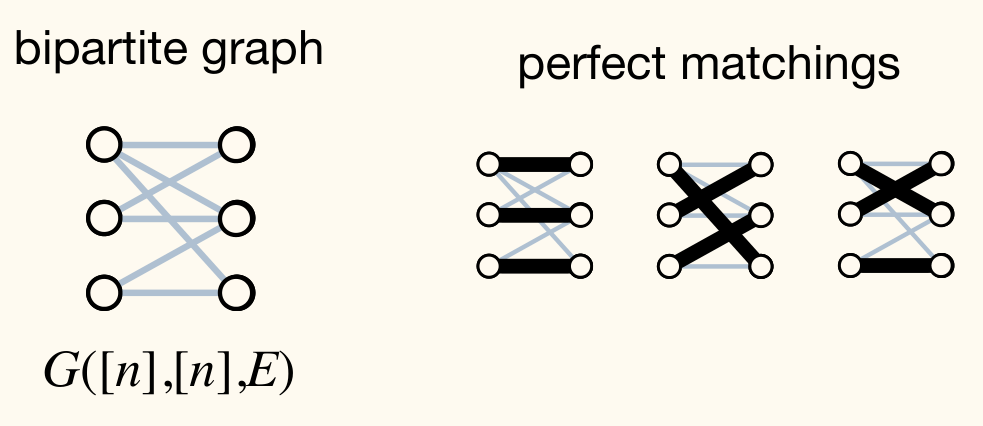从确定性到随机性
在经典算法设计中,我们习惯于追求确定性的正确答案。然而,许多看似简单的问题在确定性框架下却有着不可逾越的复杂度下界。随机化为我们提供了突破这些下界的可能——只要允许极小的错误概率,就能获得确定性算法无法企及的效率。
本讲的核心概念是 fingerprinting (指纹技术),一种贯穿随机算法设计的基本范式。
什么是 Fingerprinting
Fingerprinting 的核心思想是:不直接比较两个庞大的对象,而是将它们映射为短小的「指纹」,通过比较指纹来间接判断相等性。
Fingerprinting 的形式化定义
一个 fingerprinting 方案是一个(随机化的)函数 FING : U → V \text{FING}\colon \mathcal{U} \to \mathcal{V} FING : U → V ∣ V ∣ ≪ ∣ U ∣ |\mathcal{V}| \ll |\mathcal{U}| ∣ V ∣ ≪ ∣ U ∣
无假阴性 :a = b ⟹ FING ( a ) = FING ( b ) a = b \implies \text{FING}(a) = \text{FING}(b) a = b ⟹ FING ( a ) = FING ( b ) 假阳性概率小 :a ≠ b ⟹ Pr [ FING ( a ) = FING ( b ) ] a \neq b \implies \Pr[\text{FING}(a) = \text{FING}(b)] a = b ⟹ Pr [ FING ( a ) = FING ( b )] 指纹短小 :FING ( a ) \text{FING}(a) FING ( a ) a a a
性质 1 保证了单边错误 (one-sided error):当算法判定「不等」时一定正确,只在判定「相等」时可能犯错(假阳性)。
这一思想贯穿本讲所有内容——从多项式恒等检验、通信复杂性中的相等性问题,到矩阵乘法验证和字符串匹配,fingerprinting 都扮演着关键角色。
多项式恒等检验
问题定义
多项式恒等检验 (Polynomial Identity Testing, PIT )是代数计算中的一个基本问题:给定两个多项式 P P P Q Q Q P ≡ Q P \equiv Q P ≡ Q Q = P 1 − P 2 Q = P_1 - P_2 Q = P 1 − P 2 Q Q Q
算术电路
在 PIT 中,多项式不是以展开形式(如 3 x 2 + 2 x + 1 3x^2 + 2x + 1 3 x 2 + 2 x + 1 算术电路 (Arithmetic Circuit),它描述的不是多项式「长什么样」,而是如何从变量和常数出发,通过一系列加、减、乘操作一步步算出它。
算术电路
算术电路是一个有向无环图(DAG),其中:
输入节点 (叶节点)标记为变量 x 1 , x 2 , … x_1, x_2, \dots x 1 , x 2 , … 内部节点 标记为 + + + − - − × \times × 有一个指定的输出节点 ,其计算结果即为电路所表示的多项式
flowchart BT
x1["x₁"] --> plus1["+"]
y1["y₁"] --> plus1
x2["x₂"] --> plus2["+"]
y2["y₂"] --> plus2
xn["xₙ"] --> plusn["+"]
yn["yₙ"] --> plusn
plus1 --> mul["× · · · ×"]
plus2 --> mul
plusn --> mul
mul --> out(("输出"))
classDef var fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef op fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef output fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
class x1,y1,x2,y2,xn,yn var
class plus1,plus2,plusn,mul op
class out output算术电路的关键特性在于它可以指数级压缩 多项式的表示。例如:
∏ i = 1 n ( x i + y i ) \prod_{i=1}^{n} (x_i + y_i)
i = 1 ∏ n ( x i + y i )
这个电路的描述长度仅为 O ( n ) O(n) O ( n ) 2 n 2^n 2 n
PIT 问题至今没有已知的高效确定性算法,这是计算复杂性理论中的一个重大未解问题。如果存在多项式时间的确定性 PIT 算法,则意味着 NEXP ≠ P/poly \textsf{NEXP} \neq \textsf{P/poly} NEXP = P/poly # P ≠ FP \#\textsf{P} \neq \textsf{FP} # P = FP
Schwartz-Zippel 引理
PIT 有一个优雅的随机化解法,其核心是以下引理:
Schwartz-Zippel 引理
设 Q ( x 1 , x 2 , … , x n ) Q(x_1, x_2, \dots, x_n) Q ( x 1 , x 2 , … , x n ) F \mathbb{F} F 总次数 (total degree)为 d d d S S S F \mathbb{F} F r 1 , r 2 , … , r n r_1, r_2, \dots, r_n r 1 , r 2 , … , r n S S S
Pr [ Q ( r 1 , r 2 , … , r n ) = 0 ] ⩽ d ∣ S ∣ \Pr[Q(r_1, r_2, \dots, r_n) = 0] \le \frac{d}{|S|}
Pr [ Q ( r 1 , r 2 , … , r n ) = 0 ] ⩽ ∣ S ∣ d
这个结论非常惊人:无论多项式有多少个变量、结构多复杂,只要在一个足够大的集合中随机取值,非零多项式求值为零的概率就很小 。而且这个界只依赖于多项式的总次数和取值集合的大小,与变量个数 n n n
这里需要注意总次数 和个体次数 (individual degree)的区别。总次数是所有单项式中变量幂次之和的最大值。例如 x 1 2 x 2 3 + x 1 x 3 4 x_1^2 x_2^3 + x_1 x_3^4 x 1 2 x 2 3 + x 1 x 3 4 max ( 2 + 3 , 1 + 4 ) = 5 \max(2+3, 1+4) = 5 max ( 2 + 3 , 1 + 4 ) = 5
证明
对变量个数 n n n
基础情形 (n = 1 n = 1 n = 1 Q ( x 1 ) Q(x_1) Q ( x 1 ) d d d d d d
Pr [ Q ( r 1 ) = 0 ] ⩽ d ∣ S ∣ \Pr[Q(r_1) = 0] \le \frac{d}{|S|}
Pr [ Q ( r 1 ) = 0 ] ⩽ ∣ S ∣ d
归纳步骤 :假设引理对 n − 1 n-1 n − 1 Q Q Q x 1 x_1 x 1
Q ( x 1 , x 2 , … , x n ) = ∑ i = 0 k x 1 i ⋅ Q i ( x 2 , … , x n ) Q(x_1, x_2, \dots, x_n) = \sum_{i=0}^{k} x_1^i \cdot Q_i(x_2, \dots, x_n)
Q ( x 1 , x 2 , … , x n ) = i = 0 ∑ k x 1 i ⋅ Q i ( x 2 , … , x n )
其中 k ⩽ d k \le d k ⩽ d x 1 x_1 x 1 Q Q Q Q k ( x 2 , … , x n ) Q_k(x_2, \dots, x_n) Q k ( x 2 , … , x n ) x 1 k x_1^k x 1 k Q k Q_k Q k d − k d - k d − k Q Q Q x 1 k x_1^k x 1 k d − k d - k d − k
利用全概率公式。令事件 A A A Q k ( r 2 , … , r n ) = 0 Q_k(r_2, \dots, r_n) = 0 Q k ( r 2 , … , r n ) = 0 B B B Q ( r 1 , r 2 , … , r n ) = 0 Q(r_1, r_2, \dots, r_n) = 0 Q ( r 1 , r 2 , … , r n ) = 0
Pr [ B ] = Pr [ B ∣ A ] ⋅ Pr [ A ] + Pr [ B ∣ A ˉ ] ⋅ Pr [ A ˉ ] \Pr[B] = \Pr[B \mid A] \cdot \Pr[A] + \Pr[B \mid \bar{A}] \cdot \Pr[\bar{A}]
Pr [ B ] = Pr [ B ∣ A ] ⋅ Pr [ A ] + Pr [ B ∣ A ˉ ] ⋅ Pr [ A ˉ ]
