多处理器编程——多线程编程
并发就是操作系统的核心之一,操作系统的很多内部数据结构(如进程列表、页表、文件系统结构)都得考虑「数据竞争」的可能。
并发的很多技术都是源自于操作系统的设计需求和其相应的解决方案。
线程
并发的基本单元是线程(thread),线程拥有独立的「上下文」和栈帧列表,共享全局变量,堆空间。
- 上下文包括程序计数器、寄存器、栈指针等
一定要注意哪些是线程私有的,哪些是线程共享的!
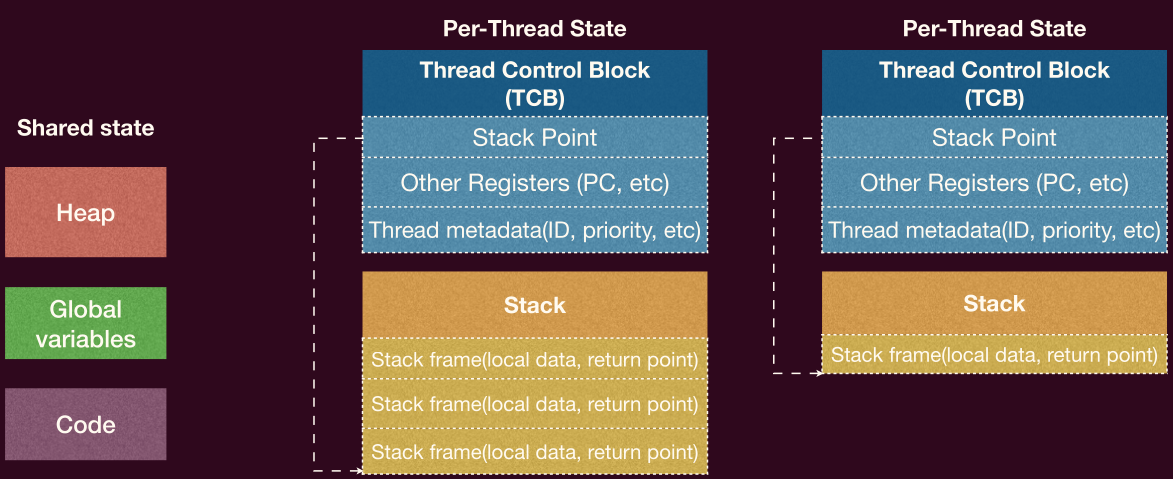
线程是操作系统调度的基本单位,线程代表程序的执行单位,操作系统可以随时运行、暂停、恢复线程。
从状态机的角度来看,多个线程就是多个共享内存的状态机。
初始状态为线程创建时刻的状态,状态迁移为调度器任意选择一个线程执行一步。
POSIX 基本线程 API
| Thread call | 描述 |
|---|---|
pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg) |
创建线程,thread 为线程 ID,attr 为线程属性,start_routine 为线程入口函数,arg 为传递给线程的参数 |
pthread_join(pthread_t thread, void **retval) |
等待线程结束,thread 为线程 ID,retval 为线程返回值 |
pthread_exit(void *retval) |
线程结束,retval 为线程返回值 |
pthread_cancel(pthread_t thread) |
取消线程,thread 为线程 ID |
pthread_detach(pthread_t thread) |
分离线程,thread 为线程 ID |
线程生存周期
线程的一生经历初始化、就绪、运行、等待和结束的周期:
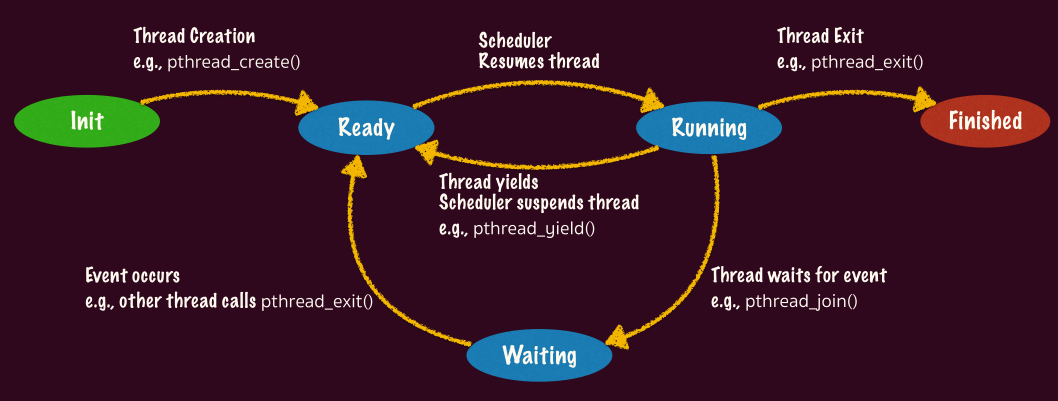
