词嵌入
词嵌入概述
什么是词嵌入
词嵌入(Word Embedding)是用低维、稠密、连续的向量来表示词语的一种方法。这种方法使得我们可以捕捉词语之间的语义关系,并在自然语言处理任务中取得更好的性能。
分布式词表示
词嵌入也称为分布式词表示(Distributed Word Representation),它与传统的独热编码(One-hot Encoding)不同,独热编码用高维稀疏向量表示词语,无法捕捉词语之间的语义关系。
分布式词表示的优缺点
- 优点:低维、稠密、连续的向量表示,可以捕捉词语之间的语义关系。
- 缺点:训练速度慢,增加新语料库困难,不易扩展到短语、句子表示。
词嵌入的发展历程
词嵌入技术的发展历程可以概括如下:
graph LR
subgraph "Latent Semantic Analysis"
A["LSA (1990)"] --> B("NNLM (2003)")
A --> F("LDA (2003)")
end
subgraph "Neural Network Language Model"
B --> C("RNNLM (2010)")
end
C --> D{"Word2Vec (2013)"}
B --> E{"SENNA (2011)"}
subgraph "Hierarchical Log-Bilinear"
F --> G("HLBL (2009)")
end
G --> C
C --> H{"GloVe (2014)"}
style A fill:#ccf,stroke:#888,stroke-width:2px
style F fill:#ccf,stroke:#888,stroke-width:2px
style B fill:#aaf,stroke:#555,stroke-width:2px
style C fill:#aaf,stroke:#555,stroke-width:2px
style G fill:#ccf,stroke:#888,stroke-width:2px
style D fill:#8cf,stroke:#333,stroke-width:2px
style E fill:#8cf,stroke:#333,stroke-width:2px
style H fill:#8cf,stroke:#333,stroke-width:2px
linkStyle 0,1,5,6 stroke:#aaa,stroke-width:1.5px
linkStyle 2,3,4,7 stroke:#555,stroke-width:2px词向量
词向量(Word Vector)是词嵌入的核心概念。每个单词都被表示为一个密集向量,其值的选择使其与出现在相似上下文中的单词向量相似。相似性通常使用向量点积(标量积)来度量。
例如,banking 和 monetary 的词向量可能如下所示:
1 | banking = [0.286, 0.792, -0.177, -0.107, 0.109, -0.542, 0.349, 0.271] |
