预训练语言模型
预训练语言模型概述
预训练语言模型(Pre-trained Language Model)是在大规模文本数据上训练的深度神经网络模型,可以学习到丰富的语言知识和上下文信息。
动态词向量模型的问题
在预训练语言模型出现之前,研究人员通常使用动态词向量模型(如 CoVe)来学习上下文相关的词表示。然而,这些模型存在以下问题:
- 数据:训练数据相对局限。例如,CoVe 需要使用双语平行句对进行训练。
- 模型:表示模型的参数量相对较小(相比预训练语言模型),模型深度不够。
- 用法:
- 通常使用这类模型时,表示模型本身不参与训练(权重无更新)。
- 表示模型本身不参与训练,一定程度上限制了表示模型在下游任务上的泛化能力。
预训练模型三要素
为了解决上述问题,预训练语言模型应运而生。它们通常具备以下三个要素:
- 大数据(无标注文本):预训练语言模型通常在海量无标注文本上进行训练,以学习通用的语言表示。
- 大模型(深度神经网络):预训练语言模型通常采用深度神经网络结构(如 Transformer),拥有大量参数,以捕捉语言中的复杂模式。
- 大算力(并行计算集群):训练预训练语言模型需要大量的计算资源,通常需要使用 GPU 或 TPU 等并行计算集群。
graph LR
subgraph 预训练模型三要素
A[大数据] --> C[预训练语言模型]
B[大模型] --> C
D[大算力] --> C
end
style A fill:#ccf,stroke:#888,stroke-width:2px
style B fill:#aaf,stroke:#555,stroke-width:2px
style C fill:#8cf,stroke:#333,stroke-width:2px
style D fill:#f9c,stroke:#333,stroke-width:2px常见计算设备
- 图形运算单元(Graphics Processing Unit, GPU):擅长并行处理大量数据,适用于深度学习模型的训练和推理。
- 张量运算单元(Tensor Processing Unit, TPU):专为机器学习任务设计的芯片,特别适用于 TensorFlow 框架下的模型训练。
自回归预训练模型:GPT
GPT 概述
GPT(Generative Pre-Training)是由 OpenAI 提出的一种生成式预训练语言模型。它采用了「生成式预训练 + 判别式微调」的框架,开启了自然语言处理领域「预训练 + 微调」的新时代。
GPT 的核心思想包括两个阶段:
- 生成式预训练:在大规模文本数据上训练一个高容量的语言模型,从而学习更丰富的上下文信息。
- 判别式任务微调:将预训练好的模型适配到下游任务中,并使用有标注数据学习判别式任务。
预训练-微调范式
受到计算机视觉领域预训练-微调范式的影响,自然语言处理领域也逐渐采用这种方法。
- ELMo 为代表的动态词向量模型开启了语言模型预训练的大门。
- GPT 和 BERT 为代表的基于 Transformer 的大规模预训练语言模型的出现,使得自然语言处理全面进入了预训练微调范式新时代。
将预训练模型应用于下游任务时:
- 不需要了解太多的任务细节。
- 不需要设计特定的神经网络结构。
- 只需要「微调」预训练模型,即使用具体任务的标注数据在预训练语言模型上进行监督训练,就可以取得显著的性能提升。
GPT 模型结构
GPT 模型是典型的生成式预训练语言模型之一,由多层 Transformer 组成的单向语言模型。
模型组成
GPT 模型主要可以分为三部分:
- 输入层:将输入文本序列映射为稠密的向量表示。
- 编码层:由多个 Transformer 模块堆叠而成,每个模块包含自注意力机制和前馈神经网络。
- 输出层:基于最后一层的表示,预测每个位置上的条件概率。
%%{ init: { 'flowchart': {'defaultRenderer': 'elk' } } }%%
graph LR
subgraph GPT-2 模型结构
