运行时环境
运行时环境导论
在编译器成功生成中间代码之后,后端的工作便开始了。后端不仅要将中间代码翻译成目标机器代码,还必须处理程序运行时(runtime)的各种支撑问题。运行时环境(Runtime Environment)是编译器、操作系统和目标机器之间的一个重要接口,它负责管理目标程序在执行期间的各种资源。
运行时环境
运行时环境是一个在程序执行期间管理内存和数据对象的系统。它负责协调一系列关键任务,包括:
- 为程序中的数据对象(变量、数组等)分配存储空间。
- 建立一套机制,使程序能够访问这些数据。
- 管理过程(函数)调用和返回的控制流。
- 实现参数传递。
- 提供与操作系统交互的接口(如 I/O)。
本章的核心议题将围绕存储管理展开,特别是程序如何组织和使用内存。
存储组织
一个正在执行的目标程序,其内存空间通常会被划分为几个逻辑区域,每个区域都有特定的用途。
graph TD
subgraph "低地址"
direction TB
Code["<b>代码区(Code/Text)</b><br>存放编译后的机器指令<br>通常是只读的"]
Static["<b>静态/全局数据区(Static/Global)</b><br>存放全局变量和静态变量<br>生命周期贯穿整个程序"]
Heap["<b>堆区(Heap)</b><br>向上增长<br>用于动态内存分配(如 new, malloc)"]
style Code fill:#e8f5e9,stroke:#1b5e20
style Static fill:#fffde7,stroke:#f57f17
style Heap fill:#fbe9e7,stroke:#bf360c
end
subgraph " "
direction TB
Free["…<br>空闲内存<br>…"]
style Free fill:#fafafa,stroke:#616161,stroke-dasharray: 5 5
end
subgraph "高地址"
direction TB
Stack["<b>栈区(Stack)</b><br>向下增长<br>存储活动记录(局部变量、函数参数)"]
style Stack fill:#e3f2fd,stroke:#0d47a1
end
Stack --> Free
