绪论
mindmap
root((绪论))
基本概念
研究内容与应用
难点
研究
基本范式
基于规则的方法
基于机器学习的方法
基于深度学习的方法
基于大模型的方法基本概念
自然语言处理(Natural Language Processing,NLP)旨在探索实现人与计算机之间用自然语言进行有效交流的理论与方法。——《大规模文本处理》
- 自然语言理解(Natural Language Understanding,NLU):能够理解自然语言的意义。
- 自然语言生成(Natural Language Generation,NLG):以自然语言文本来表达给定的意图、思想等。
语言是思维的载体,是人类交流思想、表达情感最自然、最方便的工具。自然语言指的是人类语言,特指文本符号,而非语音信号。
自然语言处理(Natural Language Processing,NLP)是用计算机来理解和生成自然语言的各种理论和方法
研究内容与应用
自然语言处理的主要研究内容:
- 整体:基础算法研究和应用技术研究
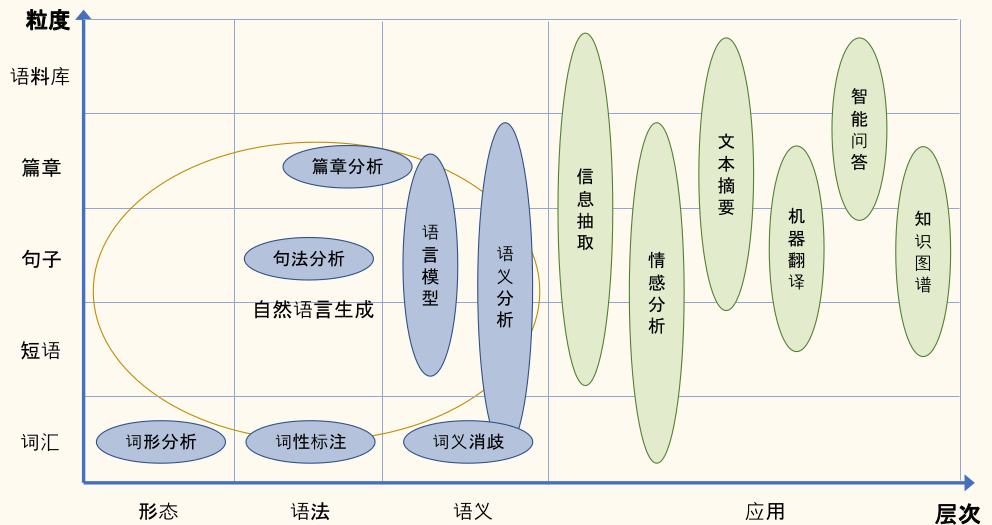
- 语言单位角度:字、词、短语、句子、段落以及篇章等不同粒度
- 语言学研究角度:形态学、语法学、语义学、语用学等不同层面
- 机器学习方法层面:有监督、无监督、半监督、强化学习等
难点
自然语言处理难的根本原因:自然语言在各个层面都广泛存在的各种各样的歧义性:
- 自然语言文本从形式上是由字符(包括中文汉字、英文字母、符号)组成的字符串
- 由字母或者汉字可以组成词,由词可以组成词组,由词组可以组成句子,进而组成段落、篇章
- 无论哪种粒度的语言单元,还是从一个层级向上一个层级转变中都存在歧义和多义现象
语音歧义(Phonetic Ambiguity)主要体现在口语中,是由于语言中同音异义词(Homophone)、爆破音不完全、重音位置不明确等原因造成的。
- 汉语中只有 413 个不同的音(节),如果结合声调的变化组合,也仅有 1277 个音(节),但是汉字则多达数万个
- 英语中连读、爆破音、重音位置等造成的语音异义也非常常见
词语切分歧义(Word Segmentation Ambiguity)是由字符组成词语时的歧义现象。
- 英语等印欧语系的语言来说,绝大部分单词之间都由空格或标点分割
- 汉语、日语等语言来说,单词之间通常没有分隔符。
词义歧义(Word Sense Ambiguity)是指词语具有相同形式但是不同意义。
结构歧义(Structural Ambiguity)是由词组成词组或者句子时,由于其组成的词或词组间可能存在不同的语法或语义关系而出现的(潜在)歧义现象。
- 「反对的是少数人」:被反对的对象是少数人,还是提出反对意见的人是少数?
