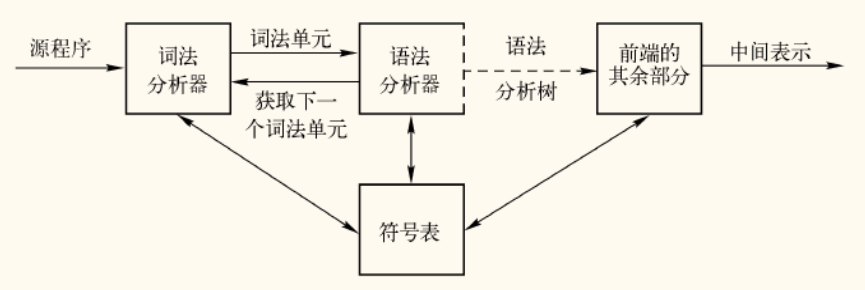
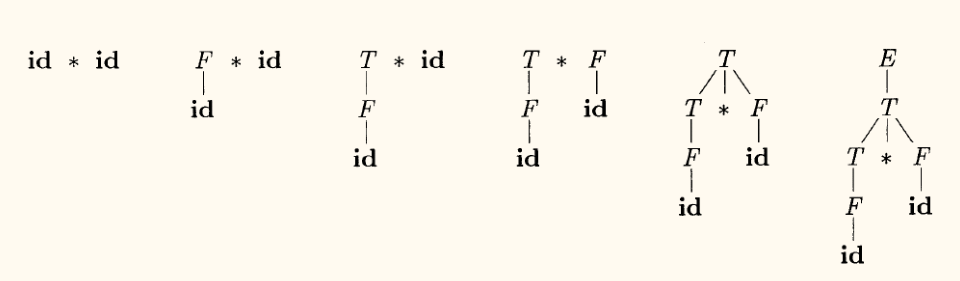语法分析的角色与任务
在编译器的整体流程中,语法分析 (Syntax Analysis 或 Parsing)是继词法分析之后的第二个核心阶段。它扮演着承上启下的关键角色。
语法分析器
语法分析器 (Parser)从词法分析器获取词法单元 (token)序列作为输入,其核心任务是根据语言的语法规则,将这个线性的序列构造成一个能够反映程序层次结构的树形表示,通常是语法分析树 (Parse Tree)或抽象语法树 (Abstract Syntax Tree, AST)。
语法分析器的主要功能可以概括为:
结构验证 :检查词法单元序列是否符合语言的语法规则。例如,i f \mathbf{if} if t h e n \mathbf{then} then e l s e \mathbf{else} else 结构构建 :为合法的源程序构建一个数据结构(通常是树),清晰地表示出程序的语法结构。这个结构是后续语义分析和代码生成的基础。错误处理 :对于不符合语法的程序,能够检测、报告错误,并尝试从错误中恢复,以便继续分析程序的其余部分,从而一次性报告多个错误。
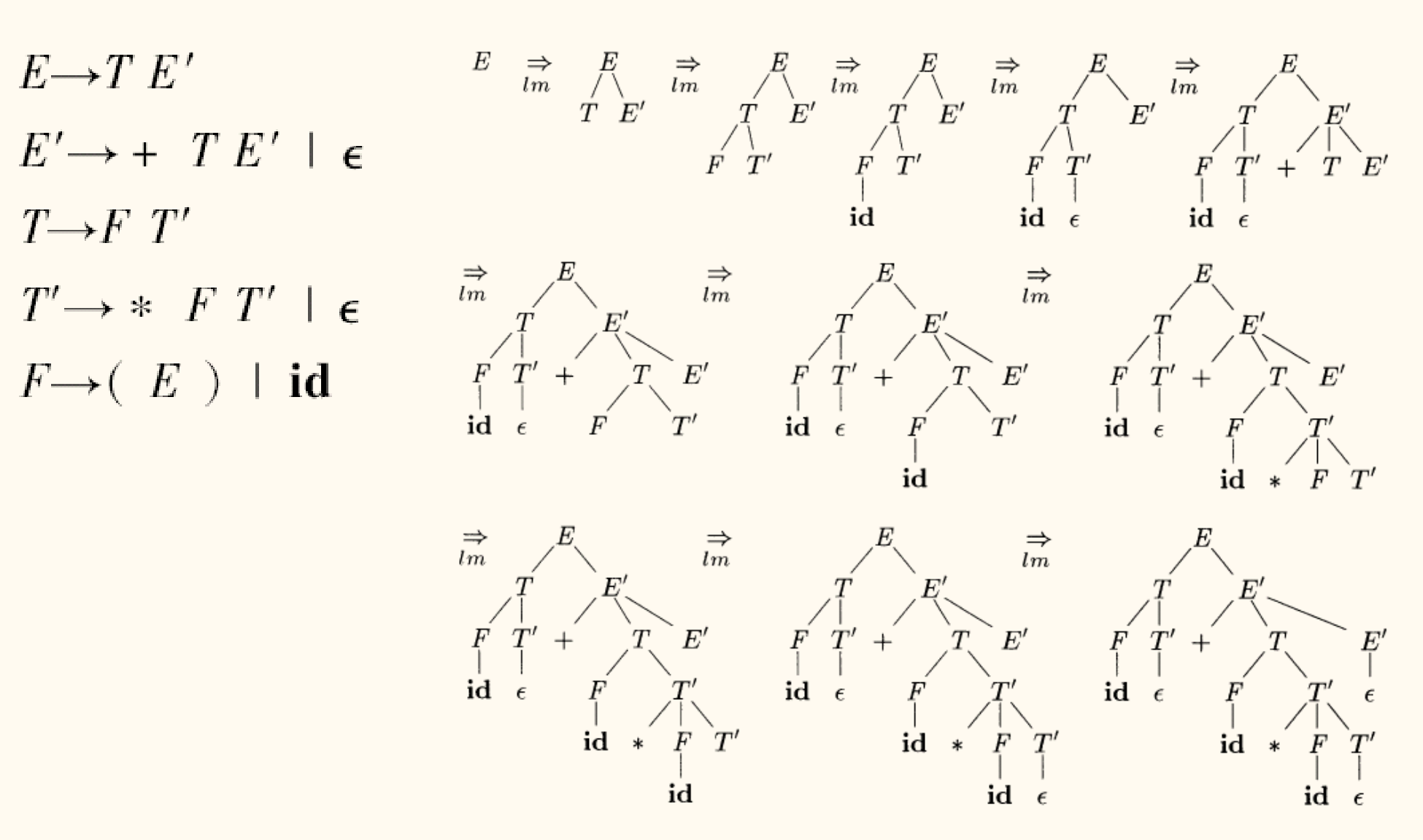
考虑一个简单的赋值语句:position = initial + rate * 60
词法分析器 将其转换为词法单元流:<id, 1> <assign, => <id, 2> <plus, +> <id, 3> <mul, *> <number, 60>
语法分析器 接收这个流,并根据算术表达式的语法规则(如乘法优先于加法),构建出如下的语法分析树:
1
2
3
4
5
6
7
= /\ <id, 1> + /\ <id, 2> * /\ <id, 3> 60
这棵树明确地表达了运算的层次和优先级,即 rate * 60 是一个子树,其结果再与 initial 相加。
上下文无关文法
为了精确地描述程序设计语言的语法结构,我们需要一种形式化的工具。上下文无关文法 (Context-Free Grammar, CFG)就是这样一种强大而简洁的表示方法。它能够自然地描述大多数程序设计语言中存在的嵌套 和递归 结构,如算术表达式、if-else 语句、循环等。
上下文无关文法
一个上下文无关文法 G G G ( V T , V N , P , S ) (V_T, V_N, P, S) ( V T , V N , P , S )
V T V_T V T 终结符号 (terminal symbol)的集合。它们是构成语言的基本符号,相当于词法分析中的词法单元,如 i d , n u m b e r , + , i f \mathbf{id}, \mathbf{number}, +, \mathbf{if} id , number , + , if V N V_N V N 非终结符号 (non-terminal symbol)的集合。它们是语法变量,代表了由终结符号构成的串的集合,用于表示语言的层次结构,如 e x p r e s s i o n , s t a t e m e n t \mathit{expression}, \mathit{statement} expression , statement P P P 产生式 (production)的集合。它定义了非终结符号可以被替换(重写)的方式,因此又可称为重写规则 (rewriting rule)。
每个产生式形如 A → α A \to \alpha A → α A A A 头 ),α \alpha α 体 )。
S S S 开始符号 。它是一个特殊的非终结符号,表示文法所定义的整个语言。
符号表示约定
为了书写方便,我们通常遵循以下约定:
非终结符号 :大写字母,如 A , B , E , T , F A, B, E, T, F A , B , E , T , F s t m t \mathit{stmt} stmt 终结符号 :小写字母、数字、标点符号,或粗体名称如 i d \mathbf{id} id 文法符号 :大写字母 X , Y , Z X, Y, Z X , Y , Z 文法符号串 :小写希腊字母 α , β , γ \alpha, \beta, \gamma α , β , γ ε \varepsilon ε 开始符号 :通常是文法中第一个产生式的头,或者显式指定为 S S S 多选产生式 :将多个头的产生式 A → α 1 , A → α 2 , … , A → α n A \to \alpha_1, A \to \alpha_2, \ldots, A \to \alpha_n A → α 1 , A → α 2 , … , A → α n A → α 1 ∣ α 2 ∣ ⋯ ∣ α n A \to \alpha_1 \mid \alpha_2 \mid \dots \mid \alpha_n A → α 1 ∣ α 2 ∣ ⋯ ∣ α n
算术表达式文法
一个描述加法和乘法表达式的经典文法如下:
这个文法不仅定义了合法的表达式,还通过层次结构(E → T → F E \to T \to F E → T → F ∗ * ∗ + + +
推导
推导 (Derivation)是从文法的开始符号出发,通过反复应用产生式进行重写,最终得到一个由终结符号组成的串(即句子)的过程。
一步推导 :如果 A → γ A \to \gamma A → γ α A β \alpha A \beta α A β α γ β \alpha \gamma \beta α γ β α A β ⇒ α γ β \alpha A \beta \Rightarrow \alpha \gamma \beta α A β ⇒ α γ β 多步推导 :
α ⇒ ∗ β \alpha \xRightarrow{*} \beta α ∗ β α \alpha α β \beta β α ⇒ + β \alpha \xRightarrow{+} \beta α + β α \alpha α β \beta β
推导示例
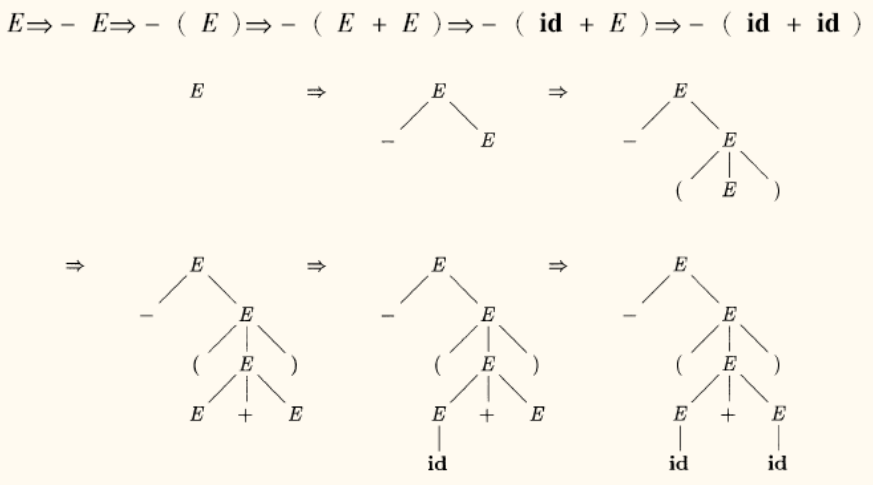
使用文法 E → E + E ∣ E ∗ E ∣ − E ∣ ( E ) ∣ i d E \to E + E \mid E * E \mid -E \mid (E) \mid \mathbf{id} E → E + E ∣ E ∗ E ∣ − E ∣ ( E ) ∣ id − ( i d + i d ) -(\mathbf{id} + \mathbf{id}) − ( id + id ) E ⇒ − E ⇒ − ( E ) ⇒ − ( E + E ) ⇒ − ( i d + E ) ⇒ − ( i d + i d ) E \Rightarrow -E \Rightarrow -(E) \Rightarrow -(E + E) \Rightarrow -(\mathbf{id} + E) \Rightarrow -(\mathbf{id} + \mathbf{id}) E ⇒ − E ⇒ − ( E ) ⇒ − ( E + E ) ⇒ − ( id + E ) ⇒ − ( id + id )
句型、句子和语言
句型 (Sentential Form):从开始符号 S S S α \alpha α
句型中可以同时包含终结符和非终结符 ,也可以是空串 ε \varepsilon ε
即 S ⇒ ∗ α S \xRightarrow{*} \alpha S ∗ α
句子 (Sentence):一个不包含任何非终结符号 的句型被称为该文法的一个句子。语言 (Language):由一个文法 G G G 语言 ,记为 L ( G ) L(G) L ( G ) 所有句子的集合 。
ω ∈ L ( G ) \omega \in L(G) ω ∈ L ( G ) S ⇒ ∗ ω S \xRightarrow{*} \omega S ∗ ω ω \omega ω
最左推导与最右推导
在推导的每一步,如果句型中有多个非终结符号,我们可以选择替换其中任意一个。为了使推导过程规范化,通常采用两种策略:
最左推导 (Leftmost Derivation):在每一步推导中,总是选择句型中最左边 的非终结符号进行替换。记作 ⇒ l m ∗ \xRightarrow[\mathrm{lm}]{*} ∗ lm 最右推导 (Rightmost Derivation):在每一步推导中,总是选择句型中最右边 的非终结符号进行替换。记作 ⇒ r m ∗ \xRightarrow[\mathrm{rm}]{*} ∗ rm
语法分析树
语法分析树 (Parse Tree)是推导过程的一种图形化表示,它直观地展示了一个句子是如何由文法的产生式生成的,并清晰地反映了句子的语法结构。
一棵语法分析树具有以下特征:
根节点 :标号为文法的开始符号。内部节点 :标号为非终结符号。叶子节点 :标号为终结符号或 ε \varepsilon ε 父子关系 :如果一个内部节点 A A A X 1 , X 2 , … , X n X_1, X_2, \dots, X_n X 1 , X 2 , … , X n A → X 1 X 2 … X n A \to X_1 X_2 \dots X_n A → X 1 X 2 … X n
一棵语法分析树的所有叶子节点从左到右连接起来,就构成了该树的产出 (yield),它是一个句型。如果该句型只包含终结符,那么它就是一个句子。
树与推导的对应关系
一棵语法分析树唯一地对应一个最左推导 和一个最右推导 。反之,一个最左(或最右)推导也唯一地确定一棵语法分析树。
然而,一棵树可能对应多个不同的普通推导序列(因为替换顺序不同)。
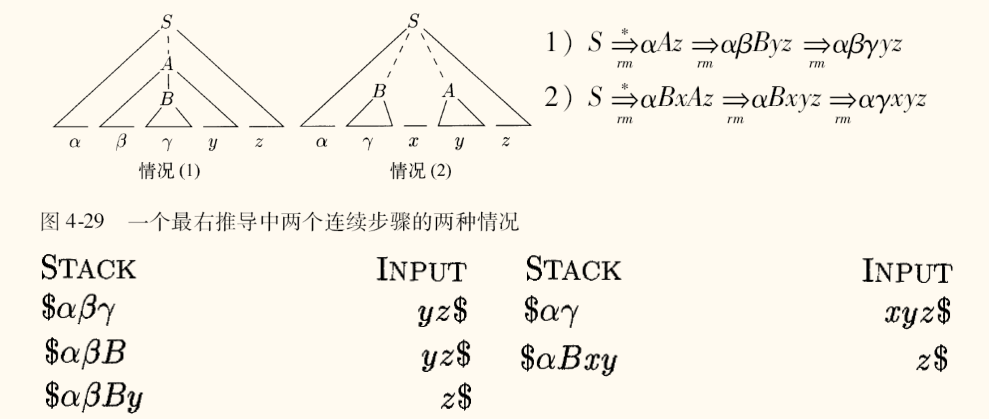
假设有推导序列 A ⇒ α 1 ⇒ α 2 ⇒ ⋯ ⇒ α n A \Rightarrow \alpha_1 \Rightarrow \alpha_2 \Rightarrow \dots \Rightarrow \alpha_n A ⇒ α 1 ⇒ α 2 ⇒ ⋯ ⇒ α n
初始化,α 1 \alpha_1 α 1 A A A
假设已经构造出了 α i − 1 = X 1 X 2 … X k \alpha_{i-1} = X_1 X_2 \dots X_{k} α i − 1 = X 1 X 2 … X k T i − 1 T_{i-1} T i − 1 α i − 1 ⇒ α i \alpha_{i-1} \Rightarrow \alpha_i α i − 1 ⇒ α i X j X_{j} X j β \beta β j j j ε \varepsilon ε β \beta β α i \alpha_i α i T i T_i T i β = ε \beta = \varepsilon β = ε ε \varepsilon ε
重复上述过程,直到构造出 α n \alpha_n α n T n T_n T n
文法的二义性
一个理想的文法应该为每个合法的句子提供唯一一种语法结构解释。
二义性文法
如果一个文法可以为某个句子生成多于一棵 的语法分析树,那么这个文法就是二义性 (ambiguous)的。
二义性对于编译器来说是致命的,因为它意味着同一个程序可以有多种不同的解释(即不同的语义)。
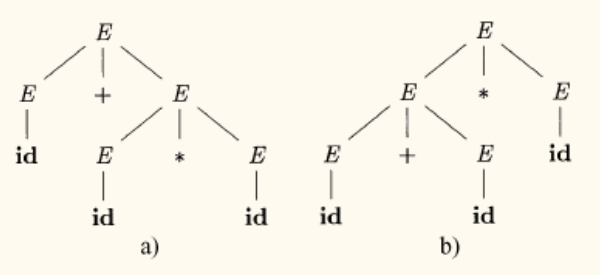
表达式的二义性
考虑文法 E → E + E ∣ E ∗ E ∣ i d E \to E + E \mid E * E \mid \mathbf{id} E → E + E ∣ E ∗ E ∣ id i d + i d ∗ i d \mathbf{id} + \mathbf{id} * \mathbf{id} id + id ∗ id
树 a 对应 i d + ( i d ∗ i d ) \mathbf{id} + (\mathbf{id} * \mathbf{id}) id + ( id ∗ id )
树 b 对应 ( i d + i d ) ∗ i d (\mathbf{id} + \mathbf{id}) * \mathbf{id} ( id + id ) ∗ id
这两种解释显然会导致不同的计算结果。
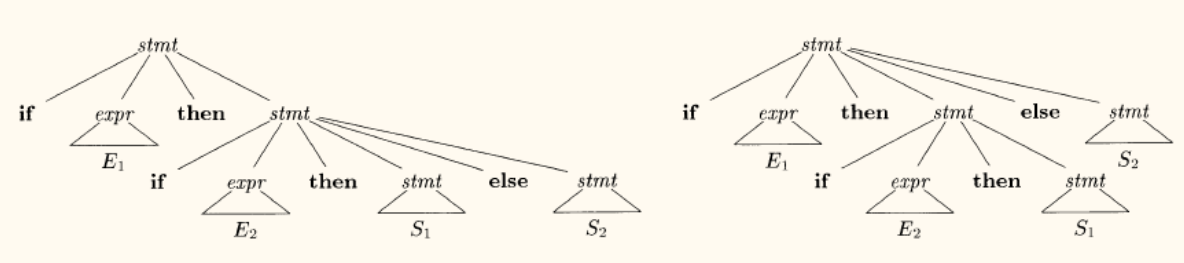
「悬空 e l s e \mathbf{else} else
考虑 i f \mathbf{if} if
s t m t → i f e x p r t h e n s t m t ∣ i f e x p r t h e n s t m t e l s e s t m t ∣ o t h e r \begin{aligned}
\mathit{stmt} \to\ &\ \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt}\\
\mid&\ \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt}\ \mathbf{else}\ \mathit{stmt}\\
\mid &\ \mathit{other}
\end{aligned}
stmt → ∣ ∣ if expr then stmt if expr then stmt else stmt other
对于句子 i f E 1 t h e n i f E 2 t h e n S 1 e l s e S 2 \mathbf{if}\ E_1\ \mathbf{then}\ \mathbf{if}\ E_2\ \mathbf{then}\ S_1\ \mathbf{else}\ S_2 if E 1 then if E 2 then S 1 else S 2
e l s e \mathbf{else} else i f \mathbf{if} if i f E 2 \mathbf{if}\ E_2 if E 2 e l s e \mathbf{else} else i f \mathbf{if} if i f E 1 \mathbf{if}\ E_1 if E 1
这会导致 e l s e \mathbf{else} else
验证文法生成的语言
验证文法 G G G L L L
首先证明 L ( G ) ⊆ L L(G) \subseteq L L ( G ) ⊆ L G G G L L L
然后证明 L ⊆ L ( G ) L \subseteq L(G) L ⊆ L ( G ) L L L L L L G G G
结合上述两点,得出 L ( G ) = L L(G) = L L ( G ) = L
例子
定义语言 L L L G G G
语言 L L L :所有由 n n n a a a n n n b b b n ⩾ 0 n \ge 0 n ⩾ 0
即 L = { a n b n ∣ n ⩾ 0 } = { ε , a b , a a b b , a a a b b b , … } L = \{ a^n b^n \mid n \ge 0 \} = \{ \varepsilon, ab, aabb, aaabbb, \dots \} L = { a n b n ∣ n ⩾ 0 } = { ε , ab , aabb , aaabbb , … }
文法 G G G :
终结符:{ a , b } \{a, b\} { a , b }
非终结符:{ S } \{S\} { S }
产生式:
S → a S b S \to aSb S → a S b S → ε S \to \varepsilon S → ε
证明 L ( G ) ⊆ L L(G) \subseteq L L ( G ) ⊆ L G G G L L L
证明方法 :对推导序列的长度(即产生式应用次数)进行数学归纳。归纳基础 :
当推导序列长度为 1 时,唯一的推导是 S ⇒ ε S \Rightarrow \varepsilon S ⇒ ε
ε \varepsilon ε a 0 b 0 a^0 b^0 a 0 b 0 L L L
归纳假设 :
假设任何长度小于 k k k S ⇒ ∗ w ′ S \xRightarrow{*} w' S ∗ w ′ w ′ w' w ′ L L L
归纳步骤 :
考虑一个长度为 k k k S ⇒ k w S \xRightarrow{k} w S k w
由于 k > 1 k > 1 k > 1 k = 1 k=1 k = 1 S → a S b S \to aSb S → a S b S → ε S \to \varepsilon S → ε
所以,推导形式为 S ⇒ a S b ⇒ k − 1 a w ′ b S \Rightarrow aSb \xRightarrow{k-1} aw'b S ⇒ a S b k − 1 a w ′ b
其中,S ⇒ k − 1 w ′ S \xRightarrow{k-1} w' S k − 1 w ′ k − 1 k-1 k − 1
根据归纳假设,w ′ w' w ′ L L L w ′ = a j b j w' = a^j b^j w ′ = a j b j j ⩾ 0 j \ge 0 j ⩾ 0
因此,w = a ( a j b j ) b = a j + 1 b j + 1 w = a(a^j b^j)b = a^{j+1} b^{j+1} w = a ( a j b j ) b = a j + 1 b j + 1
这个字符串形式 a j + 1 b j + 1 a^{j+1} b^{j+1} a j + 1 b j + 1 L L L a n b n a^n b^n a n b n n = j + 1 n=j+1 n = j + 1
结论 :根据数学归纳法,所有由 G G G L L L L ( G ) ⊆ L L(G) \subseteq L L ( G ) ⊆ L
证明 L ⊆ L ( G ) L \subseteq L(G) L ⊆ L ( G ) L L L G G G
证明方法 :对字符串的长度进行数学归纳。归纳基础 :
当字符串长度为 0 时,唯一的字符串是 ε \varepsilon ε
文法 G G G S → ε S \to \varepsilon S → ε ε \varepsilon ε G G G
归纳假设 :
假设任何长度小于 m m m w ′ ∈ L w' \in L w ′ ∈ L G G G w ′ ∈ L ( G ) w' \in L(G) w ′ ∈ L ( G )
归纳步骤 :
考虑一个长度为 m m m w ∈ L w \in L w ∈ L m > 0 m > 0 m > 0
由于 w ∈ L w \in L w ∈ L w ≠ ε w \ne \varepsilon w = ε a n b n a^n b^n a n b n n > 0 n > 0 n > 0
这意味着 w w w a a a b b b w w w w = a w ′ b w = a w' b w = a w ′ b
那么 w ′ w' w ′ a n − 1 b n − 1 a^{n-1} b^{n-1} a n − 1 b n − 1
显然,w ′ w' w ′ L L L
而且,∣ w ′ ∣ = m − 2 |w'| = m-2 ∣ w ′ ∣ = m − 2 ∣ w ′ ∣ < m |w'| < m ∣ w ′ ∣ < m
根据归纳假设,w ′ w' w ′ G G G S ⇒ ∗ w ′ S \xRightarrow{*} w' S ∗ w ′
现在,我们可以构造 w w w S → a S b ⇒ ∗ a w ′ b = w S \to aSb \xRightarrow{*} a w' b = w S → a S b ∗ a w ′ b = w
因此,w w w G G G
结论 :根据数学归纳法,所有属于 L L L G G G L ⊆ L ( G ) L \subseteq L(G) L ⊆ L ( G )
结合上述两点,得出 L ( G ) = L L(G) = L L ( G ) = L
由于 L ( G ) ⊆ L L(G) \subseteq L L ( G ) ⊆ L L ⊆ L ( G ) L \subseteq L(G) L ⊆ L ( G ) G G G L L L
为语法分析器设计文法
虽然上下文无关文法很强大,但并非所有文法都适合直接用于构建高效的语法分析器。特别是自顶向下的分析方法,对文法的形式有严格要求。因此,在进行语法分析之前,我们常常需要对文法进行改造。
主要的处理步骤包括:
消除二义性 :重写文法以确保每个句子只有唯一的分析树。消除左递归 :改造产生式,以避免自顶向下分析器陷入无限循环。提取左公因子 :改造产生式,以帮助分析器在面临多个选择时做出确定性的决策。
消除二义性
消除二义性没有通用的算法,通常需要根据我们期望的语义(如运算符的优先级和结合性)来重写文法。
消除左递归
左递归
一个文法是左递归 (Left Recursive)的,如果它存在一个非终结符号 A A A A A A A A A A ⇒ + A α A \xRightarrow{+} A\alpha A + A α
立即左递归 :存在形如 A → A α A \to A\alpha A → A α
左递归对于自顶向下的分析器是致命的,因为它会导致分析过程无限循环。
消除立即左递归
立即左递归消除
对于一组具有立即左递归 的产生式:
A → A α 1 ∣ A α 2 ∣ ⋯ ∣ A α m ∣ β 1 ∣ β 2 ∣ ⋯ ∣ β n A \to A\alpha_1 \mid A\alpha_2 \mid \dots \mid A\alpha_m \mid \beta_1 \mid \beta_2 \mid \dots \mid \beta_n
