设备管理
设备管理是操作系统核心功能之一,负责计算机系统中所有输入/输出(I/O)设备的操作、控制和资源分配。其目标是提供一个统一、抽象、高效的接口,屏蔽底层硬件的复杂性和多样性,使得应用程序能够方便、安全地使用各种设备。
典型的系统架构
现代计算机系统通常采用层次化的总线结构来连接 CPU、内存和各种 I/O 设备。这种结构旨在平衡性能、成本和物理限制。
总线
总线(Bus)是一组电子信号线,用于在计算机的不同组件之间传输数据、地址和控制信号。
典型的系统架构包含以下几个关键部分:
- CPU:执行指令,处理数据。
- 内存:存储程序和数据。CPU 通过内存总线高速访问内存。内存总线通常是专有的,速度极快。
- 图形处理器(Graphics Processing Unit, GPU):通常通过高速的 PCIe(Peripheral Component Interconnect Express) 总线连接到系统,负责图形渲染和并行计算。
- 通用 I/O 总线:如 PCIe,用于连接需要较高带宽的设备,如网卡、高性能存储控制器等。
- 外围 I/O 总线:如 SCSI(Small Computer System Interface)、SATA(Serial ATA)、USB(Universal Serial Bus),用于连接速度相对较慢的外部设备,如键盘、鼠标、普通硬盘、U 盘等。
graph LR
CPU <-->|内存总线| Memory[内存]
CPU <-->|通用 I/O 总线(如 PCIe)| Graphics[显卡]
CPU <-->|通用 I/O 总线(如 PCIe)| IO_Controller[I/O 控制器/芯片组]
subgraph I/O 控制器/芯片组
direction LR
IO_Controller -->|PCIe| Network[网卡]
IO_Controller -->|SATA/eSATA| SSD[固态硬盘]
IO_Controller -->|SATA/eSATA| HDD[机械硬盘]
IO_Controller -->|USB| Keyboard[键盘]
IO_Controller -->|USB| Mouse[鼠标]
IO_Controller -->|USB| UDisk[U 盘]
end
style CPU fill:#lightgreen,stroke:#333,stroke-width:2px
style Memory fill:#lightblue,stroke:#333,stroke-width:2px
style Graphics fill:#orange,stroke:#333,stroke-width:2px
style IO_Controller fill:#lightgrey,stroke:#333,stroke-width:2px层次结构的设计考量:
- 物理与成本:总线速度越快,其物理长度通常需要越短,以保证信号完整性,同时高速总线的成本也更高。
- 性能需求:高性能设备(如显卡、NVMe SSD)需要更靠近 CPU,连接到速度更快的总线上。
- 芯片组:现代系统通常使用专用芯片组(如 Intel 的 PCH - Platform Controller Hub)来管理各种 I/O 总线和设备,并通过 DMI(Direct Media Interface) 或类似接口与 CPU 通信,以提高整体 I/O 性能。
主板(Motherboard)是承载这些组件的物理平台。CPU 和内存插槽通常占据核心位置,其余部分则布满了各种 I/O 控制器和接口。由于硬件的多样性,操作系统必须能够处理不同机器上配置各异的硬件。
I/O 设备
I/O 设备种类繁多,但大体上可以分为两类:
- 块设备
- 以固定大小的块或扇区为单位存储和传输信息。常见的块大小有 512 字节、4KB 等。
- 传输的基本单位是整个块。
- 通常是可寻址的,即可以直接访问任意一个块。
- 示例:硬盘(HDD)、固态硬盘(SSD)、光盘驱动器。
- 字符设备
- 以单个字符(字节)为单位传递或接收字符流。
- 通常是不可寻址的,数据按顺序处理,没有随机访问的概念。
- 示例:键盘、鼠标、打印机、串行端口、终端。
一个典型设备的构成
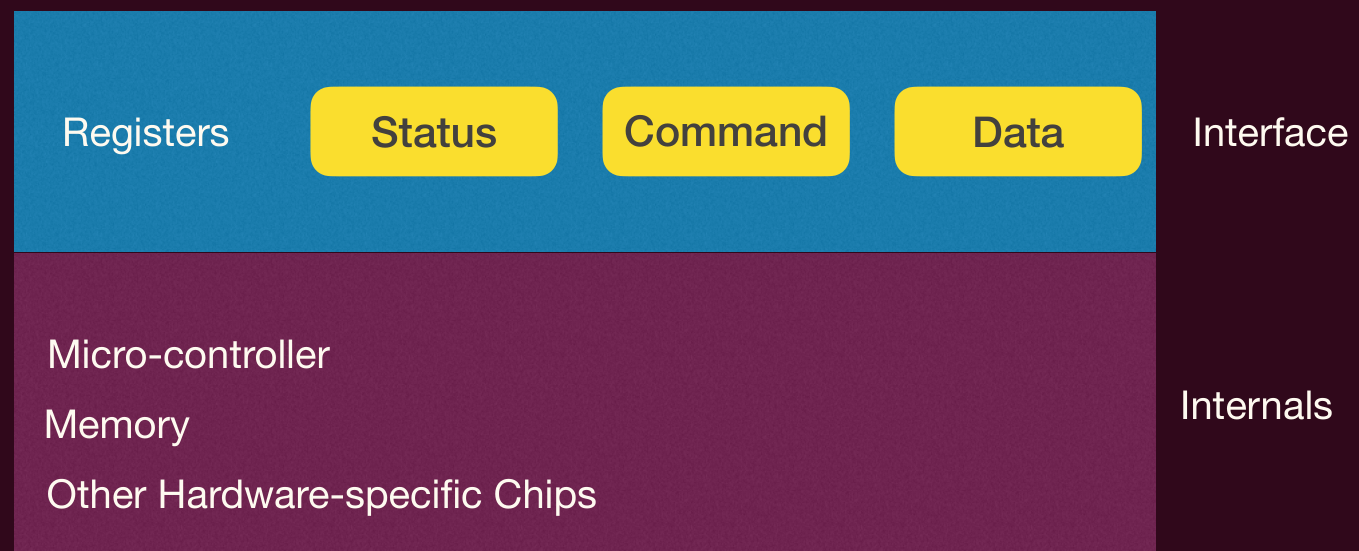
一个典型的 I/O 设备通常包含两个主要部分:
- 硬件接口:设备向系统其余部分(主要是 CPU 和操作系统)呈现的部分,允许操作系统控制其运行和交换数据。这通常通过一组设备寄存器实现:
- 状态寄存器:只读,用于查询设备的当前状态(如:是否忙碌、操作是否完成、是否出错)。
- 命令寄存器:可写,用于指示设备执行特定任务(如:读取数据、写入数据、寻道)。
- 数据寄存器:可读可写,用于在 CPU 和设备之间传递数据。
- 内部结构:设备的具体物理实现,对操作系统通常是透明的。可能包括:
- 微控制器
- 板载内存
- 其他特定功能的硬件芯片
CPU 和设备的通信
CPU 通过与设备控制器的寄存器交互来控制设备。设备控制器是嵌入在设备或主板上的电子元件,负责管理设备的具体操作。
访问设备寄存器
处理器访问设备寄存器主要有两种方式:
- 端口映射 I/O(Port-Mapped I/O, PMIO)
- 为设备寄存器分配独立的 I/O 端口地址空间,与内存地址空间分开。
- CPU 使用特殊的 I/O 指令(如 x86 架构的
in和out指令)来读写这些端口。 - 这些 I/O 指令通常是特权指令,只能在内核模式下执行。
- 每个控制寄存器被分配一个或多个 I/O 端口号。
x86 典型 I/O 端口
0x0060: 键盘数据/命令端口0x01F0 - 0x01F7: 主 IDE 硬盘控制器端口0x03F8 - 0x03FF: 第一个串行端口(COM1)
- 内存映射 I/O(Memory-Mapped I/O, MMIO)
- 将设备寄存器映射到主内存的物理地址空间中。
- CPU 可以使用标准的
load和store指令(如mov指令)像访问普通内存一样访问这些寄存器。 - 硬件负责将对这些特定内存地址的访问重定向到设备寄存器,而不是主内存。
内存映射 I/O 与缓存
使用内存映射 I/O 时必须特别注意 CPU 缓存。如果设备寄存器的值被缓存,CPU 后续读取的可能是缓存中的旧值,而不是设备状态的实时更新。
-
问题:例如,轮询一个状态寄存器时,如果第一次读取的值被缓存,后续轮询将一直读取缓存中的旧值,无法感知设备状态的真实变化。
1 2 3 4 5 6
Loop: test memory_mapped_io_address // 检查设备状态 jz ready // 如果为 0 (ready), 跳转 goto loop // 否则, 继续轮询 ready: // ...设备就绪…
-
解决方案:操作系统或驱动程序通常需要将映射设备寄存器的内存区域配置为不可缓存或写通透,以确保每次访问都直接到达设备。
获知设备通信状态
在向设备发出操作指令后,操作系统需要知道操作何时完成或是否发生错误。主要有两种方法:
- 轮询:操作系统(或驱动程序)定期主动检查设备的状态寄存器,看操作是否完成。
- 优点:实现简单,对于快速设备或预期操作很快完成的情况,开销较低(没有上下文切换)。
- 缺点:如果设备较慢或操作耗时较长,会持续占用 CPU 时间进行无效检查,浪费 CPU 周期。
- 中断:设备在完成操作或发生需要注意的事件(如错误)时,会向 CPU 发送一个中断信号。CPU 接收到中断信号后,会暂停当前执行的程序,保存其上下文,然后跳转到预先设定的中断服务例程(Interrupt Service Routine, ISR)或中断处理程序来处理该中断。处理完毕后,恢复之前被中断的程序。
- 优点:CPU 无需等待,可以执行其他任务,效率较高。
- 缺点:中断处理本身有开销(上下文切换、保存和恢复状态等)。对于高速设备产生大量中断的情况,中断开销可能变得显著。
在实践中,常常混合使用轮询和中断。例如,对于某些高性能网络设备,可能会在数据包到达初期使用轮询来降低延迟,如果一段时间内没有数据,则切换到中断模式以节省 CPU。
谁来控制数据传输命令?
