信息抽取
本章主要介绍信息抽取(Information Extraction, IE)的基本概念、核心任务及其相关技术。信息抽取旨在从非结构化的文本中自动提取结构化的信息,是自然语言处理领域的重要研究方向。
信息抽取概述
信息抽取
信息抽取(Information Extraction, IE)是指从非结构化或半结构化的自然语言文本中,自动识别并提取出用户感兴趣的、预定义类型的「结构化信息」(如实体、关系、事件等)的过程。
动机与目标
随着互联网信息的爆炸式增长,人们面临严重的信息过载问题。信息抽取技术应运而生,其核心目标是:
- 应对信息过载:自动化地处理海量文本,抽取关键信息。
- 结构化信息:将非结构化文本转化为结构化数据,便于存储、查询和分析。
- 特定需求驱动:不同于旨在完全理解文本的阅读理解,IE 通常针对特定任务需求,仅抽取相关的特定信息片段。
示例:从非结构化文本到结构化信息
苹果公司将于北京时间 9 月 13 日举行新品发布会,这一次发布会地点是史蒂夫·乔布斯剧院。CEO 蒂姆·库克可能会在这次发布会上公布 iPhone 13 以及全新 Apple TV。
抽取出的结构化信息:
| 事件类型 | 发布会 |
|---|---|
| 时间 | 北京时间 9 月 13 日 |
| 公司 | 苹果公司 |
| 地点 | 史蒂夫·乔布斯剧院 |
| 人员 | 蒂姆·库克 |
| 产品 | iPhone 13, Apple TV |
| 实体关系 | 苹果公司、蒂姆·库克、CEO |
应用与意义
信息抽取是许多下游 NLP 任务和应用的基础:
- 信息检索:提高检索精度,支持结构化查询。
- 知识图谱构建:自动抽取实体、关系、属性,填充知识库。
- 问答系统:理解问题,从文本中抽取答案。
- 机器翻译:识别专有名词、实体关系,提升翻译质量。
- 文本摘要:识别关键事件、实体,生成摘要。
- 舆情分析:抽取观点、情感相关的实体和事件。
信息抽取技术突破了传统信息检索依赖人工阅读理解的局限,实现了信息的自动查找、理解和抽取,极大地提升了处理海量文本信息的效率。
广义信息抽取
虽然通常处理对象是文本,但广义上的信息抽取也可以应用于语音、图像、视频等多媒体数据。
核心子任务
信息抽取包含多个具体的子任务,主要有:
- 命名实体识别(Named Entity Recognition, NER):识别文本中具有特定意义的实体(人名、地名、机构名等)。
- 关系抽取(Relation Extraction, RE):识别实体之间的语义关系。
- 事件抽取(Event Extraction):识别文本中描述的事件及其要素(时间、地点、参与者等)。
- 时间表达式识别(Temporal Expression Recognition):识别和规范化时间信息。
- 实体归一化/链接(Entity Normalization/Linking):将文本中的实体指称链接到知识库中的唯一实体。
- 模板填充(Template Filling):根据预定义模板,从文本中抽取信息填入槽位。
- 话题检测与跟踪(Topic Detection and Tracking, TDT):检测新话题并跟踪相关报道。
本章将重点介绍 NER、RE 和 Event Extraction 三个核心任务。
命名实体识别(NER)
命名实体(Named Entity, NE)& 命名实体识别(NER)
- 命名实体(Named Entity, NE):指文本中具有特定意义和指代作用的实体,通常是名词短语,如人名(PER)、地名(LOC)、机构名(ORG)、专有名词、时间、货币等。
- 命名实体识别(Named Entity Recognition, NER):是从文本中定位实体边界并分类实体类型的任务。
NER 通常包含两个步骤:
- 实体边界识别:确定实体字符串在文本中的起始和结束位置。
- 实体类型分类:判断识别出的实体字符串属于哪个预定义的类别(如 PER, LOC, ORG)。
示例表格:
| 实体名 | 标签 | 示例 |
|---|---|---|
| 人名 | PER | [马云]PER 企业家:致力于推动互联网商业模式的变革 |
| 地名 | LOC | 2021 世界人工智能大会将于 7 月 8 日至 10 日在 [上海]LOC 召开 |
| 机构名 | ORG | [中国科学院大学]ORG 是中国科学院直属的一所以研究生教育为主的高等学府 |
| 疾病名 | DIS | [高血压]DIS 已成为影响全球死亡率的第二大危险因素 |
| 药品名 | DRU | [奥司他韦]DRU 是治疗流感的首选药物 |
NER 主要难点:
- 歧义性(Ambiguity):同一个名称在不同上下文中可能指代不同类型的实体。
- 「南京大学」在「我们明天在南京大学见」中是地点(LOC),在「南京大学共有鼓楼、仙林…四个校区」中是机构(ORG)。
- 「Harvard」可以是人名(John Harvard)、机构名(Harvard University)或地名(Harvard, Massachusetts)。需要依赖上下文判断。
- 未登录词(Out-Of-Vocabulary, OOV):训练语料或词典中未出现过的实体。命名实体表达随意、形式多变,使得 OOV 问题比中文分词更严重。
从表现形式上,命名实体可分为:
- 非嵌套命名实体(Non-nested Named Entities/Flat Named Entities):实体之间没有重叠或包含关系,每个词(或 token)最多属于一个实体。这是最常见的情况。
- 嵌套命名实体(Nested Named Entities):一个实体内部包含另一个或多个实体。
- 「
[南京大学]ORG[苏州]LOC 校区」整体是机构名(ORG),内部包含地名「苏州」(LOC)和另一个机构名「南京大学」(ORG)。
- 「
非嵌套命名实体识别(Flat NER)
Flat NER 通常被建模为「序列标注」问题。目标是为输入序列(通常是句子)中的每一个元素(token,可以是词或字)分配一个标签。
标注体系
标签需要同时表示实体的边界和类别。
- BIO 体系:最常用。
B-X:表示当前元素是类型为 X 的实体的开始(Begin)。I-X:表示当前元素是类型为 X 的实体的内部(Inside)。O:表示当前元素不属于任何实体(Outside)。
- BIOES 体系:在 BIO 基础上增加:
S-X:表示当前元素本身构成一个单个(Single)字符的类型 X 实体。E-X:表示当前元素是类型为 X 的实体的结束(End)。I-X在此体系中表示实体中间部分。
通过这种转换,NER 变成了一个序列标注任务,可以使用多种序列模型解决,如隐马尔可夫模型(HMM)、条件随机场(CRFs)、长短时记忆网络(LSTM)及其变种(BiLSTM-CRF)。
条件随机场(CRF)
线性链 CRF 是 NER 任务中常用的模型。
- 原理:给定观测序列 (如句子中的字或词),CRF 学习条件概率分布 ,其中 是标签序列。
- 马尔可夫性: 满足马尔可夫性,即标签 只依赖于 和其邻近标签 。
- 对数线性模型:
其中, 是全局特征向量, 是特征函数向量, 是模型参数(权重)。
- 训练:通过最大化训练数据的对数似然函数来估计参数 。
- 局限性:线性链 CRF 主要捕捉局部依赖特征,对于 NER 中可能存在的长距离依赖或全局特征(如实体一致性)能力有限。
半马尔可夫 CRF
为了更好地利用片段级特征,Sarawagi 和 Cohen (2004) 提出了 Semi-CRF。
- 动机:NER 更自然地是识别实体片段,而非单个标签。片段特征(如实体长度、与已知实体相似度)对识别很有帮助。
- 原理:放松了 CRF 中每个标签满足马尔可夫性的要求,改为要求由邻接词组成的「片段」之间满足马尔可夫性。
- 表示:输入 被表示为片段集合 ,其中 代表从位置 到 的片段,其标签为 。片段覆盖整个序列且不重叠。
- 约束条件:。
- 模型:
其中 是片段级别的全局特征向量, 是片段特征函数向量。
- 推断:使用 Viterbi 算法寻找最优片段序列 。
递推公式:
其中 是最大片段长度。
- 训练:最大化对数似然 。
基于 Transformer 的 NER
Transformer 因其并行性和长距离建模能力被广泛应用,但在 NER 上直接使用存在问题:
- 位置编码缺乏方向信息:标准正弦位置编码只捕捉距离,无法区分相对方向(如「位于」前后的「南京大学」类型不同)。
- 注意力分布平滑:Transformer 的 Scaled Dot-Product Attention 中的缩放因子()会平滑注意力分布,可能引入噪声,因为 NER 通常只需要关注少数上下文词。
TENER(Transformer Encoder for NER) 提出改进:
- 相对位置编码:引入能感知方向的相对位置编码 。
- 去除缩放因子:取消注意力计算中的缩放因子,使注意力分布更稀疏、更集中。
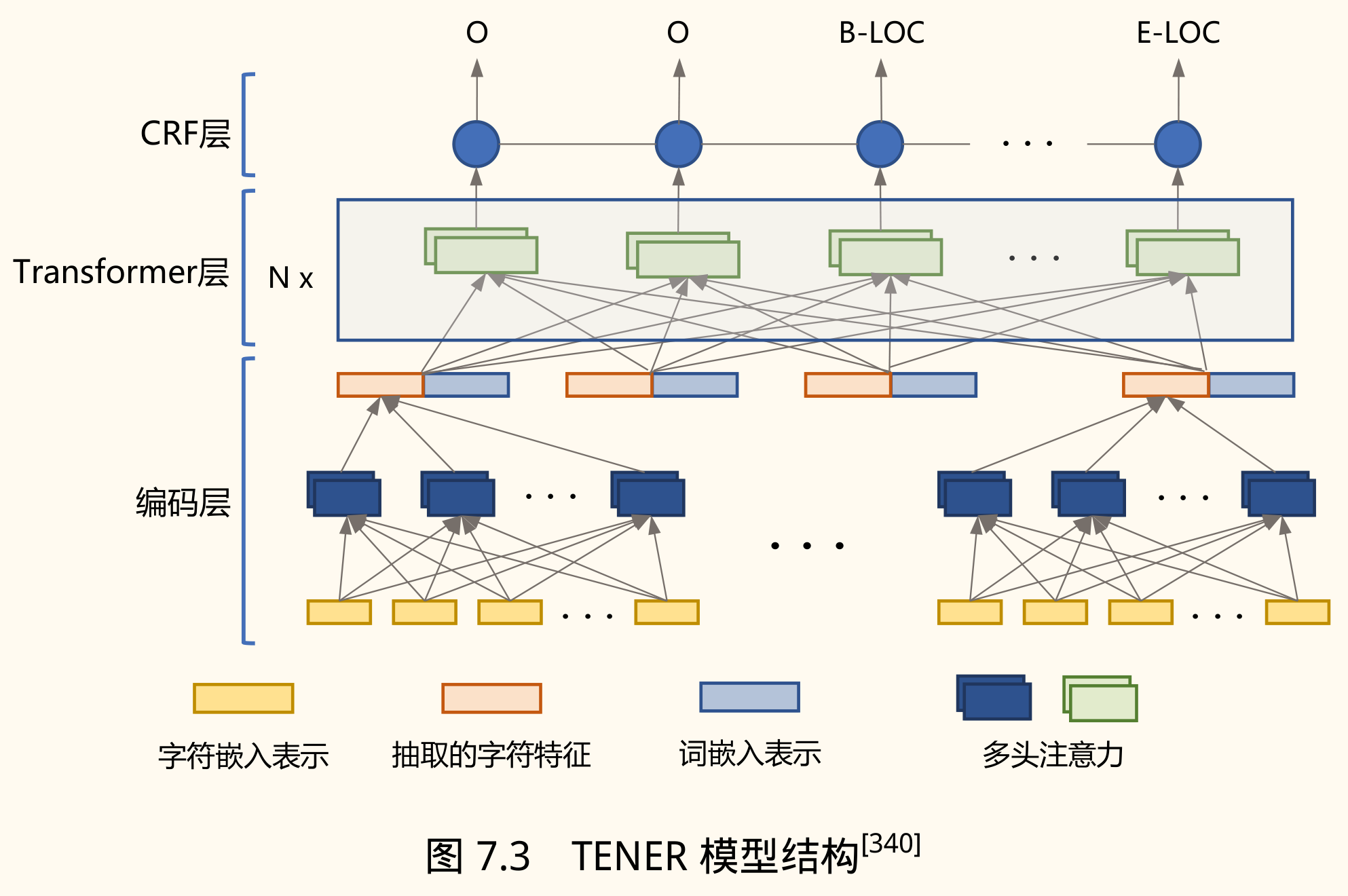
中文 NER 的特殊挑战与方法
中文 NER 比英文更复杂,主要因为没有显式的单词边界。
- 基于分词的方法:先分词,再在词序列上进行 NER。
- 优点:可以利用词汇信息。
