同步(进阶)
互斥锁、条件变量与信号量回顾
在讨论更高级的同步机制之前,我们先简要回顾一下基础原语:
- 互斥锁(Mutex):提供最基本的互斥访问,确保临界区代码的原子性。
- 条件变量(Condition Variable, CV):允许线程在特定条件不满足时阻塞等待,并在条件满足时被唤醒。它本身不存储条件状态,必须与互斥锁配合使用,并在
while循环中检查条件(Mesa 语义)。 - 信号量(Semaphore):包含一个内部计数值,通过
P(wait/down) 和V(post/up) 原子操作进行管理。可用于互斥(初始值为 1)、顺序控制(初始值为 0)和资源计数(初始值为 N)。
工具间的关系与选择
- 信号量可以实现互斥锁的功能(使用二元信号量)。
- 信号量也能方便地实现某些线程执行顺序的控制。
- 条件变量与互斥锁结合,可以实现信号量的功能(如上一章笔记所示)。
- 然而,信号量不适合表达任意复杂的同步条件,此时条件变量通常更灵活。正如 Butler Lampson 提醒的,要小心过度泛化[1]。
- 条件变量配合互斥锁,可以构建几乎任何同步逻辑。
"All problems in computer science can be solved by another level of indirection, except for the problem of too many layers of indirection." - 虽然原话是关于间接层,但其对泛化的警示同样适用。 ↩︎
接下来,我们将探讨更复杂的同步问题和更高级的同步技术。
读者-写者问题(Readers-Writers Problem)
这是一个经典的并发控制问题,旨在优化对共享数据的访问,特别是当读操作远多于写操作时。
问题定义与挑战
- 场景:多个线程需要访问共享数据。部分线程只需要读取数据(读者,Reader),部分线程需要修改数据(写者,Writer)。
- 核心矛盾:
- 读取操作本身不会修改数据,因此多个读者同时读取是安全的,允许并发进行以提高性能。
- 写入操作会修改数据,必须保证其原子性和排他性:
- 任意时刻最多只能有一个写者在修改数据(写-写互斥)。
- 当有写者在修改数据时,不能有任何读者或其他写者在访问(写-读/写-写互斥)。
graph LR
subgraph "读者-写者并发控制"
DB[(共享数据区)]
subgraph "读操作"
R1[读者 1]
R2[读者 2]
R3[读者 3]
end
subgraph "写操作"
W1[写者 1]
W2[写者 2]
end
R1 -->|可以<br>同时读取| DB
R2 -->|可以<br>同时读取| DB
R3 -->|可以<br>同时读取| DB
W1 <== 互斥<br>写入 ==> W2
classDef reader fill:#b5e2fa,stroke:#0077b6,color:black
classDef writer fill:#ffafcc,stroke:#9d4edd,color:black
classDef database fill:#caffbf,stroke:#38b000,color:black
class R1,R2,R3 reader
class W1,W2 writer
class DB database
end
写操作 --> DB
subgraph "访问规则"
style 访问规则 fill:none,stroke:#666,stroke-width:1px
Rule1["✓ 读-读并发: 多个读者可同时访问"]
Rule2["✗ 写-写互斥: 写者之间互相排斥"]
Rule3["✗ 读-写互斥: 读者与写者互相排斥"]
