中间代码生成
中间代码生成导论
在编译器的前端完成词法分析、语法分析和语义分析(如类型检查)之后,许多编译器会生成一个明确的、机器无关的中间表示(Intermediate Representation, IR),也常被称为中间代码(Intermediate Code)。这个阶段是连接编译器前端和后端的桥梁。
graph LR
%% 定义样式
classDef sourceCode fill:#e1f5fe,stroke:#01579b,stroke-width:2px
classDef intermediateCode fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
classDef targetCode fill:#e8f5e8,stroke:#1b5e20,stroke-width:2px
classDef process fill:#fff3e0,stroke:#e65100,stroke-width:1.5px
classDef decision fill:#ffebee,stroke:#c62828,stroke-width:1.5px
%% 前端子图 - 使用更清晰的布局
subgraph Frontend[前端处理]
direction LR
B1[📝 词法分析] --> B2[📊 语法分析] --> B3[🔍 语义分析]
end
%% 后端子图
subgraph Backend[后端处理]
direction LR
D1[⚡ 代码优化] --> D2[🚀 代码生成]
end
%% 主流程
A[源代码] --> B1
C[中间代码] --> D1
D2 --> F[目标代码]
%% 连接子图
B3 --> C
%% 应用样式
class A sourceCode
class C intermediateCode
class F targetCode
class B1,B2,B3,D1,D2 process
class B,D decision
%% 添加标题
linkStyle default stroke:#666,stroke-width:1.5px中间代码
中间代码是一种介于源语言和目标机器语言之间的表示形式。它应该具备两个重要特性:
- 易于生成:能够从源语言的语法结构(如语法分析树)直接、系统地生成。
- 易于翻译:能够相对容易地翻译成目标机器代码。
引入中间代码的好处是显而易见的:
- 解耦与可移植性:将编译器清晰地划分为前端和后端。对于 种源语言和 种目标机器,我们只需要 个前端和 个后端,而不是 个完整的编译器。
- 优化:许多重要的代码优化技术(如公共子表达式消除、代码移动等)都作用于中间代码,因为 IR 的结构比源代码更规整,又比机器代码更具高层信息。
本章将重点介绍几种主流的中间表示形式,以及如何使用语法制导翻译来生成它们。
中间表示的形式
中间表示可以大致分为两类:图形表示和线性表示。
抽象语法树与有向无环图
抽象语法树是源代码语法结构的树状表示,它省略了语法分析树中不必要的细节(如标点符号、表示优先级的非终结符等)。
然而,AST 有一个缺点:对于表达式中的公共子表达式(common subexpressions),AST 会为每一次出现都创建一个独立的子树。
表达式 a + a * (b - c) + (b - c) * d 的 AST
在 AST 中,a 出现了两次,(b - c) 也出现了两次,它们会分别对应两个独立的节点和两棵独立的子树。
为了更紧凑地表示并识别公共子表达式,我们可以使用有向无环图(Directed Acyclic Graph, DAG)。
有向无环图(DAG)
一个 DAG 是 AST 的一种变体。在 DAG 中,一个节点可以有多个父节点。对于一个公共子表达式,DAG 中只有一个节点来表示它,所有使用该子表达式的地方都会指向这个唯一的节点。
对于表达式 a + a * (b - c) + (b - c) * d,其 DAG 如下:
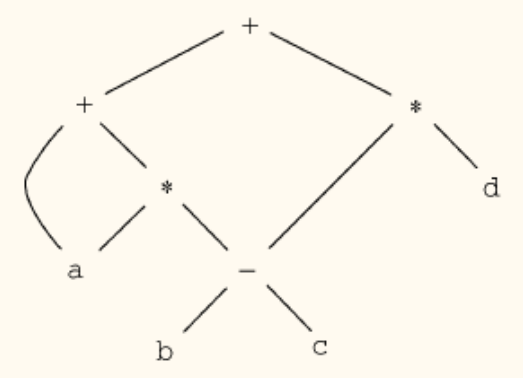
可以看到,变量 a 和子表达式 b - c 都只对应一个节点,有效地暴露了可优化的结构。
DAG 的构造过程与 AST 非常相似,可以使用相同的 SDD。关键的区别在于实现 new Node(...) 和 new Leaf(...) 这两个函数时:
- 在创建一个新节点之前,首先检查是否已存在一个具有相同操作符和子节点的节点。