只有在「运行」阶段,其上下文才会在 CPU 上,其余都在内核栈上,当线程处于就绪阶段时其 TCB(Thread Control Block, 线程控制块) 会被放入就绪队列,等待调度器调度。
Heisenbug
多线程编程中的一个常见问题是 Heisenbug,即由于线程调度的不确定性,导致程序的行为不可预测。
- 不确定的线程调度
- 被迫改变的线程状态(因为内存共享)
根本原因:
- 原子化丧失
- 顺序化丧失
- 全局一致化丧失
原子性丧失
原子性
一个原子性(atomicity)的操作即是一个在其「更高」的层面上无法感知到它的实现是由多个部分组成的,一般来说,其具有两个属性:
- All or nothing:一个原子性操作要么会按照预想那样一次全部执行完毕,要么一点也不做,不会给外界暴露中间态。
- Isolation:一个原子性的操作共享变量时中途不会被其他操作干扰!其他所有关于这个共享变量的操作要么在这个原子性操作之前,要么在其之后。
1 | include <pthread.h> |
执行结果(示例):
1 | ./pthread_demo |
因为 sum++ 可以分解为下面的汇编(x86-64):
1 | mov $sum, %rax ; 将 sum 的值加载到寄存器 rax |
若是顺序执行:
1 | ; T1 |
那就是 sum 会被加 2,但是由于线程调度的不确定性,可能会出现下面的情况:
1 | mov $sum, %rax ; T1: %rax_1 = 0 |
这种情况下,sum 只会被加 1。
理论 sum 最小值是 2:
1 | ; 先让线程 2 不写回 $sum,以便后续线程 1 前功尽弃 |
有点像写 RISC-V 递归时那种「包裹」的感觉?
即使换成「单个指令」仍然是错误的:
1 | ... |
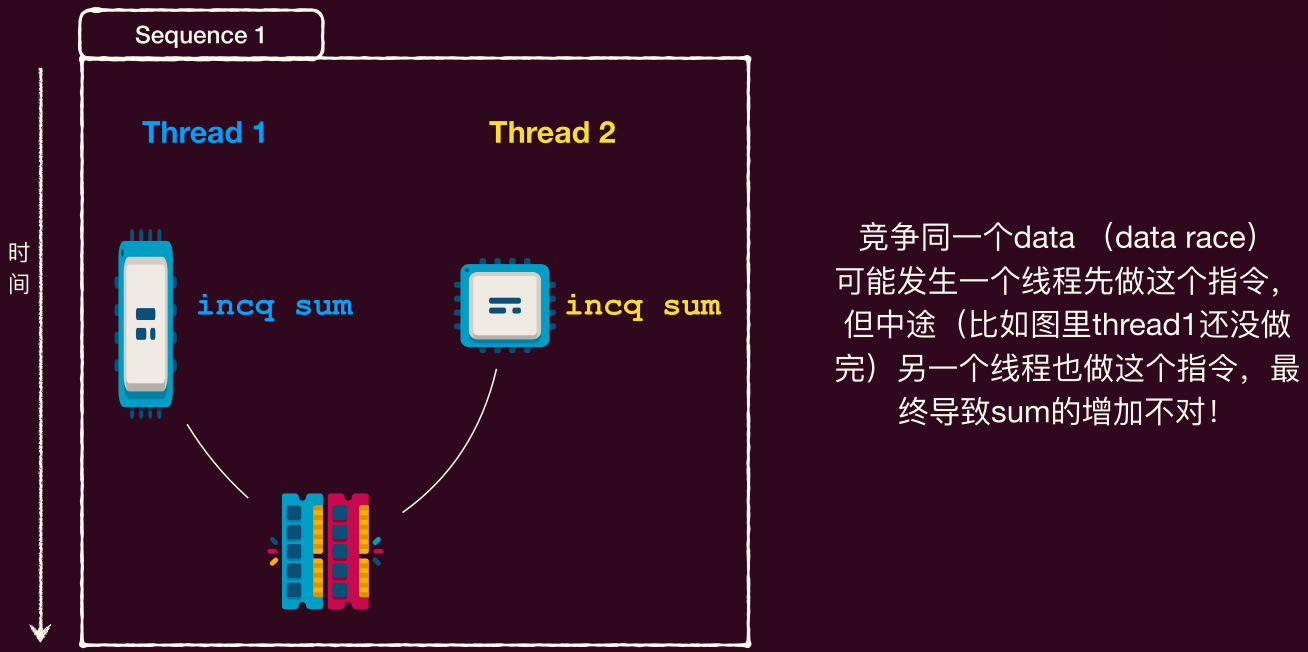
原子性的丧失
- 单处理器多线程:线程在运行时可能被中断,切换到另一个线程执行(All or nothing 无法保证)
