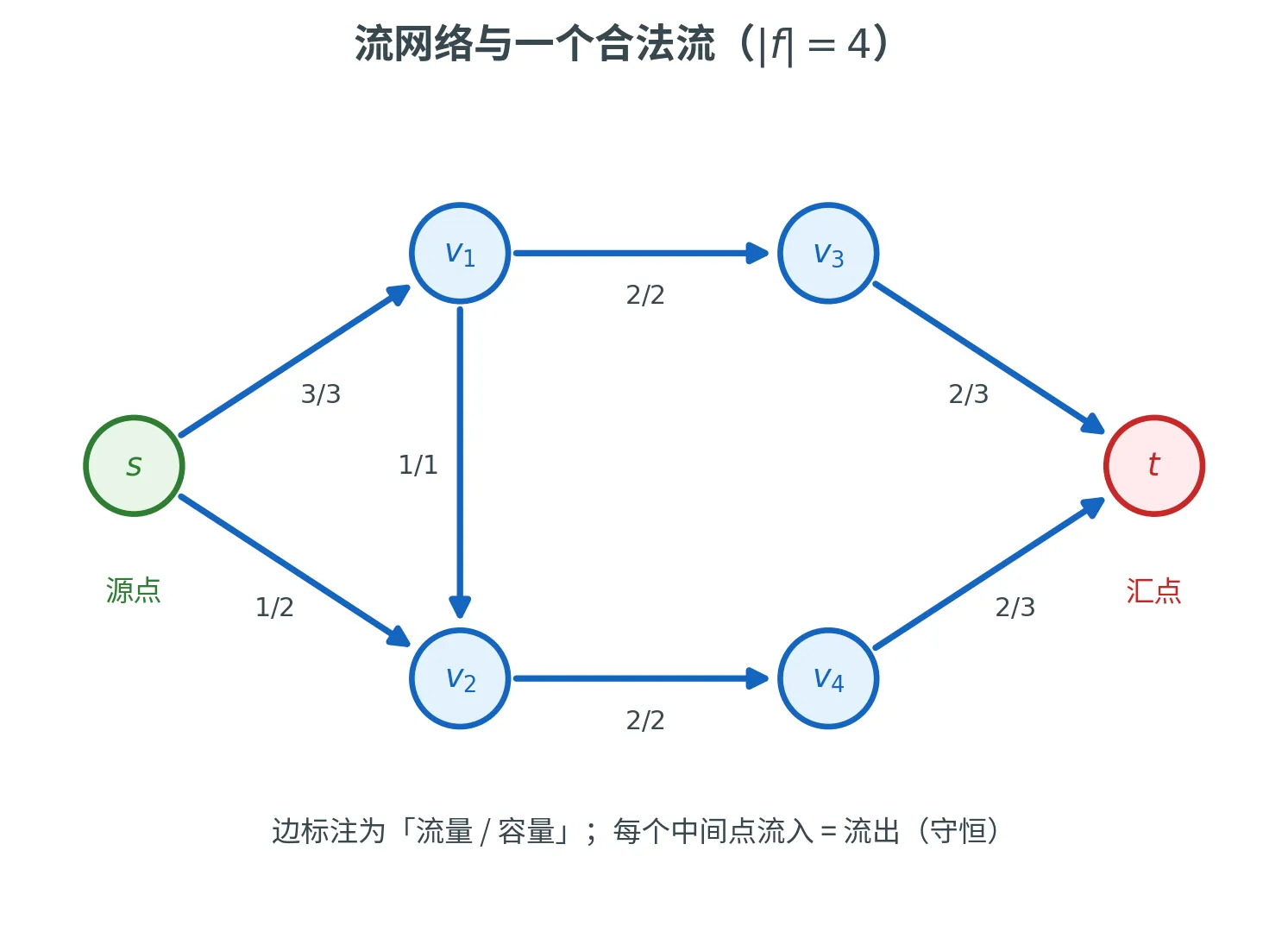
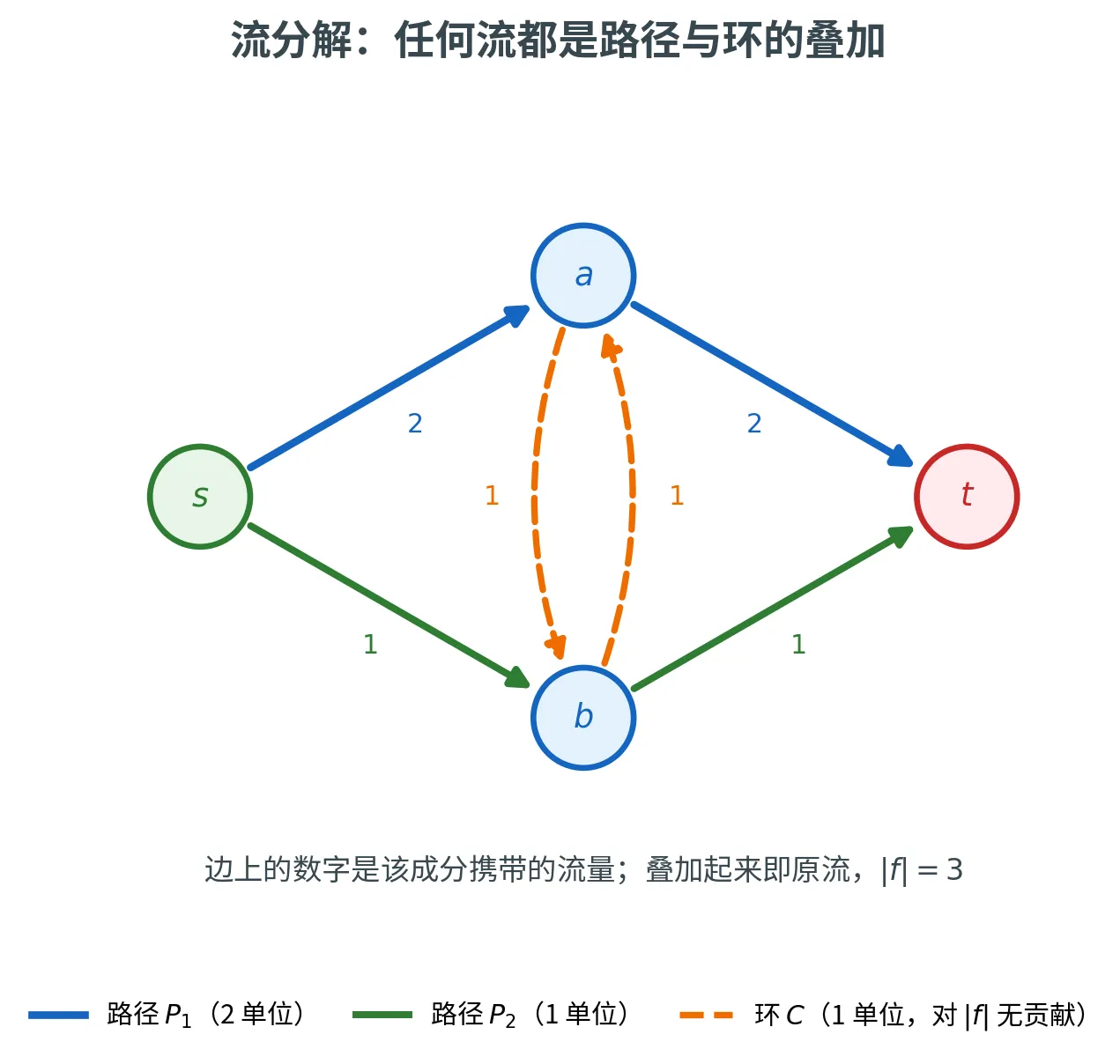
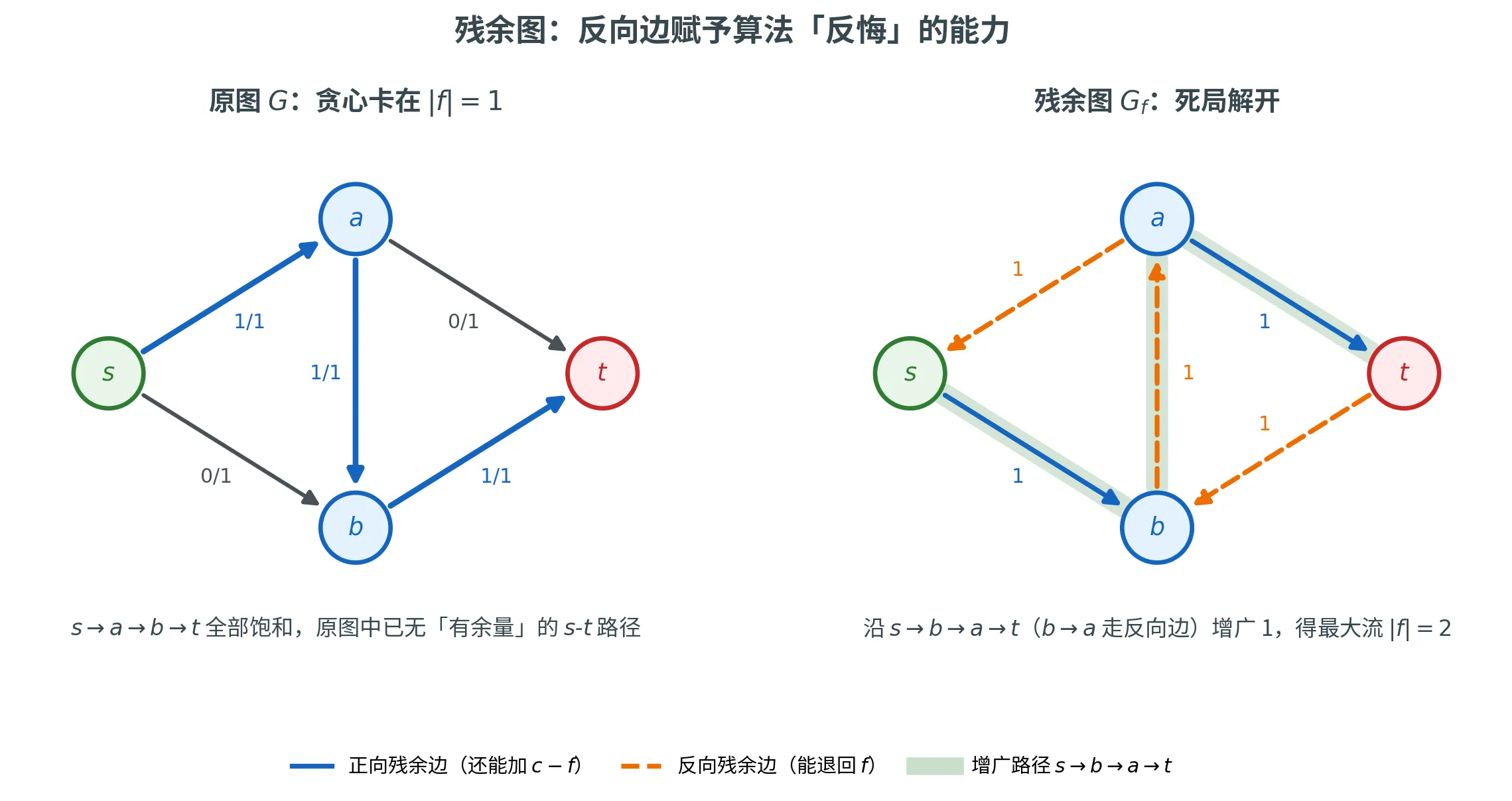
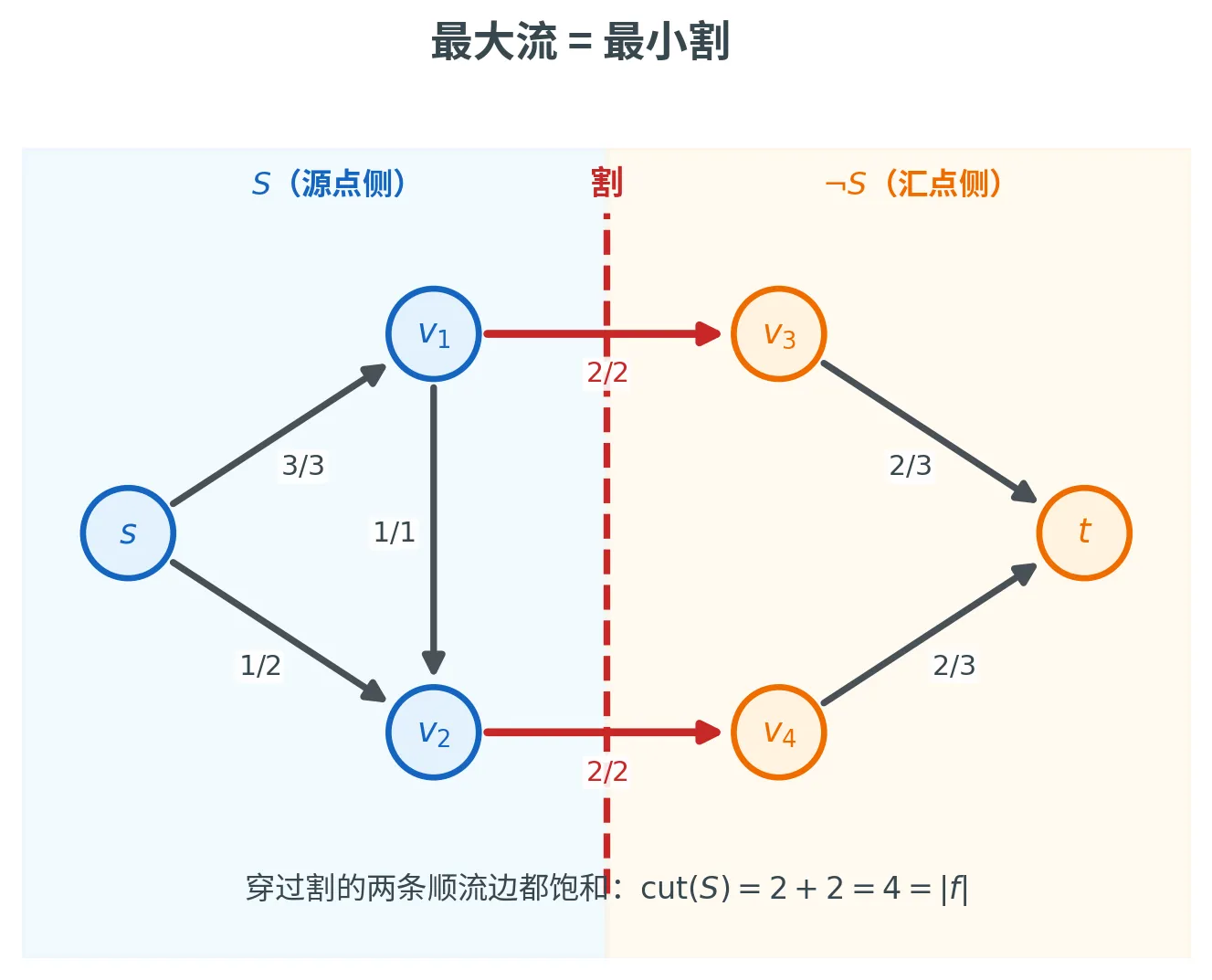
一条贯穿全局的主线:流、割与对偶
设想你是一位后勤指挥官,要把物资从大本营 s s s t t t 一次最多能运多少物资过去?
这就是最大流 (Maximum Flow)问题。它看起来只是个调度问题,但藏着一个惊人的对偶现象:你能运过去的最大流量,恰好等于敌人用最小代价「切断」整张网络所需付出的代价——最小割 (Minimum Cut)。运得越多和切得越省,本是风马牛不相及的两件事,却在数值上分毫不差。这种「一个最大化问题的最优值 = 另一个最小化问题的最优值」的现象,就是本讲的灵魂——对偶 (Duality)。
为什么要从网络流讲起?因为它是理解对偶最好的具体例子,而对偶又是现代算法设计中最强大的思想之一。本讲会沿着这样一条线索层层展开:
先把网络流彻底讲清楚:怎么定义、怎么求解、求得多快;
看到「最大流 = 最小割」这个对偶现象,并理解它为什么成立;
把网络流抽象成线性规划 (Linear Programming, LP )——一个能统一刻画海量优化问题的框架,而且能在多项式时间内求解;
用线性规划当「锤子」去砸 NP-难问题:通过松弛 (Relaxation)与舍入 (Rounding)得到近似解;
最后揭示线性规划自带的对偶结构,并把它锻造成一套通用的算法设计范式——原始对偶框架 (Primal-Dual Schema)。
这是一条从具体到抽象、再回到具体的旅程。读完它,你会发现「最大流 = 最小割」不是孤立的巧合,而是一个普遍规律的冰山一角。
网络流模型
流网络
一切从一张带容量的有向图开始。
流网络
流网络 (Flow Network)是一个有向图 G = ( V , E ) G = (V, E) G = ( V , E )
每条边 e ∈ E e \in E e ∈ E 容量 (Capacity)c e ∈ R + c_e \in \R^+ c e ∈ R +
指定两个特殊顶点:源点 (Source)s ∈ V s \in V s ∈ V 汇点 (Sink)t ∈ V t \in V t ∈ V
我们要在这张图上「注入」流量。流量用一个函数 f : E → R + f\colon E \to \R^+ f : E → R + f ( e ) f(e) f ( e ) e e e
合法流
函数 f : E → R + f\colon E \to \R^+ f : E → R + 合法流 (Valid Flow),若满足:
容量约束 (Capacity Constraint):∀ e ∈ E , 0 ⩽ f ( e ) ⩽ c e \forall e \in E,\ 0 \le f(e) \le c_e ∀ e ∈ E , 0 ⩽ f ( e ) ⩽ c e 流量守恒 (Flow Conservation):除源点与汇点外,每个顶点流入等于流出:∀ v ∈ V ∖ { s , t } , ∑ e ∈ δ in ( v ) f ( e ) = ∑ e ∈ δ out ( v ) f ( e ) \forall v \in V \setminus \{s, t\},\quad \sum_{e \in \delta^{\text{in}}(v)} f(e) = \sum_{e \in \delta^{\text{out}}(v)} f(e)
∀ v ∈ V ∖ { s , t } , e ∈ δ in ( v ) ∑ f ( e ) = e ∈ δ out ( v ) ∑ f ( e )
这里 δ in ( v ) \delta^{\text{in}}(v) δ in ( v ) δ out ( v ) \delta^{\text{out}}(v) δ out ( v ) v v v
如果去掉源汇点的特殊地位,要求所有 顶点都满足守恒,那么流就「自给自足」地循环起来,称为循环流 (Circulation)。源汇点的存在,正是为了让流量有「来处」和「去处」。
流量与最大流问题
源点 s s s 流量 (Value),记作 ∣ f ∣ |f| ∣ f ∣
∣ f ∣ = ∑ e ∈ δ out ( s ) f ( e ) − ∑ e ∈ δ in ( s ) f ( e ) |f| = \sum_{e \in \delta^{\text{out}}(s)} f(e) - \sum_{e \in \delta^{\text{in}}(s)} f(e)
∣ f ∣ = e ∈ δ out ( s ) ∑ f ( e ) − e ∈ δ in ( s ) ∑ f ( e )
由守恒律可以证明,源点净流出 = 汇点净流入,所以 ∣ f ∣ |f| ∣ f ∣ t t t
最大流问题
给定流网络 G = ( V , E ) G = (V, E) G = ( V , E ) c c c s s s t t t f f f ∣ f ∣ |f| ∣ f ∣
接下来的几节就是要回答:这样的最大流长什么样?怎么求?为了求解,我们先要理解流的「结构」——任何一个流,本质上都是若干条路径和环的叠加。
流分解定理
直接面对「一个流函数」是抽象的:它给每条边分配一个数,看不出物资究竟是怎么从 s s s t t t
流分解定理
任何 s s s t t t s s s t t t 路径 (Path)和若干个环 (Cycle)。也就是说,存在一组 s s s t t t f f f
这个定理之所以重要,是因为它把「流」还原成了「运输方案」:物资沿着哪几条路走、各走多少,一目了然。而环则是「空转」的部分——绕一圈回到原地,对净流量毫无贡献,往往可以直接删掉。
构造性证明
证明本身就是一个剥离算法,每一步抽出一条路径或一个环。
抽路径 :只要源点还有流出(∑ e ∈ δ out ( s ) f ( e ) > 0 \sum_{e \in \delta^{\text{out}}(s)} f(e) > 0 ∑ e ∈ δ out ( s ) f ( e ) > 0 s s s t t t s s s t t t P P P δ ( P ) = min e ∈ P f e \delta(P) = \min_{e \in P} f_e δ ( P ) = min e ∈ P f e δ ( P ) \delta(P) δ ( P )
抽环 :路径抽完后,若图中还有正流量,那么这些剩余流量在每个顶点(包括 s , t s, t s , t
每一步都至少清零一条边,边数有限,所以算法必然终止,且终止时流量恰好被这些路径和环表示完毕。
流分解定理会在后面反复用到——无论是证明「流量 ⩽ \le ⩽ m m m m = ∣ E ∣ m = |E| m = ∣ E ∣ m m m n = ∣ V ∣ n = |V| n = ∣ V ∣
增广路径与 Ford-Fulkerson 算法
一个朴素的贪心,和它的陷阱
既然流就是一条条路径的叠加,求最大流最自然的想法就是贪心:只要还能从 s s s
形式化地,对一条 s s s t t t P P P 剩余容量 (Residual Capacity)为 δ ( P ) = min e ∈ P ( c e − f e ) \delta(P) = \min_{e \in P}(c_e - f_e) δ ( P ) = min e ∈ P ( c e − f e )
当存在剩余容量 δ ( P ) > 0 \delta(P) > 0 δ ( P ) > 0 s s s t t t P P P P P P δ ( P ) \delta(P) δ ( P )
这个贪心有什么问题吗?有,而且很致命。看下面这个经典反例:
考虑四个点 s , a , b , t s, a, b, t s , a , b , t s → a s \to a s → a 1 1 1 a → t a \to t a → t 1 1 1 s → b s \to b s → b 1 1 1 b → t b \to t b → t 1 1 1 a → b a \to b a → b 1 1 1 2 2 2 s → a → t s \to a \to t s → a → t s → b → t s \to b \to t s → b → t 1 1 1 s → a → b → t s \to a \to b \to t s → a → b → t 1 1 1 s → a , a → b , b → t s\to a, a\to b, b\to t s → a , a → b , b → t s s s t t t 1 1 1
贪心的致命缺陷
一旦把流量「错误地」灌到某条边上,朴素贪心无法反悔 。它没有「把已经送出的流量退回来、改道而行」的机制,于是会卡在次优解。
问题的根源是:我们需要一种方式来表达「撤销」。如果算法能意识到「a → b a \to b a → b a → t a \to t a → t
残余图
残余图的核心想法是:在描述「还能怎么调整流量」时,不仅要记录每条边还能正向加多少 ,还要记录它已经流了多少、因而能反向退多少 。
残余图
给定流网络 G = ( V , E ) G = (V, E) G = ( V , E ) c c c f f f 残余图 (Residual Graph)G f = ( V , E ′ ) G_f = (V, E') G f = ( V , E ′ )
正向残余边 :对每条 e = ( u , v ) ∈ E e = (u, v) \in E e = ( u , v ) ∈ E c e > f e c_e > f_e c e > f e E ′ E' E ′ ( u , v ) (u, v) ( u , v ) c e ′ = c e − f e c'_e = c_e - f_e c e ′ = c e − f e 反向残余边 :对每条 e = ( u , v ) ∈ E e = (u, v) \in E e = ( u , v ) ∈ E f e > 0 f_e > 0 f e > 0 E ′ E' E ′ 反向 边 ( v , u ) (v, u) ( v , u ) c e ′ ′ = f e c'_{e'} = f_e c e ′ ′ = f e
反向边是整个构造的精髓。它代表「撤销」的能力:沿反向边「推送」流量,实际效果是抵消原边上已有的流量,等价于让那部分物资改道。有了反向边,前面的死局立刻解开——卡住后,残余图里出现了一条 s → b → a → t s \to b \to a \to t s → b → a → t b → a b \to a b → a a → b a \to b a → b a → b a \to b a → b
Ford-Fulkerson 算法
把贪心搬到残余图上,就得到了求最大流的奠基性算法。残余图里的一条 s s s t t t 增广路径 (Augmenting Path)——沿着它调整流量,总流量必然增加。
Ford-Fulkerson 算法
令 δ ( P ) \delta(P) δ ( P ) P P P
当残余图 G f G_f G f δ ( P ) > 0 \delta(P) > 0 δ ( P ) > 0 s s s t t t P P P P P P f f f δ ( P ) \delta(P) δ ( P )
「沿 P P P 增加 流量,反向残余边对应的原边减少 流量。无论哪种,源点的净流出都恰好增加 δ ( P ) \delta(P) δ ( P )
算法的框架朴素到极致:不停找增广路径,找到就增广,直到残余图里再没有 s s s t t t
最大流最小割定理
割
要刻画「最大流何时达到上限」,需要引入它的对偶概念——割。
割
一个 s s s t t t 割 (Cut)是顶点集的一个划分 ( S , ¬ S ) (S, \neg S) ( S , ¬ S ) s ∈ S , t ∈ ¬ S s \in S, t \in \neg S s ∈ S , t ∈ ¬ S 容量 (Capacity)是所有从 S S S ¬ S \neg S ¬ S
cut ( S ) = ∑ a ∈ S , b ∉ S ( a , b ) ∈ E c a , b \operatorname{cut}(S) = \sum_{\substack{a \in S,\, b \notin S \\ (a, b) \in E}} c_{a, b}
cut ( S ) = a ∈ S , b ∈ / S ( a , b ) ∈ E ∑ c a , b
直观上,割就是把网络一刀切成「源点这边」和「汇点那边」,容量是切断所有「顺流」边所需的总代价。注意从 ¬ S \neg S ¬ S S S S 不计入 割容量——我们只关心切断顺流方向。
三个等价命题
下面这个定理是网络流理论的基石,它把「最大流」「无增广路径」「存在饱和割」三件事钉死在一起。
最大流最小割定理
对一个流网络中的流 f f f
f f f 残余图 G f G_f G f > 0 > 0 > 0 s s s t t t
存在一个割 ( S , ¬ S ) (S, \neg S) ( S , ¬ S ) cut ( S ) = ∣ f ∣ \operatorname{cut}(S) = |f| cut ( S ) = ∣ f ∣
命题 (1) ⟺ (2) 保证了 Ford-Fulkerson 的正确性:当算法因「找不到增广路径」而停止时,得到的就是最大流。命题 (3) 则揭示了对偶——最大流的流量等于某个割的容量。再配上后面会证的「任意流 ⩽ \le ⩽
最大流 = 最小割
max f ∣ f ∣ = min S cut ( S ) \max_{f} |f| = \min_{S} \operatorname{cut}(S)
f max ∣ f ∣ = S min cut ( S )
一张网络能通过的最大流量,等于切断它的最小割容量。
下面逐一证明三个蕴含,串成一个环 ( 1 ) ⇒ ( 2 ) ⇒ ( 3 ) ⇒ ( 1 ) (1) \Rightarrow (2) \Rightarrow (3) \Rightarrow (1) ( 1 ) ⇒ ( 2 ) ⇒ ( 3 ) ⇒ ( 1 )
证明
( 1 ) ⇒ ( 2 ) (1) \Rightarrow (2) ( 1 ) ⇒ ( 2 ) ¬ ( 2 ) ⇒ ¬ ( 1 ) \neg(2) \Rightarrow \neg(1) ¬ ( 2 ) ⇒ ¬ ( 1 ) δ ( P ) > 0 \delta(P) > 0 δ ( P ) > 0 δ ( P ) > 0 \delta(P) > 0 δ ( P ) > 0 f f f
( 2 ) ⇒ ( 3 ) (2) \Rightarrow (3) ( 2 ) ⇒ ( 3 ) S S S G f G_f G f s s s s s s t t t t ∉ S t \notin S t ∈ / S ( S , ¬ S ) (S, \neg S) ( S , ¬ S )
对每条 e = ( a , b ) ∈ E e = (a, b) \in E e = ( a , b ) ∈ E a ∈ S , b ∉ S a \in S, b \notin S a ∈ S , b ∈ / S f e = c e f_e = c_e f e = c e c e − f e > 0 c_e - f_e > 0 c e − f e > 0 a → b a \to b a → b b b b s s s b ∉ S b \notin S b ∈ / S
对每条 e = ( b , a ) ∈ E e = (b, a) \in E e = ( b , a ) ∈ E a ∈ S , b ∉ S a \in S, b \notin S a ∈ S , b ∈ / S f e = 0 f_e = 0 f e = 0 f e > 0 f_e > 0 f e > 0 a → b a \to b a → b b b b
也就是说,所有顺流边满载 、所有逆流边空载 。而 ∣ f ∣ |f| ∣ f ∣ S S S − - − S S S s s s
