情感分析
情感分析概述
定义
情感分析(Sentiment Analysis),有时也称为观点挖掘(Opinion Mining),是自然语言处理(NLP)中的一个重要领域。其核心目标是自动识别、提取、量化和研究文本中所表达的「情感」「评价」「态度」和「观点」。这些信息通常是针对特定的「主题」「实体」「属性」或「事件」的。
人类语言充满了丰富的情感色彩,理解这些情感是机器理解人类语言的关键挑战之一。情感分析旨在让计算机能够像人一样理解文本中的主观信息。
相关概念与任务
情感分析是一个涵盖广泛的领域,涉及多个子任务和相关术语。由于不同研究领域(如 NLP、数据挖掘、机器学习)的研究者都对此感兴趣,术语使用有时会显得繁杂。刘兵教授在其专著中梳理了一些常见任务,包括:
- 情感分析/观点挖掘:通常指识别文本整体或特定目标的情感极性(正面/负面/中性)或情感类别。
- 观点抽取/评价抽取:更侧重于抽取构成观点的具体元素,如评价对象、评价词、观点持有者等。
- 情感挖掘:有时与情感分析同义,或特指从大规模数据中挖掘情感趋势。
- 主客观分析:判断文本是包含主观观点还是陈述客观事实。
- 感情分析:更广泛地研究文本中的各种感情状态,不仅限于评价性观点。
- 情绪分析:专注于识别更细粒度的情绪类别(如喜、怒、哀、惧等)。
这些任务紧密相关,有时界限并不明确。情感分析技术在舆情监控、市场调研、产品评论分析、金融市场预测、智能客服、推荐系统等领域有着广泛的应用。
情感模型
情感分析主要关注两大核心任务:
- 分析文本中针对某个主题或实体的评价或观点。
- 分析文本中所表达的情绪类的情感。
虽然处理这两类任务的 NLP 算法可能相似,但在语言学和心理学层面,观点和情绪是不同的概念。
观点模型
观点(Opinion)
观点是指个体从特定立场或角度出发,对事物所持有的看法或态度。它是感觉、看法或信念的陈述。
观点的核心特征包括:
- 情感倾向/极性:描述观点是正面(褒义)、负面(贬义)还是中性。
- 示例:「这台相机很棒。」(正面)vs「这家餐厅太糟糕了。」(负面)
- 情感强度:描述情感倾向的强烈程度。
- 示例:「完美」比「好」表达的正面强度更高。
- 副词作用:很多副词可以增强或减弱情感强度。
- 增强词:很、非常、极其(very, extremely)
- 减弱词:有点、稍微、可能(slightly, a little bit, maybe)
- 情感评分:为了量化强度,常用离散评分(如 1-5 分,1 分表示强烈负面,5 分表示强烈正面)或连续分数。
观点的分类
从不同维度可以将观点划分为多种类型:
-
常规型观点 vs. 比较型观点
- 常规型观点:直接或间接对单个事物表达观点。
- 直接示例:「这家餐厅非常差。」
- 间接示例:「换了这台显示器后,我的眼睛感觉非常舒服。」
- 通过描述感受间接表达对显示器的正面评价
- 比较型观点:通过比较两个或多个事物的相同或不同点,表达对其中一个事物的偏好或态度。
- 示例:「这家餐厅的环境比人民路上那家好很多。」
- 示例:「新一代显卡的显存相较于上一代有了大幅度的提升。」
