并发问题
并发 Bug 的分类
根据 Shan Lu 等人在 ASPLOS'08 发表的论文(获 Most Influential Paper Award)对四个大型软件(MySQL, Apache, Mozilla, OpenOffice)的实证研究,除死锁外,绝大多数(约 97%)的并发 Bug 可归为两类:
- 原子性违背(Atomicity Violation, AV)
- 定义:一段本应原子执行的代码序列被其他线程中断,导致非预期结果。
- 常见原因:忘记加锁,或者锁的粒度过小,未能覆盖所有需要原子执行的操作。
- 顺序性违背(Order Violation, OV)
- 定义:两个(或多个)内存访问或事件的实际执行顺序与程序预期的顺序不符。
- 常见原因:缺少必要的同步机制(如条件变量、信号量)来强制保证特定执行顺序,或者同步条件编写错误。
人类的倾向
经验性研究更能反映出开发者在并发编程中常见的思维误区和易犯的错误类型。除了上述两类,死锁也是并发系统中常见的问题。
原子性违背(AV)示例
即使开发者意识到了需要加锁,也可能因为锁的范围不当而导致原子性违背。
Check-Then-Act 问题:
- 线程 1 检查一个条件(如
thd->proc_info是否非空)。 - 在线程 1 根据检查结果执行操作(如
fputs(thd->proc_info, ...))之前,线程 2 可能修改了该条件(如thd->proc_info = NULL;)。 - 导致线程 1 的操作基于一个过时的状态,引发错误(如空指针解引用)。
1 | // MySQL ha_innodb.cc 示例(示意) |
sequenceDiagram
participant T1 as 线程 1
participant T2 as 线程 2
participant Shared as thd->proc_info
T1->>Shared: 读取(proc_info != NULL)
Note over T1: 条件成立
T2->>Shared: 写入(proc_info = NULL)
Note over T2: 状态改变
T1->>Shared: 读取(proc_info 现在是 NULL!)
Note over T1: 解引用 NULL 指针,崩溃!原子性要求
从检查条件到基于该条件执行操作,这整个逻辑单元通常需要是原子的。仅仅对检查和操作分别加锁是不够的,必须用同一个锁保护整个 check-then-act 序列。
顺序性违背(OV)示例
当代码逻辑依赖于特定事件发生的先后顺序,但没有使用同步机制来保证这个顺序时,就可能发生顺序性违背。
「BA」问题:事件 B 在预期的事件 A 之前发生了。
- 线程 1 发起一个异步操作(
PBReadAsync),然后设置一个标志io_pending = TRUE,并循环等待该标志变为FALSE。 - 线程 2 是异步操作的回调函数,负责在操作完成后将
io_pending设置为FALSE。 - 预期顺序:线程 1 设置
TRUE(S1) -> 线程 2 设置FALSE(S2)。 - 错误顺序:如果由于调度原因,线程 2 在线程 1 设置
TRUE之前 就执行了io_pending = FALSE(S2),那么线程 1 随后设置io_pending = TRUE并进入while循环,将永远等待下去,导致程序挂起(hang)。
1 | // Mozilla macio.c & macthr.c 示例(示意) |
graph TD
subgraph "正确顺序"
T1_S1["线程 1:io_pending = TRUE"] --> T2_S2["线程 2:io_pending = FALSE"];
T2_S2 --> T1_WhileEnd["线程 1:while 循环结束"];
end
subgraph "错误顺序(顺序性违背)"
T2_S2_Buggy["线程 2:io_pending = FALSE"] --> T1_S1_Buggy["线程 1:io_pending = TRUE"];
T1_S1_Buggy --> T1_WhileHang["线程 1: while 循环永远挂起"];
end
style T1_S1 fill:#cfc,stroke:#333
style T2_S2 fill:#ccf,stroke:#333
style T1_WhileEnd fill:#cfc,stroke:#333
style T2_S2_Buggy fill:#ccf,stroke:#333
style T1_S1_Buggy fill:#cfc,stroke:#333
style T1_WhileHang fill:#f99,stroke:#333同步是关键
需要使用条件变量、信号量或其他同步原语来确保 S1 happens-before S2,或者确保线程 1 在检查 io_pending 前等待 S2 的完成信号。
死锁
死锁是并发系统中另一种重要的活性问题。
死锁
死锁(Deadlock)是指在一个进程(或线程)组中,每个成员都在等待其他成员释放资源(如锁、消息等),导致所有成员都无法继续执行的一种状态。

死锁类型与示例
-
自死锁(Self-deadlock/A-A 型死锁)
- 描述:一个线程在已经持有某个锁的情况下,再次尝试获取同一个锁。如果锁是不可重入的(non-reentrant),线程将永远等待自己释放锁。
- 原因:在复杂的系统中,由于多层函数调用或隐藏的控制流(如回调),开发者可能没有意识到重复加锁。
- 示例:
1
2
3
4
5
6
7
8mutex_t lk;
void foo() {
lock(&lk); // 加锁
// ... 复杂逻辑 ...
foo(); // 递归调用,试图再次加锁 lock(&lk)!
