预训练语言模型进阶
本章在前一章介绍的 GPT 和 BERT 等基础预训练语言模型(Pre-trained Language Model, PLM)之上,进一步探讨了近年来对预训练模型进行的各种优化和扩展,主要涵盖模型优化、长文本处理、模型压缩与蒸馏以及生成模型等方向。
模型优化
随着以 GPT、BERT 为代表的预训练语言模型的提出,许多后续工作都致力于进一步优化模型结构、预训练任务和训练策略,以期在各类自然语言处理任务上获得更好的效果。本节将介绍几个代表性的优化模型:XLNet, RoBERTa, ALBERT, ELECTRA 和 MacBERT。
XLNet
XLNet: Generalized Autoregressive Pretraining for Language Understanding
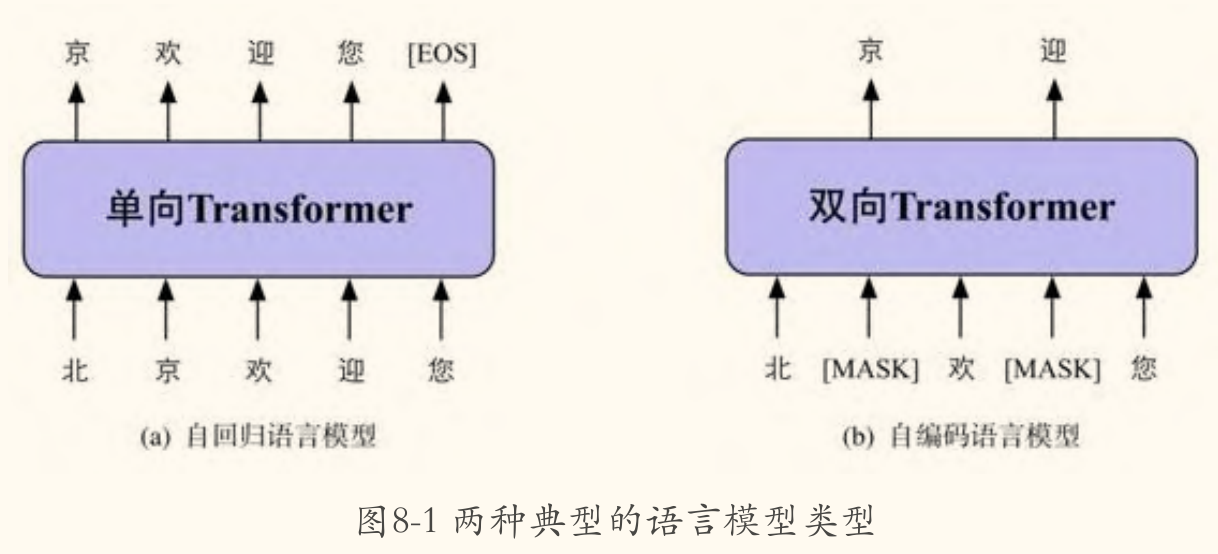
XLNet 旨在融合自回归(Autoregressive, AR)语言模型(如 GPT)和自编码(Autoencoding, AE)语言模型(如 BERT)的优点。
AR vs. AE 模型回顾
- 自回归(AR)模型:通过预测下一个词来建模文本序列 。
- 代表模型:GPT
- 优点:能自然地应用于生成任务,且建模了词之间的依赖关系。
- 缺点:通常只能利用单向(从左到右或从右到左)的上下文信息。
- 自编码(AE)模型:通过从损坏的输入(例如,带
[MASK]标记的文本)中重构原始文本来学习表示 。- (其中 是带掩码的输入, 表示 被掩码)
- 代表模型:BERT
- 优点:能同时利用双向上下文信息。
- 缺点:预训练阶段引入的人造标记
[MASK]在下游微调阶段并不存在,造成了预训练-微调不一致(Pretrain-Finetune Discrepancy)的问题;同时,BERT 假设被预测的[MASK]标记之间是相互独立的(给定未掩码的词),忽略了它们之间的依赖关系。
XLNet 的核心特点:
- 排列语言模型(Permutation Language Model, PLM):
- 目标:在保留 AR 模型形式的同时,引入双向上下文信息。
- 方法:对于一个长度为 的序列 ,存在 种可能的排列(因子分解顺序)。PLM 通过最大化所有可能排列下的对数似然期望来进行训练:
其中
- 是长度为 的序列所有可能排列的集合,
- 是其中一种排列,
- 是排列中的第 个位置的原始索引,
- 是排列中前 个位置的原始索引集合。
- 效果:通过采样不同的排列顺序,模型在预测某个位置的词时,可以利用到其左右两边的上下文信息,从而实现了双向上下文建模。这解决了 AR 模型的单向性问题。同时,由于没有使用
[MASK]标记,也避免了 BERT 的预训练-微调不一致问题。 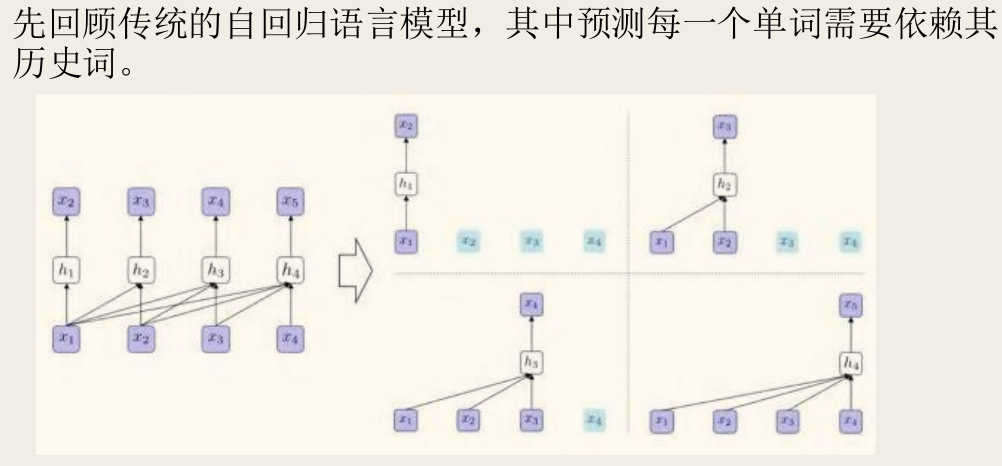
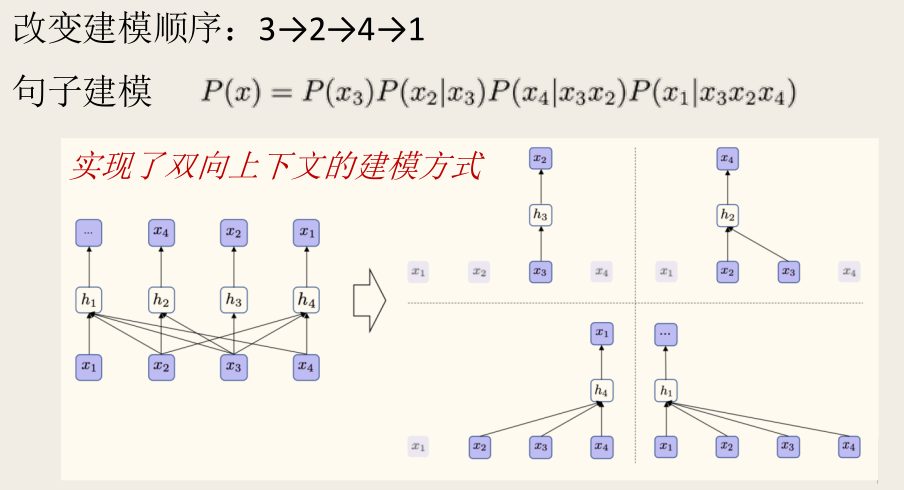
- 双流自注意力机制(Two-Stream Self-Attention):
- 问题:标准的 Transformer 无法直接实现 PLM。如果模型在预测 时看到了 本身的内容,任务就变得过于简单;但如果完全不编码 的信息,又无法为后续预测提供上下文。
- 解决方案:引入两种并行的注意力流:
- 内容流(Content Stream):与标准 Transformer 类似,编码上下文和当前词 的内容信息,用 表示。实际使用时用内容流 进行预测。
- 查询流(Query Stream):只编码上下文信息 和当前位置 的信息,但不包含当前词 的内容,用 表示。预测 时使用查询流 。
- 计算:两套流使用相同的参数,但在注意力计算时,查询流对当前位置进行了掩码。
RoBERTa
RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa 并没有提出全新的模型结构,而是通过仔细评估和改进 BERT 的预训练策略,显著提升了模型性能。
主要改进点:
- 动态掩码(Dynamic Masking):
- 原始 BERT 在数据预处理阶段进行一次静态掩码,每个训练样本在所有训练周期(epoch)中看到的掩码模式都是相同的。
- RoBERTa 采用动态掩码,每次向模型输入序列时才执行掩码操作。这意味着在不同的训练周期中,同一个句子可能会有不同的掩码模式,增加了数据的多样性,提高了模型的鲁棒性。

- 移除 NSP 任务(Next Sentence Prediction):
