坐标变换与相机标定
从模型到实务
上一讲(图像采集)建立了从世界到像素的投影模型 。模型很优雅,但有一个关键的实务问题没有回答:这 12 个数字怎么得到? 你拿到一台新相机,盒子上印着「焦距 ,传感器 」,但当算法需要 这些精确到亚像素的内参,以及在某个特定姿态下的 时——出厂参数远远不够。
更要命的是:拿到内外参之后,我们能拿它们做什么?光是「给定 3D 点求 2D 投影」并不是大多数计算机视觉任务的目标。真正常见的任务是反过来的——给定两张图像中已经匹配好的若干点对,反推它们之间的几何关系:把一张图旋转、扭曲、对齐到另一张上。这是全景拼接、人脸对齐、文档校正、AR 贴图等所有「图像变换」类任务的共同骨架。
本讲围绕这两个互补的问题展开:
- 正向问题:如何通过实验测定相机的内外参?
- 反向问题:给定图像之间的对应关系,如何求出它们之间的二维变换并应用?
在路上还会顺手解决两个基础问题——图像采样的离散化(采样和量化),以及在离散化的像素网格上如何谈论邻居和距离。这些是后续所有图像处理算法的语言。
相机标定
标定的目标
相机标定(Camera Calibration)的目的是通过一组已知 3D-2D 对应关系,反求相机的参数:
- 内参矩阵 :焦距 和主点 ,相机自身固有,不随场景变化
- 外参 :相机相对于世界坐标系的姿态,每次拍摄都不同
- 畸变参数:径向畸变和切向畸变的多项式系数,用于后续畸变校正
最常用的工具是棋盘格标定板(Chessboard Calibration Target)——一张印着黑白方格的硬纸板。它的优势在于:
- 角点(黑白格交界)易于亚像素精度地自动检测
- 角点在标定板自身坐标系中的位置完全已知(行列乘以方格边长)
- 角点位于同一平面上,这一约束极大简化了求解过程
用对应点列方程
设标定板上某角点在世界坐标系下的坐标为 ,其在图像中检测到的像素坐标为 。完整投影矩阵 是一个 矩阵,为节省记号写为:
齐次坐标下 ,消去齐次比例因子 得到两个方程:
把分母交叉乘到左边,整理为关于 的线性方程:
每对 提供 2 个方程; 共有 12 个未知数(齐次坐标下其实只有 11 个独立自由度),所以理论上 对点就能求解。
把 个角点的方程联立得到齐次线性方程组 ,其中 , 是 矩阵。
求解齐次最小二乘
显然有平凡解 ,我们要找的是非平凡且与数据「最一致」的解。在约束 下,最小化 的解是 的最小特征值对应的特征向量(等价于 的最小奇异值的右奇异向量)。
这种「齐次最小二乘」模式在多视图几何中无处不在——单应性、本质矩阵、基础矩阵都是这样求的。
平面标定的简化:
棋盘格的所有角点都在同一平面上,可以将这个平面直接选为世界坐标系的 平面,于是 。这一约束让方程组发生了关键的简化:含 的列在 中变成了全零,对应的未知量 无法从这一组数据中确定。
幸运的是,我们不需要它们。把 代入完整投影后,可以发现剩下的 8 个独立参数恰好编码了一个 的单应性矩阵(Homography,记作 ),它把标定板平面上的点 直接映射到图像点 :
这里 是旋转矩阵 的前两列(第三列对应 那一项被消去了)。这个观察是张正友标定法(Zhang's Method)的起点。
张正友平面标定法
张正友(Zhengyou Zhang)于 2000 年提出的平面标定法是目前最广泛使用的标定方案,几乎所有开源工具(OpenCV、MATLAB Camera Calibrator)默认采用它。其核心思想:
- 从不同姿态拍多张照片。每张照片对应一个不同的 ,但共享同一个内参
- 每张图独立估计单应性 。用上一节的齐次最小二乘
- 利用旋转矩阵的正交性反求 。 的前两列必须是单位正交向量,这给出关于 的线性约束;多张图像的多个 联立后, 唯一确定
- 从 和各 反解
- 加入畸变模型,做非线性细化。以重投影误差为目标,用 Levenberg-Marquardt 同时优化 、 和畸变系数
为什么需要多张图
单张图能给出一个 ,对应 8 个独立参数;而 自身就有 4 个未知量(,假设无倾斜)。一张图的约束不足以同时确定 和当前位姿 (共 6 + 4 = 10 个未知量)。多张图共享 ,每多一张就多 8 个约束、6 个新未知量,从第二张开始约束就富余了。实践中通常拍 15–20 张不同姿态,过约束的最小二乘有助于压制噪声。
标定流程实务
一个完整的标定实验如下:
flowchart LR
A["打印棋盘格<br/>贴在硬平面上"] --> B["从不同角度<br/>拍 15+ 张"]
B --> C["亚像素角点<br/>检测"]
C --> D["逐图估计<br/>单应性 H_i"]
