动态规划
Intro: The Rod-Cutting Problem
Given a rod of length inches and a table of prices for , determine the maximum revenue obtainable by cutting up the rod and selling the pieces.
There are ways to cut up a length rod. So enumerating all possibilities is not a good idea.
实际上是上界,这个问题实际上更复杂一点,参见整数分拆
Optimal structure property: .
The greedy choice property(Always cut at most profitable position ) doesn't hold. For example , the optimal solution is not to cut.
A simple recursive algorithm:
1 2 3 4 5 6 7 | CutRodRec(prices, n): if n = 0 return 0 r := -INF for i := 1 to n r := max(r, prices[i] + CutRodRec(prices, n - i)) return r |
This algorithm actually enumerates all possibilities:
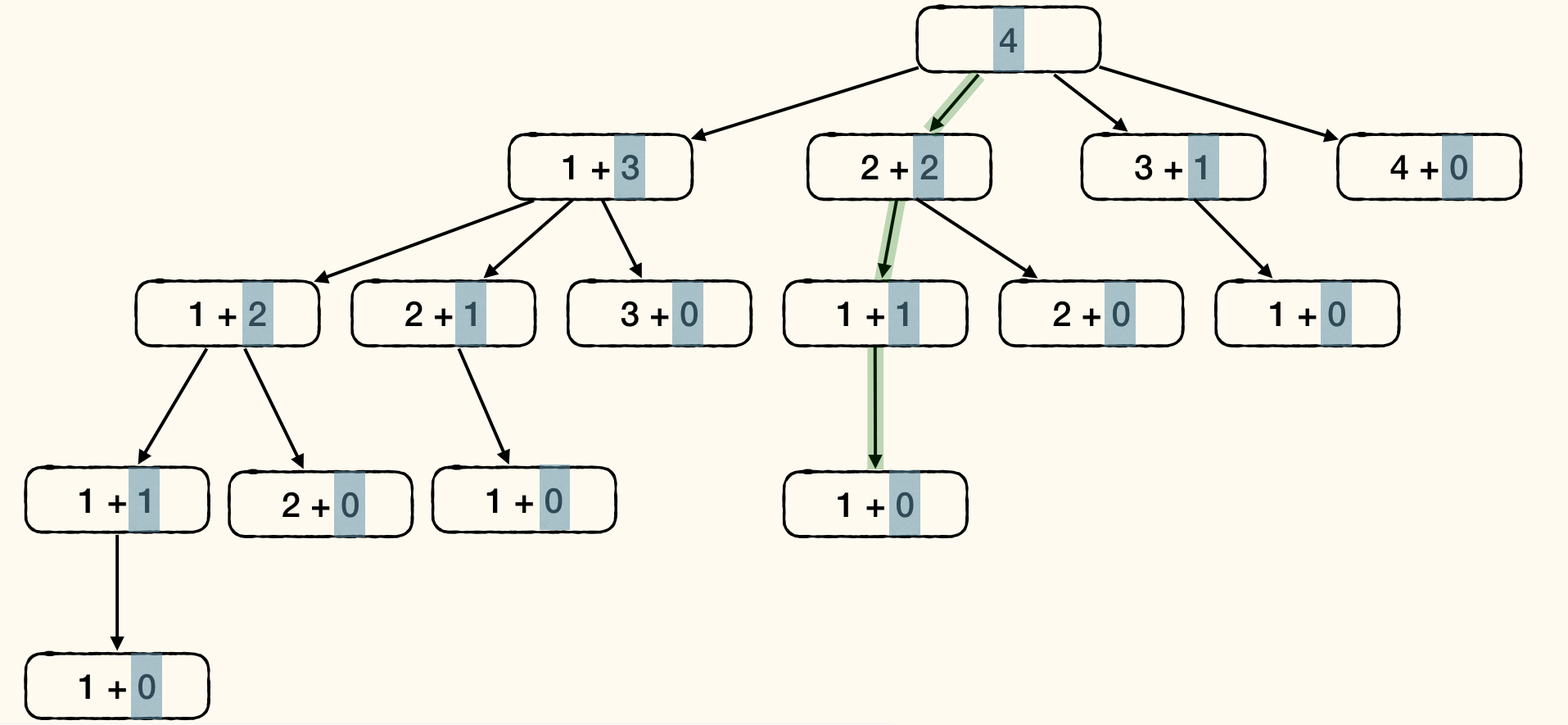
For each subproblem, only need to solve it once. Each node denotes a subproblem of certain size. Some subproblems appear multiple times:
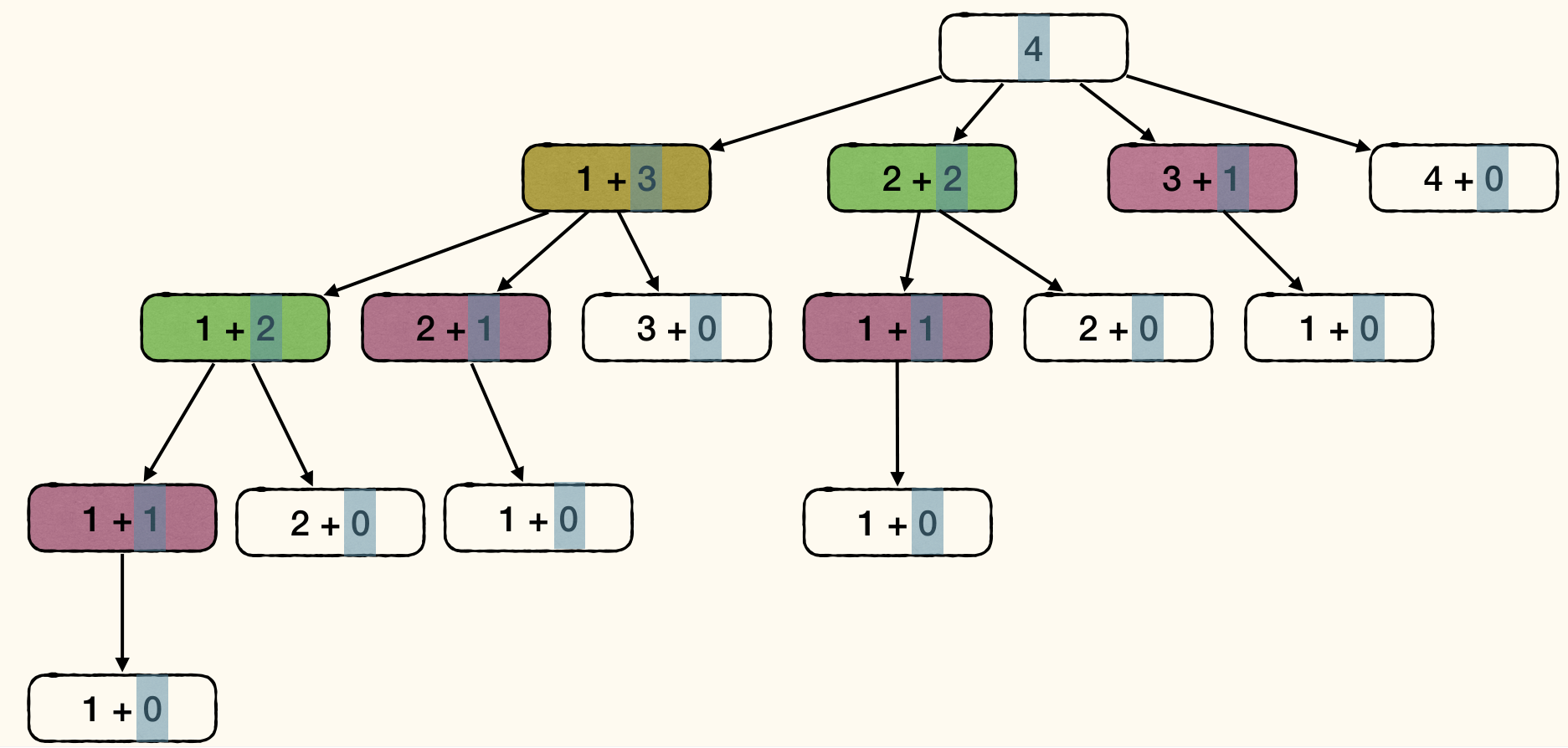
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | CutRodRecMem(prices, n): for i := 0 to n r[i] := -INF return CutRodRecMemAux(prices, r, n) CutRodRecMemAux(prices, r, n): if r[n] >= 0 return r[n] if n = 0 q := 0 else q := -INF for i := 1 to n q := max(q, prices[i] + CutRodRecMemAux(prices, r, n - i)) r[n] := q return q |
Runtime: Each subproblem is solved once. Solving size problem itself without subproblems needs time. Thus total runtime is .