- RoBERTa 的实验发现,移除 NSP 任务,仅保留 MLM 任务,并在训练时始终输入来自同一文档(或跨文档)的连续长片段(Full-Sentences),其性能优于原始 BERT 使用 NSP 的设置。
- 这表明 NSP 任务可能不如 MLM 任务对下游任务那么有帮助,甚至可能带来负面影响。
- 更大的训练数据和更长的训练时间:
- RoBERTa 使用了比 BERT 大得多的数据集进行预训练(包括 BookCorpus, Wikipedia, CC-News, OpenWebText, Stories,总计约 160GB),并显著增加了训练步数。
- 更大的批次大小(Batch Size):
- 实验证明,使用非常大的批次(例如 8K)进行训练可以提升模型性能和训练稳定性。
- 字节级 BPE(Byte-Level BPE):
- 使用基于字节而非字符的 BPE 词汇表(通过 SentencePiece 实现),词汇量扩大到 50K。
- 优点:可以编码任意文本,无需引入 "unknown" 标记来处理未登录词(Out-Of-Vocabulary, OOV)。
RoBERTa 启示
RoBERTa 的成功表明,除了模型结构创新,优化预训练过程中的超参数、数据量、训练策略等工程细节同样至关重要,有时甚至能带来比结构创新更大的性能提升。
ALBERT
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT 旨在通过参数削减技术,在保持甚至提升性能的同时,显著降低 BERT 类模型的参数量和内存占用,提高训练和推理效率。
核心技术:
- 词向量因式分解(Factorized Embedding Parameterization):
- 原始 BERT 中,词向量(WordPiece embedding)维度 与 Transformer 隐藏层维度 是相等的 ()。这意味着词向量矩阵的大小是 ( 是词表大小),参数量巨大。
- ALBERT 认为词向量学习的是与上下文无关的表示,而隐藏层学习的是与上下文相关的表示,后者需要更大的维度。因此,将词向量维度 与隐藏层维度 解耦,通常设置 。
- 具体做法是先将 one-hot 向量映射到一个低维的词向量空间(大小 ),然后再将其投影到隐藏层空间(大小 )。
- 参数量从 降低到 ,当 时,削减效果显著。
- 示例:若 ,BERT 词向量参数约为 30.7M,而 ALBERT 约为 3.97M。
- 跨层参数共享(Cross-Layer Parameter Sharing):
- ALBERT 在 Transformer 的所有层之间共享参数。可以选择只共享前馈网络(Feed-Forward Network, FFN)参数,或只共享注意力(Attention)参数,或两者都共享(ALBERT 默认)。
- 这极大地减少了模型的总参数量(从 降为 ,L 为层数),但也可能影响模型性能(尽管 ALBERT 通过其他优化弥补了这一点)。
- 注意:虽然参数共享,但每层的输入和梯度是不同的,因此训练时仍需存储每层的激活值;推理时也需要逐层计算,并不能直接减少推理时间。
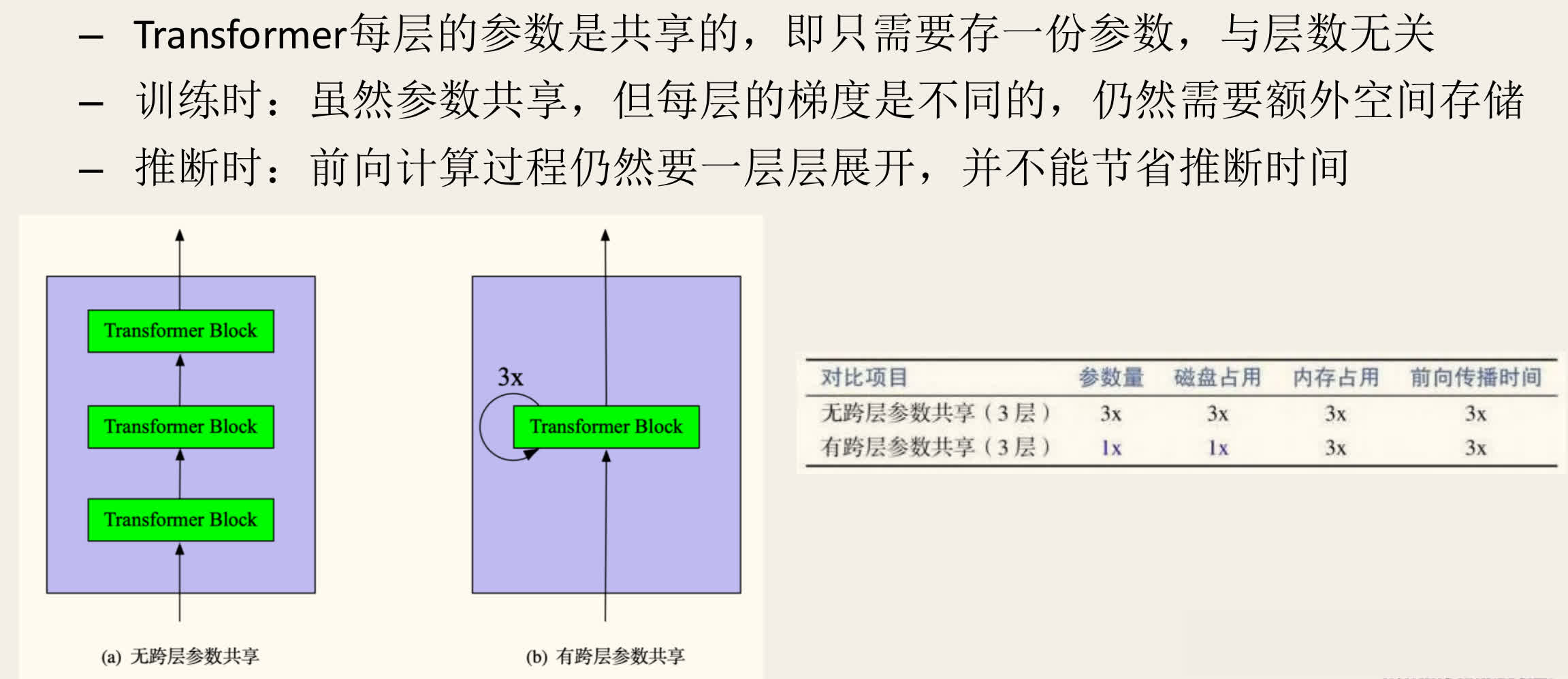
- 句子顺序预测(Sentence Order Prediction, SOP):
- ALBERT 认为 BERT 的 NSP 任务过于简单,因为它混合了主题预测和连贯性预测(负样本对通常主题也不同,因此难度比较低)。
- 提出 SOP 任务:正样本与 NSP 相同(来自同一文档的连续句子对),负样本则通过交换这两个连续句子的顺序来构造。
- SOP 任务更专注于句子间的连贯性建模,实验证明比 NSP 更有效。
ELECTRA
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
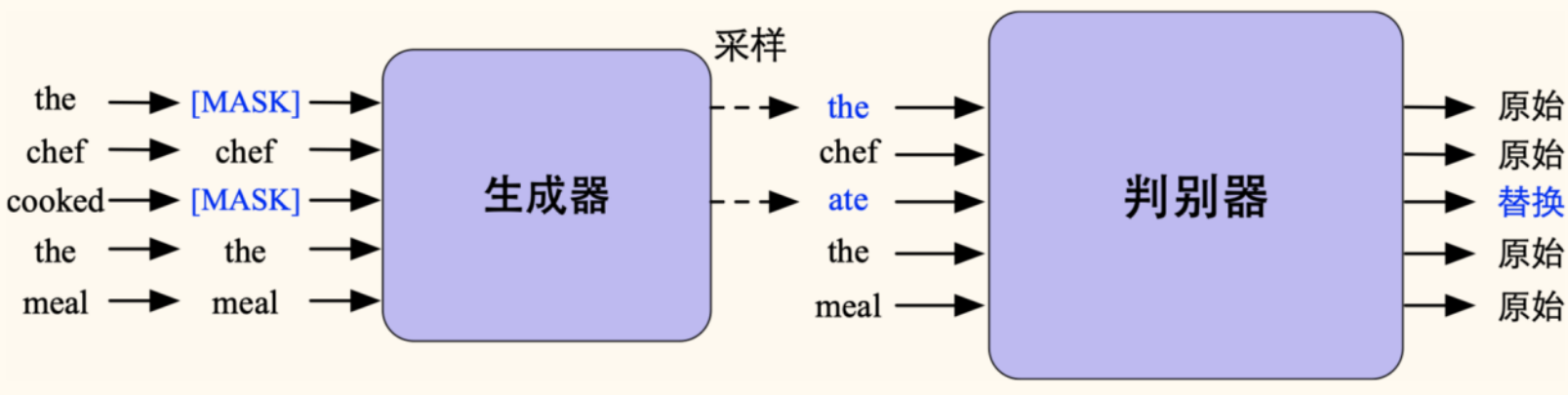
ELECTRA 提出了一种新的、更高效的预训练范式——替换词检测(Replaced Token Detection, RTD)。
核心思想:不再使用传统的 MLM(预测被掩码的词),而是训练一个判别器(Discriminator)来判断输入序列中的每个词是原始词还是被一个生成器(Generator)替换过的「伪造」词。
模型结构与训练过程:
- 生成器(Generator):
- 通常是一个小型的 MLM 模型(类似小型 BERT)。
- 输入:原始文本序列,其中一部分(例如 15%)词被
[MASK]替换。 - 任务:预测被
[MASK]的原始单词。