- 缺点:分词错误会传递给 NER;命名实体(尤其是 OOV)可能被错误切分。
- 基于字符的方法:直接在字符序列上进行 NER。
- 优点:避免分词错误。
- 缺点:无法直接利用词汇信息。
融合词汇信息的方法:
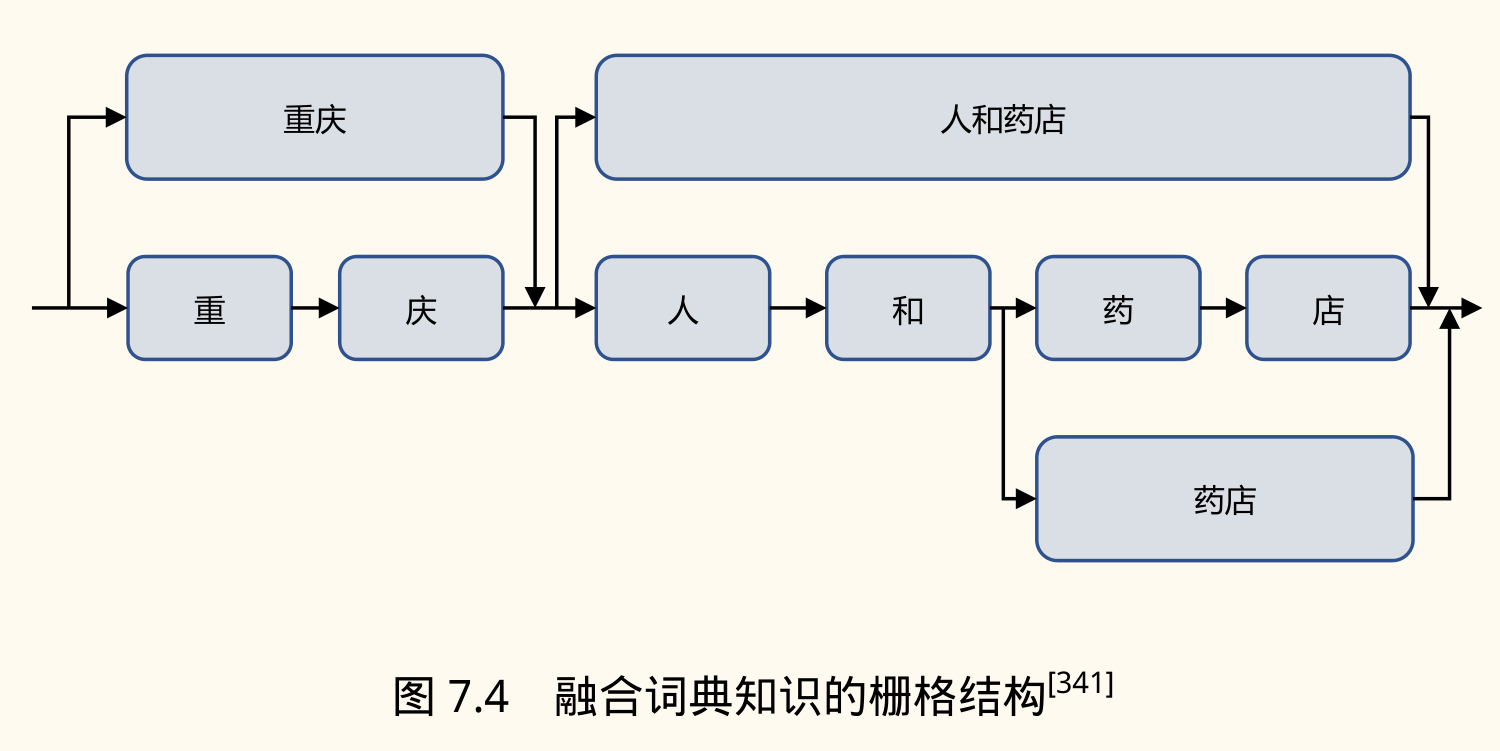
-
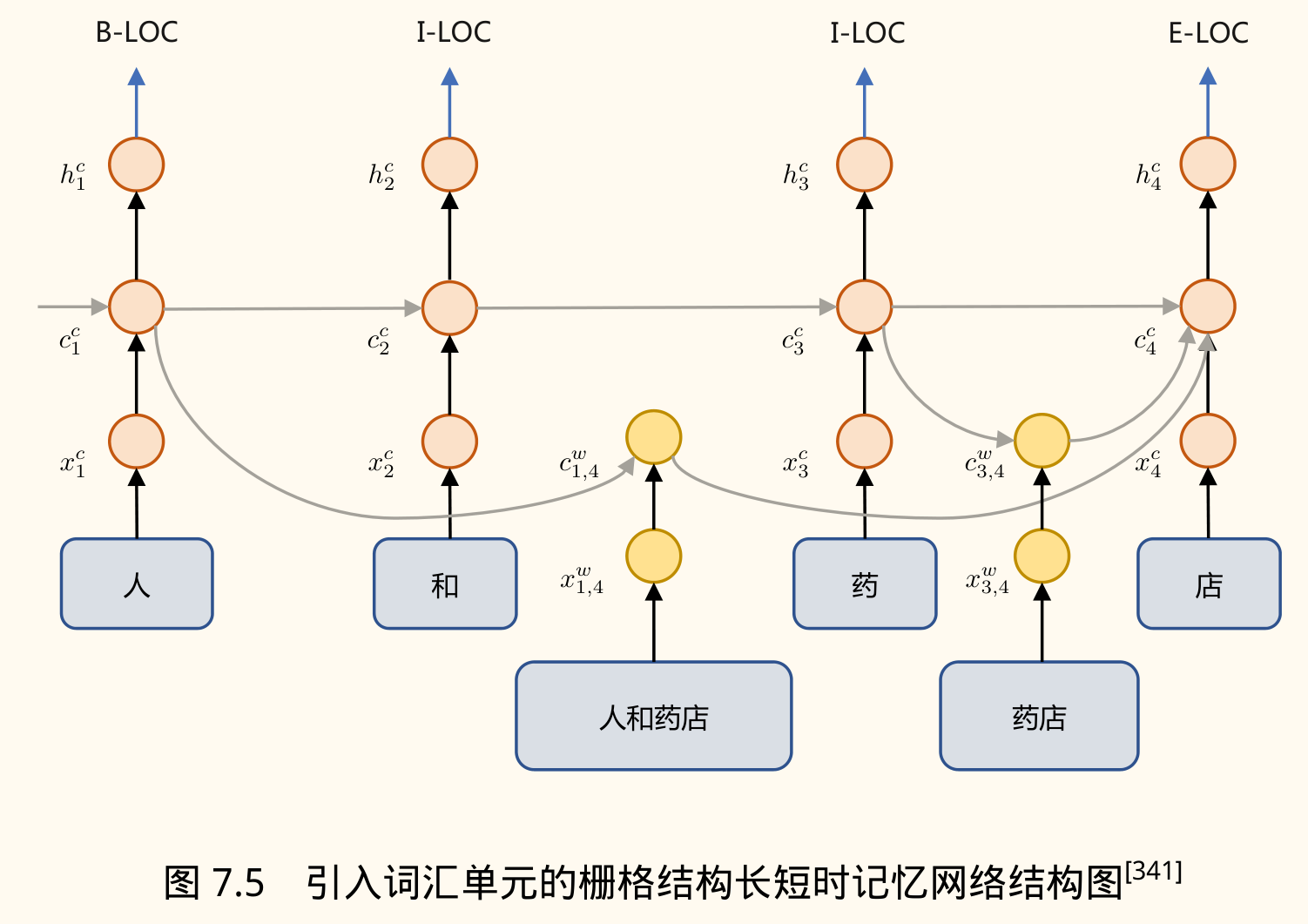
Lattice LSTM (Zhang & Yang, 2018):
- 思想:在字符 LSTM 基础上,动态地融入与词典匹配的词语信息。
- 结构:构建一个包含字符和匹配词的「格子」(Lattice)结构。
- 机制:引入额外的词汇单元 ,表示从字符 到 组成的词 的信息。通过额外的门控单元 控制词汇信息流入字符状态。在计算字符 的单元状态 时,会融合所有以 结尾的词汇单元信息,并使用注意力机制加权。
- 公式:
其中 是字符路径计算的候选状态, 是词汇单元状态, 是注意力权重。
- 缺点:基于栅格网络可以有效的融合词典知识,但是 LSTM 的速度较慢,无法很好并行化。
-
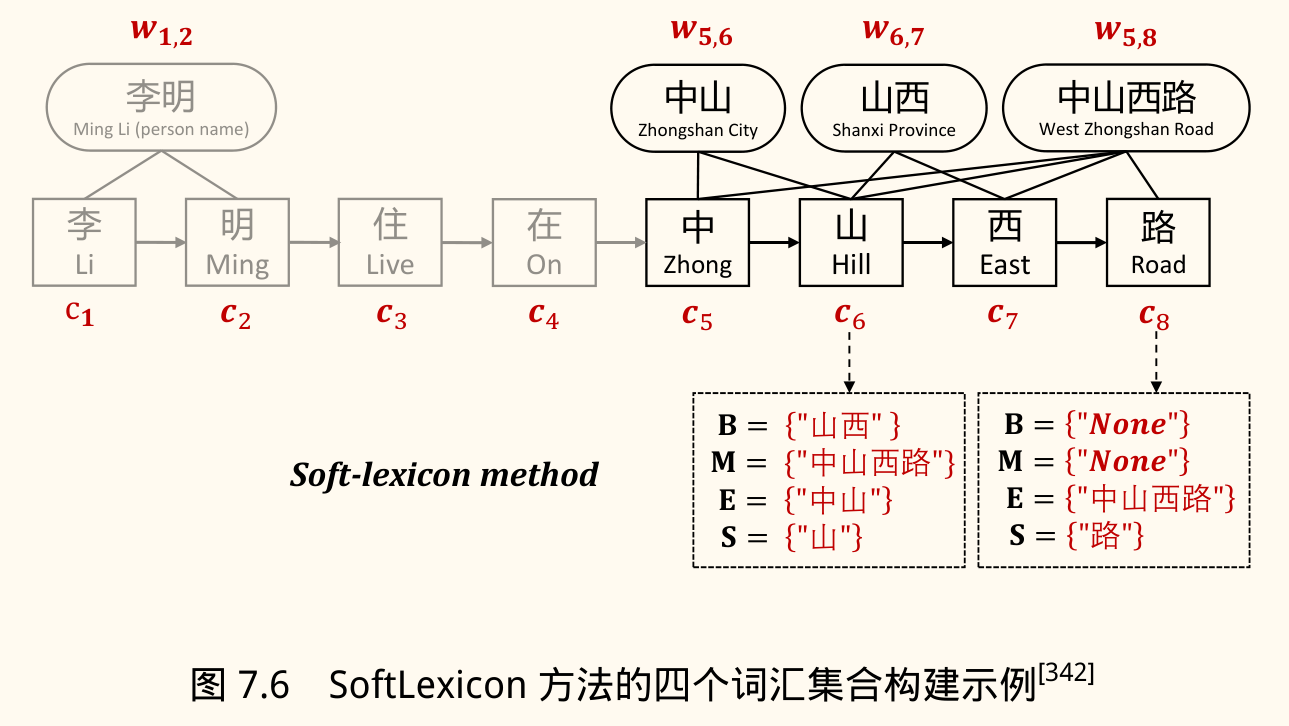
SoftLexicon (Ma et al., 2020):
- 思想:将与字符 相关的词典词信息编码为固定维度的「词汇特征」,并融入字符表示。
- 步骤:
- 构建词汇集合:对每个字符 ,找到词典中所有与 匹配的词。将这些词根据 在词中的位置(Begin, Middle, End, Single)划分到四个集合 BMES。
- 压缩词汇集合:使用加权算法(如基于词频)将每个 BMES 集合中的词向量压缩成一个固定维度的向量 。
- 结合:将四个集合的压缩向量 拼接起来,再与原始字符嵌入 拼接,得到最终的输入表示 。
- 优点:模型无关,可用于不同神经网络结构;静态权重避免复杂计算。
- 思想:将与字符 相关的词典词信息编码为固定维度的「词汇特征」,并融入字符表示。
嵌套命名实体识别(Nested NER)
嵌套 NER 任务允许一个实体包含其他实体。
- 示例:「
[北京大学]ORG」包含「[北京]LOC」;「[华为 P50 Pro]PRODUCT」包含「[华为]ORG」。 - 形式化:输出 ,其中 是一个标签集合,m 是嵌套层数。
- 挑战:传统序列标注方法(HMM, CRF)只能为每个位置输出一个标签,无法直接处理嵌套;标签间可能存在依赖;嵌套层次不确定。
解决方法
-
基本方法(有局限性):
- 穷举法:识别所有可能的单词序列,再用 Flat NER 分类器判断。计算量大。
- 组合标签:为可能共同出现的标签创建新标签(如 B-LOC|ORG)。标签数量指数增长。
- 多目标学习:修改序列标注算法,允许输出多个标签,使用 KL 散度等作为损失。
-
类比句法分析:
- 将嵌套 NER 视为构建类似成分句法树的过程。
- 基于状态转移:
- 维护:堆栈 S(已规约实体/待规约词),动作序列 A,队列 Q(剩余输入词)。
- 动作:
Shift:将 Q 队首词移入 S。Reduce-X:弹出 S 栈顶两个元素 ,合并为类型 X 的实体,压回 S。Unary-X:弹出 S 栈顶元素 ,标注为类型 X,压回 S。
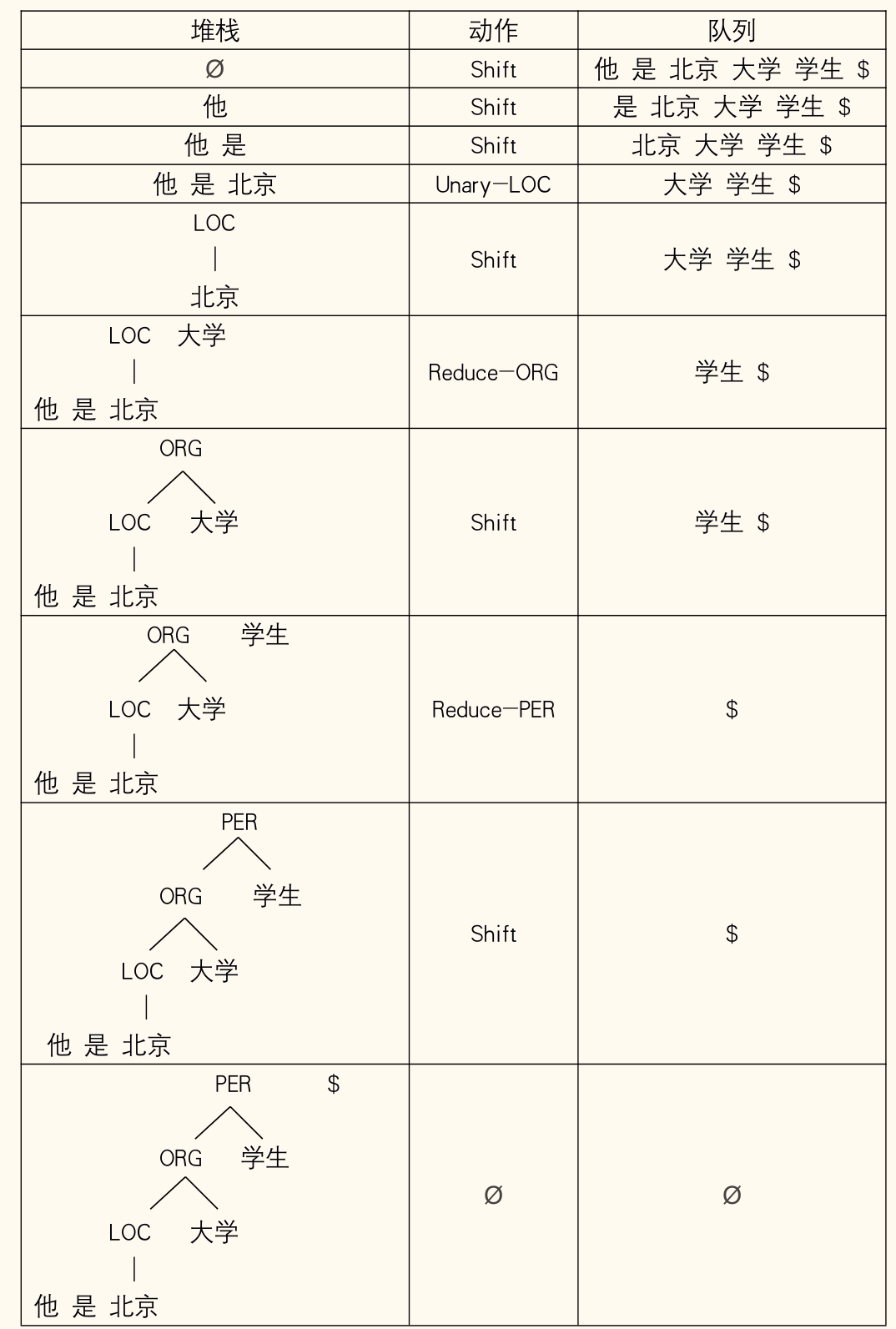
- 建模:将问题转化为分类任务,根据当前状态 [S, A, Q] 预测下一步动作。通常使用 Stack-LSTM 对状态进行编码。
- 状态编码:。 作为分类器输入。
-
基于跨度(Span-based):
- 思想:枚举句子中所有可能的跨度(span,即连续子序列 ),并对每个跨度进行分类,判断其是否构成某种类型的实体。
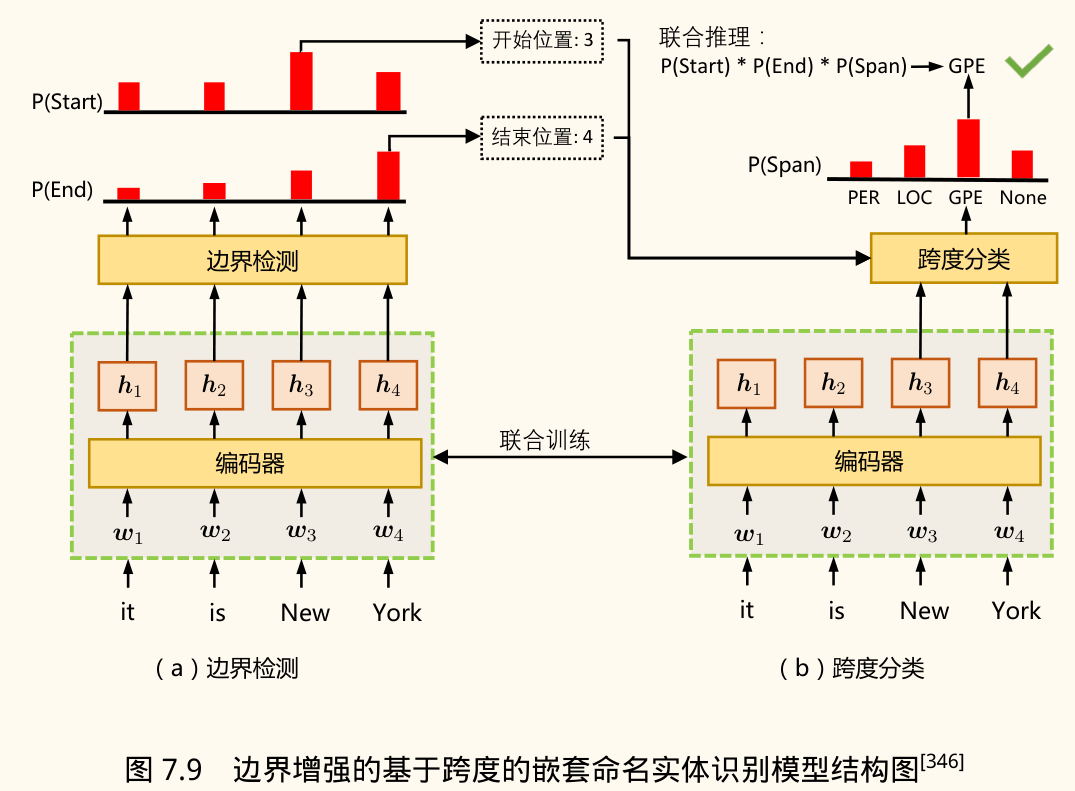
- 流程:
- 编码层:使用 BiLSTM 或 Transformer 获取每个 token 的上下文表示 。
- 边界检测(可选但常用):训练两个分类器,预测每个 token 是实体开始的概率 和是实体结束的概率 。损失函数为所有边界的交叉熵 。
- 跨度表示:对于跨度 ,其表示 可以通过 以及跨度内 token 的表示计算得到(如端点拼接、注意力加权等)。
- 跨度分类:对每个跨度 ,预测其属于各个实体类型 (包括 None) 的概率 。损失函数为所有跨度的交叉熵 。
- 联合训练:通常联合优化边界检测和跨度分类任务,总损失 。
- 推理:组合边界预测和跨度分类结果,得到最终的嵌套实体。
多规范命名实体识别(Multi-paradigm NER)