- 「咬死了猎人的狗」:是指的是狗咬死了猎人,还是猎人的狗被咬死了?
- 「桌子和椅子的腿」:是「桌子和椅子」的腿,还是「桌子」和「椅子的腿」?
指代歧义(Demonstrative Ambiguity)是指代词(如我,你,他等)和代词词组(如「那件事」,「这一点」等)所指的事件可能存在歧义。
省略歧义(Ellipsis Ambiguity)是指自然语言中由于省略所产生的歧义。
语用歧义(Pragmatic Ambiguity)是指由于上下文、说话人属性、场景等语用方面的原因造成的歧义。一句话在不同的场合、由不同的人说、不同的语境,都可能产生不同的理解。
自然语言并不是一成不变的,而是在动态发展中,存在大量未知语言现象。新词汇、新含义、新用法、新句型等层出不穷。
自然语言处理成为制约人工智能取得更大突破和更广泛应用的瓶颈,被誉为「人工智能皇冠上的明珠」。
研究
归结为四个基本问题:
- 文本匹配问题
- 文本分类问题
- 序列到序列问题
- 结构预测问题
- 结构预测问题
自然语言处理研究对象与层次:
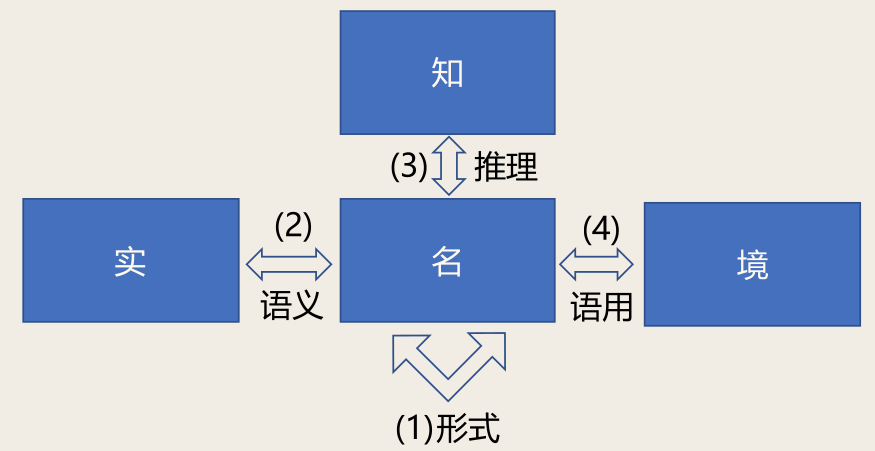
对象:
- 名:语言符号
- 实:客观事实、主观意见
- 知:知识
- 境:语言所处环境
层次:
- 形式:名
- 语义:名 + 实
- 推理:名 + 实 + 知
- 语用:名 + 实 + 知 + 境
层次x任务二维表:
| 分类 | 解析 | 匹配 | 生成 | |
|---|---|---|---|---|
| 形式 | 文本分类 | 词性标注、句法分析 | 搜索 | 机械式文摘 |
| 语义 | 情感分析 | 命名实体识别、语义角色标注 | 问答 | 机器翻译 |
| 推理 | 隐式情感分析 | - | 文本蕴含 | 写故事结尾 |
| 语境 | 反语 | - | - | 聊天 |
基本范式
自然语言处理的发展经历了从「理性主义」到「经验主义」,再到「深度学习」三大历史阶段。
包含四种范式:
- 基于规则的方法
- 基于机器学习的方法
- 基于深度学习的方法
- 基于大模型的方法
基于规则的方法
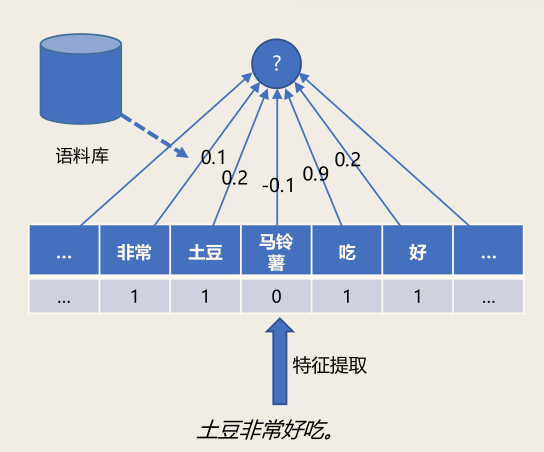
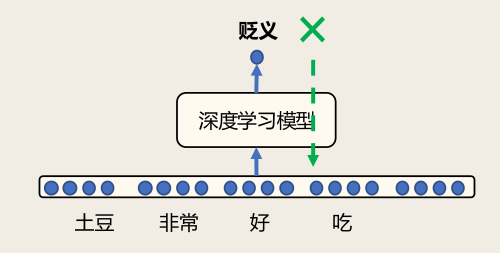
基于符号(字符串)表示的专家知识:例如「土豆非常好吃」的情感倾向性?