Free --> Heap- 代码区:存放程序的可执行指令。这部分内存在程序加载时确定,通常是只读的,以防止程序意外修改自身指令。
- 静态区:用于存放全局变量和静态变量。编译器在编译时就能确定这些变量的大小和相对地址,它们的生命周期从程序开始到程序结束。
- 堆区:用于动态内存分配。当程序需要一块生命周期不遵循函数调用规则的内存时(例如,通过 C++ 的
new或 C 的malloc),就会在堆上分配。堆的管理相对复杂,需要运行时系统来处理分配和回收。 - 栈区:用于管理函数调用。每当一个函数被调用,就会在栈顶分配一块内存区域来存储其局部信息。栈的分配和回收遵循严格的「后进先出」(LIFO)原则,与函数的嵌套调用完美契合。
存储分配策略
根据数据对象的生命周期,编译器采用不同的存储分配策略:
-
静态分配(Static Allocation)
- 时机:在编译时完成。
- 对象:全局变量、静态变量、代码。
- 特点:编译器可以直接确定这些数据在内存中的绝对或相对地址,因为它们的生命周期是整个程序的运行时间。
-
动态分配(Dynamic Allocation)
- 时机:在运行时进行。
- 对象:函数局部变量、动态创建的对象。
- 特点:数据的大小或数量在编译时无法确定,或者其生命周期与程序的执行流紧密相关。动态分配主要分为两种:
- 栈式分配:用于管理函数调用。效率极高,因为分配和释放只是移动栈顶指针。
- 堆式分配:用于生命周期更灵活的数据。分配和释放的开销较大,且可能产生内存碎片。
栈式存储分配
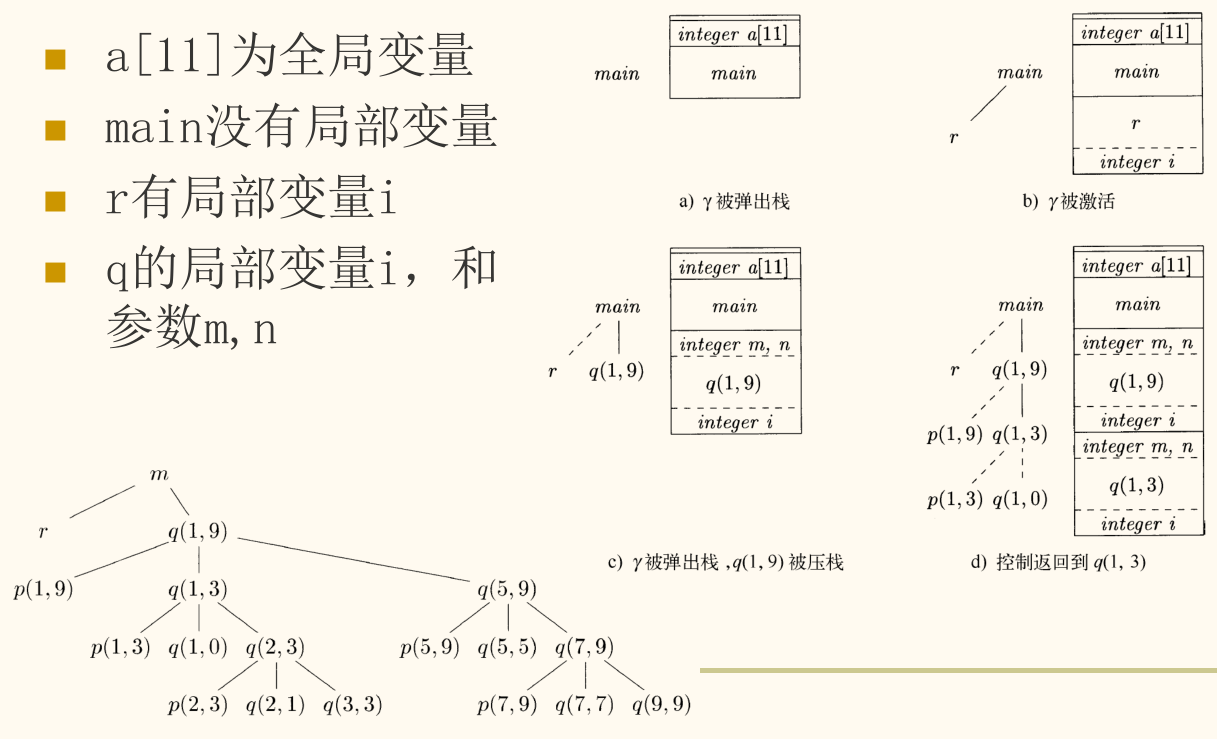
过程(或函数)的调用在时间上具有嵌套(nested)的特性:如果过程 P 调用了过程 Q,那么 Q 必须在 P 返回之前返回。这种「后调用、先返回」的行为模式天然地适合用栈来管理。
活动树
我们可以用一棵活动树(Activation Tree)来可视化地表示程序运行期间过程调用的层次关系。
- 树的根节点是
main函数的活动。 - 节点
P的子节点代表由P调用的那些过程的活动,子节点的排列顺序(从左到右)对应于调用的时间顺序。
活动树与运行时栈
在任意时刻,运行时栈上的活动记录序列恰好对应于活动树中从当前活动节点到根节点的路径。栈顶是当前活动节点,栈底是根节点。

活动记录