现实应用中可能同时存在非嵌套、嵌套和不连续(Discontinuous)命名实体(如「华为,这家全球知名的技术有限公司,正在拓展市场」中「技术有限公司」指代「华为」)。传统方法通常只针对特定范式,缺乏通用性。
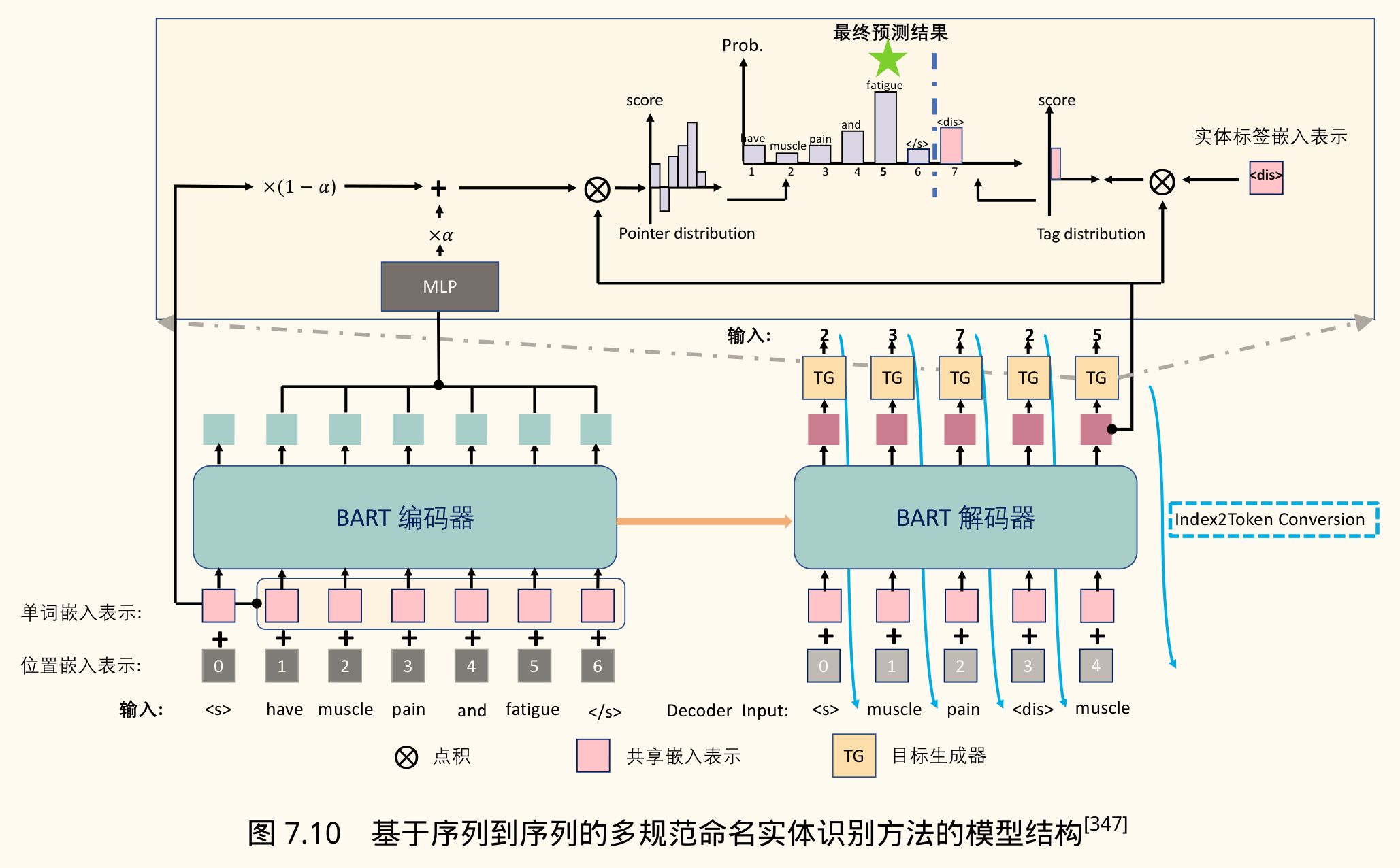
统一方法——基于 Seq2Seq 的生成方法:将 NER 视为一个序列生成任务。
- 模型:通常使用 Encoder-Decoder 架构,如 BART。
- 输入:原始句子。
- 输出:一个描述所有实体的线性化序列。例如,用
<s_start> <s_end> <type> ...表示每个实体跨度和类型。对于不连续实体,可以输出多个跨度。- 示例输入:
南京大学 - 示例输出:
1 2 5 1 4 6(表示:跨度 1-2 类型 5 (LOC),跨度 1-4 类型 6 (ORG))
- 示例输入:
- 指针网络(Pointer Network):可以结合指针网络来精确地从输入中复制边界索引。
- BART 修改:由于 BART 使用 BPE,一个词可能被分成多个子词。需要调整指针表示:
Span:指向实体原始词的起止位置。BPE:指向实体对应的所有 BPE token 的位置索引。Word:指向实体每个词的第一个 BPE token 的位置索引。

NER 评价方法
- 标准:精确匹配(Exact Match),即实体边界和实体类型都必须完全正确。
- 指标:
- 精确率(Precision, P):预测正确的实体数 / 预测出的实体总数。
- 召回率(Recall, R):预测正确的实体数 / 真实实体总数。
- F1 值(F-score):P 和 R 的调和平均值,。
- 多类别评估:
- 宏平均 F1:分别计算每个实体类别的 F1 值,然后取算术平均。平等对待每个类别。
- 微平均 F1:将所有类别的 TP, FP, FN 汇总后,计算总的 P, R, F1。侧重于样本数量多的类别。
关系抽取(RE)
关系抽取
关系抽取(Relation Extraction, RE)旨在从文本中识别和判断两个或多个实体之间存在的语义关系。
- 目标:识别实体对(通常是二元关系)之间的关系类型。
- 表示:通常用三元组
<Head Entity, Relation, Tail Entity>或<e1, r, e2>表示。- 示例:从句子「刘翔出生于上海」中抽取
<刘翔, 出生地, 上海>。
- 示例:从句子「刘翔出生于上海」中抽取
- 重要性:是信息检索、智能问答、知识图谱构建等应用的关键技术。
RE 主要难点:
- 关系类型繁多:现实世界关系复杂,预定义关系类型可能非常多(如 Freebase 有 4000+ 种关系类型,7000+ 种属性类型)。考虑多元关系和关系重叠会更复杂。
- 语义建模要求高:需要理解句子深层语义才能准确判断关系。
- 表达形式多样:同一语义关系可以用多种不同的词汇和句法结构表达。
- 示例:「位于」关系
[南京大学]ORG 始创于 1902 年,位于中国[南京]LOC。[南京大学]ORG 地址:江苏省[南京]LOC 市栖霞区仙林大道 163 号。[南京]LOC 市栖霞区坐落着多所高等院校,包括:[南京大学]ORG、南京师范大学等。
这三个句子表达了(南京大学, 位于, 南京)的关系,但表述方式、距离、句式差异很大。
- 示例:「位于」关系
- 数据标注成本高:有监督方法需要大量标注数据,成本高昂。
RE 方法分类
可以从不同维度对 RE 方法进行分类:
- 根据是否需要预先识别实体:
- 流水线式抽取:先运行 NER 识别实体,再运行 RE 模型判断已识别实体对之间的关系。
- 优点:任务分解,模型相对简单。
- 缺点:NER 的错误会传递给 RE。
- 联合式抽取:使用单个模型同时完成 NER 和 RE 任务。
- 优点:能捕捉 NER 和 RE 任务间的依赖,缓解错误传播。
- 缺点:模型设计更复杂,学习难度可能增加(需要同时处理无关系实体和有关系实体对)。
- 流水线式抽取:先运行 NER 识别实体,再运行 RE 模型判断已识别实体对之间的关系。
- 根据是否需要预定义关系类型:
- 预定义关系抽取:针对一个或多个领域内预先定义好的关系类型进行抽取。
- 有监督:使用大量人工标注数据训练模型。准确率高,但标注成本高。
- 远程监督:利用现有知识库(如 Freebase, Wikidata)自动生成标注数据。标注成本低,但易引入噪声。
- 开放关系抽取:不限定关系类型,从文本中抽取尽可能多的关系三元组,关系短语通常直接从文本中提取。适应性强,但关系规范性和准确性面临挑战。
- 预定义关系抽取:针对一个或多个领域内预先定义好的关系类型进行抽取。