-
如果:出现褒义词「好」「喜欢」等
-
那么:结果为褒义
-
如果:出现「不」
-
那么:结果倾向性取反
-
优点
- 符合人类的直觉
- 可解释、可干预性好
-
缺点
- 知识完备性不足
- 需要专家构建和维护
- 不便于计算
基于规则的方法:通过词汇、形式文法等制定的规则引入语言学知识,从而完成相应的自然语言处理任务。
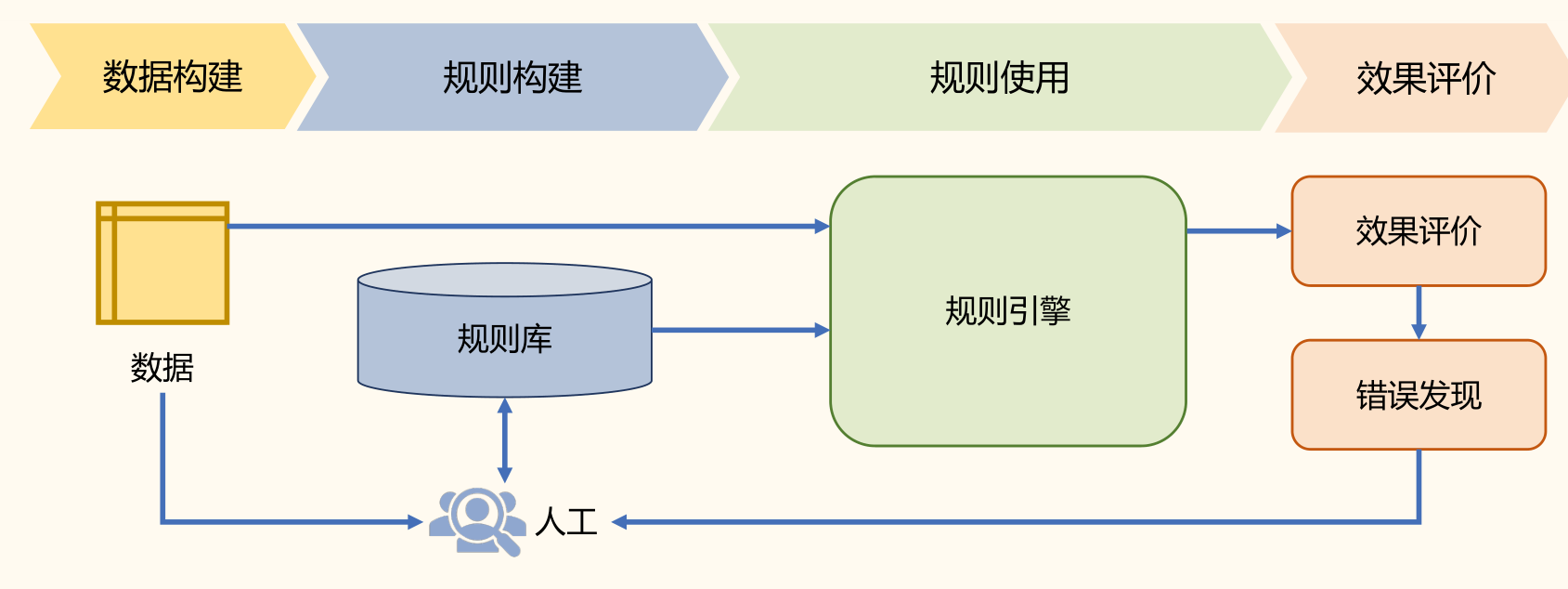
对于机器翻译任务可以构造如下规则库:
- IF 源语言主语 = 我 THEN 英语译文主语 = I
- IF 英语译文主语 = I THEN 英语译文 be 动词为 am/was
- IF 源语言 = 苹果 AND 没有修饰量词 THEN 英语译文 = apples
基于规则的方法从某种程度上可以说是在试图模拟人类完成某个任务时的思维过程。
- 优点:直观、可解释、不依赖大规模数据。利用规则所表达出来的语言知识具有一定的可读性,不同的人之间可以相互理解。
- 缺点:覆盖率差、大规模规则构建代价大、难度高等
