永远无法准确地判断,但可以量化我们的把握:
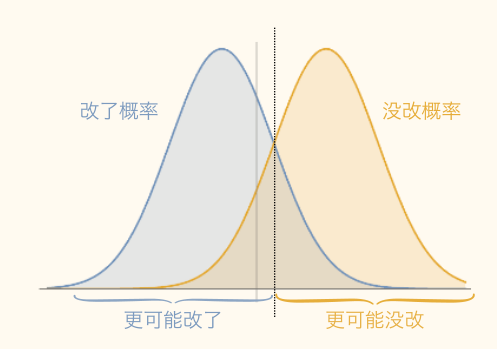
假设检验
概念
- 原假设(零假设,null hypothesis)
- 备择假设(alternative hypothesis)
- 检验法则(decision rule):
- 接受域(acceptance region):应该接受原假设
- 拒绝域(rejection region)/临界域(critical region):应该拒绝原假设
|
接受原假设 |
拒绝原假设 |
| 原假设为真 |
正确(TP) |
一类错误(弃真/假阳性 FP) |
| 原假设为假 |
二类错误(取伪/假阴性 FN) |
正确(TN) |
一种假设检验基本步骤:
- 提出统计假设:原假设 H0 和备择假设 H1
- 针对两种假设确定能区分它们的统计量
- 根据统计量确定拒绝域和接受域
- 采样,从样本中计算出统计值
- 判断统计值是否在拒绝域内,做出决策
对这种方法,考虑边界情况、判断的可信度、出错率?
犯错概率,有
- 原假设为真,犯一类错误概率为 α
- 显著性(significance):α
- 置信水平 γ=1−α
- 备择假设为真,犯二类错误概率为 β
- 检验功效(power):1−β
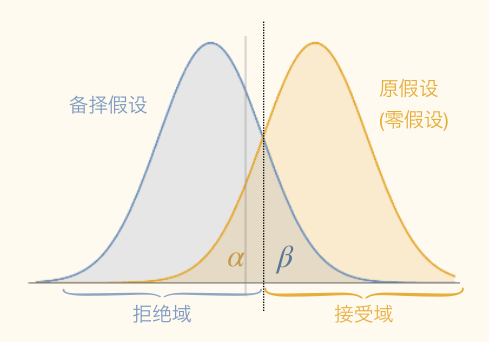
Fisher 显著性检验:
|
接受原假设 |
拒绝原假设 |
| 原假设为真 |
1−α |
α |
| 原假设为假 |
β |
1−β |
生男生女
John Arbuthnot(1710)统计了 82 年间(1629 ~ 1710)伦敦出生的男女比例,均为男比女多。如果假设男女比例相等,那么这种情况发生的概率是 2821。
改版女士品茶
某个吃货能否区分:
- 先吃一口夏洛特蛋糕,再吃一口便利店鸡排
- 先吃一口便利店鸡排,再吃一口夏洛特蛋糕
原假设是这两种吃法口味一样,备择假设是不一样。
- 试验:有四组实验,每组各有一份,让她在无感知情况下随机品尝,并从中选出一份先吃夏洛特蛋糕的。
- 数据:受试者对了 k 次
- 原假设为真情况下样本出现的概率为 (k4)/(48)。
原版女士品茶中,受试者藻类学家 Muriel Bristol 全对,概率为 1/(48)=701≈1.429%。
由此添加了第三步「规定显著性水平 α」。
假设检验基本步骤(Neyman-Pearson's approach):
- 提出统计假设:原假设 H0 和备择假设 H1
- 针对两种假设确定能区分它们的统计量
- 规定显著性水平 α
- 根据统计量确定拒绝域和接受域
- 采样,从样本中计算出统计值
- 判断统计值是否在拒绝域内,做出决策:「在显著性水平 α 下接受/拒绝原假设」
α,β 互相矛盾(像是精确度 P 和召回率 R)。
可以增大样本量,减小假设样本方差,假设样本更集中,重叠区域更小:
- 固定 α,提高样本量使 β⩽α
- 样本量由 β 确定(功耗)
正态总体参数检验
已知方差 σ2,检验期望 μ
例如一洗衣粉包装机,额定标准为 500g/包,袋装重量服从正态分布 N(μ,σ2),称得样本 X1,…,Xn,取显著性水平 α,包装机是否工作正常?