// ...
unlock(&lk); // 解锁
} - 防御:
- 使用「可重入锁」(Recursive Lock)。
- 防御性编程:在
acquire函数中检查当前线程是否已持有该锁(如 xv6 的holding()函数)。1
2
3
4
5
6
7// xv6 acquire(简化版)
void acquire(struct spinlock *lk) {
// ... push_off() 等操作 ...
if (holding(lk)) // 检查当前 CPU 是否已经持有该锁
panic("acquire"); // 如果持有,抛出异常
// ... 获取锁 ...
}
-
循环等待死锁(ABBA/Mutually Recursive Locking)
- 描述:涉及多个线程和多个锁,形成循环依赖。
- 线程 T1 持有锁 A,需要锁 B。
- 线程 T2 持有锁 B,需要锁 A。
- 结果:T1 等待 T2 释放 B,T2 等待 T1 释放 A,形成死锁。
- 示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20mutex_t A, B; // 定义两个互斥锁
int sum = 0; // 共享变量
void T1() {
lock(&A); // 获取锁 A
// 需要锁 B
lock(&B); // 获取锁 B
sum++; // 临界区,需要同时持有锁 A 和锁 B
unlock(&B); // 释放锁 B
unlock(&A); // 释放锁 A
}
void T2() {
lock(&B); // 获取锁 B
// 需要锁 A
lock(&A); // 获取锁 A
sum++; // 临界区,需要同时持有锁 A 和锁 B
unlock(&A); // 释放锁 A
unlock(&B); // 释放锁 B
} - 关联:这是「哲学家进餐问题」中经典死锁场景的简化版。
- 描述:涉及多个线程和多个锁,形成循环依赖。
-
条件变量与死锁
- 描述:当线程等待条件变量时,如果它持有的锁是其他线程发出信号或改变条件所需访问的,就可能发生死锁。
- 示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26mutex_t A, B; // 定义两个互斥锁
cond_t cv; // 定义条件变量
int condition_met = 0; // 条件标志
// 线程 T1(等待)
void T1_wait() {
lock(&A); // 持有锁 A
lock(&B); // 持有锁 B
while (!condition_met) {
// 错误:在线程持有锁 A 的情况下,等待与锁 B 关联的条件变量
// 如果 T2 需要锁 A 来发出信号,则会导致死锁
cond_wait(&cv, &B); // 等待条件变量
}
unlock(&B); // 释放锁 B
unlock(&A); // 释放锁 A
}
// 线程 T2(发出信号)
void T2_signal() {
lock(&A); // 需要锁 A(被 T1 持有)
lock(&B); // 需要锁 B(被 T1 持有,但在 cond_wait 中释放)
condition_met = 1; // 改变条件
cond_signal(&cv); // 发出与锁 B 关联的信号
unlock(&B); // 释放锁 B
unlock(&A); // 释放锁 A
} - 关键:
cond_wait只释放与其直接关联的锁(示例中是B),但线程仍然持有其他锁(A)。如果唤醒者需要这些其他锁,就会死锁。
死锁产生的必要条件
死锁的发生必须同时满足以下四个条件:
- 互斥
- 资源是互斥使用的,一次只有一个线程能持有。
- 推广:资源有限(Bounded Resources),即能够同时访问资源的线程数量有限。可以看作是多个同类互斥资源的集合。
- 持有并等待
- 线程至少持有一个资源,并且正在等待获取其他线程持有的额外资源。
- 非抢占
- 资源不能被强制性地从持有者线程中抢占,只能由持有者自愿释放。
- 循环等待
- 存在一个线程等待队列 ,使得 等待 持有的资源, 等待 持有的资源,…, 等待 持有的资源,而 等待 持有的资源,形成一个环路。
必要非充分
这四个是必要条件,意味着死锁发生时,这四个条件一定都成立。但反之不一定,即使四个条件都满足,也不一定会发生死锁。例如:
- 如果资源有多个实例(如多个同类型的筷子),即使形成等待环,也可能有线程能获得所需资源而打破僵局。
- 环外的某个线程可能释放资源,使得环内的某个线程得以继续执行,从而打破循环。
处理死锁的策略
主要有四种策略:
- 忽略问题:鸵鸟方法,假装问题不存在。适用于死锁发生概率极低,且发生后代价不大(如重启系统)的场景。很多桌面操作系统采用此策略。
- 死锁预防:通过破坏死锁产生的四个必要条件之一,从结构上确保死锁永远不会发生。
- 死锁避免:在资源分配时进行判断,只进行「安全」的分配,即确保系统不会进入可能导致死锁的不安全状态。需要预知未来的资源需求。
- 死锁检测与恢复:允许死锁发生,但系统具备检测死锁的能力,并在检测到死锁后采取措施进行恢复(如终止进程、抢占资源)。
死锁预防:破坏必要条件
目标是破坏四个必要条件中的至少一个。
-
破坏互斥
- 思路:允许多个线程同时访问资源。
- 困难:很多资源(如打印机、锁保护的数据结构)本质上是互斥的。互斥是保证并发安全性的基础。
- 可行性:对于某些数据结构,可以通过「无锁算法」实现,依赖于硬件原子指令。例如 RCU。
- 缺点:无锁算法设计复杂,容易出错,且通常性能开销不低。
1
2
3
4
5
6
7
8// 示例:使用 CAS 实现原子增量(无锁)
void AtomicIncrement(int *value, int amount) {
int old_val, new_val;
do {
old_val = *value; // Read current value
new_val = old_val + amount;
} while (compare_and_swap(value, old_val, new_val) == 0); // 若 value 未被其他线程修改,则原子更新
}
-
破坏持有并等待
- 思路 1:一次性获取所有资源。线程开始执行前,必须一次性获得其所需的所有资源,否则就等待,不持有任何资源。
1
2
3
4
5
6
7lock(prevention_lock); // 原子地获得所有资源的锁的元锁
lock(L1);
lock(L2);
...
