自然语言处理基础
文本的表示
文本表示是自然语言处理中的核心问题之一。它决定了如何将人类语言转化为计算机能够理解的形式,从而为后续任务提供基础支持。
符号表示:早期方法基于符号(字符串)表示,例如通过专家知识规则判断句子的情感倾向性。
- 优点:符合人类直觉,具有良好的可解释性和可干预性。
- 缺点:知识完备性不足,依赖专家构建和维护,难以扩展到复杂场景。
向量表示:向量表示将词或文本映射到高维空间中,常见的有离散表示和稠密表示两种形式。
- 离散表示:如独热编码(One-hot Encoding),维度等于词表大小,仅有一位为1,其余为0。
- 示例:「土豆」可以表示为
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, ...]。 - 缺点:存在严重的数据稀疏问题,无法处理多义词或多词一义现象。
- 示例:「土豆」可以表示为
- 稠密表示:通过低维、连续的向量表示词,称为词嵌入(Word Embedding)。
- 常见模型包括 Word2Vec, GloVe 和 BERT 等。
- 优势:解决了稀疏性问题,能够捕捉语义相似性。
传统的解决离散表示的方案:
- 增加额外的特征
- 词性特征:名词、动词、形容词等。
- 前后缀特征
- 语义词典
- 如 WordNet,提供词义、同义词、反义词等信息。
- 需解决一词多义问题
- 收录不全且更新慢
- 词聚类特征
分布语义假设
根据分布语义假设(Distributional Semantic Hypothesis),词的含义由其上下文词的分布决定。
You shall know a word by the company it keeps. —— Firth J.R. 1957
分布词向量:
| shinning | bright | trees | dark | look | |
|---|---|---|---|---|---|
| moon | 38 | 45 | 2 | 27 | 12 |
于是语义相似度通过计算向量相似度获得。
但仍然存在高维、稀疏、离散的问题。
- 分布表示的加权:降低高频词的权重,提高低频词的权重。
- 降低高频但无意义词(如 the, a)的权重
- 提升低频但重要词的显著性
采用「点互信息」(Pointwise Mutual Information, PMI) 来衡量词 和上下文词 的相关性。

- 分布表示的降维:避免稀疏性,反映高阶共现关系。
- 保留主要语义特征
- 得到稠密低维表示
采用「奇异值分解」(Singular Value Decomposition, SVD)将高维稀疏矩阵转换为低维稠密矩阵。
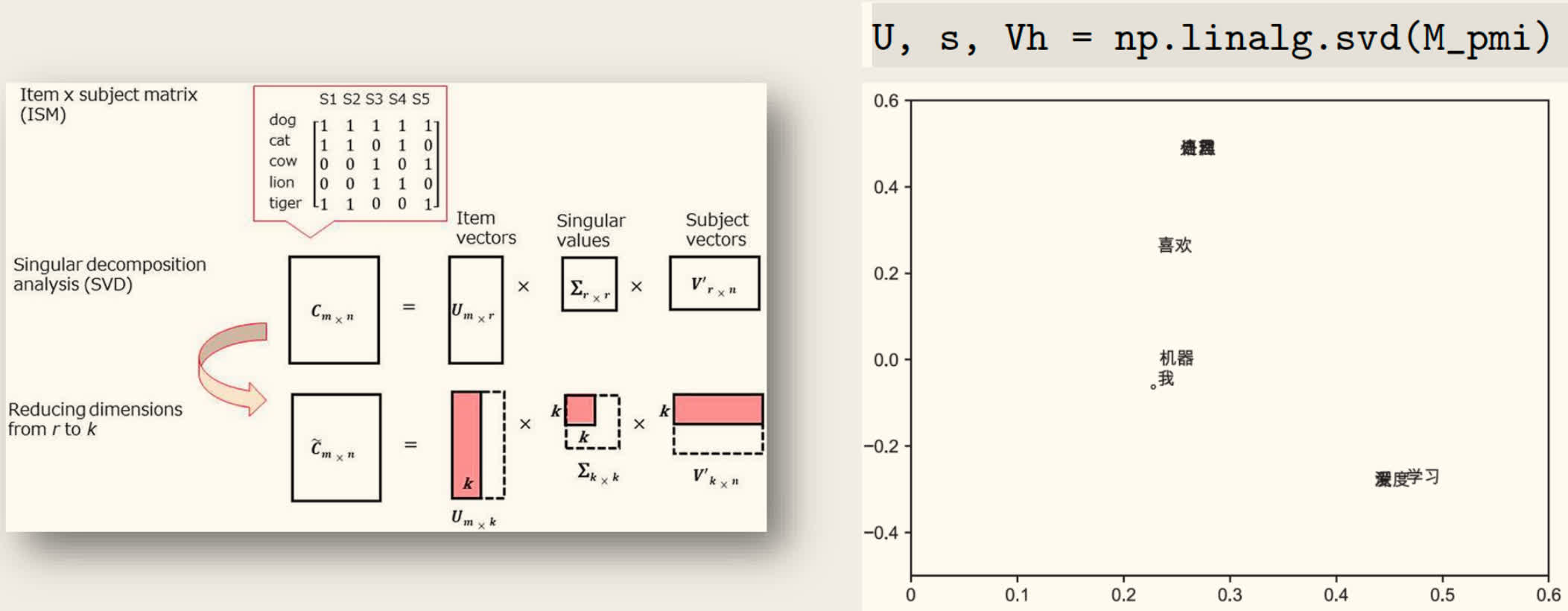
分布式词表示的缺点:
- 训练速度慢,增加新语料库困难
- 不易扩展到短语、句子表示
分布式表示直接使用低维、稠密、连续的向量表示词
- 通过「自监督」的方法直接学习词向量
- 也称词嵌入(Word Embedding)
自然语言处理任务
自然语言处理涵盖多种任务,从基础的语言建模到复杂的生成任务,以下是主要任务分类:
语言模型
语言模型(Language Model, LM)描述一段自然语言的概率或给定上文时下一个词出现的概率:
链式法则有
广泛应用于多种自然语言处理任务
- 机器翻译(词排序)
- 语音识别(词选择)
基本任务
- 中文分词
- 将汉字序列切分为独立的词语。例如:「严守一把手机关了」可以有不同的分词结果[1]。
- 挑战:歧义问题显著。
- 英文分词
- 英文以空格作为分隔符,但仍需考虑词形变化(如
computer、computers)。 - 挑战:数据稀疏性和未登录词问题。
- 英文以空格作为分隔符,但仍需考虑词形变化(如
英文分词:I enjoy watching movies and reading books.
