从高维到低维
上几讲反复出现一个隐喻:要在不丢失重要信息的前提下,把庞大的数据「压缩」成更小的对象。Sketching 把流压缩成 O ( log n ) O(\log n) O ( log n ) O ( n ) O(n) O ( n ) 几何点 ——我们有一堆 R d \R^d R d
为什么需要这件事?数据科学里的几乎所有实际向量都是高维的:一张 1000 × 1000 1000 \times 1000 1000 × 1000 10 6 10^6 1 0 6 维度的诅咒 (Curse of Dimensionality):
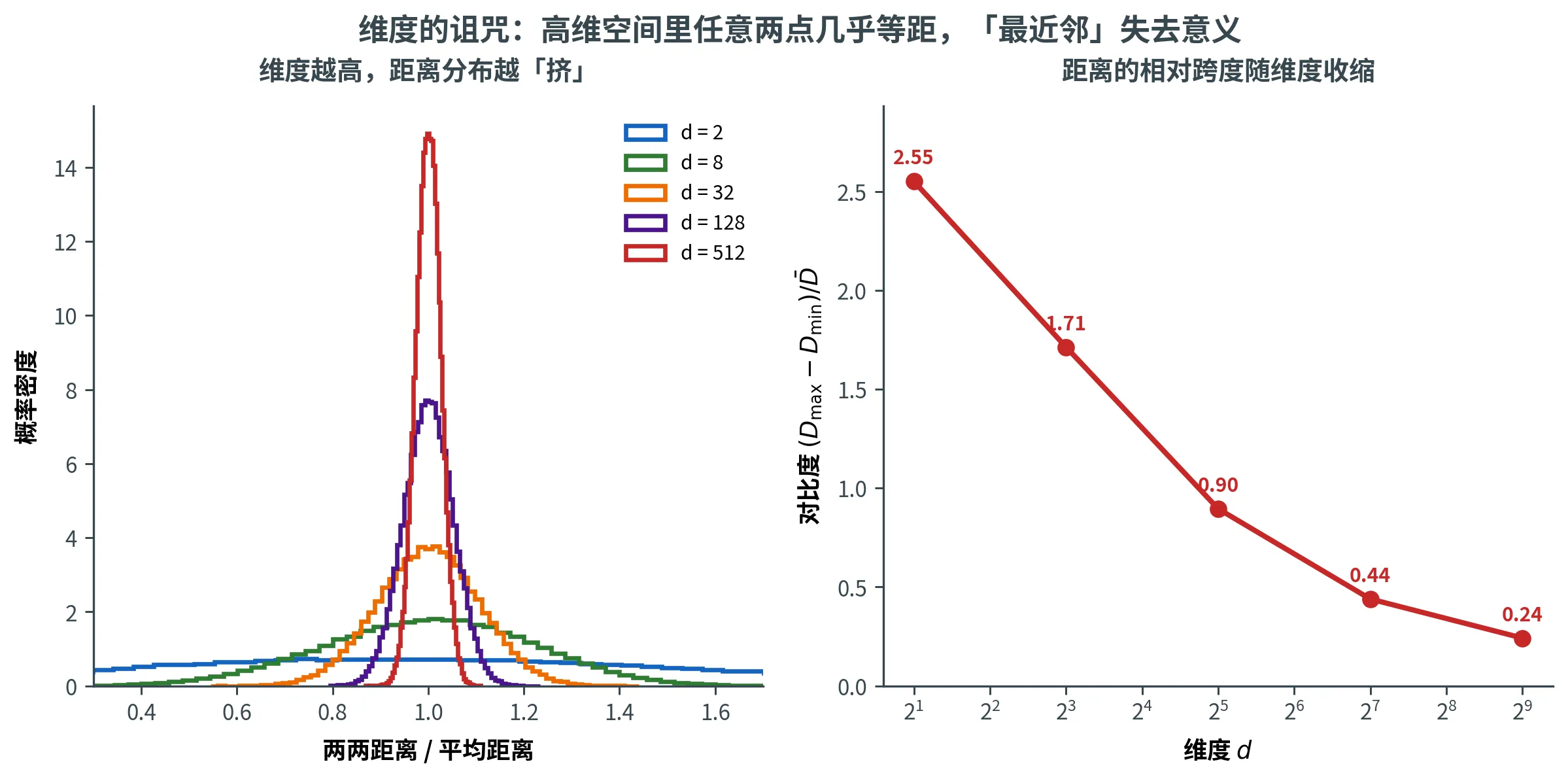
距离的「分辨率」消失。在高维球面上,任意两点的距离都集中在某个固定值附近,导致「最近邻」和「最远邻」几乎一样远。
算法复杂度爆炸。k k k d ≳ log n d \gtrsim \log n d ≳ log n n Ω ( d ) n^{\Omega(d)} n Ω ( d )
下图直观展示第一条诅咒:左图是不同维度下「两两距离 / 平均距离」的分布,维度越高,分布越集中在 1 1 1 0 0 0
降维就是与这一诅咒正面对抗的武器。本讲的核心问题是:至少需要多少维才能保住所有 ( n 2 ) \binom{n}{2} ( 2 n ) 答案出乎意料——只需 O ( log n ) O(\log n) O ( log n ) d d d
高维 Hamming 空间里的近似最近邻;
局部敏感哈希(LSH )——把 JL 的思想推广到「哈希值碰撞」的语言;
比朴素 JL 更快的 Fast JL 变换;
把降维从点集推广到整个子空间的子空间嵌入(OSE ),以及它在大规模线性回归中的应用。
度量嵌入与降维问题
度量嵌入
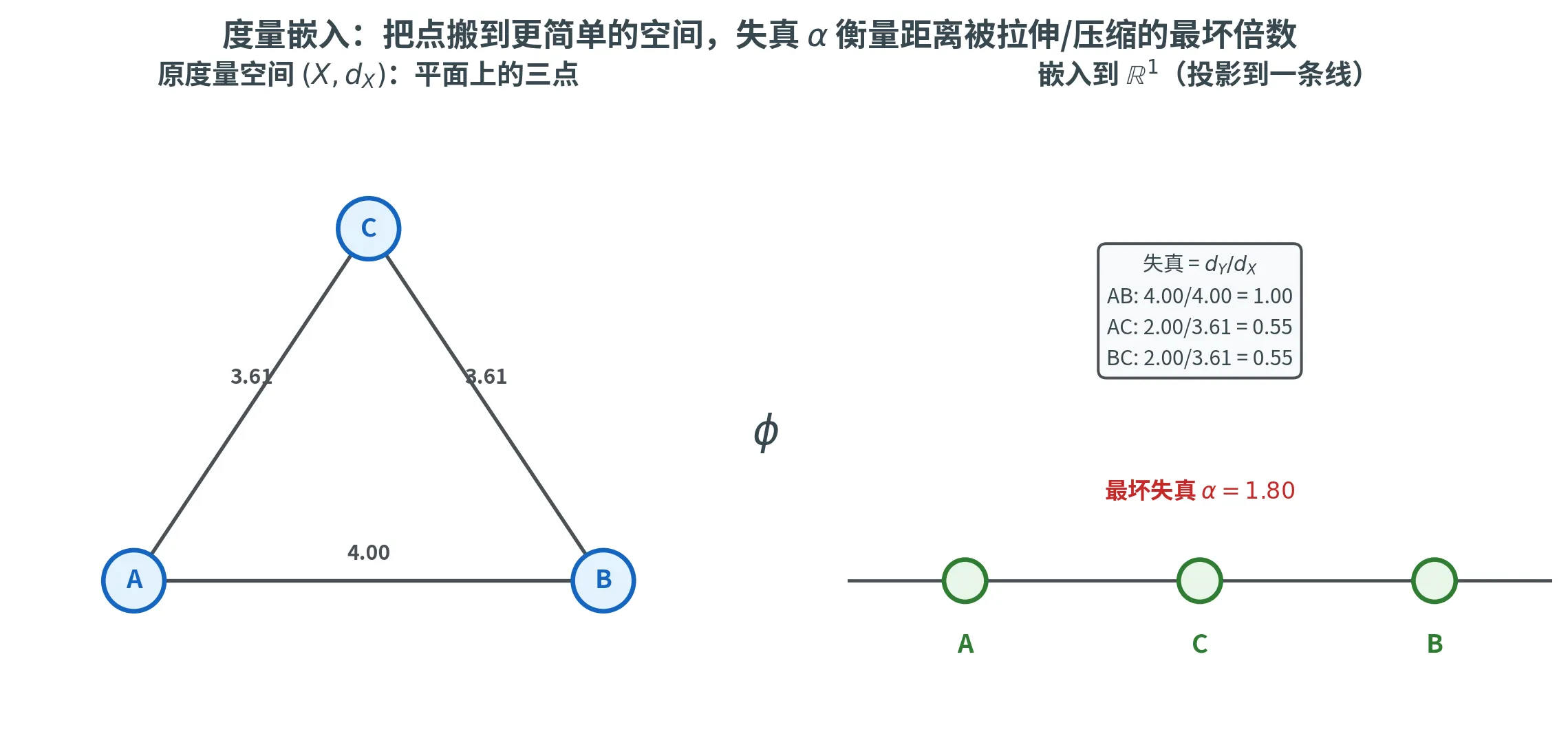
给定两个度量空间 ( X , d X ) (X, d_X) ( X , d X ) ( Y , d Y ) (Y, d_Y) ( Y , d Y ) 度量嵌入 (Metric Embedding)是一个映射 ϕ : X → Y \phi\colon X \to Y ϕ : X → Y X X X Y Y Y 失真 (Distortion)刻画:若存在 α ⩾ 1 \alpha \ge 1 α ⩾ 1 x 1 , x 2 ∈ X \bm{x}_1, \bm{x}_2 \in X x 1 , x 2 ∈ X
1 α d X ( x 1 , x 2 ) ⩽ d Y ( ϕ ( x 1 ) , ϕ ( x 2 ) ) ⩽ α ⋅ d X ( x 1 , x 2 ) \frac{1}{\alpha} d_X(\bm{x}_1, \bm{x}_2) \le d_Y(\phi(\bm{x}_1), \phi(\bm{x}_2)) \le \alpha \cdot d_X(\bm{x}_1, \bm{x}_2)
α 1 d X ( x 1 , x 2 ) ⩽ d Y ( ϕ ( x 1 ) , ϕ ( x 2 )) ⩽ α ⋅ d X ( x 1 , x 2 )
则称 ϕ \phi ϕ α \alpha α α = 1 \alpha = 1 α = 1 α \alpha α 1 1 1
降维问题
把 X X X R d \R^d R d Y Y Y R k \R^k R k 给定的 n n n (而非整个空间)保距,就得到降维问题:
降维(Dimension Reduction)
输入 :n n n x 1 , … , x n ∈ R d \bm{x}_1, \dots, \bm{x}_n \in \R^d x 1 , … , x n ∈ R d 0 < ε < 1 0 < \varepsilon < 1 0 < ε < 1 输出 :n n n y 1 , … , y n ∈ R k \bm{y}_1, \dots, \bm{y}_n \in \R^k y 1 , … , y n ∈ R k ∀ 1 ⩽ i , j ⩽ n \forall 1 \le i, j \le n ∀1 ⩽ i , j ⩽ n
( 1 − ε ) ∥ x i − x j ∥ ⩽ ∥ y i − y j ∥ ⩽ ( 1 + ε ) ∥ x i − x j ∥ (1 - \varepsilon)\|\bm{x}_i - \bm{x}_j\| \le \|\bm{y}_i - \bm{y}_j\| \le (1 + \varepsilon)\|\bm{x}_i - \bm{x}_j\|
( 1 − ε ) ∥ x i − x j ∥ ⩽ ∥ y i − y j ∥ ⩽ ( 1 + ε ) ∥ x i − x j ∥
三个核心问题:
k k k k ≪ d k \ll d k ≪ d 用什么范数 ∥ ⋅ ∥ \|\cdot\| ∥ ⋅ ∥ ℓ 2 \ell_2 ℓ 2
嵌入是否能「高效」构造?
一个动机:k k k
为什么我们关心降维?因为下游算法(聚类、回归、近邻搜索)的时间通常与维数 d d d k k k
k k k
给定数据 X = { x 1 , … , x n } ⊂ R d X = \{\bm{x}_1, \dots, \bm{x}_n\} \subset \R^d X = { x 1 , … , x n } ⊂ R d k k k y 1 , … , y k ∈ R d \bm{y}_1, \dots, \bm{y}_k \in \R^d y 1 , … , y k ∈ R d
∑ i ∈ [ n ] min j ∈ [ k ] ∥ x i − y j ∥ 2 2 \sum_{i \in [n]} \min_{j \in [k]} \|\bm{x}_i - \bm{y}_j\|_2^2
i ∈ [ n ] ∑ j ∈ [ k ] min ∥ x i − y j ∥ 2 2
固定一个划分 P = ( P 1 , … , P k ) \mathcal{P} = (\mathcal{P}_1, \dots, \mathcal{P}_k) P = ( P 1 , … , P k )
min k -parts P ∑ j ∈ [ k ] 1 ∣ P j ∣ ∑ i ≠ i ′ ∈ P j ∥ x i − x i ′ ∥ 2 2 \min_{k\text{-parts } \mathcal{P}} \sum_{j \in [k]} \frac{1}{|\mathcal{P}_j|} \sum_{i \ne i' \in \mathcal{P}_j} \|\bm{x}_i - \bm{x}_{i'}\|_2^2
k -parts P min j ∈ [ k ] ∑ ∣ P j ∣ 1 i = i ′ ∈ P j ∑ ∥ x i − x i ′ ∥ 2 2
如果降维矩阵 Π \bm{\Pi} Π ( 1 ± ε ) (1 \pm \varepsilon) ( 1 ± ε ) k k k Π x i \bm{\Pi} \bm{x}_i Π x i ( 1 ± ε ) 2 (1 \pm \varepsilon)^2 ( 1 ± ε ) 2 R k \R^k R k R d \R^d R d
Johnson-Lindenstrauss 定理
降维的故事真正的起点是下面这个 1984 年的定理。
Johnson-Lindenstrauss 定理(1984)
∀ 0 < ε < 1 \forall 0 < \varepsilon < 1 ∀0 < ε < 1 R d \R^d R d n n n S S S A ∈ R k × d \bm{A} \in \R^{k \times d} A ∈ R k × d k = O ( ε − 2 log n ) k = O(\varepsilon^{-2} \log n) k = O ( ε − 2 log n )
∀ x , y ∈ S : ( 1 − ε ) ∥ x − y ∥ 2 2 ⩽ ∥ A x − A y ∥ 2 2 ⩽ ( 1 + ε ) ∥ x − y ∥ 2 2 \forall \bm{x}, \bm{y} \in S\colon \quad (1 - \varepsilon)\|\bm{x} - \bm{y}\|_2^2 \le \|\bm{A}\bm{x} - \bm{A}\bm{y}\|_2^2 \le (1 + \varepsilon)\|\bm{x} - \bm{y}\|_2^2
∀ x , y ∈ S : ( 1 − ε ) ∥ x − y ∥ 2 2 ⩽ ∥ A x − A y ∥ 2 2 ⩽ ( 1 + ε ) ∥ x − y ∥ 2 2
"In Euclidean space, it is always possible to embed a set of n n n O ( log n ) O(\log n) O ( log n ) n n n O ( log n ) O(\log n) O ( log n )
最反直觉的是 k k k d d d 10 3 10^3 1 0 3 10 9 10^9 1 0 9 n n n O ( log n ) O(\log n) O ( log n )
三种构造
定理的证明使用概率方法 :随机抽取一个矩阵 A \bm{A} A A \bm{A} A
概率方法到底是什么?
它不是某个具体算法,而是一种存在性证明技巧 :要证「存在某个对象具有性质 P P P P P P > 0 > 0 > 0 → 1 \to 1 → 1 > 0 > 0 > 0 P P P 存在 。
一旦失败概率被压到非常小(比如 1 / n 1/n 1/ n
构造
A i j \bm{A}_{ij} A ij 提出者
均匀随机 k k k
A \bm{A} A k k k R d \R^d R d Johnson-Lindenstrauss; Dasgupta-Gupta
独立高斯
A i j ∼ N ( 0 , 1 / k ) \bm{A}_{ij} \sim \mathcal{N}(0, 1/k) A ij ∼ N ( 0 , 1/ k ) Indyk-Motwani
独立 ± 1 \pm 1 ± 1
A i j ∈ { − 1 / k , + 1 / k } \bm{A}_{ij} \in \{-1/\sqrt{k}, +1/\sqrt{k}\} A ij ∈ { − 1/ k , + 1/ k } Achlioptas
三种构造的失败概率都形如 O ( 1 / n ) O(1/n) O ( 1/ n )
范数保持归约
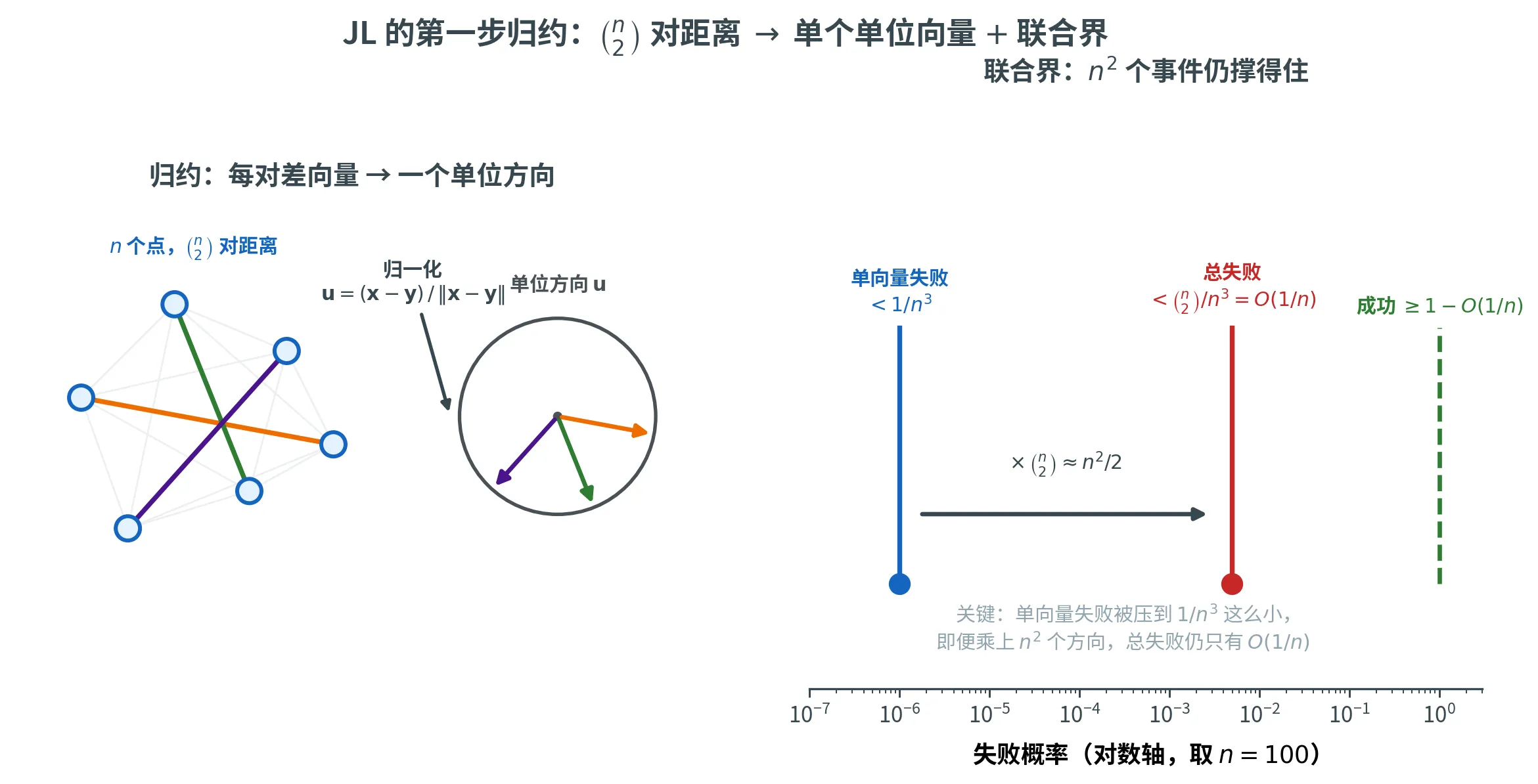
直接证明「所有 ( n 2 ) \binom{n}{2} ( 2 n )
注意 A ( x − y ) \bm{A}(\bm{x} - \bm{y}) A ( x − y ) ∥ A x − A y ∥ 2 2 ∈ ( 1 ± ε ) ∥ x − y ∥ 2 2 \|\bm{A}\bm{x} - \bm{A}\bm{y}\|_2^2 \in (1 \pm \varepsilon)\|\bm{x} - \bm{y}\|_2^2 ∥ A x − A y ∥ 2 2 ∈ ( 1 ± ε ) ∥ x − y ∥ 2 2 u = ( x − y ) / ∥ x − y ∥ \bm{u} = (\bm{x} - \bm{y})/\|\bm{x} - \bm{y}\| u = ( x − y ) /∥ x − y ∥ ∥ A u ∥ 2 2 ∈ 1 ± ε \|\bm{A}\bm{u}\|_2^2 \in 1 \pm \varepsilon ∥ A u ∥ 2 2 ∈ 1 ± ε
范数保持引理
对任意单位向量 u ∈ R d \bm{u} \in \R^d u ∈ R d
Pr [ ∣ ∥ A u ∥ 2 2 − 1 ∣ > ε ] < 1 n 3 \Pr\bigl[\bigl|\|\bm{A}\bm{u}\|_2^2 - 1\bigr| > \varepsilon\bigr] < \frac{1}{n^3}
Pr [ ∥ A u ∥ 2 2 − 1 > ε ] < n 3 1
一旦有了这个,对 ( n 2 ) = O ( n 2 ) \binom{n}{2} = O(n^2) ( 2 n ) = O ( n 2 ) x − y \bm{x} - \bm{y} x − y ⩾ 1 − O ( n 2 ) ⋅ 1 / n 3 = 1 − O ( 1 / n ) \ge 1 - O(n^2) \cdot 1/n^3 = 1 - O(1/n) ⩾ 1 − O ( n 2 ) ⋅ 1/ n 3 = 1 − O ( 1/ n )
下图把这步归约拆成两半:左边——任意一对点 x , y \bm{x}, \bm{y} x , y ( n 2 ) \binom{n}{2} ( 2 n ) 1 / n 3 1/n^3 1/ n 3 ( n 2 ) ≈ n 2 / 2 \binom{n}{2} \approx n^2/2 ( 2 n ) ≈ n 2 /2 O ( 1 / n ) O(1/n) O ( 1/ n ) 1 / n 3 1/n^3 1/ n 3
至此,降维问题被压缩为一个一维的问题:分析 ∥ A u ∥ 2 2 \|\bm{A}\bm{u}\|_2^2 ∥ A u ∥ 2 2 固定 单位向量 u \bm{u} u
高斯构造的证明
设 A ∈ R k × d \bm{A} \in \R^{k \times d} A ∈ R k × d A i j ∼ N ( 0 , 1 / k ) \bm{A}_{ij} \sim \mathcal{N}(0, 1/k) A ij ∼ N ( 0 , 1/ k )
期望计算
A u \bm{A}\bm{u} A u k k k i i i
( A u ) i = ∑ j = 1 d A i j u j (\bm{A}\bm{u})_i = \sum_{j=1}^d \bm{A}_{ij} u_j
( A u ) i = j = 1 ∑ d A ij u j
由「独立高斯之和仍是高斯」的性质,N ( μ 1 , σ 1 2 ) + N ( μ 2 , σ 2 2 ) → N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) \mathcal{N}(\mu_1, \sigma_1^2) + \mathcal{N}(\mu_2, \sigma_2^2) \to \mathcal{N}(\mu_1 + \mu_2, \sigma_1^2 + \sigma_2^2) N ( μ 1 , σ 1 2 ) + N ( μ 2 , σ 2 2 ) → N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 )
( A u ) i ∼ N ( 0 , ∑ j = 1 d u j 2 k ) = N ( 0 , 1 k ) (\bm{A}\bm{u})_i \sim \mathcal{N}\left(0,\ \frac{\sum_{j=1}^d u_j^2}{k}\right) = \mathcal{N}\left(0, \frac{1}{k}\right)
( A u ) i ∼ N ( 0 , k ∑ j = 1 d u j 2 ) = N ( 0 , k 1 )
最后一步用了 u \bm{u} u ∥ u ∥ 2 2 = 1 \|\bm{u}\|_2^2 = 1 ∥ u ∥ 2 2 = 1 u \bm{u} u u \bm{u} u 球对称性 在起作用。即 ( A u ) i (\bm{A} \bm{u})_i ( A u ) i N ( 0 , 1 / k ) \mathcal{N}(0, 1/k) N ( 0 , 1/ k )
由 E [ Z 2 ] = V a r ( Z ) + E [ Z ] 2 \mathbb{E}[Z^2] = \mathrm{Var}(Z) + \mathbb{E}[Z]^2 E [ Z 2 ] = Var ( Z ) + E [ Z ] 2 E [ ( A u ) i 2 ] = V a r ( ( A u ) i ) = 1 / k \mathbb{E}[(\bm{A}\bm{u})_i^2] = \mathrm{Var}((\bm{A}\bm{u})_i) = 1/k E [( A u ) i 2 ] = Var (( A u ) i ) = 1/ k
E [ ∥ A u ∥ 2 2 ] = ∑ i = 1 k E [ ( A u ) i 2 ] = k ⋅ 1 k = 1 \mathbb{E}\bigl[\|\bm{A}\bm{u}\|_2^2\bigr] = \sum_{i=1}^k \mathbb{E}[(\bm{A}\bm{u})_i^2] = k \cdot \frac{1}{k} = 1
E [ ∥ A u ∥ 2 2 ] = i = 1 ∑ k E [( A u ) i 2 ] = k ⋅ k 1 = 1
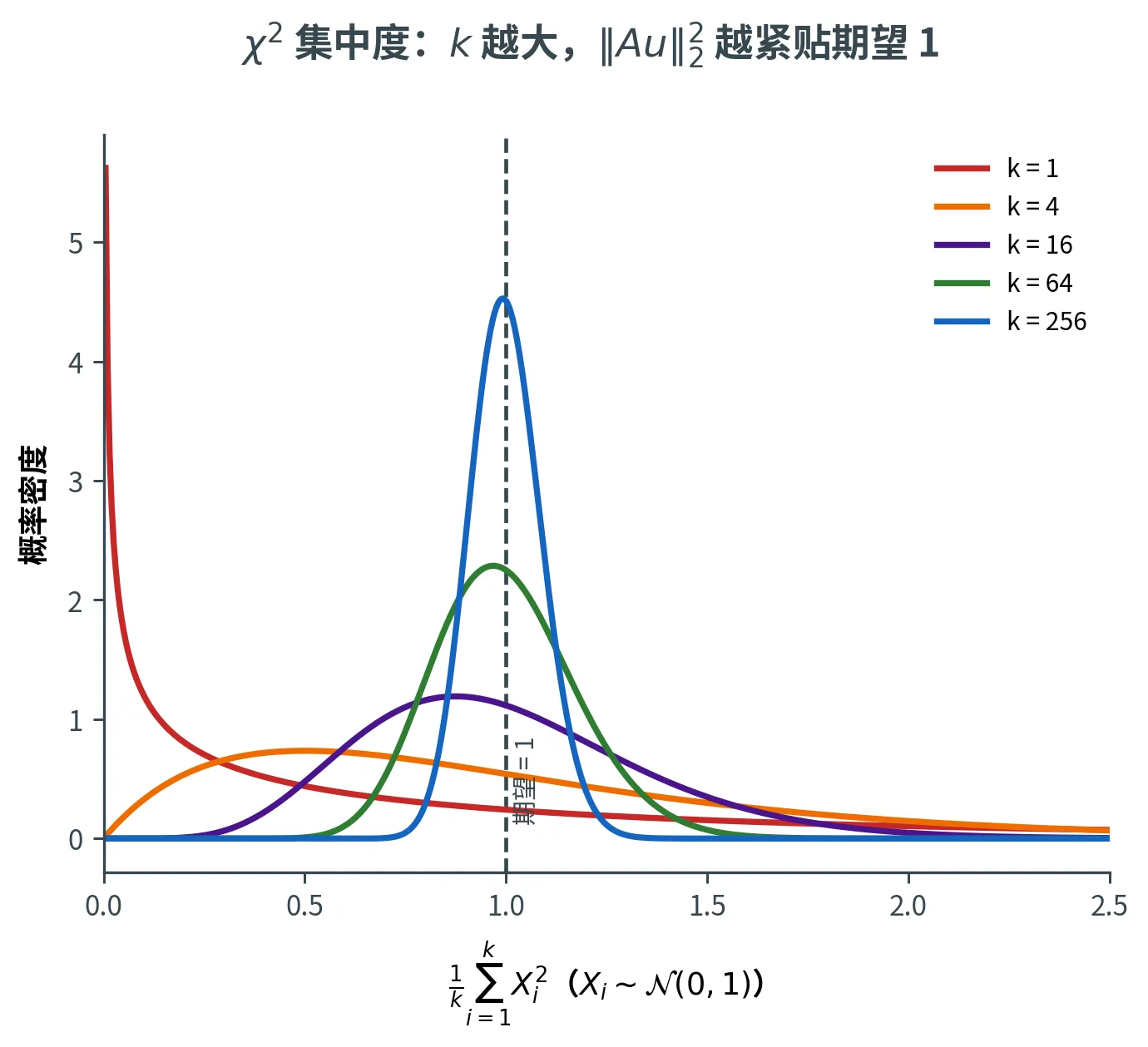
期望已经对了(即无偏)。接下来要证 ∥ A u ∥ 2 2 \|\bm{A}\bm{u}\|_2^2 ∥ A u ∥ 2 2 1 1 1
χ 2 \chi^2 χ 2 令 Y i = ( A u ) i Y_i = (\bm{A}\bm{u})_i Y i = ( A u ) i Y i ∼ N ( 0 , 1 / k ) Y_i \sim \mathcal{N}(0, 1/k) Y i ∼ N ( 0 , 1/ k ) X i = k ⋅ Y i ∼ N ( 0 , 1 ) X_i = \sqrt{k} \cdot Y_i \sim \mathcal{N}(0, 1) X i = k ⋅ Y i ∼ N ( 0 , 1 )
∥ A u ∥ 2 2 = ∑ i = 1 k Y i 2 = 1 k ∑ i = 1 k X i 2 \|\bm{A}\bm{u}\|_2^2 = \sum_{i=1}^k Y_i^2 = \frac{1}{k} \sum_{i=1}^k X_i^2
∥ A u ∥ 2 2 = i = 1 ∑ k Y i 2 = k 1 i = 1 ∑ k X i 2
事件 ∣ ∥ A u ∥ 2 2 − 1 ∣ > ε \bigl|\|\bm{A}\bm{u}\|_2^2 - 1\bigr| > \varepsilon ∥ A u ∥ 2 2 − 1 > ε ∣ ∑ i X i 2 − k ∣ > ε k \bigl|\sum_i X_i^2 - k\bigr| > \varepsilon k ∑ i X i 2 − k > ε k ∑ i X i 2 \sum_i X_i^2 ∑ i X i 2 k k k χ 2 \chi^2 χ 2 k k k = k = k = k 集中不等式 ——刻画 ∑ i X i 2 \sum_i X_i^2 ∑ i X i 2 k k k
下图画出 1 k ∑ i X i 2 \frac{1}{k}\sum_i X_i^2 k 1 ∑ i X i 2 ∥ A u ∥ 2 2 \|\bm{A}\bm{u}\|_2^2 ∥ A u ∥ 2 2 k = 1 k = 1 k = 1 k k k 1 1 1 k k k ∥ A u ∥ 2 2 \|\bm{A}\bm{u}\|_2^2 ∥ A u ∥ 2 2 1 ± ε 1 \pm \varepsilon 1 ± ε
χ 2 \chi^2 χ 2
设 X 1 , … , X k ∼ N ( 0 , 1 ) X_1, \dots, X_k \sim \mathcal{N}(0, 1) X 1 , … , X k ∼ N ( 0 , 1 )
Pr [ ∑ i = 1 k X i 2 > ( 1 + ε ) k ] < e − ε 2 k / 8 Pr [ ∑ i = 1 k X i 2 < ( 1 − ε ) k ] < e − ε 2 k / 8 \begin{aligned}
\Pr\left[\sum_{i=1}^k X_i^2 > (1 + \varepsilon) k\right] &< \e^{-\varepsilon^2 k / 8} \\
\Pr\left[\sum_{i=1}^k X_i^2 < (1 - \varepsilon) k\right] &< \e^{-\varepsilon^2 k / 8}
\end{aligned}
Pr [ i = 1 ∑ k X i 2 > ( 1 + ε ) k ] Pr [ i = 1 ∑ k X i 2 < ( 1 − ε ) k ] < e − ε 2 k /8 < e − ε 2 k /8
