进程管理
什么是进程?
在操作系统中,我们运行的程序需要被管理和调度。简单地将一个程序放在内存里执行是不够的,操作系统需要一种方式来组织和控制这些并发执行的任务。进程(Process)就是操作系统对一个正在运行的程序的抽象。
进程定义演进
关于进程的定义,没有一个绝对统一的说法,但我们可以从不同层面理解它:
- A program in execution:一个正在执行中的程序。这是最基础的理解。
- An instance of a running program:一个运行程序的实例。强调了程序(静态代码)和进程(动态执行)的区别,同一个程序可以运行多次,产生多个进程实例。
- The entity that can be assigned to, and executed on, a processor:能够被分配给处理器并执行的实体。突出了进程作为调度单位的角色。
- A unit of activity characterized by a single sequential thread of execution, a current state, and an associated set of system resources:一个活动单元,其特点是拥有单一顺序执行流(至少一个线程)、当前状态以及一组关联的系统资源。这是更全面的描述,点明了进程包含执行流、状态和资源。
进程与线程
在引入线程概念后,进程的定义变得更加清晰:
- 进程:是操作系统进行资源分配(如内存地址空间、文件句柄、设备等)的基本单位。它提供了一个独立的执行环境。
- 线程:是操作系统进行CPU 调度的基本单位。它是在进程内部执行的单一顺序控制流。
一个进程可以包含一个或多个线程。这些线程共享进程的地址空间(代码段、全局变量、堆)和资源(文件描述符等),但每个线程拥有自己独立的执行栈(Stack)、程序计数器(PC)和寄存器状态。
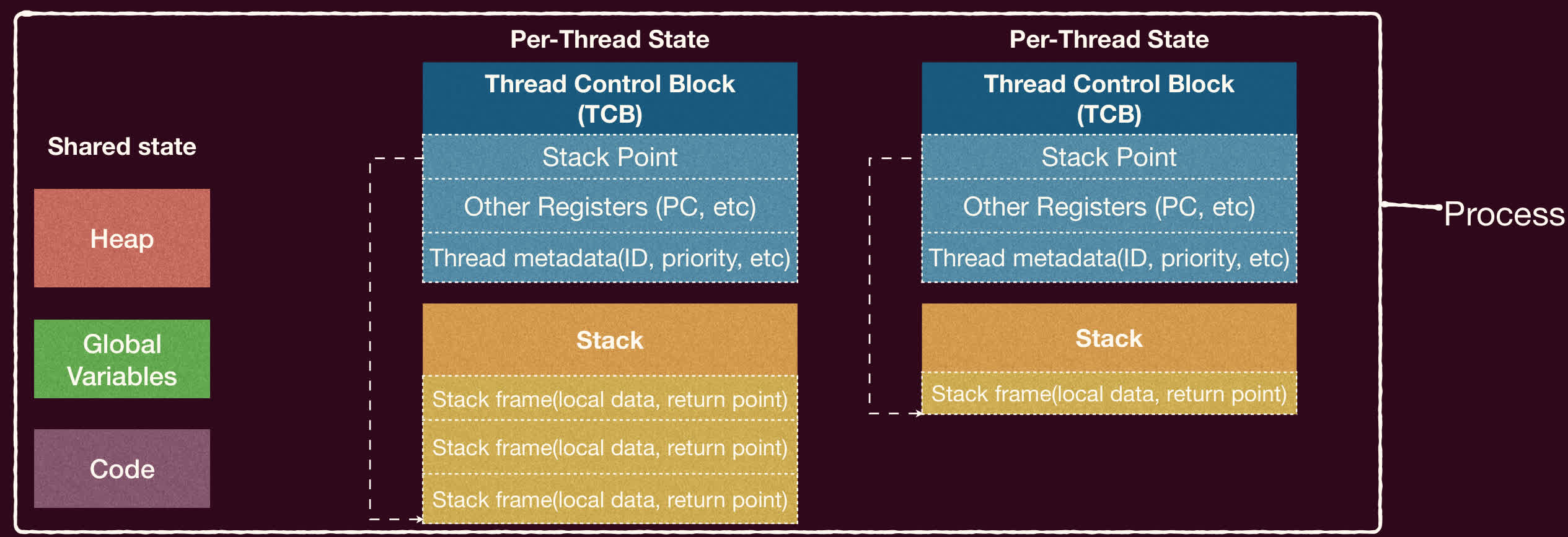
进程的表示:进程控制块(PCB)
为了管理进程,操作系统需要存储每个进程的相关信息。这些信息被集中存放在一个称为进程控制块(Process Control Block, PCB)的数据结构中。PCB 是进程存在的唯一标识,操作系统通过 PCB 来感知和控制进程。
进程控制块(PCB)
PCB 是操作系统内核中用于描述和管理进程的数据结构。它包含了操作系统对进程进行管理和调度所需的全部信息。
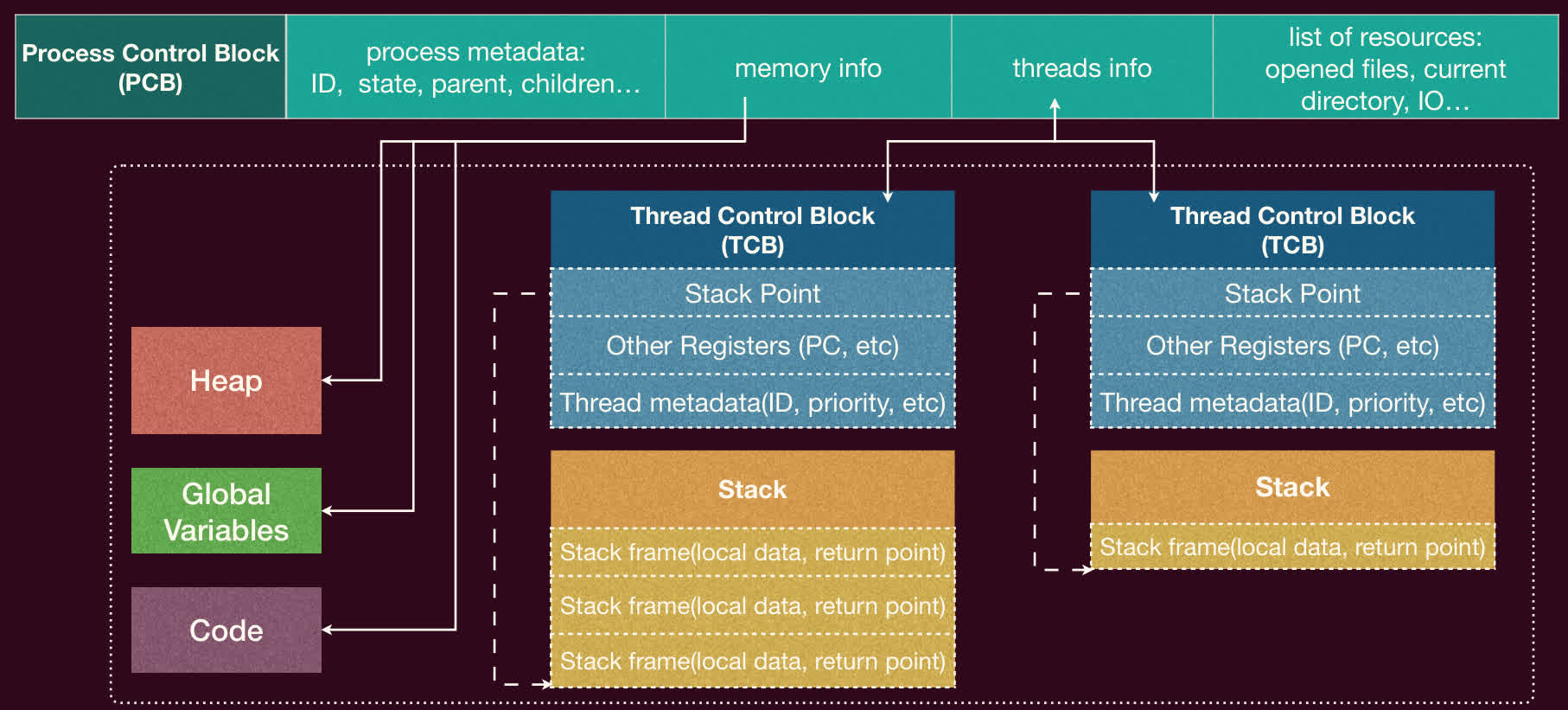
PCB 通常包含以下信息:
- 进程标识符(PID):每个进程唯一的 ID。
- 进程状态:如运行、就绪、等待等(详见生命周期)。
- 程序计数器(PC):指示进程下次要执行的指令地址。
- CPU 寄存器:进程运行时 CPU 寄存器的内容(用于上下文切换时保存和恢复)。
- CPU 调度信息:如进程优先级、调度队列指针等。
- 内存管理信息:如指向页表或段表的指针、地址空间布局信息。
