。
graph LR
subgraph "ISP 路由器"
A["端口 1"] --> B["110000**"]
C["端口 2"] --> D["110001**"]
E["端口 3"] --> F["11001***"]
G["端口 4"] --> H["1101****"]
end
style A fill:#ccf,stroke:#888,stroke-width:2px
style B fill:#ccf,stroke:#888,stroke-width:2px
style C fill:#ccf,stroke:#888,stroke-width:2px
style D fill:#ccf,stroke:#888,stroke-width:2px
style E fill:#ccf,stroke:#888,stroke-width:2px
style F fill:#ccf,stroke:#888,stroke-width:2px
style G fill:#ccf,stroke:#888,stroke-width:2px
style H fill:#ccf,stroke:#888,stroke-width:2px高效查找
- 逐个测试条目以查找匹配项的效率很低。
- 平均:O(条目数)
- 利用二进制字符串的树结构(Tree Structure)。
- 建立类似树的数据结构。
graph TD
A["\***"] -->|0| B["0**"]
A -->|1| C{"1**"}
B -->|0| D["00*"]
B -->|1| E{"01*"}
C -->|0| F["10*"]
C -->|1| G["11*"]
D -->|0| H{"000"}
D -->|1| I{"001"}
E -->|0| J["010"]
E -->|1| K["011"]
F -->|0| L["100"]
F -->|1| M["101"]
G -->|0| N["110"]
G -->|1| O["111"]
H -.->|"端口 1"| P1
I -.->|"端口 2"| P2
J -.->|"端口 3"| P3
K -.->|"端口 3"| P3
L -.->|"端口 4"| P4
M -.->|"端口 4"| P4
N -.->|"端口 4"| P4
O -.->|"端口 4"| P4
style A fill:#fff,stroke:#888,stroke-width:2px
style B fill:#ffd,stroke:#888,stroke-width:2px
style C fill:#ffd,stroke:#888,stroke-width:2px
style D fill:#fd7,stroke:#888,stroke-width:2px
style E fill:#fd7,stroke:#888,stroke-width:2px
style F fill:#fd7,stroke:#888,stroke-width:2px
style G fill:#fd7,stroke:#888,stroke-width:2px
style H fill:#fcc,stroke:#888,stroke-width:2px
style I fill:#fcc,stroke:#888,stroke-width:2px
style J fill:#fcc,stroke:#888,stroke-width:2px
style K fill:#fcc,stroke:#888,stroke-width:2px
style L fill:#fcc,stroke:#888,stroke-width:2px
style M fill:#fcc,stroke:#888,stroke-width:2px
style N fill:#fcc,stroke:#888,stroke-width:2px
style O fill:#fcc,stroke:#888,stroke-width:2px记录与最新匹配关联的端口,并且仅当它与遍历树时的另一个前缀匹配时才覆盖。
主要挑战是处理速度。涉及的任务有
- 更新数据包头(简单)
- 对目标地址进行 LPM 查找(更难)
因此主要使用专用硬件实现。
交换结构
交换结构(Switching Fabric):将数据包从输入端口转发到输出端口。
交换速率指数据包从输入端口到输出端口的传输速率。
共有三种类型:
- 基于内存的交换(Switching via Memory):
- 早期路由器采用。
- 在 CPU 的直接控制下进行交换。
- 数据包复制到系统内存。
- 受限于内存带宽。
- 基于总线的交换(Switching via a Bus):
- 数据报通过共享总线从输入端口内存传输到输出端口内存。
- 总线竞争:受限于总线带宽。
- 基于互连网络的交换(Switching via a Mesh):
- 克服总线带宽限制。
- 采用 Banyan 网络、纵横式交换(crossbar)等互连网络。
- 将数据报分割成固定长度的信元(cell),通过交换结构进行交换。
输出端口处理
- 数据包分类:将数据包映射到流。
- 缓冲区管理:决定何时以及丢弃哪个数据包。
- 调度器:决定何时以及传输哪个数据包。
- 在排队的包中选择传输。
- 当缓冲区饱和时,选择要丢弃的包。
数据包分类
数据包分类(Packet Classification):根据数据包头部中的多个字段对 IP 数据包进行分类,例如:
- 源/目标 IP 地址(32 位)
- 源/目标 TCP 端口号(16 位)
- 服务类型(TOS)字节(8 位)
- 协议类型(8 位)
通常,字段由范围指定,分类需要多维范围搜索。
排队
- 输入端口排队:
- 如果交换结构速度慢于输入端口组合速度,则可能在输入队列中发生排队。
- 由于输入缓冲区溢出而导致排队延迟和丢失。
- 线头阻塞(Head-of-the-Line, HOL Blocking):队列前面的数据报阻止队列中的其他数据报前进。
- 如果交换结构速度慢于输入端口组合速度,则可能在输入队列中发生排队。
- 输出端口排队:
- 当数据包从交换结构的到达速度快于链路传输速度时,需要缓冲。
- 丢包策略:如果没有空闲缓冲区,则决定丢弃哪些数据报。
- 调度规则:选择要传输的排队数据报。
- 优先级调度:谁获得最佳性能,网络中立性。
需要多少缓冲比较合适呢?