每当一个过程被调用,它都需要一块内存来存放自己的局部信息。这块专用的内存区域被称为活动记录(Activation Record),也常被称为栈帧(Stack Frame)。
活动记录
活动记录是为单次过程调用而在运行时栈上分配的一块连续内存。它包含了管理这次调用所需的所有信息。
一个典型的活动记录包含以下部分:
| 区域 | 描述 |
|---|---|
| 实在参数 | 调用者传递给被调用者的实际参数值。 |
| 返回值 | 为被调用者存放返回值的空间。 |
| 控制链 | 指向前一个(即调用者的)活动记录的指针,用于在函数返回时恢复现场。 |
| 访问链 | (用于支持嵌套作用域) 指向定义该过程的词法外层过程的活动记录。 |
| 保存的机器状态 | 保存调用发生时某些寄存器的值(如程序计数器 PC、栈指针 SP)。 |
| 局部数据 | 过程内声明的局部变量。 |
| 临时变量 | 编译器为存放表达式求值的中间结果而生成的临时变量。 |
调用与返回序列
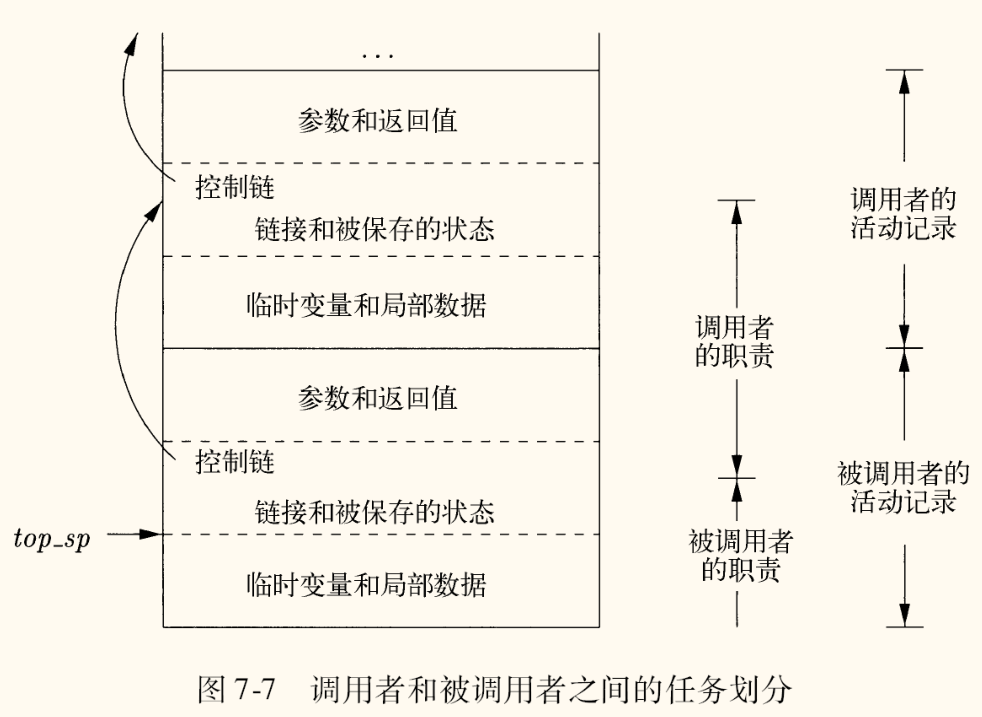
为了正确地创建和销毁活动记录,并传递控制权,调用者和被调用者必须遵循一套约定的操作,这套操作被称为调用序列(Calling Sequence)和返回序列(Return Sequence)。
调用序列(由调用者 caller 发起):
- 计算参数:
caller计算所有传递给被调用者callee的参数值。 - 分配空间:
caller在栈上为callee的活动记录分配空间(或增加栈顶指针),并将参数和返回地址填入指定位置。 - 保存状态:
caller保存自己需要保留的寄存器。 - 转移控制:
caller跳转到callee的代码入口。
调用序列(由被调用者 callee 执行):
- 保存状态:
callee保存自己的寄存器状态和其它信息(如建立访问链)。 - 分配局部变量:
callee在自己的活动记录中为局部变量分配空间。 - 执行代码:
callee开始执行其主体代码。
返回序列(由被调用者 callee 发起):
- 存放返回值:
callee将返回值放入预定的位置(通常是某个寄存器或活动记录的特定字段)。 - 恢复状态:
callee恢复它在开始时保存的寄存器状态。 - 转移控制:
callee跳转到caller保存的返回地址。
返回序列(由调用者 caller 执行):