unlock(prevention_lock);
// ... 临界区 ...
unlock(L1); unlock(L2); ...- 缺点:
- 需要预知所有资源,难以实现(尤其资源动态创建时)。
- 显著降低并发度,线程可能长时间持有不需要的资源。
- 缺点:
- 思路 2:尝试获取,失败则释放。如果线程无法立即获得所需的额外资源,则释放其当前持有的所有资源,稍后重试。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 哲学家进餐问题变种(可能导致活锁)
void philosopher(int i) {
while(1) {
think();
while(1) {
P(forks[left(i)]); // 拿起左筷
int ret = tryP(forks[right(i)]); // 尝试拿起右筷
if (ret != 0) { // 拿起右筷失败
V(forks[left(i)]); // 放下左筷
sleep(random_time); // 随机等待
} else { // 同时拿起了两只筷子
break; // 退出循环,开始吃饭
}
}
eat();
V(forks[left(i)]); V(forks[right(i)]); // 放下筷子
}
}- 缺点:
- 可能导致活锁:线程不断尝试、失败、释放、重试,但总是无法取得进展(例如所有哲学家同时拿起左筷,同时尝试右筷失败,同时放下左筷,无限循环)。随机退避(
sleep(random_time))可以缓解但不能完全消除活锁。 - 实现复杂,需要追踪线程持有的所有锁,不易管理(尤其锁被封装时)。
- 可能导致活锁:线程不断尝试、失败、释放、重试,但总是无法取得进展(例如所有哲学家同时拿起左筷,同时尝试右筷失败,同时放下左筷,无限循环)。随机退避(
- 缺点:
- 思路 1:一次性获取所有资源。线程开始执行前,必须一次性获得其所需的所有资源,否则就等待,不持有任何资源。
-
破坏非抢占
- 思路:允许系统强制剥夺线程已持有的资源。
- 可行性:
- 对于 CPU:通过「上下文切换」实现抢占。
- 对于内存:通过「虚拟内存/交换」机制,可以将一个进程的内存暂时移到磁盘,让给其他进程。
- 困难:
- 并非所有资源都适合抢占(如打印机,抢占会导致打印内容混乱)。
- 需要确保被抢占资源的线程能够安全地恢复到抢占前的状态,这可能很复杂。
-
破坏循环等待
- 思路:对所有资源类型进行全局排序,强制所有线程按此顺序申请资源。
- 实现:锁排序。为每个锁分配一个唯一的序号(如基于内存地址),线程在需要获取多个锁时,必须按照序号递增(或递减)的顺序获取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 示例:按锁地址排序获取
void do_something(mutex_t *m1, mutex_t *m2) {
// 确保锁的顺序一致(例如,地址较小的锁先获取)
mutex_t *first = (m1 < m2) ? m1 : m2;
mutex_t *second = (m1 < m2) ? m2 : m1;
pthread_mutex_lock(first);
pthread_mutex_lock(second);
// ... 临界区使用 m1 和 m2 ...