- RFC 3439 经验法则:平均缓冲等于「典型」(例如,250 毫秒)乘以链路容量 。
- 最近的建议:对于 个流,缓冲等于 。
- 但是过多的缓冲会增加延迟(特别是在家庭路由器中)
- 长 RTT:实时应用程序性能差,TCP 响应迟钝
- 回顾基于延迟的拥塞控制:保持瓶颈链路刚好满(忙),狠狠压榨价值
缓冲区管理
缓冲区管理(Buffer Management):
- 丢弃(Drop):添加哪个数据包,缓冲区满时丢弃哪个数据包。
- 尾部丢弃(Tail Drop):丢弃到达的数据包。
- 优先级(Priority):根据优先级丢弃/删除。
- 标记(Marking):标记哪些数据包以指示拥塞(ECN, RED)。
调度器
调度器(Scheduler):
- 每个「流」(flow)一个队列。
- 调度器决定何时以及从哪个队列发送数据包。
- 调度算法的目标:
- 快,Faster,もっと速く
- 取决于正在实施的策略(公平性、优先级等)
调度策略
- 先进先出:按照数据包到达的顺序进行调度。
- 无分类。
- 丢尾缓冲区管理:当缓冲区已满时,丢弃传入的数据包。
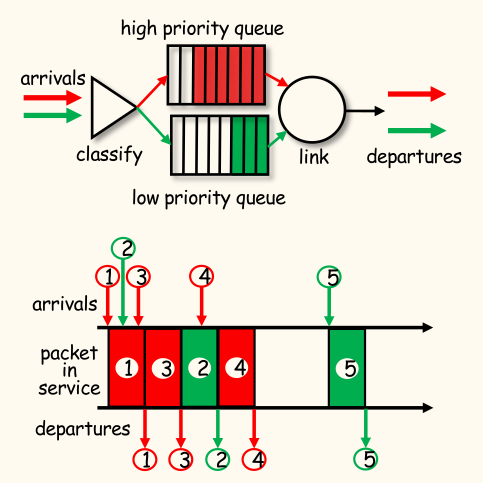
- 优先级:
- 到达的流量按类别分类和排队。
- 任何报头字段都可用于分类。
- 从具有已缓冲数据包的最高优先级队列发送数据包。
- 优先级类中的 FCFS。
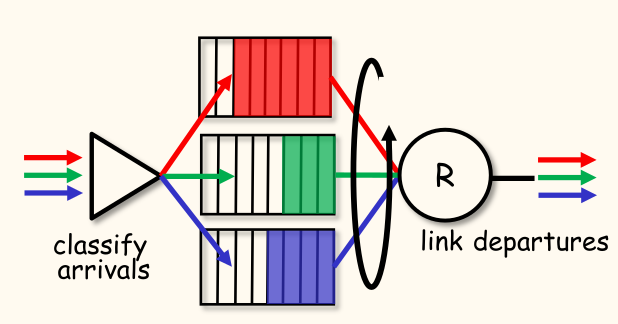
- 轮询(Round Robin, RR):
- 到达的流量按类别分类和排队。
- 任何报头字段都可用于分类。
- 服务器循环扫描类队列,依次从每个类发送一个完整的数据包(如果可用)。
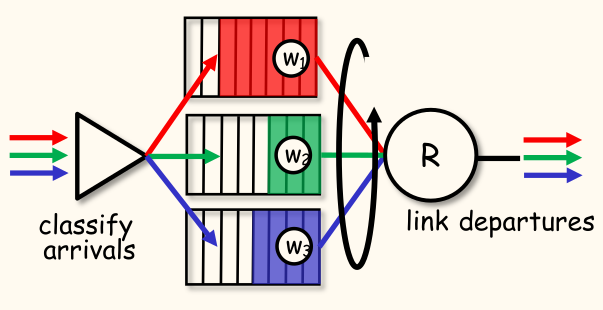
- 加权公平排队(Weighted Fair Queuing, WFQ):
- 广义轮询。
- 每个类 都有权重 ,并在每个周期中获得加权的服务量:。
- 最小带宽保证(每个流量类)。
IPv4 报头
报头字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 0 4 8 16 19 31 +------+------+------------+---------------------+ | 版本 | IHL | 服务类型 | 总长度 | +------+------+------------+---------------------+ | 标识 | 标志 | 片偏移 | +------+------+------------+---------------------+ | TTL | 协议 | 报头校验和 | +------+------+------------+---------------------+ | 源地址 | +------------------------------------------------+ | 目标地址 | +------------------------------------------------+ | 选项(可选) | +------------------------------------------------+ |
- 版本(Version)(4 位):
- 当前为 4(IPv4)。
- 互联网报头长度(Internet Header Length, IHL)(4 位):
- 以 32 位字(4 个八位字节)为单位。
- 最小固定报头(20 个八位字节)+ 选项。
- 服务类型(Type of Service, TOS)(8 位):
- 优先级(Precedence):3 位,定义了 8 个级别。
- 可靠性(Reliability):1 位,正常或高。
- 延迟(Delay):1 位,正常或低。
- 吞吐量(Throughput):1 位,正常或高。
- 总长度(Total Length)(16 位):
- 数据报的长度,以八位字节为单位。
- 标识(Identification)(16 位):
- 序列号。
- 与地址和用户协议一起使用以唯一标识数据报。
- 标志(Flags)(3 位):
- 更多标志,不分段。
- 片偏移(Fragmentation Offset)(13 位)。
- 生存时间(Time to Live, TTL)(8 位)。
- 协议(Protocol)(8 位):
- 下一个更高级别的协议在目标接收数据字段。
- 报头校验和(Header Checksum)(16 位):
- 报头中所有 16 位字的补码和。
- 如果不正确,路由器会丢弃数据包。
- 在每个路由器重新验证和重新计算,在计算期间设置为 0。
- 源地址(Source Address)(32 位)。
- 目标地址(Destination Address)(32 位)。
- 选项(Options)(可变 ≤ 40 个八位字节)。
数据字段
- 携带来自上一层的用户数据。
- 8 位长的倍数(即八位字节)。
- 数据报的最大长度(报头 + 数据)为 65535 个八位字节。
IP 地址寻址
IP 地址是分配给网络中每个设备接口的唯一标识符,用于在互联网上定位和识别设备。IPv4 地址是一个 32 位的数字标识符。
IP 地址结构
一个 IP 地址通常包含两个部分:
- 网络部分:地址的高位部分,用于标识设备所连接的特定网络。同一物理网络上的所有接口共享相同的网络部分。
- 主机部分:地址的低位部分,用于标识网络内的特定主机或接口。
物理网络(从 IP 角度)
物理网络(Physical Network)是指一组可以通过数据链路层(如以太网交换机)相互通信,而无需经过路由器干预的设备接口。
graph LR
subgraph 网络 223.1.1.0/24
A[主机 223.1.1.1]
B[主机 223.1.1.2]
C[主机 223.1.1.3]
D[路由器接口 223.1.1.4]
A -- L1 --- D
B -- L1 --- D
C -- L1 --- D
end
subgraph 网络 223.1.2.0/24
E[主机 223.1.2.1]
F[主机 223.1.2.2]
G[路由器接口 223.1.2.9]
E -- L2 --- G
F -- L2 --- G
end
subgraph 网络 223.1.3.0/24
H[主机 223.1.3.1]
I[主机 223.1.3.2]
J[路由器接口 223.1.3.27]
H -- L3 --- J
I -- L3 --- J
end
R((路由器)) --- D
R --- G
R --- J
style A fill:#ccf,stroke:#888
style B fill:#ccf,stroke:#888
style C fill:#ccf,stroke:#888
style E fill:#ccf,stroke:#888
style F fill:#ccf,stroke:#888
style H fill:#ccf,stroke:#888
style I fill:#ccf,stroke:#888
style D fill:#fcc,stroke:#888
style G fill:#fcc,stroke:#888
style J fill:#fcc,stroke:#888