A → A α 1 ∣ A α 2 ∣ ⋯ ∣ A α m ∣ β 1 ∣ β 2 ∣ ⋯ ∣ β n
其中 β i \beta_i β i A A A
可以等价地替换为:
A T m → β 1 T m A ′ T m ∣ β 2 T m A ′ T m ∣ ⋯ ∣ β n T m A ′ T m A ′ T m → α 1 T m A ′ T m ∣ α 2 T m A ′ T m ∣ ⋯ ∣ α m T m A ′ T m ∣ ε T m \gdef\nt#1{\rlap{$#1$}\phantom{T_m}}
\begin{aligned}
\nt A &\to \nt{\beta_1}\nt{A'} \mid \nt{\beta_2} \nt{A'} \mid \dots \mid \nt{\beta_n} \nt{A'} \\
\nt{A'} &\to \nt{\alpha_1}\nt{A'} \mid \nt{\alpha_2} \nt{A'} \mid \dots \mid \nt{\alpha_m} \nt{A'} \mid \nt\varepsilon
\end{aligned}
A T m A ′ T m → β 1 T m A ′ T m ∣ β 2 T m A ′ T m ∣ ⋯ ∣ β n T m A ′ T m → α 1 T m A ′ T m ∣ α 2 T m A ′ T m ∣ ⋯ ∣ α m T m A ′ T m ∣ ε T m
这个变换的直观理解是:任何由 A A A β i \beta_i β i α j \alpha_{j} α j
例子
原始文法:
E T m → E T m + T m T T m ∣ T T m T T m → T T m ∗ T m F T m ∣ F T m \begin{aligned}
\nt{E} &\to \nt{E} \nt{+} \nt{T} \mid \nt T \\
\nt{T} &\to \nt{T} \nt{*} \nt{F} \mid \nt F
\end{aligned}
E T m T T m → E T m + T m T T m ∣ T T m → T T m ∗ T m F T m ∣ F T m
消除左递归后:
E T m → T T m E ′ T m E ′ T m → + T m T T m E ′ T m ∣ ε T m T T m → F T m T ′ T m T ′ T m → ∗ T m F T m T ′ T m ∣ ε T m \begin{aligned}
\nt{E} &\to \nt{T} \nt{E'} \\
\nt{E'} &\to \nt{+} \nt{T} \nt{E'} \mid \nt{\varepsilon} \\
\nt{T} &\to \nt{F} \nt{T'} \\
\nt{T'} &\to \nt{*} \nt{F} \nt{T'} \mid \nt{\varepsilon}
\end{aligned}
E T m E ′ T m T T m T ′ T m → T T m E ′ T m → + T m T T m E ′ T m ∣ ε T m → F T m T ′ T m → ∗ T m F T m T ′ T m ∣ ε T m
消除一般左递归
多步左递归
一个文法是多步左递归 (Indirect Left Recursive)的,如果它存在一个非终结符号 A A A A A A A A A A ⇒ + A α A \xRightarrow{+} A\alpha A + A α A → A α A \to A\alpha A → A α
例如,文法中存在产生式 A → B α A \to B\alpha A → B α B → A β B \to A\beta B → A β A ⇒ + A β α A \xRightarrow{+} A\beta\alpha A + A β α
消除立即左递归的方法不足以处理所有左递归情况。对于更一般的左递归(包括多步左递归),我们需要一个更通用的算法。
下面的算法能够消除文法中的所有左递归,无论是立即左递归还是多步左递归。
通用算法
对非终结符号排序 :任意选择一个顺序,将文法中的所有非终结符号排序为 A 1 , A 2 , … , A n A_1, A_2, \dots, A_n A 1 , A 2 , … , A n
迭代处理每个非终结符号 :对于 i = 1 , 2 , … , n i = 1, 2, \dots, n i = 1 , 2 , … , n
消除对「更早」非终结符号的左递归 :对于 j = 1 , 2 , … , i − 1 j = 1, 2, \dots, i-1 j = 1 , 2 , … , i − 1
检查所有形如 A i → A j γ A_i \to A_j \gamma A i → A j γ
对于每一个这样的产生式,用 A j A_j A j A j A_j A j
如果 A j → δ 1 ∣ δ 2 ∣ ⋯ ∣ δ k A_j \to \delta_1 \mid \delta_2 \mid \dots \mid \delta_k A j → δ 1 ∣ δ 2 ∣ ⋯ ∣ δ k A i → A j γ A_i \to A_j \gamma A i → A j γ A i → δ 1 γ ∣ δ 2 γ ∣ ⋯ ∣ δ k γ A_i \to \delta_1 \gamma \mid \delta_2 \gamma \mid \dots \mid \delta_k \gamma A i → δ 1 γ ∣ δ 2 γ ∣ ⋯ ∣ δ k γ
重复此步骤,直到 A i A_i A i A j A_j A j j < i j < i j < i
此步骤的目的是将所有形如 A i → A j γ A_i \to A_j \gamma A i → A j γ A i → … A_i \to \dots A i → … A j A_j A j
消除立即左递归 :此时,A i A_i A i A i → A i α ∣ β A_i \to A_i \alpha \mid \beta A i → A i α ∣ β β \beta β A i A_i A i A i A_i A i
例子
原始文法:
S → A a ∣ b A → S c ∣ d \begin{aligned}
S &\to A a \mid b \\
A &\to S c \mid d
\end{aligned}
S A → A a ∣ b → S c ∣ d
这个文法存在多步左递归:A → S c → A a c A \to S c \to A a c A → S c → A a c
消除左递归的步骤:
排序非终结符号 :设 A 1 = S A_1 = S A 1 = S A 2 = A A_2 = A A 2 = A 处理 A 1 = S A_1 = S A 1 = S (i = 1 i = 1 i = 1
消除对「更早」非终结符号的左递归 :没有 j < 1 j < 1 j < 1 消除立即左递归 :S S S S → A a ∣ b S \to A a \mid b S → A a ∣ b S S S S → A a ∣ b S \to A a \mid b S → A a ∣ b
处理 A 2 = A A_2 = A A 2 = A (i = 2 i = 2 i = 2
消除对 A 1 A_1 A 1 (j = 1 j = 1 j = 1
我们有产生式 A → S c A \to S c A → S c
将 S S S S → A a ∣ b S \to A a \mid b S → A a ∣ b A → S c A \to S c A → S c A → ( A a ) c ∣ ( b ) c ∣ d A \to (A a) c \mid (b) c \mid d A → ( A a ) c ∣ ( b ) c ∣ d
整理后得到:A → A a c ∣ b c ∣ d A \to A a c \mid b c \mid d A → A a c ∣ b c ∣ d
现在 A A A A 1 A_1 A 1 S S S
消除立即左递归 :
消除左递归后的文法:
S → A a ∣ b A → b c A ′ ∣ d A ′ A ′ → a c A ′ ∣ ε \begin{aligned}
S &\to A a \mid b \\
A &\to b c A' \mid d A' \\
A' &\to a c A' \mid \varepsilon
\end{aligned}
S A A ′ → A a ∣ b → b c A ′ ∣ d A ′ → a c A ′ ∣ ε
这个转换后的文法不再包含任何左递归,适合自顶向下的分析。
提取左公因子
提取左公因子
当一个非终结符号的多个产生式体具有相同的公共前缀 时,自顶向下的分析器在读入这个前缀后,将无法确定使用哪个产生式。提取左公因子 (Left Factoring)就是解决这个问题的技术。
提取方法
对于一组产生式:
A → α β 1 ∣ α β 2 ∣ ⋯ ∣ α β n ∣ γ \begin{aligned}
A &\to \alpha \beta_1 \mid \alpha \beta_2 \mid \dots \mid \alpha \beta_n \mid \gamma
\end{aligned}
A → α β 1 ∣ α β 2 ∣ ⋯ ∣ α β n ∣ γ
其中 α \alpha α
可以等价地替换为:
A → α A ′ ∣ γ A ′ → β 1 ∣ β 2 ∣ ⋯ ∣ β n \begin{aligned}
A &\to \alpha A' \mid \gamma \\
A' &\to \beta_1 \mid \beta_2 \mid \dots \mid \beta_n
\end{aligned}
A A ′ → α A ′ ∣ γ → β 1 ∣ β 2 ∣ ⋯ ∣ β n
例子
原始文法:
s t m t → i f e x p r t h e n s t m t e l s e s t m t ∣ i f e x p r t h e n s t m t \begin{aligned}
\mathit{stmt} \to&\ \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt}\ \mathbf{else}\ \mathit{stmt} \\
\mid&\ \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt}
\end{aligned}
stmt → ∣ if expr then stmt else stmt if expr then stmt
提取左公因子后:
s t m t → i f e x p r t h e n s t m t s t m t _ t a i l s t m t _ t a i l → e l s e s t m t ∣ ε \begin{aligned}
\mathit{stmt} \to&\ \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt}\ \mathit{stmt\_tail} \\
\mathit{stmt\_tail} \to&\ \mathbf{else}\ \mathit{stmt} \mid \varepsilon
\end{aligned}
stmt → stmt_tail → if expr then stmt stmt_tail else stmt ∣ ε
文法与语言的层级补充
乔姆斯基体系(Chomsky Hierarchy)
语言学家诺姆·乔姆斯基将文法按照产生式形式的限制,划分为四个层级,描述能力从强到弱依次为:
0 型文法 (短语结构文法):α → β \alpha \to \beta α → β 图灵机 。1 型文法 (上下文相关文法):α A β → α γ β \alpha A \beta \to \alpha \gamma \beta α A β → α γ β γ \gamma γ A A A α \alpha α β \beta β 线性有界自动机 。2 型文法 (上下文无关文法):A → γ A \to \gamma A → γ A A A 下推自动机 。这是大多数程序设计语言语法描述的基础 。3 型文法 (正则文法):A → t A \to t A → t A → t B A \to tB A → tB A → B t A \to Bt A → B t 有限自动机 (DFA/NFA)。
上下文无关文法 vs. 正则表达式
表达能力 :上下文无关文法(CFG)的表达能力强于 正则表达式。
所有可以用正则表达式描述的语言(正则语言),都可以用 CFG 描述。
但存在一些 CFG 能描述而正则表达式无法描述的语言。
经典反例 :语言 L = { a n b n ∣ n ⩾ 1 } L = \{a^n b^n \mid n \ge 1\} L = { a n b n ∣ n ⩾ 1 }
这个语言可以用简单的 CFG S → a S b ∣ a b S \to aSb \mid ab S → a S b ∣ ab
但它不是正则语言,因为识别它需要一个能够「计数」的机制(b b b a a a
例如说假定 DFA 有 k k k a k + 1 b k + 1 a^{k+1}b^{k+1} a k + 1 b k + 1 k + 1 k+1 k + 1 a a a a a a b b b
适用场景 :
正则表达式 :简洁、高效,非常适合描述词法单元(如标识符、数字)这类扁平、非嵌套的结构。上下文无关文法 :能够自然地描述具有递归和嵌套特性的语法结构(如表达式、语句块),是语法分析的核心。
为 NFA 构造等价文法
假设我们有一个 NFA M = ( Q , Σ , δ , q 0 , F ) M = (Q, \Sigma, \delta, q_0, F) M = ( Q , Σ , δ , q 0 , F )
Q Q Q Σ \Sigma Σ δ \delta δ δ : Q × ( Σ ∪ { ε } ) → 2 Q \delta\colon Q \times (\Sigma \cup \{\varepsilon\}) \to 2^Q δ : Q × ( Σ ∪ { ε }) → 2 Q q 0 ∈ Q q_0 \in Q q 0 ∈ Q F ⊆ Q F \subseteq Q F ⊆ Q
我们要构造一个等价的 CFG G = ( V , Σ , P , S ) G = (V, \Sigma, P, S) G = ( V , Σ , P , S )
V V V Σ \Sigma Σ P P P S S S
步骤:
创建非终结符 :
对于 NFA 中的每一个状态 q ∈ Q q \in Q q ∈ Q A q A_q A q
将 CFG 的起始非终结符 S S S q 0 q_0 q 0 S = A q 0 S = A_{q_0} S = A q 0
创建转移产生式 :
对于 NFA 中的每一个转移 δ ( q , x ) = { p 1 , p 2 , … , p k } \delta(q, x) = \{p_1, p_2, \dots, p_k\} δ ( q , x ) = { p 1 , p 2 , … , p k } q , p i ∈ Q q, p_i \in Q q , p i ∈ Q x ∈ Σ ∪ { ε } x \in \Sigma \cup \{\varepsilon\} x ∈ Σ ∪ { ε }
对于每一个 p i ∈ { p 1 , … , p k } p_i \in \{p_1, \dots, p_k\} p i ∈ { p 1 , … , p k } A q → x A p i A_q \to x A_{p_i} A q → x A p i
如果 x = ε x = \varepsilon x = ε A q → A p i A_q \to A_{p_i} A q → A p i
创建终结状态产生式 :
对于 NFA 中的每一个终结状态 q f ∈ F q_f \in F q f ∈ F
在 CFG 中添加一个产生式:A q f → ε A_{q_f} \to \varepsilon A q f → ε
例子
考虑一个接受所有以 a 结尾的字符串的 NFA,例如 (a|b)*a。
状态 (Q Q Q { q 0 , q 1 } \{q_0, q_1\} { q 0 , q 1 } 输入字母表 (Σ \Sigma Σ { a , b } \{a, b\} { a , b } 起始状态 (q 0 q_0 q 0 q 0 q_0 q 0 终结状态 (F F F { q 1 } \{q_1\} { q 1 } 转移函数 (δ \delta δ
δ ( q 0 , a ) = { q 0 , q 1 } \delta(q_0, a) = \{q_0, q_1\} δ ( q 0 , a ) = { q 0 , q 1 } q 0 q_0 q 0 a a a q 0 q_0 q 0 q 1 q_1 q 1 δ ( q 0 , b ) = { q 0 } \delta(q_0, b) = \{q_0\} δ ( q 0 , b ) = { q 0 } q 0 q_0 q 0 b b b q 0 q_0 q 0 δ ( q 1 , a ) = ∅ \delta(q_1, a) = \empty δ ( q 1 , a ) = ∅ δ ( q 1 , b ) = ∅ \delta(q_1, b) = \empty δ ( q 1 , b ) = ∅
NFA 图示:
graph LR
start:::hidden -->|start| q0((q0))
q0 -- a, b --> q0
q0 -- a --> q1(((q1)))
q1
classDef hidden display:none
style start fill:#fff,stroke:#fff,stroke-width:0px,color:#333
style q0 fill:#fff,stroke:#333,stroke-width:2px
style q1 fill:#fff,stroke:#333,stroke-width:2px其中 q0 是起始状态,q1 是终结状态。
构造 CFG 的步骤:
创建非终结符 :
对于状态 q 0 q_0 q 0 Q 0 Q_0 Q 0
对于状态 q 1 q_1 q 1 Q 1 Q_1 Q 1
CFG 的起始非终结符 S = Q 0 S = Q_0 S = Q 0 q 0 q_0 q 0
创建转移产生式 :
从 δ ( q 0 , a ) = { q 0 , q 1 } \delta(q_0, a) = \{q_0, q_1\} δ ( q 0 , a ) = { q 0 , q 1 }
Q 0 → a Q 0 Q_0 \to a Q_0 Q 0 → a Q 0 Q 0 → a Q 1 Q_0 \to a Q_1 Q 0 → a Q 1
从 δ ( q 0 , b ) = { q 0 } \delta(q_0, b) = \{q_0\} δ ( q 0 , b ) = { q 0 }
Q 0 → b Q 0 Q_0 \to b Q_0 Q 0 → b Q 0
创建终结状态产生式 :
q 1 q_1 q 1 Q 1 → ε Q_1 \to \varepsilon Q 1 → ε
最终得到的 CFG G G G
非终结符 (V):{ Q 0 , Q 1 } \{Q_0, Q_1\} { Q 0 , Q 1 } 终结符 (Σ \Sigma Σ { a , b } \{a, b\} { a , b } 起始非终结符 (S):Q 0 Q_0 Q 0 产生式 (P):
Q 0 → a Q 0 Q_0 \to a Q_0 Q 0 → a Q 0 Q 0 → a Q 1 Q_0 \to a Q_1 Q 0 → a Q 1 Q 0 → b Q 0 Q_0 \to b Q_0 Q 0 → b Q 0 Q 1 → ε Q_1 \to \varepsilon Q 1 → ε
上下文无关文法的局限性
尽管 CFG 功能强大,但它无法描述程序设计语言的所有规则。例如,「变量必须先声明后使用」这类规则。
抽象地看,这类规则类似于语言 L = { w c w ∣ w ∈ ( a ∣ b ) ∗ } L = \{wcw \mid w \in (a\mid b)*\} L = { w c w ∣ w ∈ ( a ∣ b ) ∗ } w w w
这个语言不是上下文无关的,因为它要求两个 w w w
这类依赖于上下文的规则,通常不在语法分析阶段处理,而是留给语义分析 阶段来检查。我们之所以在语法分析阶段坚持使用 CFG,是因为它具有高效的分析算法。
自顶向下分析
自顶向下分析 (Top-Down Parsing)是一种重要的语法分析策略。顾名思义,它试图从文法的开始符号 (根节点)出发,通过不断应用产生式,自上而下、从左到右地为输入串构建一棵语法分析树。
这个过程可以等价地看作是寻找输入串的最左推导 。
核心挑战
在推导的每一步,当面临一个非终结符号 A A A A A A A → α 1 ∣ α 2 ∣ … A \to \alpha_1 \mid \alpha_2 \mid \dots A → α 1 ∣ α 2 ∣ … 选择哪一个产生式 来替换 A A A
这个选择的正确与否,是自顶向下分析的关键。
上图展示了为输入串 id + id * id 进行自顶向下分析,并逐步构建语法分析树的过程。
