从 Sketching 到 Hashing
上两讲中,哈希函数是我们反复使用的工具:Flajolet-Martin 用哈希值的末尾零估计不同元素个数,Count-Min Sketch 用哈希将元素分桶,Bloom filter 用多个哈希函数实现近似成员查询。但我们一直把哈希函数当作黑盒使用——给它一个元素,它返回一个「看起来随机」的值。
本讲要打开这个黑盒。我们将系统地研究哈希的理论基础:什么样的哈希函数「够好」?它需要多少随机性?能在多少空间内实现 O ( 1 ) O(1) O ( 1 )
一切从一个最基本的概率模型开始:将球随机扔进桶里(Balls into Bins) 。
Balls into Bins
随机函数与球桶模型
将 m m m n n n 1 / n m 1/n^m 1/ n m [ m ] [m] [ m ] [ n ] [n] [ n ] f f f f f f 1 / n m 1/n^m 1/ n m
这个看似简单的模型蕴含了丰富的问题:
问题
描述
关注点
Birthday
是否有两个球落入同一桶?
碰撞
Coupon Collector
多少球才能覆盖所有桶?
覆盖
Occupancy
最满的桶有多少球?
最大负载
Pre-image Size
某个桶收到多少球?
桶大小分布
其中占有问题 (Occupancy Problem)与哈希表的性能直接相关——哈希表中最长链表的长度就是最大负载。
最大负载分析
每个桶 i i i X i X_i X i X i ∼ Bin ( m , 1 / n ) X_i \sim \text{Bin}(m, 1/n) X i ∼ Bin ( m , 1/ n ) m m m 1 / n 1/n 1/ n i i i μ = m / n \mu = m/n μ = m / n max 1 ⩽ i ⩽ n X i \max\limits_{1 \le i \le n} X_i 1 ⩽ i ⩽ n max X i
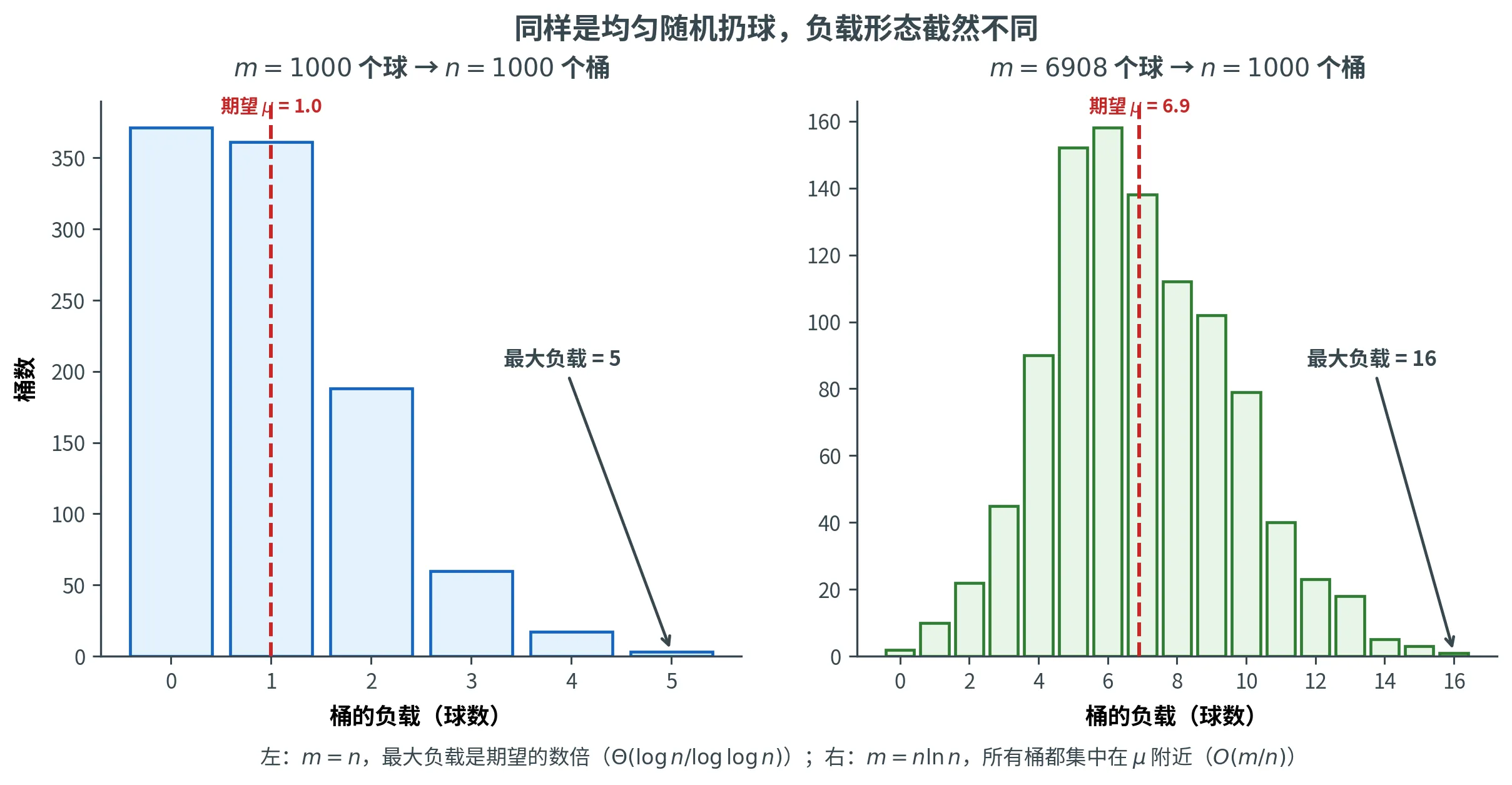
用 Markov 和 Chebyshev 分析这个问题太粗糙了。以 m = n m = n m = n μ = 1 \mu = 1 μ = 1
Markov 只能给出 Pr [ X i ⩾ k ] ⩽ 1 / k \Pr[X_i \ge k] \le 1/k Pr [ X i ⩾ k ] ⩽ 1/ k Pr [ max i X i ⩾ k ] ⩽ n / k \Pr[\max_i X_i \ge k] \le n/k Pr [ max i X i ⩾ k ] ⩽ n / k
Chebyshev 利用 X i ∼ Bin ( n , 1 / n ) X_i \sim \operatorname{Bin}(n, 1/n) X i ∼ Bin ( n , 1/ n ) Var ( X i ) = n p ( 1 − p ) = 1 − p ⩽ 1 \text{Var}(X_i) =np(1-p)=1-p \le 1 Var ( X i ) = n p ( 1 − p ) = 1 − p ⩽ 1 Pr [ ∣ X i − 1 ∣ ⩾ n ] ⩽ 1 / n \Pr[|X_i - 1| \ge \sqrt{n}] \le 1/n Pr [ ∣ X i − 1∣ ⩾ n ] ⩽ 1/ n
最大负载不超过 O ( n ) O(\sqrt{n}) O ( n )
真正有效的工具是 Chernoff bound 。在分析最大负载之前,让我们先完整地建立这个重要的概率工具。
Chernoff Bound
上一讲已经使用过 Chernoff-Hoeffding 界来分析 median trick 的置信度提升。当时直接给出了结论而没有证明(虽然已经在《数据科学基础》课程中证明过 )。本讲将完整推导 Chernoff bound——它不仅是分析 balls into bins 的核心工具,也是本课程中反复出现的技术。
矩生成函数
Chernoff bound 的关键在于矩生成函数 (Moment Generating Function, MGF )。
矩生成函数
随机变量 X X X
M X ( t ) = E [ e t X ] = ∑ k ⩾ 0 t k E [ X k ] k ! M_X(t) = \mathbb{E}[\e^{tX}] = \sum_{k \ge 0} \frac{t^k \mathbb{E}[X^k]}{k!}
M X ( t ) = E [ e tX ] = k ⩾ 0 ∑ k ! t k E [ X k ]
它「编码」了 X X X k k k E [ X k ] \mathbb{E}[X^k] E [ X k ] M X ( k ) ( 0 ) M_X^{(k)}(0) M X ( k ) ( 0 )
为什么矩生成函数比直接用矩更有力?因为对于独立随机变量之和,MGF 有乘法性质:M X + Y ( t ) = M X ( t ) ⋅ M Y ( t ) M_{X+Y}(t) = M_X(t) \cdot M_Y(t) M X + Y ( t ) = M X ( t ) ⋅ M Y ( t ) n n n
独立 Bernoulli 之和的 MGF :设 X 1 , … , X n ∈ { 0 , 1 } X_1, \dots, X_n \in \{0,1\} X 1 , … , X n ∈ { 0 , 1 } Pr [ X i = 1 ] = p i , X = ∑ X i , μ = E [ X ] = ∑ p i \Pr[X_i = 1] = p_i,\, X = \sum X_i,\, \mu = \mathbb{E}[X] = \sum p_i Pr [ X i = 1 ] = p i , X = ∑ X i , μ = E [ X ] = ∑ p i
M X ( t ) = E [ e t X ] = ∏ i = 1 n E [ e t X i ] = ∏ i = 1 n ( e t p i + ( 1 − p i ) ) ⩽ ∏ i = 1 n e ( e t − 1 ) p i = e ( e t − 1 ) μ \begin{aligned}
M_X(t) = \mathbb{E}[\e^{tX}] &= \prod_{i=1}^n \mathbb{E}[\e^{tX_i}] = \prod_{i=1}^n (\e^t p_i + (1 - p_i)) \\
&\le \prod_{i=1}^n \e^{(\e^t - 1)p_i} = \e^{(\e^t - 1)\mu}
\end{aligned}
M X ( t ) = E [ e tX ] = i = 1 ∏ n E [ e t X i ] = i = 1 ∏ n ( e t p i + ( 1 − p i )) ⩽ i = 1 ∏ n e ( e t − 1 ) p i = e ( e t − 1 ) μ
第二步用了独立性(独立随机变量的 MGF 等于各自 MGF 的乘积),第三步对每个因子用了 1 + x ⩽ e x 1 + x \le \e^x 1 + x ⩽ e x e t p i + ( 1 − p i ) = 1 + ( e t − 1 ) p i \e^t p_i + (1 - p_i) = 1 + (\e^t - 1)p_i e t p i + ( 1 − p i ) = 1 + ( e t − 1 ) p i x = ( e t − 1 ) p i x = (\e^t - 1)p_i x = ( e t − 1 ) p i ⩽ e ( e t − 1 ) p i \le \e^{(\e^t - 1)p_i} ⩽ e ( e t − 1 ) p i
上尾界
Chernoff 上尾界
设 X 1 , … , X n ∈ { 0 , 1 } X_1, \dots, X_n \in \{0,1\} X 1 , … , X n ∈ { 0 , 1 } X = ∑ X i , μ = E [ X ] X = \sum X_i,\, \mu = \mathbb{E}[X] X = ∑ X i , μ = E [ X ] δ > 0 \delta > 0 δ > 0
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ ( e δ ( 1 + δ ) ( 1 + δ ) ) μ \Pr[X \ge (1+\delta)\mu] \le \left(\frac{\e^\delta}{(1+\delta)^{(1+\delta)}}\right)^\mu
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ ( ( 1 + δ ) ( 1 + δ ) e δ ) μ
证明
对任意 t > 0 t > 0 t > 0 MGF 界:
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ Pr [ e t X ⩾ e t ( 1 + δ ) μ ] ⩽ e − t ( 1 + δ ) μ ⋅ E [ e t X ] \Pr[X \ge (1+\delta)\mu] \le \Pr[\e^{tX} \ge \e^{t(1+\delta)\mu}] \le \e^{-t(1+\delta)\mu} \cdot \mathbb{E}[\e^{tX}]
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ Pr [ e tX ⩾ e t ( 1 + δ ) μ ] ⩽ e − t ( 1 + δ ) μ ⋅ E [ e tX ]
第二步是 Markov 不等式。
代入 MGF 的上界 E [ e t X ] ⩽ e ( e t − 1 ) μ \mathbb{E}[\e^{tX}] \le \e^{(\e^t - 1)\mu} E [ e tX ] ⩽ e ( e t − 1 ) μ
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ e ( e t − 1 − t ( 1 + δ ) ) μ \Pr[X \ge (1+\delta)\mu] \le \e^{(\e^t - 1 - t(1+\delta))\mu}
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ e ( e t − 1 − t ( 1 + δ )) μ
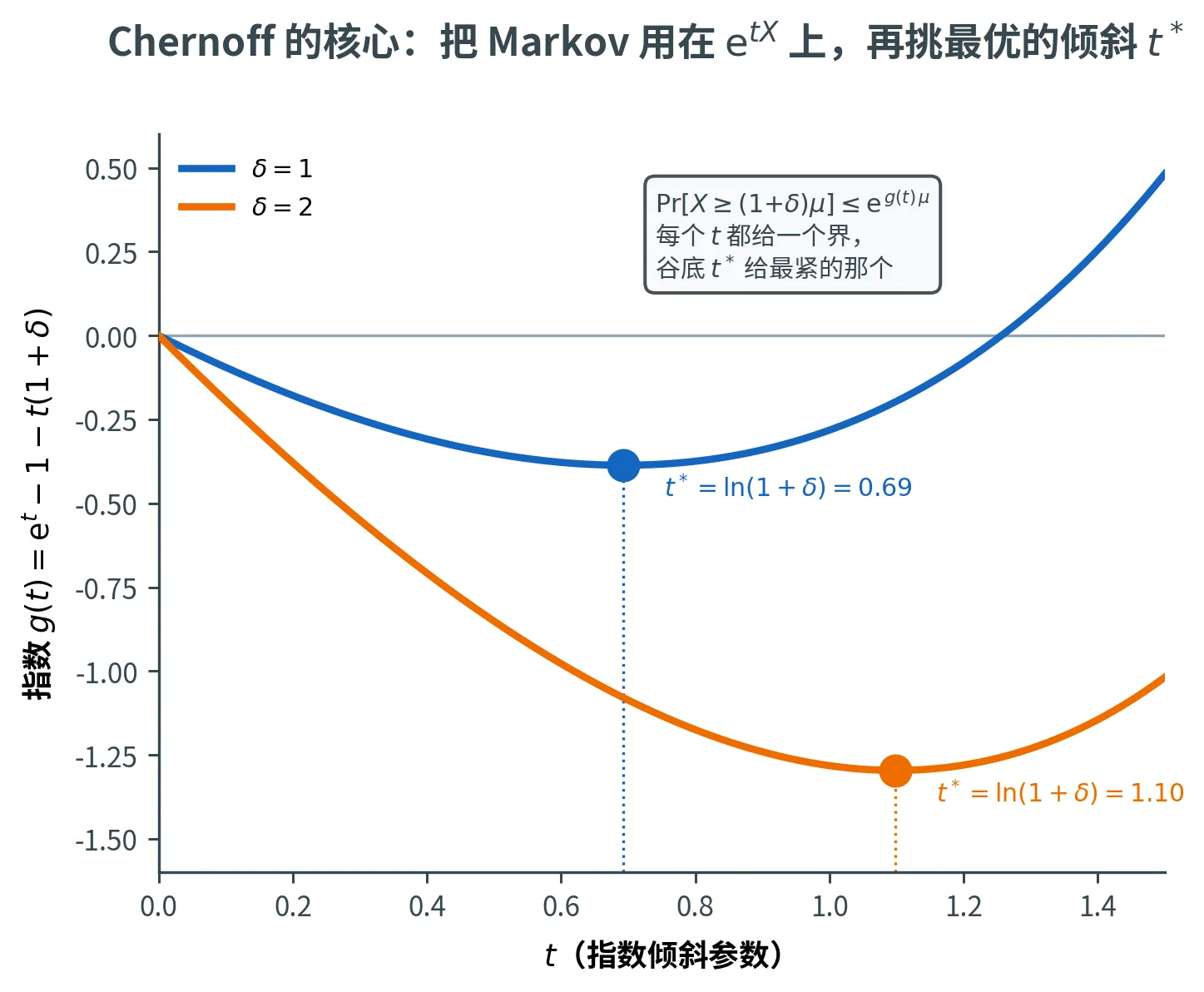
指数中的函数 g ( t ) = e t − 1 − t ( 1 + δ ) g(t) = \e^t - 1 - t(1+\delta) g ( t ) = e t − 1 − t ( 1 + δ ) t = ln ( 1 + δ ) t = \ln(1+\delta) t = ln ( 1 + δ ) g ′ ( t ) = e t − ( 1 + δ ) = 0 g'(t) = \e^t - (1+\delta) = 0 g ′ ( t ) = e t − ( 1 + δ ) = 0
g ( ln ( 1 + δ ) ) = δ − ( 1 + δ ) ln ( 1 + δ ) g(\ln(1+\delta)) = \delta - (1+\delta)\ln(1+\delta)
g ( ln ( 1 + δ )) = δ − ( 1 + δ ) ln ( 1 + δ )
因此
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ e ( δ − ( 1 + δ ) ln ( 1 + δ ) ) μ = ( e δ ( 1 + δ ) ( 1 + δ ) ) μ \Pr[X \ge (1+\delta)\mu] \le \e^{(\delta - (1+\delta)\ln(1+\delta))\mu} = \left(\frac{\e^\delta}{(1+\delta)^{(1+\delta)}}\right)^\mu
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ e ( δ − ( 1 + δ ) l n ( 1 + δ )) μ = ( ( 1 + δ ) ( 1 + δ ) e δ ) μ
证明的精髓在最后一步「取最优的 t t t t > 0 t > 0 t > 0 e g ( t ) μ \e^{g(t)\mu} e g ( t ) μ g ( t ) = e t − 1 − t ( 1 + δ ) g(t) = \e^t - 1 - t(1+\delta) g ( t ) = e t − 1 − t ( 1 + δ ) g ( t ) g(t) g ( t ) t ∗ = ln ( 1 + δ ) t^* = \ln(1+\delta) t ∗ = ln ( 1 + δ ) g ( t ) g(t) g ( t )
下尾界
Chernoff 下尾界
对任意 0 < δ < 1 0 < \delta < 1 0 < δ < 1
Pr [ X ⩽ ( 1 − δ ) μ ] ⩽ ( e − δ ( 1 − δ ) ( 1 − δ ) ) μ \Pr[X \le (1-\delta)\mu] \le \left(\frac{\e^{-\delta}}{(1-\delta)^{(1-\delta)}}\right)^\mu
Pr [ X ⩽ ( 1 − δ ) μ ] ⩽ ( ( 1 − δ ) ( 1 − δ ) e − δ ) μ
证明方法完全对称:取 t = ln ( 1 − δ ) < 0 t = \ln(1-\delta) < 0 t = ln ( 1 − δ ) < 0 Pr [ X ⩽ ( 1 − δ ) μ ] = Pr [ e t X ⩾ e t ( 1 − δ ) μ ] \Pr[X \le (1-\delta)\mu] = \Pr[\e^{tX} \ge \e^{t(1-\delta)\mu}] Pr [ X ⩽ ( 1 − δ ) μ ] = Pr [ e tX ⩾ e t ( 1 − δ ) μ ] t < 0 t < 0 t < 0 MGF 上界。
简化形式
精确的 Chernoff bound 涉及 ( 1 + δ ) ( 1 + δ ) (1+\delta)^{(1+\delta)} ( 1 + δ ) ( 1 + δ )
上尾 :
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ { e − μ δ 2 / 3 若 0 < δ < 1 2 − ( 1 + δ ) μ 若 ( 1 + δ ) ⩾ 2 e \Pr[X \ge (1+\delta)\mu] \le
\begin{cases}
\e^{-\mu\delta^2/3} & \text{若 } 0 < \delta < 1 \\
2^{-(1+\delta)\mu} & \text{若 } (1+\delta) \ge 2\e
\end{cases}
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ { e − μ δ 2 /3 2 − ( 1 + δ ) μ 若 0 < δ < 1 若 ( 1 + δ ) ⩾ 2 e
下尾 :
Pr [ X ⩽ ( 1 − δ ) μ ] ⩽ e − μ δ 2 / 2 \Pr[X \le (1-\delta)\mu] \le \e^{-\mu\delta^2/2}
Pr [ X ⩽ ( 1 − δ ) μ ] ⩽ e − μ δ 2 /2
第一个上尾简化在 δ \delta δ δ \delta δ
何时用哪个简化形式?