有监督关系抽取
将 RE 视为一个多分类问题。
- 输入:文本内容 + 待判断的实体提及对(Mention Pair)。
- 输出:提及对之间表达的关系类型(或「无关系」)。
基于特征的方法
早期常用方法,依赖人工设计特征,结合传统分类器(如 SVM、最大熵模型)。
最大熵模型:
- 原理:在满足已知约束(特征期望)的条件下,选择熵最大的概率分布 ,认为这是最均匀、最不偏袒的分布。
- 目标函数:
- 条件熵:
- 模型期望:
- 经验期望:
- 模型形式(最优解):
其中 是归一化因子, 是特征权重(通过优化算法如 GIS, L-BFGS 学习)。
- 常用特征
- 词汇特征:实体本身、实体之间的词、实体窗口内的词等。
- 实体类型特征:两个实体的类型(PER, LOC, ORG 等)。
- 重叠性特征:实体间词数、其他实体数、词性是否相同等。
- 依赖特征:依存句法树上连接实体的路径、路径上的词和词性、依赖关系类型等。
- 语法树特征:成分句法树上连接实体的最短路径、路径上的非终结符等。
- 示例(句子片段「担任其董事会主席」, 提及对「董事会」ORGm2,「主席」PERSONm1):
- 词汇:m1="主席", m2="董事会"
- 实体类型:NOMINALm1, NOMINALm2
- 重叠:中间词数为 0
- 语法树路径:(PERSON-NP-ORGANIZATION)
基于深度学习的方法
自动学习特征表示,避免了繁琐的特征工程。常用模型包括 CNN, RNN, GCN, Transformer 等。
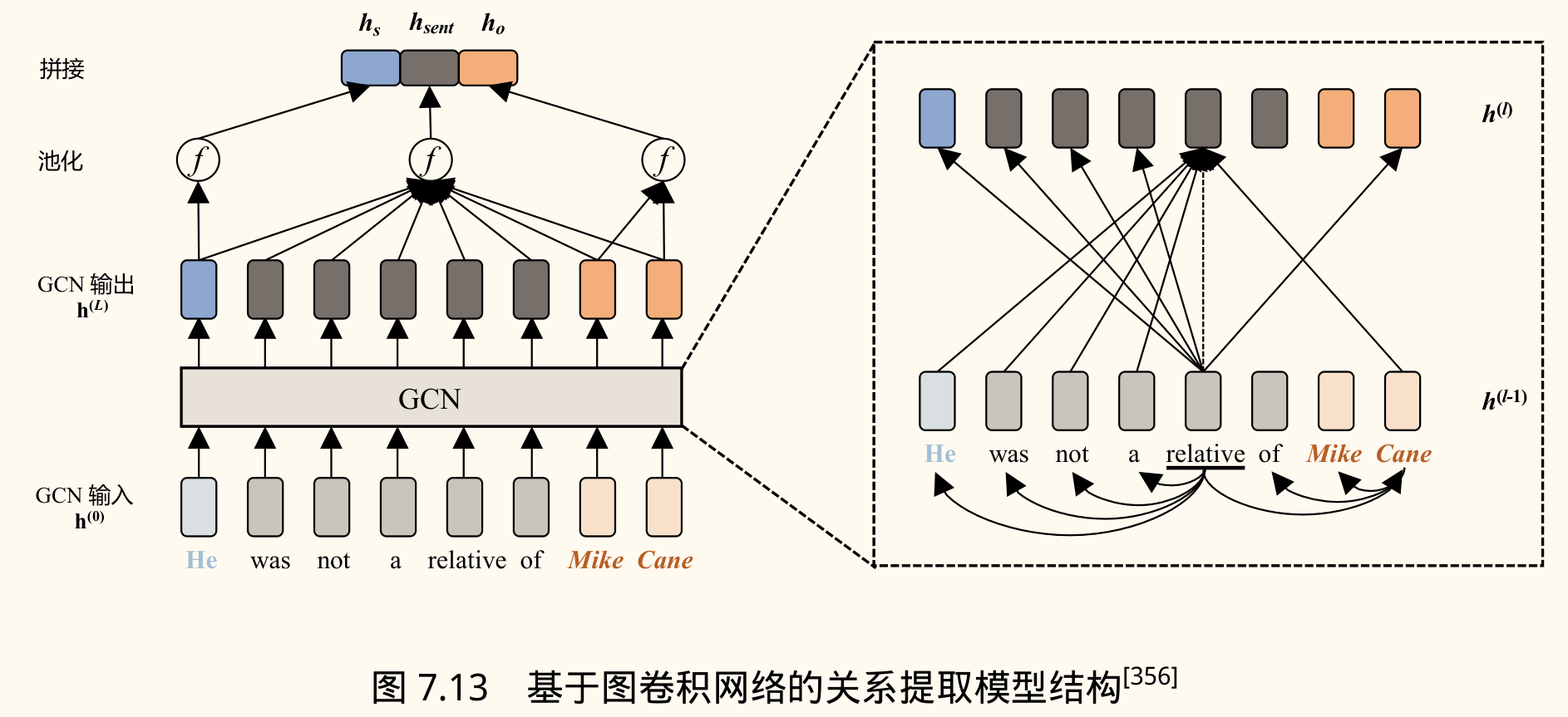
图卷积网络(GCN)用于 RE:
- 动机:句子的依存句法树能显式地表示词语间的长距离依赖关系,有助于关系抽取。
- 方法:将 GCN 应用于句子的依存树结构。
- 图构建:将依存树转换为邻接矩阵 ,若词 和 之间有依存边,则 。
- GCN 层:对每个节点(词),聚合其邻居节点的信息:
- :节点 在第 层的表示。
- :非线性激活函数(如 ReLU)。
- :加入自环的邻接矩阵,使节点能接收自身信息。
- :节点 的度(用于标准化)。
- :第 层的可学习参数。
- 输入表示: 通常是词向量(如 GloVe, Word2Vec)。
- 实体/句子表示:经过 L 层 GCN 后,得到每个词的最终表示 。句子表示 可以是 的某种池化。头实体 和尾实体 的表示 可以通过其对应词表示的池化(如 Max Pooling)得到。
- 分类:将句子表示、头实体表示、尾实体表示拼接起来,输入到一个前馈神经网络(FFNN)或线性层进行关系分类:
远程监督关系抽取
旨在利用知识库(KB)自动生成训练数据,降低标注成本。
- 核心假设:如果知识库中存在关系三元组 ,那么任何同时包含实体提及 和 的句子都表达了关系 。
- 数据生成:
- 从 KB 中选取关系三元组 。
- 在大型文本语料库中查找所有同时包含 和 的句子。
- 将这些句子标记为关系 的正例。
- 示例:KB 中有
(/business/company/founders, Apple, Steve Jobs)。在语料中找到句子:Steve Jobswas the co-founder and CEO ofAppleand formerly Pixar.- 标记为
/founders
- 标记为
Steve Jobspassed away the day beforeAppleunveiled iPhone 4S in late 2011.- 标记为
/founders
- 标记为
- 问题:错误标注:上述假设过强,很多句子虽然包含实体对,但并不表达 KB 中的关系(如例 2)。这导致训练数据中存在大量噪声。
缓解噪声的方法:多示例学习
- 思想:将所有提及相同实体对 的句子视为一个包。不再对单个句子进行标注,而是对整个包进行标注。假设包中至少有一个句子表达了关系 ,则该包的标签为 。
- 模型:在包级别进行训练和推断。
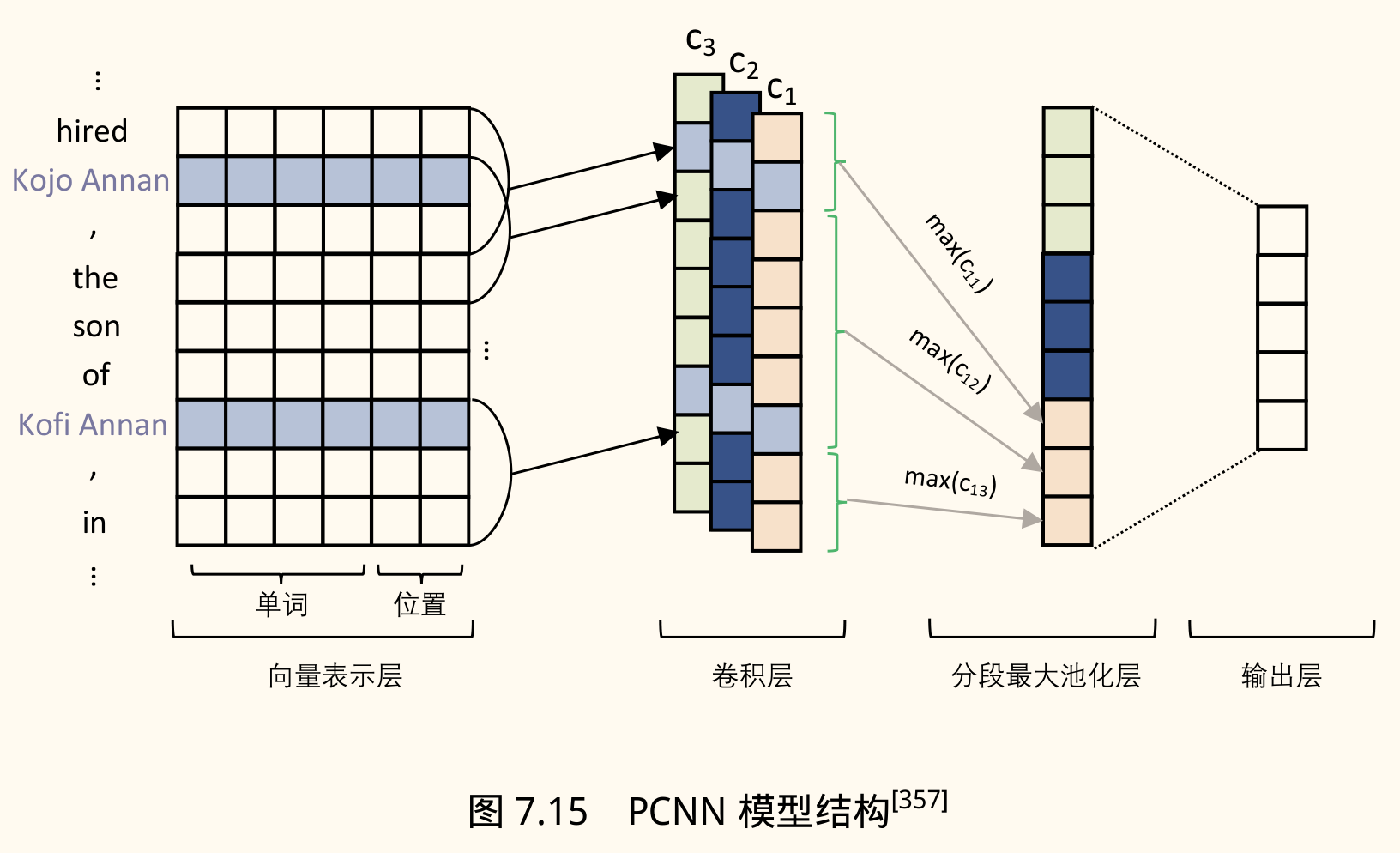
- PCNN(Piecewise Convolutional Neural Networks):一种结合 CNN 和 MIL 的方法。
- 向量表示层:输入词向量 + 位置向量(表示当前词与头尾实体的相对距离)。
- 卷积层:标准 CNN 操作,提取局部特征。
- 分段最大池化层(Piecewise Max Pooling):将卷积输出的特征图按头尾实体位置划分为三段(实体前、实体间、实体后),对每段分别进行 Max Pooling,然后拼接得到句子的全局特征表示。这使得模型能关注实体对相关的局部上下文。