∣ f ∣ = ∑ a ∈ S , b ∉ S f a , b − ∑ a ∈ S , b ∉ S f b , a = ∑ a ∈ S , b ∉ S c a , b − 0 = cut ( S ) |f| = \sum_{\substack{a \in S,\, b \notin S}} f_{a, b} - \sum_{\substack{a \in S,\, b \notin S}} f_{b, a} = \sum_{\substack{a \in S,\, b \notin S}} c_{a, b} - 0 = \operatorname{cut}(S)
∣ f ∣ = a ∈ S , b ∈ / S ∑ f a , b − a ∈ S , b ∈ / S ∑ f b , a = a ∈ S , b ∈ / S ∑ c a , b − 0 = cut ( S )
( 3 ) ⇒ ( 1 ) (3) \Rightarrow (1) ( 3 ) ⇒ ( 1 ) 对任意流 f f f S S S ∣ f ∣ ⩽ cut ( S ) |f| \le \operatorname{cut}(S) ∣ f ∣ ⩽ cut ( S ) (这就是「弱对偶」)。用流分解:把 f f f s s s t t t ∣ f ∣ |f| ∣ f ∣ p p p s ∈ S s \in S s ∈ S t ∉ S t \notin S t ∈ / S 正向 跨过割一次(即便来回穿越,正向次数也比逆向多一),每次正向跨越都占用 cut ( S ) \operatorname{cut}(S) cut ( S ) p p p
∣ f ∣ = ∑ P p ⩽ cut ( S ) |f| = \sum_P p \le \operatorname{cut}(S)
∣ f ∣ = P ∑ p ⩽ cut ( S )
有了这个上界,命题 (3) 的威力就显现了:若某个流 f f f S S S ∣ f ∣ = cut ( S ) |f| = \operatorname{cut}(S) ∣ f ∣ = cut ( S ) f ′ f' f ′ ∣ f ′ ∣ ⩽ cut ( S ) = ∣ f ∣ |f'| \le \operatorname{cut}(S) = |f| ∣ f ′ ∣ ⩽ cut ( S ) = ∣ f ∣ f f f ■ \blacksquare ■
这个证明的副产品值得单独强调:任意流 ⩽ \le ⩽ 。最大流要往上顶,最小割要往下压,两者从两侧逼近同一个值并在最优处相遇。这种「最大化的下界由最小化提供、反之亦然」的夹逼结构,是对偶的本质,后面在线性规划里会以更一般的面貌再次登场。
让 Ford-Fulkerson 跑得更快
Ford-Fulkerson 保证了正确性,但「不停找增广路径」这句话留了个大坑:到底要找多少次?答案取决于怎么选 增广路径——选得好与选得差,效率天差地别。这一节我们顺着「越选越聪明」的脉络,把求最大流的算法从「伪多项式」一路优化到「强多项式」。
朴素 Ford-Fulkerson:伪多项式的陷阱
最朴素的实现随便选一条增广路径。每次增广至少让整数容量下的流量增加 1 1 1 ∣ f ∗ ∣ |f^*| ∣ f ∗ ∣ O ( m ) O(m) O ( m ) O ( ∣ f ∗ ∣ ⋅ m ) O(|f^*| \cdot m) O ( ∣ f ∗ ∣ ⋅ m )
这看似多项式,实则暗藏杀机。考虑这样一张图:s → a s \to a s → a s → b s \to b s → b 10 9 10^9 1 0 9 a → t a \to t a → t b → t b \to t b → t 10 9 10^9 1 0 9 a → b a \to b a → b 1 1 1 s → a → b → t s \to a \to b \to t s → a → b → t s → b → a → t s \to b \to a \to t s → b → a → t b → a b \to a b → a 1 1 1 2 × 10 9 2 \times 10^9 2 × 1 0 9 4 4 4 5 5 5
伪多项式
O ( ∣ f ∗ ∣ ⋅ m ) O(|f^*| \cdot m) O ( ∣ f ∗ ∣ ⋅ m ) ∣ f ∗ ∣ |f^*| ∣ f ∗ ∣ 数值 ,而非输入规模。容量写成二进制只需 O ( log ∣ f ∗ ∣ ) O(\log |f^*|) O ( log ∣ f ∗ ∣ ) 指数 。这种「随数值大小线性、随输入位数指数」的复杂度称为伪多项式 (Pseudo-polynomial)。当容量是无理数时,算法甚至可能永不停机。
病根在于「选路太随意」。下面三种策略,分别从「选粗路」「按位逼近」「选短路」三个角度根治这个问题。
策略一:总挑最粗的路(Fattest Path)
既然每次只推一点点太亏,那就每次都挑能推最多流量的路——剩余容量最大的增广路径,俗称「最肥的路」。
收敛速度
设当前流为 f f f f ∗ f^* f ∗ f ′ = f ∗ − f f' = f^* - f f ′ = f ∗ − f f ′ f' f ′ G f G_f G f ∣ f ∗ ∣ − ∣ f ∣ |f^*| - |f| ∣ f ∗ ∣ − ∣ f ∣ f ′ f' f ′ m m m ∣ f ′ ∣ / m |f'| / m ∣ f ′ ∣/ m 1 / m 1/m 1/ m
∣ f ′ ∣ ⩽ ∣ f ∗ ∣ ( 1 − 1 m ) t ( 经过 t 次迭代 ) |f'| \le |f^*| \left(1 - \frac{1}{m}\right)^t \quad (\text{经过 } t \text{ 次迭代})
∣ f ′ ∣ ⩽ ∣ f ∗ ∣ ( 1 − m 1 ) t ( 经过 t 次迭代 )
由 ( 1 − 1 / m ) t ⩽ e − t / m (1 - 1/m)^t \le \e^{-t/m} ( 1 − 1/ m ) t ⩽ e − t / m ∣ f ∗ ∣ |f^*| ∣ f ∗ ∣ < 1 < 1 < 1 t = O ( m log ∣ f ∗ ∣ ) t = O(m \log |f^*|) t = O ( m log ∣ f ∗ ∣ ) 1 / m 1/m 1/ m
怎么高效找到最肥的路?靠另一个简单观察:肥路径由肥边组成 ——瓶颈 ⩾ W \ge W ⩾ W ⩾ W \ge W ⩾ W W W W < W < W < W s s s t t t ⩾ W \ge W ⩾ W O ( m log ∣ f ∗ ∣ ) O(m \log |f^*|) O ( m log ∣ f ∗ ∣ )
最肥路策略把迭代次数降到了 O ( m log ∣ f ∗ ∣ ) O(m \log |f^*|) O ( m log ∣ f ∗ ∣ ) ∣ f ∗ ∣ |f^*| ∣ f ∗ ∣ log ∣ f ∗ ∣ \log |f^*| log ∣ f ∗ ∣ 弱多项式 (Weakly-polynomial):随输入位数多项式,但仍含容量数值的对数。而且面对无理容量,收敛性依旧没有保证。
策略二:按容量位数缩放(Scaling)
缩放法换了个思路:不追求一步到位,而是按二进制位从高到低 逐步逼近。先只考虑「粗管道」,把大流量的骨架搭好,再逐步加入细管道修补。
容量缩放
对 i = ⌈ log 2 C ⌉ , … , 1 , 0 i = \lceil \log_2 C \rceil, \dots, 1, 0 i = ⌈ log 2 C ⌉ , … , 1 , 0 C C C i i i G i G_i G i G i G_i G i ⩾ 2 i \ge 2^i ⩾ 2 i
E ′ ′ ≜ { e ∈ E ′ : c e ′ ⩾ 2 i } E'' \triangleq \{e \in E' : c'_e \ge 2^i\}
E ′′ ≜ { e ∈ E ′ : c e ′ ⩾ 2 i }
在这一轮里,每条增广路径都至少贡献 2 i 2^i 2 i O ( m ) O(m) O ( m )
为什么每轮增广次数 ⩽ m \le m ⩽ m i i i 2 i + 1 2^{i+1} 2 i + 1 G i + 1 G_{i+1} G i + 1 s s s t t t < 2 i + 1 < 2^{i+1} < 2 i + 1 G i + 1 G_{i+1} G i + 1 < m ⋅ 2 i + 1 < m \cdot 2^{i+1} < m ⋅ 2 i + 1 2 i 2^i 2 i 2 m 2m 2 m
总共 O ( log C ) O(\log C) O ( log C ) O ( m ) O(m) O ( m ) O ( m ) O(m) O ( m )
O ( log 2 C ⋅ m ⋅ m ) = O ( m 2 log C ) O(\log_2 C \cdot m \cdot m) = O(m^2 \log C)
O ( log 2 C ⋅ m ⋅ m ) = O ( m 2 log C )
这同样是弱多项式(依赖容量的对数 log C \log C log C
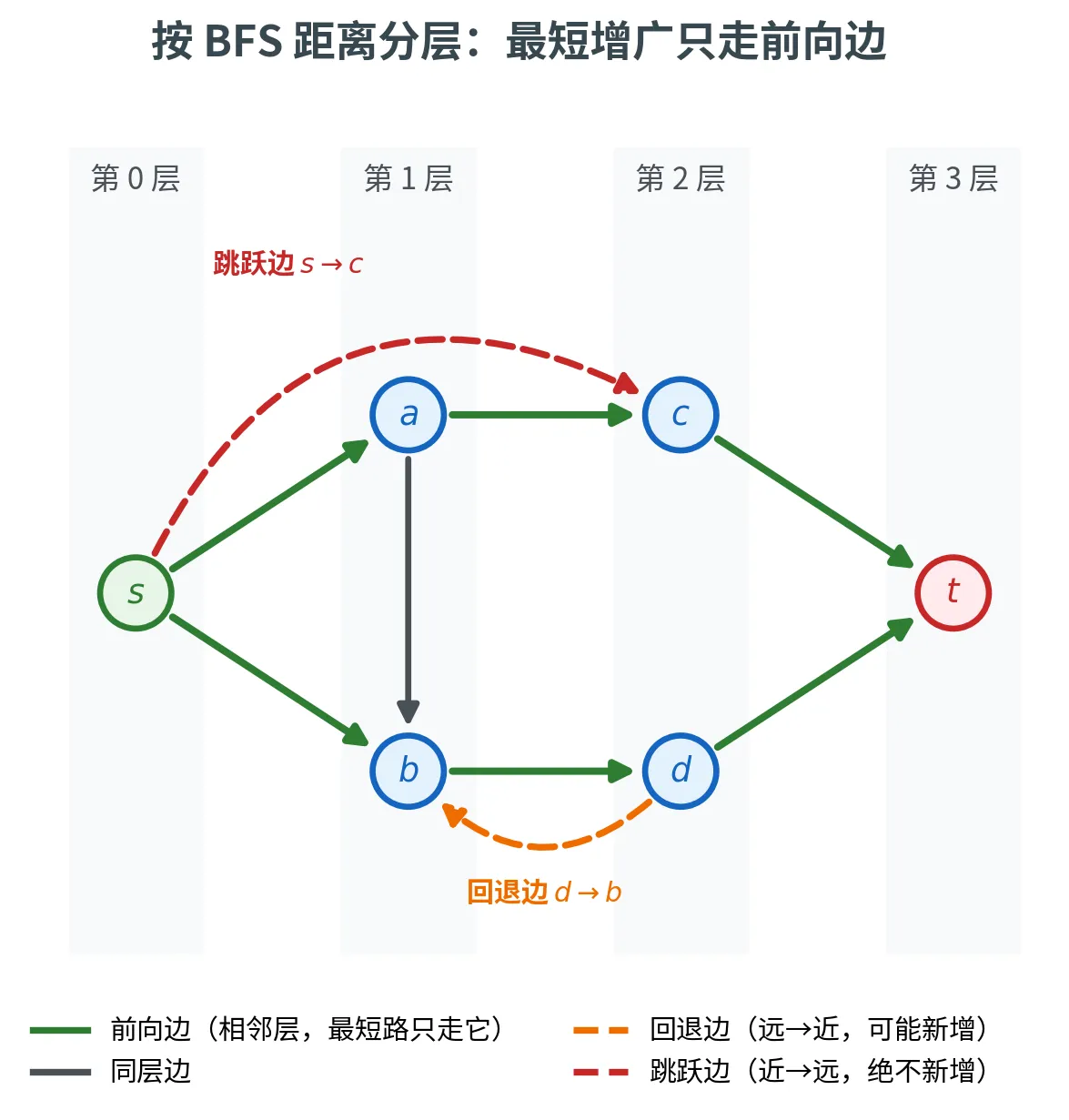
策略三:总挑最短的路(Edmonds-Karp / Dinitz)
最漂亮的思路来自一个反直觉的选择:不挑最肥的,挑最短的 (边数最少的)增广路径。神奇之处在于——这样选,复杂度居然彻底摆脱了容量数值,变成强多项式 (Strongly-polynomial,只依赖 n , m n, m n , m
把残余图按到 s s s
前向边 (Forth Edge):连接相邻两层(距离差 1 1 1 同层边 (Side Edge):连接同一层的两点;回退边 (Back Edge):从远层指向近层;跳跃边 (Jumping Edge):从近层跨到不相邻的远层。
最短路只增不减
沿最短增广路径增广时:
至少删掉一条前向边(瓶颈边饱和后从残余图消失);
只可能新增回退边——增广只在前向边上推流量,新冒出来的残余边都是前向边的反向,恰好从第 i + 1 i+1 i + 1 i i i
绝不会新增跳跃边 。
因此从 s s s t t t 单调不减 :想变短就得靠跳跃边「抄近道」,而跳跃边永远不会被造出来。
有了这个单调性,复杂度就好数了:最短距离取值范围是 1 , … , n 1, \dots, n 1 , … , n m m m m m m O ( n m ) O(nm) O ( nm ) O ( m ) O(m) O ( m )
O ( n m ) × O ( m ) = O ( m 2 n ) O(nm) \times O(m) = O(m^2 n)
O ( nm ) × O ( m ) = O ( m 2 n )
这就是 Edmonds-Karp 算法 。
Dinitz 的改进:一次性榨干一层
Edmonds-Karp 每找到一条最短路就增广一次,太浪费了——同一个距离值下其实可以一口气把所有 最短路径都增广掉。这就是 Dinitz 算法 (也写作 Dinic)的核心。
阻塞流
在一个固定最短距离下,只保留前向边构成分层图 ,在其上用一次 DFS 找出一个阻塞流 (Blocking Flow)——一组增广,使得每条 s s s t t t
每个「阶段」(一个固定的最短距离)用一次 DFS 构造阻塞流,耗时 O ( n m ) O(nm) O ( nm ) 1 , … , n 1, \dots, n 1 , … , n O ( n ) O(n) O ( n )
O ( n ) × O ( n m ) = O ( n 2 m ) O(n) \times O(nm) = O(n^2 m)
O ( n ) × O ( nm ) = O ( n 2 m )
由于通常 m ⩾ n m \ge n m ⩾ n O ( n 2 m ) O(n^2 m) O ( n 2 m ) O ( m 2 n ) O(m^2 n) O ( m 2 n )
算法全景
把这一节的成果汇成一张表——同一个 Ford-Fulkerson 框架,仅仅因为「怎么选增广路径」的不同,复杂度就跨越了三个量级:
算法
策略
时间复杂度
类型
Ford-Fulkerson
任意增广路径
O ( ∣ f ∗ ∣ ⋅ m ) O(\lvert f^* \rvert \cdot m) O (∣ f ∗ ∣ ⋅ m ) 伪多项式
最肥路径
最大瓶颈增广
O ( m 2 log 2 ∣ f ∗ ∣ ) O(m^2 \log^2 \lvert f^* \rvert) O ( m 2 log 2 ∣ f ∗ ∣) 弱多项式
容量缩放
按位缩放
O ( m 2 log C ) O(m^2 \log C) O ( m 2 log C ) 弱多项式
Edmonds-Karp
最短增广路径
O ( m 2 n ) O(m^2 n) O ( m 2 n ) 强多项式
Dinitz
阻塞流
O ( n 2 m ) O(n^2 m) O ( n 2 m ) 强多项式
三种「多项式」
伪多项式 :随数值大小多项式,随输入位数指数(如 ∣ f ∗ ∣ |f^*| ∣ f ∗ ∣ 弱多项式 :随输入位数多项式,但仍含数值的对数(如 log C \log C log C 强多项式 :只依赖输入中「数的个数」n , m n, m n , m
这条优化之路的终点——强多项式——正是算法理论追求的理想形态:无论容量是 1 1 1 10 100 10^{100} 1 0 100
最大流的应用
最大流的真正威力,在于它是一台「归约机器」:许多看似与流毫无关系的问题,只要巧妙地构造一张网络,就能转化为求最大流。这一节看几个经典归约。
多源多汇
最直接的推广是允许多个源点和多个汇点。
多源多汇最大流
给定网络 G = ( V , E ) G = (V, E) G = ( V , E ) c c c S = { s 1 , … , s k } S = \{s_1, \dots, s_k\} S = { s 1 , … , s k } T = { t 1 , … , t ℓ } T = \{t_1, \dots, t_\ell\} T = { t 1 , … , t ℓ } S S S T T T
归约只需一个小技巧:添加一个超级源点 s ∗ s^* s ∗ s i s_i s i ∞ \infty ∞ 超级汇点 t ∗ t^* t ∗ t j t_j t j ∞ \infty ∞ s ∗ s^* s ∗ t ∗ t^* t ∗
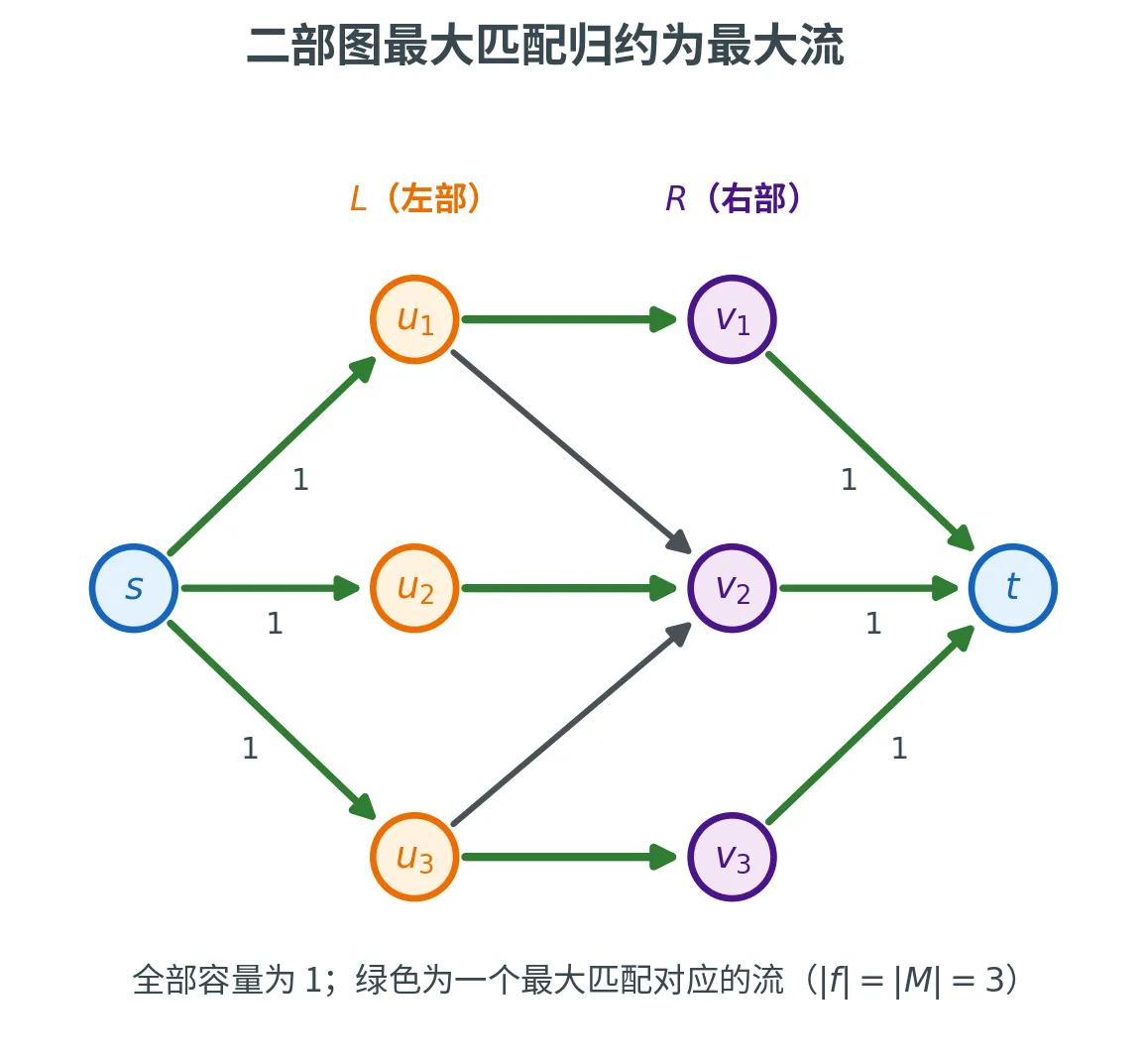
二部图最大匹配
这是最优美的归约之一。回忆第一讲,我们曾用 Edmonds 矩阵和随机化来判定二部图是否存在完美匹配;现在用最大流,我们能直接求出 最大匹配。
二部图最大匹配
二部图 (Bipartite Graph)G = ( L ∪ R , E ) G = (L \cup R, E) G = ( L ∪ R , E ) L , R L, R L , R 匹配 (Matching)M ⊆ E M \subseteq E M ⊆ E 完美匹配 (Perfect Matching)。最大匹配 就是边数最多的匹配。
把匹配问题「流化」的构造:
加源点 s s s s s s u ∈ L u \in L u ∈ L 1 1 1
每条原边 ( u , v ) ∈ E (u, v) \in E ( u , v ) ∈ E u ∈ L , v ∈ R u \in L, v \in R u ∈ L , v ∈ R u → v u \to v u → v 1 1 1
加汇点 t t t v ∈ R v \in R v ∈ R t t t 1 1 1
所有容量都是 1 1 1
匹配 ⟺ 流
最大匹配的大小 = 这张网络的最大流值,且二者可以互相转换:
匹配 ⇒ \Rightarrow ⇒ :给定匹配 M M M ( u , v ) ∈ M (u, v) \in M ( u , v ) ∈ M f s u = f u v = f v t = 1 f_{su} = f_{uv} = f_{vt} = 1 f s u = f uv = f v t = 1 0 0 0 ∣ f ∣ = ∣ M ∣ |f| = |M| ∣ f ∣ = ∣ M ∣ 流 ⇒ \Rightarrow ⇒ :给定整数流 f f f M = { ( u , v ) ∈ E : u ∈ L , v ∈ R , f u v > 0 } M = \{(u, v) \in E : u \in L, v \in R, f_{uv} > 0\} M = {( u , v ) ∈ E : u ∈ L , v ∈ R , f uv > 0 } 1 1 1 u ∈ L u \in L u ∈ L 1 1 1 v ∈ R v \in R v ∈ R 1 1 1 M M M ∣ M ∣ = ∣ f ∣ |M| = |f| ∣ M ∣ = ∣ f ∣