-
程序控制 I/O(Programmed I/O, PIO)
- CPU 直接参与每个字节或字的数据传输。
- CPU 通过执行
in/out(PMIO)或load/store(MMIO)指令,将数据从设备寄存器读入 CPU 寄存器,再存入内存,或者反之。 - 优点:硬件简单,易于编程。
- 缺点:
- 消耗大量 CPU 周期,因为 CPU 必须亲自处理每一个数据的传输。
- 如果结合中断使用,CPU 会频繁被中断,进一步降低效率。
- 数据传输速率受限于 CPU 的处理速度和总线速度。
-
直接内存访问(Direct Memory Access, DMA)
- 允许设备控制器直接与主内存进行数据传输,无需 CPU 的直接参与(CPU 只在开始和结束时介入)。
- DMA 控制器(DMAC)是一种专用硬件,负责管理 DMA传输。
- 过程:
- CPU 向 DMA 控制器编程:设置源地址、目标地址、数据块大小、传输方向(读/写)。
- CPU 命令设备开始 I/O 操作。
- DMA 控制器接管数据传输,在设备和内存之间直接拷贝数据。CPU 在此期间可以执行其他任务。
- 传输完成后,DMA 控制器通过中断通知 CPU。
sequenceDiagram participant CPU participant DMAC as DMA 控制器 participant Device as I/O 设备 participant Memory as 内存 CPU->>DMAC: 1. 配置 DMA(源、目标、大小) CPU->>Device: 2. 命令设备开始 I/O Note over DMAC, Device: 设备准备数据 Device->>DMAC: 请求传输 loop 数据传输 DMAC->>Memory: 读/写数据块 DMAC->>Device: 读/写数据块 end DMAC->>CPU: 3. 传输完成(中断)- 优点:极大减轻 CPU 负担,提高系统并行度和 I/O 吞吐量。
- 缺点:需要额外的 DMA 控制器硬件;可能引入缓存一致性问题(需要确保 DMA 操作的数据与 CPU 缓存中的数据同步)。
关于「通用」和「专用」
之前的讨论中,CPU 通常指通用 CPU,设计用于执行各种类型的计算任务。然而,计算机系统内部存在许多专用处理器,它们为特定任务优化:
- DMA 控制器:可以看作是专门负责内存拷贝(
memcpy())的 CPU。 - GPU:专门负责图形渲染和大规模并行计算的 CPU。
- 许多设备(如硬盘、网卡)自身也带有嵌入式处理器(逻辑处理芯片)来执行特定功能。
I/O 管理可以看作是通用 CPU 与这些外部专用芯片(设备控制器、DMA、GPU 等)之间的协调与交流。
为什么不都用通用 CPU?
- 代价:通用 CPU 为了通用性,设计复杂,功耗较高。
- 任务特性:特定领域的任务往往不需要通用 CPU 的全部功能,但可能对某些特定操作(如并行浮点运算)有极高要求。
- 优化:专用处理器可以针对特定任务的指令集和架构进行深度优化,从而在这些任务上获得远超通用 CPU 的性能。例如,GPU 的大量并行核心非常适合图形处理和科学计算。
这也体现在编程语言(如 DSL, Domain Specific Language)和算法设计上,针对特定问题域的解决方案往往更高效。
GPU 加速
显卡(Graphic Processing Unit, GPU)最初为图形处理而设计,其架构天然适合高度并行化的问题。
- 特点:
- 拥有大量(成百上千甚至上万)相对简单的计算核心。
- 高内存带宽。
- 设计用于处理可大规模并行化的问题。
- 计算速度极快且强大,但通常功耗也较高。
- 演进:从最初的专用图形渲染,发展到能够进行通用计算(General-Purpose computing on GPUs, GPGPU)。
应用示例 1:光线追踪
光线追踪是一种三维图形渲染技术。对于图像中的每个像素:
- 从摄像机发出一条可视光线。
- 计算光线与场景中物体的交点。
- 从交点向光源发出阴影光线,判断该点是否在阴影中。
- 根据材质、光照等计算该像素的颜色。
- 如果材质是反射或折射的(如玻璃、水面),则会递归追踪新的光线。
每个像素的计算过程基本独立,可以大规模并行处理,非常适合 GPU 加速。
1 2 3 4 5 6 7 8 | // 伪代码 - 光线追踪并行性 for all pixels (i,j) in image: // 这一层循环可以并行 From camera eye point, calculate ray point and direction in 3D space if ray intersects object: calculate lighting at closest object point store color of (i,j) Assemble into image file |
应用示例 2:数组相加
将两个大数组 A 和 B 的对应元素相加,结果存入数组 C:C[i] = A[i] + B[i]。
- CPU 实现: 虽然可以使用多线程,但物理核心数量有限,大量线程只是 CPU 的并发模拟。
1 2 3 4 5
float *C = malloc(N * sizeof(float)); for (int i = 0; i < N; i++) { // 循环,串行计算 C[i] = A[i] + B[i]; } return C;
- GPU 实现:
- 在 GPU 内存中为数组 A、B、C 分配空间。
- 定义一个核函数,该函数描述单个线程的操作(即一个加法操作