pthread_mutex_unlock(second);
pthread_mutex_unlock(first);
} - 原理:
- 锁的申请过程可以看作是在构造一个「锁依赖」有向图 ,边 表示持有锁 的线程尝试获取锁 。
- 如果所有线程都按全局顺序申请锁(例如,总是从序号小的锁申请到序号大的锁),那么图中不可能出现环。因为如果存在边 ,则意味着 。一个由这种边组成的环 将意味着 ,这是不可能的。
- 没有环的图意味着没有循环等待,因此不会发生死锁。这与有向无环图(DAG)的「拓扑序」概念相关:强制按序申请相当于保证了锁依赖图总是无环的,因此总存在拓扑序。
- 应用:广泛应用于操作系统内核。
- 局限性:
- 在大系统中维护全局锁序可能很困难(「5000 lock hierarchy」问题)。
- 当引入新锁时,需要确定其在全局顺序中的位置。
- 封装是更好的实践:锁应尽可能被限制在模块内部,不跨模块持有。如果一个函数只获取一个它内部管理的锁,就不会引入跨模块的死锁风险。
死锁避免:避免进入不安全状态
这种策略允许前三个必要条件存在,但在资源分配时动态决策,确保系统不会进入「不安全状态」。
安全状态 vs. 不安全状态
- 安全状态:系统存在一个「安全序列」,即所有线程可以按此顺序逐个完成执行。对于序列中的每个线程 ,它当前请求的资源 + 未来可能需要的最大资源 系统当前可用资源 + 所有排在它之前的线程 持有的资源。
- 不安全状态:系统不存在任何安全序列。不安全状态不一定是死锁状态,但系统可能会进入死锁状态。死锁避免的目标就是阻止系统进入不安全状态。
有两个线程 A 和 B, 每个线程都需要用到需要如下的两个互斥的资源:打印机和绘图仪。
- 线程 A 从指令 到 之间需要打印机,从指令 到 之间需要绘图仪
- 线程 B 从指令 到 之间需要绘图仪,从指令 到 之间需要打印机
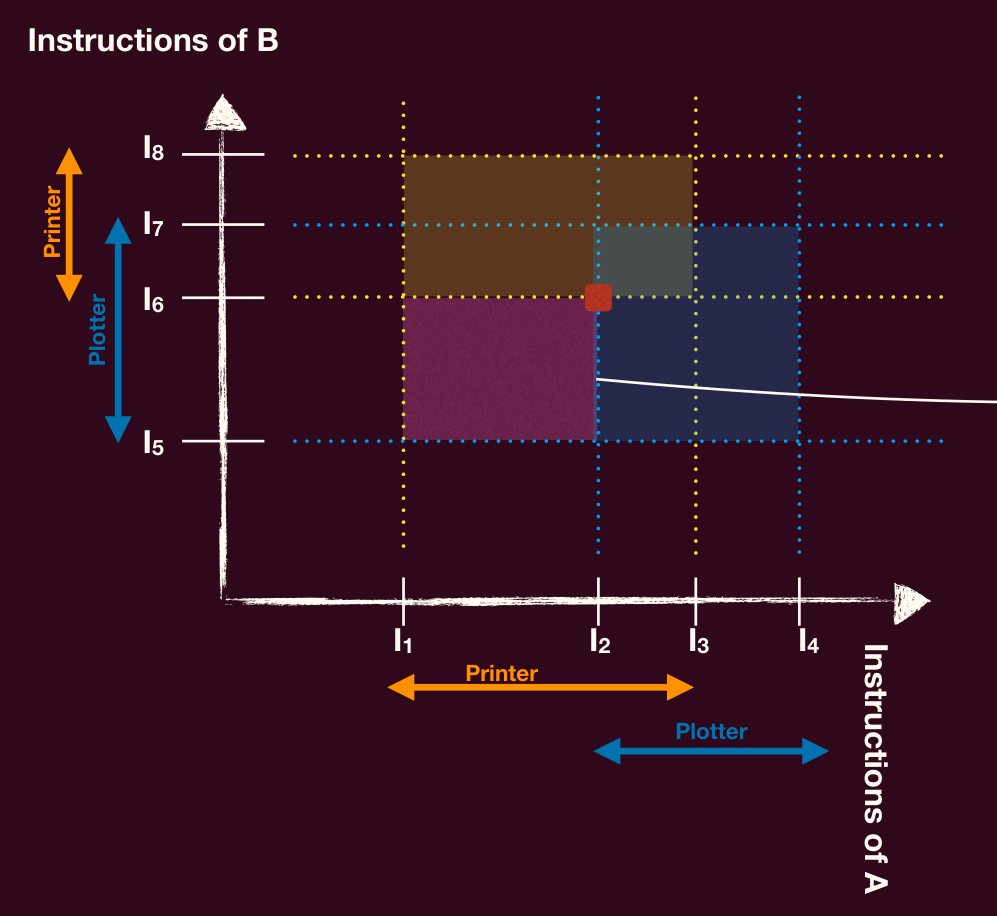
黄色区域是两个都获得打印机的状态,蓝色区域是两个都获得绘图仪的状态,在红点 处,是 ABBA 型死锁,系统无法再行进。
而紫色区域已经是处于「不可挽回」状态了,因为随着系统行进最终都会无可避免地走向死锁状态。因此只要能避免进入该区域就不会发生死锁,这要求了系统尝试进入该区域时,调度系统直接拒绝相应的线程得到想要的资源。
但是知道每个线程在未来哪段指令间需要什么资源是不现实的。
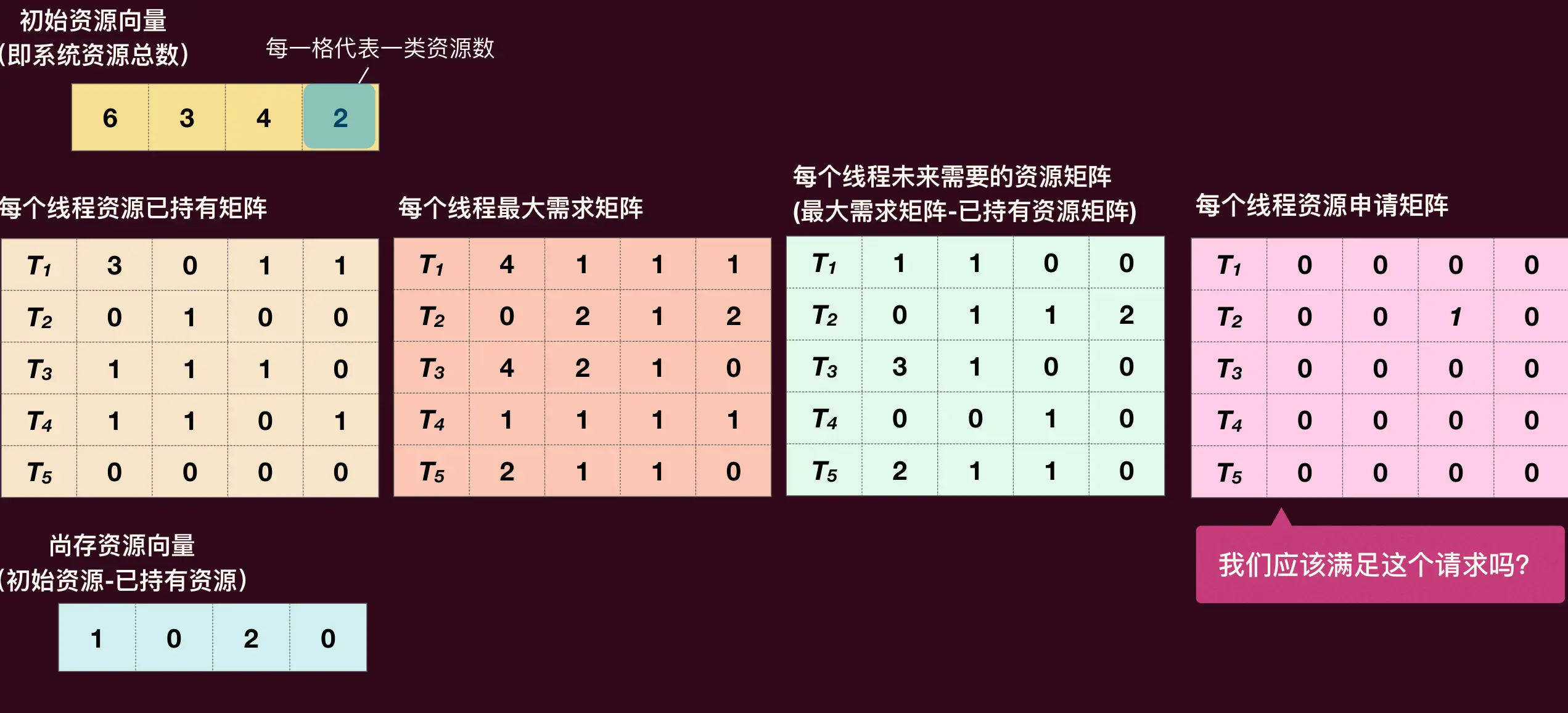
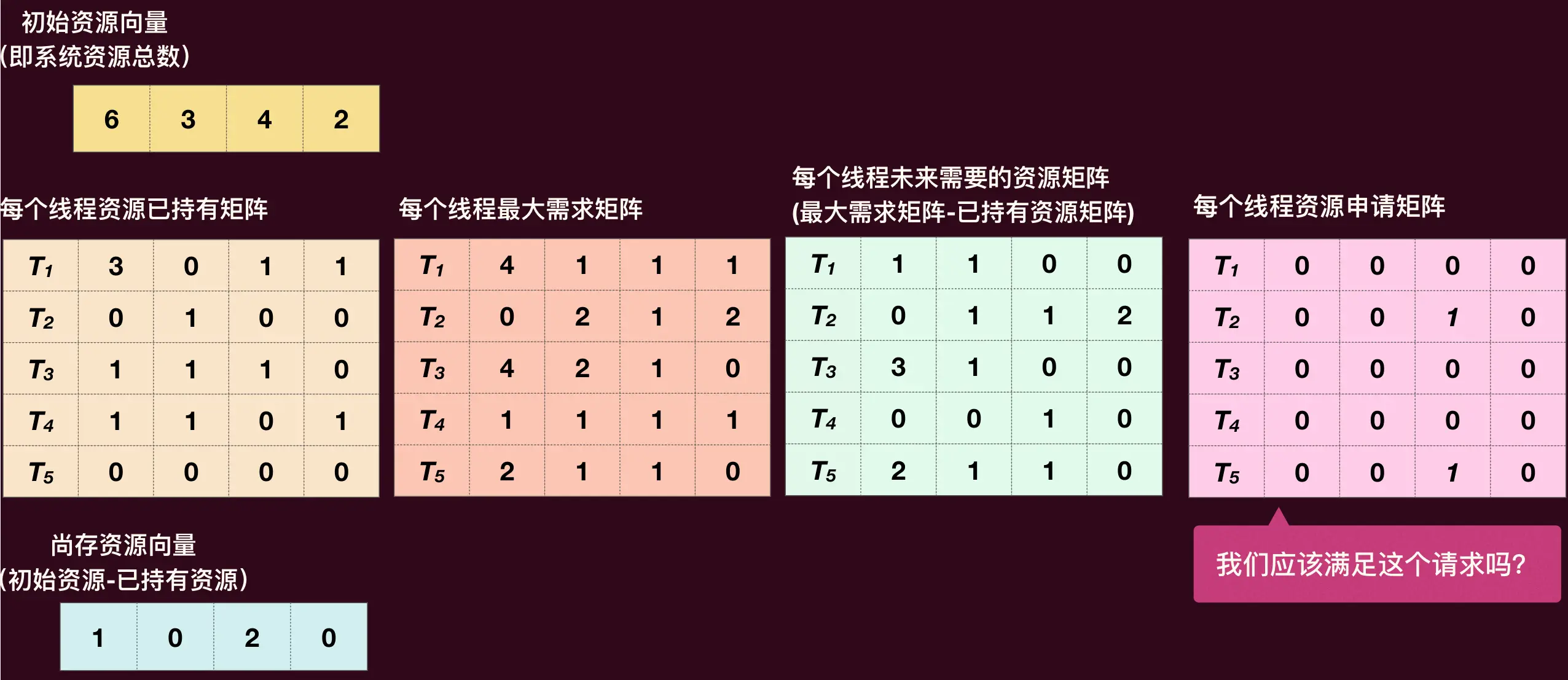
将条件放宽一点,假设我们知道每个线程在整个执行期间需要哪些互斥资源。更一般地假设资源不只为 1,假设能知道每个线程在其执行期间需要哪些互斥资源的最大数量,即每个线程 有一个最大需求向量 ,所有线程最大需求向量形成一个最大需求矩阵 。
银行家算法是最著名的死锁避免算法。它要求:
- 系统中的资源种类和数量固定。
- 系统中的线程数量固定。
- 每个线程必须预先声明它对每种资源的最大需求量。