style Rule1 fill:#d8f3dc,stroke:#2d6a4f,color:black
style Rule2 fill:#ffddd2,stroke:#e71d36,color:black
style Rule3 fill:#ffddd2,stroke:#e71d36,color:black
end目标
设计一种同步机制,允许多个读者并发访问,但写者必须独占访问权限。简单的全局互斥锁虽然能保证安全,但限制了读者的并发性,性能较低。
读写锁(Readers-Writers Lock)
为了解决读者-写者问题,引入了读写锁(Readers-Writers Lock, RW Lock)。典型的 API 接口如下:
1 | // 假设的读写锁结构体 |
1 | // 使用模式 |
实现方案与策略
读写锁的实现需要管理内部状态(如当前读者数量、是否有写者等),并处理读者和写者之间的竞争。不同的实现策略会导致不同的公平性表现。
方案 1:读者优先(Reader Preference)
这种策略下,只要当前没有写者持有锁,新的读者就可以立即获得读锁,即使有写者正在等待。
核心逻辑:
- 使用一个计数器
readers记录当前持有读锁的读者数量。 - 使用一个互斥锁
lock保护readers计数器的访问。 - 使用一个信号量
rwlk(初始值为 1)控制对临界区的访问(写者直接获取,第一个读者获取,最后一个读者释放)。
进入条件:
- 读者:如果临界区为空(
readers == 0)或已有其他读者(readers > 0),且没有写者持有锁,则可进入。 - 写者:只有当临界区为空(没有读者也没有写者)时才可进入。
1 | // 读者优先实现(基于信号量) |
写者饿死
如果读者持续不断地到来,readers 计数将一直大于 0,导致 rwlk 信号量一直被读者持有(从第一个读者获取后直到最后一个读者释放前)。这会使得等待的写者永远无法获得 rwlk,发生「饿死」。
方案 2:写者优先(Writer Preference)
这种策略下,一旦有写者在等待,后续到达的读者将被阻塞,直到所有等待的写者完成操作。
核心逻辑:
- 增加
writers计数,记录等待和正在写的写者总数。 - 增加一个信号量
tryRead,当有写者希望进入时,写者会持有tryRead,阻止新读者尝试获取读锁。
1 | // 写者优先实现(概念性,基于课件代码) |
读者饿死
如果写者持续不断地到来,writers 计数将一直大于 0,导致 tryRead 信号量一直被写者持有。这会使得等待的读者永远无法通过 P(&rw->tryRead),发生「饿死」。
方案 3:公平性考量(Ticket Lock)
为了避免读者或写者饿死,可以引入排队机制,确保请求按到达顺序得到服务。Ticket Lock 是一种实现 FIFO(先进先出)排队的方式。
Ticket Lock 机制:
ticket:一个全局递增的票号分发器。turn:当前允许进入临界区的票号。- 获取锁:原子地获取当前
ticket值作为自己的myturn,并将ticket加 1。然后自旋等待,直到turn等于myturn。 - 释放锁:将
turn加 1,允许下一位等待者进入。
1 | // Ticket Lock 实现 |
基于 Ticket Lock 的公平读写锁:
- 所有读者和写者先通过同一个 Ticket Lock (
queue) 排队获取进入许可。 - 获得许可后,再根据是读者还是写者,执行类似读者优先的逻辑(使用
rlock保护readers,使用rwlk控制实际临界区访问)。 - 关键在于,Ticket Lock 保证了无论是读者还是写者,都按照到达顺序获得尝试进入临界区的机会,避免了某一方无限等待。