这里有一个需要补的细节:流可能是分数的,但匹配要求整数。所幸最大流问题有整性定理 ——当所有容量为整数时,Ford-Fulkerson 全程只做整数加减,必然给出整数最大流 。所以求出的流自动是 0 / 1 0/1 0/1
边不相交路径与最小割
容量为 1 1 1
最大边不相交路径
给定有向图 G = ( V , E ) G = (V, E) G = ( V , E ) s , t s, t s , t s s s t t t 最多条边不相交 (Edge-disjoint)路径。
把每条边容量设为 1 1 1 s s s t t t 1 1 1
而最大流最小割定理在这里化身为图论里著名的 Menger 定理 :s s s t t t s , t s, t s , t 1 1 1
最小割问题
s s s t t t s , t s, t s , t s , t s, t s , t 全局最小割 (Global Min-Cut):不指定源汇,求删除后能让整张图断开的最小割。可以固定一个点为 s s s t t t s s s t t t t t t s s s s s s t t t 2 ( n − 1 ) 2(n - 1) 2 ( n − 1 )
最小费用流
现实中,运输不仅有容量限制,还有成本 :同样把货送到,走高速要过路费,走小路则免费但慢。我们想在「送得最多」的前提下「花得最少」。
最小费用流问题
最小费用流问题 (Minimum-Cost Flow Problem, MCFP ):每条边 e e e c e c_e c e 费用 a e ∈ R + a_e \in \R^+ a e ∈ R +
min ∑ e ∈ E a e ⋅ f ( e ) s.t. ∑ e ∈ δ out ( s ) f ( e ) 达到最大 \min \sum_{e \in E} a_e \cdot f(e) \quad \text{s.t. } \sum_{e \in \delta^{\text{out}}(s)} f(e) \text{ 达到最大}
min e ∈ E ∑ a e ⋅ f ( e ) s.t. e ∈ δ out ( s ) ∑ f ( e ) 达到最大
它的一个著名特例是指派问题 (Assignment Problem):把 n n n n n n
怎么求最小费用流?思路依然是「改进当前解」,但改进的目标从「流量」换成了「费用」。一个已经达到最大流量的解,若还想降低费用,唯一的办法是重新分配 流量:在某条路径上少送一点、在另一条更便宜的路径上多送一点,保持总流量不变。这样一次「此消彼长」的重分配,在残余图里恰好对应一个环 ——一部分流量退回(沿反向边),一部分流量新增(沿正向边)。
消圈算法
一次重分配能降低费用,当且仅当它对应残余图中一个负费用环 (费用之和为负的环,反向边的费用取相反数)。于是算法朴素得惊人:
当残余图中存在负费用环时,沿该环重分配流量,消去这个负环。
没有负费用环时,当前流就是最小费用流。这就是消圈算法 (Cycle Canceling)。
负环的判定可用 Bellman-Ford 完成。消圈算法的正确性源于一个漂亮的事实:一个最大流是最小费用的,当且仅当它的残余图中不含负费用环——与「最大流 ⟺ 无增广路径」如出一辙,都是「局部最优 ⟺ 全局最优」的体现。
一个理论注脚:最大流是 P-完全的
最后一个值得知道的事实:在对数空间归约下,最大流问题是 P-完全的 (P-complete)。
这意味着什么?P-完全问题是 P 类中「最难并行化」的代表——如果最大流能被高效并行(落入 NC 类),那么整个 P 类都能高效并行,而这被广泛认为不太可能。换句话说,最大流大概率是「本质串行」的:增广路径一条接一条,难以拆成大量独立的并行子任务。这与它「易于串行求解」(多项式时间)并不矛盾——多项式时间说的是串行效率,P-完全说的是并行困难。
至此,网络流的故事告一段落。我们见识了一个具体优化问题的完整生命周期:定义、求解、加速、应用,以及贯穿始终的「流-割对偶」。接下来,我们要把视野从网络流拉高到一个更宏大的框架——它能把网络流、匹配乃至无数优化问题都收纳其中。
从网络流到线性规划
一个似曾相识的问题
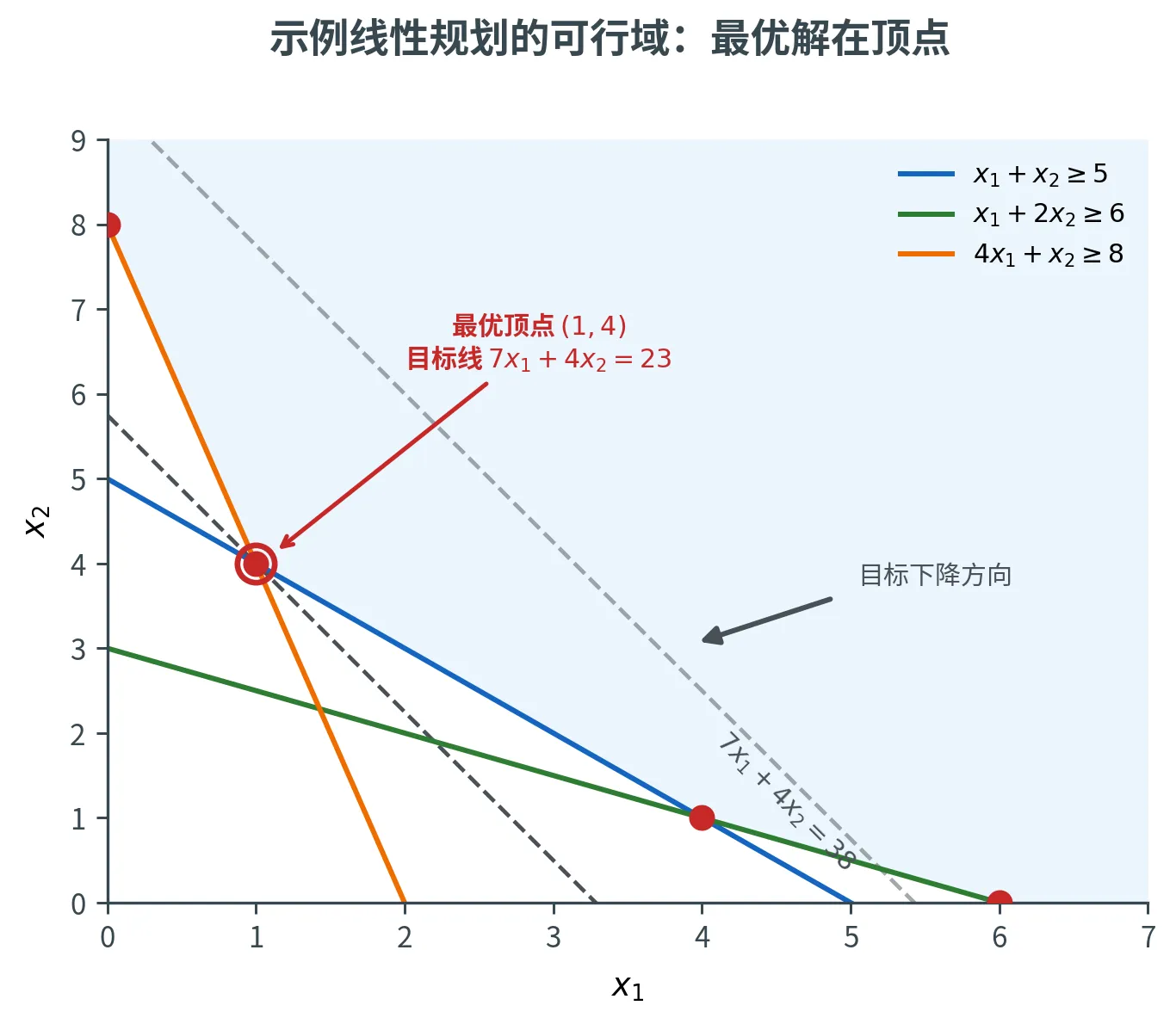
先看一个中学就见过的优化问题:
minimize 7 x 1 + 4 x 2 subject to x 1 + x 2 ⩾ 5 x 1 + 2 x 2 ⩾ 6 4 x 1 + x 2 ⩾ 8 x 1 , x 2 ⩾ 0 \begin{aligned}
\text{minimize} \quad & 7x_1 + 4x_2 \\
\text{subject to} \quad & x_1 + x_2 \ge 5 \\
& x_1 + 2x_2 \ge 6 \\
& 4x_1 + x_2 \ge 8 \\
& x_1, x_2 \ge 0
\end{aligned}
minimize subject to 7 x 1 + 4 x 2 x 1 + x 2 ⩾ 5 x 1 + 2 x 2 ⩾ 6 4 x 1 + x 2 ⩾ 8 x 1 , x 2 ⩾ 0
目标函数是变量的线性组合,约束也都是线性不等式。这类问题——线性的目标 + 线性的约束 ——就是线性规划。上面这个例子的最优解是 x 1 = 1 , x 2 = 4 x_1 = 1, x_2 = 4 x 1 = 1 , x 2 = 4 7 × 1 + 4 × 4 = 23 7 \times 1 + 4 \times 4 = 23 7 × 1 + 4 × 4 = 23
线性规划的几何图像很美:每个不等式约束划出一个半平面,所有约束的交集是一个多边形(高维下是多面体)的可行区域;目标函数 7 x 1 + 4 x 2 = 常数 7x_1 + 4x_2 = \text{常数} 7 x 1 + 4 x 2 = 常数 顶点 上取得。这个「最优解在顶点」的现象,是后面所有算法的基石。
最大流其实是线性规划
为什么在讲完网络流后突然转向线性规划?因为最大流本身就是一个线性规划 。把流的每条边流量 f u v f_{uv} f uv
maximize ∑ u : ( s , u ) ∈ E f s u subject to 0 ⩽ f u v ⩽ c u v ∀ ( u , v ) ∈ E ∑ w : ( w , u ) ∈ E f w u − ∑ v : ( u , v ) ∈ E f u v = 0 ∀ u ∈ V ∖ { s , t } \begin{aligned}
\text{maximize} \quad & \sum_{u : (s, u) \in E} f_{su} \\
\text{subject to} \quad & 0 \le f_{uv} \le c_{uv} & \forall (u, v) \in E \\
& \sum_{w : (w, u) \in E} f_{wu} - \sum_{v : (u, v) \in E} f_{uv} = 0 & \forall u \in V \setminus \{s, t\}
\end{aligned}
maximize subject to u : ( s , u ) ∈ E ∑ f s u 0 ⩽ f uv ⩽ c uv w : ( w , u ) ∈ E ∑ f w u − v : ( u , v ) ∈ E ∑ f uv = 0 ∀ ( u , v ) ∈ E ∀ u ∈ V ∖ { s , t }
目标(最大化源点流出)是线性的,容量约束和守恒约束也都是线性的——这就是一个不折不扣的线性规划。这个观察有深远意义:网络流的所有结构(包括最大流最小割对偶)都是线性规划一般理论的特例。当我们后面建立起线性规划的对偶理论,会发现「最大流 = 最小割」不过是「线性规划强对偶定理」的一个具体实例。
线性规划的统一能力远不止于此。匹配、最短路、覆盖、调度、运输、网络设计……数不清的优化问题都能写成线性规划。掌握它,就掌握了一把能撬动整个组合优化领域的杠杆。
线性规划的三种形式
要研究线性规划,先要把五花八门的写法统一起来。同一个线性规划可以有多种等价形式,互相之间可以机械地转换。
一般形式
最一般的线性规划允许等式约束、不等式约束、有界变量、自由变量混杂:
线性规划(一般形式)
给定矩阵 A = { a i j } [ m ] × [ n ] \bm{A} = \{a_{ij}\}_{[m] \times [n]} A = { a ij } [ m ] × [ n ] M ⊆ [ m ] , N ⊆ [ n ] M \subseteq [m], N \subseteq [n] M ⊆ [ m ] , N ⊆ [ n ]
minimize c ⊺ x subject to a i ⊺ x = b i i ∈ M a i ⊺ x ⩾ b i i ∉ M x j ⩾ 0 j ∈ N x j 无约束 j ∉ N \begin{aligned}
\text{minimize} \quad & \bm{c}^{\intercal} \bm{x} \\
\text{subject to} \quad & \bm{a}_i^{\intercal} \bm{x} = b_i & i \in M \\
& \bm{a}_i^{\intercal} \bm{x} \ge b_i & i \notin M \\
& x_j \ge 0 & j \in N \\
& x_j \text{ 无约束} & j \notin N
\end{aligned}
minimize subject to c ⊺ x a i ⊺ x = b i a i ⊺ x ⩾ b i x j ⩾ 0 x j 无约束 i ∈ M i ∈ / M j ∈ N j ∈ / N
这里 a i ⊺ \bm{a}_i^{\intercal} a i ⊺ A \bm{A} A i i i
规范形式与标准形式
规范形式与标准形式
规范形式 (Canonical Form):只有 ⩾ \ge ⩾
min c ⊺ x s.t. A x ⩾ b , x ⩾ 0 \min \bm{c}^{\intercal} \bm{x} \quad \text{s.t. } \bm{A}\bm{x} \ge \bm{b},\ \bm{x} \ge \bm{0}
min c ⊺ x s.t. A x ⩾ b , x ⩾ 0
标准形式 (Standard Form):只有 = = =
min c ⊺ x s.t. A x = b , x ⩾ 0 \min \bm{c}^{\intercal} \bm{x} \quad \text{s.t. } \bm{A}\bm{x} = \bm{b},\ \bm{x} \ge \bm{0}
min c ⊺ x s.t. A x = b , x ⩾ 0
两种形式各有用处:规范形式(不等式)便于讨论几何与对偶,标准形式(等式)便于代数操作与单纯形法。任意线性规划都能转成它们,靠的是几个小变换。
一般形式 → \to → :
等式 a i ⊺ x = b i \bm{a}_i^{\intercal} \bm{x} = b_i a i ⊺ x = b i a i ⊺ x ⩾ b i \bm{a}_i^{\intercal} \bm{x} \ge b_i a i ⊺ x ⩾ b i − a i ⊺ x ⩾ − b i -\bm{a}_i^{\intercal} \bm{x} \ge -b_i − a i ⊺ x ⩾ − b i
自由变量 x j x_j x j x j = x j + − x j − x_j = x_j^+ - x_j^- x j = x j + − x j − x j + , x j − ⩾ 0 x_j^+, x_j^- \ge 0 x j + , x j − ⩾ 0
最大化 c ⊺ x \bm{c}^{\intercal}\bm{x} c ⊺ x − c ⊺ x -\bm{c}^{\intercal}\bm{x} − c ⊺ x ⩽ \le ⩽ ⩾ \ge ⩾
规范形式 → \to → :每个不等式 a i ⊺ x ⩾ b i \bm{a}_i^{\intercal} \bm{x} \ge b_i a i ⊺ x ⩾ b i 松弛变量 (Slack Variable)s i ⩾ 0 s_i \ge 0 s i ⩾ 0 b i b_i b i s i s_i s i a i ⊺ x − s i = b i \bm{a}_i^{\intercal} \bm{x} - s_i = b_i a i ⊺ x − s i = b i ⩽ \le ⩽ + s i + s_i + s i A \bm{A} A A ′ = [ A ∣ − I ] \bm{A}' = [\bm{A} \mid -\bm{I}] A ′ = [ A ∣ − I ]
形式之间可以自由穿梭
三种形式互相等价、可机械转换。证明定理时挑最顺手的那个用就行——讲几何用规范形式,讲单纯形用标准形式。下面默认线性规划都能在多项式时间内求解(具体算法稍后介绍),先来理解它的几何结构。
线性规划的几何
线性规划「最优解在顶点」的直觉需要严格的几何语言来支撑。这一节建立可行域的几何图像:它是一个由半空间相交而成的「多面体」,而最优解总能在它的「角」上找到。先看本讲开头那个例子的可行域长什么样:
三条 ⩾ \ge ⩾ 7 x 1 + 4 x 2 = 常数 7x_1 + 4x_2 = \text{常数} 7 x 1 + 4 x 2 = 常数 ( 1 , 4 ) (1, 4) ( 1 , 4 )
凸多面体
先从凸性这个基本概念说起。
凸集与凸包
集合 S ⊆ R n S \subseteq \R^n S ⊆ R n 凸集 (Convex Set),若 ∀ x , y ∈ S \forall \bm{x}, \bm{y} \in S ∀ x , y ∈ S λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ ∈ [ 0 , 1 ] λ x + ( 1 − λ ) y ∈ S \lambda \bm{x} + (1 - \lambda) \bm{y} \in S λ x + ( 1 − λ ) y ∈ S 凸体 (Convex Body)。集合 S S S 凸包 (Convex Hull)是包含它的最小凸集。
线性规划的可行域是由一组线性不等式(每个划出一个「半空间」)交出来的,这种集合有专门的名字。
超平面、半空间与多面体
超平面 (Hyperplane):n n n n − 1 n - 1 n − 1 { x : ∑ j = 1 n a j x j = b } \left\{\bm{x} : \sum_{j=1}^n a_j x_j = b\right\} { x : ∑ j = 1 n a j x j = b } (闭仿射)半空间 (Halfspace):超平面的一侧 { x : ∑ j = 1 n a j x j ⩾ b } \left\{\bm{x} : \sum_{j=1}^n a_j x_j \ge b\right\} { x : ∑ j = 1 n a j x j ⩾ b } 凸多面体 (Convex Polyhedron):有限多个半空间的交集 { x : A x ⩾ b } \{\bm{x} : \bm{A}\bm{x} \ge \bm{b}\} { x : A x ⩾ b } 凸多胞形 (Convex Polytope):有界的凸多面体(等价地,有限个点的凸包)。
规范形式线性规划的可行域 { x : A x ⩾ b , x ⩾ 0 } \{\bm{x} : \bm{A}\bm{x} \ge \bm{b},\ \bm{x} \ge \bm{0}\} { x : A x ⩾ b , x ⩾ 0 }
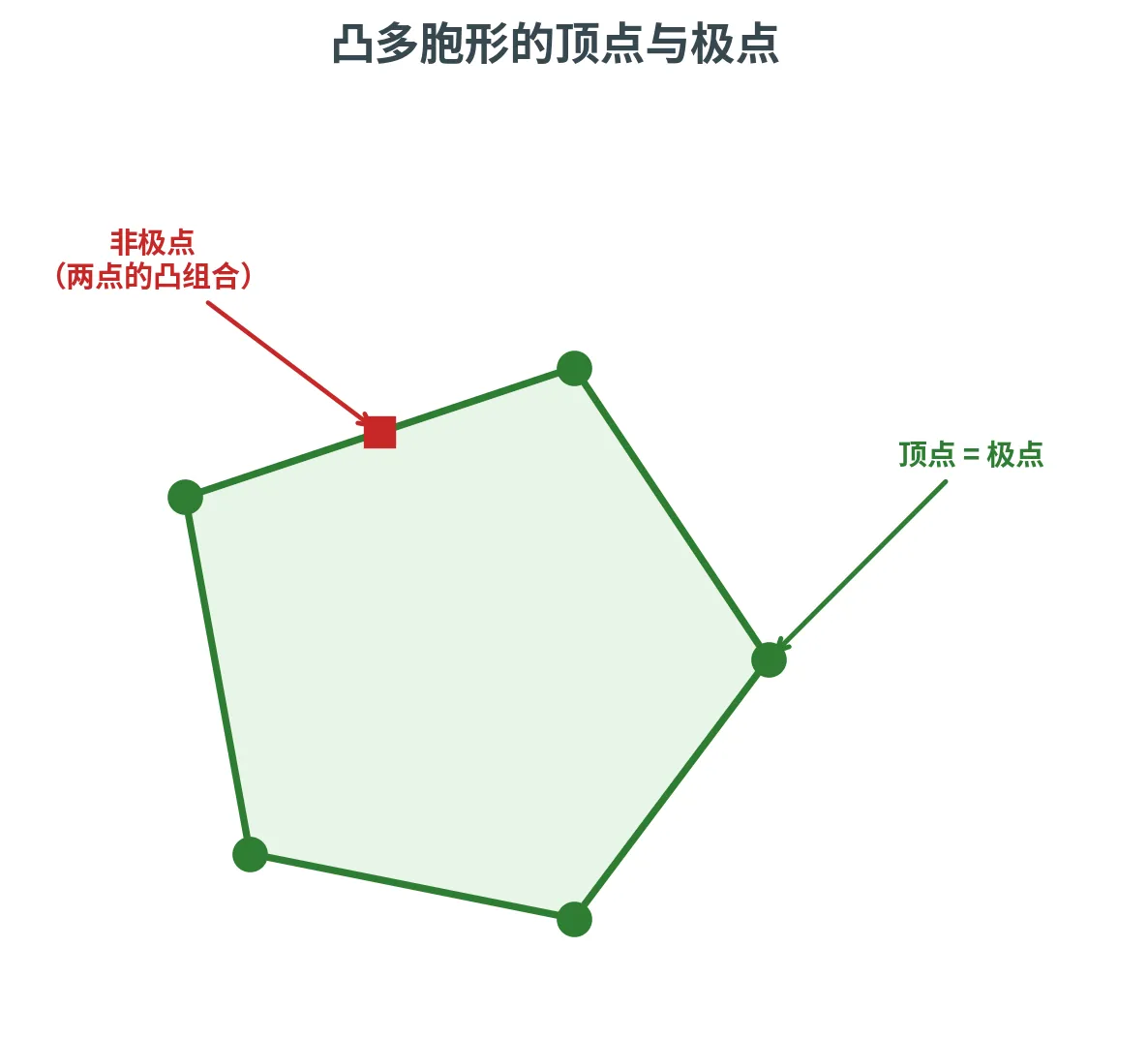
顶点与极点
多面体的「角」有两种看似不同、实则等价的定义方式:一种从优化角度(顶点),一种从几何角度(极点)。
顶点与极点
设 P = { x ∈ R n : A x ⩾ b } P = \{\bm{x} \in \R^n : \bm{A}\bm{x} \ge \bm{b}\} P = { x ∈ R n : A x ⩾ b }