- 线程获得资源后,必须在有限时间内释放。
算法核心是「安全性检查」。当一个线程请求资源时,系统执行以下检查:
- 假装分配:假设满足该线程的请求,更新系统状态(可用资源减少,该线程持有资源增加)。
- 检查新状态是否安全:
- 初始化:
Work= 当前可用资源向量,Finish= 所有线程标记为false的向量。 - 循环查找:寻找一个线程
i,满足:Finish[i] == false(线程尚未完成)Need[i] <= Work(线程未来所需资源 当前可用资源)。其中Need[i] = Max[i] - Allocation[i]。
- 如果找到这样的线程
i:- 假装线程
i执行完毕并释放资源:Work = Work + Allocation[i]。 - 标记线程
i完成:Finish[i] = true。 - 回到循环查找步骤。
- 假装线程
- 如果找不到这样的线程
i:- 检查是否所有线程都已标记
Finish = true。如果是,则状态安全。 - 否则,状态不安全。
- 检查是否所有线程都已标记
- 初始化:
- 决策:
- 如果假装分配后的状态是安全的,则批准该资源请求,实际更新系统状态。
- 如果假装分配后的状态是不安全的,则拒绝该资源请求,线程必须等待。
数据结构:
Available: 向量,表示每种资源当前可用的实例数。Max: 矩阵,Max[i][j]表示线程i对资源j的最大需求量。Allocation: 矩阵,Allocation[i][j]表示线程i当前已分配到的资源j的实例数。Need: 矩阵,Need[i][j] = Max[i][j] - Allocation[i][j],表示线程i还需要的资源j的实例数。
银行家算法的局限性:
- 不实用:
- 通常无法预知线程的最大资源需求。
- 系统资源(如内存)和线程数量通常是动态变化的。
- 线程持有资源的时间不确定。
- 开销大:每次资源请求都需要运行安全性检查算法。
死锁检测与恢复
这种策略允许系统进入死锁状态,然后通过检测机制发现死锁,并采取措施解除死锁。
死锁检测
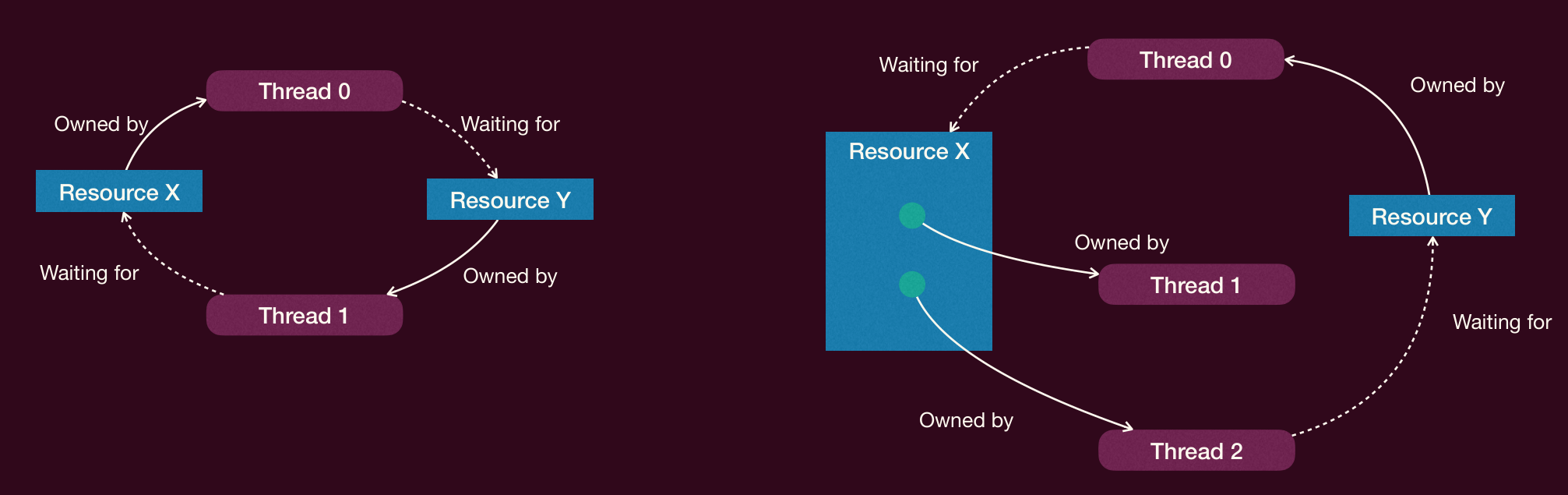
- 单一实例资源(如锁):
- 构建等待图(Wait-for Graph, WFG):节点代表线程,有向边 表示线程 正在等待线程 持有的资源。
- 检测环路:定期在 WFG 中运行「环检测算法」(如基于深度优先搜索 DFS)。如果检测到环,则存在死锁。
- 动态构建与检测(lockdep 原理):
- 记录每次锁的
acquire/release事件(线程 ID, 锁标识符)。 - 当线程 T 持有锁 u 尝试获取锁 v 时,动态在 WFG 中添加边( 的持有者)。
- 每次添加边后,检查是否形成环。可以使用 DFS 检测是否存在从 v 到 T 的路径。
- 锁标识符:可以用锁变量的内存地址,或锁所在的文件和行号(近似,成本低)。
- 记录每次锁的
- 多实例资源(如信号量、内存页):
- 简单的环检测不足够。即使存在等待环,也可能因为有足够的空闲资源实例而不会死锁。