- 判别器(Discriminator):
- 通常是一个与 BERT 结构类似的模型(可以是 large 版本)。
- 输入:将生成器预测出的词替换回原始
[MASK]位置后得到的「损坏」文本序列。 - 任务:对序列中的每一个词进行二分类,判断该词是原始词(original)还是被生成器替换过的词(replaced)。
- 训练目标:
- 生成器使用标准的 MLM 损失 进行训练。
- 判别器使用所有词上的二分类交叉熵损失 进行训练。
- 总损失为两者加权和:。
由于生成器和判别器衔接的部分涉及采样环节,判别器的损失并不会直接回传到生成器,因为采样操作是不可导的。
另外,当预训练结束后,只需要使用判别器进行下游任务精调,而不再使用生成器。
ELECTRA 的优势
- 更高的计算效率:判别器需要对所有输入词进行预测(判断是否被替换),而不是像 MLM 只预测被掩盖的一小部分(如 15%)。这意味着每个样本提供了更多的学习信号,使得 ELECTRA 的预训练效率远高于 BERT。
- 下游任务性能:在相同计算资源下,ELECTRA 通常能达到比 BERT 更好的下游任务性能。
- 参数共享:可以选择性地在生成器和判别器之间共享词向量参数(如果维度匹配,可通过 ALBERT 的因式分解实现)。
- 微调:预训练结束后,只使用判别器进行下游任务微调。
MacBERT
MacBERT: MLM as Correction
MacBERT 主要针对中文 NLP 任务,旨在解决 BERT 中 [MASK] 标记带来的预训练-微调不一致问题。
核心思想:将 MLM 任务视为一种文本纠错(Correction)任务。在预训练阶段,不再使用 [MASK] 标记,而是用相似词来替换原始词。
预训练策略:
- 掩码策略:
- 采用整词掩码(Whole Word Masking, WWM)和 N-gram 掩码。
- 对于选定的 15% 的词(或 N-gram),进行如下替换:
- 80% 概率:替换为相似词。相似词通过同义词词典(如 Synonyms)查找得到。如果是 N-gram,则对 N-gram 中的每个词查找并替换。
- 10% 概率:替换为随机词。
- 10% 概率:保持原词不变。
- 模型的目标是预测被替换位置的原始单词。
- 句子关系预测:
- 使用 ALBERT 提出的 SOP 任务,而非 BERT 的 NSP 任务。
MacBERT 的优点
通过使用相似词替换而非 [MASK],MacBERT 的预训练输入形式更接近下游任务的自然文本,缓解了预训练-微调的不一致性,尤其适用于文本纠错等任务。
模型优化小结
下表总结了本节介绍的几种优化模型的关键特性:
| 模型 | 类型 | 分词器 | 核心预训练任务 | 主要创新点/特点 |
|---|---|---|---|---|
| BERT | 自编码 | WordPiece | MLM + NSP | 基础双向模型 |
| XLNet | 自回归 | SentencePiece | 排列语言模型(PLM) | 融合 AR 和 AE 优点,双流注意力 |
| RoBERTa | 自编码 | SentencePiece | 动态 MLM(移除 NSP) | 优化训练策略(大数据、大批次、长训练),字节级 BPE |
| ALBERT | 自编码 | SentencePiece | MLM + SOP | 参数削减(词向量因式分解、跨层参数共享) |
| ELECTRA | 自编码 | WordPiece | 替换词检测(RTD)(G+D 架构) | 更高效的预训练范式,对所有词进行预测 |
| MacBERT | 自编码 | WordPiece | 纠错式 MLM(Mac) + SOP | 用相似词替换 [MASK],缓解预训练-微调不一致,适用于中文 |
长文本处理
标准 Transformer 的自注意力机制具有 的时间和空间复杂度( 为序列长度),这限制了其处理长文本(如长文档、书籍)的能力。传统方法通常是将长文本切分成固定长度(如 512)的块,独立处理后再整合结果,但这会丢失块之间的长距离依赖信息。
![]()
本节介绍几种旨在高效处理长文本的 Transformer 变种。
Transformer-XL
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL 通过引入片段级循环(Segment-Level Recurrence)和相对位置编码(Relative Positional Encoding)来解决标准 Transformer 的上下文碎片化问题。