style R fill:#eee,stroke:#555,stroke-width:2px上图中,通过路由器连接了三个独立的物理网络(子网)。每个主机或路由器的接口(Interface)都需要一个独立的 IP 地址。路由器的作用是连接不同的网络,并在它们之间转发数据包。
地址表示与管理
- 点分十进制表示法(Dotted-Decimal Notation):为了便于人类阅读,32 位 IP 地址通常被分成 4 个 8 位(字节),每个字节用十进制表示,并用点号分隔。例如:
223.1.1.1对应的二进制是11011111 00000001 00000001 00000001。 - 网络 ID(netid):地址的网络部分,必须是唯一的。由区域互联网注册管理机构(Regional Internet Registries, RIRs)如 ARIN(北美)、RIPE NCC(欧洲、中东、中亚)、APNIC(亚太地区)等进行全球管理和分配。
- 主机 ID(hostid):地址的主机部分,在特定网络内由该网络的管理员分配。
IPv4 地址格式(分类寻址 - 历史)
最初,IPv4 地址根据其最高几位被划分为不同的类别(Class),这种方式称为分类地址(Classful Addressing)。
- A 类地址:
- 首位为
0。 - 网络部分 7 位,主机部分 24 位。
- 范围:
1.0.0.0到126.255.255.255(网络号0和127保留)。 - 每个 A 类网络可容纳 百万个主机(主机号全 0 代表网络本身,全 1 代表广播地址,不可分配给具体主机)。
- 地址空间巨大,但网络数量少( 个)。
- 已全部分配完毕。
- 首位为
特殊地址:127.0.0.1
地址 127.0.0.1 是环回地址(Loopback Address),通常命名为 localhost,用于测试本地网络协议栈。发送到此地址的数据包不会离开主机。
实际上 IPv4 网络标准为回环目的保留了整个地址块 127.0.0.0/8(即 127.*.*.*)。
-
B 类地址:
- 前两位为
10。 - 网络部分 14 位,主机部分 16 位。
- 范围:
128.0.0.0到191.255.255.255。 - 每个 B 类网络可容纳 个主机。
- 网络数量适中( 个)。
- 已全部分配完毕。
- 前两位为
-
C 类地址:
- 前三位为
110。 - 网络部分 21 位,主机部分 8 位。
- 范围:
192.0.0.0到223.255.255.255。 - 每个 C 类网络可容纳 个主机。
- 网络数量多( 百万个),但每个网络容量小。
- 几乎全部分配完毕。
- 前三位为
-
D 类地址:
- 前四位为
1110。 - 用于多播(Multicast)。
- 范围:
224.0.0.0到239.255.255.255。
- 前四位为
-
E 类地址:
- 前四位为
1111。 - 保留(Reserved)供将来使用。
- 范围:
240.0.0.0到255.255.255.255。
- 前四位为
分类寻址的局限性
分类寻址方式存在严重问题:
- 地址浪费:A 类和 B 类网络太大,很多地址未被使用;C 类网络又太小,无法满足许多组织的需求。
- 路由表膨胀:互联网核心路由器需要为每个网络(尤其是大量的 C 类网络)维护一条路由条目。
这些问题导致了子网划分和无类别域间路由(CIDR)的出现。
子网划分
子网划分(Subnetting)是一种将一个大的网络(如一个 A 类、B 类或 C 类网络)进一步划分为多个较小的、互连的子网络(Subnet)的技术。
- 动机:
- 解决网络地址不足的问题(在组织内部更有效地利用已分配的地址块)。
- 提高网络灵活性和管理效率。
- 隔离内部网络结构,减少对外部路由表的压力(从外部看,整个组织仍然像一个单一的网络)。
- 机制:
- 借用主机部分的一些位作为子网号(Subnet Number)。
- 子网掩码(Subnet Mask):一个 32 位的数值,用于指示 IP 地址中哪些位属于网络部分 + 子网部分(对应位为 1),哪些位属于主机部分(对应位为 0)。
- 例如,一个 C 类网络
192.168.1.0,默认掩码是255.255.255.0。如果借用主机部分 3 位作为子网号,则子网掩码变为255.255.255.224(二进制11111111.11111111.11111111.11100000)。
- 路由:
- 组织内部的路由器(本地路由器)根据子网号进行路由。
- 外部路由器只知道该组织的整体网络地址,不知道其内部子网结构。
子网划分示例:假设一个组织获得了网络地址 141.14.0.0(B 类)。他们内部有多个 LAN。通过使用子网掩码 255.255.255.0,可以将第三个字节用作子网号。
- 子网 1:
141.14.2.0/24 - 子网 2:
141.14.7.0/24 - 子网 3:
141.14.22.0/24
对于外部世界,这些子网都属于 141.14.0.0 网络。内部路由器 R1 负责在这些子网之间以及与外部互联网之间转发数据包。
使用子网掩码确定网络/子网地址:将 IP 地址与子网掩码进行按位与运算,即可得到该地址所属的网络/子网地址。
例如,主机 IP 192.228.17.57,子网掩码 255.255.255.224:
1 2 3 4 | 11000000.11100100.00010001.00111001 (192.228.17.57) & 11111111.11111111.11111111.11100000 (255.255.255.224) ------------------------------------- 11000000.11100100.00010001.00100000 (192.228.17.32) |
该主机属于子网 192.228.17.32。
无类别域间路由(CIDR)
无类别域间路由(Classless Inter-Domain Routing, CIDR)是目前互联网上 IP 地址分配和路由的主导方案,旨在取代分类寻址。
- 核心思想:取消 A、B、C 类的划分,使用网络前缀来表示网络部分。
- 表示法:
A.B.C.D/n,其中n是网络前缀的长度(即 IP 地址中前n位表示网络部分)。- 例如,
10.217.112.0/20表示前 20 位是网络部分,后 12 位是主机部分。其对应的子网掩码是255.255.240.0(20 个 1 后跟 12 个 0)。
- 例如,
- 优势:
- 地址分配更灵活:可以分配任意大小的地址块,不再受限于 A/B/C 类的固定大小。
- 路由聚合:ISP 可以将其分配给多个客户的地址块聚合成一个更大的地址块(具有更短的前缀),向互联网其他部分通告。这极大地减少了全球路由表的规模。
路由聚合示例:一个 ISP 拥有地址块 200.23.16.0/20。它可以将其划分为更小的块分配给客户:
- 组织 0:
200.23.16.0/23 - 组织 1:
200.23.18.0/23 - 组织 2:
200.23.20.0/23 - …
- 组织 7:
200.23.30.0/23
该 ISP 只需要向外部世界通告一条路由 200.23.16.0/20,而不是通告其内部所有客户的路由。
如何获取 IP 地址
获取 IP 地址涉及两个层面:
- 网络如何获取 IP 地址块?