- 如果存在,则直接返回指向现有节点的指针。
- 如果不存在,才创建一个新节点并返回。
三地址代码
三地址代码(Three-Address Code, TAC)是一种应用广泛的线性中间表示。它的形式类似于一种抽象的汇编语言,其核心特点是每条指令的右侧最多只有一个运算符。
三地址代码
一条典型的三地址指令形式如下:
x = y op z
其中 x, y, z 是名字、常量或编译器生成的临时变量。op 是一个运算符,如加法、乘法等。
由于每条指令只执行一个操作,复杂的算术表达式需要被分解为一系列简单的三地址指令。
三地址代码的「地址」是一个抽象概念,它可以是:
- 名字:源程序中定义的变量名。
- 常量:程序中出现的字面量。
- 临时变量:编译器为存储中间结果而生成的变量,通常记为
t1,t2等。
常见的三地址指令集包括:
- 赋值指令
x = y op z:二元运算x = op y:一元运算,如取负x = minus yx = y:复制
- 控制转移指令
goto L:无条件跳转if x goto L/if false x goto L:条件跳转if x relop y goto L:关系运算条件跳转
- 过程调用指令
param x:设置参数call p, n:调用过程p,n为参数个数y = call p, n:带返回值的调用
- 带下标的赋值指令
x = y[i]x[i] = y
- 地址与指针赋值指令
x = &y:取地址x = *y:解引用/间接取值*x = y:间接赋值
do i = i + 1; while (a[i] < v); 的三地址代码
1 2 3 4 5 | L: t1 = i + 1 i = t1 t2 = i * 8 // 假设每个元素占 8 字节 t3 = a[t2] // a 的基地址是 a if t3 < v goto L |
跳转的目标地址 L 可以用符号标号(如上)或指令的位置号(如 100, 101, …)来表示。
三地址代码的实现
在编译器内部,三地址指令序列通常存储在一个对象数组中。每个对象代表一条指令。有几种常见的实现方式:
- 四元式(Quadruples)
- 结构:
(op, arg1, arg2, result) - 描述:一个包含四个字段的记录。
op是操作符,arg1和arg2是源操作数,result是目标地址。对于一元运算,arg2通常不使用。 - 优点:结构规整,易于移动和重排指令(优化),因为结果的引用是显式的(通过
result字段)。
- 结构:
a = b * -c + b * -c 的四元式表示
| # | op | arg1 | arg2 | result |
|---|---|---|---|---|
| 0 | minus | c | - | t1 |
| 1 | * | b | t1 | t2 |
| 2 | minus | c | - | t3 |
| 3 | * | b | t3 | t4 |
| 4 | + | t2 | t4 | t5 |
| 5 | = | t5 | - | a |
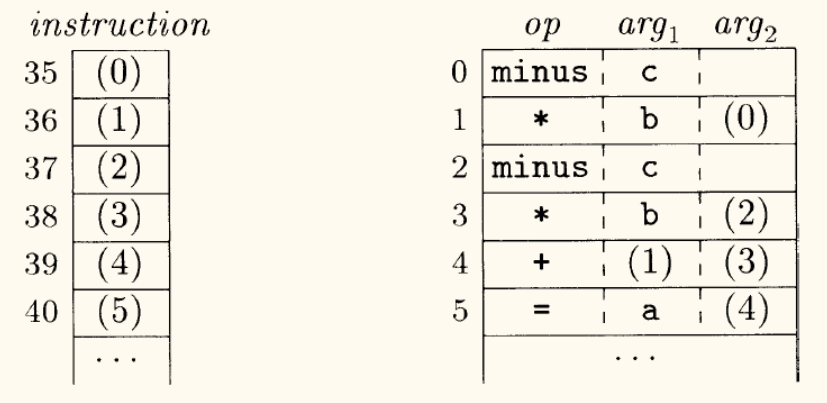
- 三元式(Triples)
- 结构:
(op, arg1, arg2) - 描述:只包含三个字段。指令的结果通过其在指令列表中的位置来隐式引用。
- 缺点:如果需要移动指令(例如,在循环优化中将指令移出循环),所有引用该指令的地方都需要被更新,这使得优化变得非常困难。
- 结构:
a = b * -c + b * -c 的三元式表示
| # | op | arg1 | arg2 |
|---|---|---|---|
| 0 | minus | c | - |
| 1 | * | b | (0) |
| 2 | minus | c | - |
| 3 | * | b | (2) |
| 4 | + | (1) | (3) |
| 5 | = | a | (4) |
- 间接三元式(Indirect Triples)
- 结构:由一个指令列表(三元式)和一个指向这些指令的指针列表组成。
- 描述:执行顺序由指针列表决定。优化时,我们只需要重排指针列表,而无需改动实际的三元式指令,从而解决了三元式的移动难题。
静态单赋值形式
静态单赋值(Static Single Assignment, SSA)是现代编译器中一种非常流行的 IR。其核心思想是:程序中的每个变量都只被赋值一次。