需要 ( 1 ± ε ) (1 \pm \varepsilon) ( 1 ± ε ) e − μ δ 2 / 3 \e^{-\mu\delta^2/3} e − μ δ 2 /3
需要证明某事「几乎不可能」(超大偏差)时:用 2 − ( 1 + δ ) μ 2^{-(1+\delta)\mu} 2 − ( 1 + δ ) μ
上一讲中 median trick 的分析实际上用的是 Chernoff-Hoeffding 界(对有界随机变量),与这里的 Bernoulli 版本是同一族的工具
回到最大负载
m = n m = n m = n 现在我们用 Chernoff bound 分析 m = n m = n m = n n n n i i i X i ∼ Bin ( n , 1 / n ) X_i \sim \text{Bin}(n, 1/n) X i ∼ Bin ( n , 1/ n ) μ = 1 \mu = 1 μ = 1
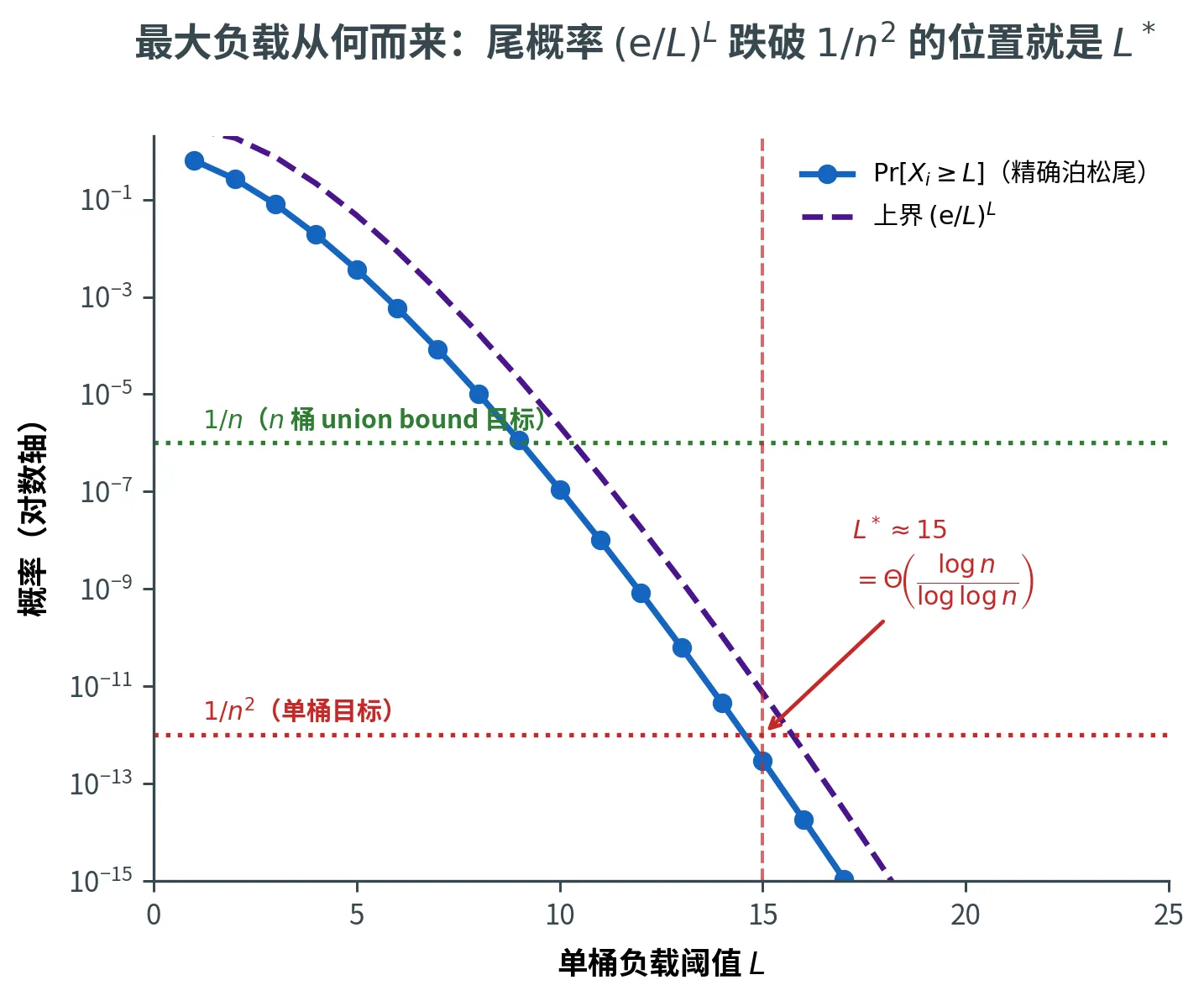
取 L = e ln n ln ln n L = \dfrac{\e\ln n}{\ln\ln n} L = ln ln n e ln n μ = 1 \mu = 1 μ = 1
Pr [ X i ⩾ L ] ⩽ e L e L L \Pr[X_i \ge L] \le \dfrac{\e^L}{\e L^L}
Pr [ X i ⩾ L ] ⩽ e L L e L
代入 L L L L ln ( L / e ) = e ln n ln ln n ⋅ ln ( ln n ln ln n ) = e ln n ln ln n ( ln ln n − ln ln ln n ) ≈ e ln n L \ln(L/\e) = \dfrac{\e\ln n}{\ln\ln n} \cdot \ln\left(\dfrac{\ln n}{\ln\ln n}\right) = \dfrac{\e\ln n}{\ln\ln n}(\ln\ln n - \ln\ln\ln n) \approx \e\ln n L ln ( L / e ) = ln ln n e ln n ⋅ ln ( ln ln n ln n ) = ln ln n e ln n ( ln ln n − ln ln ln n ) ≈ e ln n n n n ( e / L ) L ⩽ 1 / n 2 (\e/L)^L \le 1/n^2 ( e / L ) L ⩽ 1/ n 2 n n n
Pr [ X i ⩾ L ] ⩽ e L e L L ⩽ 1 n 2 \Pr[X_i \ge L] \le \dfrac{\e^L}{\e L^L} \le \frac{1}{n^2}
Pr [ X i ⩾ L ] ⩽ e L L e L ⩽ n 2 1
最后一步需要 L ln ( L / e ) ⩾ 2 ln n L\ln(L/\e) \ge 2\ln n L ln ( L / e ) ⩾ 2 ln n n n n
由联合界 (union bound):
Pr [ max 1 ⩽ i ⩽ n X i ⩾ L ] ⩽ ∑ i = 1 n Pr [ X i ⩾ L ] ⩽ n ⋅ 1 n 2 = 1 n \Pr\left[\max_{1 \le i \le n} X_i \ge L\right] \le \sum_{i=1}^n \Pr[X_i \ge L] \le n \cdot \frac{1}{n^2} = \frac{1}{n}
Pr [ 1 ⩽ i ⩽ n max X i ⩾ L ] ⩽ i = 1 ∑ n Pr [ X i ⩾ L ] ⩽ n ⋅ n 2 1 = n 1
因此,以高概率(with high probability, w.h.p.),最大负载为
max 1 ⩽ i ⩽ n X i = O ( log n log log n ) \max_{1 \le i \le n} X_i = O\left(\frac{\log n}{\log\log n}\right)
1 ⩽ i ⩽ n max X i = O ( log log n log n )
为什么是 log n / log log n \log n / \log\log n log n / log log n log n \log n log n
直觉上,L L L ( 1 / n ) L (1/n)^L ( 1/ n ) L n n n L L L n ⋅ ( 1 / n ) L ≈ 1 n \cdot (1/n)^L \approx 1 n ⋅ ( 1/ n ) L ≈ 1 n 1 − L ≈ 1 n^{1-L} \approx 1 n 1 − L ≈ 1 L ≈ 1 L \approx 1 L ≈ 1
更精确地,Pr [ X i ⩾ L ] ≈ ( n L ) ( 1 / n ) L ≈ ( e / L ) L \Pr[X_i \ge L] \approx \binom{n}{L}(1/n)^L \approx (\e/L)^L Pr [ X i ⩾ L ] ≈ ( L n ) ( 1/ n ) L ≈ ( e / L ) L ( e / L ) L = 1 / n 2 (\e/L)^L = 1/n^2 ( e / L ) L = 1/ n 2 L ( ln L − 1 ) ≈ 2 ln n L(\ln L - 1) \approx 2\ln n L ( ln L − 1 ) ≈ 2 ln n L = Θ ( log n / log log n ) L = \Theta(\log n / \log\log n) L = Θ ( log n / log log n )
下图把这套推导画了出来(取 n = 10 6 n = 10^6 n = 1 0 6 Pr [ X i ⩾ L ] \Pr[X_i \ge L] Pr [ X i ⩾ L ] L L L ( e / L ) L (\e/L)^L ( e / L ) L L ∗ = Θ ( log n / log log n ) L^* = \Theta(\log n/\log\log n) L ∗ = Θ ( log n / log log n ) 1 / n 2 1/n^2 1/ n 2 n n n ⩾ 1 − 1 / n \ge 1 - 1/n ⩾ 1 − 1/ n L ∗ L^* L ∗
m ⩾ n ln n m \ge n\ln n m ⩾ n ln n 当球数远多于桶数时,每个桶的期望负载 μ = m / n ⩾ ln n \mu = m/n \ge \ln n μ = m / n ⩾ ln n ( 1 + δ ) = 2 e (1+\delta) = 2\e ( 1 + δ ) = 2 e
Pr [ X i ⩾ 2 e m n ] = Pr [ X i ⩾ 2 e μ ] ⩽ 2 − 2 e μ ⩽ 2 − 2 e ln n ⩽ 1 n 2 \Pr\left[X_i \ge \frac{2\e m}{n}\right] = \Pr[X_i \ge 2\e\mu] \le 2^{-2\e\mu} \le 2^{-2\e\ln n} \le \frac{1}{n^2}
Pr [ X i ⩾ n 2 e m ] = Pr [ X i ⩾ 2 e μ ] ⩽ 2 − 2 e μ ⩽ 2 − 2 e l n n ⩽ n 2 1
联合界得到 max i X i = O ( m / n ) \max_i X_i = O(m/n) max i X i = O ( m / n ) m / n m/n m / n
下图用同一套均匀随机扔球的实验对照这两种情形:m = n m = n m = n 5 5 5 1 1 1 m = n ln n m = n\ln n m = n ln n μ ≈ 6.9 \mu \approx 6.9 μ ≈ 6.9
Power of Two Choices
从 log n / log log n \log n / \log\log n log n / log log n log log n \log\log n log log n
O ( log n / log log n ) O(\log n / \log\log n) O ( log n / log log n ) 给每个球两个候选桶,选负载更小的那个 。
Power of Two Choices
每个球独立均匀随机选择两个桶 h 1 ( x ) h_1(x) h 1 ( x ) h 2 ( x ) h_2(x) h 2 ( x )
这个看似微小的改变带来了指数级的改进:最大负载从 Θ ( log n / log log n ) \Theta(\log n / \log\log n) Θ ( log n / log log n ) Θ ( log log n ) \Theta(\log\log n) Θ ( log log n )
直觉分析
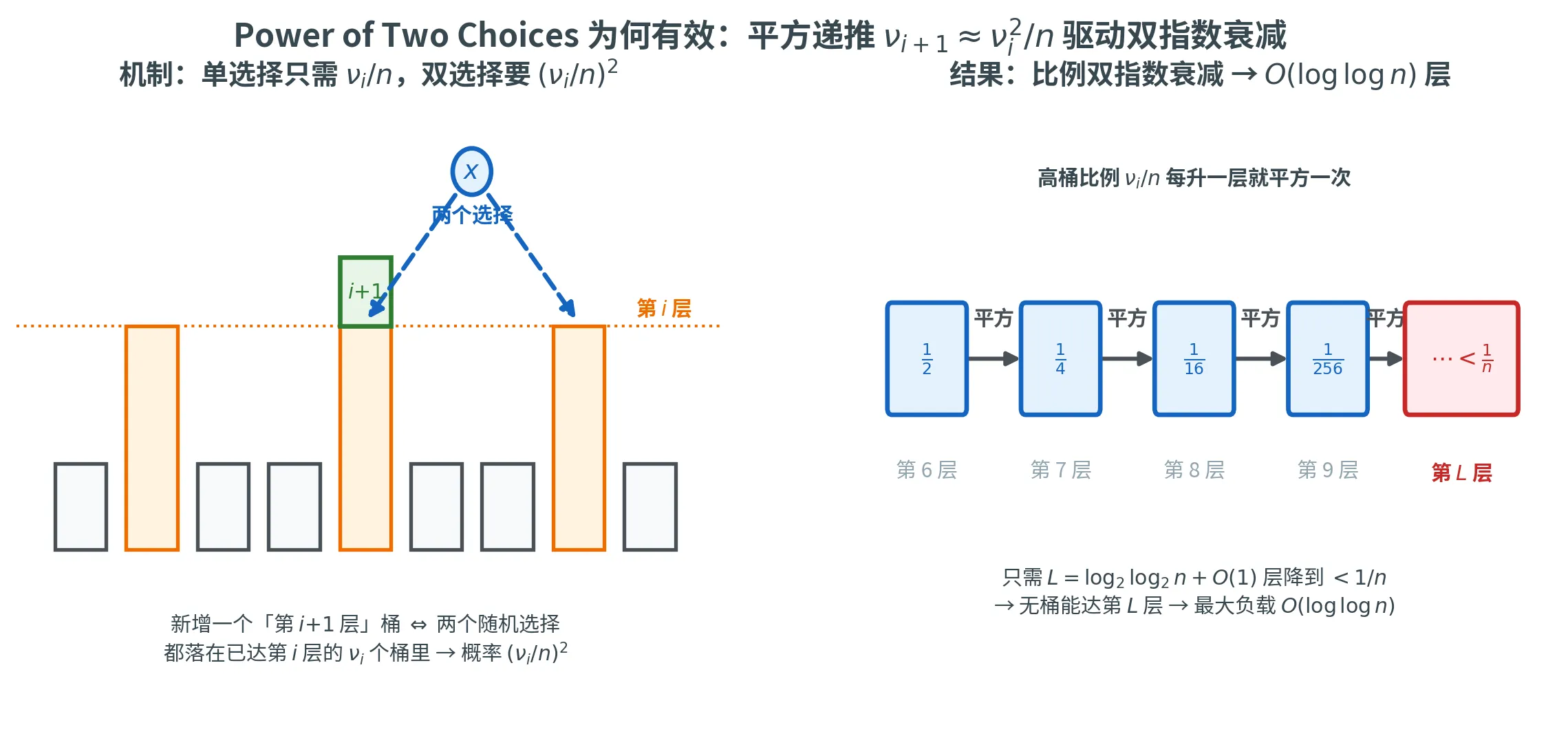
为什么两个选择的效果如此显著?定义 B i B_i B i ⩾ i \ge i ⩾ i
在单选择方案中,一个球落入负载 ⩾ i \ge i ⩾ i B i / n B_i / n B i / n ⩾ i \ge i ⩾ i 两个 候选桶的负载都 ⩾ i − 1 \ge i-1 ⩾ i − 1 ( B i − 1 / n ) 2 (B_{i-1}/n)^2 ( B i − 1 / n ) 2
E [ B i ] ≈ n ⋅ ( B i − 1 / n ) 2 = B i − 1 2 / n \mathbb{E}[B_i] \approx n \cdot (B_{i-1}/n)^2 = B_{i-1}^2 / n
E [ B i ] ≈ n ⋅ ( B i − 1 / n ) 2 = B i − 1 2 / n
这意味着 B i / n ≈ ( B i − 1 / n ) 2 B_i / n \approx (B_{i-1}/n)^2 B i / n ≈ ( B i − 1 / n ) 2 平方衰减 。从 B 2 / n ⩽ 1 / 2 B_2/n \le 1/2 B 2 / n ⩽ 1/2
B 2 + j n ⩽ 1 2 2 j \frac{B_{2+j}}{n} \le \frac{1}{2^{2^j}}
n B 2 + j ⩽ 2 2 j 1
最大负载 L L L B L / n < 1 / n B_L/n < 1/n B L / n < 1/ n 2 2 L − 2 > n 2^{2^{L-2}} > n 2 2 L − 2 > n L ≈ log 2 log 2 n + O ( 1 ) L \approx \log_2\log_2 n + O(1) L ≈ log 2 log 2 n + O ( 1 )
从 1 到 2 的飞跃
增加到三个或更多选择只会带来边际改善——真正的飞跃发生在从 1 个选择到 2 个选择之间。这使得 power of two choices 成为一个极具性价比的策略:仅多做一次比较,就获得指数级的负载均衡改进。
这个原理在实践中被广泛应用于负载均衡系统(如 HAProxy、Nginx):不是将请求随机分配到一台服务器,而是随机选两台、挑负载低的那台。
严格证明
严格证明采用逐层归纳 的策略:定义「负载至少为 i i i ν i \nu_i ν i β i \beta_i β i i i i E i : ν i ⩽ β i \mathcal{E}_i \colon \nu_i \le \beta_i E i : ν i ⩽ β i 1 − O ( 1 / n ) 1-O(1/n) 1 − O ( 1/ n ) β i \beta_i β i < 1 <1 < 1 i i i L < i L < i L < i
下图概括了整个论证的两个引擎。左侧是平方机制 :要把某个桶从第 i i i i + 1 i+1 i + 1 都 落在已达第 i i i ν i \nu_i ν i ( ν i / n ) 2 (\nu_i/n)^2 ( ν i / n ) 2 ν i / n \nu_i/n ν i / n 双指数衰减 :高层桶的比例 ν i / n \nu_i/n ν i / n log 2 log 2 n + O ( 1 ) \log_2\log_2 n + O(1) log 2 log 2 n + O ( 1 ) 1 / n 1/n 1/ n O ( log log n ) O(\log\log n) O ( log log n )
定义阈值序列 β 6 = n / 6 , β i + 1 = 2 e β i 2 / n \beta_6 = n/6, \beta_{i+1} = 2\e\beta_i^2/n β 6 = n /6 , β i + 1 = 2 e β i 2 / n E i : 负载 ⩾ i 的桶数 ν i ⩽ β i \mathcal{E}_i\colon \text{负载 }\ge i\text{ 的桶数 }\nu_i \le \beta_i E i : 负载 ⩾ i 的桶数 ν i ⩽ β i Pr [ ⋀ i E i ] = ∏ i Pr [ E i ∣ E < i ] ⩾ 1 − O ( 1 / n ) \Pr[\bigwedge_i \mathcal{E}_i] = \prod_i \Pr[\mathcal{E}_i \mid \mathcal{E}_{<i}] \ge 1 - O(1/n) Pr [ ⋀ i E i ] = ∏ i Pr [ E i ∣ E < i ] ⩾ 1 − O ( 1/ n )
ν i \nu_i ν i ⩾ i \ge i ⩾ i β i \beta_i β i ν i \nu_i ν i ν i ⩽ β i \nu_i \le \beta_i ν i ⩽ β i E i \mathcal{E}_i E i { ν i ⩽ β i } \left\lbrace \nu_i \le \beta_i\right\rbrace { ν i ⩽ β i }
通过构造一个上界序列 β i \beta_i β i E i \mathcal E_i E i β i < 1 \beta_i<1 β i < 1 ν i = 0 \nu_i=0 ν i = 0
递推式 β i + 1 = 2 e β i 2 / n \beta_{i+1} = 2\e\beta_i^2/n β i + 1 = 2 e β i 2 / n ν i + 1 ≈ ν i 2 / n \nu_{i+1} \approx \nu_i^2 / n ν i + 1 ≈ ν i 2 / n 2 e 2\e 2 e Pr ( X ⩾ L ) ⩽ 2 − L ( L ⩾ 2 e μ ) \Pr(X \ge L) \le 2^{-L}\quad(L \ge 2\e \mu) Pr ( X ⩾ L ) ⩽ 2 − L ( L ⩾ 2 e μ )
在 two choices 下,只有当这个球的两个候选桶都已经负载至少 i i i ( i + 1 ) (i+1) ( i + 1 ) ⩾ i \ge i ⩾ i β i \beta_i β i i i i ( β i / n ) 2 \left(\beta_i / n\right)^2 ( β i / n ) 2
总共有 n n n i + 1 i+1 i + 1 ( β i / n ) 2 (\beta_i/n)^2 ( β i / n ) 2 E i \mathcal{E}_i E i ⩾ i \ge i ⩾ i B i n ( n , β i 2 / n 2 ) \mathrm{Bin}(n, \beta_i^2/n^2) Bin ( n , β i 2 / n 2 )
严格说这些事件不是独立的,所以不能说「恰好服从」二项分布;更准确的说法是:
在事件 E i \mathcal E_i E i ν i + 1 \nu_{i+1} ν i + 1 B i n ( n , β i 2 / n 2 ) \mathrm{Bin}\left(n,\beta_i^2/n^2\right) Bin ( n , β i 2 / n 2 )
ν i + 1 ⪯ B i n ( n , β i 2 n 2 ) \nu_{i+1}\preceq\mathrm{Bin}\left(n,\frac{\beta_i^2}{n^2}\right)
ν i + 1 ⪯ Bin ( n , n 2 β i 2 )
令 X ∼ B i n ( n , β i 2 / n 2 ) , μ = E [ X ] = β i 2 / n X \sim \mathrm{Bin}(n, \beta_i^2 / n^2),\, \mu = \mathbb{E}[X] = \beta_i^2 / n X ∼ Bin ( n , β i 2 / n 2 ) , μ = E [ X ] = β i 2 / n Pr [ X ⩾ 2 e μ ] ⩽ 2 − 2 e μ \Pr[X \ge 2\e\mu] \le 2^{-2\e\mu} Pr [ X ⩾ 2 e μ ] ⩽ 2 − 2 e μ
Pr [ X ⩾ β i + 1 ] = Pr [ X ⩾ 2 e μ ] ⩽ 2 − 2 e μ = 2 − 2 e β i 2 / n \Pr[X \ge \beta_{i+1}] = \Pr[X \ge 2\e\mu] \le 2^{-2\e\mu} = 2^{-2\e\beta_i^2/n}
Pr [ X ⩾ β i + 1 ] = Pr [ X ⩾ 2 e μ ] ⩽ 2 − 2 e μ = 2 − 2 e β i 2 / n
即
Pr [ ¬ E i + 1 ∣ E ⩽ i ] ⩽ 2 − 2 e β i 2 / n \Pr[\lnot\mathcal{E}_{i+1} \mid \mathcal{E}_{\le i}] \le 2^{-2\e\beta_i^2/n}
Pr [ ¬ E i + 1 ∣ E ⩽ i ] ⩽ 2 − 2 e β i 2 / n
第一种情况:当 β i 2 / n ⩾ log 2 n \beta_i^2/n \ge \log_2 n β i 2 / n ⩾ log 2 n Pr [ ¬ E i + 1 ∣ E ⩽ i ] ⩽ 1 / n 2 e \Pr[\lnot\mathcal{E}_{i+1} \mid \mathcal{E}_{\le i}] \le 1/n^{2\e} Pr [ ¬ E i + 1 ∣ E ⩽ i ] ⩽ 1/ n 2 e O ( log log n ) O(\log\log n) O ( log log n ) Pr [ ⋀ i E i ] ⩾ 1 − O ( 1 / n ) \Pr\left[\bigwedge_i \mathcal E_i\right]\ge 1-O(1/n) Pr [ ⋀ i E i ] ⩾ 1 − O ( 1/ n )
第二种情况:当 β i 2 / n < log 2 n \beta_i^2 / n < \log_2 n β i 2 / n < log 2 n ν i ⩽ β i < n log 2 n \nu_i \le \beta_i < \sqrt{n \log_2 n} ν i ⩽ β i < n log 2 n μ i = β i 2 / n < log 2 n \mu_i = \beta_i^2 / n < \log_2 n μ i = β i 2 / n < log 2 n ν i + 1 \nu_{i+1} ν i + 1 O ( log n ) O(\log n) O ( log n ) C > 2 e C > 2\e C > 2 e C = 6 C=6 C = 6
Pr [ ν i + 1 ⩾ C log 2 n ∣ E i ] ⩽ 2 − C log 2 n = 1 n C ⩽ 1 n 2 \Pr[\nu_{i+1} \ge C\log_2 n \mid \mathcal{E}_i] \le 2^{-C\log_2 n} = \frac{1}{n^C} \le \frac{1}{n^2}
Pr [ ν i + 1 ⩾ C log 2 n ∣ E i ] ⩽ 2 − C l o g 2 n = n C 1 ⩽ n 2 1
若进一步有 ν i + 1 < C log n \nu_{i+1} < C \log n ν i + 1 < C log n i + 2 i+2 i + 2 ( C log n / n ) 2 (C\log n / n)^2 ( C log n / n ) 2
Pr [ ν i + 2 ⩾ 1 ∣ ν i + 1 < C log n ] ⩽ n ( C log n n ) 2 = O ( log 2 n n ) \Pr[\nu_{i+2} \ge 1 \mid \nu_{i+1} < C \log n] \le n \left(\frac{C\log n}{n}\right)^2 = O\left(\frac{\log^2 n}{n}\right)
Pr [ ν i + 2 ⩾ 1 ∣ ν i + 1 < C log n ] ⩽ n ( n C log n ) 2 = O ( n log 2 n )
因此再往上两层,ν i + 2 = 0 \nu_{i+2} = 0 ν i + 2 = 0 1 − O ( log 2 n / n ) 1 - O(\log^2 n / n) 1 − O ( log 2 n / n ) Pr [ E i + 2 ∣ E i ] ⩾ 1 − O ( log 2 n / n ) \Pr[\mathcal{E}_{i+2} \mid \mathcal{E}_i] \ge 1 - O(\log^2 n / n) Pr [ E i + 2 ∣ E i ] ⩾ 1 − O ( log 2 n / n ) i + 2 i+2 i + 2
在情况一中,阈值满足递推
β i + 1 = 2 e β i 2 n \beta_{i+1}=\frac{2e\beta_i^2}{n}
β i + 1 = n 2 e β i 2
这表明 β i / n \beta_i/n β i / n j j j β 6 + j n ⩽ 2 − 2 j \frac{\beta_{6+j}}{n}\le 2^{-2^j} n β 6 + j ⩽ 2 − 2 j
当 β i 2 n < log n \frac{\beta_i^2}{n}<\log n n β i 2 < log n i = log 2 log n + O ( 1 ) i=\log_2\log n+O(1) i = log 2 log n + O ( 1 )
进入情况二后,再经过至多两层,负载达到该层的桶数就降为 0。因此再多经过常数层后,就以高概率不存在负载达到该层的桶。
综上,最大负载满足
L max ⩽ log 2 log n + O ( 1 ) with high probability L_{\max}\le \log_2\log n + O(1) \qquad \text{with high probability}
L m a x ⩽ log 2 log n + O ( 1 ) with high probability
Birthday Paradox
经典分析
Birthday paradox (生日佯谬)是 balls into bins 最经典的应用:在一个班级中,58 个人就有超过 99 % 99\% 99%
Birthday Paradox
将 n n n m m m n , m n, m n , m m m m n n n
Pr [ 无碰撞 ] = ∏ i = 0 n − 1 ( 1 − i m ) \Pr[\text{无碰撞}] = \prod_{i=0}^{n-1} \left(1 - \frac{i}{m}\right)
Pr [ 无碰撞 ] = i = 0 ∏ n − 1 ( 1 − m i )
用链式法则理解:第 1 个球任意放,第 2 个球避开 1 个桶的概率为 ( 1 − 1 / m ) (1-1/m) ( 1 − 1/ m ) i i i i − 1 i-1 i − 1 ( 1 − ( i − 1 ) / m ) (1-(i-1)/m) ( 1 − ( i − 1 ) / m )
利用近似 1 − x ≈ exp ( − x ) 1 - x \approx \exp(-x) 1 − x ≈ exp ( − x ) x = o ( 1 ) x = o(1) x = o ( 1 )
Pr [ 无碰撞 ] ≈ ∏ i = 0 n − 1 exp ( − i m ) = exp ( − n ( n − 1 ) 2 m ) ≈ exp ( − n 2 2 m ) \Pr[\text{无碰撞}] \approx \prod_{i=0}^{n-1} \exp\left(-\tfrac{i}{m}\right) = \exp\left(\tfrac{-n(n-1)}{2m}\right) \approx \exp\left(-\tfrac{n^2}{2m}\right)
Pr [ 无碰撞 ] ≈ i = 0 ∏ n − 1 exp ( − m i ) = exp ( 2 m − n ( n − 1 ) ) ≈ exp ( − 2 m n 2 )
令碰撞概率为 1 − p 1 - p 1 − p
n ≈ 2 m ln ( 1 / p ) n \approx \sqrt{2m \ln(1/p)}
n ≈ 2 m ln ( 1/ p )
个球就有概率 1 − p 1 - p 1 − p m = 365 , p = 0.5 m = 365,\, p = 0.5 m = 365 , p = 0.5 n ≈ 23 n \approx 23 n ≈ 23
成对独立下的 Birthday Paradox
上面的分析需要球的位置完全独立 。如果我们只有 2-universal 哈希函数(成对独立,Pr [ h ( x i ) = h ( x j ) ] ⩽ 1 m \Pr[h(x_i) = h(x_j)] \le \frac{1}{m} Pr [ h ( x i ) = h ( x j )] ⩽ m 1
定义碰撞数 Y = ∑ i < j I [ X i = X j ] Y = \sum_{i < j} \mathbb{I}[X_i = X_j] Y = ∑ i < j I [ X i = X j ] X i = h ( x i ) X_i = h(x_i) X i = h ( x i ) i i i
E [ Y ] = ∑ i < j Pr [ X i = X j ] ⩽ ∑ i < j 1 m = ( n 2 ) ⋅ 1 m = n ( n − 1 ) 2 m ⩽ n 2 2 m \mathbb{E}[Y] = \sum_{i < j} \Pr[X_i = X_j] \le \sum_{i<j} \dfrac{1}{m} = \binom{n}{2} \cdot \frac{1}{m} = \frac{n(n-1)}{2m} \le \frac{n^2}{2m}
E [ Y ] = i < j ∑ Pr [ X i = X j ] ⩽ i < j ∑ m 1 = ( 2 n ) ⋅ m 1 = 2 m n ( n − 1 ) ⩽ 2 m n 2
当 n ⩽ 2 m ε n \le \sqrt{2m\varepsilon} n ⩽ 2 m ε E [ Y ] ⩽ ε \mathbb{E}[Y] \le \varepsilon E [ Y ] ⩽ ε
Pr [ 有碰撞 ] = Pr [ Y ⩾ 1 ] ⩽ E [ Y ] ⩽ ε \Pr[\text{有碰撞}] = \Pr[Y \ge 1] \le \mathbb{E}[Y] \le \varepsilon
Pr [ 有碰撞 ] = Pr [ Y ⩾ 1 ] ⩽ E [ Y ] ⩽ ε
这个结论的意义在于:birthday paradox 只需要成对独立 ——2-universal 哈希函数就足够了。这为后面的完美哈希奠定了基础。
哈希表
字典问题
字典问题
数据 :一个集合 S = { x 1 , … , x n } ⊆ U = [ N ] S = \{x_1, \dots, x_n\} \subseteq U = [N] S = { x 1 , … , x n } ⊆ U = [ N ] 查询 :给定 x ∈ U x \in U x ∈ U x ∈ S x \in S x ∈ S
表示一个 n n n log 2 ( N n ) = O ( n log N ) \log_2\binom{N}{n} = O(n\log N) log 2 ( n N ) = O ( n log N )
数据结构
空间
查询时间
更新时间
平衡搜索树
O ( n log N ) O(n\log N) O ( n log N ) O ( log n ) O(\log n) O ( log n ) O ( log n ) O(\log n) O ( log n )
链式哈希表
O ( n log N ) O(n\log N) O ( n log N ) 期望 O ( 1 ) O(1) O ( 1 )
期望 O ( 1 ) O(1) O ( 1 )
完美哈希
O ( n log N ) O(n\log N) O ( n log N ) O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 )
链式哈希表
回顾:链式哈希表
选取哈希函数 h : U → [ m ] h\colon U \to [m] h : U → [ m ] m m m x x x L h ( x ) L_{h(x)} L h ( x )
Insert(x x x :计算 h ( x ) h(x) h ( x ) O ( 1 ) O(1) O ( 1 ) Search(x x x :计算 h ( x ) h(x) h ( x ) L h ( x ) L_{h(x)} L h ( x ) Remove(x x x :从链表中删除 — O ( 1 ) O(1) O ( 1 )
最坏情况下,所有元素哈希到同一位置,查询退化为 Θ ( n ) \Theta(n) Θ ( n )
链式哈希表的性能完全取决于哈希函数的质量。如果使用 SUHA (Simple Uniform Hash Assumption,即完全随机的哈希函数),期望链表长度为 n / m n/m n / m O ( 1 ) O(1) O ( 1 ) m = Θ ( n ) m = \Theta(n) m = Θ ( n ) Ω ( N log m ) \Omega(N\log m) Ω ( N log m )
这就引出了核心问题:能否用少量随机比特描述一个「足够好」的哈希函数?
