连续随机变量
有关随机变量的内容,可以参见前面的笔记「随机变量」。
一个随机变量 X:Ω→R 是连续(continuous)的,若其累积分布函数 CDF 可以表示为
FX(x)=Pr[X⩽x]=∫−∞xfX(u)du
的形式。其中 fX:R→[0,∞) 是一个可积函数,称为 X 的概率密度函数(probability density function, pdf)。
密度函数 f 并不唯一由上式确定,概率密度函数实际上有无穷多个。
若 FX 可微(differentiable),一般取 fX(x)=FX′(x)。
对于连续随机变量 X,有(it holds that)
∀x∈R,Pr[X=x]=0
概率质量函数 pmf 是一个概率,概率密度函数 pdf 不是概率,而是 proportion(density, 密度)
Pr[x<X⩽x+Δx]=FX(x+Δx)−Fx(x)≈fX(x)Δx

fX 是一个连续随机变量 X:Ω→R 的 pdf 当且仅当
∫−∞∞fX(x)dx=1
与 ∀x∈R,fX(x)⩾0。
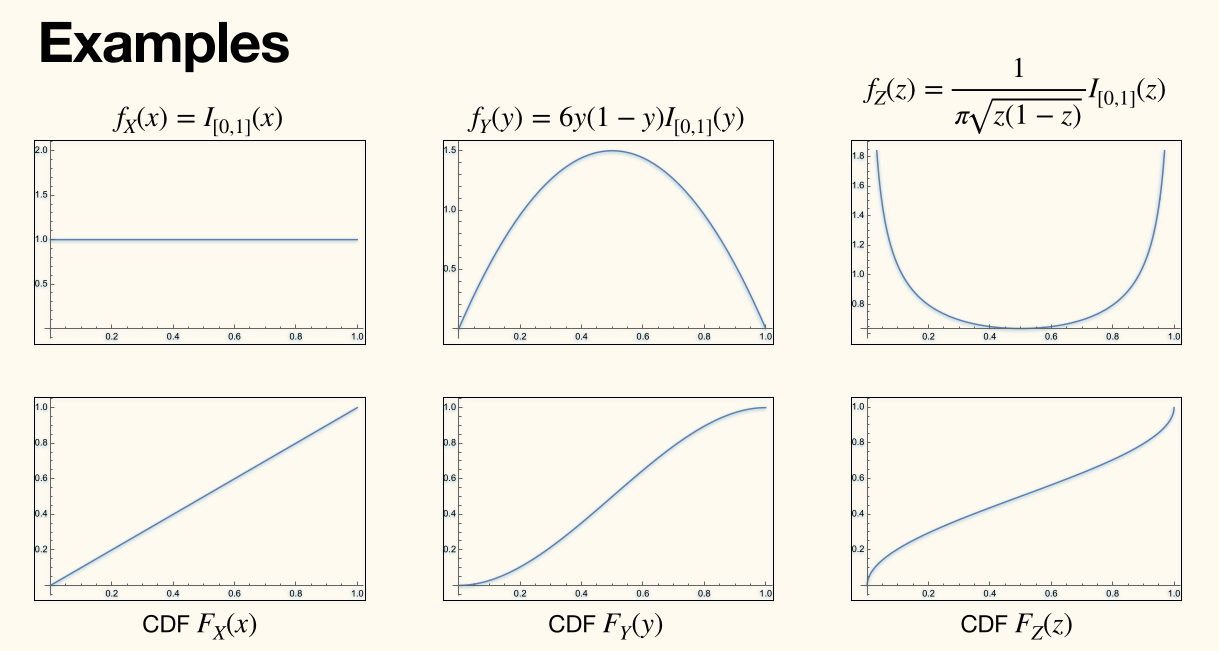
上面的 I[0,1] 将自变量范围限制在了 [0,1] 中。
连续概率空间*
令 I 是 R 中全部开区间的集合,博雷尔(Borel)σ-代数 B(Borel σ-field)是最小的包含 I 的 σ-代数。每个 B∈B 称为博雷尔集(Borel set),是一个对开区间由可数个 ∩,∪,∖ 进行可数次操作得到的集合。
对于博雷尔集 B∈B,勒贝格积分(Lebesgue integral)
μ(B):=Pr[X∈B]=∫BfX(x)dx=∫−∞∞IB(x)dFX(x)
则 (R,B,μ) 是一个良定义的概率空间。
若 g:R→R 是博雷尔可测(Borel-measurable)的,即 ∀y∈R,{x∈R∣g(x)⩽y}∈B,则 g(X) 也是一个随机变量。
勒贝格积分
这部分只是「科普性质」的「简单介绍」。
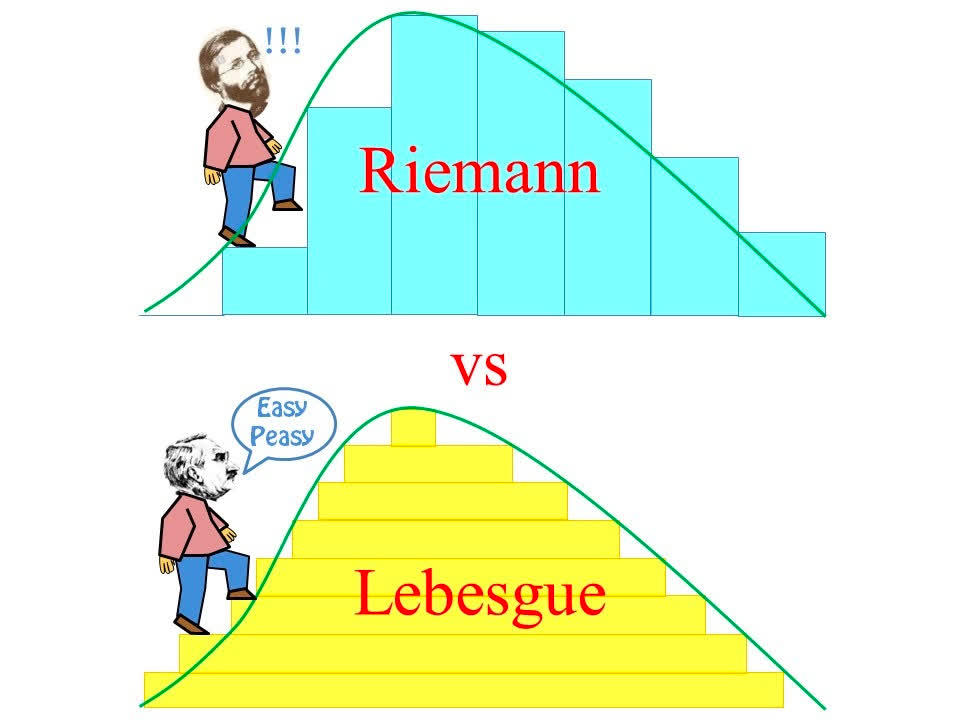
令 (R,B,μ) 是一个概率空间(测度空间)。
假设 f 是(博雷尔)可测的,且非负,对于 B∈B,定义
f∗(t)=μ({x∈B∣f(x)>t})
勒贝格积分(Lebesgue integral)定义为
∫Bf(x)dμ(x)=∫0∞f∗(t)dt
对于一般的 f,可令 f=f+−f−,其中 f+,f− 非负。
病态(Pathological)例子
- 不可测集的例子
- 维塔利集(Vitali set):V⊆[0,1],包含每个有理数陪集的一个元素。
- contains a single point from each coset of Q in R
- 勒贝格可积但黎曼不可积的函数
- 狄利克雷函数(Dirichlet function):有理数的指示函数。
- [0,1] 的不可数子集,但测度为 0
- 康托尔集(Cantor set)

联合分布
随机变量 X,Y 的联合分布函数(joint distribution function)是函数 FX,Y:R2→[0,1] 定义为
FX,Y(x,y)=Pr[X⩽x∩Y⩽y]
随机变量 X,Y 是以联合概率密度函数(joint pdf)fX,Y:R2→[0,∞) (联合)连续的((jointly) continuous),若对任意 x,y∈R 有
FX,Y(x,y)=∫v=−∞y∫u=−∞xfX,Y(u,v)dudv
设 FX,Y 充分可微(sufficiently differentiable),则
fX,Y(x,y)=∂x∂y∂2FX,Y(x,y)
边缘分布
X,Y 的边缘分布函数(marginal distribution function)为
FX(x)=Pr[X⩽x]=FX,Y(x,∞)=∫−∞x∫−∞∞fX,Y(u,y)dyduFY(y)=Pr[Y⩽y]=FX,Y(∞,y)=∫−∞y∫−∞∞fX,Y(x,v)dxdv
X,Y 的边缘密度函数(marginal density function)为
fX(x)=∫−∞∞fX,Y(x,y)dyfY(y)=∫−∞∞fX,Y(x,y)dx

独立性
随机变量 X,Y 是独立的(independent),若对任意 x,y∈R 有 X⩽x 与 Y⩽y 是独立事件,即
FX,Y(x,y)=FX(x)FY(y)
对于连续随机变量 X,Y,等价于
fX,Y(x,y)=fX(x)fY(y)
对于博雷尔可测的 g,h:R→R(即 g(X),h(Y) 是随机变量),则 X,Y 独立可以推出 g(X),h(Y) 也是独立的。
- 因为 X 是 Σ-可测的,g 是博雷尔可测的,于是 g(X) 是 Σ-可测的。
条件分布
令 X 是一个连续随机变量,A 是一个事件,且 Pr(A)>0,则 X 在 A 条件下的条件分布函数(conditional distribution function)为
FX∣A(x)=Pr[X⩽x∣A]=∫−∞xfX∣A(u)du
其中密度函数 fX∣A=dxdFX∣A(x)。
全概率法则(离散)
对于 Ω 的划分 B1,…,Bn,且任意 Bi 有 Pr(Bi)>0,有
fX(x)=i=1∑nPr(Bi)fX∣Bi(x)
证明
对下式两边同时求导即可
Pr[X⩽x]=i=1∑nPr(Bi)Pr[X⩽x∣Bi]
对于(联合)连续随机变量 X,Y,则 X 在给定 Y=y 条件下的条件分布函数为
FX∣Y(x∣y)=Pr[X⩽x∣Y=y]=∫−∞xfY(y)fX,Y(u,y)du
这个定义是有意义的,因为
Pr[X⩽x∣y⩽Y⩽y+dy]=Pr[y⩽Y⩽y+dy]Pr[X⩽x∩y⩽Y⩽y+dy]=fY(y)dy∫u=−∞xfX,Y(u,y)dydu=∫u=−∞xfY(y)fX,Y(u,y)du
FX∣Y 的条件密度函数定义为
fX∣Y(x∣y)=fY(y)fX,Y(x,y)
对于任意 y 使得 fY(y)>0。
全概率法则
令 B⊆R 是一个集合(博雷尔集),对于联合连续随机变量 X,Y,其中 Y 在 ΩY⊆R 上有着正密度,则有
Pr[X∈B]=∫ΩYPr[X∈B∣Y=y]⋅fY(y)dy=∫ΩYfY(y)∫BfY(y)fX,Y(x,y)dxdy=∫ΩYfY(y)∫BfX∣Y(x∣y)dxdy
期望
以 fX 为 pdf(与 CDF FX)的连续随机变量 X 的期望(expectation,亦称为均值 mean)定义为
E[X]=∫−∞∞xfX(x)dx=∫−∞∞xdFX(x)
X 的 k-阶矩(k-th moment)类似地定义为
E[Xk]=∫−∞∞xkfX(x)dx=∫−∞∞xkdFX(x)
这些定义当积分存在时,都是良定义的。
双重计数法
若连续随机变量 X 仅取非负值,则
E[X]=∫0∞(1−FX(x))dx=∫0∞Pr[X>x]dx
证明
∫0∞(1−FX(x))dx=∫0∞Pr[X>x]dx=∫0∞(∫x∞fX(u)du)dx=∫u=0∞fX(u)∫x=0udxdu=∫0∞ufX(u)du=E[X]
LOTUS
若 X 是一个连续随机变量,且 g(X) 是一个随机变量,则
E[g(X)]=∫−∞∞g(x)fX(x)dx
证明
先假设 g⩾0,令 By={x∣g(x)>y},于是
E[g(X)]=∫0∞Pr[g(X)>y]dy=∫0∞∫ByfX(x)dxdy=∫−∞∞fX(x)∫0g(x)dydx=∫−∞∞g(x)fX(x)dx
对于一般的 g:R→R,可令 g=g+−g−,其中 g+,g− 非负,于是
E[g(X)]=E[g+(X)]−E[g−(X)]=∫−∞∞g+(x)fX(x)dx−∫−∞∞g−(x)fX(x)dx=∫−∞∞g(x)fX(x)dx
期望的线性性质就略了,证明也是类似的,就不再写一次了。
额外写一个 E[X+Y]=E[X]+E[Y] 的证明:
证明
E[X+Y]=∬R2(x+y)fX,Y(x,y)dxdy=∬R2xfX,Y(x,y)dxdy+∬R2yfX,Y(x,y)dxdy=∫−∞∞xfX(x)dx+∫−∞∞yfY(y)dy=E[X]+E[Y]
期望的单调性:
- 若 X⩾0,则 E[X]⩾0;
- 若 X⩾Y,则 E[X]⩾E[Y]。
接下来是全期望,离散的部分就不写了,可见前面的笔记。
E[E[X∣Y]]=∫−∞∞E[X∣y]fY(y)dy=∫−∞∞fY(y)∫−∞∞xfX∣Y(x∣y)dxdy=∫−∞∞fY(y)∫−∞∞xfY(y)fX,Y(x,y)dxdy=∫−∞∞∫−∞∞xfX,Y(x,y)dxdy=∫−∞∞xfX(x)dx=E[X]
对独立随机变量 X,Y,可根据变量代换证明期望的乘积:
E[XY]=∬R2xyfX,Y(x,y)dxdy=∬R2xyfX(x)fY(y)dxdy=(∫−∞∞xfX(x)dx)(∫−∞∞yfY(y)dy)=E[X]E[Y]
连续概率分布
连续均匀分布
随机变量 X 在 a 到 b 的区间上是均匀分布(uniform)的,若其概率密度函数 pdf 为
f(x)=⎩⎨⎧b−a10if a⩽x⩽botherwise
与累积分布函数 CDF 为
F(x)=⎩⎨⎧0b−ax−a1if x⩽aif a<x⩽bif x>b


期望(与离散均匀分布的期望相同)
E[X]=∫abb−axdx=2a+b
方差(这与离散均匀分布的方差不同)
Var[X]=E[X2]−E[X]2=∫abb−ax2dx−(2a+b)2=12(b−a)2
对于连续均匀随机变量 X,有期望
E[X]=2a+b
与方差
Var[X]=12(b−a)2
拒绝采样(Rejection Sampling)
令 X 是 [a,b] 上的一个均匀随机变量,则对任意 [c,d]⊆[a,b] 有
Pr(X∈[c,d])=b−ad−c
同时给定 X∈[c,d] 条件,X 的条件分布在 [c,d] 上也是均匀的:
Pr(X⩽x∣X∈[c,d])=⎩⎨⎧0d−cx−c1if x<cif c⩽x⩽dif x>d
因为有
Pr(X⩽x∣X∈[c,d])=Pr(X∈[c,d])Pr(X∈[a,x]∩[c,d])=Pr(X∈[c,d])Pr(X∈[c,x])
Induced probability distribution (诱导概率分布)
对于 pdf 为 fX 的连续随机变量 X,若 Y=g(X) 是一个随机变量(g:R→R 博雷尔可测),则其 pdf fY 为什么呢?
不妨假设 g 单调递增,则 Y 的 CDF 是
FY(y)=Pr[Y⩽y]=Pr[g(X)⩽y]=∫{x∣g(x)⩽y}fX(x)dx=∫−∞g−1(y)fX(x)dx=FX(g−1(y))
于是 Y 的 pdf 为
fY(y)=dydFY(y)=dydFX(g−1(y))=fX(g−1(y))dydg−1(y)=fX(g−1(y))dydg−1(y)=fX(g−1(y))g′(g−1(y))1
g 单调递减结果是一样的。
最后绝对值里面要再看看,课件上写的是 g′(y)1。
又称「逆万流齐一」或「逆万流归宗」。
令随机变量 U 在 [0,1] 上均匀分布。令 F:R→[0,1] 是一个 CDF
- 若 F 是连续的,则随机变量 X=F−1(U) 有 CDF 为 F;
- 若 F 是一个整数值的离散随机变量的 CDF,则离散随机变量 X=k 当且仅当 F(k−1)<U⩽F(k) 有 CDF 为 F。
反函数 F−1 给出了随机变量 X 的分位点(quantile):
Pr[X⩽x]=Pr[F−1(U)⩽x]=Pr[U⩽F(x)]=1−0F(x)−0=F(x)
与
Pr[X=k]=Pr[F(k−1)<U⩽F(k)]=F(k)−F(k−1)
Stochastic Domination and Coupling
若随机变量 X,Y 满足
FX(u)⩽FY(u),∀u∈R
则称 X 随机支配 Y,记作 X⪰stY。
用另一种说法就是,对任意 u∈R,都有 Pr[X⩾u]⩾Pr[Y⩾u]。

上图中,红线对应的随机变量随机支配黑线对应的随机变量。

上图中,红线对应的随机变量,与黑线对应的随机变量不可比。
X⪰stY 当且仅当存在 X,Y 的一个耦合(coupling)(X′,Y′),满足边缘分布 FX′=FX,FY′=FY,使得 Pr(X′⩾Y′)=1(即 X′⩾Y′ 几乎必然发生)。
证明
令 U 为 [0,1] 上的均匀随机变量,X′=FX−1(U),Y′=FY−1(U)。
若 X,Y 是离散的,则令 X′=k⟺FX(k−1)<U⩽FX(k),Y′=k⟺FY(k−1)<U⩽FY(k)。
通过「逆万流归宗」,边缘分布 FX′=FX,FY′=FY,且有 X′=FX−1(U)⩾FY−1(U)=Y′,因为对任意 u∈R 都有 FX(u)⩽FY(u)。
指数分布
随机变量 X 是一个以 λ>0 为参数的指数分布(exponential distribution),若其概率密度函数 pdf 为
f(x)=λe−λx
与累积分布函数 CDF 为
F(x)=1−e−λx,x⩾0


指数分布是几何分布的连续极限版本。
每隔 δ 时间间隔,进行一次 i.i.d. 伯努利试验(p=λδ),并令随机变量 X 表示第一次成功的时间,则
Pr(X>x)=(1−p)δx=(1−λδ)δx→e−λx
当 δ→0 时。
几何分布也可以从指数分布得到,对于 X∼exp(λ),有 ⌈X⌉∼Geo(1−e−λ)。因为
Pr(⌈X⌉=k)=Pr(k−1<X⩽k)=F(k)−F(k−1)=(1−e−λk)−(1−e−λ(k−1))=e−λ(k−1)(1−e−λ)
期望
E[X]=∫0∞xλe−λxdx=−∫0∞xde−λx=(−xe−λx)0∞+∫0∞e−λxdx=λ1
或者也可以这样算:
E[X]=∫0∞(1−F(x))dx=∫0∞e−λxdx=λ1
而二阶矩
E[X2]=∫0∞x2λe−λxdx=λ22
从而方差
Var[X]=E[X2]−E[X]2=λ22−λ21=λ21
对于指数分布 X∼exp(λ),有期望
E[X]=λ1
与方差
Var[X]=λ21
与几何分布类似,指数分布也有「无记忆性」,即对于 s,t⩾0,有
Pr(X>s+t∣X>t)=Pr(X>s)
若 X1,⋯,Xn 是独立的指数分布随机变量,且 Xi∼exp(λi),则 X=min{X1,⋯,Xn} 是一个指数分布随机变量,且 X∼exp(∑i=1nλi)。
证明
Pr(1⩽i⩽nminXi>x)=Pr(1⩽i⩽n⋂(Xi>x))=i=1∏nPr(Xi>x)=i=1∏ne−λix=e−∑i=1nλix
泊松点过程
泊松点过程是一个连续时间的随机过程,其间隔时间 Xi 是独立的指数分布随机变量,即 Xi∼exp(λ)。
具体来说,泊松过程(Poisson process){N(t)∣t⩾0} 与参数(rate)λ>0 是一个连续时间过程定义如下——假设我们有这样一个闹钟:
- N(t) 表示在闹钟在时间 t 前响起的次数,初始状态 N(0)=0;
- 任意两个连续的响铃之间的时间间隔(interarrival time)Xi 是独立的指数分布随机变量,即 Xi∼exp(λ)。
由于无记忆性与最小性,由 k 个独立的以 λ 为相同参数的这样的闹钟,可以视作一个以 λk 为参数的闹钟。
对于任意 t,s⩾0 与自然数 n,有
Pr(N(t+s)−N(s)=n)=Pr(N(t)=n)=e−λtn!(λt)n
证明
Xi 表示第 i−1,i 个闹钟响起的时间间隔,于是有 Xi∼exp(λ)。
零次有
Pr(N(t)=0)=Pr(X1>t)=e−λt
一次有
Pr(N(t)=1)=Pr(X1⩽t∩X1+X2>t)=∫0tfX1(x)Pr(X2>t−x)dx=∫0tλe−λxe−λ(t−x)dx=∫0tλe−λtdx=λte−λt
数学归纳法,设 Pr(N(t)=n)=e−λtn!(λt)n,则有
Pr(N(t)=n+1)=∫0tfX1(x)Pr(N(t−x)=n)dx=∫0tλe−λxe−λ(t−x)n!(λ(t−x))ndx=n!λn+1e−λt∫0t(t−x)ndx=e−λt(n+1)!(λt)n+1
正态分布(高斯分布)
想象一个场景,在一个高维空间中采样一个均匀随机单位向量 U∈Rn 使得 ∥U∥2=1。
有一种方案就是随机采样 i.i.d. X1,…,Xn∈R,并将其标准化
U=∥(X1,…,Xn)∥2(X1,…,Xn)
但是这样其实并不正确。考虑二维的情况,X1,X2 就像是在单位正方形内是均匀的,然后再将其标准化到单位圆上,这样得到的在单位圆上的分布是不均匀的。图就懒得画了。
U 需要在单位球体上是均匀的,所以需要 (X1,⋯,Xn) 的联合密度是球面对称的,即在给定 ∥x∥2=∥y∥2 时要有
fX(x)=i=1∏nfXi(xi)=i=1∏nfXi(yi)=fX(y)
而这就要求了随机变量的概率密度函数
f(x)∝exp(−cx2)
说明
设概率密度函数 f:R→R+,并假设 f(0)=0。
考虑二维情况,采样到 (x,y) 时,有
f(x)f(y)=f(x2+y2)f(0)
定义 g(x)=lnf(0)f(x),则得到
g(x)+g(y)=g(x2+y2)
则存在 a∈R 使得
g(x)=ax2
于是有 f(x)=f(x)eax2,且 a<0。
证明略。
随机变量 X 是一个以 μ∈R,σ>0 为参数的正态分布(normal distribution),记作 X∼N(μ,σ2),若其概率密度函数 pdf 为
f(x)=2πσ1exp(−2σ2(x−μ)2)

当 μ=0,σ=1 时,称为标准正态分布(standard normal distribution),有
fX(x)=2π1exp(−2x2)
这个概率分布是良定义的,因为有高斯积分
∫−∞∞e−x2dx=π
正态分布是二项分布的连续极限,这是「德莫弗-拉普拉斯定理」(De Moivre-Laplace theorem)。
这个定理是中心极限定理(central limit theorem, CLT)的一个特例,即多个独立随机变量的和近似服从正态分布。
期望显然有 E[X]=μ,因为 pdf fX(x) 是关于 x=μ 对称的。
而方差
Var[X]=2πσ1∫−∞∞(x−μ)2exp(−2σ2(x−μ)2)dx=2πσ2∫−∞∞y2exp(−2y2)dy=2πσ2(−yexp(−2y2))−∞∞+σ2∫−∞∞2π1exp(−2y2)dy=σ2
对于正态分布 X∼N(μ,σ2),有期望
E[X]=μ
与方差
Var[X]=σ2
线性变换
若 X∼N(μ,σ2),则对任意常数 a=0,b,有随机变量
Y=aX+b∼N(aμ+b,a2σ2)
证明
假设 a>0,则有
FY(y)=Pr(Y⩽y)=Pr(X⩽ay−b)=FX(ay−b)
链式法则有
fY(y)=dydFY(y)=a1fX(ay−b)
同理可得 a<0 时的情况,综合有
fY(y)=∣a∣1fX(ay−b)=2π∣a∣σ1exp(−2a2σ2(y−aμ−b)2)
也就是说,若 X∼N(μ,σ2),那么有 σX−μ∼N(0,1),也就是说可以将随机变量进行标准化。
反过来也有若 X∼N(0,1),则 σX+μ∼N(μ,σ2)。
卷积(Convolution)
密度函数 fX,fY 的卷积(convolution)fX∗fY 定义为
fX∗fY(z)=∫−∞∞fX(x)fY(z−x)dx=∫−∞∞fX(z−y)fY(y)dy
若连续随机变量 X,Y 独立,则有 fX+Y=fX∗fY。
证明
有 FX+Y(z) 为
Pr(X+Y⩽z)=∬u+v⩽zfX(u)fY(v)dudv=∫u=−∞∞∫v=−∞z−ufX(u)fY(v)dvdu=∫x=−∞∞fX(x)∫y=−∞zfY(y−x)dydx
从而
fX+Y(z)=dzdFX+Y(z)=∫−∞∞fX(x)fY(z−x)dx=fX∗fY(z)
若随机变量 X∼N(μ,σ2),Y∼N(ν,τ2) 独立,则
X+Y∼N(μ+ν,σ2+τ2)
证明
使用卷积即可,过程比较繁琐,略。
标准正态分布
若有服从标准正态分布的随机变量 X∼N(0,1),则其概率密度函数 pdf
φ(x)=2π1exp(−2x2)
若有标准正态分布的随机变量 X∼N(0,1),则其累积分布函数 CDF
Φ(z)=Pr(X⩽z)=∫−∞z2π1exp(−2x2)dx=21+21erf(2z)
Φ(z) 没有一个简单的解析形式(no closed-form expression),但是可以通过数值积分得到。
其中定义误差函数(error function)
erf(z)=π2∫0zexp(−t2)dt
根据对称性,有 Φ(−z)=1−Φ(z)。
对于一般的正态分布,X∼N(μ,σ2),有
Pr(X⩽x)=Φ(σx−μ)
矩生成函数(矩母函数,Moment Generating Function)
随机变量 X 的矩生成函数(moment generating function, MGF)定义为
MX(t)=E[etX]
可根据麦克劳林级数展开得到
MX(t)=k⩾0∑k!tkE[Xk]
因此第 k 阶矩为 E[Xk]=MX(k)(0)。
若对于一些 δ>0 有,MX(t)=MY(t) 对于任意 t∈[−δ,δ] 恒成立,则 X,Y 同分布。
标准正态分布 X∼N(0,1) 的 MGF 为
MX(t)=exp(2t2)
证明
MX(t)=E[etX]=2π1∫−∞∞exp(−2x2+tx)dx=2π1∫−∞∞exp(−2(x−t)2+2t2)dx=2π1exp(2t2)∫−∞∞exp(−2(x−t)2)dx=exp(2t2)
Large Deviation (Concentration) Bound
若 X∼N(μ,σ2),则对任意 a>0 有
Pr(∣X−μ∣⩾aσ)⩽2exp(−2a2)
证明
考虑标准化 Z=σX−μ∼N(0,1).
上尾(upper tail)有
Pr(X−μ⩾aσ)=Pr(Z⩾a)=Pr(etZ⩾eta)⩽etaE[etZ]=exp(2t2−at)⩽exp(−2a2)
最后一步取 t=a 是因为此时可以使得 exp(2t2−ta) 最小。
下尾(lower tail)Pr(X−μ⩽−aσ)=Pr(Z⩽−a) 根据对称性也有同样的结论。
68-95-99.7 法则:

二元正态分布(Bivariate Normal Distribution)
以 ρ∈(−1,1) 为参数的标准二元正态随机变量 (X,Y) 的联合密度函数为
fX,Y(x,y)=2π1−ρ21exp(−2(1−ρ2)1(x2−2ρxy+y2))
X,Y 的边缘分布均为标准正态分布 N(0,1),同时有
Cov(X,Y)=E[XY]−E[X]E[Y]=∫−∞∞∫−∞∞xyfX,Y(x,y)dxdy=ρ
因此,ρ=0 可以得到 fX,Y(x,y)=φ(x)φ(y)。
也就是说,标准二元正态随机变量相互独立,当且仅当他们无关(相关系数为 0)。
「独立」⟹「不相关」,但标准二元正态随机变量「独立」⟺「不相关」。
对于一般的二元正态随机变量 (X,Y),其中其均值分别为 μ1,μ2,方差分别为 σ12,σ22,相关系数为 ρ,它的联合密度函数为
fX,Y(x,y)=2πσ1σ21−ρ21exp(−21Q(x,y))
其中
Q(x,y)=(x−μ1,y−μ2)[σ12σ1σ2ρσ1σ2ρσ22]−1(x−μ1,y−μ2)⊺
边缘分布有 X∼N(μ1,σ12),Y∼N(μ2,σ22),同时协方差 Cov(X,Y)=σ1σ2ρ。
中间的矩阵就是协方差矩阵 Σ 的逆矩阵。
多元正态分布(Multivariate Normal Distribution)*
随机向量 Y=(Y1,⋯,Yn) 有着多元正态分布,当且仅当存在矩阵 A∈Rn×k 与 k 个独立的标准正态随机变量的向量 X=(X1,⋯,Xk) 与向量 μ=(μ1,⋯,μn)∈Rn 使得
Y⊺=AX⊺+μ⊺
若更进一步的,协方差矩阵 Σ=AA⊺=E[(Y−μ)(Y−μ)⊺] 满秩,则 Y 的密度函数为
f(y)=f(y1,…,yn)=(2π)ndet(Σ)1exp(−21(y−μ)Σ−1(y−μ)⊺)
表示为 Y∼N(μ,Σ)。
边缘分布有 Yi∼N(μi,Σii) 与 Cov(Yi,Yj)=Σij。
对任意 a∈Rn,有 ⟨a,Y⟩=a1Y1+⋯+anYn 也服从正态分布。
其他连续概率分布
卡方分布(Chi-Squared Distribution)*
若 Z1,…,Zk 是 k 个独立的标准正态分布随机变量,则随机变量
Q=i=1∑kZi2
服从 k 个自由度(degrees of freedom)的卡方分布(chi-squared distribution),记作 Q∼χ2(k)。

卡方分布有期望
E[Q]=i=1∑kE[Zi2]=i=1∑kVar[Zi]=k
独立的 χ2(k) 与 χ2(l) 随机变量的和服从 χ2(k+l)。
令 Z∼N(0,1) 与 Y=Z2,于是对于任意 y⩾0 有
FY(y)=Pr(Y⩽y)=Pr(Z2⩽y)=Pr(−y⩽Z⩽y)=Φ(y)−Φ(−−y)=2Φ(y)−1
链式法则有
fY(y)=dydFY(y)=y1φ(y)=2πy1exp(−2y)
于是 χ2(1) 有 pdf f(x)=2πx1exp(−2x)。
对于更一般的整数 k⩾1,χ2(k) 有 pdf f(x)=2k/2Γ(k/2)1xk/2−1exp(−2x)。
学生 t 分布(Student's t Distribution)*
若随机变量 X∼N(0,1),Y∼χ2(n) 独立,则随机变量
T=Y/nX
服从 n 个自由度的学生 t 分布(Student's t distribution),记作 T∼t(n)。
F 分布(F Distribution)*
若随机变量 X∼χ2(n),Y∼χ2(m) 独立,则随机变量
F=Y/mX/n
服从 n,m 个自由度的 F 分布(F distribution),记作 F∼F(n,m)。
伽马分布(Gamma Distribution)*
Gamma 函数
Gamma 函数是阶乘的解析延拓(Γ(n)=(n−1)!),定义为
Γ(z)=∫0∞tz−1exp(−t)dt,Re(z)>0
Γ(1)=∫0∞e−tdt=1 给出了 λ=1 的指数分布。
而 Γ(k)=∫0∞(λt)k−1λe−λtdt=E[(λX)k−1] 则是 λ>0 的指数随机变量 X。
随机变量 X 服从参数为 k,λ>0 的伽马分布(gamma distribution),记作 X∼Γ(k,λ),若其概率密度函数为
fX(x)=Γ(k)1λkxk−1exp(−λx),x⩾0
- Γ(1,λ) 是参数为 λ 的指数分布。
- Γ(2k,21) 是参数为 k 的卡方分布,其中 k⩾1 为整数。
- 若 X∼Γ(α,λ),Y∼Γ(β,γ) 独立,则 X+Y∼Γ(α+β,λ+γ)。
伽马随机变量 X∼Γ(k,λ) 的 MGF 为
MX(t)=(1−λt)−k,t<λ
证明
MX(t)=E[etX]=∫0∞etxfX(x)dx=Γ(k)λk∫0∞xk−1e−(λ−t)xdx=Γ(k)(λ−t)kλk∫0∞uk−1e−udu=Γ(k)(λ−t)kλkΓ(k)=(1−λt)−k
令 {N(t)∣t⩾0} 是一个参数为 λ 的泊松过程,对于任意 t,s⩾0 与自然数 n,有
Pr(N(t+s)−N(t)=n)=n!(λs)ne−λs
证明
无记忆性有,等价于证明 Pr(N(t)=n)=n!(λt)ne−λt。
对于 i.i.d. 以 λ 为参数的指数随机变量 Xi,有
Pr(N(t)=n)=Pr(i=1∑nXi⩽t∩i=1∑n+1Xi>t)=∫0tf∑i=1nXi(x)⋅Pr(Xn+1>t−x)dx=∫0tΓ(n)(λx)n−1λe−λxe−λ(t−x)dx=Γ(n)λne−λt∫0txn−1dx=nΓ(n)λne−λttn=e−λtn!(λt)n
贝塔分布(Beta Distribution)*
随机变量 X 服从参数为 a,b>0 的贝塔分布(beta distribution),记作 X∼Beta(a,b),若其概率密度函数为
fX(x)=B(α,β)1xα−1(1−x)β−1,0⩽x⩽1
其中贝塔函数(beta function)
B(a,b)=Γ(a+b)Γ(a)Γ(b)=∫01ta−1(1−t)b−1dt

- Beta(1,1) 是 [0,1] 上的均匀分布。
- Beta(1,n) 是 1⩽i⩽nminXi 的分布,其中 Xi 是独立的 [0,1] 上的均匀分布。
- 若 X∼Γ(α,λ),Y∼Γ(β,λ) 独立,则 X+YX∼Beta(α,β)。
柯西分布(Cauchy Distribution)*
随机变量 X 服从柯西分布(Cauchy distribution),若其概率密度函数为
fX(x)=π(1+x2)1

柯西随机变量 X 不存在任何矩。即 E[Xk]=∞ 对于任意 k⩾1 成立。
也就是说其 MGF 不存在。