- 回收空间:
caller回收为callee的活动记录分配的栈空间(通常是调整栈顶指针)。 - 恢复状态:
caller恢复它在调用前保存的寄存器。 - 使用返回值:
caller可以从预定位置获取callee的返回值,并继续执行。
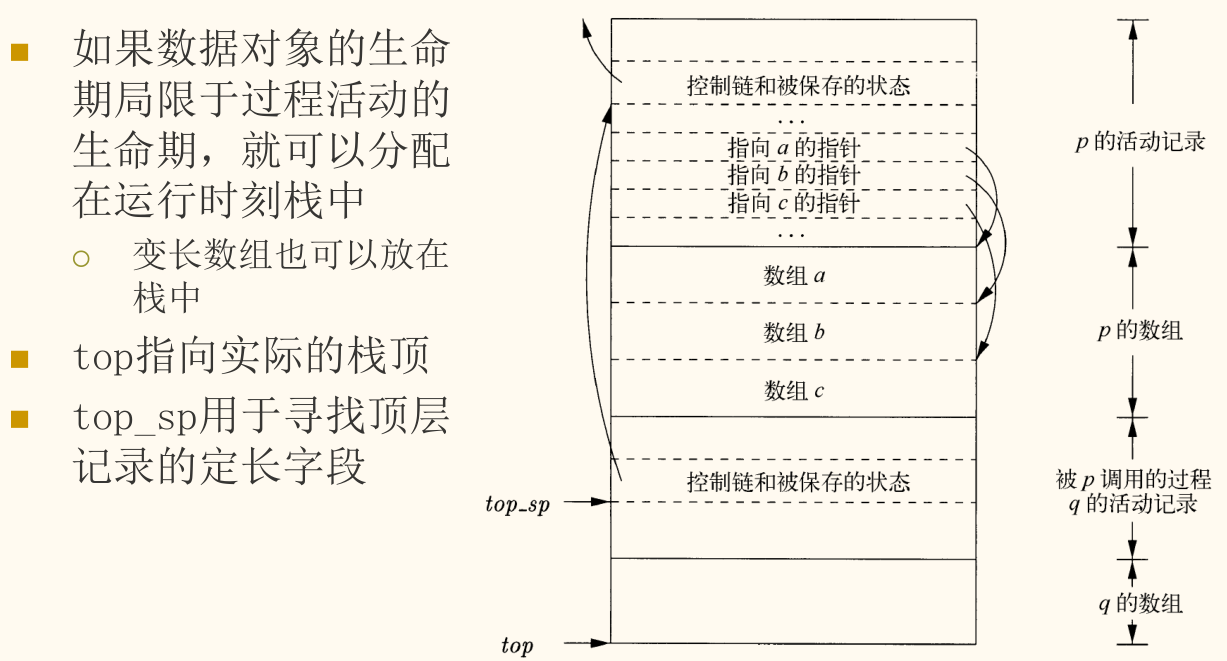
栈中的变长数据
某些语言允许在运行时确定大小的局部数组。这些变长数据无法放在活动记录的固定部分。
- 解决方案:将活动记录分为两部分:一个「定长部分」(包含控制信息、局部标量等)和一个「变长部分」(用于存放变长数组)。
- 访问局部数据时,通过一个指向定长部分末尾的帧指针(Frame Pointer, FP)加上一个编译时已知的偏移量来定位。变长数据则通过存储在定长部分中的指针来访问。
对非局部数据的访问
一个过程不仅能访问自己的局部变量,还能访问定义在它之外的变量(非局部变量)。访问机制取决于语言的作用域规则(scoping rules)。
无嵌套作用域的语言(如 C)
在 C 语言中,函数不能嵌套定义。因此,一个函数能够访问的非局部数据只有一种:全局变量。
- 局部变量:存放在当前函数的活动记录中,通过栈顶指针或帧指针加上一个偏移量即可访问。
- 全局变量:存放在静态数据区,它们的地址在编译时就已经确定,可以直接通过绝对地址访问。
这种简单的模型使得将函数作为参数传递也变得容易:只需要传递函数代码的入口地址即可。
支持嵌套作用域的语言(如 Pascal)
像 Pascal 或 ML 这样的语言允许在一个过程内部定义另一个过程。这引入了词法作用域(lexical scope)的概念:一个内层过程可以访问其所有外层过程的变量。
词法作用域问题
1 2 3 4 5 6 7 8 9 10 | procedure A(); var x: integer; procedure B(); var y: integer; begin x := y; // B 可以访问 A 的变量 x end; begin B(); end; |
当 B 执行时,它需要访问 A 的变量 x。但此时,A 的活动记录不一定就在 B 的活动记录的正下方。例如,如果 A 调用 C,C 再调用 B,那么 C 的活动记录会夹在 A 和 B 之间。我们如何从 B 的活动记录找到 A 的活动记录呢?