- 多处理器多线程:线程根本就是并行执行的(All or nothing 和 Isolate 都无法保证)
顺序性丧失
顺序性
程序语句按照既定的顺序执行。
然而只要不影响语义,指令的执行顺序可以被调整。因此编译器会通过指令重排来提高性能。这些优化在单线程下往往没有问题,但是在多线程下可能会导致问题。
上面的代码的 for 循环会直接被优化成 sum += N。但这不代表就正确了,还是有小概率结果与 2 * N 不相等。
控制执行顺序的方法:
- 使用
volatile修饰变量,告诉编译器不要优化volatile int sum = 0;
- 使用
memory barrier,告诉 CPU 不要重排指令asm volatile("" ::: "memory");asm为内联汇编,volatile为不优化,""为汇编代码,:::为输入输出约束,"memory"为内存约束
操作系统给出的解决方案是「锁」。
全局一致性丧失
现代处理器往往允许指令乱序执行(编译器是将原始执行语句打乱,处理器本身面对指令序列进行乱序执行)。比如对于高时延的访存指令(如 cache miss),处理器可以选择调度后续其他指令执行,从而隐藏访存操作的时延。
然而这种乱序会导致多个处理器看到不一致的访存顺序。
内存一致性模型(Memory Consistency Model,简称内存模型)明确定义了不同核心对于共享内存操作需要遵循的顺序。
顺序一致性模型(Sequential Consistency)提供了保证:
- 不同核心看到的访存操作顺序完全一致,这个顺序称为全局顺序
- 在全局顺序中,每个核心自己的读写操作可见顺序必须与其程序顺序保持一致
可以看成一个「时间单位」上只能选择一个线程读或写共享内存一次,最终形成一个统一的全局的访问内存的顺序。
1 | int x = 0, y = 0; |
建立两个线程,线程 1 执行 T1,线程 2 执行 T2,若是顺序一致性模型,那么输出应该是?