Universal Hashing
定义
Carter 和 Wegman(1979)提出的 universal hashing 正是对「足够好」的精确刻画。
k k k
一个哈希函数族 H = { h : U → [ m ] } \mathcal{H} = \{h\colon U \to [m]\} H = { h : U → [ m ]} k k k ⩽ k \le k ⩽ k x 1 , … , x k ∈ U x_1, \dots, x_k \in U x 1 , … , x k ∈ U
Pr h ∼ H [ h ( x 1 ) = ⋯ = h ( x k ) ] ⩽ 1 m k − 1 \Pr_{h \sim \mathcal{H}}[h(x_1) = \dots = h(x_k)] \le \frac{1}{m^{k-1}}
h ∼ H Pr [ h ( x 1 ) = ⋯ = h ( x k )] ⩽ m k − 1 1
更强的版本:H \mathcal{H} H strongly k k k (k k k ⩽ k \le k ⩽ k y 1 , … , y k ∈ [ m ] y_1, \dots, y_k \in [m] y 1 , … , y k ∈ [ m ]
Pr h ∼ H [ ⋀ i = 1 k h ( x i ) = y i ] = 1 m k \Pr_{h \sim \mathcal{H}}\left[\bigwedge_{i=1}^k h(x_i) = y_i\right] = \frac{1}{m^k}
h ∼ H Pr [ i = 1 ⋀ k h ( x i ) = y i ] = m k 1
k k k k k k k k k k k k k k k k k k k k k k = 2 k = 2 k = 2
线性同余构造
线性同余哈希族
选取大于 N N N p p p
H = { h a , b ( x ) = ( ( a x + b ) m o d p ) m o d m ∣ a ∈ Z p ∖ { 0 } , b ∈ Z p } \mathcal{H} = \{h_{a,b}(x) = ((ax + b) \bmod p) \bmod m \mid a \in \mathbb{Z}_p \setminus \{0\},\, b \in \mathbb{Z}_p\}
H = { h a , b ( x ) = (( a x + b ) mod p ) mod m ∣ a ∈ Z p ∖ { 0 } , b ∈ Z p }
该族是 2-wise 独立 的。描述一个函数 h a , b h_{a,b} h a , b a , b a, b a , b O ( log N ) O(\log N) O ( log N )
推广到 k k k :使用 Z p \mathbb{Z}_p Z p k − 1 k-1 k − 1
h a 0 , … , a k − 1 ( x ) = ( ∑ i = 0 k − 1 a i x i m o d p ) m o d m h_{a_0, \dots, a_{k-1}}(x) = \left(\sum_{i=0}^{k-1} a_i x^i \bmod p\right) \bmod m
h a 0 , … , a k − 1 ( x ) = ( i = 0 ∑ k − 1 a i x i mod p ) mod m
可以构造 k k k k k k O ( k log N ) O(k\log N) O ( k log N )
二进制域上的构造 :对于 GF ( 2 w ) → GF ( 2 l ) \text{GF}(2^w) \to \text{GF}(2^l) GF ( 2 w ) → GF ( 2 l ) GF ( 2 w ) \text{GF}(2^w) GF ( 2 w ) 2 w 2^w 2 w h a , b ( x ) = ( a ⋅ x + b ) ≫ ( w − l ) h_{a,b}(x) = (a \cdot x + b) \gg (w - l) h a , b ( x ) = ( a ⋅ x + b ) ≫ ( w − l ) GF ( 2 w ) \text{GF}(2^w) GF ( 2 w )
Perfect Hashing
现在我们有了理论上「够好」的哈希函数族。下一个问题是:能否实现 O ( 1 ) O(1) O ( 1 ) 最坏情况 查询时间?链式哈希表只能保证期望 O ( 1 ) O(1) O ( 1 ) Θ ( n ) \Theta(n) Θ ( n )
一级完美哈希
最直接的想法:选一个哈希函数 h : [ N ] → [ m ] h\colon [N] \to [m] h : [ N ] → [ m ] S S S n n n O ( 1 ) O(1) O ( 1 )
由 birthday paradox(成对独立版本),使用 2-universal 哈希族,取 m > ( n 2 ) m > \binom{n}{2} m > ( 2 n ) m = Θ ( n 2 ) m = \Theta(n^2) m = Θ ( n 2 )
Pr [ 不完美 ] ⩽ n ( n − 1 ) 2 m < 1 \Pr[\text{不完美}] \le \frac{n(n-1)}{2m} < 1
Pr [ 不完美 ] ⩽ 2 m n ( n − 1 ) < 1
因此存在一个 h ∈ H h \in \mathcal{H} h ∈ H S S S O ( 1 ) O(1) O ( 1 ) O ( n 2 ) O(n^2) O ( n 2 ) n n n
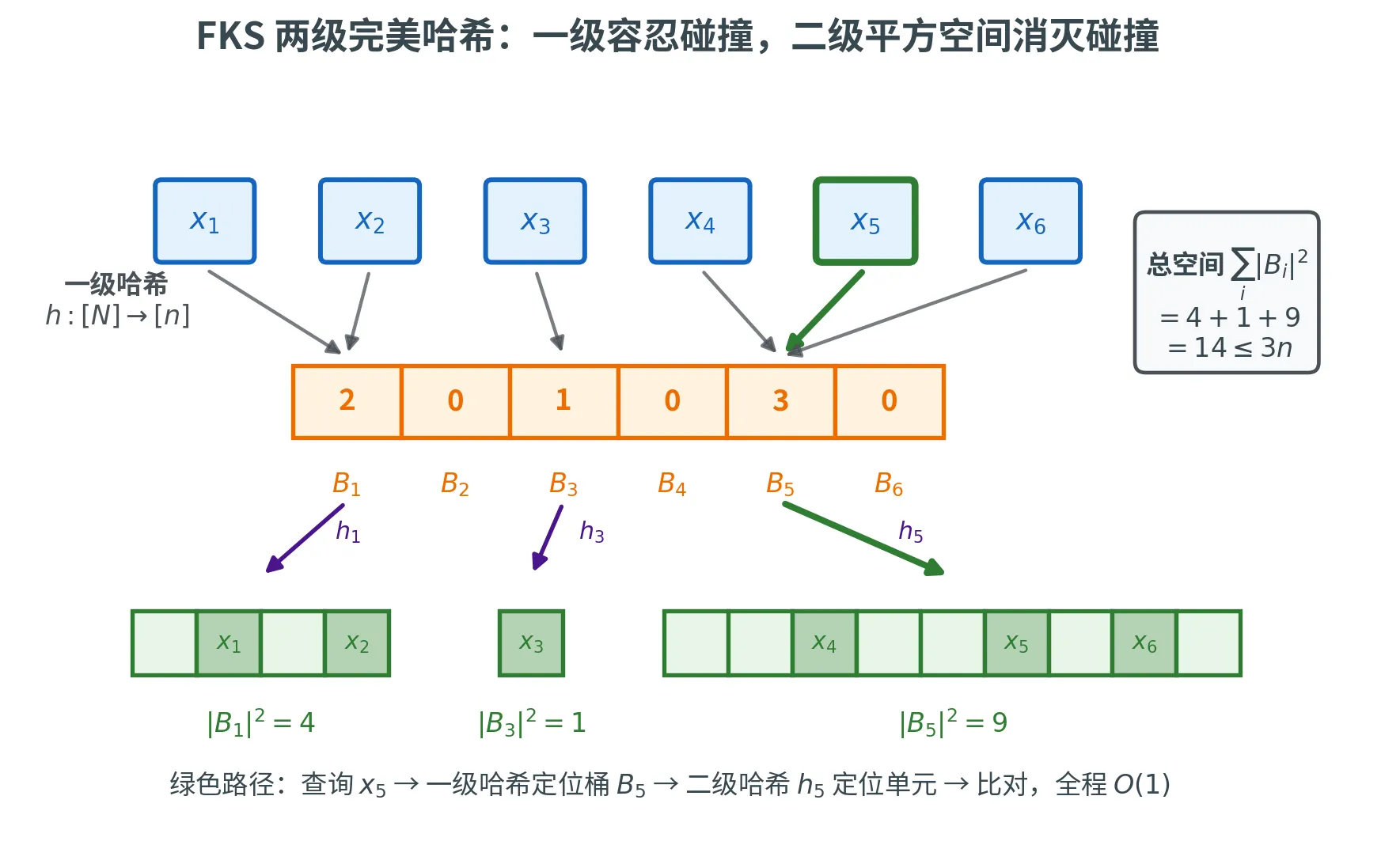
FKS 两级完美哈希Fredman、Komlós 和 Szemerédi (1984) 给出了一个精妙的两级方案,将空间降到了 O ( n ) O(n) O ( n ) n = ∑ i n i , ∑ i n i 2 = O ( n ) n = \sum_i n_i,\, \sum_i n_i^2 = O(n) n = ∑ i n i , ∑ i n i 2 = O ( n )
FKS Perfect Hashing
分级:
第一级 :用 2-universal 哈希 h : [ N ] → [ n ] h\colon [N] \to [n] h : [ N ] → [ n ] n n n n n n i i i B i B_i B i 第二级 :对每个桶 B i B_i B i 独立的 2-universal 哈希 h i : [ N ] → [ ∣ B i ∣ 2 ] h_i\colon [N] \to [|B_i|^2] h i : [ N ] → [ ∣ B i ∣ 2 ] ∣ B i ∣ 2 |B_i|^2 ∣ B i ∣ 2
查询 x x x :
计算 i = h ( x ) i = h(x) i = h ( x ) i i i
计算 h i ( x ) h_i(x) h i ( x ) i i i
检查该位置是否存储了 x x x
下图用一个 n = 6 n = 6 n = 6 6 6 6 6 6 6 B 1 , B 3 , B 5 B_1, B_3, B_5 B 1 , B 3 , B 5 2 , 1 , 3 2, 1, 3 2 , 1 , 3 B i B_i B i ∣ B i ∣ 2 |B_i|^2 ∣ B i ∣ 2 4 + 1 + 9 = 14 ⩽ 3 n 4 + 1 + 9 = 14 \le 3n 4 + 1 + 9 = 14 ⩽ 3 n x 5 x_5 x 5 B 5 B_5 B 5 h 5 h_5 h 5 O ( 1 ) O(1) O ( 1 )
空间分析
关键问题是:二级表的总空间 ∑ i = 1 n ∣ B i ∣ 2 \sum_{i=1}^n |B_i|^2 ∑ i = 1 n ∣ B i ∣ 2
回顾碰撞数 Y = ∑ i < j I [ h ( x i ) = h ( x j ) ] Y = \sum_{i < j} \mathbb{I}[h(x_i) = h(x_j)] Y = ∑ i < j I [ h ( x i ) = h ( x j )]
Y = ∑ i = 1 n ( ∣ B i ∣ 2 ) = 1 2 ∑ i = 1 n ∣ B i ∣ ( ∣ B i ∣ − 1 ) Y = \sum_{i=1}^n \binom{|B_i|}{2} = \frac{1}{2}\sum_{i=1}^n |B_i|(|B_i| - 1)
Y = i = 1 ∑ n ( 2 ∣ B i ∣ ) = 2 1 i = 1 ∑ n ∣ B i ∣ ( ∣ B i ∣ − 1 )
为什么碰撞数是 ( ∣ B i ∣ 2 ) \binom{|B_i|}{2} ( 2 ∣ B i ∣ )
这里的 Y Y Y 碰撞的元素对数 。若桶 B i B_i B i b = ∣ B i ∣ b=|B_i| b = ∣ B i ∣ x a , x b ∈ B i x_a,x_b\in B_i x a , x b ∈ B i h ( x a ) = h ( x b ) = i h(x_a)=h(x_b)=i h ( x a ) = h ( x b ) = i ( b 2 ) \binom{b}{2} ( 2 b )
因此
∑ i = 1 n ∣ B i ∣ 2 = 2 Y + ∑ i = 1 n ∣ B i ∣ = 2 Y + n \sum_{i=1}^n |B_i|^2 = 2Y + \sum_{i=1}^n |B_i| = 2Y + n
i = 1 ∑ n ∣ B i ∣ 2 = 2 Y + i = 1 ∑ n ∣ B i ∣ = 2 Y + n
由 2-universal 性,E [ Y ] ⩽ ( n 2 ) / n < n / 2 \mathbb{E}[Y] \le \binom{n}{2}/n < n/2 E [ Y ] ⩽ ( 2 n ) / n < n /2
E [ ∑ i = 1 n ∣ B i ∣ 2 ] = 2 E [ Y ] + n < 2 n \mathbb{E}\left[\sum_{i=1}^n |B_i|^2\right] = 2\mathbb{E}[Y] + n < 2n
E [ i = 1 ∑ n ∣ B i ∣ 2 ] = 2 E [ Y ] + n < 2 n
由 Markov 不等式,存在一个一级哈希函数 h h h ∑ ∣ B i ∣ 2 ⩽ 3 n \sum |B_i|^2 \le 3n ∑ ∣ B i ∣ 2 ⩽ 3 n ⩾ 2 / 3 \ge 2/3 ⩾ 2/3
总空间 :O ( n ) O(n) O ( n ) O ( log N ) O(\log N) O ( log N ) O ( 1 ) O(1) O ( 1 )
FKS 的历史意义
FKS 完美哈希解决了一个长期悬而未决的问题:是否可能同时实现 O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 )
原始论文中给出了一个具体的例子:S = { 2 , 4 , 5 , 15 , 18 , 30 } , p = 31 , n = 6 S = \{2, 4, 5, 15, 18, 30\},\, p = 31,\, n = 6 S = { 2 , 4 , 5 , 15 , 18 , 30 } , p = 31 , n = 6 6 n = 36 6n = 36 6 n = 36
Dietzfelbinger 等人(1994)进一步给出了 FKS 的动态版本,支持期望 O ( 1 ) O(1) O ( 1 )
Cuckoo Hashing
FKS 哈希是静态的——适合一次性构建后只做查询的场景。如果需要动态地插入和删除元素,同时保持 O ( 1 ) O(1) O ( 1 )
Cuckoo hashing (布谷鸟哈希)巧妙地解决了这个问题。它的名字来源于布谷鸟(cuckoo bird)的寄生行为:布谷鸟会把蛋下在别的鸟巢里,雏鸟孵化后把原来的蛋和幼鸟挤出去 ——cuckoo hashing 中,新元素可以「踢走」已有元素,被踢走的元素再去找自己的替代位置。
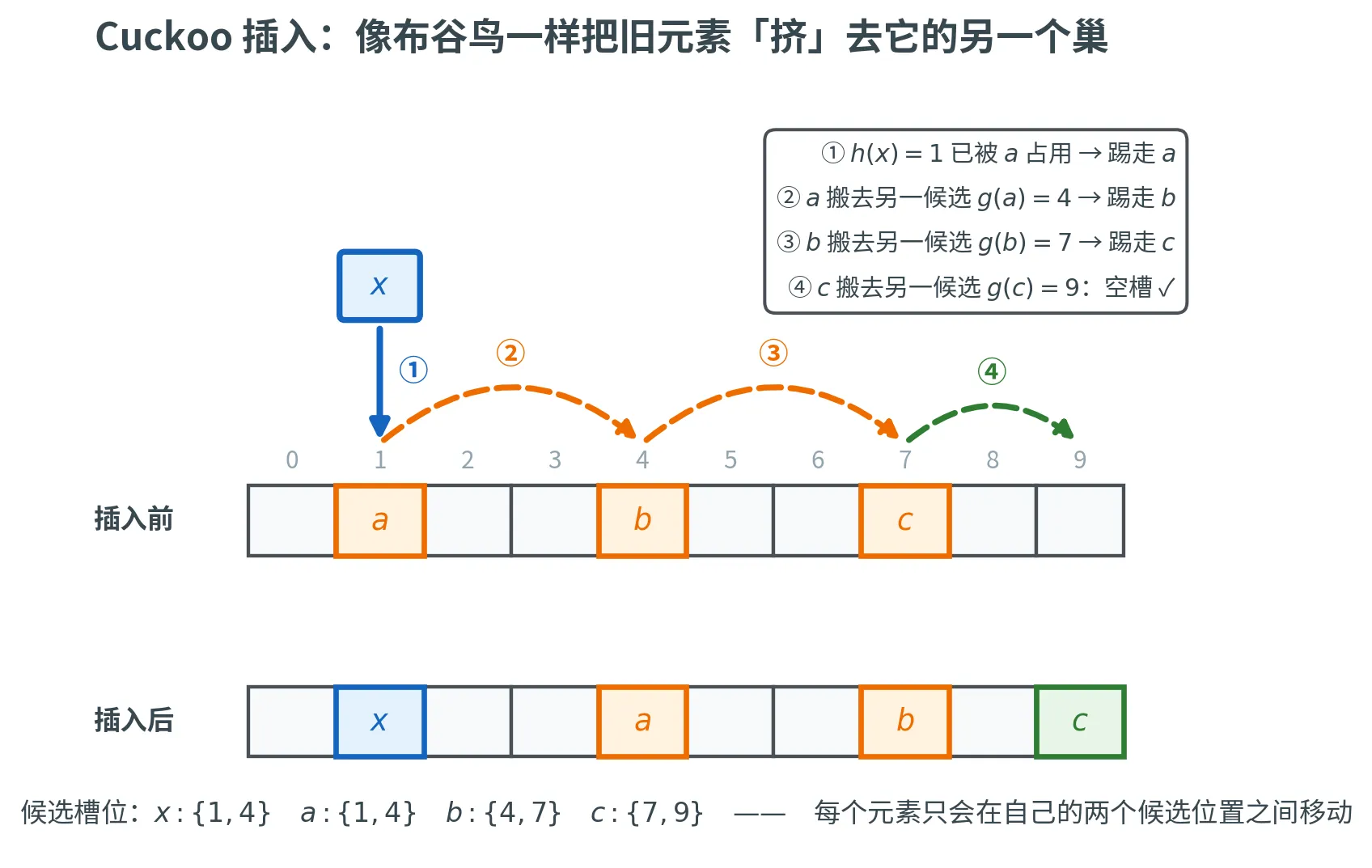
Cuckoo Hashing
使用两个独立的哈希函数 h , g : [ N ] → [ m ] h, g\colon [N] \to [m] h , g : [ N ] → [ m ] A [ 1 … m ] A[1 \dots m] A [ 1 … m ]
查询 x x x :检查 A [ h ( x ) ] A[h(x)] A [ h ( x )] A [ g ( x ) ] A[g(x)] A [ g ( x )] 2 次 内存访问插入 x x x :若 A [ h ( x ) ] A[h(x)] A [ h ( x )] A [ g ( x ) ] A[g(x)] A [ g ( x )] 空间 :O ( n ) O(n) O ( n )
查询的优势极其明显:恰好 2 次 内存访问,最坏情况确定性保证,没有链表遍历、没有探测序列。
下图追踪一次典型插入:新元素 x x x h ( x ) = 1 h(x)=1 h ( x ) = 1 a a a a a a g ( a ) = 4 g(a)=4 g ( a ) = 4 b b b c c c g ( c ) = 9 g(c)=9 g ( c ) = 9
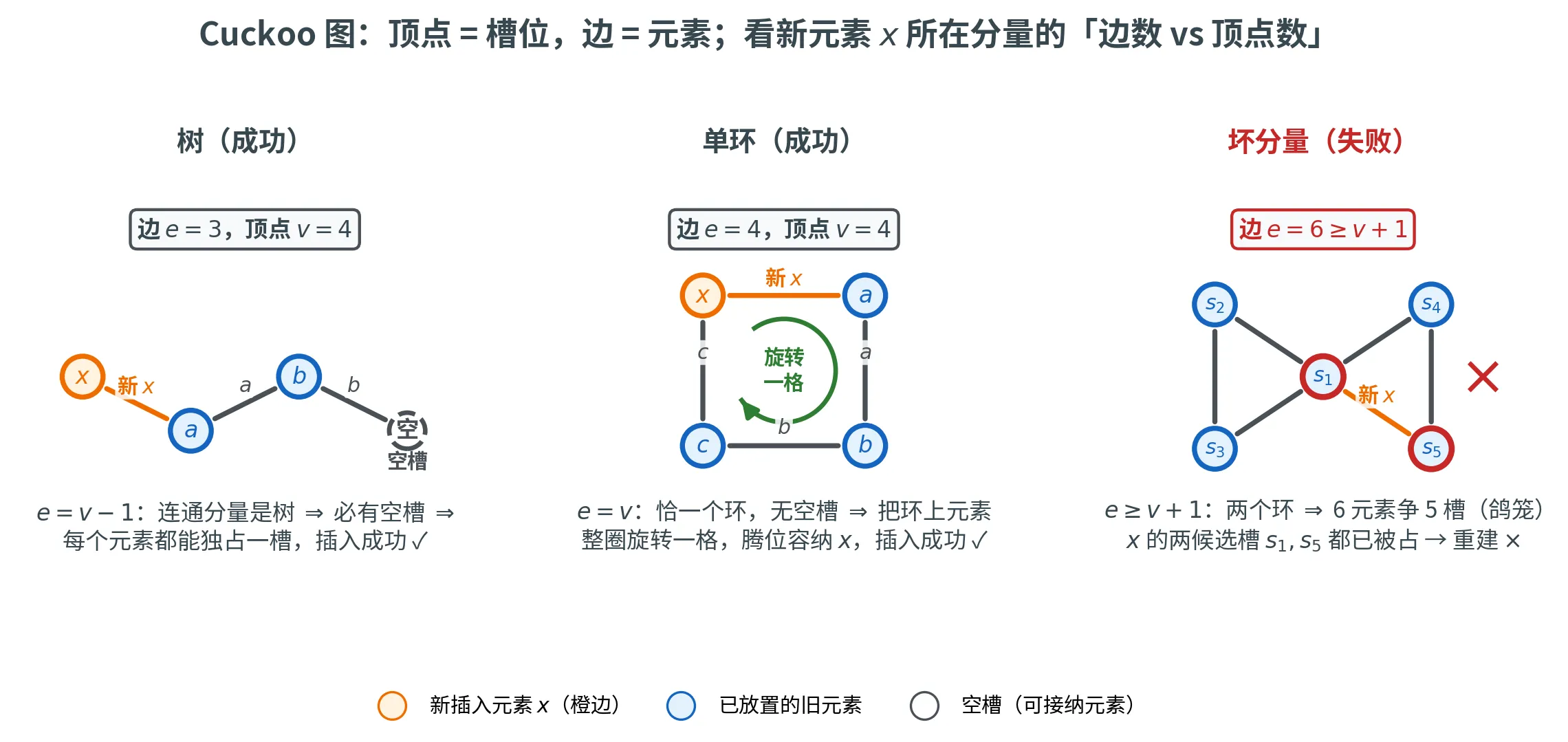
Cuckoo 图
分析 cuckoo hashing 的关键工具是 Cuckoo 图 (Cuckoo Graph)。定义多重图 G = ( V , E ) G = (V, E) G = ( V , E )
V = [ m ] V = [m] V = [ m ] E = { ( h ( x ) , g ( x ) ) : x ∈ S } E = \{(h(x), g(x)) : x \in S\} E = {( h ( x ) , g ( x )) : x ∈ S }
每次插入 x x x h ( x ) h(x) h ( x ) g ( x ) g(x) g ( x ) 连通分量 的结构——把每条边(元素)分配给一个端点(槽位)、且每个端点至多被一条边占用,本质上是一个「边定向」问题。
下图按新元素 x x x e e e v v v x x x 树 (e = v − 1 e = v - 1 e = v − 1 单环 (e = v e = v e = v x x x 坏分量 (e ⩾ v + 1 e \ge v + 1 e ⩾ v + 1
插入一个元素相当于在图中增加一条新边,然后尝试为所有边(元素)分配一个端点(槽位),使得每个顶点最多被一条边占用(每个槽位最多存一个元素)。这个分配过程沿着图上的路径或环进行:
路径 :从新元素的一个槽位出发,沿已占用的边走到另一个槽位,再沿该槽位对应的元素的另一条边……最终遇到空槽位,即可顺次移动,插入成功。单环 :若路径形成一个环(没有空槽),但环上每个顶点恰好连两条边(每个槽位两个可能的位置),则可以将环上所有元素旋转一圈,从而腾出一个位置,插入成功。双环 :两个环共享一个顶点,或者更一般地,连通分量中边数 ≥ 顶点数 + 1,此时无法通过踢移完成分配,需要重建。过长路径 :即使最终能成功,但踢移次数太多(如超过对数级),也会触发重建以保持性能。
期望插入时间分析
核心引理
一条固定的长度为 k k k m − 2 k − 1 m^{-2k-1} m − 2 k − 1
路径形如 x , slot 1 , y , slot 2 , z , slot 3 , … x, \text{slot}_1, y, \text{slot}_2, z, \text{slot}_3, \dots x , slot 1 , y , slot 2 , z , slot 3 , … k k k k + 1 k+1 k + 1 h h h g g g 1 / m 1/m 1/ m 2 k + 1 2k+1 2 k + 1 x x x
更具体一点,假设有 k k k
x , s 0 , y 1 , s 1 , y 2 , s 2 , … , y k , s k x,\ s_0,\ y_1,\ s_1,\ y_2,\ s_2,\ \dots,\ y_k,\ s_k
x , s 0 , y 1 , s 1 , y 2 , s 2 , … , y k , s k
这里:
x x x y 1 , … , y k y_1,\dots,y_k y 1 , … , y k s 0 , … , s k s_0,\dots,s_k s 0 , … , s k 路径长度可以理解为有 k k k
最后如果 s k s_k s k
对新元素 x x x s 0 s_0 s 0 h ( x ) h(x) h ( x ) g ( x ) g(x) g ( x ) s 0 s_0 s 0 1 / m 1/m 1/ m 2 m \frac{2}{m} m 2
对每个被踢走的元素 y i y_i y i y i ↔ ( s i − 1 , s i ) y_i \leftrightarrow (s_{i-1}, s_i) y i ↔ ( s i − 1 , s i ) y i y_i y i Θ ( 1 / m 2 ) \Theta(1/m^2) Θ ( 1/ m 2 ) k k k ( 1 / m 2 ) k = 1 / m 2 k (1/m^2)^k = 1/m^{2k} ( 1/ m 2 ) k = 1/ m 2 k
再乘上新元素开始位置那个 1 / m 1/m 1/ m 1 / m 2 k + 1 1/m^{2k+1} 1/ m 2 k + 1
长度 ⩾ k \ge k ⩾ k k k k ( n m ) k (nm)^k ( nm ) k ⩽ m − 2 k − 1 \le m^{-2k-1} ⩽ m − 2 k − 1
Pr [ 路径长度 ⩾ k ] ⩽ ( n m ) k m 2 k + 1 ⩽ n k m k + 1 = exp ( − Ω ( k ) ) \Pr[\text{路径长度} \ge k] \le \frac{(nm)^k}{m^{2k+1}} \le \frac{n^k}{m^{k+1}} = \exp(-\Omega(k))
Pr [ 路径长度 ⩾ k ] ⩽ m 2 k + 1 ( nm ) k ⩽ m k + 1 n k = exp ( − Ω ( k ))
其中用到了 m = Θ ( n ) m = \Theta(n) m = Θ ( n ) n / m = Θ ( 1 ) = c < 1 n / m = \Theta(1) = c < 1 n / m = Θ ( 1 ) = c < 1 c k c^k c k
同理,Pr [ 环长度 ⩾ k ] = exp ( − Ω ( k ) ) \Pr[\text{环长度} \ge k] = \exp(-\Omega(k)) Pr [ 环长度 ⩾ k ] = exp ( − Ω ( k ))
插入的期望时间 E [ T ] \mathbb{E}[T] E [ T ]
E [ T ] ⩽ E [ 路径长度 ] ⏟ O ( 1 ) + E [ 环长度 ] ⏟ O ( 1 ) + Pr [ 双环(坏连通分量)或过长路径 ] ⋅ n ⋅ E [ T ] ⏟ 重建代价 \mathbb{E}[T] \le \underbrace{\mathbb{E}[\text{路径长度}]}_{O(1)} + \underbrace{\mathbb{E}[\text{环长度}]}_{O(1)} + \underbrace{\Pr[\text{双环(坏连通分量)或过长路径}] \cdot n \cdot \mathbb{E}[T]}_{\text{重建代价}}
E [ T ] ⩽ O ( 1 ) E [ 路径长度 ] + O ( 1 ) E [ 环长度 ] + 重建代价 Pr [ 双环(坏连通分量)或过长路径 ] ⋅ n ⋅ E [ T ]
其中:
E [ 路径长度 ] ⩽ ∑ k ⩾ 1 exp ( − Ω ( k ) ) = O ( 1 ) \mathbb{E}[\text{路径长度}] \le \sum_{k \ge 1} \exp(-\Omega(k)) = O(1) E [ 路径长度 ] ⩽ ∑ k ⩾ 1 exp ( − Ω ( k )) = O ( 1 ) E [ 环长度 ] ⩽ O ( 1 ) \mathbb{E}[\text{环长度}] \le O(1) E [ 环长度 ] ⩽ O ( 1 ) Pr [ 双环(更一般地,坏连通分量) ] \Pr[\text{双环(更一般地,坏连通分量)}] Pr [ 双环(更一般地,坏连通分量) ] v v v e e e e ⩾ v + 1 e \ge v+1 e ⩾ v + 1
固定这样一个分量后,选择其边和顶点的方式至多有 n e m v n^e m^v n e m v m − 2 e m^{-2e} m − 2 e n e m v m 2 e \frac{n^e m^v}{m^{2e}} m 2 e n e m v
由于 e ⩾ v + 1 e \ge v+1 e ⩾ v + 1 v ⩽ e − 1 v \le e-1 v ⩽ e − 1 n e m v m 2 e ⩽ n e m e + 1 \frac{n^e m^v}{m^{2e}}\le\frac{n^e}{m^{e+1}} m 2 e n e m v ⩽ m e + 1 n e
当 n = c m ( c < 1 ) n=c m\quad (c<1) n = c m ( c < 1 ) n e m e + 1 = 1 m ( n m ) e = 1 n c e + 1 \frac{n^e}{m^{e+1}} = \frac{1}{m}\left(\frac{n}{m}\right)^e = \frac{1}{n}c^{e+1} m e + 1 n e = m 1 ( m n ) e = n 1 c e + 1
对所有可能的 e e e ∑ e = 1 n c e + 1 1 n ⩽ 1 n ∑ e ⩾ 1 c e + 1 = O ( 1 n ) \sum\limits_{e=1}^n c^{e+1} \frac{1}{n} \le \frac{1}{n} \sum\limits_{e\ge 1} c^{e+1} = O\left(\frac{1}{n}\right) e = 1 ∑ n c e + 1 n 1 ⩽ n 1 e ⩾ 1 ∑ c e + 1 = O ( n 1 ) O ( 1 / n ) O(1/n) O ( 1/ n )
Pr [ 路径 ⩾ 2 log n ] ⩽ exp ( − Ω ( log n ) ) = 1 / n Ω ( 1 ) \Pr[\text{路径} \ge 2\log n] \le \exp(-\Omega(\log n)) = 1/n^{\Omega(1)} Pr [ 路径 ⩾ 2 log n ] ⩽ exp ( − Ω ( log n )) = 1/ n Ω ( 1 )
因此 E [ T ] ⩽ O ( 1 ) + O ( 1 / n ) ⋅ n ⋅ E [ T ] \mathbb{E}[T] \le O(1) + O(1/n) \cdot n \cdot \mathbb{E}[T] E [ T ] ⩽ O ( 1 ) + O ( 1/ n ) ⋅ n ⋅ E [ T ] E [ T ] = O ( 1 ) \mathbb{E}[T] = O(1) E [ T ] = O ( 1 )
Cuckoo Hashing 性能:
指标
复杂度
空间
O ( n ) O(n) O ( n )
查询
2 次内存访问(最坏情况)
插入
期望摊还 O ( 1 ) O(1) O ( 1 )
Succinct Dictionaries
从最优到极致
到目前为止,FKS 和 cuckoo hashing 都实现了 O ( n ) O(n) O ( n ) O ( log N ) O(\log N) O ( log N ) O ( n log N ) O(n\log N) O ( n log N ) Θ ( n log N ) \Theta(n\log N) Θ ( n log N ) n n n log 2 ( N n ) \log_2\binom{N}{n} log 2 ( n N )
方案
空间
查询时间
更新时间
平衡搜索树
O ( n log N ) O(n\log N) O ( n log N ) O ( log n ) O(\log n) O ( log n ) O ( log n ) O(\log n) O ( log n )
链式哈希
O ( n log N ) O(n\log N) O ( n log N ) 期望 O ( 1 ) O(1) O ( 1 )
期望 O ( 1 ) O(1) O ( 1 )
一级完美哈希
O ( n 2 log N ) O(n^2\log N) O ( n 2 log N ) O ( 1 ) O(1) O ( 1 ) -
FKS 二级完美哈希O ( n log N ) O(n\log N) O ( n log N ) O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 )
Cuckoo 哈希
O ( n log N ) O(n\log N) O ( n log N ) 2 次访问
期望摊还 O ( 1 ) O(1) O ( 1 )
Succinct dictionary ( 1 + o ( 1 ) ) n log N (1+o(1))n\log N ( 1 + o ( 1 )) n log N O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 )
表面上 FKS 已经追平了信息论下界的数量级 Θ ( n log N ) \Theta(n \log N) Θ ( n log N ) Succinct dictionary 追求的是一个更精细的目标:不仅 是 O ( n log N ) O(n\log N) O ( n log N ) ( 1 + o ( 1 ) ) (1 + o(1)) ( 1 + o ( 1 ))
总空间 = log 2 ( N n ) ⏟ 信息论下界 + o ( n log N ) ⏟ 低阶冗余 \text{总空间} = \underbrace{\log_2 \binom{N}{n}}_{\text{信息论下界}} + \underbrace{o(n\log N)}_{\text{低阶冗余}}
总空间 = 信息论下界 log 2 ( n N ) + 低阶冗余 o ( n log N )
这几乎是空间复杂度的「天花板」:信息论告诉我们冗余不能是负的,而 succinct 意味着冗余是主项的 o ( 1 ) o(1) o ( 1 )
FKS 究竟浪费在哪FKS 看起来已经达到 O ( n log N ) O(n \log N) O ( n log N )
设每个元素占 v v v v = log N v = \log N v = log N FKS 的空间由两部分构成:
原始数据 :n n n v v v n v n v n v 结构开销 :一级/二级桶的哈希参数、桶边界指针、表大小描述等,合计 O ( n log n ) O(n \log n) O ( n log n ) O ( log n ) O(\log n) O ( log n )
于是
FKS 总空间 = n v + O ( n log n ) = n v ⋅ ( 1 + O ( log n v ) ) 比特 \text{FKS 总空间} = n v + O(n \log n) = n v \cdot \left(1 + O\left(\tfrac{\log n}{v}\right)\right) \text{ 比特}
FKS 总空间 = n v + O ( n log n ) = n v ⋅ ( 1 + O ( v l o g n ) ) 比特
关键观察 :当 log n ≪ v \log n \ll v log n ≪ v O ( n log n ) O(n \log n) O ( n log n ) n v nv n v FKS 自动就是 succinct 的。比如用 FKS 维护 n = polylog ( N ) n = \operatorname{polylog}(N) n = polylog ( N ) O ( n log n ) = O ( n log log N ) = o ( n log N ) O(n \log n) = O(n \log\log N) = o(n \log N) O ( n log n ) = O ( n log log N ) = o ( n log N )
但当 v v v log n \log n log n N = n O ( 1 ) N = n^{O(1)} N = n O ( 1 ) FKS 不再 succinct。这就是我们要攻克的情形。
换个角度看:FKS 为每个桶维护一整套二级数据结构——哈希函数参数、表大小、表内容指针等。这套「结构」的开销与桶内元素数无关:桶里即便只有一两个元素,也得照付一整套。桶数大、每桶元素少时,这种「为每桶付一份结构税」的方式就显得浪费。
Succinct 的思路:把每个桶压成「一个字」
既然 FKS 的浪费来自「为每个桶维护传统数据结构」,一个激进的想法是:当桶足够小时,干脆不要结构,而是把整个桶直接编码成一小块连续的比特,查询时在这块比特上用位运算直接搜 。
Word RAM 模型
假设机器字长为 w w w w ⩾ log 2 ( 问题规模 ) w \ge \log_2 (\text{问题规模}) w ⩾ log 2 ( 问题规模 ) w = Θ ( log n ) w = \Theta(\log n) w = Θ ( log n )
一个字内的算术 / 逻辑 / 位运算(加、比较、AND、XOR、移位等)都在 O ( 1 ) O(1) O ( 1 )
更强地,对一个字内的数据做几乎任意的「固定函数」,都可以靠预计算查找表在 O ( 1 ) O(1) O ( 1 ) n 1 / 3 n^{1/3} n 1/3
直觉:字长只有 Θ ( log n ) \Theta(\log n) Θ ( log n ) O ( log n ) O(\log n) O ( log n ) n O ( 1 ) n^{O(1)} n O ( 1 ) O ( 1 ) O(1) O ( 1 )
这条性质决定了一个核心尺寸选择:把桶编码到 O ( log n ) O(\log n) O ( log n ) ,则桶内查询可以 O ( 1 ) O(1) O ( 1 )
小字典的目标
经过合适的编码,可以把 m = log n / log log n m = \log n / \log\log n m = log n / log log n O ( log n ) O(\log n) O ( log n ) ,且支持 O ( 1 ) O(1) O ( 1 )
这个数字 m = log n / log log n m = \log n / \log\log n m = log n / log log n
直觉:落入同一个桶的 key 共享哈希值,所以桶索引已经「带了一半信息」,桶内只需存每个 key 的「差异部分」。这部分差异能压得多紧,决定了 m m m
带着这个假设,整个 Succinct 字典的骨架就清晰了:
把 n n n n / m n/m n / m m = log n / log log n m = \log n / \log\log n m = log n / log log n O ( log n ) O(\log n) O ( log n )
分析溢出——一些桶会超过 m m m
溢出元素用另一种数据结构(trie)处理
把所有冗余加起来,证明 o ( n log N ) o(n \log N) o ( n log N )
Method of Four Russians:让「字内 O ( 1 ) O(1) O ( 1 )
上一节 Word RAM admonition 里有一个看起来很神秘的承诺:「对一个字内的数据做几乎任意的固定函数 ,都可以靠预计算查找表在 O ( 1 ) O(1) O ( 1 ) Method of Four Russians (4-Russians 法)兑现。
它的命名稍有点尴尬:1970 年 Arlazarov、Dinic、Kronrod、Faradzhev 四位苏联数学家用这个技巧给出了布尔矩阵乘法的 O ( n 3 / log n ) O(n^3 / \log n) O ( n 3 / log n ) O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 )
核心配方
4-Russians 的精神可以用三个词概括:分块 → 预计算 → 查表 。
设输入规模为 L L L L / b L/b L / b b b b b b b O ( 1 ) O(1) O ( 1 )
flowchart LR
IN["输入<br>L bits"] --> SP["切成 L/b 块"]
SP --> B1["块 1"]
SP --> B2["块 2"]
SP --> BK["块 L/b"]
B1 --> T1["查表"]
B2 --> T2["查表"]
BK --> TK["查表"]
T1 -->|"状态"| T2
T2 -->|"状态"| TK
TK --> ANS["最终答案"]
classDef in fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef block fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef table fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
classDef out fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
class IN,SP in
class B1,B2,BK block
class T1,T2,TK table
class ANS out每块的可能编码有 2 b 2^b 2 b poly ( b ) \operatorname{poly}(b) poly ( b ) 2 b ⋅ poly ( b ) 2^b \cdot \operatorname{poly}(b) 2 b ⋅ poly ( b ) poly ( b ) \operatorname{poly}(b) poly ( b )
b = log n c ⋅ c o n s t , b = \frac{\log n}{c \cdot \mathrm{const}},
b = c ⋅ const log n ,
则 2 b ⩽ n 1 / ( c ⋅ c o n s t ) 2^b \le n^{1/(c \cdot \mathrm{const})} 2 b ⩽ n 1/ ( c ⋅ const ) poly ( b ) = polylog ( n ) \operatorname{poly}(b) = \operatorname{polylog}(n) poly ( b ) = polylog ( n ) n 1 / c ⋅ polylog ( n ) n^{1/c} \cdot \operatorname{polylog}(n) n 1/ c ⋅ polylog ( n )
参数 c c c c c c c c c
升温例子:字内 popcount
具体看一个最简单的应用:32 位字的 popcount(数比特中 1 1 1
把字分成两个 16 位半字。预计算
T [ i ] = popcount ( i ) , i = 0 , 1 , … , 2 16 − 1 T[i] = \operatorname{popcount}(i), \qquad i = 0, 1, \dots, 2^{16}-1
T [ i ] = popcount ( i ) , i = 0 , 1 , … , 2 16 − 1
表项每个 5 5 5 log 2 17 \log_2 17 log 2 17 40 40 40
popcount ( x ) = T [ x & 0 x F F F F ] + T [ x ≫ 16 ] , \operatorname{popcount}(x) = T[x \,\&\, \mathrm{0xFFFF}] + T[x \gg 16],
popcount ( x ) = T [ x & 0xFFFF ] + T [ x ≫ 16 ] ,
两次查表 + 一次加,恒为 O ( 1 ) O(1) O ( 1 ) 256 256 256 O ( 1 ) O(1) O ( 1 )
这就是 4-Russians 的精神:把指数多的可能输入用一张多项式大小的表压缩,查询时只走表 。注意「分段」之间需要一个简单的合并操作(这里是加法),更复杂的应用里这一步会通过状态传递完成。
应用:把小字典查询变成字内 O ( 1 ) O(1) O ( 1 )
回到主线。每桶用 O ( log n ) O(\log n) O ( log n ) m = log n / log log n m = \log n / \log\log n m = log n / log log n O ( 1 ) O(1) O ( 1 )
按 4-Russians 套路,整张「桶编码 + 查询商」的组合空间是
2 O ( log n ) ⏟ 桶编码 × 2 O ( log n ) ⏟ 查询商 = n O ( 1 ) \underbrace{2^{O(\log n)}}_{\text{桶编码}} \times \underbrace{2^{O(\log n)}}_{\text{查询商}} = n^{O(1)}
桶编码 2 O ( l o g n ) × 查询商 2 O ( l o g n ) = n O ( 1 )
项。预计算每项的输出(「该桶里是否包含查询 key」),写成一张表。查询时一次查表即可。
调一下指数常数(取适当的 c c c n 1 / 3 n^{1/3} n 1/3 n 1 / 3 n^{1/3} n 1/3
进阶应用:在 O ( log n ) O(\log n) O ( log n )
接下来是一个稍微复杂、但精神完全相同的应用。后面溢出处理会用到压缩 Trie,那里查询时间也要 O ( 1 ) O(1) O ( 1 )
问题
给定一棵用 O ( log n ) O(\log n) O ( log n ) q q q q q q O ( n 1 / c log n ) O(n^{1/c} \log n) O ( n 1/ c log n ) O ( c ) O(c) O ( c ) c c c
固定 Trie 编码 。先用平衡括号或 DFS 序列编码树形,再附上每条压缩边的「下一段比较位置和长度」,以及每个终止节点对应串的字典序。整体长度记为 L ⩽ A log n L \le A \log n L ⩽ A log n A A A
分块 。把 L L L b b b L / b = O ( c ) L/b = O(c) L / b = O ( c ) O ( log n ) O(\log n) O ( log n )
表索引 T [ block , state , query-fragment ] T[\text{block}, \text{state}, \text{query-fragment}] T [ block , state , query-fragment ]
block :当前 b b b 2 b 2^b 2 b state :进入该块时的局部状态(当前节点编号、压缩边偏移等),共 O ( b K ) O(b^K) O ( b K ) K K K query-fragment :该块要读取的至多 b b b 2 b 2^b 2 b
表项输出 :(离开该块时的新状态,是否在该块内失败,是否遇到一个终止节点,若有则其字典序)。每项 O ( log n ) O(\log n) O ( log n )
表大小 :
2 b ⋅ O ( b K ) ⋅ 2 b ⋅ O ( log n ) = 2 2 b ⋅ O ( b K ) ⋅ O ( log n ) bits 2^b \cdot O(b^K) \cdot 2^b \cdot O(\log n) = 2^{2b} \cdot O(b^K) \cdot O(\log n) \text{ bits}