Z 检验
若样本 X1,…,Xn 服从正态分布 N(μ,σ2),取显著性水平 α,则:
检验统计量 Z=σ/nXˉ−μ0,若原假设 H0:μ=μ0 成立,则 Z∼N(0,1)。
令 X∼N(0,1),有
- 备择假设 H1:μ=μ0(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
- 备择假设:H1:μ<μ0(左侧检验)拒绝域
{z:Pr(X⩽z)⩽α}
- 备择假设 H1:μ>μ0(右侧检验)拒绝域
{z:Pr(X⩾z)⩽α}
zα 表示使得 Pr(X⩾zα)=α 的 z 值,其中 X∼N(0,1)。
已知期望 μ,检验方差 σ2
例如一洗衣粉包装机,额定标准为 500g/包,袋装重量服从正态分布 N(μ,σ2),称得样本 X1,…,Xn,取显著性水平 α,检验 σ2=σ02。
卡方检验
若样本 X1,…,Xn 服从正态分布 N(μ,σ2),则:
样本方差 S2=n−1∑i(Xi−Xˉ)2,有 E[S2]=σ2。
检验统计量 Z=σ02∑i(Xi−μ)2,若原假设 H0:σ2=σ02,则 Z∼χ2(n)。
令 X∼χ2(n),有
- 备择假设 H1:σ2=σ02(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
卡方分布
若 X1,…,Xn 独立同分布,且 Xi∼N(0,1),则 Q=∑iXi2∼χ2(n),称 Q 服从自由度为 n 的卡方分布。
若 Q∼χ2(n),则有 E[Q]=n。若 X1∼χ2(m),X2∼χ2(n) 相互独立,则 X1+X2∼χ2(m+n)。
未知期望 μ,检验方差 σ2
例如一洗衣粉包装机,额定标准为 500g/包,袋装重量服从正态分布 N(μ,σ2),称得样本 X1,…,Xn,已知 μ=μ0,取显著性水平 α,检验 σ2=σ02。
卡方检验
未知期望,检验统计量 Z=σ02∑i(Xi−Xˉ)2,若原假设 σ2=σ02 成立,则 Z∼χ2(n−1)。
证明
即证若 X1,…,Xn∼N(0,1),则 Z=∑i(Xi−Xˉ)2∼χ2(n−1)。
样本方差 S2=i=1∑nn−1(Xi−Xˉ)2。
有 i=1∑n(Xi−Xˉ)2=i=1∑nXi2−nXˉ2,显然 i=1∑nXi2∼χ2(n)。
又 Xˉ∼N(0,n1),于是 nXˉ∼N(0,1),且 nXˉ2∼χ2(1)。
改写 i=1∑nXi2=(n−1)S2+nXˉ2,记作 χ2(n)=(n−1)S2+χ2(1),这两个是相互独立的(样本方差与样本均值相互独立)。
于是可以用 MGF 有
Mχn2(t)=M(n−1)S2+χ2(1)(t)=M(n−1)S2(t)⋅Mχ2(1)(t)
而 Mχn2(t)=(1−2t)−n/2,则有
M(n−1)S2(t)=Mχn2(t)/Mχ2(1)(t)=(1−2t)−n/2⋅(1−2t)1/2=(1−2t)−(n−1)/2
因此 i=1∑n(Xi−Xˉ)2=(n−1)S2∼χ2(n−1)。
上面的证明还有两步未完成,即「样本方差与样本均值相互独立」和「MGF 的计算」,先看后者:
令 X∼χn2,则其概率密度函数为
f(x)=2n/2Γ(n/2)xn/2−1e−x/2
Γ(z)=∫0∞tz−1e−tdt
于是
MX(t)=E[exp(tX)]=∫0∞exp(tx)⋅f(x)dx=2n/2Γ(n/2)1∫0∞xn/2−1exp(−(1/2−t)x)dx=2n/2Γ(n/2)1∫0∞(1/2−tu)n/2−11/2−te−udu=2n/2Γ(n/2)(1/2−t)n/21∫0∞un/2−1e−udu=2n/2Γ(n/2)(1/2−t)n/21Γ(n/2)=(1−2t)−n/2(u=(1/2−t)x)
另一个见下面。
令 X∼χ2(n−1),有
- 备择假设 H1:σ2=σ02(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
未知方差 σ2,检验期望 μ
t 检验
样本 X1,…,Xn 服从某正态分布 N(μ,σ2),方差 σ2 未知。取显著性水平 α,检验 μ=μ0:
- 原假设 H0:μ=μ0;
- 备择假设 H1:μ=μ0。