The result of subproblem 4 is unknown if subproblems 0, …, 3 is not finished. Therefore, these relationship can be represented as a DAG:
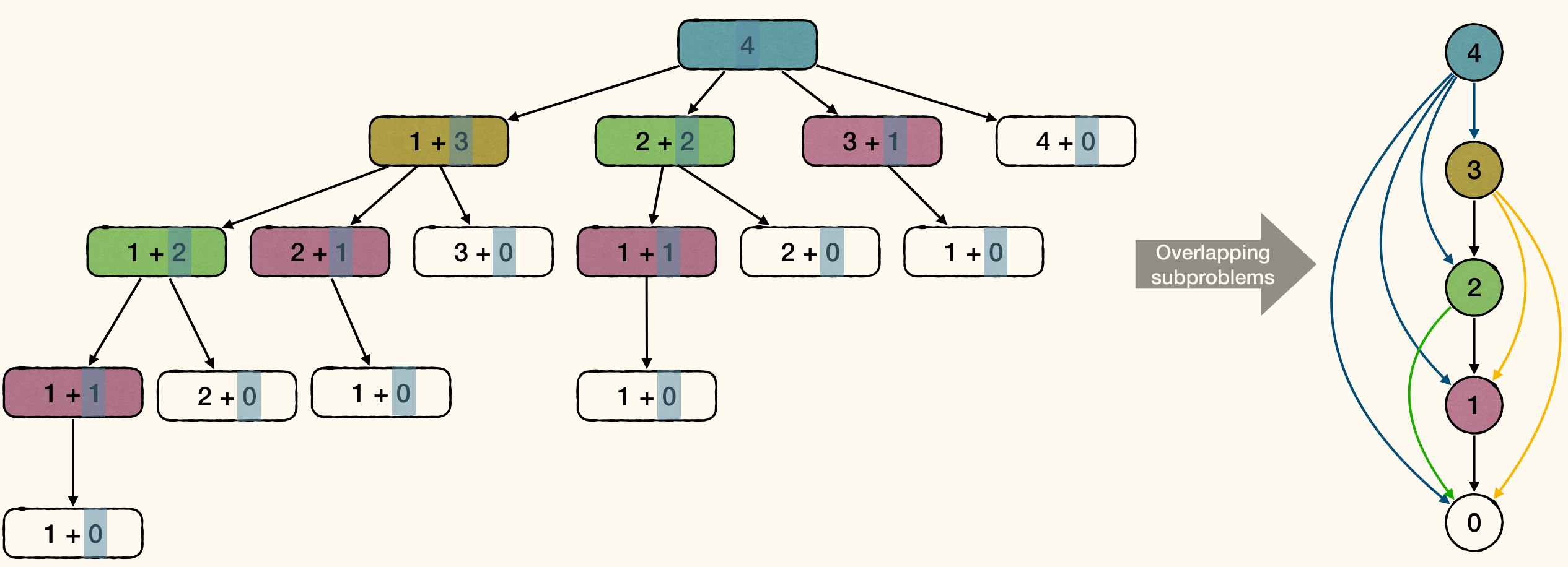
Then, we can use DFS to get the topological order of the DAG, and solve the subproblems in this order:
1 2 3 4 5 6 7 8 | CutRodIter(prices, n): r[0] := 0 for i := 1 to n q := -INF for j := 1 to i q := max(q, prices[j] + r[i - j]) r[i] := q return r[n] |
Runtime is still .