注意这与上一讲对 Bernoulli 之和的 Chernoff 界形式一致:偏离 ε \varepsilon ε { 0 , 1 } \{0,1\} { 0 , 1 }
证明(上尾,下尾对称)
对任意 λ > 0 \lambda > 0 λ > 0
Pr [ ∑ i X i 2 > ( 1 + ε ) k ] = Pr [ e λ ∑ i X i 2 > e λ ( 1 + ε ) k ] ⩽ e − λ ( 1 + ε ) k ⋅ ∏ i = 1 k E [ e λ X i 2 ] \Pr\left[\sum_i X_i^2 > (1 + \varepsilon) k\right] = \Pr\left[\e^{\lambda \sum_i X_i^2} > \e^{\lambda(1+\varepsilon)k}\right] \le \e^{-\lambda(1+\varepsilon)k} \cdot \prod_{i=1}^k \mathbb{E}[\e^{\lambda X_i^2}]
Pr [ i ∑ X i 2 > ( 1 + ε ) k ] = Pr [ e λ ∑ i X i 2 > e λ ( 1 + ε ) k ] ⩽ e − λ ( 1 + ε ) k ⋅ i = 1 ∏ k E [ e λ X i 2 ]
第一步是 Markov 不等式的指数化(把 Pr [ Y > a ] \Pr[Y > a] Pr [ Y > a ] Pr [ e λ Y > e λ a ] ⩽ E [ e λ Y ] / e λ a \Pr[\e^{\lambda Y} > \e^{\lambda a}] \le \mathbb{E}[\e^{\lambda Y}] / \e^{\lambda a} Pr [ e λY > e λa ] ⩽ E [ e λY ] / e λa E [ e λ Y ] \mathbb{E}[\e^{\lambda Y}] E [ e λY ] Y Y Y 矩生成函数(MGF ) ——能把高阶矩信息编码进一个解析函数。第二步用了独立性:和的 MGF 是各项 MGF 的乘积。
对单个标准高斯 X ∼ N ( 0 , 1 ) X \sim \mathcal{N}(0, 1) X ∼ N ( 0 , 1 ) X 2 X^2 X 2
E [ e λ X 2 ] = ∫ − ∞ ∞ 1 2 π e − x 2 / 2 e λ x 2 d x = 1 1 − 2 λ , λ < 1 2 \mathbb{E}[\e^{\lambda X^2}] = \int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} \e^{-x^2/2} \e^{\lambda x^2} \d x = \frac{1}{\sqrt{1 - 2\lambda}}, \quad \lambda < \frac{1}{2}
E [ e λ X 2 ] = ∫ − ∞ ∞ 2 π 1 e − x 2 /2 e λ x 2 d x = 1 − 2 λ 1 , λ < 2 1
直接对积分指数 − x 2 / 2 + λ x 2 = − ( 1 − 2 λ ) x 2 / 2 -x^2/2 + \lambda x^2 = -(1 - 2\lambda)x^2 / 2 − x 2 /2 + λ x 2 = − ( 1 − 2 λ ) x 2 /2
代回去:
Pr [ ∑ i X i 2 > ( 1 + ε ) k ] ⩽ e − λ ( 1 + ε ) k ( 1 − 2 λ ) k / 2 \Pr\left[\sum_i X_i^2 > (1 + \varepsilon) k\right] \le \frac{\e^{-\lambda(1+\varepsilon)k}}{(1 - 2\lambda)^{k/2}}
Pr [ i ∑ X i 2 > ( 1 + ε ) k ] ⩽ ( 1 − 2 λ ) k /2 e − λ ( 1 + ε ) k
取 λ = ε / 4 \lambda = \varepsilon / 4 λ = ε /4 λ < 1 / 4 < 1 / 2 \lambda < 1/4 < 1/2 λ < 1/4 < 1/2 1 − 2 λ ⩾ e − 2 λ − 2 λ 2 1 - 2\lambda \ge \e^{-2\lambda - 2\lambda^2} 1 − 2 λ ⩾ e − 2 λ − 2 λ 2 λ \lambda λ
1 ( 1 − 2 λ ) k / 2 ⩽ e ( λ + λ 2 ) k = e ( ε / 4 + ε 2 / 16 ) k \frac{1}{(1 - 2\lambda)^{k/2}} \le \e^{(\lambda + \lambda^2) k} = \e^{(\varepsilon/4 + \varepsilon^2/16)k}
( 1 − 2 λ ) k /2 1 ⩽ e ( λ + λ 2 ) k = e ( ε /4 + ε 2 /16 ) k
因此
Pr [ ⋅ ] ⩽ e − ( ε / 4 ) ( 1 + ε ) k + ( ε / 4 + ε 2 / 16 ) k = e − ε 2 k / 8 + O ( ε 3 k ) \Pr[\cdot] \le \e^{-(\varepsilon/4)(1+\varepsilon)k + (\varepsilon/4 + \varepsilon^2/16)k} = \e^{-\varepsilon^2 k / 8 + O(\varepsilon^3 k)}
Pr [ ⋅ ] ⩽ e − ( ε /4 ) ( 1 + ε ) k + ( ε /4 + ε 2 /16 ) k = e − ε 2 k /8 + O ( ε 3 k )
对 0 < ε < 1 0 < \varepsilon < 1 0 < ε < 1 − ε 2 k / 8 -\varepsilon^2 k / 8 − ε 2 k /8 − X 2 -X^2 − X 2
选取 k k k
由 χ 2 \chi^2 χ 2
Pr [ ∣ ∥ A u ∥ 2 2 − 1 ∣ > ε ] ⩽ 2 e − ε 2 k / 8 \Pr\bigl[\bigl|\|\bm{A}\bm{u}\|_2^2 - 1\bigr| > \varepsilon\bigr] \le 2 \e^{-\varepsilon^2 k / 8}
Pr [ ∥ A u ∥ 2 2 − 1 > ε ] ⩽ 2 e − ε 2 k /8
要使这个概率 < 1 / n 3 < 1/n^3 < 1/ n 3
k = 8 ⋅ 3 ln n ε 2 = O ( ε − 2 log n ) k = \frac{8 \cdot 3 \ln n}{\varepsilon^2} = O\bigl(\varepsilon^{-2} \log n\bigr)
k = ε 2 8 ⋅ 3 ln n = O ( ε − 2 log n )
即可。这正是 JL 定理中的 k k k JL 定理对高斯构造成立。
子空间投影构造
把 A \bm{A} A k k k d / k \sqrt{d / k} d / k JL 定理最早的构造。它与高斯构造给出形式相同的尾界 (同阶的 k k k
几何直觉与放缩因子
把单位向量 u \bm{u} u k k k k k k k / d k/d k / d ( d − k ) / d (d - k)/d ( d − k ) / d d / k \sqrt{d / k} d / k 1 1 1
A u = d k ⋅ Proj S ( u ) , E [ ∥ A u ∥ 2 2 ] = 1 \bm{A}\bm{u} = \sqrt{\frac{d}{k}} \cdot \operatorname{Proj}_S(\bm{u}), \qquad \mathbb{E}\bigl[\|\bm{A}\bm{u}\|_2^2\bigr] = 1
A u = k d ⋅ Proj S ( u ) , E [ ∥ A u ∥ 2 2 ] = 1
与高斯构造的对比:
构造
几何描述
高斯
随机选 k k k 不一定正交 的高斯方向,把向量投过去
子空间投影
随机选一个真正的 k k k d / k \sqrt{d/k} d / k
旋转不变性把问题翻过来
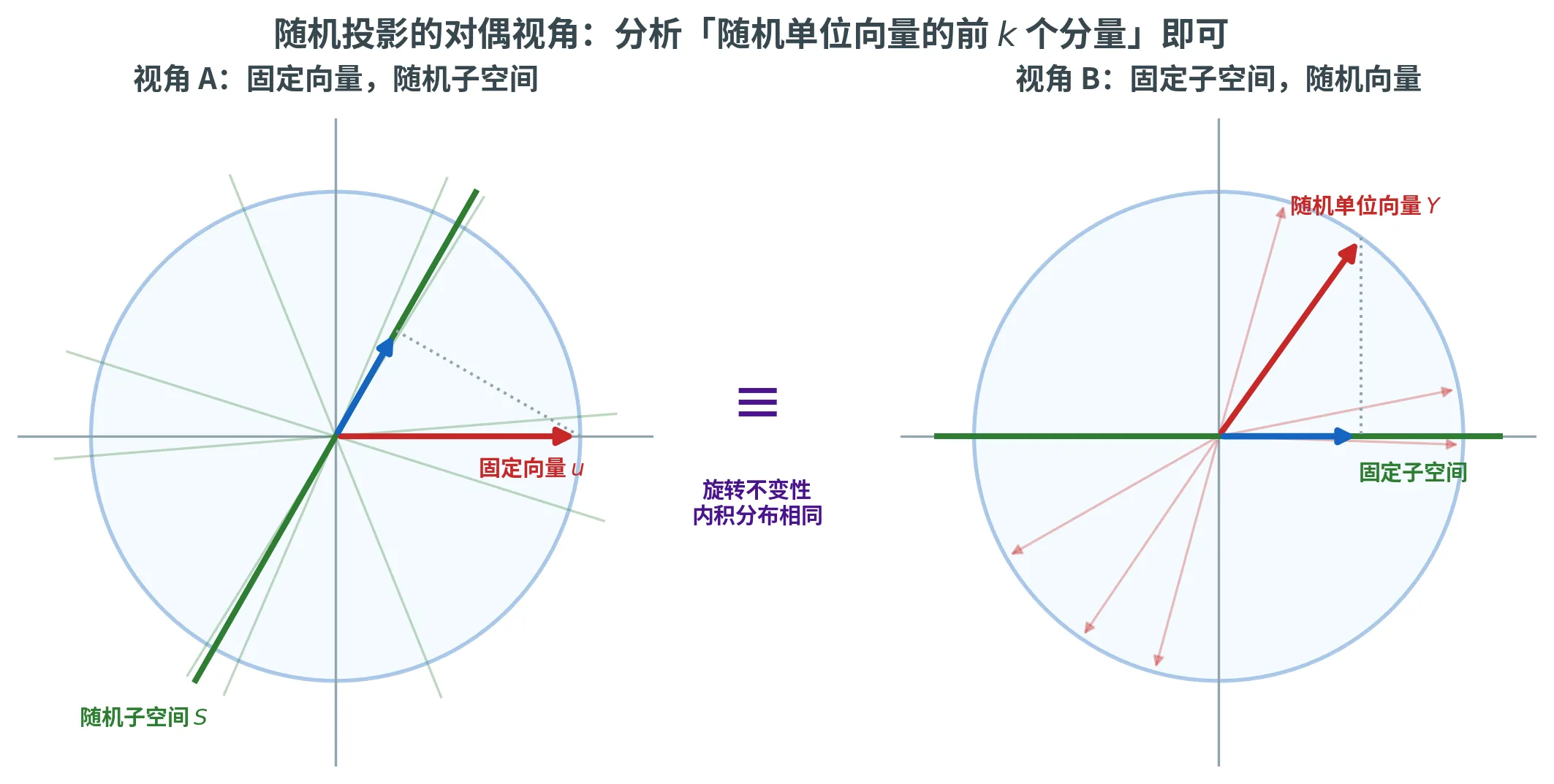
直接分析「固定向量 + 随机正交矩阵」不容易,但有一个非常优雅的对偶视角。考虑两个分布:
视角 A
视角 B
固定单位向量 u \bm{u} u k k k S S S ∥ Proj S ( u ) ∥ \|\operatorname{Proj}_S(\bm{u})\| ∥ Proj S ( u ) ∥
固定 k k k S 0 S_0 S 0 k k k Y ∈ S d − 1 \bm{Y} \in \mathbb{S}^{d-1} Y ∈ S d − 1 ∥ Proj S 0 ( Y ) ∥ \|\operatorname{Proj}_{S_0}(\bm{Y})\| ∥ Proj S 0 ( Y ) ∥
等价性
两个分布相同。核心理由 :内积在旋转下不变。把视角 A 中的随机子空间 S S S S 0 S_0 S 0 Q \bm{Q} Q S 0 S_0 S 0 Proj S ( u ) = Q Proj S 0 ( Q ⊺ u ) \operatorname{Proj}_S(\bm{u}) = \bm{Q} \operatorname{Proj}_{S_0}(\bm{Q}^\intercal \bm{u}) Proj S ( u ) = Q Proj S 0 ( Q ⊺ u ) Q ⊺ u \bm{Q}^\intercal \bm{u} Q ⊺ u Q \bm{Q} Q
因此 ∥ A u ∥ 2 \|\bm{A}\bm{u}\|^2 ∥ A u ∥ 2
d k ⋅ ∑ i = 1 k Y i 2 , Y = ( Y 1 , … , Y d ) 是 S d − 1 上的均匀单位向量 \frac{d}{k} \cdot \sum_{i=1}^k Y_i^2, \qquad \bm{Y} = (Y_1, \dots, Y_d) \text{ 是 } \mathbb{S}^{d-1} \text{ 上的均匀单位向量}
k d ⋅ i = 1 ∑ k Y i 2 , Y = ( Y 1 , … , Y d ) 是 S d − 1 上的均匀单位向量
同分布。问题从「分析正交矩阵」转到「分析均匀单位向量的前 k k k
下图对照这两个视角:左边固定向量 u \bm{u} u k k k Y \bm{Y} Y 完全相同 的投影长度分布——这正是把「随机子空间」难题翻译成「随机单位向量的前 k k k
均匀单位向量的高斯生成
如何在 S d − 1 \mathbb{S}^{d-1} S d − 1 球对称性 :
抽 X = ( X 1 , … , X d ) \bm{X} = (X_1, \dots, X_d) X = ( X 1 , … , X d ) X i ∼ N ( 0 , 1 ) X_i \sim \mathcal{N}(0, 1) X i ∼ N ( 0 , 1 )
令 Y = X / ∥ X ∥ \bm{Y} = \bm{X} / \|\bm{X}\| Y = X /∥ X ∥
理由是标准多维高斯的密度函数
p ( x ) = ∏ i = 1 d 1 2 π e − x i 2 / 2 = ( 2 π ) − d / 2 e − ∥ x ∥ 2 2 / 2 p(\bm{x}) = \prod_{i=1}^d \frac{1}{\sqrt{2\pi}} \e^{-x_i^2/2} = (2\pi)^{-d/2} \e^{-\|\bm{x}\|_2^2/2}
p ( x ) = i = 1 ∏ d 2 π 1 e − x i 2 /2 = ( 2 π ) − d /2 e − ∥ x ∥ 2 2 /2
仅依赖于 ∥ x ∥ \|\bm{x}\| ∥ x ∥
归约到独立 χ 2 \chi^2 χ 2
由上一步,
∑ i = 1 k Y i 2 = ∑ i = 1 k X i 2 ∑ i = 1 d X i 2 \sum_{i=1}^k Y_i^2 = \frac{\sum_{i=1}^k X_i^2}{\sum_{i=1}^d X_i^2}
i = 1 ∑ k Y i 2 = ∑ i = 1 d X i 2 ∑ i = 1 k X i 2
要证明
Pr [ ∑ i = 1 k Y i 2 > ( 1 + ε ) ⋅ k d ] < 1 2 n 3 \Pr\left[\sum_{i=1}^k Y_i^2 > (1 + \varepsilon) \cdot \frac{k}{d}\right] < \frac{1}{2 n^3}
Pr [ i = 1 ∑ k Y i 2 > ( 1 + ε ) ⋅ d k ] < 2 n 3 1
即 Pr [ ∑ i = 1 k X i 2 > ( 1 + ε ) ⋅ k d ⋅ ∑ i = 1 d X i 2 ] < 1 2 n 3 \Pr\left[\sum_{i=1}^k X_i^2 > (1 + \varepsilon)\cdot \dfrac{k}{d} \cdot \sum_{i=1}^d X_i^2\right] < \dfrac{1}{2 n^3} Pr [ ∑ i = 1 k X i 2 > ( 1 + ε ) ⋅ d k ⋅ ∑ i = 1 d X i 2 ] < 2 n 3 1
把比例移到一边、合并同类项:
Pr [ ( d − ( 1 + ε ) k ) ∑ i = 1 k X i 2 − ( 1 + ε ) k ∑ i = k + 1 d X i 2 > 0 ] < 1 2 n 3 \Pr\left[(d - (1 + \varepsilon)k) \sum_{i=1}^k X_i^2 - (1 + \varepsilon)k \sum_{i=k+1}^d X_i^2 > 0\right] < \frac{1}{2 n^3}
Pr [ ( d − ( 1 + ε ) k ) i = 1 ∑ k X i 2 − ( 1 + ε ) k i = k + 1 ∑ d X i 2 > 0 ] < 2 n 3 1
这是两个独立 χ 2 \chi^2 χ 2 MGF 技巧处理。
上尾的详细推导
对任意 λ > 0 \lambda > 0 λ > 0
Pr [ ( d − ( 1 + ε ) k ) ∑ i = 1 k X i 2 − ( 1 + ε ) k ∑ i = k + 1 d X i 2 > 0 ] = Pr [ e λ ⋅ LHS > 1 ] ⩽ E [ e λ ⋅ LHS ] \Pr\left[(d - (1 + \varepsilon)k) \sum_{i=1}^k X_i^2 - (1 + \varepsilon)k \sum_{i=k+1}^d X_i^2 > 0\right] = \Pr\left[\e^{\lambda \cdot \text{LHS}} > 1\right] \le \mathbb{E}\left[\e^{\lambda \cdot \text{LHS}}\right]
Pr [ ( d − ( 1 + ε ) k ) i = 1 ∑ k X i 2 − ( 1 + ε ) k i = k + 1 ∑ d X i 2 > 0 ] = Pr [ e λ ⋅ LHS > 1 ] ⩽ E [ e λ ⋅ LHS ]
按 X 1 , … , X d X_1, \dots, X_d X 1 , … , X d k k k d − k d-k d − k
E [ e λ ⋅ LHS ] = ∏ i = 1 k E [ e λ ( d − ( 1 + ε ) k ) X i 2 ] ⋅ ∏ i = k + 1 d E [ e − λ ( 1 + ε ) k X i 2 ] \mathbb{E}\left[\e^{\lambda \cdot \text{LHS}}\right] = \prod_{i=1}^k \mathbb{E}\bigl[\e^{\lambda (d - (1+\varepsilon)k) X_i^2}\bigr] \cdot \prod_{i=k+1}^d \mathbb{E}\bigl[\e^{-\lambda (1+\varepsilon)k X_i^2}\bigr]
E [ e λ ⋅ LHS ] = i = 1 ∏ k E [ e λ ( d − ( 1 + ε ) k ) X i 2 ] ⋅ i = k + 1 ∏ d E [ e − λ ( 1 + ε ) k X i 2 ]
用 E [ e s X 2 ] = ( 1 − 2 s ) − 1 / 2 \mathbb{E}[\e^{s X^2}] = (1 - 2s)^{-1/2} E [ e s X 2 ] = ( 1 − 2 s ) − 1/2 s < 1 / 2 s < 1/2 s < 1/2
= ( 1 − 2 λ ( d − ( 1 + ε ) k ) ) − k / 2 ⋅ ( 1 + 2 λ ( 1 + ε ) k ) − ( d − k ) / 2 = (1 - 2\lambda(d - (1+\varepsilon)k))^{-k/2} \cdot (1 + 2\lambda (1+\varepsilon)k)^{-(d-k)/2}
= ( 1 − 2 λ ( d − ( 1 + ε ) k ) ) − k /2 ⋅ ( 1 + 2 λ ( 1 + ε ) k ) − ( d − k ) /2
取 λ = ε 4 ( d − k ) \lambda = \dfrac{\varepsilon}{4(d - k)} λ = 4 ( d − k ) ε e − ε 2 k / 8 + O ( ε 3 k ) \e^{-\varepsilon^2 k / 8 + O(\varepsilon^3 k)} e − ε 2 k /8 + O ( ε 3 k ) ε ∈ ( 0 , 1 ) \varepsilon \in (0, 1) ε ∈ ( 0 , 1 ) k = Θ ( ε − 2 log n ) k = \Theta(\varepsilon^{-2} \log n) k = Θ ( ε − 2 log n ) < 1 / ( 2 n 3 ) < 1 / (2 n^3) < 1/ ( 2 n 3 )
因此
Pr [ ∑ i = 1 k Y i 2 > ( 1 + ε ) k d ] < 1 2 n 3 , Pr [ ∑ i = 1 k Y i 2 < ( 1 − ε ) k d ] < 1 2 n 3 \Pr\left[\sum_{i=1}^k Y_i^2 > (1 + \varepsilon)\frac{k}{d}\right] < \frac{1}{2 n^3},\quad \Pr\left[\sum_{i=1}^k Y_i^2 < (1 - \varepsilon)\frac{k}{d}\right] < \frac{1}{2 n^3}
Pr [ i = 1 ∑ k Y i 2 > ( 1 + ε ) d k ] < 2 n 3 1 , Pr [ i = 1 ∑ k Y i 2 < ( 1 − ε ) d k ] < 2 n 3 1
合起来即 Pr [ ∣ ∥ A u ∥ 2 2 − 1 ∣ > ε ] < 1 / n 3 \Pr[\,|\|\bm{A}\bm{u}\|_2^2 - 1| > \varepsilon\,] < 1/n^3 Pr [ ∣∥ A u ∥ 2 2 − 1∣ > ε ] < 1/ n 3 JL 定理的「最干净」构造——它和高斯构造给出形式相同的尾界(χ 2 \chi^2 χ 2
± 1 \pm 1 ± 1 高斯条目要采样实数、计算时也要做实数乘法;如果换成简单的 ± 1 \pm 1 ± 1
与 Count Sketch 的同构
回顾上一讲 Count Sketch 估计 ∥ x ∥ 2 2 \|\bm{x}\|_2^2 ∥ x ∥ 2 2 ± 1 \pm 1 ± 1 σ j \sigma_j σ j k k k k \sqrt{k} k
A i j = r i j k , r i j ∈ { − 1 , + 1 } 等概率 i.i.d. \bm{A}_{ij} = \dfrac{r_{ij}}{\sqrt{k}}, \qquad r_{ij} \in \{-1, +1\} \text{ 等概率 i.i.d.}
A ij = k r ij , r ij ∈ { − 1 , + 1 } 等概率 i.i.d.