- 输出层:Softmax 分类器。
- MIL 训练:对于一个包 ,其预测概率 通常基于包中最可能表达关系 的那个句子 :
损失函数基于 计算。
- 局限性:只使用置信度最高的句子进行训练,仍会丢失包内其他句子的信息;包级别训练和推断仍可能受噪声影响。
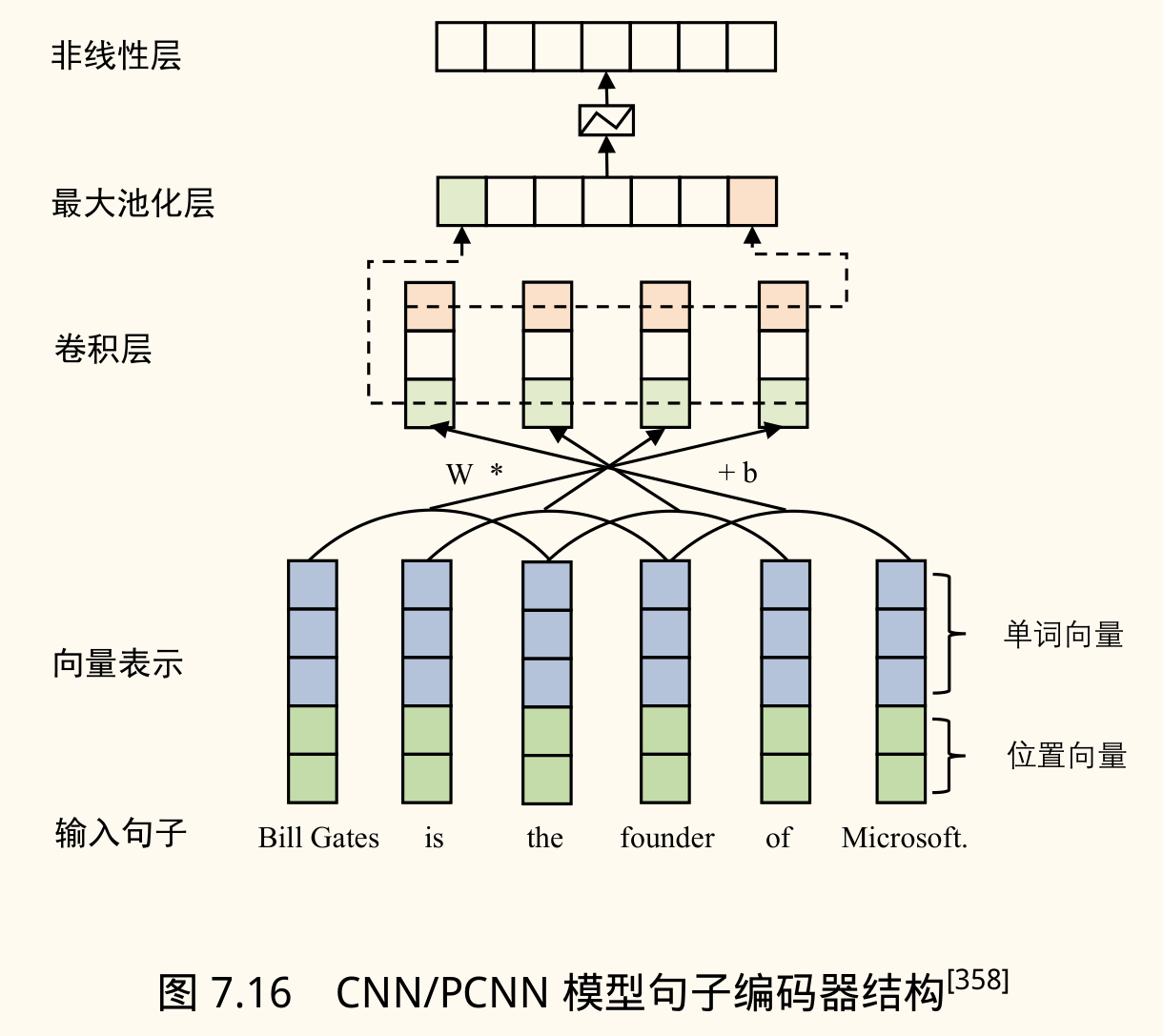
缓解噪声的方法:句子级注意力
- 思想:为包中的每个句子赋予一个可学习的「注意力权重」,表示该句子对于预测关系 的重要性。动态地降低噪声实例的权重,聚合所有实例的信息。
- 模型:
- 句子编码器:使用 CNN 或 PCNN 将每个句子 编码为一个向量表示。
- 实例选择注意力:
- 计算每个句子 与待预测关系 的匹配度(查询分数)。通常使用双线性形式:,其中 是关系 的向量表示, 是可学习的对角矩阵或全矩阵。
- 通过 Softmax 计算注意力权重 。
- 计算包 的加权表示 。
- 分类:基于包表示 进行关系分类:
其中 是关系表示矩阵, 是偏置向量。
开放关系抽取
旨在从大规模文本中抽取任意关系,无需预定义关系类型。
- 目标:提取
<e1, relation_phrase, e2>形式的三元组,其中relation_phrase通常是动词或动词短语。 - 挑战:关系短语形式多样,需要规范化;抽取的准确性;如何评估。
基于规则和模式的方法
- TextRunner:早期代表系统。
- 自监督学习器:用少量样本训练分类器,判断抽取候选
<e1, rel, e2>是否「可信」。利用依存句法分析和启发式规则(如路径长度、是否跨句、是否含代词)自动标注正负样本。 - 信息抽取器:对语料进行 POS 标注和 NP 分块,识别实体 e1, e2。通过分析实体间的文本(通常是动词短语),利用启发式规则提取关系短语
rel。使用学习器过滤不可信三元组。 - 基于冗余信息的评估器:利用信息冗余假设(同一关系会在不同句子中多次出现),为多次被抽取的三元组分配更高置信度。
- 局限性:
- 不连贯抽取:关系短语无意义或不完整。
- 无意义关系:关系短语过于泛化(如 "is", "has"),忽略了关键信息(如名词谓语)。
- 自监督学习器:用少量样本训练分类器,判断抽取候选
- Reverb:对 TextRunner 的改进。
- 句法约束:使用 POS 模式限制关系短语的形式(如
V | VP | VW*P,V=动词, P=介词/小品词, W=名词/形容词/副词/代词/限定词),避免不连贯抽取。 - 词汇约束:限制关系短语的词汇构成。
- 句法约束:使用 POS 模式限制关系短语的形式(如
基于聚类的方法
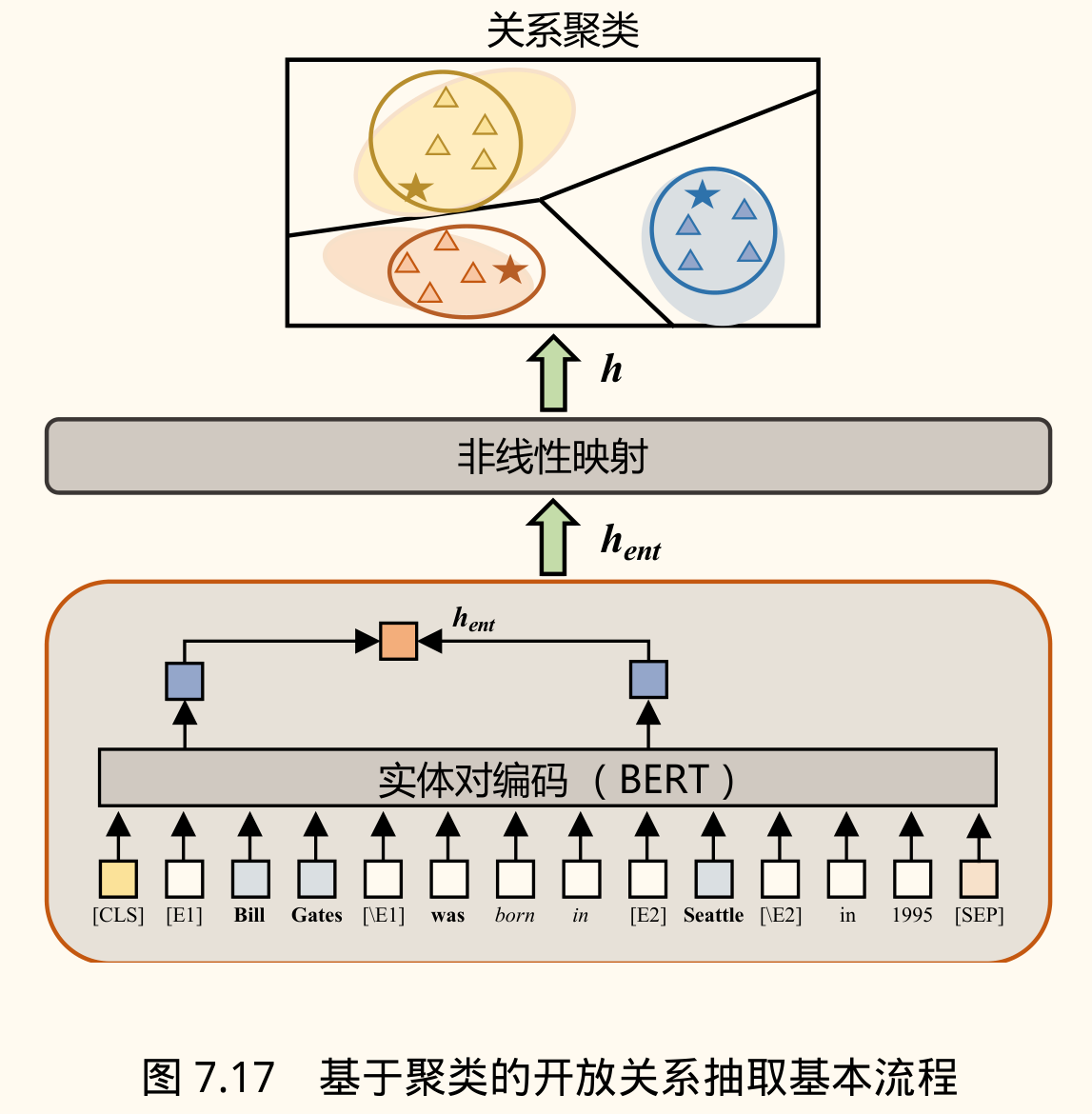
- 思想:即使不知道具体关系类型,也可以判断一系列关系实例是否属于同一语义类别。目标是学习关系的语义表示模型,并在新关系类别中识别三元组。
- SelfORE:一种基于聚类的 ORE 算法。
- 实体对编码:使用预训练模型(BERT, RoBERTa)获取包含实体对的句子的表示。
- 实体标记:为了让模型聚焦关系信息,在预处理时用特殊标记(如
[E1],[/E1],[E2],[/E2])包围实体对。取特殊标记位置的输出向量作为关系表示。 - 关系向量 。
- 实体标记:为了让模型聚焦关系信息,在预处理时用特殊标记(如
- 编码非线性映射:将关系向量 投影到低维空间 ,以便聚类。通常使用带 Dropout 的前馈网络。
- 关系聚类:使用 K-Means 等聚类算法对 进行聚类,得到簇 。
- 自监督优化:为提高聚类效果,可以根据样本嵌入点 与聚类质心 的距离(如基于 t 分布计算置信度 ),将高置信度的样本及其伪标签(簇 ID)作为监督数据,微调编码器和映射层。
$$ q_{nk} = \frac{(1 + \lVert\bm{z}_n - \bm{\mu}_k\rVert^2 / \alpha)^{-\frac{\alpha+1}{2}}}{\sum_{k'} (1 + \lVert\bm{z}_n - \bm{\mu}_{k'}\rVert^2 / \alpha)^{-\frac{\alpha+1}{2}}} $$- 簇解释:人工检查每个簇中的样本,确定该簇代表的语义关系。
- 实体对编码:使用预训练模型(BERT, RoBERTa)获取包含实体对的句子的表示。
RE 评价方法
- 预定义 RE:
- 与 NER 类似,使用 Precision, Recall, F1-score。
- 也可用 Accuracy。