This outputs the optimal revenue without the actual cutting plan. To get the cutting plan, we can store the cut position for each subproblem:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | CutRodIter(prices, n): r[0] := 0 for i := 1 to n q := -INF for j := 1 to i if q < prices[j] + r[i - j] q := prices[j] + r[i - j] cuts[i] := j r[i] := q return r[n] PrintOpt(cuts, n): while n > 0 Print cuts[n] n := n - cuts[n] |
Dynamic Programming(DP) Concept
An optimal problem:
- Build optimal solution step by step.
- Problem has optimal substructure property.
- We can design a recursive algorithm.
- Problem has lots of overlapping subproblems.
- Recursion and memorize solutions. (Top-Down)
- Or, consider subproblems in the right order. (Bottom-Up)
The Floyd-Warshall Algorithm is a example of DP via bottom-up approach.
Procedure of developing a DP algorithm:
- Characterize the structure if solution.
- e.g., (one cut of length ) + (solution for length )
- Recursively define the value of an optimal solution.
- e.g.,
- Compute the value of an optimal solution.
- Top-down or Bottom-up.
- Usually bottom-up is more efficient.
- (Optional) Construct an optimal solution
- Remember optimal choices beside optimal solution values.
Examples
Matrix-Chain Multiplication
- Input: Matrices with size
- Output:
- Problem: Compute output with minimum work.
Since matrix multiplication is associative, the order of multiplication doesn't matter in terms of the result. But the number of scalar multiplications can be different.
For example, can be computed in two ways:
- : multiplications
- : multiplications
If , then The number of the seconds multiplications is ten times of the first one.
Procedure:
- Characterize the structure of an optimal solution.
- For every order, the last step is
- In general,
- Recursively define the value of an optimal solution.
- Let be the minimal cost for computing
To get the bottom-up method, we have to find out the dependency of . Actually, depends on where .
Then we can compute in length increasing order:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | MatrixChainDP(A1, ..., An): for i := 1 to n m[i, i] := 0 for l := 2 to n for i := 1 to n - l + 1 j := i + l - 1 m[i, j] := INF for k := i to j - 1 cost := m[i, k] + m[k+1, j] + p[i-1] * p[k] * p[j] if cost < m[i, j] m[i, j] := cost s[i, j] := k return m, s MatrixChainPrintOpt(s, i, j): if i = j Print "A" + i else Print "(" MatrixChainPrintOpt(s, i, s[i, j]) MatrixChainPrintOpt(s, s[i, j] + 1, j) Print ")" |
Edit Distance
Given two strings, how similar are they?
Here are following three types of operations for a string:
- Insertion: Insert a character at a position.
- Deletion: Remove a character at a position.
- Substitution: Change a character to another one.
Edit Distance of string is the minimal number of ops to transform into .