顶点 (Vertex):点 x ∈ P \bm{x} \in P x ∈ P c ∈ R n \bm{c} \in \R^n c ∈ R n x \bm{x} x P P P c ⊺ y \bm{c}^{\intercal} \bm{y} c ⊺ y c ⊺ x < c ⊺ y \bm{c}^{\intercal}\bm{x} < \bm{c}^{\intercal}\bm{y} c ⊺ x < c ⊺ y y ≠ x \bm{y} \ne \bm{x} y = x P P P x \bm{x} x 极点 (Extreme Point):点 x ∈ P \bm{x} \in P x ∈ P 不能 表示成 P P P y , z \bm{y}, \bm{z} y , z x \bm{x} x
多胞形的五个角都既是顶点又是极点;而上边中点(红色方块)能写成相邻两顶点的凸组合,所以不是极点。这两种「角」的刻画殊途同归,再加上关于「最优解落在哪」的结论,构成三个奠基命题。
三个关键命题
顶点存在性 :凸多面体 P P P x , y \bm{x}, \bm{y} x , y y ≠ 0 \bm{y} \ne \bm{0} y = 0 x + λ y ∈ P \bm{x} + \lambda \bm{y} \in P x + λ y ∈ P λ ∈ R \lambda \in \R λ ∈ R 顶点 = 极点 :对非空凸多面体 P P P x ∈ P \bm{x} \in P x ∈ P x \bm{x} x ⟺ \iff ⟺ x \bm{x} x 顶点是最优解 :若可行域 { x : A x ⩾ b } \{\bm{x} : \bm{A}\bm{x} \ge \bm{b}\} { x : A x ⩾ b } min { c ⊺ x : A x ⩾ b } \min\{\bm{c}^{\intercal}\bm{x} : \bm{A}\bm{x} \ge \bm{b}\} min { c ⊺ x : A x ⩾ b } 存在一个最优解是顶点 。
命题 3 是整个单纯形法的理论支柱:要找最优解,不必在整个连续的可行域里大海捞针,只需在有限多个顶点中搜索。直觉上,线性目标函数沿某方向单调,把它推到底,最优值必然顶在可行域的「角」上——除非目标方向恰好与某条边平行,但那种情况下那条边的端点(仍是顶点)也是最优的。
基本可行解
顶点是几何概念,但算法需要代数的抓手。在标准形式下,顶点有一个纯代数的等价描述——基本可行解 。
把标准形式 min { c ⊺ x : A x = b , x ⩾ 0 } \min\{\bm{c}^{\intercal}\bm{x} : \bm{A}\bm{x} = \bm{b},\ \bm{x} \ge \bm{0}\} min { c ⊺ x : A x = b , x ⩾ 0 } A ∈ R m × n \bm{A} \in \R^{m \times n} A ∈ R m × n m = rank ( A ) ⩽ n m = \operatorname{rank}(\bm{A}) \le n m = rank ( A ) ⩽ n
基本可行解
基 (Basis)B ⊆ [ n ] B \subseteq [n] B ⊆ [ n ] A \bm{A} A m m m 基本解 (Basic Solution):令非基变量 x [ n ] ∖ B = 0 x_{[n] \setminus B} = 0 x [ n ] ∖ B = 0 A [ m ] × B x B = b \bm{A}_{[m] \times B}\, \bm{x}_B = \bm{b} A [ m ] × B x B = b x \bm{x} x A x = b \bm{A}\bm{x} = \bm{b} A x = b ⩾ 0 \ge 0 ⩾ 0 基本可行解 (Basic Feasible Solution, bfs ):满足 x ⩾ 0 \bm{x} \ge \bm{0} x ⩾ 0 bfs 与图搜索的 BFS(宽度优先搜索)无关。
代数与几何在这里完美对接:
bfs = 顶点
x \bm{x} x min { c ⊺ x : A x = b ∧ x ⩾ 0 } \min\{\bm{c}^{\intercal}\bm{x} : \bm{A}\bm{x} = \bm{b} \wedge \bm{x} \ge \bm{0}\} min { c ⊺ x : A x = b ∧ x ⩾ 0 } x \bm{x} x { x : A x = b ∧ x ⩾ 0 } \{\bm{x} : \bm{A}\bm{x} = \bm{b} \wedge \bm{x} \ge \bm{0}\} { x : A x = b ∧ x ⩾ 0 }
这座桥让算法得以「计算」顶点:每选定一组基 B B B m m m ( n m ) \binom{n}{m} ( m n )
单纯形法与求解器
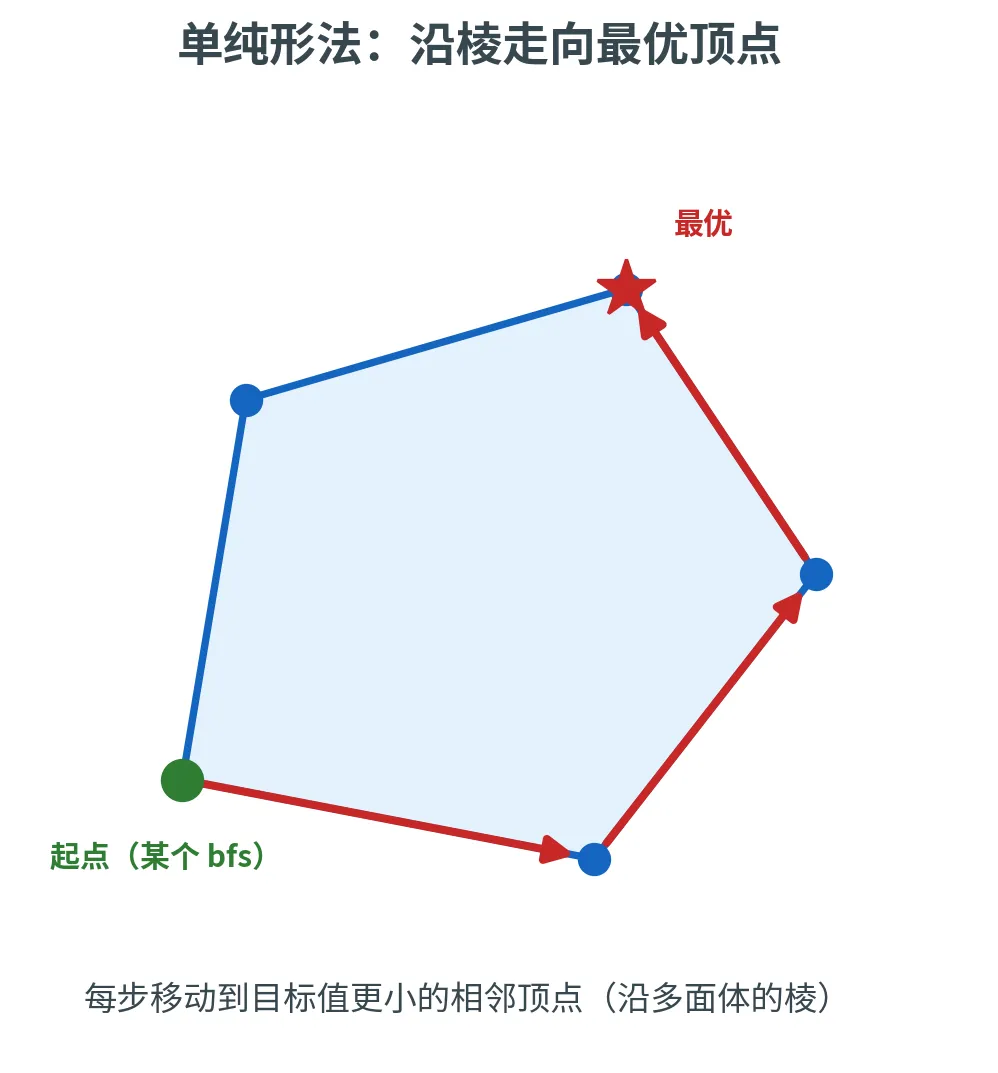
单纯形法
有了「最优解在顶点」与「顶点 = bfs 」,求解线性规划的第一个算法呼之欲出:从一个顶点出发,沿着多面体的棱不断走向更好的相邻顶点,直到无路可走。
单纯形法(Dantzig 1947)
称两个 bfs 为相邻 (Neighbor),若它们的基共享 m − 1 m - 1 m − 1 单纯形法 (Simplex Method):
从某个 bfs x \bm{x} x bfs x ′ \bm{x}' x ′ c ⊺ x ′ < c ⊺ x \bm{c}^{\intercal}\bm{x}' < \bm{c}^{\intercal}\bm{x} c ⊺ x ′ < c ⊺ x x ′ \bm{x}' x ′
单纯形法本质是「沿棱下山」的局部搜索:从某个 bfs 出发,每次挪到目标值更小的相邻顶点,直到无路可走。
它为什么能找到全局最优?因为线性规划是凸优化 :
局部最优即全局最优
可行域是凸集、目标函数是线性(从而是凸)函数,所以任何局部最优 自动是全局最优 。单纯形法停在一个「所有邻居都不更优」的顶点,这个顶点就是全局最优解。
凸性是这里的关键魔法。在非凸问题里,局部搜索会困在山谷中的次优解;但凸性抹平了所有「假谷底」,让简单的爬山法直达真正的最优。
单纯形法的复杂度与其他求解器
单纯形法在实践中极快,但它有一个理论上的尴尬:
单纯形法的最坏情况是指数的
Klee-Minty(1972)构造了一个「扭曲的立方体」,让单纯形法被迫访问几乎所有 2 n 2^n 2 n 平滑复杂度 (Smoothed Complexity)是多项式的:对输入做微小随机扰动后,期望运行时间是多项式。这解释了「最坏情况指数、实践中飞快」的反差。
那么线性规划到底能不能保证多项式时间求解?能——但要靠另外两类算法。
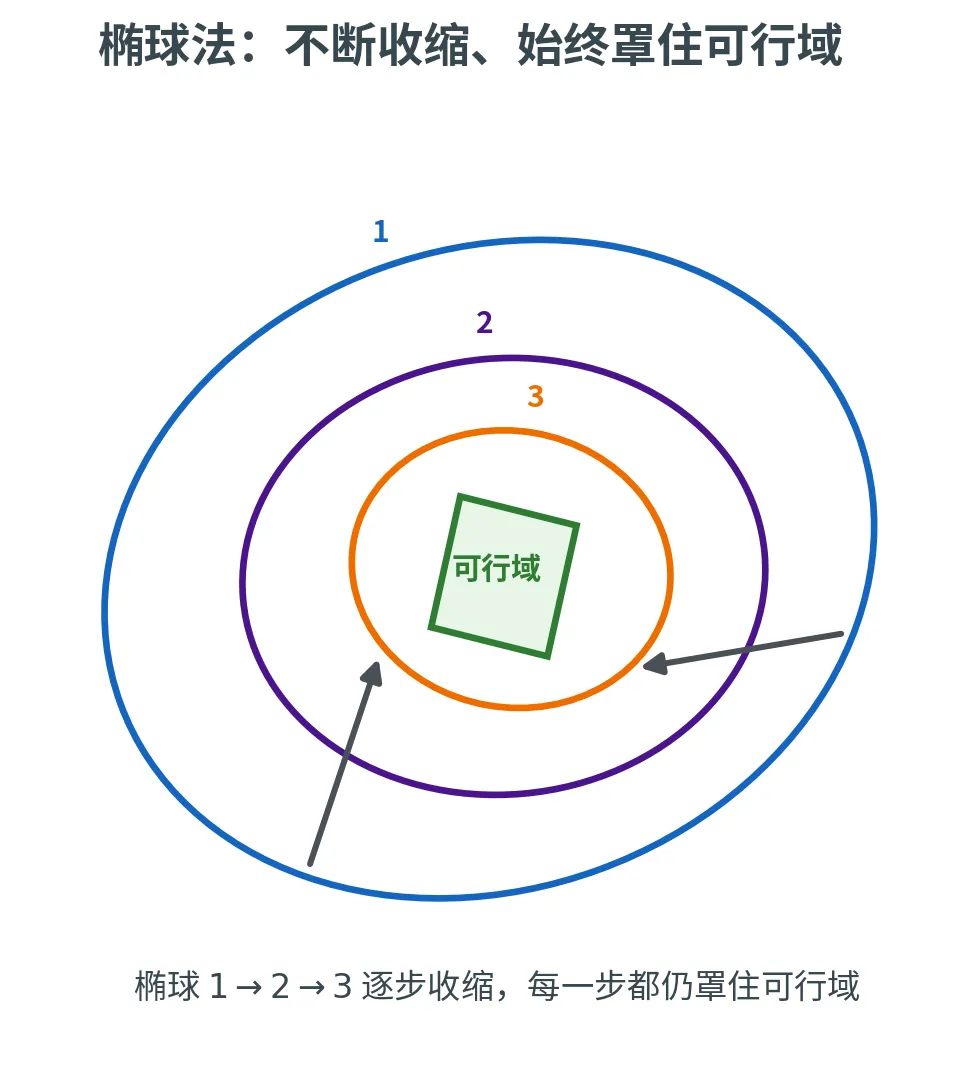
椭球法(Khachiyan 1979)
椭球法 (Ellipsoid Method)维护一个包含可行域的椭球 ,每步用一个超平面把椭球切成两半,找一个更小的椭球罩住「正确的那一半」,不断收缩,直到锁定可行点。它首次证明了线性规划属于 P \mathsf{P} P O ( n 6 ) O(n^6) O ( n 6 )
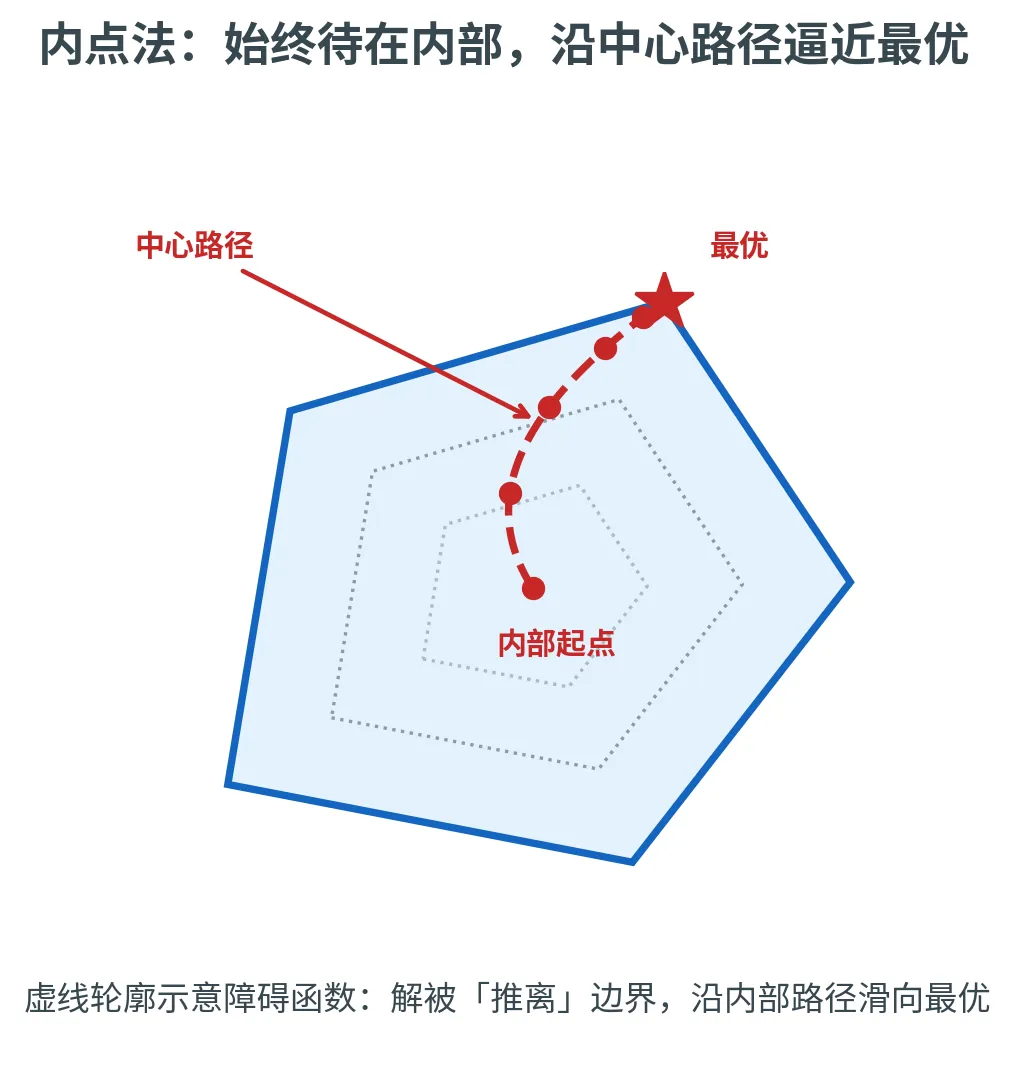
内点法(Karmarkar 1984)
内点法 (Interior-Point Method)让解始终待在多面体内部 ,用一个「障碍惩罚函数」阻止它过早贴到边界上,沿内部的「中心路径」滑向最优,最终任意逼近最优解。Karmarkar 开创此路线后,Vaidya(1989)将运行时间改进到 O ( n 2.5 ) O(n^{2.5}) O ( n 2.5 )
这两类算法的对比,连同单纯形法一起汇成下表——它们走的「路线」截然不同:单纯形法沿边界的顶点跳,椭球法和内点法则一个从外包夹、一个从内部逼近。
求解器
最坏复杂度
特点
单纯形法
指数(平滑多项式)
实践极快,沿顶点游走
椭球法
O ( n 6 ) O(n^6) O ( n 6 ) 首个多项式算法,理论价值大
内点法
O ( n 2.5 ) O(n^{2.5}) O ( n 2.5 ) 多项式且实践快,沿内部路径
线性规划的研究方向
围绕线性规划的算法研究不止「解得更快」一条线:除了多项式时间精确算法,还包括多项式时间近似 算法、把线性规划作为整数规划分支定界 (Branch-and-Bound)法的子程序,以及在线算法、分布式算法、动态算法、快速算法等其他计算模型下的线性规划求解。
把线性规划当黑箱
本讲后半部分只需记住一个事实:线性规划可以在多项式时间内求解 。具体用哪种求解器无关紧要——我们要把它当成一个现成的「优化引擎」,去攻克那些本来很难的组合问题。
线性规划的应用横跨计算机科学、数学、运筹学、经济学,涵盖运输、调度、聚类、网络路由、资源分配、设施选址等问题。而它在算法设计中最迷人的用法,是作为攻克 NP-难问题 的跳板——这正是下一节的主题。
线性规划松弛与舍入
顶点覆盖问题
我们用一个经典的 NP-难问题作主角:顶点覆盖。
顶点覆盖
给定无向图 G = ( V , E ) G = (V, E) G = ( V , E ) C ⊆ V C \subseteq V C ⊆ V C C C C C C
顶点覆盖是经典的 NP-难问题。它其实是集合覆盖 (Set Cover)的一个特例:把每个顶点看作一个「集合」,包含与它相邻的边——由于每条边恰有两个端点,每个元素(边)恰好出现在两个集合里,即「频率为 2 2 2
用贪心的集合覆盖算法可得 ln n \ln n ln n
有一个漂亮的 2 2 2 极大匹配 (Maximal Matching,即不能再添加任何边的匹配——注意它不同于边数最多的「最大」匹配,极大的不一定最大),输出所有被匹配的顶点;
Khot-Regev(2008)证明:假设唯一博弈猜想 (Unique Games Conjecture, UGC )成立,不存在多项式时间的 ( 2 − ϵ ) (2 - \epsilon) ( 2 − ϵ )
近似比
一个最小化问题的算法是 α \alpha α α ⩾ 1 \alpha \ge 1 α ⩾ 1 SOL \text{SOL} SOL SOL ⩽ α ⋅ OPT \text{SOL} \le \alpha \cdot \text{OPT} SOL ⩽ α ⋅ OPT α \alpha α 1 1 1 2 2 2 UGC 下,顶点覆盖的 2 2 2 2 2 2
下面我们用线性规划重新得到这个 2 2 2
整数规划与它的松弛
第一步是把组合问题写成整数线性规划 (Integer Linear Program, ILP )——和线性规划一样,但变量被限制为整数。
顶点覆盖的整数规划
为每个顶点 v v v 0 / 1 0/1 0/1 x v x_v x v x v = 1 x_v = 1 x v = 1 C C C
minimize ∑ v ∈ V x v (线性目标) subject to ∑ v ∈ e x v ⩾ 1 ∀ e ∈ E (线性约束) x v ∈ { 0 , 1 } ∀ v ∈ V (整数域) \begin{aligned}
\text{minimize} \quad & \sum_{v \in V} x_v & \text{(线性目标)} \\
\text{subject to} \quad & \sum_{v \in e} x_v \ge 1 & \forall e \in E \quad \text{(线性约束)} \\
& x_v \in \{0, 1\} & \forall v \in V \quad \text{(整数域)}
\end{aligned}
minimize subject to v ∈ V ∑ x v v ∈ e ∑ x v ⩾ 1 x v ∈ { 0 , 1 } ( 线性目标 ) ∀ e ∈ E ( 线性约束 ) ∀ v ∈ V ( 整数域 )
约束 ∑ v ∈ e x v ⩾ 1 \sum_{v \in e} x_v \ge 1 ∑ v ∈ e x v ⩾ 1 e = ( u , w ) e = (u, w) e = ( u , w ) x u + x w ⩾ 1 x_u + x_w \ge 1 x u + x w ⩾ 1
这个整数规划精确 刻画了顶点覆盖——但 x v ∈ { 0 , 1 } x_v \in \{0, 1\} x v ∈ { 0 , 1 }
关键的一步叫松弛:把碍事的整数约束 x v ∈ { 0 , 1 } x_v \in \{0, 1\} x v ∈ { 0 , 1 } x v ∈ [ 0 , 1 ] x_v \in [0, 1] x v ∈ [ 0 , 1 ]
线性规划松弛
minimize ∑ v ∈ V x v subject to ∑ v ∈ e x v ⩾ 1 ∀ e ∈ E x v ∈ [ 0 , 1 ] ∀ v ∈ V (分数域) \begin{aligned}
\text{minimize} \quad & \sum_{v \in V} x_v \\
\text{subject to} \quad & \sum_{v \in e} x_v \ge 1 && \forall e \in E \\
& x_v \in [0, 1] && \forall v \in V \quad \text{(分数域)}
\end{aligned}
minimize subject to v ∈ V ∑ x v v ∈ e ∑ x v ⩾ 1 x v ∈ [ 0 , 1 ] ∀ e ∈ E ∀ v ∈ V ( 分数域 )
把整数域 { 0 , 1 } \{0, 1\} { 0 , 1 } [ 0 , 1 ] [0, 1] [ 0 , 1 ] 多项式时间可解 的线性规划。代价是:解出来的 x v ∗ x_v^* x v ∗ 1 / 2 1/2 1/2
松弛与舍入
线性规划松弛与舍入
求线性规划松弛的最优解 x ∗ ∈ [ 0 , 1 ] V \bm{x}^* \in [0, 1]^V x ∗ ∈ [ 0 , 1 ] V
把 x ∗ \bm{x}^* x ∗ x ^ ∈ { 0 , 1 } V \hat{\bm{x}} \in \{0, 1\}^V x ^ ∈ { 0 , 1 } V x ^ v = { 1 x v ∗ ⩾ 0.5 0 否则 \hat{x}_v = \begin{cases} 1 & x_v^* \ge 0.5 \\ 0 & \text{否则} \end{cases}
x ^ v = { 1 0 x v ∗ ⩾ 0.5 否则
阈值 0.5 0.5 0.5
舍入后要回答两个问题:得到的 x ^ \hat{\bm{x}} x ^ 可行性 )?它离最优有多远(近似比 )?
可行性 :对任意边 e = ( u , w ) e = (u, w) e = ( u , w ) x u ∗ + x w ∗ ⩾ 1 x_u^* + x_w^* \ge 1 x u ∗ + x w ∗ ⩾ 1 ⩾ 0.5 \ge 0.5 ⩾ 0.5 < 1 < 1 < 1 ⩾ 0.5 \ge 0.5 ⩾ 0.5 1 1 1 x ^ u + x ^ w ⩾ 1 \hat{x}_u + \hat{x}_w \ge 1 x ^ u + x ^ w ⩾ 1 e e e x ^ \hat{\bm{x}} x ^ 0.5 0.5 0.5
近似比 :舍入规则有个关键性质——x ^ v ⩽ 2 x v ∗ \hat{x}_v \le 2 x_v^* x ^ v ⩽ 2 x v ∗ x ^ v = 1 \hat{x}_v = 1 x ^ v = 1 x v ∗ ⩾ 0.5 x_v^* \ge 0.5 x v ∗ ⩾ 0.5 2 x v ∗ ⩾ 1 = x ^ v 2x_v^* \ge 1 = \hat{x}_v 2 x v ∗ ⩾ 1 = x ^ v x ^ v = 0 \hat{x}_v = 0 x ^ v = 0
SOL = ∑ v ∈ V x ^ v ⩽ 2 ∑ v ∈ V x v ∗ = 2 ⋅ OPT LP \text{SOL} = \sum_{v \in V} \hat{x}_v \le 2 \sum_{v \in V} x_v^* = 2 \cdot \text{OPT}_{\text{LP}}
SOL = v ∈ V ∑ x ^ v ⩽ 2 v ∈ V ∑ x v ∗ = 2 ⋅ OPT LP
再用一个核心不等式把松弛最优值与真实最优值联系起来:
松弛是真实问题的下界
OPT = OPT Int ⩾ OPT LP \text{OPT} = \text{OPT}_{\text{Int}} \ge \text{OPT}_{\text{LP}}