- 记账信息:如 CPU 使用时间、进程创建时间等。
- I/O 状态信息:如分配给进程的 I/O 设备列表、打开的文件列表(文件描述符表)等。
- 上下文信息:指向线程控制块(TCB)列表(如果支持多线程)、父进程、子进程信息等。
所有这些元信息(PCB 及包含的 TCB)都由操作系统内核负责维护,对用户程序通常是透明的。
不同系统的实现差异
虽然 PCB 的概念是通用的,但具体实现会因操作系统而异:
- Linux:不严格区分进程和线程的 PCB。使用
task_struct结构统一表示,通过共享地址空间(mm_struct)和资源(files_struct等)来体现同一进程下的多个线程。pid通常指线程 ID (TID),tgid(Thread Group ID) 指进程 ID。相关定义在<linux/sched.h>。 - Solaris:明确区分进程(
proc_t)、内核线程(kthread_t) 和轻量级进程(klwp_t,用户态可见的内核线程接口)。它们之间通过指针相互引用。 - Windows:进程由
EPROCESS对象表示,线程由ETHREAD对象表示。EPROCESS包含进程资源信息(句柄表、虚拟内存 VADs、安全令牌等),并有一个指向其包含的ETHREAD链表的指针。此外,还有用户态可见的PEB(Process Environment Block) 和TEB(Thread Environment Block) 提供给应用程序访问某些进程/线程信息。
进程的生命周期
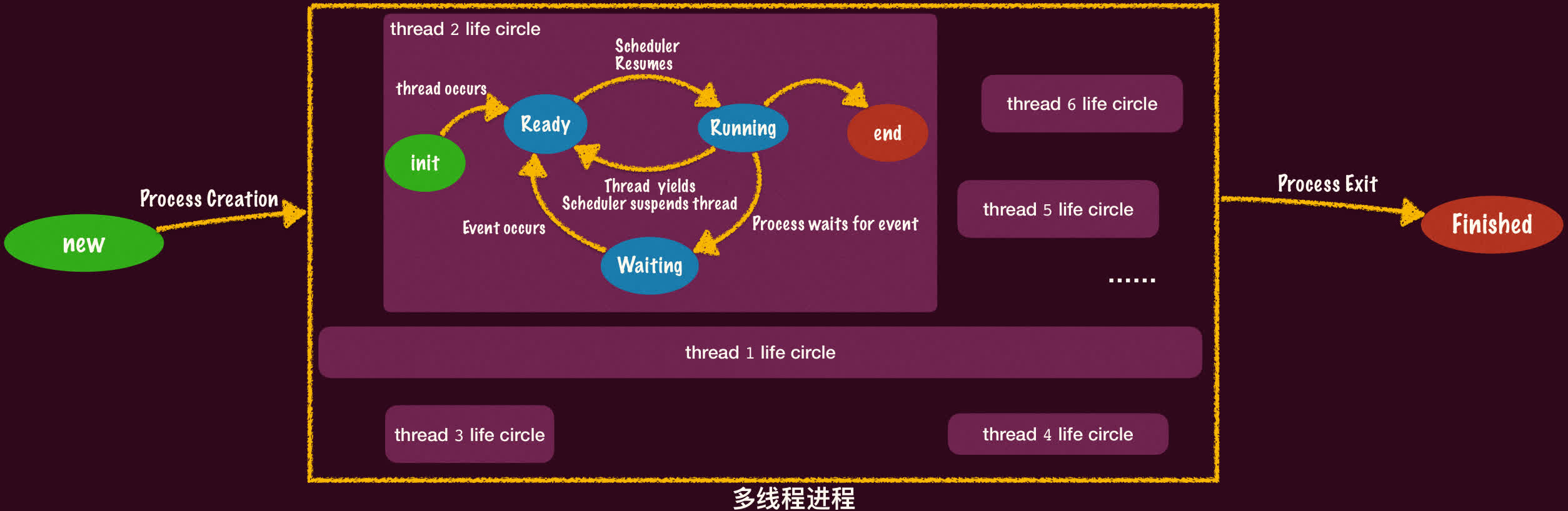
从创建到终止,进程会经历一系列状态变化。这些状态及其转换构成了进程的生命周期。
stateDiagram-v2
[*] --> New : Process Creation
state "New" as New
state "Ready" as Ready
state "Running" as Running
state "Waiting" as Waiting
state "Finished" as Finished
New --> Ready : Admitted (OS 准备好)
Ready --> Running : Scheduler Dispatch (调度器选中)
Running --> Ready : Scheduler Suspend/Timeout (时间片用完或被抢占)
Running --> Waiting : Process waits for event (等待 I/O, 信号等)
Running --> Finished : Process Exit (进程终止)
Waiting --> Ready : Event occurs (等待的事件发生)
Finished --> [*] : Cleanup (资源回收)
note right of Running
CPU 执行进程指令
end note
note left of Waiting