期望仍然无偏
固定单位向量 u ∈ R d \bm{u} \in \R^d u ∈ R d i i i u \bm{u} u
( A u ) i = 1 k ∑ j = 1 d r i j u j = 1 k Y i , Y i = ∑ j = 1 d r i j u j (\bm{A}\bm{u})_i = \frac{1}{\sqrt{k}} \sum_{j=1}^d r_{ij} u_j = \frac{1}{\sqrt{k}} Y_i, \qquad Y_i = \sum_{j=1}^d r_{ij} u_j
( A u ) i = k 1 j = 1 ∑ d r ij u j = k 1 Y i , Y i = j = 1 ∑ d r ij u j
于是 ∥ A u ∥ 2 2 = 1 k ∑ i = 1 k Y i 2 \|\bm{A}\bm{u}\|_2^2 = \dfrac{1}{k} \sum_{i=1}^k Y_i^2 ∥ A u ∥ 2 2 = k 1 ∑ i = 1 k Y i 2 独立同分布的 Y 1 2 , … , Y k 2 Y_1^2, \dots, Y_k^2 Y 1 2 , … , Y k 2 1 1 1 ?
展开 Y i 2 Y_i^2 Y i 2
Y i 2 = ( ∑ j r i j u j ) 2 = ∑ j r i j 2 u j 2 + ∑ p ≠ q r i p r i q u p u q Y_i^2 = \left(\sum_j r_{ij} u_j\right)^2 = \sum_j r_{ij}^2 u_j^2 + \sum_{p \ne q} r_{ip} r_{iq} u_p u_q
Y i 2 = ( j ∑ r ij u j ) 2 = j ∑ r ij 2 u j 2 + p = q ∑ r i p r i q u p u q
注意 r i j 2 = 1 r_{ij}^2 = 1 r ij 2 = 1 { r i p } , { r i q } \{r_{ip}\}, \{r_{iq}\} { r i p } , { r i q } 0 0 0 E [ r i p r i q ] = 0 \mathbb{E}[r_{ip} r_{iq}] = 0 E [ r i p r i q ] = 0 p ≠ q p \ne q p = q
E [ Y i 2 ] = ∑ j u j 2 = ∥ u ∥ 2 2 = 1 , E [ ∥ A u ∥ 2 2 ] = 1 \mathbb{E}[Y_i^2] = \sum_j u_j^2 = \|\bm{u}\|_2^2 = 1, \quad \mathbb{E}\bigl[\|\bm{A}\bm{u}\|_2^2\bigr] = 1
E [ Y i 2 ] = j ∑ u j 2 = ∥ u ∥ 2 2 = 1 , E [ ∥ A u ∥ 2 2 ] = 1
与高斯构造一样,期望已经无偏。剩下要看的就是方差,即 ∥ A u ∥ 2 2 \|\bm{A}\bm{u}\|_2^2 ∥ A u ∥ 2 2 1 1 1
方差为 O ( 1 / k ) O(1/k) O ( 1/ k )
下一步是计算 V a r ( Y i 2 ) = E [ Y i 4 ] − 1 \mathrm{Var}(Y_i^2) = \mathbb{E}[Y_i^4] - 1 Var ( Y i 2 ) = E [ Y i 4 ] − 1
Y i 4 = ( ∑ j r i j u j ) 4 = ∑ a , b , c , d r i a r i b r i c r i d ⋅ u a u b u c u d Y_i^4 = \left(\sum_j r_{ij} u_j\right)^4 = \sum_{a, b, c, d} r_{ia} r_{ib} r_{ic} r_{id} \cdot u_a u_b u_c u_d
Y i 4 = ( j ∑ r ij u j ) 4 = a , b , c , d ∑ r ia r ib r i c r i d ⋅ u a u b u c u d
由 Rademacher 的对称性 E [ r i a r i b r i c r i d ] \mathbb{E}[r_{ia} r_{ib} r_{ic} r_{id}] E [ r ia r ib r i c r i d ] 1 1 1 0 0 0 ( a = b , c = d ) , ( a = c , b = d ) , ( a = d , b = c ) (a=b, c=d),\, (a=c, b=d),\, (a=d, b=c) ( a = b , c = d ) , ( a = c , b = d ) , ( a = d , b = c ) a = b = c = d a=b=c=d a = b = c = d
E [ Y i 4 ] = 3 ∑ j ≠ j ′ u j 2 u j ′ 2 + ∑ j u j 4 = 3 ( ∥ u ∥ 2 4 − ∑ j u j 4 ) + ∑ j u j 4 = 3 − 2 ∑ j u j 4 ⩽ 3 \mathbb{E}[Y_i^4] = 3 \sum_{j \ne j'} u_j^2 u_{j'}^2 + \sum_j u_j^4 = 3\bigl(\|\bm{u}\|_2^4 - \sum_j u_j^4\bigr) + \sum_j u_j^4 = 3 - 2 \sum_j u_j^4 \le 3
E [ Y i 4 ] = 3 j = j ′ ∑ u j 2 u j ′ 2 + j ∑ u j 4 = 3 ( ∥ u ∥ 2 4 − j ∑ u j 4 ) + j ∑ u j 4 = 3 − 2 j ∑ u j 4 ⩽ 3
所以 V a r ( Y i 2 ) ⩽ 2 \mathrm{Var}(Y_i^2) \le 2 Var ( Y i 2 ) ⩽ 2 Y i 2 Y_i^2 Y i 2
V a r ( ∥ A u ∥ 2 2 ) = 1 k 2 ∑ i = 1 k V a r ( Y i 2 ) ⩽ 2 k = O ( 1 k ) \mathrm{Var}\bigl(\|\bm{A}\bm{u}\|_2^2\bigr) = \frac{1}{k^2} \sum_{i=1}^k \mathrm{Var}(Y_i^2) \le \frac{2}{k} = O\left(\frac{1}{k}\right)
Var ( ∥ A u ∥ 2 2 ) = k 2 1 i = 1 ∑ k Var ( Y i 2 ) ⩽ k 2 = O ( k 1 )
Chebyshev 不等式给出
Pr [ ∣ ∥ A u ∥ 2 2 − 1 ∣ ⩾ ε ] ⩽ O ( 1 / k ) ε 2 = O ( 1 k ε 2 ) \Pr\bigl[\,\bigl|\|\bm{A}\bm{u}\|_2^2 - 1\bigr| \ge \varepsilon\,\bigr] \le \frac{O(1/k)}{\varepsilon^2} = O\left(\frac{1}{k \varepsilon^2}\right)
Pr [ ∥ A u ∥ 2 2 − 1 ⩾ ε ] ⩽ ε 2 O ( 1/ k ) = O ( k ε 2 1 )
Chebyshev 路线的瓶颈
要让上式 < 1 / n 3 < 1/n^3 < 1/ n 3 k = Ω ( n 3 / ε 2 ) k = \Omega(n^3 / \varepsilon^2) k = Ω ( n 3 / ε 2 ) JL 所需的 Θ ( ε − 2 log n ) \Theta(\varepsilon^{-2} \log n) Θ ( ε − 2 log n ) Θ ( n 3 / log n ) \Theta(n^3 / \log n) Θ ( n 3 / log n )
矩比较:拿到与高斯同阶的 k k k
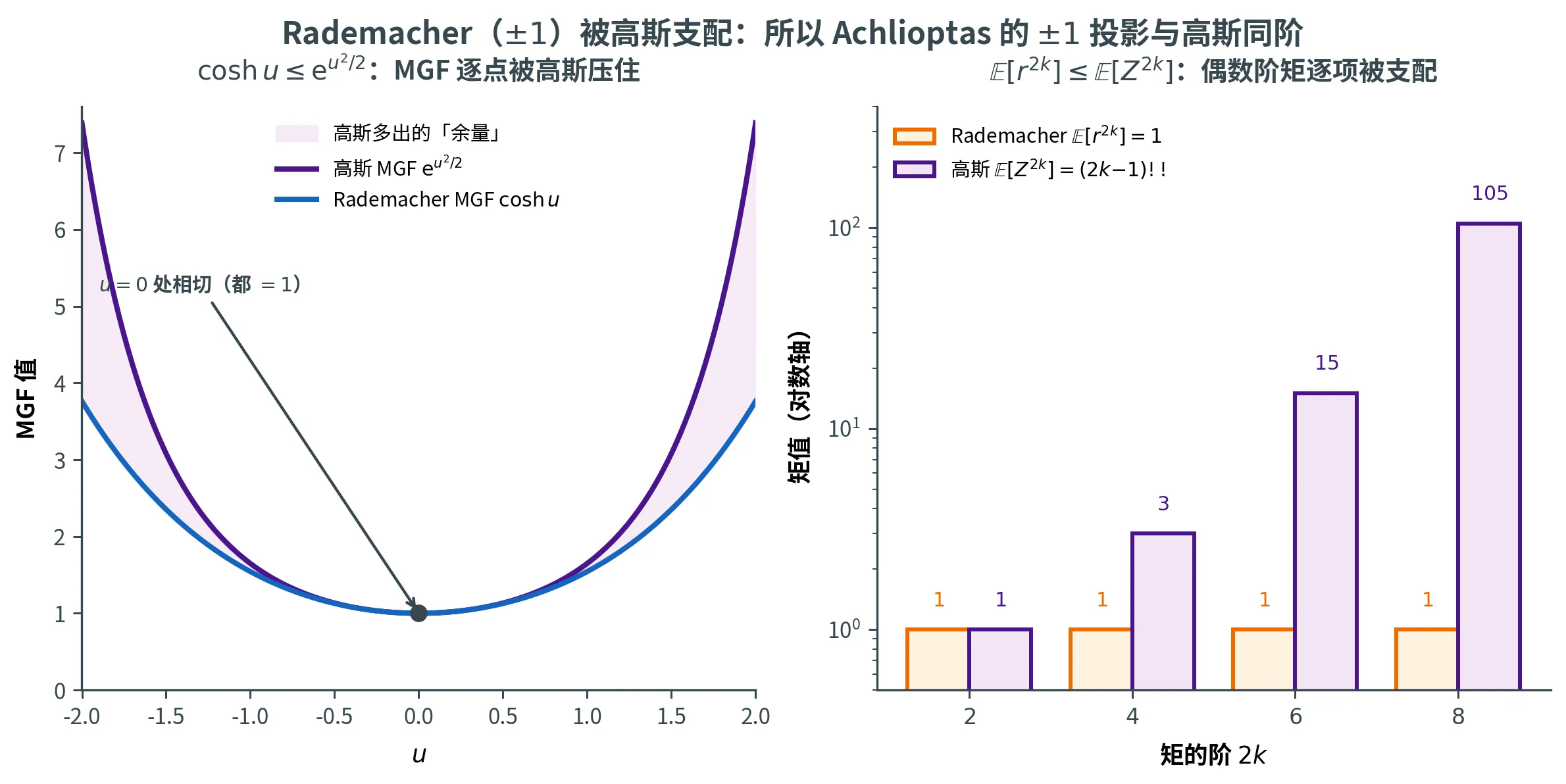
Achlioptas 的关键观察是:Rademacher 加权和 Y i = ∑ j r i j u j Y_i = \sum_j r_{ij} u_j Y i = ∑ j r ij u j ∑ j Z i j u j ∼ N ( 0 , 1 ) \sum_j Z_{ij} u_j \sim \mathcal{N}(0, 1) ∑ j Z ij u j ∼ N ( 0 , 1 ) 1 1 1 Rademacher 的所有偶数阶矩都被高斯支配 。于是可以照搬高斯的 MGF 计算,得到完全同阶的指数级尾界。
矩比较引理
令 w = ( 1 , 1 , … , 1 ) ∈ R d \bm{w} = (1, 1, \dots, 1) \in \R^d w = ( 1 , 1 , … , 1 ) ∈ R d Z ∈ R d \bm{Z} \in \R^d Z ∈ R d N ( 0 , 1 ) \mathcal{N}(0, 1) N ( 0 , 1 ) r ∈ { − 1 , + 1 } d \bm{r} \in \{-1, +1\}^d r ∈ { − 1 , + 1 } d k ∈ N k \in \N k ∈ N ∥ x ∥ 2 2 = d \|\bm{x}\|_2^2 = d ∥ x ∥ 2 2 = d x \bm{x} x
E [ ⟨ x , r ⟩ 2 k ] ⩽ E [ ⟨ w , r ⟩ 2 k ] ⩽ E [ ⟨ w , Z ⟩ 2 k ] \mathbb{E}\bigl[\langle \bm{x}, \bm{r} \rangle^{2k}\bigr] \le \mathbb{E}\bigl[\langle \bm{w}, \bm{r} \rangle^{2k}\bigr] \le \mathbb{E}\bigl[\langle \bm{w}, \bm{Z} \rangle^{2k}\bigr]
E [ ⟨ x , r ⟩ 2 k ] ⩽ E [ ⟨ w , r ⟩ 2 k ] ⩽ E [ ⟨ w , Z ⟩ 2 k ]
关于归一化 :引理把 x \bm{x} x ∥ x ∥ 2 2 = d \|\bm{x}\|_2^2 = d ∥ x ∥ 2 2 = d 1 1 1 w \bm{w} w ∥ u ∥ 2 = 1 \|\bm{u}\|_2 = 1 ∥ u ∥ 2 = 1 u \bm{u} u x = d ⋅ u \bm{x} = \sqrt{d} \cdot \bm{u} x = d ⋅ u d k d^k d k
引理由两个不等式串起来,下面分别给出思路。
第一个不等式
x \bm{x} x w \bm{w} w
直观地,w = ( 1 , … , 1 ) \bm{w} = (1, \dots, 1) w = ( 1 , … , 1 ) x \bm{x} x ∥ x ∥ 2 2 = d \|\bm{x}\|_2^2 = d ∥ x ∥ 2 2 = d
形式化地,把 ⟨ x , r ⟩ 2 k \langle \bm{x}, \bm{r}\rangle^{2k} ⟨ x , r ⟩ 2 k r \bm{r} r ∏ j x j 2 m j \prod_j x_j^{2 m_j} ∏ j x j 2 m j ∑ j m j = k \sum_j m_j = k ∑ j m j = k ∑ j x j 2 = d \sum_j x_j^2 = d ∑ j x j 2 = d ∑ j x j 2 m j \sum_j x_j^{2 m_j} ∑ j x j 2 m j x = w \bm{x} = \bm{w} x = w
第二个不等式
Rademacher 的偶数阶矩 ≤ 高斯
由 w = ( 1 , … , 1 ) \bm{w} = (1, \dots, 1) w = ( 1 , … , 1 ) ⟨ w , r ⟩ 2 k = ( ∑ i r i ) 2 k \langle \bm{w}, \bm{r}\rangle^{2k} = (\sum_i r_i)^{2k} ⟨ w , r ⟩ 2 k = ( ∑ i r i ) 2 k
⟨ w , r ⟩ 2 k = ∑ i 1 , … , i 2 k r i 1 ⋯ r i 2 k \langle \bm{w}, \bm{r}\rangle^{2k} = \sum_{i_1, \dots, i_{2k}} r_{i_1} \cdots r_{i_{2k}}
⟨ w , r ⟩ 2 k = i 1 , … , i 2 k ∑ r i 1 ⋯ r i 2 k
仅当每个指标出现偶数次时期望非零。设某项可记作 r j 1 2 ℓ 1 r j 2 2 ℓ 2 ⋯ r j m 2 ℓ m r_{j_1}^{2\ell_1} r_{j_2}^{2\ell_2} \cdots r_{j_m}^{2\ell_m} r j 1 2 ℓ 1 r j 2 2 ℓ 2 ⋯ r j m 2 ℓ m ∑ p ℓ p = k \sum_p \ell_p = k ∑ p ℓ p = k
E [ r j 1 2 ℓ 1 ⋯ r j m 2 ℓ m ] = 1 \mathbb{E}\bigl[r_{j_1}^{2\ell_1} \cdots r_{j_m}^{2\ell_m}\bigr] = 1
E [ r j 1 2 ℓ 1 ⋯ r j m 2 ℓ m ] = 1
对应的高斯项:
E [ Z j 1 2 ℓ 1 ⋯ Z j m 2 ℓ m ] = ∏ p E [ Z 2 ℓ p ] = ∏ p ( 2 ℓ p ) ! ℓ p ! ⋅ 2 ℓ p \mathbb{E}\bigl[Z_{j_1}^{2\ell_1} \cdots Z_{j_m}^{2\ell_m}\bigr] = \prod_p \mathbb{E}[Z^{2\ell_p}] = \prod_p \frac{(2\ell_p)!}{\ell_p! \cdot 2^{\ell_p}}
E [ Z j 1 2 ℓ 1 ⋯ Z j m 2 ℓ m ] = p ∏ E [ Z 2 ℓ p ] = p ∏ ℓ p ! ⋅ 2 ℓ p ( 2 ℓ p )!
由 ( 2 ℓ ) ! ⩾ ℓ ! ⋅ 2 ℓ (2\ell)! \ge \ell! \cdot 2^\ell ( 2 ℓ )! ⩾ ℓ ! ⋅ 2 ℓ ( 2 ℓ ) ! ℓ ! ⋅ 2 ℓ = ( 2 ℓ − 1 ) ! ! ⩾ 1 \dfrac{(2\ell)!}{\ell! \cdot 2^\ell} = (2\ell - 1)!! \ge 1 ℓ ! ⋅ 2 ℓ ( 2 ℓ )! = ( 2 ℓ − 1 )!! ⩾ 1 ⩾ 1 \ge 1 ⩾ 1
下图从两个角度看「Rademacher 被高斯支配」:左图是 MGF 层面——cosh u ⩽ e u 2 / 2 \cosh u \le \e^{u^2/2} cosh u ⩽ e u 2 /2 E [ r 2 k ] = 1 ⩽ ( 2 k − 1 ) ! ! = E [ Z 2 k ] \mathbb{E}[r^{2k}] = 1 \le (2k-1)!! = \mathbb{E}[Z^{2k}] E [ r 2 k ] = 1 ⩽ ( 2 k − 1 )!! = E [ Z 2 k ] ± 1 \pm 1 ± 1
借助矩比较,对 Rademacher 版本套用与高斯相同的 MGF 上界(MGF 是偶数阶矩的指数级数,逐项受高斯 MGF 控制),可以得到
Pr [ ∣ ∥ A u ∥ 2 2 − 1 ∣ > ε ] ⩽ 2 e − Ω ( ε 2 k ) \Pr\bigl[\,\bigl|\|\bm{A}\bm{u}\|_2^2 - 1\bigr| > \varepsilon\,\bigr] \le 2 \e^{-\Omega(\varepsilon^2 k)}
Pr [ ∥ A u ∥ 2 2 − 1 > ε ] ⩽ 2 e − Ω ( ε 2 k )
因此 k = O ( ε − 2 log n ) k = O(\varepsilon^{-2} \log n) k = O ( ε − 2 log n )
最近邻搜索
到目前为止,我们已经把 JL 定理证完了三遍——高斯、子空间投影、± 1 \pm 1 ± 1 O ( log n ) O(\log n) O ( log n ) 这能解决什么问题?