OPT = OPT Int ⩾ OPT LP
线性规划松弛的可行域包含 整数规划的可行域({ 0 , 1 } ⊂ [ 0 , 1 ] \{0, 1\} \subset [0, 1] { 0 , 1 } ⊂ [ 0 , 1 ] 下界 。
把两步串起来:
SOL ⩽ 2 ⋅ OPT LP ⩽ 2 ⋅ OPT \text{SOL} \le 2 \cdot \text{OPT}_{\text{LP}} \le 2 \cdot \text{OPT}
SOL ⩽ 2 ⋅ OPT LP ⩽ 2 ⋅ OPT
这就证明了线性规划松弛舍入是顶点覆盖的 2 2 2
通用范式
刚才的过程不是顶点覆盖独有的,而是一套适用于海量 NP-难问题的通用范式:
flowchart LR
A["原问题<br/>(NP-难组合优化)"] --> B["建模<br/>写成整数规划 ILP"]
B --> C["松弛<br/>整数域 → 分数域"]
C --> D["求解<br/>多项式时间解 LP"]
D --> E["舍入<br/>分数解 → 整数解"]
E --> F["分析<br/>证明 SOL ≤ α·OPT"]
classDef problem fill:#ffebee,stroke:#c62828,stroke-width:2px
classDef model fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef solve fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef analyze fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
class A problem
class B,C model
class D,E solve
class F analyze
建模 :把优化问题写成整数线性规划;松弛 :放宽整数约束,得到线性规划;求解 :用高效线性规划求解器找松弛最优解;舍入 :把分数最优解舍入成可行的整数解;分析 :证明舍入解与最优解相差不远(通常拿松弛最优值作下界来比较)。
这套范式的精髓是:用一个能在多项式时间解出的「松弛版本」当跳板,借它的最优值作标尺,再把它的解小心地「圆整」回合法的整数解。
整性间隙
松弛舍入法能做到多好,有一个内在的极限——它取决于「松弛」这一步丢失了多少信息。这个损失由整性间隙度量。
整性间隙
一个整数规划与其线性规划松弛之间的整性间隙 (Integrality Gap)是二者最优值之比在所有实例上的最坏值:
整性间隙 = sup I OPT ( I ) OPT LP ( I ) \text{整性间隙} = \sup_{I} \frac{\text{OPT}(I)}{\text{OPT}_{\text{LP}}(I)}
整性间隙 = I sup OPT LP ( I ) OPT ( I )
(最小化问题中此比值 ⩾ 1 \ge 1 ⩾ 1 OPT / OPT LP ⩽ 1 \text{OPT} / \text{OPT}_{\text{LP}} \le 1 OPT / OPT LP ⩽ 1 1 1 1
整性间隙刻画了松弛的「先天质量」。它有两层含义:
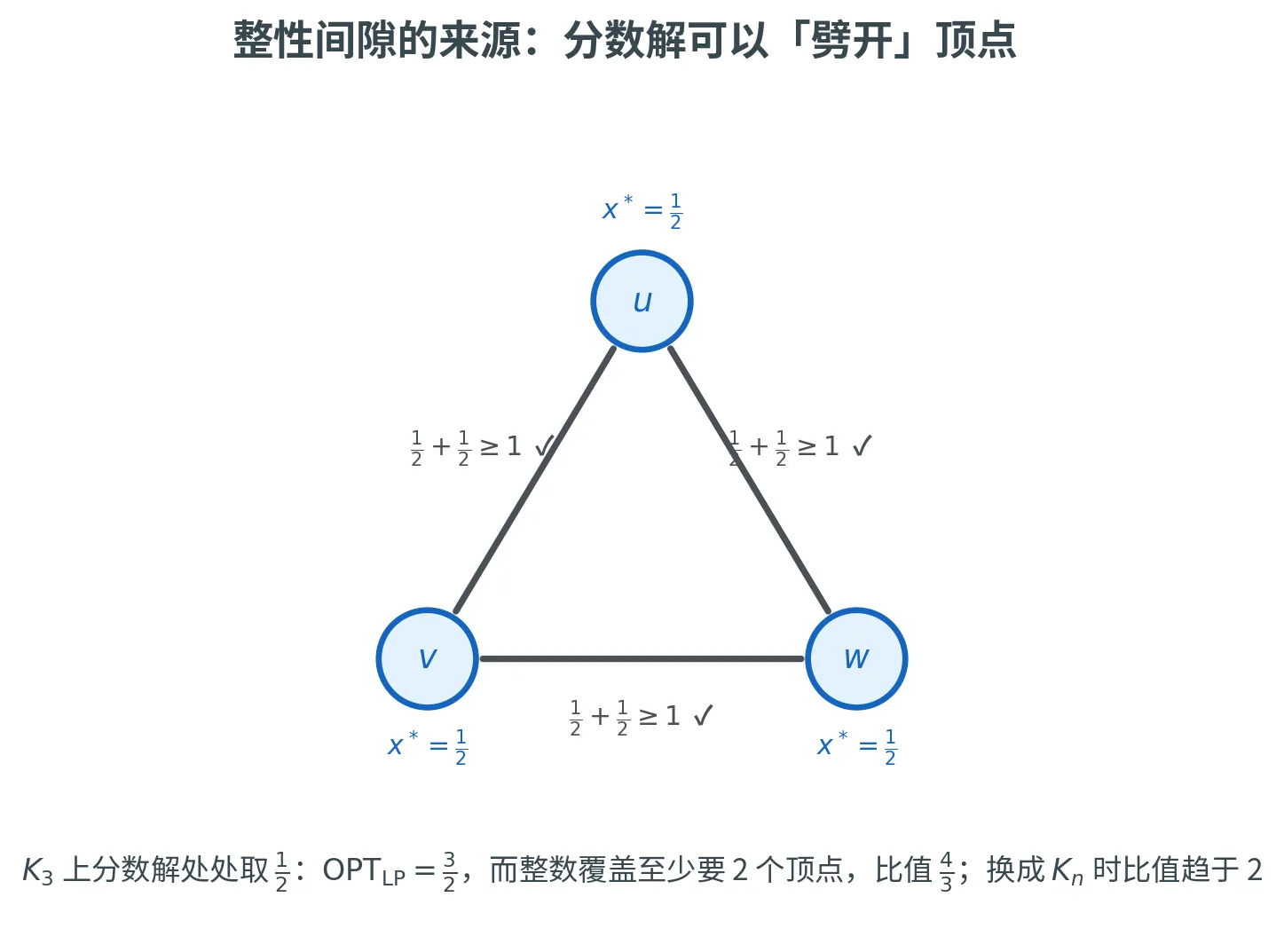
我们的 2 2 2 ⩽ 2 \le 2 ⩽ 2 2 ⋅ OPT LP 2 \cdot \text{OPT}_{\text{LP}} 2 ⋅ OPT LP
反过来,存在实例使比值逼近 2 2 2 n n n 完全图 K n K_n K n x v = 1 / 2 x_v = 1/2 x v = 1/2 OPT LP = n / 2 \text{OPT}_{\text{LP}} = n/2 OPT LP = n /2 OPT = n − 1 \text{OPT} = n - 1 OPT = n − 1 n − 1 n / 2 → 2 \frac{n-1}{n/2} \to 2 n /2 n − 1 → 2
最小的非平凡情形 K 3 K_3 K 3
所以顶点覆盖线性规划松弛的整性间隙恰好等于 2 2 2 。
整性间隙是松弛方法的天花板
整性间隙是这个特定线性规划松弛能达到的近似比下限——只要算法的分析是「拿松弛最优值作下界」,就不可能 做得比整性间隙更好。要突破它,必须换更强的松弛(如半定规划)或全新的方法。
Singh(2019)给出了更精细的刻画:在图 G G G 2 − 2 χ f ( G ) 2 - \frac{2}{\chi^f(G)} 2 − χ f ( G ) 2 χ f ( G ) \chi^f(G) χ f ( G ) G G G 分数色数 。图越「稠密复杂」(分数色数越大),间隙越逼近 2 2 2
整性间隙提醒我们:松弛舍入虽强大,但有先天局限。接下来的 Max-SAT 会展示更精巧的舍入技巧,把整性间隙「榨」到极致。
Max-SAT:舍入技巧的博物馆
Max-SAT 是展示「随机化舍入」威力的绝佳舞台。我们会看到四种逐步进化的算法:从最朴素的随机赋值,到线性规划舍入,再到两者的巧妙组合,最后是一个把组合的优势浓缩进单一算法的非线性舍入。
Max-SAT
给定一个合取范式 (Conjunctive Normal Form, CNF )公式 Φ = C 1 ∧ C 2 ∧ ⋯ ∧ C m \Phi = C_1 \wedge C_2 \wedge \dots \wedge C_m Φ = C 1 ∧ C 2 ∧ ⋯ ∧ C m x ∈ { T , F } n \bm{x} \in \{\texttt{T}, \texttt{F}\}^n x ∈ { T , F } n
CNF 子句 (Clause)的合取(∧ \wedge ∧ 子句 :若干文字 (Literal)的析取(∨ \vee ∨ C = ( x 1 ∨ ¬ x 2 ∨ x 3 ) C = (x_1 \vee \neg x_2 \vee x_3) C = ( x 1 ∨ ¬ x 2 ∨ x 3 ) 文字 :一个变量 x i x_i x i ¬ x i \neg x_i ¬ x i
Max-SAT 是 NP-难的。
记子句 C j C_j C j k j k_j k j OPT \text{OPT} OPT
算法一:纯随机赋值
最朴素的想法:抛硬币。每个变量 x i x_i x i T \texttt{T} T F \texttt{F} F
子句 C j = ( ℓ 1 ∨ ⋯ ∨ ℓ k j ) C_j = (\ell_1 \vee \dots \vee \ell_{k_j}) C j = ( ℓ 1 ∨ ⋯ ∨ ℓ k j ) k j k_j k j 全部 取假——每个文字独立地以 1 / 2 1/2 1/2
Pr [ C j 被满足 ] = 1 − 2 − k j ⩾ 1 2 \Pr[C_j \text{ 被满足}] = 1 - 2^{-k_j} \ge \frac{1}{2}
Pr [ C j 被满足 ] = 1 − 2 − k j ⩾ 2 1
最后一步用了 k j ⩾ 1 k_j \ge 1 k j ⩾ 1
E [ 满足子句数 ] = ∑ j = 1 m Pr [ C j 被满足 ] ⩾ m 2 ⩾ OPT 2 \mathbb{E}[\text{满足子句数}] = \sum_{j=1}^m \Pr[C_j \text{ 被满足}] \ge \frac{m}{2} \ge \frac{\text{OPT}}{2}
E [ 满足子句数 ] = j = 1 ∑ m Pr [ C j 被满足 ] ⩾ 2 m ⩾ 2 OPT
最后一步因为 OPT ⩽ m \text{OPT} \le m OPT ⩽ m m m m 纯随机赋值是 1 2 \frac{1}{2} 2 1 ——什么都没算,靠抛硬币就赢了一半。这个朴素界会成为后面组合算法的一块基石。注意它对「子句长」的情形特别好:k j k_j k j 1 − 2 − k j 1 - 2^{-k_j} 1 − 2 − k j 1 1 1
算法二:线性规划舍入
随机赋值的弱点是对短子句 (尤其 k j = 1 k_j = 1 k j = 1 1 / 2 1/2 1/2
为每个变量设 x i ∈ { 0 , 1 } x_i \in \{0, 1\} x i ∈ { 0 , 1 } 1 1 1 T \texttt{T} T y j ∈ { 0 , 1 } y_j \in \{0, 1\} y j ∈ { 0 , 1 } 1 1 1 C j C_j C j S j + = { i : x i 出现在 C j } S_j^+ = \{i : x_i \text{ 出现在 } C_j\} S j + = { i : x i 出现在 C j } S j − = { i : ¬ x i 出现在 C j } S_j^- = \{i : \neg x_i \text{ 出现在 } C_j\} S j − = { i : ¬ x i 出现在 C j }
Max-SAT 的整数规划与松弛
maximize ∑ j = 1 m y j subject to ∑ i ∈ S j + x i + ∑ i ∈ S j − ( 1 − x i ) ⩾ y j 1 ⩽ j ⩽ m x i , y j ∈ { 0 , 1 } ( 松弛为 [ 0 , 1 ] ) \begin{aligned}
\text{maximize} \quad & \sum_{j=1}^m y_j \\
\text{subject to} \quad & \sum_{i \in S_j^+} x_i + \sum_{i \in S_j^-} (1 - x_i) \ge y_j & 1 \le j \le m \\
& x_i, y_j \in \{0, 1\} \quad (\text{松弛为 } [0, 1])
\end{aligned}
maximize subject to j = 1 ∑ m y j i ∈ S j + ∑ x i + i ∈ S j − ∑ ( 1 − x i ) ⩾ y j x i , y j ∈ { 0 , 1 } ( 松弛为 [ 0 , 1 ]) 1 ⩽ j ⩽ m
约束的含义:左边是「为 C j C_j C j ⩾ 1 \ge 1 ⩾ 1 y j y_j y j 1 1 1 [ 0 , 1 ] [0, 1] [ 0 , 1 ]
设松弛最优解为 x ∗ ∈ [ 0 , 1 ] n , y ∗ ∈ [ 0 , 1 ] m \bm{x}^* \in [0, 1]^n, \bm{y}^* \in [0, 1]^m x ∗ ∈ [ 0 , 1 ] n , y ∗ ∈ [ 0 , 1 ] m 线性随机舍入 :每个变量独立地以概率 x i ∗ x_i^* x i ∗ 1 1 1
x ^ i = { 1 以概率 x i ∗ 0 以概率 1 − x i ∗ ( 相互独立 ) \hat{x}_i = \begin{cases} 1 & \text{以概率 } x_i^* \\ 0 & \text{以概率 } 1 - x_i^* \end{cases} \quad (\text{相互独立})
x ^ i = { 1 0 以概率 x i ∗ 以概率 1 − x i ∗ ( 相互独立 )
把分数值直接当概率用——这是「随机化舍入」的核心思想。来分析单个子句被满足的概率:
Pr [ C j 被满足 ] = 1 − ∏ i ∈ S j + ( 1 − x i ∗ ) ∏ i ∈ S j − x i ∗ \Pr[C_j \text{ 被满足}] = 1 - \prod_{i \in S_j^+} (1 - x_i^*) \prod_{i \in S_j^-} x_i^*
Pr [ C j 被满足 ] = 1 − i ∈ S j + ∏ ( 1 − x i ∗ ) i ∈ S j − ∏ x i ∗
右边减去的是「所有文字都为假」的概率。要给它一个下界,用两个不等式:
用到的两个不等式
AM-GM 不等式 :k k k ⩽ \le ⩽ ∏ a i ⩽ ( ∑ a i k ) k \prod a_i \le \left(\frac{\sum a_i}{k}\right)^k ∏ a i ⩽ ( k ∑ a i ) k Jensen 不等式 :对凹函数 g g g t ∈ [ 0 , 1 ] t \in [0, 1] t ∈ [ 0 , 1 ] g ( t ⋅ v ) ⩾ t ⋅ g ( v ) + ( 1 − t ) g ( 0 ) g(t \cdot v) \ge t \cdot g(v) + (1-t)g(0) g ( t ⋅ v ) ⩾ t ⋅ g ( v ) + ( 1 − t ) g ( 0 ) g ( z ) = 1 − ( 1 − z / k ) k g(z) = 1 - (1 - z/k)^k g ( z ) = 1 − ( 1 − z / k ) k [ 0 , 1 ] [0,1] [ 0 , 1 ] g ( 0 ) = 0 g(0)=0 g ( 0 ) = 0 g ( t ) ⩾ t ⋅ g ( 1 ) g(t) \ge t \cdot g(1) g ( t ) ⩾ t ⋅ g ( 1 )
由 AM-GM,把那 k j k_j k j k j k_j k j k j k_j k j C j C_j C j ⩾ y j ∗ \ge y_j^* ⩾ y j ∗ ⩽ 1 − y j ∗ / k j \le 1 - y_j^* / k_j ⩽ 1 − y j ∗ / k j
Pr [ C j 被满足 ] ⩾ 1 − ( 1 − y j ∗ k j ) k j ⩾ ( 1 − ( 1 − 1 k j ) k j ) y j ∗ ⩾ ( 1 − 1 e ) y j ∗ \Pr[C_j \text{ 被满足}] \ge 1 - \left(1 - \frac{y_j^*}{k_j}\right)^{k_j} \ge \left(1 - \left(1 - \frac{1}{k_j}\right)^{k_j}\right) y_j^* \ge \left(1 - \frac{1}{\e}\right) y_j^*
Pr [ C j 被满足 ] ⩾ 1 − ( 1 − k j y j ∗ ) k j ⩾ ( 1 − ( 1 − k j 1 ) k j ) y j ∗ ⩾ ( 1 − e 1 ) y j ∗
中间一步是 Jensen 不等式(凹函数的弦在函数下方),最后一步用了 ( 1 − 1 / k ) k (1 - 1/k)^k ( 1 − 1/ k ) k k k k 1 / e 1/\e 1/ e 1 − ( 1 − 1 / k ) k ⩾ 1 − 1 / e 1 - (1 - 1/k)^k \ge 1 - 1/\e 1 − ( 1 − 1/ k ) k ⩾ 1 − 1/ e
E [ SOL ] = ∑ j = 1 m Pr [ C j 被满足 ] ⩾ ( 1 − 1 e ) ∑ j = 1 m y j ∗ = ( 1 − 1 e ) OPT LP ⩾ ( 1 − 1 e ) OPT \mathbb{E}[\text{SOL}] = \sum_{j=1}^m \Pr[C_j \text{ 被满足}] \ge \left(1 - \frac{1}{\e}\right) \sum_{j=1}^m y_j^* = \left(1 - \frac{1}{\e}\right) \text{OPT}_{\text{LP}} \ge \left(1 - \frac{1}{\e}\right) \text{OPT}
E [ SOL ] = j = 1 ∑ m Pr [ C j 被满足 ] ⩾ ( 1 − e 1 ) j = 1 ∑ m y j ∗ = ( 1 − e 1 ) OPT LP ⩾ ( 1 − e 1 ) OPT
末尾用到 OPT LP ⩾ OPT \text{OPT}_{\text{LP}} \ge \text{OPT} OPT LP ⩾ OPT 最大化 问题,与顶点覆盖方向相反:松弛扩大可行域,最大化的最优值只会更大,所以松弛最优值是真实最优值的上界 。
所以线性规划舍入是 ( 1 − 1 / e ) ≈ 0.632 (1 - 1/\e) \approx 0.632 ( 1 − 1/ e ) ≈ 0.632 。它和随机赋值的优劣恰好相反:对短子句更好(k j k_j k j 1 − ( 1 − 1 / k j ) k j 1 - (1 - 1/k_j)^{k_j} 1 − ( 1 − 1/ k j ) k j k j = 1 k_j=1 k j = 1 1 1 1
