散列表
Hashing
SIR in time
Efficient implementation for ORDERED DICTIONARY:
Search(S, k) |
Insert(S, x) |
Remove(S, x) |
|
|---|---|---|---|
| BinarySearchTree | in worst case | in worst case | in worst case |
| Treap | in expectation | in expectation | in expectation |
| RB-Tree | in worst case | in worst case | in worst case |
| SkipList | in expectation | in expectation | in expectation |
If we only care about Search, Insert and Remove operation, can we be faster?
Assuming keys are distinct integers from universe . Just allocate an array of size and Search, Insert and Remove can be done in time.

Problem: What if keys are not integers, e.g., strings?
The real problem is that the universe can be very large. Sometime the space complexity is unacceptable.
Hash function
We are given huge universe of possible keys and much smaller number of actual keys. And we only want to spend (i.e., ) space, meanwhile supporting very fast SIR.
Hash function(散列函数/哈希函数) maps keys from universe to buckets of a hash table .
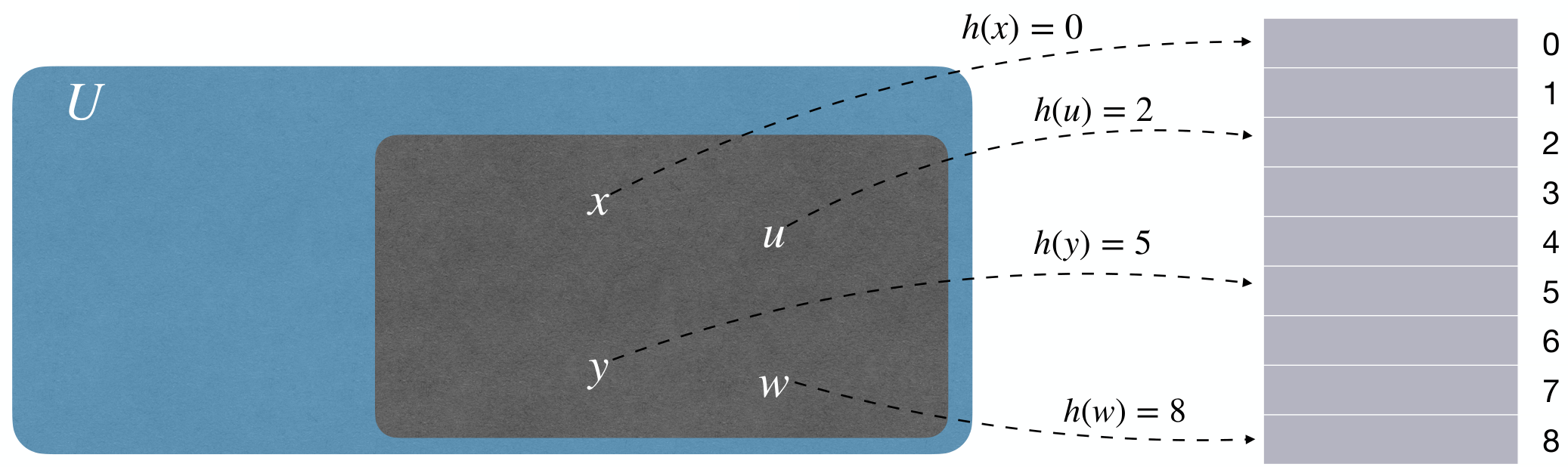
The time complexity of hash function should be for every key.
And we want to avoid collisions. That is, we want maps distinct keys to distinct indices.
Two distinct keys collide(冲突) if .
However this is impossible cos (pigeonhole principle). Therefore, collisions are unavoidable and we have to cope with them.
Hashing with Chaining
Chaining(链接法) is a simple way to resolve collisions. We store all the keys that hash to the same bucket in a LINKEDLIST.
Each bucket stores a pointer to a LINKEDLIST and all keys that are hashed to index go to .