递归下降分析
递归下降分析 (Recursive Descent Parsing)是自顶向下分析的一种直接实现方式。其核心思想是为文法中的每一个非终结符号 编写一个对应的递归函数(或过程) 。
程序的执行从与开始符号 对应的函数开始。
每个函数的功能是识别并扫描输入中能够由其对应非终结符号推导出的那部分字符串。
在函数内部,它根据产生式的结构来决定下一步操作:
如果遇到终结符号 ,就与当前输入符号进行匹配。匹配成功则消耗输入,继续;失败则报告错误。
如果遇到非终结符号 ,就递归调用 该非终结符号对应的函数。
递归下降分析框架
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// lookahead 指向下一个输入词法单元 Token lookahead ; // 对应非终结符号 A 的函数 void A () { // 1. 选择一个 A 的产生式, 假设为 A -> X1 X2 ... Xk // 这是最关键也是最困难的一步 // 2. 依次处理产生式体中的每个符号 for ( int i = 1 ; i <= k ; i ++ ) { if ( Xi is a non - terminal ) { // 递归调用过程 Xi (); } else if ( Xi is a terminal ) { // 匹配终结符号 match ( Xi ); } else { // 处理 ε 产生式 } } } void match ( Terminal t ) { if ( lookahead . type == t ) { lookahead = getNextToken (); // 消耗输入 } else { error (); } }
简单的递归下降分析器在面临选择时,可能会选错产生式。
回溯与左递归问题
回溯 (Backtracking):如果一个选择导致了后续的匹配失败,分析器需要撤销 这次选择,将输入指针重置 到选择前的位置,然后尝试该非终结符号的下一个产生式。这种反复的尝试和重置称为回溯。回溯会极大地降低分析效率,甚至可能导致对输入的重复扫描。左递归 :如果文法存在左递归(特别是立即左递归,如 A → A α A \to A\alpha A → A α 无限递归 。函数 A() 会无条件地立即再次调用自身,而输入指针没有任何移动,从而导致栈溢出。
回溯的问题
考虑文法 S → a S a ∣ a a S \to a S a \mid aa S → a S a ∣ aa a a a S → a a S \to aa S → aa a a aa aa S → a S a S \to a S a S → a S a
但实际上,这个递归下降分析器无法识别串 a 6 = a a a a a a a^6 = aaaaaa a 6 = aaaaaa a 2 n a^{2^n} a 2 n a 2 n a^{2n} a 2 n
解释说明
借用 Stack Overflow 上的图 来说明 a 2 , a 4 , a 6 , a 8 a^2, a^4, a^6, a^8 a 2 , a 4 , a 6 , a 8
我在查证这个问题的解答的时候实际上非常困惑:为什么回溯的时候,前面一直都是一层一层地减,但是到倒数第二个树的时候,突然就是减了两层了。
关键在于:递归下降分析器仅在发生错误的时候才回溯 。这个话在现在可能还比较难懂,虽然说现在看起来更像是一句废话。
实际上所谓的「仅在错误发生时才回溯」,其含义是分析器是「贪婪的」,只要第一个产生式规则在技术上匹配局部字符,它就会消耗输入,即使这种选择稍后会使全局匹配变得不可能。
先从最简单的情况,即 a 6 a^6 a 6
看倒数第二棵树,它是在第二个 S S S S 2 → a S 3 a S_2 \to a S_3 a S 2 → a S 3 a S 2 → a S 3 a S_2 \to a S_3 a S 2 → a S 3 a S 2 → a a S_2 \to a a S 2 → aa
但实际上是 S 3 S_3 S 3 S 3 → a S 4 a S_3 \to a S_4 a S 3 → a S 4 a S 3 → a a S_3 \to a a S 3 → aa S 3 S_3 S 3 S 2 S_2 S 2
明白了这一点,就可以对带回溯的递归下降分析器具体能够识别的语言进行分析了。
首先根据文法设能识别的语言为 a 2 n a^{2n} a 2 n n n n
先构建一个层高为 2 n 2n 2 n 2 n + 1 2n + 1 2 n + 1 S S S 2 n 2n 2 n a a a 2 n + 1 2n + 1 2 n + 1 S S S S 2 n → a S 2 n + 1 a S_{2n} \to a S_{2n+1} a S 2 n → a S 2 n + 1 a S 2 n → a a S_{2n} \to a a S 2 n → aa a a a 2 n 2n 2 n S 2 n − 1 S_{2n-1} S 2 n − 1 S 2 n − 1 → a S 2 n a S_{2n-1} \to a S_{2n} a S 2 n − 1 → a S 2 n a S 2 n − 1 → a a S_{2n-1} \to a a S 2 n − 1 → aa
这时候树的左侧有 2 n − 1 2n - 1 2 n − 1 a a a S 2 n − 1 S_{2n-1} S 2 n − 1 a a a S 2 n − 2 S_{2n-2} S 2 n − 2 a a a S 2 n − 2 S_{2n-2} S 2 n − 2 S 2 n − 2 → a S 2 n − 1 a S_{2n-2} \to a S_{2n-1} a S 2 n − 2 → a S 2 n − 1 a S 2 n − 2 → a a S_{2n-2} \to a a S 2 n − 2 → aa
这时候,树的左侧有 2 n − 2 2n - 2 2 n − 2 a a a 2 n − 2 , 2 n − 3 2n - 2, 2n - 3 2 n − 2 , 2 n − 3 S 2 n − 4 S_{2n-4} S 2 n − 4 a a a S 2 n − 4 S_{2n-4} S 2 n − 4 S 2 n − 4 → a a S_{2n-4} \to a a S 2 n − 4 → aa
假设树的高度现在为 2 n − 2 m 2n - 2^m 2 n − 2 m 2 m ⩽ n 2^m \le n 2 m ⩽ n 2 n − 2 m , … , 2 n − 2 m + 1 + 1 ⏞ 2 m \overbrace{2n - 2^m, \dots, 2n - 2^{m+1} + 1}^{2^m} 2 n − 2 m , … , 2 n − 2 m + 1 + 1 2 m a a a 2 m = n 2^m = n 2 m = n S 1 S_1 S 1 a a a 2 m < n 2^m < n 2 m < n S 2 n − 2 m + 1 S_{2n - 2^{m+1}} S 2 n − 2 m + 1 a a a S 2 n − 2 m + 1 S_{2n - 2^{m+1}} S 2 n − 2 m + 1 S 2 n − 2 m + 1 → a a S_{2n - 2^{m+1}} \to a a S 2 n − 2 m + 1 → aa 2 n − 2 m + 1 2n - 2^{m+1} 2 n − 2 m + 1
如果此时不再满足 2 m + 1 ⩽ n 2^{m+1} \le n 2 m + 1 ⩽ n 2 m + 1 > n 2^{m+1} > n 2 m + 1 > n a a a a a a
于是数学归纳可以得出,当且仅当 n = 2 m n = 2^m n = 2 m a 2 n a^{2n} a 2 n L = { a 2 n ∣ n > 0 } L = \left\{a^{2^n} | n > 0\right\} L = { a 2 n ∣ n > 0 }
之所以说上面的图不太清晰,是因为数字比较小,有点难看出来。可以使用下面 Python 版本的代码来模拟这个过程,然后使用调试器观察回溯的细节:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
class RecursiveDescentParser : def __init__ ( self ): self . input_string = "" self . index = 0 # 当前解析到的位置 def parse ( self , text ): self . input_string = text self . index = 0 # 1. 尝试从 S 开始解析 # 2. 检查是否消耗了所有输入 if self . parse_S () and self . index == len ( self . input_string ): return True else : return False def parse_S ( self ): # --- 尝试规则 1:S -> aSa --- # 1.1 保存当前位置,以便回溯 save_index_for_aSa = self . index # 1.2 尝试匹配 'a' if self . match ( " a " ): # 1.3 尝试递归匹配 'S' if self . parse_S (): # 1.4 尝试匹配 'a' if self . match ( " a " ): # aSa 路径匹配成功 return True # 1.5 回溯:如果 aSa 路径失败,重置索引 self . index = save_index_for_aSa # --- 尝试规则 2:S -> aa --- # 2.1 保存当前位置 save_index_for_aa = self . index # 2.2 尝试匹配 'a' if self . match ( " a " ): # 2.3 尝试匹配 'a' if self . match ( " a " ): # aa 路径匹配成功 return True # 2.4 回溯:如果 aa 路径失败,重置索引 self . index = save_index_for_aa # 如果两个规则都失败了 return False def match ( self , terminal ): if ( self . index < len ( self . input_string ) and self . input_string [ self . index ] == terminal ): self . index += 1 # 消耗字符 return True return False if __name__ == " __main__ " : parser = RecursiveDescentParser () parser . parse ( " aaaaaa " )
后面补了一个回答 。
由于存在这些严重问题,需要回溯的通用递归下降分析方法在实践中很少使用。我们需要一种更「聪明」的方法,能够在做出选择前就「预知」哪条路是正确的,从而避免回溯。
预测分析
预测分析 (Predictive Parsing)是一种特殊的、无回溯 的自顶向下分析技术。它通过向前预读 一个或多个输入符号(通常是一个,称为向前看符号 ,lookahead symbol),来唯一地 确定当前应该使用哪个产生式。
为了实现预测分析,文法必须满足特定条件,即经过改造,消除了二义性、左递归,提取了左公因子等。这样的文法通常被称为 LL(1) 文法 。
LL(1)
第一个 L :表示从左 (Left)到右扫描输入。
第二个 L :表示构造最左 (Leftmost)推导。
1 :表示在做分析决定时,只需要向前看 1 个输入符号。
为了系统地实现预测分析,我们需要两个关键的辅助函数:FIRST 和 FOLLOW 。
FIRST 集
F I R S T ( α ) \mathrm{FIRST}(\alpha) FIRST ( α )
对于任意文法符号串 α \alpha α F I R S T ( α ) \mathrm{FIRST}(\alpha) FIRST ( α ) α \alpha α 首个终结符号 的集合。
如果 α ⇒ ∗ ε \alpha \xRightarrow{*} \varepsilon α ∗ ε ε \varepsilon ε F I R S T ( α ) \mathrm{FIRST}(\alpha) FIRST ( α )
F I R S T \mathrm{FIRST} FIRST
计算 FIRST 集
计算所有文法符号 X X X F I R S T ( X ) \mathrm{FIRST}(X) FIRST ( X )
初始化 :对所有文法符号 X X X F I R S T ( X ) = ∅ \mathrm{FIRST}(X) = \empty FIRST ( X ) = ∅ 迭代计算 :不断应用以下规则,直到所有 F I R S T \mathrm{FIRST} FIRST
规则 1 (终结符):如果 X X X F I R S T ( X ) = { X } \mathrm{FIRST}(X) = \{X\} FIRST ( X ) = { X } 规则 2 (产生式):如果存在产生式 X → Y 1 Y 2 … Y k X \to Y_1 Y_2 \dots Y_k X → Y 1 Y 2 … Y k
将 F I R S T ( Y 1 ) \mathrm{FIRST}(Y_1) FIRST ( Y 1 ) ε \varepsilon ε F I R S T ( X ) \mathrm{FIRST}(X) FIRST ( X )
如果 ε ∈ F I R S T ( Y 1 ) \varepsilon \in \mathrm{FIRST}(Y_1) ε ∈ FIRST ( Y 1 ) F I R S T ( Y 2 ) \mathrm{FIRST}(Y_2) FIRST ( Y 2 ) ε \varepsilon ε F I R S T ( X ) \mathrm{FIRST}(X) FIRST ( X )
…以此类推,如果对所有的 j < i j < i j < i ε ∈ F I R S T ( Y j ) \varepsilon \in \mathrm{FIRST}(Y_j) ε ∈ FIRST ( Y j ) F I R S T ( Y i ) \mathrm{FIRST}(Y_i) FIRST ( Y i ) ε \varepsilon ε F I R S T ( X ) \mathrm{FIRST}(X) FIRST ( X )
规则 3 (ε \varepsilon ε
如果存在产生式 X → ε X \to \varepsilon X → ε ε \varepsilon ε F I R S T ( X ) \mathrm{FIRST}(X) FIRST ( X )
如果存在产生式 X → Y 1 Y 2 … Y k X \to Y_1 Y_2 \dots Y_k X → Y 1 Y 2 … Y k i i i ε ∈ F I R S T ( Y i ) \varepsilon \in \mathrm{FIRST}(Y_i) ε ∈ FIRST ( Y i ) ε \varepsilon ε F I R S T ( X ) \mathrm{FIRST}(X) FIRST ( X )
对于一个文法符号串 α = X 1 X 2 … X n \alpha = X_1 X_2 \dots X_n α = X 1 X 2 … X n F I R S T ( α ) \mathrm{FIRST}(\alpha) FIRST ( α )
计算例子 1
考虑以下文法 G:
E → T E ′ E \to T E' E → T E ′ E ′ → + T E ′ ∣ ε E' \to + T E' \mid \varepsilon E ′ → + T E ′ ∣ ε T → F T ′ T \to F T' T → F T ′ T ′ → ∗ F T ′ ∣ ε T' \to * F T' \mid \varepsilon T ′ → ∗ F T ′ ∣ ε F → ( E ) ∣ i d F \to ( E ) \mid \mathbf{id} F → ( E ) ∣ id
其中,非终结符是 { E , E ′ , T , T ′ , F } \{E, E', T, T', F\} { E , E ′ , T , T ′ , F } { + , ∗ , ( , ) , i d } \{+, *, (, ), \mathbf{id}\} { + , ∗ , ( , ) , id }
计算各符号的 FIRST 集。
过程
初始化
首先,为所有非终结符创建一个空的 FIRST 集:
F I R S T ( E ) = ∅ \mathrm{FIRST}(E) = \empty FIRST ( E ) = ∅ F I R S T ( E ′ ) = ∅ \mathrm{FIRST}(E') = \empty FIRST ( E ′ ) = ∅ F I R S T ( T ) = ∅ \mathrm{FIRST}(T) = \empty FIRST ( T ) = ∅ F I R S T ( T ′ ) = ∅ \mathrm{FIRST}(T') = \empty FIRST ( T ′ ) = ∅ F I R S T ( F ) = ∅ \mathrm{FIRST}(F) = \empty FIRST ( F ) = ∅
根据规则 1 ,知道所有终结符的 FIRST 集就是它们自身:
F I R S T ( + ) = { + } \mathrm{FIRST}(+) = \{+\} FIRST ( + ) = { + } F I R S T ( ∗ ) = { ∗ } \mathrm{FIRST}(*) = \{*\} FIRST ( ∗ ) = { ∗ } F I R S T ( ( ) = { ( } \mathrm{FIRST}(() = \{(\} FIRST (( ) = {( } F I R S T ( ) ) = { ) } \mathrm{FIRST}()) = \{)\} FIRST ( )) = { )} F I R S T ( i d ) = { i d } \mathrm{FIRST}(\mathbf{id}) = \{\mathbf{id}\} FIRST ( id ) = { id }
第 1 轮迭代:
对于 F F F :
产生式 F → ( E ) F \to ( E ) F → ( E ) ( ( ( 规则 2 ,将 ( ( ( F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F )
产生式 F → i d F \to \mathbf{id} F → id i d \mathbf{id} id i d \mathbf{id} id F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F )
更新后 :F I R S T ( F ) = { ( , i d } \mathrm{FIRST}(F) = \{ (, \mathbf{id} \} FIRST ( F ) = {( , id }
对于 T ′ T' T ′ :
产生式 T ′ → ∗ F T ′ T' \to * F T' T ′ → ∗ F T ′ ∗ * ∗ ∗ * ∗ F I R S T ( T ′ ) \mathrm{FIRST}(T') FIRST ( T ′ )
产生式 T ′ → ε T' \to \varepsilon T ′ → ε 规则 3 ,将 ε \varepsilon ε F I R S T ( T ′ ) \mathrm{FIRST}(T') FIRST ( T ′ )
更新后 :F I R S T ( T ′ ) = { ∗ , ε } \mathrm{FIRST}(T') = \{ *, \varepsilon \} FIRST ( T ′ ) = { ∗ , ε }
对于 T T T :
产生式 T → F T ′ T \to F T' T → F T ′ F F F 规则 2 ,将 F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F ) ε \varepsilon ε F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T )
F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F ) { ( , i d } \{ (, \mathbf{id} \} {( , id } ε \varepsilon ε { ( , i d } \{ (, \mathbf{id} \} {( , id } F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T ) 更新后 :F I R S T ( T ) = { ( , i d } \mathrm{FIRST}(T) = \{ (, \mathbf{id} \} FIRST ( T ) = {( , id }
对于 E ′ E' E ′ :
产生式 E ′ → + T E ′ E' \to + T E' E ′ → + T E ′ + + + + + + F I R S T ( E ′ ) \mathrm{FIRST}(E') FIRST ( E ′ )