- 虽然没有直接评价好坏,但隐含了对新一代的积极看法
- 常规型观点:直接或间接对单个事物表达观点。
-
显式观点 vs. 隐式观点
- 显式观点:句子中直接使用带有情感色彩的词语(评价词)来表达观点、看法或感受。
- 示例:「不错,交通便利,方便出行!」
- 示例:「展馆太小了,场景少,一般般。」
- 隐式观点:通过陈述客观事实或描述性语言间接蕴含观点持有者的态度,句子本身可能不包含明显的情感词。
- 示例:「这款电动车续航里程可达 1000 公里。」
- 通常隐含正面评价
- 示例:「雪山脚下的一个景点,从进门到出去给了半个小时游览。」
- 可能隐含负面评价,时间太短
- 隐式观点识别难度较高,通常需要结合常识或领域知识进行判断。
- 示例:「这款电动车续航里程可达 1000 公里。」
- 显式观点:句子中直接使用带有情感色彩的词语(评价词)来表达观点、看法或感受。
-
理性情感 vs. 感性情感
- 理性情感:观点主要基于客观事实和逻辑推理,较少夹杂主观情绪。
- 示例:「笔记本电池不错,可以连续使用 40 小时。」
- 示例:「酒店环境很好,距离沙滩仅有 200 米。」
- 感性情感:观点主要来源于观点持有者的主观感受和情绪表达,通常更强烈。
- 示例:「这个酒店太垃圾了。」
- 示例:「这是最好的车。」
- 感性情感在评论中数量更多,表达也更直接。
- 理性情感:观点主要基于客观事实和逻辑推理,较少夹杂主观情绪。
情绪模型
情绪(Emotion)
情绪是人对外界刺激产生的反应,是一种复杂的生理和心理状态,涉及多种感觉、思想和行为。常见的如喜爱、欢乐、悲伤、愤怒等。
由于自然语言的复杂性和人类情绪的多样性,不同领域对情绪的分类方式各不相同。
- 中国古代《礼记》:「七情」—— 喜、怒、哀、惧、爱、恶、欲。
- Parrott:提出了一个更细粒度的分层情绪分类体系,包含基本情绪、二级情绪和三级情绪。
- Plutchik(1980s):基于进化理论提出了情绪轮(Wheel of Emotions)模型。
- 定义了 8 种基本情绪,分为 4 对反义组合:
- 高兴(Joy) vs. 悲伤(Sadness)
- 信任(Trust) vs. 厌恶(Disgust)
- 恐惧(Fear) vs. 愤怒(Anger)
- 期待(Anticipation) vs. 诧异(Surprise)
- 情绪强度:情绪轮中,颜色深浅或离圆心远近代表情绪的饱和度/强度。例如,「宁静(Serenity)」是低强度的高兴,「狂喜(Ecstasy)」是高强度的高兴。
- 情绪组合:相邻的基本情绪可以组合成更复杂的情绪。例如:快乐(Joy) + 期待(Anticipation) = 乐观(Optimism)。
- 定义了 8 种基本情绪,分为 4 对反义组合:
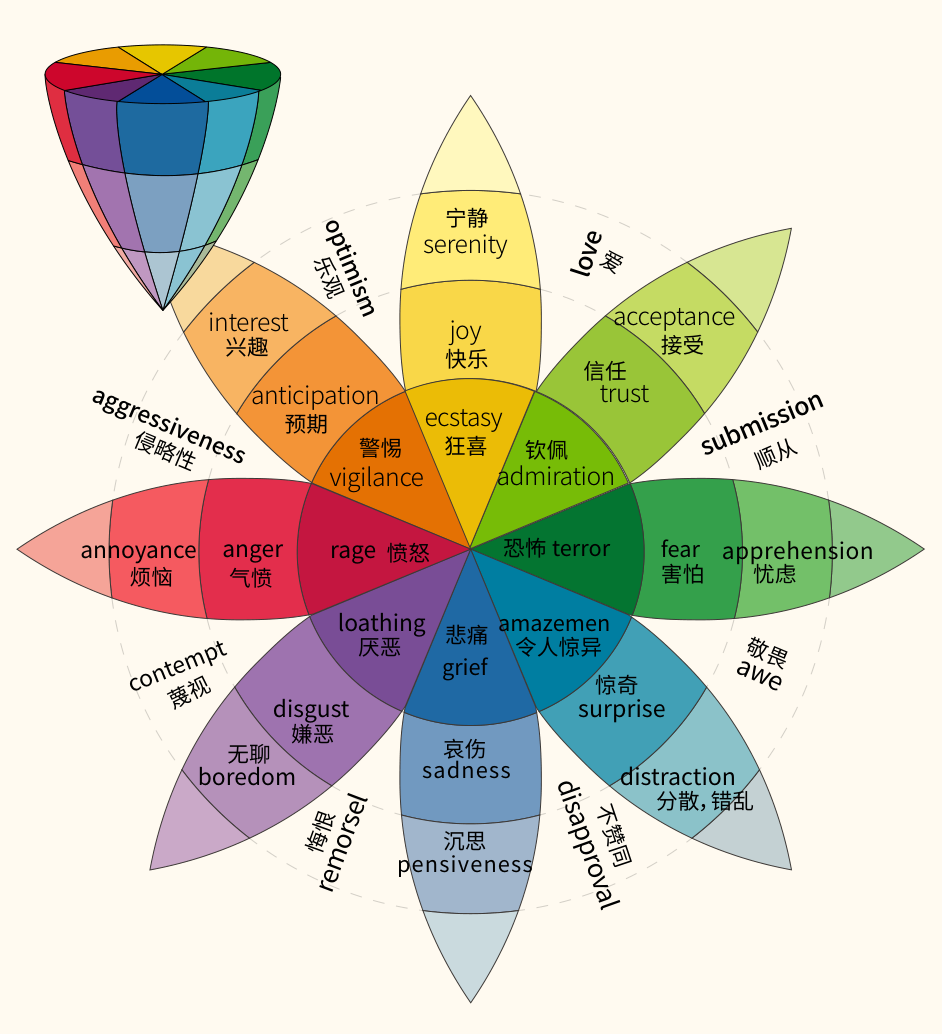
- 维度空间表示:另一种常用的方法是在连续的多维空间中表示情感,最常见的是 VAD 模型:
- 愉悦度(Valence):情感的积极或消极程度(好-坏)。