由归纳假设,Q k Q_k Q k n − 1 n-1 n − 1 ⩽ d − k \le d - k ⩽ d − k Pr [ A ] ⩽ d − k ∣ S ∣ \Pr[A] \le \dfrac{d - k}{|S|} Pr [ A ] ⩽ ∣ S ∣ d − k
当 A ˉ \bar{A} A ˉ Q k ( r 2 , … , r n ) ≠ 0 Q_k(r_2, \dots, r_n) \neq 0 Q k ( r 2 , … , r n ) = 0 r 2 , … , r n r_2, \dots, r_n r 2 , … , r n Q ( x 1 , r 2 , … , r n ) Q(x_1, r_2, \dots, r_n) Q ( x 1 , r 2 , … , r n ) x 1 x_1 x 1 x 1 k x_1^k x 1 k Q k ( r 2 , … , r n ) ≠ 0 Q_k(r_2, \dots, r_n) \neq 0 Q k ( r 2 , … , r n ) = 0 k k k Pr [ B ∣ A ˉ ] ⩽ k ∣ S ∣ \Pr[B \mid \bar{A}] \le \dfrac{k}{|S|} Pr [ B ∣ A ˉ ] ⩽ ∣ S ∣ k
由此:
Pr [ B ] ⩽ 1 ⋅ d − k ∣ S ∣ + k ∣ S ∣ ⋅ 1 = d ∣ S ∣ \Pr[B] \le 1 \cdot \frac{d - k}{|S|} + \frac{k}{|S|} \cdot 1 = \frac{d}{|S|}
Pr [ B ] ⩽ 1 ⋅ ∣ S ∣ d − k + ∣ S ∣ k ⋅ 1 = ∣ S ∣ d
应用于 PIT
要检验 Q ≡ 0 Q \equiv 0 Q ≡ 0 S S S ( r 1 , … , r n ) (r_1, \dots, r_n) ( r 1 , … , r n ) Q ( r 1 , … , r n ) Q(r_1, \dots, r_n) Q ( r 1 , … , r n )
若结果 ≠ 0 \neq 0 = 0 Q Q Q
若结果 = 0 = 0 = 0 Q Q Q d / ∣ S ∣ d/|S| d /∣ S ∣
这正是 fingerprinting 的范式:FING ( Q ) = Q ( r 1 , … , r n ) \text{FING}(Q) = Q(r_1, \dots, r_n) FING ( Q ) = Q ( r 1 , … , r n )
降低错误概率
通过独立重复 t t t ( d / ∣ S ∣ ) t (d/|S|)^t ( d /∣ S ∣ ) t ∣ S ∣ ⩾ 2 d |S| \ge 2d ∣ S ∣ ⩾ 2 d ⩽ 1 / 2 \le 1/2 ⩽ 1/2 t t t ⩽ 2 − t \le 2^{-t} ⩽ 2 − t
Schwartz-Zippel 引理的应用远不止 PIT 。它还可以用于判断图是否有完美匹配、验证矩阵乘法、检验有根树同构、分析 Reed-Muller 码的距离性质、构造概率可检验证明(PCP)等。本讲后续的几个应用都是它的直接推论。
通信复杂性与相等性问题
问题模型
通信复杂性 (Communication Complexity)研究以下场景:Alice 持有输入 a a a b b b f ( a , b ) f(a, b) f ( a , b )
考虑最基本的相等性问题 (Equality):Alice 有一个 n n n a ∈ { 0 , 1 } n a \in \{0,1\}^n a ∈ { 0 , 1 } n n n n b ∈ { 0 , 1 } n b \in \{0,1\}^n b ∈ { 0 , 1 } n a = b a = b a = b
flowchart LR
A["Alice<br/>持有 a ∈ {0,1}ⁿ"] -- "交换消息" --> B["Bob<br/>持有 b ∈ {0,1}ⁿ"]
B -- "a = b?" --> C["输出"]
classDef person fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef output fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
class A,B person
class C output确定性下界
在确定性协议中,相等性问题的确定性通信复杂度为 Θ ( n ) \Theta(n) Θ ( n ) ——Alice 和 Bob 必须交换线性于 n n n
直观理解 :如果 Alice 发送的消息总共不到 n n n k < n k < n k < n 2 n 2^n 2 n
这个直觉可以用组合矩形 (Combinatorial Rectangle)的语言严格化。
组合矩形
想象一个 2 n × 2 n 2^n \times 2^n 2 n × 2 n a a a b b b ( a , b ) (a, b) ( a , b ) f ( a , b ) f(a,b) f ( a , b )
确定性协议中,每个叶节点(输出节点)对应的输入集合构成一个组合矩形 R × C R \times C R × C R ⊆ { 0 , 1 } n R \subseteq \{0,1\}^n R ⊆ { 0 , 1 } n C ⊆ { 0 , 1 } n C \subseteq \{0,1\}^n C ⊆ { 0 , 1 } n
为什么是笛卡尔积的形状?因为 Alice 发送的消息只取决于她自己的输入 a a a b b b a 1 , a 2 a_1, a_2 a 1 , a 2 b b b ( a 1 , b ) (a_1, b) ( a 1 , b ) ( a 2 , b ) (a_2, b) ( a 2 , b ) R × C R \times C R × C
一个正确的协议要求每个矩形内的所有输入都有相同的正确输出。
现在将这一工具应用于相等函数。所有使 f ( a , b ) = 1 f(a,b) = 1 f ( a , b ) = 1 a = b a = b a = b { ( a , a ) : a ∈ { 0 , 1 } n } \{(a,a) : a \in \{0,1\}^n\} {( a , a ) : a ∈ { 0 , 1 } n } 2 n 2^n 2 n 对角线上的每个组合矩形最多只包含 1 个点 。
为什么?假设某个标记为「相等」的矩形 R × C R \times C R × C ( a 1 , a 1 ) (a_1, a_1) ( a 1 , a 1 ) ( a 2 , a 2 ) (a_2, a_2) ( a 2 , a 2 ) a 1 ≠ a 2 a_1 \ne a_2 a 1 = a 2 a 1 , a 2 ∈ R a_1, a_2 \in R a 1 , a 2 ∈ R a 1 , a 2 ∈ C a_1, a_2 \in C a 1 , a 2 ∈ C ( a 1 , a 2 ) (a_1, a_2) ( a 1 , a 2 ) a 1 ≠ a 2 a_1 \ne a_2 a 1 = a 2 ( a 1 , a 2 ) (a_1, a_2) ( a 1 , a 2 )
因此,协议至少需要 2 n 2^n 2 n 2 n 2^n 2 n 2 n 2^n 2 n ⩾ log 2 2 n = n \ge \log_2 2^n = n ⩾ log 2 2 n = n
随机化协议
随机化可以将通信复杂度从 Θ ( n ) \Theta(n) Θ ( n ) O ( log n ) O(\log n) O ( log n )
公共随机协议
在公共随机 (public coin)模型中,Alice 和 Bob 共享一个随机源(如一个公开的随机比特串),但各自的输入是私有的。
模运算与域
后续频繁使用 Z p \mathbb{Z}_p Z p p p p { 0 , 1 , … , p − 1 } \{0, 1, \dots, p-1\} { 0 , 1 , … , p − 1 } p p p Z 7 \mathbb{Z}_7 Z 7 3 + 5 = 1 , 3 × 4 = 5 3 + 5 = 1,\, 3 \times 4 = 5 3 + 5 = 1 , 3 × 4 = 5 p p p Z p \mathbb{Z}_p Z p 域 (Field)——支持加减乘除。Z p [ x ] \mathbb{Z}_p[x] Z p [ x ] Z p \mathbb{Z}_p Z p
将 a ∈ { 0 , 1 } n a \in \{0,1\}^n a ∈ { 0 , 1 } n f a ( x ) = ∑ i = 1 n a i ⋅ x i ∈ Z p [ x ] f_a(x) = \sum_{i=1}^{n} a_i \cdot x^i \in \mathbb{Z}_p[x] f a ( x ) = ∑ i = 1 n a i ⋅ x i ∈ Z p [ x ] p p p p = Θ ( n 2 ) p = \Theta(n^2) p = Θ ( n 2 ) b b b f b ( x ) f_b(x) f b ( x )