为了实现这一点,当一个原始变量被多次赋值时,SSA 形式会创建该变量的多个版本(通常通过下标区分,如 x_1, x_2)。
SSA 的核心规则
如果源程序中有赋值 x = ...,在 SSA 形式中它会被改写为 x_i = ...,其中 x_i 是变量 x 的一个新版本。后续对 x 的使用将被替换为对 x_i 的使用,直到 x 被再次赋值。
一个关键问题是,当不同的控制流路径对同一个变量赋了不同的值时,如何在路径汇合后确定该变量的值?SSA 引入了 Φ-函数来解决这个问题。
使用 Φ-函数
原始代码:
1 2 3 4 5 | if (flag) x = -1; else x = 1; y = x * a; |
SSA 形式:
1 2 3 4 5 6 | if (flag) x_1 = -1; else x_2 = 1; x_3 = Φ(x_1, x_2); y = x_3 * a; |
Φ-函数 x_3 = Φ(x_1, x_2) 的意思是:如果控制流来自 if 分支,x_3 的值就是 x_1;如果来自 else 分支,x_3 的值就是 x_2。Φ-函数是一种逻辑构造,在最终生成机器代码时会被替换为相应的复制指令。
声明的处理
在生成代码之前,编译器需要处理变量声明,以收集每个名字的类型和存储布局信息。这些信息通常存储在符号表中。
类型表达式
为了系统地表示类型,我们使用类型表达式(type expression):
- 基本类型:如
integer,float,char,void。 - 类型名:使用
typedef,using等定义的别名。 - 类型构造器:
- 数组:
array(I, T)表示一个元素个数位I、元素类型为T的数组。例如,int a[10]的类型是array(10, integer)。 - 记录/结构体:
record((f1, T1), (f2, T2), ...)表示一个包含字段f1,f2… 且类型分别为T1,T2… 的记录。 - 指针:
pointer(T)表示一个指向类型为T的对象的指针。 - 函数:
T1 × T2 -> T3表示一个接受类型为T1和T2的两个参数并返回类型为T3的函数。
- 数组:
存储布局与地址计算
对于一个过程或函数中的局部变量,编译器会在其活动记录(栈帧)中分配一块连续的内存区域。我们需要为每个变量计算一个相对于该区域起始位置的相对地址或偏移量(offset)。
这个计算依赖于每个变量的类型宽度(width),即该类型占据的字节数。
integer:4 字节float:8 字节array(n, T):n × width(T)record(...):各字段宽度之和
声明的语法制导翻译
我们可以设计一个 SDT 来处理声明,同时计算类型、宽度和偏移量。考虑如下文法:
目标:
- 为每个
id确定其完整的类型(如array(2, array(3, integer)))。 - 计算该类型的总宽度。
- 为
id分配一个相对地址offset,并更新下一个可用的offset。 - 将
(id, type, offset)存入符号表。
这可以通过组合使用综合属性和继承属性(或使用全局变量模拟继承属性)来实现。
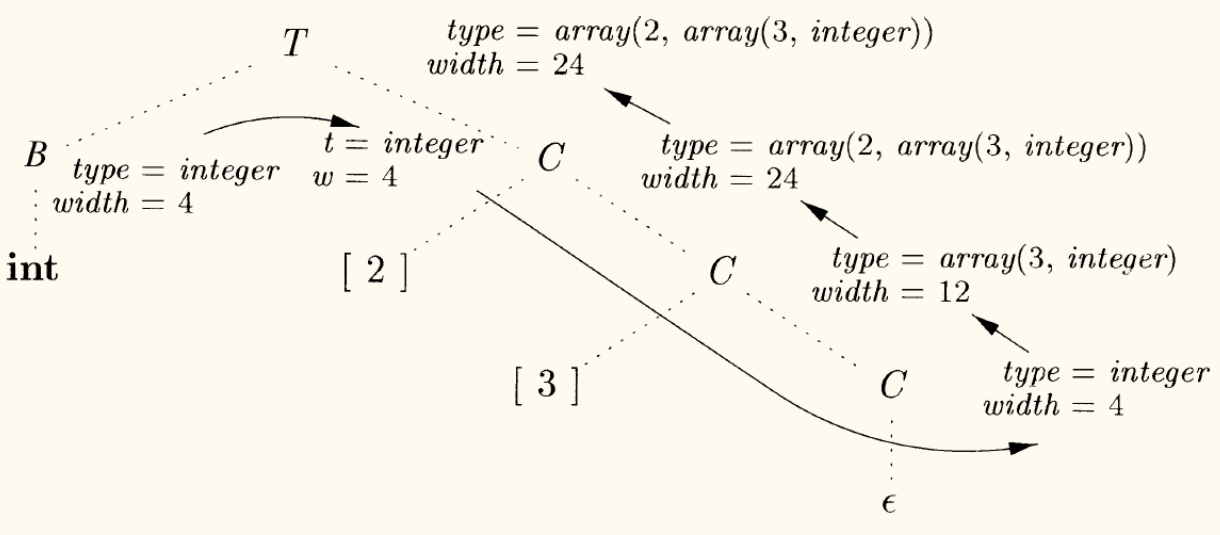
计算类型和宽度的 SDT
这个 SDT 使用继承属性 来传递基本类型,并使用综合属性 自底向上构建最终的类型和宽度。
| 产生式 | 语义规则 |
|---|---|
下图展示了处理 int [2][3] 时属性值的流动:
处理声明序列和偏移量:我们可以维护一个全局变量 offset。
1 2 3 4 | P -> { offset = 0; } D D -> T id; { top.put(id.lexeme, T.type, offset); offset = offset + T.width; } D1 | ε |
这里,top.put 是将信息添加到当前作用域的符号表中的函数。
对于记录字段的处理,可以为每个记录创建单独的符号表:
- 首先创建一个新的符号表,压到栈顶
- 然后处理对应于字段声明的 ,字段都被加入到新符号表中
- 最后根据栈顶的符号表构造出
record类型表达式;符号表出栈
1 2 | T -> record{ { Env.push(top); top = new Env(); Stack.push(offset); offset = 0; } D} { T.type = record(top); T.width = offset; top = Env.pop(); offset = Stack.pop(); } |