核心机制:
- 片段级循环(Segment-Level Recurrence):
- 在处理当前文本片段(Segment) 时,缓存并复用上一个片段 计算得到的隐藏状态序列 。
- 将 与当前片段的隐藏状态 拼接起来,作为计算当前片段注意力时的 Key 和 Value 来源:,其中 SG 表示停止梯度(Stop Gradient),避免梯度穿过上一个片段。
- 这使得模型能够利用超出当前片段长度的历史信息,建立长距离依赖。同时,在评估阶段可以更快地处理长序列。
- 相对位置编码(Relative Positional Encoding):
- 由于引入了循环机制,每个片段内的绝对位置信息不再具有全局唯一性。
- Transformer-XL 采用相对位置编码,只考虑 Key 和 Query 之间的相对距离 ,而不是它们的绝对位置。注意力分数的计算中包含了基于相对位置的偏置项。
- 这使得位置编码在片段之间保持一致性。
![]()
graph TD
subgraph "Transformer-XL 处理片段 τ"
H_prev[缓存的上一片段状态 h<sub>τ-1</sub>] -- "Key, Value(无梯度)" --> Attention
X_curr[当前片段输入 x<sub>τ</sub>] --> Embed --> H_curr[当前片段状态 h<sub>τ</sub>]
H_curr -- "Query, Key, Value" --> Attention
Attention --> Output_curr[当前片段输出]
H_curr -- "缓存供下一片段使用" --> H_next_cache
end
style H_prev fill:#eee,stroke:#999,stroke-dasharray: 5 5Reformer
Reformer: The Efficient Transformer
Reformer 通过引入局部敏感哈希(Locality-Sensitive Hashing, LSH)注意力和可逆残差网络(Reversible Residual Network)等技术,显著降低了 Transformer 的内存消耗和计算复杂度。
核心机制:
- QK 共享(Query-Key Sharing):
- 实验发现,让 Query 和 Key 使用相同的权重矩阵对性能影响不大,因此 Reformer 中 ,减少了一部分计算和参数。
- 局部敏感哈希注意力:
- 动机:在 Softmax 注意力中,大部分注意力权重集中在少数几个 Key 上。无需计算所有 对 Query-Key 的相似度。
- 方法:
- 使用 LSH 将具有相似 Query 向量(在高维空间中接近)的词分到同一个桶(bucket)中。LSH 函数 设计为使得邻近的向量有高概率得到相同的哈希值。
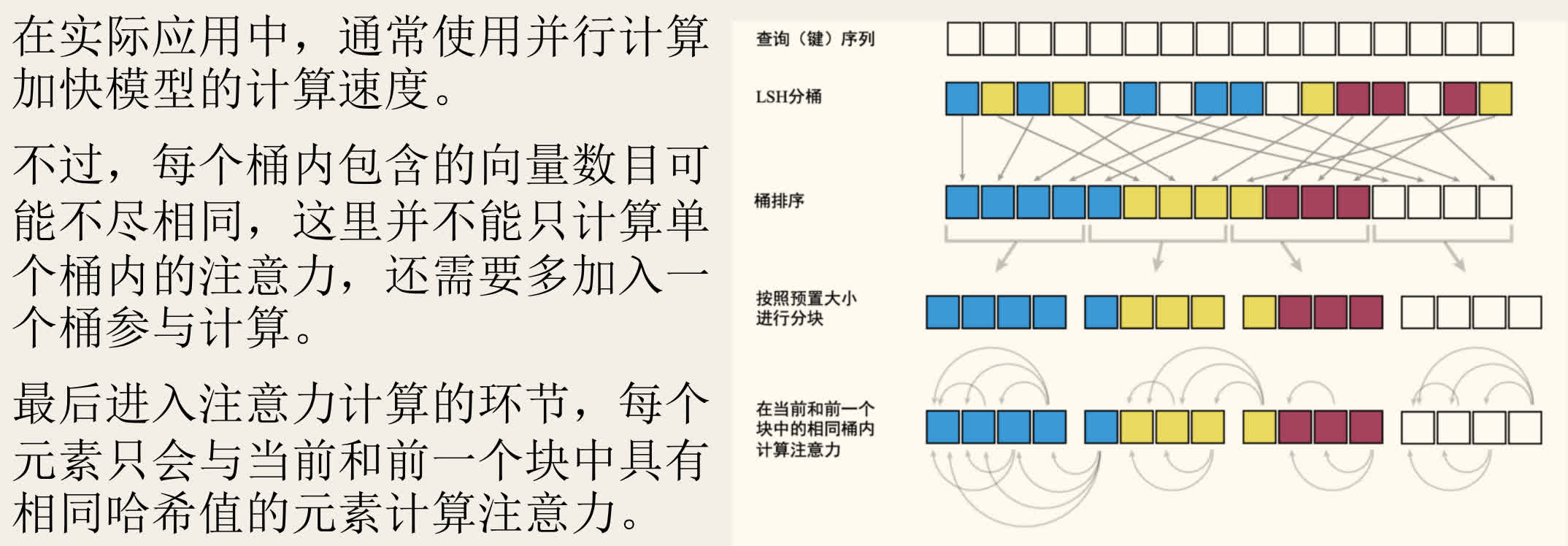
- 在计算注意力时,每个 Query 只需关注与其在同一个桶内的 Key(以及可能的前一个桶,以处理边界情况)。
- 具体实现:对序列按桶 ID 排序,然后分块(chunk),在块内计算完整的注意力。
- 复杂度:将注意力计算复杂度从 降低到近似 。
- 多轮 LSH:为降低 LSH 失败(相似向量被分到不同桶)的概率,可以并行执行多轮 LSH,取结果的并集。
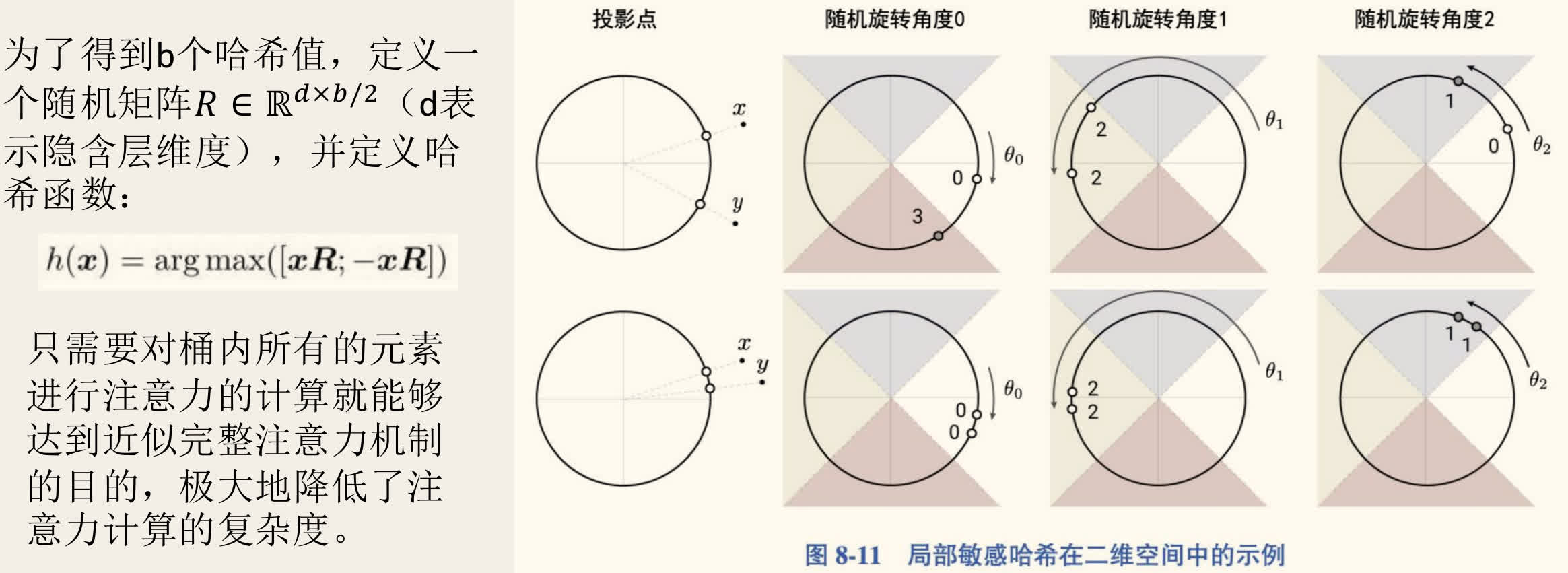
- 同时考虑 与 ,以考虑正相关和负相关的情况(只是剔除不相关的词)。
- 可逆残差网络:
- 动机:标准 Transformer 需要存储每一层的激活值以供反向传播计算梯度,内存消耗随层数线性增长。
- 方法:借鉴 RevNet,设计可逆的 Transformer 层。在前向传播时,每一层的激活值可以根据下一层的激活值重新计算出来,因此无需存储中间层的激活值。
- 效果:显著降低了训练时的内存占用,使得训练更深、更长的模型成为可能。
Longformer
Longformer: The Long-Document Transformer
Longformer 提出了一种结合局部窗口注意力(Sliding Window Attention)和全局注意力(Global Attention)的稀疏注意力(Sparse Attention)机制。
注意力模式:
- 滑动窗口注意力(Sliding Window Attention):
- 每个词只关注其左右固定大小(窗口大小 )的邻近词。
- 复杂度为 ,远小于 。