1 | // 公平读写锁(基于 Ticket Lock 和读者优先逻辑) |
公平性与性能
公平锁通常能避免饿死,但可能牺牲一定的吞吐量。例如,即使临界区当前只有读者,一个等待的写者也会阻止后续读者进入,直到写者完成。
POSIX 读写锁
POSIX 标准提供了 pthread_rwlock_t 类型和相关函数:
1 |
|
Linux Pthread 实现
在 Linux 中,pthread_rwlock_t 的默认行为通常是读者优先。但是,可以通过 pthread_rwlockattr_setkind_np 函数设置属性,选择写者优先(PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP)或其他策略(具体可用策略依赖于库版本)。
无锁编程:Read-Copy-Update (RCU)
在追求极致性能的场景下,即使是读写锁带来的开销(尤其是写锁的排他性)也可能成为瓶颈。Read-Copy-Update(RCU) 是一种高级的、主要用于内核的同步技术,旨在实现极低开销的读取操作,甚至达到「无锁」读取。
动机——锁的开销与瓶颈:
- 锁操作代价:获取和释放锁(即使是互斥锁或读写锁)涉及原子操作、缓存一致性协议交互、可能的上下文切换,其 CPU 周期消耗远高于普通指令。
- 短临界区问题:当临界区非常短时,锁本身的开销可能超过临界区内有效工作的时间,成为性能瓶颈。线程越多,竞争越激烈,性能可能反而下降。
- 读写锁的局限:虽然读写锁允许多读并发,但写操作仍然需要排他性,会阻塞所有读者和写者。
RCU 的思想源于对数据一致性要求的放宽:
- 强一致性:任何更新操作完成后,所有后续读取都能立即看到新数据。锁机制通常提供强一致性。
- 最终一致性(Eventual Consistency):系统保证如果没有新的更新,最终所有访问都会读取到最后更新的值。但在更新期间,读取操作可能读到旧数据。
RCU 利用最终一致性,允许读者在写者更新数据期间继续访问数据的旧版本,从而避免阻塞。
RCU 读者视角
当写者更新数据时,正在进行的读者操作:
- 要么读到更新前的旧数据。
- 要么(如果读操作开始在写者发布更新之后)读到更新后的新数据。
- 绝不会读到写操作过程中的中间状态(RCU 保证写的「发布」是原子的)。
RCU 的基本思路是:
- 读者:读取数据时不加锁。它们直接访问数据。
- 写者:
- 复制(Copy):不直接在原地修改数据,而是创建一个数据的副本。
- 修改(Update):在副本上进行修改。
- 发布(Publish/Removal):通过一次原子操作(通常是修改指针),将共享引用指向新的、修改后的副本。旧版本的数据暂时保留。
- 等待宽限期(Grace Period):等待系统中所有可能还在引用旧版本数据的读者完成它们的读操作。
- 回收(Reclamation):在宽限期结束后,安全地释放(回收)旧版本数据的内存。
RCU 特点
- 读者零开销:读操作几乎没有同步开销(可能只有内存屏障或简单的计数器操作)。
- 写者不阻塞读者:写操作(复制、修改、发布)可以与读者并发进行。
- 写者有额外成本:写者需要复制数据、等待宽限期和管理旧版本回收,成本相对较高。
- 适用于读多写少:非常适合读取操作远多于写入操作的场景。
- 允许多版本共存:在更新期间,新旧版本数据会短暂共存。读者可能读到旧版本,也可能读到新版本,但保证读到的版本是一致的(不会读到写操作进行到一半的中间状态)。这是一种最终一致性的体现。
RCU 机制详解
RCU 主要由针对读者和写者的不同机制组成。
读者:近乎零开销