表达式与控制流的翻译
赋值语句的翻译
我们可以设计一个 SDD 来将表达式翻译成三地址代码。主要使用两个属性:
- :一个综合属性,表示存放表达式 结果的地址(通常是一个临时变量)。
- :一个综合属性,表示为计算 而生成的三地址指令序列。
表达式翻译的 SDD
| 产生式 | 语义规则 |
|---|---|
| |
|
| |
|
其中, 返回一个新的临时变量, 生成一条三地址指令字符串, 表示字符串连接。这种方式会构造巨大的 code 字符串,效率不高。更实用的方法是采用增量式翻译方案,在语法分析过程中直接生成(打印)指令,而不是作为属性返回。
数组引用的翻译
翻译数组引用的核心是地址计算。
数组元素的地址计算
对于一个 维数组 ,假设其声明为 ,且元素类型宽度为 。在行主序(row-major order)存储下,元素 的相对地址可以计算为:
这个计算过程可以分解为一系列三地址指令。
数组引用的 SDT
我们设计一个 SDT 来处理数组访问,如 或 。非终结符 需要以下属性:
- :一个临时变量,用于保存计算出的偏移量(不包含基地址)。
- :指向数组 在符号表中的条目,从中可以获取基地址和类型信息。
- :表示 所代表的(子)数组的元素类型。
的语义动作
这个产生式处理多维数组的后续维度,如 中的 部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 | { t = newTemp(); // 临时变量存 E 的值 * 元素宽度 L.addr = newTemp(); // 临时变量存最终偏移量 // L.type 是 L1[E] 的元素类型,即 L1 的下一级子数组类型 L.type = L1.type.elem; // 计算当前维度的偏移量 gen(t, '=', E.addr, '*', L.type.width); // 总偏移量 = 上一维度的偏移量 + 当前维度的偏移量 gen(L.addr, '=', L1.addr, '+', t); } |
c + a[i][j] 的翻译
假设 a 是 int a[2][3](array(2, array(3, integer))),int 宽度为 4。
- 处理
a[i]:a的基类型是array(3, integer),宽度为3 * 4 = 12。- 生成代码
t1 = i * 12。此时L.addr是t1。
- 处理
a[i][j](即(a[i])[j]):a[i]的类型是array(3, integer),其元素类型是integer,宽度为 4。- 生成代码
t2 = j * 4。 - 生成代码
t3 = t1 + t2。t3就是总偏移量。
- 获取数组元素的值:
- 生成代码
t4 = a[t3]。这里a代表基地址,a[t3]是取值操作。
- 生成代码
- 完成加法:
- 生成代码
t5 = c + t4。
- 生成代码
最终生成的三地址代码序列为:
1 2 3 4 5 | t1 = i * 12 t2 = j * 4 t3 = t1 + t2 t4 = a[t3] t5 = c + t4 |
类型检查与转换
在生成三地址代码的过程中,我们不仅要处理程序的结构,还要处理其类型(type)语义。类型检查(Type Checking)是编译器确保程序中运算符和操作数类型匹配的过程,它是静态语义分析的核心部分。
类型系统
一个类型系统(Type System)由两部分组成:
- 为程序各个部分(如变量、表达式、函数)赋予类型表达式的规则。
- 一组用于确定这些类型表达式是否有效的逻辑规则(类型规则)。
一个健全的类型系统能够帮助编译器发现程序中的语义错误(如将函数指针与整数相加)、为代码生成选择正确的指令(如整数加法 vs. 浮点数加法),并确定存储数据所需的内存大小。
类型综合与类型推导
确定一个构造的类型主要有两种方式:
- 类型综合(Type Synthesis):自下而上地确定类型。一个表达式的类型由其子表达式的类型决定。这与 S-属性的 SDD 模型非常契合。
- 例如:在函数调用
f(x)中,如果已知f的类型是s -> t(一个接受类型s返回类型t的函数),且x的类型是s,那么我们可以综合出f(x)的类型是t。
- 例如:在函数调用
- 类型推导(Type Inference):根据一个语言构造的使用方式来推断其类型。这通常需要求解一组类型约束。