进程无法执行,等待外部事件
end note
note left of Ready
进程准备就绪,等待CPU
end note进程状态说明:
- New(新建):进程正在被创建,尚未准备好运行(例如,PCB 正在创建,资源尚未分配)。
- Ready(就绪):进程已具备运行所需的所有条件(资源已分配,等待事件已发生),只等待 CPU 时间片。所有就绪进程排列在一个或多个就绪队列中。
- Running(运行):进程正在 CPU 上执行指令。
- Waiting(等待/阻塞):进程因等待某个事件(如 I/O 完成、信号、锁)而暂时无法执行。事件发生后会转换到就绪态。
- Finished(终止/完成):进程执行完毕或被终止,正在进行资源回收。
多线程进程的生命周期
对于包含多个线程的进程,进程本身的状态(如是否拥有资源)和其内部线程的状态(是否在运行、等待等)是关联但不同的概念。进程的生命周期通常反映了其整体状态和资源占用情况,而内部每个线程有自己的生命周期状态转换(类似上图,但可能更细化)。一个进程只有在其所有线程都终止后才会进入 Finished 状态。
进程创建与进程树
进程通常由其他进程创建(除了第一个进程)。这形成了一种父子关系:创建者是父进程,被创建者是子进程。系统中所有用户进程构成了一个以 init 进程[1]为根的进程树。
- 在 Linux 中,可以使用
pstree命令查看当前的进程树。 - init 进程(通常 PID 为 1)是所有用户进程的祖先,由操作系统内核在启动时最后阶段加载。它的创建过程比较特殊,需要从零开始准备所有资源。一旦 init 运行起来,后续用户进程的创建就相对容易了(通常通过
fork)。
进程终止与资源回收
进程终止后,其占用的资源(内存、文件等)需要被操作系统回收。同时,父进程通常需要知道子进程的终止状态(是正常结束还是异常退出,退出码是多少)。
僵尸进程(Zombie Process)
- 当一个子进程终止时,它的 PCB 并不会立即被完全清除。内核会保留一部分信息(如 PID、退出状态、资源使用统计),等待父进程通过
wait()或waitpid()系统调用来获取这些信息。 - 在子进程终止后、父进程调用
wait()之前,这个子进程就处于僵尸状态(Zombie State)。它已经不再运行,不占用 CPU,但其 PCB 仍然保留在内核进程表中。
为什么需要僵尸状态?
为了让父进程有机会获取子进程的退出信息。如果子进程一终止就彻底消失,父进程将无法得知其执行结果。
潜在问题
如果父进程一直不调用 wait()(比如父进程自己挂了或者代码有 bug),僵尸进程会一直存在,虽然不消耗太多资源,但会占用进程表中的一个条目。大量僵尸进程可能耗尽 PID 资源。
僵尸进程 vs. 孤儿进程
僵尸进程是有父进程的,只是父进程还没来「收尸」(调用 wait)。
孤儿进程(Orphan Process)
如果一个父进程在它的子进程之前终止了,那么这些子进程就成了孤儿进程(Orphan Process)。
谁来照顾孤儿?