- 需要使用类似银行家算法的「资源分配图简化」方法来检测:
- 给定:当前可用资源向量
Available,当前分配矩阵Allocation,当前请求矩阵Request。 - 初始化:
Work = Available,Finish[i] = false对所有活跃线程i. - 循环查找:寻找一个线程
i满足:Finish[i] == falseRequest[i] <= Work(线程当前的请求可以被满足)
- 如果找到这样的线程
i:- 假装满足其请求并让其完成:
Work = Work + Allocation[i],Finish[i] = true。 - 回到循环查找步骤。
- 假装满足其请求并让其完成:
- 如果循环结束:
- 所有
Finish[i] == true的线程「不在」死锁状态。 - 任何
Finish[i] == false的线程「处于」死锁状态。
- 所有
- 给定:当前可用资源向量
死锁恢复
检测到死锁后,需要采取措施打破循环等待:
- 终止进程:
- 终止死锁环中的一个或多个进程。选择哪个进程终止?(基于优先级、已运行时间、已占用资源等)。
- 终止所有死锁进程。简单粗暴,但可能丢失工作。
- 资源抢占:
- 强制从一个或多个死锁进程中抢占资源,分配给其他死锁进程,直到打破环路。
- 选择哪个进程/资源抢占?(成本最低原则)。
- 回滚:被抢占资源的进程需要回滚到一个安全状态,并稍后重新执行。实现复杂。
使用动态分析检测并发 Bug
除了死锁,原子性违背和顺序性违背(尤其是数据竞争)也可以通过动态分析技术来检测。
动态分析
动态分析是指在程序运行时收集其执行信息(如日志、内存访问、系统调用),并根据这些信息来分析程序的行为、检测潜在错误。
- 通常需要插桩(Instrumentation):在编译时或运行时向代码中插入额外的指令来收集信息,这会带来一定的性能开销。
- 分析函数 :对收集到的执行历史 进行分析,判断是否存在特定问题(如 表示存在 Bug, 表示未检测到)。
AddressSanitizer(ASan)
- 目标:检测非法内存访问错误。
- 原理:
- 编译器在分配内存(栈、堆、全局)时,在有效内存区域周围插入不可访问的「中毒区域」(Poisoned Redzones)。
- 在每次内存访问指令(读/写)前插入检查代码,判断访问地址是否落在中毒区域。
- 对
free后的内存区域或return后的栈帧进行投毒,以检测 Use-After-Free/Use-After-Return。
- 可检测:
- 缓冲区溢出(Heap, Stack, Global)
- Use-After-Free
- Use-After-Return
- Double-Free
- …
- 使用:编译时添加
-fsanitize=address选项(GCC/Clang)。
ThreadSanitizer(TSan)
- 目标:检测数据竞争。
- 回顾数据竞争:
- 两个或多个线程
- 并发地访问同一内存位置
- 至少一次访问是写操作