D --> E["联立反求<br/>内参 K"]
E --> F["反解外参<br/>R_i, t_i"]
F --> G["非线性优化<br/>+ 畸变模型"]
G --> H["重投影误差<br/>评估"]
classDef setup fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef solve fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef verify fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
class A,B,C setup
class D,E,F,G solve
class H verify重投影误差(Reprojection Error)是衡量标定质量的标准指标:用估计出的 把已知的 3D 角点重新投影回图像,与实际检测到的 2D 角点比较:
良好的标定结果通常在 0.1–0.5 像素之间。误差过大说明角点检测不准、标定板有形变、或者拍摄姿态不够多样。
平面标定法的优劣
优点:只需打印一张棋盘格,对任何手机/相机都适用——成本几乎为零。
局限:仍然需要事先知道棋盘格上格子的边长(或至少边长比例),并依靠角点检测算法把图像点和模板点一一对应。完全无标定(self-calibration)则更难,需要场景中的强约束(如多视图的极线几何)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # 用 OpenCV 标定的简化示例 import cv2 as cv import numpy as np # 棋盘格内角点数 (cols, rows),边长 25mm PATTERN, SIZE = (9, 6), 25.0 objp = np.zeros((PATTERN[0] * PATTERN[1], 3), np.float32) objp[:, :2] = np.mgrid[:PATTERN[0], :PATTERN[1]].T.reshape(-1, 2) * SIZE obj_points, img_points = [], [] for img in load_images(): # 读 15+ 张 gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) found, corners = cv.findChessboardCorners(gray, PATTERN) if found: corners = cv.cornerSubPix(gray, corners, (11, 11), (-1, -1), (cv.TERM_CRITERIA_EPS, 30, 0.001)) obj_points.append(objp) img_points.append(corners) ret, K, dist, rvecs, tvecs = cv.calibrateCamera( obj_points, img_points, gray.shape[::-1], None, None) print("内参 K =\n", K) print("畸变系数 =", dist.ravel()) print("平均重投影误差 =", ret, "像素") |
采样和量化
标定告诉我们一个三维点应该落在哪个像素上——但「像素」本身是什么?它是连续光强场被两次离散化的产物:采样确定空间上有多少个像素,量化确定每个像素能取多少个不同的值。
空间分辨率:采样
传感器把成像平面上的连续光强 离散为 个采样点,每个采样点就是一个像素。 称为图像的空间分辨率(Spatial Resolution)——也就是日常说的「图像尺寸」。采样率越高,采样点越密,能保留的细节就越精细;采样率不足时,原本平滑变化的图像会出现明显的方块状伪影。

从 降到 ,人脸的轮廓首先消失,然后是身体的轮廓,最终图像退化为一组难以辨认的色块。 已经能识别人物姿态但难辨身份; 几乎只剩下大块的明暗区域。
采样不足的根源
人眼能轻松辨识出 的图与原图差异巨大,但量化地说,「细节丢失」对应的是采样定理意义下的混叠(Aliasing)——超过采样率一半(奈奎斯特频率)的高频成分被错误地折叠到了低频上。这是后续滤波与频域分析的核心话题,本讲点到为止。
幅度分辨率:量化
每个像素采集到的连续光强还需要离散为有限个可表示的灰度值。设量化级数为 ,常见的选择是 , 时就是常见的 8 位灰度图(256 级)。 称为幅度分辨率(Amplitude Resolution)。