操作系统不能让孤儿进程永远漂泊。在类 Unix 系统(如 Linux)中,这些孤儿进程会被 init 进程「收养」。init 进程会成为它们的新父进程。
init 进程会周期性地调用 wait() 来清理它收养的所有已终止的子进程(包括那些变成僵尸的孤儿进程),从而回收它们的 PCB 资源。
核心进程操作:系统调用
操作系统提供了一系列系统调用来管理进程的生命周期。其中最核心的有三个:
fork():创建新进程。execve():加载并运行新程序。exit():终止当前进程。
创建进程:fork()
fork() 系统调用是类 Unix 系统创建新进程的主要方式。
1 |
|
基本行为:
- 创建子进程:调用
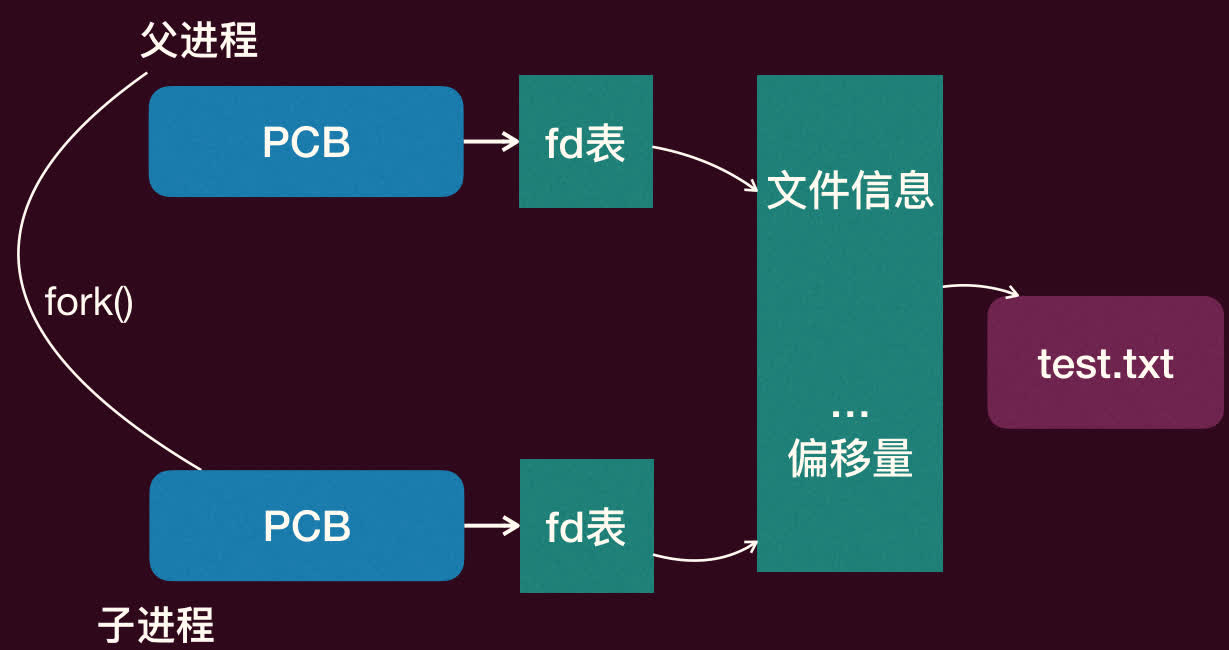
fork()的进程(父进程)会创建一个几乎与自己一模一样的子进程。 - 复制状态:子进程获得父进程地址空间(内存映像)的副本、CPU 寄存器状态的副本、文件描述符表的副本等。
- 内存复制:早期实现是完全复制,现代系统通常采用写时复制(COW) 优化。
- 文件描述符复制:父子进程共享同一个文件表项(file table entry)。这意味着它们共享文件偏移量。例如,如果父进程打开一个文件并读取了一部分,然后
fork,子进程从该文件描述符读取时会从父进程上次读取的位置继续。
- 独立执行:
fork()调用之后,父、子进程都从fork()返回点之后的指令开始,并发地、独立地继续执行。它们拥有各自独立的内存空间(COW 保证了这一点,一旦写入就会分离)和执行状态。 - 返回值区分:如何区分当前代码是在父进程还是子进程中执行?通过
fork()的返回值:- 在父进程中,
fork()返回新创建子进程的 PID(一个正整数)。 - 在子进程中,
fork()返回 0。 - 如果
fork()失败(例如,达到进程数限制),则在父进程中返回 -1,并设置errno,不创建子进程。
- 在父进程中,
示例代码:
1 |
|
示例输出:
1 | I am the parent process! |
写时复制(Copy-On-Write, COW)
早期的 fork() 实现需要完整复制父进程的整个地址空间给子进程,这非常耗时且浪费内存,特别是当 fork() 之后子进程立即调用 execve() 时,之前复制的内存完全没用。
COW 优化解决了这个问题:
- 共享物理内存:
fork()时,内核并不立即复制物理内存页。而是让父、子进程的页表条目指向相同的物理内存页。同时,内核将这些共享的页标记为「只读」(即使它们原本是可写的)。 - 写操作触发复制:当父进程或子进程「尝试写入」某个共享页时,会触发一个页错误异常,因为违反了只读权限。
- 内核处理页错误:内核捕获这个异常,识别出这是一个 COW 事件。
- 复制页面:内核为触发写入的进程分配一个新的物理页,将旧页的内容复制到新页。
- 更新页表:内核更新触发写入进程的页表,使其指向新的、可写的物理页副本。另一个进程的页表仍然指向旧的(现在只被它自己使用的)只读页(如果它也没写过,则保持共享只读;如果它也要写,则重复此过程)。
- 恢复执行:页错误处理完毕,写入操作在新的内存页上成功执行。
graph TB
%% 颜色定义
classDef shared fill:#f9f,stroke:#333,stroke-width:2px
classDef copied fill:#9cf,stroke:#333,stroke-width:2px
classDef fault fill:#f66,stroke:#333,stroke-width:2px
classDef process fill:#c9f7c1,stroke:#2e8b57,stroke-width:2px
classDef readonly fill:#ffd700,stroke:#daa520,stroke-width:2px
classDef readwrite fill:#98fb98,stroke:#3cb371,stroke-width:2px
%% 三个阶段
subgraph "COW 处理完成"
direction TB
A3[进程 A 虚拟地址]:::process --> P3(物理页 P):::shared
P3 -.-> RO2[(只读)]:::readonly
B3[进程 B 虚拟地址]:::process --> P4(新物理页 P'):::copied
P4 -.-> RW[(读写)]:::readwrite
end
subgraph "进程 B 尝试写入"
direction TB