- RCU 读者的临界区(read-side critical section)通常不需要获取任何锁,也不需要进行原子写操作。
- 读者只需标记其临界区的开始和结束(例如,通过
rcu_read_lock()和rcu_read_unlock())。这些标记本身开销极低,在某些实现中甚至可能只是禁用/启用抢占或中断。 - 由于不获取锁,读者不会被写者阻塞,可以并发执行。
写者:Removal 与 Reclamation
RCU 的写操作(更新)被分解为两个关键阶段:
-
Removal(移除)阶段:
- 写者创建一个数据的新副本,并在副本上进行修改。
- 通过一次原子操作(如原子指针赋值,通常需要内存屏障保证顺序)将指向旧数据的指针更新为指向新副本。
- 这个阶段完成后,新的读者将看到新数据。但旧数据不能立即删除,因为可能还有读者正在访问它。
- 关键:Removal 阶段可以与读者并发进行。
-
Reclamation(回收)阶段:
- 写者需要等待一个宽限期结束。
- 宽限期是指从写者完成 Removal 操作开始,直到系统中所有在 Removal 操作之前就已经进入 RCU 读临界区的读者全部退出临界区为止的时间段。
- 宽限期结束后,写者可以安全地回收(例如,释放内存)旧版本的数据,因为此时已没有任何读者会访问它。
- 关键:Reclamation 阶段需要与读者进行同步(等待宽限期)。
示例:链表更新
假设要更新链表中的节点 d 为 d':
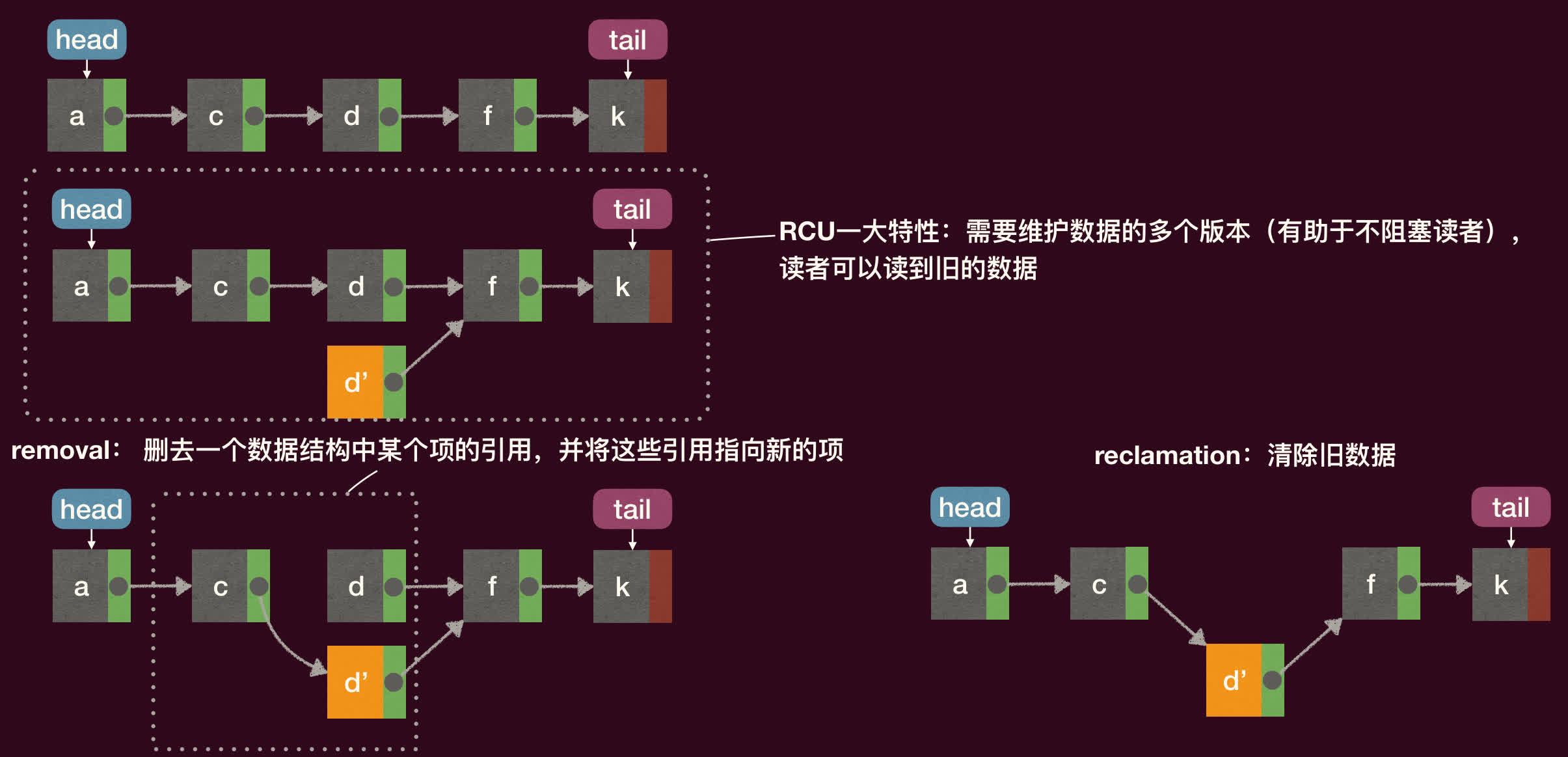
RCU 的一个特点是需要维护数据的多个版本(至少是旧版本和新版本),直到旧版本可以安全回收。
保证 Removal 原子性:订阅-发布与内存屏障
简单地在写者端加锁、读者端不加锁,并不能保证 Removal 的原子性。编译器优化和弱内存模型可能导致指令重排,使得读者看到处于中间状态的数据(例如,新节点的数据还没完全初始化好,指针就已经被更新了)。
1 | // 潜在问题代码(无内存屏障) |
RCU 使用了类似订阅-发布(Publish-Subscribe)的模式,并结合内存屏障来解决这个问题:
- 发布(Write/Publish):写者使用特殊原语(如 Linux 内核的
rcu_assign_pointer())来更新指针。这个原语内部包含内存屏障,确保在更新指针之前,对新数据的所有修改都已完成并对其他 CPU 可见。 - 订阅(Read/Subscribe):读者使用特殊原语(如
rcu_dereference())来读取指针。这个原语内部也包含内存屏障,确保读取指针的操作不会被重排到读取数据内容之后,并且能正确观察到写者发布的数据。
1 | // RCU API 使用示例(概念性) |
保证 Reclamation 安全性:宽限期(Grace Period)
写者如何知道何时可以安全回收旧数据?需要等待所有在 Removal 之前就已存在的读者完成它们的读操作。
- 读者标记:
rcu_read_lock()和rcu_read_unlock()用于显式标记读者访问 RCU 保护数据的区间。 - 写者等待:
synchronize_rcu()是一个阻塞函数,调用它的写者线程会一直等待,直到当前 RCU 宽限期结束。
宽限期图示(Grace Period Timeline):
sequenceDiagram
participant Writer as 写者
participant RCU as RCU 子系统
participant Reader1 as 读者 1(旧)
participant Reader2 as 读者 2(旧)
participant Reader3 as 读者 3(新)
participant Reader4 as 读者 4(新)