- 扩张滑动窗口注意力(Dilated Sliding Window Attention):
- 在滑动窗口的基础上,引入空洞(dilation),即窗口内词的采样间隔大于 1。
- 可以在不增加计算量的情况下,扩大感受野(receptive field)。
- 全局注意力(Global Attention):
- 允许少数预先指定的词(例如
[CLS]标记、任务相关的特殊标记如问答任务中的问题词)能够关注序列中的所有其他词,并且所有其他词也能关注这些全局词。 - 这对于需要整合全局信息的任务(如文本分类、问答)至关重要。
- 复杂度仍为线性 (假设全局词数量远小于 )。
- 允许少数预先指定的词(例如
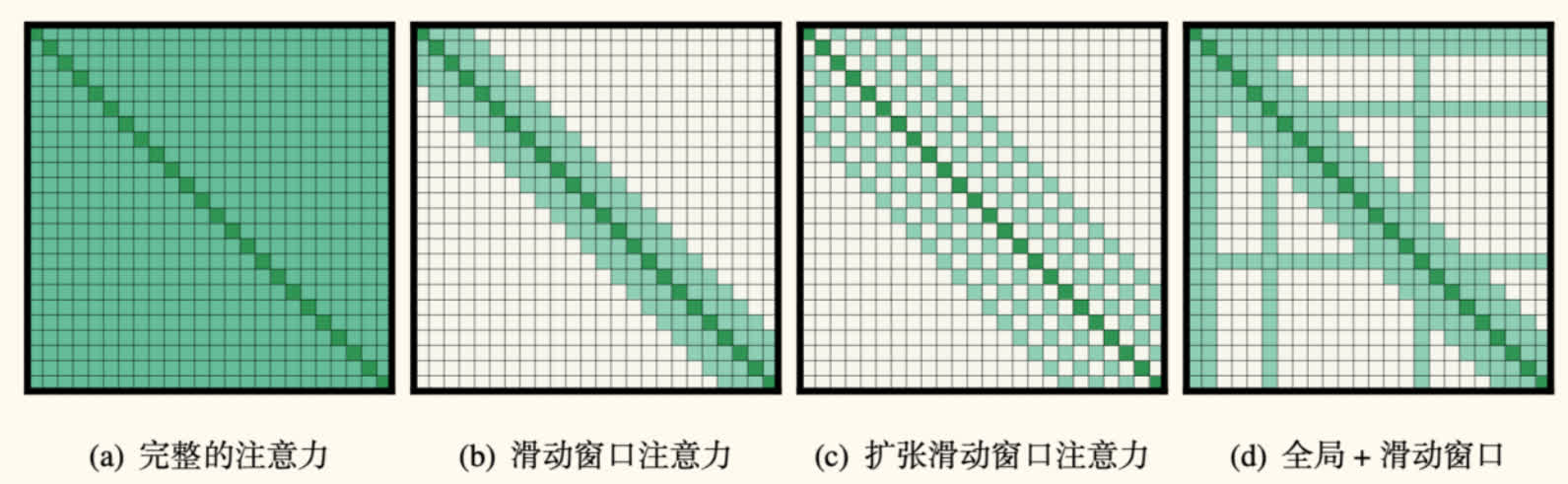
Longformer 通过组合这些稀疏模式,实现了对长达 4096 甚至更长序列的高效处理,同时保持了较强的建模能力。
BigBird
BigBird: Transformers for Longer Sequences
BigBird 同样采用稀疏注意力机制,其目标是设计一种既能逼近完全 Transformer 能力,又保持线性复杂度的稀疏模式。
BigBird 结合了三种注意力机制:
- 随机注意力(Random Attention):
- 每个 Query 随机选择 个 Key 进行关注。
- 窗口注意力(Window Attention):
- 每个 Query 关注其邻近的 个 Key(与 Longformer 类似)。
- 全局注意力(Global Attention):
- 少数( 个)「全局」词可以关注所有词,并且所有词都可以关注这些全局词(与 Longformer 类似)。BigBird 区分了内部 Transformer 模式(从输入中选择全局词)和外部 Transformer 模式(添加额外的全局标记)。
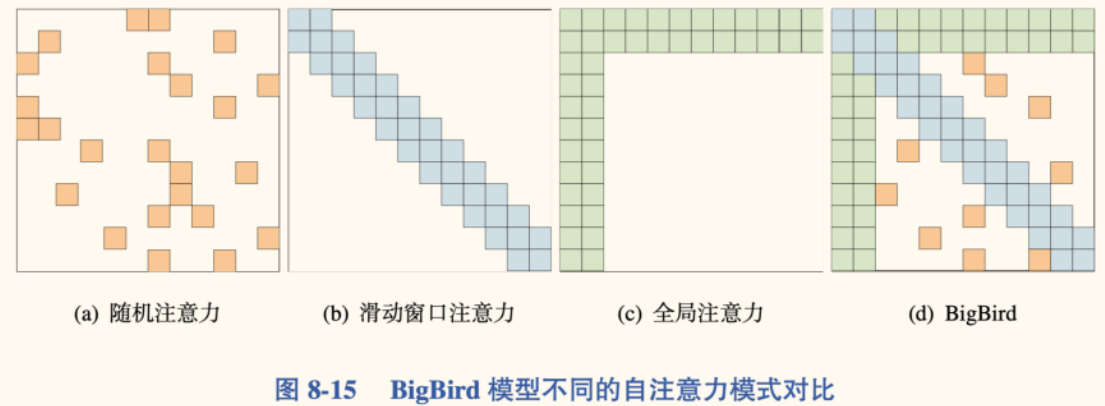
BigBird 的理论分析表明,这种组合的稀疏注意力模式可以模拟完全 Transformer 的许多性质(如图灵完备性),并在多种长文本任务上取得了优异表现。
长文本处理模型对比
| 模型 | 主要思想 | 注意力机制 | 复杂度(近似) |
|---|---|---|---|
| Transformer | 完全自注意力 | Full Attention | |
| Transformer-XL | 片段循环 | Full Attention + State Reuse | |
| Reformer | 效率优化 | LSH Attention | |
| Longformer | 稀疏注意力 | Window + Global Attention | |
| BigBird | 稀疏注意力 | Random + Window + Global Attn. |
表中复杂度主要指注意力计算部分。Transformer-XL 本身注意力复杂度仍是平方级,但通过片段循环处理了更长的有效上下文。Reformer, Longformer, BigBird 等通过稀疏化将复杂度降低到线性或接近线性。
模型蒸馏与压缩
预训练语言模型(尤其是大型模型)参数量巨大(动辄数亿甚至千亿),导致存储开销大、推理速度慢,难以部署到资源受限的环境(如移动设备)。模型压缩(Model Compression)和知识蒸馏(Knowledge Distillation, KD)技术旨在在尽可能保持模型性能的前提下,减小模型体积、提升推理速度。
知识蒸馏(Knowledge Distillation)
知识蒸馏是一种常见的模型压缩技术。其核心思想是:训练一个参数量较小的学生模型(Student Model),使其模仿一个参数量较大、性能更好的教师模型(Teacher Model)的行为。通过这种方式,将教师模型的「知识」迁移给学生模型。
DistilBERT
DistilBERT 是 BERT 的一个小型化版本,通过知识蒸馏技术训练得到。
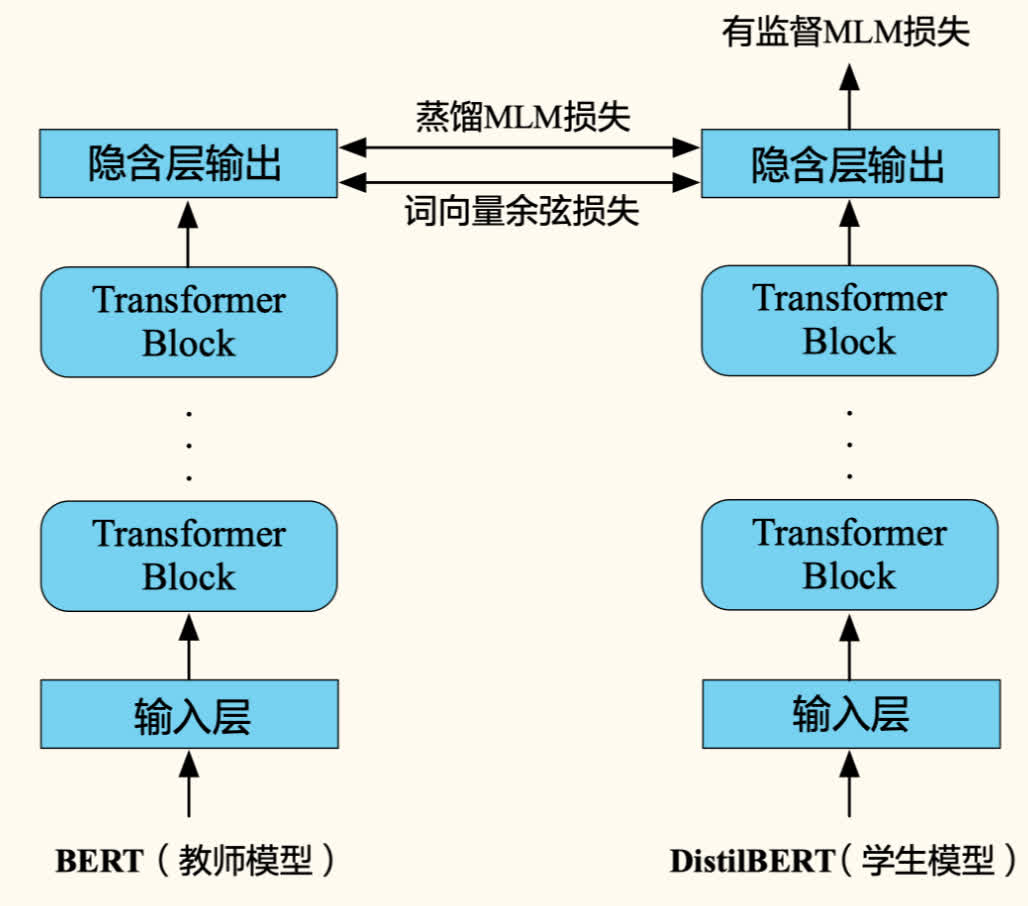
特点:
- 结构:层数减半(6 层),保留了 BERT-base 的隐藏层维度。参数量约为 BERT-base 的 60%。
- 性能:在 GLUE 基准上达到 BERT-base 性能的 97%,但推理速度快 60%。
- 蒸馏方法:在预训练阶段进行蒸馏,移除了 NSP 任务。
- 蒸馏损失函数:由三部分组成:
- 监督 MLM 损失():学生模型使用带标签数据(硬标签)计算的标准 MLM 损失。