- 网络管理员(如 ISP 或大型组织)向其上级 ISP 或 RIR 申请地址块。
- 主机如何获取网络内的 IP 地址?
- 静态配置(Static Configuration):由系统管理员手动配置在设备的网络设置中(例如,在 UNIX/Linux 的
/etc/rc.config或类似文件中)。适用于服务器或网络设备。 - 动态主机配置协议(Dynamic Host Configuration Protocol, DHCP):主机在加入网络时,自动从 DHCP 服务器获取 IP 地址及其他网络配置信息。这是最常见的方式,尤其适用于普通用户设备和移动设备。
- 静态配置(Static Configuration):由系统管理员手动配置在设备的网络设置中(例如,在 UNIX/Linux 的
DHCP 工作原理
目标:让主机能够动态地获取 IP 地址、子网掩码、默认网关地址、DNS 服务器地址等信息,实现即插即用(Plug-and-Play)。
优点:
- 简化网络管理。
- 允许地址重用(设备离线后地址可分配给其他设备)。
- 支持移动用户。
DHCP 交互过程(DORA):
sequenceDiagram
participant 客户端
participant 服务器
Note over 客户端, 服务器: 客户端加入网络,需要 IP 地址
客户端->>服务器: DHCP 发现报文(广播,源地址:0.0.0.0,目的地址:255.255.255.255)
服务器->>客户端: DHCP 提供报文(广播或单播,提供 IP 地址、租期等信息)
Note over 客户端: 可能收到多个提供报文
客户端->>服务器: DHCP 请求报文(广播,向特定服务器请求提供的 IP)
服务器->>客户端: DHCP 确认报文(广播或单播,确认租约,提供配置)- DHCP 发现(Discover):新接入的主机广播一个 DHCP Discover 消息,寻找网络中的 DHCP 服务器。源 IP 为
0.0.0.0,目标 IP 为255.255.255.255。 - DHCP 提供(Offer):收到 Discover 消息的 DHCP 服务器(可能不止一个)回复一个 DHCP Offer 消息,提供一个可用的 IP 地址、租期(Lease Time)、服务器自身的 IP 地址等。
- DHCP 请求(Request):主机从收到的 Offer 中选择一个(通常是第一个到达的),然后广播一个 DHCP Request 消息,请求使用该 IP 地址,并指明选择的是哪个服务器。
- DHCP 确认(ACK):被选中的 DHCP 服务器回复一个 DHCP ACK 消息,确认将该 IP 地址和相关配置信息分配给该主机,并指定租期。
DHCP 服务器位置
DHCP 服务器通常与路由器集成在一起(例如家庭路由器),服务于其连接的所有子网。
DHCP 提供的不仅仅是 IP 地址,DHCP ACK 消息通常还包含:
- 子网掩码
- 默认网关的 IP 地址
- DNS 服务器的名称和 IP 地址
DHCP 报文封装:
DHCP 消息本身封装在 UDP 报文段中(服务器端口 67,客户端端口 68),UDP 报文段封装在 IP 数据报中,IP 数据报再封装在以太网帧(或其他链路层帧)中进行传输。
网络地址转换(NAT)
网络地址转换(Network Address Translation, NAT)是一种在 IP 数据包通过路由器或防火墙时,重写源或目标 IP 地址的技术。
主要目的与功能
- IP 地址共享/复用:允许多个内部(私有)网络设备共享一个或少数几个外部(公共)IP 地址接入互联网。这是 NAT 最常见的用途,极大地缓解了 IPv4 地址耗尽问题。
私有地址范围
RFC 1918 定义了三段私有地址范围,不会在全球互联网上路由,可以在组织内部自由使用:
10.0.0.0到10.255.255.255(10.0.0.0/8)172.16.0.0到172.31.255.255(172.16.0.0/12)192.168.0.0到192.168.255.255(192.168.0.0/16)
- 增强安全性:隐藏内部网络结构和 IP 地址,外部网络无法直接访问内部主机,起到一定的防火墙作用。
- 简化网络管理:当更换 ISP 或重新规划内部网络时,无需更改内部主机的 IP 地址。
NAT 工作原理
NAT 通常在连接内部私有网络和外部公共互联网的边界路由器(NAT Router)上实现。
- 出站流量(内部 外部):
- NAT 路由器接收到来自内部网络的 IP 数据包(源 IP 为私有地址)。
- 它将数据包的源 IP 地址替换为路由器的公共 IP 地址。
- 为了区分来自不同内部主机的连接,NAT 通常还会修改源端口号。