对于顺序一致性模型有:
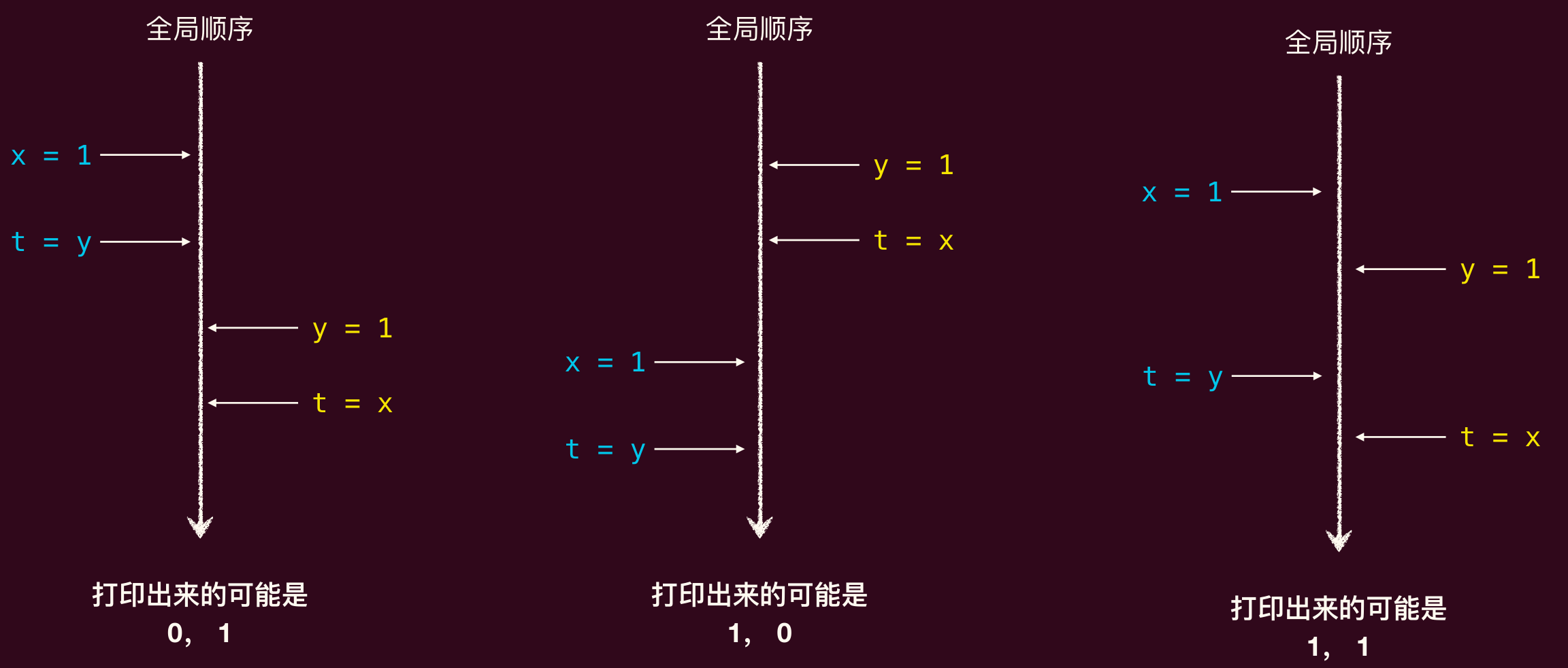
如此看来不可能输出 00,但实际执行结果并不是这样的。说明 x86 的 CPU 不支持顺序一致性。
测试结果
测试代码:
1 |
|
测试:
1 | $ g++ -o mem_order main.cpp -pthread |
课件上的结果是(代码不完全相同)
1 | 16798 0 0 |
?
实际上市面上已经没有支持顺序一致性的 CPU 了,因为对此的支持需要在架构和性能上要付出很多。
x86 采用的实际上是 TSO(Total Store Order) 内存模型,即对于每个核心,其自己的读写操作可见顺序必须与其程序顺序保持一致,但是不同核心看到的访存操作顺序不一定完全一致。
00 是这样得到的:
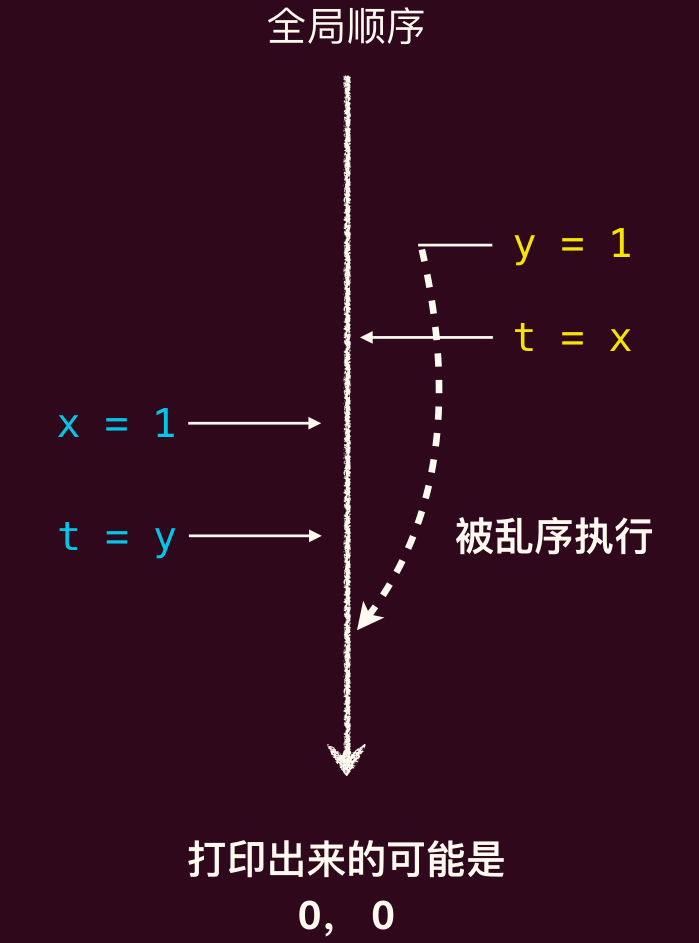
线程 1 看到线程 2 是先读 x,然后写 y,但对于线程 2 而言,其是先执行写 y,然后再读 x(虽然这个顺序被处理器打乱了,因为处理器觉得两个顺序不重要,x 和 y 不存在依赖),因此不再一致。
TSO 一致性模型中,其保证对不同地址且无依赖的的「读读」「读写」「写写」操作之间的全局可见性,但不保证「写读」的全局可见顺序。