Note over Writer: T0: 发布更新(e.g., rcu_assign_pointer)
Reader1->>Reader1: rcu_read_lock()
Reader1->>Reader1: 读取旧数据(R1)
Reader2->>Reader2: rcu_read_lock()
Reader2->>Reader2: 读取旧数据(R2)
Writer->>RCU: synchronize_rcu()/开始等待宽限期
Reader1->>Reader1: rcu_read_unlock() (T_R1_end)
Note over RCU: 检测到 CPU_Reader1 静止
Reader3->>Reader3: rcu_read_lock()
Reader3->>Reader3: 读取新数据(R3)
Reader2->>Reader2: rcu_read_unlock() (T_R2_end)
Note over RCU: 检测到 CPU_Reader2 静止
Reader4->>Reader4: rcu_read_lock()
Reader4->>Reader4: 读取新数据(R4)
Note over RCU: 所有 CPU 均经历静止状态
RCU-->>Writer: 宽限期结束(Grace Period Expires)
Writer->>Writer: 安全回收旧数据
Reader3->>Reader3: rcu_read_unlock() (T_R3_end)
Reader4->>Reader4: rcu_read_unlock() (T_R4_end)
宽限期的实现机制
如何检测宽限期结束?关键在于检测所有 CPU 是否都经历了一个静止状态(quiescent state),表明它们已经处理完了在宽限期开始前就在运行的 RCU 读临界区。
经典内核实现:
- 读者
rcu_read_lock()可能只是禁用抢占(阻止当前线程被切换出去)。 - 读者
rcu_read_unlock()则重新启用抢占。 - 静止状态可以是 CPU 发生上下文切换、进入 idle 状态、或执行用户态代码(因为内核 RCU 读临界区必须在内核态)。
synchronize_rcu()会等待,直到检测到系统中的所有 CPU 都至少经历过一次静止状态。这保证了任何在synchronize_rcu()调用前开始的 RCU 读临界区都已经结束。
RCU 的具体实现非常复杂,涉及多种优化和变体(如 Tree RCU)。上述只是简化模型。关键在于理解「宽限期」的概念和「静止状态」检测的必要性。
异步 Reclamation 与用户态 RCU
如果写者不想在 synchronize_rcu() 处阻塞,可以使用 call_rcu(callback_func, data)。它注册一个回调函数,在宽限期结束后,系统会自动调用该函数来执行旧数据的回收操作。
RCU 的概念也可以应用于用户态程序,例如 liburcu 库。用户态实现需要不同的机制来标记读临界区和检测静止状态(例如,基于线程信号、内存屏障和 epoch 机制)。
RCU 适用场景
RCU 是一种强大的优化技术,但并非万能。
- 优点:
- 读取操作非常快(接近零开销),且不被写者阻塞。
- 在高并发、读多写少(read-mostly)的场景下性能极佳。
- 适用于需要高可扩展性的数据结构(如内核路由表、系统配置信息等)。
- 缺点:
- 写操作相对复杂,需要管理数据副本和处理回收逻辑。
- 写者可能因等待宽限期而延迟。
- 需要额外的内存来存储旧版本数据。
- 只适用于基于指针访问的数据结构。
- 编程模型比锁更复杂,需要仔细理解其语义。
何时考虑 RCU?