- 这种结合了 IP 地址和端口号转换的技术称为 NAPT 或 PAT (Port Address Translation)。
- NAT 路由器在 NAT 转换表中记录下这种映射关系
内部 IP:内部端口 <-> 外部 IP:外部端口
- 将修改后的数据包发送到互联网。
- 入站流量(外部 内部):
- NAT 路由器接收到来自互联网的响应数据包(目标 IP 为路由器的公共 IP 地址,目标端口为之前分配的外部端口)。
- 在 NAT 转换表中查找该目标 IP 和端口对应的内部主机 IP 和端口。
- 将数据包的目标 IP 地址和目标端口号替换回原始的内部私有地址和端口号。
- 将数据包转发给内部网络中的目标主机。
![]()
NAT 转换表示例:
| WAN Side (Public) Addr:Port | LAN Side (Private) Addr:Port | Protocol | Other Info (e.g., Lease) |
|---|---|---|---|
138.76.29.7:5001 |
10.0.0.1:3345 |
TCP | … |
138.76.29.7:5002 |
10.0.0.2:4000 |
UDP | … |
| … | … | … | … |
基本结构:
- WAN Side 是公网地址和端口
- LAN Side 是私有地址和端口
- 中间是协议类型和其他信息
- 其他信息列可能包含:映射的剩余时间(租期)、连接状态、流量统计等
具体示例分析:
- 第一行表示:
- 公网地址 138.76.29.7 的 5001 端口
- 映射到内网 10.0.0.1 主机的 3345 端口
- 使用 TCP 协议
- 第二行表示:
- 同一个公网 IP(138.76.29.7) 的不同端口(5002)
- 映射到内网另一台主机 10.0.0.2 的 4000 端口
- 使用 UDP 协议
NAT 工作原理:
- 当内网主机(如 10.0.0.1:3345)访问外网时
- NAT 路由器会创建一个映射条目
- 将
私有 IP:端口转换为公网 IP:端口 - 外网看到的源地址是公网地址(138.76.29.7:5001)
- 返回的流量会根据这个映射表转发到正确的内网主机
![]()
示例流程:
- 内部主机
10.0.0.1发送数据包(源10.0.0.1:3345,目标128.119.40.186:80)。 - NAT 路由器收到数据包,将其源地址/端口改为
138.76.29.7:5001,并在表中记录138.76.29.7:5001 <-> 10.0.0.1:3345。修改后的数据包(源138.76.29.7:5001,目标128.119.40.186:80)被发送出去。 - 外部服务器
128.119.40.186回复数据包(源128.119.40.186:80,目标138.76.29.7:5001)。 - NAT 路由器收到回复,查找转换表,找到
138.76.29.7:5001对应10.0.0.1:3345。将目标地址/端口改回10.0.0.1:3345,并将数据包转发给内部主机10.0.0.1。
NAT 的争议与问题
- 破坏端到端原则:NAT 修改了 IP 地址和端口号,使得通信不再是透明的端到端连接。
- 对某些应用不友好:需要外部主动连接内部主机的应用(如 P2P、一些 VoIP 协议)可能无法正常工作,需要额外的配置(如端口转发、UPnP、STUN/TURN 服务器)。
- 使 IPsec 等协议复杂化:NAT 修改了 IP 头,可能干扰 IPsec 等依赖 IP 头信息的协议。
尽管存在争议,NAT 在 IPv4 网络中仍然被广泛使用,是应对地址耗尽的关键技术之一。
IPv6
IPv6(Internet Protocol version 6) 是 IP 协议的下一代版本,旨在解决 IPv4 的局限性,特别是地址耗尽问题。
主要动机
- 地址空间耗尽(Address Space Exhaustion):IPv4 的 32 位地址空间(约 43 亿个地址)已不足以满足全球互联网设备的爆炸式增长。IPv6 采用 128 位地址,提供了近乎无限的地址空间( 个地址)。
- 改进的报头格式:
- 简化处理:固定长度(40 字节)的基本报头,移除了校验和、分片相关字段等,加快了路由器的处理速度。
- 更好的 QoS 支持:引入了流标签(Flow Label)和流量类别(Traffic Class)字段。
- 无路由器分片:IPv6 要求分片只能在源主机进行,中间路由器不再执行分片,提高了效率。
- 扩展性:可选功能(如分片、认证、加密)通过扩展报头(Extension Headers)实现,插入在基本报头和上层协议数据之间。