一个处理器会比其他处理器更早的看到自己的读。因此,「写读」全局不一致。但所有的处理器都对所有的写操作到共享内存的顺序是一致的。
此外还有 arm 和 RISC-V 采用的宽松内存模型(Relaxed Memory Model),不保证任何不同地址且无依赖的访存操作之间的顺序,也即「读读」,「读写」,「写读」与「写写」操作之间都可以乱序全局可见。
下面展示了一种基于共享内存的消息传递机制。两个需要通讯的线程分别运 thread_A 与 thread_B 代码段。发送者先填充数据,再通过标记 flag 来通知接收者数据准备就绪。然而,在宽松内存模型下,可能会出错(写写全局顺序不一致),TSO 模型下是正确的。
1 | define NOT_READY 0 |
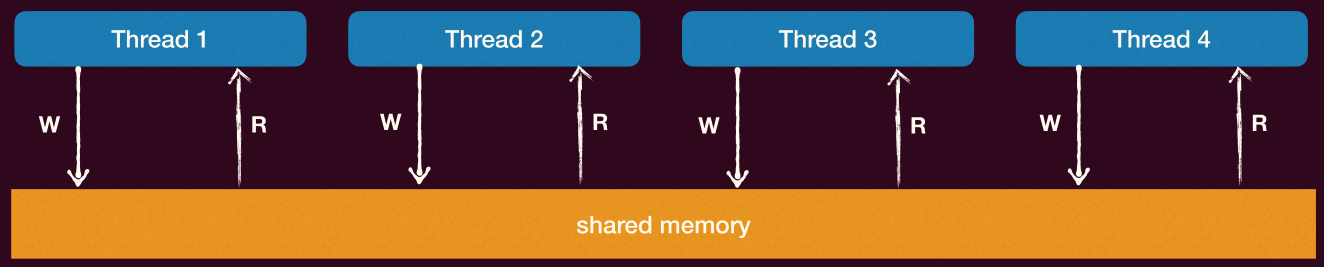
共享与独享
回忆线程的上下文,线程共享全局变量,堆空间,但是线程私有的有栈空间,寄存器等。
虽然栈空间是每个线程独享的,但这只是线程之间的「约定」,操作系统并没有强制要求这样。即对于线程而言,并没有地址空间「保护」的概念,地址空间「保护」针对的对象是进程。
因为在操作系统看来,线程都隶属于一个进程,它们应该是协作的关系,而不应该存有相互的恶意行为。