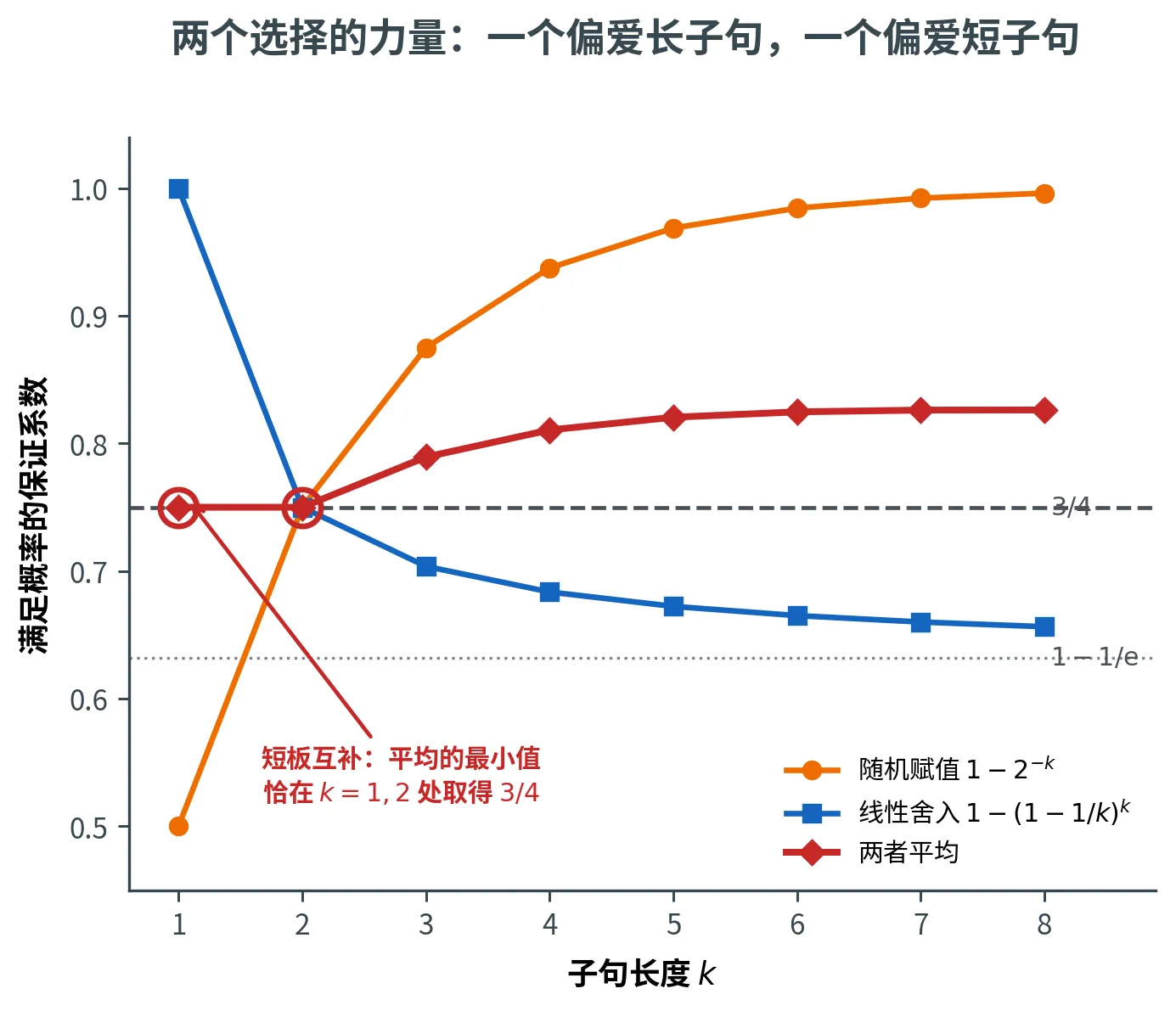
算法三:两个选择的力量
我们手上有两个互补的算法:随机赋值偏爱长子句,线性规划舍入偏爱短子句。能不能取长补短?
两个选择的力量
用随机赋值满足 M 1 M_1 M 1
用线性规划舍入满足 M 2 M_2 M 2
输出两者中满足子句更多的那个。
「取较大者」至少不小于「取平均」,这个朴素的观察是关键:
E [ max { M 1 , M 2 } ] ⩾ E [ M 1 + M 2 2 ] \mathbb{E}[\max\{M_1, M_2\}] \ge \mathbb{E}\left[\frac{M_1 + M_2}{2}\right]
E [ max { M 1 , M 2 }] ⩾ E [ 2 M 1 + M 2 ]
分别代入两个算法对单个子句的贡献下界:
E [ M 1 ] ⩾ ∑ j = 1 m ( 1 − 2 − k j ) y j ∗ , E [ M 2 ] ⩾ ∑ j = 1 m ( 1 − ( 1 − 1 k j ) k j ) y j ∗ \mathbb{E}[M_1] \ge \sum_{j=1}^m (1 - 2^{-k_j}) y_j^*, \qquad \mathbb{E}[M_2] \ge \sum_{j=1}^m \left(1 - \left(1 - \frac{1}{k_j}\right)^{k_j}\right) y_j^*
E [ M 1 ] ⩾ j = 1 ∑ m ( 1 − 2 − k j ) y j ∗ , E [ M 2 ] ⩾ j = 1 ∑ m ( 1 − ( 1 − k j 1 ) k j ) y j ∗
(随机赋值的 1 − 2 − k j ⩾ ( 1 − 2 − k j ) y j ∗ 1 - 2^{-k_j} \ge (1 - 2^{-k_j}) y_j^* 1 − 2 − k j ⩾ ( 1 − 2 − k j ) y j ∗ y j ∗ ⩽ 1 y_j^* \le 1 y j ∗ ⩽ 1
( 1 − 2 − k j ) + ( 1 − ( 1 − 1 / k j ) k j ) 2 \frac{(1 - 2^{-k_j}) + \left(1 - (1 - 1/k_j)^{k_j}\right)}{2}
2 ( 1 − 2 − k j ) + ( 1 − ( 1 − 1/ k j ) k j )
逐一验证这个量对所有 k j k_j k j ⩾ 3 / 4 \ge 3/4 ⩾ 3/4
k j k_j k j 随机赋值 1 − 2 − k 1 - 2^{-k} 1 − 2 − k
线性舍入 1 − ( 1 − 1 / k ) k 1 - (1-1/k)^k 1 − ( 1 − 1/ k ) k
平均
1 1 1 1 / 2 1/2 1/2 1 1 1 3 / 4 3/4 3/4
2 2 2 3 / 4 3/4 3/4 3 / 4 3/4 3/4 3 / 4 3/4 3/4
⩾ 3 \ge 3 ⩾ 3 ⩾ 7 / 8 \ge 7/8 ⩾ 7/8 ⩾ 1 − 1 / e ≈ 0.63 \ge 1 - 1/\e \approx 0.63 ⩾ 1 − 1/ e ≈ 0.63 > 3 / 4 > 3/4 > 3/4
最小值恰好在 k j = 1 , 2 k_j = 1, 2 k j = 1 , 2 3 / 4 3/4 3/4
所以
E [ max { M 1 , M 2 } ] ⩾ 3 4 ∑ j = 1 m y j ∗ ⩾ 3 4 OPT \mathbb{E}[\max\{M_1, M_2\}] \ge \frac{3}{4} \sum_{j=1}^m y_j^* \ge \frac{3}{4} \text{OPT}
E [ max { M 1 , M 2 }] ⩾ 4 3 j = 1 ∑ m y j ∗ ⩾ 4 3 OPT
两个选择的组合是 3 4 \frac{3}{4} 4 3 ——比单独任一个都好。一个算法的短板(随机赋值在 k = 1 k=1 k = 1 1 / 2 1/2 1/2 k = 1 k=1 k = 1
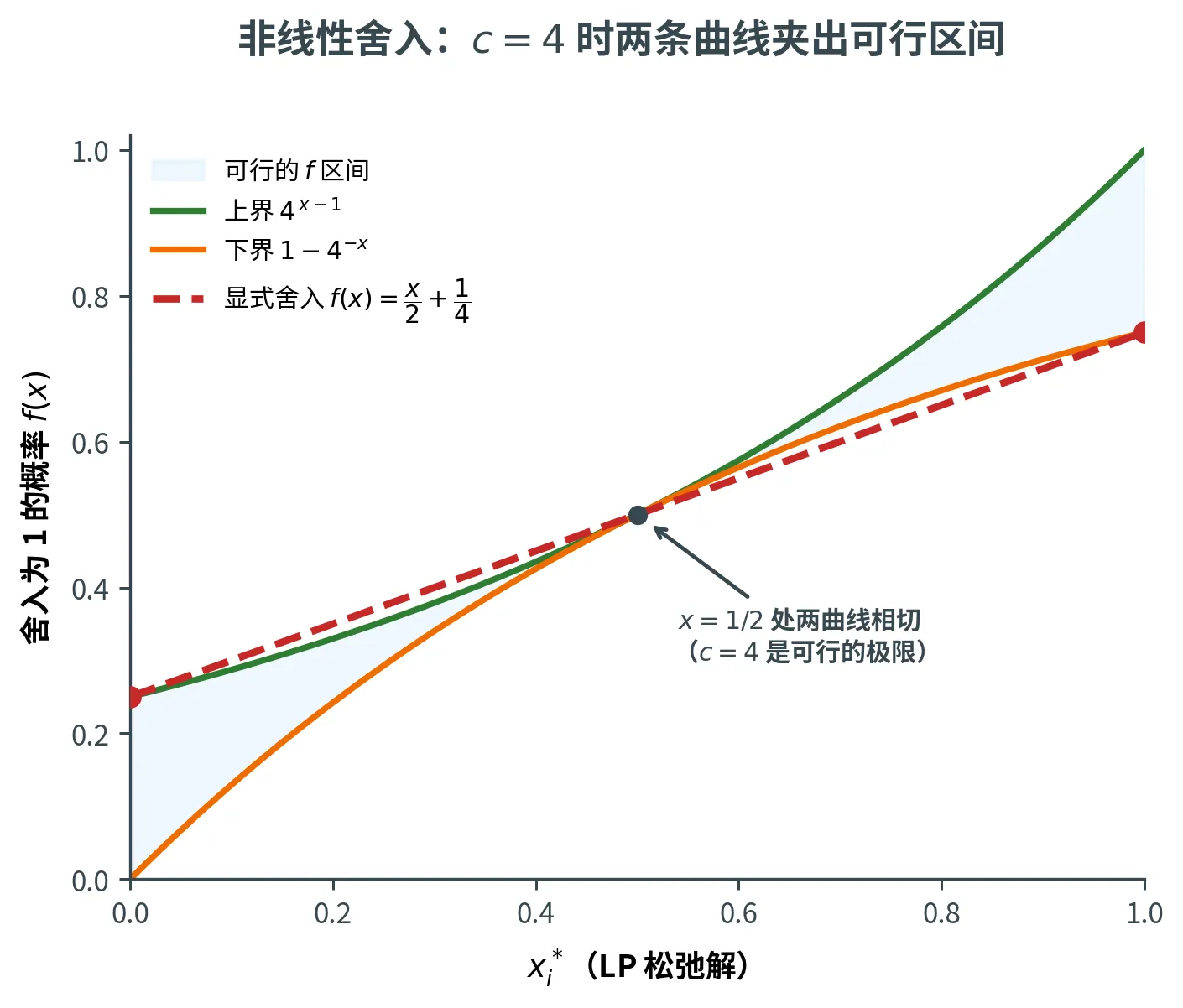
算法四:非线性舍入
组合算法虽好,却要跑两个算法再比较。能否用单个 算法直接达到 3 / 4 3/4 3/4
线性舍入直接把 x i ∗ x_i^* x i ∗ 非线性舍入 则先用一个函数 f f f f ( x i ∗ ) f(x_i^*) f ( x i ∗ ) 1 1 1
Pr [ C j 不被满足 ] = ∏ i ∈ S j + ( 1 − f ( x i ∗ ) ) ∏ i ∈ S j − f ( x i ∗ ) \Pr[C_j \text{ 不被满足}] = \prod_{i \in S_j^+} (1 - f(x_i^*)) \prod_{i \in S_j^-} f(x_i^*)
Pr [ C j 不被满足 ] = i ∈ S j + ∏ ( 1 − f ( x i ∗ )) i ∈ S j − ∏ f ( x i ∗ )
关键想法:若能找到 f f f c > 1 c > 1 c > 1
1 − c − x ⩽ f ( x ) ⩽ c x − 1 ∀ x ∈ [ 0 , 1 ] 1 - c^{-x} \le f(x) \le c^{x - 1} \quad \forall x \in [0, 1]
1 − c − x ⩽ f ( x ) ⩽ c x − 1 ∀ x ∈ [ 0 , 1 ]
那么正文字的「为假概率」由下界控制——f ( x ) ⩾ 1 − c − x f(x) \ge 1 - c^{-x} f ( x ) ⩾ 1 − c − x 1 − f ( x i ∗ ) ⩽ c − x i ∗ 1 - f(x_i^*) \le c^{-x_i^*} 1 − f ( x i ∗ ) ⩽ c − x i ∗ f ( x ) ⩽ c x − 1 f(x) \le c^{x-1} f ( x ) ⩽ c x − 1 f ( x i ∗ ) ⩽ c − ( 1 − x i ∗ ) f(x_i^*) \le c^{-(1 - x_i^*)} f ( x i ∗ ) ⩽ c − ( 1 − x i ∗ )
Pr [ C j 不被满足 ] ⩽ c − ( ∑ i ∈ S j + x i ∗ + ∑ i ∈ S j − ( 1 − x i ∗ ) ) ⩽ c − y j ∗ \Pr[C_j \text{ 不被满足}] \le c^{-\left(\sum_{i \in S_j^+} x_i^* + \sum_{i \in S_j^-}(1 - x_i^*)\right)} \le c^{-y_j^*}
Pr [ C j 不被满足 ] ⩽ c − ( ∑ i ∈ S j + x i ∗ + ∑ i ∈ S j − ( 1 − x i ∗ ) ) ⩽ c − y j ∗
于是 Pr [ C j 被满足 ] ⩾ 1 − c − y j ∗ ⩾ ( 1 − 1 / c ) y j ∗ \Pr[C_j \text{ 被满足}] \ge 1 - c^{-y_j^*} \ge (1 - 1/c) y_j^* Pr [ C j 被满足 ] ⩾ 1 − c − y j ∗ ⩾ ( 1 − 1/ c ) y j ∗ 1 − c − z 1 - c^{-z} 1 − c − z [ 0 , 1 ] [0,1] [ 0 , 1 ]
E [ SOL ] ⩾ ( 1 − 1 / c ) OPT \mathbb{E}[\text{SOL}] \ge (1 - 1/c)\, \text{OPT}
E [ SOL ] ⩾ ( 1 − 1/ c ) OPT
要让近似比 1 − 1 / c 1 - 1/c 1 − 1/ c c c c c c c f f f 1 − c − x 1 - c^{-x} 1 − c − x c x − 1 c^{x-1} c x − 1 f f f x ∈ [ 0 , 1 ] x \in [0,1] x ∈ [ 0 , 1 ] 1 − c − x ⩽ c x − 1 1 - c^{-x} \le c^{x-1} 1 − c − x ⩽ c x − 1
两条曲线的最窄处在哪?考察差 c x − 1 − ( 1 − c − x ) = c x − 1 − 1 + c − x c^{x-1} - (1 - c^{-x}) = c^{x-1} - 1 + c^{-x} c x − 1 − ( 1 − c − x ) = c x − 1 − 1 + c − x x x x 驻点在 x = 1 / 2 x = 1/2 x = 1/2 ,此处差值为
2 c − 1 = min 0 ⩽ x ⩽ 1 ( c x − 1 − 1 + c − x ) \frac{2}{\sqrt{c}} - 1 = \min_{0 \le x \le 1}\left(c^{x-1} - 1 + c^{-x}\right)
c 2 − 1 = 0 ⩽ x ⩽ 1 min ( c x − 1 − 1 + c − x )
要让这个最小差 ⩾ 0 \ge 0 ⩾ 0 f f f 2 c − 1 ⩾ 0 \frac{2}{\sqrt c} - 1 \ge 0 c 2 − 1 ⩾ 0 c ⩽ 4 c \le 4 c ⩽ 4 c = 4 c = 4 c = 4 1 − 1 / 4 = 3 / 4 1 - 1/4 = 3/4 1 − 1/4 = 3/4
一个显式的舍入函数
c = 4 c = 4 c = 4 1 − 4 − x ⩽ f ( x ) ⩽ 4 x − 1 1 - 4^{-x} \le f(x) \le 4^{x-1} 1 − 4 − x ⩽ f ( x ) ⩽ 4 x − 1 x = 1 / 2 x = 1/2 x = 1/2 线性函数
f ( x ) = x 2 + 1 4 f(x) = \frac{x}{2} + \frac{1}{4}
f ( x ) = 2 x + 4 1
它正是「两个选择」的逐变量翻版:对每个变量独立抛一枚公平硬币,正面用纯随机赋值(以 1 / 2 1/2 1/2 1 1 1 x i ∗ x_i^* x i ∗ 1 1 1 1 1 1 1 2 ⋅ 1 2 + 1 2 x i ∗ = f ( x i ∗ ) \frac{1}{2} \cdot \frac{1}{2} + \frac{1}{2} x_i^* = f(x_i^*) 2 1 ⋅ 2 1 + 2 1 x i ∗ = f ( x i ∗ )
有趣的是,这个 f f f 并不 处处满足夹逼条件——上图中可以看出,它只在 x = 0 , 1 2 , 1 x = 0, \frac{1}{2}, 1 x = 0 , 2 1 , 1
Pr [ C j 不被满足 ] = ∏ i ∈ S j + ( 3 4 − x i ∗ 2 ) ∏ i ∈ S j − ( 1 4 + x i ∗ 2 ) ⩽ ( 3 4 − y j ∗ 2 k j ) k j \Pr[C_j \text{ 不被满足}] = \prod_{i \in S_j^+}\left(\frac{3}{4} - \frac{x_i^*}{2}\right) \prod_{i \in S_j^-}\left(\frac{1}{4} + \frac{x_i^*}{2}\right) \le \left(\frac{3}{4} - \frac{y_j^*}{2k_j}\right)^{k_j}
Pr [ C j 不被满足 ] = i ∈ S j + ∏ ( 4 3 − 2 x i ∗ ) i ∈ S j − ∏ ( 4 1 + 2 x i ∗ ) ⩽ ( 4 3 − 2 k j y j ∗ ) k j
括号里的因子都能写成 3 4 \frac{3}{4} 4 3 ⩾ y j ∗ \ge y_j^* ⩾ y j ∗
Pr [ C j 被满足 ] ⩾ 1 − ( 3 4 − y j ∗ 2 k j ) k j ⩾ [ 1 − ( 3 4 − 1 2 k j ) k j ] y j ∗ ⩾ 3 4 y j ∗ \Pr[C_j \text{ 被满足}] \ge 1 - \left(\frac{3}{4} - \frac{y_j^*}{2k_j}\right)^{k_j} \ge \left[1 - \left(\frac{3}{4} - \frac{1}{2k_j}\right)^{k_j}\right] y_j^* \ge \frac{3}{4}\, y_j^*
Pr [ C j 被满足 ] ⩾ 1 − ( 4 3 − 2 k j y j ∗ ) k j ⩾ [ 1 − ( 4 3 − 2 k j 1 ) k j ] y j ∗ ⩾ 4 3 y j ∗
最后一个不等式对一切 k j ⩾ 1 k_j \ge 1 k j ⩾ 1 k j = 1 , 2 k_j = 1, 2 k j = 1 , 2 3 4 \frac{3}{4} 4 3 单次舍入就是 3 4 \frac{3}{4} 4 3 ,无需跑两遍再比较。
Max-SAT 小结
我们用四种算法把 Max-SAT 的近似比从 1 / 2 1/2 1/2 3 / 4 3/4 3/4
算法
近似比
关键思想
纯随机赋值
1 / 2 1/2 1/2 抛硬币,偏爱长子句
线性规划舍入
1 − 1 / e ≈ 0.63 1 - 1/\e \approx 0.63 1 − 1/ e ≈ 0.63 分数解当概率,偏爱短子句
两个选择
3 / 4 3/4 3/4 取两者较优,长短互补
非线性舍入
3 / 4 3/4 3/4 单算法,曲线夹逼定 c = 4 c = 4 c = 4
几个值得记住的收尾事实:
上述随机算法都可以用条件期望法 (Method of Conditional Expectation)去随机化,得到确定性的 3 / 4 3/4 3/4
Max-SAT 线性规划松弛的整性间隙恰好是 3 / 4 3/4 3/4 ——所以 3 / 4 3/4 3/4
对每个子句恰好 3 3 3 Max-3SAT ,用半定规划 (Semidefinite Programming, SDP )松弛舍入可达 7 / 8 7/8 7/8 P = N P \mathsf{P} = \mathsf{NP} P = NP 7 / 8 7/8 7/8
线性规划松弛已被榨到 3 / 4 3/4 3/4 SDP )。但在转向那之前,我们还欠一笔账:本讲开头的「最大流 = 最小割」,到底为什么成立?答案藏在线性规划自身的对偶结构里。
线性规划对偶
一个朴素的问题:怎么知道自己已经最优?
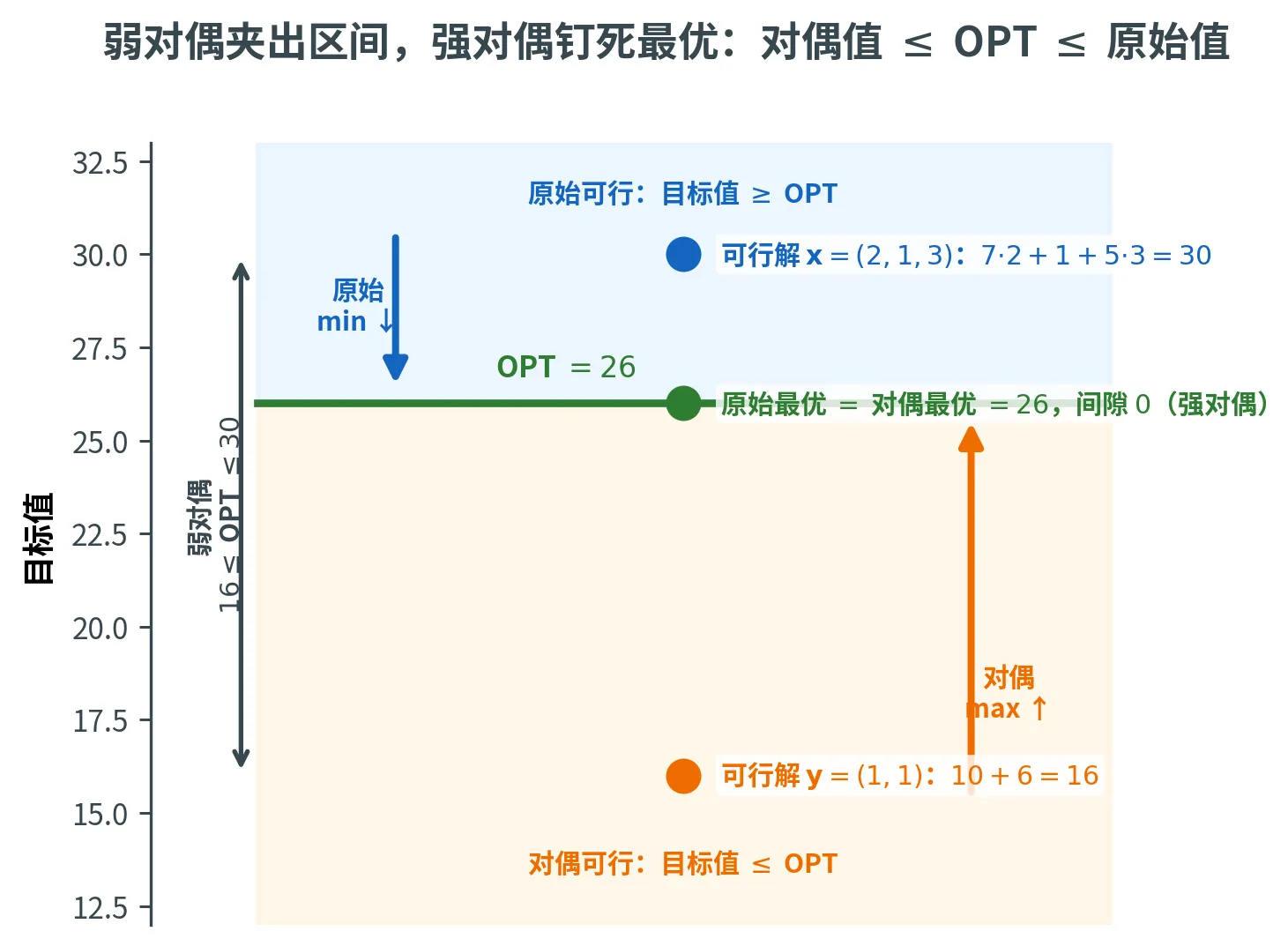
考虑这个最小化线性规划:
minimize 7 x 1 + x 2 + 5 x 3 subject to x 1 − x 2 + 3 x 3 ⩾ 10 5 x 1 + 2 x 2 − x 3 ⩾ 6 x 1 , x 2 , x 3 ⩾ 0 \begin{aligned}
\text{minimize} \quad & 7x_1 + x_2 + 5x_3 \\
\text{subject to} \quad & x_1 - x_2 + 3x_3 \ge 10 \\
& 5x_1 + 2x_2 - x_3 \ge 6 \\
& x_1, x_2, x_3 \ge 0
\end{aligned}
minimize subject to 7 x 1 + x 2 + 5 x 3 x 1 − x 2 + 3 x 3 ⩾ 10 5 x 1 + 2 x 2 − x 3 ⩾ 6 x 1 , x 2 , x 3 ⩾ 0
随手找一个可行解,比如 x = ( 2 , 1 , 3 ) \bm{x} = (2, 1, 3) x = ( 2 , 1 , 3 ) 2 − 1 + 9 = 10 ⩾ 10 , 10 + 2 − 3 = 9 ⩾ 6 2 - 1 + 9 = 10 \ge 10,\, 10 + 2 - 3 = 9 \ge 6 2 − 1 + 9 = 10 ⩾ 10 , 10 + 2 − 3 = 9 ⩾ 6 7 ⋅ 2 + 1 + 5 ⋅ 3 = 30 7 \cdot 2 + 1 + 5 \cdot 3 = 30 7 ⋅ 2 + 1 + 5 ⋅ 3 = 30 OPT ⩽ 30 \text{OPT} \le 30 OPT ⩽ 30 上界 。
但我们怎么知道 30 30 30 下界 。一个绝妙的技巧是:把约束非负线性组合 起来。给两个约束分别配权重 y 1 , y 2 ⩾ 0 y_1, y_2 \ge 0 y 1 , y 2 ⩾ 0