- 新的地址模式:支持任播(Anycast)地址,允许数据包被路由到一组接口中「最近」的一个。
- 增强的安全性:IPsec(IP Security) 被设计为 IPv6 的强制组成部分(虽然实际部署中不一定启用)。
- 更好的移动性支持。
- 地址自动配置(Address Auto-configuration):简化了主机地址的配置过程。
IPv6 报头结构
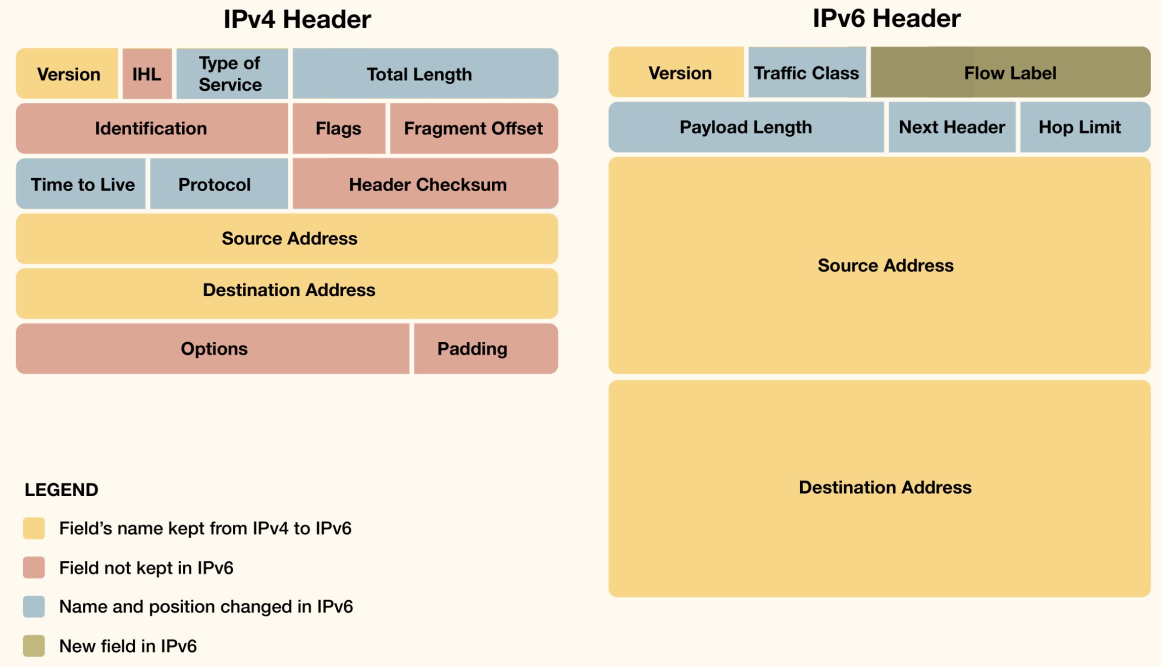
主要字段解释:
- 版本(Version)(4 位):值为 6。
- 流量类别(Traffic Class)(8 位):类似于 IPv4 的 ToS/DiffServ 字段,用于区分不同类别或优先级的 IPv6 数据包,支持 QoS。
- 上层协议可以指定该值。
- 源、转发路由器、接收方都可能修改此值。
- 流标签(Flow Label)(20 位):用于标识属于同一「流」的数据包序列。路由器可以基于流标签对数据包进行特殊处理(如 QoS 或特定路由),而无需检查内部报头。
- 流:从特定源到特定目的地(单播或多播)的一系列数据包,发送方希望路由器对其进行特殊处理。
- 流由源地址、目的地址和非零的流标签唯一标识。
- 流的要求(如 QoS)在流开始前定义好,并分配一个唯一的流标签。
- 路由器可以通过查找流标签表来快速决定如何处理数据包,无需检查传输层等信息。
- 有效载荷长度(Payload Length)(16 位):指紧跟 IPv6 基本报头之后的部分(包括所有扩展报头和上层数据)的总长度,以字节为单位。最大长度 65535 字节。
- 下一个报头(Next Header)(8 位):标识紧跟在 IPv6 基本报头之后的第一个扩展报头的类型,或者上层协议(如 TCP=6, UDP=17)的类型(如果没有扩展报头)。形成一个报头链。
- 跳数限制(Hop Limit)(8 位):类似于 IPv4 的 TTL(Time to Live),数据包每经过一个路由器,该值减 1。当减到 0 时,数据包被丢弃。防止数据包在网络中无限循环。
- 源地址(Source Address)(128 位):发送方的 IP 地址。
- 目的地址(Destination Address)(128 位):接收方的 IP 地址(可以是单播、多播或任播)。
IPv4 与 IPv6 报头对比
- 移除字段:IHL(报头长度固定为 40 字节)、标识/标志/片偏移(分片信息移至扩展报头)、报头校验和(由链路层和传输层保证完整性,路由器无需重算)。
- 新增字段:流标签。
- 名称和位置改变:服务类型 流量类别,TTL 跳数限制,协议 下一个报头。
- 地址长度:32 位 128 位。
IPv6 的优势总结
- 扩展的寻址能力:解决了地址耗尽问题,支持更多设备接入。支持多播、任播、地址自动配置。
- 简化的报头处理:固定长度、移除校验和等,提高了路由器转发效率。
- 改进的选项机制:使用扩展报头,更灵活、高效。
- 资源分配支持:流量类别和流标签有助于实现 QoS。
- 增强的安全性:内置 IPsec 支持。
- 更好的移动性。
从 IPv4 向 IPv6 过渡
由于不可能瞬间将整个互联网从 IPv4 升级到 IPv6,需要过渡机制允许两者共存和互操作。
主要挑战:网络中同时存在仅支持 IPv4、仅支持 IPv6 以及同时支持两者的(双栈)路由器和主机。
两种主要过渡策略:
- 双栈(Dual Stack):
- 节点(主机或路由器)同时实现 IPv4 和 IPv6 协议栈。
- 如果通信双方都支持 IPv6,则优先使用 IPv6。
- 如果一方只支持 IPv4,另一方是双栈,则使用 IPv4。
- 当 IPv6 数据包需要通过 IPv4 网络传输到另一个 IPv6 网络时,边界的双栈路由器可能需要进行地址转换(类似于 NAT,但用于 v6 v4),这可能导致 IPv6 的某些特性丢失。
- 优点:兼容性好。
- 缺点:需要维护两套协议栈;地址转换可能复杂且丢失信息。
- 隧道技术(Tunneling):
- 将 IPv6 数据包封装在 IPv4 数据包中,使其能够穿越 IPv4 网络段。
- 在 IPv6 网络与 IPv4 网络交界处的路由器(隧道端点)执行封装和解封装。
- 逻辑上,隧道形成了一条跨越 IPv4 网络的 IPv6 链路。
- 优点:保持了 IPv6 数据包的完整性,避免了地址转换问题。
- 缺点:增加了封装开销;可能引入 MTU 问题;配置管理相对复杂。
graph TD
subgraph 隧道方法
F[IPv6 节点] -- IPv6 --> G(IPv6/v4 路由器 - 隧道入口)
G -- IPv4(IPv6 负载) --> H(IPv4 路由器)
H -- IPv4(IPv6 负载) --> I(IPv6/v4 路由器 - 隧道出口)