检验统计量 Z=S/nXˉ−μ0,若原假设成立,则 Z∼t(n−1)。
有
⎩⎨⎧Xˉnσ2(n−1)S2Z∼N(μ0,σ2/n)∼χ2(n−1)=((n−1)S2/(nσ2))/(n−1)(Xˉ−μ0)/(σn)
令 X∼t(n−1),有
- 备择假设 H1:μ=μ0(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
学生 t 分布
若随机变量 X∼N(0,1),Y∼χ2(n) 独立,则随机变量
T=Y/nX
服从 n 个自由度的学生 t 分布,记作 T∼t(n)。
正态总体样本均值和样本方差相互独立的证明
若 X1,…,Xn∼N(μ,σ2),则有 Xˉ2 与 S2 相互独立。
(不严格地证明)有
f(x1,…,xn)=(2πσ2)−n/2exp(−2σ2∑i(xi−μ)2)=(2πσ2)−n/2exp(−2σ2∑i(xi−xˉ)2)exp(−2σ2n(xˉ−μ)2)
第一个 exp 可以看作 S2,第二个 exp 可以看作 Xˉ,即联合分布可以分解为 Xˉ 和 S2 的乘积,因此 Xˉ 与 S2 相互独立。
严格证明,有 Xˉ∼N(μ,σ2/n),与 Xˉ−Xj=n1i=j∑Xi−nn−1Xj,于是
Xˉ−Xj∼N(n(n−1)μ−n(n−1)μ,(n−1)n2σ2+(n−1)2n2σ2)=N(0,nn−1σ2)
两两之间的协方差有
Cov(Xˉ−Xj,Xˉ)=Cov(Xˉ,Xˉ)−Cov(Xj,Xˉ)=nn−1σ2
而 Cov(Xj,Xˉ)=Cov(Xj,Xj/n)=nσ2,同时 Cov(Xˉ,Xˉ)=nσ2,即 Xˉ 与 Xˉ−Xj 不相关。
在联合正态分布中,不相关等价于相互独立,因此 Xˉ 与 S2 相互独立。
检验比较两个正态总体
已知方差 σ12,σ22,检验期望差 μ1−μ2
样本 X1,…,Xn1∼N(μ1,σ12),Y1,…,Yn2∼N(μ2,σ22),取显著性水平 α,检验 μ1=μ2:
- 原假设 H0:μ1=μ2;
- 备择假设 H1:μ1=μ2(双侧检验)。
检验统计量 Z=σ12/n1+σ22/n2(Xˉ−Yˉ)−(μ1−μ2),若原假设成立,则 Z∼N(0,1)。
令 X∼N(0,1),有
- 备择假设 H1:μ1=μ2(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
未知方差 σ12=σ22,检验期望差 μ1−μ2
样本 X1,…,Xn1∼N(μ1,σ12),Y1,…,Yn2∼N(μ2,σ22),取显著性水平 α,检验 μ1=μ2:
- 原假设 H0:μ1=μ2;
- 备择假设 H1:μ1=μ2(双侧检验)。
检验统计量 Z=(n11+n21)n1+n2−2(n1−1)S12+(n2−1)S22(Xˉ−Yˉ)−(μ1−μ2),若原假设成立,则 Z∼t(n1+n2−2)。
令 X∼t(n1+n2−2),有
- 备择假设 H1:μ1=μ2(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
未知方差 σ12=σ22,检验期望差 μ1−μ2*
Behrens-Fisher problem
Welech's 近似 t 解法(Welch's approximate t solution):
令 S2=S12/n1+S22/n2,则 S2 近似服从卡方分布。
检验统计量 Z=S2/?(Xˉ−Yˉ)−(μ1−μ2)。
近似自由度 ℓ≈g12/(n1−1)+g22/(n2−1)(g1+g2)2,其中 g1=S12/n1,g2=S22/n2。
比较方差 σ12,σ22
F 检验
样本 X1,…,Xn1∼N(μ1,σ12),样本 Y1,…,Yn2∼N(μ2,σ22),取显著性水平 α,检验 σ12=σ22:
- 原假设 H0:σ12=σ22;
- 备择假设 H1:σ12=σ22(双侧检验)。
检验统计量 Z=S22/σ22S12/σ12,若原假设成立,则 Z∼F(n1−1,n2−2)。
令 X∼F(n1−1,n2−2),有
- 备择假设 H1:σ12=σ22(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