2 b ⋅ O ( b K ) ⋅ 2 b ⋅ O ( log n ) = 2 2 b ⋅ O ( b K ) ⋅ O ( log n ) bits
取 b = log n ( K + 3 ) c b = \dfrac{\log n}{(K+3)c} b = ( K + 3 ) c log n 2 2 b ⩽ n 2 / ( ( K + 3 ) c ) 2^{2b} \le n^{2/((K+3)c)} 2 2 b ⩽ n 2/ (( K + 3 ) c ) n n n b K ⩽ ( log n ) K ⩽ n K / ( ( K + 3 ) c ) b^K \le (\log n)^K \le n^{K/((K+3)c)} b K ⩽ ( log n ) K ⩽ n K / (( K + 3 ) c ) n ( K + 2 ) / ( ( K + 3 ) c ) ⩽ n 1 / c n^{(K+2)/((K+3)c)} \le n^{1/c} n ( K + 2 ) / (( K + 3 ) c ) ⩽ n 1/ c O ( log n ) O(\log n) O ( log n )
O ( n 1 / c log n ) bits O(n^{1/c} \log n) \text{ bits}
O ( n 1/ c log n ) bits
K + 3 K+3 K + 3
K K K + 3 +3 + 3 b K b^K b K log n \log n log n n 1 / c n^{1/c} n 1/ c O ( n 1 / c log n ) O(n^{1/c} \log n) O ( n 1/ c log n )
查询算法 。从含根节点的第一块出发,初始状态为「位于根节点」,并在表索引之外维护一个寄存器 ans 记录目前找到的最优前缀字典序:
用当前 (block, state) 决定要读取哪些查询比特,从 q q q
查表得到新状态、是否失败、是否遇到终止节点
若遇到终止节点,更新 ans
转到下一块,直到失败、查询结束或所有块处理完
每块只做 O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 ) O ( c ) O(c) O ( c ) O ( c ) O(c) O ( c )
正确性 。表对每种 (block, state, query-fragment) 三元组都精确模拟了 Trie 上对应步骤的真实行为。归纳:进入某块时算法状态与真实查询状态一致,则查表后离开时仍一致;遇到终止节点会被 ans 收下。最终算法报告的字典序对应 Trie 中某个作为查询串前缀的存储串。
这就是 4-Russians 在 Succinct 字典里的两次落地:一次为主桶的 O ( 1 ) O(1) O ( 1 ) O ( c ) O(c) O ( c )
第一次尝试:大桶方案的失败
先看一个直观但不完全成功的方案:取 m = log 3 n m = \log^3 n m = log 3 n n n n n / log 3 n n / \log^3 n n / log 3 n μ = m = log 3 n \mu = m = \log^3 n μ = m = log 3 n exp ( − μ δ 2 / 3 ) \exp(-\mu \delta^2 / 3) exp ( − μ δ 2 /3 ) 0 < δ < 1 0 < \delta < 1 0 < δ < 1 δ = 2 / log n \delta = 2/\log n δ = 2/ log n
Pr [ 某桶负载 ⩾ ( 1 + 2 log n ) log 3 n ] ⩽ exp ( − μ δ 2 3 ) = exp ( − log 3 n ⋅ 4 / log 2 n 3 ) = exp ( − 4 log n 3 ) = n − 4 / 3 \Pr\left[\text{某桶负载} \ge (1 + \tfrac{2}{\log n}) \log^3 n\right] \le \exp\left(-\tfrac{\mu \delta^2}{3}\right) = \exp\left(-\tfrac{\log^3 n \cdot 4/\log^2 n}{3}\right) = \exp\left(-\tfrac{4\log n}{3}\right) = n^{-4/3}
Pr [ 某桶负载 ⩾ ( 1 + l o g n 2 ) log 3 n ] ⩽ exp ( − 3 μ δ 2 ) = exp ( − 3 l o g 3 n ⋅ 4/ l o g 2 n ) = exp ( − 3 4 l o g n ) = n − 4/3
课件用稍紧的 exp ( − μ δ 2 / 2 ) \exp(-\mu\delta^2/2) exp ( − μ δ 2 /2 ) n − 2 n^{-2} n − 2 n / log 3 n n/\log^3 n n / log 3 n ⩽ ( 1 + 2 / log n ) log 3 n \le (1 + 2/\log n)\log^3 n ⩽ ( 1 + 2/ log n ) log 3 n
设 n ′ ≔ ( 1 + 2 / log n ) log 3 n n' \coloneqq (1 + 2/\log n)\log^3 n n ′ : = ( 1 + 2/ log n ) log 3 n n ′ v n'v n ′ v O ( n ′ log n ′ ) O(n' \log n') O ( n ′ log n ′ )
( n / log 3 n ) ⋅ O ( n ′ log n ′ ) : − O ( n log log n ) ⏟ 所有桶的结构冗余 + ( 2 / log n ) ⋅ n log N ⏟ δ 预留的空位 = o ( n log N ) \underbrace{(n/\log^3 n) \cdot O(n' \log n') \coloneq \textcolor{ff0099}{O(n\log\log n)}}_{\text{所有桶的结构冗余}} + \underbrace{\textcolor{ff0099}{(2/\log n) \cdot n \log N}}_{\text{$\delta$ 预留的空位}} = o(n \log N)
所有桶的结构冗余 ( n / log 3 n ) ⋅ O ( n ′ log n ′ ) : − O ( n l o g l o g n ) + δ 预留的空位 ( 2/ l o g n ) ⋅ n l o g N = o ( n log N )
从空间上看似乎已经 succinct 了。但致命问题在查询时间:
每桶要装 log 3 n \log^3 n log 3 n q q q Ω ( 1 ) \Omega(1) Ω ( 1 ) ≫ log n \gg \log n ≫ log n
更直白地:桶编码大约 log 3 n ⋅ ( 每 key 的最小商位数 ) \log^3 n \cdot (\text{每 key 的最小商位数}) log 3 n ⋅ ( 每 key 的最小商位数 ) log n \log n log n
这意味着桶内查询要跨越多个字,桶内基本操作不再是 O ( 1 ) O(1) O ( 1 ) n 1 / 3 n^{1/3} n 1/3 单个字 大小的数据,桶一旦跨字这个加速就不适用了。
为了让查询回到 O ( 1 ) O(1) O ( 1 ) m m m
正确选择:m = log n / log log n m = \log n / \log\log n m = log n / log log n
取 m = log n / log log n m = \log n / \log\log n m = log n / log log n n n n n / m n / m n / m m m m ⩽ O ( log n ) \le O(\log n) ⩽ O ( log n ) O ( 1 ) O(1) O ( 1 )
代价是:桶容量更小,会出现溢出 ,即某些桶装不下所有落入它的元素。我们允许这部分元素「溢出」,交给另一套机制处理。
先量化溢出。每桶期望负载 μ = m \mu = m μ = m δ \delta δ δ = c log log n / log n \delta = c \log\log n / \sqrt{\log n} δ = c log log n / log n c c c exp ( − μ δ 2 / 3 ) \exp(-\mu\delta^2/3) exp ( − μ δ 2 /3 )
Pr [ 某桶负载 ⩾ ( 1 + δ ) m ] ⩽ exp ( − m δ 2 3 ) \Pr[\text{某桶负载} \ge (1 + \delta)m] \le \exp\left(-\tfrac{m\delta^2}{3}\right)
Pr [ 某桶负载 ⩾ ( 1 + δ ) m ] ⩽ exp ( − 3 m δ 2 )
把 m , δ m, \delta m , δ
m δ 2 3 = 1 3 ⋅ log n log log n ⋅ c 2 ( log log n ) 2 log n = c 2 log log n 3 \frac{m \delta^2}{3} = \frac{1}{3} \cdot \frac{\log n}{\log\log n} \cdot \frac{c^2 (\log\log n)^2}{\log n} = \frac{c^2 \log\log n}{3}
3 m δ 2 = 3 1 ⋅ log log n log n ⋅ log n c 2 ( log log n ) 2 = 3 c 2 log log n
所以
Pr [ 某桶溢出 ] ⩽ exp ( − c 2 log log n 3 ) = ( log n ) − c 2 / 3 \Pr[\text{某桶溢出}] \le \exp\left(-\tfrac{c^2 \log\log n}{3}\right) = (\log n)^{-c^2/3}
Pr [ 某桶溢出 ] ⩽ exp ( − 3 c 2 l o g l o g n ) = ( log n ) − c 2 /3
换句话说,c c c ⩽ log − 9 n \le \log^{-9} n ⩽ log − 9 n n / log 9 n n/\log^9 n n / log 9 n c 2 / 3 ⩾ 9 c^2/3 \ge 9 c 2 /3 ⩾ 9 c ⩾ 27 c \ge \sqrt{27} c ⩾ 27 c = 6 c = 6 c = 6 δ = o ( 1 ) \delta = o(1) δ = o ( 1 )
期望溢出元素数 :由线性期望,每个元素独立以 ⩽ log − 12 n \le \log^{-12} n ⩽ log − 12 n
E [ N overflow ] ⩽ n ⋅ log − 12 n = n log 12 n \mathbb{E}[N_{\text{overflow}}] \le n \cdot \log^{-12} n = \frac{n}{\log^{12} n}
E [ N overflow ] ⩽ n ⋅ log − 12 n = log 12 n n
δ \delta δ
两个约束必须同时成立:
失败概率要足够小 :后面「溢出的两级处理」把溢出元素分到 n / log 9 n n/\log^9 n n / log 9 n o ( 1 ) o(1) o ( 1 ) N overflow ≪ n / log 9 n N_{\text{overflow}} \ll n/\log^9 n N overflow ≪ n / log 9 n ⩽ log − 9 n \le \log^{-9}n ⩽ log − 9 n m δ 2 / 3 ⩾ 9 log log n m\delta^2/3 \ge 9\log\log n m δ 2 /3 ⩾ 9 log log n δ \delta δ δ ⋅ n log N \delta \cdot n\log N δ ⋅ n log N o ( n log N ) o(n\log N) o ( n log N ) δ = o ( 1 ) \delta = o(1) δ = o ( 1 )
把 m = log n / log log n m = \log n/\log\log n m = log n / log log n c 2 ⩾ 27 c^2 \ge 27 c 2 ⩾ 27 c = 6 c = 6 c = 6 δ = O ( log log n / log n ) = o ( 1 ) \delta = O(\log\log n / \sqrt{\log n}) = o(1) δ = O ( log log n / log n ) = o ( 1 ) δ \delta δ
现在剩下的问题是:如何为 O ( n / log 12 n ) O(n/\log^{12} n) O ( n / log 12 n )
前置:前缀树(Trie)
处理溢出用到的主要工具是前缀树 (trie)。
前缀树
前缀树 (trie)是一种按「共享前缀」组织字符串的多叉树。把每个 key 视为比特串 x 1 x 2 … x l x_1 x_2 \dots x_l x 1 x 2 … x l
根节点代表「空前缀」,每个内部节点代表一段前缀
从根节点开始,每一层按 key 的一个比特(0 或 1)决定往左还是往右走
插入 key 时,沿对应路径下行,遇到未创建的节点就新建,最终 key 对应树中一个叶子(或被标记的内部节点)
查询 / 插入 时间是 O ( l ) O(l) O ( l ) 空间 是所有 key 共享前缀之后的总节点数。
flowchart TD
R(("ε")) --> N0(("0"))
R --> N1(("1"))
N0 --> N00(("00"))
N0 --> N01(("01"))
N01 --> L011["011"]
N1 --> N10(("10"))
N10 --> L100["100"]
N10 --> L101["101"]
N00 --> L001["001"]
classDef root fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef node fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef leaf fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
class R root
class N0,N1,N00,N01,N10 node
class L001,L011,L100,L101 leaf标准 trie 有一个缺点:节点数可能远大于 key 数。比如只存 000011 这一个 key 就得建 6 层节点链——大量中间节点只有一个子节点,毫无信息量。
压缩 trie (compressed trie)通过「只保留真正分叉的节点」解决这个问题:
压缩 Trie
若一条路径上的节点只有一个子节点,则把这整段路径折叠成一条边(不再为其上每个比特建节点)。分叉点(两个或更多 key 在此处才分歧)仍保留为节点。
节点数 = 分叉数 ⩽ O ( key 数 ) \le O(\text{key 数}) ⩽ O ( key 数 ) 插入 沿路径下行,直到某个叶子;继续比较直到发现新的分歧点,在该处「生长」出一小段新路径,使两个 key 在此分开
我们要分析的,就是随机 key 下压缩 trie 的节点数——即「每次插入平均生长多少层」。
一个直观例子
按顺序插入四个 4-bit key:0110、1001、1011、0111:
插入 0110:trie 只是根 → 一个叶子,没有「生长」可言
插入 1001:与 0110 在第 1 比特就分歧(1 vs 0),不需要延伸——根分两支即可。G 2 = 0 G_2 = 0 G 2 = 0
插入 1011:沿 1 走到叶子 1001,与之比较:bit 2 都是 0、bit 3 上 0 vs 1 分歧。共同前缀长度 1,G 3 = 1 G_3 = 1 G 3 = 1
插入 0111:沿 0 走到叶子 0110,比较:bit 2 都是 1、bit 3 都是 1、bit 4 上 0 vs 1 分歧。共同前缀长度 2,G 4 = 2 G_4 = 2 G 4 = 2
最终的压缩 trie:
flowchart TD
R(("ε"))
R -->|"0"| N0(("bit 4"))
N0 -->|"0"| L0110["0110"]
N0 -->|"1"| L0111["0111"]
R -->|"1"| N1(("bit 3"))
N1 -->|"0"| L1001["1001"]
N1 -->|"1"| L1011["1011"]
classDef root fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef node fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef leaf fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
class R root
class N0,N1 node
class L0110,L0111,L1001,L1011 leaf总节点数 = 7 = 4 叶子 + 3 内部节点 = 7 = 4\, \text{叶子} + 3\, \text{内部节点} = 7 = 4 叶子 + 3 内部节点 G = 0 + 1 + 2 = 3 G = 0 + 1 + 2 = 3 G = 0 + 1 + 2 = 3 1 1 1 1 1 1
Trie 编码溢出元素:空间分析
假设 key 独立均匀随机(哈希后的残余对此近似成立)。考察第 i i i G i G_i G i
单次生长的几何分布 :两个独立均匀随机比特串前 k k k 2 − k 2^{-k} 2 − k k ⩾ 1 k \ge 1 k ⩾ 1
Pr [ G i ⩾ k ] = 2 − k \Pr[G_i \ge k] = 2^{-k}
Pr [ G i ⩾ k ] = 2 − k
对应的分布是 Pr [ G i = k ] = 2 − ( k + 1 ) , k = 0 , 1 , 2 , … \Pr[G_i = k] = 2^{-(k+1)},\, k = 0, 1, 2, \dots Pr [ G i = k ] = 2 − ( k + 1 ) , k = 0 , 1 , 2 , … 1 / 2 1/2 1/2
E [ G i ] = ∑ k ⩾ 1 Pr [ G i ⩾ k ] = ∑ k ⩾ 1 2 − k = 1 \mathbb{E}[G_i] = \sum_{k \ge 1} \Pr[G_i \ge k] = \sum_{k \ge 1} 2^{-k} = 1
E [ G i ] = k ⩾ 1 ∑ Pr [ G i ⩾ k ] = k ⩾ 1 ∑ 2 − k = 1
这里用了非负整数随机变量的尾和公式 E [ Y ] = ∑ k ⩾ 1 Pr [ Y ⩾ k ] \mathbb{E}[Y] = \sum_{k \ge 1}\Pr[Y \ge k] E [ Y ] = ∑ k ⩾ 1 Pr [ Y ⩾ k ]
累计生长 :插入 n ′ n' n ′
G = ∑ i = 1 n ′ G i , E [ G ] = n ′ ⋅ E [ G i ] = n ′ G = \sum_{i=1}^{n'} G_i, \qquad \mathbb{E}[G] = n' \cdot \mathbb{E}[G_i] = n'
G = i = 1 ∑ n ′ G i , E [ G ] = n ′ ⋅ E [ G i ] = n ′
注意压缩 trie 的节点数 ⩽ n ′ + G \le n' + G ⩽ n ′ + G n ′ n' n ′ G G G G G G
为什么用 MGF ?