当你的应用场景符合「读操作极其频繁、写操作相对较少、读取性能是瓶颈、可以容忍读取到稍旧的数据(最终一致性)」这些特点时,RCU 是一个值得考虑的选项。
经典同步问题:哲学家就餐(Dining Philosophers Problem)
这是由 Edsger Dijkstra 提出的另一个经典的并发问题,用于说明死锁(Deadlock)和饿死(Starvation)的概念及避免策略。
问题描述
- 场景:N 位哲学家围坐在一张圆桌旁,桌上放着 N 支筷子[1],每两位哲学家之间放一支。
- 行为:哲学家要么思考(不需要资源),要么吃饭(需要资源)。
- 资源需求:每位哲学家需要同时拿起左右两边的两支筷子才能吃饭。
- 目标:设计一个协议(算法),让哲学家们能够合理地交替思考和吃饭,满足以下条件:
- 互斥:一支筷子同一时刻只能被一位哲学家持有。
- 无死锁:系统不会进入所有(或部分)哲学家永远无法获得足够筷子吃饭的状态。
- 无饿死:任何一位想吃饭的哲学家最终都能吃到饭(不会无限期等待)。
- 高并发:允许多位哲学家同时吃饭(理想情况下最多 N/2 位)。

死锁与饿死
这两个概念都关乎系统的活性(Liveness),即系统能否持续做有用的工作。它们不违背安全性(Safety,即系统不会进入错误状态)。
- 饿死(Starvation):一个线程在有限时间内无法获得所需资源或 CPU 时间,导致其无法向前推进。
- 死锁(Deadlock):一种特殊的饿死状态。它发生在多个线程形成一个循环等待链,每个线程持有至少一个资源,并等待链中下一个线程所持有的资源。由于等待关系是循环的,没有任何线程能打破这个循环,导致所有涉及的线程都永久阻塞。
死锁必然导致饿死,但饿死不一定是死锁。例如,由于调度策略不公或运气不好,一个线程可能总是抢不到锁,即使没有形成死锁环路,也会饿死。
解决方案探索
我们将筷子视为资源,每支筷子可以用一个信号量(初始值为 1)或互斥锁来表示。
方案 1:朴素尝试(导致死锁)
每个哲学家都先尝试拿起左手边的筷子,再尝试拿起右手边的筷子。
1 |
|
死锁风险
如果所有哲学家同时拿起他们左手边的筷子,那么每位哲学家都持有了一支筷子,并等待右手边的筷子。而右手边的筷子正被邻居持有并等待更右边的。形成了一个循环等待,所有哲学家都无法获得第二支筷子,导致死锁。

方案 2:尝试获取与释放(导致饿死/活锁)
为了避免死锁,哲学家在拿不到第二支筷子时,主动放下第一支筷子,稍等片刻再重试。
1 | int tryP(sem_t *s) { // 尝试 P 操作(非阻塞) |
活锁/饿死风险
虽然避免了死锁(因为线程会释放资源),但可能出现活锁(Livelock)或饿死。
例如,运气不好的话,所有哲学家可能在同一时间尝试拿筷子、失败、放下、等待,然后又在同一时间再次尝试……陷入一种不断尝试但无法前进的状态。
即使不是严格的活锁,某个哲学家也可能因为运气差或 sleep 时间不当而持续失败,导致饿死。
方案 2 改进:随机退避