y 1 ( x 1 − x 2 + 3 x 3 ) + y 2 ( 5 x 1 + 2 x 2 − x 3 ) ⩾ 10 y 1 + 6 y 2 y_1(x_1 - x_2 + 3x_3) + y_2(5x_1 + 2x_2 - x_3) \ge 10 y_1 + 6 y_2
y 1 ( x 1 − x 2 + 3 x 3 ) + y 2 ( 5 x 1 + 2 x 2 − x 3 ) ⩾ 10 y 1 + 6 y 2
左边整理成 x x x ( y 1 + 5 y 2 ) x 1 + ( − y 1 + 2 y 2 ) x 2 + ( 3 y 1 − y 2 ) x 3 (y_1 + 5y_2)x_1 + (-y_1 + 2y_2)x_2 + (3y_1 - y_2)x_3 ( y 1 + 5 y 2 ) x 1 + ( − y 1 + 2 y 2 ) x 2 + ( 3 y 1 − y 2 ) x 3 不超过 目标函数对应的系数(7 , 1 , 5 7, 1, 5 7 , 1 , 5 x ⩾ 0 \bm{x} \ge 0 x ⩾ 0 ⩾ \ge ⩾ ⩾ 10 y 1 + 6 y 2 \ge 10y_1 + 6y_2 ⩾ 10 y 1 + 6 y 2 y y y
y 1 + 5 y 2 ⩽ 7 , − y 1 + 2 y 2 ⩽ 1 , 3 y 1 − y 2 ⩽ 5 , y 1 , y 2 ⩾ 0 y_1 + 5y_2 \le 7, \quad -y_1 + 2y_2 \le 1, \quad 3y_1 - y_2 \le 5, \quad y_1, y_2 \ge 0
y 1 + 5 y 2 ⩽ 7 , − y 1 + 2 y 2 ⩽ 1 , 3 y 1 − y 2 ⩽ 5 , y 1 , y 2 ⩾ 0
那么 10 y 1 + 6 y 2 10y_1 + 6y_2 10 y 1 + 6 y 2 OPT \text{OPT} OPT y = ( 1 , 1 ) \bm{y} = (1, 1) y = ( 1 , 1 ) 6 ⩽ 7 , 1 ⩽ 1 , 2 ⩽ 5 6 \le 7,\, 1 \le 1,\, 2 \le 5 6 ⩽ 7 , 1 ⩽ 1 , 2 ⩽ 5 10 + 6 = 16 10 + 6 = 16 10 + 6 = 16 16 ⩽ OPT ⩽ 30 16 \le \text{OPT} \le 30 16 ⩽ OPT ⩽ 30
为了得到最好 的下界,我们要最大化 10 y 1 + 6 y 2 10y_1 + 6y_2 10 y 1 + 6 y 2
对偶的一般构造
把上面的推导抽象出来,就得到了线性规划对偶的一般定义。
线性规划对偶
原始 (Primal)与对偶 (Dual)成对出现:
Primal: min c ⊺ x s.t. A x ⩾ b , x ⩾ 0 ⟺ Dual: max b ⊺ y s.t. A ⊺ y ⩽ c , y ⩾ 0 \text{Primal:} \quad \min \bm{c}^{\intercal}\bm{x} \ \text{ s.t. } \bm{A}\bm{x} \ge \bm{b},\ \bm{x} \ge \bm{0}
\qquad\Longleftrightarrow\qquad
\text{Dual:} \quad \max \bm{b}^{\intercal}\bm{y} \ \text{ s.t. } \bm{A}^{\intercal}\bm{y} \le \bm{c},\ \bm{y} \ge \bm{0}
Primal: min c ⊺ x s.t. A x ⩾ b , x ⩾ 0 ⟺ Dual: max b ⊺ y s.t. A ⊺ y ⩽ c , y ⩾ 0
对偶变量 y i y_i y i i i i A ⊺ y ⩽ c \bm{A}^{\intercal}\bm{y} \le \bm{c} A ⊺ y ⩽ c y ⊺ A ⩽ c ⊺ \bm{y}^{\intercal}\bm{A} \le \bm{c}^{\intercal} y ⊺ A ⩽ c ⊺
一个生动的解释是「维生素定价问题」(即经典的膳食问题 ,Diet Problem):
维生素定价
原始问题(消费者视角):n n n c 1 , … , c n c_1, \dots, c_n c 1 , … , c n a i j a_{ij} a ij A x ⩾ b \bm{A}\bm{x} \ge \bm{b} A x ⩾ b min c ⊺ x \min \bm{c}^{\intercal}\bm{x} min c ⊺ x
对偶问题(药商视角):药商想卖 m m m y i y_i y i A ⊺ y ⩽ c \bm{A}^{\intercal}\bm{y} \le \bm{c} A ⊺ y ⩽ c max b ⊺ y \max \bm{b}^{\intercal}\bm{y} max b ⊺ y
强对偶定理(下面会讲)说:药商的最大收入 = 消费者的最小花费。无论你买食物还是买药片,达到健康标准的最低成本是同一个数。
对偶还有一个优雅的对称性:
对偶的对偶是原始
对对偶问题再取一次对偶,得到的就是原始问题:dual ( dual ( LP ) ) = LP \text{dual}(\text{dual}(\text{LP})) = \text{LP} dual ( dual ( LP )) = LP
弱对偶与强对偶
前面「下界」的推导,本质上证明了对偶的第一个核心定理。
弱对偶定理
对任意原始可行解 x \bm{x} x y \bm{y} y
y ⊺ b ⩽ y ⊺ A x ⩽ c ⊺ x \bm{y}^{\intercal}\bm{b} \le \bm{y}^{\intercal}\bm{A}\bm{x} \le \bm{c}^{\intercal}\bm{x}
y ⊺ b ⩽ y ⊺ A x ⩽ c ⊺ x
即任意对偶可行值 ⩽ \le ⩽ 。
证明只是两次「夹」:由 A x ⩾ b \bm{A}\bm{x} \ge \bm{b} A x ⩾ b y ⩾ 0 \bm{y} \ge 0 y ⩾ 0 y ⊺ b ⩽ y ⊺ ( A x ) \bm{y}^{\intercal}\bm{b} \le \bm{y}^{\intercal}(\bm{A}\bm{x}) y ⊺ b ⩽ y ⊺ ( A x ) y ⊺ A ⩽ c ⊺ \bm{y}^{\intercal}\bm{A} \le \bm{c}^{\intercal} y ⊺ A ⩽ c ⊺ x ⩾ 0 \bm{x} \ge 0 x ⩾ 0 ( y ⊺ A ) x ⩽ c ⊺ x (\bm{y}^{\intercal}\bm{A})\bm{x} \le \bm{c}^{\intercal}\bm{x} ( y ⊺ A ) x ⩽ c ⊺ x ⩽ \le ⩽
弱对偶只说对偶值不超过原始值,但没说它们能否相等。令人惊叹的是,对线性规划而言,二者总能相遇 。
强对偶定理
原始线性规划有有限最优解 x ∗ \bm{x}^* x ∗ y ∗ \bm{y}^* y ∗
y ∗ ⊺ b = c ⊺ x ∗ \bm{y}^{*\intercal}\bm{b} = \bm{c}^{\intercal}\bm{x}^*
y ∗ ⊺ b = c ⊺ x ∗
强对偶是线性规划理论的皇冠。它说最大化的对偶和最小化的原始不仅互为界限,最优处还严丝合缝地重合——没有任何「间隙」。这与网络流里「最大流 = 最小割」是同一回事,只是更普遍。
把前面那个「怎么知道已经最优」的例子画成一根目标值轴,弱对偶与强对偶就一目了然:原始可行解的目标值都落在 OPT 上方(如 x = ( 2 , 1 , 3 ) \bm{x} = (2,1,3) x = ( 2 , 1 , 3 ) 30 30 30 y = ( 1 , 1 ) \bm{y} = (1,1) y = ( 1 , 1 ) 16 16 16 16 ⩽ OPT ⩽ 30 16 \le \text{OPT} \le 30 16 ⩽ OPT ⩽ 30 OPT = 26 \text{OPT} = 26 OPT = 26
线性规划属于 N P ∩ c o N P \mathsf{NP} \cap \mathsf{coNP} NP ∩ coNP
强对偶有一个漂亮的复杂度推论:要证明「最优值 ⩽ k \le k ⩽ k ⩽ k \le k ⩽ k ⩾ k \ge k ⩾ k ⩾ k \ge k ⩾ k N P \mathsf{NP} NP c o N P \mathsf{coNP} coNP P \mathsf{P} P
最大流最小割就是线性规划对偶
现在可以兑现本讲开头的承诺了。把最大流写成线性规划,取它的对偶,会精确地得到最小割。
最大流的线性规划(用一条容量无穷的 t → s t \to s t → s f t s f_{ts} f t s
max f t s s.t. f u v ⩽ c u v ∀ ( u , v ) ∈ E ∑ w f w u − ∑ v f u v ⩽ 0 ∀ u ∈ V f u v ⩾ 0 ∀ ( u , v ) ∈ E \begin{aligned}
\max \quad & f_{ts} \\
\text{s.t.} \quad & f_{uv} \le c_{uv} & \forall (u, v) \in E \\
& \sum_{w} f_{wu} - \sum_{v} f_{uv} \le 0 & \forall u \in V \\
& f_{uv} \ge 0 & \forall (u, v) \in E
\end{aligned}
max s.t. f t s f uv ⩽ c uv w ∑ f w u − v ∑ f uv ⩽ 0 f uv ⩾ 0 ∀ ( u , v ) ∈ E ∀ u ∈ V ∀ ( u , v ) ∈ E
守恒约束写成「流入 ⩽ \le ⩽ − - − ⩽ \le ⩽ = = =
这样写的好处是:最大化问题中全部约束都是 ⩽ \le ⩽ max \max max ⩽ \le ⩽
为容量约束配对偶变量 d u v ⩾ 0 d_{uv} \ge 0 d uv ⩾ 0 p u ⩾ 0 p_u \ge 0 p u ⩾ 0 f u v f_{uv} f uv ⩾ \ge ⩾
普通边 f u v f_{uv} f uv 0 0 0 1 1 1 d u v d_{uv} d uv u u u − 1 -1 − 1 p u p_u p u v v v 1 1 1 p v p_v p v d u v − p u + p v ⩾ 0 d_{uv} - p_u + p_v \ge 0 d uv − p u + p v ⩾ 0
回边 f t s f_{ts} f t s 1 1 1 t t t s s s p s − p t ⩾ 1 p_s - p_t \ge 1 p s − p t ⩾ 1
整理出来就是:
最小割的线性规划(最大流的对偶)
min ∑ ( u , v ) ∈ E c u v d u v s.t. d u v − p u + p v ⩾ 0 ∀ ( u , v ) ∈ E p s − p t ⩾ 1 d u v ⩾ 0 , p u ⩾ 0 \begin{aligned}
\min \quad & \sum_{(u, v) \in E} c_{uv}\, d_{uv} \\
\text{s.t.} \quad & d_{uv} - p_u + p_v \ge 0 & \forall (u, v) \in E \\
& p_s - p_t \ge 1 \\
& d_{uv} \ge 0,\ p_u \ge 0
\end{aligned}
min s.t. ( u , v ) ∈ E ∑ c uv d uv d uv − p u + p v ⩾ 0 p s − p t ⩾ 1 d uv ⩾ 0 , p u ⩾ 0 ∀ ( u , v ) ∈ E
这个对偶的整数版本(d , p ∈ { 0 , 1 } d, p \in \{0, 1\} d , p ∈ { 0 , 1 }
p u ∈ { 0 , 1 } p_u \in \{0, 1\} p u ∈ { 0 , 1 } u u u p u = 1 p_u = 1 p u = 1 u ∈ S u \in S u ∈ S p s − p t ⩾ 1 p_s - p_t \ge 1 p s − p t ⩾ 1 p s = 1 , p t = 0 p_s = 1, p_t = 0 p s = 1 , p t = 0 s ∈ S , t ∉ S s \in S, t \notin S s ∈ S , t ∈ / S d u v ∈ { 0 , 1 } d_{uv} \in \{0, 1\} d uv ∈ { 0 , 1 } ( u , v ) (u, v) ( u , v ) d u v ⩾ p u − p v d_{uv} \ge p_u - p_v d uv ⩾ p u − p v u ∈ S u \in S u ∈ S p u = 1 p_u=1 p u = 1 v ∉ S v \notin S v ∈ / S p v = 0 p_v=0 p v = 0 d u v ⩾ 1 d_{uv} \ge 1 d uv ⩾ 1 目标 min ∑ c u v d u v \min \sum c_{uv} d_{uv} min ∑ c uv d uv
这个线性规划松弛恰好有整数最优解(其约束矩阵的特殊结构——所谓全单位模 (Totally Unimodular),即每个方子式都是 0 , ± 1 0, \pm 1 0 , ± 1 max -flow = min -cut \max\text{-flow} = \min\text{-cut} max -flow = min -cut 网络流里那个看似神奇的对偶,原来只是线性规划强对偶定理的一个特例。
互补松弛
强对偶定理还有一个更精细的「局部」版本,它刻画了原始解与对偶解在最优时必须满足的配对关系。
互补松弛条件
对原始可行解 x \bm{x} x y \bm{y} y 都最优 当且仅当:
∀ i : A i ⋅ x = b i 或 y i = 0 ∀ j : y ⊺ A ⋅ j = c j 或 x j = 0 \begin{aligned}
&\forall i: \quad \bm{A}_{i \cdot}\bm{x} = b_i \ \text{ 或 } \ y_i = 0 \\
&\forall j: \quad \bm{y}^{\intercal}\bm{A}_{\cdot j} = c_j \ \text{ 或 } \ x_j = 0
\end{aligned}
∀ i : A i ⋅ x = b i 或 y i = 0 ∀ j : y ⊺ A ⋅ j = c j 或 x j = 0
直觉是「不浪费」:第一行说,要么原始第 i i i 取等 (紧),要么对应的对偶变量 y i = 0 y_i = 0 y i = 0 ⩽ \le ⩽
互补松弛是从弱对偶推来的:弱对偶 y ⊺ b ⩽ y ⊺ A x ⩽ c ⊺ x \bm{y}^{\intercal}\bm{b} \le \bm{y}^{\intercal}\bm{A}\bm{x} \le \bm{c}^{\intercal}\bm{x} y ⊺ b ⩽ y ⊺ A x ⩽ c ⊺ x
松弛的互补松弛
为了把对偶用于近似算法 ,我们需要允许互补松弛「不那么严格」——这是原始对偶框架的技术核心。
松弛的互补松弛条件
对 α , β ⩾ 1 \alpha, \beta \ge 1 α , β ⩾ 1 x \bm{x} x y \bm{y} y
∀ i : A i ⋅ x ⩽ α b i 或 y i = 0 ∀ j : y ⊺ A ⋅ j ⩾ c j / β 或 x j = 0 \begin{aligned}
&\forall i: \quad \bm{A}_{i \cdot}\bm{x} \le \alpha\, b_i \ \text{ 或 } \ y_i = 0 \\
&\forall j: \quad \bm{y}^{\intercal}\bm{A}_{\cdot j} \ge c_j / \beta \ \text{ 或 } \ x_j = 0
\end{aligned}
∀ i : A i ⋅ x ⩽ α b i 或 y i = 0 ∀ j : y ⊺ A ⋅ j ⩾ c j / β 或 x j = 0
则