- 整体效果常用 Micro-F1, Micro-P, Micro-R。
- 开放 RE:
- 由于没有预定义标签,常用聚类评价指标。
- V-measure:基于条件熵计算聚类结果的同质性(Homogeneity,每个簇只包含一个类别的成员)和完整性(Completeness,同一类别的所有成员都在一个簇中)的调和平均值。
- 调整兰德系数(Adjusted Rand Index, ARI):衡量聚类结果与真实类别划分的相似度,考虑了偶然性。取值范围 ,值越大越好。
事件抽取
事件抽取
事件抽取目标是从文本中发现特定类型的事件,并抽取与该事件相关的要素(如时间、地点、参与者等)。
- 定义(根据 ACE):事件由事件触发词和事件论元组成。
- 触发词(Trigger):最能清晰、明确地表示事件发生的核心词(通常是动词或名词)。
- 论元(Argument):事件的参与者或属性,通常是实体、时间表达式、数值等。也称事件元素。
- 目标:识别事件类型,定位触发词,抽取论元并确定其论元角色(即论元在事件中扮演的角色)。
- 应用:问答系统、文本摘要、舆情监控、情报分析等。
示例:
2022 年卡塔尔世界杯(FIFA World Cup Qatar 2022)是第二十二届国际足联世界杯足球赛,在当地时间 2022 年 11 月 20 日到 12 月 18 日间在卡塔尔国内 5 个城市的 8 座球场举行。
- 事件类型:体育赛事
- 触发词:举行
- 论元及角色:
- 赛事名称:第二十二届国际足联世界杯足球赛(Argument: 22nd FIFA World Cup) Role: Event
- 时间:2022 年 11 月 20 日到 12 月 18 日(Argument: Nov 20 - Dec 18, 2022) Role: Time
- 地点:卡塔尔(Argument: Qatar) Role: Place
限定域事件抽取
需要预先定义好事件类型以及每种类型对应的论元角色。
核心组件:
- 事件类型:标识事件的类别,如
会议,袭击,雇佣,审判,结婚等。 - 事件触发词:表达事件发生的核心词,如
击打,结婚,辞职。 - 事件论元:事件的参与者或相关信息,如实体(人、组织)、时间、地点等。
- 论元角色:论元在事件中扮演的角色,如
袭击事件中的攻击者,受害者,工具,地点;结婚事件中的结婚人,时间,地点。
示例:
句子:「小明 2022 年在上海与小李举行婚礼」
- 触发词:「举行婚礼」 事件类型:「结婚」
- 论元:
- 人物:「小明」和「小李」 论元角色:结婚人(Person Married)
- 时间:「2022 年」 论元角色:结婚时间(Time)
- 地点:「上海」 论元角色:结婚地点(Place)
流水线方法
将事件抽取分解为一系列子任务:
- 触发词识别:识别文本中的触发词。
- 触发词分类:确定识别出的触发词对应的事件类型。
- 论元识别:识别与每个事件提及相关的论元(实体、时间等)。
- 论元分类:确定每个论元在该事件中扮演的角色。
- 属性分配(可选):确定事件的模态、极性、时态等属性。
- 事件共指(可选):确定不同事件提及是否指向同一真实世界事件。
实现细节:
- 触发词识别/分类:由于触发词多为单个词(ACE2005 > 95%),可视为词分类任务。
- 预筛选:文本中词语众多,直接分类效率低且正负样本不均衡。可利用词性信息(触发词常为名词、动词、形容词)进行预筛选。
- 两阶段:
- 二分类器判断筛选后的词是否为触发词;
- 多分类器判断候选触发词的事件类型。
- 论元识别/分类:可简化为成对分类任务。将包含事件描述的句子与同句中的候选论元(实体、时间等)组成待分类对,利用分类模型判断该候选论元是否是事件的论元,以及其扮演的角色。
缺点:
- 错误传播:前面子任务的错误会影响后续任务。
- 依赖特征工程:传统机器学习方法需要精心设计的语言特征。
联合方法
旨在克服流水线方法的缺点,使用单个模型同时预测触发词和论元。
- 基于神经网络:常用 RNN, CNN, Transformer 等。
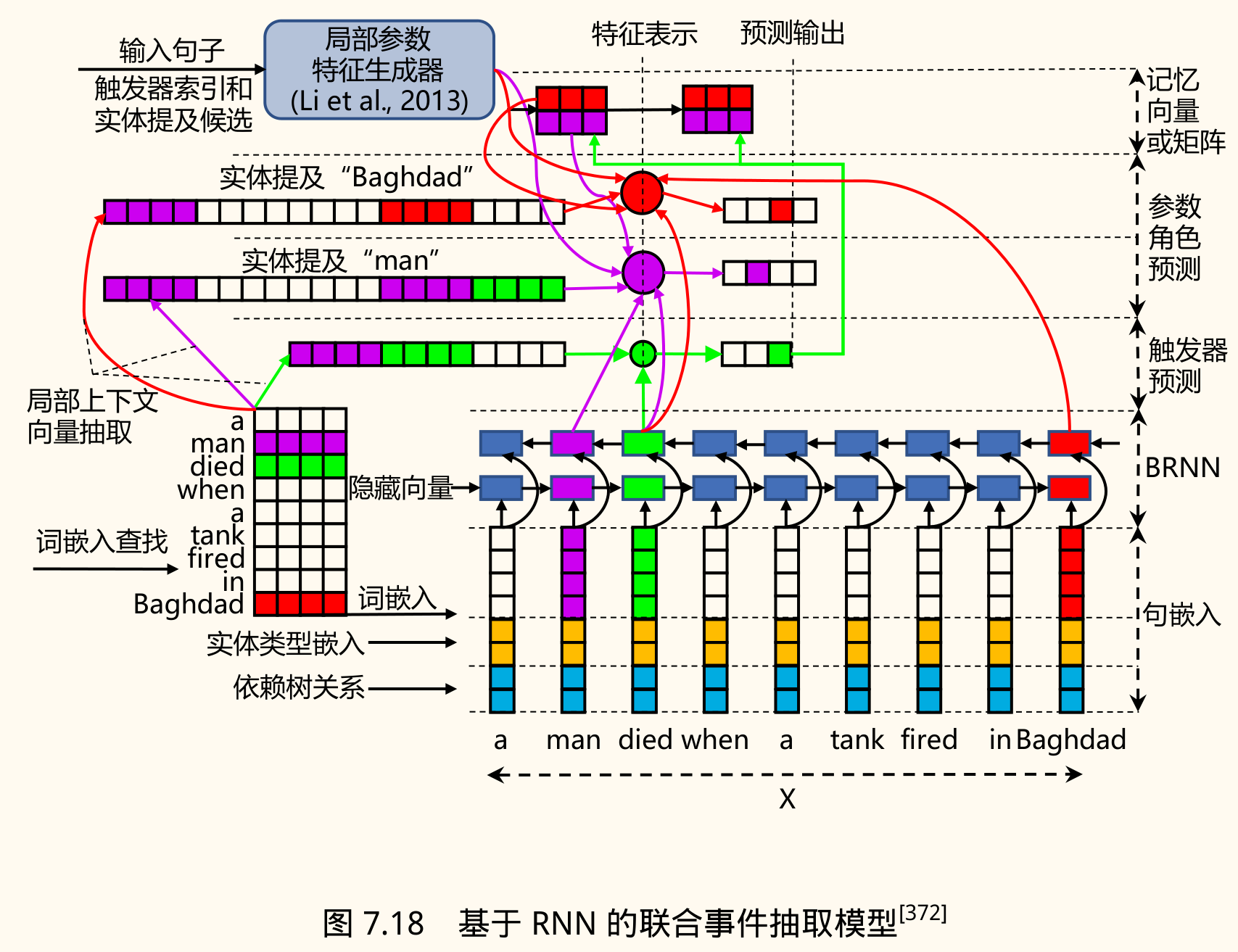
- JRNN(Joint RNN):使用 RNN 捕捉句子中触发词和论元间的长距离依赖。
- 编码层:对输入句子进行编码,通常拼接多种嵌入:
- 词编码:预训练词向量。
- 实体类型编码:当前词的实体标签(如 BIO 格式)的嵌入。
- 依存关系编码:当前词与其依存父节点的关系类型的嵌入。
- 预测层:联合预测触发词和论元角色。
- 利用额外的记忆向量来编码触发词标签和论元角色之间的依赖关系:
- :二元记忆向量,记录触发词之间的关联。