( 是真实标签 one-hot, 是学生模型预测概率)
- 蒸馏 MLM 损失():学生模型模仿教师模型输出的软标签(Soft Labels,即教师模型对掩码词的预测概率分布)。通常使用带有温度(Temperature, T)的 Softmax 来平滑教师的输出概率,使学生更容易学习。
( 是教师模型输出的软标签概率,通常 , )
- 余弦嵌入损失():最小化教师模型和学生模型隐藏层状态向量之间的余弦距离,促使学生模型学习教师模型的中间表示。
- 总损失为三者加权和:。
- 监督 MLM 损失():学生模型使用带标签数据(硬标签)计算的标准 MLM 损失。
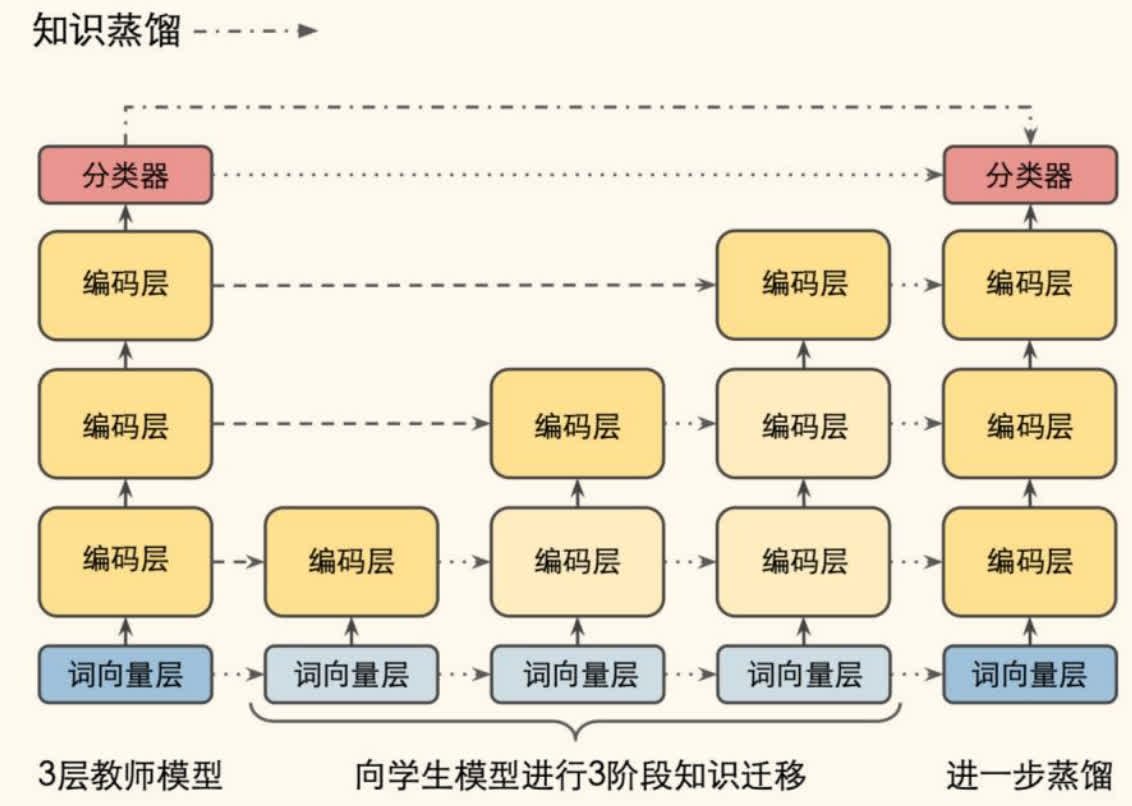
TinyBERT
TinyBERT 是一种更小的 BERT 模型,采用了两阶段蒸馏策略,并在蒸馏过程中匹配了 Transformer 不同层级的知识。
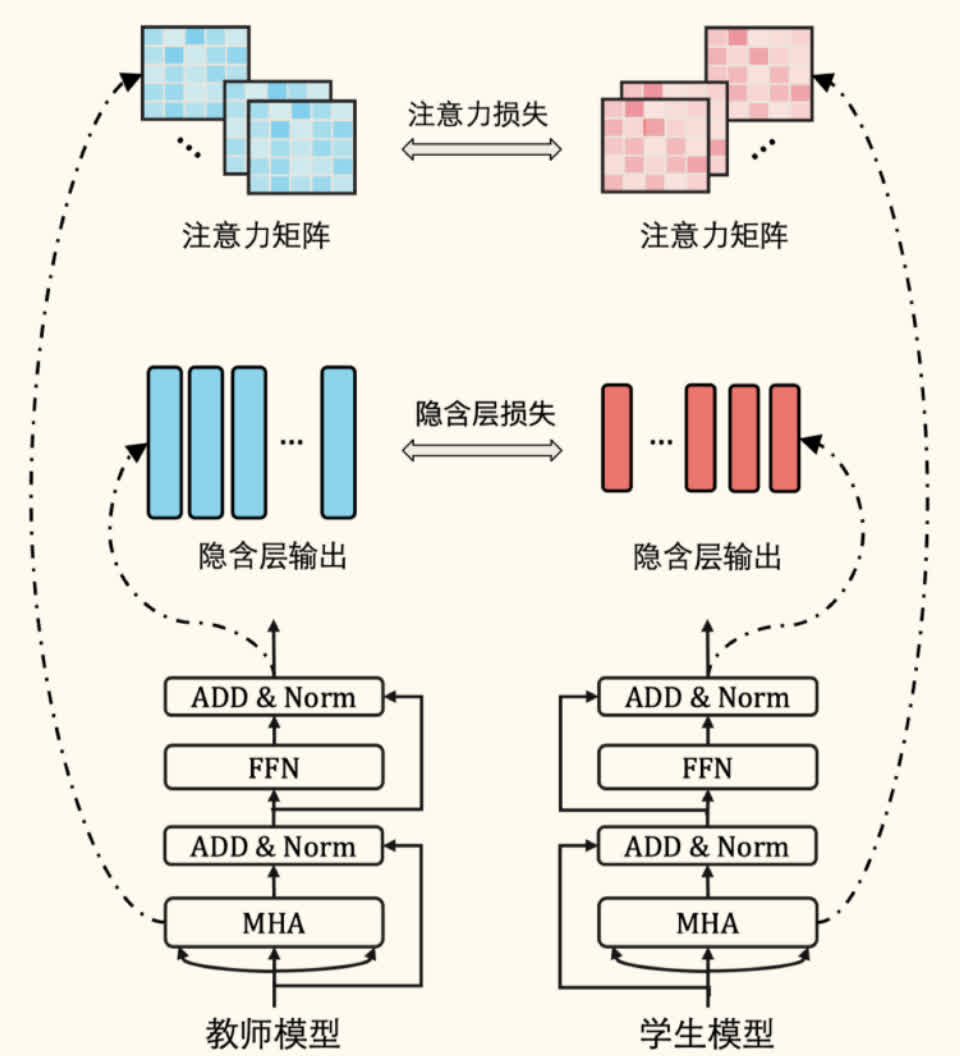
特点:
-
大小:参数量约为 BERT-base 的 13.3%(4 层,隐藏维度 312)。
-
性能:在 GLUE 上达到 BERT-base 性能的 96%。
-
层级蒸馏损失:不仅匹配最后的预测层输出,还匹配了:
- 词向量层损失():学生和教师词向量输出的均方误差(MSE)。
- 隐藏层损失():学生和教师对应 Transformer 层隐藏状态输出的 MSE(需要一个线性变换 匹配维度)。
- 注意力损失():学生和教师对应 Transformer 层注意力矩阵的 MSE(或 KL 散度)。
- 预测层损失():学生和教师最终预测层输出(logits)的交叉熵(或 MSE)。
- 总损失为各部分加权和:。
-
两阶段蒸馏(Two-Stage Distillation):
- 通用蒸馏(General Distillation):在大规模无标注语料上,使用原始 BERT 作为教师,训练一个通用的 TinyBERT 模型(主要进行 MLM 任务蒸馏)。
- 特定任务蒸馏(Task-Specific Distillation):在下游任务的标注数据上,使用精调过的 BERT 作为教师,并结合数据增强(Data Augmentation)技术,对通用 TinyBERT 进行进一步蒸馏,得到针对特定任务的 TinyBERT。
graph LR
subgraph 数据准备
A[大规模语料] --> B(通用蒸馏<br/>教师:BERT-base<br/>任务:MLM);
D[任务数据] --> E(数据增强);
E --> F[增强后任务数据];
end
subgraph 模型蒸馏
B --> C[通用 TinyBERT];
C & F --> G(特定任务蒸馏<br/>教师:Fine-tuned BERT<br/>任务:下游任务);
G --> H[精调后 TinyBERT];
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style D fill:#f9f,stroke:#333,stroke-width:2px
style F fill:#fcf,stroke:#333,stroke-width:2px
style C fill:#ccf,stroke:#333,stroke-width:2px
style H fill:#aaf,stroke:#333,stroke-width:2px
classDef process fill:#e2e2e2,stroke:#333,stroke-width:2px,rx:5px,ry:5px
classDef data fill:#ffe4e1,stroke:#333,stroke-width:2px
class B,E,G process
class A,D,F,C,H dataMobileBERT
MobileBERT 旨在设计一个既小又快,同时性能接近 BERT-base 的模型,特别关注移动端部署。
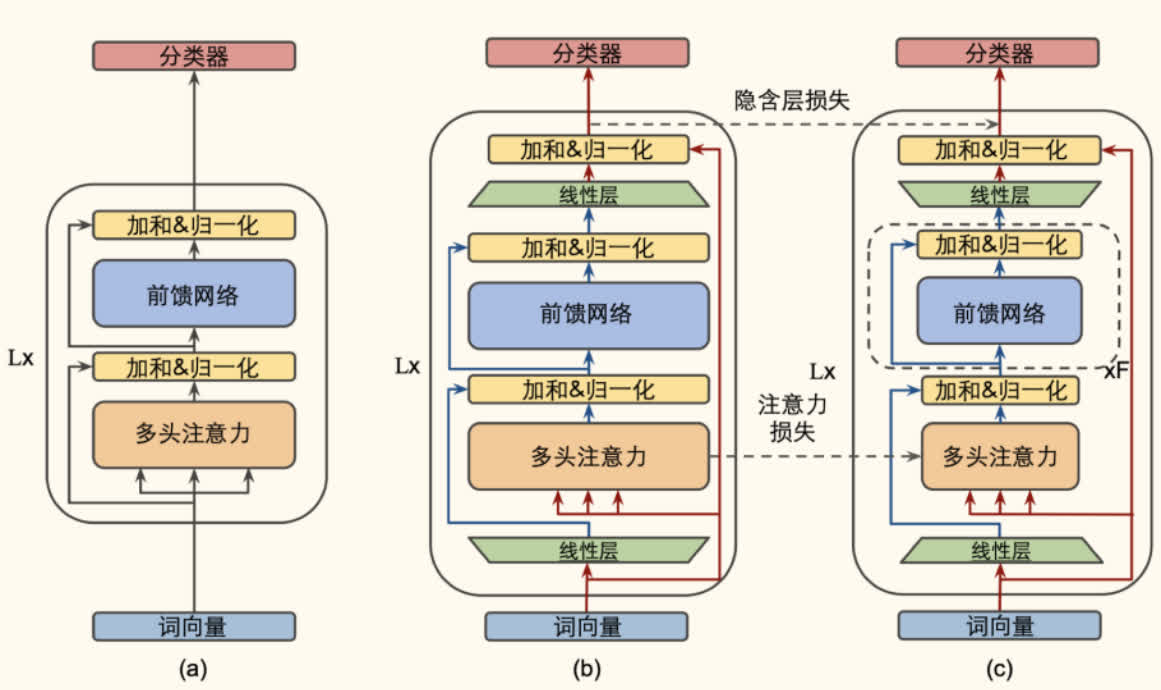
特点:
- 结构:深度与 BERT-large 相同(24 层),但通过精心设计的瓶颈结构(Bottleneck Structure)和堆叠前馈网络(Stacked FFNs)大幅减少了每层的参数量,使其整体比 BERT-base 更「苗条」。参数量约为 BERT-base 的 23.2%。
- 性能:在 GLUE 上达到 BERT-base 性能的 99.2%,推理速度快 5.5 倍。