- 唤醒度(Arousal):情感的强度或激动程度(平静-激动)。
- 支配度(Dominance):个体对情境的控制感(受控-掌控)。
情感分析的主要任务
情感分析可以从「任务类型」和「语言单元粒度」两个维度进行划分。
- 按任务类型划分:
- 情感分类任务
- 情感信息抽取任务
- 按语言单元粒度划分:
- 篇章级情感分析
- 句子级情感分析
- 属性级情感分析,也称方面级或细粒度情感分析。
情感分类任务
目标是根据给定文本内容,识别其蕴含的情感或观点,并确定其类别或倾向性。
主客观分类
判断给定文本是主观性的(包含情感或观点)还是客观性的(陈述事实)。
- 主观示例:「味道不错!团购很实惠。」
- 客观示例:「南京大学共有鼓楼、仙林、浦口、苏州四个校区。」
情感极性分类
判断文本表达的情感是正面、负面还是中性。
- 正面示例:「环境相当不错,业务水平很专业。」
- 负面示例:「实在是很坑的一个景区。」
- 中性示例:「地理位置也还可以。」
中性 vs. 客观
中性评价不等于客观陈述。中性评价仍然是一种主观判断,只是其情感倾向既不明显偏向正面,也不明显偏向负面。
情绪分类
判断文本蕴含的具体情绪类别,如喜、怒、哀、惧、惊等。需要预先定义一个情绪分类体系(如 Plutchik 模型)。
- 快乐示例:「我的心里绽开了朵朵鲜花,就要蹦出来似的。」
- 悲伤示例:「钟表,可以回到起点,却已不是昨天。」
情感强度判断
判断文本情感的强度,如强烈正向、正向、中性、负向、强烈负向。可以使用离散等级或连续分数表示。
- 负面示例:「这地方交通不太方便了。」
- 强烈负面示例:「这地方交通实在是太不方便了。」(强度更高)
粒度交叉
上述分类任务可以在不同粒度(篇章、句子、属性)上进行。例如,篇章级主客观分类、句子级情绪分类、属性级情感强度判断等。篇章级和句子级的主要区别在于处理的文本单元大小。属性级则关注文本中特定属性的情感,而非整体。
情感信息抽取任务
目标是从文本中抽取表达情感的核心要素,获得结构化的情感信息。也称为评价要素抽取。
评价词抽取
抽取文本中表达评价或情感的词语(也称情感词、观点词)。
- 示例:「车窗采用无边框玻璃设计,很酷,但吹毛求疵一点,隔音不算太好。」
- 评价词:「很酷」「不算太好」
评价搭配抽取
识别文本中评价对象(也称属性、方面)及其对应的评价词。通常表示为 <评价对象, 评价词> 二元组。
- 示例:「车窗采用无边框玻璃设计,很酷,但吹毛求疵一点,隔音不算太好。」
- 评价搭配:
<车窗, 很酷>,<隔音, 不算太好>,
- 评价搭配:
评价搭配极性判别
判断特定评价搭配所表达的情感极性。
- 示例:「车窗采用无边框玻璃设计,很酷,但吹毛求疵一点,隔音不算太好。」
<车窗, 很酷>:正面<隔音, 不算太好>:负面
观点持有者抽取
抽取文本中表达某个观点的主体。
- 示例:「懂车会:车窗采用无边框玻璃设计,很酷…」
- 观点持有者:「懂车会」
- 注意:观点持有者通常是文本作者,但也可能是作者引用的其他人。
信息抽取与属性级分析的关系