- 访问没有通过锁或其他同步机制进行协调
- 关键:如何判断「并发地」?使用 Happens-Before 关系。
- Happens-Before(HB):定义了事件之间的偏序关系。如果事件 A happens-before 事件 B(),则 A 的影响对 B 可见。
- HB 关系来源:同一线程内的程序顺序、锁的
unlock到后续lock、signal到wait返回、线程创建/join 等。 - 并发:如果事件 A 和 B 之间既没有 ,也没有 ,则它们是并发的。
- 原理:
- TSan 在运行时跟踪每个内存位置的访问历史(读写线程、逻辑时间戳等)。
- 使用「向量时钟」等算法维护线程间的 Happens-Before 关系。
- 当发生内存访问时,检查该访问是否与历史上其他线程对同一位置的冲突访问(至少一个是写)存在 HB 关系。
- 如果两个冲突访问来自不同线程且没有 HB 关系(即并发),则报告数据竞争。
- 使用:编译时添加
-fsanitize=thread选项。
其他 Sanitizers
现代编译器(如 GCC, Clang)和内核提供了多种 Sanitizer 工具:
- KASAN(Kernel Address Sanitizer): ASan 的内核版本。
- KCSAN(Kernel Concurrency Sanitizer): TSan 的内核版本,用于检测内核数据竞争。
- MemorySanitizer(MSan): 检测未初始化内存读取。
- UBSanitizer(Undefined Behavior Sanitizer): 检测 C/C++ 标准中定义的未定义行为(如整数溢出、非法位移、越界访问等)。
「低配版」Sanitizer 实现(用于教学/资源受限环境)
在没有现成 Sanitizer 工具或难以实现完整版本的情况下,可以实现一些简化版本来辅助调试:
-
Canary(金丝雀值)
- 原理:「牺牲」少量内存单元,填入特殊值(Canary),用于预警内存错误。
- Stack Guard: 在函数栈帧的关键位置(如返回地址前、缓冲区边界)放置 Canary 值。函数返回前检查 Canary 是否被修改,若被修改则可能发生缓冲区溢出。
- Heap Guard: 在
malloc分配的内存块前后放置 Canary 值,free时检查。 - 示例代码(Stack Guard/Buffer Overflow Canary):
1
2
3
4
5
6
7
8
9
10
11
12
int foo() {
char buffer[10];
volatile uint32_t canary = MAGIC; // 在缓冲区后放置金丝雀值
// ... 函数逻辑,可能会写入缓冲区 ...
strcpy(buffer, "This string is too long!"); // 溢出!
// ...
if (canary != MAGIC) { // 返回前检查金丝雀值
panic("Stack overflow detected!"); // 检测到溢出