协议 :
Alice 和 Bob 共享随机元素 r ∈ Z p r \in \mathbb{Z}_p r ∈ Z p
Alice 计算 f a ( r ) = ∑ i = 1 n a i ⋅ r i m o d p f_a(r) = \sum_{i=1}^{n} a_i \cdot r^i \bmod p f a ( r ) = ∑ i = 1 n a i ⋅ r i mod p
Bob 计算 f b ( r ) = ∑ i = 1 n b i ⋅ r i m o d p f_b(r) = \sum_{i=1}^{n} b_i \cdot r^i \bmod p f b ( r ) = ∑ i = 1 n b i ⋅ r i mod p f a ( r ) = f b ( r ) f_a(r) = f_b(r) f a ( r ) = f b ( r )
通信量仅为 O ( log p ) = O ( log n ) O(\log p) = O(\log n) O ( log p ) = O ( log n ) Z p \mathbb{Z}_p Z p
错误分析 :若 a ≠ b a \neq b a = b f a − f b f_a - f_b f a − f b Z p [ x ] \mathbb{Z}_p[x] Z p [ x ] ⩽ n \le n ⩽ n
Pr [ f a ( r ) = f b ( r ) ] ⩽ n p \Pr[f_a(r) = f_b(r)] \le \frac{n}{p}
Pr [ f a ( r ) = f b ( r )] ⩽ p n
取 p = Θ ( n 2 ) p = \Theta(n^2) p = Θ ( n 2 ) ⩽ 1 / n \le 1/n ⩽ 1/ n
另一种更极端的公共随机协议只需 1 比特 通信:Alice 和 Bob 共享随机向量 r ∈ { 0 , 1 } n \bm{r} \in \{0,1\}^n r ∈ { 0 , 1 } n ⟨ a , r ⟩ m o d 2 \langle a, \bm{r} \rangle \bmod 2 ⟨ a , r ⟩ mod 2 ⟨ b , r ⟩ m o d 2 \langle b, \bm{r} \rangle \bmod 2 ⟨ b , r ⟩ mod 2 a ≠ b a \neq b a = b ⟨ a − b , r ⟩ m o d 2 \langle a - b, \bm{r} \rangle \bmod 2 ⟨ a − b , r ⟩ mod 2 r \bm{r} r a − b a - b a − b d = 1 , ∣ S ∣ = 2 d = 1,\, |S| = 2 d = 1 , ∣ S ∣ = 2 ⩽ 1 / 2 \le 1/2 ⩽ 1/2
这里的 fingerprint 是 FING ( a ) = f a ( r ) = ∑ a i ⋅ r i m o d p \text{FING}(a) = f_a(r) = \sum a_i \cdot r^i \bmod p FING ( a ) = f a ( r ) = ∑ a i ⋅ r i mod p n n n O ( log n ) O(\log n) O ( log n )
私有随机协议
在私有随机 (private coin)模型中,Alice 和 Bob 各自拥有独立的随机源,不共享随机性。
将 a , b ∈ { 0 , 1 } n a, b \in \{0,1\}^n a , b ∈ { 0 , 1 } n [ 0 , 2 n ) [0, 2^n) [ 0 , 2 n )
协议 :
Alice 从不超过 k k k p p p k k k
Alice 将 ( p , a m o d p ) (p, \, a \bmod p) ( p , a mod p )
Bob 检查 a m o d p ≡ b m o d p a \bmod p \equiv b \bmod p a mod p ≡ b mod p
通信量为 O ( log k ) = O ( log n ) O(\log k) = O(\log n) O ( log k ) = O ( log n ) FING p ( a ) = a m o d p \text{FING}_p(a) = a \bmod p FING p ( a ) = a mod p
私有随机协议的错误分析
若 a = b a = b a = b a m o d p = b m o d p a \bmod p = b \bmod p a mod p = b mod p
若 a ≠ b a \neq b a = b z = ∣ a − b ∣ z = |a - b| z = ∣ a − b ∣ 0 < z < 2 n 0 < z < 2^n 0 < z < 2 n p ∣ z p \mid z p ∣ z p p p z z z
关键观察:z z z z < 2 n z < 2^n z < 2 n n n n 2 × 3 × 5 × ⋯ × p n ⩾ 2 n 2 \times 3 \times 5 \times \dots \times p_n \ge 2^n 2 × 3 × 5 × ⋯ × p n ⩾ 2 n z z z n n n z z z n n n z ⩾ 2 n z \ge 2^n z ⩾ 2 n z < 2 n z < 2^n z < 2 n z z z n − 1 n - 1 n − 1
素数计数函数与素数定理
由素数定理 (Prime Number Theorem),不超过 N N N
π ( N ) ∼ N ln N ( N → ∞ ) \pi(N) \sim \frac{N}{\ln N} \quad (N \to \infty)
π ( N ) ∼ ln N N ( N → ∞ )
这意味着 [ 1 , k ] [1, k] [ 1 , k ] k ln k \dfrac{k}{\ln k} ln k k
对于我们的分析,更有用的一个推论是:对于足够大的 N N N π ( N ) ⩾ N 2 ln N \pi(N) \ge \dfrac{N}{2\ln N} π ( N ) ⩾ 2 ln N N
错误概率为:
Pr [ error ] = # { p ⩽ k : p 是素数且 p ∣ z } π ( k ) ⩽ n − 1 π ( k ) ≈ n ln k k \Pr[\text{error}] = \frac{\#\{p \le k : p \text{ 是素数且 } p \mid z\}}{\pi(k)} \le \frac{n - 1}{\pi(k)} \approx \frac{n \ln k}{k}
Pr [ error ] = π ( k ) # { p ⩽ k : p 是素数且 p ∣ z } ⩽ π ( k ) n − 1 ≈ k n ln k
选取 k = n 3 k = n^3 k = n 3
Pr [ error ] ⩽ n ⋅ 3 ln n n 3 = 3 ln n n 2 = O ( 1 n ) \Pr[\text{error}] \le \frac{n \cdot 3\ln n}{n^3} = \frac{3\ln n}{n^2} = O\left(\frac{1}{n}\right)
Pr [ error ] ⩽ n 3 n ⋅ 3 ln n = n 2 3 ln n = O ( n 1 )
注意 fingerprint 函数 FING p ( a ) = a m o d p \text{FING}_p(a) = a \bmod p FING p ( a ) = a mod p p p p n n n O ( log n ) O(\log n) O ( log n )
Newman 定理
Newman 定理
公共随机和私有随机两种模型的通信复杂度之间有什么关系?显然私有随机不弱于公共随机(后者可以模拟前者),因为若有一个 private-coin 协议 Π \Pi Π R A , R B R_{A}, R_{B} R A , R B Π ′ \Pi' Π ′
取公共随机串 R = ( R A , R B ) R=\left(R_{A}, R_{B}\right) R = ( R A , R B )
Alice 在 Π ′ \Pi' Π ′ R A R_{A} R A
Bob 在 Π ′ \Pi' Π ′ R B R_{B} R B
则 Π ′ \Pi' Π ′ ( x , y ) (x, y) ( x , y ) Π \Pi Π
R p u b ( f ) ⩽ R p r i v ( f ) R^{\mathrm{pub}}(f) \le R^{\mathrm{priv}}(f)
R pub ( f ) ⩽ R priv ( f )
即 public-coin 的随机通信复杂度不大于 private-coin。
但反过来呢?