产生式 E ′ → ε E' \to \varepsilon E ′ → ε 规则 3 ,将 ε \varepsilon ε F I R S T ( E ′ ) \mathrm{FIRST}(E') FIRST ( E ′ )
更新后 :F I R S T ( E ′ ) = { + , ε } \mathrm{FIRST}(E') = \{ +, \varepsilon \} FIRST ( E ′ ) = { + , ε }
对于 E E E :
产生式 E → T E ′ E \to T E' E → T E ′ T T T F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T ) ε \varepsilon ε F I R S T ( E ) \mathrm{FIRST}(E) FIRST ( E )
F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T ) { ( , i d } \{ (, \mathbf{id} \} {( , id } ε \varepsilon ε { ( , i d } \{ (, \mathbf{id} \} {( , id } F I R S T ( E ) \mathrm{FIRST}(E) FIRST ( E ) 更新后 :F I R S T ( E ) = { ( , i d } \mathrm{FIRST}(E) = \{ (, \mathbf{id} \} FIRST ( E ) = {( , id }
第 1 轮迭代结束,各集合状态如下:
F I R S T ( E ) = { ( , i d } \mathrm{FIRST}(E) = \{ (, \mathbf{id} \} FIRST ( E ) = {( , id } F I R S T ( E ′ ) = { + , ε } \mathrm{FIRST}(E') = \{ +, \varepsilon \} FIRST ( E ′ ) = { + , ε } F I R S T ( T ) = { ( , i d } \mathrm{FIRST}(T) = \{ (, \mathbf{id} \} FIRST ( T ) = {( , id } F I R S T ( T ′ ) = { ∗ , ε } \mathrm{FIRST}(T') = \{ *, \varepsilon \} FIRST ( T ′ ) = { ∗ , ε } F I R S T ( F ) = { ( , i d } \mathrm{FIRST}(F) = \{ (, \mathbf{id} \} FIRST ( F ) = {( , id }
第 2 轮迭代:
对于 F F F :其产生式右侧都以终结符开始,F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F ) 对于 T ′ T' T ′ :其产生式右侧以终结符或 ε \varepsilon ε F I R S T ( T ′ ) \mathrm{FIRST}(T') FIRST ( T ′ ) 对于 T T T :
产生式 T → F T ′ T \to F T' T → F T ′ F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F ) F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F ) { ( , i d } \{ (, \mathbf{id} \} {( , id } F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T ) ε ∉ F I R S T ( F ) \varepsilon \notin \mathrm{FIRST}(F) ε ∈ / FIRST ( F ) T ′ T' T ′ F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T )
对于 E ′ E' E ′ :其产生式右侧以终结符或 ε \varepsilon ε F I R S T ( E ′ ) \mathrm{FIRST}(E') FIRST ( E ′ ) 对于 E E E :
产生式 E → T E ′ E \to T E' E → T E ′ F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T ) F I R S T ( T ) \mathrm{FIRST}(T) FIRST ( T ) { ( , i d } \{ (, \mathbf{id} \} {( , id } F I R S T ( E ) \mathrm{FIRST}(E) FIRST ( E ) ε ∉ F I R S T ( T ) \varepsilon \notin \mathrm{FIRST}(T) ε ∈ / FIRST ( T ) E ′ E' E ′ F I R S T ( E ) \mathrm{FIRST}(E) FIRST ( E )
在第 2 轮迭代中,所有 FIRST 集都没有增大。因此,算法终止。
最终所有非终结符的 FIRST 集计算完毕:
F I R S T ( E ) = { ( , i d } \mathrm{FIRST}(E) = \{ (, \mathbf{id} \} FIRST ( E ) = {( , id } F I R S T ( E ′ ) = { + , ε } \mathrm{FIRST}(E') = \{ +, \varepsilon \} FIRST ( E ′ ) = { + , ε } F I R S T ( T ) = { ( , i d } \mathrm{FIRST}(T) = \{ (, \mathbf{id} \} FIRST ( T ) = {( , id } F I R S T ( T ′ ) = { ∗ , ε } \mathrm{FIRST}(T') = \{ *, \varepsilon \} FIRST ( T ′ ) = { ∗ , ε } F I R S T ( F ) = { ( , i d } \mathrm{FIRST}(F) = \{ (, \mathbf{id} \} FIRST ( F ) = {( , id }
计算例子 2
在上面的文法中,计算一个符号串 α = T ′ F \alpha = T' F α = T ′ F F I R S T \mathrm{FIRST} FIRST F I R S T ( T ′ F ) \mathrm{FIRST}(T' F) FIRST ( T ′ F )
过程
考察第一个符号 T ′ T' T ′ :
F I R S T ( T ′ ) = { ∗ , ε } \mathrm{FIRST}(T') = \{ *, \varepsilon \} FIRST ( T ′ ) = { ∗ , ε } 将其中所有非 ε \varepsilon ε F I R S T ( T ′ F ) \mathrm{FIRST}(T' F) FIRST ( T ′ F )
当前 F I R S T ( T ′ F ) = { ∗ } \mathrm{FIRST}(T' F) = \{ * \} FIRST ( T ′ F ) = { ∗ }
检查 T ′ T' T ′ ε \varepsilon ε :
ε ∈ F I R S T ( T ′ ) \varepsilon \in \mathrm{FIRST}(T') ε ∈ FIRST ( T ′ ) 因此,需要继续考察下一个符号 F F F
考察第二个符号 F F F :
F I R S T ( F ) = { ( , i d } \mathrm{FIRST}(F) = \{ (, \mathbf{id} \} FIRST ( F ) = {( , id } 将 F I R S T ( F ) \mathrm{FIRST}(F) FIRST ( F ) ε \varepsilon ε F I R S T ( T ′ F ) \mathrm{FIRST}(T' F) FIRST ( T ′ F )
当前 F I R S T ( T ′ F ) = { ∗ , ( , i d } \mathrm{FIRST}(T' F) = \{ *, (, \mathbf{id} \} FIRST ( T ′ F ) = { ∗ , ( , id }
检查 F F F ε \varepsilon ε :
ε ∉ F I R S T ( F ) \varepsilon \notin \mathrm{FIRST}(F) ε ∈ / FIRST ( F ) 计算过程停止。
所以,F I R S T ( T ′ F ) = { ∗ , ( , i d } \mathrm{FIRST}(T' F) = \{ * , (, \mathbf{id} \} FIRST ( T ′ F ) = { ∗ , ( , id }
FOLLOW 集
当一个产生式可能推导出 ε \varepsilon ε A → ε A \to \varepsilon A → ε F I R S T \mathrm{FIRST} FIRST 紧跟在 A A A a a a A → ε A \to \varepsilon A → ε F O L L O W \mathrm{FOLLOW} FOLLOW
FOLLOW(A)
对于任意非终结符号 A A A F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) 紧跟在 A A A 终结符号 的集合。
如果 A A A 输入结束标记 $ \$ $ F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) $ \$ $
计算 FOLLOW 集
计算所有非终结符号 A A A F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A )
初始化 :对所有非终结符号 A A A F O L L O W ( A ) = ∅ \mathrm{FOLLOW}(A) = \empty FOLLOW ( A ) = ∅ 规则 1(开始符号) :将 $ \$ $ F O L L O W ( S ) \mathrm{FOLLOW}(S) FOLLOW ( S ) S S S 迭代计算 :不断应用以下规则,直到所有 F O L L O W \mathrm{FOLLOW} FOLLOW
规则 2 :如果存在产生式 A → α B β A \to \alpha B \beta A → α B β
将 F I R S T ( β ) \mathrm{FIRST}(\beta) FIRST ( β ) ε \varepsilon ε F O L L O W ( B ) \mathrm{FOLLOW}(B) FOLLOW ( B )
规则 3 :如果存在产生式 A → α B A \to \alpha B A → α B A → α B β A \to \alpha B \beta A → α B β ε ∈ F I R S T ( β ) \varepsilon \in \mathrm{FIRST}(\beta) ε ∈ FIRST ( β )
将 F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) F O L L O W ( B ) \mathrm{FOLLOW}(B) FOLLOW ( B )
表达式文法的 FIRST 与 FOLLOW 集
考虑熟悉的表达式文法(已消除左递归):
E → T E ′ E ′ → + T E ′ ∣ ε T → F T ′ T ′ → ∗ F T ′ ∣ ε F → ( E ) ∣ i d \begin{aligned}
E &\to T E' \\
E' &\to + T E' \mid \varepsilon \\
T &\to F T' \\
T' &\to * F T' \mid \varepsilon \\
F &\to ( E ) \mid \mathbf{id}
\end{aligned}
E E ′ T T ′ F → T E ′ → + T E ′ ∣ ε → F T ′ → ∗ F T ′ ∣ ε → ( E ) ∣ id
计算该文法的 FOLLOW 集。
过程
FIRST 集计算结果:
F I R S T ( F ) = { ( , i d } \mathrm{FIRST}(F) = \{ (, \mathbf{id} \} FIRST ( F ) = {( , id } F I R S T ( T ) = { ( , i d } \mathrm{FIRST}(T) = \{ (, \mathbf{id} \} FIRST ( T ) = {( , id } F I R S T ( E ) = { ( , i d } \mathrm{FIRST}(E) = \{ (, \mathbf{id} \} FIRST ( E ) = {( , id } F I R S T ( E ′ ) = { + , ε } \mathrm{FIRST}(E') = \{ +, \varepsilon \} FIRST ( E ′ ) = { + , ε } F I R S T ( T ′ ) = { ∗ , ε } \mathrm{FIRST}(T') = \{ *, \varepsilon \} FIRST ( T ′ ) = { ∗ , ε }
FOLLOW 集计算结果:
将 $ \$ $ F O L L O W ( E ) \mathrm{FOLLOW}(E) FOLLOW ( E ) F ( E ) \mathbf{F}(E) F ( E )
从 F → ( E ) F \to (E) F → ( E ) ) ) ) F ( E ) \mathbf{F}(E) F ( E ) F ( E ) = { ) , $ } \mathbf{F}(E) = \{ ), \$ \} F ( E ) = { ) , $ }
从 E → T E ′ E \to TE' E → T E ′ F ( E ) \mathbf{F}(E) F ( E ) F ( E ′ ) \mathbf{F}(E') F ( E ′ ) F ( E ′ ) = { ) , $ } \mathbf{F}(E') = \{ ), \$ \} F ( E ′ ) = { ) , $ }
从 E ′ → + T E ′ E' \to +TE' E ′ → + T E ′ F ( E ′ ) \mathbf{F}(E') F ( E ′ ) F ( E ′ ) \mathbf{F}(E') F ( E ′ )
从 E → T E ′ E \to TE' E → T E ′ E ′ → + T E ′ E' \to +TE' E ′ → + T E ′ F I R S T ( E ′ ) \mathrm{FIRST}(E') FIRST ( E ′ ) + + + + + + F ( T ) \mathbf{F}(T) F ( T )
从 E → T E ′ E \to TE' E → T E ′ ε ∈ F I R S T ( E ′ ) \varepsilon \in \mathrm{FIRST}(E') ε ∈ FIRST ( E ′ ) F ( E ) \mathbf{F}(E) F ( E ) F ( T ) \mathbf{F}(T) F ( T )
从 E ′ → + T E ′ E' \to +TE' E ′ → + T E ′ ε ∈ F I R S T ( E ′ ) \varepsilon \in \mathrm{FIRST}(E') ε ∈ FIRST ( E ′ ) F ( E ′ ) \mathbf{F}(E') F ( E ′ ) F ( T ) \mathbf{F}(T) F ( T )
综合 5, 6, 7,F ( T ) = { + , ) , $ } \mathbf{F}(T) = \{ +, ), \$ \} F ( T ) = { + , ) , $ }
从 T → F T ′ T \to FT' T → F T ′ F ( T ) \mathbf{F}(T) F ( T ) F ( T ′ ) \mathbf{F}(T') F ( T ′ ) F ( T ′ ) = { + , ) , $ } \mathbf{F}(T') = \{ +, ), \$ \} F ( T ′ ) = { + , ) , $ }
从 T ′ → ∗ F T ′ T' \to *FT' T ′ → ∗ F T ′ F ( T ′ ) \mathbf{F}(T') F ( T ′ ) F ( T ′ ) \mathbf{F}(T') F ( T ′ )
从 T → F T ′ T \to FT' T → F T ′ T ′ → ∗ F T ′ T' \to *FT' T ′ → ∗ F T ′ F I R S T ( T ′ ) \mathrm{FIRST}(T') FIRST ( T ′ ) ∗ * ∗ ∗ * ∗ F ( F ) \mathbf{F}(F) F ( F )
从 T → F T ′ T \to FT' T → F T ′ ε ∈ F I R S T ( T ′ ) \varepsilon \in \mathrm{FIRST}(T') ε ∈ FIRST ( T ′ ) F ( T ) \mathbf{F}(T) F ( T ) F ( F ) \mathbf{F}(F) F ( F )
从 T ′ → ∗ F T ′ T' \to *FT' T ′ → ∗ F T ′ ε ∈ F I R S T ( T ′ ) \varepsilon \in \mathrm{FIRST}(T') ε ∈ FIRST ( T ′ ) F ( T ′ ) \mathbf{F}(T') F ( T ′ ) F ( F ) \mathbf{F}(F) F ( F )
综合 10, 11, 12,F ( F ) = { ∗ , + , ) , $ } \mathbf{F}(F) = \{ *, +, ), \$ \} F ( F ) = { ∗ , + , ) , $ }
最终结果:
F O L L O W ( E ) = { ) , $ } \mathrm{FOLLOW}(E) = \{ ), \$ \} FOLLOW ( E ) = { ) , $ } F O L L O W ( E ′ ) = { ) , $ } \mathrm{FOLLOW}(E') = \{ ), \$ \} FOLLOW ( E ′ ) = { ) , $ } F O L L O W ( T ) = { + , ) , $ } \mathrm{FOLLOW}(T) = \{ +, ), \$ \} FOLLOW ( T ) = { + , ) , $ } F O L L O W ( T ′ ) = { + , ) , $ } \mathrm{FOLLOW}(T') = \{ +, ), \$ \} FOLLOW ( T ′ ) = { + , ) , $ } F O L L O W ( F ) = { ∗ , + , ) , $ } \mathrm{FOLLOW}(F) = \{ *, +, ), \$ \} FOLLOW ( F ) = { ∗ , + , ) , $ }
LL(1) 文法的判定
一个文法是 LL(1) 文法,当且仅当对于该文法的任意一个非终结符号 A A A A → α A \to \alpha A → α A → β A \to \beta A → β
F I R S T ( α ) \mathrm{FIRST}(\alpha) FIRST ( α ) F I R S T ( β ) \mathrm{FIRST}(\beta) FIRST ( β ) F I R S T ( α ) ∩ F I R S T ( β ) = ∅ \mathrm{FIRST}(\alpha) \cap \mathrm{FIRST}(\beta) = \empty FIRST ( α ) ∩ FIRST ( β ) = ∅
这个条件保证了当向前看符号 a a a F I R S T \mathrm{FIRST} FIRST
如果 β ⇒ ∗ ε \beta \xRightarrow{*} \varepsilon β ∗ ε ε ∈ F I R S T ( β ) \varepsilon \in \mathrm{FIRST}(\beta) ε ∈ FIRST ( β ) F I R S T ( α ) \mathrm{FIRST}(\alpha) FIRST ( α ) F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) F I R S T ( α ) ∩ F O L L O W ( A ) = ∅ \mathrm{FIRST}(\alpha) \cap \mathrm{FOLLOW}(A) = \empty FIRST ( α ) ∩ FOLLOW ( A ) = ∅
这个条件处理了 ε \varepsilon ε a a a F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) A → ε A \to \varepsilon A → ε a a a A → α A \to \alpha A → α F I R S T \mathrm{FIRST} FIRST