C[i] = A[i] + B[i])。 - 启动大量 GPU 线程(例如,NVIDIA A100 GPU 可同时支持数十万线程),每个线程负责计算一个或少数几个元素的和。
- 等待所有 GPU 线程同步(完成计算)。
- 将结果从 GPU 内存拷回 CPU 内存。
CUDA(Compute Unified Device Architecture) 是 NVIDIA 推出的 GPU 并行计算平台和编程模型。
- 核函数:在 GPU 设备上执行的 C/C++ 函数,由大量线程并行调用。
1 2 3 4 5 6 7 8
// CUDA 核函数示例 __global__ void cudaAddVectorsKernel(float *a, float *b, float *c, int N) { // 计算当前线程应该处理的全局索引 int index = blockIdx.x * blockDim.x + threadIdx.x; if (index < N) { // 防止越界 c[index] = a[index] + b[index]; } }
__global__:声明这是一个可以从 CPU (host) 调用,在 GPU (device) 上执行的核函数。blockIdx.x:当前线程块在网格 中的 X 维度索引。blockDim.x:每个线程块在 X 维度的大小(线程数量)。threadIdx.x:当前线程在线程块中的 X 维度索引。
- 调用核函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// 伪代码 - 调用 CUDA 核函数 void cudaAddVectors(const float* h_a, const float* h_b, float* h_c, int N) { // ... (1) 在 GPU 上分配内存 dev_a, dev_b, dev_c ... // ... (2) 将 h_a, h_b 从 CPU 内存拷贝到 dev_a, dev_b ... // 定义线程块大小和网格大小 int threadsPerBlock = 256; int blocksPerGrid = (N + threadsPerBlock - 1)/threadsPerBlock; // 向上取整 // 调用核函数 cudaAddVectorsKernel<<<blocksPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_c, N); // ... (3) 检查 CUDA 错误 ... // ... (4) 将结果 dev_c 从 GPU 内存拷贝回 h_c ... // ... (5) 释放 GPU 内存 ... }
<<<blocksPerGrid, threadsPerBlock>>>:执行配置,指定启动的线程块数量和每个块内的线程数量。
硬件抽象与设备驱动程序
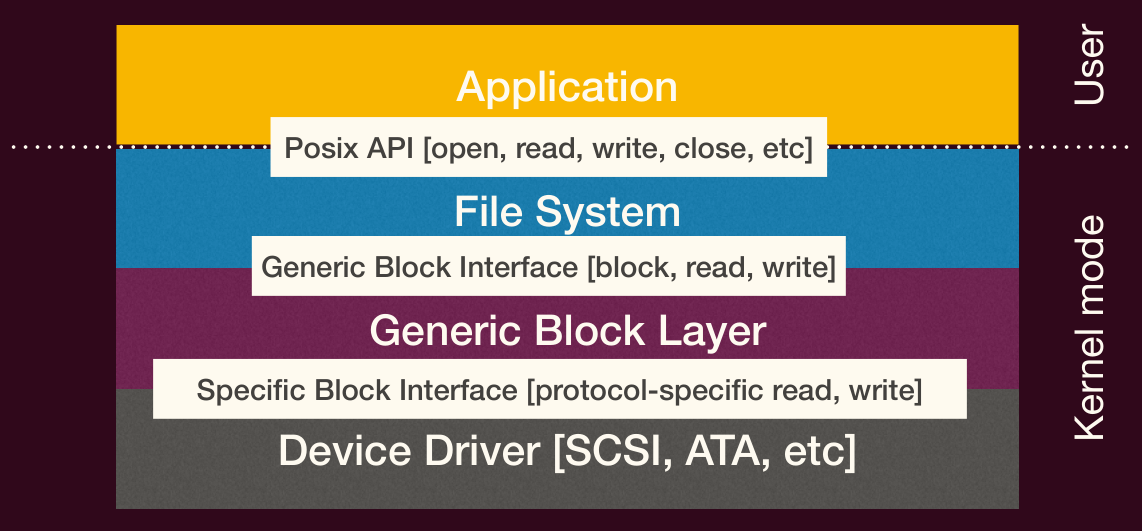
操作系统的一个核心任务是提供硬件抽象,隐藏底层硬件的复杂性和多样性,为应用程序提供统一的接口。
分层存储视图
操作系统创建了一个分层的存储/I/O 视图,即使在内核内部,抽象也是一项不断使用的技术。
分层方法允许较低层部分的实现细节更改,而不影响较高层。例如,文件系统的实现可以独立于具体的磁盘类型(如 SCSI 硬盘、ATA 硬盘、SSD)。
设备驱动程序
管理特定 I/O 设备的代码通常封装在内核的设备驱动程序中。
- 每个设备类型(甚至同类型不同型号的设备)通常都需要自己的驱动程序。
- 设备驱动程序是操作系统内核代码的重要组成部分。例如,据称 Linux 内核代码中约 70% 是设备驱动程序,因为需要支持的设备种类繁多,且每个设备都可能不同。
- 设备驱动程序也是内核错误的常见来源,因为特定驱动可能只被少数系统使用,测试覆盖率可能不如核心内核代码高。
设备驱动程序的结构
设备驱动程序通常可以概念性地分为两部分:
- 上半部分
- 在系统调用的调用路径中被访问,即响应用户进程的请求。
- 实现一组标准的、跨设备的调用接口,如
open(),close(),read(),write(),ioctl()(I/O 控制)。这是内核其他部分与该驱动程序交互的接口。 - 上半部分通常会启动设备的 I/O 操作。对于同步 I/O,它可能会使调用线程休眠,直到操作完成;对于异步 I/O,它会立即返回,操作在后台进行。
- 下半部分/中断处理程序
- 作为中断服务例程的一部分运行,响应来自设备的硬件中断。
- 当设备完成操作或发生事件时,会触发中断,下半部分被调用。
- 负责处理中断事件,例如:
- 获取输入数据,存入缓冲区。
- 准备并传输下一块输出数据。
- 如果 I/O 操作完成,可能会唤醒因等待此操作而休眠的线程(例如,通过条件变量或信号量)。
一次 I/O 请求的生命周期
下面是一个典型的 I/O 请求(例如,从磁盘读取数据)的处理流程:
sequenceDiagram
participant UserLand as 用户空间
participant Kernel as 内核(VFS/文件系统)
participant IOSubsystem as 内核 I/O 子系统
participant Driver as 设备驱动程序
participant Controller as 设备控制器
participant Device as 硬件设备
UserLand->>Kernel: 请求 I/O(例如,读取文件)(系统调用)
Kernel->>IOSubsystem: 能否从缓存满足?