}
return 0;
}
-
低配版 Lockdep(Spin Count Limit)
- 原理:检测死锁(或活锁)的一个简单启发式方法是监控自旋锁的自旋次数。
- 实现:在自旋锁的循环中增加一个计数器,如果计数超过一个非常大的阈值(如 1 亿次),则认为可能发生了死锁或严重性能问题,触发
panic并报告位置。 - 作用:不能精确诊断死锁,但能快速定位到「卡住」的代码点,配合调试器分析。
1
2
3
4
5
6
7int spin_cnt = 0;
while (xchg(&lk->locked, 1) != 0) { // 自旋锁
if (spin_cnt++ > SPIN_LIMIT) {
panic("Spin limit exceeded @ %s:%d\n", __FILE__, __LINE__);
}
}
-
低配版 ASan(Allocator Checks)
- 原理:在自定义内存分配器中加入检查,利用特定值(如
MAGIC)进行内存状态标记(投毒)。 - 实现:
kalloc: 分配内存后,用MAGIC值填充。如果发现内存已被MAGIC填充,则可能是 Double Allocation。free: 释放内存前,检查内存是否已被清零(或特定「已释放」标记),如果不是,则可能是 Double Free。释放后,用 0 或「已释放」标记填充。
- 作用:检测内存分配器自身或使用者违反规范(如重复分配/释放)。
- 原理:在自定义内存分配器中加入检查,利用特定值(如
-
低配版 TSan(Delayed Observation)
- 原理:数据竞争的后果(原子性破坏)通常难以观测,因为指令执行速度太快。通过人为「拖慢」读写操作之间的间隔,「放大」被其他线程干扰的可能性。
- 实现:在对共享变量的两次连续读取(或读后写)之间插入短暂延时
delay()。如果两次读取的值不同,则表明在此期间发生了原子性违背。 - 作用:增加复现数据竞争导致的不一致状态的概率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 假设 x 是一个共享变量,受锁保护,但可能在其他地方忘记加锁
lock(&lk);
int observe1 = x;
unlock(&lk);
delay(); // 引入延迟
lock(&lk);
int observe2 = x;
unlock(&lk);
if (observe1 != observe2) {
// 在延迟期间可能发生了原子性违规
report_potential_data_race();
}
低配版的意义
- 规范验证:给定程序正确运行的规范,动态分析的目标就是验证运行时是否破坏了规范。
- 弱化规范:完整规范可能非常复杂或难以形式化(如图像识别软件的「正确」识别)。可以从完整规范推导出一些更容易验证的弱化规范(如内存安全、无死锁、无数据竞争),并实现对应的(低配版)Sanitizer。
- 实用价值:即使精度不高,这些简单的检查在实际调试中往往能高效地发现许多常见的并发 Bug。