F 分布
若随机变量 X∼χ2(n),Y∼χ2(m) 独立,则随机变量
F=Y/mX/n
服从 n,m 个自由度的 F 分布,记作 F∼F(n,m)。
配对差异检验(paired difference test)
现实场景往往较为复杂,没有大量理想样本:
- 比较两种肥料的效果:不同农田本身条件不同。
- 检验药效:不同志愿者本身体质不同、病情不同。
- 比较机器学习算法性能:不同数据集性质不同。
配对差异检验
假设机器学习算法 LA,LB 在数据集 i 上的准确度分别服从正态分布 N(μiA,σ12) 和 N(μiB,σ22)。σ1,σ2 未知。取显著性水平 α,比较两种算法的性能 ∑iμiA/n=∑iμiB/n。
- 原假设 H0:∑iμiA/n=∑iμiB/n;
- 备择假设 H1:∑iμiA/n=∑iμiB/n(双侧检验)。
检验统计量 Z=(n11+n21)n1+n2−2(n1−1)S12+(n2−1)S22Xˉ−Yˉ,若原假设成立,则 Z∼t(n1+n2−2)。
令 X∼t(n1+n2−2),有
- 备择假设 H1:∑iμiA/n=∑iμiB/n(双侧检验)拒绝域
{z:Pr(X⩽z)⩽α/2 or Pr(X⩾z)⩽α/2}
更多的例子:如比较两种不同的教学方法:
- 不同的学生现有成绩不同,优生可能方法 A 更有效,差生可能应该用方法 B
- 不同知识点不一样,不能对同一个学生先后应用两种不同的方法以比较
- 同一个学生对不同学科的天赋不同,不能对同一个学生的不同科目应用不
同的教学方法
复杂的场景需要更为细致的分类和精妙的实验设计。
p-值(p-value / prob-value)
假设检验基本步骤(Neyman-Pearson's approach):
- 提出统计假设:原假设 H0 和备择假设 H1
- 针对两种假设确定能区分它们的统计量
- 规定显著性水平 α
- 根据统计量确定拒绝域和接受域
- 采样,从样本中计算出统计值
- 判断统计值是否在拒绝域内,做出决策:「在显著性水平 α 下接受/拒绝原假设」
可以「丢掉」备择假设。
假设原假设为真,样本有多罕见?
统计假设:样本相互独立。中心极限定理:样本总体近似正态分布。
ppp=Pr(T⩾t∣H0)=Pr(T⩽t∣H0)=2min{Pr(T⩽t∣H0),Pr(T⩾t∣H0)}
利用 p-值进行检验(Fisher's approach):
- 提出统计假设:原假设 H0
- 采样并从样本中计算出 p-值
- 报告样本确切的 p-值,而非简单的「接受」或「拒绝」
p-值误用:如下图


原假设
将不同的假设作为原假设,可以得出完全相反的结论。
原假设反映了实验者的倾向:
- 同样的数据在不同倾向下有不同的假设
- 应选择较为中立和保守的原假设
原假设应该是清晰的,必须为分析概率分布提供基础。
应尽可能考虑多种不同的原假设。
非正态总体的参数检验*
样本 X1,…,Xn∼exp(λ),取显著性水平 α,检验 λ=λ0:
- 原假设 H0:λ=λ0
检验统计量 Xˉ,有 E[Xˉ]=λ1。
Gamma 分布
随机变量 X 服从参数为 k,λ>0 的伽马分布,记作 X∼Γ(k,λ),若其概率密度函数为
fX(x)=Γ(k)1λkxk−1exp(−λx),x⩾0
运用 Gamma 分布,有 exp(λ)=Γ(1,λ),χ2(n)=Γ(2n,21),从而有 nXˉ∼Γ(n,λ),2λnXˉ∼Γ(n,21)=χ2(2n)。
p 值为 2min{Pr(χ2(2n)⩽2λnXˉ),Pr(χ2⩾2λnXˉ)}。
似然比检验(likelihood ratio test, LRT)
似然函数 L(x;θ0),L(x;θ1) 分别表示两种假设下样本的概率。:
- L(x;θ0):原假设下的似然函数
- L(x;θ1):备择假设下的似然函数
则 L(x;θ0)⩾L(x;θ1) 时更应该支持原假设 H0(反之亦然)。即 L(x;θ0)/L(x;θ1)⩾1 更应该支持原假设。
Neyman-Pearson 引理
给定显著性 α,LRT 是功效 1−β 最高的检验方法。
非参数假设检验
拟合优度检验(goodness of fit)
德军轰炸分布是否服从泊松分布?期末成绩得分是否符合正态分布?
步骤:
- 将所有可能的结果分成不相交的事件 E1,…,Em;
- 通过点估计确定猜测分布的部分参数,假设服从分布 p(Ei)(可选);
- 检验统计量 χ2=i=1∑mp(Ei)(p(Ei)−Ei)2,其中 Ei 是样本中事件 Ei 发生的频率,k 是估计的未定参数个数;
- 若服从分布,则统计量 χ2≈χ2(m−k−1);
- p 值显著性检验。
Pearson's chi-squared test
考虑二项分布 X∼Bin(n,p),由中心极限定理有 Z=np(1−p)X−npDN(0,1),于是 Z2Dχ2(1)。
令 p1=p,p2=1−p,Y=n−X,于是有 Z2=np1(X−np1)2+np2(Y−np2)2Dχ2(1)。
多项式分布也可以得出相似的结论。
独立性检验(statistical independence)
两种因素对样本有影响吗?数据样本的特征和它的分类是否相互独立?
步骤:
- 根据 r 种分类和 c 种特征,构建 r×c 的「列联表」(contingency table/cross tabulation/crosstab);
- 从样本中估计分类与特征的分布函数 pi⊙,p⊙j;
- 若分类与特征相互独立,有 nij≈npi⊙p⊙j;
- 检验统计量 χ2=i=1∑rj=1∑cnpi⊙p⊙j(nij−npi⊙p⊙j)2;
- 若相互独立,则统计量 χ2≈χ2((r−1)(c−1));
- p 值显著性检验。
同质性检验(statistical homogeneity)
两种因素对样本有影响吗?两种机器学习算法在不同数据集上有性能差异吗?
步骤:
- 根据 2 种算法和 c 个数据集,构建 2×c 的「列联表」(contingency table/cross tabulation/crosstab);
- 从样本中估计每组数据的正确率 pj;
- 若没有性能差异,则 n1j≈n2j≈pj;
- 检验统计量 χ2=i=1∑2j=1∑cpj(nij−pj)2;
- 若相互独立,则统计量 χ2≈χ2(c−1);
- p 值显著性检验。
符号检验(sign test)
检验总体的中位数 m=m0?检验上了课的学生 GPA 变高?
步骤:
- 对每个样本 X1,…,Xn 检验是否 X1<m0 并记录 +/−;
- 若原假设成立,则 #−∼Bin(n,21);
- p 值显著性检验。
对于上面 GPA 的检验,就是把步骤中的 #− 换成 #+,21 换成 p>21。
秩和检验(rank-sum test)
Mann-Whitney-Wilcoxon U test
这里的 rank 实际是「排名」,「排名和检验」比「秩和检验」更清晰易懂。
两个总体 D1,D2 是否有差不多 Pr(X>Y)=Pr(Y>X),其中 X∈D1,Y∈D2?
步骤:
- 采样样本 X1,…,Xn1∼D1,Y1,…,Yn2∼D2;
- 将 X1,…,Xn1,Y1,…,Yn2 按大小顺序排序,并记录每个样本的排名;
- 检验统计量 min{U1,U2},其中
- U1=n1n2+2n1(n1+1)−R1
- U2=n1n2+2n2(n2+1)−R2
- R1,R2 分别表示两组样本的排名之和
- U1+U2=n1n2;
- U 统计量外部资料
- 若原假设成立,小样本时查表,大样本时利用中心极限定理;
- p 值显著性检验。
符号秩检验(Wilcoxon signed-rank test)
样本 X1,…,Xn 来自总体 D,检验 D 是否关于 0 轴对称?
步骤:
- 将样本按 ∣Xi∣ 排序,并记录排名;
- 检验统计量 T+=i:Xi>θ∑Ri,其中 Ri 表示 Xi 在上述排序中的排名,θ 为检验的中位数;
- 若原假设成立,小样本时查表,大样本时中心极限定理有 T+∼N(μ,σ2),其中 E[T+]=4n(n+1),Var[T+]=24n(n+1)(2n+1);
- p 值显著性检验。