alt 请求能从缓存满足(例如,缓冲区缓存)
IOSubsystem-->>Kernel: 是,数据来自缓存
Kernel-->>UserLand: 返回数据(从系统调用返回)
else 请求需要设备访问
IOSubsystem-->>Driver: 否,发送请求到设备驱动程序
Note over Driver: 如果是同步 I/O,进程可能在此阻塞
Driver->>Controller: 发出命令(例如,读取扇区 X)
Driver->>Controller: 配置控制器,直到中断(或轮询)才阻塞
Controller->>Device: 执行命令,监控设备
Device-->>Controller: I/O 操作进行中…
Device-->>Controller: I/O 完成
Controller->>Driver: 生成中断
Driver->>Driver: 中断处理程序(下半部)
Driver->>Controller: 接收中断,将数据存储在驱动程序缓冲区(如果是输入)
Driver->>IOSubsystem: 发信号解除进程阻塞/指示 I/O 完成
IOSubsystem->>Kernel: 确定哪个 I/O 完成,更新状态
Kernel->>UserLand: 将数据放入用户缓冲区,返回值
Kernel-->>UserLand: 从系统调用返回
end一个设备驱动样例(xv6 简化版 IDE 硬盘驱动)
以下是对一个简化的 IDE (Integrated Drive Electronics) 硬盘驱动程序(类似 xv6 操作系统中的)关键部分的解读,用于理解驱动如何与硬件交互。IDE 驱动通常使用端口映射 I/O。
关键寄存器(端口地址):
- 控制寄存器:
0x3F6- 用于控制设备行为,如复位设备、允许/禁止中断。例如,写入
0x00(bit 1nIEN=0) 允许中断。
- 用于控制设备行为,如复位设备、允许/禁止中断。例如,写入
- 命令块寄存器:
0x1F0-0x1F70x1F0:数据端口:读写数据缓冲区。0x1F1:错误寄存器:读取错误信息(当状态寄存器的错误位被设置时)。0x1F2:扇区计数:要读/写的扇区数量。0x1F3:LBA 低字节0x1F4:LBA 中字节0x1F5:LBA 高字节0x1F6:驱动器/磁头 & LBA 最高 4 位:选择驱动器(主/从),寻址模式(LBA/CHS),LBA 地址的最高 4 位。0x1F7:命令/状态寄存器- 写入时:发送命令(如读扇区、写扇区)。
- 读取时:获取状态(如
BUSY设备忙,READY设备就绪,DRQ数据请求,ERROR发生错误)。
驱动程序主要函数逻辑:
-
ide_wait_ready():轮询状态寄存器(0x1F7)直到设备不忙(IDE_BSY位为 0)并且准备好(IDE_DRDY位为 1)。1 2 3 4 5 6 7 8 9
// 概念性代码 static int ide_wait_ready() { int r; // Loop until drive isn't busy and is ready for command while ( (((r = inb(0x1f7)) & (IDE_BSY | IDE_DRDY)) != IDE_DRDY) ) { // spin or yield } return 0; // or error code if timeout }