最直接的下游应用是最近邻搜索 (Nearest Neighbor Search, NNS )——给定一堆数据点,找出离查询点最近的一个。这是数据库系统、图像检索、机器学习中最普遍的查询模式。但很快我们会发现,光有 JL 不够;高维下的 NNS 还有更深的困难需要克服。
问题定义
最近邻搜索(NNS)
设 ( X , dist ) (X, \operatorname{dist}) ( X , dist )
数据 :n n n y 1 , y 2 , … , y n ∈ X \bm{y}_1, \bm{y}_2, \dots, \bm{y}_n \in X y 1 , y 2 , … , y n ∈ X 查询 :给一个新点 x ∈ X \bm{x} \in X x ∈ X x \bm{x} x y i \bm{y}_i y i
NNS 广泛出现在数据库系统、模式匹配、机器学习、图像处理、生物信息学等领域。
低维下的经典方法
当维度 d d d
k k k O ( log n ) O(\log n) O ( log n ) Voronoi 图 :将空间预先划分为「每点的最近邻区域」,配合点定位结构做查询。
这些算法的代价随维度指数增长,如 k k k d ≳ 20 d \gtrsim 20 d ≳ 20 d d d n Θ ( d ) n^{\Theta(d)} n Θ ( d )
维度的诅咒
当 d ≫ log n d \gg \log n d ≫ log n
维度诅咒
人们普遍猜测:在高维下精确求解 NNS 需要超多项式空间 或超多项式查询时间 (其中一者)。换言之,不存在 p o l y ( n , d ) \mathrm{poly}(n, d) poly ( n , d ) p o l y ( n , d ) \mathrm{poly}(n, d) poly ( n , d ) NNS 算法。
证据来自细粒度复杂性理论:精确 NNS 已被归约到强指数时间假设(SETH)等硬度问题。
诅咒之下,唯一的出路就是牺牲一点精度 + 接受一点随机性 ,这正是接下来要做的事情。
近似最近邻(ANN )
c c c ANN 与 ( c , r ) (c, r) ( c , r ) ANN 放宽对「最近」的要求:只要找到一个「近似最近」的点即可。
c c c ( c , r ) (c, r) ( c , r )
c c c ANN (Approximate Nearest Neighbor)y i \bm{y}_i y i
dist ( x , y i ) ⩽ c ⋅ min 1 ⩽ j ⩽ n dist ( x , y j ) \operatorname{dist}(\bm{x}, \bm{y}_i) \le c \cdot \min_{1 \le j \le n} \operatorname{dist}(\bm{x}, \bm{y}_j)
dist ( x , y i ) ⩽ c ⋅ 1 ⩽ j ⩽ n min dist ( x , y j )
( c , r ) (c, r) ( c , r ) ANN (Approximate Near Neighbor)
若 ∃ y j , dist ( x , y j ) ⩽ r \exists \bm{y}_j,\, \operatorname{dist}(\bm{x}, \bm{y}_j) \le r ∃ y j , dist ( x , y j ) ⩽ r y i \bm{y}_i y i dist ( x , y i ) ⩽ c ⋅ r \operatorname{dist}(\bm{x}, \bm{y}_i) \le c \cdot r dist ( x , y i ) ⩽ c ⋅ r
若 ∀ y i , dist ( x , y i ) > c ⋅ r \forall \bm{y}_i,\, \operatorname{dist}(\bm{x}, \bm{y}_i) > c \cdot r ∀ y i , dist ( x , y i ) > c ⋅ r
否则任意。
c c c ANN 是「近似比」目标,( c , r ) (c, r) ( c , r ) ANN 则把问题卡在某个阈值 r r r
从 ( c , r ) (c, r) ( c , r ) c c c ANN 的归约
两者之间有一个简洁的归约。先记下数据中两两距离的极值:
D min = min i ≠ j dist ( y i , y j ) , D max = max i ≠ j dist ( y i , y j ) , R = D max D min D_{\min} = \min_{i \ne j} \operatorname{dist}(\bm{y}_i, \bm{y}_j), \quad D_{\max} = \max_{i \ne j} \operatorname{dist}(\bm{y}_i, \bm{y}_j), \quad R = \frac{D_{\max}}{D_{\min}}
D m i n = i = j min dist ( y i , y j ) , D m a x = i = j max dist ( y i , y j ) , R = D m i n D m a x
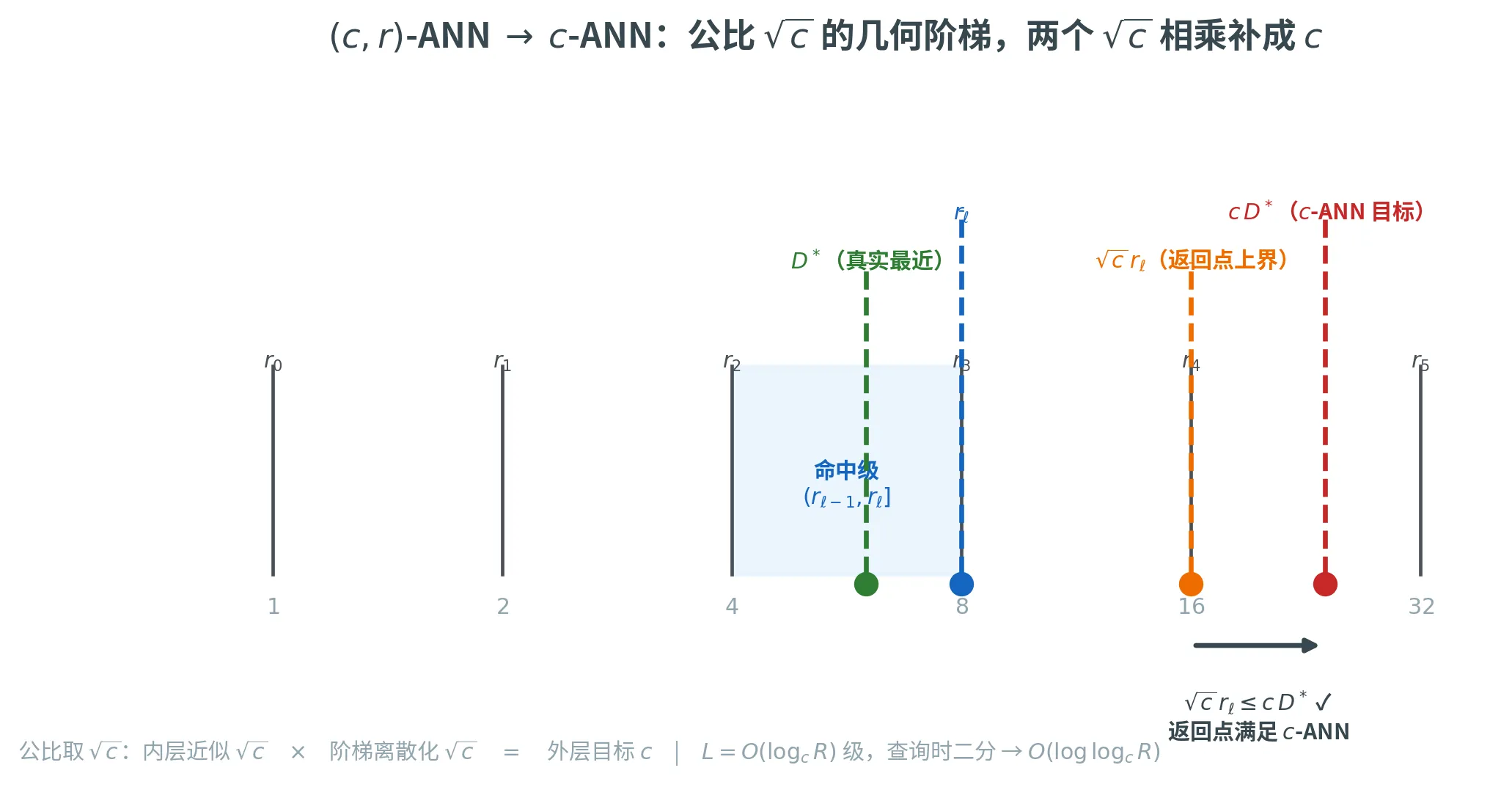
构造一个公比为 c \sqrt{c} c
r 0 = D min , r ℓ = c ⋅ r ℓ − 1 , … , r L ⩾ D max r_0 = D_{\min},\quad r_\ell = \sqrt{c} \cdot r_{\ell - 1},\quad \dots,\quad r_L \ge D_{\max}
r 0 = D m i n , r ℓ = c ⋅ r ℓ − 1 , … , r L ⩾ D m a x
共 L = ⌈ log c R ⌉ L = \lceil\log_{\sqrt{c}} R\rceil L = ⌈ log c R ⌉ L = O ( log c R ) L = O(\log_c R) L = O ( log c R ) log c R \log_c R log c R log c R \log_c R log c R r ℓ r_\ell r ℓ ( c , r ℓ ) (\sqrt{c}, r_\ell) ( c , r ℓ ) ANN 数据结构,查询时对 ℓ \ell ℓ
为什么公比是 c \sqrt{c} c
这是归约能成立的关键。设真实最近距离为 D ∗ = min j dist ( x , y j ) D^* = \min_j \operatorname{dist}(\bm{x}, \bm{y}_j) D ∗ = min j dist ( x , y j ) D ∗ ⩾ D min = r 0 D^* \ge D_{\min} = r_0 D ∗ ⩾ D m i n = r 0 ℓ ⩾ 1 \ell \ge 1 ℓ ⩾ 1 r ℓ − 1 < D ∗ ⩽ r ℓ r_{\ell - 1} < D^* \le r_\ell r ℓ − 1 < D ∗ ⩽ r ℓ D ∗ = D min D^* = D_{\min} D ∗ = D m i n ℓ = 1 \ell = 1 ℓ = 1
r ℓ c < D ∗ ⩽ r ℓ \frac{r_\ell}{\sqrt{c}} < D^* \le r_\ell
c r ℓ < D ∗ ⩽ r ℓ
此时 ( c , r ℓ ) (\sqrt{c}, r_\ell) ( c , r ℓ ) ANN 返回的点 y i \bm{y}_i y i dist ( x , y i ) ⩽ c ⋅ r ℓ \operatorname{dist}(\bm{x}, \bm{y}_i) \le \sqrt{c} \cdot r_\ell dist ( x , y i ) ⩽ c ⋅ r ℓ c c c ANN 的目标是 dist ( x , y i ) ⩽ c ⋅ D ∗ \operatorname{dist}(\bm{x}, \bm{y}_i) \le c \cdot D^* dist ( x , y i ) ⩽ c ⋅ D ∗
c ⋅ r ℓ ⩽ c ⋅ c ⋅ D ∗ = c ⋅ D ∗ ✓ \sqrt{c} \cdot r_\ell \le \sqrt{c} \cdot \sqrt{c} \cdot D^* = c \cdot D^* \quad\checkmark
c ⋅ r ℓ ⩽ c ⋅ c ⋅ D ∗ = c ⋅ D ∗ ✓
若公比改成 c c c D ∗ D^* D ∗ r ℓ / c r_\ell / c r ℓ / c c ⋅ r ℓ ⩽ c ⋅ D ∗ = r ℓ \sqrt{c} \cdot r_\ell \le c \cdot D^* = r_\ell c ⋅ r ℓ ⩽ c ⋅ D ∗ = r ℓ c > 1 \sqrt{c} > 1 c > 1
本质:内层算法的近似比(c \sqrt{c} c c \sqrt{c} c c c c
下图把这条几何阶梯画出来(取 c = 4 c = 4 c = 4 c = 2 \sqrt c = 2 c = 2 r 0 , r 1 , … r_0, r_1, \dots r 0 , r 1 , … c \sqrt c c D ∗ D^* D ∗ ( r ℓ − 1 , r ℓ ] (r_{\ell-1}, r_\ell] ( r ℓ − 1 , r ℓ ] ( c , r ℓ ) (\sqrt c, r_\ell) ( c , r ℓ ) ANN 保证返回点距离 ⩽ c r ℓ \le \sqrt c\, r_\ell ⩽ c r ℓ r ℓ < c D ∗ r_\ell < \sqrt c\, D^* r ℓ < c D ∗ c \sqrt c c c D ∗ c\,D^* c D ∗ c \sqrt c c
归约结论
若 ( c , r ) (\sqrt{c}, r) ( c , r ) ANN 能以 s s s t t t c c c ANN 可以以 O ( s log c R ) O(s \log_c R) O ( s log c R ) O ( t log log c R ) O(t \log \log_c R) O ( t log log c R ) log log c R \log \log_c R log log c R L L L
从而只需把精力放在 ( c , r ) (c, r) ( c , r ) ANN 上,距离参数 r r r
Hamming 空间上的降维与 ANN
归约把我们送到了 ( c , r ) (c, r) ( c , r ) ANN ——半径已知的近邻查询。但怎么解 这个子问题?JL 的欧氏构造在这里不直接适用(Hamming 距离不是 ℓ 2 \ell_2 ℓ 2 { 0 , 1 } d \{0, 1\}^d { 0 , 1 } d
接下来在一个具体度量空间——{ 0 , 1 } d \{0, 1\}^d { 0 , 1 } d Hamming 距离 (两向量不同坐标的数量)——上构造 ( c , r ) (c, r) ( c , r ) ANN 算法。Hamming 空间是文本匹配、序列比较、稀疏特征比较的常用模型,本身也是高维问题最棘手的代表。
高维下的暴力算法困境
数据是 n n n y 1 , … , y n ∈ { 0 , 1 } d \bm{y}_1, \dots, \bm{y}_n \in \{0, 1\}^d y 1 , … , y n ∈ { 0 , 1 } d d ≫ log n d \gg \log n d ≫ log n O ( 2 d ) O(2^d) O ( 2 d ) 2 d 2^d 2 d p o l y ( n , d ) \mathrm{poly}(n, d) poly ( n , d ) ( c , r ) (c, r) ( c , r ) ANN ?
策略 :先做降维 ——用一个随机矩阵 A \bm{A} A d d d k = O ( log n ) k = O(\log n) k = O ( log n ) 2 k 2^k 2 k
Boolean 矩阵降维
随机抽取 k × d k \times d k × d A \bm{A} A A i j ∼ Bernoulli ( p ) \bm{A}_{ij} \sim \operatorname{Bernoulli}(p) A ij ∼ Bernoulli ( p ) p p p
z i = A y i ( m o d 2 ) ∈ { 0 , 1 } k \bm{z}_i = \bm{A}\bm{y}_i \pmod 2 \in \{0, 1\}^k
z i = A y i ( mod 2 ) ∈ { 0 , 1 } k
所有乘法和加法都在 G F ( 2 ) \mathrm{GF}(2) GF ( 2 ) y i \bm{y}_i y i s s s u \bm{u} u y i \bm{y}_i y i x \bm{x} x A x \bm{A}\bm{x} A x
单坐标的碰撞概率
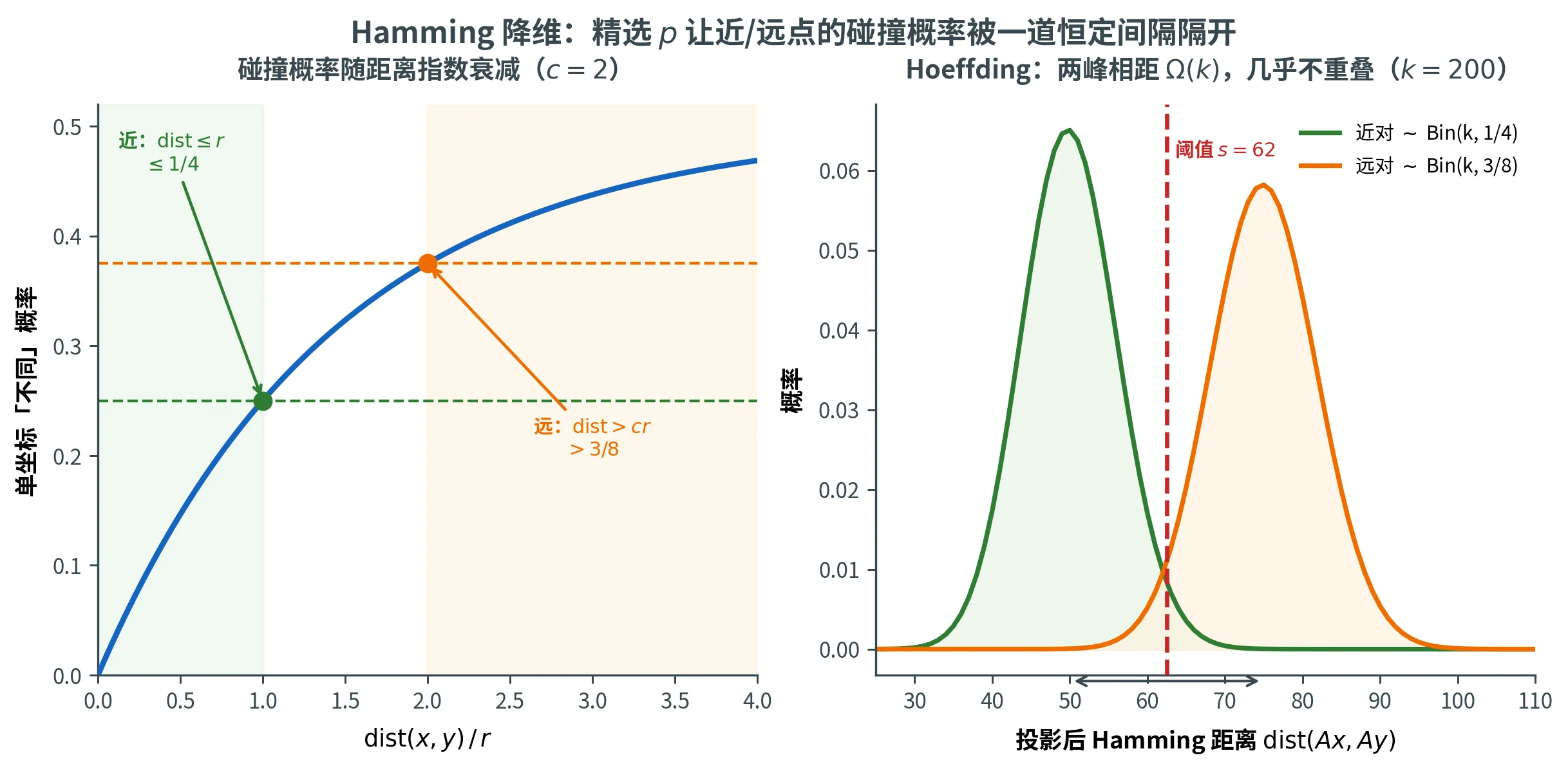
降维成立的核心是下面的公式,它把碰撞概率显式地写成 Hamming 距离的函数:
单坐标碰撞概率
对任意 x , y ∈ { 0 , 1 } d \bm{x}, \bm{y} \in \{0, 1\}^d x , y ∈ { 0 , 1 } d i i i
Pr [ ( A x ) i ≠ ( A y ) i ] = 1 2 ( 1 − ( 1 − 2 p ) dist ( x , y ) ) \Pr[(\bm{A}\bm{x})_i \ne (\bm{A}\bm{y})_i] = \frac{1}{2}\bigl(1 - (1 - 2p)^{\operatorname{dist}(\bm{x}, \bm{y})}\bigr)
Pr [( A x ) i = ( A y ) i ] = 2 1 ( 1 − ( 1 − 2 p ) dist ( x , y ) )
直接对 A i , ⋅ \bm{A}_{i,\cdot} A i , ⋅ Bernoulli ( p ) \operatorname{Bernoulli}(p) Bernoulli ( p ) 等价生成 技巧把概率结构展开。
等价生成
假设 p ⩽ 1 / 2 p \le 1/2 p ⩽ 1/2 A i j ∼ Bernoulli ( p ) \bm{A}_{ij} \sim \operatorname{Bernoulli}(p) A ij ∼ Bernoulli ( p )
每个 j ∈ [ d ] j \in [d] j ∈ [ d ] 2 p 2p 2 p D ⊆ [ d ] D \subseteq [d] D ⊆ [ d ]
对 j ∈ D j \in D j ∈ D A i j ∈ { 0 , 1 } \bm{A}_{ij} \in \{0, 1\} A ij ∈ { 0 , 1 }
对 j ∉ D j \notin D j ∈ / D A i j = 0 \bm{A}_{ij} = 0 A ij = 0
验证:单个 A i j \bm{A}_{ij} A ij 1 1 1 = Pr [ j ∈ D ] ⋅ ( 1 / 2 ) = 2 p ⋅ 1 / 2 = p = \Pr[j \in D] \cdot (1/2) = 2p \cdot 1/2 = p = Pr [ j ∈ D ] ⋅ ( 1/2 ) = 2 p ⋅ 1/2 = p Bernoulli ( p ) \operatorname{Bernoulli}(p) Bernoulli ( p ) 2 p 2p 2 p p ⩽ 1 / 2 p \le 1/2 p ⩽ 1/2 2 p ⩽ 1 2p \le 1 2 p ⩽ 1 p p p
为什么要这么生成?因为它把概率结构「拆开」:进入活跃集 D D D
记 D ′ = { j : x j ≠ y j } D' = \{j\colon x_j \ne y_j\} D ′ = { j : x j = y j } x , y \bm{x}, \bm{y} x , y ∣ D ′ ∣ = dist ( x , y ) |D'| = \operatorname{dist}(\bm{x}, \bm{y}) ∣ D ′ ∣ = dist ( x , y ) A i , ⋅ \bm{A}_{i, \cdot} A i , ⋅ j ∉ D ′ j \notin D' j ∈ / D ′ x j = y j x_j = y_j x j = y j ( A x ) i − ( A y ) i (\bm{A}\bm{x})_i - (\bm{A}\bm{y})_i ( A x ) i − ( A y ) i
( A x ) i ≠ ( A y ) i ⟺ ⨁ j ∈ D ′ A i j ⋅ ( x j − y j ) ≡ 1 ( m o d 2 ) ⟺ ⨁ j ∈ D ′ A i j = 1 (\bm{A}\bm{x})_i \ne (\bm{A}\bm{y})_i \iff \bigoplus_{j \in D'} \bm{A}_{ij}\cdot(x_j - y_j) \equiv 1 \pmod 2 \iff \bigoplus_{j \in D'} \bm{A}_{ij} = 1
( A x ) i = ( A y ) i ⟺ j ∈ D ′ ⨁ A ij ⋅ ( x j − y j ) ≡ 1 ( mod 2 ) ⟺ j ∈ D ′ ⨁ A ij = 1
最后一步用了 j ∈ D ′ j \in D' j ∈ D ′ x j − y j ≡ 1 ( m o d 2 ) x_j - y_j \equiv 1 \pmod 2 x j − y j ≡ 1 ( mod 2 )
情形
D ∩ D ′ D \cap D' D ∩ D ′ ⨁ j ∈ D ′ A i j \bigoplus_{j \in D'} \bm{A}_{ij} ⨁ j ∈ D ′ A ij Pr [ 为 1 ] \Pr[\text{为 } 1] Pr [ 为 1 ]
活跃集错过差异
D ∩ D ′ = ∅ D \cap D' = \empty D ∩ D ′ = ∅ 所有 A i j = 0 \bm{A}_{ij} = 0 A ij = 0 = 0 = 0 = 0
0 0 0
活跃集命中差异
D ∩ D ′ ≠ ∅ D \cap D' \ne \empty D ∩ D ′ = ∅ ⩾ 1 \ge 1 ⩾ 1 1 / 2 1/2 1/2
综合:
Pr [ ( A x ) i ≠ ( A y ) i ] = Pr [ D ∩ D ′ ≠ ∅ ] ⋅ 1 2 \Pr[(\bm{A}\bm{x})_i \ne (\bm{A}\bm{y})_i] = \Pr[D \cap D' \ne \empty] \cdot \frac{1}{2}
Pr [( A x ) i = ( A y ) i ] = Pr [ D ∩ D ′ = ∅ ] ⋅ 2 1
而 D ∩ D ′ = ∅ D \cap D' = \empty D ∩ D ′ = ∅ j ∈ D ′ j \in D' j ∈ D ′ D D D ( 1 − 2 p ) ∣ D ′ ∣ (1 - 2p)^{|D'|} ( 1 − 2 p ) ∣ D ′ ∣
Pr [ ( A x ) i ≠ ( A y ) i ] = 1 2 ( 1 − ( 1 − 2 p ) dist ( x , y ) ) \Pr[(\bm{A}\bm{x})_i \ne (\bm{A}\bm{y})_i] = \frac{1}{2}\bigl(1 - (1 - 2p)^{\operatorname{dist}(\bm{x}, \bm{y})}\bigr)
Pr [( A x ) i = ( A y ) i ] = 2 1 ( 1 − ( 1 − 2 p ) dist ( x , y ) )
选取 p p p s s s
精妙的选取:取 p p p ( 1 − 2 p ) = 2 − 1 / r (1 - 2p) = 2^{-1/r} ( 1 − 2 p ) = 2 − 1/ r ( 1 − 2 − dist / r ) / 2 (1 - 2^{-\operatorname{dist}/r})/2 ( 1 − 2 − dist / r ) /2
情形
dist / r \operatorname{dist}/r dist / r Pr [ ( A x ) i ≠ ( A y ) i ] \Pr[(\bm{A}\bm{x})_i \ne (\bm{A}\bm{y})_i] Pr [( A x ) i = ( A y ) i ]
dist ( x , y ) ⩽ r \operatorname{dist}(\bm{x}, \bm{y}) \le r dist ( x , y ) ⩽ r ⩽ 1 \le 1 ⩽ 1 ⩽ ( 1 − 2 − 1 ) / 2 = 1 / 4 \le (1 - 2^{-1})/2 = 1/4 ⩽ ( 1 − 2 − 1 ) /2 = 1/4
dist ( x , y ) > c r \operatorname{dist}(\bm{x}, \bm{y}) > c r dist ( x , y ) > cr > c > c > c > ( 1 − 2 − c ) / 2 = 1 / 2 − 2 − ( c + 1 ) > (1 - 2^{-c})/2 = 1/2 - 2^{-(c+1)} > ( 1 − 2 − c ) /2 = 1/2 − 2 − ( c + 1 )
记示性变量 X i = 1 [ ( A x ) i ≠ ( A y ) i ] X_i = \mathbf{1}[(\bm{A}\bm{x})_i \ne (\bm{A}\bm{y})_i] X i = 1 [( A x ) i = ( A y ) i ] X = ∑ i = 1 k X i = dist ( A x , A y ) X = \sum_{i=1}^k X_i = \operatorname{dist}(\bm{A}\bm{x}, \bm{A}\bm{y}) X = ∑ i = 1 k X i = dist ( A x , A y )
E [ X ] ⩽ k 4 (近) , E [ X ] > ( 1 2 − 2 − ( c + 1 ) ) k (远) \mathbb{E}[X] \le \frac{k}{4} \text{(近)}, \qquad \mathbb{E}[X] > \left(\frac{1}{2} - 2^{-(c+1)}\right) k \text{(远)}
E [ X ] ⩽ 4 k (近) , E [ X ] > ( 2 1 − 2 − ( c + 1 ) ) k (远)
两段期望被一道恒定间隔 Δ = 1 / 4 − 2 − ( c + 1 ) > 0 \Delta = 1/4 - 2^{-(c+1)} > 0 Δ = 1/4 − 2 − ( c + 1 ) > 0 s s s A = k / 4 A = k/4 A = k /4 B = ( 1 / 2 − 2 − ( c + 1 ) ) k B = (1/2 - 2^{-(c+1)})k B = ( 1/2 − 2 − ( c + 1 ) ) k
s = A + B 2 = ( 3 8 − 2 − ( c + 2 ) ) k s = \frac{A + B}{2} = \left(\frac{3}{8} - 2^{-(c+2)}\right) k
s = 2 A + B = ( 8 3 − 2 − ( c + 2 ) ) k
这样近的情形要求 X X X ⩾ Δ k / 2 \ge \Delta k/2 ⩾ Δ k /2 X X X ⩾ Δ k / 2 \ge \Delta k/2 ⩾ Δ k /2 t = ( 1 / 8 − 2 − ( c + 2 ) ) k t = (1/8 - 2^{-(c+2)})k t = ( 1/8 − 2 − ( c + 2 ) ) k
Hoeffding 给出集中
Hoeffding 不等式
对 X = ∑ i = 1 k X i X = \sum_{i=1}^k X_i X = ∑ i = 1 k X i X i ∈ { 0 , 1 } X_i \in \{0, 1\} X i ∈ { 0 , 1 } t > 0 t > 0 t > 0
Pr [ X ⩾ E [ X ] + t ] ⩽ exp ( − 2 t 2 k ) , Pr [ X ⩽ E [ X ] − t ] ⩽ exp ( − 2 t 2 k ) \Pr[X \ge \mathbb{E}[X] + t] \le \exp\left(-\frac{2t^2}{k}\right), \qquad \Pr[X \le \mathbb{E}[X] - t] \le \exp\left(-\frac{2t^2}{k}\right)
Pr [ X ⩾ E [ X ] + t ] ⩽ exp ( − k 2 t 2 ) , Pr [ X ⩽ E [ X ] − t ] ⩽ exp ( − k 2 t 2 )
这是「加性偏差」的指数集中,与上一讲讨论的 Chernoff 乘性偏差形式不同,但常被一并称作 Chernoff-Hoeffding 不等式。
代入 t = ( 1 / 8 − 2 − ( c + 2 ) ) k t = (1/8 - 2^{-(c+2)})k t = ( 1/8 − 2 − ( c + 2 ) ) k 2 t 2 / k = Ω ( k ) 2 t^2/k = \Omega(k) 2 t 2 / k = Ω ( k ) c c c k k k
dist ( x , y ) ⩽ r ⟹ Pr [ dist ( A x , A y ) > s ] < e − Ω ( k ) dist ( x , y ) > c r ⟹ Pr [ dist ( A x , A y ) ⩽ s ] < e − Ω ( k ) \begin{aligned}
\operatorname{dist}(\bm{x}, \bm{y}) \le r &\implies \Pr\bigl[\operatorname{dist}(\bm{A}\bm{x}, \bm{A}\bm{y}) > s\bigr] < \e^{-\Omega(k)} \\
\operatorname{dist}(\bm{x}, \bm{y}) > c r &\implies \Pr\bigl[\operatorname{dist}(\bm{A}\bm{x}, \bm{A}\bm{y}) \le s\bigr] < \e^{-\Omega(k)}
\end{aligned}
dist ( x , y ) ⩽ r dist ( x , y ) > cr ⟹ Pr [ dist ( A x , A y ) > s ] < e − Ω ( k ) ⟹ Pr [ dist ( A x , A y ) ⩽ s ] < e − Ω ( k )
取 k = O ( log n ) k = O(\log n) k = O ( log n ) < 1 / n 2 < 1/n^2 < 1/ n 2 ( c , r ) (c, r) ( c , r ) ANN 以高概率正确。
下图把这套机制画在一起(取 c = 2 c = 2 c = 2 p p p ⩽ 1 / 4 \le 1/4 ⩽ 1/4 > 3 / 8 > 3/8 > 3/8 k = 200 k = 200 k = 200 k / 4 = 50 k/4 = 50 k /4 = 50 3 k / 8 = 75 3k/8 = 75 3 k /8 = 75 Ω ( k ) \Omega(k) Ω ( k ) s ≈ 62 s \approx 62 s ≈ 62
复杂度小结
最终的数据结构:
操作
代价
空间
O ( n ⋅ 2 k ) = O ( n ⋅ p o l y ( n ) ) O(n \cdot 2^k) = O(n \cdot \mathrm{poly}(n)) O ( n ⋅ 2 k ) = O ( n ⋅ poly ( n )) y i \bm{y}_i y i s s s ( k ⩽ s ) ⩽ 2 k \binom{k}{\le s} \le 2^k ( ⩽ s k ) ⩽ 2 k
查询时间
O ( k d ) O(k d) O ( k d ) A x \bm{A}\bm{x} A x + O ( 1 ) + O(1) + O ( 1 )
空间是 n n n k = O ( log n ) k = O(\log n) k = O ( log n ) 2 k = p o l y ( n ) 2^k = \mathrm{poly}(n) 2 k = poly ( n ) O ( d log n ) O(d \log n) O ( d log n )
局部敏感哈希(LSH )
上一节的 Hamming 算法把「近点降到同桶、远点降到不同桶」当成核心机制。这个机制其实不依赖 Hamming 特殊性——任何度量空间,只要能找到合适的「随机哈希函数」让近的点更容易碰撞,就能玩出相同的把戏。把这个机制抽出来,就是局部敏感哈希 。
LSH 把降维 + 桶定位两步合并成一个哈希函数,并明确写出这个哈希函数需要满足的「近/远」条件,从而把整个算法框架推广到任意度量空间。
LSH 的定义局部敏感哈希(LSH)
设 ( X , dist ) (X, \operatorname{dist}) ( X , dist ) h : X → U h\colon X \to U h : X → U ( r , c r , p , q ) (r, cr, p, q) ( r , cr , p , q ) LSH x , y ∈ X x, y \in X x , y ∈ X
dist ( x , y ) ⩽ r ⟹ Pr [ h ( x ) = h ( y ) ] ⩾ p dist ( x , y ) > c ⋅ r ⟹ Pr [ h ( x ) = h ( y ) ] ⩽ q \begin{aligned}
\operatorname{dist}(x, y) \le r &\implies \Pr[h(x) = h(y)] \ge p \\
\operatorname{dist}(x, y) > c \cdot r &\implies \Pr[h(x) = h(y)] \le q
\end{aligned}
dist ( x , y ) ⩽ r dist ( x , y ) > c ⋅ r ⟹ Pr [ h ( x ) = h ( y )] ⩾ p ⟹ Pr [ h ( x ) = h ( y )] ⩽ q
直观地:「近」的点哈希到同一桶的概率高(至少 p p p q q q p > q p > q p > q
张量化:拉开概率间隔
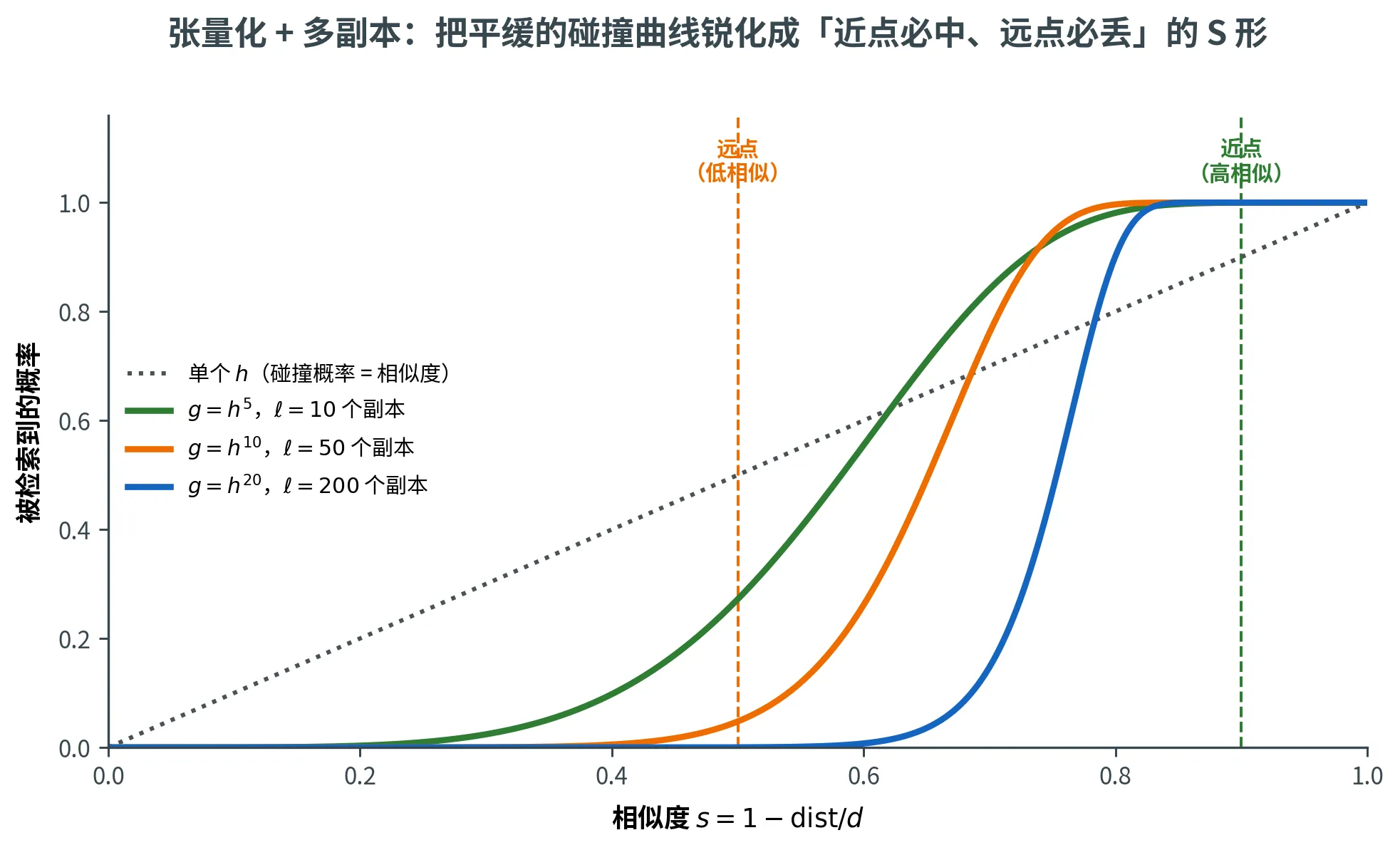
直接拿一个 LSH 一般不够好——p p p q q q p = 0.5 , q = 0.4 p = 0.5, q = 0.4 p = 0.5 , q = 0.4
张量化 是把概率间隔指数级放大的标准技巧:并联 k k k LSH 实例,要求全部都同值 才算碰撞。
张量化命题
若存在 ( r , c r , p , q ) (r, cr, p, q) ( r , cr , p , q ) LSH h : X → U h\colon X \to U h : X → U ( r , c r , p k , q k ) (r, cr, p^k, q^k) ( r , cr , p k , q k ) LSH g : X → U k g\colon X \to U^k g : X → U k
g ( x ) = ( h 1 ( x ) , h 2 ( x ) , … , h k ( x ) ) g(x) = (h_1(x), h_2(x), \dots, h_k(x))
g ( x ) = ( h 1 ( x ) , h 2 ( x ) , … , h k ( x ))
h 1 , … , h k h_1, \dots, h_k h 1 , … , h k h h h
一句话证明:g ( x ) = g ( y ) g(x) = g(y) g ( x ) = g ( y ) k k k h i h_i h i
张量化的代价是两个概率都同时缩小 。但由于 p > q p > q p > q p k p^k p k q k q^k q k 慢 ——这是我们想要的不对称效果。
选 k k k :取 k = log 1 / q n k = \log_{1/q} n k = log 1/ q n q k = 1 / n q^k = 1/n q k = 1/ n
p k = p log 1 / q n = n − ρ , ρ : = log ( 1 / p ) log ( 1 / q ) = log p log q ∈ ( 0 , 1 ) p^k = p^{\log_{1/q} n} = n^{-\rho}, \quad \rho := \frac{\log(1/p)}{\log(1/q)} = \frac{\log p}{\log q} \in (0, 1)
p k = p l o g 1/ q n = n − ρ , ρ := log ( 1/ q ) log ( 1/ p ) = log q log p ∈ ( 0 , 1 )
记 p ∗ = p k = n − ρ p^* = p^k = n^{-\rho} p ∗ = p k = n − ρ LSH g g g
近点碰撞概率 ⩾ p ∗ = n − ρ \ge p^* = n^{-\rho} ⩾ p ∗ = n − ρ
远点碰撞概率 ⩽ 1 / n \le 1/n ⩽ 1/ n
参数 ρ \rho ρ 0 0 0
下图展示张量化 + 多副本如何把「平缓」的碰撞曲线锐化成「近点必中、远点必丢」的 S 形:单个 h h h k k k g = h k g = h^k g = h k ℓ \ell ℓ k k k
LSH 数据结构现在我们有了张量化后的 LSH g g g ( c , r ) (c, r) ( c , r ) ANN ?