- 蒸馏损失:包括 MLM 损失、隐含层匹配损失(Feature Map Transfer)和注意力匹配损失(Attention Transfer,使用 KL 散度)。
- 渐进式知识迁移(Progressive Knowledge Transfer):
- 采用逐层训练的策略。首先直接拷贝教师模型的词向量层和最终输出层给学生模型(这些层在后续训练中冻结或只微调)。
- 然后,逐步训练学生模型的中间 Transformer 层。训练学生模型的第 层时,以教师模型的第 层( 是层映射函数)的输出作为监督信号,同时冻结学生模型中所有层数小于 的参数。
TextBrewer
TextBrewer: A PyTorch-based Knowledge Distillation Toolkit
TextBrewer 是一个开源的、专为 NLP 领域设计的知识蒸馏工具包。
特点:
- 易用性:提供了简洁的 API,只需少量代码即可实现复杂的蒸馏流程。
- 灵活性:支持多种蒸馏方法(软标签、中间层表示匹配等)的自由组合,支持自定义损失函数和适配器(adaptor)。
- 模型无关:适用于多种模型结构(尤其 Transformer 类)。
- 非侵入式:无需修改教师或学生模型的内部代码。
- 功能丰富:包含多种预设配置、损失函数、学习率调度器以及模型分析工具。
- 架构:主要包括 Distillers(执行蒸馏)、Configurations(配置)和 Utilities(辅助工具)。
- 实验效果:展示了其蒸馏效果,例如 T6(6 层 BERT)能达到教师 99% 性能,T4-tiny 优于 TinyBERT,并支持多教师蒸馏。
生成模型
除了优化判别式任务(如分类、标注)的表示能力,预训练模型在生成式任务(如文本摘要、机器翻译、对话生成)中也扮演着越来越重要的角色。本节介绍几种代表性的生成式或具备生成能力的预训练模型。
BART
BART: Denoising Sequence-to-Sequence Pre-training
BART 是一种基于标准 Transformer 编码器-解码器(Encoder-Decoder)架构的预训练模型,其预训练任务是去噪自编码(Denoising Autoencoding)。
结构:
- 编码器:双向 Transformer(类似 BERT)。
- 解码器:自回归 Transformer(类似 GPT)。
预训练:
- 通过对原始文本施加各种噪声(corruption)来构造输入,然后训练模型恢复原始文本。
- 噪声类型包括:
- 单词掩码(Token Masking):随机替换部分单词为
[MASK]。 - 单词删除(Token Deletion):随机删除部分单词。
- 文本填充(Text Infilling):将一个或多个连续文本片段(span)替换为单个
[MASK]标记,模型需要预测被替换的完整片段。 - 句子排列变换(Sentence Permutation):随机打乱文档中句子的顺序。
- 文档旋转(Document Rotation):随机选择一个词作为文档的起始词,进行循环位移。
- 单词掩码(Token Masking):随机替换部分单词为
微调:
- 序列分类:将相同输入送入编码器和解码器,使用解码器最终时刻的隐藏状态进行分类。
- 序列标注:将相同输入送入编码器和解码器,使用解码器每个时刻的隐藏状态进行标注。
- 序列生成(如摘要、翻译):编码器处理输入序列,解码器自回归地生成输出序列。对于机器翻译,通常需要将 BART 的编码器替换为一个针对源语言的新编码器。
UniLM
UniLM: Unified Language Model Pre-training
UniLM (Unified Language Model) 旨在用一个 Transformer 模型统一处理双向(Bidirectional)、单向(Unidirectional)和序列到序列(Sequence-to-Sequence)三种语言模型任务。
核心思想:
-
使用不同的自注意力掩码矩阵(Self-Attention Masks)来控制每个词能关注到的上下文范围,从而在同一个模型框架下实现不同的建模方式。
- 双向 LM(BERT-like):允许每个词关注所有其他词(除了自身)。
- 单向 LM(GPT-like):只允许每个词关注其左侧(或右侧)的词和自身。
- Seq2Seq LM:对于源序列部分(Source),使用双向掩码;对于目标序列部分(Target),使用单向掩码,且目标序列词只能关注源序列所有词和目标序列中其左侧的词。
-