基于向量表示的统计模型:使用高维、离散、稀疏的向量表示词,被称为独热编码(One-Hot Encoding)。
- 例如维度为词表的大小,其中只有一位为 1,其余为 0。
缺点:
- 严重的数据稀疏问题
- 无法处理「多词一义」的现象
基于机器学习的方法
基于机器学习的方法:将自然语言处理任务转化为某种分类任务
分为四个步骤:
- 数据构建:针对任务的要求构建训练语料,也称为语料库(Corpus)
- 数据预处理:利用自然语言处理基础算法对原始输入,从词汇、句法、结构、语义等层面进行处理,为特征构建提供基础。
- 特征构建:针对不同任务从原始输入、词性标注、句法分析、语义分析等结果和数据中提取对于机器学习模型有用的特征。
- 模型学习:根据任务,选择合适的机器学习模型,确定学习准则,采用相应的优化算法,利用语料库训练模型参数。

特点:
- 以人工特征构建为核心,针对所需的信息利用自然语言处理基础算法对原始数据进行预处理,并需要选择合适的机器学习模型,确定学习准则,以及采用相应的优化算法
- 整个流程中需要人工参与和选择的环节非常多,从特征设计到模型,再到优化方法以及超参数,并且这些选择非常依赖经验,缺乏有效的理论支持