B2[进程 B 虚拟地址]:::process -- 写操作 --> P2(物理页 P):::shared
P2 -- 触发 --> PF{页错误}:::fault
end
subgraph "fork() 初始化阶段"
direction TB
A1[进程 A 虚拟地址]:::process --> P1(物理页 P):::shared
B1[进程 B 虚拟地址]:::process --> P1
P1 -.-> RO1[(只读)]:::readonly
end
%% 样式调整
linkStyle 0,1 stroke:#999,stroke-width:2px,stroke-dasharray:5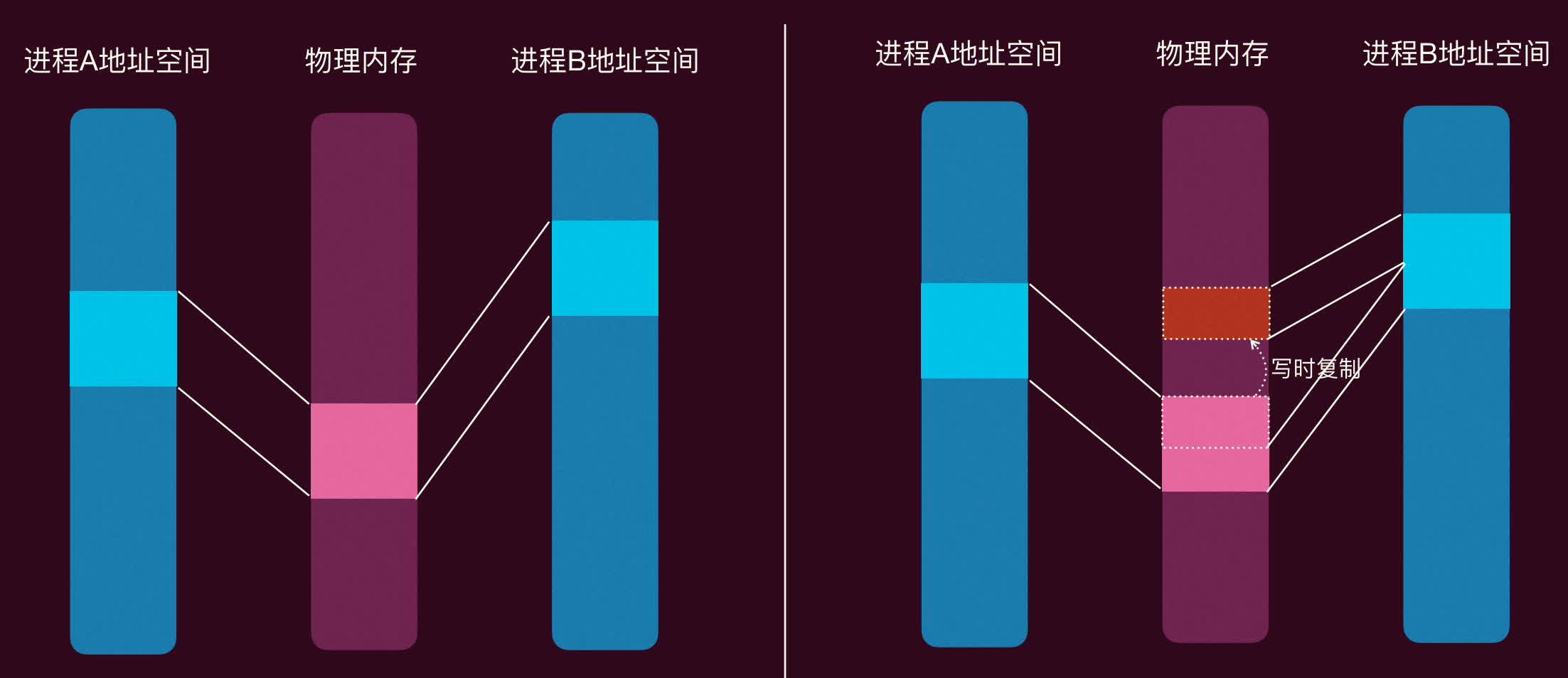
COW 的优点:
- 高效:
fork()调用本身非常快,因为它避免了大量的内存复制。 - 节省内存:只有在写入时才实际分配和复制内存。对于那些只读的内存(如代码段)或从未被写入的数据,永远不需要复制。
fork() 的细节与陷阱
- 多线程进程
fork():POSIX 标准规定,当多线程进程中的某个线程调用fork()时,只有调用fork()的那个线程会被复制到子进程中。子进程是单线程的。这可能导致问题,例如,如果父进程中其他线程持有锁,这些锁的状态会被复制到子进程,但持有锁的线程不存在了,子进程可能会死锁。因此,在fork()之后,子进程通常应只调用异步信号安全的函数,并且最常见的做法是立即调用execve()。 - 文件描述符共享:父子进程共享文件表项,这意味着它们共享文件状态,如文件偏移量。这既是特性(可以协同读写文件),也可能导致意外(一个进程的
lseek会影响另一个)。 - I/O 缓冲:标准 I/O 库(
stdio)通常使用用户态缓冲。fork()会复制这些缓冲区。如果缓冲区中有未刷出的数据,父子进程都会持有这份数据的副本。这可能导致数据被打印多次。- 行缓冲:通常用于终端输出。缓冲区在遇到换行符
\n、缓冲区满或显式fflush时刷出。 - 全缓冲:通常用于文件输出或管道输出。缓冲区只在满或显式
fflush时刷出。
- 行缓冲:通常用于终端输出。缓冲区在遇到换行符
1 |
|
1 | $ gcc fork_test.c -o fork_test |
- 终端结果:6 个 Hello;
- 重定向结果:8 个 Hello。
原因分析:
- 终端输出(行缓冲):
- 第一次
fork()后两个进程各输出一次"Hello\n"(立即刷新) - 第二次
fork()后四个进程各输出一次"Hello\n" - 总计:2 + 4 = 6 次
- 第一次
- 重定向输出(全缓冲):
- 第一次
fork()时"Hello\n"仍在缓冲区(未刷新),被复制到子进程 - 第二次
fork()时四个进程的缓冲区各含"Hello\n" - 程序结束时四个进程各刷新两次
"Hello\n" - 总计:4 × 2 = 8 次
- 第一次
Fork 炸弹
while(1) { fork(); } 这样的代码会创建指数级增长的进程,迅速耗尽系统资源(PID、内存、CPU),导致系统瘫痪。切勿尝试! 玩过几次 :(){ :|:& };:。
:(){ ... }定义了一个名为:的函数。:|:这部分表示函数内部调用自身并通过管道连接,导致递归调用。&将每个调用放入后台运行,导致大量进程被创建。- 最后的
:调用了这个递归函数。
加载新程序:execve()
fork() 只是创建了父进程的副本。如果想让子进程运行一个不同的程序,就需要 execve() 系统调用(或其变体,如 execl, execvp 等,它们最终都调用 execve)。
1 |
|
基本行为:
- 加载新程序:内核根据
pathname找到可执行文件,将其加载到当前进程的地址空间。 - 替换进程映像:当前进程的代码段、数据段、堆和栈都会被新程序的内容完全替换。进程的内存映像被重置为新程序的初始状态。
- 保留部分 PCB 信息:进程的 PID、父进程 PID、文件描述符表等不会改变。
- 设置入口点:CPU 的程序计数器(PC) 被设置为新程序定义的入口点(通常是 C 运行时库的启动代码,最终会调用
main函数)。 - 传递参数和环境:
argv数组(参数列表,argv[0]通常是程序名)和envp数组(环境变量列表,格式为"KEY=VALUE")被传递给新程序的main函数。
成功时无返回值
- 如果
execve()调用成功,它永远不会返回到调用它的程序中,因为调用程序的代码已经被新程序覆盖了。 - 如果
execve()返回了(返回值为 -1),那一定意味着调用失败(例如,文件未找到、无执行权限),此时errno会被设置。