我们需要的不是 G G G E [ G ] = n ′ \mathbb{E}[G] = n' E [ G ] = n ′ 尾 ——Pr [ G ⩾ a ] \Pr[G \ge a] Pr [ G ⩾ a ]
直接的策略行不通。G G G n ′ n' n ′ n ′ n' n ′
MGF 是把独立和的尾压紧的标准武器MGF 等于各自 MGF 的乘积,再用 Markov Pr [ e t G ⩾ e t a ] ⩽ e − t a E [ e t G ] \Pr[\e^{tG} \ge \e^{ta}] \le \e^{-ta} \mathbb{E}[\e^{tG}] Pr [ e tG ⩾ e t a ] ⩽ e − t a E [ e tG ] MGF 的比值。整个套路三步:
算单个分量 G i G_i G i MGF
用独立性把和的 MGF 写成 n ′ n' n ′ MGF 的乘积
选具体 t t t MGF 形式干净,再用 Markov 给出尾界
下面就是这个套路的完整执行。先算单个 G i G_i G i MGF 。对 e t < 2 \e^t < 2 e t < 2
E [ e t G i ] = ∑ k ⩾ 0 e t k ⋅ 2 − ( k + 1 ) = 1 2 ∑ k ⩾ 0 ( e t 2 ) k = 1 2 − e t \mathbb{E}\left[\e^{tG_i}\right] = \sum_{k \ge 0} \e^{tk} \cdot 2^{-(k+1)} = \frac{1}{2} \sum_{k \ge 0}\left(\frac{\e^t}{2}\right)^k = \frac{1}{2 - \e^t}
E [ e t G i ] = k ⩾ 0 ∑ e t k ⋅ 2 − ( k + 1 ) = 2 1 k ⩾ 0 ∑ ( 2 e t ) k = 2 − e t 1
由独立性,n ′ n' n ′ MGF 为各自 MGF 的乘积:
E [ e t G ] = ( 2 − e t ) − n ′ \mathbb{E}[\e^{tG}] = (2 - \e^t)^{-n'}
E [ e tG ] = ( 2 − e t ) − n ′
接下来挑 t t t 让 MGF 等于一个干净的常数 ,这样乘积就是 常数 n ′ \text{常数}^{n'} 常数 n ′ e t = 3 / 2 \e^t = 3/2 e t = 3/2 t = ln ( 3 / 2 ) t = \ln(3/2) t = ln ( 3/2 ) ( 1 , 2 ) (1, 2) ( 1 , 2 ) E [ e t G i ] = 1 / ( 2 − 3 / 2 ) = 2 \mathbb{E}[\e^{tG_i}] = 1/(2 - 3/2) = 2 E [ e t G i ] = 1/ ( 2 − 3/2 ) = 2
E [ e t G ] = 2 n ′ \mathbb{E}[\e^{tG}] = 2^{n'}
E [ e tG ] = 2 n ′
由 Markov 不等式 Pr [ e t G ⩾ e t a ] ⩽ e − t a E [ e t G ] \Pr[\e^{tG} \ge \e^{ta}] \le \e^{-ta}\mathbb{E}[\e^{tG}] Pr [ e tG ⩾ e t a ] ⩽ e − t a E [ e tG ] a > 0 a > 0 a > 0
Pr [ G ⩾ a ] ⩽ ( 3 / 2 ) − a ⋅ 2 n ′ \Pr[G \ge a] \le (3/2)^{-a} \cdot 2^{n'}
Pr [ G ⩾ a ] ⩽ ( 3/2 ) − a ⋅ 2 n ′
注意这个上界把「尾」和「期望」分别对应到两个因子:( 3 / 2 ) − a (3/2)^{-a} ( 3/2 ) − a a a a 2 n ′ 2^{n'} 2 n ′ MGF 集体贡献的「质量」。我们需要前者压制后者。
代入溢出处理的尺度 :下一小节会证明,每个溢出桶中至多 m = log n / log log n m = \log n/\log\log n m = log n / log log n n ′ = O ( log n / log log n ) n' = O(\log n / \log\log n) n ′ = O ( log n / log log n ) a = C log n a = C \log n a = C log n
2 n ′ = 2 O ( log n / log log n ) = n O ( 1 / log log n ) = n o ( 1 ) 2^{n'} = 2^{O(\log n / \log\log n)} = n^{O(1/\log\log n)} = n^{o(1)} 2 n ′ = 2 O ( l o g n / l o g l o g n ) = n O ( 1/ l o g l o g n ) = n o ( 1 ) ( 3 / 2 ) − a = n − C log 2 ( 3 / 2 ) ≈ n − 0.58 C (3/2)^{-a} = n^{-C \log_2(3/2)} \approx n^{-0.58\, C} ( 3/2 ) − a = n − C l o g 2 ( 3/2 ) ≈ n − 0.58 C
选 C C C C = 4 C = 4 C = 4
Pr [ G ⩾ C log n ] ⩽ n − Ω ( 1 ) \Pr[G \ge C\log n] \le n^{-\Omega(1)}
Pr [ G ⩾ C log n ] ⩽ n − Ω ( 1 )
结论:高概率下,压缩 trie 的总节点数是 O ( log n ) O(\log n) O ( log n ) ——这是一棵非常小的二叉树。
编码成比特 :一棵有 O ( log n ) O(\log n) O ( log n ) O ( log n ) O(\log n) O ( log n ) 平衡括号编码 :按 DFS 序遍历,每次进入一个节点写一个 (,退出一个节点写一个 ),共 2 ⋅ ( 节点数 ) 2 \cdot (\text{节点数}) 2 ⋅ ( 节点数 ) O ( log n ) O(\log n) O ( log n )
溢出的两级处理
回到主线。现在情况是:
主表:n / m n / m n / m ⩽ O ( log n ) \le O(\log n) ⩽ O ( log n )
溢出:⩽ n / log 12 n \le n / \log^{12} n ⩽ n / log 12 n
如果为每个主桶各自挂一棵 trie,总共 n / m n / m n / m × O ( log n ) \times O(\log n) × O ( log n ) = O ( n log log n ) = O(n \log\log n) = O ( n log log n ) n log N n \log N n log N 把所有溢出元素汇总后再次分桶 。
取 B ≔ n / log 9 n B \coloneqq n / \log^9 n B : = n / log 9 n B B B n ′ n' n ′ N overflow ⩽ n / log 12 n N_{\text{overflow}} \le n/\log^{12} n N overflow ⩽ n / log 12 n B B B B B B
让每桶期望负载 ⩽ N overflow / B ⩽ 1 / log 3 n = o ( 1 ) \le N_{\text{overflow}} / B \le 1/\log^3 n = o(1) ⩽ N overflow / B ⩽ 1/ log 3 n = o ( 1 ) O ( log n / log log n ) O(\log n / \log\log n) O ( log n / log log n )
让总桶数 B B B O ( log n ) O(\log n) O ( log n ) o ( n log N ) o(n \log N) o ( n log N )
最大负载分析 :为简化,按「B B B B B B N overflow ⩽ B / log 3 n N_{\text{overflow}} \le B/\log^3 n N overflow ⩽ B / log 3 n B B B
Pr [ 负载 ⩾ m ] ⩽ ∑ k ⩾ m ( B k ) ( 1 B ) k \Pr[\text{负载} \ge m] \le \sum_{k \ge m} \binom{B}{k} \left(\frac{1}{B}\right)^k
Pr [ 负载 ⩾ m ] ⩽ k ⩾ m ∑ ( k B ) ( B 1 ) k
用 ( B k ) ⩽ ( B e / k ) k \binom{B}{k} \le (B \e / k)^k ( k B ) ⩽ ( B e / k ) k 斯特林上界 ( a b ) ⩽ ( a e / b ) b \binom{a}{b} \le (a\e/b)^b ( b a ) ⩽ ( a e / b ) b
( B k ) ( 1 B ) k ⩽ ( e k ) k \binom{B}{k} \left(\frac{1}{B}\right)^k \le \left(\frac{\e}{k}\right)^k
( k B ) ( B 1 ) k ⩽ ( k e ) k
尾部求和用几何级数粗化 :考察相邻项比值
( e / ( k + 1 ) ) k + 1 ( e / k ) k = e k + 1 ⋅ ( k k + 1 ) k → k → ∞ e k + 1 ⋅ 1 e = 1 k + 1 \frac{(\e/(k+1))^{k+1}}{(\e/k)^k} = \frac{\e}{k+1} \cdot \left(\frac{k}{k+1}\right)^k \xrightarrow{k\to\infty} \frac{\e}{k+1} \cdot \frac{1}{\e} = \frac{1}{k+1}
( e / k ) k ( e / ( k + 1 ) ) k + 1 = k + 1 e ⋅ ( k + 1 k ) k k → ∞ k + 1 e ⋅ e 1 = k + 1 1
当 k ⩾ m k \ge m k ⩾ m m m m m ⩾ 2 m \ge 2 m ⩾ 2 ⩽ 1 / 2 \le 1/2 ⩽ 1/2 ( e / m ) m (\e/m)^m ( e / m ) m
Pr [ 负载 ⩾ m ] ⩽ ∑ k ⩾ m ( e k ) k ⩽ 2 ⋅ ( e m ) m = exp ( ln 2 − m ( ln m − 1 ) ) = exp ( − Ω ( m log m ) ) \Pr[\text{负载} \ge m] \le \sum_{k \ge m} \left(\frac{\e}{k}\right)^k \le 2 \cdot \left(\frac{\e}{m}\right)^m = \exp\big(\ln 2 - m(\ln m - 1)\big) = \exp(-\Omega(m \log m))
Pr [ 负载 ⩾ m ] ⩽ k ⩾ m ∑ ( k e ) k ⩽ 2 ⋅ ( m e ) m = exp ( ln 2 − m ( ln m − 1 ) ) = exp ( − Ω ( m log m ))
取 m = log n / log log n m = \log n / \log\log n m = log n / log log n
m log m = log n log log n ⋅ log ( log n log log n ) = log n log log n ⋅ ( log log n − log log log n ) ∼ log n m \log m = \frac{\log n}{\log\log n} \cdot \log\left(\frac{\log n}{\log\log n}\right) = \frac{\log n}{\log\log n} \cdot (\log\log n - \log\log\log n) \sim \log n
m log m = log log n log n ⋅ log ( log log n log n ) = log log n log n ⋅ ( log log n − log log log n ) ∼ log n
所以单桶失败概率 ⩽ exp ( − Ω ( log n ) ) = n − Ω ( 1 ) \le \exp(-\Omega(\log n)) = n^{-\Omega(1)} ⩽ exp ( − Ω ( log n )) = n − Ω ( 1 ) B ⩽ n B \le n B ⩽ n n − Ω ( 1 ) n^{-\Omega(1)} n − Ω ( 1 ) 每个溢出桶的负载都不超过 m = log n / log log n m = \log n / \log\log n m = log n / log log n 。
于是每个溢出桶都可以套用上一小节的 trie 分析(那里的 n ′ n' n ′ = O ( log n / log log n ) = O(\log n / \log\log n) = O ( log n / log log n )
单桶 trie 节点数 :O ( log n ) O(\log n) O ( log n ) 单桶编码 :O ( log n ) O(\log n) O ( log n )
溢出处理总空间 :B ⋅ O ( log n ) = O ( ( n / log 9 n ) ⋅ log n ) = O ( n / log 8 n ) B \cdot O(\log n) = O((n / \log^9 n) \cdot \log n) = O(n / \log^8 n) B ⋅ O ( log n ) = O (( n / log 9 n ) ⋅ log n ) = O ( n / log 8 n )
为什么恰好是 log 9 n \log^9 n log 9 n
这里的 9 没有特别意义——它只是「足够大的多项式」。真正的约束是:
下界 :溢出桶数 B B B o ( 1 ) o(1) o ( 1 ) B ≫ N overflow B \gg N_{\text{overflow}} B ≫ N overflow δ \delta δ N overflow ⩽ n / log 12 n N_{\text{overflow}} \le n/\log^{12} n N overflow ⩽ n / log 12 n B = n / log 9 n B = n/\log^9 n B = n / log 9 n ⩽ 1 / log 3 n \le 1/\log^3 n ⩽ 1/ log 3 n 上界 :B ⋅ O ( log n ) = o ( n log N ) B \cdot O(\log n) = o(n\log N) B ⋅ O ( log n ) = o ( n log N ) B = o ( n log N / log n ) = o ( n ) B = o(n\log N / \log n) = o(n) B = o ( n log N / log n ) = o ( n )
任何 B = n / log c n B = n / \log^c n B = n / log c n 1 ⩽ c < 12 1 \le c < 12 1 ⩽ c < 12 c = 9 c = 9 c = 9
总冗余汇总
把所有冗余来源汇总:
来源
冗余
主桶中 δ m \delta m δ m
O ( δ n ) O(\delta n) O ( δ n ) = O ( δ n log N ) = O(\delta n \log N) = O ( δ n log N )
主桶「字长对齐」的尾部浪费
O ( n / m ) O(n / m) O ( n / m ) n / m n/m n / m
溢出两级处理
O ( n / log 8 n ) O(n / \log^8 n) O ( n / log 8 n )
主项是第一条:O ( δ n log N ) O(\delta n \log N) O ( δ n log N ) δ = 6 log log n / log n \delta = 6\log\log n / \sqrt{\log n} δ = 6 log log n / log n c c c c c c O O O
O ( δ n log N ) = O ( log log n log n ⋅ n log N ) = o ( n log N ) O(\delta n \log N) = O\left(\frac{\log\log n}{\sqrt{\log n}} \cdot n \log N\right) = o(n \log N)
O ( δ n log N ) = O ( log n log log n ⋅ n log N ) = o ( n log N )
因为 log log n / log n → 0 \log\log n / \sqrt{\log n} \to 0 log log n / log n → 0 n log N + o ( n log N ) = ( 1 + o ( 1 ) ) log 2 ( N n ) n\log N + o(n\log N) = (1+o(1))\log_2 \binom{N}{n} n log N + o ( n log N ) = ( 1 + o ( 1 )) log 2 ( n N )
但还能更紧。下面用 Feistel 网络把上表第一条进一步从「字」单位压到「比特」单位。
Feistel 网络与 quotienting
一轮 Feistel
Feistel 网络 是密码学里构造可逆置换的标准结构。先看最简单的一轮版本——把 2 t 2t 2 t ( x 1 , x 2 ) (x_1, x_2) ( x 1 , x 2 ) t t t
F f ( x 1 , x 2 ) = ( f ( x 2 ) ⊕ x 1 , x 2 ) F_f(x_1, x_2) = (f(x_2) \oplus x_1,\ x_2)
F f ( x 1 , x 2 ) = ( f ( x 2 ) ⊕ x 1 , x 2 )
其中 f : { 0 , 1 } t → { 0 , 1 } t f\colon \{0,1\}^t \to \{0,1\}^t f : { 0 , 1 } t → { 0 , 1 } t k k k ⊕ \oplus ⊕
flowchart LR
X1["x₁"] --> XOR(("⊕"))
X2["x₂"] --> F["f(·)"]
F --> XOR
XOR --> Y1["f(x₂) ⊕ x₁"]
X2 --> Y2["x₂"]
classDef in fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef func fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
classDef op fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef out fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
class X1,X2 in
class F func
class XOR op
class Y1,Y2 out它是双射 :给定输出 ( y 1 , y 2 ) (y_1, y_2) ( y 1 , y 2 )
F f − 1 ( y 1 , y 2 ) = ( y 1 ⊕ f ( y 2 ) , y 2 ) F_f^{-1}(y_1, y_2) = (y_1 \oplus f(y_2),\ y_2)
F f − 1 ( y 1 , y 2 ) = ( y 1 ⊕ f ( y 2 ) , y 2 )
注意这里不要求 f f f ——XOR 自身的可逆性就够了。这是 Feistel 的关键卖点:用一个不可逆的函数 f f f
为什么需要双射 ?因为我们后面要把 key x x x i i i q q q ( i , q ) (i, q) ( i , q ) x x x
多轮 Feistel
把单轮 Feistel 串联多次(每轮换一个不同的 f f f f f f k k k f f f
Quotienting:把 key 拆成 (桶号, 商)
回到 succinct 字典。每个 key x ∈ [ N ] x \in [N] x ∈ [ N ] log N \log N log N i ∈ [ n / m ] i \in [n/m] i ∈ [ n / m ] log ( n / m ) \log(n/m) log ( n / m ) 桶内不必再存 x x x log N \log N log N ——只需存能与 i i i x x x 商 (quotient)q q q
但简单的「把 x x x h h h i = h ( x ) i = h(x) i = h ( x ) x x x 可逆 的「key → (桶号, 商)」映射。
Feistel 给出这种映射 。把 x x x ( x 1 , x 2 ) (x_1, x_2) ( x 1 , x 2 ) ( y 1 , y 2 ) = F f ( x 1 , x 2 ) (y_1, y_2) = F_f(x_1, x_2) ( y 1 , y 2 ) = F f ( x 1 , x 2 ) log N \log N log N log N \log N log N log ( n / m ) \log(n/m) log ( n / m ) i i i log ( N m / n ) \log(Nm/n) log ( N m / n ) q q q
i ⏞ log ( n / m ) q ⏞ log ( N m / n ) ⏟ ( y 1 , y 2 ) 的 log N 比特 \underbrace{\overbrace{\quad\,i\,\quad}^{\log(n/m)}\quad\overbrace{\quad\quad\,q\,\quad\quad}^{\log(Nm/n)}}_{(y_1,\,y_2)\,\text{的 }\log N\,\text{ 比特}}
( y 1 , y 2 ) 的 l o g N 比特 i l o g ( n / m ) q l o g ( N m / n )
由于 Feistel 是双射,( i , q ) ↔ x (i, q) \leftrightarrow x ( i , q ) ↔ x q q q ( i , q ) (i, q) ( i , q ) x x x log N \log N log N log ( N m / n ) ≈ log ( N / n ) + O ( log log n ) \log(Nm/n) \approx \log(N/n) + O(\log\log n) log ( N m / n ) ≈ log ( N / n ) + O ( log log n ) log ( n / m ) \log(n/m) log ( n / m )
把第一条冗余 O ( δ n ) O(\delta n) O ( δ n ) O ( δ n log N ) O(\delta n \log N) O ( δ n log N ) O ( δ n log ( N / n ) ) O(\delta n \log(N/n)) O ( δ n log ( N / n )) log N / log ( N / n ) \log N / \log(N/n) log N / log ( N / n ) N = n O ( 1 ) N = n^{O(1)} N = n O ( 1 ) N ≫ n N \gg n N ≫ n
这就是 quotienting 技术 的密码学实现:用一个可逆置换把「桶索引带走的信息」干净地从存储里挖掉,只留补差。
在 [ n ] [n] [ n ]
二进制 Feistel 的灵魂是 XOR。如果 key 来自一般集合 [ n ] [n] [ n ] n n n 阿贝尔群 结构——因为 XOR 在 { 0 , 1 } t \{0,1\}^t { 0 , 1 } t
最自然的替代是 [ n ] [n] [ n ] 模加法 :
⊕ n : [ n ] × [ n ] → [ n ] , ( a , b ) ↦ ( a + b ) m o d n \oplus_n\colon [n] \times [n] \to [n], \quad (a, b) \mapsto (a + b) \bmod n
⊕ n : [ n ] × [ n ] → [ n ] , ( a , b ) ↦ ( a + b ) mod n
把 XOR 全部替换成 ⊕ n \oplus_n ⊕ n [ n ] [n] [ n ]
F h ( x 1 , x 2 ) = ( ( x 1 + h ( x 2 ) ) m o d n , x 2 ) F_h(x_1, x_2) = ((x_1 + h(x_2)) \bmod n,\ x_2)
F h ( x 1 , x 2 ) = (( x 1 + h ( x 2 )) mod n , x 2 )
其中 x 1 , x 2 ∈ [ n ] x_1, x_2 \in [n] x 1 , x 2 ∈ [ n ] h : X 2 → [ n ] h\colon X_2 \to [n] h : X 2 → [ n ]
[ n ] [n] [ n ]
对每个固定的 x 2 x_2 x 2 x 1 ↦ ( x 1 + h ( x 2 ) ) m o d n x_1 \mapsto (x_1 + h(x_2)) \bmod n x 1 ↦ ( x 1 + h ( x 2 )) mod n [ n ] [n] [ n ] y 1 ↦ ( y 1 − h ( x 2 ) ) m o d n y_1 \mapsto (y_1 - h(x_2)) \bmod n y 1 ↦ ( y 1 − h ( x 2 )) mod n
F h − 1 ( y 1 , y 2 ) = ( ( y 1 − h ( y 2 ) ) m o d n , y 2 ) F_h^{-1}(y_1, y_2) = ((y_1 - h(y_2)) \bmod n,\ y_2)
F h − 1 ( y 1 , y 2 ) = (( y 1 − h ( y 2 )) mod n , y 2 )
是 [ n ] × [ n ] [n] \times [n] [ n ] × [ n ]
保持 k k k 。设 h h h k k k ⩽ k \le k ⩽ k x 2 x_2 x 2 [ n ] [n] [ n ] r ⩽ k r \le k r ⩽ k ( x 1 , 1 , x 2 , 1 ) , … , ( x 1 , r , x 2 , r ) (x_{1,1}, x_{2,1}), \dots, (x_{1,r}, x_{2,r}) ( x 1 , 1 , x 2 , 1 ) , … , ( x 1 , r , x 2 , r ) x 2 , j x_{2,j} x 2 , j y 1 , … , y r ∈ [ n ] y_1, \dots, y_r \in [n] y 1 , … , y r ∈ [ n ]
⋀ j = 1 r ( x 1 , j + h ( x 2 , j ) ) m o d n = y j \bigwedge_{j=1}^r (x_{1,j} + h(x_{2,j})) \bmod n = y_j
j = 1 ⋀ r ( x 1 , j + h ( x 2 , j )) mod n = y j
等价于
⋀ j = 1 r h ( x 2 , j ) = ( y j − x 1 , j ) m o d n \bigwedge_{j=1}^r h(x_{2,j}) = (y_j - x_{1,j}) \bmod n
j = 1 ⋀ r h ( x 2 , j ) = ( y j − x 1 , j ) mod n
由 h h h k k k r r r 1 / n r 1/n^r 1/ n r k k k x 1 ∈ [ n ] x_1 \in [n] x 1 ∈ [ n ] [ n ] [n] [ n ]
为什么需要 strongly k k k k k k
课程定义的 k k k k k k 不保证 单点均匀,更不保证多点联合均匀。要让上面的推导成立——即新映射的输出 y j y_j y j [ n ] [n] [ n ] h h h k k k
换句话说,碰撞版 k k k k k k h h h h h h
与二进制版本的关系 。二进制 Feistel 是 n = 2 t n = 2^t n = 2 t ⊕ n = \oplus_n = ⊕ n = N = n O ( 1 ) N = n^{O(1)} N = n O ( 1 ) N N N
综合起来,Succinct dictionary 的总空间是
n log N + o ( n log N ) = ( 1 + o ( 1 ) ) log 2 ( N n ) 比特 n \log N + o(n \log N) = (1 + o(1)) \log_2 \binom{N}{n} \text{ 比特}
n log N + o ( n log N ) = ( 1 + o ( 1 )) log 2 ( n N ) 比特
同时支持 O ( 1 ) O(1) O ( 1 )
flowchart LR
BB["n 个元素"] --> BIN["n/m 个主桶<br>m = log n / log log n"]
BIN --> SD1["每桶编码 ≤ O(log n) 比特<br>= 一个机器字"]
SD1 --> WORD["字内 O(1) 查询<br>(借助预计算表)"]
BIN -.->|"每桶以 ≤ 1/log¹² n 概率溢出"| OVF["溢出元素<br>≤ n/log¹² n 个"]
OVF --> OVF2["B = n/log⁹ n 个溢出桶"]
OVF2 --> LOAD["每桶负载 ≤ log n / log log n<br>(w.h.p.)"]
LOAD --> TRIE["压缩 trie 编码<br>每棵 O(log n) 节点 = O(log n) 比特"]
classDef main fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef hot fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef cold fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
class BB,BIN,SD1,WORD main
class OVF hot
class OVF2,LOAD,TRIE coldChernoff Bound 的推广
上面所有的分析都假设完全独立的哈希函数——但正如我们所见,k k k O ( k ) O(k) O ( k )
困境:经典 Chernoff 为什么需要完全独立
经典 Chernoff 走的是 MGF 路线:E [ e t X ] \mathbb{E}[\e^{tX}] E [ e tX ] MGF 比值。但 e t X = ∑ j ⩾ 0 ( t X ) j / j ! \e^{tX} = \sum_{j \ge 0} (tX)^j / j! e tX = ∑ j ⩾ 0 ( tX ) j / j ! 所有阶 X j X^j X j X 1 , … , X n X_1, \dots, X_n X 1 , … , X n 全部 联合矩,必须完全独立才行。
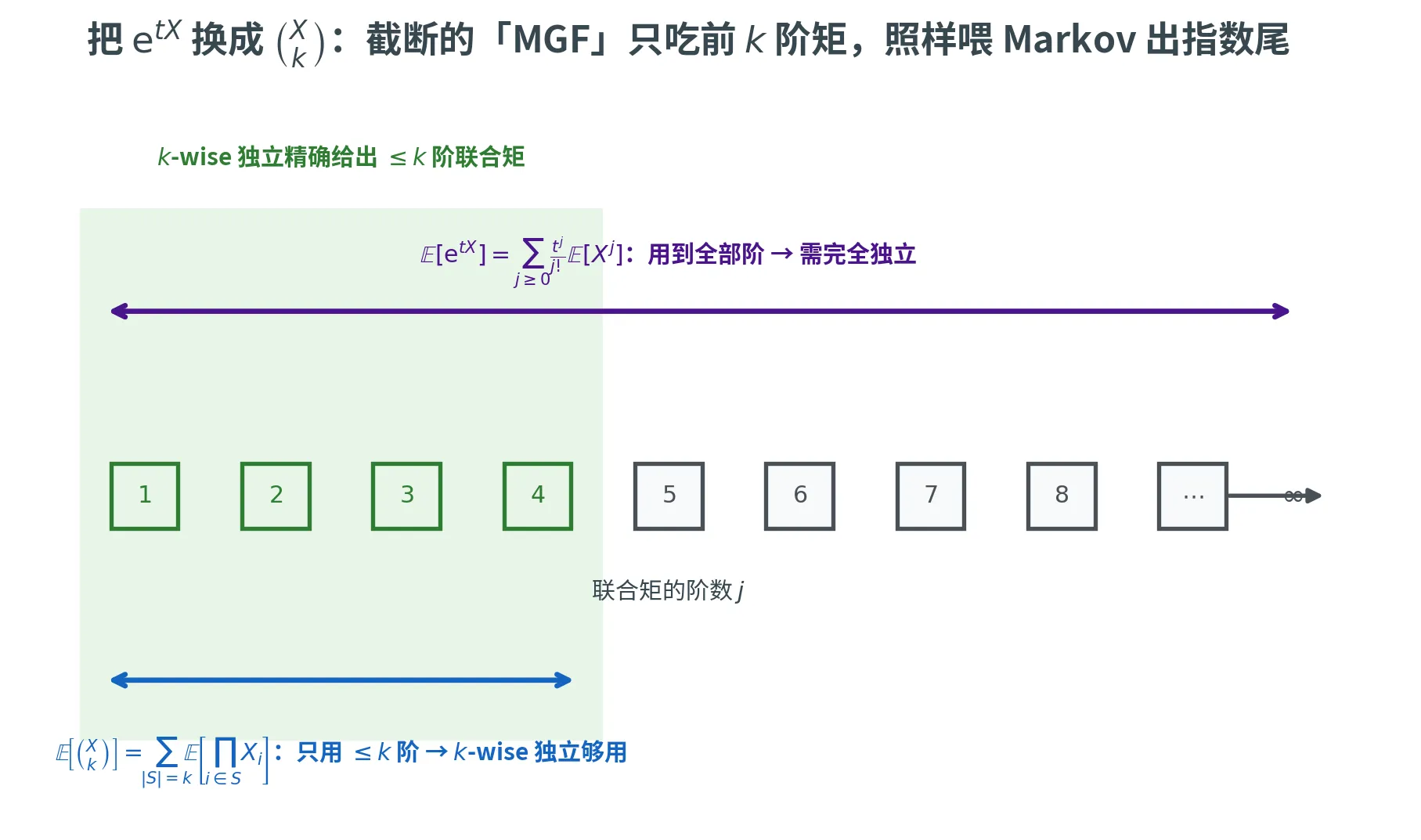
如果只有 k k k k k k 只用前 k k k 的「替代 MGF 」?