- 对于复杂的自然语言处理任务需要在数据预处理阶段引入很多不同的模块,这些模块之间需要单独优化,其目标并不一定与任务总体目标一致,多模块的级联会造成错误传播
基于深度学习的方法
基于嵌入表示的深度学习模型:词嵌入(word embedding)直接使用一个低维、连续、稠密的向量表示词。词嵌入表示的赋值方法是通过优化在下游任务上的表现自动学习。
基于深度学习的方法:将特征学习和预测模型融合,通过优化算法使得模型自动地学习出好的特征表示,并基于此进行结果预测。
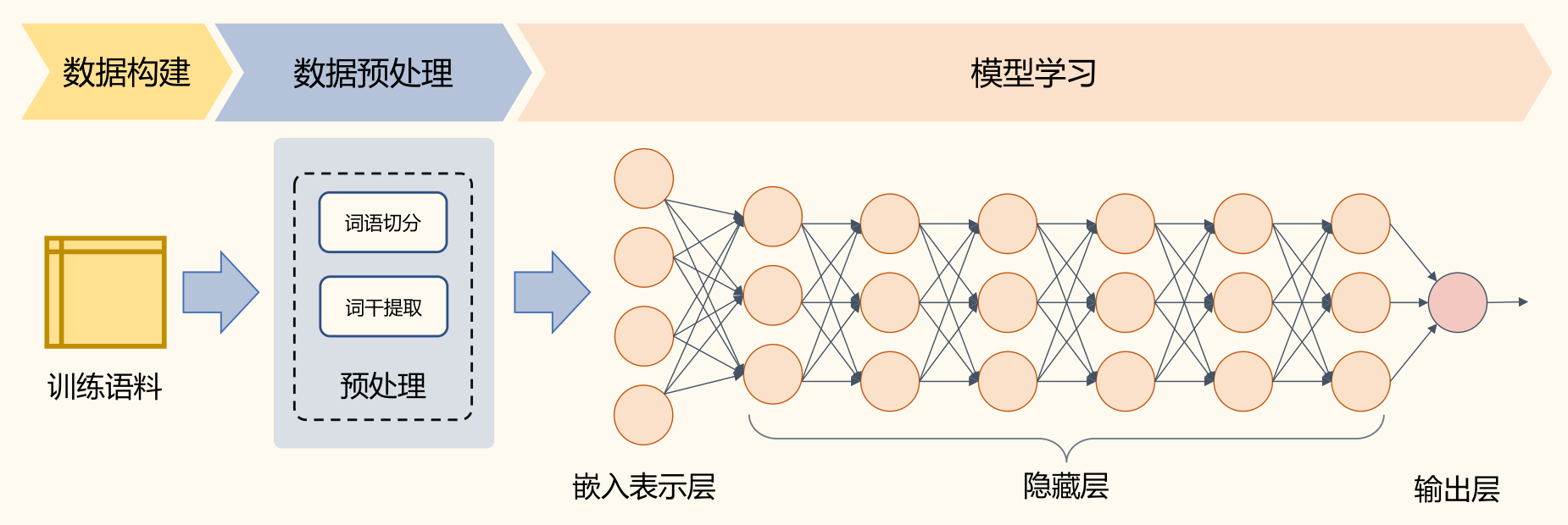
- 基于深度学习方法的流程简化很多,通常仅包含数据构建、数据预处理和模型学习三个部分
- 在数据预处理方面也大幅度简化,仅包含非常少量的模块
- 通过多层的特征转换,将原始数据转换为更抽象的表示。这些学习到的表示可以在一定程度上完全代替人工设计的特征,这个过程也叫做表示学习(Represen-tation Learning)
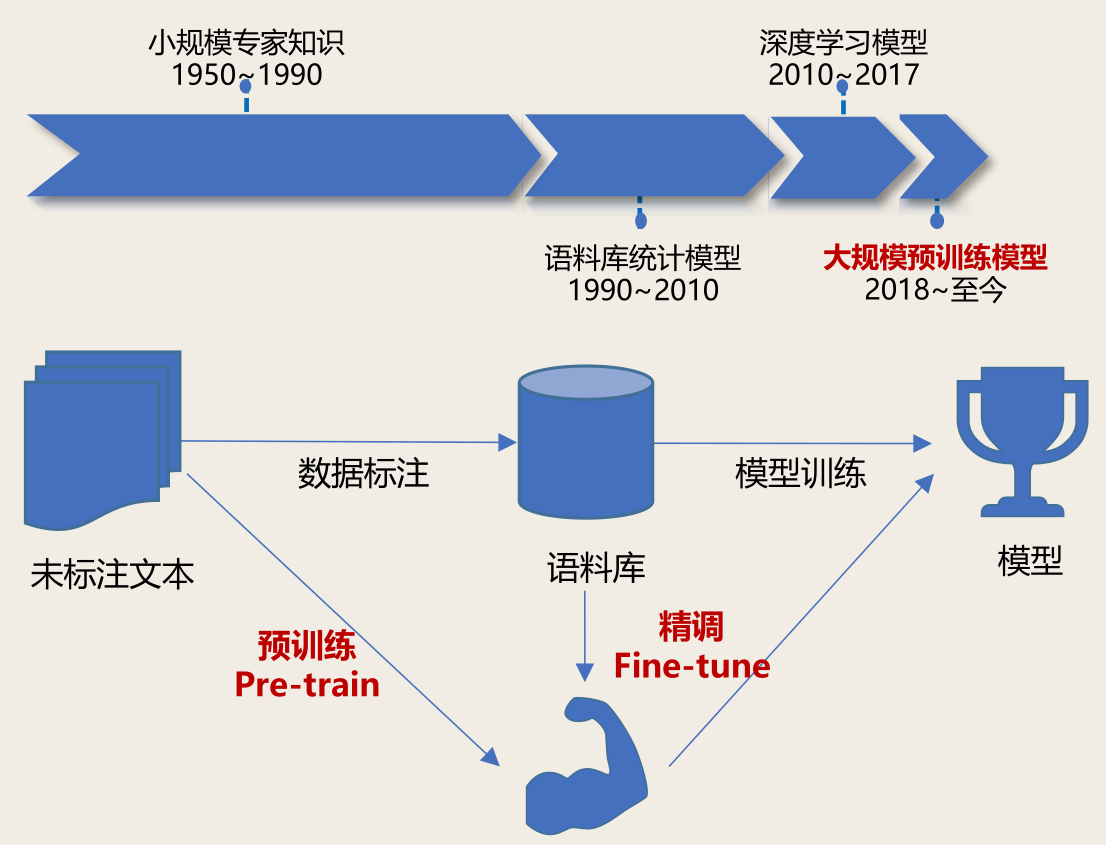