Newman 定理
对于任意函数 f f f R ϵ pub ( f ) R^{\text{pub}}_\epsilon(f) R ϵ pub ( f ) R ϵ priv ( f ) R^{\text{priv}}_\epsilon(f) R ϵ priv ( f ) ϵ \epsilon ϵ
R ϵ priv ( f ) ⩽ R ϵ pub ( f ) + O ( log n ) R^{\text{priv}}_\epsilon(f) \le R^{\text{pub}}_\epsilon(f) + O(\log n)
R ϵ priv ( f ) ⩽ R ϵ pub ( f ) + O ( log n )
Newman 定理告诉我们,私有随机最多比公共随机多 O ( log n ) O(\log n) O ( log n ) 。
其证明思想如下:假设已有一个公共随机协议 Π \Pi Π s s s ⩽ ϵ \le \epsilon ⩽ ϵ t = poly ( n ) t = \text{poly}(n) t = poly ( n ) s 1 , … , s t s_1, \dots, s_t s 1 , … , s t t t t ( a , b ) (a,b) ( a , b )
有了这组串,Alice 和 Bob 事先约定好 s 1 , … , s t s_1, \dots, s_t s 1 , … , s t i ∈ [ t ] i \in [t] i ∈ [ t ] i i i ⌈ log 2 t ⌉ = O ( log n ) \lceil \log_2 t \rceil = O(\log n) ⌈ log 2 t ⌉ = O ( log n ) s i s_i s i O ( log n ) O(\log n) O ( log n )
对于相等性问题,两种模型的通信复杂度都是 Θ ( log n ) \Theta(\log n) Θ ( log n )
应用:二部图完美匹配
问题与经典方法
给定一个二部图 (Bipartite Graph)G = ( U , V , E ) G = (U, V, E) G = ( U , V , E ) ∣ U ∣ = ∣ V ∣ = n |U| = |V| = n ∣ U ∣ = ∣ V ∣ = n G G G 完美匹配 (Perfect Matching),即一个边集 M ⊆ E M \subseteq E M ⊆ E U U U V V V M M M
二部图与完美匹配
二部图 是指顶点可以分成两组 U U U V V V 完美匹配 是一种配对方案:将 U U U V V V ∣ U ∣ = ∣ V ∣ |U| = |V| ∣ U ∣ = ∣ V ∣
一个直观例子:n n n n n n
经典的确定性算法基于增广路径(从一个未匹配的顶点出发,沿交替使用匹配边和非匹配边的路径扩展当前匹配):如 Hopcroft-Karp 算法,时间复杂度为 O ( m n ) O(m\sqrt{n}) O ( m n ) m = ∣ E ∣ m = |E| m = ∣ E ∣
Edmonds 定理与 Edmonds 矩阵
Edmonds 定理 (Edmonds' Theorem)建立了图的匹配与矩阵行列式之间的深刻联系,将组合问题转化为代数问题。
定义二部图 G G G Edmonds 矩阵 M \bm{M} M n × n n \times n n × n
M i j = { x i j if ( u i , v j ) ∈ E 0 otherwise M_{ij} = \begin{cases} x_{ij} & \text{if } (u_i, v_j) \in E \\ 0 & \text{otherwise} \end{cases}
M ij = { x ij 0 if ( u i , v j ) ∈ E otherwise
其中 { x i j } \{x_{ij}\} { x ij } 形式变量 (indeterminates)——它们不是具体的数值,而是纯粹的符号占位符。可以把每个 x i j x_{ij} x ij ( u i , v j ) (u_i, v_j) ( u i , v j ) det ( M ) \det(\bm{M}) det ( M )
具体例子
考虑一个 3 × 3 3 \times 3 3 × 3 U = { u 1 , u 2 , u 3 } , V = { v 1 , v 2 , v 3 } U = \{u_1, u_2, u_3\},\, V = \{v_1, v_2, v_3\} U = { u 1 , u 2 , u 3 } , V = { v 1 , v 2 , v 3 } E = { ( u 1 , v 1 ) , ( u 1 , v 2 ) , ( u 2 , v 1 ) , ( u 2 , v 3 ) , ( u 3 , v 2 ) , ( u 3 , v 3 ) } E = \{(u_1,v_1), (u_1,v_2), (u_2,v_1), (u_2,v_3), (u_3,v_2), (u_3,v_3)\} E = {( u 1 , v 1 ) , ( u 1 , v 2 ) , ( u 2 , v 1 ) , ( u 2 , v 3 ) , ( u 3 , v 2 ) , ( u 3 , v 3 )}
M = ( x 11 x 12 0 x 21 0 x 23 0 x 32 x 33 ) \bm{M} = \begin{pmatrix} x_{11} & x_{12} & 0 \\ x_{21} & 0 & x_{23} \\ 0 & x_{32} & x_{33} \end{pmatrix}
M = x 11 x 21 0 x 12 0 x 32 0 x 23 x 33
行列式展开后,6 个排列中只有对应完美匹配的排列贡献非零项。例如排列 σ = ( 1 , 2 , 3 ) \sigma = (1,2,3) σ = ( 1 , 2 , 3 ) { ( u 1 , v 1 ) , ( u 2 , v 2 ) , ( u 3 , v 3 ) } \{(u_1,v_1),(u_2,v_2),(u_3,v_3)\} {( u 1 , v 1 ) , ( u 2 , v 2 ) , ( u 3 , v 3 )} M 2 , 2 = 0 M_{2,2} = 0 M 2 , 2 = 0 σ = ( 1 , 3 , 2 ) \sigma = (1,3,2) σ = ( 1 , 3 , 2 ) { ( u 1 , v 1 ) , ( u 2 , v 3 ) , ( u 3 , v 2 ) } \{(u_1,v_1),(u_2,v_3),(u_3,v_2)\} {( u 1 , v 1 ) , ( u 2 , v 3 ) , ( u 3 , v 2 )} − x 11 x 23 x 32 -x_{11}x_{23}x_{32} − x 11 x 23 x 32 σ = ( 2 , 1 , 3 ) \sigma = (2,1,3) σ = ( 2 , 1 , 3 ) { ( u 1 , v 2 ) , ( u 2 , v 1 ) , ( u 3 , v 3 ) } \{(u_1,v_2),(u_2,v_1),(u_3,v_3)\} {( u 1 , v 2 ) , ( u 2 , v 1 ) , ( u 3 , v 3 )} − x 12 x 21 x 33 -x_{12}x_{21}x_{33} − x 12 x 21 x 33 det ( M ) = − x 11 x 23 x 32 − x 12 x 21 x 33 ≢ 0 \det(\bm{M}) = -x_{11}x_{23}x_{32} - x_{12}x_{21}x_{33} \not\equiv 0 det ( M ) = − x 11 x 23 x 32 − x 12 x 21 x 33 ≡ 0
对于一般图(非二部图),对应的概念是 Tutte 矩阵 ,定义为反对称矩阵:
T i j = { x i j if ( i , j ) ∈ E and i < j − x i j if ( i , j ) ∈ E and i > j 0 if ( i , j ) ∉ E or i = j T_{ij} = \begin{cases} x_{ij} & \text{if } (i,j) \in E \text{ and } i < j \\ -x_{ij} & \text{if } (i,j) \in E \text{ and } i > j \\ 0 & \text{if } (i,j) \notin E \text{ or } i = j \end{cases}
T ij = ⎩ ⎨ ⎧ x ij − x ij 0 if ( i , j ) ∈ E and i < j if ( i , j ) ∈ E and i > j if ( i , j ) ∈ / E or i = j
Edmonds 矩阵可以看作 Tutte 矩阵在二部图上的简化版本。Edmonds 定理同样适用于一般图:G G G
Edmonds 定理
二部图 G G G det ( M ) \det(\bm{M}) det ( M ) { x i j } \{x_{ij}\} { x ij }
为什么 Edmonds 定理成立
行列式的定义为:
det ( M ) = ∑ σ ∈ S n sgn ( σ ) ∏ i = 1 n M i , σ ( i ) \det(\bm{M}) = \sum_{\sigma \in S_n} \operatorname{sgn}(\sigma) \prod_{i=1}^{n} M_{i,\sigma(i)}
det ( M ) = σ ∈ S n ∑ sgn ( σ ) i = 1 ∏ n M i , σ ( i )
其中求和遍历所有 n ! n! n ! σ ∈ S n \sigma \in S_n σ ∈ S n sgn ( σ ) ∈ { + 1 , − 1 } \operatorname{sgn}(\sigma) \in \{+1, -1\} sgn ( σ ) ∈ { + 1 , − 1 } + 1 +1 + 1 − 1 -1 − 1 σ \sigma σ U U U V V V u i u_i u i v σ ( i ) v_{\sigma(i)} v σ ( i )
乘积 ∏ i = 1 n M i , σ ( i ) \prod_{i=1}^{n} M_{i,\sigma(i)} ∏ i = 1 n M i , σ ( i ) i i i ( u i , v σ ( i ) ) ∈ E (u_i, v_{\sigma(i)}) \in E ( u i , v σ ( i ) ) ∈ E { ( u i , v σ ( i ) ) : i = 1 , … , n } \{(u_i, v_{\sigma(i)}) : i = 1, \dots, n\} {( u i , v σ ( i ) ) : i = 1 , … , n } G G G
若 G G G 没有 完美匹配,则行列式中每一项的乘积都包含至少一个零因子,故 det ( M ) ≡ 0 \det(\bm{M}) \equiv 0 det ( M ) ≡ 0
若 G G G 有 完美匹配 σ ∗ \sigma^* σ ∗ sgn ( σ ∗ ) ∏ i x i , σ ∗ ( i ) \operatorname{sgn}(\sigma^*) \prod_{i} x_{i,\sigma^*(i)} sgn ( σ ∗ ) ∏ i x i , σ ∗ ( i ) 由于各 x i j x_{ij} x ij (因为它们涉及不同的变量子集),所以非零项之间不会相消,det ( M ) \det(\bm{M}) det ( M )
随机算法
Edmonds 定理将完美匹配的存在性归结为多项式是否恒为零,而这正是 PIT 问题。结合 Schwartz-Zippel 引理,得到如下算法:
将每个形式变量 x i j x_{ij} x ij S = { 1 , 2 , … , 2 n } S = \{1, 2, \dots, 2n\} S = { 1 , 2 , … , 2 n }
计算数值矩阵的行列式(高斯消元 O ( n 3 ) O(n^3) O ( n 3 ) O ( n ω ) O(n^\omega) O ( n ω )
若行列式为 0 0 0
det ( M ) \det(\bm{M}) det ( M ) n n n n n n ∣ S ∣ = 2 n |S| = 2n ∣ S ∣ = 2 n ⩽ n / ( 2 n ) = 1 / 2 \le n/(2n) = 1/2 ⩽ n / ( 2 n ) = 1/2
这个算法虽然在判定问题上并不比 Hopcroft-Karp 更快,但它揭示了匹配问题与线性代数之间的深刻联系。更重要的是,这一代数方法可以推广到并行算法 :计算行列式可以高效并行化(属于复杂性类 NC \textsf{NC} NC O ( polylog n ) O(\operatorname{polylog} n) O ( polylog n ) O ( ( log n ) k ) O\left((\log n)^k\right) O ( ( log n ) k ) RNC \textsf{RNC} RNC
一个至今未解的问题是:完美匹配判定是否可以确定性并行化(即属于 NC \textsf{NC} NC RNC \textsf{RNC} RNC
应用:矩阵乘法验证
问题背景
给定三个 n × n n \times n n × n A , B , C \bm{A}, \bm{B}, \bm{C} A , B , C A B = C \bm{A}\bm{B} = \bm{C} A B = C
直接计算 A B \bm{A}\bm{B} A B ω \omega ω n × n n \times n n × n O ( n ω ) O(n^\omega) O ( n ω ) ω \omega ω
年份
作者
ω \omega ω
-
朴素算法
3 3 3
1969
Strassen
2.807 2.807 2.807
…
…
…
2024
Williams, Xu, Xu, Zhou
2.3716 2.3716 2.3716
目前 ω > 2 \omega > 2 ω > 2 ω = 2 \omega = 2 ω = 2 A B = C \bm{AB} = \bm{C} AB = C A B \bm{AB} AB O ( n 2 ) O(n^2) O ( n 2 )
Freivalds 算法
Freivalds 算法 的核心思想是对矩阵做 fingerprinting:FING ( M ) = M r \text{FING}(\bm{M}) = \bm{M}\bm{r} FING ( M ) = M r n × n n \times n n × n n n n
随机选取向量 r ∈ { 0 , 1 } n \bm{r} \in \{0,1\}^n r ∈ { 0 , 1 } n 0 0 0 1 1 1
计算 A ( B r ) \bm{A}(\bm{B}\bm{r}) A ( B r ) C r \bm{C}\bm{r} C r
若 A ( B r ) ≠ C r \bm{A}(\bm{B}\bm{r}) \neq \bm{C}\bm{r} A ( B r ) = C r A B ≠ C \bm{AB} \neq \bm{C} AB = C A B = C \bm{AB} = \bm{C} AB = C
计算顺序
步骤 2 中必须先计算 B r \bm{B}\bm{r} B r O ( n 2 ) O(n^2) O ( n 2 ) A \bm{A} A O ( n 2 ) O(n^2) O ( n 2 ) ( A B ) r (\bm{A}\bm{B})\bm{r} ( A B ) r A B \bm{A}\bm{B} A B O ( n ω ) O(n^\omega) O ( n ω ) O ( n 2 ) O(n^2) O ( n 2 )
正确性分析
令 D = A B − C \bm{D} = \bm{AB} - \bm{C} D = AB − C D r = 0 \bm{D}\bm{r} = \bm{0} D r = 0
若 D = 0 \bm{D} = \bm{0} D = 0 A B = C \bm{AB} = \bm{C} AB = C D r = 0 \bm{D}\bm{r} = \bm{0} D r = 0
若 D ≠ 0 \bm{D} \neq \bm{0} D = 0 Pr [ D r = 0 ] ⩽ 1 / 2 \Pr[\bm{D}\bm{r} = \bm{0}] \le 1/2 Pr [ D r = 0 ] ⩽ 1/2
由于 D ≠ 0 \bm{D} \neq \bm{0} D = 0 i i i d i ≠ 0 \bm{d}_i \neq \bm{0} d i = 0 d i j ≠ 0 d_{ij} \neq 0 d ij = 0 ( D r ) i (\bm{D}\bm{r})_i ( D r ) i
( D r ) i = ∑ k = 1 n d i k r k = d i j r j + ∑ k ≠ j d i k r k ⏟ ≔ W (\bm{D}\bm{r})_i = \sum_{k=1}^{n} d_{ik} r_k = d_{ij} r_j + \underbrace{\sum_{k \neq j} d_{ik} r_k}_{\coloneqq\, W}
( D r ) i = k = 1 ∑ n d ik r k = d ij r j + : = W k = j ∑ d ik r k
这里使用了延迟决策原则 (Principle of Deferred Decisions):我们可以假设先确定所有 r k r_k r k k ≠ j k \neq j k = j r j r_j r j r k r_k r k k ≠ j k \neq j k = j W W W
( D r ) i = 0 ⟺ r j = − W d i j (\bm{D}\bm{r})_i = 0 \iff r_j = -\frac{W}{d_{ij}}
( D r ) i = 0 ⟺ r j = − d ij W
无论 W W W ( D r ) i = 0 (\bm{D}\bm{r})_i = 0 ( D r ) i = 0 d i j r j + W = 0 d_{ij} r_j + W = 0 d ij r j + W = 0 r j r_j r j r j r_j r j { 0 , 1 } \{0,1\} { 0 , 1 } r k r_k r k { 0 , 1 } \{0,1\} { 0 , 1 } r j r_j r j 1 / 2 1/2 1/2 { 0 , 1 } \{0,1\} { 0 , 1 } 0 0 0