情感信息抽取任务与属性级情感分析紧密相关。抽取出的评价词和评价搭配是进行属性级情感分类和强度判断的基础,并能提供更好的「可解释性」。
情感相关其他任务
观点摘要
针对某个评价对象(如一款手机)及其不同属性(屏幕、电池、摄像头),从单篇或多篇文档中生成简洁的摘要,概括主要观点和情感倾向。可以结合情感信息抽取的结果进行可视化展示。
辩论立场检测
识别用户在辩论性文本中对特定辩论主题(如「是否应该支持死刑」)所持有的立场(支持/反对/中立)。与属性级分析类似,但辩论主题通常非预定义,更加多样化。
垃圾评论检测
识别虚假或恶意的评论信息。这通常需要结合评论内容、发布者行为(如发布频率、评分模式)以及群体行为进行综合判断,仅靠内容分析往往不够。
篇章级情感分析
将整篇文档(如一篇影评、一篇产品评论)作为一个整体进行情感分析。
定义与特点
- 目标:预测给定篇章的整体情感标签(主客观、极性、情绪、强度等)。
- 假设:通常假设整个文档主要针对一个实体或主题进行评论。
- 挑战:
- 篇章中可能混合包含主观评价和客观事实描述(如电影评论中包含情节描述)。
- 篇章可能涉及对主要实体不同属性的评价,甚至包含对其他相关事物的评价,这些可能与整体情感不一致。
- 粒度:相对粗糙,不关注文档内部具体实体或属性的细粒度情感。
基于传统机器学习的方法(以 SVM 为例)
篇章级情感分析常被视为一个文本分类问题。
-
输入:数据集 ,其中 是第 篇文档的内容, 是对应的分类标签(如 +1 代表褒义,-1 代表贬义;或 +1 代表主观,-1 代表客观)。
-
流程:
- 特征工程:将文档 转换为特征向量 。
- 模型训练:使用带标签的数据训练分类器(如 SVM)。
- 预测:用训练好的模型预测新文档的情感标签。
-
常用特征:
- 词袋/N-gram:最基础的文本表示。
- 词性:形容词和副词通常是情感的重要载体,可以赋予更高权重。
- 情感词典:利用预先构建的情感词(如「好」「差」)及其极性/强度信息作为特征。
- 观点规则:基于语言学模式或结构设计的规则,用于捕捉隐含情感。
- 情感转置词:如否定词(「不」「没」)可以反转情感极性,需要特殊处理或作为特征。
- 句法信息:利用句法分析树的结构信息,如通过树核方法直接在树结构上计算相似度。
-
支持向量机:一种常用的、效果较好的分类算法。其目标是找到一个最优超平面,最大化不同类别样本之间的间隔。
- 优化目标:
- 优化目标:
基于深度学习的方法(以 HAN 为例)
考虑到篇章具有层次结构(单词组成句子,句子组成篇章),可以使用深度学习模型自动学习特征表示。
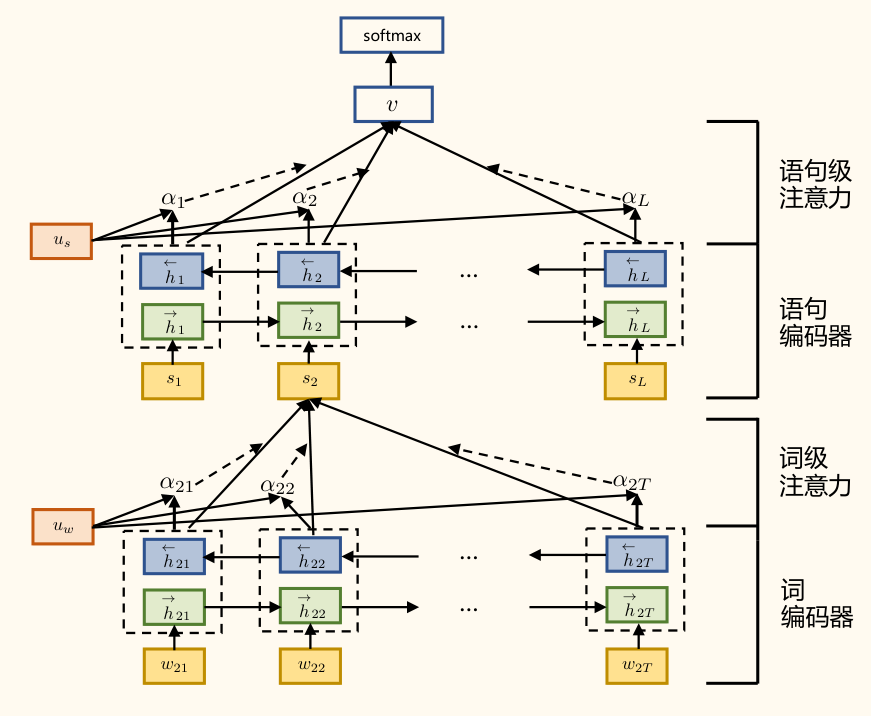
- 层次注意力网络:
- 动机:并非所有单词对句子含义同等重要,也并非所有句子对篇章主旨同等重要。HAN 利用注意力机制来捕捉这种重要性差异。
- 结构:
- 单词编码器:通常使用双向 GRU 或 LSTM 对每个句子中的单词序列进行编码,得到单词的上下文表示 (第 句第 个词)。
- 单词级注意力:计算每个单词的重要性权重 ,通过加权求和得到句子表示 。