- 空格切分:I / enjoy / watching / movies / and / reading / books
- 优点:语义明确
- 缺点:数据稀疏,词表过大,降低处理速度,OOV
- 字母切分:I / e / n / j / o / y / w / a / t / c / h / …
- 优点:词表极小,无 OOV
- 缺点:语义信息不明确,编码解码效率低
子词切分(Subword Tokenization)是一种折中方案,将单词切分为更小的片段。
- I /enjoy / watch / ing / movie / s / and / read / ing / book / s
- 常用算法:使用尽量长且频次高的子词对单词进行切分
- BPE(Byte-Pair Encoding)
- BBPE(Byte-level BPE)
- WordPiece
- Unigram Language Model
- 优势:解决未登录词(Out Of Vocabulary, OOV)问题,同时保持语义明确性和计算效率。
算法拓展
BPE(Byte Pair Encoding)
- 核心思想: 通过迭代合并高频字符对(或子词)构建词表,从字符级逐步生成更长的子词。
- 算法流程:
- 初始化词表为所有基础字符。
- 统计文本中所有相邻字符对的频率。
- 合并频率最高的字符对,将新组合加入词表。
- 重复步骤 2-3,直到达到预设词表大小。
- 特点:
- 贪心策略:每次合并当前最优的字符对。
- 频率驱动:优先合并高频组合。
- 应用场景:GPT系列、RoBERTa等模型。
BBPE(Byte-Level BPE)
- 核心思想:BPE 的扩展版本,基于字节(Byte)而非 Unicode 字符进行编码,直接处理原始字节流。
- 改进点:
- 解决 Unicode 字符编码问题(如生僻字、多语言混合)。
- 避免 OOV(Out-Of-Vocabulary)问题,理论上能覆盖所有字符。
- 应用场景:GPT-4、多语言模型(XLM-R)。
WordPiece
- 核心思想:与BPE类似,但合并策略基于概率(似然最大化),而非单纯频率。
- 算法流程:
- 初始化词表为所有基础字符。
- 计算合并每对子词后的语言模型似然增益。
- 合并增益最大的子词对。
- 重复步骤 2-3,直到达到预设词表大小。
- 特点:
- 概率驱动:合并能最大提升语言模型概率的子词。
- 应用场景:BERT 系列、DistilBERT。
Unigram Language Model
- 核心思想:基于统计语言模型,假设每个子词独立,通过迭代剪枝生成最优词表。
- 算法流程:
- 初始化一个大词表(如所有字符 + 高频 n-gram)。
- 训练语言模型,估计每个子词的概率。
- 移除对整体似然影响最小的子词。
- 重复步骤 2-3,直到达到预设词表大小。
- 特点:
- 概率剪枝:保留高概率子词,删除低贡献子词。
- 灵活性:支持多种分词可能性(概率加权)。
- 应用场景:ALBERT, SentencePiece 工具。
| 特征 | BPE | BBPE | WordPiece | Unigram |
|---|---|---|---|---|
| 合并策略 | 频率驱动 | 频率驱动(字节级) | 概率驱动 | 概率剪枝 |
| 训练方向 | 自底向上(合并) | 同 BPE | 自底向上(合并) | 自顶向下(剪枝) |
| OOV 处理 | 依赖词表覆盖 | 无 OOV(字节级) | 依赖词表覆盖 | 依赖词表覆盖 |
| 多语言支持 | 有限 | 优秀 | 一般 | 优秀 |
| 分词速度 | 快 | 较快 | 快 | 较慢(需概率计算) |
| 典型应用 | GPT, RoBERTa | GPT-4, XLM-R | BERT, DistilBERT | ALBERT, SentencePiece |
应用场景:
- BPE:单语言任务、资源有限场景(简单高效)。
- BBPE:多语言混合、需要强泛化能力(如低资源语言)。
- WordPiece:预训练语言模型(BERT 系列),需平衡语义和粒度。
- Unigram:灵活分词需求(如日韩语粘着语)、支持概率加权输出。
关键选择因素:
- 语言特性:
- 黏着语(如日语) Unigram/BBPE。
- 拉丁语系 BPE/WordPiece。
- 数据规模:
- 小数据 BPE/WordPiece(避免过拟合)。
- 大数据 BBPE/Unigram(更细粒度)。
- 计算资源:
- 低资源 BPE/WordPiece。
- 高资源 Unigram/BBPE。
高级任务
- 句法分析:将线性文本转换为树状结构,识别主谓宾等成分。
- 语义分析:包括词义消歧(WSD)、语义角色标注(SRL)和语义依存图生成。
- 信息抽取:从非结构化文本中提取结构化信息。
- 示例:从新闻中提取公司并购事件。
- 情感分析:判断文本的情感倾向性(正面、负面或中性)。
- 示例:「这款手机的屏幕很不错,性能也还可以」表达正面情感。
- 问答系统:根据用户提问,从文档、知识库或互联网中检索答案。
- 类型:检索式、知识库式、常问问题集式和阅读理解式。
应用任务
- 机器翻译:将源语言文本翻译为目标语言。
- 对话系统:包括任务型对话、聊天机器人、知识问答和推荐系统。
- 特点:不同类型的对话系统在目的、领域和交互方式上有所区别。
自然语言处理的基本问题
自然语言处理的核心问题可以归结为以下四类:
- 文本分类问题:将输入文本映射到预定义类别集合中。
- 示例:垃圾邮件过滤、情感分类。
- 文本匹配问题:判断两段文本之间的关系(如复述、蕴含)。
- 解决方案:双塔结构或单塔结构。
- 结构预测问题:输出类别之间具有强关联性,常见任务包括:
- 序列标注:如词性标注、命名实体识别。
- 序列分割:如分句、分词。
- 图结构生成:如依存句法分析。
- 序列到序列问题:输入和输出均为序列,不要求长度一致或词表相同。
- 示例:机器翻译、文本摘要生成。
自然语言处理的评价指标
评价自然语言处理模型的性能需要根据任务选择合适的指标:
- 准确率(Accuracy)
- 最直观的指标,适用于文本分类、词性标注等任务。
- F 值
- 综合考虑精确率(Precision)和召回率(Recall),公式如下:
- 当 时,称为 F1 值。
- 综合考虑精确率(Precision)和召回率(Recall),公式如下:
- 依存分析评价
- UAS(Unlabeled Attachment Score):父节点正确识别的准确率。
- LAS(Labeled Attachment Score):父节点及句法关系均正确识别的准确率。
- 机器翻译评价
- BLEU 值:统计机器译文与参考译文中 n-gram 的匹配比例。
- 对话系统评价
- 主要依赖人工评价,关注流畅度、相关性和准确性。
基础工具集与常用数据集
自然语言处理领域有许多成熟的工具和数据集,以下是一些常用的资源:
工具集
- NLTK:提供丰富的语料库和词典资源,支持分句、词性标注、命名实体识别等任务。
- spaCy:高性能的开源 NLP 库,支持多语言处理,内置预训练模型。
- TextBlob:简单易用的 Python 库,适合快速原型开发。
- LTP:针对中文的高效 NLP 平台,支持词法、句法和语义分析。
- PyTorch:深度学习框架,支持动态神经网络构建,广泛应用于 NLP 模型开发。
数据集
- 维基百科(Wikipedia):提供大规模的纯文本数据,常用于语言模型预训练。
- Common Crawl:大规模网络爬虫数据集,涵盖多种语言。
- 严守一/把/手机/关/了(大概率是这个)
- 严守/一把手/机关/了(不明所以)
- 严守/一把/手机/关/了(一般来说是「一把把」)
- 严守一/把手/机关/了(不明所以)