8 位(256 级)足以让人眼感觉连续;4 位(16 级)开始在天空、皮肤这样的渐变区域出现可见的「色阶」(Banding);2 位(4 级)只剩四档明暗;1 位则成了纯黑白二值图。量化级数对渐变区域的影响远比对纹理丰富区域的影响显著——后者的高频细节天然掩盖了量化误差。
存储位数
一幅 的图像,每像素用 位编码灰度值,对于 通道彩色图像总位数为:
典型的 8 位 RGB 图像 占 (未压缩)。这也解释了为什么图像压缩(JPEG、HEIC、WebP)几乎是工业标准——原始数据量太大。
| 量化位数 | 灰度级数 | 典型用途 |
|---|---|---|
| 1 bit | 2 | 二值图、文档扫描 |
| 4 bit | 16 | 早期游戏、调色板图像 |
| 8 bit | 256 | 标准消费级图像 |
| 10–12 bit | 1024–4096 | 专业摄影 RAW |
| 16 bit | 65536 | 医学影像、HDR 合成中间格式 |
| 32 bit float | 连续 | 物理仿真、HDR 渲染 |
像素间联系
采样把图像变成了离散的像素网格 。在这个网格上,「邻居是谁」「两个像素相距多远」需要重新定义——欧氏几何只是众多选择之一。这套语言会贯穿后续的形态学、连通分量、距离变换、卷积等所有局部操作。
像素邻域
对于位于 的像素 ,定义三种邻域:
![]()
- 4-邻域:,上下左右共 4 个像素
- 对角邻域:,四个对角共 4 个像素
- 8-邻域:,全部 8 个相邻像素
在做连通分量分析或图像填充时,选 4-邻域还是 8-邻域会直接影响结果——比如对角线相连的两个像素,4-邻域下视为不连通,8-邻域下视为连通。
像素间距离
设像素 ,,记 ,。三种常用距离对应不同的范数:
直觉上,三者描述的是「从 到 走最短路径要走多远」,但允许的步长方式不同:
![]()
- :允许沿任意方向走直线(连续意义下的距离)
- :每步只能上下左右走一格(出租车在曼哈顿网格街道上的距离)
- :每步可以走 8-邻域的任意一个(国际象棋中王走一步的距离)
三种距离的具体计算
设 ,,则 ,:
始终有 。这一不等式在距离变换和形态学算法中常被用来加速计算。
坐标变换
有了像素的离散网格语言,可以来谈最核心的话题:把图像「搬」到另一个位置、形状或视角。这类操作统称为坐标变换(Coordinate Transformation),也叫几何变换(Geometric Transformation)——它们改变像素的空间位置,但不改变像素自身的强度值。
滤波 vs 扭曲 vs 对齐
先理清三个概念,它们各自回答不同的问题:
| 操作 | 改变的是 | 输入 | 典型例子 |
|---|---|---|---|
| 滤波(Filtering) | 像素值 | 一张图像 + 一个核 | 模糊、锐化、边缘检测 |
| 扭曲(Warping) | 像素位置 | 一张图像 + 已知变换 | 图像旋转、放缩、视角变换 |
| 对齐(Alignment) | (求出)像素位置间的关系 | 两张图像 | 全景拼接、人脸对齐 |
滤波在下一讲展开。本讲剩余部分聚焦扭曲——给定 ,输出扭曲后的图像;以及对齐的简化版——给定匹配点对,反求 。
flowchart LR
subgraph WARP["扭曲:T 已知"]
W1["源图像 f"] --> W3["输出 g"]
W2["变换 T"] --> W3
end
subgraph ALIGN["对齐:T 未知"]
A1["图像 1"] --> A3["求出 T"]
A2["图像 2"] --> A3
end
classDef known fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
classDef unknown fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
class W1,W2,W3 known
class A1,A2,A3 unknown线性变换:缩放、旋转、镜像、错切
最简单的坐标变换可以写成 矩阵作用于列向量 :
不同的 给出不同的几何效果:
缩放(Scaling)沿坐标轴按 倍率拉伸:
时是均匀缩放(保持形状), 时是非均匀缩放(圆变椭圆)。
旋转(Rotation)绕原点逆时针转角度 :
从极坐标推导旋转矩阵
设原点到点 的距离为 ,与 轴夹角为 ,则 ,。逆时针旋转 后,点的极坐标变为 ,即:
矩阵化即得 。注意虽然 是 的非线性函数,但 是 的线性组合——所以旋转是线性变换。
旋转矩阵的关键性质:,即 。这种「转置即逆」的矩阵叫正交矩阵(Orthogonal Matrix)。
镜像(Mirror)沿坐标轴翻转。水平镜像(关于 轴)和垂直镜像(关于 轴)分别为:
把这两种镜像复合就得到对角镜像(Diagonal Mirror),几何上等价于绕原点旋转 :图像既左右翻转又上下翻转。
转置(Transpose)交换 ,即关于直线 镜像:
错切(Shearing,又称剪切)沿一个轴按另一个轴坐标比例位移,会让矩形变成平行四边形:
水平错切 :, 越大水平偏移越多——直立的字母变成倾斜体的效果。
平移与齐次坐标
上面所有变换都属于线性变换——它们能写成 的形式。但有一个最简单、最常用的变换却不是线性的:
平移(Translation)有常数项 ,无法用 矩阵乘法表示。如果只用 矩阵,每次平移都得单独处理,无法和其他变换统一复合,工程上很别扭。
解决方案是上一讲已经引入过的齐次坐标(Homogeneous Coordinates):把 扩展为 ,多出来的第三维度让平移可以纳入矩阵乘法:
类似地,所有 线性变换都可以无损地嵌入到 齐次矩阵的左上角,第三行写为 :
下图展示这些基本变换施加于字母 F 上的效果——选择 F 是因为它没有任何对称性,能清楚呈现镜像、旋转、错切等会破坏对称的操作:
![]()
复合:变换的级联
齐次坐标最大的工程价值在于:多步变换的复合 = 矩阵相乘。先应用 再应用 等价于一次性应用矩阵 。这意味着任意复杂的变换链可以被预先「合并」成一个 矩阵,后续每个像素只需做一次矩阵乘法。
顺序敏感
矩阵乘法不可交换:。变换的顺序会显著改变最终结果。
以「绕图像中心 旋转 」为例,正确的复合是:
分三步读:先把图像中心平移到原点,绕原点旋转,再平移回去。如果不先平移到原点而直接旋转,整张图会绕图像左上角的原点旋转——结果完全不同。
一个简单的复合例子
设要对一个点先平移 再绕原点旋转 ,计算 :
如果倒过来——先旋转再平移——结果会是:
两者的左上 旋转部分相同,但右上的平移列截然不同。
各基本变换的逆矩阵
齐次坐标下做反向变换时(下一节会用到)需要求逆。基本变换的逆矩阵几乎都不需要真正去算 ——根据几何直觉就能直接写出:
旋转矩阵的逆等于其转置(,前面已说明)。复合变换的逆按相反顺序求逆:——「先穿外套再穿鞋」的逆是「先脱鞋再脱外套」。
变换的层次
把上面零散的变换组织起来,可以得到一个清晰的包含层次——每一层在前一层的基础上增加新的自由度,同时丢失某种几何不变性:
| 变换 | 矩阵形式 | DOF | 保持的性质 |
|---|---|---|---|
| 平移 | 2 | 长度、角度、面积、方向 | |
| 刚体(欧氏) | 3 | 长度、角度、面积 | |
| 相似 | 4 | 角度、长度比 | |
| 仿射 | 6 | 平行性、面积比 | |
| 投影(单应性) | (任意) | 8 | 直线(仅此而已) |
DOF 数从 2 一路增到 8。越往下变换越灵活,能保持的几何不变量越少——这是个普遍原则:自由度是把双刃剑,更多的灵活性意味着更弱的约束,对应到对齐问题上意味着需要更多的匹配点对来唯一确定。
下图直观展示三类典型变换施加于「圆 + 正方形 + 平行网格」上的效果:
![]()
- 相似变换:旋转 + 等比缩放 + 平移。圆仍是圆、正方形仍是正方形、网格仍正交。整体形状没有变化,只是位姿和大小不同
- 仿射变换:还允许非均匀缩放和错切。圆变椭圆、正方形变平行四边形——但平行线仍保持平行,网格保持「平行四边形」结构
- 投影变换:连平行性都不再保持。原本平行的网格线在远处汇聚——这正是「近大远小」的几何根源
仿射变换
仿射变换(Affine Transformation)是最常用的二维变换,足以描述「平面对平面」的几乎所有变化(除了透视)。其完整形式:
6 个独立参数,对应 6 个自由度。
仿射变换可以分解为「线性部分 + 平移 」,其中线性部分进一步可以做 RQ 分解,写为「旋转 × 错切 × 缩放」的复合。一切由旋转、缩放、错切、平移按任意顺序组合得到的变换都是仿射变换。前面讲的平移、刚体、相似变换都是仿射变换的特例:
- 欧氏(刚体)变换:,正交且行列式为 。3 DOF:1 个旋转角 + 2 个平移
- 相似变换:,正交矩阵乘以一个标量 。4 DOF:1 个旋转角 + 1 个尺度 + 2 个平移
仿射变换的关键不变量:
- 直线仍是直线:变换不会把直线弯成曲线
- 平行线仍平行:上图中第二个面板的对角线仍互相平行