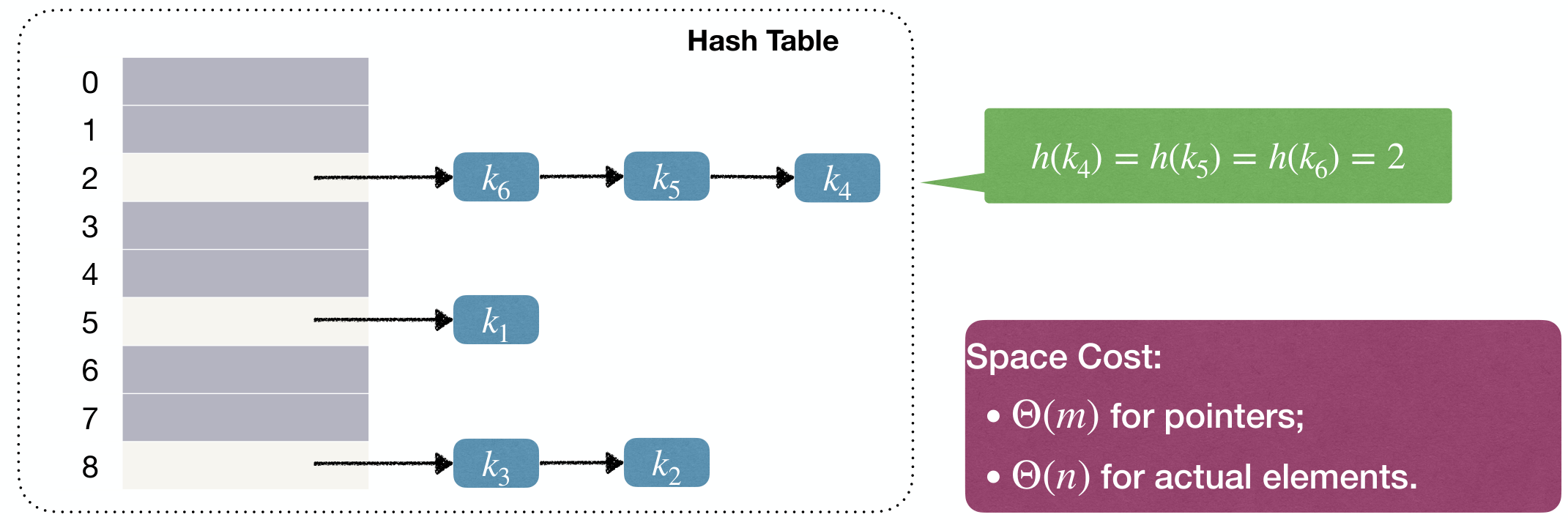
Space Cost:
- for pointers;
- for actual elements.
Operation:
Search(k): wherekis a key.- Compute
h(k)and go through the corresponding list to search item with keyk.
- Compute
Insert(x): wherexis a pointer to an item.- Compute
h(x.key)and insertxto the head of the corresponding list.
- Compute
Remove(x): wherexis a pointer to an item.- Simply remove
xfrom the LINKEDLIST.
- Simply remove
Search can cost in worst-case if all keys hash to the same bucket. At this time, the hashing table with chaining degrades to a LINKEDLIST.
Performance
Simple Uniform Hashing Assumption
- Every key is equally likely to map to every bucket.
- Keys are mapped independently.
Each key goes to a randomly chosen bucket, if there are enough number of buckets, each bucket will not have too many keys.
Consider a hash table containing buckets and storing keys.
Define load factor(负载因子) .
Intuitively, Search will on average cost time. for computing hash value and for traversing the LINKEDLIST.
Expected cost of unsuccessful search is . The cost is the sum of computing hash value and traversing the entire LINKEDLIST in a bucket.
Expected cost of successful search is too. The cost is the sum of computing hash value and traversing LINKEDLIST in a bucket till key found.
Let be the cost for finding the -th inserted element . We want to compute .
Let be an IRV taking value 1 if and only if h(x_i.key) = h(x_j.key).
So, what is the expected maximum cost for Search? That is, the expected length of the longest LINKEDLIST. This is equivalent to the Max-Load problem(balls into bins problem)
If , the answer is .
Here's a hand wavy proof in Stack Overflow: Maximum load when placing N balls in N bins.
However SUH doesn't hold. Keys are not that random (they usually have patterns). Patterns in keys can induce patterns in hash functions.
And once is fixed and known, we can find a set of bad keys that hash to same value.
Designs of Hash function
Some bad hash functions
Assume keys are English words.
One bucket for each letter (i.e., 26 buckets). A hash function is the first letter of the word . This is not uniform since words starting with 'a' are more common than words starting with 'z'.
One bucket for each number in . Another hash function is the sum of indices of letters in . This is not uniform since most of words are short words.
The Division Method
This is a common technique when designing hash functions.
Hash function
Two keys collide if .
The key is to pick appropriate .
Say we want to store keys.
Here's an idea: Let and set . Then computing is very fast: h(k) = k - ((k >> r) << r).