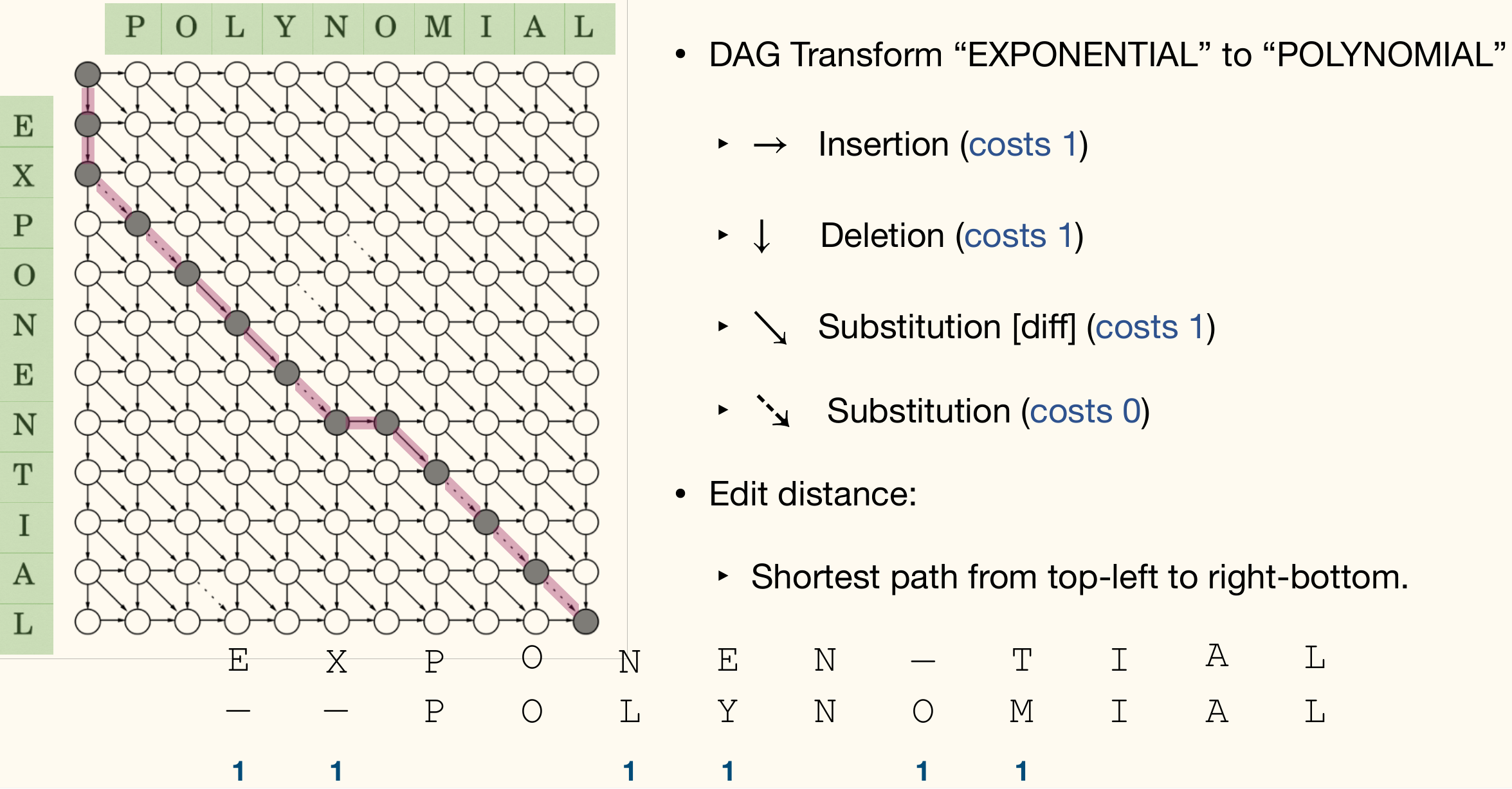
Example of transforming SNOWY to SUNNY:
- SNOWY SUNOWY (Insert 'U' at position 1)
- SUNOWY SUNOY (Delete 'W' at position 4)
- SUNOY SUNNY (Substitute 'O' with 'N' at position 3)
It's edit distance is at most 3 and it is 3 actually.
One way to visualize the editing process:
- Align above
- A gap in the first line indicates an insertion to
- A gap in the second line indicates a deletion from
- A column with different characters indicates a substitution.