FIRST/FOLLOW 冲突
考虑文法 G G G
S → A a A → a ∣ ε \begin{aligned}
S &\to A a\\
A &\to a \mid \varepsilon
\end{aligned}
S A → A a → a ∣ ε
这个文法定义了语言 a a a a a aa aa
非终结符 A A A A → a A \to a A → a A → ε A \to \varepsilon A → ε
计算 FIRST 和 FOLLOW 集:
F I R S T ( A ) = { a , ε } \mathrm{FIRST}(A) = \{ a, \varepsilon \} FIRST ( A ) = { a , ε } F O L L O W ( A ) = { a } \mathrm{FOLLOW}(A) = \{ a \} FOLLOW ( A ) = { a } S → A a S \to A a S → A a a a a A A A
F I R S T ( a ) ∩ F O L L O W ( A ) = { a } ≠ ∅ \mathrm{FIRST}(a) \cap \mathrm{FOLLOW}(A) = \{ a \} \ne \empty FIRST ( a ) ∩ FOLLOW ( A ) = { a } = ∅
当分析器要推导 A A A a a a F I R S T ( A → a ) \mathrm{FIRST}(A \to a) FIRST ( A → a ) F I R S T ( a ) \mathrm{FIRST}(a) FIRST ( a ) F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A )
表驱动的预测分析
有了 FIRST 和 FOLLOW 集,我们就可以构建一个预测分析表 (Predictive Parsing Table),从而实现一个高效的、非递归的预测分析器。
预测分析表的构造
预测分析表是一个二维数组 M [ A , a ] M[A, a] M [ A , a ]
A A A a a a $ \$ $ 表项 M [ A , a ] M[A, a] M [ A , a ] A A A a a a A A A
构造算法 :对于文法中的每一个产生式 A → α A \to \alpha A → α
对于 F I R S T ( α ) \mathrm{FIRST}(\alpha) FIRST ( α ) a a a A → α A \to \alpha A → α M [ A , a ] M[A, a] M [ A , a ]
如果 ε ∈ F I R S T ( α ) \varepsilon \in \mathrm{FIRST}(\alpha) ε ∈ FIRST ( α ) F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) b b b $ \$ $ A → α A \to \alpha A → α M [ A , b ] M[A, b] M [ A , b ]
所有未被填充的表项都标记为错误 (Error)。
如果在这个过程中,任何一个表项 M [ A , a ] M[A, a] M [ A , a ] 多于一个 产生式,那么该文法就不是 LL(1) 文法 。这种在同一个表项中的多个产生式称为冲突 (conflict)。
非递归预测分析器模型
一个表驱动的预测分析器由以下几个部分组成:
输入缓冲区 :存放待分析的词法单元串,以 $ \$ $ 分析栈 :存放文法符号。初始时,栈底是 $ \$ $ S S S 预测分析表 M :指导分析过程的决策。驱动程序 :读取输入,查询分析表,并操作分析栈。
graph TD
%% 定义子图
subgraph "预测分析器"
direction LR
%% 节点定义与样式
Input[输入缓冲区:<br>id+id*id$]:::input-node --> Driver{驱动程序}:::driver-node
Stack[分析栈]:::stack-node -- 读栈顶 --> Driver
Driver -- 查询 M[栈顶,输入] --> M[预测分析表]:::table-node
M -- 返回产生式 --> Driver
Driver -- 操作 --> Stack
Driver --> Output[输出:<br>产生式序列]:::output-node
end
%% 样式定义
classDef input-node fill:#f0f8ff, stroke:#3498db, stroke-width:2px, font-size:14px, text-align:left
classDef stack-node fill:#e8f8f5, stroke:#1abc9c, stroke-width:2px, font-size:14px
classDef driver-node fill:#fef9e7, stroke:#f39c12, stroke-width:2px, font-size:14px
classDef table-node fill:#f9e7f7, stroke:#e74c3c, stroke-width:2px, font-size:14px
classDef output-node fill:#f6ddcc, stroke:#d35400, stroke-width:2px, font-size:14px, text-align:left
%% 边的样式
style Input stroke:#3498db, stroke-width:1.5px
style Stack stroke:#1abc9c, stroke-width:1.5px
style M stroke:#e74c3c, stroke-width:1.5px
style Output stroke:#d35400, stroke-width:1.5px分析算法
初始化:输入指针 ip 指向输入串的第一个符号,栈中放入 $ \$ $ S S S S S S
循环执行,令 X X X a a a ip 指向的输入符号:
如果 X X X $ \$ $
若 X = a X = a X = a 匹配成功 。从栈中弹出 X X X ip 前进。
若 X ≠ a X \neq a X = a 语法错误 。
如果 X X X
查询分析表 M [ X , a ] M[X, a] M [ X , a ]
若 M [ X , a ] M[X, a] M [ X , a ] X → Y 1 Y 2 … Y k X \to Y_1 Y_2 \dots Y_k X → Y 1 Y 2 … Y k 预测 。从栈中弹出 X X X Y k , Y k − 1 , … , Y 1 Y_k, Y_{k-1}, \dots, Y_1 Y k , Y k − 1 , … , Y 1 逆序 压入栈中(保证 Y 1 Y_1 Y 1
若 M [ X , a ] M[X, a] M [ X , a ] 语法错误 。
结束条件:
当栈顶为 $ \$ $ $ \$ $ $ \$ $ 分析成功 。
在任何其他情况下遇到错误,则分析失败 。
分析过程
分析 id + id * id 的过程。
预测分析表 M:
非终结符号\输入符号
i d \mathbf{id} id + + + ∗ * ∗ ( ( ( ) ) ) $ \$ $
E E E E → T E ′ E \to T E' E → T E ′ -
-
E → T E ′ E \to T E' E → T E ′ -
-
E ′ E' E ′ -
E ′ → + T E ′ E' \to + T E' E ′ → + T E ′ -
-
E ′ → ε E' \to \varepsilon E ′ → ε E ′ → ε E' \to \varepsilon E ′ → ε
T T T T → F T ′ T \to F T' T → F T ′ -
-
T → F T ′ T \to F T' T → F T ′ -
-
T ′ T' T ′ -
T ′ → ε T' \to \varepsilon T ′ → ε T ′ → ∗ F T ′ T' \to * F T' T ′ → ∗ F T ′ -
T ′ → ε T' \to \varepsilon T ′ → ε T ′ → ε T' \to \varepsilon T ′ → ε
F F F F → i d F \to \mathbf{id} F → id -
-
F → ( E ) F \to (E) F → ( E ) -
-
分析过程追踪:
匹配
栈
输入
动作
-
$Eid+id*id$预测 E → T E ′ E\to TE' E → T E ′
-
$E'Tid+id*id$预测 T → F T ′ T\to FT' T → F T ′
-
$E'T'Fid+id*id$预测 F → i d F\to \mathbf{id} F → id
-
$E'T'idid+id*id$匹配 i d \mathbf{id} id
id$E'T'+id*id$预测 T ′ → ε T'\to \varepsilon T ′ → ε
id$E'+id*id$预测 E ′ → + T E ′ E'\to +TE' E ′ → + T E ′
id$E'T++id*id$匹配 + + +
id+$E'Tid*id$预测 T → F T ′ T\to FT' T → F T ′
id+$E'T'Fid*id$预测 F → i d F\to \mathbf{id} F → id
id+$E'T'idid*id$匹配 i d \mathbf{id} id
id+id$E'T'*id$预测 T ′ → ∗ F T ′ T'\to *FT' T ′ → ∗ F T ′
id+id$E'T'F**id$匹配 ∗ * ∗
id+id*$E'T'Fid$预测 F → i d F\to \mathbf{id} F → id
id+id*$E'T'idid$匹配 i d \mathbf{id} id
id+id*id$E'T'$预测 T ′ → ε T'\to \varepsilon T ′ → ε
id+id*id$E'$预测 E ′ → ε E'\to \varepsilon E ′ → ε
id+id*id$$接受
自底向上分析
与从开始符号出发推导输入串的自顶向下分析相反,自底向上分析 (Bottom-Up Parsing)采用一种「逆向」的策略。它从输入的词法单元串(即语法树的叶子节点)开始,通过一系列的归约 (Reduction)操作,逐步将子串替换为非终结符号,层层向上构建,最终目标是归约到文法的开始符号(即语法树的根节点)。
这个过程可以看作是寻找输入串的最右推导 的逆过程 移进-归约分析 (Shift-Reduce Parsing),这是实现该策略的最通用、最强大的技术框架。
上图直观地展示了为 id * id 进行自底向上分析的过程,从叶子节点 id 开始,逐步归约为 F、T,最终到达根节点 E。
归约与句柄
自底向上分析的核心操作是归约 。
归约
归约 (Reduction)是推导的逆向操作。在分析的某一步,如果当前句型中的某个子串 β \beta β A → β A \to \beta A → β β \beta β A A A
自底向上分析的关键挑战在于,在每一步中,如何正确地选择要归约的子串。一个错误的归约选择可能会导致无法最终归约到开始符号。
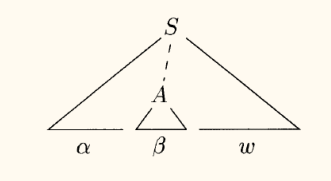
为了确保分析的正确性,我们必须在每一步都选择一个特定的、正确的子串进行归约,这个子串被称为句柄 。
句柄
句柄 (Handle)是当前最右句型中与某个产生式体匹配的子串,并且对它的归约代表了相应最右推导 的一个逆向步骤。
更形式化地说,如果 S ⇒ r m ∗ α A w ⇒ r m α β w S \xRightarrow[\mathrm{rm}]{*} \alpha A w \xRightarrow[\mathrm{rm}]{} \alpha \beta w S ∗ rm α A w rm α β w A → β A \to \beta A → β α β w \alpha \beta w α β w
在一个无二义性的文法中,每个最右句型有且仅有 一个句柄。
自底向上分析的本质,就是一个不断寻找并归约句柄的「句柄剪枝」过程。
句柄识别
考虑文法
E → E + T ∣ T T → T ∗ F ∣ F F → i d \begin{aligned}
E &\to E + T \mid T\\
T &\to T * F \mid F\\
F &\to \mathbf{id}
\end{aligned}
E T F → E + T ∣ T → T ∗ F ∣ F → id
对输入串 id + id * id 的最右推导的逆过程如下:
最右句型
句柄
归约用的产生式
id + id * ididF → i d F \to \mathbf{id} F → id
F + id * idFT → F T \to F T → F
T + id * ididF → i d F \to \mathbf{id} F → id
T + F * ididF → i d F \to \mathbf{id} F → id
T + F * FFT → F T \to F T → F
T + T * FT * FT → T ∗ F T \to T * F T → T ∗ F
T + TTE → T E \to T E → T
E + TE + TE → E + T E \to E + T E → E + T
E(开始符号)-
-
第三步选择归约 id 为 F,而非将 T 归约为 E,是因为后者操作后 E * id 不再是个句型。
移进-归约分析
移进-归约分析 (Shift-Reduce Parsing)是实现自底向上分析的标准算法模型。它使用一个分析栈 来暂存文法符号,并通过四种基本动作来驱动分析过程。
分析器的主要组件包括:
分析栈 :用于存放已处理的文法符号。输入缓冲区 :存放剩余的输入词法单元。
分析器在栈顶和当前输入符号的基础上,做出以下四种决策之一:
移入 (Shift):将下一个输入符号压入分析栈顶。归约 (Reduce):当栈顶形成一个句柄 β \beta β A → β A \to \beta A → β
具体操作是:从栈顶弹出 β \beta β ∣ β ∣ |\beta| ∣ β ∣ A A A
接受 (Accept):当栈中只剩下开始符号且输入缓冲区为空时,宣布分析成功。报错 (Error):在无法执行任何有效动作时,报告语法错误。
一个关键的性质是:对于任何正确的移进-归约分析过程,句柄总是出现在栈的顶端 。这使得我们无需在整个已处理的符号串中搜索句柄,只需关注栈顶即可。
移进-归约过程
对输入串 id * id 的分析过程:
栈
输入
动作
$id * id $移入
$ id* id $归约(F → i d F \to \mathbf{id} F → id
$ F* id $归约(T → F T \to F T → F
$ T* id $移入
$ T *id $移入
$ T * id$归约(F → i d F \to \mathbf{id} F → id
$ T * F$归约(T → T ∗ F T \to T * F T → T ∗ F
$ T$归约(E → T E \to T E → T
$ E$接受
移进-归约冲突
移进-归约分析器的核心挑战在于决策 :在某个状态下,是应该继续移入,还是应该进行归约?对于某些文法,分析器可能会面临无法唯一决策的困境,这称为冲突 。
冲突类型
移进/归约冲突 (Shift/Reduce Conflict):分析器无法确定是应该将下一个输入符号移入栈中,还是应该对栈顶的句柄进行归约。
经典的「悬空 e l s e \mathbf{else} else … i f e x p r t h e n s t m t \dots \ \mathbf{if} \ \mathit{expr} \ \mathbf{then}\ \mathit{stmt} … if expr then stmt e l s e \mathbf{else} else e l s e \mathbf{else} else i f \mathbf{if} if i f e x p r t h e n s t m t \mathbf{if} \ \mathit{expr} \ \mathbf{then}\ \mathit{stmt} if expr then stmt s t m t \mathit{stmt} stmt
归约/归约冲突 (Reduce/Reduce Conflict):栈顶的符号串可以匹配多个不同的产生式体,分析器不知道应该使用哪个产生式进行归约。
这种冲突通常源于文法设计不佳或语言本身的模糊性。例如,如果文法中有 e x p r → i d \mathit{expr} \to \mathbf{id} expr → id p a r a m → i d \mathit{param} \to \mathbf{id} param → id i d \mathbf{id} id e x p r \mathit{expr} expr p a r a m \mathit{param} param
LR 语法分析
LR 语法分析 是目前最强大、最通用的移进-归约分析技术。它能够处理比 LL 分析方法更广泛的文法类别,并且可以被高效地实现。
LR(k)
L :表示从左 (Left)到右扫描输入。R :表示构造最右 (Rightmost)推导的逆过程。k :表示在做分析决定时,需要向前看 k 个输入符号。
在实践中,我们主要关注 k = 0 k=0 k = 0 k = 1 k=1 k = 1
LR 分析器的主要优点:
强大的文法处理能力 :能够处理几乎所有用于描述程序设计语言的上下文无关文法。自动生成 :LR 分析器(特别是其核心的分析表)可以由工具根据文法自动生成。高效性 :分析过程无回溯,效率高。精确的错误定位 :能够尽早地(在扫描到第一个不匹配的符号时)检测到错误。
LL(k) 与 LR(k) 的对比:
LR(k) 的宽松 :
LR 分析器在做归约决策时,它已经完全看到了产生式的右部 α \alpha α α \alpha α
在此基础上,它再向前看 k k k k k k 紧跟在 α \alpha α 的。
所以,LR 分析器在做决策时,拥有更丰富的上下文信息:它知道要归约的子串是什么,以及这个子串后面跟着什么 。
LL(k) 的严格 :
LL 分析器在做预测决策时,它还没有看到产生式的右部 α \alpha α A A A α i \alpha_i α i
它向前看的 k k k α i \alpha_i α i
这意味着 LL 分析器必须仅仅根据这 k k k α i \alpha_i α i α i \alpha_i α i
LR 分析的核心思想是利用一个确定有限自动机 (DFA)来识别句柄。这个自动机的每个状态 (state)都代表了我们已经识别出的、可能构成句柄前缀的文法符号串的信息。
LR 分析器本质上是一个由分析表驱动的、精确的移进-归约分析器。其核心结构由以下几个部分组成:
LR 分析器结构
graph TD
subgraph LR Parser
Driver(分析驱动程序)
Stack(分析栈)
Table(分析表)
end
Input[输入缓冲区: a₁a₂...aₙ$] --> Driver
Driver -- 查看栈顶状态 s --> Stack
Driver -- 查看当前输入 a --> Input
Driver -- (s, a) --> Table
Table -- 动作 --> Driver
Driver -- 操作 --> Stack
Driver -- 推进 --> Input
Driver --> Output(输出分析结果或错误)
style Stack fill:#f9f,stroke:#333,stroke-width:2px
style Table fill:#ccf,stroke:#333,stroke-width:2px
style Driver fill:#cfc,stroke:#333,stroke-width:2px
style Input fill:#ffc,stroke:#333,stroke-width:2px
style Output fill:#fcc,stroke:#333,stroke-width:2px
输入缓冲区 :存放待分析的整个输入串,以结束符 $ \$ $ 分析栈 :存储状态序列 s 0 s 1 … s m s_0s_1\dots s_m s 0 s 1 … s m s m s_m s m 分析表 :这是 LR 分析器的核心,它是一个二维表,指导分析驱动程序的所有决策。它包含两部分:
ACTION 表 :根据当前栈顶状态 s m s_m s m a i a_i a i GOTO 表 :在执行归约操作 A → β A \to \beta A → β s k s_k s k s k s_k s k A A A
分析驱动程序 :执行一个简单的循环,根据栈顶状态和当前输入符号,查询分析表来决定下一步动作,并更新分析栈和输入。
这个模型是所有 LR 类分析器(包括 SLR、LALR、LR(1))的通用工作框架。它们之间的区别仅在于分析表的构造方法 不同。
LR(0) 项
为了构建这个自动机,我们首先需要一个能够表示「识别进度」的工具,这就是 LR(0) 项 。
LR(0) 项
一个 LR(0) 项 (item)是在一个产生式的产生式体中,某个位置插入一个点「. \boldsymbol{.} .