But we only use rightmost bits of the input key. For example, if all input keys are even, we use at most half space.
In general, we want to be a prime number.
Assume to be a composite number and key and have common divisor . is also divisible by since . If all input keys are divisible by , we use at most space.
Rule of thumb(经验法则)
Pick to be a prime number not too close to a power of (or ).
The Multiplication Method
Here's another common technique.
Assume key length is at most bits. Fix table size for some . Fix constant .
Hash function

This is faster than the Division Method, cos Multiplication ant bit-shifting are faster than division.
Universal Hashing(全域散列)
However, once hash function is fixed and known, there must exist a set of bad keys that hash to the same value. Such adversarial input will result in poor performance.
The solution is to use randomization.
Pick a random hash function when the hash table is first built. Once chosen, is fixed throughout entire execution. Since is randomly chosen, no input is always bad.
A collection of hash functions is universal if for any distinct keys , at most hash functions in lead to . Therefore for all .
Source of uncertainty:
- SUH: randomness of input.
- Universal Hashing: choice of function (and potentially randomness of input).
Performance of hashing with chaining
Let be the length of list at index , and we want to compute .
Claims:
- If key is not in table , then .
- For any key , define IRV taking value 1 if and only if . Then we have
- If key is is table , then .
- We have
If the hash table is not overloaded, i.e., , SIR can be done in expected time.
Typical Universal Hash Family
Proposed by Carter and Wegman in 1977.
Find a large prime larger than the max possible key value.
Let and .
Define , then
is a universal hash family.
We want to prove that, for all , , where .
Let .
Claim 1
Proof.
We have . However and , since is a prime.
So .
Claim 2
Fix , there is a 1-to-1 mapping between and pairs.
Proof.
这里涉及了「模乘法的逆」的概念,可回看《离散数学》笔记。
Recall , then we get and . is the modular multiplicative inverse of and it is unique since is a prime.
Then we get unique given distinct .
There are pairs of and pairs of . As a result, there is a 1-to-1 mapping between and pairs.
Thus, for any given pair of distinct inputs of , if we pick uniformly at random from , the resulting pair is equally likely to be any pair of distinct values modulo .
Therefore, the probability that distinct keys collide is equal to the probability that .
Lemma
Open Addressing
可参考「概率论」笔记。
Here's another way to resolve collisions except chaining.
Basic idea: On collision, probe a sequence of buckets until an empty one is found.

We redefine , where the first means the probe number and the second one means table index.
1 2 3 4 5 6 7 8 9 10 | HashInsert(T, k): i := 0 repeat j := h(k, i) if T[j] == NULL or T[j] == DEL T[j] := k return j else i := i + 1 until i == m error "overflow" |
1 2 3 4 5 6 7 8 9 | HashSearch(T, k): i := 0 repeat j := h(k, i) if T[j] == k return j else i := i + 1 until i == m or T[j] == NULL return NULL |
1 2 3 4 5 | HashRemove(T, k): pos := HashSearch(T, k) if pos != NULL T[pos] := DEL return pos |
Without DEL mark:
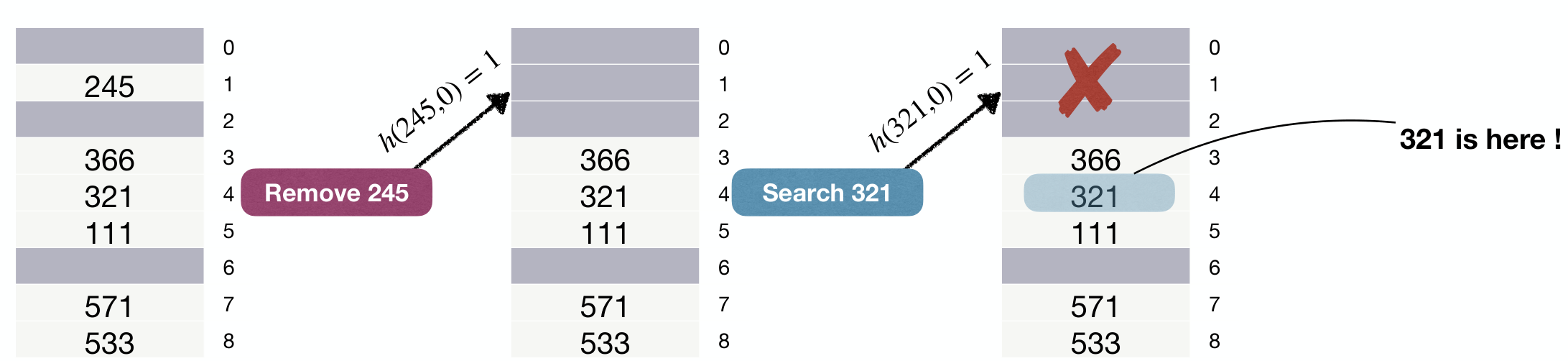
With DEL mark:

Linear Probing
where is an auxiliary hash function.
Since the initial probe position determines the entire probe sequence, only distinct probe sequences are used with linear probing.
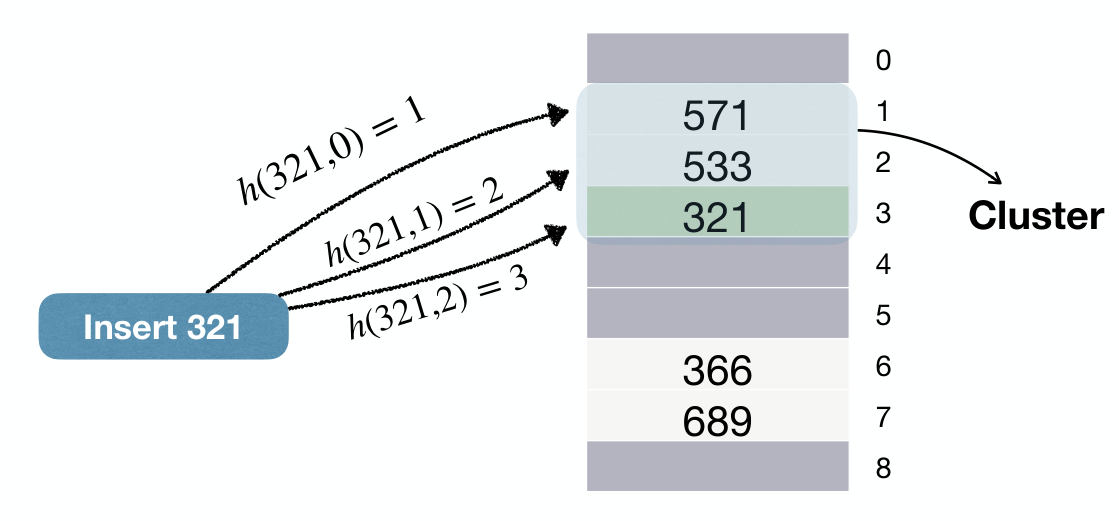
Another problem with linear probing is Clustering:
- Empty slot after a "cluster" has higher chance to be chosen.
- Cluster grows larger and larger.
- Cluster leads to higher search time in theory.
The remove mechanism (i.e., the
DELmark) causes "anti-clustering" effect, improving the performance of linear-probing hash tables.
Quadratic Probing
where are constants.
Problem: (Secondary) Clustering
- Keys having same value result in same probe sequences.
- As in linear probing, the initial probe determines the entire sequence, so only distinct probe sequences are used.
Double Hashing
where are auxiliary hash functions.
Why doubling? Observations:
- If is good, looks random.
- If is good, probe sequence looks random.
Linear and quadratic probing doesn't give observation 2.
The value must be relatively prime to for the entire hash table to be searched. Conveniently, let be a prime number.
Otherwise if and have greatest common divisor for some key , then a search for key would examine only of the hash table.
Each possible pair yields a distinct probe sequence. Therefore double hashing can use different probe sequences.
This is not the best. Uniform hashing gives the permutation of elements, which is .
Performance of Open Addressing
Let random variable be the number of probes made in an unsuccessful search. Then
where is the load factor.
Proof.
证明在「概率论」中就已经证过了,这里略。
Insight: Always make 1st probe, and make 2nd probe with probability , 3rd probe with probability , and so on.
Let random variable be the number of probes made in an successful search. Then
Proof.
Let be the expected number of probes made when searching the -th inserted key.
Due to previous analysis, we have
Therefore
Chaining v.s. Open-addressing
- Good parts of Open-addressing
- No memory allocation
- Chaining needs to allocate list-nodes
- Better cache performance
- Hash table stores in a continuous region in memory
- Fewer accesses brings table into cache
- No memory allocation
- Bad parts of Open-addressing
- Sensitive to choice of hash functions
- Clustering is a common problem
- Sensitive to load factor
- Poor performance when
- Sensitive to choice of hash functions