- 例如:在处理
f(x)时,如果我们不知道f和x的类型,但知道f(x)是一个合法的表达式,我们可以推断出:必然存在某个类型α,使得f的类型是α -> β,且x的类型是α。
- 例如:在处理
隐式类型转换
在许多语言中,当运算符的操作数类型不匹配但兼容时,编译器会自动插入类型转换(type conversion)指令。这种由编译器自动完成的转换称为隐式类型转换(implicit type conversion)或类型强制转换(coercion)。
整数与浮点数相乘
考虑表达式 x * i,其中 x 是浮点数,i 是整数。
- 问题:整数和浮点数在计算机内部有完全不同的二进制表示。此外,整数乘法和浮点数乘法通常对应不同的机器指令(如
imulvs.fmul)。 - 解决方案:编译器必须先将整数
i转换为一个等效的浮点数,然后再执行浮点数乘法。1 2
t1 = (float) i // 整数转浮点数 t2 = x fmul t1 // 浮点数乘法
拓宽与窄化
类型转换可以根据是否会丢失信息分为两类:
- 拓宽(Widening):将一个值从一个「较小」的类型转换为一个「较大」的类型,通常不会丢失信息。例如,从
int转换为float,或从float转换为double。 - 窄化(Narrowing):将值从「较大」类型转换为「较小」类型,可能会丢失精度或范围。例如,从
double转换为int。
隐式类型转换通常只允许拓宽转换,以保证程序的安全性。
处理类型转换的 SDT
我们可以扩展表达式翻译的 SDT,使其在生成代码的同时处理类型检查和转换。
考虑产生式 。其语义动作需要完成三项任务:
- 确定结果 的类型。
- 检查 和 的类型是否需要拓宽,如果需要,则生成相应的类型转换代码。
- 生成加法指令。
1 2 3 4 5 6 7 8 9 10 11 12 | E -> E1 + E2 { // 1. 确定结果类型 E.type = max(E1.type, E2.type); // 2. 对操作数进行必要的拓宽 a1 = widen(E1.addr, E1.type, E.type); a2 = widen(E2.addr, E2.type, E.type); // 3. 生成加法指令 E.addr = newTemp(); gen(E.addr, '=', a1, '+', a2); } |
max(t1, t2):根据类型拓宽层次结构,返回t1和t2的最小公共祖先类型。例如max(integer, float)返回float。widen(addr, from_type, to_type):一个辅助函数。如果from_type和to_type相同,直接返回addr。否则,生成将addr从from_type转换为to_type的三地址代码,并将结果存入一个新的临时变量,最后返回这个新变量。
重载
重载(Overloading)允许同一个运算符或函数名根据上下文(通常是参数的类型)具有不同的含义。例如,+ 既可以表示整数加法,也可以表示浮点数加法。
类型检查器需要根据操作数的类型来解析重载的符号。
- 对于
E -> f(E1),如果f是一个重载函数,编译器会检查E1.type是否与f的某个签名的参数类型匹配。如果找到唯一的匹配项sk -> tk,则E.type被确定为tk。
布尔表达式的翻译
布尔表达式在程序中有两种截然不同的用途,这导致了两种不同的翻译策略。
布尔表达式的双重角色
- 改变控制流:在
if、while等语句中,布尔表达式的值不被显式计算,而是通过其结果是「真」还是「假」来决定程序的执行路径。 - 计算逻辑值:在赋值语句中,如
x = a < b;,布尔表达式需要被求值,并将结果(true或false)存入一个变量。
为了区分这两种情况,我们可以在语法分析时使用不同的非终结符(例如,用 B 表示用于控制流的布尔表达式,用 E 表示用于求值的表达式),或者在遍历 AST 时根据上下文选择不同的代码生成函数。
短路求值
对于布尔表达式 B1 || B2 和 B1 && B2,许多语言采用短路求值(Short-Circuit Evaluation)策略:
B1 || B2:如果B1为真,则整个表达式必为真,无需再对B2求值。B1 && B2:如果B1为假,则整个表达式必为假,无需再对B2求值。
这种策略非常适合将布尔表达式翻译成包含跳转指令的短路代码(short-circuit code)。表达式的值由控制流的跳转目标位置隐式地表示。