- :二元记忆矩阵,记录论元之间的关联。
- :记忆矩阵,记录触发词和论元之间的关联。
- 触发词预测:基于 RNN 输出和记忆向量预测每个词是否是触发词及其类型。
- 论元预测:基于 RNN 输出、已预测的触发词信息和记忆向量,预测每个实体/值是否是论元及其角色。
- 利用额外的记忆向量来编码触发词标签和论元角色之间的依赖关系:
- 优化目标:联合优化触发词预测和论元预测的损失函数。
- 编码层:对输入句子进行编码,通常拼接多种嵌入:
开放域事件抽取
- 目标:在没有预定义事件类型和论元角色的情况下,从非结构化文本中挖掘和提取有意义的事件信息。
- 早期方法:侧重于事件检测与跟踪(TDT),使用聚类、语义分割等方法对文本内容进行分析,检测新事件并跟踪相关报道。
- 近期方法:试图给出更细粒度的信息,如输出事件集合,包含每个事件的触发词和论元列表。
基于聚类的方法
- 目标:从无结构文本中抽取若干主题相关的文档/内容,组成一系列事件。
- 类型:
- 回顾事件抽取:对整个语料库进行离线分组,每组视为一个事件。
- 在线事件抽取:实时处理到来的文本,判断是属于已有事件还是构成新事件。
- Yang et al. 方法:
- 文档表示:使用基于词袋模型的向量空间模型(VSM),采用 TF-IDF 加权,并标准化。
- 聚类算法:
- GAC(Group-Average Clustering):多层次聚类算法,用于回顾抽取。采用自底向上贪心策略,结合分治,目标是最大化簇内文档平均相似度。
- INCR(Incremental Clustering):增量聚类算法,用于在线抽取(也适用于回顾)。依次处理文档,若与某簇中心相似度高于阈值,则加入最相似的簇;否则创建新簇。可引入「新事件」/「旧事件」标签,利用时间属性和动态阈值。
- 时间窗口:在线抽取中限制只考虑最近 m 个文档,提高效率。
基于神经网络隐变量的方法
- ODEE:一种无监督生成模型,用于从新闻文本中抽取事件。
- 输入:新闻集合(可能包含同一事件的不同报道)。
- 输出:一系列事件,每个事件包含一个触发词和该事件模式对应的论元列表。
- 模型:提取无约束的事件类型,并从新闻集合中归纳通用事件模式。
- 假设每个新闻集合 对应一个隐事件类型向量 ,该向量来自全局参数化的高斯分布。
- 模型包含隐变量(如事件类型 , 槽填充变量 )和可观测变量(如实体 , 中心词 , 实体特征 )。
- 提出了三个模型变体(ODEE-F, ODEE-FE, ODEE-FER),逐步增加模型复杂度。
- 谓词提取:利用依存句法分析(如 Stanford Dependency Parser)和规则(如中心词支配者是 VB 或 WordNet 中的 noun.ACT/noun.EVENT)提取每个实体提及的中心词(谓词)。
- 论元生成:将相同共指链的实体提及的谓词合并。对于每个谓词 ,找到其谓词集合包含 的实体,视为由 触发的事件的论元。排序后输出 Top N 个事件。
事件抽取评价方法
- 指标:主要使用 Precision, Recall, F1-score。
- 流水线子任务评价:有时会分别评估各子任务的性能:
- TI(Trigger Identification): 触发词识别(位置正确即可)。
- TC(Trigger Classification): 触发词分类(位置和类型都正确)。
- AI(Argument Identification): 论元识别(识别出论元实体即可)。
- AC(Argument Classification): 论元分类(论元实体和角色都正确)。
报告每个子任务的 P, R, F1。
小结
本章系统介绍了信息抽取(IE)的基本概念、重要性、发展历程及其核心子任务:命名实体识别(NER)、关系抽取(RE)和事件抽取(Event Extraction)。
- NER 旨在识别文本中的命名实体及其类型,涉及 Flat NER 和 Nested NER,常用方法包括序列标注(CRF, BiLSTM-CRF)、状态转移(Shift-Reduce)、跨度分类(Span-based)以及针对中文的 Lattice LSTM 和 SoftLexicon 等。
- RE 旨在抽取实体间的语义关系,分为预定义 RE(有监督、远程监督)和开放 RE。常用方法包括基于特征(MaxEnt)、基于深度学习(GCN)、多示例学习(PCNN, Attention)以及基于规则/聚类的 ORE 方法。
- Event Extraction 旨在识别事件触发词和论元及其角色,分为限定域(流水线、联合抽取 JRNN)和开放域(聚类、隐变量模型 ODEE)。