- 面积比保持:任意两个区域的面积比例不变(虽然绝对面积可能变)
- 共线点的比例保持:若 在 、 之间满足 ,变换后仍然满足
仿射变换有 6 个自由度,每对匹配点提供 2 个方程,所以至少需要 3 对匹配点才能唯一确定。
投影变换(单应性)
投影变换(Projective Transformation),也叫单应性(Homography),是最一般的二维线性变换:
注意第三行不再是固定的 ,而是任意的 。这意味着输出齐次坐标的第三个分量 不再恒为 1,恢复笛卡尔坐标时必须做除法——这一步引入的非线性,正是投影变换能表达「近大远小」的关键。
自由度
矩阵 有 9 个元素,但齐次坐标的尺度等价性意味着 与 (任意非零 )描述同一个变换。所以独立自由度是 。每对匹配点给出 2 个方程,至少需要 4 对匹配点。
几何意义:不同投影平面间的映射
单应性的物理直觉
单应性描述的是同一个投影中心,两个不同投影平面之间的映射。想象自己站在房间中央,透过两扇朝向不同的窗户看外面的同一个场景——两扇窗户的图像之间的关系就是一个单应性。在两种情形下成立:
- 相机绕光心旋转拍摄的多张图像之间(场景任意,但相机不能平移,否则有视差)
- 相机从不同位置拍摄同一平面物体的图像之间(场景必须是平面)
这两种情形也正是单应性最常见的两个应用:全景拼接和平面物体的视角变换。
单应性的应用
- 全景拼接:相机绕光心旋转,相邻图像间用单应性对齐后融合
- 平面校正:把斜视拍摄的文档/海报反扭成正视图
- AR 贴图:把虚拟图层(菜单、广告)「贴」到真实平面物体上
- 鸟瞰图变换:把汽车前方斜视的车道图像变换为俯视视角
分块仿射
整张图共享一个全局 或 时,能描述的变形有限。对于人脸表情、布料褶皱这种局部变形,常采用分块仿射变换(Piecewise Affine Warp):把图像三角剖分(如 Delaunay 三角化),每个三角形内部应用一个独立的仿射变换。三角形之间的位移在边界处保持连续,整体效果可以是高度非线性的。这种方法在人脸对齐、面部动画(AAM、人脸 morphing)中非常常用。
计算空间变换
前面讨论的都是「给定 ,看看效果如何」。但实际任务中我们经常面对反过来的问题:已知一组对应点对 ,反推变换矩阵 。这类问题统称几何失真校正或对齐,通常分两步:
- 求解变换 :从匹配点列方程并求解
- 应用变换 + 插值填充:把源图像变换到目标坐标系,并填补浮点位置带来的间隙
第二步又有两种方向相反的实现策略——正向变换与反向变换,下一节单独讨论。
从匹配点求解变换
以仿射变换为例。设一个匹配点对 ,仿射方程为:
整理为线性方程:
每对点提供 2 个方程,6 个未知数,所以 3 对点可以恰好唯一求解(但不鲁棒)。实际中我们会用 对点,得到超定方程组 ,用最小二乘求解:
NumPy 中一行:m = np.linalg.lstsq(A, b, rcond=None)[0]。
求解单应性 的方程组形式略不同(因为 自带尺度等价性,方程组是齐次的 ),但思路完全一样——这与前面相机标定中求解 用的是同一套技术。
当匹配点含错误:要用 RANSAC
最小二乘对异常值(错误匹配)极为敏感——一个错配点就能严重扭曲结果。实际系统中通常用 RANSAC 在匹配集合中筛出内点(inliers),再用内点做最小二乘细化。这部分内容会在后续的特征匹配/对齐章节深入展开,本讲先用「干净的匹配」假设简化叙述。
一个直观的例子:从三角形的对应推变换类型
设两个三角形 和 ,已知 ,,。仅从这 3 对点,我们能确定多少?
3 对匹配点恰好提供 6 个方程——刚好够确定一个仿射变换的 6 个参数。所以任意三角形到任意三角形的变换都是仿射变换(前提是不退化为共线)。一旦发现 或角度不保持,就说明这不是相似变换;如果再做检查发现某些「平行性」也变了,就说明这甚至不只是仿射——但靠 3 对点列方程是无法识别出投影变换的,因为投影变换需要至少 4 对点。
| 变换 | 最少匹配点对 | 说明 |
|---|---|---|
| 平移 | 1 | 1 对点 → 2 个方程 → 2 个未知数 |
| 刚体 | 2 | 2 对点 → 4 个方程 → 3 个未知数(过约束) |
| 相似 | 2 | 同上,4 个方程 → 4 个未知数(恰好) |
| 仿射 | 3 | 6 个方程 → 6 个未知数(恰好) |
| 投影 | 4 | 8 个方程 → 8 个未知数(恰好) |
正向变换 vs 反向变换
求出变换 之后,下一步是把源图像 实际「搬」到目标图像 上。这里有一个看似无关紧要、实际上决定算法成败的选择:遍历哪一边的整数像素?