subgraph B[编码层:12x Transformer Block]
temp0:::hidden --> D[多头自注意力] --> temp1((\+)) --> E[层归一化]
E --> F[全连接层]
F --> temp2((\+)) --> G[层归一化]
temp0 --> temp1
E --> temp2
end
A[输入层:词向量层] --> B
B --> C[输出层:文本预测/任务分类器];
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#efc,stroke:#333,stroke-width:2px
style C fill:#aaf,stroke:#333,stroke-width:2px
style D fill:#9cf,stroke:#333,stroke-width:2px
style E fill:#f9c,stroke:#333,stroke-width:2px
style F fill:#ccf,stroke:#333,stroke-width:2px
style G fill:#aaf,stroke:#333,stroke-width:2px
classDef hidden display: none;GPT 采用生成式预训练方法,单向意味着模型只能从左到右或从右到左对文本序列建模,所采用的 Transformer 结构保证了输入文本每个位置只能依赖过去时刻的信息。
输入层
给定文本序列 ,GPT-2 首先在输入层中将其映射为稠密的向量:
其中:
- 是词 的词向量。
- 是词 的位置向量。
- 为第 个位置的单词经过模型输入层(第 0 层)后的输出。
编码层
经过输入层编码,模型得到表示向量序列 ,随后将其送入模型编码层。
编码层由 个 Transformer 模块组成。在自注意力机制的作用下,每一层的每个表示向量都会包含之前位置表示向量的信息,使每个表示向量都具备丰富的上下文信息。
经过多层解码后,GPT-2 能得到每个单词层次化的组合式表示,其计算过程如下:
输出层
GPT-2 模型的输出层基于最后一层的表示 ,预测每个位置上的条件概率,其计算过程可以表示为:
单向语言模型是按照阅读顺序输入文本序列 ,用常规语言模型目标优化 的最大似然估计,使之能根据输入历史序列对当前词能做出准确的预测:
GPT 无监督预训练
GPT 采用从左至右对输入文本进行建模,给定文本序列计算最大似然估计:
GPT 使用了多层 Transformer 作为模型的基本结构:
GPT 有监督任务微调
利用下游任务的有标注数据,对 GPT 模型进行微调。
利用 GPT 最后一层的表示来完成相关预测任务:
为缓解灾难性遗忘(Catastrophic Forgetting)问题,通常会采用混合预训练任务损失和下游精调损失:
GPT 适配不同的下游任务
根据任务特点,设置不同的输入输出形式。
| 任务类型 | 输入形式 | 输出形式 |
|---|---|---|
| 文本分类 | 开始 + 文本 + 结束 | 类别 |
| 文本蕴含 | 开始 + 前提 + 分隔符 + 假设 + 结束 | 类别 |
| 相似度计算 | 开始 + 文本 1 + 分隔符 + 文本 2 + 结束 | 相似度 |
| 选择型阅读理解 | 开始 + 篇章 + 问题 + 分隔符 + 选项 1 + 结束 开始 + 篇章 + 问题 + 分隔符 + 选项 2 + 结束 …… 开始 + 篇章 + 问题 + 分隔符 + 选项 N + 结束 |
概率分布 |
自编码预训练模型:BERT
BERT(Bidirectional Encoder Representations from Transformers)是一种双向预训练语言模型方法,由 Google 提出。
BERT 的主要贡献
- 提出了一种双向预训练语言模型方法。
- 利用大规模自由文本训练两个无监督预训练任务。
- BERT 在众多 NLP 任务中获得了显著性能提升。
- 进一步强调了使用通用预训练取代繁杂的任务特定的模型设计。