- 句子编码器:使用另一个双向 GRU/LSTM 对句子表示序列 进行编码,得到句子的篇章级表示 。
- 句子级注意力:计算每个句子的重要性权重 ,通过加权求和得到整个篇章的表示 。
- 分类器:将篇章表示 输入 Softmax 层进行最终的情感分类。
句子级情感分析
将单个句子作为分析单元,判断其情感倾向。
定义与特点
- 目标:预测给定句子 的情感标签 (极性、主客观等),或给出连续的情感分数。
- 粒度:比篇章级更精细。
- 假设:通常假设一个句子只针对一个实体进行评论(尽管也可能包含比较或转折)。
- 优势:相比篇章级,句子级分析能更好地处理篇章内情感变化,且「一个句子一个主要目标」的假设相对更易满足。
- 挑战:
- 句子长度短:可利用的上下文信息有限。
- 隐式情感表达占比高:如讽刺、比喻等,更难识别。据 SemEval-2014 统计,隐式观点占比可达 30% 左右。
- 复杂语言现象:如条件句、转折句、比较句、反问句、双重否定等,对模型理解能力要求高。
基于词典的方法(以 SO-CAL 为例)
利用情感词典和规则进行评分。
- SO-CAL(Semantic Orientation CALculator):
- 核心思想:基于文档中每个词或短语的预定义情感分数和组合规则,计算整体情感倾向和强度。
- 主要组成:
- 情感词典:包含大量带有情感极性分数的词语(形容词、名词、动词、副词)。例如,赋予每个词 -5(极度负面)到 +5(极度正面)的分数。
- 示例:
monstrosity: -5,hate: -4,relish: +4,masterpiece: +5
- 示例:
- 情感强化/弱化词:识别增强词(如
very,really)和减弱词(如slightly,somewhat),并赋予它们影响相邻情感词分数的因子或偏移量。- 示例:
slightly: -50%,somewhat: -30%,pretty: -10%,really: +15%(这些数值仅为示例)
- 示例:
- 情感否定词:识别否定词(如
not,never,nothing),它们通常会反转情感词的极性。- 示例:「这个服务并不是特别好。」
特别好: +5,并不是(乘以 -1 或进行特定计算,如 -4 影响),句子整体得分:+5 - 4 = +1(示例计算)。
- 示例:「这个服务并不是特别好。」
- 情感词典:包含大量带有情感极性分数的词语(形容词、名词、动词、副词)。例如,赋予每个词 -5(极度负面)到 +5(极度正面)的分数。
- 计算方式:综合考虑句子中情感词、强化/弱化词、否定词,根据预设规则计算总分。
基于深度学习的方法
递归神经网络
- 动机:利用句子的句法结构(通常是句法分析树)来组合词语的含义。注意这里的 RNN 指 Recursive Neural Network,而非 Recurrent Neural Network。
- 核心思想:递归地将子短语的向量表示组合成父短语的向量表示,直至得到整个句子的表示。组合函数通常是一个神经网络层。