也可以从计数的角度看:满足 D r = 0 \bm{D}\bm{r} = \bm{0} D r = 0 r ∈ { 0 , 1 } n \bm{r} \in \{0,1\}^n r ∈ { 0 , 1 } n 2 n − 1 2^{n-1} 2 n − 1 r − j r_{-j} r − j r j r_j r j r j r_j r j r \bm{r} r 2 n 2^n 2 n
Pr [ D r = 0 ] ⩽ 2 n − 1 2 n = 1 2 \Pr[\bm{D}\bm{r} = \bm{0}] \le \frac{2^{n-1}}{2^n} = \frac{1}{2}
Pr [ D r = 0 ] ⩽ 2 n 2 n − 1 = 2 1
独立重复 t t t r \bm{r} r 2 − t 2^{-t} 2 − t O ( t n 2 ) O(tn^2) O ( t n 2 ) t = O ( log n ) t = O(\log n) t = O ( log n ) O ( n 2 log n ) O(n^2 \log n) O ( n 2 log n )
Schwartz-Zippel 视角
Freivalds 算法也可以从 Schwartz-Zippel 引理的角度统一理解。将 ( D r ) i = ∑ k d i k r k (\bm{D}\bm{r})_i = \sum_k d_{ik} r_k ( D r ) i = ∑ k d ik r k r 1 , … , r n r_1, \dots, r_n r 1 , … , r n 1 1 1 d = 1 , ∣ S ∣ = 2 d = 1,\, |S| = 2 d = 1 , ∣ S ∣ = 2 S = { 0 , 1 } S = \{0,1\} S = { 0 , 1 } ⩽ 1 / ∣ S ∣ = 1 / 2 \le 1/|S| = 1/2 ⩽ 1/∣ S ∣ = 1/2
Karp-Rabin 字符串匹配
问题定义
模式匹配 (Pattern Matching)是字符串算法中的经典问题:给定文本串 T [ 1 … n ] T[1 \dots n] T [ 1 … n ] P [ 1 … m ] P[1 \dots m] P [ 1 … m ] m ⩽ n m \le n m ⩽ n P P P T T T T [ j … j + m − 1 ] = P T[j \dots j+m-1] = P T [ j … j + m − 1 ] = P j j j
朴素算法逐位置对齐并逐字符比较,最坏时间 O ( n m ) O(nm) O ( nm ) O ( n + m ) O(n + m) O ( n + m ) O ( m ) O(m) O ( m )
通用框架:Fingerprinting 方法
在介绍具体算法之前,先看 fingerprinting 方法解决模式匹配的一般框架:
计算模式的指纹 FING ( P ) \text{FING}(P) FING ( P )
对每个位置 j j j FING ( T j ) \text{FING}(T_j) FING ( T j ) T j = T [ j … j + m − 1 ] T_j = T[j \dots j+m-1] T j = T [ j … j + m − 1 ]
比较 FING ( T j ) \text{FING}(T_j) FING ( T j ) FING ( P ) \text{FING}(P) FING ( P )
这个框架要求指纹函数满足一个额外条件:增量可计算性 ——能够从 FING ( T j ) \text{FING}(T_j) FING ( T j ) O ( 1 ) O(1) O ( 1 ) FING ( T j + 1 ) \text{FING}(T_{j+1}) FING ( T j + 1 ) O ( n m ) O(nm) O ( nm )
Karp-Rabin 算法
Karp-Rabin 算法 给出了一个满足增量可计算性的 fingerprinting 方案。
将二进制字符串 s = s 1 s 2 … s m s = s_1 s_2 \dots s_m s = s 1 s 2 … s m s ˉ = ∑ i = 1 m s i ⋅ 2 m − i \bar{s} = \sum_{i=1}^{m} s_i \cdot 2^{m-i} s ˉ = ∑ i = 1 m s i ⋅ 2 m − i
FING p ( s ) = s ˉ m o d p \text{FING}_p(s) = \bar{s} \bmod p
FING p ( s ) = s ˉ mod p
其中 p p p m n 3 mn^3 m n 3
滑动窗口与增量更新
关键观察:相邻位置的子串 T j T_j T j T j + 1 T_{j+1} T j + 1
T ˉ j + 1 = 2 ( T ˉ j − T [ j ] ⋅ 2 m − 1 ) + T [ j + m ] \bar{T}_{j+1} = 2\big(\bar{T}_j - T[j] \cdot 2^{m-1}\big) + T[j+m]
T ˉ j + 1 = 2 ( T ˉ j − T [ j ] ⋅ 2 m − 1 ) + T [ j + m ]
直觉很简单:从 T j T_j T j T j + 1 T_{j+1} T j + 1 T [ j ] T[j] T [ j ] 2 2 2 T [ j + m ] T[j+m] T [ j + m ]
由于模运算与加法、乘法兼容(即 ( a + b ) m o d p = ( ( a m o d p ) + ( b m o d p ) ) m o d p (a + b) \bmod p = ((a \bmod p) + (b \bmod p)) \bmod p ( a + b ) mod p = (( a mod p ) + ( b mod p )) mod p p p p
FING p ( T j + 1 ) = ( 2 ⋅ ( FING p ( T j ) − T [ j ] ⋅ 2 m − 1 ) + T [ j + m ] ) m o d p \text{FING}_p(T_{j+1}) = \big(2 \cdot (\text{FING}_p(T_j) - T[j] \cdot 2^{m-1}) + T[j+m]\big) \bmod p
FING p ( T j + 1 ) = ( 2 ⋅ ( FING p ( T j ) − T [ j ] ⋅ 2 m − 1 ) + T [ j + m ] ) mod p
只需预计算 2 m − 1 m o d p 2^{m-1} \bmod p 2 m − 1 mod p O ( 1 ) O(1) O ( 1 )
算法流程
flowchart LR
A["随机选取素数 p ≤ mn³"] --> B["预计算 FING(P) 和 FING(T₁)<br/>以及 2^(m-1) mod p"]
B --> C{"FING(T_j) = FING(P)?"}
C -- 是 --> D["报告位置 j 匹配"]
C -- 否 --> E["跳过"]
D --> F{"j < n - m + 1?"}
E --> F
F -- 是 --> G["O(1) 递推 FING(T_{j+1})"]
G --> C
F -- 否 --> H["结束"]
classDef init fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef decision fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef match fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef skip fill:#f8f9fa,stroke:#495057,stroke-width:2px
classDef endclass fill:#ffebee,stroke:#c62828,stroke-width:2px
class A,B init
class C,F decision
class D match
class E,G skip
class H endclass复杂度 :
时间:预处理 O ( m ) O(m) O ( m ) O ( 1 ) O(1) O ( 1 ) n − m + 1 n - m + 1 n − m + 1 O ( n ) O(n) O ( n )
空间:O ( log ( m n ) ) O(\log(mn)) O ( log ( mn )) p p p 2 m − 1 m o d p 2^{m-1} \bmod p 2 m − 1 mod p
错误分析
对于某个固定位置 j j j T j ≠ P T_j \neq P T j = P p ∣ ( T ˉ j − P ˉ ) p \mid (\bar{T}_j - \bar{P}) p ∣ ( T ˉ j − P ˉ ) z j = ∣ T ˉ j − P ˉ ∣ z_j = |\bar{T}_j - \bar{P}| z j = ∣ T ˉ j − P ˉ ∣ 0 < z j < 2 m 0 < z_j < 2^m 0 < z j < 2 m z j z_j z j m m m