核心想法:用 ( X k ) \binom{X}{k} ( k X ) e t X \e^{tX} e tX
注意,对 { 0 , 1 } \{0, 1\} { 0 , 1 } X 1 , … , X n X_1, \dots, X_n X 1 , … , X n X = ∑ X i X = \sum X_i X = ∑ X i
( X k ) = ∑ S ⊆ [ n ] ∣ S ∣ = k ∏ i ∈ S X i \binom{X}{k} = \sum_{\substack{S \subseteq [n] \\ |S| = k}} \prod_{i \in S} X_i
( k X ) = S ⊆ [ n ] ∣ S ∣ = k ∑ i ∈ S ∏ X i
这是一个 k k k 多项式 (每项是 k k k X i X_i X i
E [ ( X k ) ] = ∑ S ⊆ [ n ] ∣ S ∣ = k E [ ∏ i ∈ S X i ] \mathbb{E}\left[\binom{X}{k}\right] = \sum_{\substack{S \subseteq [n] \\ |S| = k}} \mathbb{E}\left[\prod_{i \in S} X_i\right]
E [ ( k X ) ] = S ⊆ [ n ] ∣ S ∣ = k ∑ E [ i ∈ S ∏ X i ]
只用到 X i X_i X i k k k k k k
下图对比这两个「检验函数」各自吃掉多少阶联合矩:经典 MGF e t X = ∑ j ( t X ) j / j ! \e^{tX} = \sum_j (tX)^j/j! e tX = ∑ j ( tX ) j / j ! 所有 阶矩,必须完全独立才能逐项计算;而 ( X k ) \binom{X}{k} ( k X ) k k k ⩽ k \le k ⩽ k k k k ( X k ) \binom{X}{k} ( k X ) MGF 」的来由。
更具体地,假设每个 X i X_i X i Pr [ X i = 1 ] = p \Pr[X_i = 1] = p Pr [ X i = 1 ] = p μ = E [ X ] = n p \mu = \mathbb{E}[X] = np μ = E [ X ] = n p k k k
E [ ∏ i ∈ S X i ] = ∏ i ∈ S p = p k = ( μ n ) k \mathbb{E}\left[\prod_{i \in S} X_i\right] = \prod_{i \in S} p = p^k = \left(\frac{\mu}{n}\right)^k
E [ i ∈ S ∏ X i ] = i ∈ S ∏ p = p k = ( n μ ) k
共 ( n k ) \binom{n}{k} ( k n ) k k k
E [ ( X k ) ] = ( n k ) ( μ n ) k \mathbb{E}\left[\binom{X}{k}\right] = \binom{n}{k}\left(\frac{\mu}{n}\right)^k
E [ ( k X ) ] = ( k n ) ( n μ ) k
接下来用 Markov:注意 ( x k ) \binom{x}{k} ( k x ) x ⩾ k x \ge k x ⩾ k x x x X ⩾ a X \ge a X ⩾ a ( X k ) ⩾ ( a k ) \binom{X}{k} \ge \binom{a}{k} ( k X ) ⩾ ( k a ) a ⩾ k a \ge k a ⩾ k
Pr [ X ⩾ a ] ⩽ Pr [ ( X k ) ⩾ ( a k ) ] ⩽ E [ ( X k ) ] ( a k ) = ( n k ) ( μ / n ) k ( a k ) \boxed{\Pr[X \ge a] \le \Pr\left[\binom{X}{k} \ge \binom{a}{k}\right] \le \frac{\mathbb{E}\!\left[\binom{X}{k}\right]}{\binom{a}{k}} = \frac{\binom{n}{k}(\mu/n)^k}{\binom{a}{k}}}
Pr [ X ⩾ a ] ⩽ Pr [ ( k X ) ⩾ ( k a ) ] ⩽ ( k a ) E [ ( k X ) ] = ( k a ) ( k n ) ( μ / n ) k
这就是 k k k a = ( 1 + δ ) μ a = (1+\delta)\mu a = ( 1 + δ ) μ
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ ( n k ) ( μ / n ) k ( ( 1 + δ ) μ k ) \Pr[X \ge (1+\delta)\mu] \le \frac{\binom{n}{k}(\mu/n)^k}{\binom{(1+\delta)\mu}{k}}
Pr [ X ⩾ ( 1 + δ ) μ ] ⩽ ( k ( 1 + δ ) μ ) ( k n ) ( μ / n ) k
解读
右边的两个二项式系数有明确的几何意义:
分子 ( n k ) ( μ / n ) k \binom{n}{k}(\mu/n)^k ( k n ) ( μ / n ) k k k k
分母 ( a k ) \binom{a}{k} ( k a ) a a a
比值告诉我们:实际质量被「k k k
最优 k k k k ≈ μ δ / ( 1 − μ / n ) k \approx \mu\delta / (1 - \mu/n) k ≈ μ δ / ( 1 − μ / n ) δ = Θ ( 1 ) \delta = \Theta(1) δ = Θ ( 1 ) μ \mu μ k ≈ μ δ k \approx \mu\delta k ≈ μ δ
( e μ a ) k = ( e 1 + δ ) k = exp ( − Θ ( k ) ) \left(\frac{\e\mu}{a}\right)^k = \left(\frac{\e}{1+\delta}\right)^k = \exp(-\Theta(k))
( a e μ ) k = ( 1 + δ e ) k = exp ( − Θ ( k ))
和经典 Chernoff 量级一致——只要 k k k
把握全局
把 ( X k ) \binom{X}{k} ( k X ) MGF 」是理解这套技巧的关键:MGF 用所有阶,需要完全独立;( X k ) \binom{X}{k} ( k X ) k k k k k k 指数尾的精神被保留 ——只要能把 k k k
应用:k k k
直接套用上面的 bound,把课堂讲过的两种 balls into bins 情形翻译过来。固定桶 j j j X i = I [ 第 i 个球落入桶 j ] X_i = \mathbb{I}[\text{第 }i\text{ 个球落入桶 }j] X i = I [ 第 i 个球落入桶 j ] X = ∑ X i X = \sum X_i X = ∑ X i j j j L j L_j L j
情况一:m = n m = n m = n n n n
每个桶期望负载 μ = 1 \mu = 1 μ = 1 max j X = O ( log n / log log n ) \max_j X = O(\log n / \log\log n) max j X = O ( log n / log log n )
Pr [ X ⩾ L ] ⩽ n − 2 , L = O ( log n / log log n ) \Pr[X \ge L] \le n^{-2}, \qquad L = O(\log n / \log\log n)
Pr [ X ⩾ L ] ⩽ n − 2 , L = O ( log n / log log n )
代入 bound(用 a = L a = L a = L μ = 1 \mu = 1 μ = 1
Pr [ X ⩾ L ] ⩽ ( n k ) ( 1 / n ) k ( L k ) ⩽ ( n e / k ) k ( 1 / n ) k ( L / k ) k = ( e L ) k \Pr[X \ge L] \le \frac{\binom{n}{k}(1/n)^k}{\binom{L}{k}} \le \frac{(n\e/k)^k (1/n)^k}{(L/k)^k} = \left(\frac{\e}{L}\right)^k
Pr [ X ⩾ L ] ⩽ ( k L ) ( k n ) ( 1/ n ) k ⩽ ( L / k ) k ( n e / k ) k ( 1/ n ) k = ( L e ) k
其中用 ( n k ) ⩽ ( n e / k ) k \binom{n}{k} \le (n\e/k)^k ( k n ) ⩽ ( n e / k ) k ( L k ) ⩾ ( L / k ) k \binom{L}{k} \ge (L/k)^k ( k L ) ⩾ ( L / k ) k
要让上式 ⩽ n − 2 \le n^{-2} ⩽ n − 2 k = L k = L k = L ( e / L ) L ⩽ n − 2 (\e/L)^L \le n^{-2} ( e / L ) L ⩽ n − 2 L ln ( L / e ) ⩾ 2 ln n L\ln(L/\e) \ge 2\ln n L ln ( L / e ) ⩾ 2 ln n L = Θ ( log n / log log n ) L = \Theta(\log n / \log\log n) L = Θ ( log n / log log n ) k = Θ ( log n / log log n ) k = \Theta(\log n / \log\log n) k = Θ ( log n / log log n )
情况二:m ⩾ n ln n m \ge n\ln n m ⩾ n ln n n n n
每个桶期望负载 μ = m / n ⩾ ln n \mu = m/n \ge \ln n μ = m / n ⩾ ln n X = O ( m / n ) X = O(m/n) X = O ( m / n ) a = 2 e μ a = 2\e\mu a = 2 e μ δ = 2 e − 1 \delta = 2\e - 1 δ = 2 e − 1
Pr [ X ⩾ 2 e μ ] ⩽ ( m k ) ( μ / m ) k ( 2 e μ k ) ⩽ ( e 2 e ) k = 2 − k \Pr[X \ge 2\e\mu] \le \frac{\binom{m}{k}(\mu/m)^k}{\binom{2\e\mu}{k}} \le \left(\frac{\e}{2\e}\right)^k = 2^{-k}
Pr [ X ⩾ 2 e μ ] ⩽ ( k 2 e μ ) ( k m ) ( μ / m ) k ⩽ ( 2 e e ) k = 2 − k
同样用斯特林上下界。要 ⩽ n − 2 \le n^{-2} ⩽ n − 2 k = 2 log 2 n k = 2\log_2 n k = 2 log 2 n k = Θ ( log n ) k = \Theta(\log n) k = Θ ( log n )
总结
情形
所需独立度 k k k
最大负载
m = n m = n m = n Θ ( log n / log log n ) \Theta(\log n / \log\log n) Θ ( log n / log log n ) O ( log n / log log n ) O(\log n / \log\log n) O ( log n / log log n )
m ⩾ n ln n m \ge n\ln n m ⩾ n ln n Θ ( log n ) \Theta(\log n) Θ ( log n ) O ( m / n ) O(m/n) O ( m / n )
两种情形都能用有限独立完全复现 完全随机情形下的 max load 上界——只要 k k k k k k O ( k ) O(k) O ( k ) O ( k ) O(k) O ( k )
警示:k = 2 k = 2 k = 2 n \sqrt n n
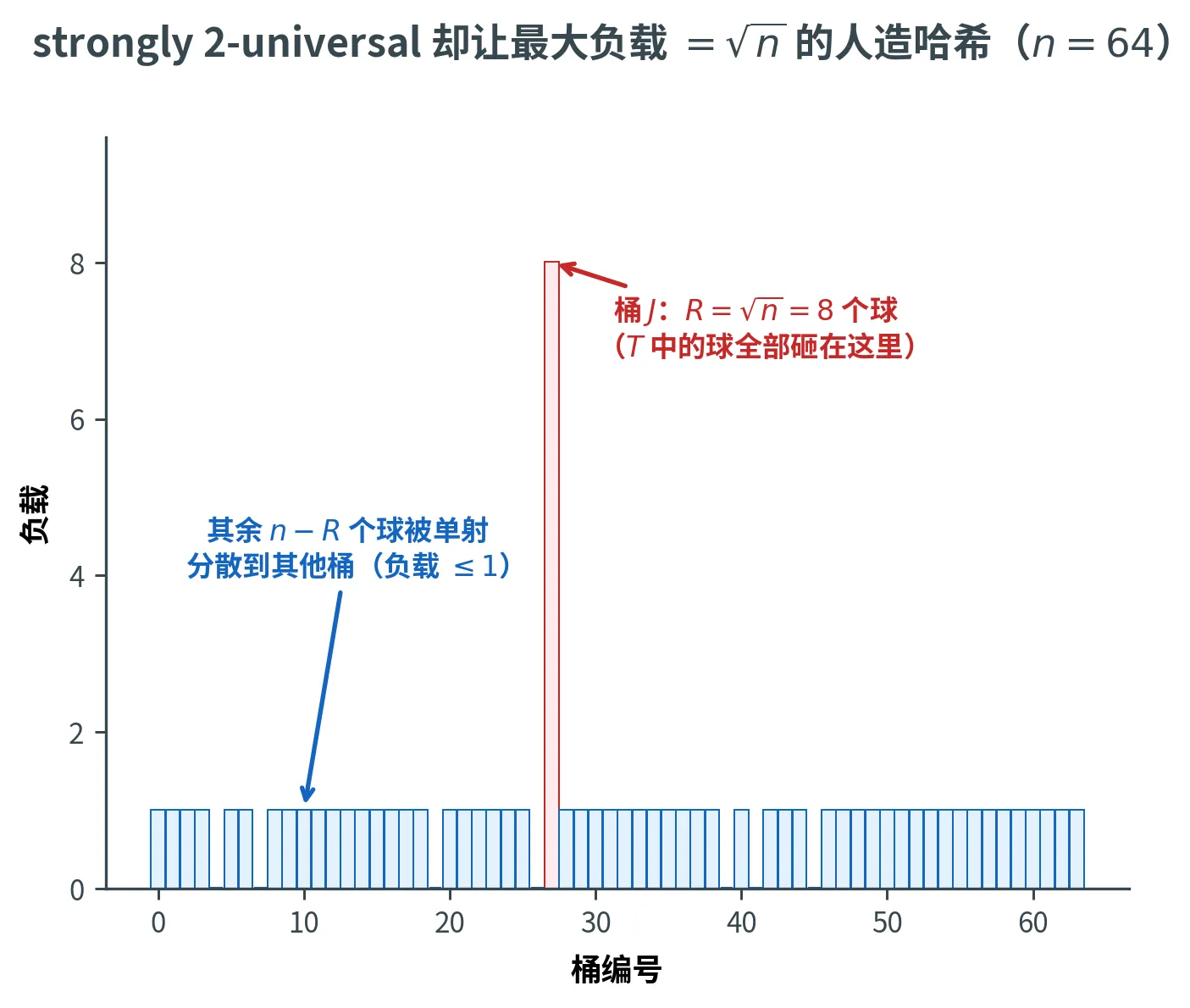
上面说「k k k k = 2 k = 2 k = 2 远远不行 。下面构造一个 strongly 2-universal 的哈希函数族,但 n n n n n n L max = Θ ( n ) L_{\max} = \Theta(\sqrt n) L m a x = Θ ( n ) 1 1 1 O ( log n / log log n ) O(\log n / \log\log n) O ( log n / log log n )
构造
球集合和桶集合都是 [ n ] [n] [ n ] 随机整数 R R R
E [ R ( R − 1 ) ] = n − 1 , R = Θ ( n ) \mathbb{E}[R(R-1)] = n - 1, \qquad R = \Theta(\sqrt n)
E [ R ( R − 1 )] = n − 1 , R = Θ ( n )
具体取法:令 r r r r ( r − 1 ) ⩽ n − 1 ⩽ r ( r + 1 ) r(r-1) \le n - 1 \le r(r+1) r ( r − 1 ) ⩽ n − 1 ⩽ r ( r + 1 ) r = Θ ( n ) r = \Theta(\sqrt n) r = Θ ( n )
R = { r + 1 , 概率 α , r , 概率 1 − α , α = n − 1 − r ( r − 1 ) 2 r R = \begin{cases} r + 1, & \text{概率 }\alpha,\\ r, & \text{概率 } 1 - \alpha,\end{cases}
\qquad \alpha = \frac{n - 1 - r(r-1)}{2r}
R = { r + 1 , r , 概率 α , 概率 1 − α , α = 2 r n − 1 − r ( r − 1 )
代入验证 E [ R ( R − 1 ) ] = ( 1 − α ) r ( r − 1 ) + α r ( r + 1 ) = n − 1 \mathbb{E}[R(R-1)] = (1-\alpha)r(r-1) + \alpha r(r+1) = n - 1 E [ R ( R − 1 )] = ( 1 − α ) r ( r − 1 ) + α r ( r + 1 ) = n − 1
给定 R R R h h h
从 [ n ] [n] [ n ] R R R T T T
从 [ n ] [n] [ n ] J J J
对所有 x ∈ T x \in T x ∈ T h ( x ) = J h(x) = J h ( x ) = J
对所有 x ∉ T x \notin T x ∈ / T 单射 映射到 [ n ] ∖ { J } [n] \setminus \{J\} [ n ] ∖ { J }
也就是说:T T T R R R J J J n − R n - R n − R n − 1 n - 1 n − 1
Maximum load = n \sqrt n n
由构造,桶 J J J R R R ⩽ 1 \le 1 ⩽ 1
L max = R = Θ ( n ) 以概率 1 L_{\max} = R = \Theta(\sqrt n) \quad \text{以概率 }1
L m a x = R = Θ ( n ) 以概率 1
下图画出这个人造哈希的负载分布(取 n = 64 n = 64 n = 64 R = n = 8 R = \sqrt n = 8 R = n = 8 J J J R R R n \sqrt n n 恰恰满足 strongly 2-universal ——这种「看起来够随机、实际却灾难性失衡」的反差,正是这个反例全部的冲击力所在。
但 h h h
要验证两件事:单点均匀 + 两两独立。
单点均匀 。固定球 x x x a a a
若 x ∈ T x \in T x ∈ T h ( x ) = J h(x) = J h ( x ) = J Pr [ h ( x ) = a ∣ x ∈ T ] = Pr [ J = a ] = 1 / n \Pr[h(x) = a \mid x \in T] = \Pr[J = a] = 1/n Pr [ h ( x ) = a ∣ x ∈ T ] = Pr [ J = a ] = 1/ n
若 x ∉ T x \notin T x ∈ / T h ( x ) h(x) h ( x ) [ n ] ∖ { J } [n] \setminus \{J\} [ n ] ∖ { J } Pr [ h ( x ) = a ∣ x ∉ T ] = Pr [ J ≠ a ] ⋅ 1 n − 1 = n − 1 n ⋅ 1 n − 1 = 1 n \Pr[h(x) = a \mid x \notin T] = \Pr[J \ne a] \cdot \frac{1}{n-1} = \frac{n-1}{n} \cdot \frac{1}{n-1} = \frac{1}{n} Pr [ h ( x ) = a ∣ x ∈ / T ] = Pr [ J = a ] ⋅ n − 1 1 = n n − 1 ⋅ n − 1 1 = n 1
无论哪种情况都有 Pr [ h ( x ) = a ] = 1 / n \Pr[h(x) = a] = 1/n Pr [ h ( x ) = a ] = 1/ n
两两独立 。固定两个不同球 x ≠ y x \ne y x = y a , b ∈ [ n ] a, b \in [n] a , b ∈ [ n ]
p ≔ Pr [ x , y ∈ T ] = E [ R ( R − 1 ) n ( n − 1 ) ] = E [ R ( R − 1 ) ] n ( n − 1 ) = n − 1 n ( n − 1 ) = 1 n p \coloneqq \Pr[x, y \in T] = \mathbb{E}\!\left[\frac{R(R-1)}{n(n-1)}\right] = \frac{\mathbb{E}[R(R-1)]}{n(n-1)} = \frac{n-1}{n(n-1)} = \frac{1}{n}
p : = Pr [ x , y ∈ T ] = E [ n ( n − 1 ) R ( R − 1 ) ] = n ( n − 1 ) E [ R ( R − 1 )] = n ( n − 1 ) n − 1 = n 1
这就是为什么要让 E [ R ( R − 1 ) ] = n − 1 \mathbb{E}[R(R-1)] = n-1 E [ R ( R − 1 )] = n − 1
情况 a = b a = b a = b 。两个不同球同时进同一个桶只能发生在二者都在 T T T
Pr [ h ( x ) = a , h ( y ) = a ] = Pr [ x , y ∈ T ] ⋅ Pr [ J = a ] = 1 n ⋅ 1 n = 1 n 2 \Pr[h(x) = a, h(y) = a] = \Pr[x, y \in T] \cdot \Pr[J = a] = \frac{1}{n} \cdot \frac{1}{n} = \frac{1}{n^2}
Pr [ h ( x ) = a , h ( y ) = a ] = Pr [ x , y ∈ T ] ⋅ Pr [ J = a ] = n 1 ⋅ n 1 = n 2 1
情况 a ≠ b a \ne b a = b 。x , y x, y x , y T T T h ( x ) = h ( y ) h(x) = h(y) h ( x ) = h ( y ) h ( x ) = a ≠ b = h ( y ) h(x) = a \ne b = h(y) h ( x ) = a = b = h ( y ) T T T x ∈ T , y ∉ T x \in T, y \notin T x ∈ T , y ∈ / T x ∉ T , y ∈ T x \notin T, y \in T x ∈ / T , y ∈ T x , y ∉ T x, y \notin T x , y ∈ / T 1 n ( n − 1 ) \frac{1}{n(n-1)} n ( n − 1 ) 1
Pr [ h ( x ) = a , h ( y ) = b ] = ( 1 − p ) ⋅ 1 n ( n − 1 ) = n − 1 n ⋅ 1 n ( n − 1 ) = 1 n 2 \Pr[h(x) = a, h(y) = b] = (1 - p) \cdot \frac{1}{n(n-1)} = \frac{n-1}{n} \cdot \frac{1}{n(n-1)} = \frac{1}{n^2}
Pr [ h ( x ) = a , h ( y ) = b ] = ( 1 − p ) ⋅ n ( n − 1 ) 1 = n n − 1 ⋅ n ( n − 1 ) 1 = n 2 1
两情况合并:对任意 a , b a, b a , b Pr [ h ( x ) = a , h ( y ) = b ] = 1 / n 2 = Pr [ h ( x ) = a ] Pr [ h ( y ) = b ] \Pr[h(x) = a, h(y) = b] = 1/n^2 = \Pr[h(x) = a]\Pr[h(y) = b] Pr [ h ( x ) = a , h ( y ) = b ] = 1/ n 2 = Pr [ h ( x ) = a ] Pr [ h ( y ) = b ] h h h
教训
构造出的 h h h = Θ ( n ) = \Theta(\sqrt n) = Θ ( n ) O ( log n / log log n ) O(\log n / \log\log n) O ( log n / log log n )
这说明:Chernoff 量级的集中绝不仅是「两两独立 + 均匀」就能换来的 ——它真的依赖更高阶的独立性。课程上一节中之所以要求 k = Θ ( log n / log log n ) k = \Theta(\log n / \log\log n) k = Θ ( log n / log log n ) k = 2 k = 2 k = 2
独立性的代价
k k k O ( k ) O(k) O ( k )
应用
所需独立度
链式哈希 / 最大负载
Θ ( log n / log log n ) \Theta(\log n / \log\log n) Θ ( log n / log log n )
线性探测
⩽ 5 \le 5 ⩽ 5 ⩾ 5 \ge 5 ⩾ 5
Cuckoo 哈希
O ( log n ) O(\log n) O ( log n )
F 2 F_2 F 2 4
Min-wise 独立
Θ ( log ( 1 / ε ) ) \Theta(\log(1/\varepsilon)) Θ ( log ( 1/ ε ))
Siegel (1989) 证明了一个下界:如果求值时间为 t < k t < k t < k ∣ U ∣ 1 / t |U|^{1/t} ∣ U ∣ 1/ t Ω ( 1 ) \Omega(1) Ω ( 1 ) O ( 1 ) O(1) O ( 1 ) ∣ U ∣ Ω ( 1 ) |U|^{\Omega(1)} ∣ U ∣ Ω ( 1 ) k k k
Tabulation Hashing