- 示例:对于短语 "very good",先获取 "very" 和 "good" 的词向量,然后通过一个函数 计算出短语向量 。
- 公式示例(基础版):,(其中 是激活函数, 是权重矩阵, 表示向量拼接)。
递归神经张量网络
- 改进:在 RNN (Recursive) 的基础上,引入张量运算来更丰富地捕捉词语组合时的交互关系,而不仅仅是简单的线性组合或拼接。
- 组合函数:
其中 是一个张量(可以看作 个 的矩阵切片,k 是词向量维度,d 是输出向量维度), 是标准 RNN 的权重矩阵。张量项能捕捉更复杂的组合语义。
基于预训练模型的方法(以 SKEP 为例)
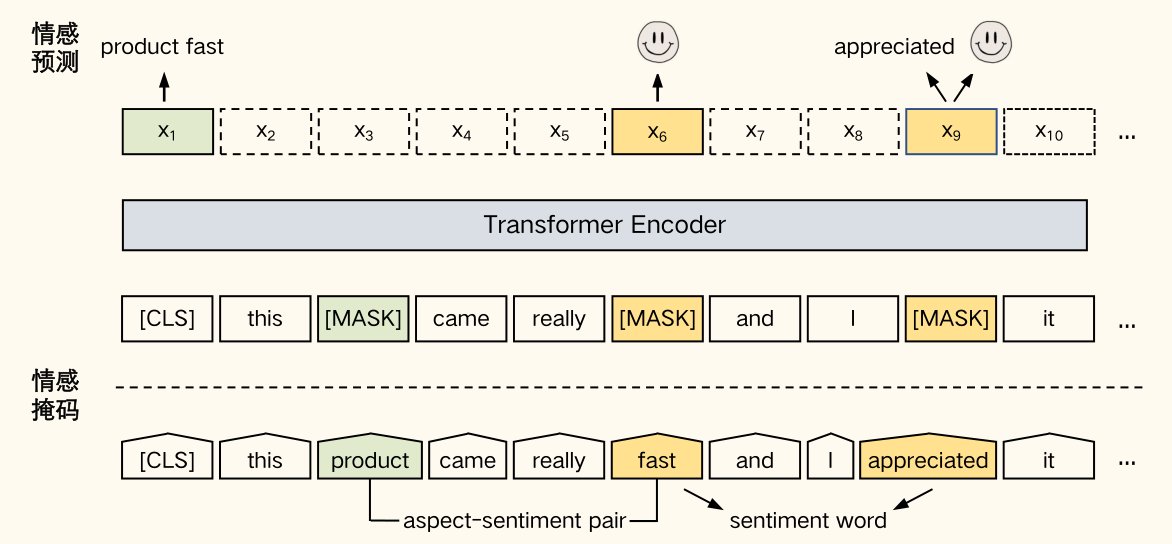
- 动机:通用预训练模型(如 BERT)在 NLP 任务上表现优异,但可以通过情感知识增强进一步提升在情感分析任务上的效果。
- SKEP(Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis):
- 核心思想:通过专门设计的预训练任务,让模型学习情感相关的知识。利用点互信息 等无监督方法自动挖掘情感信息(情感词、极性、属性-情感词对)。
- 预训练任务(掩盖与预测):
- 掩盖属性词-情感词对:随机选择句子中的属性词-情感词对进行掩盖。
- 掩盖情感词:随机选择不超过 10% 的情感词进行掩盖。
- 掩盖通用词:如果情感词比例不足 10%,随机选择其他词补充至 10% 进行掩盖。
- 损失函数:包含三个部分:情感词预测损失 、情感词极性预测损失 、属性词-情感词对预测损失 。
- 应用:预训练完成后,在下游句子级情感分析任务(如情感分类)上进行微调。通常使用 [CLS] 位置的输出向量作为句子表示。
属性级情感分析
关注文本中针对特定属性(或称方面)的情感。
定义与特点
- 目标:识别文本中提到的属性,并判断对这些特定属性的情感倾向、情绪或强度。
- 粒度:最精细的情感分析级别。
- 重要性:解决了篇章级和句子级分析无法区分同一文本中对不同属性可能存在的不同甚至相反情感的问题。
- 示例:「我买了一台新相机,照片质量很好,但是电池寿命太短。」
- 对「照片质量」是正面情感。
- 对「电池寿命」是负面情感。
- 示例:「我买了一台新相机,照片质量很好,但是电池寿命太短。」
- 任务:ABSA 通常包含两大类子任务:
- 属性级情感分类:给定文本和目标属性,判断对该属性的情感。
- 输入:文本 ,目标属性 。
- 输出:关于属性 的情感标签 或评价词 。
- 情感信息抽取:在属性层面进行,主要包括:
- 属性词抽取:识别句子中描述属性的词语。
- 评价词抽取:识别与属性相关的评价词。
- 属性-评价词对抽取。
- 属性级情感分类(作为抽取任务的一部分,判断抽取出的属性的情感)。
- 属性级情感分类:给定文本和目标属性,判断对该属性的情感。
- 挑战:
- 除了句子级分析面临的挑战(短文本、隐式表达、复杂句型),ABSA 还需要处理:
- 句子中可能包含大量与给定属性无关的内容,需要模型具备聚焦能力。
- 需要准确关联评价词和其对应的属性词。