直觉 :把 n n n y 1 , … , y n \bm{y}_1, \dots, \bm{y}_n y 1 , … , y n g g g ⟨ g ( y i ) , y i ⟩ \langle g(\bm{y}_i), \bm{y}_i\rangle ⟨ g ( y i ) , y i ⟩ x \bm{x} x g ( x ) g(\bm{x}) g ( x ) g g g
若 ∃ y s \exists \bm{y}_s ∃ y s x \bm{x} x ⩾ p ∗ = n − ρ \ge p^* = n^{-\rho} ⩾ p ∗ = n − ρ x \bm{x} x n − ρ n^{-\rho} n − ρ 1 1 1
每个远点有概率 ⩽ 1 / n \le 1/n ⩽ 1/ n x \bm{x} x ⩽ n ⋅ 1 / n = 1 \le n \cdot 1/n = 1 ⩽ n ⋅ 1/ n = 1
真正的问题:近邻可能错过 。补救:跑 ℓ \ell ℓ 独立 的 LSH 副本 g 1 , … , g ℓ g_1, \dots, g_\ell g 1 , … , g ℓ x \bm{x} x y s \bm{y}_s y s ( 1 − p ∗ ) (1 - p^*) ( 1 − p ∗ ) ( 1 − p ∗ ) ℓ (1 - p^*)^\ell ( 1 − p ∗ ) ℓ ℓ = 1 / p ∗ = n ρ \ell = 1/p^* = n^\rho ℓ = 1/ p ∗ = n ρ ⩽ 1 / e \le 1/\e ⩽ 1/ e
副作用:远点变多了 。ℓ \ell ℓ ⩽ ℓ \le \ell ⩽ ℓ 扫描时设上限 ,最多看 10 ℓ 10\ell 10 ℓ 10 ℓ 10\ell 10 ℓ ⩽ 1 / 10 \le 1/10 ⩽ 1/10
把上面几条合起来就是 LSH 算法:
flowchart LR
subgraph DataStruct["数据结构"]
direction TB
H1["g₁: 字典 ⟨g₁(y_i), y_i⟩"]
H2["g₂: 字典 ⟨g₂(y_i), y_i⟩"]
Hl["g_ℓ: 字典 ⟨g_ℓ(y_i), y_i⟩"]
H1 -.- H2 -.- Hl
end
Q["查询 x"] --> DataStruct
DataStruct --> R["扫描所有<br/>y_i s.t. ∃j, g_j(x)=g_j(y_i)<br/>≤ 10ℓ 个"]
R --> A{"是否存在<br/>dist(x,y_i) ≤ cr ?"}
A -->|是| Yes["返回该 y_i"]
A -->|否| No["返回 no"]
classDef data fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef query fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef ans fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
class H1,H2,Hl,DataStruct data
class Q,R query
class Yes,No,A ans具体地:
预处理 :抽取 i.i.d. 的 g 1 , … , g ℓ g_1, \dots, g_\ell g 1 , … , g ℓ ℓ = 1 / p ∗ = n ρ \ell = 1/p^* = n^\rho ℓ = 1/ p ∗ = n ρ j j j ⟨ g j ( y i ) , y i ⟩ \langle g_j(\bm{y}_i), \bm{y}_i\rangle ⟨ g j ( y i ) , y i ⟩ 查询 x \bm{x} x :扫描所有与 x \bm{x} x g j g_j g j y i \bm{y}_i y i 至多扫 10 ℓ 10\ell 10 ℓ ,超过则停止);若遇到 dist ( x , y i ) ⩽ c r \operatorname{dist}(\bm{x}, \bm{y}_i) \le c r dist ( x , y i ) ⩽ cr y i \bm{y}_i y i
正确性与复杂度分析
正确性(永远正确的情形) :若真实答案是 "no"(所有 y i \bm{y}_i y i dist ( x , y i ) ⩽ c r \operatorname{dist}(\bm{x}, \bm{y}_i) \le c r dist ( x , y i ) ⩽ cr y i \bm{y}_i y i 总是返回 "no" 。
错失近邻的两个失败源 (当存在 y s \bm{y}_s y s dist ( x , y s ) ⩽ r \operatorname{dist}(\bm{x}, \bm{y}_s) \le r dist ( x , y s ) ⩽ r
未被任何 g j g_j g j :∀ j , g j ( x ) ≠ g j ( y s ) \forall j, g_j(\bm{x}) \ne g_j(\bm{y}_s) ∀ j , g j ( x ) = g j ( y s ) ⩽ ( 1 − p ∗ ) ℓ ⩽ 1 / e \le (1 - p^*)^\ell \le 1/\e ⩽ ( 1 − p ∗ ) ℓ ⩽ 1/ e ℓ = 1 / p ∗ \ell = 1/p^* ℓ = 1/ p ∗ 被坏点淹没 :超过 10 ℓ 10\ell 10 ℓ g j g_j g j x \bm{x} x ⩽ ℓ ⋅ n ⋅ 1 / n = ℓ \le \ell \cdot n \cdot 1/n = \ell ⩽ ℓ ⋅ n ⋅ 1/ n = ℓ Pr [ 坏点数 > 10 ℓ ] ⩽ 1 / 10 \Pr[\text{坏点数} > 10\ell] \le 1/10 Pr [ 坏点数 > 10 ℓ ] ⩽ 1/10
合并:错失概率 ⩽ 1 / e + 0.1 < 0.5 \le 1/\e + 0.1 < 0.5 ⩽ 1/ e + 0.1 < 0.5
复杂度 (用 FKS 完美哈希实现字典):
空间:O ( n ℓ ) = O ( n / p ∗ ) = O ( n 1 + ρ ) O(n \ell) = O(n / p^*) = O(n^{1 + \rho}) O ( n ℓ ) = O ( n / p ∗ ) = O ( n 1 + ρ )
查询时间:O ( ℓ ⋅ 每次 g j 计算 ) = O ( n ρ log n ) O(\ell \cdot \text{每次 } g_j \text{ 计算}) = O(n^\rho \log n) O ( ℓ ⋅ 每次 g j 计算 ) = O ( n ρ log n )
LSH 主定理
若度量空间 ( X , dist ) (X, \operatorname{dist}) ( X , dist ) ( r , c r , p , q ) (r, c r, p, q) ( r , cr , p , q ) LSH ,则 ( c , r ) (c, r) ( c , r ) ANN 可以用空间 O ( n 1 + ρ ) O(n^{1+\rho}) O ( n 1 + ρ ) O ( n ρ log n ) O(n^\rho \log n) O ( n ρ log n ) < 0.5 < 0.5 < 0.5
ρ = log p log q \rho = \frac{\log p}{\log q}
ρ = log q log p
ρ \rho ρ ρ \rho ρ LSH ,算法就快。剩下的工作是为每个度量空间设计具体的 LSH 。
Hamming 空间的具体 LSH
抽象框架建好了,回头看 Hamming 空间最简单的 LSH 实例:对 x ∈ { 0 , 1 } d \bm{x} \in \{0, 1\}^d x ∈ { 0 , 1 } d
h ( x ) = x i , i ∼ Uniform ( [ d ] ) h(\bm{x}) = x_i, \quad i \sim \operatorname{Uniform}([d])
h ( x ) = x i , i ∼ Uniform ([ d ])
也就是随机挑一个坐标返回 。这个简单的哈希函数为什么能保持距离?因为
h ( x ) = h ( y ) ⟺ x i = y i ⟺ i ∉ { j : x j ≠ y j } h(\bm{x}) = h(\bm{y}) \iff x_i = y_i \iff i \notin \{j\colon x_j \ne y_j\}
h ( x ) = h ( y ) ⟺ x i = y i ⟺ i ∈ / { j : x j = y j }
随机选中「相同坐标」的概率正好是「不同坐标数 / d / d / d
Pr [ h ( x ) = h ( y ) ] = 1 − dist ( x , y ) d \Pr[h(\bm{x}) = h(\bm{y})] = 1 - \frac{\operatorname{dist}(\bm{x}, \bm{y})}{d}
Pr [ h ( x ) = h ( y )] = 1 − d dist ( x , y )
代入两个区间:
情形
dist ( x , y ) \operatorname{dist}(\bm{x}, \bm{y}) dist ( x , y ) 碰撞概率
近
⩽ r \le r ⩽ r ⩾ 1 − r / d \ge 1 - r/d ⩾ 1 − r / d
远
> c r > cr > cr ⩽ 1 − c r / d \le 1 - cr/d ⩽ 1 − cr / d
所以 h h h ( r , c r , 1 − r / d , 1 − c r / d ) (r, cr, 1 - r/d, 1 - cr/d) ( r , cr , 1 − r / d , 1 − cr / d ) LSH 。其 ρ \rho ρ
ρ = log ( 1 − r / d ) log ( 1 − c r / d ) ⩽ 1 c \rho = \frac{\log(1 - r/d)}{\log(1 - cr/d)} \le \frac{1}{c}
ρ = log ( 1 − cr / d ) log ( 1 − r / d ) ⩽ c 1
最后一步用 log ( 1 − x ) ≈ − x \log(1 - x) \approx -x log ( 1 − x ) ≈ − x x x x r / d ≪ 1 r/d \ll 1 r / d ≪ 1 LSH 主定理:
Hamming 空间 ANN
Hamming 空间上的 ( c , r ) (c, r) ( c , r ) ANN 可以以空间 O ( n 1 + 1 / c ) O(n^{1 + 1/c}) O ( n 1 + 1/ c ) O ( n 1 / c log n ) O(n^{1/c} \log n) O ( n 1/ c log n ) < 0.5 < 0.5 < 0.5
c c c n 1 / c n^{1/c} n 1/ c c = 2 c = 2 c = 2 O ( n 1.5 ) O(n^{1.5}) O ( n 1.5 ) O ( n log n ) O(\sqrt{n} \log n) O ( n log n ) O ( n d ) O(n d) O ( n d )
跨学科彩蛋
Dasgupta, Stevens 和 Navlakha(2017)发现,果蝇的嗅觉回路本质上是一个 LSH :50 个嗅觉投影神经元通过稀疏随机连接矩阵映射到 2000 个 Kenyon 细胞,激活其中 5% 形成「气味标签」。相似的气味产生相似的稀疏激活模式,天然的局部敏感性。这说明 LSH 不只是工程方便的产物,也是生物神经回路演化出的算法策略。
Fast Johnson-Lindenstrauss 变换
LSH 解决了一个独立的问题(高维 ANN ),现在回到 JL 本身。JL 矩阵 A ∈ R k × d \bm{A} \in \R^{k \times d} A ∈ R k × d ± 1 \pm 1 ± 1 A x \bm{A}\bm{x} A x O ( k d ) = O ( d log n / ε 2 ) O(k d) = O(d \log n / \varepsilon^2) O ( k d ) = O ( d log n / ε 2 ) x \bm{x} x n n n O ( n d log n / ε 2 ) O(n d \log n / \varepsilon^2) O ( n d log n / ε 2 ) d d d n n n
能否让 JL 本身更快? Ailon-Chazelle 2006 年给出了答案:把 JL 的「稠密随机矩阵」换成「有快速算法的结构化矩阵 + 随机扰动」的复合,可以把单次降维的时间从 O ( d log n ) O(d \log n) O ( d log n ) O ( d log d ) O(d \log d) O ( d log d ) JL 变换。
本节记号
Fast JL 沿用 Π ∈ R m × d \bm{\Pi} \in \R^{m \times d} Π ∈ R m × d m m m k k k FJLT 文献一致)。本质上 m m m JL 章节的 k k k
两条加速思路
思路
原理
加速
稀疏构造
A \bm{A} A 2 / 3 2/3 2/3 0 0 0 常数倍
良结构构造
A \bm{A} A O ( d log d ) O(d \log d) O ( d log d )
朴素加速:随机采样的失败
最朴素的加速:随机挑 m m m i ∈ [ m ] i \in [m] i ∈ [ m ]
y i = x j i ⋅ d / m , j i ∼ Uniform ( [ d ] ) y_i = x_{j_i} \cdot \sqrt{d/m}, \quad j_i \sim \operatorname{Uniform}([d])
y i = x j i ⋅ d / m , j i ∼ Uniform ([ d ])
无偏:E [ y i 2 ] = 1 d ∑ j x j 2 ⋅ d m = ∥ x ∥ 2 2 m \mathbb{E}[y_i^2] = \dfrac{1}{d}\sum_j x_j^2 \cdot \dfrac{d}{m} = \dfrac{\|\bm{x}\|_2^2}{m} E [ y i 2 ] = d 1 ∑ j x j 2 ⋅ m d = m ∥ x ∥ 2 2 E [ ∥ y ∥ 2 2 ] = ∥ x ∥ 2 2 \mathbb{E}[\|\bm{y}\|_2^2] = \|\bm{x}\|_2^2 E [ ∥ y ∥ 2 2 ] = ∥ x ∥ 2 2 O ( m ) O(m) O ( m )
朴素采样的失败模式
设 x = ( d , 0 , 0 , … ) \bm{x} = (\sqrt{d}, 0, 0, \dots) x = ( d , 0 , 0 , … ) ∥ x ∥ 2 2 = d \|\bm{x}\|_2^2 = d ∥ x ∥ 2 2 = d j i = 1 j_i = 1 j i = 1 1 / d 1/d 1/ d y \bm{y} y ∥ y ∥ 2 2 = 0 ≠ d \|\bm{y}\|_2^2 = 0 \ne d ∥ y ∥ 2 2 = 0 = d
用方差刻画:V a r ( y i 2 ) \mathrm{Var}(y_i^2) Var ( y i 2 ) d ∥ x ∥ ∞ 4 m 2 \dfrac{d \|\bm{x}\|_\infty^4}{m^2} m 2 d ∥ x ∥ ∞ 4 ∥ x ∥ ∞ 4 = d 2 \|\bm{x}\|_\infty^4 = d^2 ∥ x ∥ ∞ 4 = d 2 d 3 / m 2 d^3/m^2 d 3 / m 2
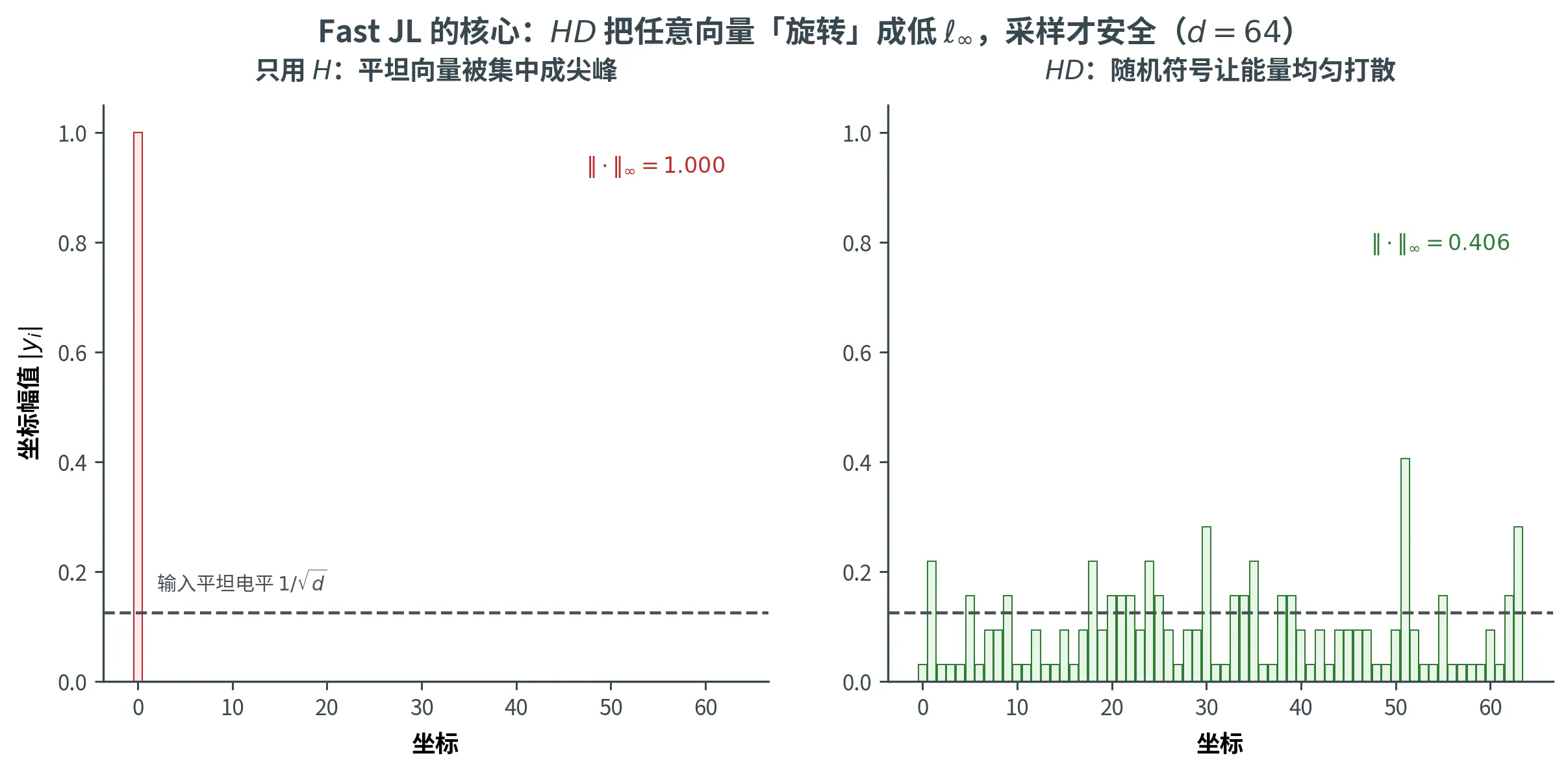
根因 :x \bm{x} x ℓ ∞ \ell_\infty ℓ ∞ 预处理 x \bm{x} x ,让它变得「均匀」(低 ℓ ∞ \ell_\infty ℓ ∞
用 Hadamard 矩阵做快速旋转
预处理的工具是 Hadamard 矩阵 ——一个递归构造的 ± 1 \pm 1 ± 1 O ( d log d ) O(d \log d) O ( d log d )
Hadamard 矩阵
d = 2 k d = 2^k d = 2 k
H 1 = ( 1 ) , H 2 d = ( H d H d H d − H d ) \bm{H}_1 = (1), \qquad \bm{H}_{2d} = \begin{pmatrix} \bm{H}_d & \bm{H}_d \\ \bm{H}_d & -\bm{H}_d \end{pmatrix}
H 1 = ( 1 ) , H 2 d = ( H d H d H d − H d )
满足 H d H d ⊺ = d I \bm{H}_d \bm{H}_d^\intercal = d \bm{I} H d H d ⊺ = d I H d / d \bm{H}_d / \sqrt{d} H d / d H d x \bm{H}_d \bm{x} H d x O ( d log d ) O(d \log d) O ( d log d )
但只用 H \bm{H} H x = e 1 \bm{x} = \bm{e}_1 x = e 1 H e 1 \bm{H} \bm{e}_1 H e 1 H \bm{H} H ( 1 , 1 , … , 1 ) ⊺ (1, 1, \dots, 1)^\intercal ( 1 , 1 , … , 1 ) ⊺ ℓ ∞ \ell_\infty ℓ ∞ x = ( 1 , 1 , … , 1 ) / d \bm{x} = (1, 1, \dots, 1)/\sqrt{d} x = ( 1 , 1 , … , 1 ) / d H x \bm{H} \bm{x} H x x \bm{x} x x \bm{x} x
解决方法是先用随机 Rademacher 翻转每个坐标的符号,把所有 x \bm{x} x
FJLT(Ailon-Chazelle)
Π = 1 m S H D \bm{\Pi} = \frac{1}{\sqrt{m}} \bm{S}\bm{H}\bm{D}
Π = m 1 S H D
其中:
D \bm{D} D ± 1 \pm 1 ± 1 d × d d \times d d × d H \bm{H} H d × d d \times d d × d H H ⊺ = d I \bm{H}\bm{H}^\intercal = d \bm{I} H H ⊺ = d I S \bm{S} S m × d m \times d m × d
计算时间 :D x \bm{D}\bm{x} D x O ( d ) O(d) O ( d ) H ( D x ) \bm{H}(\bm{D}\bm{x}) H ( D x ) O ( d log d ) O(d \log d) O ( d log d ) S ( H D x ) \bm{S}(\bm{H}\bm{D}\bm{x}) S ( H D x ) O ( m ) O(m) O ( m ) O ( d log d + m ) O(d \log d + m) O ( d log d + m ) O ( d k ) O(d k) O ( d k ) k ≈ log n k \approx \log n k ≈ log n
关键引理:H D \bm{H}\bm{D} H D ℓ ∞ \ell_\infty ℓ ∞
令 z = D x \bm{z} = \bm{D} \bm{x} z = D x x j x_j x j y = H z \bm{y} = \bm{H} \bm{z} y = H z
y i = ∑ j H i j δ j x j , δ j ∈ { − 1 , + 1 } 独立 Rademacher y_i = \sum_j \bm{H}_{ij} \delta_j x_j, \quad \delta_j \in \{-1, +1\} \text{ 独立 Rademacher}
y i = j ∑ H ij δ j x j , δ j ∈ { − 1 , + 1 } 独立 Rademacher
由于 H i j ∈ { − 1 , + 1 } \bm{H}_{ij} \in \{-1, +1\} H ij ∈ { − 1 , + 1 } ε j : = H i j δ j \varepsilon_j := \bm{H}_{ij} \delta_j ε j := H ij δ j y i = ∑ j ε j x j y_i = \sum_j \varepsilon_j x_j y i = ∑ j ε j x j
下图说明为什么非要 D \bm{D} D d = 64 d = 64 d = 64 H \bm{H} H ℓ ∞ = 1 \ell_\infty = 1 ℓ ∞ = 1 D \bm{D} D H \bm{H} H ℓ ∞ \ell_\infty ℓ ∞ ≈ 0.31 \approx 0.31 ≈ 0.31
Khintchine 不等式
对 i.i.d. Rademacher 向量 σ ∈ { − 1 , + 1 } d \bm{\sigma} \in \{-1, +1\}^d σ ∈ { − 1 , + 1 } d x ∈ R d \bm{x} \in \R^d x ∈ R d
Pr [ ∣ ⟨ σ , x ⟩ ∣ ⩾ λ ] ⩽ 2 exp ( − λ 2 2 ∥ x ∥ 2 2 ) \Pr[|\langle \bm{\sigma}, \bm{x} \rangle| \ge \lambda] \le 2 \exp\left(-\frac{\lambda^2}{2 \|\bm{x}\|_2^2}\right)
Pr [ ∣ ⟨ σ , x ⟩ ∣ ⩾ λ ] ⩽ 2 exp ( − 2∥ x ∥ 2 2 λ 2 )
即:Rademacher 和的尾部以高斯 速率衰减,是 sub-Gaussian 随机变量。
Khintchine 不等式的证明
设 X = ∑ i σ i x i X = \sum_i \sigma_i x_i X = ∑ i σ i x i t > 0 t > 0 t > 0
Pr [ X ⩾ λ ] ⩽ e − t λ E [ e t X ] \Pr[X \ge \lambda] \le \e^{-t\lambda} \mathbb{E}[\e^{tX}]
Pr [ X ⩾ λ ] ⩽ e − t λ E [ e tX ]
由独立性:
E [ e t X ] = ∏ i E [ e t σ i x i ] = ∏ i e − t x i + e t x i 2 = ∏ i cosh ( t x i ) \mathbb{E}[\e^{tX}] = \prod_i \mathbb{E}[\e^{t \sigma_i x_i}] = \prod_i \frac{\e^{-t x_i} + \e^{t x_i}}{2} = \prod_i \cosh(t x_i)
E [ e tX ] = i ∏ E [ e t σ i x i ] = i ∏ 2 e − t x i + e t x i = i ∏ cosh ( t x i )