c ⊺ x ⩽ α β b ⊺ y ⩽ α β OPT LP \bm{c}^{\intercal}\bm{x} \le \alpha\beta\, \bm{b}^{\intercal}\bm{y} \le \alpha\beta\, \text{OPT}_{\text{LP}}
c ⊺ x ⩽ α β b ⊺ y ⩽ α β OPT LP
结论的证明就是把弱对偶的链条「放松」一遍:第二组条件保证每个 x j > 0 x_j > 0 x j > 0 c j ⩽ β y ⊺ A ⋅ j c_j \le \beta\, \bm{y}^{\intercal}\bm{A}_{\cdot j} c j ⩽ β y ⊺ A ⋅ j y i > 0 y_i > 0 y i > 0 A i ⋅ x ⩽ α b i \bm{A}_{i\cdot}\bm{x} \le \alpha\, b_i A i ⋅ x ⩽ α b i
c ⊺ x = ∑ j c j x j ⩽ β ∑ j ( y ⊺ A ⋅ j ) x j = β y ⊺ A x = β ∑ i ( A i ⋅ x ) y i ⩽ α β ∑ i b i y i = α β b ⊺ y \bm{c}^{\intercal}\bm{x} = \sum_j c_j x_j \le \beta \sum_j (\bm{y}^{\intercal}\bm{A}_{\cdot j})\, x_j = \beta\, \bm{y}^{\intercal}\bm{A}\bm{x} = \beta \sum_i (\bm{A}_{i\cdot}\bm{x})\, y_i \le \alpha\beta \sum_i b_i y_i = \alpha\beta\, \bm{b}^{\intercal}\bm{y}
c ⊺ x = j ∑ c j x j ⩽ β j ∑ ( y ⊺ A ⋅ j ) x j = β y ⊺ A x = β i ∑ ( A i ⋅ x ) y i ⩽ α β i ∑ b i y i = α β b ⊺ y
把严格的「取等」放松成「相差不超过 α \alpha α β \beta β α β \alpha\beta α β α β \alpha\beta α β
原始对偶框架
前面我们用「松弛 + 求解 + 舍入」攻克 NP-难问题,但那条路要真的调用线性规划求解器去解松弛。原始对偶框架走一条更聪明的路:根本不解线性规划,只利用对偶的结构 ,同时「生长」出一个原始整数解和一个对偶解,让二者通过松弛的互补松弛绑在一起,近似比自动浮现。
先看一个对偶现象:顶点覆盖与匹配
回到顶点覆盖。它的线性规划松弛 min { ∑ v x v : ∑ v ∈ e x v ⩾ 1 , x v ⩾ 0 } \min\{\sum_v x_v : \sum_{v \in e} x_v \ge 1,\ x_v \ge 0\} min { ∑ v x v : ∑ v ∈ e x v ⩾ 1 , x v ⩾ 0 } 对偶 是什么?机械地取对偶——每条边一个对偶变量 y e y_e y e
顶点覆盖与匹配互为对偶
Primal (顶点覆盖): min ∑ v x v , ∑ v ∈ e x v ⩾ 1 ⟺ Dual (分数匹配): max ∑ e y e , ∑ e ∋ v y e ⩽ 1 \text{Primal (顶点覆盖):} \ \min \sum_{v} x_v,\ \sum_{v \in e} x_v \ge 1
\quad\Longleftrightarrow\quad
\text{Dual (分数匹配):} \ \max \sum_{e} y_e,\ \sum_{e \ni v} y_e \le 1
Primal ( 顶点覆盖 ): min v ∑ x v , v ∈ e ∑ x v ⩾ 1 ⟺ Dual ( 分数匹配 ): max e ∑ y e , e ∋ v ∑ y e ⩽ 1
对偶恰好是分数匹配 (Fractional Matching)问题!顶点覆盖的约束 (每条边)变成匹配的变量 (每条边 y e y_e y e 变量 (每个顶点)变成匹配的约束 (每个顶点 ∑ e ∋ v y e ⩽ 1 \sum_{e \ni v} y_e \le 1 ∑ e ∋ v y e ⩽ 1
这解释了一个早已存在的经典算法:求一个极大匹配 M M M C C C 2 2 2
C C C e e e C C C e e e M M M M M M ∣ M ∣ ⩽ OPT VC |M| \le \text{OPT}_{\text{VC}} ∣ M ∣ ⩽ OPT VC 专属 的覆盖顶点(匹配边两两不共享顶点),所以覆盖至少要 ∣ M ∣ |M| ∣ M ∣ 合起来:∣ C ∣ = 2 ∣ M ∣ ⩽ 2 OPT VC |C| = 2|M| \le 2\,\text{OPT}_{\text{VC}} ∣ C ∣ = 2∣ M ∣ ⩽ 2 OPT VC
匹配(对偶)给出了顶点覆盖(原始)的下界——这正是弱对偶在组合问题里的化身。原始对偶框架把这个洞察系统化。
顶点覆盖的原始对偶算法
算法同时维护原始解 x \bm{x} x 0 0 0 y \bm{y} y 0 0 0 v v v 紧 (Tight / Saturated),若它的对偶约束取等:∑ e ∋ v y e = 1 \sum_{e \ni v} y_e = 1 ∑ e ∋ v y e = 1
1
2
3
4
初始 x = 0, y = 0; while E ≠ ∅: 任取一条边 e ∈ E,增大 y_e 直到某个端点 v 变紧(∑_{e∋v} y_e = 1); 对所有变紧的 v 置 x_v = 1,并从 E 中删去所有与 v 相关的边;
算法不停地「抬高」某条边的对偶价格,直到压紧某个顶点,就把那个顶点选进覆盖,并删掉它覆盖的所有边。来验证它的正确性与近似比:
x \bm{x} x v v v x v = 1 x_v = 1 x v = 1 ∀ e : ∑ v ∈ e x v ⩾ 1 \forall e: \sum_{v \in e} x_v \ge 1 ∀ e : ∑ v ∈ e x v ⩾ 1
近似比由松弛互补松弛给出 。检查两组条件:
∀ e \forall e ∀ e ∑ v ∈ e x v ⩽ 2 \sum_{v \in e} x_v \le 2 ∑ v ∈ e x v ⩽ 2 y e = 0 y_e = 0 y e = 0 ∑ v ∈ e x v ⩽ 2 \sum_{v \in e} x_v \le 2 ∑ v ∈ e x v ⩽ 2 永远成立 ——取 α = 2 \alpha = 2 α = 2 ∀ v \forall v ∀ v ∑ e ∋ v y e = 1 \sum_{e \ni v} y_e = 1 ∑ e ∋ v y e = 1 v v v x v = 0 x_v = 0 x v = 0 v v v x v = 1 x_v = 1 x v = 1 x v = 1 ⇒ v x_v = 1 \Rightarrow v x v = 1 ⇒ v β = 1 \beta = 1 β = 1
代入松弛互补松弛的结论:
SOL = ∑ v x v ⩽ α β ∑ e y e = 2 ∑ e y e ⩽ 2 OPT LP ⩽ 2 OPT \text{SOL} = \sum_v x_v \le \alpha\beta \sum_e y_e = 2 \sum_e y_e \le 2\,\text{OPT}_{\text{LP}} \le 2\,\text{OPT}
SOL = v ∑ x v ⩽ α β e ∑ y e = 2 e ∑ y e ⩽ 2 OPT LP ⩽ 2 OPT
所以这个原始对偶算法是 2 2 2 原始对偶算法与极大匹配算法殊途同归 ,但前者揭示了「为什么是 2 2 2 2 2 2 α = 2 \alpha = 2 α = 2
原始对偶的妙处
整个过程没有调用任何线性规划求解器,只是从 x = 0 , y = 0 \bm{x} = \bm{0}, \bm{y} = \bm{0} x = 0 , y = 0 y \bm{y} y 记账 ——它给出的 ∑ e y e ⩽ OPT LP \sum_e y_e \le \text{OPT}_{\text{LP}} ∑ e y e ⩽ OPT LP
通用框架
把顶点覆盖的做法抽象出来,就是适用于大量覆盖类问题的原始对偶框架。
flowchart TD
A["写出 LP 松弛及其对偶<br/>min cᵀx, Ax≥b ⟷ max bᵀy, yᵀA≤c"] --> B["初始化<br/>原始 x 不可行、对偶 y 可行<br/>(通常 x=0, y=0)"]
B --> C{"x 可行了吗?"}
C -->|否| D["抬高对偶 y<br/>直到某条对偶约束变紧 yᵀA·ⱼ = cⱼ"]
D --> E["按变紧的对偶约束<br/>整数地抬高对应的 xⱼ"]
E --> C
C -->|是| F["验证松弛互补松弛<br/>∀i: A·x≤αbᵢ 或 yᵢ=0<br/>∀j: yᵀA·ⱼ=cⱼ 或 xⱼ=0"]
F --> G["得近似比<br/>cᵀx ≤ αβ·bᵀy ≤ αβ·OPT"]
classDef setup fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef loop fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef decide fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef result fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
class A,B setup
class D,E loop
class C decide
class F,G result原始对偶框架
写出松弛与对偶 :把原始整数规划 min { c ⊺ x : A x ⩾ b , x ∈ Z ⩾ 0 } \min\{\bm{c}^{\intercal}\bm{x} : \bm{A}\bm{x} \ge \bm{b},\ \bm{x} \in \Z_{\ge 0}\} min { c ⊺ x : A x ⩾ b , x ∈ Z ⩾ 0 } max { b ⊺ y : y ⊺ A ⩽ c ⊺ , y ⩾ 0 } \max\{\bm{b}^{\intercal}\bm{y} : \bm{y}^{\intercal}\bm{A} \le \bm{c}^{\intercal},\ \bm{y} \ge \bm{0}\} max { b ⊺ y : y ⊺ A ⩽ c ⊺ , y ⩾ 0 } 初始化 :原始 x \bm{x} x y \bm{y} y x = 0 , y = 0 \bm{x} = \bm{0}, \bm{y} = \bm{0} x = 0 , y = 0 同步生长 :在 x \bm{x} x y \bm{y} y y ⊺ A ⋅ j = c j \bm{y}^{\intercal}\bm{A}_{\cdot j} = c_j y ⊺ A ⋅ j = c j x j x_j x j 验证松弛互补松弛 :∀ i \forall i ∀ i A i ⋅ x ⩽ α b i \bm{A}_{i\cdot}\bm{x} \le \alpha b_i A i ⋅ x ⩽ α b i y i = 0 y_i = 0 y i = 0 ∀ j \forall j ∀ j y ⊺ A ⋅ j = c j \bm{y}^{\intercal}\bm{A}_{\cdot j} = c_j y ⊺ A ⋅ j = c j x j = 0 x_j = 0 x j = 0 x j x_j x j β = 1 \beta = 1 β = 1 由此得到 c ⊺ x ⩽ α β b ⊺ y ⩽ α β OPT LP ⩽ α β OPT IP \bm{c}^{\intercal}\bm{x} \le \alpha\beta\, \bm{b}^{\intercal}\bm{y} \le \alpha\beta\, \text{OPT}_{\text{LP}} \le \alpha\beta\, \text{OPT}_{\text{IP}} c ⊺ x ⩽ α β b ⊺ y ⩽ α β OPT LP ⩽ α β OPT IP α β \alpha\beta α β
最后一步的不等式链值得回味:b ⊺ y ⩽ OPT LP \bm{b}^{\intercal}\bm{y} \le \text{OPT}_{\text{LP}} b ⊺ y ⩽ OPT LP y \bm{y} y OPT LP ⩽ OPT IP \text{OPT}_{\text{LP}} \le \text{OPT}_{\text{IP}} OPT LP ⩽ OPT IP y \bm{y} y OPT \text{OPT} OPT
章节小结
本讲从一个朴素的运输问题出发,最终抵达了组合优化的核心思想——对偶。回顾这条主线:
flowchart TD
Flow["网络流<br/>最大流问题"] --> FF["Ford-Fulkerson<br/>残余图 + 增广路径"]
FF --> MFMC["最大流 = 最小割<br/>(对偶现象初现)"]
FF --> Algo["算法加速<br/>缩放 / 最短增广 / Dinitz"]
Flow --> App["应用<br/>二部匹配 / 最小割 / 最小费用流"]
MFMC --> LP["线性规划<br/>(统一框架)"]
LP --> Geo["几何<br/>多面体 / 顶点 / bfs"]
LP --> Solve["求解器<br/>单纯形 / 椭球 / 内点"]
LP --> Round["LP 松弛与舍入<br/>顶点覆盖 2-近似 / Max-SAT 3/4"]
LP --> Dual["LP 对偶<br/>弱对偶 / 强对偶 / 互补松弛"]
Dual --> MFMC2["最大流最小割<br/>= 强对偶特例"]
Dual --> PD["原始对偶框架<br/>不解 LP 也能近似"]
Round --> PD
classDef flow fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef lp fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef apply fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef dual fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
class Flow,FF,Algo flow
class LP,Geo,Solve lp
class App,Round apply
class MFMC,Dual,MFMC2,PD dual几条贯穿全讲的核心思想:
对偶无处不在 。「最大流 = 最小割」「匹配 = 顶点覆盖」「消费者最小花费 = 药商最大收入」,看似不相干的最大化与最小化问题成对出现、最优值相等。它们都是线性规划强对偶定理的具体面孔。线性规划是统一的语言 。网络流、匹配、覆盖、可满足性……都能写成线性规划或整数规划。线性规划可在多项式时间求解,于是成了攻克难题的通用引擎。松弛—舍入是攻克 NP-难的标准套路 。把整数约束放宽成连续、解出分数最优、再小心舍回整数,近似比由整性间隙这个内在量决定。对偶可以「不解就用」 。原始对偶框架同步生长原始整数解与对偶解,用对偶当标尺,不调用求解器就得到近似保证——往往更快、更有洞察力。
问题
最优结构
关键结果
最大流
增广路径耗尽
max -flow = min -cut \max\text{-flow} = \min\text{-cut} max -flow = min -cut O ( n 2 m ) O(n^2 m) O ( n 2 m )
线性规划
最优在顶点
多项式时间可解(椭球 / 内点)
顶点覆盖
LP 松弛 + 舍入2 2 2 = 2 = 2 = 2
Max-SAT
随机化舍入
3 / 4 3/4 3/4 = 3 / 4 = 3/4 = 3/4
LP 对偶强对偶
原始最优 = 对偶最优
原始对偶
松弛互补松弛
近似比 = α β = \alpha\beta = α β
从一次物资运输,到一套攻克难题的通用哲学——这就是网络流与线性规划交给我们的礼物:当一个问题难以直接求解时,去寻找它的对偶;当一个问题难以精确求解时,去松弛它、再小心地舍回来。