为了解决这个问题,我们需要一种方法来定位正确的词法外层(lexically enclosing)过程的活动记录。
嵌套深度(Nesting Depth)是一个静态概念,用于表示一个过程在词法上嵌套的层级。
- 不嵌套在任何其他过程中的过程(全局过程),深度为 1。
- 如果过程
P嵌套在深度为i的过程Q中,那么P的深度为i+1。
访问链(Access Link),也称为静态链(Static Link),是解决非局部数据访问问题的经典机制。
- 定义:每个活动记录中增加一个指针,即访问链。如果过程
P的嵌套深度是 ,并且它在过程Q(深度为 )中声明,那么P的任意一个活动记录的访问链都指向Q最近一次的活动记录。 - 使用:当深度为 的过程
P需要访问在深度为 的外层过程中声明的变量x时,它需要沿着访问链回溯 次,以找到存放x的那个活动记录。然后,通过该活动记录的基地址加上x的编译时偏移量来访问x。 - 维护:当过程
Q调用过程P时,设置P的访问链是一个关键任务,具体取决于P和Q的嵌套关系:P的深度 >Q的深度:P必须直接在Q中声明。因此,P的访问链就指向Q的活动记录(调用者的活动记录)。P的深度 =Q的深度:P和Q是兄弟过程或递归调用。它们的外层过程相同,因此P的访问链与Q的访问链相同。P的深度 <Q的深度:Q嵌套在某个过程中,而P在更外层。Q需要沿着自己的访问链回溯depth(Q) - depth(P)次,找到P的直接外层过程的活动记录,并将其作为P的访问链。
访问链的缺点是,如果嵌套层次很深,访问一个外层变量可能需要多次间接寻址,效率较低。显示表(Display)是一种优化技术,可以实现对非局部变量的 时间访问。
- 结构:一个全局数组
d,其大小等于程序的最大嵌套深度。d[i]始终指向嵌套深度为i的当前活跃的过程的最新活动记录。 - 使用:当过程
P(深度为 )访问变量x(在深度为 的过程中声明)时,它直接通过d[n_x]找到正确的活动记录,然后加上x的偏移量即可。 - 维护:
- 调用过程
P(深度 ):在P的活动记录中保存d[n_p]的旧值,然后将d[n_p]更新为指向P的新活动记录。 - 从
P返回:使用保存在P活动记录中的值恢复d[n_p]。
- 调用过程
堆管理
堆用于存放生命周期无法用栈的 LIFO 规则管理的动态对象。堆管理器是一个运行时子系统,负责响应程序的内存分配和释放请求。
堆空间分配
堆管理器维护着一个大的内存池,并记录哪些部分是已分配的,哪些是空闲的。
- 分配:当程序请求一块大小为
n的内存时,堆管理器需要在一片连续的空闲区域中找到一个大小至少为n的块(称为hole或window),将其分配给程序。 - 回收:当程序释放一块内存时,堆管理器将其标记为空闲,并可能将其与相邻的空闲块合并(coalesce),形成一个更大的空闲块,以备后续分配。
随着不断的分配和回收,堆会变得零散,产生许多不连续的小空闲块,这种现象称为碎片(Fragmentation)。
分配策略
常见的堆分配策略包括:
- 首次适配(First-Fit):从头开始扫描空闲块列表,使用第一个足够大的空闲块。
- 优点:速度快。
- 缺点:容易在列表前端产生大量小碎片。
- 最佳适配(Best-Fit):扫描整个列表,找到大小与请求最接近(但仍足够大)的空闲块。
- 优点:能为大请求保留大的空闲块。
- 缺点:速度慢,且容易产生大量无法使用的小碎片。
手工存储管理的问题
在 C/C++ 等需要程序员手动管理堆内存的语言中,容易出现两类严重错误:
- 内存泄漏(Memory Leak):分配了内存,但使用完毕后忘记释放,导致这块内存永远无法被再次使用。
- 悬空指针(Dangling Pointer):内存已经被释放,但仍然有指针指向它。后续通过这个指针访问内存会导致未定义行为。
垃圾回收
为了解决手动内存管理的难题,许多现代语言(如 Java, Python, C#)都提供了自动存储管理,即垃圾回收(Garbage Collection, GC)。
基本概念
- 垃圾(Garbage):程序在未来执行中不可能再访问到的内存对象。
- 可达性(Reachability):判断一个对象是否为垃圾的核心标准。一个对象是可达的(reachable),如果:
- 它是根(root)的一部分。
- 有一个从可达对象到它的指针。