由 cosh ( u ) = ∑ k ⩾ 0 u 2 k ( 2 k ) ! \cosh(u) = \sum_{k \ge 0} \dfrac{u^{2k}}{(2k)!} cosh ( u ) = ∑ k ⩾ 0 ( 2 k )! u 2 k ( 2 k ) ! ⩾ k ! ⋅ 2 k (2k)! \ge k! \cdot 2^k ( 2 k )! ⩾ k ! ⋅ 2 k
cosh ( u ) = ∑ k ⩾ 0 u 2 k ( 2 k ) ! ⩽ ∑ k ⩾ 0 u 2 k k ! ⋅ 2 k = e u 2 / 2 \cosh(u) = \sum_{k \ge 0} \frac{u^{2k}}{(2k)!} \le \sum_{k \ge 0} \frac{u^{2k}}{k! \cdot 2^k} = \e^{u^2/2}
cosh ( u ) = k ⩾ 0 ∑ ( 2 k )! u 2 k ⩽ k ⩾ 0 ∑ k ! ⋅ 2 k u 2 k = e u 2 /2
因此 E [ e t X ] ⩽ exp ( t 2 ∥ x ∥ 2 2 / 2 ) \mathbb{E}[\e^{tX}] \le \exp(t^2 \|\bm{x}\|_2^2 / 2) E [ e tX ] ⩽ exp ( t 2 ∥ x ∥ 2 2 /2 ) t = λ / ∥ x ∥ 2 2 t = \lambda / \|\bm{x}\|_2^2 t = λ /∥ x ∥ 2 2
Pr [ X ⩾ λ ] ⩽ exp ( t 2 ∥ x ∥ 2 2 / 2 − t λ ) = exp ( − λ 2 2 ∥ x ∥ 2 2 ) \Pr[X \ge \lambda] \le \exp\left(t^2 \|\bm{x}\|_2^2/2 - t \lambda\right) = \exp\left(-\frac{\lambda^2}{2 \|\bm{x}\|_2^2}\right)
Pr [ X ⩾ λ ] ⩽ exp ( t 2 ∥ x ∥ 2 2 /2 − t λ ) = exp ( − 2∥ x ∥ 2 2 λ 2 )
下尾对 − X -X − X 2 exp ( − λ 2 / ( 2 ∥ x ∥ 2 2 ) ) 2 \exp(-\lambda^2 / (2\|\bm{x}\|_2^2)) 2 exp ( − λ 2 / ( 2∥ x ∥ 2 2 ))
对单位向量 x \bm{x} x ∥ x ∥ 2 = 1 \|\bm{x}\|_2 = 1 ∥ x ∥ 2 = 1 λ = 2 ln ( 4 d / δ ) \lambda = \sqrt{2 \ln(4d/\delta)} λ = 2 ln ( 4 d / δ )
Pr [ ∣ y i ∣ ⩾ 2 ln ( 4 d / δ ) ] ⩽ 2 exp ( − 2 ln ( 4 d / δ ) 2 ) = 2 4 d / δ = δ 2 d \Pr\bigl[|y_i| \ge \sqrt{2 \ln(4d/\delta)}\bigr] \le 2 \exp\left(-\frac{2 \ln(4d/\delta)}{2}\right) = \frac{2}{4d/\delta} = \frac{\delta}{2 d}
Pr [ ∣ y i ∣ ⩾ 2 ln ( 4 d / δ ) ] ⩽ 2 exp ( − 2 2 ln ( 4 d / δ ) ) = 4 d / δ 2 = 2 d δ
(注意 Khintchine 自带的因子 2 2 2 4 d / δ 4d/\delta 4 d / δ 4 4 4 1 / 2 1/2 1/2 d d d ∥ y ∥ ∞ \|\bm{y}\|_\infty ∥ y ∥ ∞
Pr [ ∥ y ∥ ∞ > 2 ln ( 4 d / δ ) ] ⩽ d ⋅ δ 2 d = δ 2 \Pr\bigl[\|\bm{y}\|_\infty > \sqrt{2 \ln(4d/\delta)}\bigr] \le d \cdot \frac{\delta}{2d} = \frac{\delta}{2}
Pr [ ∥ y ∥ ∞ > 2 ln ( 4 d / δ ) ] ⩽ d ⋅ 2 d δ = 2 δ
即
Pr [ ∥ y ∥ ∞ ⩽ 2 ln ( 4 d / δ ) ] ⩾ 1 − δ / 2 \Pr\bigl[\|\bm{y}\|_\infty \le \sqrt{2 \ln(4d/\delta)}\bigr] \ge 1 - \delta/2
Pr [ ∥ y ∥ ∞ ⩽ 2 ln ( 4 d / δ ) ] ⩾ 1 − δ /2
旋转后的 y \bm{y} y O ( log ( d / δ ) ) O(\sqrt{\log(d/\delta)}) O ( log ( d / δ ) )
范数保持的最后一步
记上述「ℓ ∞ \ell_\infty ℓ ∞ E \mathcal{E} E ⩾ 1 − δ / 2 \ge 1 - \delta/2 ⩾ 1 − δ /2 E \mathcal{E} E S \bm{S} S
注意 ∥ y ∥ 2 2 = ∥ H D x ∥ 2 2 = d ∥ x ∥ 2 2 = d \|\bm{y}\|_2^2 = \|\bm{H}\bm{D}\bm{x}\|_2^2 = d \|\bm{x}\|_2^2 = d ∥ y ∥ 2 2 = ∥ H D x ∥ 2 2 = d ∥ x ∥ 2 2 = d H H ⊺ = d I \bm{H}\bm{H}^\intercal = d \bm{I} H H ⊺ = d I D \bm{D} D S \bm{S} S i ∈ [ m ] i \in [m] i ∈ [ m ] [ d ] [d] [ d ] j i j_i j i
∥ Π x ∥ 2 2 = 1 m ∑ i = 1 m y j i 2 \|\bm{\Pi} \bm{x}\|_2^2 = \frac{1}{m} \sum_{i=1}^m y_{j_i}^2
∥ Π x ∥ 2 2 = m 1 i = 1 ∑ m y j i 2
每项 y j i 2 y_{j_i}^2 y j i 2 1 d ∑ j y j 2 = 1 \dfrac{1}{d} \sum_j y_j^2 = 1 d 1 ∑ j y j 2 = 1 E \mathcal{E} E 2 ln ( 4 d / δ ) 2 \ln(4d/\delta) 2 ln ( 4 d / δ )
有界变量的 Chernoff
设 W 1 , … , W m W_1, \dots, W_m W 1 , … , W m W i ∈ [ 0 , B ] W_i \in [0, B] W i ∈ [ 0 , B ] μ = E [ W i ] \mu = \mathbb{E}[W_i] μ = E [ W i ]
Pr [ ∣ 1 m ∑ i W i − μ ∣ ⩾ ε μ ] ⩽ 2 exp ( − Ω ( ε 2 μ m B ) ) \Pr\left[\left|\frac{1}{m}\sum_i W_i - \mu\right| \ge \varepsilon \mu\right] \le 2 \exp\left(-\Omega\left(\frac{\varepsilon^2 \mu m}{B}\right)\right)
Pr [ m 1 i ∑ W i − μ ⩾ ε μ ] ⩽ 2 exp ( − Ω ( B ε 2 μ m ) )
代入 W i = y j i 2 W_i = y_{j_i}^2 W i = y j i 2 μ = 1 \mu = 1 μ = 1 B = 2 ln ( 4 d / δ ) B = 2 \ln(4 d/\delta) B = 2 ln ( 4 d / δ )
Pr [ ∣ ∥ Π x ∥ 2 2 − 1 ∣ ⩾ ε ∣ E ] ⩽ 2 exp ( − Ω ( ε 2 m ln ( d / δ ) ) ) \Pr\Bigl[\bigl|\|\bm{\Pi} \bm{x}\|_2^2 - 1\bigr| \ge \varepsilon\ \big|\ \mathcal{E}\Bigr] \le 2 \exp\left(-\Omega\left(\frac{\varepsilon^2 m}{\ln(d/\delta)}\right)\right)
Pr [ ∥ Π x ∥ 2 2 − 1 ⩾ ε E ] ⩽ 2 exp ( − Ω ( ln ( d / δ ) ε 2 m ) )
取 m = O ( ε − 2 log n ⋅ log d ) m = O(\varepsilon^{-2} \log n \cdot \log d) m = O ( ε − 2 log n ⋅ log d ) E \mathcal{E} E ⩽ 1 / n 3 \le 1/n^3 ⩽ 1/ n 3 JL 多了 log d \log d log d 构造时间 从 O ( d k ) O(d k) O ( d k ) O ( d log d ) O(d \log d) O ( d log d )
子空间嵌入(OSE )
迄今为止,我们的降维都对一个有限的点集 生效:JL 保 n n n LSH 保 n n n 整个线性子空间 ——比如线性回归中,回归参数 β \bm{\beta} β R d \R^d R d X β \bm{X}\bm{\beta} X β X \bm{X} X
这就引出了一个更激进的目标:保持整个子空间 中所有向量的范数。
记号约定
本节及之后,把降维矩阵改记为 Π \bm{\Pi} Π m m m OSE 文献惯例一致),这与前面 JL 部分的 A , k \bm{A}, k A , k X \bm{X} X A \bm{A} A OSE 上下文中,Π \bm{\Pi} Π
从点集到子空间
子空间嵌入
设 T ⊂ R n T \subset \R^n T ⊂ R n d d d Π : T → R m \bm{\Pi}\colon T \to \R^m Π : T → R m ε \varepsilon ε
∀ x ∈ T , ∥ Π x ∥ 2 2 = ( 1 ± ε ) ∥ x ∥ 2 2 \forall \bm{x} \in T,\ \|\bm{\Pi} \bm{x}\|_2^2 = (1 \pm \varepsilon) \|\bm{x}\|_2^2
∀ x ∈ T , ∥ Π x ∥ 2 2 = ( 1 ± ε ) ∥ x ∥ 2 2
(写成平方形式与 OSE 主流文献一致,也让后面的 Sketch-and-Solve 证明常数更干净。)
这比 JL 强得多——JL 只保证有限多个固定向量被保持,OSE 要求连续无穷多 的向量都被保持。
但子空间嵌入也有可能很简单:如果允许「看数据」,可以直接用 T T T U \bm{U} U Π = U ⊺ \bm{\Pi} = \bm{U}^\intercal Π = U ⊺ ∥ Π x ∥ 2 = ∥ x ∥ 2 \|\bm{\Pi} \bm{x}\|_2 = \|\bm{x}\|_2 ∥ Π x ∥ 2 = ∥ x ∥ 2 U \bm{U} U SVD ,时间 O ( n d 2 ) O(n d^2) O ( n d 2 )
数据无关 vs 数据相关
更有挑战的是数据无关 (oblivious)的嵌入:希望同一个随机 Π \bm{\Pi} Π
Oblivious 子空间嵌入(OSE)
随机矩阵 Π ∈ R m × n \bm{\Pi} \in \R^{m \times n} Π ∈ R m × n ( d , ε , δ ) (d, \varepsilon, \delta) ( d , ε , δ ) OSE ,若对所有 R n \R^n R n d d d T T T
Pr [ ∀ x ∈ T , ∥ Π x ∥ 2 2 = ( 1 ± ε ) ∥ x ∥ 2 2 ] ⩾ 1 − δ \Pr\bigl[\forall \bm{x} \in T,\ \|\bm{\Pi} \bm{x}\|_2^2 = (1 \pm \varepsilon)\|\bm{x}\|_2^2\bigr] \ge 1 - \delta
Pr [ ∀ x ∈ T , ∥ Π x ∥ 2 2 = ( 1 ± ε ) ∥ x ∥ 2 2 ] ⩾ 1 − δ
等价表述:对所有 A ∈ R n × d \bm{A} \in \R^{n \times d} A ∈ R n × d β ∈ R d \bm{\beta} \in \R^d β ∈ R d ∥ Π A β ∥ 2 2 = ( 1 ± ε ) ∥ A β ∥ 2 2 \|\bm{\Pi} \bm{A} \bm{\beta}\|_2^2 = (1 \pm \varepsilon)\|\bm{A} \bm{\beta}\|_2^2 ∥ Π A β ∥ 2 2 = ( 1 ± ε ) ∥ A β ∥ 2 2
OSE 的设计目标:
精度:上述 1 ± ε 1 \pm \varepsilon 1 ± ε
降维:m ≪ n m \ll n m ≪ n
快速计算:Π A \bm{\Pi} \bm{A} Π A
OSE 怎么造?JL 矩阵其实自动就是 OSE ,还会介绍稀疏的 Count Sketch OSE 。在此之前,先看一个 OSE 的标志性应用:大规模线性回归。
OSE 的应用:线性回归OSE 一个最直接的应用是大规模线性回归。
经典最小二乘
最小二乘
给定数据 X ∈ R n × d \bm{X} \in \R^{n \times d} X ∈ R n × d y ∈ R n \bm{y} \in \R^n y ∈ R n β ∈ R d \bm{\beta} \in \R^d β ∈ R d ∥ X β − y ∥ 2 \|\bm{X} \bm{\beta} - \bm{y}\|_2 ∥ X β − y ∥ 2
β L S = ( X ⊺ X ) + X ⊺ y \bm{\beta}^{\mathrm{LS}} = (\bm{X}^\intercal \bm{X})^+ \bm{X}^\intercal \bm{y}
β LS = ( X ⊺ X ) + X ⊺ y
观察:y \bm{y} y y = y ∥ + y ⊥ \bm{y} = \bm{y}^\parallel + \bm{y}^\perp y = y ∥ + y ⊥ y ∥ \bm{y}^\parallel y ∥ X \bm{X} X y ⊥ \bm{y}^\perp y ⊥
∥ X β − y ∥ 2 2 = ∥ X β − y ∥ ∥ 2 2 + ∥ y ⊥ ∥ 2 2 \|\bm{X} \bm{\beta} - \bm{y}\|_2^2 = \|\bm{X} \bm{\beta} - \bm{y}^\parallel\|_2^2 + \|\bm{y}^\perp\|_2^2
∥ X β − y ∥ 2 2 = ∥ X β − y ∥ ∥ 2 2 + ∥ y ⊥ ∥ 2 2
最小化第一项即令 X β = y ∥ \bm{X} \bm{\beta} = \bm{y}^\parallel X β = y ∥ SVD 得到,时间 O ( n d 2 ) O(n d^2) O ( n d 2 ) n n n
Sketch-and-Solve
OSE 给出一个干净的近似算法:在草图后的小问题上解最小二乘。
Sketch-and-Solve
令 Π \bm{\Pi} Π s p a n ( c o l s ( X ) ∪ { y } ) \mathrm{span}(\mathrm{cols}(\bm{X}) \cup \{\bm{y}\}) span ( cols ( X ) ∪ { y }) ε \varepsilon ε OSE 。计算
β ~ L S = arg min β ∥ Π X β − Π y ∥ 2 2 \tilde{\bm{\beta}}^{\mathrm{LS}} = \arg\min_{\bm{\beta}} \|\bm{\Pi} \bm{X} \bm{\beta} - \bm{\Pi} \bm{y}\|_2^2
β ~ LS = arg β min ∥ Π X β − Π y ∥ 2 2
则
∥ X β ~ L S − y ∥ 2 2 ⩽ 1 + ε 1 − ε ⋅ ∥ X β L S − y ∥ 2 2 \|\bm{X} \tilde{\bm{\beta}}^{\mathrm{LS}} - \bm{y}\|_2^2 \le \frac{1 + \varepsilon}{1 - \varepsilon} \cdot \|\bm{X} \bm{\beta}^{\mathrm{LS}} - \bm{y}\|_2^2
∥ X β ~ LS − y ∥ 2 2 ⩽ 1 − ε 1 + ε ⋅ ∥ X β LS − y ∥ 2 2
证明(三步夹挤) :
对任意 β \bm{\beta} β X β − y \bm{X}\bm{\beta} - \bm{y} X β − y Π \bm{\Pi} Π OSE 给出 ( 1 − ε ) ∥ ⋅ ∥ 2 ⩽ ∥ Π ⋅ ∥ 2 ⩽ ( 1 + ε ) ∥ ⋅ ∥ 2 (1 - \varepsilon)\|\cdot\|^2 \le \|\bm{\Pi} \cdot\|^2 \le (1 + \varepsilon)\|\cdot\|^2 ( 1 − ε ) ∥ ⋅ ∥ 2 ⩽ ∥ Π ⋅ ∥ 2 ⩽ ( 1 + ε ) ∥ ⋅ ∥ 2
( 1 − ε ) ∥ X β ~ L S − y ∥ 2 2 ⩽ ∥ Π X β ~ L S − Π y ∥ 2 2 ⩽ ∥ Π X β L S − Π y ∥ 2 2 ⩽ ( 1 + ε ) ∥ X β L S − y ∥ 2 2 (1 - \varepsilon)\|\bm{X} \tilde{\bm{\beta}}^{\mathrm{LS}} - \bm{y}\|_2^2 \le \|\bm{\Pi} \bm{X} \tilde{\bm{\beta}}^{\mathrm{LS}} - \bm{\Pi} \bm{y}\|_2^2 \le \|\bm{\Pi} \bm{X} \bm{\beta}^{\mathrm{LS}} - \bm{\Pi} \bm{y}\|_2^2 \le (1 + \varepsilon)\|\bm{X} \bm{\beta}^{\mathrm{LS}} - \bm{y}\|_2^2
( 1 − ε ) ∥ X β ~ LS − y ∥ 2 2 ⩽ ∥ Π X β ~ LS − Π y ∥ 2 2 ⩽ ∥ Π X β LS − Π y ∥ 2 2 ⩽ ( 1 + ε ) ∥ X β LS − y ∥ 2 2
第一、第三步用 OSE ;
第二步用 β ~ L S \tilde{\bm{\beta}}^{\mathrm{LS}} β ~ LS 草图问题 的最优(所以草图目标值 ⩽ \le ⩽ β \bm{\beta} β ⩽ \le ⩽ β L S \bm{\beta}^{\mathrm{LS}} β LS
代价:O ( m d 2 ) O(m d^2) O ( m d 2 ) m ≪ n m \ll n m ≪ n + + + Π X \bm{\Pi} \bm{X} Π X
梯度下降的收敛分析
Sketch-and-Solve 只能拿到 ( 1 + O ( ε ) ) (1 + O(\varepsilon)) ( 1 + O ( ε )) 梯度下降 ——但下面会看到它在原始数据上跑得有多慢,然后用 OSE 把它救回来。
梯度下降
β ( t + 1 ) ← β ( t ) − γ ∇ f ( β ( t ) ) \bm{\beta}^{(t+1)} \leftarrow \bm{\beta}^{(t)} - \gamma \nabla f(\bm{\beta}^{(t)})
β ( t + 1 ) ← β ( t ) − γ ∇ f ( β ( t ) )
对 f ( β ) = ∥ X β − y ∥ 2 2 f(\bm{\beta}) = \|\bm{X} \bm{\beta} - \bm{y}\|_2^2 f ( β ) = ∥ X β − y ∥ 2 2 ∇ f ( β ) = 2 X ⊺ ( X β − y ) \nabla f(\bm{\beta}) = 2 \bm{X}^\intercal (\bm{X} \bm{\beta} - \bm{y}) ∇ f ( β ) = 2 X ⊺ ( X β − y ) γ = 1 / 2 \gamma = 1/2 γ = 1/2
β ( t + 1 ) = β ( t ) + X ⊺ y − X ⊺ X β ( t ) \bm{\beta}^{(t+1)} = \bm{\beta}^{(t)} + \bm{X}^\intercal \bm{y} - \bm{X}^\intercal \bm{X} \bm{\beta}^{(t)}
β ( t + 1 ) = β ( t ) + X ⊺ y − X ⊺ X β ( t )
由最优性条件 X ⊺ y = X ⊺ X β L S \bm{X}^\intercal \bm{y} = \bm{X}^\intercal \bm{X} \bm{\beta}^{\mathrm{LS}} X ⊺ y = X ⊺ X β LS
β ( t + 1 ) − β L S = ( I − X ⊺ X ) ( β ( t ) − β L S ) \bm{\beta}^{(t+1)} - \bm{\beta}^{\mathrm{LS}} = (\bm{I} - \bm{X}^\intercal \bm{X})(\bm{\beta}^{(t)} - \bm{\beta}^{\mathrm{LS}})
β ( t + 1 ) − β LS = ( I − X ⊺ X ) ( β ( t ) − β LS )
接下来要把误差展开到 SVD 基里、看每个方向各自收缩多少。设 X = U Σ V ⊺ \bm{X} = \bm{U}\bm{\Sigma}\bm{V}^\intercal X = U Σ V ⊺ e ( t ) = V ⊺ ( β ( t ) − β L S ) \bm{e}^{(t)} = \bm{V}^\intercal(\bm{\beta}^{(t)} - \bm{\beta}^{\mathrm{LS}}) e ( t ) = V ⊺ ( β ( t ) − β LS ) V \bm{V} V
V ⊺ ( I − X ⊺ X ) V = I − Σ 2 \bm{V}^\intercal(\bm{I} - \bm{X}^\intercal \bm{X})\bm{V} = \bm{I} - \bm{\Sigma}^2
V ⊺ ( I − X ⊺ X ) V = I − Σ 2
是对角矩阵,第 i i i 1 − σ i 2 1 - \sigma_i^2 1 − σ i 2 V \bm{V} V ∣ 1 − σ i 2 ∣ |1 - \sigma_i^2| ∣1 − σ i 2 ∣ e i ( t + 1 ) = ( 1 − σ i 2 ) e i ( t ) \bm{e}^{(t+1)}_i = (1 - \sigma_i^2) \bm{e}^{(t)}_i e i ( t + 1 ) = ( 1 − σ i 2 ) e i ( t )