Siegel 的下界似乎说明了高效哈希是不可能的——但实践中有一种方法工作得出奇地好。
构造
Tabulation Hashing(Zobrist, 1979)
将键 x ∈ [ u c ] x \in [u^c] x ∈ [ u c ] c c c x = ( x 1 , … , x c ) , x i ∈ [ u ] x = (x_1, \dots, x_c),\, x_i \in [u] x = ( x 1 , … , x c ) , x i ∈ [ u ] c c c T 1 , … , T c : [ u ] → [ m ] T_1, \dots, T_c\colon [u] \to [m] T 1 , … , T c : [ u ] → [ m ]
h ( x ) = T 1 [ x 1 ] ⊕ T 2 [ x 2 ] ⊕ ⋯ ⊕ T c [ x c ] h(x) = T_1[x_1] \oplus T_2[x_2] \oplus \dots \oplus T_c[x_c]
h ( x ) = T 1 [ x 1 ] ⊕ T 2 [ x 2 ] ⊕ ⋯ ⊕ T c [ x c ]
其中 ⊕ \oplus ⊕
空间 :c u cu c u 求值时间 :O ( c ) O(c) O ( c ) c c c c − 1 c-1 c − 1
以 32 位键为例,取 c = 4 , u = 256 c = 4,\, u = 256 c = 4 , u = 256 256 256 256 4 × 256 = 1024 4 \times 256 = 1024 4 × 256 = 1024
独立性分析
Tabulation hashing 是 3-universal 的,但不是 4-universal 的。
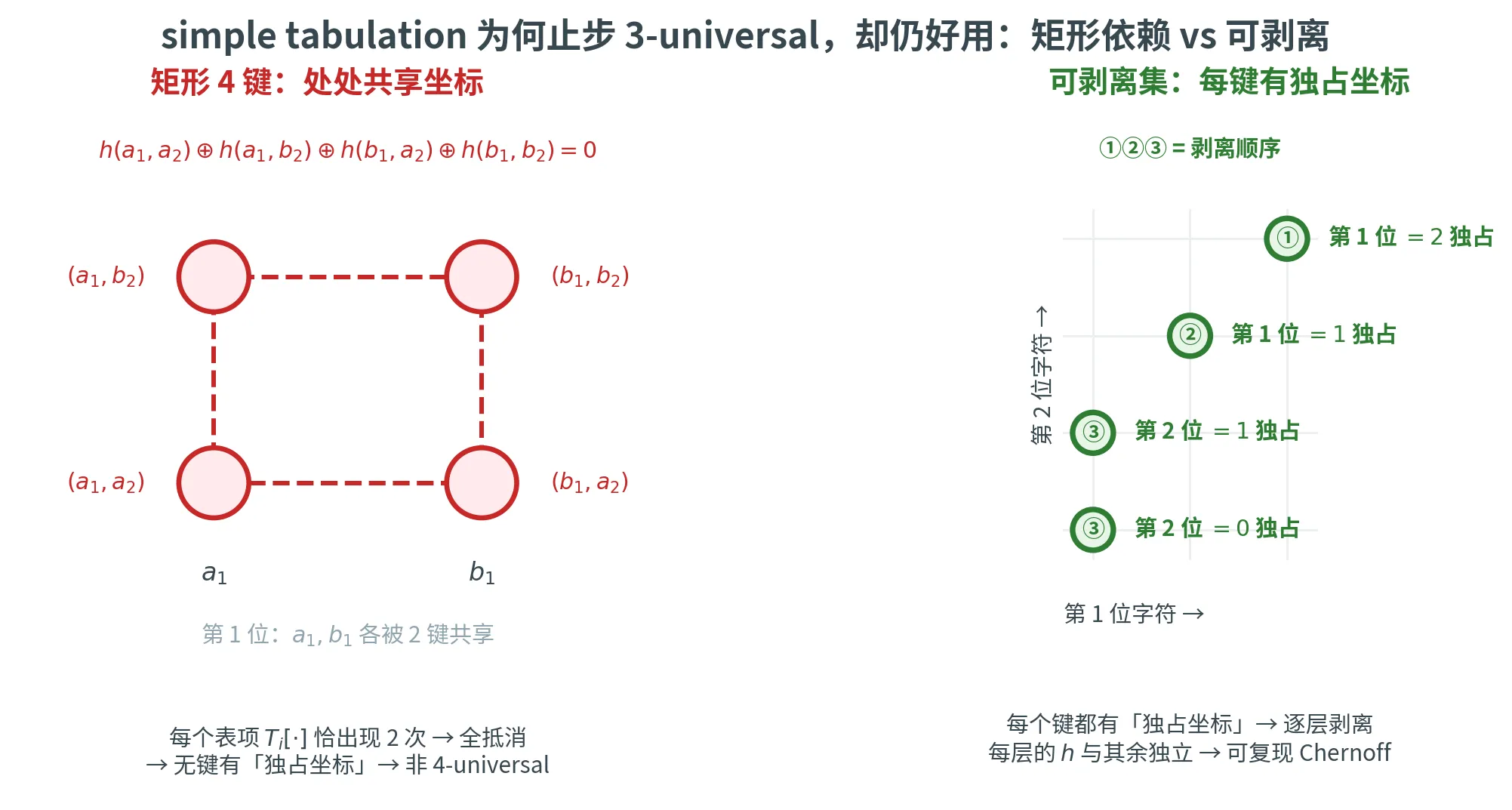
3-universal 的证明思路:对于任意三个不同的键 x , y , z x, y, z x , y , z i i i i i i T i T_i T i
但 4-universal 可以被显式反例击破:取四个键 ( a 1 , a 2 ) (a_1, a_2) ( a 1 , a 2 ) ( a 1 , b 2 ) (a_1, b_2) ( a 1 , b 2 ) ( b 1 , a 2 ) (b_1, a_2) ( b 1 , a 2 ) ( b 1 , b 2 ) (b_1, b_2) ( b 1 , b 2 )
h ( a 1 , a 2 ) ⊕ h ( a 1 , b 2 ) ⊕ h ( b 1 , a 2 ) ⊕ h ( b 1 , b 2 ) = 0 h(a_1, a_2) \oplus h(a_1, b_2) \oplus h(b_1, a_2) \oplus h(b_1, b_2) = 0
h ( a 1 , a 2 ) ⊕ h ( a 1 , b 2 ) ⊕ h ( b 1 , a 2 ) ⊕ h ( b 1 , b 2 ) = 0
恒成立(每个 T i T_i T i
为什么它仍然有效:Peelability
尽管只有 3-wise 独立,tabulation hashing 在实践中(以及理论上)对许多应用都工作得很好——包括本来需要更高独立性的 cuckoo hashing 和线性探测。
关键概念是可剥离性 (peelability)。
Position Character 与独立性
对于键 x x x { y 1 , y 2 , … } \{y_1, y_2, \dots\} { y 1 , y 2 , … } i i i x i ≠ y j , i x_i \ne y_{j,i} x i = y j , i j j j ( i , x i ) (i, x_i) ( i , x i ) x x x position character 。
当 x x x h ( x ) h(x) h ( x ) { h ( y j ) } \{h(y_j)\} { h ( y j )} T i [ x i ] T_i[x_i] T i [ x i ] h ( x ) h(x) h ( x )
一个集合 S S S 可剥离的 (peelable),如果 S S S
一个直观对比
设 c = 2 c = 2 c = 2 { 0 , 1 , 2 , 3 } \{0, 1, 2, 3\} { 0 , 1 , 2 , 3 }
例 1(可剥离) :S = { ( 0 , 0 ) , ( 0 , 1 ) , ( 1 , 2 ) , ( 2 , 3 ) } S = \{(0, 0), (0, 1), (1, 2), (2, 3)\} S = {( 0 , 0 ) , ( 0 , 1 ) , ( 1 , 2 ) , ( 2 , 3 )}
元素
第 1 位
第 2 位
Position character
( 0 , 0 ) (0, 0) ( 0 , 0 ) 0(与 ( 0 , 1 ) (0,1) ( 0 , 1 )
0 (唯一)( 2 , 0 ) (2, 0) ( 2 , 0 )
( 0 , 1 ) (0, 1) ( 0 , 1 ) 0(与 ( 0 , 0 ) (0,0) ( 0 , 0 )
1 (唯一)( 2 , 1 ) (2, 1) ( 2 , 1 )
( 1 , 2 ) (1, 2) ( 1 , 2 ) 1 (唯一)2(唯一)
( 1 , 1 ) (1, 1) ( 1 , 1 ) ( 2 , 2 ) (2, 2) ( 2 , 2 )
( 2 , 3 ) (2, 3) ( 2 , 3 ) 2 (唯一)3(唯一)
( 1 , 2 ) (1, 2) ( 1 , 2 ) ( 2 , 3 ) (2, 3) ( 2 , 3 )
每个元素都有至少一个坐标,其值不与集合内其他元素重复——这就是 position character。集合可剥离。
例 2(不可剥离) :S = { ( a 1 , a 2 ) , ( a 1 , b 2 ) , ( b 1 , a 2 ) , ( b 1 , b 2 ) } S = \{(a_1, a_2), (a_1, b_2), (b_1, a_2), (b_1, b_2)\} S = {( a 1 , a 2 ) , ( a 1 , b 2 ) , ( b 1 , a 2 ) , ( b 1 , b 2 )}
元素
第 1 位
第 2 位
( a 1 , a 2 ) (a_1, a_2) ( a 1 , a 2 ) a 1 a_1 a 1 ( a 1 , b 2 ) (a_1, b_2) ( a 1 , b 2 ) a 2 a_2 a 2 ( b 1 , a 2 ) (b_1, a_2) ( b 1 , a 2 )
( a 1 , b 2 ) (a_1, b_2) ( a 1 , b 2 ) a 1 a_1 a 1 ( a 1 , a 2 ) (a_1, a_2) ( a 1 , a 2 ) b 2 b_2 b 2 ( b 1 , b 2 ) (b_1, b_2) ( b 1 , b 2 )
( b 1 , a 2 ) (b_1, a_2) ( b 1 , a 2 ) b 1 b_1 b 1 ( b 1 , b 2 ) (b_1, b_2) ( b 1 , b 2 ) a 2 a_2 a 2 ( a 1 , a 2 ) (a_1, a_2) ( a 1 , a 2 )
( b 1 , b 2 ) (b_1, b_2) ( b 1 , b 2 ) b 1 b_1 b 1 ( b 1 , a 2 ) (b_1, a_2) ( b 1 , a 2 ) b 2 b_2 b 2 ( a 1 , b 2 ) (a_1, b_2) ( a 1 , b 2 )
没有任何元素 有 position character——任何坐标的任何值都被另一个元素分享。这正是 4-universal 失败的根源:四个键的哈希值在 T 1 , T 2 T_1, T_2 T 1 , T 2
下图把这两个例子并排对照:左边的「矩形」四键每个坐标值都被两个键共享,于是每个查表项在四个哈希值里恰好出现两次、XOR 全部抵消,四个哈希值线性相关,4-universal 失效;右边的可剥离集里每个键都有一个「独占坐标」(position character),可以层层剥离,每剥一层其哈希值都独立于其余,从而复现 Chernoff 级别的集中度。
Peeling 过程
如果集合可剥离,可以这样层层剥离 它:
在集合 S S S x x x h ( x ) h(x) h ( x ) { h ( y ) : y ∈ S ∖ { x } } \{h(y) : y \in S \setminus \{x\}\} { h ( y ) : y ∈ S ∖ { x }}
将 x x x S ∖ { x } S \setminus \{x\} S ∖ { x }
每次剥离都得到一层独立的元素
这使得我们可以将原本需要全局独立性的分析分解为层层独立的分析。虽然每次剥离出的独立集不是全局独立的,但可以利用条件期望的性质(E [ X α ∣ X β = x β , … ] = E [ X α ] \mathbb{E}[X_\alpha \mid X_\beta = x_\beta, \dots] = \mathbb{E}[X_\alpha] E [ X α ∣ X β = x β , … ] = E [ X α ]
可剥离子集大小的下界
对于任意 ∣ S ∣ = d |S| = d ∣ S ∣ = d 可剥离子集 ,大小至少为 max { d 1 / c , log 2 d } \max\{d^{1/c}, \log_2 d\} max { d 1/ c , log 2 d }
d 1 / c d^{1/c} d 1/ c S S S c c c i i i S i = { x i : x ∈ S } S_i = \{x_i : x \in S\} S i = { x i : x ∈ S } S ⊆ S 1 × ⋯ × S c S \subseteq S_1 \times \cdots \times S_c S ⊆ S 1 × ⋯ × S c ∏ i = 1 c ∣ S i ∣ ⩾ ∣ S ∣ = d \prod_{i=1}^c |S_i| \ge |S| = d ∏ i = 1 c ∣ S i ∣ ⩾ ∣ S ∣ = d i ∗ i^* i ∗ ∣ S i ∗ ∣ ⩾ d 1 / c |S_{i^*}| \ge d^{1/c} ∣ S i ∗ ∣ ⩾ d 1/ c S S S i ∗ i^* i ∗ 一个 代表元素,得到大小 ∣ S i ∗ ∣ ⩾ d 1 / c |S_{i^*}| \ge d^{1/c} ∣ S i ∗ ∣ ⩾ d 1/ c i ∗ i^* i ∗
log 2 d \log_2 d log 2 d ∣ S ∣ > 1 |S| > 1 ∣ S ∣ > 1 i i i S i S_i S i x x x ∣ S ∣ / 2 |S|/2 ∣ S ∣/2 x x x S ∖ { x } S \setminus \{x\} S ∖ { x } log 2 d \log_2 d log 2 d
两个下界各有适用区间:当 d d d c c c d 1 / c d^{1/c} d 1/ c d d d log 2 d \log_2 d log 2 d
把 peeling 接到 Chernoff 上
结合 balls-into-bins 的分析和 Chernoff bound 的推广形式,可以证明 tabulation hashing 在以下应用中达到与最优 k k k [ 0 , d ] [0, d] [ 0 , d ]
Chernoff Bound for Bounded Variables with Fixed Means
设 X 1 , X 2 , … X_1, X_2, \dots X 1 , X 2 , … [ 0 , d ] [0, d] [ 0 , d ] μ = E [ ∑ X i ] \mu = \mathbb{E}[\sum X_i] μ = E [ ∑ X i ]
Pr [ ∑ X i ⩾ ( 1 + δ ) μ ] ⩽ ( e δ ( 1 + δ ) 1 + δ ) μ / d \Pr\left[\sum X_i \ge (1+\delta)\mu\right] \le \left(\frac{\e^\delta}{(1+\delta)^{1+\delta}}\right)^{\mu/d}
Pr [ ∑ X i ⩾ ( 1 + δ ) μ ] ⩽ ( ( 1 + δ ) 1 + δ e δ ) μ / d
这与标准 Chernoff 的区别在于指数从 μ \mu μ μ / d \mu/d μ / d
Peeling 的每一层剥离出一个独立集 S α S_\alpha S α ∣ S α ∣ ⩽ n 1 − 1 / c |S_\alpha| \le n^{1-1/c} ∣ S α ∣ ⩽ n 1 − 1/ c n ⩽ m 1 − ε n \le m^{1-\varepsilon} n ⩽ m 1 − ε S α S_\alpha S α d d d m 1 − ε t / c m^{1-\varepsilon t/c} m 1 − εt / c t t t
应用
Tabulation 的保证
链式哈希 / 最大负载
O ( log n / log log n ) O(\log n / \log\log n) O ( log n / log log n )
线性探测
O ( 1 ) O(1) O ( 1 )
Cuckoo 哈希
O ( 1 ) O(1) O ( 1 )
F 2 F_2 F 2 无偏,方差 ⩽ 2 F 2 2 \le 2F_2^2 ⩽ 2 F 2 2
Min-wise 独立
O ( log ( 1 / ε ) ) O(\log(1/\varepsilon)) O ( log ( 1/ ε ))
理论与实践的桥梁
Tabulation hashing 是一个理论与实践完美结合的例子:
实践上 :极快(几纳秒),缓存友好,实现简单理论上 :只有 3-wise 独立,但通过 peelability 分析可以证明它对几乎所有常见应用都「够好」
这提醒我们,独立性不是越高越好,关键是结构化的独立性 能否被利用。
Tabulation 的扩展
Simple tabulation hashing(也称 Zobrist hashing)虽然好用,但只有 3-wise 独立,对某些场景仍然不够。围绕 simple tabulation,研究者发展出一系列变体——核心思路都是「在保留 tabulation 工程优势的同时,通过额外的混合层削弱低阶依赖结构」。
Twisted Tabulation Hashing
思想 :把键写成 x = ( x 0 , x 1 , … , x c − 1 ) x = (x_0, x_1, \dots, x_{c-1}) x = ( x 0 , x 1 , … , x c − 1 ) ( x 1 , … , x c − 1 ) (x_1, \dots, x_{c-1}) ( x 1 , … , x c − 1 ) t t t x 0 ′ = x 0 ⊕ t x_0' = x_0 \oplus t x 0 ′ = x 0 ⊕ t ( x 0 ′ , x 1 , … , x c − 1 ) (x_0', x_1, \dots, x_{c-1}) ( x 0 ′ , x 1 , … , x c − 1 )
改善什么 。Simple tabulation 失败的核心是「矩形依赖」——四个键 ( a 1 , a 2 ) , ( a 1 , b 2 ) , ( b 1 , a 2 ) , ( b 1 , b 2 ) (a_1, a_2), (a_1, b_2), (b_1, a_2), (b_1, b_2) ( a 1 , a 2 ) , ( a 1 , b 2 ) , ( b 1 , a 2 ) , ( b 1 , b 2 )
优点 :仍然只做常数次查表 + XOR,速度接近 simple tabulation;论文证明它在集中界、linear probing、Cuckoo hashing、min-wise hashing 等具体应用中得到强于 simple tabulation 的概率保证;保留缓存友好的工程优势。
缺点 :构造和分析比 simple tabulation 更复杂,需要额外的 tabulation 表来产生 twister;并不在所有意义上是「fully random hashing」的替代品——某些严格要求 strongly k k k
Double Tabulation Hashing
思想 :做两层 tabulation。第一层 simple tabulation 把原始键扩展成更多 derived characters,第二层再对这些 derived characters 做 simple tabulation:
x → h 1 derived characters → h 2 final hash value x \xrightarrow{h_1} \text{derived characters} \xrightarrow{h_2} \text{final hash value}
x h 1 derived characters h 2 final hash value
Thorup 在 2013 年系统分析了这种结构。
改善什么 。Simple tabulation 只有 3-wise 独立。Double tabulation 利用第一层把键集合「展开」为更容易剥离的 derived characters,再让第二层利用这些可剥离结构产生最终哈希。在合适参数下,整个组合在固定有限集合上可以达到任意高的独立度 ,而仍然只用常数次查表。
优点 :常数次查表获得高独立性效果,绕开了普通 k k k k k k
缺点 :比 simple tabulation 需要更多表和更多查表操作,常数因子更大;理论保证依赖较细的参数(derived characters 数量、字符域大小等),调参不当性能下降。
Mixed Tabulation Hashing
思想 :原字符 ( x 0 , … , x c − 1 ) (x_0, \dots, x_{c-1}) ( x 0 , … , x c − 1 ) ( d 1 , … , d k ) (d_1, \dots, d_k) ( d 1 , … , d k )
改善什么 。Sketching、sampling、统计估计等任务往往需要比 3-wise 独立更强的集中保证。Mixed tabulation 通过增加 derived characters,让输出对论文研究的许多分区统计量表现得接近 fully random hashing,从而能直接套用类似完全独立时的 Chernoff 集中界。
优点 :仍是 tabulation 风格,速度快;对分区统计量、采样估计等任务有更强 concentration 保证;比 fully k k k
缺点 :分析门槛高,正确使用需要理解参数约束;与 simple tabulation 相比,表数量和查表次数更多;针对性较强,特别适合「statistics over partitions」场景,未必是所有任务的最简单选择。
三者对比
方法
主要思想
改善的问题
优点
缺点
Simple tabulation
分字符查表 + XOR
普通 k k k
极快、缓存友好
仅 3-wise 独立
Twisted tabulation
tail 生成 twister 混入 head
矩形依赖结构
接近 simple 的速度,特定应用更强
构造与分析更复杂
Double tabulation
两层 tabulation,先扩展 derived characters
提升可剥离性
常数查表得高独立性
表更多、常数更大
Mixed tabulation
原字符 + derived characters 混合
分区统计场景的集中性
适合 sketching / 统计
参数与证明较复杂
四者共同的权衡:普通 k k k 。
总结
flowchart LR
BB["Balls into Bins<br>随机函数模型"] --> OCC["Occupancy Problem<br>最大负载 O(log n/log log n)"]
BB --> BD["Birthday Paradox<br>碰撞阈值 √m"]
BB --> POW["Power of Two Choices<br>最大负载 O(log log n)"]
BD --> UH["Universal Hashing<br>用 O(log N) 比特<br>模拟「足够好」的随机"]
OCC --> UH
UH --> CH["链式哈希表<br>期望 O(1) 查询"]
UH --> PH["Perfect Hashing<br>O(1) 最坏查询"]
UH --> CK["Cuckoo Hashing<br>O(1) 查询 + 动态"]
PH --> FKS["FKS 两级方案<br>O(n) 空间"]
FKS --> SD["Succinct Dictionary<br>(1+o(1))·OPT 空间"]
POW --> CK
UH --> TAB["Tabulation Hashing<br>3-universal 但<br>实践中够用"]
classDef model fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef result fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef hash fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
classDef structure fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef advanced fill:#fce4ec,stroke:#c62828,stroke-width:2px
class BB model
class OCC,BD,POW result
class UH,TAB hash
class CH,PH,CK,FKS structure
class SD advanced本讲围绕一个核心问题展开:如何用有限的随机资源实现高效的字典数据结构?
从 balls into bins 的概率模型出发,我们建立了分析哈希表性能的理论工具(Chernoff bound、birthday paradox)。Universal hashing 回答了「多少随机性足够」的问题:2-wise 独立就足以支撑大多数基本应用,但要换来 Chernoff 量级的集中度则需要更高的 k k k n \sqrt n n
在此基础上,我们看到了三条不同的优化路线:
查询时间最优 :FKS perfect hashing — O ( 1 ) O(1) O ( 1 ) O ( n ) O(n) O ( n ) 动态最优 :Cuckoo hashing — O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 ) 空间极致 :Succinct dictionary — ( 1 + o ( 1 ) ) (1+o(1)) ( 1 + o ( 1 ))
Succinct dictionary 用上了一整套工具组合:Method of Four Russians 让字内查询用 O ( 1 ) O(1) O ( 1 )
最后,tabulation hashing 展示了一个深刻的洞见:独立性的「质」比「量」更重要 ——精心设计的 3-wise 独立哈希在实践和理论上都能匹配需要更高独立性的方案;而 twisted、double、mixed 等扩展进一步证明,这条路线还能继续走得很远。