- 根集(Root Set):程序可以直接访问的指针集合,通常包括全局变量、静态变量以及当前调用栈上所有活动记录中的局部变量和参数。
垃圾回收的基本思想是:定期找出所有可达对象,然后将所有不可达的对象回收。
引用计数回收器
这是一种简单的 GC 策略。
- 原理:为每个堆对象维护一个引用计数(reference count),记录有多少个指针指向它。
- 维护:
- 对象创建时,计数为 1。
- 指针赋值
u = v时,u原指向对象的计数减 1,v指向对象的计数加 1。 - 指针离开作用域时(如函数返回),其指向对象的计数减 1。
- 回收:当一个对象的引用计数变为 0 时,它就成了垃圾,可以立即被回收。回收该对象时,还需要递归地减少它所引用的所有其他对象的计数。
- 缺点:无法回收循环引用的垃圾。例如,对象 A 指向 B,对象 B 又指向 A,即使没有外部指针指向它们,它们的引用计数也永远不会为 0。
跟踪式回收器
这类回收器通过从根集出发遍历对象图来确定可达性,能够正确处理循环引用。
标记-清扫(Mark-and-Sweep)
这是最经典的跟踪式 GC 算法,分为两个阶段:
- 标记阶段:从根集开始,进行图遍历(如 DFS 或 BFS),找到所有可达对象,并给它们打上一个「可达」标记。
- 清扫阶段:遍历整个堆,将所有没有「可达」标记的对象回收,并清除所有已标记对象上的标记,为下一次 GC 做准备。
优缺点:
- 优点:算法简单,能处理循环引用。
- 缺点:
- 会导致 Stop-the-World,即 GC 期间整个应用程序暂停。
- 会产生内存碎片。
标记-压缩(Mark-and-Compact)
这是对标记-清扫算法的改进,旨在解决碎片问题。
- 标记阶段:与 Mark-and-Sweep 相同。
- 压缩阶段:将所有可达对象移动到堆的一端,使它们连续排列。这样,堆的另一端就成了一整块大的空闲空间。
- 指针修复:移动对象后,必须更新所有指向这些对象的指针,使其指向新的地址。
优缺点:
- 优点:消除了碎片,使得内存分配非常高效(只需移动一个指针)。
- 缺点:移动对象的开销较大。
拷贝回收器(Copying Collector)
这种算法将堆空间平分为两个大小相等的半空间(semispace):From-space 和 To-space。
- 程序总是在其中一个半空间(当前空间,如 From-space)中分配内存。
- 当 From-space 被占满时,触发 GC。
- GC 遍历 From-space 中的可达对象,并将它们拷贝到 To-space 中。
- 拷贝完成后,From-space 中的所有对象都是垃圾。此时,两个半空间的角色互换,To-space 成为新的分配空间。
优缺点:
- 优点:
- 分配速度极快。
- 永远不会产生碎片。
- GC 过程与对象拷贝合二为一。
- 缺点:
- 可用内存空间减半,空间利用率低。
Stop-the-World (STW)
Stop-the-World (STW) 是垃圾回收过程中一个非常重要的概念,尤其是在讨论跟踪式回收器时。
- 定义:STW 指的是在 GC 执行的某个阶段,必须完全暂停所有应用程序线程(也称为 mutator 线程)的执行。从用户角度来看,应用程序会短暂地「冻结」或「卡顿」。
- 原因:GC 需要一个一致性的快照来分析内存中的对象图(即对象间的引用关系)。如果在 GC 遍历(例如标记阶段)的同时,应用程序线程还在修改这些引用关系(例如,将一个对象从不可达变为可达,或者反之),GC 就可能做出错误的判断,导致:
- 漏标:将一个本应存活的对象错误地当作垃圾回收(导致程序后续崩溃)。
- 错标:将一个本应是垃圾的对象错误地标记为存活(导致内存泄漏)。
- 影响:STW 的主要缺点是它会中断应用程序的响应。对于需要低延迟和高吞吐量的系统(如实时交易、游戏服务器、GUI 应用),频繁或长时间的 STW 是不可接受的。
- 优化:几乎所有简单的 GC 算法(如上面提到的 Mark-and-Sweep)都会引发 STW。现代 GC 算法(如分代 GC、并发 GC、增量 GC)的核心目标之一就是缩短或消除 STW 停顿时间,例如通过只回收部分区域(分代),或者让 GC 线程与应用程序线程并发执行(并发标记)。