fork() + execve() 组合
创建新进程来运行不同程序的最常用模式就是 fork() 紧跟着 execve():
- 父进程调用
fork()创建一个子进程。 - 子进程调用
execve()加载并执行新程序。 - 父进程通常调用
wait()或waitpid()来等待子进程结束,并获取其退出状态(或者继续并发执行其他任务)。
示例:简易 Shell
1 |
|
文件描述符的继承与利用
execve() 不会关闭原进程打开的文件描述符。这是一个非常有用的特性,是实现输入/输出重定向和管道的基础。
- 重定向:Shell 在
fork之后、execve之前,在子进程中可以通过dup2()系统调用将标准输入(fd 0)、标准输出(fd 1)或标准错误(fd 2)重定向到打开的文件。之后execve加载的新程序就会从/向被重定向的文件读写,而它本身对此毫不知情。 - 管道:见下文 IPC 部分。
fork() 时,父进程关闭读口,子进程关闭写口。这样,父进程可以向管道写入数据,子进程可以从管道读取数据。
文件描述符泄漏与 FD_CLOEXEC
虽然继承文件描述符很有用,但也可能导致问题。如果父进程打开了一个文件(例如用于日志),然后 fork + exec 了一个不相关的子程序,子程序也会继承这个文件描述符。如果子程序不关闭它,即使父进程关闭了,该文件也可能因为子进程的持有而无法完全释放资源。
为了避免这种情况,可以在打开文件时使用 open() 的 O_CLOEXEC 标志,或者使用 fcntl() 设置文件描述符的 FD_CLOEXEC (close-on-exec) 标志。设置了此标志的文件描述符会在 execve() 成功执行时自动关闭。
环境变量的传递
execve() 的 envp 参数允许父进程控制子进程的环境变量。通常,父进程会将自己的环境变量(或其子集/修改版)传递给子进程。Shell 的 export 命令就是用来将 Shell 变量添加到环境变量中,以便后续执行的命令能够继承。
终止进程:exit()
进程需要一种方式来通知操作系统它已经完成了工作或遇到了无法恢复的错误。
正常退出方式:
returnfrommain():这是最常见的退出方式。main函数的返回值会作为进程的「退出状态码」。按照惯例,返回0表示成功,非0表示出错。编译器通常会将return retval;转换为调用exit(retval);。exit(int status)(libc 函数):这是 C 标准库提供的函数(<stdlib.h>)。它执行一系列清理操作后终止进程:- 调用通过
atexit()注册的清理函数(按注册顺序的逆序调用)。 - 刷新并关闭所有打开的标准 I/O 流(
stdiostreams),确保缓冲区数据写入。 - 删除通过
tmpfile()创建的临时文件。 - 调用
_exit(status)系统调用完成最终的终止。
- 调用通过
_exit(int status)(系统调用):这是内核提供的系统调用(<unistd.h>)。它执行立即终止,不进行任何用户态的清理(不清stdio缓冲,不调atexit函数)。它会:- 关闭进程所有打开的文件描述符。
- 将所有子进程的父进程设置为 init 进程(处理孤儿进程)。
- 向父进程发送
SIGCHLD信号,通知其子进程已终止。 - 释放进程占用的资源(内存等),并将进程状态变为僵尸,等待父进程
wait()。
libc 的 _exit wrapper
在 glibc 中,库函数 _exit() 通常是一个包装器,它实际调用的是 exit_group() 系统调用。exit_group() 会终止进程中的所有线程,而不仅仅是调用 _exit() 的那个线程。直接使用 syscall(SYS_exit, status) 可以只终止当前线程(如果需要这种行为)。
exit() vs. _exit()
- 在需要确保
stdio缓冲被刷新、atexit清理函数被执行的情况下,应使用exit()。 - 在
fork()后的子进程中,如果不需要这些清理(特别是stdio缓冲可能导致数据重复输出),或者在信号处理函数中需要立即终止时,有时会使用_exit()。
异常退出方式:
abort()(libc 函数):用于异常终止(<stdlib.h>)。它向调用进程发送SIGABRT信号。默认情况下,SIGABRT会导致进程终止,并可能产生「核心转储」(core dump) 用于调试。abort()不调用atexit函数,也不保证刷新stdio流。- 由信号终止:进程可以被其他进程或内核发送的信号终止。例如:
SIGTERM:通用的终止信号(可以被捕获和处理)。SIGKILL:强制终止信号(不能被捕获或忽略)。SIGSEGV:段错误(非法内存访问)。SIGINT:中断信号(通常由 Ctrl + C 产生)。- …
posix_spawn()
fork() + execve() 的模式虽然经典,但在某些场景下(尤其是多线程环境或需要精细控制子进程属性时)可能不够高效或方便。POSIX 标准定义了 posix_spawn() 接口(<spawn.h>),它试图在一个调用中完成创建子进程并加载新程序的任务,提供了更丰富的选项来控制子进程的属性(如信号处理、文件描述符操作、调度策略等),并可能在某些系统上比 fork+exec 更高效。
1 |
|
进程间通信(IPC) 基础
进程拥有独立的地址空间,因此不能像线程那样直接访问共享内存(除非显式设置共享内存段)。操作系统需要提供机制让进程之间能够交换信息和协调工作,这就是进程间通信(Inter-Process Communication, IPC)。
常见的 IPC 机制包括:管道、信号、共享内存、消息队列、套接字等。这里简要介绍与本章内容紧密相关的管道和信号。
管道(Pipe)
管道是一种简单但有效的 IPC 机制,用于在有亲缘关系(通常是父子)的进程间传递字节流。
匿名管道(Anonymous Pipe):
- 通过
pipe()系统调用创建:1
2
3
int pipe(int pipefd[2]); pipe()创建一个管道,并返回两个文件描述符:pipefd[0]:用于读取管道。pipefd[1]:用于写入管道。
- 管道是单向的:数据从写入端流向读取端。
- 管道在内核中实现,通常有一个固定大小的缓冲区。
- 写操作:如果管道缓冲区已满,写操作会阻塞,直到有数据被读走。
- 读操作:如果管道为空,读操作会阻塞,直到有数据被写入。如果所有写端都已关闭,读操作会返回 0 (EOF)。
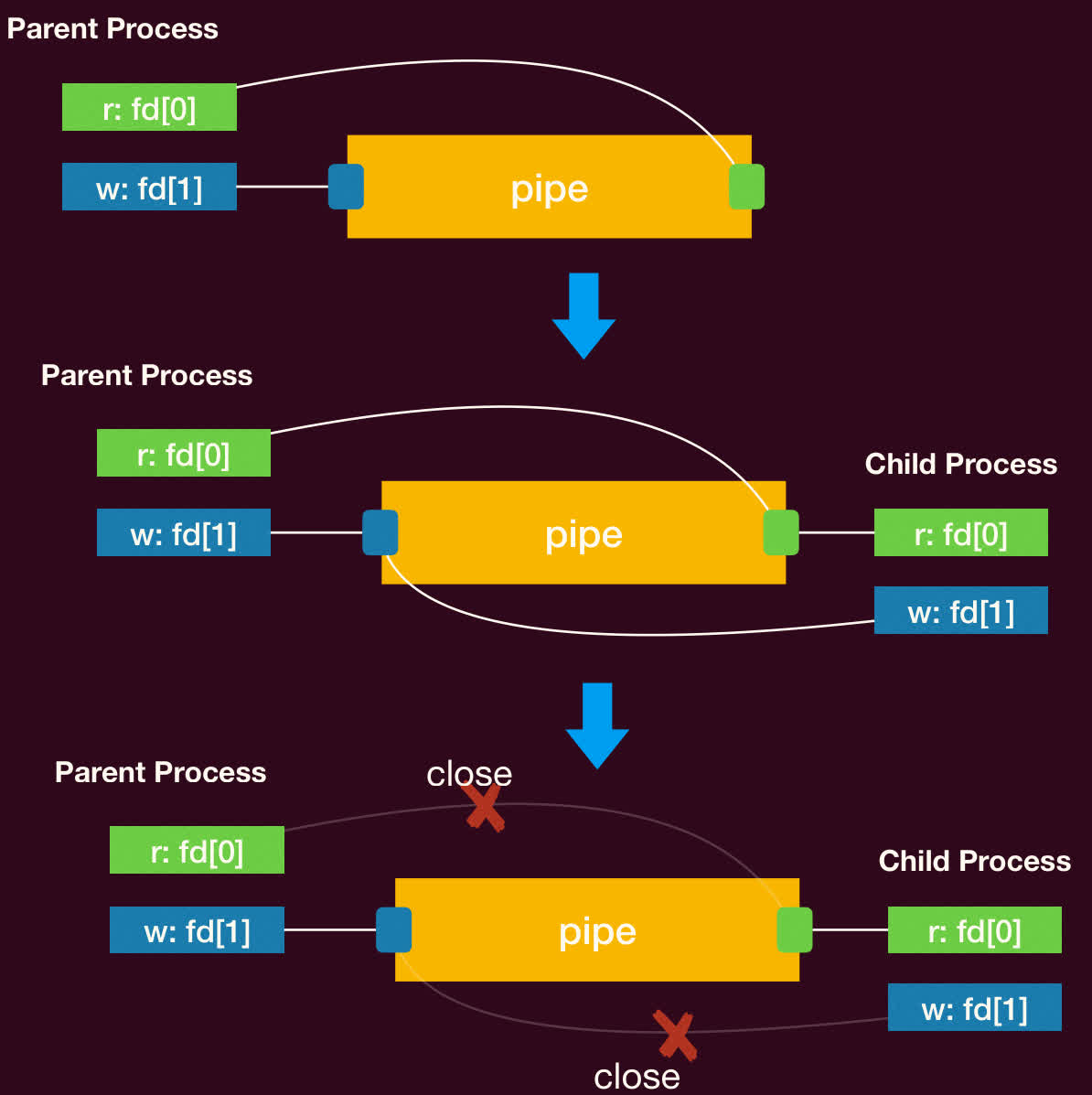
- 典型用法:
- 父进程调用
pipe()创建管道。 - 父进程调用
fork()创建子进程。此时父子进程都拥有管道的读写两端文件描述符。 - 根据数据流向,关闭不需要的端口:
- 如果父进程写、子进程读:父进程关闭
pipefd[0],子进程关闭pipefd[1]。 - 如果子进程写、父进程读:父进程关闭
pipefd[1],子进程关闭pipefd[0]。
- 如果父进程写、子进程读:父进程关闭
- 进程通过
read()和write()系统调用在保留的文件描述符上进行通信。 - 通信完成后,关闭剩余的文件描述符。
- 父进程调用
sequenceDiagram
participant 父进程
participant 子进程
participant 内核
父进程->>内核: pipe(pipefd)
内核-->>父进程: pipefd[0] (读取端), pipefd[1] (写入端)
父进程->>内核: fork()
内核-->>父进程: 子进程 PID
内核-->>子进程: 0
Note over 父进程, 子进程: 都拥有 pipefd[0] 和 pipefd[1]
opt 父进程写,子进程读
父进程->>父进程: close(pipefd[0])
子进程->>子进程: close(pipefd[1])
父进程->>内核: write(pipefd[1], data)
内核->>子进程: 数据可用
子进程->>内核: read(pipefd[0], buffer)
内核-->>子进程: 数据
end
opt 子进程写,父进程读
父进程->>父进程: close(pipefd[1])
子进程->>子进程: close(pipefd[0])
子进程->>内核: write(pipefd[1], data)
内核->>父进程: 数据可用
父进程->>内核: read(pipefd[0], buffer)
内核-->>父进程: 数据
end管道是 Shell 实现命令间 | 连接的基础。例如 ls | grep .c,Shell 会创建管道,fork 两次,一个子进程执行 ls(标准输出重定向到管道写端),另一个子进程执行 grep(标准输入重定向到管道读端)。
信号(Signal)
信号是一种异步的通知机制,用于告知进程发生了某个事件。它模拟了硬件中断,但发生在软件层面,用于进程间或内核与进程间的通信。
信号 vs. 信号量 vs. cond_signal
- 信号(Signal):操作系统事件通知机制(e.g.,
SIGINT,SIGCHLD)。 - 信号量(Semaphore):同步原语,用于控制对资源的访问(P/V 操作)。