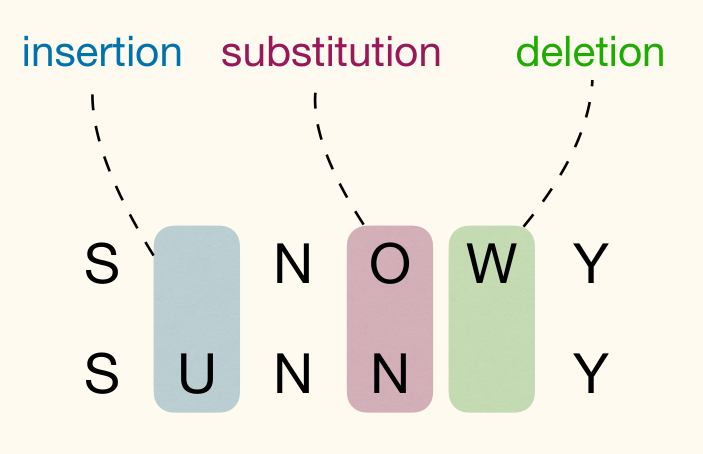
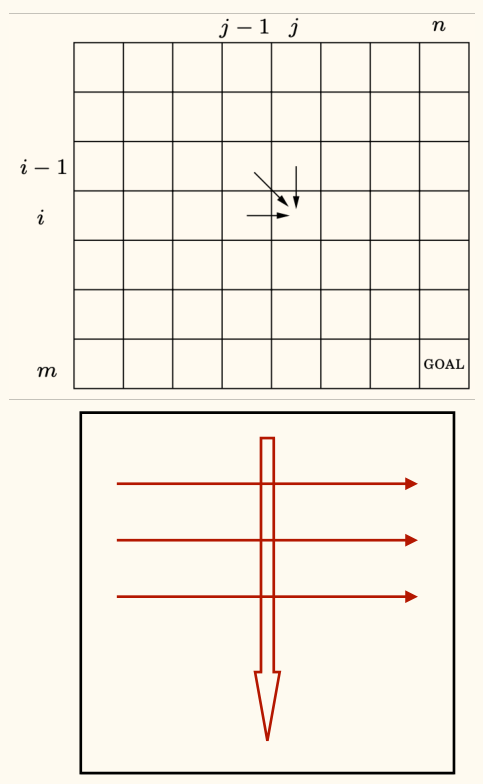
Consider transform to . Each solution can be visualized in the way described above.
Last column must be one of three cases:
Each case reduces the problem to a subproblem:
- : Edit distance of and
- : Edit distance of and
- : Edit distance of and
Then we get recursive optimal solution:
depends on , , and .
Then we can compute the edit distance in a bottom-up way: In an outer loop, increase ; in an inner loop, increase .
1 2 3 4 5 6 7 8 9 10 11 12 | EditDistDP(A[1...m], B[1...n]): for i := 0 to m dist[i, 0] := i for j := 0 to n dist[0, j] := j for i := 1 to m for j := 1 to n delDist := dist[i-1, j] + 1 insDist := dist[i, j-1] + 1 subDist := dist[i-1, j-1] + bool(A[i] != B[j]) dist[i, j] := min(delDist, insDist, subDist) return dist |
A process example:
Maximum Independent Set
Given an undirected graph , an independent set(独立集) is a subset of such that no vertices in are adjacent. Put another way, for all , we have .
A maximum independent set (MaxIS) is an independent set with the maximum number of vertices.
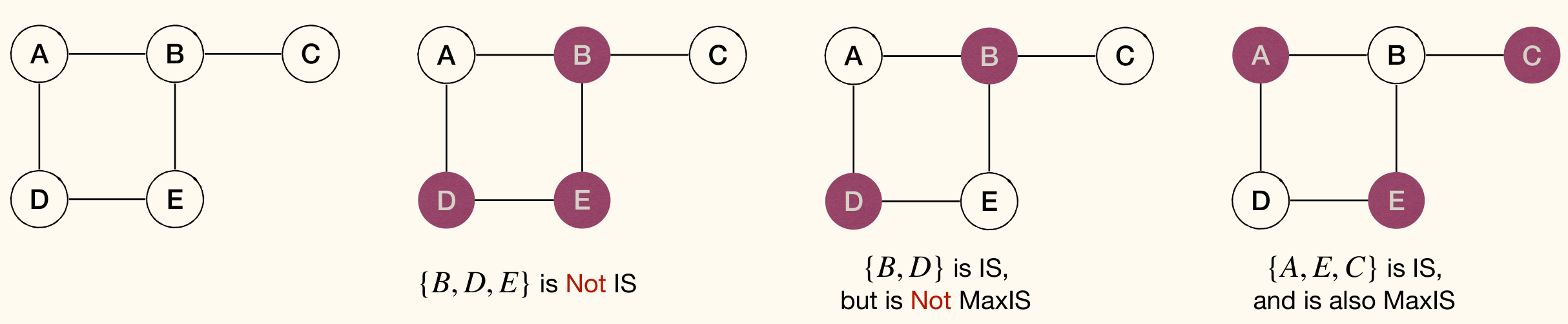
Computing MaxIS in an arbitrary graph is NP-head. Even getting an approximate MaxIS is very hard.