I -- IPv6 --> J[IPv6 节点]
style G fill:#fcc
style I fill:#fcc
end
subgraph 双栈方法
A[IPv6/v4 节点] -- IPv6 --> B(IPv6/v4 路由器)
B -- 已翻译的 IPv4 --> C(IPv4 路由器)
C -- IPv4 --> D(IPv6/v4 路由器)
D -- 已翻译的 IPv6 --> E[IPv6/v4 节点]
style B fill:#ccf
style D fill:#ccf
end目前,互联网正处于 IPv4 和 IPv6 长期共存的过渡阶段,双栈和隧道技术都在广泛使用。
通用转发与 SDN
回顾路由器的核心功能:根据转发表将数据包从输入端口转发到输出端口。传统转发主要基于目的 IP 地址。然而,现代网络需要更灵活、更智能的转发决策。
通用转发:匹配 + 动作
通用转发(Generalized Forwarding)是一种更抽象的转发模型,其核心思想是:匹配 + 动作。
- 匹配(Match):检查到达数据包的多个头部字段(不仅仅是目的 IP),如源/目的 MAC 地址、源/目的 IP 地址、协议类型、TCP/UDP 端口号、VLAN 标签等。
- 动作(Action):对匹配成功的数据包执行指定的操作,例如:
- 转发(Forward):将数据包发送到一个或多个特定输出端口。
- 丢弃(Drop):丢弃数据包。
- 修改(Modify):修改数据包头部字段(如 NAT)。
- 复制(Copy):复制数据包(例如,用于监控或发送到控制器)。
- 记录/计数(Log/Count):记录日志或更新统计计数器。
- 发送至控制器:将数据包(或其副本)发送给网络控制器进行处理。
这种模型将路由器的数据平面(执行匹配 + 动作)与控制平面(计算和下发匹配规则)分离。
流表抽象
流表是实现「匹配 + 动作」模型的关键数据结构,存在于支持通用转发的设备(如 OpenFlow 交换机)中。
- 流:一系列具有相同头部字段值(或满足相同匹配规则)的数据包。
- 流表条目:定义了一条处理特定流的规则,通常包含:
- 匹配字段:指定用于匹配数据包头部的模式(可以使用精确值、通配符
*或范围)。 - 优先级:当一个数据包可能匹配多个条目时,用于决定哪个条目生效(通常选择优先级最高的)。
- 动作:匹配成功后要执行的操作列表。
- 计数器:统计匹配该条目的数据包数量和字节数。
- 超时:条目可以有空闲超时或硬超时,超时后条目可能被移除。
- 匹配字段:指定用于匹配数据包头部的模式(可以使用精确值、通配符
graph LR
A[数据包输入] --> B{流表查找};
subgraph "流表"
direction TB
style R1 fill:#ccf,stroke:#888,stroke-width:2px
style R2 fill:#ccf,stroke:#888,stroke-width:2px
R1["匹配规则 1<br/>优先级:高<br/>动作:转发到端口 2<br/>计数器:1000"]
R2["匹配规则 2<br/>优先级:低<br/>动作:转发到端口 3<br/>计数器:500"]
R3["匹配规则 …<br/>优先级:…<br/>动作:…<br/>计数器:…"]
R4["…"]
end
B -- 匹配成功 --> C(执行动作);
B -- 匹配失败 --> D(默认动作/上报控制器);
style B fill:#fdd,stroke:#f88,stroke-width:2px
C["例如:<br/>- 修改 VLAN ID<br/>- 转发到指定端口<br/>- 丢弃"]:::left
D["例如:<br/>- 丢弃<br/>- 上报控制器"]:::left
classDef matched fill:#ccf,stroke:#888,stroke-width:2px
classDef left text-align:leftOpenFlow
OpenFlow 是实现通用转发和 SDN(Software Defined Network, 软件定义网络) 的一种标准化协议和接口。它允许远程控制器管理网络设备(如交换机、路由器)的流表。
OpenFlow 流表条目:
- 匹配字段:涵盖了链路层、网络层和传输层的多个头部字段(如入口端口、源/目的 MAC、EtherType、VLAN ID/Priority、源/目的 IP、IP 协议、IP ToS、源/目的 TCP/UDP 端口)。
- 动作:包括转发到端口、丢弃、修改字段、推/弹 VLAN 标签、设置队列、发送到控制器等。
- 统计:每个流、每个端口、每个队列都有计数器。
OpenFlow 抽象的统一性:
「匹配 + 动作」的抽象模型可以统一描述多种网络设备的功能:
- 路由器:匹配最长目的 IP 前缀,动作是转发到下一跳端口。
- 交换机:匹配目的 MAC 地址,动作是转发到对应端口或泛洪(Flood)。
- 防火墙:匹配 IP 地址和 TCP/UDP 端口号,动作是允许(Permit)或拒绝(Deny)。
- NAT:匹配 IP 地址和端口,动作是重写地址和端口。
考虑一个场景,希望来自主机 h5(10.3.0.5) 和 h6(10.3.0.6) 的数据包,无论目标是谁,都通过 s1 转发到 s2,最终到达 h3(10.2.0.3) 或 h4(10.2.0.4)。这可以通过 OpenFlow 控制器在交换机 s3、s1、s2 上配置流表来实现网络范围的行为。
- s3 流表:
- 匹配:入口端口=连接 h5/h6 的端口,源 IP=
10.3.*.* - 动作:转发到连接 s1 的端口 (3)
- 匹配:入口端口=连接 h5/h6 的端口,源 IP=
- s1 流表:
- 匹配:入口端口=连接 s3 的端口 (1),源 IP=
10.3.*.* - 动作:转发到连接 s2 的端口 (4)
- 匹配:入口端口=连接 h1/h2 的端口,目的 IP=
10.2.0.3 - 动作:转发到连接 s2 的端口 (4)
- …(其他规则)
- 匹配:入口端口=连接 s3 的端口 (1),源 IP=
- s2 流表:
- 匹配:入口端口 = 连接 s1 的端口 (1),目的 IP=
10.2.0.3 - 动作:转发到连接 h3 的端口 (3)
- 匹配:入口端口 = 连接 s1 的端口 (1),目的 IP=
10.2.0.4 - 动作:转发到连接 h4 的端口 (4)
- …(其他规则)
- 匹配:入口端口 = 连接 s1 的端口 (1),目的 IP=
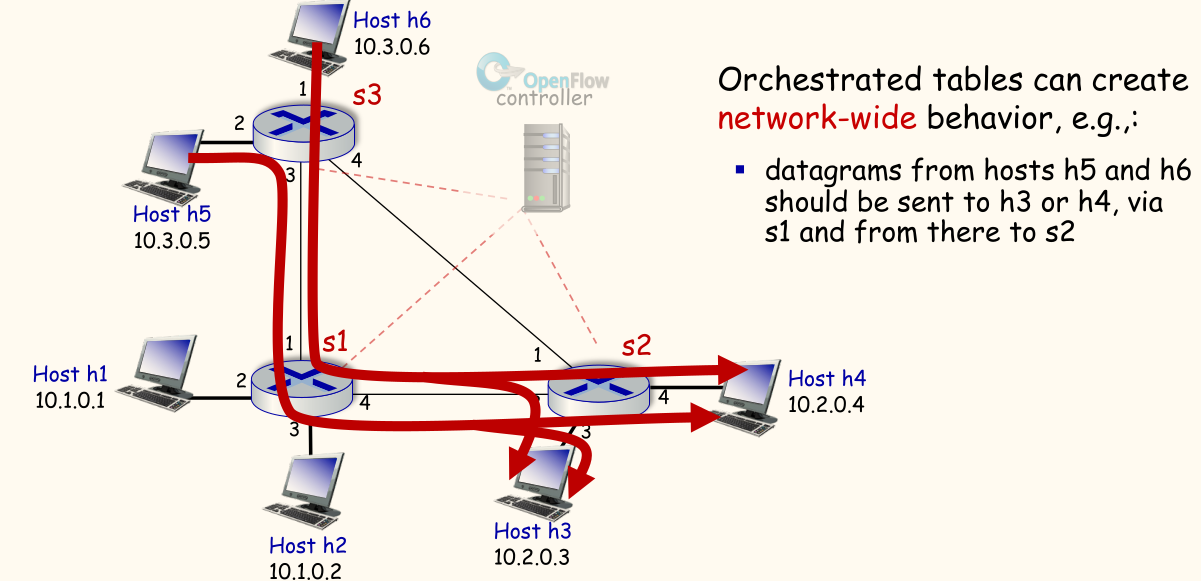
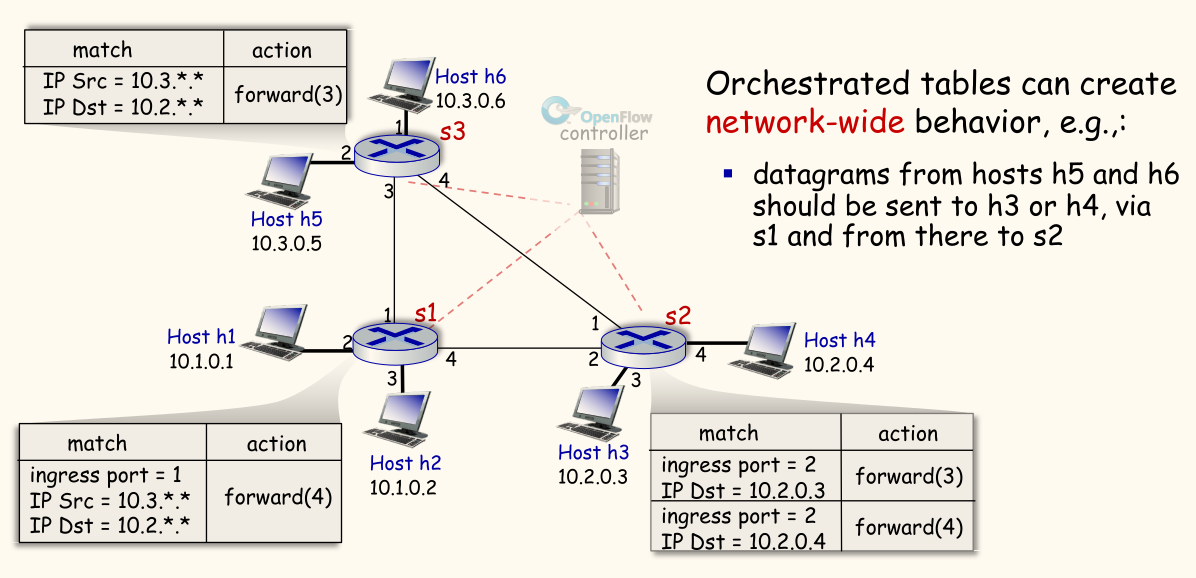
通过控制器集中编排这些流表规则,可以实现复杂的、跨越多个设备的流量工程和策略控制。
中间盒(Middleboxes)
中间盒(Middlebox)是一个通用术语,根据 RFC 3234 的定义,指在源主机和目的主机之间的数据路径上,执行除了 IP 路由器正常、标准功能之外的功能的任何中间设备。
中间盒无处不在
现代网络中充斥着各种中间盒,它们执行着关键的网络功能:
- 防火墙和入侵检测系统:提供安全防护(企业、机构、ISP)。
- 网络地址转换:实现地址共享和隐藏(家庭、蜂窝网络、企业)。
- 负载均衡器:分发流量到多个服务器(企业、服务提供商、数据中心、移动网络)。
- 缓存/内容分发网络:加速内容传递(服务提供商、移动网络、CDN)。
- 广域网优化器。
- 应用层网关。
中间盒的演进
- 初期:通常是专有的、封闭的硬件解决方案,功能固定,价格昂贵。
- 发展:逐渐转向使用「白盒」硬件(Whitebox Hardware,即通用的、基于商用芯片的硬件),并实现开放 API(如 OpenFlow)。
- 使得功能可以通过软件实现和创新(网络功能虚拟化, Network Functions Virtualization, NFV)。
- NFV:将网络功能(如防火墙、负载均衡器)从专用硬件解耦,使其能以软件形式运行在标准的 IT 基础设施(计算、存储、网络)上。
- SDN:通常用于(逻辑上)集中控制和配置管理这些虚拟化或物理的网络功能,常部署在私有云或公有云环境中。
- 实现了可编程的本地动作(通过匹配+动作)。
- 促进了软件层面的创新和差异化。
IP 沙漏模型与中间盒
IP 沙漏模型形象地描述了互联网协议栈的结构:
- 细腰:网络层只有一个协议——IP 协议。所有物理层、链路层技术(底层)和传输层、应用层协议(上层)都必须通过 IP 协议进行互联。这是互联网能够成功的关键因素之一,保证了普遍的互操作性。
- 多样性:底层和上层都有众多不同的协议。
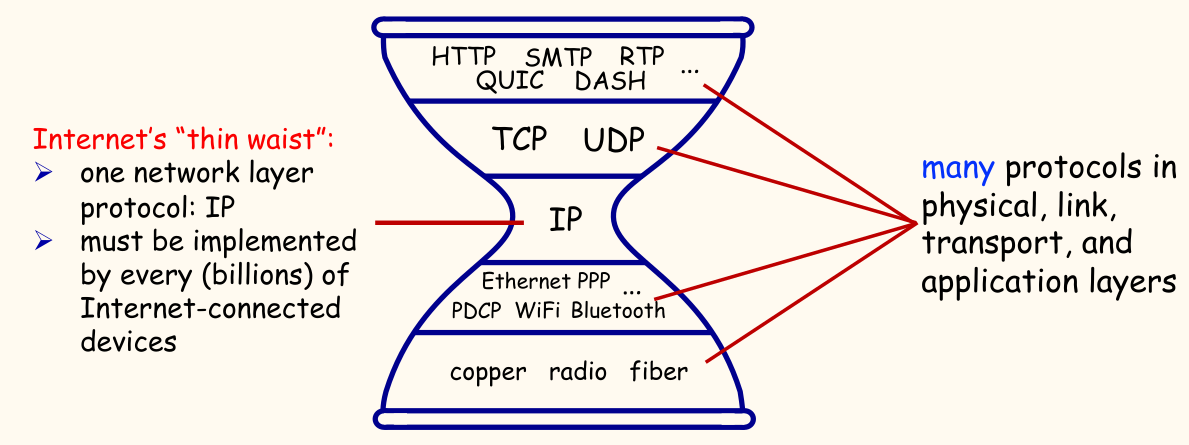
中间盒(如 NAT、防火墙、缓存等)通常在 IP 层或其附近运行,执行着超越基本 IP 转发的功能。它们可以被看作是 IP 沙漏模型在「中年」时期长出的「游泳圈」或「赘肉」(Middle Age "Love Handles")。
- 挑战:它们在网络内部操作,有时会修改数据包内容或行为,可能破坏端到端原则,增加网络复杂性。
- 必要性:然而,它们提供了许多现代网络必需的功能(安全、性能优化、地址管理等)。
中间盒的存在反映了互联网在演进过程中,为了满足不断增长的功能需求,对原始简洁模型的适应和扩展。SDN 和 NFV 的发展趋势是试图以更灵活、可编程、标准化的方式来管理和部署这些重要的网络功能。