预训练时,通过混合训练这三种任务(共享模型参数),使得 UniLM 能够同时胜任 NLU(自然语言理解)和 NLG(自然语言生成)任务。
T5
T5: Text-to-Text Transfer Transformer
T5 模型的核心理念是将所有 NLP 任务都统一为「文本到文本」(Text-to-Text)的格式。
特点:
- 统一任务形式:通过在输入文本前添加任务相关的特定前缀(Task Prefix),指示模型需要执行的任务(如 "translate English to German:", "summarize:", "cola sentence:")。模型的目标是生成相应的文本输出。
- 模型架构:采用标准的 Transformer Encoder-Decoder 架构。
- 预训练任务:提出了一种基于跨度破坏(Span Corruption)的无监督预训练任务,也称为掩码语言建模的变体(Masked Language Modeling Variant)。
- 随机选择输入文本中的一些连续片段(span)。
- 用一个唯一的哨兵标记(Sentinel Token,如
<X>,<Y>,<Z>…)替换每个被选中的片段。 - 模型的目标是预测出所有被替换掉的片段内容,每个片段前加上对应的哨兵标记,并按顺序拼接。
- 示例:
- 原始文本:
Thank you for inviting me to your party last week. - 输入:
Thank you <X> me to your party <Y> week. - 目标输出:
<X> for inviting <Y> last <Z>(这里<Z>表示序列结束)
- 原始文本:
- 数据集:使用了大规模、经过清洗的 Common Crawl 数据集,称为 C4 (Colossal Clean Crawled Corpus)。
GPT-3
GPT-3: Language Models are Few-Shot Learners
GPT-3 是 OpenAI 提出的超大规模自回归语言模型(参数量达 1750 亿),其最引人注目的特点是强大的少样本学习(Few-Shot Learning)、单样本学习(One-Shot Learning)甚至零样本学习(Zero-Shot Learning)能力。
核心思想:
- 规模效应(Scaling Laws):模型性能随着模型规模(参数量)、数据量和计算量的增加而持续提升。
- 上下文学习(In-Context Learning):对于下游任务,GPT-3 无需进行传统的模型微调(Fine-tuning,即更新模型权重)。而是通过在**模型输入(提示,Prompt)**中提供任务描述和少量示例,模型就能理解任务要求并生成正确的输出。
- Few-Shot:提供任务描述和几个示例。
- One-Shot:提供任务描述和一个示例。
- Zero-Shot:只提供任务描述,不提供示例。
示例(机器翻译):
1 | Translate English to French: |
GPT-3 的出现标志着超大规模预训练模型时代的到来,并展示了其在通用人工智能(AGI)方向上的潜力。
CTRL
CTRL: Conditional Transformer Language Model
CTRL 旨在实现可控的文本生成(Controllable Text Generation),即根据用户指定的控制代码(Control Codes)来生成符合特定属性(如领域、风格、主题、实体关系等)的文本。
核心思想:
- 条件生成:在输入文本的开头添加代表所需属性的控制代码(如
Reviews,Horror,Links等),指导模型生成相应内容的文本。 - 模型结构:仍然是基于 Transformer 的自回归语言模型。
- 训练:在包含元信息(如来源、主题、评分等)的大规模文本数据上进行训练,将元信息作为控制代码。
- 即插即用控制(Plug and Play Controllable Generation):后续研究提出了一种无需重新训练即可控制预训练模型(如 GPT-2)生成的方法:
- 前向过程:使用预训练语言模型生成文本,同时使用一个属性判别器(Attribute Discriminator) 判断当前生成文本 是否满足目标属性 。
- 反向过程:利用属性判别器回传的梯度,更新语言模型内部的隐藏状态(而非模型参数),使其朝着更符合目标属性的方向调整。
- 重采样:基于更新后的隐藏状态和概率分布,重新采样生成下一个词。
这种方法使得在不牺牲预训练模型通用性的前提下,实现了对生成内容的多样化控制。