But if the graph is a tree, we can compute MaxIS in polynomial time.
Given an IS of , for each child of , set is an IS of .
Let be size of MaxIS of subtree rooted at node , and:
- be size of MaxIS of s.t. in the MaxIS.
- be size of MaxIS of s.t. not in the MaxIS.
Then we have:
1 2 3 4 5 6 7 8 | MaxIsDP(u): mis1 := 1 mis0 := 0 for each child v of u mis1 := mis1 + MaxIsDP(v, 0).mis0 mis0 := mis0 + MaxIsDP(v).mis mis := max(mis0, mis1) return mis, mis0, mis1 |
Runtime is .
Discussions of DP
Optimal Substructure Property
DP requires the optimal substructure property. If this doesn't hold, we can't use DP, so do greedy algorithms.
Here's examples that optimal substructure property holds and doesn't hold:
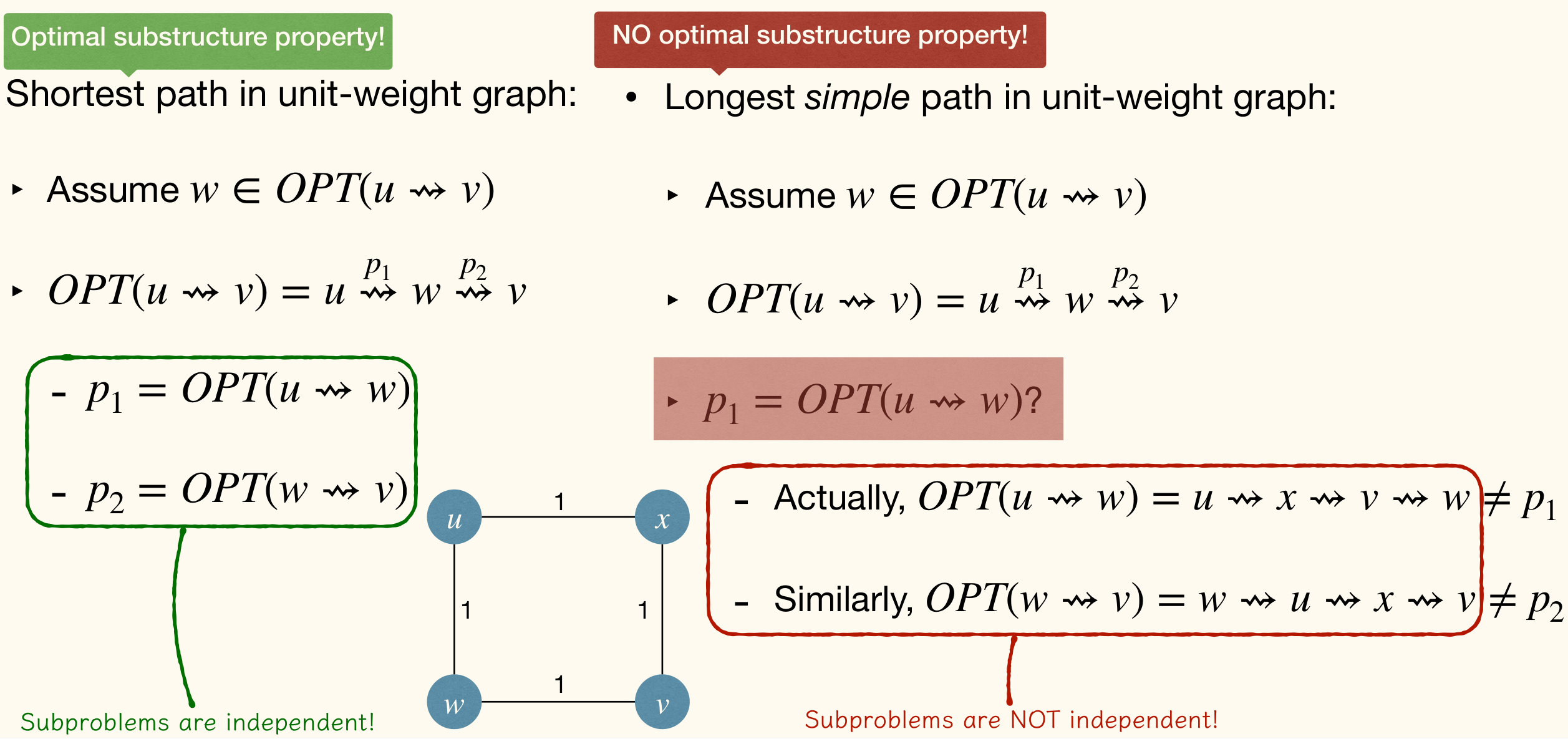
Top-Down v.s. Bottom-Up
Top-down: Recursion with memorization.
- Very straightforward, easy to write down the code.
- Use array or hash-table to memorize
solutions. - Array may cost more space, but hash-table may cost more time.
Bottom-up: Solve subproblems in the right order.
- Finding the right order might be non-trivial.
- Usually use array to memorize solutions.
- Might be able to reduce the size of array to save even more space.
Top-down often costs more time in practice cos recursion is costly. But this is not always true since Top-down only considers necessary subproblems.
APSP via DP

dist[*, *, r] only relies on dist[*, *, r-1]. So we can repeatedly use dist array to reduce space.
Edit Distance

Same as APSP.
Analysis of DP
Correctness:
- Optimal substructure property.
- Bottom-up approach: subproblems are already solved.
Complexity:
- Space complexity: usually obvious.
- Time complexity [bottom-up]: usually obvious since iterations number is known.
- Time complexity [top-down]: Master theorem.
- How many subproblems in total? (number of nodes in the subproblem DAG)
- Time to solve a problem, given subproblem solutions? (number of edges in the subproblem DAG)
Subset Sum
DP can not only work in optimization problems.
- Problem: Given an array of n positive integers, can we find a subset that sums to given integer ?
Simple solution: Recursively enumerates all subsets, leading to runtime.
Observation:
- If there is a solution , either is in it or not
- If in , then there is a solution to instance and
- If not in , then there is a solution to instance and
Let be true if there is a subset of that sums to .
Then we have:
1 2 3 4 5 6 7 8 9 10 11 | SubsetSumDP(X[1...n], T): ss[n, 0] := true for t := 1 to T ss[n, t] := (X[n] = t) for i := n - 1 down to 1 ss[i, 0] := true for t := 1 to X[i] - 1 ss[i, t] := ss[i + 1, t] for t := X[i] to T ss[i, t] := ss[i + 1, t] || ss[i + 1, t - X[i]] return ss |
Runtime is , depending on . Thus DP isn't always an improvement.
DP v.s. Greedy
Dynamic Programming
- At each step: multiple potential choices, each reducing the problem to a subproblem, compute optimal solutions of all subproblems and then find optimal solution of original problem.
- Optimal substructure + Overlapping subproblems.
Greedy
- At each step: make an optimal choice, then compute optimal solution of the subproblem induced by the choice made.
- Optimal substructure + Greedy choice