- 除了句子级分析面临的挑战(短文本、隐式表达、复杂句型),ABSA 还需要处理:
情感信息抽取方法
基于句法规则的方法
- 核心思想:利用句法依存关系来识别属性词(通常是名词)和评价词(通常是形容词)之间的联系。
- 示例:「华为手机拍出来的照片很好看!」
- 通过依存关系分析,可以发现形容词「好看」修饰名词「照片」。
- 示例:「华为手机拍出来的照片很好看!」
- 属性词与评价词的特点:
- 属性词多为名词/名词短语。
- 评价词多为形容词/动词/副词,且形容词相对稳定(闭类词)。
- 字典扩展与双向传播:
- 动机:初始的情感词典或属性词典可能不完整。
- 方法:从一个小的种子词典(如评价词典)开始,利用句法规则(如依存关系)在语料中发现新的属性词;再利用新发现的属性词,通过句法规则发现新的评价词。这个过程可以迭代进行,信息在评价词和属性词之间来回传播。
- 步骤:
- 关系识别:定义评价词与属性、属性与属性、评价词与评价词 之间的句法关系模式(直接依赖、间接依赖,考虑词性约束)。
- 传播规则:定义如何基于已知词和关系抽取新词。
- 传播算法:迭代应用规则,扩展评价词和属性词集合,直至没有新词被发现。
- 极性预测:为新发现的评价词或属性-评价对预测情感极性(基于已知词极性、上下文否定词等)。
基于序列标注的方法(以 ATE-THASTN 为例)
- 属性词抽取:将 ATE 视为一个序列标注问题。给定句子 ,目标是预测每个词的标签序列 ,其中 (B-ASP: 属性词开始,I-ASP: 属性词内部,O: 非属性词)。
- ATE-THASTN 模型:
- 动机:利用历史已抽取的属性信息和全局观点信息来辅助当前词的属性抽取。
- 关键组件:
- 属性历史注意力:建模已预测属性与当前预测属性的关系。缓存最近 个时间步的隐状态 ,计算当前时间步 对这些历史状态的注意力权重 ,得到压缩后的历史属性表示 。然后与当前隐层属性表示 结合(类似残差连接):。
- 观点选择网络:选择与当前属性候选相关的观点信息,抑制无关噪声。利用当前属性特征 更新全局观点表示 :。
- 预测:将更新后的观点摘要 和历史感知的属性表示 拼接,输入全连接层进行属性标签预测。
- 多任务学习:该模型通常还包含一个并行的观点词抽取任务(使用 进行预测),通过联合训练提升性能。总损失为属性抽取损失 和观点抽取损失 之和:。
属性级情感分类方法
基于概率混合模型的方法(以 TSM 为例)
- 主题-情感模型:
- 动机:同时对文本中的主题和情感进行建模。假设文档的情感由其讨论的主题和与主题相关的情感词共同决定。
- 模型假设:
- 语料包含 个主要主题(属性) 。
- 每个词被分为通用词(背景词,如「的」「这」)和主题词。
- 主题词进一步分为三类:中性观点词(如「价格」)、积极观点词(如「爱」「喜欢」)、消极观点词(如「讨厌」「差」)。
- 模型组成(四个多项式分布):
- : 背景主题模型(抽取通用词)。
- : 个中性主题模型。
- : 积极情感模型。
- : 消极情感模型。