Pr [ 位置 j 假阳性 ] = # { p ⩽ m n 3 : p 是素数且 p ∣ z j } π ( m n 3 ) ⩽ m π ( m n 3 ) ≈ m ⋅ ln ( m n 3 ) m n 3 \Pr[\text{位置 } j \text{ 假阳性}] = \frac{\#\{p \le mn^3 : p \text{ 是素数且 } p \mid z_j\}}{\pi(mn^3)} \le \frac{m}{\pi(mn^3)} \approx \frac{m \cdot \ln(mn^3)}{mn^3}
Pr [ 位置 j 假阳性 ] = π ( m n 3 ) # { p ⩽ m n 3 : p 是素数且 p ∣ z j } ⩽ π ( m n 3 ) m ≈ m n 3 m ⋅ ln ( m n 3 )
这里有 n − m + 1 ⩽ n n - m + 1 \le n n − m + 1 ⩽ n 联合界 (union bound:多个事件中至少一个发生的概率不超过各自概率之和,即 Pr [ ⋃ i A i ] ⩽ ∑ i Pr [ A i ] \Pr[\bigcup_i A_i] \le \sum_i \Pr[A_i] Pr [ ⋃ i A i ] ⩽ ∑ i Pr [ A i ]
Pr [ 存在假阳性 ] ⩽ n ⋅ m ⋅ ln ( m n 3 ) m n 3 = ln ( m n 3 ) n 2 = O ( log n n 2 ) = O ( 1 n ) \Pr[\text{存在假阳性}] \le n \cdot \frac{m \cdot \ln(mn^3)}{mn^3} = \frac{\ln(mn^3)}{n^2} = O\left(\frac{\log n}{n^2}\right) = O\left(\frac{1}{n}\right)
Pr [ 存在假阳性 ] ⩽ n ⋅ m n 3 m ⋅ ln ( m n 3 ) = n 2 ln ( m n 3 ) = O ( n 2 log n ) = O ( n 1 )
Karp-Rabin 的优势
与 KMP 等确定性算法相比,Karp-Rabin 的主要优势在于:
实现极简 :核心仅涉及模运算,无需复杂的预处理数据结构空间极小 :仅需 O ( log n ) O(\log n) O ( log n ) O ( m ) O(m) O ( m ) 泛化能力强 :天然适用于多模式匹配(同时搜索多个模式串)、二维模式匹配、以及大字母表上的匹配问题数据流友好 :文本可以逐字符流式输入,无需预先存储
一般字母表
上述描述假设二进制字母表 { 0 , 1 } \{0,1\} { 0 , 1 } ∣ Σ ∣ |\Sigma| ∣Σ∣ 2 2 2 ∣ Σ ∣ |\Sigma| ∣Σ∣ ∣ Σ ∣ |\Sigma| ∣Σ∣ FING p ( T j + 1 ) = ( ∣ Σ ∣ ⋅ ( FING p ( T j ) − T [ j ] ⋅ ∣ Σ ∣ m − 1 ) + T [ j + m ] ) m o d p \text{FING}_p(T_{j+1}) = (|\Sigma| \cdot (\text{FING}_p(T_j) - T[j] \cdot |\Sigma|^{m-1}) + T[j+m]) \bmod p FING p ( T j + 1 ) = ( ∣Σ∣ ⋅ ( FING p ( T j ) − T [ j ] ⋅ ∣Σ ∣ m − 1 ) + T [ j + m ]) mod p
多重集相等性检验与元素唯一性
问题定义
给定一个序列 A = ( a 1 , a 2 , … , a n ) A = (a_1, a_2, \dots, a_n) A = ( a 1 , a 2 , … , a n ) a i ∈ [ n ] = { 1 , 2 , … , n } a_i \in [n] = \{1, 2, \dots, n\} a i ∈ [ n ] = { 1 , 2 , … , n } A A A 元素唯一性问题 ,Checking Distinctness)。
等价地,如果元素两两不同,则 A A A { 1 , 2 , … , n } \{1, 2, \dots, n\} { 1 , 2 , … , n } 多重集 (Multiset)A A A I = { 1 , 2 , … , n } I = \{1, 2, \dots, n\} I = { 1 , 2 , … , n }
排序后逐个比较需要 O ( n log n ) O(n \log n) O ( n log n ) O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n ) O ( log n ) O(\log n) O ( log n )
多项式编码
将多重集编码为多项式是 Lipton 的核心思想。定义:
f A ( x ) = ∏ i = 1 n ( x − a i ) f I ( x ) = ∏ i = 1 n ( x − i ) f_A(x) = \prod_{i=1}^{n} (x - a_i) \qquad f_I(x) = \prod_{i=1}^{n} (x - i)
f A ( x ) = i = 1 ∏ n ( x − a i ) f I ( x ) = i = 1 ∏ n ( x − i )
f A f_A f A f I f_I f I R \R R n n n A A A [ n ] [n] [ n ] f A ≡ f I f_A \equiv f_I f A ≡ f I ∏ ( x − r i ) \prod (x - r_i) ∏ ( x − r i )
定义指纹:
FING ( A ) = f A ( r ) m o d p = ∏ i = 1 n ( r − a i ) m o d p \text{FING}(A) = f_A(r) \bmod p = \prod_{i=1}^{n} (r - a_i) \bmod p
FING ( A ) = f A ( r ) mod p = i = 1 ∏ n ( r − a i ) mod p
其中参数 r r r p p p
两类错误源
当 A A A f A ≢ f I f_A \not\equiv f_I f A ≡ f I R \R R FING ( A ) = FING ( I ) \text{FING}(A) = \text{FING}(I) FING ( A ) = FING ( I )
两层随机性
仅用随机素数 p p p r r r r r r p p p r r r p p p
错误源 1:f A ≡ f I f_A \equiv f_I f A ≡ f I Z p \mathbb{Z}_p Z p
虽然 f A ≠ f I f_A \neq f_I f A = f I R \R R p p p p p p f A − f I f_A - f_I f A − f I
设 f A ( x ) − f I ( x ) = ∑ k = 0 n c k x k f_A(x) - f_I(x) = \sum_{k=0}^{n} c_k x^k f A ( x ) − f I ( x ) = ∑ k = 0 n c k x k c k ∈ Z c_k \in \mathbb{Z} c k ∈ Z ∣ c k ∣ |c_k| ∣ c k ∣ ( n k ) ⋅ n k ⩽ n n \binom{n}{k} \cdot n^k \le n^n ( k n ) ⋅ n k ⩽ n n a i ∈ [ n ] a_i \in [n] a i ∈ [ n ] k k k n n n k k k c k c_k c k
log 2 ∣ c k ∣ = ln ∣ c k ∣ ln 2 ⩽ n ln n ln 2 = O ( n log n ) \log_2 |c_k| = \frac{\ln |c_k|}{\ln 2} \le \frac{n \ln n}{\ln 2} = O(n \log n)
log 2 ∣ c k ∣ = ln 2 ln ∣ c k ∣ ⩽ ln 2 n ln n = O ( n log n )
错误源 2:f A ≢ f I f_A \not\equiv f_I f A ≡ f I Z p \mathbb{Z}_p Z p f A ( r ) ≡ f I ( r ) ( m o d p ) f_A(r) \equiv f_I(r) \pmod{p} f A ( r ) ≡ f I ( r ) ( mod p )
此时 g ( x ) = f A ( x ) − f I ( x ) g(x) = f_A(x) - f_I(x) g ( x ) = f A ( x ) − f I ( x ) Z p \mathbb{Z}_p Z p n n n r ∈ Z p r \in \mathbb{Z}_p r ∈ Z p g ( r ) ≡ 0 ( m o d p ) g(r) \equiv 0 \pmod{p} g ( r ) ≡ 0 ( mod p ) n / p n/p n / p