例如,对于产生式 A → X Y Z A \to XYZ A → X Y Z
A → . X Y Z A \to \boldsymbol{.} XYZ A → . X Y Z X Y Z XYZ X Y Z A → X . Y Z A \to X\boldsymbol{.} YZ A → X . Y Z X X X Y Z YZ Y Z A → X Y . Z A \to XY\boldsymbol{.} Z A → X Y . Z X Y XY X Y Z Z Z A → X Y Z . A \to XYZ\boldsymbol{.} A → X Y Z . X Y Z XYZ X Y Z
规范 LR(0) 项集族的构造
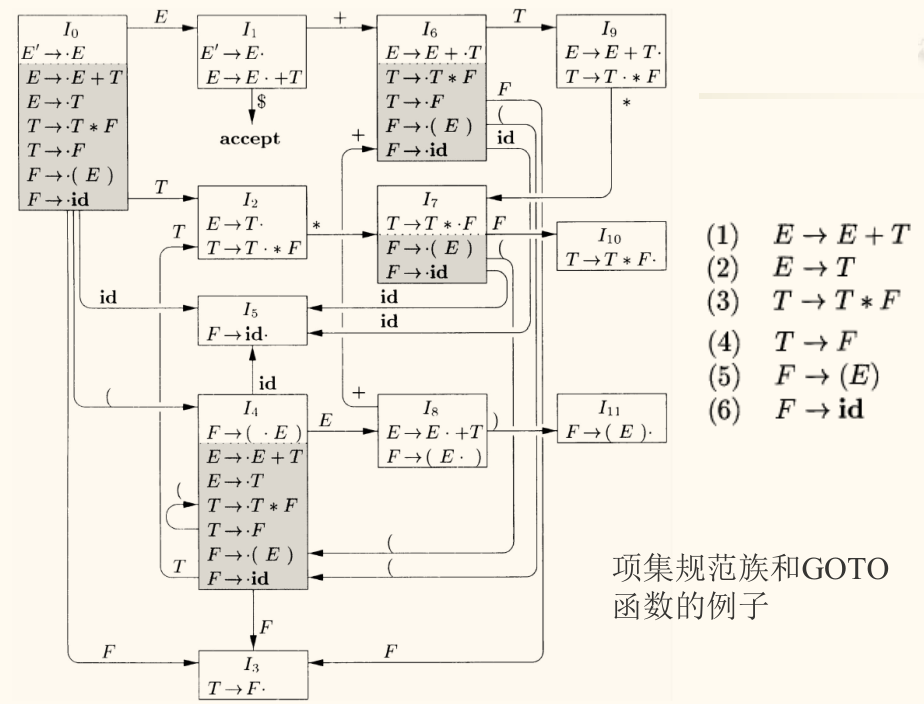
LR 分析器的自动机中的每个状态,都对应一个 LR(0) 项的集合 (即项集 )。构造这个自动机的过程,就是构造所有可能的项集(状态)以及它们之间的转换关系。
这个过程依赖于三个核心概念:
增广文法 (Augmented Grammar):
在原始文法 G G G S ′ S' S ′ S ′ → S S' \to S S ′ → S
目的 :为分析器提供一个唯一的接受状态。当分析器准备按照 S ′ → S S' \to S S ′ → S
闭包操作 C L O S U R E ( I ) \mathrm{CLOSURE}(I) CLOSURE ( I ) :
目的 :扩展一个项集,使其包含所有可能需要立即开始识别的产生式。直观含义 :如果项集 I I I A → α . B β A \to \alpha \boldsymbol{.} B \beta A → α . B β B B B B B B B B B B → . γ B \to \boldsymbol{.} \gamma B → . γ 这与 NFA 到 DFA 转换中的 ε \varepsilon ε
G O T O ( I , X ) \mathrm{GOTO}(I, X) GOTO ( I , X )
目的 :计算自动机的状态转换。直观含义 :如果当前状态是项集 I I I X X X 计算方法 :G O T O ( I , X ) \mathrm{GOTO}(I, X) GOTO ( I , X ) I I I A → α . X β A \to \alpha \boldsymbol{.} X \beta A → α . X β . \boldsymbol{.} . A → α X . β A \to \alpha X \boldsymbol{.} \beta A → α X . β
通过反复应用 C L O S U R E \mathrm{CLOSURE} CLOSURE G O T O \mathrm{GOTO} GOTO C L O S U R E ( S ′ → . S ) \mathrm{CLOSURE}({S' \to \boldsymbol{.} S}) CLOSURE ( S ′ → . S ) 规范 LR(0) 项集族 。
示例
下面使用一个简单的算术表达式文法作为例子,原始文法 G G G
E → E + T ∣ T E \to E + T \mid T E → E + T ∣ T T → T ∗ F ∣ F T \to T * F \mid F T → T ∗ F ∣ F F → ( E ) ∣ i d F \to (E) \mid \mathbf{id} F → ( E ) ∣ id
增广文法 G ′ G' G ′
S ′ → E S' \to E S ′ → E E → E + T ∣ T E \to E + T \mid T E → E + T ∣ T T → T ∗ F ∣ F T \to T * F \mid F T → T ∗ F ∣ F F → ( E ) ∣ i d F \to (E) \mid \mathbf{id} F → ( E ) ∣ id
CLOSURE
假设我们从增广文法的初始项集开始,即只包含 S ′ → . E S' \to \boldsymbol{.} E S ′ → . E
计算 C L O S U R E ( { S ′ → . E } ) \mathrm{CLOSURE}(\{S' \to \boldsymbol{.} E\}) CLOSURE ({ S ′ → . E })
初始化 :结果集 I = { S ′ → . E } I = \{S' \to \boldsymbol{.} E\} I = { S ′ → . E } 处理 S ′ → . E S' \to \boldsymbol{.} E S ′ → . E :
点 . \boldsymbol{.} . E E E
将所有 E E E . \boldsymbol{.} . I I I
I I I { S ′ → . E , E → . E + T , E → . T } \{S' \to \boldsymbol{.} E, E \to \boldsymbol{.} E + T, E \to \boldsymbol{.} T\} { S ′ → . E , E → . E + T , E → . T }
处理 E → . E + T E \to \boldsymbol{.} E + T E → . E + T :
点 . \boldsymbol{.} . E E E E E E E → . E + T , E → . T E \to \boldsymbol{.} E + T, E \to \boldsymbol{.} T E → . E + T , E → . T I I I
处理 E → . T E \to \boldsymbol{.} T E → . T :
点 . \boldsymbol{.} . T T T
将所有 T T T . \boldsymbol{.} . I I I
I I I { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F } \{S' \to \boldsymbol{.} E, E \to \boldsymbol{.} E + T, E \to \boldsymbol{.} T, T \to \boldsymbol{.} T * F, T \to \boldsymbol{.} F\} { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F }
处理 T → . T ∗ F T \to \boldsymbol{.} T * F T → . T ∗ F :
点 . \boldsymbol{.} . T T T T T T T → . T ∗ F , T → . F T \to \boldsymbol{.} T * F, T \to \boldsymbol{.} F T → . T ∗ F , T → . F I I I
处理 T → . F T \to \boldsymbol{.} F T → . F :
点 . \boldsymbol{.} . F F F
将所有 F F F . \boldsymbol{.} . I I I
I I I { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F , F → . ( E ) , F → . i d } \{S' \to \boldsymbol{.} E, E \to \boldsymbol{.} E + T, E \to \boldsymbol{.} T, T \to \boldsymbol{.} T * F, T \to \boldsymbol{.} F, F \to \boldsymbol{.} (E), F \to \boldsymbol{.} \mathbf{id}\} { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F , F → . ( E ) , F → . id }
处理 F → . ( E ) F \to \boldsymbol{.} (E) F → . ( E ) F → . i d F \to \boldsymbol{.} \mathbf{id} F → . id :
F → . ( E ) F \to \boldsymbol{.} (E) F → . ( E ) . \boldsymbol{.} . ( ( ( F → . i d F \to \boldsymbol{.} \mathbf{id} F → . id . \boldsymbol{.} . i d \mathbf{id} id
循环结束 :没有新的项可以加入。
最终结果 :C L O S U R E ( { S ′ → . E } ) = { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F , F → . ( E ) , F → . i d } \mathrm{CLOSURE}(\{S' \to \boldsymbol{.} E\}) = \{S' \to \boldsymbol{.} E, E \to \boldsymbol{.} E + T, E \to \boldsymbol{.} T, T \to \boldsymbol{.} T * F, T \to \boldsymbol{.} F, F \to \boldsymbol{.} (E), F \to \boldsymbol{.} \mathbf{id}\} CLOSURE ({ S ′ → . E }) = { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F , F → . ( E ) , F → . id }
这个闭包操作告诉我们,如果分析器期望看到一个 E E E E E E T T T T T T T T T F F F F F F ( ( ( i d \mathbf{id} id C L O S U R E \mathrm{CLOSURE} CLOSURE
GOTO
计算出了上面的项集 I 0 = C L O S U R E ( { S ′ → . E } ) I_0 = \mathrm{CLOSURE}(\{S' \to \boldsymbol{.} E\}) I 0 = CLOSURE ({ S ′ → . E }) I 0 I_0 I 0 E E E
计算 G O T O ( I 0 , E ) \mathrm{GOTO}(I_0, E) GOTO ( I 0 , E ) :
识别点后为 E E E :从 I 0 I_0 I 0 A → α . E β A \to \alpha \boldsymbol{.} E \beta A → α . E β
S ′ → . E S' \to \boldsymbol{.} E S ′ → . E E → . E + T E \to \boldsymbol{.} E + T E → . E + T
移动点 :将这些项中的点 . \boldsymbol{.} . E E E
S ′ → E . S' \to E\boldsymbol{.} S ′ → E . E → E . + T E \to E\boldsymbol{.} +T E → E . + T J ′ = { S ′ → E . , E → E . + T } J' = \{S' \to E\boldsymbol{.} , E \to E\boldsymbol{.} +T\} J ′ = { S ′ → E . , E → E . + T }
对 J ′ J' J ′ :现在,我们计算 C L O S U R E ( J ′ ) \mathrm{CLOSURE}(J') CLOSURE ( J ′ )
初始化 :结果集 J = { S ′ → E . , E → E . + T } J = \{S' \to E\boldsymbol{.} , E \to E\boldsymbol{.} +T\} J = { S ′ → E . , E → E . + T } 处理 S ′ → E . S' \to E\boldsymbol{.} S ′ → E . : 点 . \boldsymbol{.} . 处理 E → E . + T E \to E\boldsymbol{.} +T E → E . + T : 点 . \boldsymbol{.} . + + + 循环结束 :没有新的项可以加入。
最终结果 :G O T O ( I 0 , E ) = { S ′ → E . , E → E . + T } \mathrm{GOTO}(I_0, E) = \{S' \to E\boldsymbol{.} , E \to E\boldsymbol{.} +T\} GOTO ( I 0 , E ) = { S ′ → E . , E → E . + T }
当我们处于状态 I 0 I_0 I 0 E E E E E E S ′ → E . S' \to E\boldsymbol{.} S ′ → E . E E E + + + E → E . + T E \to E\boldsymbol{.} +T E → E . + T G O T O \mathrm{GOTO} GOTO
通过反复应用这两个函数,就可以构建出完整的 LR(0) 项集族,也就是 LR(0) 自动机的状态和状态转换图。
内核项与非内核项
在 LR(0) 项集中,我们根据项的来源和形式,将其分为两类:
内核项 (Kernel Items)
定义 :所有形如 A → α . X β A \to \alpha \boldsymbol{.} X \beta A → α . X β α \alpha α 不为空 (即点 . \boldsymbol{.} . 特例 :增广文法的起始项 S ′ → . S S' \to \boldsymbol{.} S S ′ → . S 直观含义 :内核项代表了分析器已经识别出了一些文法符号(点左边的 α \alpha α X β X \beta X β
非内核项 (Non-Kernel Items)
定义 :所有形如 A → . β A \to \boldsymbol{.} \beta A → . β A ≠ S ′ A \ne S' A = S ′ . \boldsymbol{.} . 直观含义 :非内核项总是通过 C L O S U R E \mathrm{CLOSURE} CLOSURE
非内核项是完全由内核项通过 C L O S U R E \mathrm{CLOSURE} CLOSURE C L O S U R E \mathrm{CLOSURE} CLOSURE
在构造 LR 自动机时,每个状态(项集)在内存中只存储其内核项。
当需要某个状态的完整信息(包括非内核项)时,例如在计算 G O T O \mathrm{GOTO} GOTO C L O S U R E \mathrm{CLOSURE} CLOSURE
示例
承袭上面的文法,有 I 0 = C L O S U R E ( { S ′ → . E } ) = { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F , F → . ( E ) , F → . i d } I_0 = \mathrm{CLOSURE}(\{S' \to \boldsymbol{.} E\}) = \{S' \to \boldsymbol{.} E, E \to \boldsymbol{.} E + T, E \to \boldsymbol{.} T, T \to \boldsymbol{.} T * F, T \to \boldsymbol{.} F, F \to \boldsymbol{.} (E), F \to \boldsymbol{.} \mathbf{id}\} I 0 = CLOSURE ({ S ′ → . E }) = { S ′ → . E , E → . E + T , E → . T , T → . T ∗ F , T → . F , F → . ( E ) , F → . id }
内核项 :
S ′ → . E S' \to \boldsymbol{.} E S ′ → . E
非内核项 :
E → . E + T E \to \boldsymbol{.} E + T E → . E + T E → . T E \to \boldsymbol{.} T E → . T T → . T ∗ F T \to \boldsymbol{.} T * F T → . T ∗ F T → . F T \to \boldsymbol{.} F T → . F F → . ( E ) F \to \boldsymbol{.} (E) F → . ( E ) F → . i d F \to \boldsymbol{.} \mathbf{id} F → . id
再看另一个项集,I 1 = G O T O ( I 0 , E ) = { S ′ → E . , E → E . + T } I_1 = \mathrm{GOTO}(I_0, E) = \{S' \to E\boldsymbol{.} , E \to E\boldsymbol{.} +T\} I 1 = GOTO ( I 0 , E ) = { S ′ → E . , E → E . + T }
内核项 :
S ′ → E . S' \to E\boldsymbol{.} S ′ → E . E → E . + T E \to E\boldsymbol{.} +T E → E . + T
非内核项 :
I 1 I_1 I 1 C L O S U R E \mathrm{CLOSURE} CLOSURE
LR(0) 自动机
LR(0) 自动机 是一个 DFA,其状态和转换定义如下:
状态 :规范 LR(0) 项集族中的每一个项集。
初始状态: C L O S U R E ( { S ′ → . S } ) \mathrm{CLOSURE}(\{S' \to \boldsymbol{.} S\}) CLOSURE ({ S ′ → . S })
接受状态:包含形如 A → α . A \to \alpha \boldsymbol{.} A → α .
转换 :如果 G O T O ( I , X ) = J \mathrm{GOTO}(I, X) = J GOTO ( I , X ) = J I I I J J J X X X
这个自动机能够识别文法的所有「可行前缀」,即可出现在移进-归约分析器栈中的最右句型的前缀。
这个自动机的核心作用是识别文法的可行前缀 。
可行前缀
可行前缀 (Viable Prefix)是指不会超过该句柄的右端的最右句型的前缀 。换句话说,一个字符串是可行前缀,如果它能作为某个正确的移进-归约分析过程中的栈内容出现。
例如 E ⇒ r m ∗ F ∗ i d ⇒ r m ( E ) ∗ i d E \xRightarrow[\mathrm{rm}]{*} F * \mathbf{id} \xRightarrow[\mathrm{rm}]{} (E) * \mathbf{id} E ∗ rm F ∗ id rm ( E ) ∗ id
( ( ( ( E (E ( E ( E ) (E) ( E ) ( E ) ∗ (E) * ( E ) ∗
LR(0) 自动机中的每一个状态都对应一个项集,这个项集精确地描述了在识别了某个可行前缀之后,我们期望看到的后续符号。
当自动机从初始状态出发,沿着一条路径 γ \gamma γ j j j γ \gamma γ
状态 j j j γ \gamma γ
如果存在项 A → α . a β A \to \alpha \boldsymbol{.} a \beta A → α . a β a a a a a a a a a 移入 动作。
如果存在项 A → α . A \to \alpha \boldsymbol{.} A → α . α \alpha α 归约 动作。
LR 分析器的执行
在实际的 LR 分析过程中,我们并不需要每次都用整个栈中的符号串去驱动 LR(0) 自动机。分析器采用了一种更高效的方式:
栈中存储状态 :分析栈中直接存储自动机的状态编号,而不是文法符号。初始时,栈中只有初始状态 s 0 s_0 s 0 移入操作 :当分析器处于状态 s m s_m s m X X X G O T O ( s m , X ) \mathrm{GOTO}(s_m, X) GOTO ( s m , X ) s j s_j s j s j s_j s j s m s_m s m X X X s j s_j s j 归约操作 :当决定使用产生式 A → β A \to \beta A → β r = ∣ β ∣ r=|\beta| r = ∣ β ∣ r r r s m − r s_{m-r} s m − r β \beta β G O T O ( s m − r , A ) \mathrm{GOTO}(s_{m-r}, A) GOTO ( s m − r , A ) s k s_k s k s k s_k s k
通过这种方式,分析栈中的状态序列始终对应于 LR(0) 自动机上的一条从初始状态开始的路径,而这条路径的标号序列就是当前栈内隐式表示的文法符号串。
SLR 分析
单纯的 LR(0) 自动机在决策时有一个缺陷:只要一个状态中包含形如 A → α . A \to \alpha\boldsymbol{.} A → α . 归约项 ,它就会无条件地选择归约。这在很多情况下会导致冲突。
SLR (Simple LR)分析是对 LR(0) 的一个简单改进。它在决定是否归约时,会额外考虑下一个输入符号。
SLR 决策规则
对于一个包含归约项 A → α . A \to \alpha\boldsymbol{.} A → α . I i I_i I i a a a F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A )
理由 :如果我们将 α \alpha α A A A A A A A A A F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A )
SLR 通过引入向前看符号(具体来说是 FOLLOW 集)来解决 LR(0) 分析中的冲突,其理论基础是有效项 (Valid Item)的概念。
有效项
我们称 LR(0) 项 A → β 1 . β 2 A \to \beta_1 \boldsymbol{.} \beta_2 A → β 1 . β 2 α β 1 \alpha\beta_1 α β 1 有效 的,如果存在一个最右推导 S ′ ⇒ r m ∗ α A w ⇒ r m α β 1 β 2 w S' \xRightarrow[\mathrm{rm}]{*} \alpha A w \xRightarrow[\mathrm{rm}]{} \alpha \beta_1 \beta_2 w S ′ ∗ rm α A w rm α β 1 β 2 w
直观含义 :一个项是有效的,意味着在当前的分析进度下(已经识别了 α β 1 \alpha\beta_1 α β 1
LR(0) 自动机的一个重要性质是:从初始状态沿着路径 γ \gamma γ I I I γ \gamma γ
SLR 正是利用这个性质来解决冲突:
当分析器处于状态 I I I γ \gamma γ I I I A → α . A \to \alpha\boldsymbol{.} A → α . A → α . A \to \alpha\boldsymbol{.} A → α . γ \gamma γ
根据有效项的定义,这意味着存在一个推导 S ′ ⇒ r m ∗ γ A w ⇒ r m γ α w S' \xRightarrow[\mathrm{rm}]{*} \gamma A w \xRightarrow[\mathrm{rm}]{} \gamma \alpha w S ′ ∗ rm γ A w rm γ α w
在这个推导中,归约完成后,下一个输入符号必然是 w w w F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A )
因此,只有当下一个输入符号 a ∈ F O L L O W ( A ) a \in \mathrm{FOLLOW}(A) a ∈ FOLLOW ( A ) A → α A \to \alpha A → α A → α . A \to \alpha\boldsymbol{.} A → α .