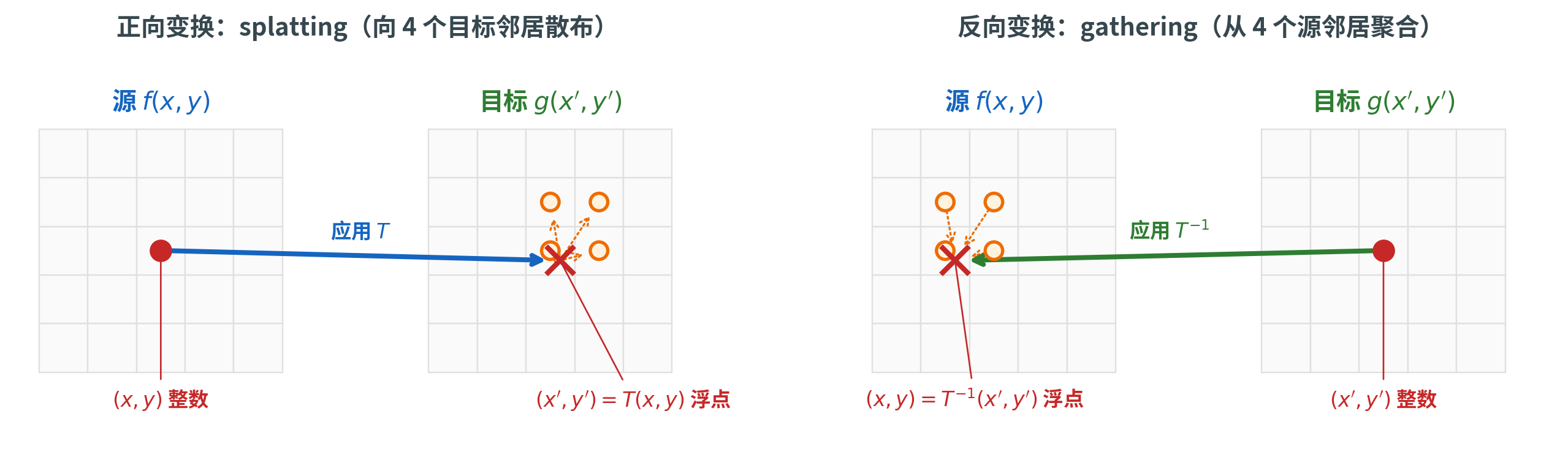
正向变换(splatting)
最直观的想法:遍历源图像中每个整数像素 ,用 计算它的目的地 ,然后把强度值 写到目标图像的 位置。
问题来了: 几乎总是浮点数。该写到哪个整数像素上?
- 最简单的方案:四舍五入到最近的整数像素。问题:当变换是放大时,目标图上会出现没有任何源像素映射到的「漏洞」(hole);当是缩小时,多个源像素映射到同一个目标像素,互相覆盖
- 改进方案:splatting(散布):把强度值按比例分配到 周围的 4 个整数邻居。这缓解了漏洞问题,但仍可能有目标像素未被任何源像素覆盖
正向变换在实践中很少使用,主要原因就是漏洞和覆盖问题难以彻底解决。
反向变换(gathering)
倒过来想:遍历目标图像中每个整数像素 ,用 反推它对应的源坐标 ,再从源图像的这个浮点位置「采集」一个值写到 。
这同样涉及浮点位置——但解决起来轻松得多:在源图像上用插值估计浮点位置的值。
反向变换的优势是决定性的:
- 目标图像的每个像素都被恰好处理一次,没有漏洞、没有覆盖
- 「在源图上做插值」是一个被研究得透彻的问题,有大量成熟方法
- 大多数图形 API(OpenGL 的纹理采样、OpenCV 的
warpAffine)默认采用反向变换
插值方法
反向变换需要从源图像的浮点位置 估计强度值 。三种最常用的插值方法精度递增、计算量也递增:
最近邻插值
最近邻(Nearest Neighbor):把 四舍五入到最近的整数像素,直接取那个像素的值:
最快——只查一次内存。但效果最差:放大后图像出现明显的方块状阶梯(aliasing);旋转后边缘出现锯齿。它的最大优点是保留原始像素值,所以在分类标签图、调色板索引图这种「像素值不能被混合」的场景中不可替代。
双线性插值
双线性插值(Bilinear Interpolation)用 周围 个整数像素的加权平均估计:
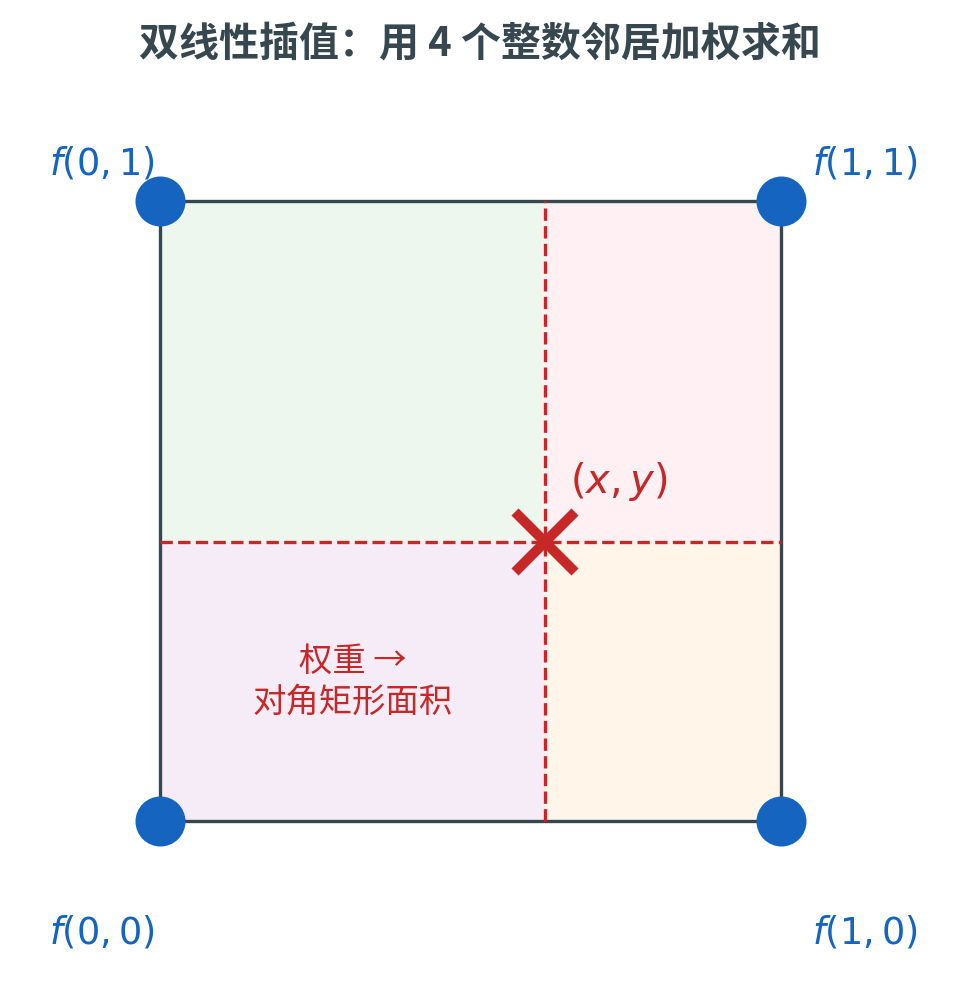
设 周围的四个整数邻居为 (已平移到原点附近以简化记号), 是 起的小数偏移:
每个邻居的权重等于对角矩形的面积(图中四个色块)——离哪个邻居近,对角矩形就大,权重也大。
可以分两步直观理解:先在水平方向做两次线性插值(行 和行 各得一个值),再在垂直方向把这两个值线性插值起来。所以「双线性 = 两次线性」。
双线性在大多数应用中是质量与速度的最佳权衡,是 OpenCV、PIL、PyTorch 默认的图像缩放与变换方法。
双三次插值
双三次插值(Bicubic Interpolation)使用 个邻居,每个方向上用三次多项式(典型的 Catmull-Rom 或 B 样条核)做更平滑的插值。理论上能保留更多细节,主观质量也常优于双线性,但计算量是双线性的 4 倍以上。
三种方法的视觉对比

将一个 的小图放大 20 倍:
- 最近邻:保留原始像素值,呈现明显的方块感——每个原像素膨胀成 的均匀色块
- 双线性:边缘平滑,但在锐利边缘处略显模糊——线性平均会让黑白边缘出现灰色过渡
- 双三次:边缘比双线性稍锐利,整体也更平滑
| 方法 | 邻居数 | 速度 | 质量 | 适用场景 |
|---|---|---|---|---|
| 最近邻 | 1 | 最快 | 最差 | 标签图、像素艺术、保留原始值 |
| 双线性 | 4 | 中 | 好 | 通用默认选择 |
| 双三次 | 16 | 慢 | 较好 | 高质量缩放、超分辨率前处理 |
| Lanczos | 36+ | 最慢 | 最好 | 摄影后期、专业缩放 |
实践:人脸对齐