Lipton 算法与参数选择
Lipton 算法 (Lipton's Algorithm)的具体参数如下:
随机选取素数 p p p ( n log n ) 2 2 ⩽ p ⩽ ( n log n ) 2 \dfrac{(n\log n)^2}{2} \le p \le (n\log n)^2 2 ( n log n ) 2 ⩽ p ⩽ ( n log n ) 2
随机选取 r ∈ Z p r \in \mathbb{Z}_p r ∈ Z p
过程:
计算 FING ( A ) = ∏ i = 1 n ( r − a i ) m o d p \text{FING}(A) = \prod_{i=1}^{n} (r - a_i) \bmod p FING ( A ) = ∏ i = 1 n ( r − a i ) mod p
计算 FING ( I ) = ∏ i = 1 n ( r − i ) m o d p \text{FING}(I) = \prod_{i=1}^{n} (r - i) \bmod p FING ( I ) = ∏ i = 1 n ( r − i ) mod p
检查 FING ( A ) = FING ( I ) \text{FING}(A) = \text{FING}(I) FING ( A ) = FING ( I )
参数范围的选取
选取素数范围为 [ L , U ] [L, U] [ L , U ] L = ( n log n ) 2 / 2 , U = ( n log n ) 2 L = (n\log n)^2/2,\, U = (n\log n)^2 L = ( n log n ) 2 /2 , U = ( n log n ) 2 [ 1 , U ] [1, U] [ 1 , U ]
由素数定理,区间 [ L , U ] [L, U] [ L , U ]
π ( U ) − π ( L ) ≈ U ln U − L ln L ≈ L ln L = Θ ( ( n log n ) 2 log ( n log n ) ) = Θ ( n 2 ( log n ) 2 log n ) = Θ ( n 2 log n ) \pi(U) - \pi(L) \approx \frac{U}{\ln U} - \frac{L}{\ln L} \approx \frac{L}{\ln L} = \Theta\left(\frac{(n\log n)^2}{\log(n\log n)}\right) = \Theta\left(\frac{n^2 (\log n)^2}{\log n}\right) = \Theta(n^2 \log n)
π ( U ) − π ( L ) ≈ ln U U − ln L L ≈ ln L L = Θ ( log ( n log n ) ( n log n ) 2 ) = Θ ( log n n 2 ( log n ) 2 ) = Θ ( n 2 log n )
错误源 1 的概率 :对于某个非零系数 c k c_k c k O ( n log n ) O(n\log n) O ( n log n ) [ L , U ] [L, U] [ L , U ] Θ ( n 2 log n ) \Theta(n^2 \log n) Θ ( n 2 log n ) p p p c k c_k c k
Pr [ 错误源 1 ] ⩽ O ( n log n ) Θ ( n 2 log n ) = O ( 1 n ) \Pr[\text{错误源 1}] \le \frac{O(n \log n)}{\Theta(n^2 \log n)} = O\left(\frac{1}{n}\right)
Pr [ 错误源 1 ] ⩽ Θ ( n 2 log n ) O ( n log n ) = O ( n 1 )
错误源 2 的概率 :由 Schwartz-Zippel 引理,随机 r ∈ Z p r \in \mathbb{Z}_p r ∈ Z p g ( x ) m o d p g(x) \bmod p g ( x ) mod p n / p ⩽ n / L n/p \le n/L n / p ⩽ n / L
Pr [ 错误源 2 ] ⩽ n ( n log n ) 2 / 2 = 2 n ( log n ) 2 = O ( 1 n ) \Pr[\text{错误源 2}] \le \frac{n}{(n\log n)^2 / 2} = \frac{2}{n(\log n)^2} = O\left(\frac{1}{n}\right)
Pr [ 错误源 2 ] ⩽ ( n log n ) 2 /2 n = n ( log n ) 2 2 = O ( n 1 )
由联合界,总错误概率为 O ( 1 / n ) O(1/n) O ( 1/ n )
复杂度与数据流适用性
指标
复杂度
时间
O ( n ) O(n) O ( n ) ( r − a i ) m o d p (r - a_i) \bmod p ( r − a i ) mod p
空间
O ( log n ) O(\log n) O ( log n ) r r r p p p
错误
O ( 1 / n ) O(1/n) O ( 1/ n )
Lipton 算法的一个重要优势是天然适合数据流模型 (Data Stream Model):元素 a 1 , a 2 , … , a n a_1, a_2, \dots, a_n a 1 , a 2 , … , a n ∏ i = 1 k ( r − a i ) m o d p \prod_{i=1}^{k}(r - a_i) \bmod p ∏ i = 1 k ( r − a i ) mod p
推广:一般多重集相等性
Lipton 算法不局限于元素唯一性,可以推广到一般的多重集相等性检验:给定两个多重集 A = ( a 1 , … , a n ) A = (a_1, \dots, a_n) A = ( a 1 , … , a n ) B = ( b 1 , … , b n ) B = (b_1, \dots, b_n) B = ( b 1 , … , b n ) A = B A = B A = B FING ( A ) = ∏ ( r − a i ) m o d p \text{FING}(A) = \prod(r - a_i) \bmod p FING ( A ) = ∏ ( r − a i ) mod p FING ( B ) = ∏ ( r − b i ) m o d p \text{FING}(B) = \prod(r - b_i) \bmod p FING ( B ) = ∏ ( r − b i ) mod p
Fingerprinting 的统一视角
回顾本讲的所有算法,它们共享一个统一的范式:
问题
对象
指纹 FING \text{FING} FING
随机源
时间
PIT 多项式 Q Q Q
Q ( r 1 , … , r n ) Q(r_1, \dots, r_n) Q ( r 1 , … , r n ) 随机取值点
取决于电路
字符串相等(公共随机)
a ∈ { 0 , 1 } n a \in \{0,1\}^n a ∈ { 0 , 1 } n ∑ a i r i m o d p \sum a_i r^i \bmod p ∑ a i r i mod p 随机 r ∈ Z p r \in \mathbb{Z}_p r ∈ Z p
O ( n ) O(n) O ( n )
字符串相等(私有随机)
a ∈ { 0 , 1 } n a \in \{0,1\}^n a ∈ { 0 , 1 } n a m o d p a \bmod p a mod p 随机素数 p p p
O ( n ) O(n) O ( n )
二部图匹配
Edmonds 矩阵 M \bm{M} M
det ( M ) ∥ x i j = r i j \det(\bm{M})\big\|_{x_{ij}=r_{ij}} det ( M ) x ij = r ij 随机赋值
O ( n ω ) O(n^\omega) O ( n ω )
矩阵乘法验证
矩阵 D \bm{D} D
D r \bm{D}\bm{r} D r 随机向量 r \bm{r} r
O ( n 2 ) O(n^2) O ( n 2 )
字符串匹配
子串 T j T_j T j
T ˉ j m o d p \bar{T}_j \bmod p T ˉ j mod p 随机素数 p p p
O ( n ) O(n) O ( n )
多重集相等
多项式 f A f_A f A
f A ( r ) m o d p f_A(r) \bmod p f A ( r ) mod p 随机 r r r p p p
O ( n ) O(n) O ( n )
Fingerprinting 的本质是一种「降维」策略 :将高维或大规模的对象映射到低维空间中,利用随机性保证「保距性」——不同对象大概率映射为不同指纹。错误分析的核心工具是两个:
Schwartz-Zippel 引理 :非零多项式在随机点处为零的概率有上界素数定理 :控制随机素数整除特定整数的概率
这一思想不仅是随机算法的基石,也是后续课程中哈希技术、数据流算法、降维方法(如 Johnson-Lindenstrauss 引理)的核心起点。