我们最终关心 ∥ X ( β ( t ) − β L S ) ∥ 2 = ∥ U Σ e ( t ) ∥ 2 = ∥ Σ e ( t ) ∥ 2 \|\bm{X}(\bm{\beta}^{(t)} - \bm{\beta}^{\mathrm{LS}})\|_2 = \|\bm{U}\bm{\Sigma}\bm{e}^{(t)}\|_2 = \|\bm{\Sigma}\bm{e}^{(t)}\|_2 ∥ X ( β ( t ) − β LS ) ∥ 2 = ∥ U Σ e ( t ) ∥ 2 = ∥ Σ e ( t ) ∥ 2 U \bm{U} U
∥ Σ e ( t ) ∥ 2 2 ∥ Σ e ( t − 1 ) ∥ 2 2 = ∑ i σ i 2 ( 1 − σ i 2 ) 2 ( e i ( t − 1 ) ) 2 ∑ i σ i 2 ( e i ( t − 1 ) ) 2 ⩽ max i ( 1 − σ i 2 ) 2 \frac{\|\bm{\Sigma}\bm{e}^{(t)}\|_2^2}{\|\bm{\Sigma}\bm{e}^{(t-1)}\|_2^2} = \frac{\sum_i \sigma_i^2 (1 - \sigma_i^2)^2 (\bm{e}^{(t-1)}_i)^2}{\sum_i \sigma_i^2 (\bm{e}^{(t-1)}_i)^2} \le \max_i (1 - \sigma_i^2)^2
∥ Σ e ( t − 1 ) ∥ 2 2 ∥ Σ e ( t ) ∥ 2 2 = ∑ i σ i 2 ( e i ( t − 1 ) ) 2 ∑ i σ i 2 ( 1 − σ i 2 ) 2 ( e i ( t − 1 ) ) 2 ⩽ i max ( 1 − σ i 2 ) 2
所以
∥ X ( β ( t ) − β L S ) ∥ 2 ⩽ max i ∣ 1 − σ i 2 ∣ ⋅ ∥ X ( β ( t − 1 ) − β L S ) ∥ 2 \|\bm{X}(\bm{\beta}^{(t)} - \bm{\beta}^{\mathrm{LS}})\|_2 \le \max_i |1 - \sigma_i^2| \cdot \|\bm{X}(\bm{\beta}^{(t-1)} - \bm{\beta}^{\mathrm{LS}})\|_2
∥ X ( β ( t ) − β LS ) ∥ 2 ⩽ i max ∣1 − σ i 2 ∣ ⋅ ∥ X ( β ( t − 1 ) − β LS ) ∥ 2
每轮误差按 max i ∣ 1 − σ i 2 ∣ \max_i |1 - \sigma_i^2| max i ∣1 − σ i 2 ∣
关键观察
若 X \bm{X} X 1 1 1 ∣ 1 − σ i 2 ∣ ⩽ 1 / 2 |1 - \sigma_i^2| \le 1/2 ∣1 − σ i 2 ∣ ⩽ 1/2 σ i ∈ [ 1 / 2 , 3 / 2 ] \sigma_i \in [1/\sqrt{2}, \sqrt{3/2}] σ i ∈ [ 1/ 2 , 3/2 ] t t t 2 − t 2^{-t} 2 − t
∥ X ( β ( t ) − β L S ) ∥ 2 ⩽ ∥ X ( β ( 0 ) − β L S ) ∥ 2 / 2 t \|\bm{X}(\bm{\beta}^{(t)} - \bm{\beta}^{\mathrm{LS}})\|_2 \le \|\bm{X}(\bm{\beta}^{(0)} - \bm{\beta}^{\mathrm{LS}})\|_2 / 2^t
∥ X ( β ( t ) − β LS ) ∥ 2 ⩽ ∥ X ( β ( 0 ) − β LS ) ∥ 2 / 2 t
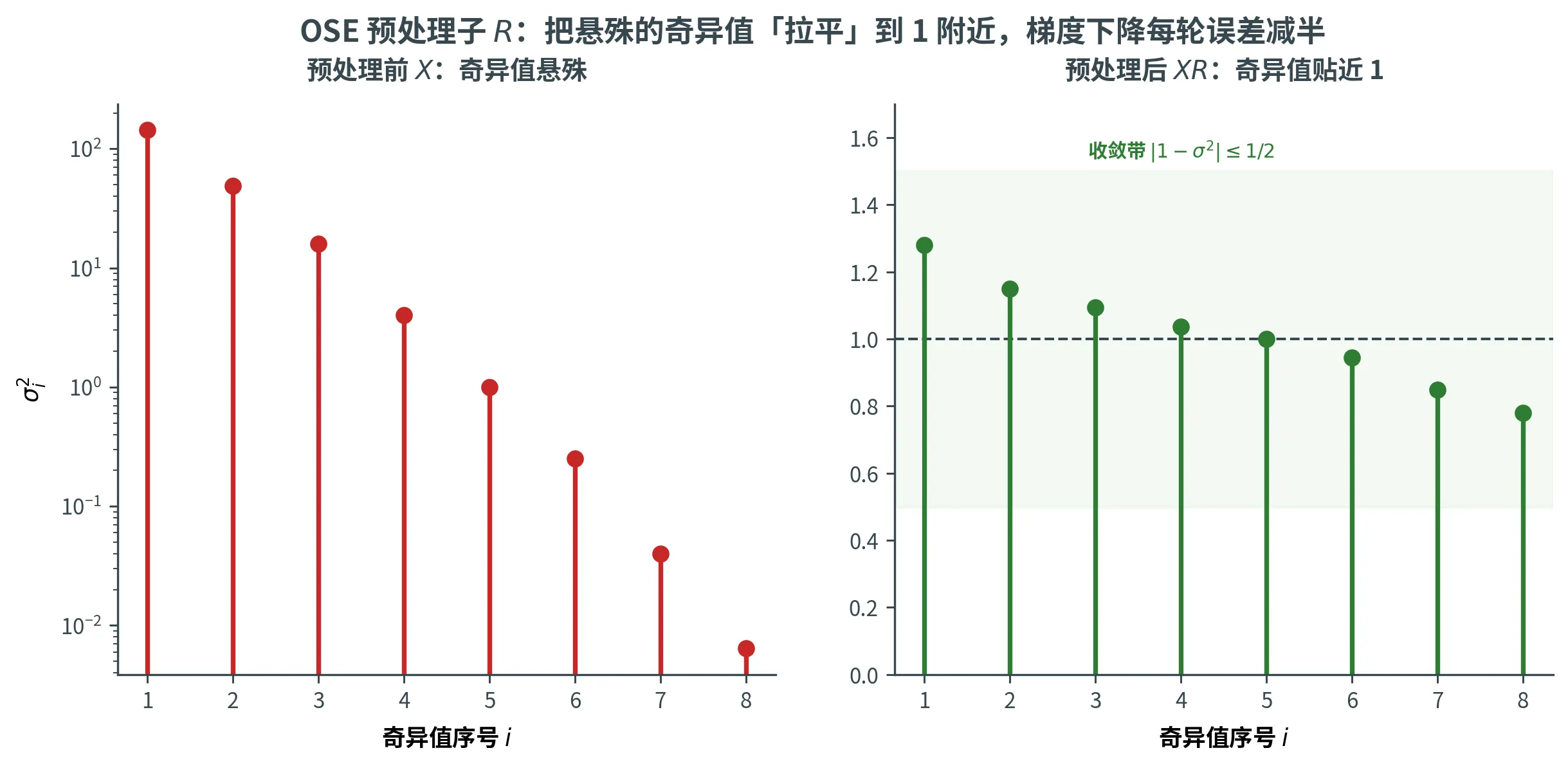
实际数据的奇异值不会自带这个性质,但可以用 OSE 「人为」造一个。
利用 OSE 构造预处理子
策略:找一个可逆矩阵 R ∈ R d × d \bm{R} \in \R^{d \times d} R ∈ R d × d X R \bm{X}\bm{R} X R 1 1 1 X R \bm{X}\bm{R} X R
设 Π \bm{\Pi} Π ε 0 \varepsilon_0 ε 0 ε 0 ≈ 0.2 \varepsilon_0 \approx 0.2 ε 0 ≈ 0.2 OSE 。计算 Π X \bm{\Pi}\bm{X} Π X SVD :
Π X = U ′ Σ ′ V ′ ⊺ \bm{\Pi}\bm{X} = \bm{U}' \bm{\Sigma}' \bm{V}'^\intercal
Π X = U ′ Σ ′ V ′ ⊺
令 R = V ′ Σ ′ − 1 \bm{R} = \bm{V}' \bm{\Sigma}'^{-1} R = V ′ Σ ′ − 1
观察 1 (X R \bm{X}\bm{R} X R 1 1 1 z \bm{z} z
Π X R z = ( U ′ Σ ′ V ′ ⊺ ) ( V ′ Σ ′ − 1 ) z = U ′ z \bm{\Pi}\bm{X}\bm{R}\bm{z} = (\bm{U}'\bm{\Sigma}'\bm{V}'^\intercal)(\bm{V}'\bm{\Sigma}'^{-1})\bm{z} = \bm{U}'\bm{z}
Π X R z = ( U ′ Σ ′ V ′ ⊺ ) ( V ′ Σ ′ − 1 ) z = U ′ z
所以 ∥ Π X R z ∥ 2 = ∥ U ′ z ∥ 2 = ∥ z ∥ 2 \|\bm{\Pi}\bm{X}\bm{R}\bm{z}\|_2 = \|\bm{U}'\bm{z}\|_2 = \|\bm{z}\|_2 ∥ Π X R z ∥ 2 = ∥ U ′ z ∥ 2 = ∥ z ∥ 2 OSE 平方形式 ∥ Π v ∥ 2 2 = ( 1 ± ε 0 ) ∥ v ∥ 2 2 \|\bm{\Pi}\bm{v}\|_2^2 = (1 \pm \varepsilon_0)\|\bm{v}\|_2^2 ∥ Π v ∥ 2 2 = ( 1 ± ε 0 ) ∥ v ∥ 2 2 v = X R z \bm{v} = \bm{X}\bm{R}\bm{z} v = X R z X \bm{X} X
1 − ε 0 ∥ X R z ∥ 2 ⩽ ∥ Π X R z ∥ 2 = ∥ z ∥ 2 ⩽ 1 + ε 0 ∥ X R z ∥ 2 \sqrt{1 - \varepsilon_0}\,\|\bm{X}\bm{R}\bm{z}\|_2 \le \|\bm{\Pi}\bm{X}\bm{R}\bm{z}\|_2 = \|\bm{z}\|_2 \le \sqrt{1 + \varepsilon_0}\,\|\bm{X}\bm{R}\bm{z}\|_2
1 − ε 0 ∥ X R z ∥ 2 ⩽ ∥ Π X R z ∥ 2 = ∥ z ∥ 2 ⩽ 1 + ε 0 ∥ X R z ∥ 2
即 X R \bm{X}\bm{R} X R [ 1 1 + ε 0 , 1 1 − ε 0 ] \left[\dfrac{1}{\sqrt{1+\varepsilon_0}}, \dfrac{1}{\sqrt{1-\varepsilon_0}}\right] [ 1 + ε 0 1 , 1 − ε 0 1 ] σ i 2 ( X R ) ∈ [ 1 / ( 1 + ε 0 ) , 1 / ( 1 − ε 0 ) ] \sigma_i^2(\bm{X}\bm{R}) \in [1/(1+\varepsilon_0), 1/(1-\varepsilon_0)] σ i 2 ( X R ) ∈ [ 1/ ( 1 + ε 0 ) , 1/ ( 1 − ε 0 )] ∣ 1 − σ i 2 ∣ ⩽ ε 0 / ( 1 − ε 0 ) |1 - \sigma_i^2| \le \varepsilon_0/(1-\varepsilon_0) ∣1 − σ i 2 ∣ ⩽ ε 0 / ( 1 − ε 0 ) ε 0 ⩽ 1 / 3 \varepsilon_0 \le 1/3 ε 0 ⩽ 1/3 ∣ 1 − σ i 2 ∣ ⩽ 1 / 2 |1 - \sigma_i^2| \le 1/2 ∣1 − σ i 2 ∣ ⩽ 1/2 i i i
下图对照预处理前后 X \bm{X} X X \bm{X} X R \bm{R} R σ i 2 \sigma_i^2 σ i 2 ∣ 1 − σ 2 ∣ ⩽ 1 / 2 |1 - \sigma^2| \le 1/2 ∣1 − σ 2 ∣ ⩽ 1/2
观察 2 (最优化等价性):X R \bm{X}\bm{R} X R X \bm{X} X R \bm{R} R
min β ′ ∥ X R β ′ − y ∥ 2 = min β ∥ X β − y ∥ 2 , β = R β ′ \min_{\bm{\beta}'} \|\bm{X}\bm{R}\bm{\beta}' - \bm{y}\|_2 = \min_{\bm{\beta}} \|\bm{X}\bm{\beta} - \bm{y}\|_2, \quad \bm{\beta} = \bm{R}\bm{\beta}'
β ′ min ∥ X R β ′ − y ∥ 2 = β min ∥ X β − y ∥ 2 , β = R β ′
二者最优解之间通过 R \bm{R} R
把两个观察拼起来:先用 OSE + SVD 拿到预处理子 R \bm{R} R X R \bm{X}\bm{R} X R T T T 2 − T 2^{-T} 2 − T
总代价 :Π X \bm{\Pi}\bm{X} Π X Π \bm{\Pi} Π + + + O ( m d 2 ) O(m d^2) O ( m d 2 ) SVD + + + T T T O ( n d + d 2 ) O(n d + d^2) O ( n d + d 2 ) X R \bm{X}\bm{R} X R O ( d 2 ) O(d^2) O ( d 2 ) T T T
γ \gamma γ JL 到 OSE 前面把 OSE 当成一个黑箱来用,但还没回答最关键的问题:它怎么造 ?最自然的想法是直接拿来一个 JL 矩阵。在动手之前,先看清楚有什么困难。
一个表面看上去过不去的鸿沟
JL 矩阵只保证:固定的 n n n ( 1 ± ε ) (1 \pm \varepsilon) ( 1 ± ε ) n n n
OSE 要的是:d d d 所有 单位向量都被保持——这是一个不可数无穷的集合。直接做 union bound 显然不可能。
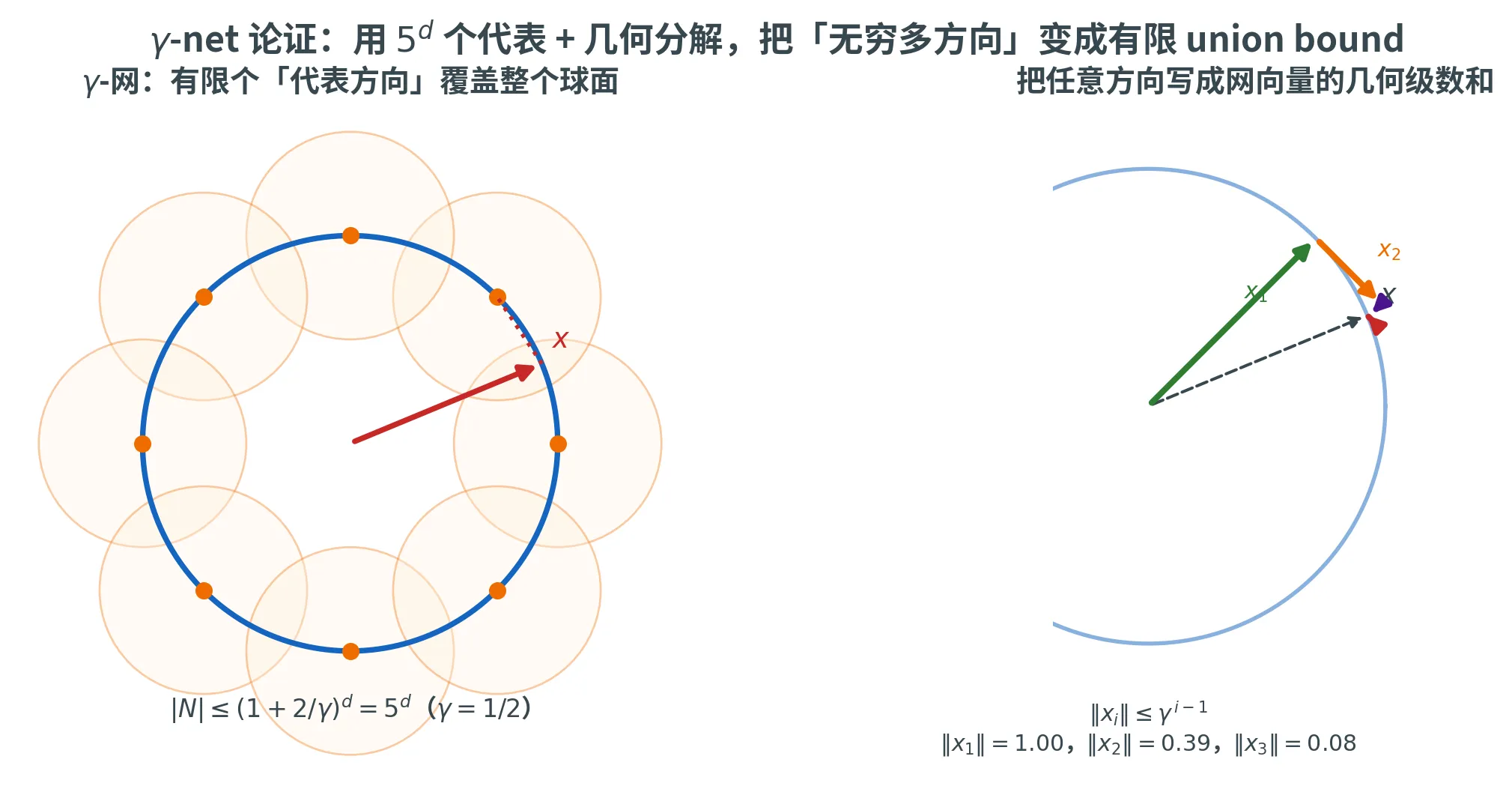
但「不可数无穷」这个直觉有个漏洞:单位球面在度量上是紧致 的。任何方向都可以用有限多个「代表方向」近似到任意精度。如果我们能:
找一个有限的「代表集」N N N JL 保持;
把任意方向写成网中向量的某个线性组合;
用「网上的保持性」推出「整个球面的保持性」;
那么 OSE 就被构造出来了。这正是 γ-net 论证的策略。下图概括了它的两个关键步骤:左边是 5 d 5^d 5 d γ \gamma γ x \bm{x} x x = x 1 + x 2 + ⋯ \bm{x} = \bm{x}_1 + \bm{x}_2 + \cdots x = x 1 + x 2 + ⋯ ∥ x i ∥ \|\bm{x}_i\| ∥ x i ∥ γ i − 1 \gamma^{i-1} γ i − 1 1.00 → 0.39 → 0.08 1.00 \to 0.39 \to 0.08 1.00 → 0.39 → 0.08
第一步:定义 γ-net
不失一般性,把 d d d R d \R^d R d OSE 要保持的就是 S d − 1 \mathbb{S}^{d-1} S d − 1 JL 矩阵的形状从原本作用于 R n \R^n R n Π ∈ R m × n \bm{\Pi} \in \R^{m \times n} Π ∈ R m × n R d \R^d R d Π ∈ R m × d \bm{\Pi} \in \R^{m \times d} Π ∈ R m × d
γ-net
集合 N ⊂ S d − 1 N \subset \mathbb{S}^{d-1} N ⊂ S d − 1 γ \gamma γ
∀ x ∈ S d − 1 , ∃ y ∈ N : ∥ x − y ∥ 2 ⩽ γ \forall \bm{x} \in \mathbb{S}^{d-1},\ \exists \bm{y} \in N\colon \|\bm{x} - \bm{y}\|_2 \le \gamma
∀ x ∈ S d − 1 , ∃ y ∈ N : ∥ x − y ∥ 2 ⩽ γ
直观地:网中的点是球面上的「代表」,球面上任何方向都能在 γ \gamma γ γ \gamma γ
第二步:体积论证给出 ∣ N ∣ ⩽ 5 d |N| \le 5^d ∣ N ∣ ⩽ 5 d
我们需要一个大小可控的 γ-网。用贪心构造 :只要还有方向与 N N N > γ > \gamma > γ N N N γ \gamma γ
终止时观察:
N N N > γ > \gamma > γ 以 N N N γ / 2 \gamma/2 γ /2 两两不交 ;
这些球都包含在原点处半径 1 + γ / 2 1 + \gamma/2 1 + γ /2
由 d d d V d ( R ) = c d R d V_d(R) = c_d R^d V d ( R ) = c d R d c d c_d c d ⩽ \le ⩽
∣ N ∣ ⋅ c d ( γ / 2 ) d ⩽ c d ( 1 + γ / 2 ) d ⟹ ∣ N ∣ ⩽ ( 1 + γ / 2 γ / 2 ) d = ( 1 + 2 γ ) d |N| \cdot c_d (\gamma/2)^d \le c_d (1 + \gamma/2)^d \implies |N| \le \left(\frac{1 + \gamma/2}{\gamma/2}\right)^d = \left(1 + \frac{2}{\gamma}\right)^d
∣ N ∣ ⋅ c d ( γ /2 ) d ⩽ c d ( 1 + γ /2 ) d ⟹ ∣ N ∣ ⩽ ( γ /2 1 + γ /2 ) d = ( 1 + γ 2 ) d
特别地,γ = 1 / 2 \gamma = 1/2 γ = 1/2 ∣ N ∣ ⩽ 5 d |N| \le 5^d ∣ N ∣ ⩽ 5 d 5 d 5^d 5 d d d d
第三步:JL 在网上的保持性
设 Π \bm{\Pi} Π R d \R^d R d JL 矩阵,对任何固定 向量 v \bm{v} v
Pr [ ∣ ∥ Π v ∥ 2 2 − 1 ∣ > ε ] ⩽ exp ( − Ω ( ε 2 m ) ) \Pr\bigl[\bigl|\|\bm{\Pi}\bm{v}\|_2^2 - 1\bigr| > \varepsilon\bigr] \le \exp(-\Omega(\varepsilon^2 m))
Pr [ ∥ Π v ∥ 2 2 − 1 > ε ] ⩽ exp ( − Ω ( ε 2 m ))
对网中 5 d 5^d 5 d
Pr [ ∃ y ∈ N : ∣ ∥ Π y ∥ 2 2 − 1 ∣ > ε ] ⩽ 5 d ⋅ exp ( − Ω ( ε 2 m ) ) \Pr\bigl[\exists \bm{y} \in N\colon \bigl|\|\bm{\Pi}\bm{y}\|_2^2 - 1\bigr| > \varepsilon\bigr] \le 5^d \cdot \exp(-\Omega(\varepsilon^2 m))
Pr [ ∃ y ∈ N : ∥ Π y ∥ 2 2 − 1 > ε ] ⩽ 5 d ⋅ exp ( − Ω ( ε 2 m ))
取 m = Ω ( d / ε 2 ) m = \Omega(d / \varepsilon^2) m = Ω ( d / ε 2 ) ⩽ exp ( − Ω ( d ) ) \le \exp(-\Omega(d)) ⩽ exp ( − Ω ( d ))
这里就是 OSE 比 JL 「容易」的根本原因
JL 要 m = O ( ε − 2 log n ) m = O(\varepsilon^{-2} \log n) m = O ( ε − 2 log n ) n n n OSE 借助 5 d 5^d 5 d m = O ( ε − 2 d ) m = O(\varepsilon^{-2} d) m = O ( ε − 2 d )
到这里,我们已经让网中所有方向都被 ( 1 ± ε ) (1 \pm \varepsilon) ( 1 ± ε )
第四步:几何级数分解
关键想法:把任意 x ∈ S d − 1 \bm{x} \in \mathbb{S}^{d-1} x ∈ S d − 1
x = x 1 + x 2 + x 3 + ⋯ , ∥ x i ∥ 2 ⩽ γ i − 1 \bm{x} = \bm{x}_1 + \bm{x}_2 + \bm{x}_3 + \cdots, \qquad \|\bm{x}_i\|_2 \le \gamma^{i-1}
x = x 1 + x 2 + x 3 + ⋯ , ∥ x i ∥ 2 ⩽ γ i − 1
其中每个 x i \bm{x}_i x i JL 也按比例保持它的范数)。∥ x i ∥ 2 \|\bm{x}_i\|_2 ∥ x i ∥ 2
递归构造 :
残差几何递减 :
∥ r i ∥ 2 = ∥ r i − 1 − x i ∥ 2 = ∥ r i − 1 ∥ 2 ⋅ ∥ r i − 1 ∥ r i − 1 ∥ 2 − y i ∥ 2 ⩽ γ ⋅ ∥ r i − 1 ∥ 2 \|\bm{r}_i\|_2 = \|\bm{r}_{i-1} - \bm{x}_i\|_2 = \|\bm{r}_{i-1}\|_2 \cdot \left\|\frac{\bm{r}_{i-1}}{\|\bm{r}_{i-1}\|_2} - \bm{y}_i\right\|_2 \le \gamma \cdot \|\bm{r}_{i-1}\|_2
∥ r i ∥ 2 = ∥ r i − 1 − x i ∥ 2 = ∥ r i − 1 ∥ 2 ⋅ ∥ r i − 1 ∥ 2 r i − 1 − y i 2 ⩽ γ ⋅ ∥ r i − 1 ∥ 2
归纳:∥ r i ∥ 2 ⩽ γ i \|\bm{r}_i\|_2 \le \gamma^i ∥ r i ∥ 2 ⩽ γ i ∥ r 0 ∥ 2 = ∥ x ∥ 2 = 1 \|\bm{r}_0\|_2 = \|\bm{x}\|_2 = 1 ∥ r 0 ∥ 2 = ∥ x ∥ 2 = 1
x i \bm{x}_i x i ∥ x i ∥ 2 = ∥ r i − 1 ∥ 2 ⩽ γ i − 1 \|\bm{x}_i\|_2 = \|\bm{r}_{i-1}\|_2 \le \gamma^{i-1} ∥ x i ∥ 2 = ∥ r i − 1 ∥ 2 ⩽ γ i − 1
x i \bm{x}_i x i x i = ∥ r i − 1 ∥ 2 ⋅ y i \bm{x}_i = \|\bm{r}_{i-1}\|_2 \cdot \bm{y}_i x i = ∥ r i − 1 ∥ 2 ⋅ y i x i / ∥ x i ∥ 2 = y i ∈ N \bm{x}_i / \|\bm{x}_i\|_2 = \bm{y}_i \in N x i /∥ x i ∥ 2 = y i ∈ N x i ≠ 0 \bm{x}_i \ne 0 x i = 0 JL 对 x i \bm{x}_i x i
最终 x = lim n → ∞ ( x − r n ) = ∑ i ⩾ 1 x i \bm{x} = \lim_{n \to \infty} (\bm{x} - \bm{r}_n) = \sum_{i \ge 1} \bm{x}_i x = lim n → ∞ ( x − r n ) = ∑ i ⩾ 1 x i 0 0 0
第五步:合成范数保持
我们要的就是 ∥ Π x ∥ 2 2 ≈ ∥ x ∥ 2 2 = 1 \|\bm{\Pi}\bm{x}\|_2^2 \approx \|\bm{x}\|_2^2 = 1 ∥ Π x ∥ 2 2 ≈ ∥ x ∥ 2 2 = 1
∥ Π x ∥ 2 2 = ∥ Π ∑ i x i ∥ 2 2 = ∑ i ∥ Π x i ∥ 2 2 + 2 ∑ i < j ⟨ Π x i , Π x j ⟩ \|\bm{\Pi}\bm{x}\|_2^2 = \left\|\bm{\Pi}\sum_i \bm{x}_i\right\|_2^2 = \sum_i \|\bm{\Pi}\bm{x}_i\|_2^2 + 2 \sum_{i < j} \langle \bm{\Pi}\bm{x}_i, \bm{\Pi}\bm{x}_j \rangle
∥ Π x ∥ 2 2 = Π i ∑ x i 2 2 = i ∑ ∥ Π x i ∥ 2 2 + 2 i < j ∑ ⟨ Π x i , Π x j ⟩
需要分别控制对角项 和交叉项 。
对角项 ——JL 已经处理好了。由于 x i = ∥ x i ∥ 2 ⋅ y i \bm{x}_i = \|\bm{x}_i\|_2 \cdot \bm{y}_i x i = ∥ x i ∥ 2 ⋅ y i y i ∈ N \bm{y}_i \in N y i ∈ N JL 在网上的保持性给出 ∥ Π y i ∥ 2 2 = 1 ± ε \|\bm{\Pi}\bm{y}_i\|_2^2 = 1 \pm \varepsilon ∥ Π y i ∥ 2 2 = 1 ± ε ∥ Π x i ∥ 2 2 = ( 1 ± ε ) ∥ x i ∥ 2 2 \|\bm{\Pi}\bm{x}_i\|_2^2 = (1 \pm \varepsilon)\|\bm{x}_i\|_2^2 ∥ Π x i ∥ 2 2 = ( 1 ± ε ) ∥ x i ∥ 2 2
∑ i ∥ Π x i ∥ 2 2 = ∑ i ∥ x i ∥ 2 2 ⋅ ( 1 ± ε ) \sum_i \|\bm{\Pi}\bm{x}_i\|_2^2 = \sum_i \|\bm{x}_i\|_2^2 \cdot (1 \pm \varepsilon)
i ∑ ∥ Π x i ∥ 2 2 = i ∑ ∥ x i ∥ 2 2 ⋅ ( 1 ± ε )
交叉项 ——需要 JL 不仅保持范数,还要保持内积。
内积保持引理
若 JL 对网中向量 y , y ′ \bm{y}, \bm{y}' y , y ′ y − y ′ \bm{y} - \bm{y}' y − y ′ ( 1 ± ε ) (1 \pm \varepsilon) ( 1 ± ε )
⟨ Π y , Π y ′ ⟩ = ⟨ y , y ′ ⟩ ± O ( ε ) \langle \bm{\Pi} \bm{y}, \bm{\Pi} \bm{y}' \rangle = \langle \bm{y}, \bm{y}' \rangle \pm O(\varepsilon)
⟨ Π y , Π y ′ ⟩ = ⟨ y , y ′ ⟩ ± O ( ε )