把上面所有概念串起来,看一个具体应用——人脸对齐(Face Alignment)。在人脸识别、表情分析、属性预测这类任务中,输入照片中的人脸总是处于不同的位置、尺度、角度。直接喂给模型会让模型同时承担「找到人脸」和「识别身份」两件事,效率低且鲁棒性差。
工程上的标准做法是先把人脸对齐到一个标准模板:把双眼、鼻尖、嘴角等关键点搬到固定的目标位置。对齐后所有人脸都「正了、居中了、大小一致」,下游模型只需关注身份特征本身。
流程
flowchart LR
A["输入照片"] --> B["人脸检测<br/>(Bounding Box)"]
B --> C["关键点检测<br/>(5 或 68 点)"]
C --> D["求解相似变换 T"]
D --> E["反向变换 + 双线性"]
E --> F["对齐后的人脸<br/>(112 × 112)"]
classDef input fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef detect fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef align fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
class A input
class B,C detect
class D,E,F align为什么用相似变换而非更灵活的仿射?人脸的非刚性形变(表情)通常不是仿射的,强行用仿射拟合反而会被表情干扰,把脸压扁或拉斜。相似变换只允许旋转、均匀缩放、平移——它能把人脸「摆正」,但不会试图改变脸型,恰好契合需求。
实现:用 5 个关键点求相似变换
设源关键点为 (输入照片中检测到的左眼、右眼、鼻尖、左嘴角、右嘴角),目标模板点为 (一组固定的标准位置)。要求一个相似变换 ,使得:
这是经典的 Procrustes 问题,有闭式解:先去中心化两组点,对两组中心化点的协方差矩阵做 SVD,旋转矩阵由 SVD 的左右奇异向量构造。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | import numpy as np import cv2 as cv # ArcFace 标准的 5 点模板(112×112 输出尺寸) TEMPLATE = np.array([ [38.29, 51.70], # 左眼 [73.53, 51.50], # 右眼 [56.03, 71.74], # 鼻尖 [41.55, 92.37], # 左嘴角 [70.73, 92.20], # 右嘴角 ], dtype=np.float32) def align_face(image, landmarks, output_size=(112, 112)): """根据 5 点关键点把人脸对齐到 ArcFace 模板。""" # estimateAffinePartial2D 求的就是相似变换(4 DOF) M, _ = cv.estimateAffinePartial2D( landmarks.astype(np.float32), TEMPLATE, method=cv.LMEDS, # 对异常关键点鲁棒 ) # warpAffine 内部用反向变换 + 双线性插值 aligned = cv.warpAffine( image, M, output_size, flags=cv.INTER_LINEAR, borderValue=0, ) return aligned |
estimateAffinePartial2D 是 OpenCV 中专门求相似变换的函数(Partial 意味着只允许旋转、均匀缩放、平移,不允许错切);warpAffine 内部就是用反向变换扫描每个目标像素 + 双线性插值。这两行代码背后蕴含的,正是本讲讨论的全部内容。