通过计算这些向量的点积,我们可以衡量它们之间的相似性。
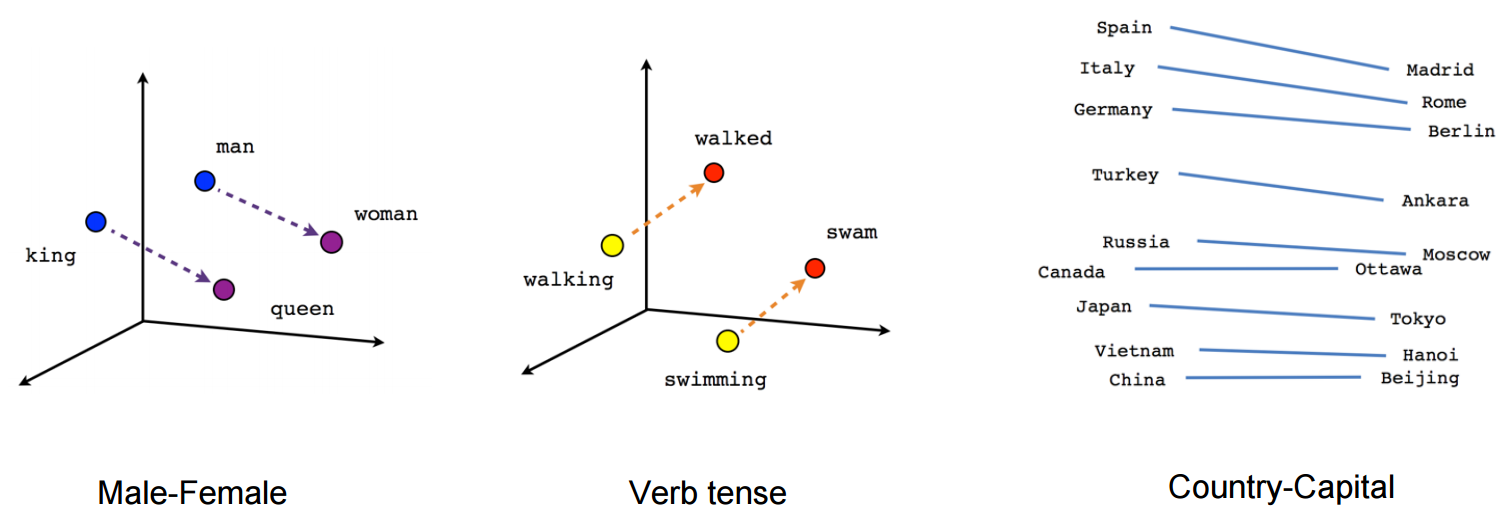
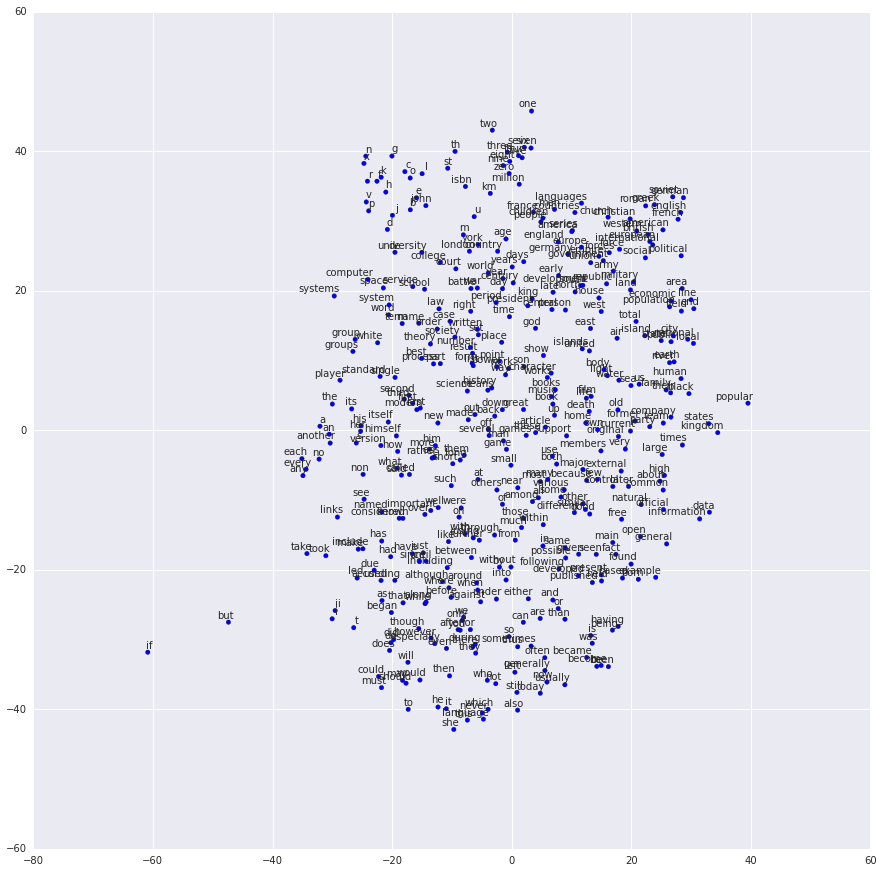
词义可视化
神经词向量的词义可以通过将词向量投影到二维或三维空间中进行可视化,从而观察词语之间的语义关系。
静态词嵌入
前馈神经网络语言模型(FF-NNLM)
FF-NNLM 根据前 个词(历史)来预测当前词,即基于「马尔可夫假设」。它使用查找表(Look-up Table)来获取词的向量表示,并通过梯度下降来优化词向量。
FF-NNLM 的主要缺点是「历史」长度不可变,限制了其对长距离依赖的建模能力。
graph LR
subgraph "FF-NNLM"
A[输入层:词的 One-hot 向量] --> B(隐藏层:词嵌入矩阵);
B --> C[隐藏层:tanh 激活函数];
C --> D(输出层:Softmax);
D --> E[预测下一个词的概率分布];
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#333,stroke-width:2px
style C fill:#aaf,stroke:#333,stroke-width:2px
style D fill:#9cf,stroke:#333,stroke-width:2px
style E fill:#f9c,stroke:#333,stroke-width:2px循环神经网络语言模型(RNNLM)
RNNLM 使用完整的「历史」信息来预测当前词,可以更好地建模不定长依赖。然而,RNNLM 存在梯度弥散/爆炸问题,通常需要使用长短时记忆网络(LSTM)来缓解这个问题。
RNNLM 的主要缺点是只利用了「历史」信息,而没有利用未来的上下文信息。
graph LR
subgraph "RNNLM"
A[输入层:当前词的 One-hot 向量] --> B(隐藏层:RNN 单元);
B --> C[隐藏层:RNN 单元(时间步 t+1)];
C --> D[隐藏层:RNN 单元(时间步 t+n)];
D --> E(输出层:Softmax);
E --> F[预测下一个词的概率分布];
B -.-> C;
C -.-> D;
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#333,stroke-width:2px
style C fill:#aaf,stroke:#333,stroke-width:2px
style D fill:#9cf,stroke:#333,stroke-width:2px
style E fill:#f9c,stroke:#333,stroke-width:2px
style F fill:#ccf,stroke:#333,stroke-width:2pxSENNA