短路代码
对于语句 if (x < 100 || x > 200 && x != y) x = 0;,其短路代码如下:
1 2 3 4 5 6 7 8 9 10 11 | // 对应 x < 100 if x < 100 goto L2 // 对应 ||,如果 x < 100 为假,则顺序执行 // 对应 x > 200 ifFalse x > 200 goto L1 // 对应 &&,如果 x > 200 为真,则顺序执行 // 对应 x != y ifFalse x != y goto L1 // 如果以上所有条件都满足,则到达这里 L2: x = 0 L1: // 语句结束后的下一条指令 |
L2是整个布尔表达式的「真出口」。L1是整个布尔表达式的「假出口」。
控制流语句的翻译
基于继承属性的翻译方案
我们可以设计一个 SDD,使用继承属性来为控制流语句生成跳转代码。
- 布尔表达式 有两个继承属性:
- :当 为真时,应跳转到的目标标号。
- :当 为假时,应跳转到的目标标号。
- 语句 有一个继承属性:
- : 执行完毕后,应跳转到的目标标号。
- 和 都有一个综合属性 ,存放生成的代码。
下面展示了 if、if-else 和 while 语句生成代码的逻辑结构:
1 2 3 4 5 6 | # if (B) S1 B.code # 计算 B,根据结果跳转到 B.true 或 B.false B.true: S1.code B.false: ... # S1 之后的指令 |
1 2 3 4 5 6 7 8 9 | # if (B) S1 else S2 B.code B.true: S1.code goto S.next B.false: S2.code S.next: ... # 之后的指令 |
1 2 3 4 5 6 7 8 | # while (B) S1 begin: B.code B.true: S1.code goto begin B.false: ... # 循环之后的指令 |
SDD 规则摘要:
| 产生式 | 语义规则 |
|---|---|
| |
|
| |
|
| |
|
| |
|
存在的问题
这种方法虽然直观,但依赖于继承属性在语法分析树中自上而下地传递标号。这意味着,在生成 的代码时,必须已经知道其跳转目标 和 。对于自底向上的 LR 分析器,实现这一点非常困难,通常需要多遍处理。
回填
为了解决上述问题,我们引入一种更强大、更适合单遍扫描的技术——回填(Backpatching)。
回填
回填是一种代码生成技术。其核心思想是:
- 在生成跳转指令(如
if ... goto __)时,暂时不指定其目标标号,而是将其留空。 - 将这些不完整的指令的地址(或索引)保存在一个或多个列表中。
- 当目标标号最终确定时,遍历相应的列表,将标号「填回」到所有不完整的指令中。
回填布尔表达式
在使用回填时,我们不再使用继承属性 B.true 和 B.false。取而代之的是两个综合属性:
B.truelist:一个列表,包含所有当B为真时应执行的跳转指令的地址。B.falselist:一个列表,包含所有当B为假时应执行的跳转指令的地址。
同时,我们需要三个辅助函数:
makelist(i):创建一个只包含指令地址i的新列表。merge(p1, p2):合并列表p1和p2,返回一个指向合并后列表的指针。backpatch(p, i):将标号i作为目标,填入列表p中的所有指令。
为了在产生式体中间获取下一条指令的地址,我们引入一个标记非终结符 M,它只推导出一个 。
-
nextinstr是一个全局变量或函数,用于记录下一条将要生成的指令的地址。- 这个动作在归约 时执行,恰好在
M后面的符号被处理之前,从而捕获了代码的当前位置。
使用回填的 SDT(布尔表达式):
| 产生式 | 语义规则 |
|---|---|
backpatch(B1.falselist, M.instr); B.truelist = merge(B1.truelist, B2.truelist); B.falselist = B2.falselist; |
|
backpatch(B1.truelist, M.instr); B.truelist = B2.truelist; B.falselist = merge(B1.falselist, B2.falselist); |
|