SLR 分析表的构造
SLR 分析器由一个分析表 驱动,该表分为两部分:ACTION 表和 GOTO 表。
A C T I O N [ i , a ] \mathrm{ACTION}[i, a] ACTION [ i , a ] i i i a a a G O T O [ i , A ] \mathrm{GOTO}[i, A] GOTO [ i , A ] i i i A A A
构造算法:
构造文法的规范 LR(0) 项集族 C = { I 0 , I 1 , … , I n } C = \{I_0, I_1, \dots, I_n\} C = { I 0 , I 1 , … , I n }
对于每个状态 i i i I i I_i I i
移入 :如果项 [ A → α . a β ] [A \to \alpha \boldsymbol{.} a \beta] [ A → α . a β ] I i I_i I i G O T O ( I i , a ) = I j \mathrm{GOTO}(I_i, a) = I_j GOTO ( I i , a ) = I j a a a A C T I O N [ i , a ] = 移入 j \mathrm{ACTION}[i, a] = \text{移入}\ j ACTION [ i , a ] = 移入 j j j j 归约 :如果项 [ A → α . ] [A \to \alpha \boldsymbol{.} ] [ A → α . ] I i I_i I i A ≠ S ′ A \ne S' A = S ′ F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) b b b A C T I O N [ i , b ] = 归约 A → α \mathrm{ACTION}[i, b] = \text{归约}\ A \to \alpha ACTION [ i , b ] = 归约 A → α A → α A \to \alpha A → α 接受 :如果项 [ S ′ → S . ] [S' \to S \boldsymbol{.} ] [ S ′ → S . ] I i I_i I i A C T I O N [ i , $ ] = 接受 \mathrm{ACTION}[i, \$] = \text{接受} ACTION [ i , $ ] = 接受 GOTO :如果 G O T O ( I i , A ) = I j \mathrm{GOTO}(I_i, A) = I_j GOTO ( I i , A ) = I j A A A G O T O [ i , A ] = j \mathrm{GOTO}[i, A] = j GOTO [ i , A ] = j
所有未被填充的表项均为错误 。
如果构造过程中,任何一个 ACTION 表项被填入了多个动作,则说明该文法不是 SLR(1) 文法 。
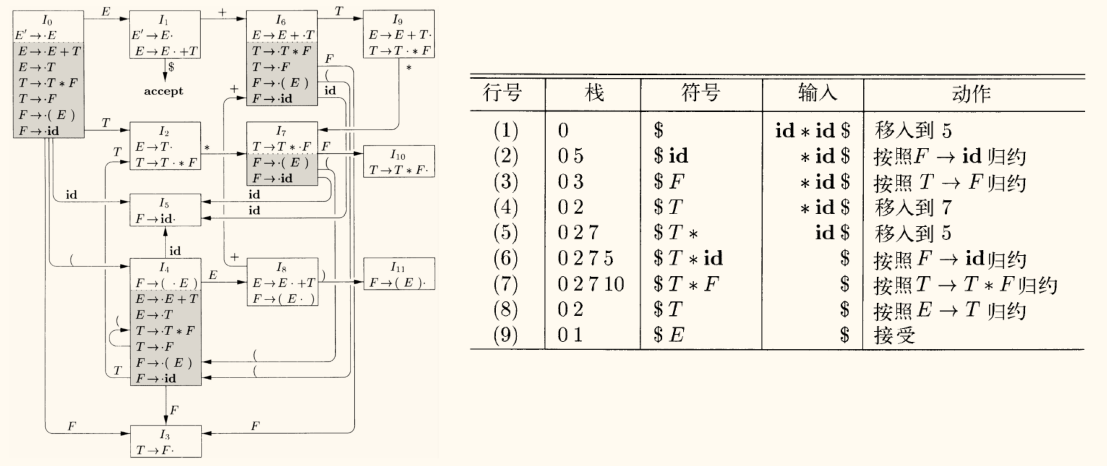
表达式文法的 SLR 分析表
下表中,i d , + , ∗ , ( , ) \mathbf{id}, +, *, (, ) id , + , ∗ , ( , ) E , T , F E, T, F E , T , F
状态
i d \mathbf{id} id + + + ∗ * ∗ ( ( ( ) ) ) $ \$ $ E E E T T T F F F
0 S 5 S_5 S 5 -
-
S 4 S_4 S 4 -
-
1
2
3
1 -
S 6 S_6 S 6 -
-
-
ACC \text{ACC} ACC -
-
-
2 -
R 2 R_2 R 2 S 7 S_7 S 7 -
R 2 R_2 R 2 R 2 R_2 R 2 -
-
-
3 -
R 4 R_4 R 4 R 4 R_4 R 4 -
R 4 R_4 R 4 R 4 R_4 R 4 -
-
-
4 S 5 S_5 S 5 -
-
S 4 S_4 S 4 -
-
8
2
3
5 -
R 6 R_6 R 6 R 6 R_6 R 6 -
R 6 R_6 R 6 R 6 R_6 R 6 -
-
-
6 S 5 S_5 S 5 -
-
S 4 S_4 S 4 -
-
-
9
3
7 S 5 S_5 S 5 -
-
S 4 S_4 S 4 -
-
-
-
10
8 -
S 6 S_6 S 6 -
-
S 11 S_{11} S 11 -
-
-
-
9 -
R 1 R_1 R 1 S 7 S_7 S 7 -
R 1 R_1 R 1 R 1 R_1 R 1 -
-
-
10 -
R 3 R_3 R 3 R 3 R_3 R 3 -
R 3 R_3 R 3 R 3 R_3 R 3 -
-
-
11 -
R 5 R_5 R 5 R 5 R_5 R 5 -
R 5 R_5 R 5 R 5 R_5 R 5 -
-
-
S j S_j S j j j j R k R_k R k k k k ACC \text{ACC} ACC
SLR 分析过程示例
现在使用上面的 SLR 分析表来分析输入串 i d + i d ∗ i d \mathbf{id} + \mathbf{id} * \mathbf{id} id + id ∗ id
分析器需要一个状态栈 (初始为 0)和一个输入缓冲区 (初始为 i d ∗ i d + i d $ \mathbf{id} * \mathbf{id} + \mathbf{id} \$ id ∗ id + id $
为了方便理解,为文法的产生式编号:
E → E + T E \to E + T E → E + T E → T E \to T E → T T → T ∗ F T \to T * F T → T ∗ F T → F T \to F T → F F → ( E ) F \to ( E ) F → ( E ) F → i d F \to \mathbf{id} F → id
步骤
状态栈
符号栈
输入缓冲区
动作
1 0 id * id + id $A C T I O N [ 0 , i d ] = S 5 \mathrm{ACTION}[0, \mathbf{id}] = S_5 ACTION [ 0 , id ] = S 5
2 0 5id* id + id $A C T I O N [ 5 , ∗ ] = R 6 \mathrm{ACTION}[5, *] = R_6 ACTION [ 5 , ∗ ] = R 6 F → i d F \to \mathbf{id} F → id
3
0F* id + id $归约 F F F G O T O [ 0 , F ] = 3 \mathrm{GOTO}[0, F] = 3 GOTO [ 0 , F ] = 3
4 0 3F* id + id $A C T I O N [ 3 , ∗ ] = R 4 \mathrm{ACTION}[3, *] = R_4 ACTION [ 3 , ∗ ] = R 4 T → F T \to F T → F
5
0T* id + id $归约 T T T G O T O [ 0 , T ] = 2 \mathrm{GOTO}[0, T] = 2 GOTO [ 0 , T ] = 2
6 0 2T* id + id $A C T I O N [ 2 , ∗ ] = S 7 \mathrm{ACTION}[2, *] = S_7 ACTION [ 2 , ∗ ] = S 7
7 0 2 7T *id + id $A C T I O N [ 7 , i d ] = S 5 \mathrm{ACTION}[7, \mathbf{id}] = S_5 ACTION [ 7 , id ] = S 5
8 0 2 7 5T * id+ id $A C T I O N [ 5 , + ] = R 6 \mathrm{ACTION}[5, +] = R_6 ACTION [ 5 , + ] = R 6 F → i d F \to \mathbf{id} F → id
9
0 2 7T * F+ id $归约 F F F G O T O [ 7 , F ] = 10 \mathrm{GOTO}[7, F] = 10 GOTO [ 7 , F ] = 10
10 0 2 7 10T * F+ id $A C T I O N [ 10 , + ] = R 3 \mathrm{ACTION}[10, +] = R_3 ACTION [ 10 , + ] = R 3 T → T ∗ F T \to T * F T → T ∗ F
11
0T+ id $归约 T T T G O T O [ 0 , T ] = 2 \mathrm{GOTO}[0, T] = 2 GOTO [ 0 , T ] = 2
12 0 2T+ id $A C T I O N [ 2 , + ] = R 2 \mathrm{ACTION}[2, +] = R_2 ACTION [ 2 , + ] = R 2 E → T E \to T E → T
13
0E+ id $归约 E E E G O T O [ 0 , E ] = 1 \mathrm{GOTO}[0, E] = 1 GOTO [ 0 , E ] = 1
14 0 1E+ id $A C T I O N [ 1 , + ] = S 6 \mathrm{ACTION}[1, +] = S_6 ACTION [ 1 , + ] = S 6
15 0 1 6E +id $A C T I O N [ 6 , i d ] = S 5 \mathrm{ACTION}[6, \mathbf{id}] = S_5 ACTION [ 6 , id ] = S 5
16 0 1 6 5E + id$A C T I O N [ 5 , $ ] = R 6 \mathrm{ACTION}[5, \$] = R_6 ACTION [ 5 , $ ] = R 6 F → i d F \to \mathbf{id} F → id
17
0 1 6E + F$归约 F F F G O T O [ 6 , F ] = 3 \mathrm{GOTO}[6, F] = 3 GOTO [ 6 , F ] = 3
18 0 1 6 3E + F$A C T I O N [ 3 , $ ] = R 4 \mathrm{ACTION}[3, \$] = R_4 ACTION [ 3 , $ ] = R 4 T → F T \to F T → F
19
0 1 6E + T$归约 T T T G O T O [ 6 , T ] = 9 \mathrm{GOTO}[6, T] = 9 GOTO [ 6 , T ] = 9
20 0 1 6 9E + T$A C T I O N [ 9 , $ ] = R 1 \mathrm{ACTION}[9, \$] = R_1 ACTION [ 9 , $ ] = R 1 E → E + T E \to E + T E → E + T
21
0E$归约 E E E G O T O [ 0 , E ] = 1 \mathrm{GOTO}[0, E] = 1 GOTO [ 0 , E ] = 1
22 0 1E$A C T I O N [ 1 , $ ] = ACC \mathrm{ACTION}[1, \$] = \text{ACC} ACTION [ 1 , $ ] = ACC
上面的步骤中,将「归约」步骤的弹出 + GOTO 分成了两步来展示,是为了更清晰地说明过程。实际表示中常常会将其合并为一步。为了表示这种区别,核心步骤的序号加粗表示。
SLR 的局限性
SLR 方法虽然简单有效,但其能力仍然有限。它使用 FOLLOW 集来决定归约动作,但 F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) A A A 全局 信息,它包含了 A A A 所有 可能上下文中后面可能跟随的符号。
SLR 冲突示例
考虑下面这个文法,它区别 L-value(左值,可出现在赋值号左边)和 R-value(右值):
S → L = R ∣ R L → ∗ R ∣ i d R → L \begin{aligned}
S &\to L = R \mid R \\
L &\to *R \mid \mathbf{id} \\
R &\to L
\end{aligned}
S L R → L = R ∣ R → ∗ R ∣ id → L
增广后,我们构造其 LR(0) 项集族,会得到一个包含以下项的状态,我们称之为 I 2 I_2 I 2
I 2 = { S → L . = R , R → L . } I_2 = \{ S \to L\boldsymbol{.} =R, R \to L\boldsymbol{.} \}
I 2 = { S → L . = R , R → L . }
现在,假设分析器处于状态 I 2 I_2 I 2 = = =
根据项 S → L . = R S \to L\boldsymbol{.} =R S → L . = R 移入 = = =
根据项 R → L . R \to L\boldsymbol{.} R → L . F O L L O W ( R ) \mathrm{FOLLOW}(R) FOLLOW ( R )
我们来计算 F O L L O W ( R ) \mathrm{FOLLOW}(R) FOLLOW ( R )
从产生式 S → L = R S \to L=R S → L = R $ \$ $ R R R S → L = R S \to L=R S → L = R $ ∈ F O L L O W ( R ) \$ \in \mathrm{FOLLOW}(R) $ ∈ FOLLOW ( R )
从产生式 L → ∗ R L \to *R L → ∗ R R R R F O L L O W ( L ) \mathrm{FOLLOW}(L) FOLLOW ( L ) F O L L O W ( R ) \mathrm{FOLLOW}(R) FOLLOW ( R )
F O L L O W ( L ) \mathrm{FOLLOW}(L) FOLLOW ( L ) S → L = R S \to L=R S → L = R = = = L L L = ∈ F O L L O W ( L ) = \in \mathrm{FOLLOW}(L) =∈ FOLLOW ( L ) 因此,= ∈ F O L L O W ( R ) = \in \mathrm{FOLLOW}(R) =∈ FOLLOW ( R )
冲突产生 :因为 = ∈ F O L L O W ( R ) = \in \mathrm{FOLLOW}(R) =∈ FOLLOW ( R ) A C T I O N [ 2 , = ] \mathrm{ACTION}[2, =] ACTION [ 2 , = ] R → L R \to L R → L S → L . = R S \to L\boldsymbol{.} =R S → L . = R A C T I O N [ 2 , = ] \mathrm{ACTION}[2, =] ACTION [ 2 , = ] 移进/归约冲突 。
问题根源 :SLR 的判断过于粗糙。虽然 = = = 在某种情况下 可以跟在 R R R ∗ i d = … *\mathbf{id} = \dots ∗ id = … ∗ i d *\mathbf{id} ∗ id L L L R R R I 2 I_2 I 2 L L L = = = 必须 是赋值语句的一部分,唯一的合法动作是移入 = = = L L L R R R R = R R=R R = R
SLR 无法区分这种上下文,因为它只看全局的 FOLLOW 集。更强大的 LR(1) 和 LALR(1) 分析方法通过在项中携带更精确的展望符信息,能够解决这类冲突。
更强大的 LR 分析器
SLR 分析方法通过引入 FOLLOW 集来解决 LR(0) 分析中的冲突,但这是一种相对「粗糙」的解决方案。F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) A A A 任何 可能上下文中后面可以跟随的终结符,它没有考虑分析器在某个特定状态下的具体上下文信息。这可能导致在某些情况下,即使 FOLLOW 集允许归约,但该归约在当前上下文中实际上是非法的,从而引发无法解决的冲突。
为了解决这一问题,我们需要更强大的分析方法,它们能够在分析决策中包含更精确的向前看信息。主要有两种:
规范 LR(1) 分析 (Canonical LR(1) Parsing):在项中直接携带精确的展望符,理论上最强大,但生成的分析器状态数最多。向前看 LR 分析 (Lookahead LR, LALR (1)):作为 LR(1) 的一种优化,它在保持强大分析能力的同时,显著减少了状态数量,使其在规模上与 SLR 分析器相当,是 YACC 等大多数语法分析器生成工具的理论基础。
规范 LR(1) 分析
规范 LR(1) 分析的核心思想是将 SLR 中用于判断归约的「向前看」信息,直接集成到自动机的状态(即项集)中。这样,每个状态不仅知道已经识别了什么,还精确地知道在何种后续输入下可以进行归约。
LR(1) 项
为了携带这种精确的展望信息,我们引入了 LR(1) 项 (LR(1) item)。
LR(1) 项
一个 LR(1) 项 由两部分组成,形式为 [ A → α . β , a ] [A \to \alpha \boldsymbol{.} \beta, a] [ A → α . β , a ]
核心 (Core):即我们熟悉的 LR(0) 项 A → α . β A \to \alpha \boldsymbol{.} \beta A → α . β 展望符 (Lookahead):一个终结符 a a a
这个项的直观含义是:我们当前期望识别一个能由 β \beta β β \beta β ε \varepsilon ε a a a α β \alpha\beta α β A A A
当 β \beta β a a a
当 β \beta β [ A → α . , a ] [A \to \alpha\boldsymbol{.} , a] [ A → α . , a ] a a a 精确条件 :只有当下一个输入符号是 a a a
对于任何有效的 LR(1) 项 [ A → α . β , a ] [A \to \alpha \boldsymbol{.} \beta, a] [ A → α . β , a ] a a a F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A )
规范 LR(1) 项集族的构造
与 LR(0) 类似,我们通过 CLOSURE 和 GOTO 两个操作来构造 LR(1) 自动机的状态(项集)。
增广文法 :与之前相同,引入新的开始符号 S ′ S' S ′ S ′ → S S' \to S S ′ → S [ S ′ → . S , $ ] [S' \to \boldsymbol{.} S, \$] [ S ′ → . S , $ ] $ \$ $ 闭包操作 C L O S U R E ( I ) \mathrm{CLOSURE}(I) CLOSURE ( I ) :
目的 :扩展项集,以包含所有因当前项而需要立即开始识别的产生式,并传播展望符 。规则 :对于项集 I I I [ A → α . B β , a ] [A \to \alpha \boldsymbol{.} B \beta, a] [ A → α . B β , a ] B B B B B B B → γ B \to \gamma B → γ [ B → . γ , b ] [B \to \boldsymbol{.} \gamma, b] [ B → . γ , b ] b b b B B B b ∈ F I R S T ( β a ) b \in \mathrm{FIRST}(\beta a) b ∈ FIRST ( β a ) 展望符的计算 :F I R S T ( β a ) \mathrm{FIRST}(\beta a) FIRST ( β a ) B B B β \beta β β \beta β ε \varepsilon ε a a a
G O T O ( I , X ) \mathrm{GOTO}(I, X) GOTO ( I , X )
目的 :计算状态转换。规则 :G O T O ( I , X ) \mathrm{GOTO}(I, X) GOTO ( I , X ) I I I [ A → α . X β , a ] [A \to \alpha \boldsymbol{.} X \beta, a] [ A → α . X β , a ] [ A → α X . β , a ] [A \to \alpha X \boldsymbol{.} \beta, a] [ A → α X . β , a ] 注意:在 GOTO 操作中,展望符保持不变。
通过这两个函数,从初始项集 C L O S U R E ( { [ S ′ → . S , $ ] } ) \mathrm{CLOSURE}(\{[S' \to \boldsymbol{.} S, \$]\}) CLOSURE ({[ S ′ → . S , $ ]}) 规范 LR(1) 项集族 。
LR(1) 分析表的构造
LR(1) 分析表的构造算法与 SLR 类似,但决策依据更加精确:
构造文法的规范 LR(1) 项集族 C = { I 0 , I 1 , … , I n } C = \{I_0, I_1, \dots, I_n\} C = { I 0 , I 1 , … , I n }
对于每个状态 i i i I i I_i I i