cond_signal:条件变量操作,用于唤醒等待某个条件的线程。
这三者名字相似但用途完全不同。
信号的来源:
- 内核:检测到硬件异常(如除零、非法内存访问
SIGSEGV)、软件事件(如管道写端关闭SIGPIPE、子进程终止SIGCHLD、定时器到期SIGALRM)等。 - 其他进程:通过
kill()系统调用发送信号。 - 用户:通过键盘输入(如 Ctrl + C 发送
SIGINT,Ctrl + Z 发送SIGTSTP)。
进程收到信号后,可以有三种处理方式:
- 忽略(Ignore):通过
signal(signum, SIG_IGN)设置。但SIGKILL和SIGSTOP不能被忽略。 - 执行默认处理(Default):通过
signal(signum, SIG_DFL)设置。每种信号都有一个内核定义的默认动作,通常是终止进程、忽略信号、停止进程或继续进程。 - 捕获并执行自定义处理函数(Catch):通过
signal(signum, handler_func)注册一个信号处理函数。当信号发生时,内核会中断进程的正常执行流,切换到用户态的信号处理函数去执行。
信号处理过程(简要):
- 内核检测到信号需要传递给某进程。
- 如果信号未被阻塞,内核保存当前进程的上下文(寄存器、PC 等)。
- 修改进程的用户态栈,使其看起来像是调用了信号处理函数。
- 将 PC 指向信号处理函数的入口地址。
- 切换回用户态,进程开始执行信号处理函数。
- 信号处理函数执行完毕后,通常会通过一个特殊的系统调用(如
sigreturn)返回内核。 - 内核恢复之前保存的上下文,进程从被中断的地方继续执行。
sequenceDiagram
participant UserProcess as 用户进程(正常执行)
participant Kernel as 内核
participant SignalHandler as 信号处理函数
Note over UserProcess, Kernel: 内核检测到信号事件
Kernel->>UserProcess: 发送信号
alt 信号被捕获
UserProcess->>Kernel: 中断,陷入内核
Kernel->>Kernel: 保存进程上下文
Kernel->>Kernel: 设置用户栈以调用 Handler
Kernel->>SignalHandler: 修改 PC 指向 Handler 入口
Kernel-->>SignalHandler: 切换回用户态执行 Handler
SignalHandler->>SignalHandler: 执行处理逻辑…
SignalHandler->>Kernel: Handler 返回(e.g., sigreturn)
Kernel->>Kernel: 恢复进程上下文
Kernel-->>UserProcess: 切换回用户态,从中断点恢复执行
else 信号被忽略或执行默认动作
Kernel->>Kernel: 执行相应操作(忽略/终止/停止…)
end信号的应用:
- 异步处理子进程退出:父进程可以捕获
SIGCHLD信号,在信号处理函数中调用waitpid()来清理僵尸进程,避免了在主逻辑中阻塞等待。 - 异步 I/O:可以设置当某个文件描述符可读或可写时,内核发送
SIGIO信号。进程可以在信号处理函数中处理 I/O,实现非阻塞的事件驱动模型。 - 进程控制:如
kill命令发送信号来终止或控制其他进程。
信号也是一种基础的 IPC 机制,虽然传递的信息量有限(只有一个信号编号),但对于异步事件通知非常有用。
总结
- 进程是运行中程序的实例,是资源分配的基本单位。它包含独立的地址空间和至少一个执行线程。
- PCB 是内核管理进程的数据结构,存储进程的所有相关信息。
- 进程有生命周期,经历新建、就绪、运行、等待、终止等状态。僵尸进程和孤儿进程是终止过程中的特殊状态。
- 核心系统调用包括:
fork():创建子进程(通过 COW 优化)。execve():用新程序替换当前进程映像(保留 PID、文件描述符)。exit()/_exit():正常终止进程,exit()会执行额外清理。wait()/waitpid():父进程用于获取子进程终止状态并回收资源。
- IPC 允许独立进程间通信,常用机制包括:
- 管道:用于父子进程间单向字节流传输。
- 信号:用于异步事件通知。
- 文件描述符和环境变量是进程上下文的重要组成部分,在
fork和execve中有特殊的继承规则。
init 进程的实现有多种方式,最常见的是
systemd和SysVinit。systemd是现代 Linux 系统的默认 init 系统,提供了更强大的功能和灵活性。 ↩︎