B.truelist = B1.falselist; B.falselist = B1.truelist; |
|
B.truelist = makelist(nextinstr); B.falselist = makelist(nextinstr + 1); gen('if', E1.addr, ..., 'goto _'); gen('goto _'); |
|
B.truelist = makelist(nextinstr); gen('goto _'); |
|
B.falselist = makelist(nextinstr); gen('goto _'); |
|
M.instr = nextinstr; |
回填控制流语句
对于语句,我们使用一个综合属性 S.nextlist,它是一个列表,包含了所有需要跳转到 S 语句之后的指令。
使用回填的 SDT(语句):
| 产生式 | 语义规则 |
|---|---|
backpatch(B.truelist, M.instr); S.nextlist = merge(B.falselist, S1.nextlist); |
|
backpatch(B.truelist, M1.instr); backpatch(B.falselist, M2.instr); temp = merge(S1.nextlist, N.nextlist); S.nextlist = merge(temp, S2.nextlist); |
|
backpatch(S1.nextlist, M1.instr); backpatch(B.truelist, M2.instr); S.nextlist = B.falselist; gen('goto', M1.instr); |
|
S.nextlist = L.nextlist; |
|
backpatch(L1.nextlist, M.instr); L.nextlist = S.nextlist; |
|
N.nextlist = makelist(nextinstr); gen('goto _'); |
M的作用是标记代码块的起始位置。N的作用是在if-then块的末尾生成一个无条件跳转,以跳过else部分。N.nextlist包含了这个goto指令的地址。
回填示例
考虑 x < 100 || x > 200 && x != y 的翻译过程:
- 生成指令坯:
1 2 3 4 5 6
100: if x < 100 goto _ 101: goto _ 102: if x > 200 goto _ 103: goto _ 104: if x != y goto _ 105: goto _
- 自底向上归约与回填:
- 处理
x < 100:truelist={100},falselist={101} - 处理
x > 200:truelist={102},falselist={103} - 处理
x != y:truelist={104},falselist={105} - 归约
&&:backpatch({102}, 104),将指令 102 的目标填为 104。新的truelist={104},falselist=merge({103}, {105})={103, 105}。 - 归约
||:backpatch({101}, 102),将指令 101 的目标填为 102。新的truelist=merge({100}, {104})={100, 104},falselist={103, 105}。
- 处理
最终,整个布尔表达式的 truelist 是 {100, 104},falselist 是 {103, 105}。当这个表达式被用在 if (B) S 语句中时,truelist 中的指令将被回填上 S 的起始地址,而 falselist 将成为 S 语句的 nextlist 的一部分。
特殊控制流的处理
break 与 continue 语句
break 和 continue 语句的跳转目标依赖于其所在的最内层循环。
- 实现方法:当编译器开始处理一个循环语句(如
while)时,它可以将该循环的相关信息(如循环开始的标号、用于break跳转的nextlist)压入一个专用的栈中。当遇到break或continue时,从栈顶获取信息来生成跳转指令。循环结束时,将信息弹出。
通过这种方式,即使是嵌套的循环,break 和 continue 也能正确地跳转到最内层循环对应的目标。