- 生成过程(简述):对文档中的每个词,首先判断是通用词还是主题词。若是主题词,判断属于哪个主题 。然后判断该主题词是中性、积极还是消极。最后根据对应的主题-情感模型(, , 或 )采样生成该单词。
- 应用:模型训练后可用于:
- 句子主题排序。
- 给定主题 的句子 的情感分类。
- 预测文档 或主题 的整体情感分布(情感覆盖度)。
基于注意力交互的方法(以 MGAN 为例)
- 动机:显式建模属性和上下文之间的交互关系对于属性级情感分类至关重要。
- 多粒度注意力网络:
- 核心思想:从粗粒度和细粒度两个层面进行属性与上下文的注意力交互。
- 结构:
- 输入嵌入层:使用预训练词向量(如 GloVe)表示属性和上下文单词。
- 上下文建模层:使用双向 LSTM 建模上下文单词的时间序列关系。
- 多粒度注意力层:
- 粗粒度注意力:建模整体属性表示与上下文单词的交互。常用属性表示的平均向量来计算上下文单词的注意力权重(如 C-Aspect2Context 机制)。
- 细粒度注意力:建模属性中的每个单词与上下文单词的交互,评估每个属性词对上下文单词的影响(如 Alignment Matrix)。
- 输出层:结合注意力加权的上下文表示和属性表示,进行最终的情感分类。
- 损失函数:通常包含交叉熵损失、属性对齐损失(鼓励模型关注相关的上下文)和正则项。
基于端到端联合抽取与分类的方法
- 动机:传统的流水线方法(先抽取属性,再分类情感)存在错误传播问题。联合模型或端到端模型旨在同时解决抽取和分类任务。
- 生成式框架 (如讲义 P56-P58 介绍的方法):
- 核心思想:将属性级情感分析的各种子任务(ATE, OTE, AESC, Pair, Triplet)统一到一个生成框架下。将目标输出(如属性词起止位置、评价词起止位置、情感极性类别)编码为一个统一的目标序列。
- 模型:通常基于 Sequence-to-Sequence 架构(如 BART、T5)。
- 表示:
- 使用特殊标记区分不同信息,如
<a>表示属性词,<o>表示评价词,<s>表示情感极性。 - 使用指针索引表示词语在原文中的起止位置。
- 使用类别索引表示情感极性(如 POS, NEG, NEU)。
- 使用特殊标记区分不同信息,如
- 训练:模型学习生成包含所有目标信息的目标序列。
- 优势:能够在一个统一模型中处理多种 ABSA 子任务,减少错误累积,并能捕捉任务间的依赖关系。
- 目标序列示例:
[a_start, a_end, o_start, o_end, sentiment_label, ...]- 例如,对于 "wine list is interesting", "service is dreadful",目标序列可能是:
1, 2 (wine list), 4, 4 (interesting), POS, 12, 12 (service), 14, 14 (dreadful), NEG, </s>
- 例如,对于 "wine list is interesting", "service is dreadful",目标序列可能是: