从 Fingerprinting 到 Sketching
上一讲中,fingerprinting 通过将大对象映射为短小的「指纹」来高效判断相等性。本讲将这一思想推向更一般的场景:sketching (概要/草图技术)。
Sketching 的核心思想
Sketch 是数据的一种有损压缩表示,使用远小于原始数据的空间,同时支持对数据的近似查询。
在大数据场景下,数据往往以数据流 (Data Stream)的形式到达——元素 x 1 , x 2 , … , x n x_1, x_2, \dots, x_n x 1 , x 2 , … , x n Ω ( n ) \Omega(n) Ω ( n ) 亚线性 (sublinear)甚至 O ( log n ) O(\log n) O ( log n )
本讲将围绕多个经典问题展开:
近似计数 :用 O ( log log n ) O(\log\log n) O ( log log n ) n n n 计数不同元素 (F 0 F_0 F 0 频率估计与 heavy hitters :估计各元素出现的频率第二频率矩 (F 2 F_2 F 2 近似集合成员查询 :Bloom filter
贯穿始终的技术主线是:如何用有限的随机资源构造无偏估计器,并通过 mean trick 和 median trick 将精度与置信度系统化地提升到任意要求。
近似计数
问题:用极少比特计数
一个自然数 n n n ⌈ log 2 ( n + 1 ) ⌉ \lceil\log_2(n+1)\rceil ⌈ log 2 ( n + 1 )⌉ log n \log n log n 近似 记录 n n n
答案是肯定的:只需 O ( log log n ) O(\log\log n) O ( log log n )
Morris 算法
Morris 算法
维护一个计数器 X X X X = 0 X = 0 X = 0
更新 :每次事件到达时,以概率 2 − X 2^{-X} 2 − X X ← X + 1 X \leftarrow X + 1 X ← X + 1 查询 :返回估计值 n ^ = 2 X − 1 \hat{n} = 2^X - 1 n ^ = 2 X − 1
直觉上,X X X log 2 n \log_2 n log 2 n X X X 2 − X 2^{-X} 2 − X X X X X X X O ( log log n ) O(\log\log n) O ( log log n ) O ( log n ) O(\log n) O ( log n )
更精确地说:由 Markov 不等式(下面会给出期望计算),Pr [ n ^ ⩾ 10 n ] ⩽ 1 / 10 \Pr[\hat{n} \ge 10n] \le 1/10 Pr [ n ^ ⩾ 10 n ] ⩽ 1/10 ⩾ 9 / 10 \ge 9/10 ⩾ 9/10 n ^ = 2 X − 1 ⩽ 10 n \hat{n} = 2^X - 1 \le 10n n ^ = 2 X − 1 ⩽ 10 n X ⩽ log 2 ( 10 n + 1 ) X \le \log_2(10n + 1) X ⩽ log 2 ( 10 n + 1 ) X X X log X ⩽ log log ( 10 n + 1 ) = log log n + O ( 1 ) \log X \le \log\log(10n + 1) = \log\log n + O(1) log X ⩽ log log ( 10 n + 1 ) = log log n + O ( 1 )
无偏性
令 X n X_n X n n n n
回顾:无偏估计器
一个随机变量 θ ^ \hat{\theta} θ ^ θ \theta θ 无偏估计器 (Unbiased Estimator),如果 E [ θ ^ ] = θ \mathbb{E}[\hat{\theta}] = \theta E [ θ ^ ] = θ 方差 Var ( θ ^ ) = E [ ( θ ^ − θ ) 2 ] \text{Var}(\hat{\theta}) = \mathbb{E}[(\hat{\theta} - \theta)^2] Var ( θ ^ ) = E [( θ ^ − θ ) 2 ]
定理:Morris 算法是无偏估计器
对所有 n ⩾ 0 n \ge 0 n ⩾ 0 E [ 2 X n ] = n + 1 \mathbb{E}[2^{X_n}] = n + 1 E [ 2 X n ] = n + 1 E [ n ^ ] = n \mathbb{E}[\hat{n}] = n E [ n ^ ] = n
证明(数学归纳法)
基础情形 :n = 0 n = 0 n = 0 X 0 = 0 , E [ 2 X 0 ] = 2 0 = 1 = 0 + 1 X_0 = 0,\, \mathbb{E}[2^{X_0}] = 2^0 = 1 = 0 + 1 X 0 = 0 , E [ 2 X 0 ] = 2 0 = 1 = 0 + 1
归纳步骤 :假设 E [ 2 X n ] = n + 1 \mathbb{E}[2^{X_n}] = n + 1 E [ 2 X n ] = n + 1 E [ 2 X n + 1 ] = n + 2 \mathbb{E}[2^{X_{n+1}}] = n + 2 E [ 2 X n + 1 ] = n + 2
处理第 n + 1 n+1 n + 1 2 − X n 2^{-X_n} 2 − X n X n X_n X n
E [ 2 X n + 1 ∣ X n ] = 2 − X n ⋅ 2 X n + 1 + ( 1 − 2 − X n ) ⋅ 2 X n = 2 + 2 X n − 1 = 2 X n + 1 \begin{aligned}
\mathbb{E}[2^{X_{n+1}} \mid X_n]
&= 2^{-X_n} \cdot 2^{X_n + 1} + (1 - 2^{-X_n}) \cdot 2^{X_n} \\
&= 2 + 2^{X_n} - 1 \\
&= 2^{X_n} + 1
\end{aligned}
E [ 2 X n + 1 ∣ X n ] = 2 − X n ⋅ 2 X n + 1 + ( 1 − 2 − X n ) ⋅ 2 X n = 2 + 2 X n − 1 = 2 X n + 1
两边取期望:E [ 2 X n + 1 ] = E [ 2 X n ] + 1 = ( n + 1 ) + 1 = n + 2 \mathbb{E}[2^{X_{n+1}}] = \mathbb{E}[2^{X_n}] + 1 = (n+1) + 1 = n + 2 E [ 2 X n + 1 ] = E [ 2 X n ] + 1 = ( n + 1 ) + 1 = n + 2
虽然估计器是无偏的,但单次运行的方差很大——Var ( n ^ ) ⩽ n 2 / 2 \text{Var}(\hat{n}) \le n^2/2 Var ( n ^ ) ⩽ n 2 /2
方差推导
类似地用归纳法证明 E [ 2 2 X n ] ⩽ 3 2 n ( n + 1 ) + 1 \mathbb{E}[2^{2X_n}] \le \dfrac{3}{2}n(n+1) + 1 E [ 2 2 X n ] ⩽ 2 3 n ( n + 1 ) + 1
归纳步骤 :
E [ 2 2 X n + 1 ∣ X n ] = 2 − X n ⋅ 2 2 ( X n + 1 ) + ( 1 − 2 − X n ) ⋅ 2 2 X n = 2 X n + 2 + 2 2 X n − 2 X n = 2 2 X n + 3 ⋅ 2 X n \begin{aligned}
\mathbb{E}[2^{2X_{n+1}} \mid X_n]
&= 2^{-X_n} \cdot 2^{2(X_n+1)} + (1 - 2^{-X_n}) \cdot 2^{2X_n} \\
&= 2^{X_n+2} + 2^{2X_n} - 2^{X_n} \\
&= 2^{2X_n} + 3 \cdot 2^{X_n}
\end{aligned}
E [ 2 2 X n + 1 ∣ X n ] = 2 − X n ⋅ 2 2 ( X n + 1 ) + ( 1 − 2 − X n ) ⋅ 2 2 X n = 2 X n + 2 + 2 2 X n − 2 X n = 2 2 X n + 3 ⋅ 2 X n
取期望:E [ 2 2 X n + 1 ] = E [ 2 2 X n ] + 3 E [ 2 X n ] = E [ 2 2 X n ] + 3 ( n + 1 ) \mathbb{E}[2^{2X_{n+1}}] = \mathbb{E}[2^{2X_n}] + 3\mathbb{E}[2^{X_n}] = \mathbb{E}[2^{2X_n}] + 3(n+1) E [ 2 2 X n + 1 ] = E [ 2 2 X n ] + 3 E [ 2 X n ] = E [ 2 2 X n ] + 3 ( n + 1 )
由归纳假设:E [ 2 2 X n + 1 ] ⩽ 3 2 n ( n + 1 ) + 1 + 3 ( n + 1 ) = 3 2 ( n + 1 ) ( n + 2 ) + 1 \mathbb{E}[2^{2X_{n+1}}] \le \frac{3}{2}n(n+1) + 1 + 3(n+1) = \frac{3}{2}(n+1)(n+2) + 1 E [ 2 2 X n + 1 ] ⩽ 2 3 n ( n + 1 ) + 1 + 3 ( n + 1 ) = 2 3 ( n + 1 ) ( n + 2 ) + 1
因此:
Var ( n ^ ) = E [ n ^ 2 ] − n 2 = E [ ( 2 X − 1 ) 2 ] − n 2 = E [ 2 2 X ] − 2 E [ 2 X ] + 1 − n 2 ⩽ 3 2 n ( n + 1 ) + 1 − 2 ( n + 1 ) + 1 − n 2 = n 2 2 − n 2 ⩽ n 2 2 \begin{aligned}
\text{Var}(\hat{n}) &= \mathbb{E}[\hat{n}^2] - n^2 = \mathbb{E}[(2^X - 1)^2] - n^2 = \mathbb{E}[2^{2X}] - 2\mathbb{E}[2^X] + 1 - n^2 \\
&\le \frac{3}{2}n(n+1) + 1 - 2(n+1) + 1 - n^2 = \frac{n^2}{2} - \frac{n}{2} \le \frac{n^2}{2}
\end{aligned}
Var ( n ^ ) = E [ n ^ 2 ] − n 2 = E [( 2 X − 1 ) 2 ] − n 2 = E [ 2 2 X ] − 2 E [ 2 X ] + 1 − n 2 ⩽ 2 3 n ( n + 1 ) + 1 − 2 ( n + 1 ) + 1 − n 2 = 2 n 2 − 2 n ⩽ 2 n 2
概率工具箱
在分析 sketch 的精度之前,我们需要几个基本的概率不等式。这些工具将在本讲中反复使用。
Jensen 不等式
若 φ \varphi φ φ ( E [ X ] ) ⩽ E [ φ ( X ) ] \varphi(\mathbb{E}[X]) \le \mathbb{E}[\varphi(X)] φ ( E [ X ]) ⩽ E [ φ ( X )] φ \varphi φ
Jensen 不等式在本讲中的典型应用:log \log log E [ log X ] ⩽ log E [ X ] \mathbb{E}[\log X] \le \log \mathbb{E}[X] E [ log X ] ⩽ log E [ X ]
Markov 不等式
对非负随机变量 X X X t > 0 t > 0 t > 0
Pr [ X ⩾ t ] ⩽ E [ X ] t \Pr[X \ge t] \le \frac{\mathbb{E}[X]}{t}
Pr [ X ⩾ t ] ⩽ t E [ X ]
Markov 不等式只需要一阶矩信息,因此适用范围广但界很松。直觉上,它说的是「如果一个非负量的平均值很小,那么它取很大值的概率不会太高」——例如,平均收入 1 万元的群体中,收入超过 100 万的人至多占 1 % 1\% 1%
Chebyshev 不等式
对随机变量 X X X t > 0 t > 0 t > 0
Pr [ ∣ X − E [ X ] ∣ ⩾ t ] ⩽ Var [ X ] t 2 \Pr\big[|X - \mathbb{E}[X]| \ge t\big] \le \frac{\text{Var}[X]}{t^2}
Pr [ ∣ X − E [ X ] ∣ ⩾ t ] ⩽ t 2 Var [ X ]
Chebyshev 利用了二阶矩(方差)信息,给出更紧的界。直觉:方差越小,随机变量越「集中」在期望附近。它本质上是对 ( X − E [ X ] ) 2 (X - \mathbb{E}[X])^2 ( X − E [ X ] ) 2
Chernoff-Hoeffding 界
设 X 1 , … , X n X_1, \dots, X_n X 1 , … , X n X i ∈ [ a i , b i ] , X = ∑ X i X_i \in [a_i, b_i],\, X = \sum X_i X i ∈ [ a i , b i ] , X = ∑ X i t > 0 t > 0 t > 0
Pr [ X ⩾ E [ X ] + t ] ⩽ exp ( − 2 t 2 ∑ i = 1 n ( b i − a i ) 2 ) Pr [ X ⩽ E [ X ] − t ] ⩽ exp ( − 2 t 2 ∑ i = 1 n ( b i − a i ) 2 ) \begin{aligned}
\Pr\big[X \ge \mathbb{E}[X] + t\big] &\le \exp\left(-\frac{2t^2}{\sum_{i=1}^{n}(b_i - a_i)^2}\right)\\
\Pr\big[X \le \mathbb{E}[X] - t\big] &\le \exp\left(-\frac{2t^2}{\sum_{i=1}^{n}(b_i - a_i)^2}\right)
\end{aligned}
Pr [ X ⩾ E [ X ] + t ] Pr [ X ⩽ E [ X ] − t ] ⩽ exp ( − ∑ i = 1 n ( b i − a i ) 2 2 t 2 ) ⩽ exp ( − ∑ i = 1 n ( b i − a i ) 2 2 t 2 )
Chernoff-Hoeffding 利用了独立性 ,给出指数衰减 的尾概率——这是与 Chebyshev 的多项式衰减的本质区别。代价是需要更强的假设(独立、有界)。直觉:独立随机变量之和的波动远小于最坏情况——大量独立的随机噪声会相互抵消。
三个不等式的关系是:
不等式
所需信息
尾概率衰减
Markov
期望
O ( 1 / t ) O(1/t) O ( 1/ t )
Chebyshev
期望 + 方差
O ( 1 / t 2 ) O(1/t^2) O ( 1/ t 2 )
Chernoff-Hoeffding
独立 + 有界
exp ( − Ω ( t 2 ) ) \exp(-\Omega(t^2)) exp ( − Ω ( t 2 ))
( ε , δ ) (\varepsilon, \delta) ( ε , δ ) 在分析 sketch 算法时,我们关心两个参数:
精度 ε \varepsilon ε ε \varepsilon ε 置信度 1 − δ 1 - \delta 1 − δ 1 − δ 1 - \delta 1 − δ
( ε , δ ) (\varepsilon, \delta) ( ε , δ )
称 n ^ \hat{n} n ^ n n n ( ε , δ ) (\varepsilon, \delta) ( ε , δ )
Pr [ ∣ n ^ − n ∣ ⩽ ε n ] ⩾ 1 − δ \Pr\big[|\hat{n} - n| \le \varepsilon n\big] \ge 1 - \delta
Pr [ ∣ n ^ − n ∣ ⩽ ε n ] ⩾ 1 − δ
如何系统化地构造 ( ε , δ ) (\varepsilon, \delta) ( ε , δ )
Mean Trick:Morris+ 算法
Mean trick 的思想很简单:独立运行 k k k
Morris+ 算法(Mean Trick)
独立运行 k k k n ^ 1 , … , n ^ k \hat{n}_1, \dots, \hat{n}_k n ^ 1 , … , n ^ k
n ^ = 1 k ∑ i = 1 k n ^ i \hat{n} = \frac{1}{k}\sum_{i=1}^{k}\hat{n}_i
n ^ = k 1 i = 1 ∑ k n ^ i
取平均保持无偏性,同时方差缩小为原来的 1 / k 1/k 1/ k
E [ n ^ ] = n , Var ( n ^ ) = Var ( n ^ 1 ) k ≈ n 2 2 k \mathbb{E}[\hat{n}] = n, \qquad \text{Var}(\hat{n}) = \frac{\text{Var}(\hat{n}_1)}{k} \approx \frac{n^2}{2k}
E [ n ^ ] = n , Var ( n ^ ) = k Var ( n ^ 1 ) ≈ 2 k n 2
由 Chebyshev 不等式:
Pr [ ∣ n ^ − n ∣ ⩾ ε n ] ⩽ Var ( n ^ ) ε 2 n 2 ⩽ 1 2 k ε 2 \Pr\big[|\hat{n} - n| \ge \varepsilon n\big] \le \frac{\text{Var}(\hat{n})}{\varepsilon^2 n^2} \le \frac{1}{2k\varepsilon^2}
Pr [ ∣ n ^ − n ∣ ⩾ ε n ] ⩽ ε 2 n 2 Var ( n ^ ) ⩽ 2 k ε 2 1
取 k = ⌈ 1 / ( 2 ε 2 δ ) ⌉ k = \lceil 1/(2\varepsilon^2 \delta) \rceil k = ⌈ 1/ ( 2 ε 2 δ )⌉ δ \delta δ k k k δ \delta δ O ( 1 / δ ) O(1/\delta) O ( 1/ δ ) δ = 10 − 6 \delta = 10^{-6} δ = 1 0 − 6
Median trick 解决了 mean trick 在 δ \delta δ
Morris++ 算法(Median Trick)
独立运行 ℓ \ell ℓ k = O ( 1 / ε 2 ) k = O(1/\varepsilon^2) k = O ( 1/ ε 2 ) ⩾ 9 / 10 \ge 9/10 ⩾ 9/10 中位数 。
关键观察:如果每个 Morris+ 实例以概率 ⩾ 2 / 3 \ge 2/3 ⩾ 2/3 ℓ \ell ℓ
设 Y i = I [ 第 i 个实例给出坏估计 ] Y_i = \mathbb{I}[\text{第 } i \text{ 个实例给出坏估计}] Y i = I [ 第 i 个实例给出坏估计 ] E [ Y i ] ⩽ 1 / 3 \mathbb{E}[Y_i] \le 1/3 E [ Y i ] ⩽ 1/3 ∑ Y i > ℓ / 2 \sum Y_i > \ell/2 ∑ Y i > ℓ /2
Pr [ ∑ Y i ⩾ ℓ / 2 ] ⩽ Pr [ ∑ Y i ⩾ μ + ℓ / 6 ] ⩽ exp ( − 2 ( ℓ / 6 ) 2 ℓ ) = exp ( − ℓ 18 ) ⩽ δ \Pr\left[\sum Y_i \ge \ell/2\right] \le \Pr\left[\sum Y_i \ge \mu + \ell/6\right] \le \exp\left(-\frac{2(\ell/6)^2}{\ell}\right) = \exp\left(-\frac{\ell}{18}\right) \le \delta
Pr [ ∑ Y i ⩾ ℓ /2 ] ⩽ Pr [ ∑ Y i ⩾ μ + ℓ /6 ] ⩽ exp ( − ℓ 2 ( ℓ /6 ) 2 ) = exp ( − 18 ℓ ) ⩽ δ
其中 μ = E [ ∑ Y i ] ⩽ ℓ / 3 \mu = \mathbb{E}[\sum Y_i] \le \ell/3 μ = E [ ∑ Y i ] ⩽ ℓ /3 ℓ = ⌈ 18 ln ( 1 / δ ) ⌉ \ell = \lceil 18\ln(1/\delta) \rceil ℓ = ⌈ 18 ln ( 1/ δ )⌉
总空间 :k ℓ = O ( ε − 2 log ( 1 / δ ) ) k\ell = O(\varepsilon^{-2} \log(1/\delta)) k ℓ = O ( ε − 2 log ( 1/ δ )) O ( log log n ) O(\log\log n) O ( log log n )
总空间 = O ( 1 ε 2 log 1 δ ⋅ log log n ) 比特 \text{总空间} = O\left(\frac{1}{\varepsilon^2} \log\frac{1}{\delta} \cdot \log\log n\right) \text{ 比特}
总空间 = O ( ε 2 1 log δ 1 ⋅ log log n ) 比特
Mean Trick 与 Median Trick 的配合
这两个技巧构成了一个通用的「精度-置信度提升管线」,在本讲的几乎所有算法中都会用到:
Mean trick :取 O ( 1 / ε 2 ) O(1/\varepsilon^2) O ( 1/ ε 2 ) ⩾ 2 / 3 \ge 2/3 ⩾ 2/3 Median trick :取 O ( log ( 1 / δ ) ) O(\log(1/\delta)) O ( log ( 1/ δ )) 1 − δ 1 - \delta 1 − δ
关于 δ \delta δ O ( 1 / δ ) O(1/\delta) O ( 1/ δ ) O ( log ( 1 / δ ) ) O(\log(1/\delta)) O ( log ( 1/ δ ))
Median trick 看起来有点像集成学习中的投票机制:多个弱学习器(每个以常数概率正确)通过投票(取中位数)形成一个强学习器(以任意高的概率正确)。这里的「弱学习器」就是单个 Morris+ 实例。
用的是中位数因为连续情形的「正确」往往是一个区间,中位数的性质——若超过一半数据都落在某个区间(正确区间)内,那中位数也一定在这个区间——可以被利用借助这样的「投票」机制来提升置信度。
而离散情形下「正确」是一个点(如分类问题),因此用众数 更合适,也是集成学习中常见的多数投票机制。
推广:一般化 Morris 计数器
Morris 算法可以推广到以任意底数 ( 1 + α ) (1+\alpha) ( 1 + α )
一般化 Morris 计数器
参数 α > 0 \alpha > 0 α > 0 X = 0 X = 0 X = 0
更新 :以概率 1 / ( 1 + α ) X 1/(1+\alpha)^X 1/ ( 1 + α ) X X ← X + 1 X \leftarrow X + 1 X ← X + 1 查询 :返回 n ^ = ( ( 1 + α ) X − 1 ) / α \hat{n} = ((1+\alpha)^X - 1)/\alpha n ^ = (( 1 + α ) X − 1 ) / α
参数 α \alpha α α \alpha α X X X
通过精细分析(Flajolet, 1985),取 α = Θ ( ε 2 δ ) \alpha = \Theta(\varepsilon^2\delta) α = Θ ( ε 2 δ ) ( ε , δ ) (\varepsilon, \delta) ( ε , δ ) O ( log log n + log ( 1 / ε ) + log ( 1 / δ ) ) O(\log\log n + \log(1/\varepsilon) + \log(1/\delta)) O ( log log n + log ( 1/ ε ) + log ( 1/ δ )) δ \delta δ O ( log log ( 1 / δ ) ) O(\log\log(1/\delta)) O ( log log ( 1/ δ ))
计数不同元素
问题定义
数据 :一个流 x 1 , x 2 , … , x n ∈ U = [ N ] x_1, x_2, \dots, x_n \in U = [N] x 1 , x 2 , … , x n ∈ U = [ N ] 查询 :估计流中不同元素的个数 F 0 = ∣ S ∣ = ∣ { x 1 , x 2 , … , x n } ∣ F_0 = |S| = |\{x_1, x_2, \dots, x_n\}| F 0 = ∣ S ∣ = ∣ { x 1 , x 2 , … , x n } ∣
精确计算 F 0 F_0 F 0 Ω ( N ) \Omega(N) Ω ( N ) Ω ( N ) \Omega(N) Ω ( N )
Min Sketch
最简单的思路:用理想均匀哈希函数把元素映射到 [ 0 , 1 ] [0,1] [ 0 , 1 ]
Min Sketch
选取理想均匀哈希函数 h : U → [ 0 , 1 ] h\colon U \to [0,1] h : U → [ 0 , 1 ] Y = min i h ( x i ) Y = \min\limits_{i} h(x_i) Y = i min h ( x i )
返回估计值 F ^ 0 = 1 / Y − 1 \hat{F}_0 = 1 / Y - 1 F ^ 0 = 1/ Y − 1
直觉:如果有 z = F 0 z = F_0 z = F 0 [ 0 , 1 ] [0,1] [ 0 , 1 ] z + 1 z+1 z + 1 1 / ( z + 1 ) 1/(z+1) 1/ ( z + 1 ) 1 / Y 1/Y 1/ Y z + 1 z+1 z + 1
方差分析 (假设 SUHA ):设 z = F 0 z = F_0 z = F 0 z z z [ 0 , 1 ] [0,1] [ 0 , 1 ] Y Y Y 0 ⩽ t ⩽ 1 0 \le t \le 1 0 ⩽ t ⩽ 1
Pr [ Y > t ] = ( 1 − t ) z \Pr[Y > t] = (1-t)^z
Pr [ Y > t ] = ( 1 − t ) z
从而密度为
f Y ( t ) = z ( 1 − t ) z − 1 f_Y(t) = z(1-t)^{z-1}
f Y ( t ) = z ( 1 − t ) z − 1
于是
E [ Y ] = ∫ 0 1 t ⋅ z ( 1 − t ) z − 1 d t = 1 z + 1 E [ Y 2 ] = ∫ 0 1 t 2 ⋅ z ( 1 − t ) z − 1 d t = 2 ( z + 1 ) ( z + 2 ) \mathbb{E}[Y] = \int_0^1 t \cdot z(1-t)^{z-1}\d t = \frac{1}{z+1}\\
\mathbb{E}[Y^2] = \int_0^1 t^2 \cdot z(1-t)^{z-1}\d t = \frac{2}{(z+1)(z+2)}
E [ Y ] = ∫ 0 1 t ⋅ z ( 1 − t ) z − 1 d t = z + 1 1 E [ Y 2 ] = ∫ 0 1 t 2 ⋅ z ( 1 − t ) z − 1 d t = ( z + 1 ) ( z + 2 ) 2
因此
Var ( Y ) = E [ Y 2 ] − E [ Y ] 2 = z ( z + 1 ) 2 ( z + 2 ) ⩽ 1 ( z + 1 ) 2 \text{Var}(Y) = \mathbb{E}[Y^2] - \mathbb{E}[Y]^2 = \frac{z}{(z+1)^2(z+2)} \le \frac{1}{(z+1)^2}
Var ( Y ) = E [ Y 2 ] − E [ Y ] 2 = ( z + 1 ) 2 ( z + 2 ) z ⩽ ( z + 1 ) 2 1
所以最小哈希值的量级稳定在 1 / z 1/z 1/ z 1 / Y 1/Y 1/ Y F 0 F_0 F 0
Min Sketch+:Mean Trick 改进
对 Min Sketch 应用 mean trick:使用 k k k h 1 , … , h k : U → [ 0 , 1 ] h_1, \dots, h_k\colon U \to [0,1] h 1 , … , h k : U → [ 0 , 1 ] Y j = min i h j ( x i ) Y_j = \min\limits_i h_j(x_i) Y j = i min h j ( x i )
Min Sketch+
返回估计值
F ^ 0 = 1 Y ˉ − 1 , Y ˉ = 1 k ∑ j = 1 k Y j \hat{F}_0 = \frac{1}{\bar{Y}} - 1, \qquad \bar{Y} = \frac{1}{k}\sum_{j=1}^{k} Y_j
F ^ 0 = Y ˉ 1 − 1 , Y ˉ = k 1 j = 1 ∑ k Y j
由于 k k k Y j Y_j Y j E [ Y ˉ ] = 1 / ( z + 1 ) \mathbb{E}[\bar{Y}] = 1/(z+1) E [ Y ˉ ] = 1/ ( z + 1 ) Var ( Y ˉ ) ⩽ 1 / ( k ( z + 1 ) 2 ) \text{Var}(\bar{Y}) \le 1/(k(z+1)^2) Var ( Y ˉ ) ⩽ 1/ ( k ( z + 1 ) 2 ) ε ⩽ 1 / 2 \varepsilon \le 1/2 ε ⩽ 1/2
Pr [ ∣ Y ˉ − 1 z + 1 ∣ > ε / 2 z + 1 ] ⩽ Var ( Y ˉ ) ( ε / ( 2 ( z + 1 ) ) ) 2 ⩽ 4 k ε 2 ⩽ δ \Pr\left[\left|\bar{Y} - \frac{1}{z+1}\right| > \frac{\varepsilon/2}{z+1}\right] \le \frac{\text{Var}(\bar{Y})}{(\varepsilon/(2(z+1)))^2} \le \frac{4}{k\varepsilon^2} \le \delta
Pr [ Y ˉ − z + 1 1 > z + 1 ε /2 ] ⩽ ( ε / ( 2 ( z + 1 )) ) 2 Var ( Y ˉ ) ⩽ k ε 2 4 ⩽ δ
取 k = ⌈ 4 / ( ε 2 δ ) ⌉ k = \lceil 4/(\varepsilon^2\delta) \rceil k = ⌈ 4/ ( ε 2 δ )⌉ O ( k ) O(k) O ( k ) [ 0 , 1 ] [0,1] [ 0 , 1 ]
SUHA 与现实
上述分析假设 h h h SUHA ),即 h h h U → [ 0 , 1 ] U \to [0,1] U → [ 0 , 1 ]
但存储一个完全均匀的哈希函数本身就需要 Ω ( N log N ) \Omega(N \log N) Ω ( N log N )
2-Universal 哈希
回顾:哈希函数的作用
哈希函数 h : U → [ m ] h\colon U \to [m] h : U → [ m ] U U U [ m ] [m] [ m ] m m m h ( x ) h(x) h ( x ) x x x O ( 1 ) O(1) O ( 1 )
碰撞(h ( x ) = h ( y ) , x ≠ y h(x) = h(y),\, x \ne y h ( x ) = h ( y ) , x = y Ω ( ∣ U ∣ log m ) \Omega(|U| \log m) Ω ( ∣ U ∣ log m )
2-universal 哈希 (也称成对独立哈希 )正是为此设计的。它只保证任意两个 不同元素的哈希值表现得像独立均匀随机——这对 sketch 中基于 Chebyshev 不等式的分析已经足够。
2-Universal 哈希函数族
一个哈希函数族 H = { h : U → [ m ] } \mathcal{H} = \{h\colon U \to [m]\} H = { h : U → [ m ]} 2-universal 的,如果对所有 x ≠ y ∈ U x \ne y \in U x = y ∈ U
Pr h ∼ H [ h ( x ) = h ( y ) ] ⩽ 1 m \Pr_{h \sim \mathcal{H}}[h(x) = h(y)] \le \frac{1}{m}
h ∼ H Pr [ h ( x ) = h ( y )] ⩽ m 1
等价条件:对任意不同的 x , y x, y x , y h ( x ) h(x) h ( x ) h ( y ) h(y) h ( y )
完全成对独立且均匀(strongly 2-universal/pairwise independent)的哈希函数族满足 Pr [ h ( x ) = a , h ( y ) = b ] = 1 / m 2 \Pr[h(x) = a, h(y) = b] = 1/m^2 Pr [ h ( x ) = a , h ( y ) = b ] = 1/ m 2 a , b ∈ [ m ] a, b \in [m] a , b ∈ [ m ]
一个经典的 2-universal 哈希族是线性同余族:
H = { h a , b ( x ) = ( ( a x + b ) m o d p ) m o d m ∣ a , b ∈ Z p } \mathcal{H} = \{h_{a,b}(x) = ((ax + b) \bmod p) \bmod m \mid a, b \in \mathbb{Z}_p\}
H = { h a , b ( x ) = (( a x + b ) mod p ) mod m ∣ a , b ∈ Z p }
其中 p p p N N N h a , b h_{a,b} h a , b a , b a, b a , b O ( log N ) O(\log N) O ( log N )
Flajolet-Martin 算法
Flajolet 和 Martin(1984)提出了一个优雅的算法:用哈希值的末尾零 (trailing zeros)个数来估计 F 0 F_0 F 0
定义 ρ ( y ) \rho(y) ρ ( y ) y y y ρ ( y ) = max { i : 2 i ∣ y } \rho(y) = \max\{i : 2^i \mid y\} ρ ( y ) = max { i : 2 i ∣ y } ρ ( 12 ) = ρ ( 1100 2 ) = 2 \rho(12) = \rho(1100_2) = 2 ρ ( 12 ) = ρ ( 110 0 2 ) = 2
Flajolet-Martin 算法
设元素 x 1 , … , x n ∈ [ N ] ⊆ [ 2 w ] x_1,\dots,x_n \in [N] \subseteq [2^w] x 1 , … , x n ∈ [ N ] ⊆ [ 2 w ] h : [ 2 w ] → [ 2 w ] h\colon [2^w] \to [2^w] h : [ 2 w ] → [ 2 w ]
R = max i ρ ( h ( x i ) ) R = \max_{i} \rho(h(x_i))
R = i max ρ ( h ( x i ))
返回估计值 F ^ 0 = 2 R \hat{F}_0 = 2^R F ^ 0 = 2 R
为什么用 [ 2 w ] → [ 2 w ] [2^w] \to [2^w] [ 2 w ] → [ 2 w ]
课件中哈希函数的域和值域都取 [ 2 w ] = { 0 , 1 , … , 2 w − 1 } [2^w] = \{0, 1, \dots, 2^w - 1\} [ 2 w ] = { 0 , 1 , … , 2 w − 1 } [ 2 w ] [2^w] [ 2 w ] 2 w − r 2^{w-r} 2 w − r 2 r 2^r 2 r Pr [ ρ ( h ( x ) ) ⩾ r ] = 2 w − r / 2 w = 2 − r \Pr[\rho(h(x)) \ge r] = 2^{w-r}/2^w = 2^{-r} Pr [ ρ ( h ( x )) ⩾ r ] = 2 w − r / 2 w = 2 − r [ N ] [N] [ N ] 2 − r 2^{-r} 2 − r G F ( 2 w ) \mathrm{GF}(2^w) GF ( 2 w ) f ( x ) = a ⋅ x + b f(x) = a \cdot x + b f ( x ) = a ⋅ x + b a , b ∈ G F ( 2 w ) a, b \in \mathrm{GF}(2^w) a , b ∈ GF ( 2 w ) O ( w ) O(w) O ( w )
直觉:ρ ( h ( x ) ) ⩾ r \rho(h(x)) \ge r ρ ( h ( x )) ⩾ r 2 − r 2^{-r} 2 − r r r r z = F 0 z = F_0 z = F 0 z ≈ 2 r z \approx 2^r z ≈ 2 r r r r 2 R 2^R 2 R F 0 F_0 F 0
令 S S S z = ∣ S ∣ = F 0 z = |S| = F_0 z = ∣ S ∣ = F 0
Y r = ∑ distinct x ∈ S I [ ρ ( h ( x ) ) ⩾ r ] Y_r = \sum_{\text{distinct } x \in S} \mathbb{I}[\rho(h(x)) \ge r]
Y r = distinct x ∈ S ∑ I [ ρ ( h ( x )) ⩾ r ]
由线性期望和成对独立性:
E [ Y r ] = z ⋅ 2 − r , Var ( Y r ) ⩽ z ⋅ 2 − r \mathbb{E}[Y_r] = z \cdot 2^{-r}, \qquad \text{Var}(Y_r) \le z \cdot 2^{-r}
E [ Y r ] = z ⋅ 2 − r , Var ( Y r ) ⩽ z ⋅ 2 − r
注意 R = max { r : Y r > 0 } R = \max\{r : Y_r > 0\} R = max { r : Y r > 0 } F ^ 0 = 2 R > C z \hat{F}_0 = 2^R > Cz F ^ 0 = 2 R > C z R ⩾ r ∗ R \ge r^* R ⩾ r ∗ Y r ∗ > 0 Y_{r^*} > 0 Y r ∗ > 0 F ^ 0 = 2 R < z / C \hat{F}_0 = 2^R < z/C F ^ 0 = 2 R < z / C R < r ∗ ∗ R < r^{**} R < r ∗∗ Y r ∗ ∗ = 0 Y_{r^{**}} = 0 Y r ∗∗ = 0
上界分析 (不会严重高估):取 r ∗ = ⌈ log 2 ( C z ) ⌉ r^* = \lceil\log_2(Cz)\rceil r ∗ = ⌈ log 2 ( C z )⌉
Pr [ F ^ 0 > C z ] ⩽ Pr [ Y r ∗ ⩾ 1 ] ⩽ E [ Y r ∗ ] = z / 2 r ∗ ⩽ 1 / C \Pr[\hat{F}_0 > Cz] \le \Pr[Y_{r^*} \ge 1] \le \mathbb{E}[Y_{r^*}] = z/2^{r^*} \le 1/C
Pr [ F ^ 0 > C z ] ⩽ Pr [ Y r ∗ ⩾ 1 ] ⩽ E [ Y r ∗ ] = z / 2 r ∗ ⩽ 1/ C
最后一步用了 Markov 不等式。
下界分析 (不会严重低估):取 r ∗ ∗ = ⌈ log 2 ( z / C ) ⌉ r^{**} = \lceil\log_2(z/C)\rceil r ∗∗ = ⌈ log 2 ( z / C )⌉
Pr [ F ^ 0 < z / C ] ⩽ Pr [ Y r ∗ ∗ = 0 ] ⩽ Var ( Y r ∗ ∗ ) E [ Y r ∗ ∗ ] 2 ⩽ 2 r ∗ ∗ z ⩽ 2 C \Pr[\hat{F}_0 < z/C] \le \Pr[Y_{r^{**}} = 0] \le \frac{\text{Var}(Y_{r^{**}})}{\mathbb{E}[Y_{r^{**}}]^2} \le \frac{2^{r^{**}}}{z} \le \frac{2}{C}
Pr [ F ^ 0 < z / C ] ⩽ Pr [ Y r ∗∗ = 0 ] ⩽ E [ Y r ∗∗ ] 2 Var ( Y r ∗∗ ) ⩽ z 2 r ∗∗ ⩽ C 2
最后一步用了 Chebyshev 不等式(Pr [ Y = 0 ] ⩽ Pr [ ∣ Y − μ ∣ ⩾ μ ] ⩽ Var / μ 2 \Pr[Y = 0] \le \Pr[|Y - \mu| \ge \mu] \le \text{Var}/\mu^2 Pr [ Y = 0 ] ⩽ Pr [ ∣ Y − μ ∣ ⩾ μ ] ⩽ Var / μ 2 Var / E 2 = z ⋅ 2 − r / ( z ⋅ 2 − r ) 2 = 2 r / z \text{Var}/\mathbb{E}^2 = z \cdot 2^{-r}/(z \cdot 2^{-r})^2 = 2^r/z Var / E 2 = z ⋅ 2 − r / ( z ⋅ 2 − r ) 2 = 2 r / z
合并两界 :
Pr [ F ^ 0 < z C 或 F ^ 0 > C z ] ⩽ 1 C + 2 C = 3 C \Pr\left[\hat{F}_0 < \frac{z}{C} \text{ 或 } \hat{F}_0 > Cz\right] \le \frac{1}{C} + \frac{2}{C} = \frac{3}{C}
Pr [ F ^ 0 < C z 或 F ^ 0 > C z ] ⩽ C 1 + C 2 = C 3
因此 2 R 2^R 2 R ⩾ 1 − 3 / C \ge 1 - 3/C ⩾ 1 − 3/ C [ z / C , C z ] [z/C,\, Cz] [ z / C , C z ] 2 2 2 ( ε , δ ) (\varepsilon, \delta) ( ε , δ )
空间上,维护 R R R O ( log log N ) O(\log\log N) O ( log log N ) R ⩽ w R \le w R ⩽ w O ( log N ) O(\log N) O ( log N )
Bottom-k k k
Flajolet-Martin 的问题在于估计值过于粗糙,只能落在 2 2 2 k k k
Bottom-k k k
设 z = F 0 = ∣ { x 1 , … , x n } ∣ z = F_0 = |\{x_1,\dots,x_n\}| z = F 0 = ∣ { x 1 , … , x n } ∣ h : [ N ] → [ M ] h\colon [N] \to [M] h : [ N ] → [ M ]
将这些哈希值从小到大排序为
Y 1 ⩽ Y 2 ⩽ ⋯ ⩽ Y z Y_1 \le Y_2 \le \dots \le Y_z
Y 1 ⩽ Y 2 ⩽ ⋯ ⩽ Y z
记 Y k Y_k Y k k k k
z ^ = k M Y k \hat{z} = \frac{kM}{Y_k}
z ^ = Y k k M
如果 z z z [ M ] [M] [ M ] k k k k / z k/z k / z
Y k ≈ k M z Y_k \approx \frac{kM}{z}
Y k ≈ z k M
因此 z ^ \hat{z} z ^ z z z
为了给出误差界,假设 ε ⩽ 1 \varepsilon \le 1 ε ⩽ 1
V = ∑ i = 1 z I [ h ( x i ) ⩽ ( 1 − ε 2 ) k M z ] , W = ∑ i = 1 z I [ h ( x i ) ⩽ ( 1 + ε 2 ) k M z ] V = \sum_{i=1}^{z} \mathbb{I}\left[h(x_i) \le \left(1-\frac{\varepsilon}{2}\right)\frac{kM}{z}\right], \qquad W = \sum_{i=1}^{z} \mathbb{I}\left[h(x_i) \le \left(1+\frac{\varepsilon}{2}\right)\frac{kM}{z}\right]
V = i = 1 ∑ z I [ h ( x i ) ⩽ ( 1 − 2 ε ) z k M ] , W = i = 1 ∑ z I [ h ( x i ) ⩽ ( 1 + 2 ε ) z k M ]
它们分别统计「落在偏小阈值以内」和「落在偏大阈值以内」的元素个数。由均匀性(每个 h ( x i ) h(x_i) h ( x i ) [ M ] [M] [ M ] M M M z z z
E [ V ] = ( 1 − ε 2 ) k , E [ W ] = ( 1 + ε 2 ) k \mathbb{E}[V] = \left(1-\frac{\varepsilon}{2}\right)k, \qquad \mathbb{E}[W] = \left(1+\frac{\varepsilon}{2}\right)k
E [ V ] = ( 1 − 2 ε ) k , E [ W ] = ( 1 + 2 ε ) k
又因为只需要成对独立,每个指示变量的方差 ⩽ \le ⩽
Var ( V ) ⩽ E [ V ] = ( 1 − ε 2 ) k ⩽ k , Var ( W ) ⩽ E [ W ] = ( 1 + ε 2 ) k ⩽ 2 k \operatorname{Var}(V) \le \mathbb{E}[V] = \left(1-\frac{\varepsilon}{2}\right)k \le k,\qquad \operatorname{Var}(W) \le \mathbb{E}[W] = \left(1+\frac{\varepsilon}{2}\right)k \le 2k
Var ( V ) ⩽ E [ V ] = ( 1 − 2 ε ) k ⩽ k , Var ( W ) ⩽ E [ W ] = ( 1 + 2 ε ) k ⩽ 2 k
V V V Y k < ( 1 − ε 2 ) k M z Y_k < \left(1-\dfrac{\varepsilon}{2}\right)\dfrac{kM}{z} Y k < ( 1 − 2 ε ) z k M k k k V ⩾ k V \ge k V ⩾ k V ⩾ k V \ge k V ⩾ k V − E [ V ] ⩾ k − ( 1 − ε / 2 ) k = ( ε / 2 ) k V - \mathbb{E}[V] \ge k - (1-\varepsilon/2)k = (\varepsilon/2)k V − E [ V ] ⩾ k − ( 1 − ε /2 ) k = ( ε /2 ) k
Pr [ V ⩾ k ] ⩽ Pr [ ∣ V − E [ V ] ∣ ⩾ ε k 2 ] ⩽ Var ( V ) ( ε k / 2 ) 2 ⩽ 4 k ε 2 k 2 = 4 ε 2 k \Pr[V \ge k] \le \Pr\left[\left|V-\mathbb{E}[V]\right| \ge \frac{\varepsilon k}{2}\right] \le \frac{\operatorname{Var}(V)}{(\varepsilon k/2)^2} \le \frac{4k}{\varepsilon^2 k^2} = \frac{4}{\varepsilon^2 k}
Pr [ V ⩾ k ] ⩽ Pr [ ∣ V − E [ V ] ∣ ⩾ 2 ε k ] ⩽ ( ε k /2 ) 2 Var ( V ) ⩽ ε 2 k 2 4 k = ε 2 k 4
W W W Y k > ( 1 + ε 2 ) k M z Y_k > \left(1+\dfrac{\varepsilon}{2}\right)\dfrac{kM}{z} Y k > ( 1 + 2 ε ) z k M k k k W < k W < k W < k W < k W < k W < k E [ W ] − W > ( 1 + ε / 2 ) k − k = ( ε / 2 ) k \mathbb{E}[W] - W > (1+\varepsilon/2)k - k = (\varepsilon/2)k E [ W ] − W > ( 1 + ε /2 ) k − k = ( ε /2 ) k
Pr [ W < k ] ⩽ Pr [ ∣ W − E [ W ] ∣ ⩾ ε k 2 ] ⩽ Var ( W ) ( ε k / 2 ) 2 ⩽ 4 ⋅ 2 k ε 2 k 2 = 8 ε 2 k \Pr[W < k] \le \Pr\left[\left|W-\mathbb{E}[W]\right| \ge \frac{\varepsilon k}{2}\right] \le \frac{\operatorname{Var}(W)}{(\varepsilon k/2)^2} \le \frac{4 \cdot 2k}{\varepsilon^2 k^2} = \frac{8}{\varepsilon^2 k}
Pr [ W < k ] ⩽ Pr [ ∣ W − E [ W ] ∣ ⩾ 2 ε k ] ⩽ ( ε k /2 ) 2 Var ( W ) ⩽ ε 2 k 2 4 ⋅ 2 k = ε 2 k 8
这里 W W W V V V 8 8 8 4 4 4 Var ( W ) ⩽ ( 1 + ε / 2 ) k ⩽ 2 k \operatorname{Var}(W) \le (1+\varepsilon/2)k \le 2k Var ( W ) ⩽ ( 1 + ε /2 ) k ⩽ 2 k Var ( V ) ⩽ k \operatorname{Var}(V) \le k Var ( V ) ⩽ k
两边合并(联合界),可得
Pr [ z ^ ∉ [ ( 1 − ε ) z , ( 1 + ε ) z ] ] ⩽ 4 ε 2 k + 8 ε 2 k = 12 ε 2 k \Pr\big[\hat{z} \notin [(1-\varepsilon)z,\, (1+\varepsilon)z]\big] \le \frac{4}{\varepsilon^2 k} + \frac{8}{\varepsilon^2 k} = \frac{12}{\varepsilon^2 k}
Pr [ z ^ ∈ / [( 1 − ε ) z , ( 1 + ε ) z ] ] ⩽ ε 2 k 4 + ε 2 k 8 = ε 2 k 12
注意这里先对 Y k Y_k Y k
( 1 − ε 2 ) k M z , ( 1 + ε 2 ) k M z , \left(1-\frac{\varepsilon}{2}\right)\frac{kM}{z},\quad \left(1+\frac{\varepsilon}{2}\right)\frac{kM}{z},
( 1 − 2 ε ) z k M , ( 1 + 2 ε ) z k M ,
而最终结论写成
z ^ = k M Y k ∈ [ ( 1 − ε ) z , ( 1 + ε ) z ] \hat z=\frac{kM}{Y_k}\in[(1-\varepsilon)z,(1+\varepsilon)z]
z ^ = Y k k M ∈ [( 1 − ε ) z , ( 1 + ε ) z ]
两者并不矛盾,因为 z ^ \hat z z ^ Y k Y_k Y k
z ^ > ( 1 + ε ) z ⟺ Y k < k M ( 1 + ε ) z , z ^ < ( 1 − ε ) z ⟺ Y k > k M ( 1 − ε ) z \hat z>(1+\varepsilon)z \iff Y_k<\frac{kM}{(1+\varepsilon)z}, \quad \hat z<(1-\varepsilon)z \iff Y_k>\frac{kM}{(1-\varepsilon)z}
z ^ > ( 1 + ε ) z ⟺ Y k < ( 1 + ε ) z k M , z ^ < ( 1 − ε ) z ⟺ Y k > ( 1 − ε ) z k M
为便于用对称的偏差量做 Chebyshev 分析,我们用更强但更简洁的条件
1 1 + ε ⩽ 1 − ε 2 , 1 1 − ε ⩾ 1 + ε 2 ( 0 < ε ⩽ 1 ) \frac{1}{1+\varepsilon}\le 1-\frac{\varepsilon}{2},\quad \frac{1}{1-\varepsilon}\ge 1+\frac{\varepsilon}{2}\quad (0<\varepsilon\le 1)
1 + ε 1 ⩽ 1 − 2 ε , 1 − ε 1 ⩾ 1 + 2 ε ( 0 < ε ⩽ 1 )
于是
Y k ∈ [ ( 1 − ε 2 ) k M z , ( 1 + ε 2 ) k M z ] ⟹ z ^ ∈ [ ( 1 − ε ) z , ( 1 + ε ) z ] Y_k\in\left[\left(1-\frac{\varepsilon}{2}\right)\frac{kM}{z},\, \left(1+\frac{\varepsilon}{2}\right)\frac{kM}{z}\right] \;\Longrightarrow\; \hat z\in[(1-\varepsilon)z,(1+\varepsilon)z]
Y k ∈ [ ( 1 − 2 ε ) z k M , ( 1 + 2 ε ) z k M ] ⟹ z ^ ∈ [( 1 − ε ) z , ( 1 + ε ) z ]
因此,前面对 Y k Y_k Y k 1 ± ε / 2 1\pm \varepsilon/2 1 ± ε /2 z ^ \hat z z ^ 1 ± ε 1\pm \varepsilon 1 ± ε
此外课件中为了统一,两边都放缩到 8 / ( ε 2 k ) 8/(\varepsilon^2 k) 8/ ( ε 2 k ) 16 / ( ε 2 k ) 16/(\varepsilon^2 k) 16/ ( ε 2 k ) k = ⌈ 16 / ( ε 2 δ ) ⌉ k = \lceil 16/(\varepsilon^2\delta)\rceil k = ⌈ 16/ ( ε 2 δ )⌉
k = ⌈ 12 ε 2 δ ⌉ k = \left\lceil \frac{12}{\varepsilon^2\delta} \right\rceil
k = ⌈ ε 2 δ 12 ⌉
就得到一个 ( ε , δ ) (\varepsilon,\delta) ( ε , δ )
若进一步取 M = N 3 M = N^3 M = N 3 O ( log N ) O(\log N) O ( log N )
O ( k log N ) = O ( 1 ε 2 δ log N ) 比特 . O(k \log N) = O\left(\frac{1}{\varepsilon^2\delta}\log N\right)\ \text{比特}.
O ( k log N ) = O ( ε 2 δ 1 log N ) 比特 .
HyperLogLog
HyperLogLog (Flajolet 等,2007)是实践中使用最广泛的 F 0 F_0 F 0
随机平均 (Stochastic Averaging):用哈希值的前 p p p m = 2 p m = 2^p m = 2 p m m m 调和平均 (Harmonic Mean):用调和平均而非算术平均合并各桶的估计值,对离群值更加稳健。
HyperLogLog 算法
维护数组 M [ m ] M[m] M [ m ] − ∞ -\infty − ∞ h ( x i ) h(x_i) h ( x i ) ρ ( x i ) \rho(x_i) ρ ( x i )
更新 :对每个 x i x_i x i M [ h ( x i ) ] = max { M [ h ( x i ) ] , ρ ( x i ) } M[h(x_i)] = \max\{M[h(x_i)],\, \rho(x_i)\} M [ h ( x i )] = max { M [ h ( x i )] , ρ ( x i )} 查询 :计算 Z = 1 / ∑ j = 1 m 2 − M [ j ] Z = 1 \Big/ \displaystyle\sum_{j=1}^{m} 2^{-M[j]} Z = 1 / j = 1 ∑ m 2 − M [ j ] α m m 2 Z \alpha_m m^2 Z α m m 2 Z
其中修正因子 α m = ( m ∫ 0 ∞ ( log 2 2 + u 1 + u ) m d u ) − 1 \alpha_m = \left(m \displaystyle\int_0^\infty \left(\log_2\dfrac{2+u}{1+u}\right)^m \d u\right)^{-1} α m = ( m ∫ 0 ∞ ( log 2 1 + u 2 + u ) m d u ) − 1
HyperLogLog 易于实现且计算高效(课件称「hard to analyze」,分析超出本课范围)。它天然支持快速合并 ——两个 sketch 的合并只需逐桶取最大值:M all [ j ] = max { M 1 [ j ] , M 2 [ j ] } M_{\text{all}}[j] = \max\{M_1[j],\, M_2[j]\} M all [ j ] = max { M 1 [ j ] , M 2 [ j ]}
标准误差为 1.04 / m 1.04/\sqrt{m} 1.04/ m m = 2 14 = 16384 m = 2^{14} = 16384 m = 2 14 = 16384 12 K B \pu{12KB} 12 KB 2 % 2\% 2% 10 9 10^9 1 0 9
频率矩
定义
给定流 x 1 , … , x n ∈ U = [ N ] x_1, \dots, x_n \in U = [N] x 1 , … , x n ∈ U = [ N ] x x x 频率 f x = ∣ { i : x i = x } ∣ f_x = |\{i : x_i = x\}| f x = ∣ { i : x i = x } ∣
频率矩
第 k k k 频率矩 (k k k
F k = ∑ x ∈ U f x k F_k = \sum_{x \in U} f_x^k
F k = x ∈ U ∑ f x k
几个重要的特殊情形:
k k k F k F_k F k 含义
0 0 0 ∑ I [ f x > 0 ] \sum \mathbb{I}[f_x > 0] ∑ I [ f x > 0 ] 不同元素个数
1 1 1 ∑ f x = n \sum f_x = n ∑ f x = n 流的总长度
2 2 2 ∑ f x 2 \sum f_x^2 ∑ f x 2 频率分布的「不均匀度」,等于自连接大小
∞ \infty ∞ max x f x \max\limits_x f_x x max f x 最大频率
空间复杂度全景
把 ε , δ \varepsilon,\delta ε , δ
k ⩽ 2 k \le 2 k ⩽ 2 polylog N \operatorname{polylog}N polylog N k > 2 k > 2 k > 2 Θ ~ ( N 1 − 2 / k ) \tilde{\Theta}(N^{1-2/k}) Θ ~ ( N 1 − 2/ k )
这说明 k = 2 k = 2 k = 2 F 2 F_2 F 2 k > 2 k > 2 k > 2 N N N
几个熟悉的特例是:
F 0 F_0 F 0 O ( ε − 2 + log N ) O(\varepsilon^{-2} + \log N) O ( ε − 2 + log N ) F 1 F_1 F 1 n n n O ( log n ) O(\log n) O ( log n ) F 2 F_2 F 2 polylog N \operatorname{polylog}N polylog N
频率估计与 Heavy Hitters
点查询问题
数据 :一个流 x 1 , x 2 , … , x n ∈ U = [ N ] x_1, x_2, \dots, x_n \in U = [N] x 1 , x 2 , … , x n ∈ U = [ N ] 查询 :给定元素 x ∈ U x \in U x ∈ U f x = ∣ { i : x i = x } ∣ f_x = |\{i : x_i = x\}| f x = ∣ { i : x i = x } ∣
精确回答点查询需要 Ω ( N ) \Omega(N) Ω ( N )
Bucket Sketch
最简单的方法:用哈希将元素分到 m m m
Bucket Sketch
选取 2-universal 哈希函数 h : [ N ] → [ m ] h\colon [N] \to [m] h : [ N ] → [ m ] m m m B [ 1 ] , … , B [ m ] \text{B}[1], \dots, \text{B}[m] B [ 1 ] , … , B [ m ] 0 0 0
更新 :每到达 x i x_i x i B [ h ( x i ) ] + = 1 \text{B}[h(x_i)] \mathrel{+}= 1 B [ h ( x i )] + = 1 查询 :返回 f ^ x = B [ h ( x ) ] \hat{f}_x = \text{B}[h(x)] f ^ x = B [ h ( x )]
查询值 B [ h ( x ) ] \text{B}[h(x)] B [ h ( x )] f x f_x f x x x x
f ^ x = f x + ∑ y ≠ x f y ⋅ I [ h ( y ) = h ( x ) ] \hat{f}_x = f_x + \sum_{y \ne x} f_y \cdot \mathbb{I}[h(y) = h(x)]
f ^ x = f x + y = x ∑ f y ⋅ I [ h ( y ) = h ( x )]
这是一个单边误差 估计器:f ^ x ⩾ f x \hat{f}_x \ge f_x f ^ x ⩾ f x
期望误差:
E [ f ^ x − f x ] = ∑ y ≠ x f y ⋅ Pr [ h ( y ) = h ( x ) ] ⩽ n m \mathbb{E}[\hat{f}_x - f_x] = \sum_{y \ne x} f_y \cdot \Pr[h(y) = h(x)] \le \frac{n}{m}
E [ f ^ x − f x ] = y = x ∑ f y ⋅ Pr [ h ( y ) = h ( x )] ⩽ m n
由 Markov 不等式(因单边误差非负而可以运用):Pr [ f ^ x − f x ⩾ ε n ] ⩽ 1 ε m \Pr[\hat{f}_x - f_x \ge \varepsilon n] \le \frac{1}{\varepsilon m} Pr [ f ^ x − f x ⩾ ε n ] ⩽ ε m 1
要让错误概率降到某个小常数,需要 m = O ( 1 / ε ) m = O(1/\varepsilon) m = O ( 1/ ε )
Count-Min Sketch
Count-Min Sketch(Cormode-Muthukrishnan, 2004)用多行取最小值 的策略巧妙解决了这个问题。
Count-Min Sketch
使用 k k k h 1 , … , h k : [ N ] → [ m ] h_1, \dots, h_k\colon [N] \to [m] h 1 , … , h k : [ N ] → [ m ] k × m k \times m k × m CMS [ k ] [ m ] \text{CMS}[k][m] CMS [ k ] [ m ] 0 0 0
更新 :每到达 x i x_i x i 1 ⩽ j ⩽ k 1 \le j \le k 1 ⩽ j ⩽ k CMS [ j ] [ h j ( x i ) ] + = 1 \text{CMS}[j][h_j(x_i)] \mathrel{+}= 1 CMS [ j ] [ h j ( x i )] + = 1 查询 :返回 f ^ x = min 1 ⩽ j ⩽ k CMS [ j ] [ h j ( x ) ] \hat{f}_x = \min\limits_{1 \le j \le k} \text{CMS}[j][h_j(x)] f ^ x = 1 ⩽ j ⩽ k min CMS [ j ] [ h j ( x )]
flowchart LR
subgraph input["数据流"]
stream["x₁, x₂, ..., xₙ"]
end
subgraph cms["Count-Min Sketch"]
direction TB
r1["行 1:h₁ → 计数器数组 [m]"]
r2["行 2:h₂ → 计数器数组 [m]"]
rk["行 k:hₖ → 计数器数组 [m]"]
end
subgraph query["查询 x"]
min["取 k 行中的最小值"]
end
stream --> r1
stream --> r2
stream --> rk
r1 --> min
r2 --> min
rk --> min
classDef inputStyle fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef cmsStyle fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef queryStyle fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
class stream inputStyle
class r1,r2,rk cmsStyle
class min queryStyle为什么取最小值有效?
每一行都是一个 Bucket Sketch,给出的估计值都 ⩾ f x \ge f_x ⩾ f x k k k 任意一行 的碰撞噪声足够小,最终估计就是好的。所有 k k k k k k
分析 :
对第 j j j Z j = CMS [ j ] [ h j ( x ) ] − f x Z_j = \text{CMS}[j][h_j(x)] - f_x Z j = CMS [ j ] [ h j ( x )] − f x
Pr [ Z j ⩾ ε n ] ⩽ 1 ε m \Pr[Z_j \ge \varepsilon n] \le \frac{1}{\varepsilon m}
Pr [ Z j ⩾ ε n ] ⩽ ε m 1
取 m = ⌈ e / ε ⌉ m = \lceil \mathrm{e}/\varepsilon \rceil m = ⌈ e / ε ⌉ Pr [ Z j ⩾ ε n ] ⩽ 1 / e \Pr[Z_j \ge \varepsilon n] \le 1/\mathrm{e} Pr [ Z j ⩾ ε n ] ⩽ 1/ e k k k
Pr [ f ^ x − f x ⩾ ε n ] = Pr [ ∀ j : Z j ⩾ ε n ] ⩽ ( 1 e ) k ⩽ δ \Pr\big[\hat{f}_x - f_x \ge \varepsilon n\big] = \Pr\big[\forall j\colon Z_j \ge \varepsilon n\big] \le \left(\frac{1}{\mathrm{e}}\right)^k \le \delta
Pr [ f ^ x − f x ⩾ ε n ] = Pr [ ∀ j : Z j ⩾ ε n ] ⩽ ( e 1 ) k ⩽ δ
取 k = ⌈ ln ( 1 / δ ) ⌉ k = \lceil \ln(1/\delta) \rceil k = ⌈ ln ( 1/ δ )⌉
指标
复杂度
空间(计数器)
O ( 1 ε log 1 δ ⋅ log n ) O\left(\dfrac{1}{\varepsilon}\log\dfrac{1}{\delta}\cdot\log n\right) O ( ε 1 log δ 1 ⋅ log n )
空间(哈希函数)
O ( log 1 δ ⋅ log N ) O\left(\log\dfrac{1}{\delta}\cdot\log N\right) O ( log δ 1 ⋅ log N )
查询时间
O ( log 1 δ ) O\left(\log\dfrac{1}{\delta}\right) O ( log δ 1 )
Count-Min Sketch 是单边误差估计器
Count-Min Sketch 的误差保证是:
Pr [ f x ⩽ f ^ x ⩽ f x + ε n ] ⩾ 1 − δ \Pr\big[f_x \le \hat{f}_x \le f_x + \varepsilon n\big] \ge 1 - \delta
Pr [ f x ⩽ f ^ x ⩽ f x + ε n ] ⩾ 1 − δ
只会高估,不会低估。这在许多应用中是有利的——例如 heavy hitter 检测中,真正的 heavy hitter 一定不会被遗漏。
线性 Sketch 与分布式计算
Count-Min Sketch 有一个重要的结构性质:线性可合并 。
如果两个流 S 1 , S 2 S_1, S_2 S 1 , S 2 CMS 1 , CMS 2 \text{CMS}_1, \text{CMS}_2 CMS 1 , CMS 2
CMS all = CMS 1 + CMS 2 \text{CMS}_{\text{all}} = \text{CMS}_1 + \text{CMS}_2
CMS all = CMS 1 + CMS 2
这使得 Count-Min Sketch 天然适合分布式计算场景:各节点独立处理本地数据流,最后只需传输并合并 sketch(大小远小于原始数据),即可得到全局的频率估计。
Heavy Hitters 的分治查找
Heavy hitter 定义为出现次数超过 ε n \varepsilon n ε n
最直接的方法是枚举全集 U U U x x x f ^ x \hat{f}_x f ^ x N N N N ≫ n N \gg n N ≫ n
分治法查找 Heavy Hitters
对全集 [ N ] [N] [ N ] log N \log N log N ℓ \ell ℓ [ N ] [N] [ N ] 2 ℓ 2^\ell 2 ℓ f I = ∣ { i : x i ∈ I } ∣ f_I = |\left\lbrace i\colon x_i \in I \right\rbrace| f I = ∣ { i : x i ∈ I } ∣
从根节点开始,只在子区间的 sketch 估计值超过阈值时才继续向下递归。由于 heavy hitter 至多 1 / ε 1/\varepsilon 1/ ε O ( 1 / ε ) O(1 / \varepsilon) O ( 1/ ε ) O ( ( 1 / ε ) log N ) O((1/\varepsilon) \log N) O (( 1/ ε ) log N )
Tug-of-War 与第二频率矩
从流位置集合 [ n ] [n] [ n ] i , j i, j i , j
Pr i , j [ x i = x j ] = ∑ x ∈ U Pr [ x i = x 且 x j = x ] = ∑ x ∈ U ( f x n ) 2 = 1 n 2 ∑ x ∈ U f x 2 = F 2 n 2 \begin{aligned}
\Pr_{i, j}[x_i=x_j] &= \sum_{x\in U}\Pr[x_i=x \text{ 且 } x_j=x]\\
&= \sum_{x\in U}\left(\frac{f_x}{n}\right)^2\\
&= \frac{1}{n^2}\sum_{x\in U} f_x^2\\
&= \frac{F_2}{n^2}
\end{aligned}
i , j Pr [ x i = x j ] = x ∈ U ∑ Pr [ x i = x 且 x j = x ] = x ∈ U ∑ ( n f x ) 2 = n 2 1 x ∈ U ∑ f x 2 = n 2 F 2
因此,F 2 F_2 F 2 n 2 n^2 n 2
为什么 Count-Min Sketch 不适用
直觉上,能否用 Count-Min Sketch 的计数器来估计 F 2 = ∑ f x 2 F_2 = \sum f_x^2 F 2 = ∑ f x 2
考虑两个频率向量:
f 1 = ( 1 , 1 , … , 1 ⏟ n ) 与 f 2 = ( 1 , 1 , … , 1 , n ⏟ n ) \bm{f}_1 = (\underbrace{1, 1, \dots, 1}_n) \quad \text{与} \quad \bm{f}_2 = (\underbrace{1, 1, \dots, 1, \sqrt{n}}_n)
f 1 = ( n 1 , 1 , … , 1 ) 与 f 2 = ( n 1 , 1 , … , 1 , n )
它们的 F 2 F_2 F 2 n n n 2 n − 1 2n - 1 2 n − 1 n \sqrt{n} n w = O ( n ) w = O(\sqrt{n}) w = O ( n ) n / w n / w n / w n / w = n n / w = \sqrt{n} n / w = n n \sqrt{n} n
核心困难在于 Count-Min Sketch 的碰撞噪声是加性的 ,而 F 2 F_2 F 2
Tug-of-War:随机符号的对消
Alon-Matias-Szegedy(1996)提出了一个精巧的想法:给每个元素分配一个随机的 ± 1 \pm 1 ± 1
Count Sketch(基本 Tug-of-War)
选取 2-universal 符号函数 σ : [ N ] → { − 1 , + 1 } \sigma\colon [N] \to \{-1, +1\} σ : [ N ] → { − 1 , + 1 } z z z 0 0 0
更新 :每到达 x i x_i x i z ← z + σ ( x i ) z \leftarrow z + \sigma(x_i) z ← z + σ ( x i ) 查询 :返回 z 2 z^2 z 2
处理完整个流后:
z = ∑ x ∈ U σ ( x ) f x z = \sum_{x \in U} \sigma(x) f_x
z = x ∈ U ∑ σ ( x ) f x
定理:无偏性
E [ z 2 ] = F 2 \mathbb{E}[z^2] = F_2
E [ z 2 ] = F 2
证明
E [ z 2 ] = E [ ( ∑ x σ ( x ) f x ) 2 ] = ∑ x , y E [ σ ( x ) σ ( y ) ] ⋅ f x f y \mathbb{E}[z^2] = \mathbb{E}\left[\left(\sum_x \sigma(x) f_x\right)^2\right] = \sum_{x, y} \mathbb{E}[\sigma(x)\sigma(y)] \cdot f_x f_y
E [ z 2 ] = E ( x ∑ σ ( x ) f x ) 2 = x , y ∑ E [ σ ( x ) σ ( y )] ⋅ f x f y
对于 2-universal 的 σ \sigma σ
x = y x = y x = y E [ σ ( x ) 2 ] = 1 \mathbb{E}[\sigma(x)^2] = 1 E [ σ ( x ) 2 ] = 1 x ≠ y x \ne y x = y E [ σ ( x ) σ ( y ) ] = E [ σ ( x ) ] ⋅ E [ σ ( y ) ] = 0 \mathbb{E}[\sigma(x)\sigma(y)] = \mathbb{E}[\sigma(x)] \cdot \mathbb{E}[\sigma(y)] = 0 E [ σ ( x ) σ ( y )] = E [ σ ( x )] ⋅ E [ σ ( y )] = 0
因此:
E [ z 2 ] = ∑ x f x 2 = F 2 \mathbb{E}[z^2] = \sum_x f_x^2 = F_2
E [ z 2 ] = x ∑ f x 2 = F 2
单个计数器的估计 z 2 z^2 z 2
定理:方差分析
Var ( z 2 ) ⩽ 2 F 2 2 \text{Var}(z^2) \le 2F_2^2
Var ( z 2 ) ⩽ 2 F 2 2
此结论需要 σ \sigma σ 4-wise 独立性 (即任意四个不同元素的符号相互独立)。
证明
Var ( z 2 ) = E [ z 4 ] − ( E [ z 2 ] ) 2 \text{Var}(z^2) = \mathbb{E}[z^4] - (\mathbb{E}[z^2])^2 Var ( z 2 ) = E [ z 4 ] − ( E [ z 2 ] ) 2 E [ z 4 ] \mathbb{E}[z^4] E [ z 4 ]
E [ z 4 ] = E [ ( ∑ x σ ( x ) f x ) 4 ] = ∑ a , b , c , d f a f b f c f d ⋅ E [ σ ( a ) σ ( b ) σ ( c ) σ ( d ) ] \mathbb{E}[z^4] = \mathbb{E}\left[\left(\sum_x \sigma(x)f_x\right)^4\right] = \sum_{a,b,c,d} f_a f_b f_c f_d \cdot \mathbb{E}[\sigma(a)\sigma(b)\sigma(c)\sigma(d)]
E [ z 4 ] = E ( x ∑ σ ( x ) f x ) 4 = a , b , c , d ∑ f a f b f c f d ⋅ E [ σ ( a ) σ ( b ) σ ( c ) σ ( d )]
在 4-wise 独立下,E [ σ ( a ) σ ( b ) σ ( c ) σ ( d ) ] = 1 \mathbb{E}[\sigma(a)\sigma(b)\sigma(c)\sigma(d)] = 1 E [ σ ( a ) σ ( b ) σ ( c ) σ ( d )] = 1
4-0-0-0 (四个下标全相同):a = b = c = d a = b = c = d a = b = c = d 2-2-0-0 (两对相同):如 a = b ≠ c = d a = b \ne c = d a = b = c = d
其他模式下,至少有一个下标出现奇数次,其 σ \sigma σ
因此(2-2-0-0 模式有 ( 4 2 ) / 2 = 3 \binom{4}{2}/2 = 3 ( 2 4 ) /2 = 3
E [ z 4 ] = ∑ a f a 4 + 3 ∑ a ≠ b f a 2 f b 2 \mathbb{E}[z^4] = \sum_a f_a^4 + 3\sum_{a \ne b} f_a^2 f_b^2
E [ z 4 ] = a ∑ f a 4 + 3 a = b ∑ f a 2 f b 2
计算方差:
Var ( z 2 ) = ∑ a f a 4 + 3 ∑ a ≠ b f a 2 f b 2 − F 2 2 = ∑ a f a 4 + 3 ( F 2 2 − ∑ a f a 4 ) − F 2 2 = 2 F 2 2 − 2 ∑ a f a 4 ⩽ 2 F 2 2 \begin{aligned}
\text{Var}(z^2) &= \sum_a f_a^4 + 3\sum_{a \ne b} f_a^2 f_b^2 - F_2^2 \\
&= \sum_a f_a^4 + 3\left(F_2^2 - \sum_a f_a^4\right) - F_2^2 \\
&= 2F_2^2 - 2\sum_a f_a^4 \\
&\le 2F_2^2
\end{aligned}
Var ( z 2 ) = a ∑ f a 4 + 3 a = b ∑ f a 2 f b 2 − F 2 2 = a ∑ f a 4 + 3 ( F 2 2 − a ∑ f a 4 ) − F 2 2 = 2 F 2 2 − 2 a ∑ f a 4 ⩽ 2 F 2 2
其中用到了:
∑ a ≠ b f a 2 f b 2 = ( ∑ a f a 2 ) 2 − ∑ a f a 4 = F 2 2 − ∑ a f a 4 \sum_{a \ne b} f_a^2 f_b^2 = \left(\sum_a f_a^2\right)^2 - \sum_a f_a^4 = F_2^2 - \sum_a f_a^4
a = b ∑ f a 2 f b 2 = ( a ∑ f a 2 ) 2 − a ∑ f a 4 = F 2 2 − a ∑ f a 4
无偏性只需 2-wise 独立,但方差界需要 4-wise 独立。这是因为 Var ( z 2 ) \text{Var}(z^2) Var ( z 2 ) E [ z 4 ] \mathbb{E}[z^4] E [ z 4 ] E [ σ ( a ) σ ( b ) σ ( c ) σ ( d ) ] \mathbb{E}[\sigma(a)\sigma(b)\sigma(c)\sigma(d)] E [ σ ( a ) σ ( b ) σ ( c ) σ ( d )]
精度不足与改进
由 Chebyshev 不等式:
Pr [ ∣ z 2 − F 2 ∣ ⩾ ε F 2 ] ⩽ Var ( z 2 ) ε 2 F 2 2 ⩽ 2 ε 2 \Pr\big[|z^2 - F_2| \ge \varepsilon F_2\big] \le \frac{\text{Var}(z^2)}{\varepsilon^2 F_2^2} \le \frac{2}{\varepsilon^2}
Pr [ ∣ z 2 − F 2 ∣ ⩾ ε F 2 ] ⩽ ε 2 F 2 2 Var ( z 2 ) ⩽ ε 2 2
当 ε < 2 ≈ 1.41 \varepsilon < \sqrt{2} \approx 1.41 ε < 2 ≈ 1.41
Count Sketch+:Mean Trick
解决方法正是 mean trick:独立运行 k k k
Count Sketch+
使用 k k k σ 1 , … , σ k : [ N ] → { − 1 , + 1 } \sigma_1, \dots, \sigma_k\colon [N] \to \{-1, +1\} σ 1 , … , σ k : [ N ] → { − 1 , + 1 } k k k CS [ 1 ] , … , CS [ k ] \text{CS}[1], \dots, \text{CS}[k] CS [ 1 ] , … , CS [ k ] 0 0 0
更新 :每到达 x i x_i x i j ⩽ k j \le k j ⩽ k CS [ j ] ← CS [ j ] + σ j ( x i ) \text{CS}[j] \leftarrow \text{CS}[j] + \sigma_j(x_i) CS [ j ] ← CS [ j ] + σ j ( x i ) 查询 :返回 z ^ 2 = 1 k ∑ j = 1 k CS [ j ] 2 \hat{z}^2 = \frac{1}{k}\sum_{j=1}^{k} \text{CS}[j]^2 z ^ 2 = k 1 ∑ j = 1 k CS [ j ] 2
由独立性,Var ( z ^ 2 ) ⩽ 2 F 2 2 / k \text{Var}(\hat{z}^2) \le 2F_2^2 / k Var ( z ^ 2 ) ⩽ 2 F 2 2 / k k = 2 / ( ε 2 δ ) k = 2/(\varepsilon^2 \delta) k = 2/ ( ε 2 δ )
Pr [ ∣ z ^ 2 − F 2 ∣ ⩾ ε F 2 ] ⩽ Var ( z ^ 2 ) ε 2 F 2 2 ⩽ 2 k ε 2 ⩽ δ \Pr\big[|\hat{z}^2 - F_2| \ge \varepsilon F_2\big] \le \frac{\text{Var}(\hat{z}^2)}{\varepsilon^2 F_2^2} \le \frac{2}{k\varepsilon^2} \le \delta
Pr [ ∣ z ^ 2 − F 2 ∣ ⩾ ε F 2 ] ⩽ ε 2 F 2 2 Var ( z ^ 2 ) ⩽ k ε 2 2 ⩽ δ
空间:k k k k k k δ \delta δ O ( log ( 1 / δ ) ) O(\log(1/\delta)) O ( log ( 1/ δ ))
Count Sketch++:频率估计
Count Sketch 的思想也可以用于频率估计(点查询),并且给出双边误差 保证——与 Count-Min Sketch 的单边误差不同。
Count Sketch++
使用 k k k h 1 , … , h k : [ N ] → [ m ] h_1, \dots, h_k\colon [N] \to [m] h 1 , … , h k : [ N ] → [ m ] k k k σ 1 , … , σ k : [ N ] → { − 1 , + 1 } \sigma_1, \dots, \sigma_k\colon [N] \to \{-1, +1\} σ 1 , … , σ k : [ N ] → { − 1 , + 1 } k × m k \times m k × m CS [ k ] [ m ] \text{CS}[k][m] CS [ k ] [ m ] 0 0 0
更新 :每到达 x i x_i x i j ⩽ k j \le k j ⩽ k CS [ j ] [ h j ( x i ) ] + = σ j ( x i ) \text{CS}[j][h_j(x_i)] \mathrel{+}= \sigma_j(x_i) CS [ j ] [ h j ( x i )] + = σ j ( x i ) 查询 :返回 f ^ x = median 1 ⩽ j ⩽ k σ j ( x ) ⋅ CS [ j ] [ h j ( x ) ] \hat{f}_x = \operatornamewithlimits{median}\limits_{1 \le j \le k}\; \sigma_j(x) \cdot \text{CS}[j][h_j(x)] f ^ x = 1 ⩽ j ⩽ k median σ j ( x ) ⋅ CS [ j ] [ h j ( x )]
查询时乘以 σ j ( x ) \sigma_j(x) σ j ( x ) σ j ( x ) \sigma_j(x) σ j ( x ) x x x f x f_x f x
定义第 j j j
E j : = σ j ( x ) ⋅ CS [ j ] [ h j ( x ) ] − f x = ∑ y ≠ x σ j ( x ) σ j ( y ) ⋅ I [ h j ( x ) = h j ( y ) ] ⋅ f y E_j := \sigma_j(x) \cdot \text{CS}[j][h_j(x)] - f_x = \sum_{y \ne x} \sigma_j(x)\sigma_j(y) \cdot \mathbb{I}[h_j(x) = h_j(y)] \cdot f_y
E j := σ j ( x ) ⋅ CS [ j ] [ h j ( x )] − f x = y = x ∑ σ j ( x ) σ j ( y ) ⋅ I [ h j ( x ) = h j ( y )] ⋅ f y
这是碰撞元素的带符号贡献之和。由于符号随机,正负贡献倾向于抵消。
误差界
( E [ ∣ E j ∣ ] ) 2 ⩽ E [ E j 2 ] ⩽ F 2 m (\mathbb{E}[|E_j|])^2 \le \mathbb{E}[E_j^2] \le \frac{F_2}{m}
( E [ ∣ E j ∣ ] ) 2 ⩽ E [ E j 2 ] ⩽ m F 2
证明
E [ E j 2 ] = E [ ∑ y , z ≠ x σ j ( y ) σ j ( z ) ⋅ I [ h j ( x ) = h j ( y ) ] ⋅ I [ h j ( x ) = h j ( z ) ] ⋅ f y f z ] \mathbb{E}[E_j^2] = \mathbb{E}\left[\sum_{y,z \ne x} \sigma_j(y)\sigma_j(z) \cdot \mathbb{I}[h_j(x) = h_j(y)] \cdot \mathbb{I}[h_j(x) = h_j(z)] \cdot f_y f_z\right]
E [ E j 2 ] = E y , z = x ∑ σ j ( y ) σ j ( z ) ⋅ I [ h j ( x ) = h j ( y )] ⋅ I [ h j ( x ) = h j ( z )] ⋅ f y f z
由于 σ j \sigma_j σ j h j h_j h j y = z y = z y = z y ≠ z y \ne z y = z
y = z y = z y = z E [ σ j ( y ) 2 ] = 1 \mathbb{E}[\sigma_j(y)^2] = 1 E [ σ j ( y ) 2 ] = 1 ∑ y ≠ x Pr [ h j ( x ) = h j ( y ) ] ⋅ f y 2 ⩽ ∑ y ≠ x f y 2 m ⩽ F 2 m \sum_{y \ne x} \Pr[h_j(x) = h_j(y)] \cdot f_y^2 \le \sum_{y \ne x} \frac{f_y^2}{m} \le \frac{F_2}{m} ∑ y = x Pr [ h j ( x ) = h j ( y )] ⋅ f y 2 ⩽ ∑ y = x m f y 2 ⩽ m F 2 y ≠ z y \ne z y = z E [ σ j ( y ) σ j ( z ) ] = 0 \mathbb{E}[\sigma_j(y)\sigma_j(z)] = 0 E [ σ j ( y ) σ j ( z )] = 0 0 0 0
因此 E [ E j 2 ] ⩽ F 2 / m \mathbb{E}[E_j^2] \le F_2/m E [ E j 2 ] ⩽ F 2 / m E [ ∣ E j ∣ ] ⩽ F 2 / m \mathbb{E}[|E_j|] \le \sqrt{F_2/m} E [ ∣ E j ∣ ] ⩽ F 2 / m
因此 E [ ∣ E j ∣ ] ⩽ F 2 / m \mathbb{E}[|E_j|] \le \sqrt{F_2/m} E [ ∣ E j ∣ ] ⩽ F 2 / m
Pr [ ∣ E j ∣ ⩾ 3 F 2 / m ] ⩽ 1 3 \Pr\big[|E_j| \ge 3\sqrt{F_2/m}\big] \le \frac{1}{3}
Pr [ ∣ E j ∣ ⩾ 3 F 2 / m ] ⩽ 3 1
设 m = 9 / ε 2 m = 9/\varepsilon^2 m = 9/ ε 2 3 F 2 / m = ε F 2 3\sqrt{F_2/m} = \varepsilon\sqrt{F_2} 3 F 2 / m = ε F 2 ⩾ 2 / 3 \ge 2/3 ⩾ 2/3 ε F 2 \varepsilon\sqrt{F_2} ε F 2
最终,用 median trick 提升置信度:取 k = 18 ln ( 1 / δ ) k = 18\ln(1/\delta) k = 18 ln ( 1/ δ ) S = ∑ i = 1 k X j S = \sum_{i=1}^{k}X_{j} S = ∑ i = 1 k X j X j X_j X j j j j ε F 2 \varepsilon\sqrt{F_2} ε F 2 μ = E [ S ] ⩽ k / 3 \mu = \mathbb{E}[S] \le k/3 μ = E [ S ] ⩽ k /3
Pr [ ∣ f ^ x − f x ∣ > ε F 2 ] ⩽ Pr [ S ⩾ k 2 ] ⩽ Pr [ S − μ ⩾ k 2 − μ ] ⩽ Pr [ S − μ ⩾ k 6 ] ⩽ exp ( − 2 ( k / 6 ) 2 k ) = exp ( − k 18 ) = δ \begin{aligned}
\Pr\big[|\hat{f}_x - f_x| > \varepsilon\sqrt{F_2}\big] &\le \Pr\left[ S \ge \dfrac{k}{2} \right] \\
&\le \Pr\left[ S - \mu \ge \dfrac{k}{2} - \mu \right] \\
&\le \Pr\left[ S - \mu \ge \dfrac{k}{6} \right] \\
&\le \exp\left(-\frac{2(k/6)^2}{k}\right)\\
&= \exp\left(-\frac{k}{18}\right) = \delta
\end{aligned}
Pr [ ∣ f ^ x − f x ∣ > ε F 2 ] ⩽ Pr [ S ⩾ 2 k ] ⩽ Pr [ S − μ ⩾ 2 k − μ ] ⩽ Pr [ S − μ ⩾ 6 k ] ⩽ exp ( − k 2 ( k /6 ) 2 ) = exp ( − 18 k ) = δ
指标
复杂度
空间
O ( ε − 2 log ( 1 / δ ) ) O\left(\varepsilon^{-2}\log(1/\delta)\right) O ( ε − 2 log ( 1/ δ ) )
误差保证
Pr [ f ^ x = f x ± ε F 2 ] ⩾ 1 − δ \Pr\big[\hat{f}_x = f_x \pm \varepsilon\sqrt{F_2}\big] \ge 1 - \delta Pr [ f ^ x = f x ± ε F 2 ] ⩾ 1 − δ
Count-Min Sketch vs. Count Sketch++ 对比
特性
Count-Min Sketch
Count Sketch++
误差类型
单边(只高估)
双边
误差界
ε n = ε F 1 \varepsilon n = \varepsilon F_1 ε n = ε F 1 ε F 2 \varepsilon\sqrt{F_2} ε F 2
查询方式
min \min min median \text{median} median
适用场景
heavy hitter 检测
一般频率估计
当频率分布较均匀时,F 2 ≈ n \sqrt{F_2} \approx \sqrt{n} F 2 ≈ n ε F 2 \varepsilon\sqrt{F_2} ε F 2 ε n \varepsilon n ε n
Bloom Filter
集合成员查询的信息论下界
数据 :一个集合 S ⊆ U = [ N ] , ∣ S ∣ = n S \subseteq U = [N],\, |S| = n S ⊆ U = [ N ] , ∣ S ∣ = n 查询 :给定 x ∈ U x \in U x ∈ U x ∈ S x \in S x ∈ S
精确表示一个 n n n
log 2 ( N n ) = Ω ( n log N ) 比特 \log_2 \binom{N}{n} = \Omega(n \log N) \text{ 比特}
log 2 ( n N ) = Ω ( n log N ) 比特
当 N ≫ n N \gg n N ≫ n n n n 近似 ——容忍一定的假阳性 (把不在集合中的元素误判为在集合中),就可以大幅节省空间。
简单哈希过滤器
最基本的近似方案:用一个均匀哈希函数和一个比特数组。
选取哈希函数 h : U → [ m ] h\colon U \to [m] h : U → [ m ] A ∈ { 0 , 1 } m A \in \{0,1\}^m A ∈ { 0 , 1 } m 0 0 0 x i ∈ S x_i \in S x i ∈ S A [ h ( x i ) ] = 1 A[h(x_i)] = 1 A [ h ( x i )] = 1 x x x A [ h ( x ) ] = 1 A[h(x)] = 1 A [ h ( x )] = 1
x ∈ S x \in S x ∈ S x ∉ S x \notin S x ∈ / S Pr [ A [ h ( x ) ] = 1 ] = 1 − ( 1 − 1 / m ) n ≈ 1 − e − n / m \Pr[A[h(x)] = 1] = 1 - (1 - 1/m)^n \approx 1 - \mathrm{e}^{-n/m} Pr [ A [ h ( x )] = 1 ] = 1 − ( 1 − 1/ m ) n ≈ 1 − e − n / m
单个哈希函数的假阳性率有限。提高精度的方法是使用多个哈希函数。
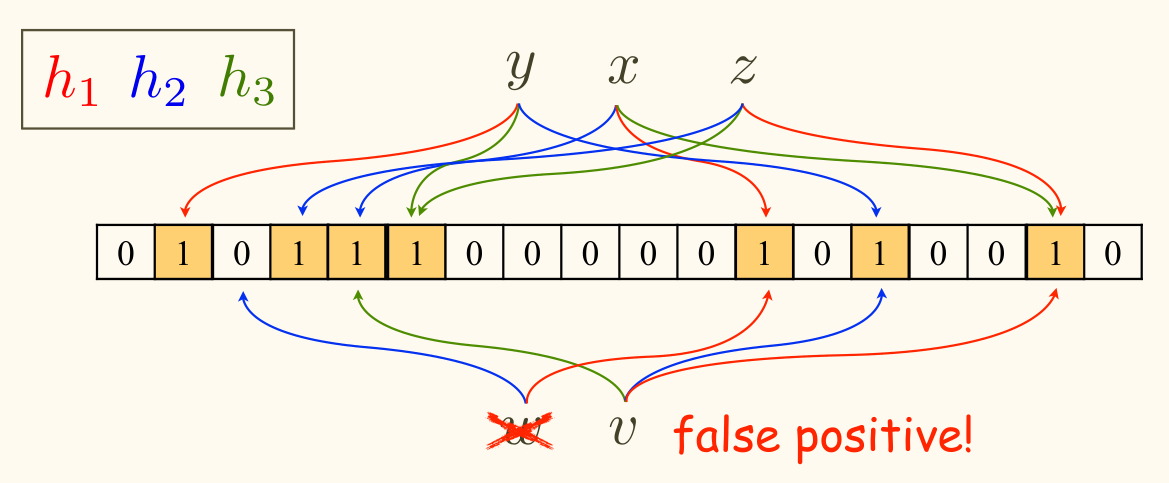
Bloom Filter
Bloom Filter (Bloom, 1970)
使用 k k k h 1 , … , h k : U → [ m ] h_1, \dots, h_k\colon U \to [m] h 1 , … , h k : U → [ m ] A ∈ { 0 , 1 } m A \in \{0, 1\}^m A ∈ { 0 , 1 } m 0 0 0
插入 :对每个 x i ∈ S x_i \in S x i ∈ S A [ h j ( x i ) ] = 1 , ∀ 1 ⩽ j ⩽ k A[h_j(x_i)] = 1,\, \forall 1 \le j \le k A [ h j ( x i )] = 1 , ∀1 ⩽ j ⩽ k 查询 :回答「是」当且仅当 A [ h j ( x ) ] = 1 , ∀ 1 ⩽ j ⩽ k A[h_j(x)] = 1,\, \forall 1 \le j \le k A [ h j ( x )] = 1 , ∀1 ⩽ j ⩽ k
flowchart LR
subgraph elements["插入元素"]
y["y"] --> h1y["h₁(y)"]
y --> h2y["h₂(y)"]
y --> h3y["h₃(y)"]
x["x"] --> h1x["h₁(x)"]
x --> h2x["h₂(x)"]
x --> h3x["h₃(x)"]
end
h1y & h2y & h3y & h1x & h2x & h3x --> A["比特数组 A[m]"]
A -->|查询 v| check{"所有 k 位都为 1?"}
check -->|"是"| yes["回答 YES<br>(可能假阳性)"]
check -->|"否"| no["回答 NO<br>(一定正确)"]
classDef elem fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef hash fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
classDef arr fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef result fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef no fill:#ffebee,stroke:#c62828,stroke-width:2px
class y,x elem
class h1y,h2y,h3y,h1x,h2x,h3x hash
class A arr
class check result
class yes result
class no no正确性 :
x ∈ S x \in S x ∈ S x x x k k k 无假阴性 )x ∉ S x \notin S x ∈ / S k k k 假阳性
假阳性分析
启发式分析 (假设各位独立):
插入 n n n ( 1 − 1 / m ) k n ≈ e − k n / m (1 - 1/m)^{kn} \approx \mathrm{e}^{-kn/m} ( 1 − 1/ m ) k n ≈ e − k n / m k k k
Pr [ 假阳性 ] ≈ ( 1 − e − k n / m ) k \Pr[\text{假阳性}] \approx \left(1 - \mathrm{e}^{-kn/m}\right)^k
Pr [ 假阳性 ] ≈ ( 1 − e − k n / m ) k
设 m = c n m = cn m = c n c c c k = c ln 2 k = c \ln 2 k = c ln 2
Pr [ 假阳性 ] ≈ ( 1 − e − ln 2 ) c ln 2 = 2 − c ln 2 ⩽ ( 0.6185 ) c \Pr[\text{假阳性}] \approx \left(1 - \mathrm{e}^{-\ln 2}\right)^{c\ln 2} = 2^{-c\ln 2} \le (0.6185)^c
Pr [ 假阳性 ] ≈ ( 1 − e − l n 2 ) c l n 2 = 2 − c l n 2 ⩽ ( 0.6185 ) c
最优参数选择
令 ε = ( 0.6185 ) c \varepsilon = (0.6185)^c ε = ( 0.6185 ) c
比特数组大小:m = c n = O ( log ( 1 / ε ) ⋅ n ) m = cn = O\left(\log(1/\varepsilon) \cdot n\right) m = c n = O ( log ( 1/ ε ) ⋅ n )
哈希函数个数:k = c ln 2 = O ( log ( 1 / ε ) ) k = c\ln 2 = O(\log(1/\varepsilon)) k = c ln 2 = O ( log ( 1/ ε ))
查询时间:O ( k ) = O ( log ( 1 / ε ) ) O(k) = O(\log(1/\varepsilon)) O ( k ) = O ( log ( 1/ ε ))
Bloom filter 的空间开销与元素个数 n n n N N N
严格分析:Azuma 不等式
上面的分析假设了各比特位相互独立——但实际上它们并不独立(一个元素同时设置了 k k k 鞅 和 Azuma 不等式 。
回顾:鞅
鞅 (martingale)是一类「公平赌博」过程。形式地,随机变量序列 { Y 0 , Y 1 , Y 2 , … } \{Y_0, Y_1, Y_2, \dots\} { Y 0 , Y 1 , Y 2 , … } n n n
E [ Y n + 1 ∣ Y 0 , … , Y n ] = Y n \mathbb{E}[Y_{n+1} \mid Y_0, \dots, Y_n] = Y_n
E [ Y n + 1 ∣ Y 0 , … , Y n ] = Y n
即已知过去所有信息后,下一步的条件期望 等于当前值——未来既不会系统性地上升也不会下降。典型例子:公平硬币赌博中累计收益就是一个鞅。
Chernoff-Hoeffding 界要求随机变量独立 ,而鞅允许变量之间有依赖关系——只要满足「条件期望不变」的结构。Azuma 不等式正是利用这一结构,在非独立 的设定下给出类似 Chernoff 的集中不等式。
Azuma 不等式
设 { Y n : n ⩾ 0 } \{Y_n : n \ge 0\} { Y n : n ⩾ 0 } ∣ Y n − Y n − 1 ∣ ⩽ c n , ∀ n ⩾ 1 |Y_n - Y_{n-1}| \le c_n,\, \forall n \ge 1 ∣ Y n − Y n − 1 ∣ ⩽ c n , ∀ n ⩾ 1 t > 0 t > 0 t > 0
Pr ( ∣ Y n − Y 0 ∣ ⩾ t ) ⩽ 2 exp ( − 2 t 2 ∑ i = 1 n c i 2 ) \Pr\left(|Y_n - Y_0| \ge t\right) \le 2\exp\left(-\frac{2t^2}{\sum_{i=1}^{n} c_i^2}\right)
Pr ( ∣ Y n − Y 0 ∣ ⩾ t ) ⩽ 2 exp ( − ∑ i = 1 n c i 2 2 t 2 )
Azuma 不等式是 Chernoff-Hoeffding 界在鞅序列上的推广。当增量有界时,鞅仍然高度集中在其初始值附近。
应用到 Bloom filter :
设 Z Z Z n n n 0 0 0 F i \mathcal{F}_i F i i i i
q i ≔ E [ Z ∣ F i ] , i = 0 , 1 , … , n q_i \coloneqq \mathbb{E}[Z \mid \mathcal{F}_i],\qquad i=0,1,\dots,n
q i : = E [ Z ∣ F i ] , i = 0 , 1 , … , n
这便是适合 Azuma 不等式的鞅。由条件期望的塔式法则:
E [ q i + 1 ∣ F i ] = E [ E [ Z ∣ F i + 1 ] ∣ F i ] = E [ Z ∣ F i ] = q i \mathbb{E}[q_{i+1} \mid \mathcal{F}_i] = \mathbb{E}\big[\mathbb{E}[Z \mid \mathcal{F}_{i+1}] \mid \mathcal{F}_i\big] = \mathbb{E}[Z \mid \mathcal{F}_i] = q_i
E [ q i + 1 ∣ F i ] = E [ E [ Z ∣ F i + 1 ] ∣ F i ] = E [ Z ∣ F i ] = q i
注意这里跟「当前还剩多少个 0」不是一回事。若把 Z i Z_i Z i i i i { Z i } \{Z_i\} { Z i }
每次插入最多触及 k k k i i i Z Z Z k k k
∣ q i − q i − 1 ∣ ⩽ k . |q_i - q_{i-1}| \le k.
∣ q i − q i − 1 ∣ ⩽ k .
另一方面,每个 bit 在 k n kn k n 0 0 0 ( 1 − 1 / m ) k n (1-1/m)^{kn} ( 1 − 1/ m ) k n
E [ Z ] = m ( 1 − 1 m ) k n . \mathbb{E}[Z] = m\left(1-\frac{1}{m}\right)^{kn}.
E [ Z ] = m ( 1 − m 1 ) k n .
又因为 q 0 = E [ Z ] q_0 = \mathbb{E}[Z] q 0 = E [ Z ] q n = Z q_n = Z q n = Z
Pr [ ∣ Z − E [ Z ] ∣ ⩾ λ ] = Pr [ ∣ q n − q 0 ∣ ⩾ λ ] ⩽ 2 exp ( − 2 λ 2 n k 2 ) \Pr\left[\left|Z-\mathbb{E}[Z]\right| \ge \lambda\right] = \Pr\left[\left|q_n-q_0\right| \ge \lambda\right] \le 2\exp\left(-\frac{2\lambda^2}{nk^2}\right)
Pr [ ∣ Z − E [ Z ] ∣ ⩾ λ ] = Pr [ ∣ q n − q 0 ∣ ⩾ λ ] ⩽ 2 exp ( − n k 2 2 λ 2 )
因此最终 0 的个数会高度集中在
E [ Z ] = m ( 1 − 1 m ) k n \mathbb{E}[Z] = m\left(1-\frac{1}{m}\right)^{kn}
E [ Z ] = m ( 1 − m 1 ) k n
附近,典型偏差 λ \lambda λ O ( k n ) O(k\sqrt{n}) O ( k n )
若最终有 Z = t Z=t Z = t x ∉ S x \notin S x ∈ / S
Pr [ 假阳性 ∣ Z = t ] = ( 1 − t m ) k . \Pr[\text{假阳性} \mid Z=t] = \left(1-\frac{t}{m}\right)^k.
Pr [ 假阳性 ∣ Z = t ] = ( 1 − m t ) k .
由于 Z Z Z
( 1 − ( 1 − 1 m ) k n ) k \left(1-\left(1-\frac{1}{m}\right)^{kn}\right)^k
( 1 − ( 1 − m 1 ) k n ) k
附近。这说明虽然 bit 之间并不独立,但启发式分析给出的主结论仍然是正确的。
Counting Bloom Filter
标准 Bloom filter 不支持删除 操作:将某一位从 1 改回 0 可能影响其他元素的查询结果。
Counting Bloom Filter 用整数计数器替代比特位:
插入 x x x j j j A [ h j ( x ) ] + = 1 A[h_j(x)] \mathrel{+}= 1 A [ h j ( x )] + = 1 删除 x x x j j j A [ h j ( x ) ] − = 1 A[h_j(x)] \mathrel{-}= 1 A [ h j ( x )] − = 1 查询 x x x A [ h j ( x ) ] > 0 , ∀ j A[h_j(x)] > 0,\, \forall j A [ h j ( x )] > 0 , ∀ j
代价是空间从每位 1 比特增加到 O ( log n ) O(\log n) O ( log n )
有可能出现误删除,例如说对假阳性的元素(实际不存在)执行删除操作,可能将一些位计数器归零,导致部分真实存在的元素查询结果也变为「否」。不过一般 Bloom Filter 关联一个真实集合(如数据库)来验证查询结果,误删除的影响可以被控制在可接受范围内。
用精确结构实现近似查询
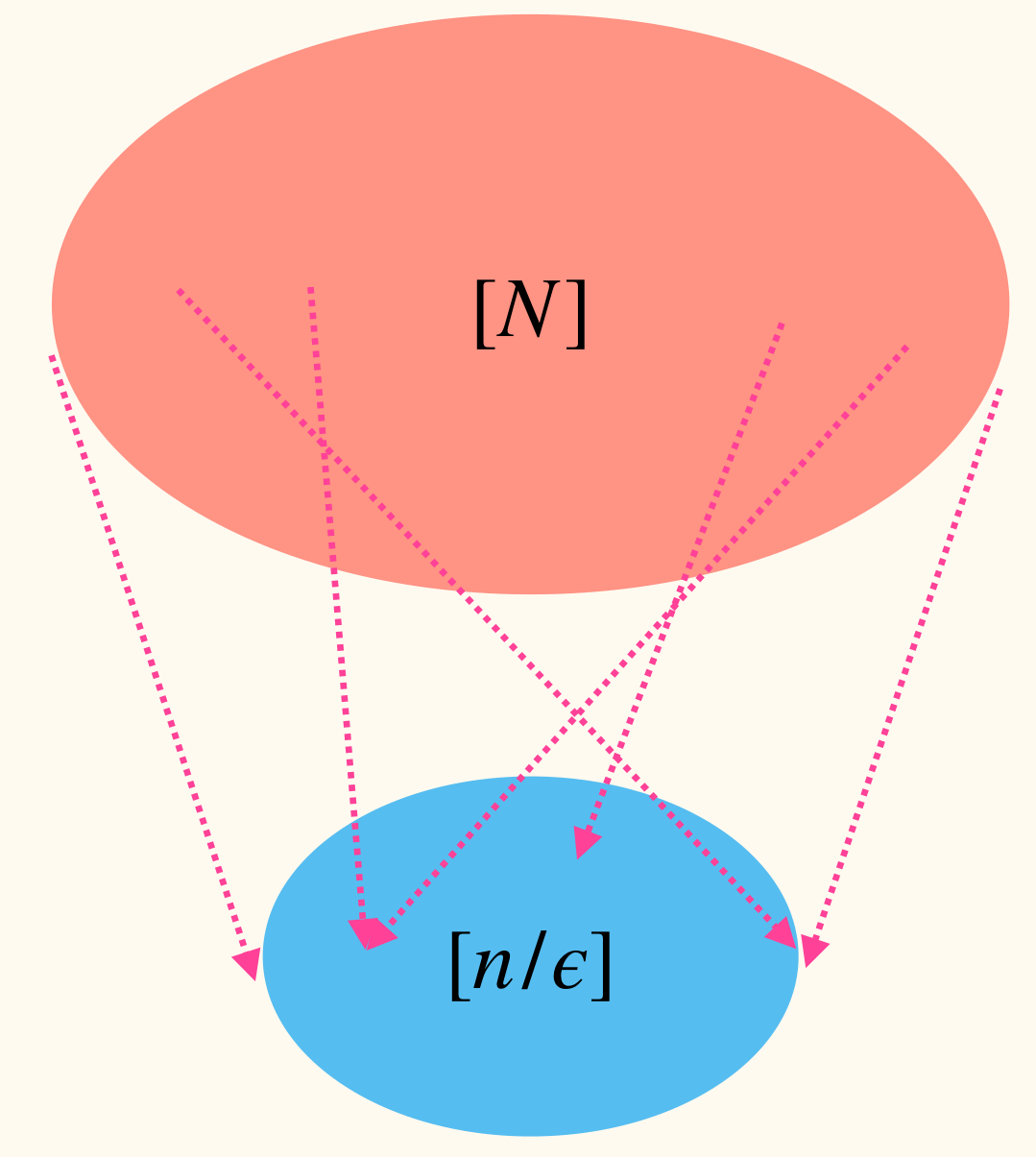
Bloom filter 并非唯一的近似成员查询方案。一个有趣的替代思路是:用哈希函数将全集「缩小」到可管理的规模,然后在小全集上使用精确 数据结构。
Approximate by Exact
选取 2-universal 哈希 h : U → [ n / ε ] h\colon U \to [n/\varepsilon] h : U → [ n / ε ] [ n / ε ] [n/\varepsilon] [ n / ε ]
插入 x x x h ( x ) h(x) h ( x ) 查询 x x x h ( x ) h(x) h ( x )
假阳性率为 ε \varepsilon ε x ∉ S x \notin S x ∈ / S h ( x ) h(x) h ( x ) h ( x i ) h(x_i) h ( x i ) n / ( n / ε ) = ε n / (n/\varepsilon) = \varepsilon n / ( n / ε ) = ε
方案
空间
查询时间
支持删除
Bloom Filter
O ( log ( 1 / ε ) ⋅ n ) O(\log(1/\varepsilon) \cdot n) O ( log ( 1/ ε ) ⋅ n ) O ( log ( 1 / ε ) ) O(\log(1/\varepsilon)) O ( log ( 1/ ε )) 否
Approximate by Exact
O ( n log ( 1 / ε ) ) O(n\log(1/\varepsilon)) O ( n log ( 1/ ε )) O ( 1 ) O(1) O ( 1 ) 是
两种方案在空间上是同阶的,但在查询时间和功能上有不同的权衡。Approximate by Exact 方案可以直接利用任何支持删除的精确集合数据结构(如哈希表),从而天然支持删除操作。
Sketching 的统一视角
回顾本讲所有算法,它们共享一个统一的架构:
问题
Sketch 结构
随机源
误差保证
空间
近似计数
Morris 计数器
概率递增
( ε , δ ) (\varepsilon, \delta) ( ε , δ ) O ( ε − 2 log 1 δ ⋅ log log n ) O(\varepsilon^{-2}\log\frac{1}{\delta}\cdot\log\log n) O ( ε − 2 log δ 1 ⋅ log log n )
F 0 F_0 F 0 最小哈希 / 末尾零
2-universal 哈希
( ε , δ ) (\varepsilon, \delta) ( ε , δ ) O ( ε − 2 log 1 δ ⋅ log N ) O(\varepsilon^{-2}\log\frac{1}{\delta}\cdot\log N) O ( ε − 2 log δ 1 ⋅ log N )
频率估计
Count-Min k × m k \times m k × m
2-universal 哈希
f ^ x ⩽ f x + ε n \hat{f}_x \le f_x + \varepsilon n f ^ x ⩽ f x + ε n O ( 1 ε log 1 δ ⋅ log n ) O(\frac{1}{\varepsilon}\log\frac{1}{\delta}\cdot\log n) O ( ε 1 log δ 1 ⋅ log n )
频率估计
Count Sketch++ k × m k \times m k × m
哈希 + 符号
∣ f ^ x − f x ∣ ⩽ ε F 2 \lvert\hat{f}_x - f_x\rvert \le \varepsilon\sqrt{F_2} ∣ f ^ x − f x ∣ ⩽ ε F 2 O ( ε − 2 log 1 δ ) O(\varepsilon^{-2}\log\frac{1}{\delta}) O ( ε − 2 log δ 1 )
F 2 F_2 F 2 Count Sketch+
4-wise 独立符号
( ε , δ ) (\varepsilon, \delta) ( ε , δ ) O ( ε − 2 log 1 δ ) O(\varepsilon^{-2}\log\frac{1}{\delta}) O ( ε − 2 log δ 1 )
成员查询
Bloom filter
k k k 假阳性 ⩽ ε \le \varepsilon ⩽ ε
O ( log 1 ε ⋅ n ) O(\log\frac{1}{\varepsilon}\cdot n) O ( log ε 1 ⋅ n )
贯穿始终的技术主线:
随机化哈希 作为空间压缩的基本手段——用 O ( log N ) O(\log N) O ( log N ) 无偏性 通过哈希的成对独立性保证,方差控制 可能需要更高阶独立性Mean trick + Median trick 管线系统化地将精度 ε \varepsilon ε δ \delta δ O ( ε − 2 log ( 1 / δ ) ) O\left(\varepsilon^{-2}\log(1/\delta)\right) O ( ε − 2 log ( 1/ δ ) ) 单边误差 vs. 双边误差 的选择取决于应用需求:Count-Min(单边,适合 heavy hitter)vs. Count Sketch(双边,更精确的 L 2 L_2 L 2
Sketching 的本质是「用随机性换空间」 :通过精心设计的随机压缩,在保留关键统计信息的同时,将空间需求从线性降到亚线性乃至对数级。这一思想是处理大数据和流数据的核心算法范式。