模板的选择
上面 TEMPLATE 中的具体坐标来自 ArcFace 论文,是工业界事实上的标准。不同任务可能用不同模板:表情分析常用 68 点模板(DLib 标准),人脸编辑常用更密集的 106 点。模板一旦选定就要前后一致——训练时用什么模板对齐,推理时也得用同一个,否则数据分布会发生偏移。
小结
flowchart TD
Start["3D 世界"] -->|"P = K[R|t]"| Project["2D 投影"]
subgraph Calib["相机标定(求 K 和 R, t)"]
C1["棋盘格<br/>多张图"] --> C2["每图估计 H_i"]
C2 --> C3["反求 K"]
C3 --> C4["反解 R_i, t_i"]
C4 --> C5["非线性细化<br/>(含畸变)"]
end
Project --> Sample["采样 + 量化"]
Sample --> Pixel["离散像素网格<br/>邻域 + 距离"]
Pixel --> Warp["坐标变换"]
subgraph Hier["变换层次(DOF 递增)"]
H1["平移 (2)"] --> H2["刚体 (3)"]
H2 --> H3["相似 (4)"]
H3 --> H4["仿射 (6)"]
H4 --> H5["投影 (8)"]
end
Warp --> Apply["应用变换"]
subgraph Compute["实施"]
I1["从匹配点<br/>列方程 + LS"] --> I2["反向变换<br/>(gathering)"]
I2 --> I3["双线性<br/>插值"]
end
classDef world fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
classDef calib fill:#fff3e0,stroke:#ef6c00,stroke-width:2px
classDef pixel fill:#f3e5f5,stroke:#4a148c,stroke-width:2px
classDef warp fill:#e8f5e8,stroke:#2e7d32,stroke-width:2px
class Start,Project,Sample world
class C1,C2,C3,C4,C5 calib
class Pixel pixel
class Warp,H1,H2,H3,H4,H5,Apply,I1,I2,I3 warp本讲围绕「正向问题」和「反向问题」两条线索展开:
正向问题——已知物理世界,求图像。重点是相机标定:用棋盘格上已知的 3D-2D 对应关系,通过齐次最小二乘求解投影矩阵,进而分解出内参 、外参 和畸变系数。张正友平面标定法之所以成为业界标准,是因为它只需一张打印的棋盘格——硬件成本几乎为零,几何约束却足够强。
反向问题——已知图像之间的对应关系,求几何变换。关键工具有:齐次坐标(让平移也能纳入矩阵乘法)、变换的层次结构(平移 → 刚体 → 相似 → 仿射 → 投影,DOF 从 2 涨到 8)、最小二乘求解(从足够多的匹配点对中估计变换参数)、反向变换 + 插值(避免正向变换的漏洞与覆盖问题)。
夹在两者之间的是「像素」本身的离散语言——采样和量化把连续的光强场变成有限的整数网格,邻域和距离则是后续所有局部图像操作的基本词汇。
下一讲将进入计算机视觉的另一条主线——滤波。我们将看到,仅仅在像素值层面(不动它们的位置)做一些简单的局部加权平均,就能实现去噪、锐化、边缘检测乃至图像金字塔——这些是后续中层视觉(边缘、特征点)的全部基础。