SENNA 使用「换词」的思想来学习词向量。它将一个词和它的上下文构成正例,将随机替换掉该词的样本构成负例。
缺点是 SENNA 的训练速度较慢。
graph TD
subgraph "SENNA"
A[输入层:句子中的词序列] --> B(查找表:词嵌入矩阵);
B --> C[卷积层:提取局部特征];
C --> D(池化层:最大池化);
D --> E[全连接层];
E --> F(输出层:任务相关);
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#333,stroke-width:2px
style C fill:#aaf,stroke:#333,stroke-width:2px
style D fill:#9cf,stroke:#333,stroke-width:2px
style E fill:#f9c,stroke:#333,stroke-width:2px
style F fill:#ccf,stroke:#333,stroke-width:2pxWord2Vec
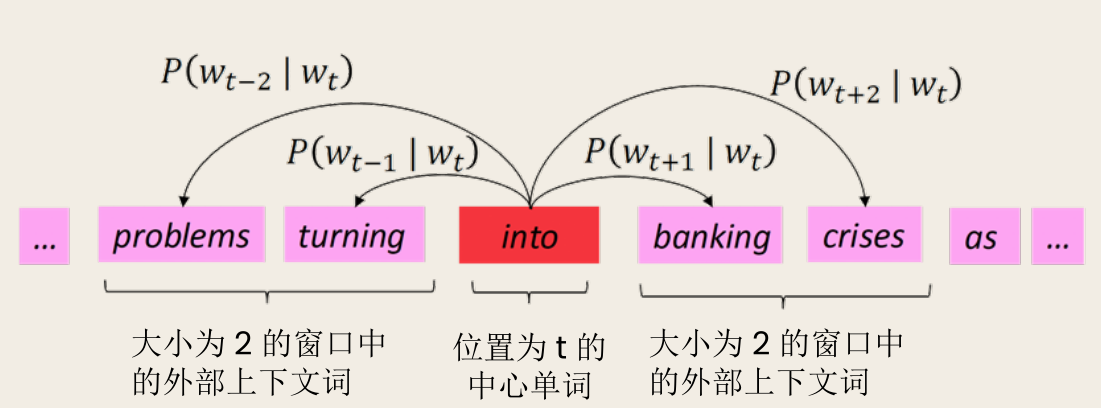
Word2Vec 是一种学习词向量的框架。它的核心思想是遍历文本中的每个位置,并利用中心词和上下文词的词向量相似性来计算在给定中心词的情况下上下文词出现的概率。通过不断调整词向量,使该概率最大化。
Word2Vec 的目标函数
Word2Vec 的目标函数是(平均)负对数似然函数:
其中, 是文本长度, 是窗口大小, 是模型参数。
Word2Vec 的向量计算
Word2Vec 为每个单词 使用两个向量:(当 是中心词时)和 (当 是上下文词时)。对于中心词 和上下文词 ,条件概率 计算如下:
其中, 是词汇表。
上面的计算使用了 Softmax 函数 ,将任意值 映射到一个概率分布 。
- max 是因为它放大了最大 的概率
- soft 是因为它仍然会给其他 一些概率
Word2Vec 的训练
Word2Vec 的训练使用随机梯度下降(SGD)算法。
Word2Vec 的主要思路
Word2Vec 的主要思路:
- 从随机词向量开始
- 遍历语料库中的每个词位置,并使用词向量来预测周围的词
- 学习:通过不断更新词向量,使其能够更好地预测实际的上下文单词
Word2Vec 通过将相似的词聚集在一起,以最大化目标函数,使得词向量可以捕捉词语之间的语义关系。
Word2Vec 的算法族
Word2Vec 有两种变体:
- Skip-gram:根据中心词预测上下文词。
- CBOW(Continuous Bag-of-Word):根据上下文词预测中心词。
- 上下文表示通过词向量取平均来表示
graph LR
subgraph "CBOW"
A[输入层:上下文词的 One-hot 向量] --> B(投影层:词嵌入矩阵);
B --> C[求和/平均];
C --> D(输出层:Softmax);
D --> E[预测中心词的概率分布];