移入 :如果项 [ A → α . a β , b ] [A \to \alpha \boldsymbol{.} a \beta, b] [ A → α . a β , b ] I i I_i I i G O T O ( I i , a ) = I j \mathrm{GOTO}(I_i, a) = I_j GOTO ( I i , a ) = I j a a a A C T I O N [ i , a ] = 移入 j \mathrm{ACTION}[i, a] = \text{移入}\ j ACTION [ i , a ] = 移入 j 归约 :如果项 [ A → α . , a ] [A \to \alpha \boldsymbol{.} , a] [ A → α . , a ] I i I_i I i A ≠ S ′ A \ne S' A = S ′ A C T I O N [ i , a ] = 归约 A → α \mathrm{ACTION}[i, a] = \text{归约}\ A \to \alpha ACTION [ i , a ] = 归约 A → α 接受 :如果项 [ S ′ → S . , $ ] [S' \to S \boldsymbol{.} , \$] [ S ′ → S . , $ ] I i I_i I i A C T I O N [ i , $ ] = 接受 \mathrm{ACTION}[i, \$] = \text{接受} ACTION [ i , $ ] = 接受 GOTO :如果 G O T O ( I i , A ) = I j \mathrm{GOTO}(I_i, A) = I_j GOTO ( I i , A ) = I j A A A G O T O [ i , A ] = j \mathrm{GOTO}[i, A] = j GOTO [ i , A ] = j
所有未被填充的表项均为错误 。
如果构造过程中,任何一个 ACTION 表项被填入了多个动作,则说明该文法不是 LR(1) 文法 。
解决 SLR 冲突
回到之前 SLR 无法解决的文法:
S → L = R ∣ R L → ∗ R ∣ i d R → L \begin{aligned}
S &\to L = R \mid R \\
L &\to *R \mid \mathbf{id} \\
R &\to L
\end{aligned}
S L R → L = R ∣ R → ∗ R ∣ id → L
在 LR(1) 分析中,我们会得到两个不同的状态,它们的核心都是 LR(0) 状态 I 2 = { S → L . = R , R → L . } I_2 = \{ S \to L\boldsymbol{.} =R, R \to L\boldsymbol{.} \} I 2 = { S → L . = R , R → L . }
一个状态可能包含项 [ S → L . = R , $ ] [S \to L\boldsymbol{.} =R, \$] [ S → L . = R , $ ] S → L = R S \to L=R S → L = R
另一个状态可能包含项 [ R → L . , = ] [R \to L\boldsymbol{.} , =] [ R → L . , = ] R → L R \to L R → L = = = ∗ i d = … *\mathbf{id} = \dots ∗ id = … ∗ i d *\mathbf{id} ∗ id L L L
具体的分析表决策如下:
当分析器处于包含 [ S → L . = R , $ ] [S \to L\boldsymbol{.} =R, \$] [ S → L . = R , $ ] = = =
根据项 [ S → L . = R , $ ] [S \to L\boldsymbol{.} =R, \$] [ S → L . = R , $ ] 移入 。
这个状态中不包含 展望符为 = = =
当分析器处于包含 [ R → L . , = ] [R \to L\boldsymbol{.} , =] [ R → L . , = ] = = =
根据项 [ R → L . , = ] [R \to L\boldsymbol{.} , =] [ R → L . , = ] 归约 R → L R \to L R → L
这个状态中不包含 点在 = = =
LR(1) 通过不同的展望符将原本在 SLR 中混合在一起的冲突情况,分离到了不同的状态中,从而消除了冲突。
LALR(1) 分析
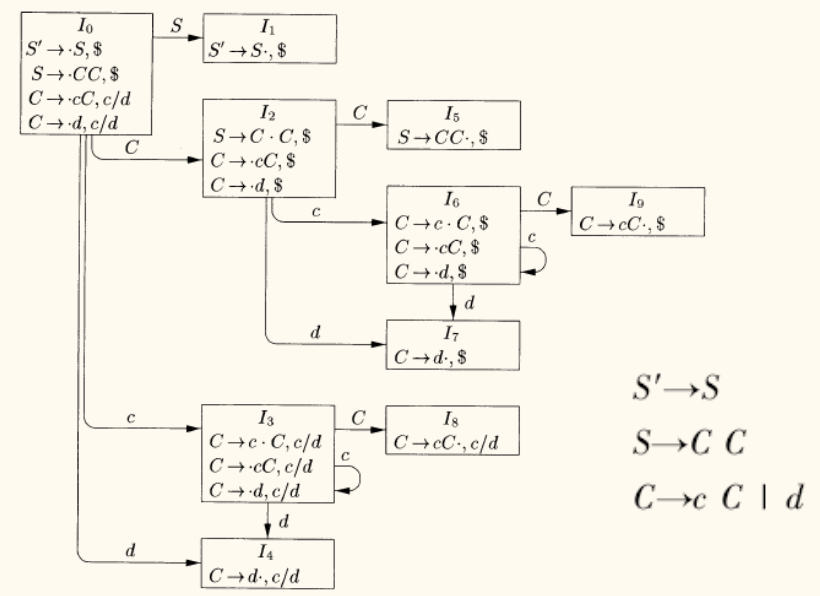
LR(1) 分析虽然强大,但其实用性受到一个严重问题的制约:对于一个典型的程序设计语言文法,LR(1) 分析器可能会产生数千个状态,而 SLR 或 LALR(1) 分析器可能只有几百个。
观察 LR(1) 项集族可以发现,其中存在大量核心相同 (即 LR(0) 部分完全一样)而仅展望符不同的项集。
如上面的项集族中,状态 3, 6、状态 4, 7 与状态 8, 9 都是核心相同的项集,实质上它们来自相同的 LR(0) 状态。
LALR(1) 的核心思想
LALR (1)(Lookahead LR)分析通过合并所有核心相同的 LR(1) 项集 来减少状态数量。合并后的新项集是原始项集的并集。
例如,如果存在两个 LR(1) 项集:
I i = { [ C → c . C , c / d ] , [ C → . c C , c / d ] , … } I_i = \{ [C \to c\boldsymbol{.} C, c/d], [C \to \boldsymbol{.} cC, c/d], \dots \} I i = {[ C → c . C , c / d ] , [ C → . c C , c / d ] , … } I j = { [ C → c . C , $ ] , [ C → . c C , $ ] , … } I_j = \{ [C \to c\boldsymbol{.} C, \$], [C \to \boldsymbol{.} cC, \$], \dots \} I j = {[ C → c . C , $ ] , [ C → . c C , $ ] , … }
它们的核心({ C → c . C , C → . c C , … } \{ C \to c\boldsymbol{.} C, C \to \boldsymbol{.} cC, \dots \} { C → c . C , C → . c C , … }
I i j = { [ C → c . C , c / d / $ ] , [ C → . c C , c / d / $ ] , … } I_{ij} = \{ [C \to c\boldsymbol{.} C, c/d/\$], [C \to \boldsymbol{.} cC, c/d/\$], \dots \} I ij = {[ C → c . C , c / d /$ ] , [ C → . c C , c / d /$ ] , … } 这里的 c / d / $ c/d/\$ c / d /$
LALR(1) 的构造与冲突
构造方法(朴素版):
首先,完整地构造出文法的规范 LR(1) 项集族 。
然后,找出所有核心相同的项集,并将它们合并成一个新的项集。
根据合并后的项集族来构造 LALR(1) 分析表。动作的确定方式与 LR(1) 相同。
合并可能产生的冲突:
合并过程不会 产生新的移进/归约冲突。因为移入动作只依赖于项的核心,如果合并前没有 S/R 冲突,合并后也不会有。
但是,合并过程可能会引入新的归约/归约冲突 。
假设状态 I i I_i I i [ A → α . , a ] [A \to \alpha\boldsymbol{.} , a] [ A → α . , a ] I j I_j I j [ B → β . , b ] [B \to \beta\boldsymbol{.} , b] [ B → β . , b ]
如果 I i I_i I i I j I_j I j
如果在合并后的新状态中,恰好 a = b a=b a = b a a a A → α A \to \alpha A → α B → β B \to \beta B → β
因此,LALR(1) 的分析能力介于 SLR(1) 和 LR(1) 之间。它能处理比 SLR(1) 更多的文法,但比 LR(1) 少。不过,对于绝大多数程序设计语言的文法,LALR(1) 的能力已经足够,并且其分析器规模远小于 LR(1),使其成为实践中的首选。
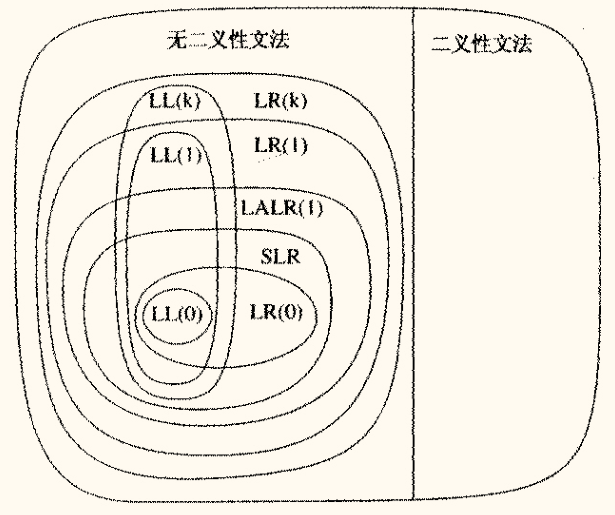
文法分析能力的比较
不同类型的语法分析方法能够处理的文法范围不同,它们之间存在一种层次关系。
LR (k) 是最强大的分析方法,能够处理所有无二义性的上下文无关文法。在 k = 1 k=1 k = 1 LR(1) > LALR(1) > SLR (1)。
LL (1) 文法是 LR(1) 文法的一个真子集,但与 LALR(1) 和 SLR(1) 的关系是相交,而非包含。也就是说,存在 LL(1) 文法不是 LALR(1) 或 SLR(1) 的,反之亦然。任何二义性文法都不是 LR 文法,因为二义性必然导致分析表中的冲突。
二义性文法的处理
虽然理论上二义性文法无法被 LR 分析器处理,但在实践中,我们有时会故意使用简洁的二义性文法,并通过「额外规则」来解决冲突,而不是重写文法。最典型的例子就是表达式文法。
考虑一个简单的二义性表达式文法:
E → E + E ∣ E ∗ E ∣ ( E ) ∣ i d E \to E + E \mid E * E \mid (E) \mid \mathbf{id}
E → E + E ∣ E ∗ E ∣ ( E ) ∣ id
这个文法没有定义 + + + ∗ * ∗ 优先级 (precedence)和结合性 (associativity),因此对于 i d + i d ∗ i d \mathbf{id} + \mathbf{id} * \mathbf{id} id + id ∗ id 移进/归约冲突 。
例如,当分析栈内容为 E + E E + E E + E ∗ * ∗
归约 :将 E + E E + E E + E E E E + + + 移入 :将 ∗ * ∗ ∗ * ∗
我们可以通过为运算符指定优先级和结合性规则来指导分析器解决这类冲突:
优先级 :
如果下一个输入符号的优先级高于 栈顶句柄中运算符的优先级,则选择移入 。
如果下一个输入符号的优先级低于 栈顶句柄中运算符的优先级,则选择归约 。
结合性 (当优先级相同时):
对于左结合 运算符(如 + + + − - − ∗ * ∗ / / / 归约 。
对于右结合 运算符(如赋值 = = = ^ \text{\textasciicircum} ^ 移入 。
悬空 else 问题
悬空 e l s e \mathbf{else} else
s t m t → i f e x p r t h e n s t m t ∣ i f e x p r t h e n s t m t e l s e s t m t ∣ o t h e r \begin{aligned}
\mathit{stmt} \to\ &\ \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt}\\
\mid&\ \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt}\ \mathbf{else}\ \mathit{stmt}\\
\mid &\ \mathit{other}
\end{aligned}
stmt → ∣ ∣ if expr then stmt if expr then stmt else stmt other
当分析器看到 i f e x p r t h e n s t m t \mathbf{if}\ \mathit{expr}\ \mathbf{then}\ \mathit{stmt} if expr then stmt e l s e \mathbf{else} else e l s e \mathbf{else} else i f \mathbf{if} if i f e x p r t h e n s t m t \mathbf{if}\ \mathit{expr} \ \mathbf{then}\ \mathit{stmt} if expr then stmt s t m t \mathit{stmt} stmt
几乎所有的编程语言都采用移入 策略,即 e l s e \mathbf{else} else i f \mathbf{if} if
语法错误处理
一个健壮的编译器必须能够处理源代码中的错误。语法分析器在错误处理中扮演着关键角色。
错误处理的目标:
清晰、准确地报告错误及其位置。
能够从错误中恢复 (recover),继续分析程序的剩余部分,以便一次性报告多个错误。
不应显著降低处理正确程序时的效率。
错误恢复策略
恐慌模式恢复(Panic Mode)
这是最简单也最常用的一种恢复策略。
思想 :当分析器检测到错误时,它会丢弃后续的输入符号,直到找到一个预定义的同步词法单元 (synchronizing token)为止。同步词法单元 :通常是能够明确标记一个语法单元开始或结束的符号,例如:
语句结束符(如 ;)
块结束符(如 })
高级结构起始的关键字(如 if, while, for)
LR 分析器中的实现 :
检测到错误(查表发现 error 条目)。
从分析栈中弹出状态,直到找到一个状态 s s s A A A A A A
在输入流中,丢弃词法单元,直到找到一个属于 F O L L O W ( A ) \mathrm{FOLLOW}(A) FOLLOW ( A ) a a a
将 G O T O ( s , A ) \mathrm{GOTO}(s, A) GOTO ( s , A ) a a a
短语层次恢复(Phrase-Level)
这是一种更复杂的策略,它试图在错误点进行局部修正。
思想 :分析器在发现错误时,不会立即进入恐慌模式,而是尝试用少量修改(如插入、删除或替换一个符号)来修正错误,使分析可以继续。实现 :通常需要为分析表中的每个 error 条目预先编写特定的错误处理例程。例如,如果在一个表达式中 ) ) ) i d \mathbf{id} id + + +
语法分析器生成工具:YACC
YACC (Yet Another Compiler-Compiler)是一个经典的语法分析器生成工具,它根据用户提供的 LALR(1) 文法规则,自动生成一个 C 语言的语法分析器。
YACC 工作流程
graph LR
A[源文件.y] -- YACC --> B{y.tab.c};
B -- C 编译器 --> C[a.out/a.exe];
D[输入流] -- 通过词法分析器 yylex() --> C;
C -- 执行分析 --> E[输出];
subgraph "编译时"
A
B
end
subgraph "运行时"
D
C
E
end
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#bbf,stroke:#333,stroke-width:2px
style C fill:#bfb,stroke:#333,stroke-width:2px
style D fill:#ffb,stroke:#333,stroke-width:2px
style E fill:#fbb,stroke:#333,stroke-width:2pxYACC 源程序结构
一个 YACC 源文件(通常以 .y 结尾)分为三个部分,由 %% 分隔:
声明部分 :
C 语言的 #include、宏定义等,写在 %{ ... %} 中。
使用 %token 声明终结符(词法单元)。
使用 %left, %right, %nonassoc 定义运算符的结合性和优先级。
翻译规则部分 :
定义文法的产生式以及与每个产生式相关联的语义动作 (semantic action)。
格式:head: body1 { action1 } | body2 { action2 };
语义动作是嵌入的 C 代码,在归约发生时执行。
$$ 代表产生式头部的属性值,$1, $2, … 代表产生式体中从左到右第 1、2、… 个符号的属性值。
辅助 C 代码部分 :
用户定义的 C 函数。
必须包含一个名为 yylex() 的词法分析器函数,它负责从输入中读取并返回下一个词法单元。这个函数通常由 Lex/Flex 工具生成。
还需包含一个 yyerror(char *s) 函数,用于报告错误。
YACC 中的错误恢复
YACC 提供了一种基于错误产生式的机制来实现恐慌模式恢复。
可以在文法规则中定义一个特殊的终结符 error。
例如,规则 stmt: error ';' 的含义是:
当分析器在解析一个 stmt 时遇到错误,它会进入错误模式。
它会从栈中弹出状态,直到进入一个可以移入 error 符号的状态。
然后,它会丢弃输入流中的词法单元,直到找到一个分号 ;。
找到分号后,它会执行归约 stmt -> error ';',并执行相应的语义动作,然后恢复正常分析。
这种方式允许程序员为语言中的主要语法结构(如语句、声明、函数定义)定义恢复点,从而实现相对健壮的错误恢复。
简单计算器
这个计算器可以处理整数的加、减、乘、除运算,支持括号,并能处理一元负号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
/* ------------------ 1. 声明部分 ------------------ */ %{ #include <stdio.h> #include <ctype.h> int yylex(void); void yyerror(char const *s); %} /* - %union 定义了所有符号(终结符和非终结符) - 可能的属性值类型。这里我们只需要整数值。 */ %union { int iVal; } /* - %token 声明终结符。 - <iVal> 表示 NUMBER 这个终结符的属性值是 iVal 类型(即 int)。 - 像 '+' '-' 这样的单字符终结符不需要声明。 */ %token <iVal> NUMBER /* - %type 声明非终结符的属性值类型。 - 这里 expr 非终结符的计算结果是整数。 */ %type <iVal> expr /* - 定义运算符的结合性和优先级。 - 在同一行的符号优先级相同。 - 后声明的行比先声明的行优先级更高。 - %left: 左结合, %right: 右结合, %nonassoc: 不结合。 */ %left '+' '-' /* 最低优先级 */ %left '*' '/' /* 中等优先级 */ %right UMINUS /* 一元负号,最高优先级 */ %% /* ------------------ 2. 翻译规则部分 ------------------ */ /* - program 是起始符号。 - 一个 program 可以是空的,也可以是一系列由换行符分隔的表达式。 - 每当计算完一个表达式(归约到 program),就打印结果。 */ program: /* 空规则,允许空输入 */ | program expr '\n' { printf("= %d\n", $2); } | program error '\n' { yyerrok; } /* 错误恢复规则 */ ; /* - expr 定义了表达式的构成。 - $$ 代表左侧非终结符(expr)的属性值。 - $1, $2, $3 代表右侧从左到右第 1, 2, 3 个符号的属性值。 */ expr: NUMBER { $$ = $1; } | expr '+' expr { $$ = $1 + $3; } | expr '-' expr { $$ = $1 - $3; } | expr '*' expr { $$ = $1 * $3; } | expr '/' expr { if ($3 == 0) { yyerror("divide by zero"); $$ = 0; } else { $$ = $1/$3; } } | '-' expr %prec UMINUS { $$ = -$2; } /* 处理一元负号 */ | '(' expr ')' { $$ = $2; } ; %% /* ------------------ 3. 辅助 C 代码部分 ------------------ */ /* - main 函数:程序的入口。 - 它调用 yyparse() 来启动语法分析。 */ int main(void) { printf("Enter expressions, one per line.\n"); return yyparse(); } /* - 词法分析器 yylex()。 - 在实际项目中,这通常由 Lex/Flex 生成。这里手写一个简化的版本。 - 它从输入中读取字符,识别出 NUMBER 或单字符运算符,并返回对应的 token。 - 识别出 NUMBER 时,需要将其值存入 yylval.iVal。 */ int yylex(void) { int c; while ((c = getchar()) == ' ' || c == '\t'); // 跳过空白字符 if (isdigit(c)) { int num = c - '0'; while (isdigit(c = getchar())) { num = num * 10 + (c - '0'); } ungetc(c, stdin); // 把多读的字符退回去 yylval.iVal = num; // 设置 NUMBER 的属性值 return NUMBER; } if (c == EOF) { return 0; // 文件结束 } // 对于其他字符(如 + - */( ) \n),直接返回其 ASCII 码作为 token return c; } /* - 错误报告函数 yyerror()。 - 当 yyparse() 遇到语法错误时,会调用此函数。 */ void yyerror(char const *s) { fprintf(stderr, "Error: %s\n", s); }
编译和运行:
保存文件 :将上述代码保存为 calc.y。生成分析器 :使用 YACC(或其现代替代品 Bison)处理 .y 文件。-d 选项会额外生成一个头文件 y.tab.h,其中包含了 token 的定义。 $ bison -d calc.y # 或者 yacc -d calc.y
y.tab.c 和 y.tab.h。编译 C 代码 :使用 C 编译器(如 GCC)编译生成的 C 文件。 运行计算器 :