BERT 利用掩码机制构造了基于上下文预测中间词的预训练任务,相较于传统的语言模型建模方法,BERT 能进一步挖掘上下文所带来的丰富语义。
GPT/BERT/ELMo 之间的对比
- GPT:单向从左至右的 Transformer 语言模型。
- ELMo:将独立的前向和后向的 LSTM 语言模型拼接所得。
- BERT:双向 Transformer 语言模型。
graph
direction LR
subgraph "BERT"
direction TB
A[输入层:E1, E2, ..., EN] --> B(多层双向 Transformer);
B --> C[输出层:T1, T2, ..., TN];
end
subgraph OpenAI GPT
direction TB
D[输入层:E1, E2, ..., EN] --> E(多层单向 Transformer);
E --> F[输出层:T1, T2, ..., TN];
end
subgraph ELMo
direction TB
G[输入层:E1, E2, ..., EN] --> H(双向 LSTM);
H --> I[输出层:T1, T2, ..., TN];
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#333,stroke-width:2px
style C fill:#aaf,stroke:#333,stroke-width:2px
style D fill:#f9f,stroke:#333,stroke-width:2px
style E fill:#ccf,stroke:#333,stroke-width:2px
style F fill:#aaf,stroke:#333,stroke-width:2px
style G fill:#f9f,stroke:#333,stroke-width:2px
style H fill:#ccf,stroke:#333,stroke-width:2px
style I fill:#aaf,stroke:#333,stroke-width:2px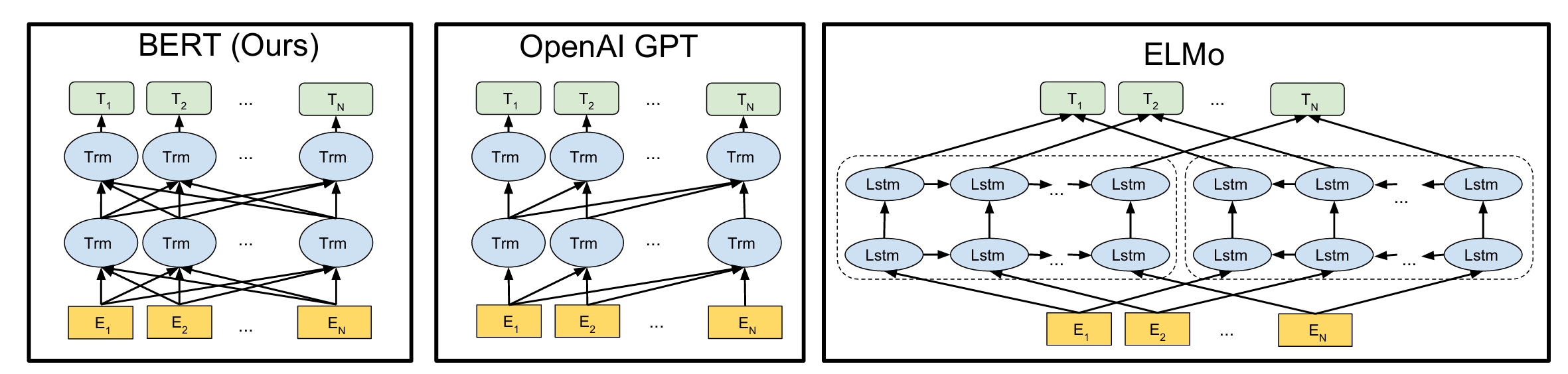
BERT 模型结构
整体结构
- 由深层 Transformer 模型构成。
- base:12 层,参数量 110M。
- large:24 层,参数量 330M。
预训练任务
- 掩码语言模型(Masked Language Model, MLM):预测被掩盖的词。
- 下一个句子预测(Next Sentence Prediction, NSP):判断两个句子是否是连续的。
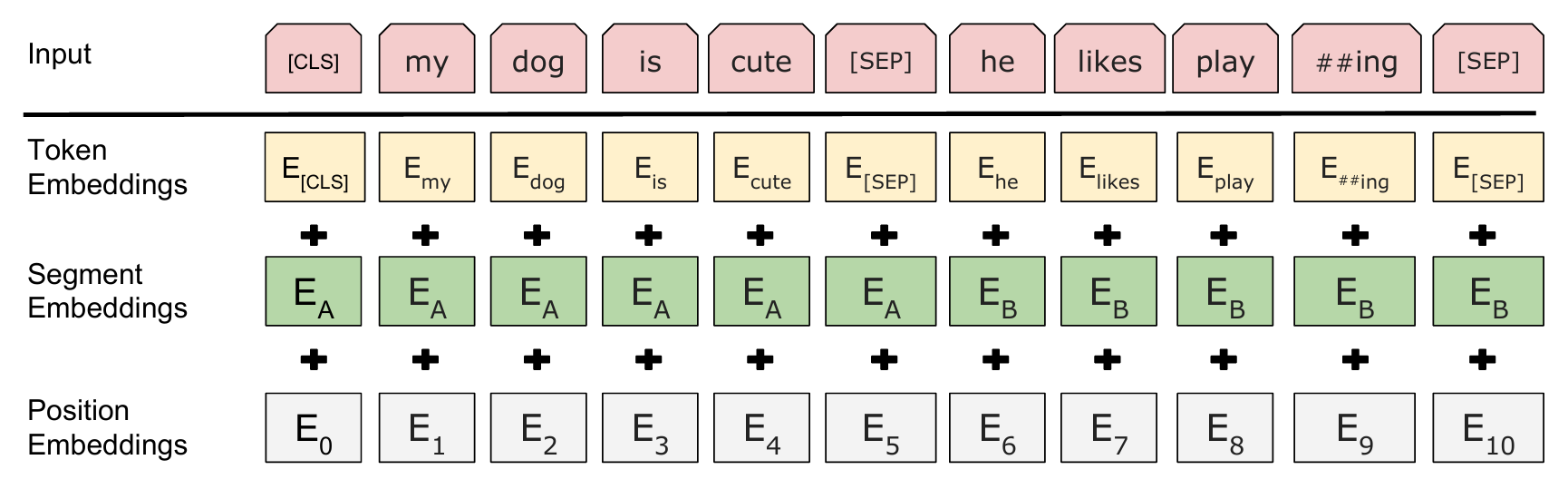
BERT 输入表示
BERT 的输入表示由三部分组成:
- 词向量(Token Embeddings):通过词向量矩阵将输入文本转换为实值向量表示。
- 块向量(Segment Embeddings):编码当前词属于哪一个块,块编码从 0 开始计数。
- 位置向量(Position Embeddings):编码当前词的绝对位置。
BERT 输入层采用了 WordPiece 分词,根据词频,决定是否将一个完整的词切分为多个子词以缓解 OOV 问题。例如:单词 highest 可以被切分为 high 和 ##est 两个子词。
BERT 双向注意力 vs 因果注意力
- GPT:约束自注意力(Constrained Self-Attention),仅关注当前单元左侧上下文。
- BERT:双向多头自注意机制,不仅关注当前单元左侧上下文情况,也会关注右侧上下文。
BERT 基本预训练任务
掩码语言模型(MLM)
将输入序列中的部分 token 进行掩码,并且要求模型将它们进行还原。在 BERT 中,会将 15% 的输入文本进行 mask:
- 以 80% 的概率替换为
[MASK]标记。- The man went to the
[MASK]to buy some milk.