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#333,stroke-width:2px
style C fill:#aaf,stroke:#333,stroke-width:2px
style D fill:#9cf,stroke:#333,stroke-width:2px
style E fill:#f9c,stroke:#333,stroke-width:2pxgraph LR
subgraph "Skip-gram"
A[输入层:中心词的 One-hot 向量] --> B(投影层:词嵌入矩阵);
B --> C(输出层:Softmax);
C --> D[预测上下文词的概率分布];
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#333,stroke-width:2px
style C fill:#aaf,stroke:#333,stroke-width:2px
style D fill:#9cf,stroke:#333,stroke-width:2px当输出类别较多时, 的归一化项需要对许多单词求和,计算开销较大。因此可以通过「负采样」实现更高效的训练。
负采样通过将多分类问题(预测上下文词是词汇表中哪一个词)转化为二分类问题(判断一个词对是否是真实的上下文词对)来解决这个问题。
- 真实词对(正样本): 中心词和其上下文窗口内的词构成的词对。
- 噪声词对(负样本): 中心词和随机从词汇表中选择的词构成的词对。
核心思想:训练二分类的对率回归模型,以区分真实词对(中心词与其上下文窗口中的单词)和多个「噪声」词对(中心词与随机选取的单词)。
- 取 个负样本(使用词概率)
- 最大化真实外部词的概率
- 最小化随机词的概率
使用的是 sigmoid 函数 而非 softmax 函数。只用计算 个词,而非整个词汇表。
- 以 进行采样,其中 是一元分布,取幂操作使得低频词被采样更频繁, 是归一化常数
在每个窗口迭代地计算梯度进行随机梯度下降(SGD)。每个窗口最多只有 个单词(采样窗口),以及通过负采样得到的 个负样本单词(每个正样本采样 个),因此 非常稀疏,只有与当前窗口中的单词相关的元素才非零。
于是我们只需要更新那些在当前窗口中出现的单词的词向量。这大大提高了更新效率,因为我们不需要更新整个词汇表的词向量。
GloVe
GloVe(Global Vectors for Word Representation)是一种利用全局统计信息(共现频次)来学习词向量的算法。它使用词向量对「词-上下文」共现矩阵进行预测(或回归)。
Word2Vec 在捕捉词的语义和句法信息方面表现出色,但它存在一些局限性:
- 局部性: Word2Vec 主要关注局部上下文信息(即滑动窗口内的词),而忽略了全局的统计信息。
- 统计信息利用不足: Word2Vec 没有充分利用词共现矩阵中蕴含的丰富的统计信息。
GloVe 的出现正是为了解决这些问题。它通过以下方式改进了词向量的学习:
- 全局统计信息: GloVe 直接对词-上下文共现矩阵进行建模,充分利用了全局统计信息。
- 更高效的训练: GloVe 的目标函数和训练过程通常比 Word2Vec 更高效,尤其是在大规模语料库上。
GloVe 的损失函数
GloVe 的损失函数如下:
其中, 是词 和词 的共现次数, 是一个权重函数。
词向量的评估
词向量的评估可以分为内在评估和外在评估。
- 内在评估针对特定的/中间子任务进行评估,例如词类比关系计算和词义相似度计算。
- 外在评估针对真实任务进行评估,例如文本分类和命名实体识别(NER)。
动态词嵌入
静态词嵌入(如 Word2Vec)的主要缺陷:
- 无法解决一词多义(Polysemy)问题
- 无法捕捉词语的语法功能变化(如动词/名词形态)
- 缺乏对上下文敏感的表征能力
动态词嵌入核心特征:
- 上下文感知:根据词语在句子中的位置动态调整向量
- 层次化表示:结合字符级、词级和句法级特征
- 双向建模:同时考虑左右两侧的上下文信息 (典型应用场景:歧义消除、指代消解、语义角色标注)
CoVe
CoVe(Contextualized Word Vectors)是早期的一种动态词嵌入方法,它将神经机器翻译(NMT)的表示迁移到通用 NLP 任务上。
问题:
- 训练依赖于双语平行语料
- 训练神经机器翻译模型需要双语平行语料,获取难度较高
- 相比单语语料,覆盖的领域也相对优先,通用性一般
- 单独使用效果一般,性价比不高
- 实验结果表明单独使用 CoVe 的效果一般
- 需要搭配传统静态词向量才能获得较为显著的性能提升
ELMo
ELMo(Embeddings from Language Models)是一种基于语言模型的动态词嵌入方法。它使用双向 LSTM 来学习词向量,并结合不同层次的向量表示。
ELMo 采取对不同层次的向量表示进行加权平均的机制,为不同的下游任务提供更多的组合自由度。
ELMo 特点:
- 动态(上下文相关):词的 ELMo 向量表示由其当前上下文决定
- 鲁棒(Robust):ELMo 向量表示使用字符级输入,对于未登录词具有强鲁棒性
- 层次:ELMo 词向量由深度预训练模型中各个层次的向量表示进行组合,为下游任务提供了较大的使用自由度
基于语言模型的动态词向量预训练
ELMo 和 BERT 等模型都采用了基于语言模型的动态词向量预训练方法。这种方法可以利用大量的单语语料来学习高质量的词向量,并在下游任务中取得更好的性能。
模型实现:
- 数据准备
- 使用清洗后并经过分词等预处理的语料
- 需要同时构建词级别与字符级别的训练语料,并建立相应的词表
- 双向语言模型
- ELMo 模型的核心是双向语言模型
- 编码器部分主要包括基于字符的输入表示层以及前向、后向 LSTM 层
- 训练
- 在数据、模型组件构建完成后,使用实际数据对模型进行训练
- 训练过程将输出每一次迭代后的前向语言模型的困惑度值
- 训练完成后,便可以利用双向语言模型的编码器编码输入文本并获取动态词向量