证明 :由极化恒等式 ∥ a − b ∥ 2 = ∥ a ∥ 2 + ∥ b ∥ 2 − 2 ⟨ a , b ⟩ \|\bm{a} - \bm{b}\|^2 = \|\bm{a}\|^2 + \|\bm{b}\|^2 - 2 \langle \bm{a}, \bm{b}\rangle ∥ a − b ∥ 2 = ∥ a ∥ 2 + ∥ b ∥ 2 − 2 ⟨ a , b ⟩ a = Π y , b = Π y ′ \bm{a} = \bm{\Pi}\bm{y}, \bm{b} = \bm{\Pi}\bm{y}' a = Π y , b = Π y ′ ∥ Π y ∥ 2 , ∥ Π y ′ ∥ 2 , ∥ Π ( y − y ′ ) ∥ 2 \|\bm{\Pi}\bm{y}\|^2, \|\bm{\Pi}\bm{y}'\|^2, \|\bm{\Pi}(\bm{y} - \bm{y}')\|^2 ∥ Π y ∥ 2 , ∥ Π y ′ ∥ 2 , ∥ Π ( y − y ′ ) ∥ 2 ( 1 ± ε ) (1 \pm \varepsilon) ( 1 ± ε )
要让 y − y ′ \bm{y} - \bm{y}' y − y ′ JL 保持范数」的对象,把网扩张为 N ∪ { y − y ′ : y , y ′ ∈ N } N \cup \{\bm{y} - \bm{y}'\colon \bm{y}, \bm{y}' \in N\} N ∪ { y − y ′ : y , y ′ ∈ N } ∣ N ∣ 2 ⩽ 25 d |N|^2 \le 25^d ∣ N ∣ 2 ⩽ 2 5 d exp ( O ( d ) ) \exp(O(d)) exp ( O ( d )) m = O ( d / ε 2 ) m = O(d/\varepsilon^2) m = O ( d / ε 2 )
把内积保持应用到 x i , x j \bm{x}_i, \bm{x}_j x i , x j
⟨ Π x i , Π x j ⟩ = ⟨ x i , x j ⟩ ± O ( ε ) ⋅ ∥ x i ∥ 2 ∥ x j ∥ 2 \langle \bm{\Pi}\bm{x}_i, \bm{\Pi}\bm{x}_j\rangle = \langle \bm{x}_i, \bm{x}_j\rangle \pm O(\varepsilon) \cdot \|\bm{x}_i\|_2 \|\bm{x}_j\|_2
⟨ Π x i , Π x j ⟩ = ⟨ x i , x j ⟩ ± O ( ε ) ⋅ ∥ x i ∥ 2 ∥ x j ∥ 2
合并对角项与交叉项 :
∥ Π x ∥ 2 2 = ∑ i ∥ x i ∥ 2 2 + 2 ∑ i < j ⟨ x i , x j ⟩ ⏟ = ∥ x ∥ 2 2 = 1 + O ( ε ) ⋅ ( ∑ i ∥ x i ∥ 2 2 + 2 ∑ i < j ∥ x i ∥ 2 ∥ x j ∥ 2 ) \|\bm{\Pi}\bm{x}\|_2^2 = \underbrace{\sum_i \|\bm{x}_i\|_2^2 + 2\sum_{i < j} \langle \bm{x}_i, \bm{x}_j\rangle}_{= \|\bm{x}\|_2^2 = 1} + O(\varepsilon) \cdot \left(\sum_i \|\bm{x}_i\|_2^2 + 2\sum_{i < j} \|\bm{x}_i\|_2 \|\bm{x}_j\|_2 \right)
∥ Π x ∥ 2 2 = = ∥ x ∥ 2 2 = 1 i ∑ ∥ x i ∥ 2 2 + 2 i < j ∑ ⟨ x i , x j ⟩ + O ( ε ) ⋅ ( i ∑ ∥ x i ∥ 2 2 + 2 i < j ∑ ∥ x i ∥ 2 ∥ x j ∥ 2 )
后一个括号 = ( ∑ i ∥ x i ∥ 2 ) 2 = \left(\sum_i \|\bm{x}_i\|_2\right)^2 = ( ∑ i ∥ x i ∥ 2 ) 2 ∑ i ∥ x i ∥ 2 ⩽ ∑ i ⩾ 1 γ i − 1 = 1 1 − γ \sum_i \|\bm{x}_i\|_2 \le \sum_{i \ge 1} \gamma^{i-1} = \dfrac{1}{1-\gamma} ∑ i ∥ x i ∥ 2 ⩽ ∑ i ⩾ 1 γ i − 1 = 1 − γ 1 ⩽ 1 ( 1 − γ ) 2 \le \dfrac{1}{(1-\gamma)^2} ⩽ ( 1 − γ ) 2 1 γ = 1 / 2 \gamma = 1/2 γ = 1/2 4 = O ( 1 ) 4 = O(1) 4 = O ( 1 )
所以 ∥ Π x ∥ 2 2 = 1 ± O ( ε ) \|\bm{\Pi}\bm{x}\|_2^2 = 1 \pm O(\varepsilon) ∥ Π x ∥ 2 2 = 1 ± O ( ε )
OSE via JL(结论)
取 m = Θ ( d / ε 2 ) m = \Theta(d/\varepsilon^2) m = Θ ( d / ε 2 ) R m × d \R^{m \times d} R m × d JL 矩阵 Π \bm{\Pi} Π ± 1 \pm 1 ± 1 ⩽ exp ( − Ω ( d ) ) \le \exp(-\Omega(d)) ⩽ exp ( − Ω ( d )) 5 d 5^d 5 d 25 d 25^d 2 5 d ⩽ exp ( − Ω ( d ) ) \le \exp(-\Omega(d)) ⩽ exp ( − Ω ( d )) Π \bm{\Pi} Π d d d O ( ε ) O(\varepsilon) O ( ε ) OSE 。
JL vs OSE 的代价对比
任务
被保持的对象数
所需维度 m m m
JL (点集)n n n O ( ε − 2 log n ) O(\varepsilon^{-2} \log n) O ( ε − 2 log n )
OSE (子空间)不可数无穷,但有 5 d 5^d 5 d
O ( ε − 2 d ) O(\varepsilon^{-2} d) O ( ε − 2 d )
两者结构完全相同(指数集中 + + + OSE 比 JL 容易」的精确含义。
Count Sketch 作为 OSE
γ-net 论证告诉我们「JL 矩阵就是 OSE 」。但 JL 是稠密矩阵,Π A \bm{\Pi} \bm{A} Π A O ( m n d ) O(m n d) O ( mn d ) 稀疏 的 A \bm{A} A n n z ( A ) ≪ n d \mathrm{nnz}(\bm{A}) \ll n d nnz ( A ) ≪ n d
能否设计一种 OSE ,让 Π A \bm{\Pi} \bm{A} Π A n n z ( A ) \mathrm{nnz}(\bm{A}) nnz ( A ) Count Sketch ——回到那个我们已经熟悉的 ±1 稀疏矩阵。
极致的稀疏
Count Sketch 矩阵
Π = S D ∈ R m × n \bm{\Pi} = \bm{S}\bm{D} \in \R^{m \times n} Π = S D ∈ R m × n
D \bm{D} D ± 1 \pm 1 ± 1 S \bm{S} S h : [ n ] → [ m ] h\colon [n] \to [m] h : [ n ] → [ m ] 恰好一个 位置为 1 1 1 h ( j ) h(j) h ( j ) 0 0 0
效果:每个 x ∈ R n \bm{x} \in \R^n x ∈ R n j j j D j j D_{jj} D j j 累加进哈希桶 h ( j ) h(j) h ( j ) 。整个 Π \bm{\Pi} Π 1 1 1
为什么这种稀疏带来速度提升 :Π A \bm{\Pi} \bm{A} Π A A i j \bm{A}_{ij} A ij O ( n n z ( A ) ) O(\mathrm{nnz}(\bm{A})) O ( nnz ( A )) O ( m n ) O(m n) O ( mn )
代价:目标维度的二次增长
但稀疏不是免费的午餐。Count Sketch 作为 d d d OSE ,目标维度
m = Θ ( d 2 ε 2 δ ) m = \Theta\left(\frac{d^2}{\varepsilon^2 \delta}\right)
m = Θ ( ε 2 δ d 2 )
比 JL 的 O ( d / ε 2 ) O(d / \varepsilon^2) O ( d / ε 2 ) d / δ d / \delta d / δ O ( n n z ( A ) ) O(\mathrm{nnz}(\bm{A})) O ( nnz ( A ))
为什么是 d 2 d^2 d 2 d d d JL 用稠密随机矩阵让每个坐标都参与「扩散」;Count Sketch 只让每个坐标参与一次,扩散能力差,需要更多桶来「容纳」。下面看具体分析为什么 d 2 d^2 d 2
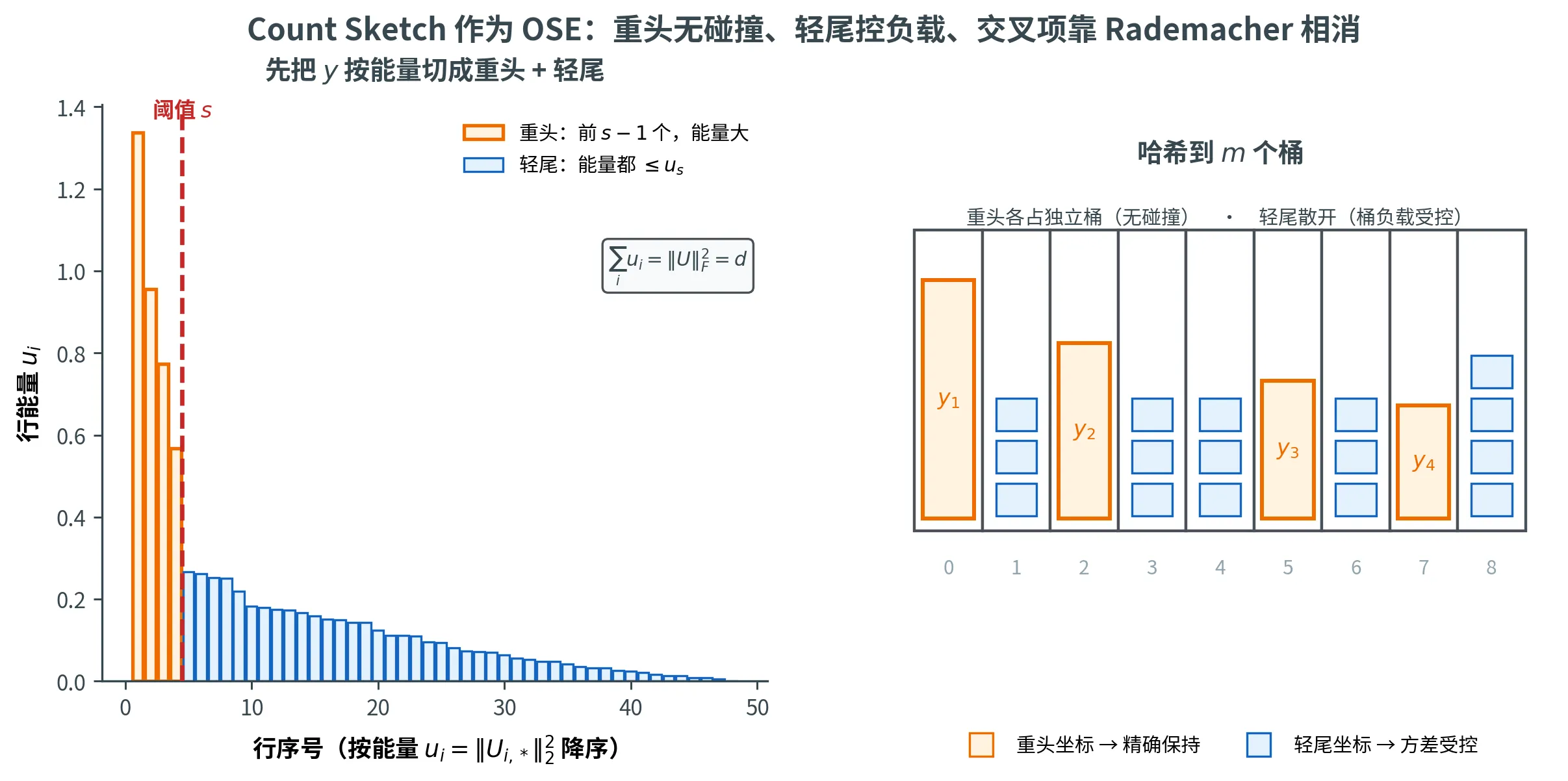
分析的整体策略
设 A \bm{A} A A \bm{A} A SVD 的左奇异向量代替——这只是换基),记为 U ∈ R n × d \bm{U} \in \R^{n \times d} U ∈ R n × d
对任意 x ∈ S d − 1 \bm{x} \in \mathbb{S}^{d-1} x ∈ S d − 1 y = U x \bm{y} = \bm{U} \bm{x} y = U x ∥ Π y ∥ 2 2 = ( 1 ± ε ) ∥ y ∥ 2 2 = 1 ± ε \|\bm{\Pi}\bm{y}\|_2^2 = (1 \pm \varepsilon) \|\bm{y}\|_2^2 = 1 \pm \varepsilon ∥ Π y ∥ 2 2 = ( 1 ± ε ) ∥ y ∥ 2 2 = 1 ± ε y \bm{y} y U \bm{U} U
记 u i = ∥ U i , ∗ ∥ 2 2 u_i = \|\bm{U}_{i, *}\|_2^2 u i = ∥ U i , ∗ ∥ 2 2 U \bm{U} U i i i i = 1 , … , n i = 1, \dots, n i = 1 , … , n
∣ y i ∣ 2 = ∣ ⟨ U i , ∗ , x ⟩ ∣ 2 ⩽ ∥ U i , ∗ ∥ 2 2 ⋅ ∥ x ∥ 2 2 = u i |y_i|^2 = |\langle \bm{U}_{i, *}, \bm{x}\rangle|^2 \le \|\bm{U}_{i, *}\|_2^2 \cdot \|\bm{x}\|_2^2 = u_i
∣ y i ∣ 2 = ∣ ⟨ U i , ∗ , x ⟩ ∣ 2 ⩽ ∥ U i , ∗ ∥ 2 2 ⋅ ∥ x ∥ 2 2 = u i
把行按 u i u_i u i 降序排列 (重排坐标不影响范数),y \bm{y} y u 1 , u 2 , … u_1, u_2, \dots u 1 , u 2 , …
把 y \bm{y} y
重头 y 1 : ( s − 1 ) \bm{y}_{1:(s-1)} y 1 : ( s − 1 ) s − 1 s - 1 s − 1 轻尾 y s : n \bm{y}_{s:n} y s : n n − s + 1 n - s + 1 n − s + 1 u s u_s u s
阈值 s s s s s s m m m m = Θ ( d 2 / ( ε 2 δ ) ) m = \Theta(d^2 / (\varepsilon^2 \delta)) m = Θ ( d 2 / ( ε 2 δ ))
下图概括这套「分而治之」:把 U \bm{U} U u i u_i u i 重头 (前 s − 1 s-1 s − 1 轻尾 (其余低能量坐标)则散开到各桶、靠桶负载受控来压住方差,两段之间的交叉项再靠 Rademacher 符号相消。三种机制各管一段,正是 m m m d 2 d^2 d 2 1 / δ 1/\delta 1/ δ
两段为什么要分开处理
两段被 Count Sketch 哈希后的行为有本质区别,需要不同的工具:
段
失败模式
控制工具
重头 y 1 : ( s − 1 ) \bm{y}_{1:(s-1)} y 1 : ( s − 1 )
两个「重」坐标哈希到同一桶(碰撞)会产生大交叉项
无碰撞事件
轻尾 y s : n \bm{y}_{s:n} y s : n
所有「轻」坐标都参与,需要它们的方差控制
桶最大负载 (max-load)
重头 × \times ×
交叉项需要 Rademacher 让其相消
Rademacher 集中
下面分别说明三段的处理思路。
重头:无碰撞 ⟹ 精确保持
设事件 E B \mathcal{E}_B E B s − 1 s - 1 s − 1 S \bm{S} S 两两不碰撞 ——它们各自落入不同的桶。在这个事件上,Π y 1 : ( s − 1 ) \bm{\Pi} \bm{y}_{1:(s-1)} Π y 1 : ( s − 1 )
∥ Π y 1 : ( s − 1 ) ∥ 2 2 = ∥ y 1 : ( s − 1 ) ∥ 2 2 (精确,无误差!) \|\bm{\Pi} \bm{y}_{1:(s-1)}\|_2^2 = \|\bm{y}_{1:(s-1)}\|_2^2 \quad \text{(精确,无误差!)}
∥ Π y 1 : ( s − 1 ) ∥ 2 2 = ∥ y 1 : ( s − 1 ) ∥ 2 2 (精确,无误差!)
把 s − 1 s - 1 s − 1 m m m 1 − ( s − 1 2 ) / m 1 - \binom{s-1}{2}/m 1 − ( 2 s − 1 ) / m ⩾ 1 − δ / 3 \ge 1 - \delta/3 ⩾ 1 − δ /3 m = Ω ( s 2 / δ ) m = \Omega(s^2 / \delta) m = Ω ( s 2 / δ ) s 2 s^2 s 2 m m m
轻尾:桶最大负载控制方差
记事件 E h \mathcal{E}_h E h j ∈ [ m ] j \in [m] j ∈ [ m ]
max j ∈ [ m ] ∑ i ⩾ s h ( i ) = j u i ⩽ τ \max_{j \in [m]} \sum_{\substack{i \ge s \\ h(i) = j}} u_i \le \tau
j ∈ [ m ] max i ⩾ s h ( i ) = j ∑ u i ⩽ τ
直观上:把轻尾的能量 { u i } i ⩾ s \{u_i\}_{i \ge s} { u i } i ⩾ s m m m u i ⩽ u s u_i \le u_s u i ⩽ u s i ⩾ s i \ge s i ⩾ s ∑ i ⩾ s u i / m ⩽ d / m \sum_{i \ge s} u_i / m \le d/m ∑ i ⩾ s u i / m ⩽ d / m ∑ i u i = ∥ U ∥ F 2 = d \sum_i u_i = \|\bm{U}\|_F^2 = d ∑ i u i = ∥ U ∥ F 2 = d
在 E h \mathcal{E}_h E h ∥ Π y s : n ∥ 2 2 ≈ ∥ y s : n ∥ 2 2 \|\bm{\Pi} \bm{y}_{s:n}\|_2^2 \approx \|\bm{y}_{s:n}\|_2^2 ∥ Π y s : n ∥ 2 2 ≈ ∥ y s : n ∥ 2 2 ± O ( ε ) \pm O(\varepsilon) ± O ( ε ) m m m m ≳ d / ε 2 m \gtrsim d/\varepsilon^2 m ≳ d / ε 2 d / m d/m d / m
交叉项:Rademacher 让它消失
最微妙的是交叉项 ⟨ Π y s : n , Π y 1 : ( s − 1 ) ⟩ \langle \bm{\Pi} \bm{y}_{s:n}, \bm{\Pi} \bm{y}_{1:(s-1)}\rangle ⟨ Π y s : n , Π y 1 : ( s − 1 ) ⟩ E h , E B \mathcal{E}_h, \mathcal{E}_B E h , E B D \bm{D} D O ( ε ) O(\varepsilon) O ( ε ) m m m m ≳ s ⋅ d / ( ε 2 δ ) m \gtrsim s \cdot d / (\varepsilon^2 \delta) m ≳ s ⋅ d / ( ε 2 δ ) s − 1 s - 1 s − 1
合成:s s s
把三段合起来:
∣ ∥ Π y ∥ 2 2 − ∥ y ∥ 2 2 ∣ = ∣ ∥ Π y 1 : ( s − 1 ) ∥ 2 2 − ∥ y 1 : ( s − 1 ) ∥ 2 2 ∣ ⏟ = 0 on E B + ∣ ∥ Π y s : n ∥ 2 2 − ∥ y s : n ∥ 2 2 ∣ ⏟ ⩽ O ( ε ) on E h + 2 ∣ ⟨ Π y s : n , Π y 1 : ( s − 1 ) ⟩ ∣ ⏟ ⩽ O ( ε ) \bigl|\|\bm{\Pi}\bm{y}\|_2^2 - \|\bm{y}\|_2^2\bigr| = \underbrace{\bigl|\|\bm{\Pi}\bm{y}_{1:(s-1)}\|_2^2 - \|\bm{y}_{1:(s-1)}\|_2^2\bigr|}_{= 0 \text{ on } \mathcal{E}_B} + \underbrace{\bigl|\|\bm{\Pi}\bm{y}_{s:n}\|_2^2 - \|\bm{y}_{s:n}\|_2^2\bigr|}_{\le O(\varepsilon) \text{ on } \mathcal{E}_h} + \underbrace{2|\langle \bm{\Pi}\bm{y}_{s:n}, \bm{\Pi}\bm{y}_{1:(s-1)}\rangle|}_{\le O(\varepsilon)}
∥ Π y ∥ 2 2 − ∥ y ∥ 2 2 = = 0 on E B ∥ Π y 1 : ( s − 1 ) ∥ 2 2 − ∥ y 1 : ( s − 1 ) ∥ 2 2 + ⩽ O ( ε ) on E h ∥ Π y s : n ∥ 2 2 − ∥ y s : n ∥ 2 2 + ⩽ O ( ε ) 2∣ ⟨ Π y s : n , Π y 1 : ( s − 1 ) ⟩ ∣
总误差 O ( ε ) O(\varepsilon) O ( ε ) ⩽ δ \le \delta ⩽ δ m m m s s s m m m
段
对 m m m
重头无碰撞
m ≳ s 2 / δ m \gtrsim s^2 / \delta m ≳ s 2 / δ
轻尾低负载
m ≳ d / ε 2 m \gtrsim d / \varepsilon^2 m ≳ d / ε 2
交叉项
m ≳ s ⋅ d / ( ε 2 δ ) m \gtrsim s \cdot d / (\varepsilon^2 \delta) m ≳ s ⋅ d / ( ε 2 δ )
三条约束里,「重头无碰撞」按 s 2 s^2 s 2 s s s s 2 / δ = s d / ( ε 2 δ ) s^2/\delta = s d/(\varepsilon^2 \delta) s 2 / δ = s d / ( ε 2 δ ) s = Θ ( d / ε 2 ) s = \Theta(d/\varepsilon^2) s = Θ ( d / ε 2 )
m = Θ ( d 2 ε 2 δ ) m = \Theta\left(\frac{d^2}{\varepsilon^2 \delta}\right)
m = Θ ( ε 2 δ d 2 )
这就是 Count Sketch OSE 的最终维度——保留了对稀疏输入的速度优势,代价是维度比 JL OSE 多一个 d / δ d / \delta d / δ
取舍
Count Sketch 在「列稀疏 d 2 d^2 d 2 JL 的「稠密 d d d
n n z ( A ) \mathrm{nnz}(\bm{A}) nnz ( A ) n d n d n d A \bm{A} A d d d JL ,维度是 d d d d 2 d^2 d 2
现代大规模数据系统常用 Count Sketch 作为 OSE 的「主力」,在稀疏特征矩阵上获得显著加速。
章节小结
本讲沿着「在低维近似保持几何」这条主线,串起了一系列关键工具:
flowchart TD
JL["JL 定理<br/>k = O(ε⁻² log n)"]
Gauss["高斯构造<br/>χ² 集中"]
Sub["子空间投影"]
Pm["±1 构造<br/>Count Sketch"]
FJLT["FJLT<br/>Hadamard + Rademacher"]
NNS["NNS / ANN"]
LSH["局部敏感哈希"]
OSE["子空间嵌入 OSE"]
Reg["大规模线性回归"]
Net["γ-net 论证"]
CS_OSE["Count Sketch as OSE"]
JL --> Gauss
JL --> Sub
JL --> Pm
JL --> FJLT
JL --> NNS
NNS --> LSH
JL --> Net
Net --> OSE
OSE --> Reg
OSE --> CS_OSE
Pm -.-> CS_OSE
classDef core fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef construct fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef app fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef tech fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
class JL,OSE core
class Gauss,Sub,Pm,FJLT,CS_OSE construct
class NNS,LSH,Reg app
class Net tech几条值得记住的「事实」:
工具
目标维度
构造时间
适用场景
JL (高斯)O ( ε − 2 log n ) O(\varepsilon^{-2} \log n) O ( ε − 2 log n ) O ( d k ) O(d k) O ( d k ) 通用降维
Count Sketch(JL )
O ( ε − 2 log n ) O(\varepsilon^{-2} \log n) O ( ε − 2 log n ) O ( d k ) O(d k) O ( d k ) ± 1 \pm 1 ± 1
FJLT O ( ε − 2 log n log d ) O(\varepsilon^{-2} \log n \log d) O ( ε − 2 log n log d ) O ( d log d ) O(d \log d) O ( d log d ) 大 d d d
Count Sketch(OSE )
O ( d 2 / ε 2 δ ) O(d^2/\varepsilon^2 \delta) O ( d 2 / ε 2 δ ) O ( n n z ( A ) ) O(\mathrm{nnz}(\bm{A})) O ( nnz ( A )) 稀疏数据
一个统一的主题:随机的几何嵌入 + 集中不等式 = 高维数据的现代工具 。