- 首先利用自监督任务对模型进行预训练,通过海量的语料学习到更为通用的语言表示,然后根据下游任务对预训练网络进行调整。这种预训练范式在几乎所有自然语言处理任务上都表现非常出色
预训练模型获得更好的表示:预训练 + 精调 = 自然语言处理新范式
基于大模型的方法
基于大模型的方法:将大量各类型自然语言处理任务,统一为生成式自然语言理解框架。
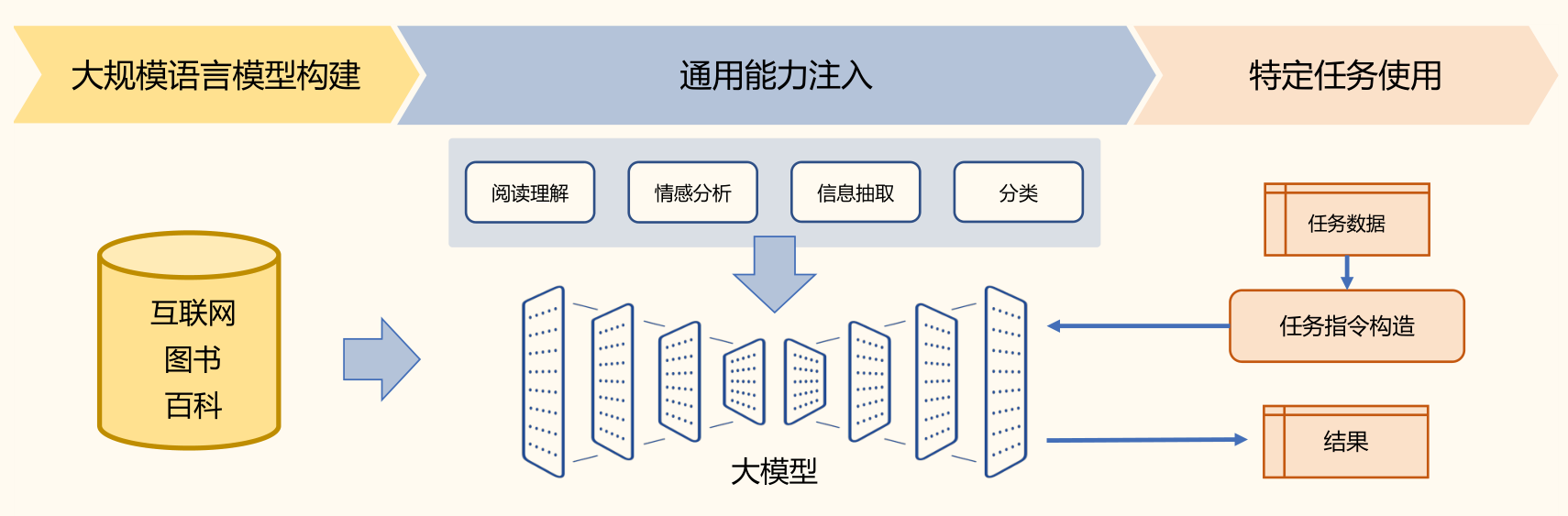
- ChatGPT 所展现出来的通用任务理解能力和未知任务泛化能力,使得未来自然语言处理的研究范式可能进一步发生变化
- 在大规模语言模型构建阶段,通过大量的文本内容,训练模型长文本的建模能力,使得模型具有语言生成能力,并使得模型获得隐式的世界知识
- 在通用能力注入阶段,利用包括阅读理解、情感分析、信息抽取等现有任务的标注数据,结合人工设计的指令词对模型进行多任务训练,从而使得模型具有很好的任务泛化能力
- 特定任务使用阶段则变得非常简单,由于模型具备了通用任务能力,只需要根据任务需求设计任务指令,将任务中所需处理的文本内容与指令结合,然后就可以利用大模型得到所需结果