-
ide_start_request(struct buf *b):启动一个磁盘读/写请求。- 调用
ide_wait_ready()等待磁盘就绪。 - 设置控制寄存器(
0x3F6)以允许中断。 - 设置扇区计数(
0x1F2)。 - 设置 LBA 地址(
0x1F3-0x1F6)。 - 根据是读操作还是写操作,向命令寄存器(
0x1F7)写入相应命令(如IDE_CMD_READ或IDE_CMD_WRITE)。 - 如果是写操作,通过数据端口(
0x1F0)将数据(通常使用outsl指令按长字输出)写入磁盘缓冲区。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// 概念性代码 static void ide_start_request(struct buf *b) { ide_wait_ready(); outb(0x3f6, 0); // 允许中断(nIEN=0) outb(0x1f2, 1); // 扇区数(e.g., 1 sector) outb(0x1f3, b->sector & 0xff); // LBA low outb(0x1f4, (b->sector >> 8) & 0xff); // LBA mid outb(0x1f5, (b->sector >> 16) & 0xff); // LBA hi // Drive select, LBA mode, LBA highest 4 bits outb(0x1f6, 0xe0 | ((b->dev&1)<<4) | ((b->sector>>24)&0x0f)); if (b->flags & B_DIRTY) { // B_DIRTY indicates a write operation outb(0x1f7, IDE_CMD_WRITE); // 发送写命令 outsl(0x1f0, b->data, 512/4); // 输出数据(512 bytes/4 bytes_per_long) } else { // Read operation outb(0x1f7, IDE_CMD_READ); // 发送读命令 } }
- 调用
-
ide_rw(struct buf *b):上半部分,处理读写请求。- 获取设备锁(
ide_lock)保证互斥访问。 - 将请求
b加入请求队列(ide_queue)。 - 如果队列之前为空(即当前请求是第一个),则调用
ide_start_request()启动它。 - 使当前进程休眠 (
sleep()),等待请求完成(由中断处理程序唤醒)。 - 释放锁。
- 获取设备锁(
-
ide_intr():下半部分,中断处理程序。- 获取设备锁。
- 从请求队列中取出已完成的请求。
- 如果是读操作,并且设备就绪,则从数据端口(
0x1F0)读取数据(通常使用insl指令按长字输入)到缓冲区。 - 标记请求完成(如清除
B_DIRTY,设置B_VALID)。 - 唤醒 (
wakeup()) 等待此请求的进程。 - 如果请求队列中还有其他请求,则调用
ide_start_request()启动下一个请求。 - 释放锁。
硬盘驱动器(Hard Disk Drives, HDDs)
磁盘
可参考《计算机组织结构》笔记相关内容。
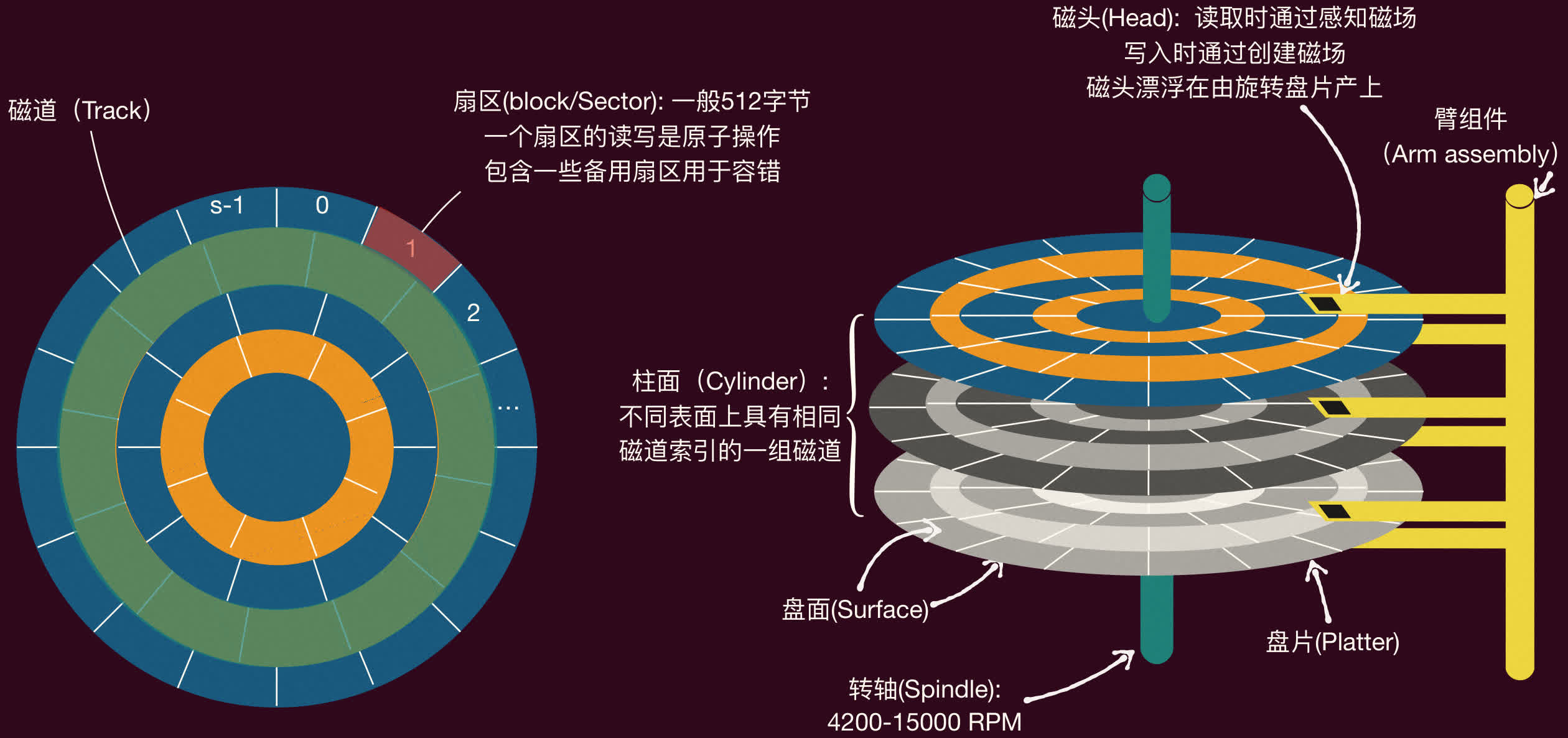
传统机械硬盘将数据磁性地存储在旋转的盘片上。盘片通常由玻璃、陶瓷或铝等材料制成,表面覆盖一层薄金属磁膜。
主要组件:
- 盘片(Platter):圆形磁盘,双面或单面可存储数据。多个盘片堆叠在一起,由一个主轴(Spindle)带动高速旋转(如 4200-15000RPM - Revolutions Per Minute)。
- 磁头(Head):每个盘面对应一个磁头。
- 写入时:通过改变电流方向在盘片上产生特定方向的磁场,从而记录 0 或 1。
- 读取时:通过感知盘片上的磁场变化来识别 0 或 1。
- 磁头在盘片高速旋转产生的气流上「漂浮」,与盘面距离极小,不能接触。
- 磁道(Track):盘片上的一系列同心圆,数据记录在磁道上。
- 扇区(Sector/Block):每个磁道被划分为若干个扇区,是磁盘读写的最小物理单位,通常为 512 字节或 4KB。一个扇区的读写是原子操作。磁盘通常包含一些备用扇区用于容错。
- 柱面(Cylinder):所有盘片上半径相同的磁道的集合。当所有磁头固定不动时,它们划过的所有磁道构成一个柱面。切换同一柱面内的磁道(即切换磁头)比移动磁头臂到不同柱面要快。
- 臂组件(Arm assembly):承载所有磁头,并能在盘片径向移动,使磁头定位到不同磁道。
磁盘读写过程与性能
磁盘被抽象为一系列可寻址的扇区。早期使用(驱动器, 柱面, 磁头, 扇区)的 CHS 地址,现代磁盘普遍使用逻辑块地址(Logical Block Address, LBA),将磁盘视为一个线性的扇区数组(0…N-1),由磁盘控制器负责 LBA 到物理 CHS 地址的转换。
一次磁盘 I/O 操作(读/写一个或多个扇区)的时间:
- 寻道时间():将磁头臂移动到目标磁道(柱面)所需的时间。这是磁盘访问中最耗时的部分之一,通常为几毫秒到十几毫秒。
- 包括磁头启动、移动、减速和稳定 的时间。
- 旋转延迟():等待目标扇区的起始位置旋转到磁头下方所需的时间。
- 平均旋转延迟是磁盘旋转一周时间的一半。例如,7200RPM 的磁盘,每转需 ,平均旋转延迟约为 。
- 传输时间():数据在磁盘和内存之间实际传输所需的时间。
- 传输速率取决于磁盘转速、记录密度和接口速度。
对于随机访问大量小数据块,寻道时间和旋转延迟会成为主要瓶颈。
磁盘优化技术
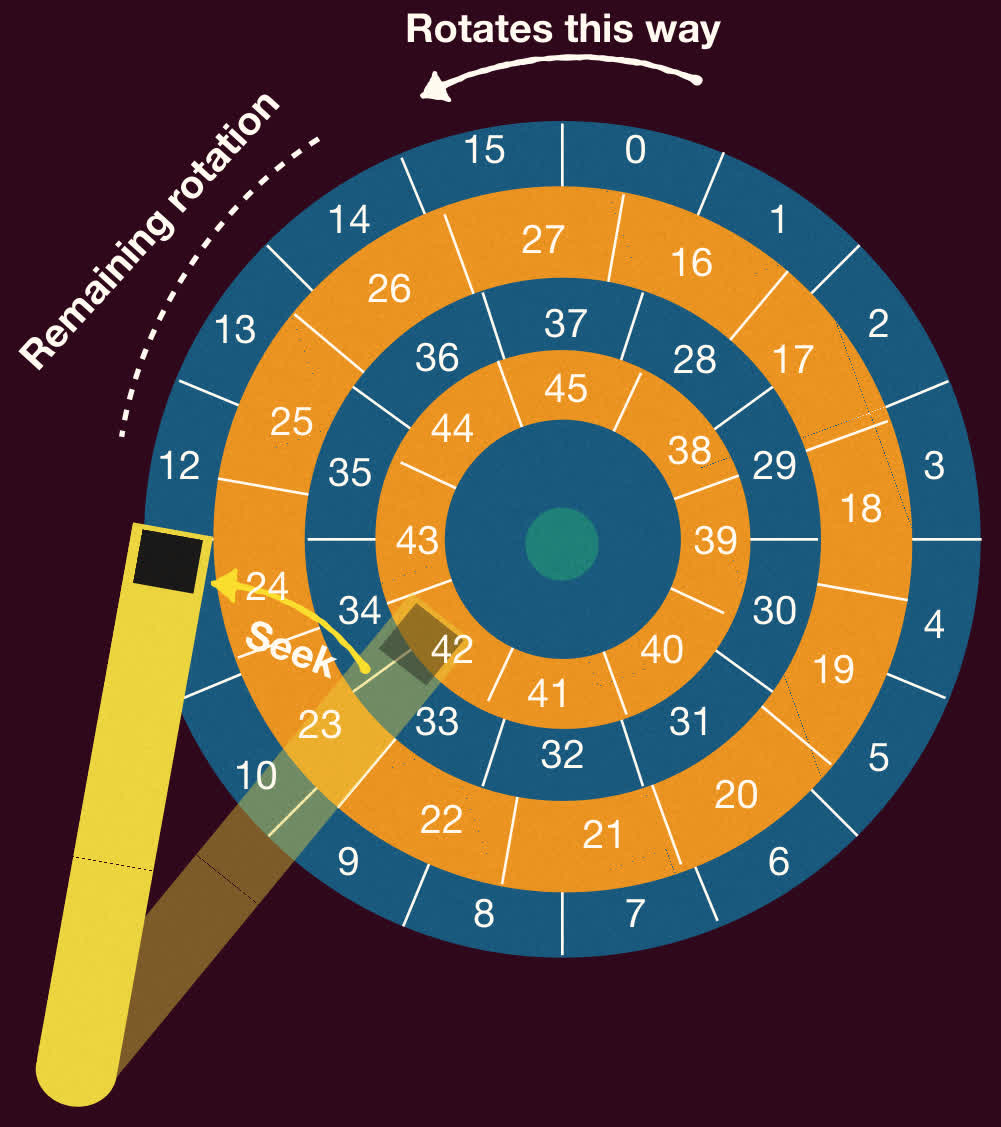
-
磁道偏移:确保在跨越磁道边界(例如,从一个磁道的最后一个扇区到下一个磁道的第一个扇区)进行顺序读取时,磁头有足够的时间切换并准备好读取下一个磁道的起始扇区。
- 实现方式:将相邻磁道的 0 号扇区在物理上错开一定角度。如果没有偏移,当磁头切换到新磁道时,新磁道的 0 号扇区可能已经转过,需要多等待几乎一整圈。
- 可以参考上图中的 15 和 16 号扇区位置。
-
多区域记录:外部磁道比内部磁道周长更长,可以容纳更多扇区。磁盘被划分为多个区域,每个区域内所有磁道的每磁道扇区数相同。外部区域的每磁道扇区数多于内部区域。
- 这提高了磁盘的存储密度和外部磁道的传输速率。
- 现代磁盘控制器处理这种复杂性,对操作系统仍呈现统一的 LBA。
-
磁盘缓存:磁盘控制器内置一块小容量内存(如 8MB 到 256MB),用作数据缓冲区。
- 读取时:当读取某个扇区时,控制器可能会将该扇区所在的整个磁道(或部分磁道)都读入缓存。后续对同一磁道上其他扇区的请求可以直接从缓存满足,速度极快。
- 写入时:
- 直写:数据同时写入缓存和磁盘。只有当数据实际写入磁盘后,才向操作系统确认写入完成。更安全,但较慢。
- 写回:数据先写入缓存,并立即向操作系统确认写入完成。缓存中的数据稍后在磁盘空闲时或缓存满时才「刷回」到磁盘。速度快,但如果发生断电,缓存中未刷回的数据会丢失。
磁头调度
由于 I/O 成本高昂(尤其是寻道时间),操作系统(或磁盘控制器自身)通过调度磁盘 I/O 请求的顺序来优化性能,主要目标是最小化磁头移动,从而最大化磁盘 I/O 吞吐量。
假设当前有一系列磁盘请求等待处理,包括:1, 9, 12, 16, 34, 36(柱面号),当前磁头在柱面 11。
-
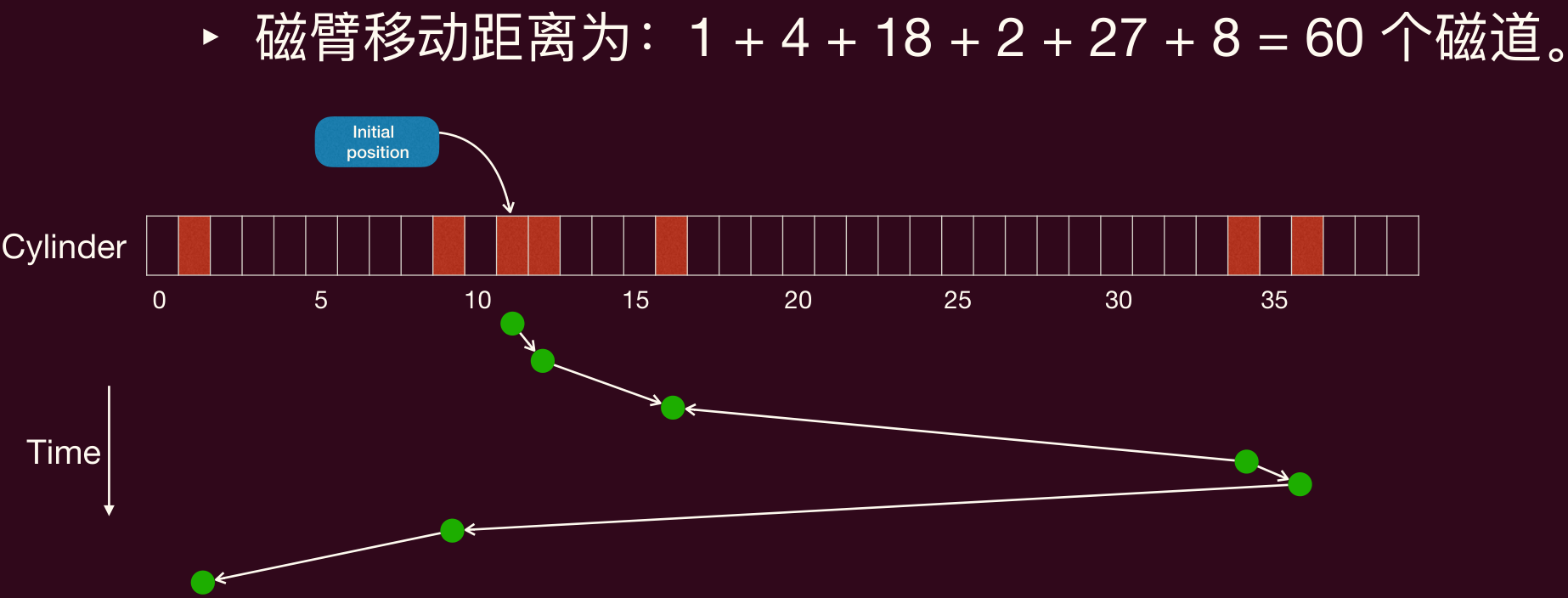
先来先服务(First-Come, First-Served, FCFS)
- 按请求到达的顺序处理。

- 优点:公平,符合应用程序预期顺序。
- 缺点:磁头移动可能是随机的,寻道时间较长,效率低。
-
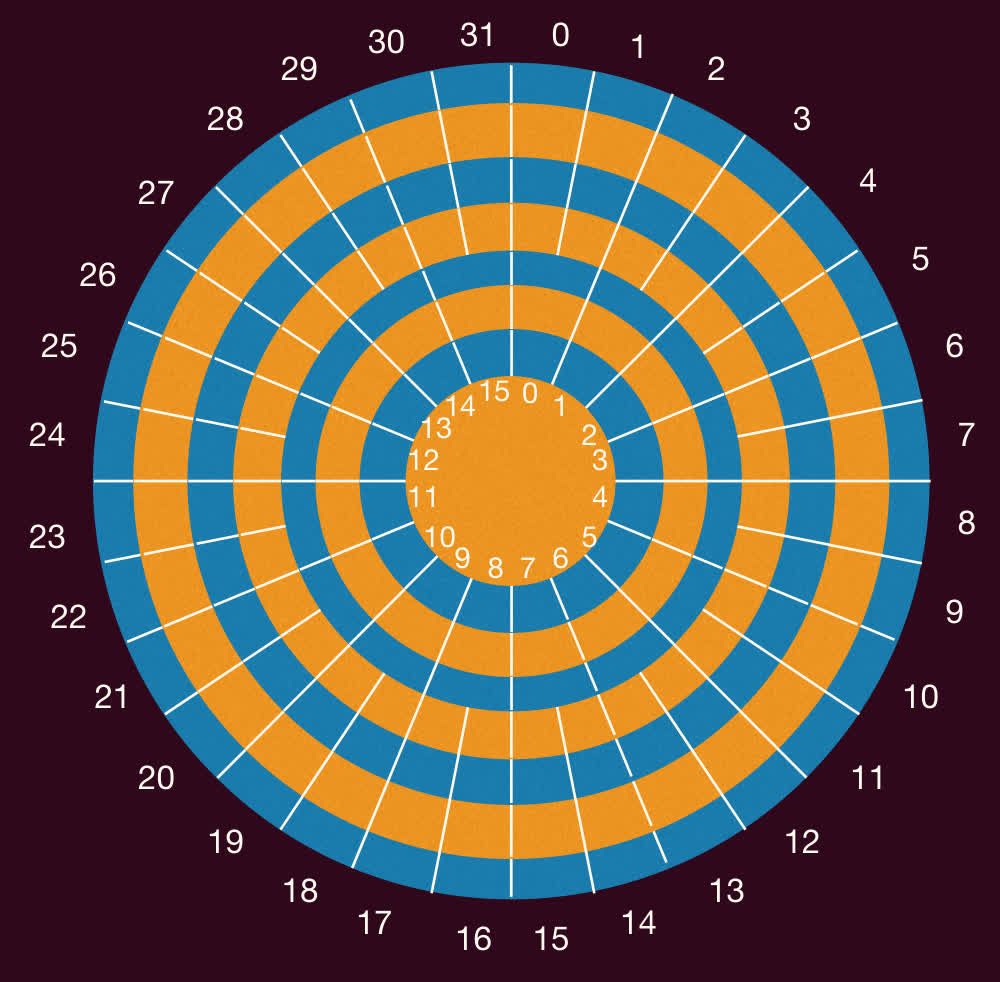
最短寻道时间优先(Shortest Seek Time First, SSTF)
- 选择与当前磁头位置最近的请求进行处理。
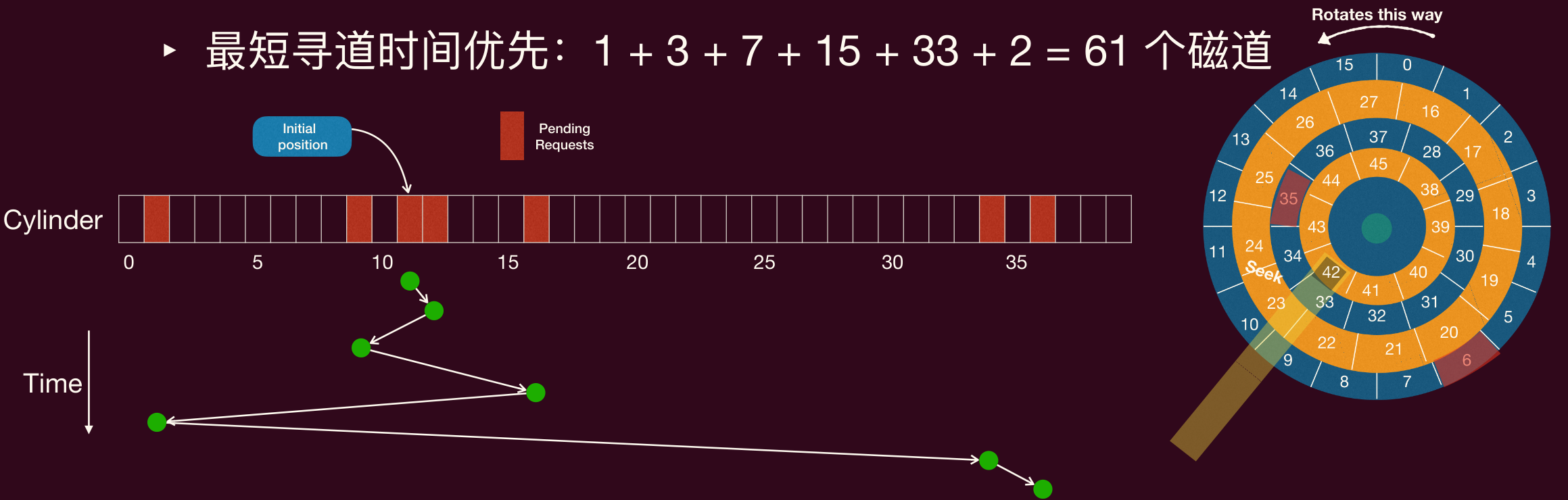
- 如右边圆盘,假设当前磁头位置在内轨道上,则依次处理请求 35(中间),然后再处理请求 6(外部)。
- 左边的示例请求队列则是:1, 36, 16, 34, 9, 12
- 优点:平均寻道时间通常较短,吞吐量较高。
- 缺点:可能导致饥饿。如果持续有靠近当前磁头位置的请求到达,远离磁头的请求可能长时间得不到服务。
-
扫描算法(SCAN, 电梯算法)
- 磁头在一个方向上移动(如从外轨到内轨),服务所有沿途的请求,到达一端后再反向移动。
- 优点:吞吐量较好,避免了饥饿。
- 缺点:对两端磁道的请求响应不如中间磁道快(刚经过的磁道需要等磁头往返一次)。
- 变体:
- 循环扫描算法(C-SCAN/Circular SCAN)
- 磁头只在一个方向上服务请求(如从外轨到内轨)。到达一端后,立即快速返回到另一端起始位置,再开始扫描。
- 这样对所有磁道提供了更均匀的等待时间。
- 优点:比 SCAN 更公平,等待时间更均匀。
- LOOK/C-LOOK
- SCAN 和 C-SCAN 的改进版。磁头在移动到磁盘的物理末端之前,如果当前方向上没有更多请求,就提前改变方向(LOOK)或快速返回到最远请求处(C-LOOK),而不是移动到磁盘的物理尽头。
- 循环扫描算法(C-SCAN/Circular SCAN)
-
最短定位时间优先(Shortest Positioning Time First, SPTF)/最近优先(Nearest First, NF)
- 同时考虑寻道时间和旋转延迟,选择使(寻道时间 + 旋转延迟)最小的请求。
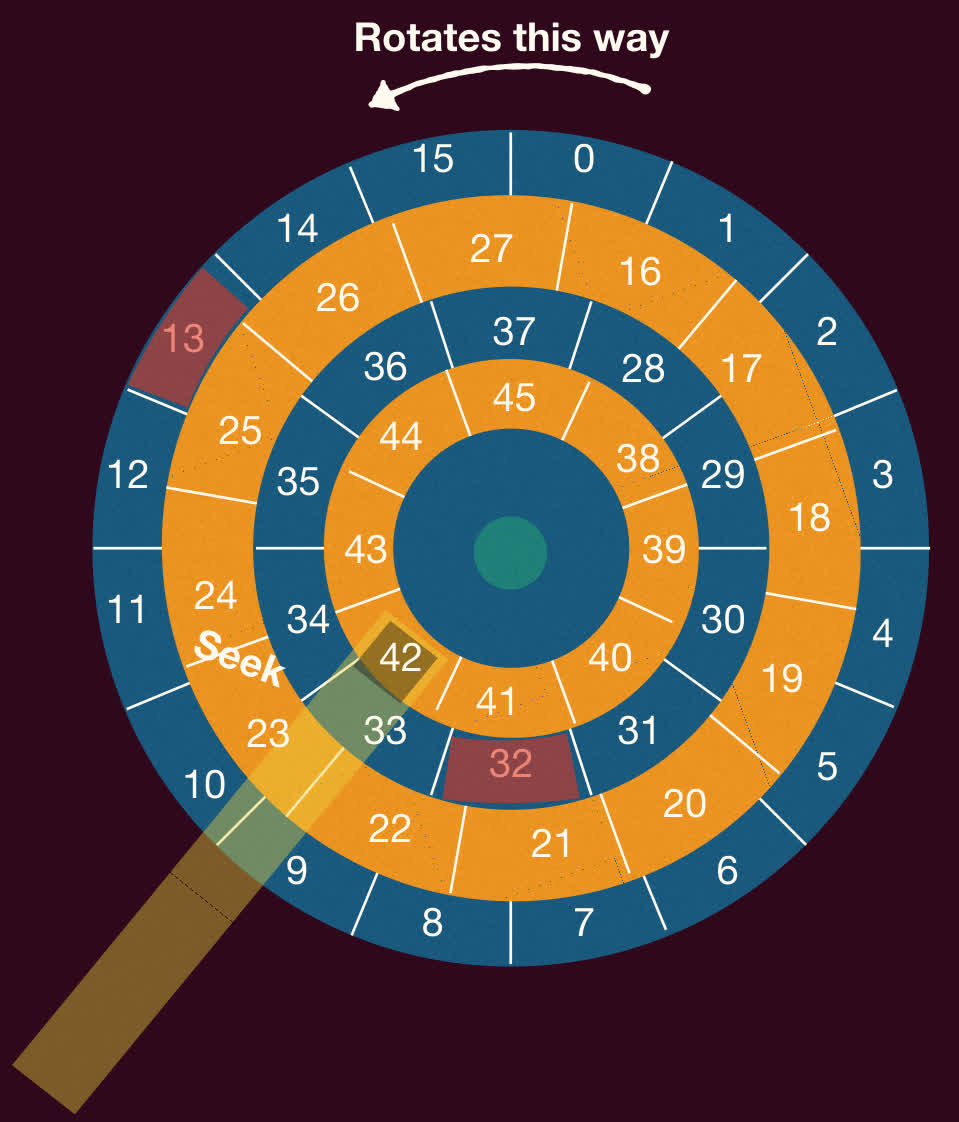
- 当前磁头位置在第 42 扇区(内轨),那么是处理请求 32(中间)还是请求 13(外轨)?
- 若寻道时间高于旋转延迟,SSF 是好的选择。
- 但如果寻道速度比旋转快得多,那么应先处理请求 13。
- 这是理论上最优的,但难以在操作系统层面精确实现,因为操作系统通常不知道磁盘的精确几何结构和当前旋转位置。现代磁盘控制器内部可能会实现类似的算法。
现代磁盘调度
过去的操作系统非常注重磁盘请求调度。如今,磁盘控制器越来越智能,拥有较大的缓存和复杂的内部调度算法。操作系统通常会将一批请求发送给磁盘,由磁盘自行进行内部优化调度。但操作系统层面至少可以假设相邻的 LBA 在磁盘上物理位置也可能相邻,因此顺序访问通常比随机访问快。
固态硬盘(Solid State Disks, SSDs)
固态硬盘(SSD)使用闪存(Flash Memory)(通常是 NAND 类型)作为存储介质,与传统机械硬盘有显著不同。
- 无运动部件:没有旋转盘片和移动磁头,因此没有寻道时间和旋转延迟。
- 访问时间:极低,通常在 甚至更低。
- 低功耗、轻量级、抗震性好。
- 读写不对称:读取速度通常很快。写入和擦除操作比较复杂且相对较慢。
- 存储单元:
- 数据存储在浮栅晶体管中,通过控制浮栅中存储的电荷量来表示 0 或 1(对于 SLC - Single-Level Cell) 或多个 bit(对于 MLC, TLC, QLC)。
- 页:闪存读取和写入的基本单位,通常为 4KB、8KB 或 16KB。
- 块:闪存擦除的基本单位,由多个页组成(如 64、128 或 256 个页,大小通常为 256KB 到 4MB)。
- 有限的擦写寿命:
- 闪存块在被写入前必须先擦除。
- 每次擦除操作都会对闪存单元造成微小损伤。一个块只能承受有限次数的擦写,之后可能变得不可靠或无法使用(dead cell)。
- SLC 寿命最长,QLC 最短。
SSD 内部工作机制与挑战
- 写入限制:不能直接覆盖一个已写入的页。必须先擦除整个块,才能在该块中的页上写入新数据。
- 擦除操作慢:擦除一个块比读取或写入一个页要慢得多。
解决方案与技术
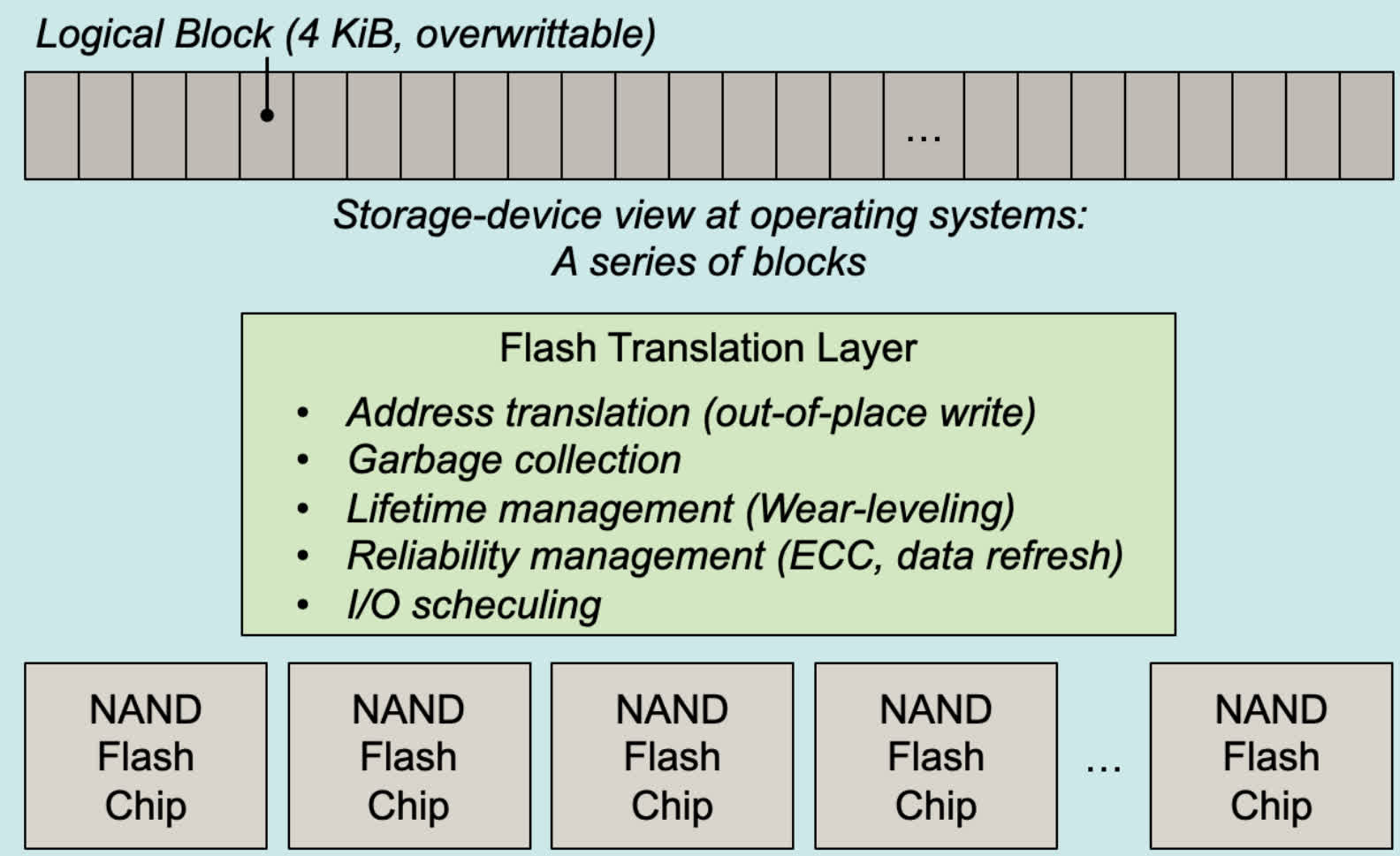
SSD 控制器内置了复杂的固件,称为闪存转换层(Flash Translation Layer, FTL),用于管理这些复杂性并向操作系统呈现标准的块设备接口(如 LBA)。
-
间接层/地址映射
- FTL 维护一个映射表,将操作系统使用的逻辑块地址(LBA)映射到闪存芯片上的物理页地址(PPA)。
- 写时复制:当操作系统请求更新一个 LBA 时,FTL 不会覆盖旧数据。而是将新数据写入到一个空闲的物理页,然后更新映射表,使 LBA 指向这个新的物理页。旧数据所在的物理页被标记为无效。
-
垃圾回收(Garbage Collection, GC)
- 由于写时复制,会产生许多包含无效页的块。
- 垃圾回收过程会选择一个包含较多无效页的块,将其中仍然有效的页复制到另一个块的空闲页中,然后擦除整个被选中的块,使其变为空闲块,可用于后续写入。
- GC 通常在 SSD 空闲时在后台进行,但如果写入压力大,可能需要在前台执行,导致性能下降(写放大)。
-
均衡磨损
- 为了延长 SSD 寿命,FTL 会尝试将写入操作均匀分布到所有闪存块上,避免某些块因过多擦写而过早失效。
- 动态磨损均衡:将热数据(频繁修改)和冷数据(不常修改)动态迁移,确保所有块的擦写次数大致相当。
-
其他:
- TRIM 命令:操作系统可以通知 SSD 哪些 LBA 不再包含有效数据(例如,文件被删除后),FTL 可以将这些 LBA 对应的物理页标记为无效,有助于 GC 更高效地回收空间。
- 预留空间:SSD 通常会预留一部分物理存储空间不暴露给用户,专门用于 GC、坏块替换和磨损均衡,以维持性能和寿命。
- ECC(Error Correction Code):用于检测和纠正闪存读写过程中可能发生的位错误。
SSD 的新问题
- 数据残留:由于写时复制和垃圾回收的延迟,被操作系统「删除」或「覆盖」的数据在物理闪存上可能仍然存在一段时间(甚至数月),直到相应的物理页被垃圾回收并擦除。这可能带来安全隐患。轻度格式化(仅清除元数据)也存在类似问题。安全擦除 SSD 通常需要专门的命令或工具。
总结
- 操作系统利用抽象技术来管理复杂的 I/O 设备,通过设备驱动程序为上层应用提供统一、标准的接口。
- 从另一个视角看,I/O 管理是通用 CPU 与各种专用处理器(如设备控制器、DMA、GPU)之间的通信与协调,设备驱动程序在其中扮演着「解释器」和「协调者」的角色。
- 硬盘是主要的持久化存储设备,主要分为:
- 磁盘(HDD):基于磁性旋转盘片,性能受限于机械部件(寻道、旋转)。通过磁盘调度算法优化性能。
- 固态硬盘(SSD):基于闪存,无机械部件,读写速度快,但有擦写寿命和内部管理(FTL)的复杂性。
- 两者各有优缺点,在现代系统中常常结合使用(例如,SSD 作系统盘和常用程序盘,HDD 作大容量数据存储盘)。