- The man went to the
- 以 10% 的概率替换为词表中的任意一个随机词。
- The man went to the apple to buy some milk.
- 以 10% 的概率保持原词不变,即不替换。
- The man went to the store to buy some milk.
输入层
BERT 编码层
输出层
下一个句子预测(NSP)
学习两段文本之间的关系(上下文信息),预测 Sentence B 是否是 Sentence A 的下一个句子。
- 正样本:文本中相邻的两个句子「句子 A」和「句子 B」,构成「下一个句子」关系。
- 负样本:将「句子 B」替换为语料库中任意一个句子,构成「非下一个句子」关系(50% 概率替换,将训练样本的正负例比例控制在 1:1)。
输入层
BERT 编码层
输出层
BERT 更多预训练任务
整词掩码(Whole Word Masking)
The quick brown fox jumps over the lazy dog.
WordPiece 分词:The quick brown fox jump[s] over the la[zy] dog.
- MLM:随机选取一定比例的 WordPiece 子词。
- The quick brown
[MASK]jump[s] over the[MASK][zy] dog. - 随机掩码了 fox 和 la
- The quick brown
- WWM:随机选取一定比例的整词,属于同一个整词的 WordPiece 子词均被掩码。
- The quick brown
[MASK][MASK]over the[MASK][MASK]dog. - 掩码了整个单词 fox 和 lazy
- The
[MASK][MASK][MASK]fox jumps over the lazy dog
- The quick brown
- 总掩码数量不变,变动的是掩码位置的选取。
N-gram 掩码(N-gram Masking)
对一个连续的 N-gram 单元进行掩码,进一步增加 MLM 任务的难度。
- 2-gram 掩码:The quick
[MASK][MASK][MASK][MASK]the lazy dog.- 掩码了 brown fox 这个 2-gram 单元。
- 3-gram 掩码:The
[MASK][MASK][MASK][MASK][MASK]the lazy dog.- 掩码了 quick brown fox 这个 3-gram 单元。
难度:N-gram Masking > Whole Word Masking > MLM
- MLM:只掩盖了单个的 token, 可能是完整单词, 也可能是一个单词的一部分。
- WWM:掩盖了整个单词。模型不仅要预测被掩盖的词是什么,还要隐式地学习到词的边界。
- N-gram Masking:掩盖了连续的 N 个单词。N-gram 掩码迫使模型更多地依赖上下文信息来做出预测,因为它需要理解更长的短语或句子片段的含义。
| 掩码策略 | 最小掩码单位(英文) | 最小掩码单位(中文) | 最大掩码单位(英文) | 最大掩码单位(中文) |
|---|---|---|---|---|
| MLM | WordPiece 子词 | 字 | WordPiece 子词 | 字 |
| WWM | WordPiece 子词 | 字 | 词 | 词 |
| N-gram Masking | WordPiece 子词 | 字 | 多个子词 | 多个字 |
预训练语言模型的应用
特征提取和模型微调
特征提取
- 仅利用 BERT 提取输入文本特征,生成对应的上下文语义表示。
- BERT 本身不参与目标任务的训练,即 BERT 部分只进行解码(无梯度回传)。
模型微调
- 利用 BERT 作为下游任务模型基底,生成文本对应的上下文语义表示。
- 参与下游任务的训练,即在下游任务学习过程中,BERT 对自身参数进行更新。
- 通常使用「模型微调」的方法,因其效果更佳。
预训练语言模型应用
- 单句文本分类(Single Sentence Classification)
- 最常见的自然语言处理任务,需要将输入文本分成不同类别。
- 例如:将影评文本输入到分类模型中,将其分成「褒义」和「贬义」类别。
- 句对文本分类(Sentence Pair Classification)
- 与单句文本分类任务类似,需要将一对文本分成不同类别。
- 例如:文本蕴含任务中,将句对分成「蕴含」或者「冲突」类别。
- 阅读理解(Reading Comprehension):以抽取式阅读理解为例进行说明,要求机器在阅读篇章和问题后给出相应的答案,而答案要求是从篇章中抽取出的一个文本片段(Span)。
- 序列标注(Sequence Tagging):以命名实体识别任务(NER)为例,对给定输入文本的每个词输出一个标签,以此指定某个命名实体的边界信息。