将 sleep(sometime) 改为 sleep(random_time)。引入随机性可以大大降低活锁的可能性。
1 | // ... 同方案 2,但使用随机等待时间 ... |
实用性
随机退避是一种在分布式系统和网络协议中常用的解决冲突和避免活锁的方法。在哲学家就餐问题中,它在实践中通常能工作得很好,但理论上仍然不能完全排除极小概率下的饿死情况。对于安全攸关系统,可能需要更确定性的解决方案。
方案 3:全局锁(并发度低)
在哲学家尝试拿起任何筷子之前,先获取一个全局的互斥锁(例如 Ticket Lock)。
1 | ticket_t turn_lock; // 全局排队锁 |
并发度极低
这种方法能有效避免死锁和饿死(因为访问是串行的),但同一时间最多只有一位哲学家能吃饭,并发度非常低,没有利用问题的潜在并行性。
方案 3 改进:限制并发数(鸽巢原理)
允许一部分哲学家(例如 N-1 位)同时尝试获取筷子。
1 |
|
鸽巢原理保证无死锁
最多只有 N-1 位哲学家在竞争 N 支筷子。根据鸽巢原理,至少有一位哲学家能够成功拿到左右两支筷子(因为即使 N-1 位哲学家每人拿了一支,也还剩下一支筷子可以被某人拿起作为第二支)。这位能吃到饭的哲学家最终会释放筷子,从而让其他人有机会吃饭。这种方法提高了并发度(允许多人同时吃饭),并保证了无死锁。
方案 4:资源分级(破坏循环等待)
破坏死锁的四个必要条件之一:循环等待。可以通过给资源(筷子)编号,并规定所有哲学家必须按「固定顺序」(例如,先拿编号较小的筷子,再拿编号较大的筷子)来获取资源。
1 | void philosopher(int i) { |
无死锁且并发性好
这种方法通过强制规定资源获取顺序,打破了潜在的循环等待链,从而保证无死锁。它不需要额外的锁或信号量,并且允许多达 N/2 位哲学家同时吃饭(如果他们的筷子不冲突),具有较好的并发性。这是解决此类问题的常用且优雅的策略。
问题启示
哲学家就餐问题是理解和解决并发系统中资源竞争、死锁和饿死问题的经典模型。它展示了:
- 简单直观的并发策略可能隐藏着严重的活性问题。
- 避免死锁的常用策略包括:资源预分配(一次性获取所有资源,可能降低并发)、资源有序分配(破坏循环等待)、引入协调者或限制并发数。
- 需要在安全性(不发生错误)、活性(系统能持续运行)和性能(高并发、低延迟)之间做出权衡。
总结
本章我们深入探讨了更高级的同步问题和技术:
- 读者-写者问题:引出了读写锁,并讨论了不同策略(读者优先、写者优先、公平策略)及其对饿死风险的影响。
- Read-Copy-Update(RCU):一种用于高性能、读密集场景的无锁读取技术。通过版本控制、原子发布和延迟回收(需等待宽限期)机制,实现极低开销的读者操作,但写者逻辑更复杂。
- 哲学家就餐问题:一个经典的用于演示死锁和饿死问题的模型。探讨了多种解决方案,包括可能导致问题的朴素方法、基于退避的方法、限制并发数的方法(鸽巢原理)以及通过资源分级破坏循环等待的有效方法。
西方哲学家用筷子……我看到的版本是刀叉。 ↩︎